
Utility Analysis about Log Data Anomaly Detection Based on Federated Learning

Abstract
:1. Introduction
- (1)
- We analyze the performance of log anomaly detection through existing general deep learning processes.
- (2)
- We apply a federated learning framework to the models in (1) to compare their performance with existing learning processes and analyze the applicability of federated learning for log anomaly detection.
- (3)
- Finally, we demonstrate that the hybrid model combining the two models perform better than the application of a single deep learning algorithm, CNN1D, LSTM, in log anomaly detection.
2. Related Works
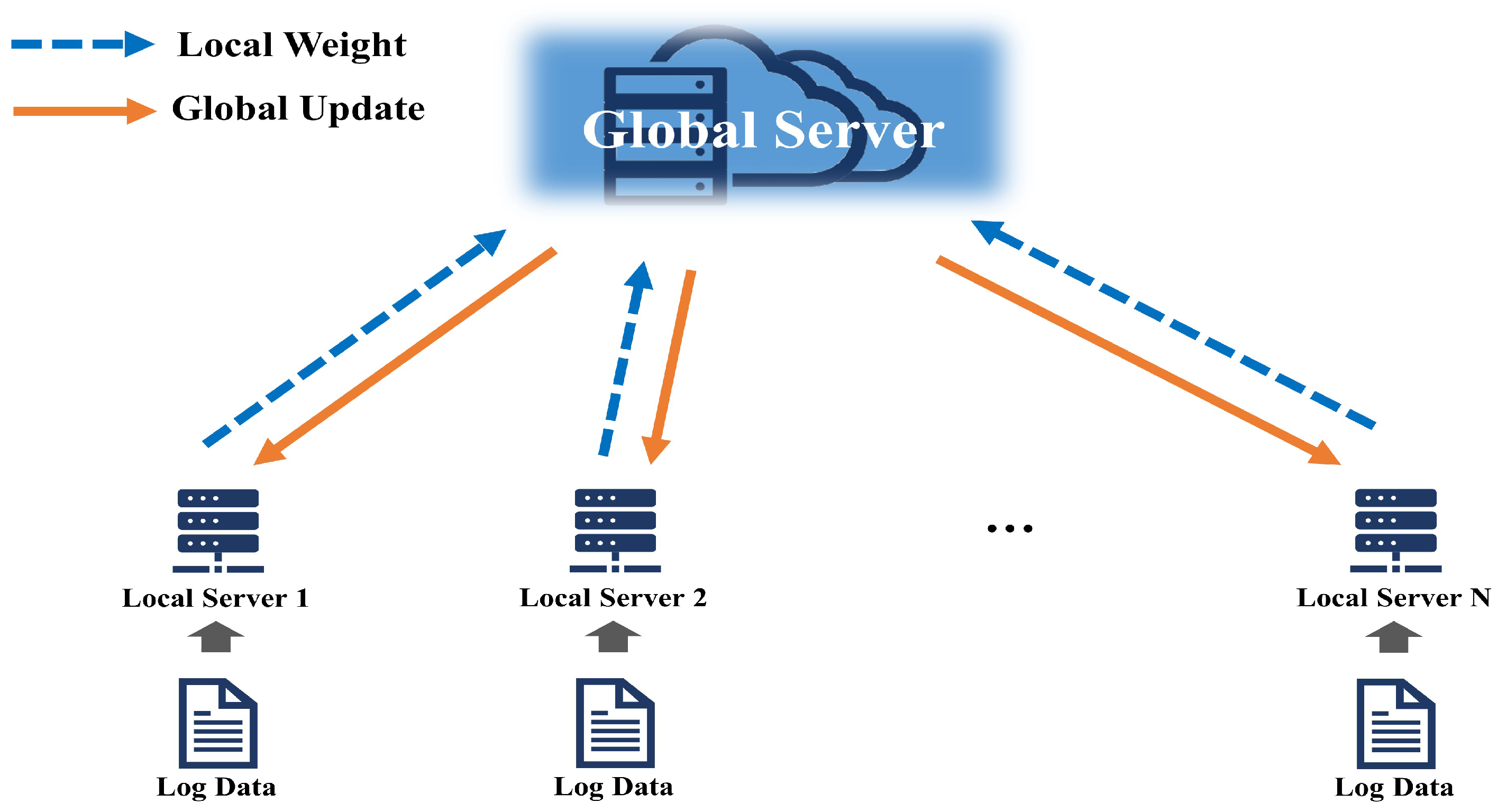
2.1. Federated Learning
2.2. Deep Learning-Based Log Anomaly Detection
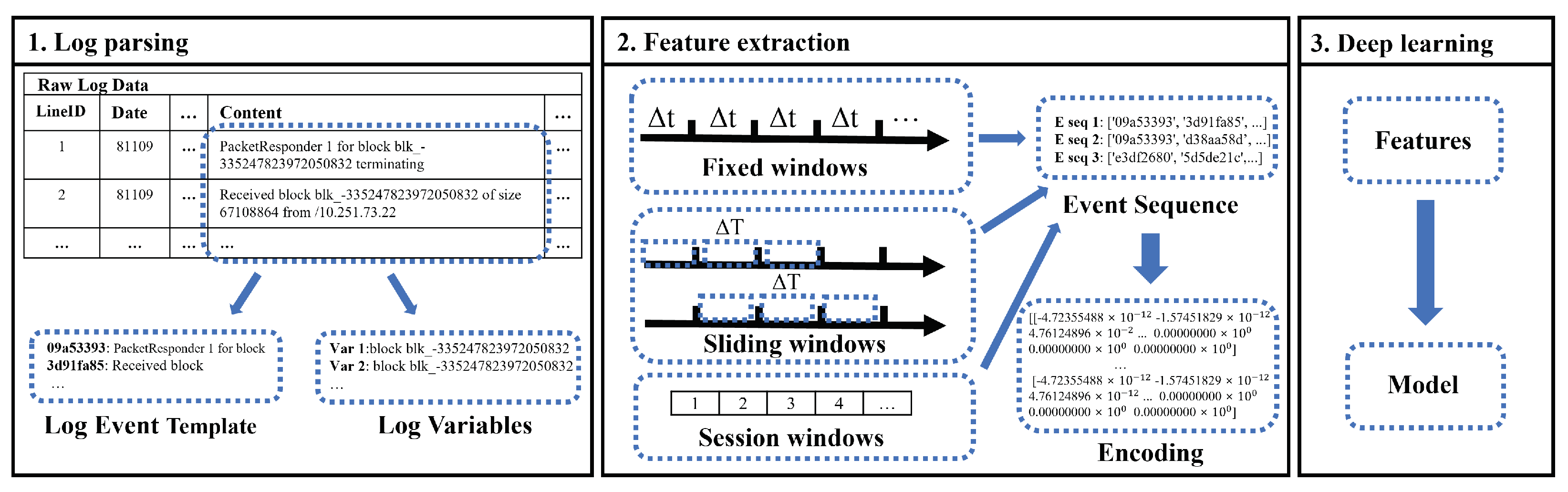
2.2.1. Log Parsing
2.2.2. Pre-Processing and Feature Extraction
2.2.3. Deep Learning for Log Anomaly Detection
- (1)
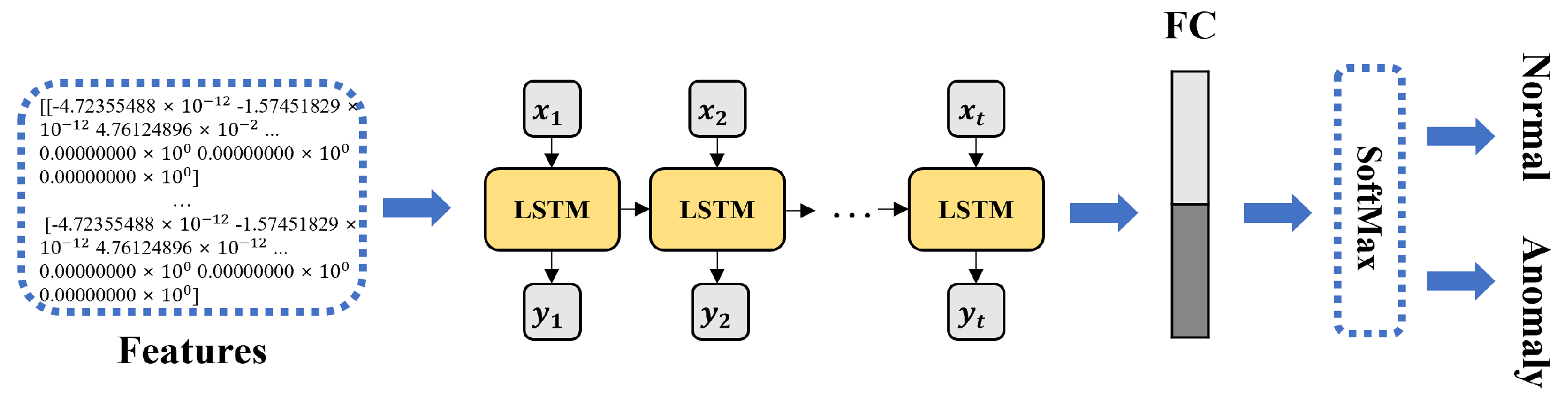
- The Long Short Term Memory (LSTM) network is a series of recurrent neural network algorithms for time-series data processing and text recognition, and studies have applied them to log data with text. Du et al. proposed Deeplog, which models sequential patterns by applying the LSTM and identifies anomalies in the log [14]. Zhang et al. proposed LogRobust, which detects anomalous logs by applying the attention mechanism-based bidirectional LSTM [15]. Meng et al. proposed LogAnomaly, which identifies anomalous logs based on sequential and quantitative log information [16].
- (2)
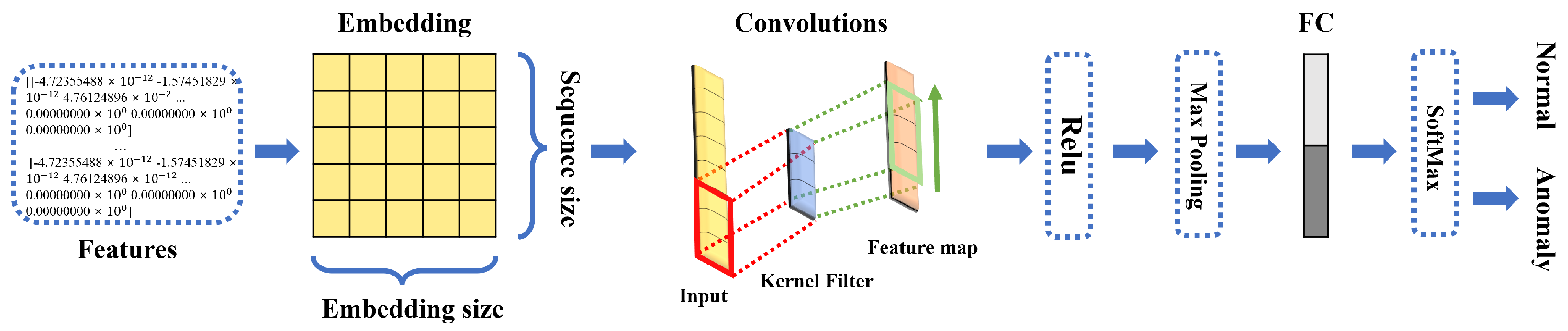
- The One-dimensional Convolutional Neural Network(CNN1D) algorithm can be applied to sequential data, unlike the two and three-dimensional CNN algorithms, because it calculates in one direction, and this method derives excellent performance in text classification through model design [17]. In addition, Lu et al. proposed a 1D CNN-based log anomaly detection model that uses fewer parameters than the models of the existing family of recurrent neural networks [18].
- (3)
- Recently, a hybrid model that combines two or more deep learning models has been proposed, and various studies have been conducted, especially in text classification and prediction problems, such as those concerning log data [19,20,21]. Among them, in text classification research, a hybrid CNN model was effective in extracting local features, such as words, and an LSTM model was effective in extracting features for contextual information or word order to derive higher performance than the existing single models [19]. Therefore, we perform anomaly detection on log data by combining the LSTM model with the proposed CNN1D model and comparing the performance results with those of existing models.
3. Proposed Federated Learning Model
3.1. Federated Learning Framework
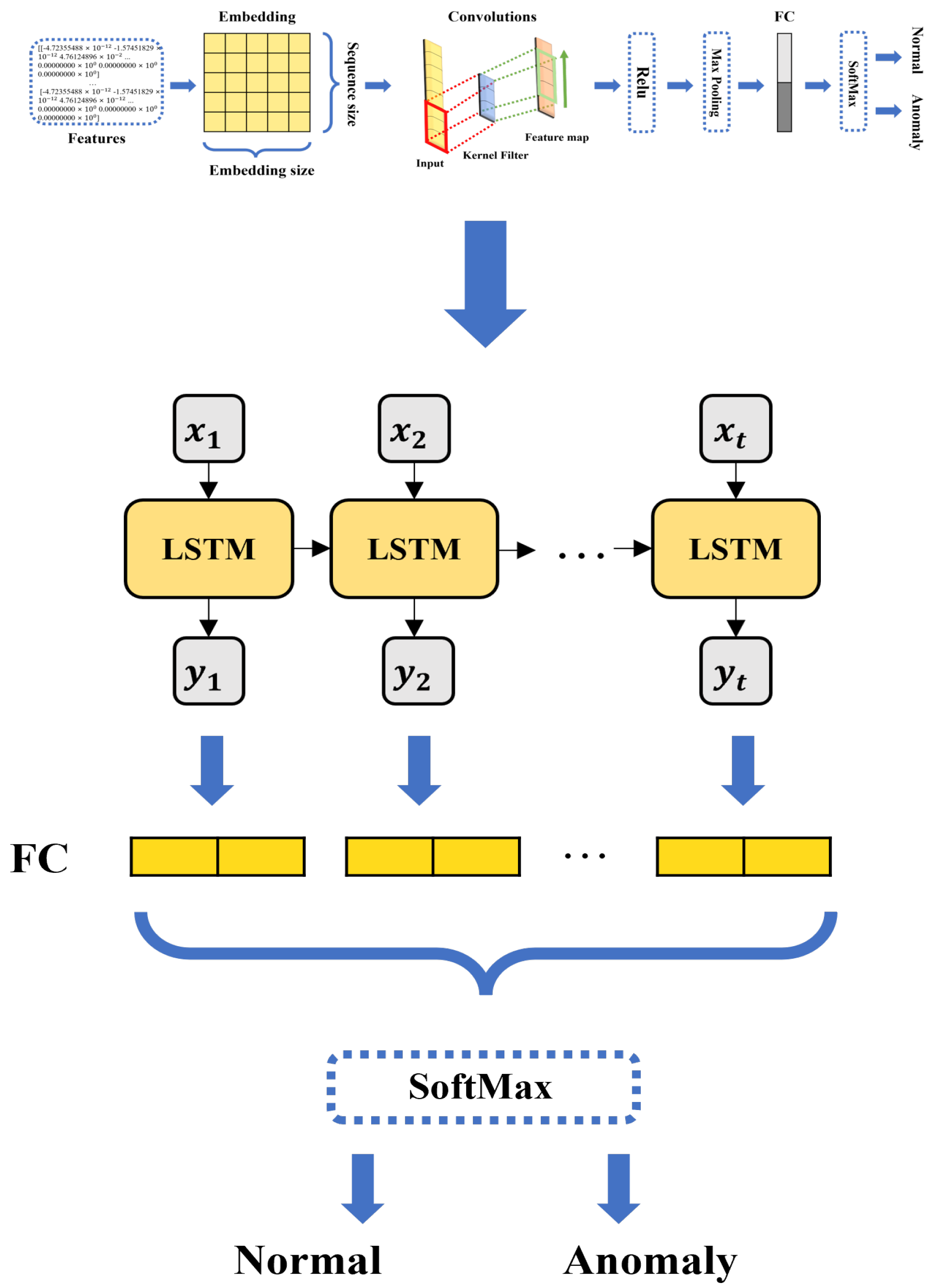
3.2. Anomaly Detection Based on CNN1D
3.3. Anomaly Detection Based on LSTM
3.4. Anomaly Detection Based on CNN1D-LSTM
4. Performance Evaluation
4.1. Dataset
4.2. Environmental Setup and Evaluation
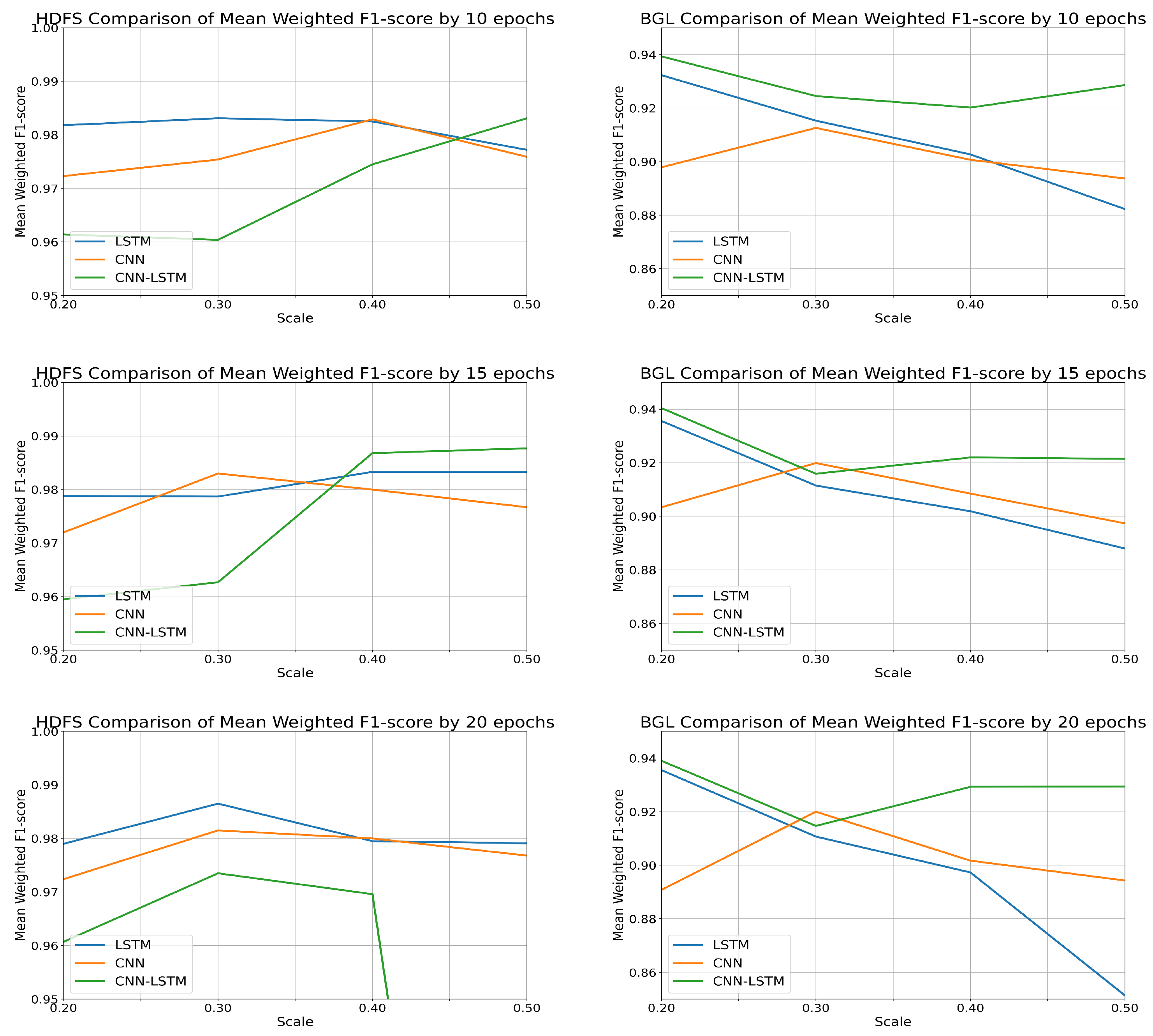
4.2.1. Federated Learning Performance Analysis
4.2.2. Performance Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| FedSGD | Federated Stochastic Gradient Descent |
| FedAVG | Federated Averaging |
| TF-IDF | Term Frequency-Inverse Document Frequency |
| LSTM | Long Short Term Memory Network |
| CNN | convolutional neural network |
| HDFS | Hadoop Distributed File System |
| BGL | Blue Gene/L |
| LLNL | Lawrence Livermore National Labs |
References
- Mi, H.; Wang, H.; Zhou, Y.; Lyu, M.R.-T.; Cai, H. Toward Fine-Grained, Unsupervised, Scalable Performance Diagnosis for Production Cloud Computing Systems. IEEE Trans. Parallel Distrib. Syst. (TPDS) 2013, 24, 1245–1255. [Google Scholar] [CrossRef]
- Anticipating the Unknowns: 2019 Cisco CIISO Benchmark Study. Available online: https://blogs.cisco.com/security/anticipating-the-unknowns-2019-cisco-ciso-benchmark-study (accessed on 13 September 2022).
- Amershi, S.; Lee, B.; Kapoor, A.; Mahajan, R.; Christian, B. Human-guided machine learning for fast and accurate network alarm triage. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence-Volume Volume Three (IJCAI’11), Catalonia, Spain, 16 July 2011. [Google Scholar]
- Le, V.-H.; Zhang, H. Log-based anomaly detection with deep learning: How far are we? In Proceedings of the 44th International Conference on Software Engineering (ICSE ’22), New York, NY, USA, 22–27 May 2022; pp. 1356–1367. [Google Scholar]
- He, S.; Zhu, J.; He, P.; Lyu, M.R. Experience Report: System Log Analysis for Anomaly Detection. In Proceedings of the 2016 IEEE 27th International Symposium on Software Reliability Engineering (ISSRE), Ottawa, ON, Canada, 23–27 October 2016; pp. 207–218. [Google Scholar]
- Web Security Lens. Available online: https://www.websecuritylens.org/tag/sensitive-data-leakage-in-log-files/ (accessed on 13 September 2022).
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.y. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on federated learning. Knowl.-Based Syst. 2021, 216, 106675. [Google Scholar] [CrossRef]
- Saha, S.; Ahmad, T. Federated transfer learning: Concept and applications. Intell. Artif. 2020, 15, 35–44. [Google Scholar] [CrossRef]
- Li, X.; Huang, K.; Yang, W.; Wang, S.; Zhang, Z. On the convergence of fedavg on non-iid data. In Proceedings of the 2020 International Conference on Learning Representations (2020 ICLR), Addis Ababa, Ethiopia, 26–30 September 2020. [Google Scholar]
- He, P.; Zhu, J.; Zheng, Z.; Lyu, M.R. Drain: An online log parsing approach with fixed depth tree. In Proceedings of the 2017 IEEE International Conference on Web Services (ICWS), Honolulu, HI, USA, 25–30 June 2017; pp. 33–40. [Google Scholar]
- Liu, X.; Liu, W.; Di, X.; Li, J.; Cai, B.; Ren, W.; Yang, H. LogNADS: Network anomaly detection scheme based on semantic representation. Future Gener. Comput. Syst. 2021, 124, 390–405. [Google Scholar] [CrossRef]
- Salton, G.; Buckley, C. Term weighting approaches in automatic text retrival. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef] [Green Version]
- Du, M.; Li, F.; Zheng, G.; Srikumar, V. Deeplog: Anomaly detection and diagnosis from system logs through deep learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security(CCS ‘17), New York, NY, USA, 11 July 2017; pp. 1285–1298. [Google Scholar]
- Zhang, X.; Xu, Y.; Lin, Q.; Qiao, B.; Zhang, H.; Dang, Y.; Xie, C.; Yang, X.; Cheng, Q.; Li, Z.; et al. Robust log-based anomaly detection on unstable log data. In Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2019), New York, NY, USA, 26–30 August 2019; pp. 807–817. [Google Scholar]
- Meng, W.; Liu, Y.; Zhu, Y.; Zhang, S.; Pei, D.; Liu, Y.; Chen, Y.; Zhang, R.; Tao, S.; Sun, P.; et al. Loganomaly: Unsupervised detection of sequential and quantitative anomalies in unstructured logs. In Proceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI’19), Macao, China, 10–16 August 2019; pp. 4739–4745. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Lu, S.; Wei, X.; Li, Y.; Wang, L. Detecting Anomaly in Big Data System Logs Using Convolutional Neural Network. In Proceedings of the 2018 IEEE 16th Intl Conf on Dependable, Autonomic and Secure Computing, 16th Intl Conf on Pervasive Intelligence and Computing, 4th Intl Conf on Big Data Intelligence and Computing and Cyber Science and Technology Congress (DASC/PiCom/DataCom/CyberSciTech), Athens, Greece, 12–15 August 2018; pp. 151–158. [Google Scholar]
- She, X.; Zhang, D. Text Classification Based on Hybrid CNN-LSTM Hybrid Model. In Proceedings of the 2018 11th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 8–9 December 2018; pp. 185–189. [Google Scholar]
- Zheng, J.; Zheng, L. A Hybrid Bidirectional Recurrent Convolutional Neural Network Attention-Based Model for Text Classification. IEEE Access 2019, 7, 106673–106685. [Google Scholar] [CrossRef]
- Lin, Y.; Xu, G.; Xu, G.; Chen, Y.; Sun, D. Sensitive Information Detection Based on Convolution Neural Network and Bi-Directional LSTM. In Proceedings of the 2020 IEEE 19th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Guangzhou, China, 29 December 2020–1 January 2021; pp. 1614–1621. [Google Scholar]
- Xu, W.; Huang, L.; Fox, A.; Patterson, D.; Jordan, M.I. Detecting large-scale system problems by mining console logs. In Proceedings of the ACM SIGOPS 22nd symposium on Operating systems principles (SOSP ’09), NewYork, NY, USA, 4–7 October 2009; pp. 117–132. [Google Scholar]
- Tao, P.; Yi, H.; Wei, C.; Ge, L.Y.; Xu, L. A method based on weighted F-score and SVM for feature selection. In Proceedings of the 2013 25th Chinese Control and Decision Conference (CCDC), Guiyang, China, 25–27 May 2013; pp. 4287–4290. [Google Scholar]
- Mothukuri, V.; Parizi, R.M.; Pouriyeh, S.; Huang, Y.; Dehghantanha, A.; Srivastava, G. A survey on security and privacy of federated learning. Future Gener. Comput. Syst. 2021, 155, 619–640. [Google Scholar] [CrossRef]
- Kang, J.; Xiong, Z.; Niyato, D.; Zou, Y.; Zhang, Y.; Guizani, M. Reliable Federated Learning for Mobile Networks. IEEE Wirel. Commun. 2020, 27, 72–80. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Output |
|---|---|
| Input: encoded log | - |
| Embedding | 50 × 16 |
| CNN1D layer: 128 | 10,368 × 128 |
| Dense layer: 128 | 129 × 128 |
| Max Pooling layer: 2 | 0 |
| Dropout layer(0.3) | 0 |
| FC: 2 | 258 |
| Softmax layer |
| Layer | Output |
|---|---|
| Input: encoded log | - |
| Embedding | 50 × 16 |
| LSTM layer: 128 | 117,760 × 128 |
| FC: 2 | 258 |
| Softmax layer |
| Dataset | Train | Test | Total |
|---|---|---|---|
| HDFS | 8,940,503 | 2,235,126 | 11,175,629 |
| BGL | 3,798,370 | 949,593 | 4,747,963 |
| HDFS (Local) | Train | Test | Total |
|---|---|---|---|
| Client 1 | 1,788,100 | 447,026 | 2,235,126 |
| Client 2 | 1,788,100 | 447,026 | 2,235,126 |
| Client 3 | 1,788,100 | 447,026 | 2,235,126 |
| Client 4 | 1,788,100 | 447,026 | 2,235,126 |
| Client 5 | 1,788,100 | 447,025 | 2,235,125 |
| BGL (Local) | Train | Test | Total |
|---|---|---|---|
| Client 1 | 759,674 | 189,919 | 949,593 |
| Client 2 | 759,674 | 189,919 | 949,593 |
| Client 3 | 759,674 | 189,919 | 949,593 |
| Client 4 | 759,674 | 189,918 | 949,592 |
| Client 5 | 759,674 | 189,918 | 949,592 |
| Model | Method | F1 Mean |
|---|---|---|
| CNN1D | Centralized | 0.987 ± 0.005 |
| Federated | 0.983 ± 0.008 | |
| LSTM | Centralized | 0.990 ± 0.0003 |
| Federated | 0.986 ± 0.004 | |
| CNN1D-LSTM | Centralized | 0.991 ± 0.0005 |
| Federated | 0.988 ± 0.006 |
| Model | Method | F1 Mean |
|---|---|---|
| CNN1D | Centralized | 0.947 ± 0.002 |
| Federated | 0.920 ± 0.007 | |
| LSTM | Centralized | 0.970 ± 0.002 |
| Federated | 0.937 ± 0.002 | |
| CNN1D-LSTM | Centralized | 0.971 ± 0.001 |
| Federated | 0.940 ± 0.002 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, T.-H.; Kim, S.-H. Utility Analysis about Log Data Anomaly Detection Based on Federated Learning. Appl. Sci. 2023, 13, 4495. https://doi.org/10.3390/app13074495
Shin T-H, Kim S-H. Utility Analysis about Log Data Anomaly Detection Based on Federated Learning. Applied Sciences. 2023; 13(7):4495. https://doi.org/10.3390/app13074495
Chicago/Turabian StyleShin, Tae-Ho, and Soo-Hyung Kim. 2023. "Utility Analysis about Log Data Anomaly Detection Based on Federated Learning" Applied Sciences 13, no. 7: 4495. https://doi.org/10.3390/app13074495