
A Review of Knowledge Graph-Based Reasoning Technology in the Operation of Power Systems


1
Bell Honor School, Nanjing University of Posts and Telecommunications, Nanjing 210023, China
2
College of Automation & College of Artificial Intelligence, Nanjing University of Posts and Telecommunications, Nanjing 210023, China
3
School of Computer Science, Nanjing University of Posts and Telecommunications, Nanjing 210023, China
4
School of Internet of Things, Nanjing University of Posts and Telecommunications, Nanjing 210023, China
*
Author to whom correspondence should be addressed.
Appl. Sci. 2023, 13(7), 4357; https://doi.org/10.3390/app13074357
Submission received: 28 February 2023
/
Revised: 27 March 2023
/
Accepted: 28 March 2023
/
Published: 29 March 2023
(This article belongs to the Special Issue Grid Innovation in the Era of Smart Grids, Volume Ⅱ)
Abstract
:Knowledge graph (KG) technology is a newly emerged knowledge representation method in the field of artificial intelligence. Knowledge graphs can form logical mappings from cluttered data and establish triadic relationships between entities. Accurate derivation and reasoning of knowledge graphs play an important role in guiding power equipment operation and decision-making. Due to the complex and weak relations from multi-source heterogeneous data, the use of KGs has become popular in research to represent potential information in power knowledge reasoning. In this review, we first summarize the key technologies of knowledge graph representation and learning. Then, based on the complexity and real-time changes of power system operation and maintenance, we present multiple data processing, knowledge representation learning, and the graph construction process. In three typical power operation and fault decision application scenarios, we investigate current algorithms in power KG acquisition, representation embedding, and knowledge completion to illustrate accurate and exhaustive recommendations. Thus, using KGs to provide reference solutions and decision guidance has a significant role in improving the efficiency of power system operations. Finally, we summarize the achievements and difficulties of current research and give an outlook for future, promising roles of KG in power systems.
1. Introduction
With the increasing demand for load at the customer end, the electric power system is transformed into a smart grid [1]. In the era of the Internet of Things (IoT), the “Internet of Everything” is an inevitable trend for future development [2]. In the graph structure, the study of the relationship between individuals in a mega-scale system has extraordinary significance for the overall control of the system and the adjustment among individuals. The graph structure can logically integrate the massive data of the power system into one, which facilitates the management of complicated information [3]. In addition, if the data are extracted and refined to become common knowledge in the field of electric power, they can also provide guidance and suggestions for practical engineering. For example, Ref. [4] analyzed a distributed knowledge graph framework for fault detection in power systems. Multiple devices train partial models for fault detection with the assistance of a central server and then interact with each other through distributed devices in the KG framework. The combination of data and knowledge greatly improves fault detection performance. The fuzzy Petri net (FPN) technique is effectively applied for fault segment estimation [5]. By constructing a fault region identification criterion for smart distribution networks, the accuracy of fault region identification in smart distribution networks can be improved, and the fault segment identification time can be shortened. Ref. [6] proposed an algorithm to evaluate the state of power systems using graph neural networks (GNN). The algorithm is trained using a randomly sampled synthetic dataset and proves the rapidity and accuracy of GNN predictions in various power system test scenarios.
As a new project of AI in power systems, KG is expected to become the core technology of next-generation power systems by shifting the vision from data-centered to knowledge-centered. KG takes the triadic form of entity, relationship, and entity as the basic constituent unit and integrates multi-source heterogeneous data into a logical graph through a series of extraction and fusion techniques. At present, the applications of KG are broadly divided into two categories: general knowledge graph (KG) applications and domain knowledge graph (DKG) applications. For the generic domain aspect, the more common research is semantic search [7]. Semantic search has not only significantly improved the accuracy and predictability of search engines such as Google and Baidu but also injected new vitality into industries such as cloud resource scheduling [8]. For domain-specific aspects, the application of KG in many fields is still not perfect. KG has only been established in a relatively small number of fields, and the more representative ones are medicine [9,10], finance [11,12], and computer technology [13,14]. Although the application of KG in specific industry fields has only just started, it can be found that the introduction of KG technology has brought great convenience and practicality to the development of various industries, and has overcome many technical difficulties that could not be resolved before.
So, why should KG be applied to electric power systems? Referring to examples of successful applications in other fields, we analyze four main characteristics of power systems. ① Complexity. As a complex nonlinear operating system, the model of a super-scale power system is complex. ② Multiplicity. Due to the coupling relationship between the power system and multiple domains, the massive data in the power grid have complex sources and different types. ③ Real-time. The power system needs to change in real-time to meet the increasing load demand on the customer side. ④ Security. Unlike other fields, the power industry requires a very high level of risk control. In more cases, expert experience is often more reliable than AI algorithms.
Based on the above characteristics of the power system, KG technologies are integrated into the power system. The form of the KG graph structure fits with the topology of the power system and can visualize the complex models in the power grid. Knowledge extraction and fusion technology can effectively integrate the massive data in the power IoT center and make full use of data resources. The whole power system is correlated by KG to synchronize the control and adjustment of multiple subsystems. The time-series dynamic KG [15] can realize the simultaneous update of KG and real-time change system to cope with the real-time change in power flow. In addition, the graph structure helps the diagnosis and analysis of events. Its reasoning process is traceable throughout, which makes up for the shortcomings of the uninterpretable neural network model.
In this paper, we provide a systematic review of current research on KG in power systems. We will pose the following research questions.
- ①
- What are the key technologies and necessary processes to build a KG? How to construct a KG in the power domain?
- ②
- Compared with other fields, what are the technical difficulties of KG in power systems? How are they solved?
- ③
- What is the progress of current research on KG, and in which areas are KGs more used in power systems? Which areas are less used?
- ④
- What is the future direction of research on KG in the field of electric power?
To answer these questions, the rest of the paper is organized as follows: Section 2 outlines the key technologies and necessary processes for building a KG. Section 3 discusses the application of KG in power systems. Among them, Section 3.1 introduces the construction method of DKG based on the characteristics of the power system. Section 3.2 describes the current popular research scenarios as well as their technical difficulties. Section 3.3 outlines the current lesser research areas and study ideas. Section 4 highlights the future directions of research on DKG for the power system, which provides a useful reference for its further in-depth application.
2. Knowledge Graph Key Technologies
KG is a structured semantic knowledge base that represents entities in the objective world and their interrelationships in the form of a graph [16]. We can also think of it as an inferable database consisting of triadic datasets. In the KG, the attribute characteristics of entities are represented by “attribute-value” pairs, and the basic unit of inter-entity relationships is the “entity-relationship-entity” triad [17,18].
The KG is essentially a kind of semantic network [19,20]. Additionally, its development history can be traced back to the “mapping knowledge domain” [21] and semantic network [22] proposed in the 1950s. With the advent of the era of big data, traditional one-sided technologies such as data processing, knowledge representation, and natural language processing can no longer meet the needs of scientific research and applications. At the same time, various fields are currently showing an urgent need for new and effective methods of massive data processing. The KG, which integrates the genes of various technologies, provides the possibility of moving from “data intelligence” to “knowledge intelligence” and has become a hot topic of attention.
The key techniques for building KGs can be broadly classified into five categories: knowledge extraction, knowledge representation learning, knowledge mining, knowledge fusion, and knowledge reasoning. The key techniques for building KGs are described in detail in the following comprehensive related research literature.
2.1. Knowledge Extraction
Knowledge extraction plays a decisive role in the process of building KGs. The quality of data extracted from various domains and different sources directly affects the quality of KG construction.
The knowledge extraction process already has well-established standards and mature tools for structured and semi-structured data. For example, the conversion from a relational database to RDF graph data can be achieved by direct mapping. The R2RML mapping [23] allows users to flexibly customize the view on relational data, while the extraction of semi-structured data on web pages is generally completed by wrappers and reduced to complete structured data [24].
The extraction of unstructured data is the difficult part of knowledge extraction. In general, the extraction of free text includes three types: entity extraction, relationship extraction, and event extraction [25].
2.1.1. Entity Extraction
Entity extraction is the first step of knowledge extraction and refers to the extraction of entity information elements from unstructured data.
Traditional knowledge extraction methods utilize a fully or partially labeled corpus for training statistical models, such as hidden Markov models, conditional Markov models, maximum entropy models, and conditional random field models. Currently, neural network learning based on named entity recognition (NER) has shown excellent performance in entity extraction, mainly for convolutional neural networks (CNN) [26], recurrent neural networks (RNN) [27], and neural networks that introduce attention mechanisms [28]. Among them, the LSTM-CRF model connects the words in a sentence into word vectors for output [29]. The long short term memory-convolutional neural networks-conditional random field (LSTM-CNNs-CRF) model [30] adds a CNN model in the embedding layer that can fully extract semantic features in combination with the context. The CNN model obtains the character-level vectors of each word connected with the word vectors and then obtains the annotation results through the LSTM and CRF layers [31]. The attention mechanism-based neural network model proposes a combination method of word vectors and character-level vectors. Such a combination enables the model to dynamically determine the importance of word vectors and character-level vectors of each word in the final features, again improving recognition accuracy [28].
2.1.2. Relationship Extraction
Relationship extraction refers to the extraction of possible relationships from two or more entities and is the subsequent step of entity extraction.
Supervised learning-based relationship extraction is essentially a manual annotation of data and classification of relationships [32,33]. In this case, a vector representation of words and positions in the input sentence based on the deep learning method is used to optimize the entities and relations in the same model using a joint extraction method [34,35]. This joint extraction can avoid the final extraction performance degradation caused by the accumulation and propagation of errors in each sub-stage of the pipeline method extraction [36,37].
Figure 1 below shows the joint model of entity extraction and relationship extraction [38]. The model consists of three layers: a word embedding layer, a word sequence-based LSTM-RNN layer, and a dependent subtree-based LSTM-RNN layer. Entity recognition is performed at the sequence layer, and relationship classification is implemented at the dependency layer. The embedding and sequence layers are shared by the entity recognition and relationship classification tasks. In addition, the shared parameters are jointly influenced by both entity and relationship labels.
2.1.3. Entity Event Extraction
Event extraction refers to extracting event information from natural language text and presenting it in a structured form, which is in line with the idea of relational extraction. The extraction methods are also divided into two categories: pipeline extraction methods and joint extraction methods. Among them, pipeline extraction applies different classifiers of machine learning algorithms at different stages, while joint extraction [42] unites the original sub-task functions into an objective function for optimization and unifies the overall results of time extraction for each sub-task.
2.2. Knowledge Representation
Knowledge must be represented as a database that can be understood and processed by the computer [43,44]. With the emergence of massive data, traditional frameworks for knowledge representation based on discrete symbols, such as RDF triples [45] and OWL languages [46], suffer from low computational efficiency and severe data sparsity. Continuous vector-based knowledge representation learning has the advantages of significantly improving computational efficiency, effectively alleviating data sparsity, and achieving heterogeneous information fusion. Thus, the research on KG embedding models is gradually intensifying.
Continuous vector-based knowledge representations can be directly docked to neural networks. The knowledge representation embedding projects the entities and relations of the KG into a low-dimensional continuous vector space. Each entity and relation can obtain a low-dimensional vector representation. In the vector space, the vectors discover new entities, new relationships, and implicit potential knowledge by numerical computation.
Classical KG embedding methods with distance transfer models [47] (such as TransE, TransH, TransR, and TransD) can solve one-to-one, one-to-many, many-to-one, and many-to-many relationships. In essence, it is a matter of transforming the vectorized triplet into a distance between the head and tail entities. For each triad , a suitable is found for the vectorized representation of the head entity and the tail entity. Additionally, the relation is a translation from the head entity vector to the tail entity vector so that the vectors corresponding to the triad eventually satisfy
In addition to the transfer distance model, knowledge graph embedding can also employ the semantic matching model, which focuses on mining the underlying semantics between entities and relationships. As the main model in this direction, the RESCAL model [48] encodes KG as a three-dimensional tensor, and then decomposes the tensor into a core tensor corresponding to the relationships and a factor matrix corresponding to the entities. The probability of triad formation for different combinations of entities and relations is calculated based on the scoring function. Moreover, the DistMul model [49] restricts the factor matrix to a diagonal matrix. Although the model is simplified, it can only deal with symmetric relations.
The embedding of KGs can be applied to link prediction [50,51,52] by implementing three KGs of the complementation. When the embedding learning of the KG is completed, for the that need to be linked to the prediction, each entity of the KG can be placed on the tail entity position. The scoring function of the RESCAL model is used to calculate the score of different entities put into the tail entity, and the highest-scoring entity is the result of link prediction.
2.3. Knowledge Mining
Knowledge mining refers to mining new knowledge from existing entities and relationships to supplement information [53], which is an essential technical tool in the process of large-scale KG construction. It mainly includes entity linking and rule mining.
2.3.1. Entity Linking
Entity linking is the process of linking entity names of text to target entities in the knowledge base. First, the entity names in the text are identified by named entity recognition techniques of knowledge extraction. Then possible candidate entities are identified by employing search engines, etc. Finally, the entity referred to by the entity name is identified from the candidate entities, and entity disambiguation is completed.
Candidate entity disambiguation [54] can be considered a ranking problem, where a given entity refers to the corresponding candidate entities in the order of connection probability. It can be implemented in the form of graphs and deep learning. Among them, graph-based approaches [55] represent entity mentions, entities, and the relationships among them in the form of graphs, and then perform collaborative reasoning on the relationships on the graphs. The deep learning-based approach [56] computes the semantic relevance of entity mentions and entities through neural networks to achieve link matching.
2.3.2. Rule Mining
Rule mining [57] focuses on discovering the associative relationships between two entities for inferential prediction. There are two common approaches to relational inference. Rule-based approaches mainly use machine learning-related techniques such as Horn clauses or inductive logic (FOIL) [58] to reason about the potential relationships between entities. Probabilistic graph-based approaches tend to efficiently classify entities and relations in a knowledge base to form Markov logic networks [59] from which potential relations between entities are inferred.
The path ranking algorithm (PRA) [60,61,62] is a KG link prediction algorithm. It uses relational paths as features to predict possible feature relationships between entities by discovering a set of relational paths that connect two entities. Since the obtained relational paths are a kind of Horn clause, they can convert the computed features into logical rules and facilitate the discovery of hidden knowledge in the graph [63].
2.4. Knowledge Fusion
Knowledge fusion [64] plays an important role in managing multiple KGs, performing KG merging, reusing knowledge, and achieving semantic interoperability among heterogeneous data sources. Knowledge interoperability and integration through ontology mapping [65] and instance matching [66] is an effective way to solve the KG heterogeneity problem. Various current fusion techniques include natural language processing-based term comparison, structure-based matching, and instance-based machine learning techniques. Among them, a model-based semi-supervised learning framework can automatically find instance matching rules by iterating [67] to gradually improve the quality of the rule set. The model uses continuously updated rules to find high-quality matching pairs, which can achieve effective matching of large amounts of instance data.
2.5. Knowledge Reasoning
Knowledge reasoning [68,69] is the most central step in KG construction and is actually used to achieve real-time updates of the KG. Among them, inference is an important goal of knowledge representation, which can be divided into deductive-based knowledge inference and inductive-based knowledge inference. In the future, the two approaches will be further integrated to take advantage of their respective strengths and accomplish the reasoning task together.
2.5.1. Deductive-Based Knowledge Reasoning
Deductive-based knowledge reasoning includes ontology reasoning and logic programming-based per-rule reasoning methods. Ontology reasoning only supports reasoning over predefined ontology axioms. Rule-based reasoning starts with the Prolog language [70], and a series of Datalog languages [71] are developed later, which can customize rules according to specific scenarios to implement user-defined reasoning processes.
2.5.2. Inductive-Based Knowledge Reasoning
Inductive-based knowledge inference no longer requires explicit inference steps but is mainly the learning and summarization of existing data. In addition to the observation of large amounts of data, it also includes rule constraints on a priori knowledge to achieve precise inference.
The embedding model for knowledge representation learning allows the algorithm to automatically capture and reason about the required features in the process of learning vector representations to accomplish the task of link prediction of multiple relationships. The classical TransE model [72] is designed to train to obtain the representation learning results of KG using a loss function with a maximum interval between positive and negative samples. The loss function is
where denotes the set of positive samples in KG; denotes the negative samples of , obtained by replacing either the head entity or the tail entity on-the-fly during training. denotes . denotes the interval in the loss function , a super parameter greater than zero that needs to be set. takes either the or norm to represent the score function of the TransE model, designed as
where the degree of approximation between and is measured by vector. To achieve the training objective of the TransE model to make the loss function as small as possible, for positive sample triples should be as small as possible, and for negative sample triples should be as large as possible. We train the function using a gradient-based optimization algorithm until convergence.
TransE is a simple and efficient method of KG representations but suffers from a lack of expressive power and can only capture one-to-one relationships. In fact, there is not only one-to-one correspondence between entities, but also one-to-many, many-to-one, and many-to-many relationships. To express more complex relationships, TransH [73], TransR [74], and TransD [75] distance transfer models are developed to enhance the expressiveness of the TransE using multiple spaces to perform triad score calculation by projection. The vector space assumptions for the above four distance transfer models are plotted in Table 1.
2.5.3. Automatic Updates for Reasoning
To meet the need for automatic KG updates, they are usually achieved by adding algorithms such as machine learning to the KG. For example, models based on a semi-supervised learning framework [67] can automatically find station matching rules and continuously train themselves. Table 2 lists the concrete information of common large-scale KBs. Automatic updating of knowledge is possible in most of the currently available large-scale knowledge bases.
In terms of automatic updating, the NELL [85] system has data from the internet and implements self-correction and automatic updating functions during the database construction process. The YAGO 4 [82] system proposes a reasonable knowledge base combining Wikidata [86] and schema.org that can also automatically update the current state. It can be observed that all of these KBs have high-quality information and cover a wide range of fields and can be used by a wide range of industries.
3. Applications of Knowledge Graphs in the Power System Operation
At present, KGs are roughly divided into two categories: the general knowledge graph and the domain knowledge graph (DKG). As a specific domain of KG research, the power DKG undertakes the mission of shifting from “data-driven power automation” to a “knowledge-driven smart grid”, which has important theoretical value and engineering significance for the power industry.
In the following, we will introduce the power DKG from several perspectives: the overall construction process of power DKGs, the typical application scenarios of KGs, and the application of KGs in other aspects.
3.1. The Overall Construction Process of KG in the Power System Field
Based on the characteristics of the power system introduced in Section 1, the KGs are applied to the power field to provide convenience for grid operation. Based on the construction methods of KGs in Section 2, this subsection proposes an overall construction model for the power domain KG [87]. The construction of a DKG is roughly divided into three parts: data collection, graph construction, and knowledge calculation. Figure 2 below shows the general process of a power KG construction.
3.1.1. Data Acquisition
As the first step to building the mapping, the collected data directly determines the quality of KG. The data in the power domain comes from a wide variety of sources and types. The structured data stored in the knowledge engineering and expert experience knowledge base in the power domain can directly participate in the top-down ontology construction of KG without processing. However, it is the massive data generated in the actual operation and the experience of experts that are the main data sources in the power domain. These data have the characteristics of high noise and sparse data density [16]. Therefore, noise filtering and data sample expansion need to be completed before knowledge processing to improve the quality of the acquired data. These processed semi-structured or unstructured data contain a large amount of potential knowledge that needs to be transformed into structured knowledge information through a series of operations [88] and then involved in the construction of the KG.
3.1.2. Graph Construction
For the characteristics of strong professionalism, complicated data, and high accuracy in the field of electric power, graph construction generally adopts a combination of top-down and bottom-up construction processes [89]. The ontology layer is defined first, and then the knowledge is extracted from the data layer to update the ontology layer. This construction method adds newly extracted knowledge using existing data to construct KG, which can meet the dynamic characteristics of real-time updates of the power system.
The quality of the extracted knowledge affects the quality of the final KG. As described in Section 2.1, the joint model of entity extraction and relationship extraction in knowledge extraction [90] has more accurate extraction results compared to pipeline extraction. This model avoids the degradation of extraction performance due to error accumulation and propagation. Moreover, considering that the extracted entities, concepts, relationships, attributes, and other power system information come from different grids and power devices, the existence of multiple representations of the same entity can lead to duplication of knowledge. We can use the knowledge fusion technique mentioned in Section 2.4 [88] to eliminate the redundancy of data from different sources and achieve interoperability of individual isolated power system knowledge. The integrated knowledge is mapped into the KG ontology to realize the bottom-up construction process of KG.
3.1.3. Knowledge Reasoning
Through ontology construction and knowledge extraction and fusion, we can obtain the overall framework of the power system KG. By processing complex KG for knowledge reasoning, we can discover more potential knowledge based on existing knowledge sets. Section 2.5 introduces several knowledge reasoning methods applicable to specific situations in the field of power systems. Through the application of knowledge reasoning technology, KG can gradually improve and provide service functions such as recommendation, Q&A, and decision-making.
Deductive and inductive reasoning, mentioned in Section 2.5.1 and Section 2.5.2, respectively, apply to different research contexts in the field of power. (1) As one of the deductive reasoning methods, the method based on generative rules strictly follows the prescribed mechanism to execute the rules to achieve the corresponding objectives. Although the process of matching rules is highly interpretable, the method is less flexible and difficult to adapt to the complex and real-time emergent situations in the electric power domain. Therefore, the method is only applied in the definition of rules such as grid dispatching regulations and customer service business processes to provide users with a logically rigorous knowledge search. (2) Common inductive reasoning methods in DKG are case-based reasoning and representation learning-based reasoning. ① Case-based reasoning first requires the establishment of a historical case events base. The similarity between the current event and the base case is then calculated to recommend a high-matching historical treatment solution for the operator as a recommendation function. ② The reasoning based on representation learning [91] automatically captures and infers the required features in the process of vector representation to complete the link prediction of multiple relationships. As a more used inference method in the power field, representation learning inference can achieve efficient inference in KG, and the score function of the triplet is highly interpretable. However, the drawback is that the inference process is limited to the form of a triad, which cannot combine other information at the same time, and the inference results may not be accurate enough on some occasions. ③ The latest research on knowledge inference reads KG features by neural network models [92] and adopts the “massive data + self-learning” model to cope with the increasingly complex grid structure and increasingly unpredictable customer behavior. However, the black-box nature of neural network machines to read and generate prediction results automatically makes it difficult to interpret the inference results.
3.1.4. Storage Options
The two main approaches to storing KG are RDF tables and graph databases. As introduced above, the traditional RDF format [45] stores data in the form of triples and uses table links to perform graph traversal. The common query language SPARQL is not designed for complex graph analysis and will lead to obvious time consumption. The graph database represented by Neo4j [93] stores data in the form of graphs, which can significantly improve the storage and processing efficiency of massive data in the power grid and provides an implementation solution for building a ubiquitous power IoT. Therefore, graph databases are widely used to store domain knowledge in the power domain KG.
Ref. [94] investigated the Neo4j storage method based on the topology of the power grid itself and verified the feasibility of the graph database in four practical scenarios in the power sector, respectively. The method visualizes the association between grid devices, provides easy equipment finding and management, and is a basic prerequisite for subsequent operations such as fault checking. Ref. [95] compared the performance of RDF tables and graph databases in a power equipment management KG. It was found that as the number of queries increased with the complexity of query content, the difference in query time between the two databases became apparent. Graph database queries were 2–3 times faster than RDF. Moreover, due to the built-in parallelism, the graph database queries were 16–17 times faster than RDF for aggregate queries with multiple starter nodes. Further, graph databases store data with attribute information that is more relevant to applications in complex power situations.
3.2. Power System Operation Application Scenarios for the KG
The current research on KG in the electric power field has just started, and the current KGs in the electric power field are all from one of the angles. Referring to other DKGs, the research of experts and scholars first focuses on typical scenarios such as power equipment operation and maintenance, customer service, and grid dispatch fault. As shown in Figure 3, with the help of KG functions such as knowledge search, knowledge Q&A, intelligent recommendation, and auxiliary decision-making, KG can achieve the engineering significance of reducing human and material costs and improving work efficiency. On this basis, future academic research on power KG will be extended to a more comprehensive power system.
3.2.1. Power Equipment Operation and Maintenance (O&M)
Highly invested power equipment requires constant inspection and maintenance to enhance its service life and meet increasing load demands. Traditional O&M of power equipment uses standards based on expert experience and requires operators to make manual judgments about faults. However, it is not accurate to report abnormal situations in the power system. In the era of big data, considering the complexity and variability of power grids, a series of self-learning methods combined with algorithms and predictive models can flexibly develop O&M plans [96]. Especially, the representation of KG in equipment O&M has unique advantages and is still worth studying. Ref. [97] compared several representations of defective texts for electrical equipment. As shown in Table 3, compared to several other representation methods, the KG representation method had the best results for the three indicators of precision, recall, and F1-score. This also explains that it is necessary to represent the power equipment data with knowledge graphs.
Long-running power equipment accumulates a large amount of text information such as O&M logs and power inspection work orders. Based on the textual data in logs and sensor data, the knowledge data structure can organically relate the interacting devices to the KG. Therefore, we could combine these unstructured data with industry-standard documents and equipment online monitoring data to build a power equipment O&M decision KG. In this way, the KG can realize the data holographic perception of power IoT and carry out intelligent operation management and fault maintenance [98]. The use of KG technology to assist in the O&M of power equipment can be summarized in four steps: ① Building a fault corpus and semantic model for text and complex scenarios in power equipment. ② Developing data cleaning modules for error identification and quality improvement of texts. ③ Automatically constructing a large power equipment KG and a fault pattern KB. ④ Assisting with appropriate machine learning methods for specific problems. Using the case-based reasoning approach in Section 3.1.3, KG technology can provide fault-assisted decisions. For a new defect record, such as transformer oil leak, the case-based reasoning approach can look for similar paths in the KG. By applying the idea of the path ranking algorithm (PRA) to these paths for similarity ranking, KG can provide a new decision based on previous processing methods. This process enables reasoning and prediction of entities and their relationships, providing the user with answers and an intuitive analysis process. As shown in Figure 4, when an operator inputs a fault, KG first obtains the input entities and relationships through extraction techniques, then matches the extracted content with the fault information corpus and the expert experience KB by path matching, and finally selects the case with the highest path matching ranking to the operator as the matching maintenance plan. Therefore, the application of KG improves the intelligence and efficiency of power equipment operation and management and is important for practical decisions on defect handling.
The named entity recognition (NER) in the fault text is a major difficulty in the equipment O&M KG construction. The subjectivity of the O&M logs, the inconsistency of the recording methods and text structure, and the deviation in the way to describe the same fault all cause trouble for knowledge extraction. Meanwhile, the same entity has multiple names. Additionally, some special characters may be accidentally lost in the text extraction. All of the above factors will affect the quality of extraction and the quality of the final KG. Nowadays, with the expansion of databases and the development of AI, LSTM-CRF [99], Bi-LSTM-CRF [100], LSTM-CNNs-CRF [101], and neural network models based on attention mechanisms [34] are widely used in the power domain. In equipment fault texts, the bi-directional LSTM model with CRF layer (Bi-LSTM-CRF) can fully extract semantic features in combination with the context: firstly, compared with neural network models, Bi-LSTM models can avoid the gradient explosion and gradient disappearance of RNNs; moreover, the CRF model can accomplish sequence labeling and avoid sequence drift. To compare the recognition effectiveness of the different models in power texts, Table 4 evaluates LSTM, Bi-LSTM, and Bi-LSTM-CRF in terms of three metrics: precision, recall, and the overall evaluation metric F1. It proves that the Bi-LSTM-CRF model can identify keywords for business operations with high accuracy, fully extract the information features of text passages, and enhance the fast retrieval and recommendation capability of the grid. Ref. [102] showed the recognition results of CRF and Bi-LSTM models. Compared with Bi-LSTM, the CRF model has an accuracy of 83% for entity extraction, which is more suitable for entity extraction in the power domain KG. Considering the influence of textual information around the numbers on the training of numerical vectors, Ref. [103] proposed an optimization model based on the Bi-LSTM-CRF. The new model can identify the information of faulty text more accurately. Additionally, the F-value is improved by 5.6% compared to the base model.
KG can also cooperate with a variety of technologies for power equipment O&M. In the error checking of defective texts, merging and sorting rules can be formulated for the difficult problem of word ambiguity to improve the accuracy of word separation. Intelligent query systems for electrical equipment can incorporate Q&A sessions into the O&M of electrical equipment: first, a pure Bayesian classifier can segment and feature word classification of user questions; then, relevant knowledge is retrieved from the Neo4j database for Q&A matching based on the extracted features to provide solutions and preventive measures. Moreover, the combination of power IoT and KG technology is the solution to problems such as the continuous increase in real-time data and complex operating situations. The graph structure form of KG allows for the organic linking of interacting devices in a graph. We can use the KG technology to achieve holographic awareness of data for the power IoT and to perform intelligent operation management [104] and fault maintenance [98] of power equipment: for example, [105] integrated multiple sources of data in power end devices in the power IoT to achieve holographic sensing of all power devices, allowing real-time knowledge of device conditions.
3.2.2. Power Customer Service
From manual consultation to the use of mobile customer service applications, customer service in the power domain is undergoing a transition from manual to intelligent service. Customer service applications on mobile can overcome geographical barriers and provide standardized services to customers. However, for demands that are hard to identify, human customer service is still required online. Manual customer service has varying response efficiency and personal experience in practice, making it difficult to ensure customer satisfaction. As an important part of power marketing, building a KG for the customer service domain to provide back-end support for mobile applications is a breakthrough in the field of intelligent customer service [106]. By extracting knowledge from dialogue business processes, voice information, and customer service experience and combining it with structured standard Q&A pairs in customer service KB, the power customer service KG is built with both top-down and bottom-up methods. The service process combined with the neural network model provides users with business consultation, fault recovery, and user satisfaction surveys, and other functions accurately and effectively locate their requests, realize efficient knowledge management [107], knowledge Q&A [108,109], and recommendation [110]. Therefore, intelligent customer service has become a research hotspot in the electric power field.
The understanding of customer intent is a difficult issue for power customer service KG. Unlike the above two scenarios, which can be handled directly by the KG, customers do not understand the expressions of terminology in the field of power. Without a clear problem description, it is difficult to query the corresponding solution. As a customer-oriented service industry, power marketing inevitably involves understanding user intent in human–machine interaction. How to identify the user’s intent from the conversation and represent the intent in a trivial form that can be understood by KG is the key to the successful application of customer service KG. The traditional method is similar to NER. For example, [111] segmented the business request text to obtain a splitting of the utterance text. The segmentation is performed with the constructed KG for entity designation recognition, candidate entity generation, and candidate entity disambiguation to determine whether it belongs to the business keyword. In a recent study, the Bert model [112] used unlabeled data to vector-code input utterances, vectorize them, and then feed them into a feedforward neural network. The network can automatically determine user intent based on the intent probability distribution. Ref. [113] first pre-trained user input utterances and then achieved an intention recognition accuracy of 92.31% with the pre-training of the Bert model. In addition, the XLNet model [114] has a higher accuracy rate compared to the Bert model. The hybrid neural network rumor detection model based on XLNet [115] achieved an accuracy of 93.56%. The XLNet model is a hot research topic in the field of NPL and a tool that can be adopted in the power market.
There are several application scenarios for KG in the field of power customer service. Ref. [113] established an intelligent Q&A architecture based on the knowledge corpus. After recognizing a customer’s intention, the expertise is integrated into the dialogue through dialogue process configuration, natural language processing (NLP), and other modules to transform the user’s natural language into structured and findable language. Customers can follow the process guidance to complete the demanded business and enjoy intelligent Q&A services. Ref. [116] stored customer service history data in the Neo4j graph database. Knowledge extraction and knowledge management are performed in the built KB to build the KG platform application system. First, the Bi-LSTM model obtains the features of input questions and marquee attributes. Then, the attribute whose objective function is closest to the input question in KG is calculated. The attribute is linked to the answer to the query question. Ref. [111] studied power customer service robots. As an AI means in the back-end of intelligent robots, the KG is used to assist robots in providing consulting services to users through mobile applications in the form of text, voice, and video. In addition, KG technology can also be used in other business scenarios in the field of power marketing [117]. Taking electricity sales as an example, fluctuations in power sales are influenced by multiple factors such as business expansion, line losses, and power substitution. We can use the KG to show all of the factors affecting the change in electricity sales in a multi-dimensional way. Thus, the graph structure can quickly identify and locate abnormal fluctuations and provide corresponding solutions. When a power failure occurs, KG technology can contact the person in charge of the area according to the location of the failure and notify the customer in time. It will also bring new vitality to power marketing in terms of electricity bill payment reminders, family identity recognition, and personalized recommendations.
Unlike previous AI customer service, KG-driven online service keyword entity matching is not just shallow similarity matching. Instead, it statistically analyzes the most interesting problems of users through big data technology and excavates customers’ real needs through deep semantic understanding. For example, a special recommendation algorithm based on users’ historical comments [118] combines with algorithmic models to provide users with the best solutions. The future customer service business of electric power systems will be dedicated to combining with various popular social media. Electricity customer service can interact with users in internet communities to determine their real needs and provide them with personalized and customized services [119].
3.2.3. Scheduling Fault Decisions
As the power system has expanded and become more complex, the dispatch fault decision mechanism has undergone a series of changes. Initially, power dispatch faults required manual decisions by operators based on personal experience [120]. Then, grid companies used dispatch expert systems to determine fault problems [121]. However, scheduling faults are never able to be detected precisely. At the same time, the past methods made it difficult to diagnose faults quickly and could not automatically provide appropriate solutions. As a guarantee for the continuous and stable operation of the power system, the dispatching link needs new technologies to automatically diagnose faults. The powerful knowledge reasoning and graphical format of KG technology are capable of mining the latent relationships between entities and giving precise and targeted decision solutions for faults present in line transmission.
The key steps to realize automatic decision-making on power dispatch faults are as follows. First, obtain a large amount of scheduling fault information, such as scheduling protocols, expert experience, and fault cases. Then, extract a large amount of dispatching terminology from the semantic text and combined it with the structured operation data of the power grid to build a corpus of terminology and faults. Eventually, a large number of dispatching rules in the semantic library are learned and reasoned [122] to build a KB exclusively for dispatching decisions. Once a fault occurs, KG technology can perform knowledge search and reasoning, mobilize the semantic and knowledge bases for the corresponding scenario, and automatically discover fault conditions such as overload, high-power loss, and voltage deviation. Based on the fault content, the corresponding control objects and operating procedures are provided from the fault decision KB [123].
The introduction of KG provides new ideas for dispatch fault handling. The business logic KG constructed by combining bottom-up and top-down approaches helps us perceive the business relationships of the dispatching system and assists operators in performing auxiliary fault analysis in the case of system faults. As the software part of a system, KG technology can search for grid equipment KG according to grid regulation and control requirements and generate new dispatching decision solutions in a shorter time. Intelligent dispatching with KG-assisted decision-making can solve the problems of long dispatching time and low dispatching frequency of the current dispatching system. Based on the integrated ontology KB, a decision support system for emergency dispatch of power systems was developed in [124]. The system enables knowledge extraction for online control of power systems in emergencies and automates intelligent emergency dispatching. In addition to this, the combination of neural network models and various algorithms enables a shift from traditional dispatching to smart grid dispatching. For example, GCN [125] can automatically learn any graphical feature. Ref. [126] used GCN to read features from the scheduling domain KG. The knowledge representation and inference of the read features provide decision support for risk management, load balancing, and system optimization in scheduling with reduced scheduling errors. Although KG research in the field of power grid dispatching accounts for the majority of the KG in power systems, most of the current research is focused on dispatching fault decision-making [127]. In addition to fault diagnosis, many other aspects of power dispatch lend themselves to fast and accurate problem-solving in the form of graph structures. We need more in-depth and systematic research on real-time monitoring and warning, safety inspection, dispatch planning, and management [128].
Scheduling has many risks in practice and requires the integration of multi-domain knowledge to improve the safety of the grid and the accuracy of decisions. As shown in Figure 5, we can carry out multiple risk coupling analyses for complex power grids. Through the construction of each sub-domain KG, the different needs of each professional field are fully considered to reduce the risks of grid operation and provide the grassroots staff with more rapid and better auxiliary decision-making solutions. In addition, based on the KG technology, how to realize automatic fault location in the dispatch automation system and achieve fully automatic completion of intelligent fault diagnosis and location is a question of great significance in the dispatch decision-making field.
3.3. Other Applications of KG in Power Operation
In the intelligent Q&A system for power grid knowledge [129], heterogeneous data can be fused to initially construct KG. Then, the paths are sorted based on the idea of a path ranking algorithm (PRA) in rule mining to realize the reasoning and prediction of keyword entities and their relationships, providing users with answers and an intuitive analysis process. For specialized terms in the electric power field that are difficult for users to grasp, multidimensional semantic search [130] and intelligent recommendation methods [131] are used to mine the user’s search intention and help users execute effective queries.
In terms of power monitoring information, KG extracts the cumbersome base station information based on the characteristics and laws of the grid, equipment, and monitoring work. After filtering redundancy, the real fault information can be stored in Neo4j [132]. In Figure 6, we constructed a grid incident behavior KG based on monitoring signals of a small substation. In the KG, we can explore an effective “event-based” monitoring method by linking the abnormal information and process disposal of events. This method can avoid misjudgments and omissions caused by a human error through knowledge reasoning, help staff to complete the processing and prediction of most daily monitoring work and improve the efficiency of incident handling. In the future, we can connect monitoring and alert information to major business platforms to provide a comprehensive analysis of the basic data to assist and enhance the dynamic alert and risk warning capabilities of power grid operation.
In the field of power metering, to construct KGs that unify terms across domains, it is necessary to fuse heterogeneous data from different sources and to fuzzify different descriptions of the same term. Ref. [133] used a Bert-based knowledge extraction model to extract triadic information from the corpus. Then, the power metering KG was constructed based on text matching. Past power meter inspection methods were excessively dependent on the operator’s skill. Recently, Ref. [134] constructed power verification KG based on the RDF storage format and performed knowledge inference using the TransE model. Although the database and the inference model are slightly outdated compared to current mapping techniques in other fields, the application has improved the accuracy and efficiency of power meter inspection and protected the interests of power companies and customers.
In the area of electric power safety regulation, two major challenges are being faced at present: the lack of entity and relationship data for electric power safety regulations and the complexity of inter-textual relationships. The current research is still stagnant in entity identification [135] and accurate extraction of entity relationships [136] in power safety regulations. As a key link in the field of electric power systems that cannot be ignored, a deeper study of power safety regulations KG will become the future research direction in the field of power safety.
In addition to this, Ref. [137] proposed an optimal KG-based penetration path scheme for when the power system is under attack. To promote the process of power system automation and reduce manual operations, the KG-based human–computer interaction model [138] uses the TextRank algorithm [139] for entity extraction and extracts logical relationship entities based on semantic rules. Knowledge fusion imports the ternary data results into the Neo4j graph database to form a KG that can be queried and used.
4. Further Improvements for KG Technologies in the Power Field
The application of KG in the electric power field is still in its initial stage, and the initial research mainly refers to the application of KG in other fields. Building KG in the electric power field still needs more adjustments and innovations in technology combined with actual scenarios. In the future development of AI, KG adapted to the field of large-scale power systems should make improvements in the following areas.
4.1. Data-Driven, Knowledge-Driven Integration
In the era of big data, massive data volumes need to be analyzed by computer before they can be used. In the current AI field, some decisions are mainly based on the data-driven model of “massive data + self-learning” to solve problems with algorithms. However, purely data-driven AI is not robust and is uncontrollable, and the black-box process of model computation is unexplainable. In general, the first-generation AI [140] is mainly knowledge-driven, relying on expert experience and industry standards to provide quality knowledge, which is highly demanding. The second-generation AI [141] is mainly data-driven, and the processing is fuzzy and unreliable. Both approaches are one-sided. The third-generation AI can incorporate knowledge into data-driven [142], which reduces the danger of data-driven while avoiding the subjectivity of knowledge itself. This way can enhance the interpretability of the process and achieve reliable and trustworthy AI.
4.2. Multi-Source Data Fusion and Dynamic Updates
The data in the field of power systems come from a wide range of sources and types, and different types of data are extracted using methods that match the characteristics of the data. For example, manually recorded subjective data such as power equipment O&M logs can be combined with neural network technology for NER [143], and for customer demands received by power customer service, deep semantic mining to understand the intent [113]. Only by extracting high-quality knowledge and providing a rich data source for subsequent knowledge calculation can high-quality recommendation and Q&A functions be realized.
The DKG needs to be updated dynamically in real-time to meet the actual situation of real-time changes in the electric power field. During the operation of the power system, the time-series dynamic KG is established according to the key technologies of the new-generation KG to constrain the real-time changing tide, load, and other attributes. Through TTransE [144], CyGNet [145], and other time-series KG representation models, the KG is synchronized to flow with the power system.
4.3. Power System Big KG Unification
The development of power IoT technology breaks the isolation of each power grid and power equipment and realizes real-time data interconnection and sharing. These data have high research value and engineering significance. At present, the grid integration data collected by the data center have not been fully mined. The presentation of the KG graph structure meets the requirements for the expression of complex models in the electric power field. Therefore, we can use graph technology to extract and mine the data from the IoT center to represent the electric power IoT integration data in a graph structure [25]. In turn, the value of the data can be brought into play by reasoning the association between entities through knowledge calculation to guide scenarios such as fault maintenance, equipment management, and customer demand in actual engineering.
At present, the power IoT has not yet established a knowledge base corresponding to practical applications using its data. Therefore, we can first study the establishment of a small-scale KB and KG construction in a certain scenario. When the construction of KGs in each field is completed, the independent KGs in each part will be fused into a unified, large KG in the electric power field to realize the transformation from “data integration” to “knowledge integration”.
5. Conclusions
In this paper, we presented a comprehensive review of current representative research efforts and trends in knowledge graph-aware power systems. In general, this paper aimed to answer two questions: how to extract knowledge from a power operation system to construct KG, and how to apply KG reasoning technology to improve power system operation. Focusing on the knowledge graph, we analyzed the graph construction process in some typical application scenarios. Additionally, based on the current research, we further discussed the future direction of graph technology development. The integration of knowledge-driven and data-driven, combined with artificial intelligence technology to build a dynamically updated KG, can meet the real-time change characteristics of power system data and improve operational efficiency. At present, the application of KGs in the power system has just started; these currently constructed KGs can only represent factual knowledge or entity-centered structured knowledge. Power system operation based on graph technology still needs to be further studied.
Funding
This research and the APC was funded by STITP (Science and Technology Innovation Training Program) of Nanjing University of Posts and Telecommunications grant number 202210293115Y. Kang Xu is supported by the Young Scientists Fund of the National Natural Science Foundation of China (Grant No.62202240).
Data Availability Statement
No new data was created for this study.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Marot, A.; Kelly, A.; Naglic, M.; Barbesant, V.; Cremer, J.; Stefanov, A.; Viebahn, J. Perspectives on future power system control centers for energy transition. J. Mod. Power Syst. Clean Energy 2022, 10, 328–344. [Google Scholar] [CrossRef]
- Xie, C.; Yu, B.; Zeng, Z.; Yang, Y.; Liu, Q. Multilayer internet-of-things middleware based on knowledge graph. IEEE Internet Things J. 2020, 8, 2635–2648. [Google Scholar] [CrossRef]
- Wu, Q.; Zhao, W.; Li, Z.; Wipf, D.P.; Yan, J. Nodeformer: A scalable graph structure learning transformer for node classification. Adv. Neural Inf. Process. Syst. 2022, 35, 27387–27401. [Google Scholar]
- Zhou, Y.; Lin, Z.; Tu, L.; Song, Y.; Wu, Z. Big Data and Knowledge Graph Based Fault Diagnosis for Electric Power Systems. EAI Endorsed Trans. Ind. Netw. Intell. Syst. 2022, 9, e1. [Google Scholar] [CrossRef]
- Liu, Z.; Qin, L.; Yu, X.; Wu, F. Fault section identification method of intelligent distribution network based on Fuzzy Petri net and multi-source data. In Proceedings of the 2022 14th International Conference on Measuring Technology and Mechatronics Automation (ICMTMA), Changsha, China, 15–16 January 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 356–360. [Google Scholar]
- Kundacina, O.; Cosovic, M.; Vukobratovic, D. State estimation in electric power systems leveraging graph neural networks. arXiv 2022, arXiv:2201.04056. [Google Scholar]
- Muennighoff, N. Sgpt: Gpt sentence embeddings for semantic search. arXiv 2022, arXiv:2202.08904. [Google Scholar]
- Liu, M.; Li, X.; Li, J.; Liu, Y.; Zhou, B.; Bao, J. A knowledge graph-based data representation approach for IIoT-enabled cognitive manufacturing. Adv. Eng. Inform. 2022, 51, 101515. [Google Scholar] [CrossRef]
- Gong, F.; Wang, M.; Wang, H.; Wang, S.; Liu, M. SMR: Medical knowledge graph embedding for safe medicine recommendation. Big Data Res. 2021, 23, 100174. [Google Scholar] [CrossRef]
- Zhang, D.; Jia, Q.; Yang, S.; Han, X.; Xu, C.; Liu, X.; Xie, Y. Traditional Chinese medicine automated diagnosis based on knowledge graph reasoning. Comput. Mater. Contin. 2022, 71, 159–170. [Google Scholar]
- Zhao, Y.; Du, H.; Liu, Y.; Wei, S.; Chen, X.; Zhuang, F.; Li, Q.; Kou, G. Stock Movement Prediction Based on Bi-Typed Hybrid-Relational Market Knowledge Graph Via Dual Attention Networks. IEEE Trans. Knowl. Data Eng. 2022. [Google Scholar] [CrossRef]
- Mao, X.; Sun, H.; Zhu, X.; Li, J. Financial fraud detection using the related-party transaction knowledge graph. Procedia Comput. Sci. 2022, 199, 733–740. [Google Scholar] [CrossRef]
- Sun, Y.; Li, G.; Du, J.; Ning, B.; Chen, H. A subgraph matching algorithm based on subgraph index for knowledge graph. Front. Comput. Sci. 2022, 16, 163606. [Google Scholar] [CrossRef]
- Lyu, M.; Li, X.; Chen, C.H. Achieving Knowledge-as-a-Service in IIoT-driven smart manufacturing: A crowdsourcing-based continuous enrichment method for Industrial Knowledge Graph. Adv. Eng. Inform. 2022, 51, 101494. [Google Scholar] [CrossRef]
- Xu, C.; Nayyeri, M.; Alkhoury, F.; Yazdi, H.S.; Lehmann, J. Temporal knowledge graph embedding model based on additive time series decomposition. arXiv 2019, arXiv:1911.07893. [Google Scholar]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Yu, P.S. A survey on knowledge graphs: Representation, acquisition, and applications. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 494–514. [Google Scholar] [CrossRef] [PubMed]
- Kor, Y.; Tan, L.; Reformat, M.Z.; Musilek, P. Gridkg: Knowledge graph representation of distribution grid data. In Proceedings of the 2020 IEEE Electric Power and Energy Conference (EPEC), Virtual, 7–8 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Ou, Q.; Zheng, W.; Qi, W.; Fang, J.; Liu, Z.; Zhu, Y. Research on the Construction Method of Knowledge Graph for Electric Power Wireless Private Network. In Proceedings of the 2020 IEEE 10th International Conference on Electronics Information and Emergency Communication (ICEIEC), Beijing, China, 17–19 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 10–13. [Google Scholar]
- Hitzler, P. A review of the semantic web field. Commun. ACM 2021, 64, 76–83. [Google Scholar] [CrossRef]
- Zhu, G.; Iglesias, C.A. Computing semantic similarity of concepts in knowledge graphs. IEEE Trans. Knowl. Data Eng. 2016, 29, 72–85. [Google Scholar] [CrossRef] [Green Version]
- Chen, L. The analysis of research frontier and hot topics about knowledge discovery (KD) based on mapping knowledge domain. In Proceedings of the 2010 WASE International Conference on Information Engineering, Qinhuangdao, China, 14–15 August 2010; IEEE: Piscataway, NJ, USA, 2010; Volume 2, pp. 28–32. [Google Scholar]
- Chen, W.; Yin, S.; Qiu, Y. Schema reasoning and semantic representation for citation semantic link network. In Proceedings of the 2009 Third International Symposium on Intelligent Information Technology Application, Nanchang, China, 21–22 November 2009; IEEE: Piscataway, NJ, USA, 2009; Volume 3, pp. 366–369. [Google Scholar]
- Kyzirakos, K.; Savva, D.; Vlachopoulos, I.; Vasileiou, A.; Karalis, N.; Koubarakis, M.; Manegold, S. GeoTriples: Transforming geospatial data into RDF graphs using R2RML and RML mappings. J. Web Semant. 2018, 52, 16–32. [Google Scholar] [CrossRef] [Green Version]
- Kasongo, S.M.; Sun, Y. A deep learning method with wrapper based feature extraction for wireless intrusion detection system. Comput. Secur. 2020, 92, 101752. [Google Scholar] [CrossRef]
- Su, Z.; Hao, M.; Zhang, Q.; Chai, B.; Zhao, T. Automatic knowledge graph construction based on relational data of power terminal equipment. In Proceedings of the 2020 5th International Conference on Computer and Communication Systems (ICCCS), Shanghai, China, 15–18 May 2020; pp. 761–765. [Google Scholar]
- Wang, J.; Xu, W.; Fu, X.; Xu, G.; Wu, Y. ASTRAL: Adversarial trained LSTM-CNN for named entity recognition. Knowl. Based Syst. 2020, 197, 105842. [Google Scholar] [CrossRef]
- Liu, C.; Fan, C.; Wang, Z.; Sun, Y. An instance transfer-based approach using enhanced recurrent neural network for domain named entity recognition. IEEE Access 2020, 8, 45263–45270. [Google Scholar] [CrossRef]
- Li, D.; Tu, Y.; Zhou, X.; Zhang, Y.; Ma, Z. End-to-End Chinese Entity Recognition Based on BERT-BiLSTM-ATT-CRF. ZTE Commun. 2022, 20 (Suppl. S1), 27–35. [Google Scholar]
- Misawa, S.; Taniguchi, M.; Miura, Y.; Ohkuma, T. Character-based Bidirectional LSTM-CRF with words and characters for Japanese Named Entity Recognition. In Proceedings of the First Workshop on Subword and Character Level Models in NLP, Copenhagen, Denmark, 7 September 2017; pp. 97–102. [Google Scholar]
- Ma, X.; Hovy, E. End-to-end sequence labeling via bi-directional lstm-cnns-crf. arXiv 2016, arXiv:1603.01354. [Google Scholar]
- Kane, B.; Rossi, F.; Guinaudeau, O.; Chiesa, V.; Quénel, I.; Chau, S. Joint Intent Detection and Slot Filling via CNN-LSTM-CRF. In Proceedings of the 2020 6th IEEE Congress on Information Science and Technology (CiSt), Agadir, Morocco, 12–18 December 2020; pp. 342–347. [Google Scholar]
- Santos, C.N.; Xiang, B.; Zhou, B. Classifying relations by ranking with convolutional neural networks. arXiv 2015, arXiv:1504.06580. [Google Scholar]
- Wang, L.; Cao, Z.; De Melo, G.; Liu, Z. Relation classification via multi-level attention cnns. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1: Long Papers, pp. 1298–1307. [Google Scholar]
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.; Li, B.; Hao, H.; Xu, B. Attention-based bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 2: Short Papers, pp. 207–212. [Google Scholar]
- Xu, K.; Feng, Y.; Huang, S.; Zhao, D. Semantic relation classification via convolutional neural networks with simple negative sampling. arXiv 2015, arXiv:1506.07650. [Google Scholar]
- Liu, Y.; Wei, F.; Li, S.; Ji, H.; Zhou, M.; Wang, H. A dependency-based neural network for relation classification. arXiv 2015, arXiv:1507.04646. [Google Scholar]
- Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J. Relation classification via convolutional deep neural network. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 2335–2344. [Google Scholar]
- Miwa, M.; Bansal, M. End-to-end relation extraction using lstms on sequences and tree structures. arXiv 2016, arXiv:1601.00770. [Google Scholar]
- Qu, J.; Ouyang, D.; Hua, W.; Ye, Y.; Li, X. Distant supervision for neural relation extraction integrated with word attention and property features. Neural Netw. 2018, 100, 59–69. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Peng, T.; Han, R.; Cui, H.; Yue, L.; Han, J.; Liu, L. Distantly supervised relation extraction using global hierarchy embeddings and local probability constraints. Knowl. Based Syst. 2022, 235, 107637. [Google Scholar] [CrossRef]
- Feng, J.; Huang, M.; Zhao, L.; Yang, Y.; Zhu, X. Reinforcement learning for relation classification from noisy data. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Qiao, B.; Zou, Z.; Huang, Y.; Fang, K.; Zhu, X.; Chen, Y. A joint model for entity and relation extraction based on BERT. Neural Comput. Appl. 2022, 34, 3471–3481. [Google Scholar] [CrossRef]
- Tan, Y.; Xu, H.; Yan, D.; Peng, G.; Wang, F. Automatic Construction of Knowledge Graph and Its Application in Electric Power System. In Proceedings of the 2021 3rd Asia Energy and Electrical Engineering Symposium (AEEES), Chengdu, China, 26–29 March 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 725–729. [Google Scholar]
- Viloria, A.; Lezama, O.B.P. An intelligent approach for the design and development of a personalized system of knowledge representation. Procedia Comput. Sci. 2019, 151, 1225–1230. [Google Scholar] [CrossRef]
- De Vos, A.; Rowbotham, C.T. Knowledge representation for power system modelling. In Proceedings of the PICA 2001, Innovative Computing for Power-Electric Energy Meets the Market, 22nd IEEE Power Engineering Society. International Conference on Power Industry Computer Applications (Cat. No. 01CH37195), Sydney, NSW, Australia, 20–24 May 2001; IEEE: Piscataway, NJ, USA, 2001; pp. 50–56. [Google Scholar]
- McGuinness, D.L.; Van Harmelen, F. OWL web ontology language overview. W3C Recomm. 2004, 10, 2004. [Google Scholar]
- Li, Z.; Qu, D.; Li, Y.; Xie, C.; Chen, Q. A Position Weighted Information Based Word Embedding Model for Machine Translation. Int. J. Artif. Intell. Tools 2020, 29, 2040005. [Google Scholar] [CrossRef]
- Bhattarai, M.; Kharat, N.; Skau, E.; Nebgen, B.; Djidjev, H.; Rajopadhye, S.; Alexandrov, B. Distributed non-negative RESCAL with Automatic Model Selection for Exascale Data. arXiv 2022, arXiv:2202.09512. [Google Scholar] [CrossRef]
- Chen, P.; Wang, Y.; Yu, Q.; Fan, Q. TransRESCAL: A Dense Feature Model for Knowledge Graph Completion. In Proceedings of the 2020 IEEE International Conference on Progress in Informatics and Computing (PIC), Online, 18–20 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 40–46. [Google Scholar]
- Chekalina, V.; Razzhigaev, A.; Sayapin, A.; Frolov, E.; Panchenko, A. MEKER: Memory Efficient Knowledge Embedding Representation for Link Prediction and Question Answering. arXiv 2022, arXiv:2204.10629. [Google Scholar]
- Zhang, Q.; Wang, R.; Yang, J.; Xue, L. Structural context-based knowledge graph embedding for link prediction. Neurocomputing 2022, 470, 109–120. [Google Scholar] [CrossRef]
- Zhang, J.; Huang, J.; Gao, J.; Han, R.; Zhou, C. Knowledge graph embedding by logical-default attention graph convolution neural network for link prediction. Inf. Sci. 2022, 593, 201–215. [Google Scholar] [CrossRef]
- Zhang, R.; Chen, X.; Luo, J. Knowledge Mining of Low Specific Speed Centrifugal Pump Impeller Based on Proper Orthogonal Decomposition Method. J. Therm. Sci. 2021, 30, 840–848. [Google Scholar] [CrossRef]
- Hu, L.; Ding, J.; Shi, C.; Shao, C.; Li, S. Graph neural entity disambiguation. Knowl. Based Syst. 2020, 195, 105620. [Google Scholar] [CrossRef]
- Oh, B.; Seo, S.; Hwang, J.; Lee, D.; Lee, K.H. Open-world knowledge graph completion for unseen entities and relations via attentive feature aggregation. Inf. Sci. 2022, 586, 468–484. [Google Scholar] [CrossRef]
- Shen, W.; Li, Y.; Liu, Y.; Han, J.; Wang, J.; Yuan, X. Entity linking meets deep learning: Techniques and solutions. IEEE Transactions on Knowledge and Data Eng. 2021. [Google Scholar] [CrossRef]
- Chen, L.; Jiang, S.; Liu, J.; Wang, C.; Zhang, S.; Xie, C.; Liang, J.; Xiao, Y.; Song, R. Rule mining over knowledge graphs via reinforcement learning. Knowl. -Based Syst. 2022, 242, 108371. [Google Scholar] [CrossRef]
- Mitchell, T.M.; Betteridge, J.; Carlson, A.; Hruschka, E.; Wang, R. Populating the semantic web by macro-reading internet text. In Proceedings of the International Semantic Web Conference, Westfields, UK, 25–29 October 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 998–1002. [Google Scholar]
- Geiger, B.C. Information-Theoretic Reduction of Markov Chains. arXiv 2022, arXiv:2204.13896. [Google Scholar]
- Sarhangnia, F.; Ali Asgharzadeholiaee, N.; Boshkani Zadeh, M. A Novel Multilayer Model for Link Prediction in Online Social Networks Based on Reliable Paths. J. Inf. Knowl. Manag. 2022, 21, 2250025. [Google Scholar] [CrossRef]
- Mazumder, S.; Liu, B. Context-aware path ranking for knowledge base completion. arXiv 2017, arXiv:1712.07745. [Google Scholar]
- Azevedo, J.A.; Costa, M.E.O.S.; Madeira, J.J.E.R.S.; Martins, E.Q.V. An algorithm for the ranking of shortest paths. Eur. J. Oper. Res. 1993, 69, 97–106. [Google Scholar] [CrossRef]
- Lao, N.; Mitchell, T.; Cohen, W. Random walk inference and learning in a large scale knowledge base. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–29 July 2011; pp. 529–539. [Google Scholar]
- Zhao, X.; Jia, Y.; Li, A.; Jiang, R.; Song, Y. Multi-source knowledge fusion: A survey. World Wide Web 2020, 23, 2567–2592. [Google Scholar] [CrossRef] [Green Version]
- Jiang, L.; Shi, J.; Wang, C. Multi-ontology fusion and rule development to facilitate automated code compliance checking using BIM and rule-based reasoning. Adv. Eng. Inform. 2022, 51, 101449. [Google Scholar] [CrossRef]
- Cao, T.; Zeng, S.; Xu, X.; Mansur, M.; Chang, B. DISK: Domain-constrained Instance Sketch for Math Word Problem Generation. arXiv 2022, arXiv:2204.04686. [Google Scholar]
- Pryzant, R.; Yang, Z.; Xu, Y.; Zhu, C.; Zeng, M. Automatic Rule Induction for Efficient Semi-Supervised Learning. arXiv 2022, arXiv:2205.09067. [Google Scholar]
- Chen, X.; Jia, S.; Xiang, Y. A review: Knowledge reasoning over knowledge graph. Expert Syst. Appl. 2020, 141, 112948. [Google Scholar] [CrossRef]
- Niu, G.; Li, B.; Zhang, Y.; Sheng, Y.; Shi, C.; Li, J.; Pu, S. Joint semantics and data-driven path representation for knowledge graph reasoning. Neurocomputing 2022, 483, 249–261. [Google Scholar] [CrossRef]
- Lloyd, J.W. Foundations of Logic Programming; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Wang, D.; Hu, P.; Wałęga, P.A.; Grau, B.C. Meteor: Practical reasoning in datalog with metric temporal operators. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22 February–1 March 2022; Volume 36, pp. 5906–5913. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. Adv. Neural Inf. Process. Syst. 2013, 26, 1–9. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; Volume 28. [Google Scholar]
- Huang, W.; Li, G.; Jin, Z. Improved knowledge base completion by the path-augmented TransR model. In Proceedings of the Knowledge Science, Engineering and Management: 10th International Conference, KSEM 2017, Melbourne, VIC, Australia, 19–20 August 2017; Proceedings 10. Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 149–159. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; Volume 1: Long Papers, pp. 687–696. [Google Scholar]
- Xiao, H.; Huang, M.; Hao, Y.; Zhu, X. Transg: A generative mixture model for knowledge graph embedding. arXiv 2015, arXiv:1509.05488. [Google Scholar]
- Zhang, X.; Yang, Q.; Xu, D. TranS: Transition-based Knowledge Graph Embedding with Synthetic Relation Representation. arXiv 2022, arXiv:2204.08401. [Google Scholar]
- Bi, Z.; Zhang, T.; Zhou, P.; Li, Y. Knowledge transfer for out-of-knowledge-base entities: Improving graph-neural-network-based embedding using convolutional layers. IEEE Access 2020, 8, 159039–159049. [Google Scholar] [CrossRef]
- Wang, Z.; Li, L.; Li, Q.; Song, F.; Wang, J. Multimodal data enhanced representation learning for knowledge graphs. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Ye, Z.; Kumar, Y.J.; Sing, G.O.; Song, F.; Wang, J. A comprehensive survey of graph neural networks for knowledge graphs. IEEE Access 2022, 10, 75729–75741. [Google Scholar] [CrossRef]
- Miller, G.A. WordNet: An Electronic Lexical Database; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Pellissier Tanon, T.; Weikum, G.; Suchanek, F. Yago 4: A reasonable knowledge base. In Proceedings of the European Semantic Web Conference, Online, 2–4 June 2020; Springer: Cham, Switzerland, 2020; pp. 583–596. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. Dbpedia: A nucleus for a web of open data. In Proceedings of the The Semantic Web; Springer: Berlin, Heidelberg, 2007; pp. 722–735. [Google Scholar]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; pp. 1247–1250. [Google Scholar]
- Jia, Y.; Wang, Y.; Cheng, X.; Jin, X.; Guo, J. OpenKN: An open knowledge computational engine for network big data. In Proceedings of the 2014 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2014), Beijing, China, 17–20 August 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 657–664. [Google Scholar]
- Vrandečić, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Wang, X.; Ma, C.; Kou, L. A survey on the development status and application prospects of knowledge graph in smart grids. IET Gener. Transm. Distrib. 2021, 15, 383–407. [Google Scholar] [CrossRef]
- Yu, J.; Wang, X.; Zhang, Y.; Liu, Y.; Zhao, S.A.; Shan, L.F. Construction and application of knowledge graph for intelligent dispatching and control. Power Syst. Prot. Control 2020, 48, 29–35. [Google Scholar]
- Zheng, S.; Wang, F.; Bao, H.; Hao, Y.; Zhou, P.; Xu, B. Joint extraction of entities and relations based on a novel tagging scheme. arXiv 2017, arXiv:1706.05075. [Google Scholar]
- Xinjie, Z.; Lingxu, G.; Jian, W.; Xu, L.; Yuze, Z.; Shengnan, L. A Construction Method for the Knowledge Graph of Power Grid Supervision Business. In Proceedings of the 2021 IEEE 4th International Conference on Renewable Energy and Power Engineering (REPE), Beijing, China, 9–11 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 277–283. [Google Scholar]
- Lin, Y.; Han, X.; Xie, R.; Liu, Z.; Sun, M. Knowledge representation learning: A quantitative review. arXiv 2018, arXiv:1812.10901. [Google Scholar]
- Zhang, Y. Knowledge Reasoning with Graph Neural Networks; Georgia Institute of Technology: Atlanta, GA, USA, 2021. [Google Scholar]
- Needham, M.; Hodler, A.E. Graph Algorithms: Practical Examples in Apache Spark and Neo4j; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- Wu, H.; Wang, Y.; Chen, P.; Shi, H.; Wu, T. Application of Graph Database for the Storage of Knowledge Map of Power Grid Model. In Proceedings of the 2020 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Macau, China, 21–24 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Tang, Y.; Liu, T.; He, M.; Wang, Q.; Zhang, H.; Liu, G.; Dai, R. Graph database based knowledge graph storage and query for power equipment management. In Proceedings of the 2020 12th IEEE PES Asia-Pacific Power and Energy Engineering Conference (APPEEC), Nanjing, China, 20–23 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Toubeau, J.F.; Pardoen, L.; Hubert, L.; Marenne, N.; Sprooten, J.; De Grève, Z.; Vallée, F. Machine learning-assisted outage planning for maintenance activities in power systems with renewables. Energy 2022, 238, 121993. [Google Scholar] [CrossRef]
- Wang, H.; Liu, Z.; Xu, Y.; Wei, X.; Wang, L. Short text mining framework with specific design for operation and maintenance of power equipment. CSEE J. Power Energy Syst. 2020, 7, 1267–1277. [Google Scholar]
- Cui, B. Electric device abnormal detection based on IoT and knowledge graph. In Proceedings of the 2019 IEEE International Conference on Energy Internet (ICEI), Nanjing, China, 27–31 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 217–220. [Google Scholar]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Bölücü, N.; Akgöl, D.; Tuç, S. Bidirectional lstm-cnns with extended features for named entity recognition. In Proceedings of the 2019 Scientific Meeting on Electrical-Electronics & Biomedical Engineering and Computer Science (EBBT), Istanbul, Turkey, 24–26 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–4. [Google Scholar]
- Ji, Z.; Wang, X.; Cai, C.; Sun, H. Power entity recognition based on bidirectional long short-term memory and conditional random fields. Glob. Energy Interconnect. 2020, 3, 186–192. [Google Scholar] [CrossRef]
- Li, J.; Fang, S.; Ren, Y.; Li, K.; Sun, M. SWVBiL-CRF: Selectable Word Vectors-based BiLSTM-CRF Power Defect Text Named Entity Recognition. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Online, 10–13 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 2502–2507. [Google Scholar]
- Tang, Y.; Liu, T.; Liu, G.; Li, J.; Dai, R.; Yuan, C. Enhancement of power equipment management using knowledge graph. In Proceedings of the 2019 IEEE Innovative Smart Grid Technologies-Asia (ISGT Asia), Chengdu, China, 21–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 905–910. [Google Scholar]
- Liu, Z.; Hu, C.; Jia, J.; Tao, F. Design of Equipment Condition Maintenance Knowledge Base in Power IoT Based on Edge Computing. In Proceedings of the 2021 IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 March 2021; IEEE: Piscataway, NJ, USA, 2021; Volume 5, pp. 1994–1998. [Google Scholar]
- Gungor, V.C.; Sahin, D.; Kocak, T.; Ergut, S.; Buccella, C.; Cecati, C.; Hancke, G.P. A survey on smart grid potential applications and communication requirements. IEEE Trans. Ind. Inform. 2012, 9, 28–42. [Google Scholar] [CrossRef] [Green Version]
- Cheng, S.; Shen, J.; Shi, Q.; Cheng, X. Research on the construction of three level customer service knowledge graph. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Tamil Nadu, India, 2–3 May 2017; IOP Publishing: Bristol, UK, 2017; Volume 242, p. 012077. [Google Scholar]
- Linsen, L. Research on innovative application of customer service robot in power supply business hall based on intelligent Q&A technology. Wirel. Internet Technol. 2019, 16, 139–140. [Google Scholar]
- Zhou, F.; Ye, J.; Xiao, L.; Liu, H.; Lou, T. Research on Intelligent Question Answering System of power grid model ontology based on Knowledge graph. China Sci. Technol. Inf. 2019, 16, 85–86. [Google Scholar]
- Palumbo, E.; Rizzo, G.; Troncy, R. Entity2rec: Learning user-item relatedness from knowledge graphs for top-n item recommendation. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31August 2017; pp. 32–36. [Google Scholar]
- Zhang, B.; Lin, H.; Zuo, S.; Liu, H.; Chen, Y.; Li, L.; Ouyang, H.; Yuan, B. Research on Intelligent Robot Engine of Electric Power Online Customer Services Based on Knowledge Graph. In Proceedings of the 2020 the 4th International Conference on Innovation in Artificial Intelligence, Xiamen, China, 8–11 May 2020; pp. 216–221. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Huang, X.; Liu, L.; Chen, Y.; Zhang, Z. Construction of Electric Power Meta Knowledge Graph Based on Electric Power Industry Terminology. In Proceedings of the 2021 IEEE 2nd International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Nanchang, China, 26–28 March 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 622–626. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]
- Xiang, S.; Dong, F.; Xu, S. A hybrid neural network based on XLNet for rumor detection. In Proceedings of the 2022 IEEE 2nd International Conference on Power, Electronics and Computer Applications (ICPECA), Shenyang, China, 21–23 January 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1207–1211. [Google Scholar]
- Meng, W.; Zhang, D.; Guo, T.; Zong, Z.; Liu, Y.; Wang, Y.; Zhu, W. Design and Implementation of Knowledge Graph Platform of Power Marketing. In Proceedings of the 2021 International Conference on Computer Engineering and Application (ICCEA), Kunming, China, 25–27 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 295–298. [Google Scholar]
- Meng, W.; Zhang, D.; Guo, T.; Zong, Z.; Liu, Y.; Wang, Y.; Li, J.; Zhu, W. Research on the Typical Application of Knowledge Graph in Power Marketing. In Proceedings of the 2021 International Conference on Computer Engineering and Application (ICCEA), Kunming, China, 25–27 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 318–321. [Google Scholar]
- Lu, W.; Altenbek, G. A recommendation algorithm based on fine-grained feature analysis. Expert Syst. Appl. 2021, 163, 113759. [Google Scholar] [CrossRef]
- Taleb, T.; Ksentini, A.; Chen, M.; Jantti, R. Coping with emerging mobile social media applications through dynamic service function chaining. IEEE Trans. Wirel. Commun. 2015, 15, 2859–2871. [Google Scholar]
- Tao, T.; Wang, Q.; Fu, Y.; Xiong, Y.; Yu, F.; Yuan, B. Knowledge Graph Based Financial News Recommendation. Comput. Eng. 2020, 11, 1–10. [Google Scholar]
- Chen, M.; Bai, X.; Zhu, Y.; Wei, H. Research on power dispatching automation system based on cloud computing. In Proceedings of the IEEE PES Innovative Smart Grid Technologies, Washington, DA, USA, 16–20 January 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1–6. [Google Scholar]
- Fan, S.; Liu, X.; Chen, Y.; Liao, Z.; Zhao, Y.; Luo, H.; Fan, H. How to construct a power knowledge graph with dispatching data? Sci. Program. 2020, 2020, 8842463. [Google Scholar] [CrossRef]
- Zhou, B.; Gao, D.; Yan, L.; Cao, J.; Zhang, S.; Zhang, Y. Research on key technologies for fault knowledge acquisition of power communication equipment. Procedia Comput. Sci. 2021, 183, 479–485. [Google Scholar] [CrossRef]
- Morkun, V.; Kotov, I.; Serdiuk, O.; Haponenko, I.A. Production rule ontology of automatized smart emergency dispatching support of the power system. Her. Adv. Inf. Technol. 2021, 4, 168–184. [Google Scholar] [CrossRef]
- Niepert, M.; Ahmed, M.; Kutzkov, K. Learning convolutional neural networks for graphs. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2014–2023. [Google Scholar]
- Peng, F.; An, T.; Li, D.; Wang, H.; Tian, C.; Chen, Z. Knowledge Graph for Power Grid Dispatching of Digital Homes based on Graph Convolutional Network. In Proceedings of the 2020 8th International Conference on Digital Home (ICDH), Dalian, China, 19–20 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 203–208. [Google Scholar]
- Qiao, J.; Wang, X.; Min, R.; Bai, S.; Yao, D.; Pu, T. Framework and key technologies of knowledge-graph-based fault handling system in power grid. In Proceedings of the CSEE, Barcelona, Spain, 10–12 June 2020; Volume 40, pp. 5837–5849. [Google Scholar]
- Yang, M.; Cui, Y.; Huang, D.; Su, X.; Wu, G. Multi-time-scale coordinated optimal scheduling of integrated energy system considering frequency out-of-limit interval. Int. J. Electr. Power Energy Syst. 2022, 141, 108268. [Google Scholar] [CrossRef]
- Tan, Y.; Xu, H.; Wu, Y.; Zhang, Z.; An, Y.; Xiong, Y.; Wang, F. Research on knowledge driven intelligent question answering system for electric power customer service. Procedia Comput. Sci. 2021, 187, 347–352. [Google Scholar] [CrossRef]
- Xu, H.; Ji, H.; Yao, X.; Li, X.; Lu, S. Knowledge graph-based semantic search algorithm in smart grid. Res. Explor. Lab. 2021, 40, 71–74. [Google Scholar]
- Chicaiza, J.; Valdiviezo-Diaz, P. A comprehensive survey of knowledge graph-based recommender systems: Technologies, development, and contributions. Information 2021, 12, 232. [Google Scholar] [CrossRef]
- Ye, K.; Cao, Y.; Xiao, F.; Bai, J.; Ma, F.; Hu, Y. Research on unified information model for big data analysis of power grid equipment monitoring. In Proceedings of the 2017 3rd IEEE International Conference on Computer and Communications (ICCC), Atlanta, GA, USA, 19–23 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2334–2337. [Google Scholar]
- Yang, J.; Zheng, K.; Li, S.; Wang, X.; Zeng, L.; Gong, Q.; Zong, K. A Text Matching-based Knowledge Fusion Method For Power Metering Domain. In Proceedings of the 2021 IEEE International Conference on Electrical Engineering and Mechatronics Technology (ICEEMT), Qingdao, China, 3 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 805–808. [Google Scholar]
- Hang, Z.; Xingzhe, H.; Hua, W.; Wenbo, Y.; Changqing, H. Standard Power Meter Verification Strategy Optimization Based on Knowledge Graph. In Proceedings of the 2020 International Conference on Wireless Communications and Smart Grid (ICWCSG), Qingdao, China, 12–14 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 204–207. [Google Scholar]
- Yu, J.; Sun, J.; Dong, Y.; Zhao, D.; Chen, X.; Chen, X. Entity recognition model of power safety regulations knowledge graph based on BERT-BiLSTM-CRF. In Proceedings of the 2021 IEEE International Conference on Power Electronics, Computer Applications (ICPECA), Chengdu, China, 1–4 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 49–53. [Google Scholar]
- Sun, J.; Zhao, D.; Wang, L.; Chen, X.; Yi, M.; Xia, L. Remote supervision relation extraction method of power safety regulations knowledge graph based on ResPCNN-ATT. In Proceedings of the 2021 IEEE International Conference on Power Electronics, Computer Applications (ICPECA), Chengdu, China, 1–4 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 54–58. [Google Scholar]
- Chen, Z.; Dong, N.; Zhong, S.; Hou, B.; Chang, J. Research on the network security vulnerability expansion attack graph based on knowledge map. Inf. Technol. 2022, 363, 30–35. [Google Scholar]
- Yin, T.; Lu, N. Knowledge Graph Model of Power Grid for Human-machine Mutual Understanding. In Proceedings of the 2020 Chinese Automation Congress (CAC), Shanghai, China, 6–8 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 6165–6169. [Google Scholar]
- Barrios, F.; López, F.; Argerich, L.; Wachenchauzer, R. Variations of the similarity function of textrank for automated summarization. arXiv 2016, arXiv:1602.03606. [Google Scholar]
- Iarovyi, S.; Mohammed, W.M.; Lobov, A.; Ferrer, B.R.; Lastra, J.L.M. Cyber–physical systems for open-knowledge-driven manufacturing execution systems. Proc. IEEE 2016, 104, 1142–1154. [Google Scholar] [CrossRef]
- Liu, Y.; Xu, B.; Botterud, A.; Kang, C. Bounding regression errors in data-driven power grid steady-state models. IEEE Trans. Power Syst. 2020, 36, 1023–1033. [Google Scholar] [CrossRef]
- Fusco, F.; Eck, B.; Gormally, R.; Purcell, M.; Tirupathi, S. Knowledge-and data-driven services for energy systems using graph neural networks. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Online, 10–13 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1301–1308. [Google Scholar]
- Zhou, J.; Luo, G.; Hu, C.; Qiu, J. A classification model of power equipment defect texts based on convolutional neural network. In Proceedings of the International Conference on Artificial Intelligence and Security, New York, NY, USA, 26–28 July 2019; Springer: Cham, Switzerland, 2019; pp. 475–487. [Google Scholar]
- García-Durán, A.; Dumančić, S.; Niepert, M. Learning sequence encoders for temporal knowledge graph completion. arXiv 2018, arXiv:1809.03202. [Google Scholar]
- Sun, H.; Zhong, J.; Ma, Y.; Han, Z.; He, K. TimeTraveler: Reinforcement learning for temporal knowledge graph forecasting. arXiv 2021, arXiv:2109.04101. [Google Scholar]
Figure 1.
A joint model of entity extraction and relationship extraction [38].
Figure 1.
A joint model of entity extraction and relationship extraction [38].

Figure 2.
The overall construction process of KG in the power field.

Figure 3.
Power system operation application scenarios of the KG.

Figure 4.
The KG technology in power equipment O&M.

Figure 5.
Multiple KG coupling in the dispatching domain.

Figure 6.
Power grid accident behavior knowledge graph.


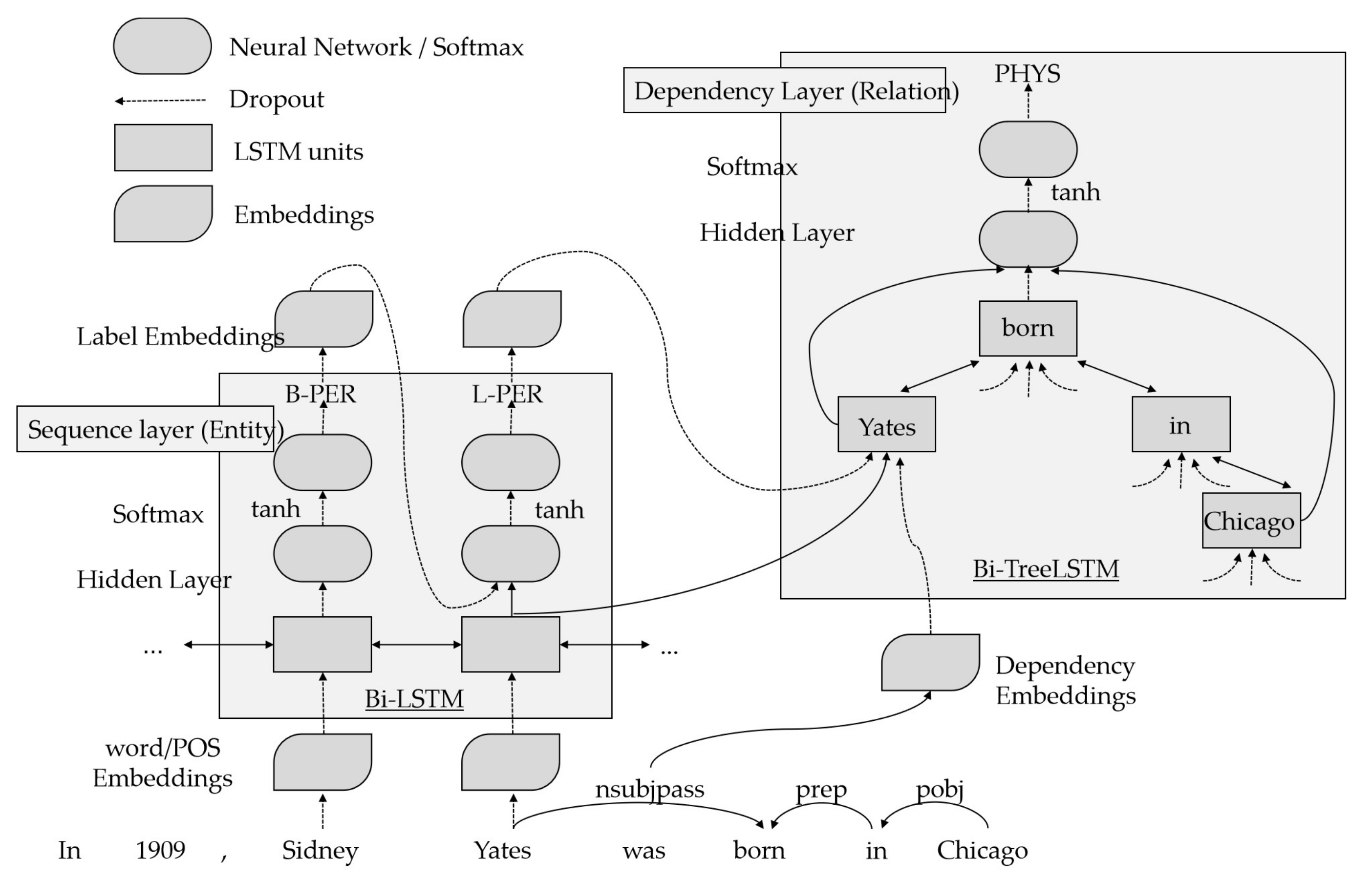{kind=link}
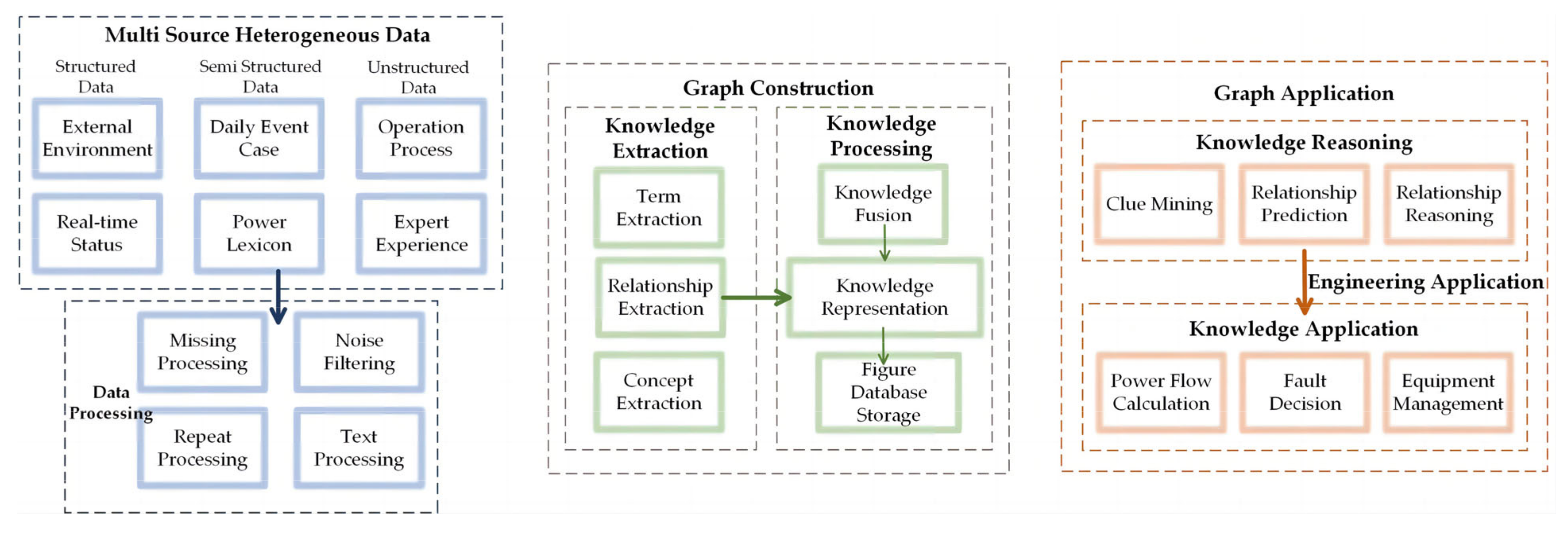{kind=link}
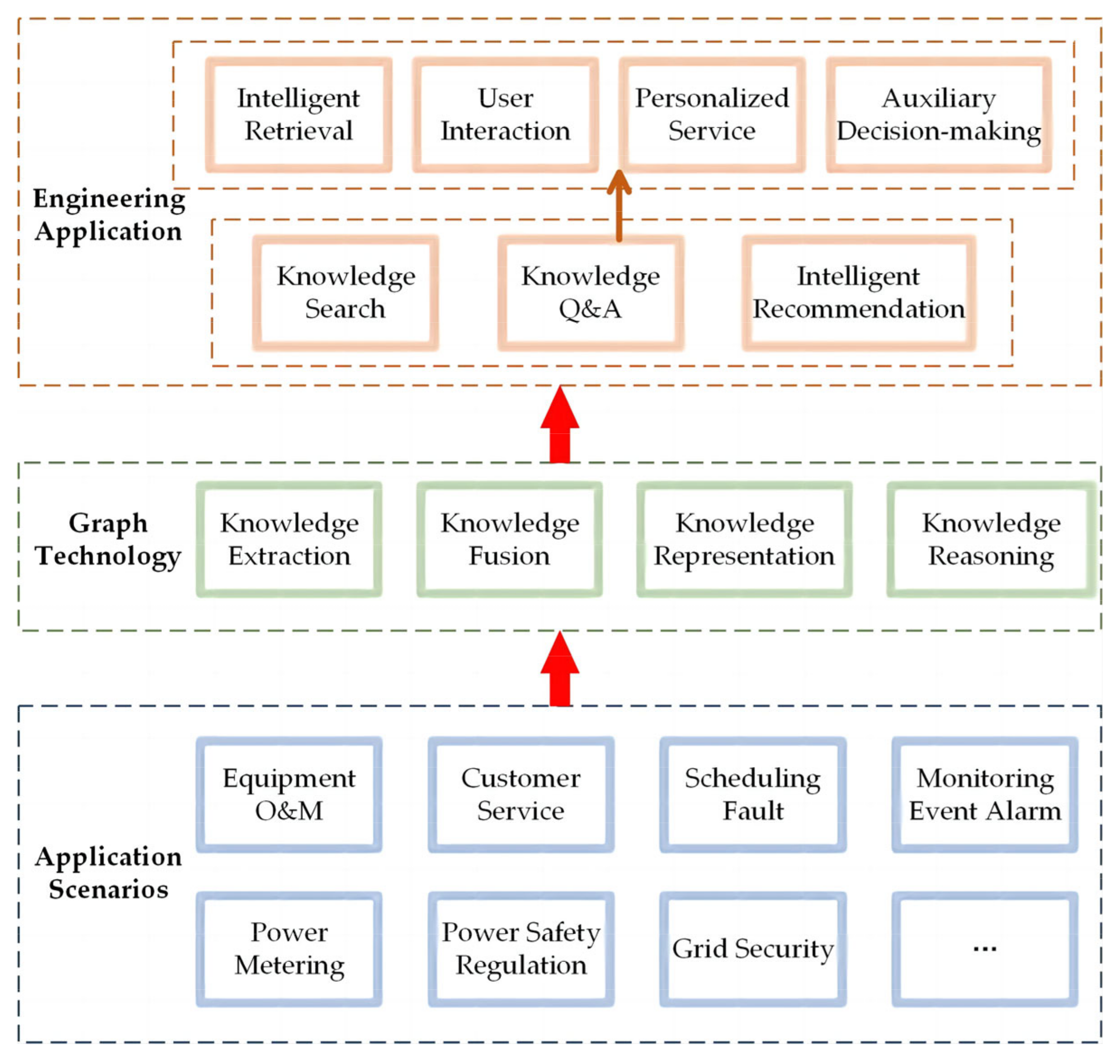{kind=link}
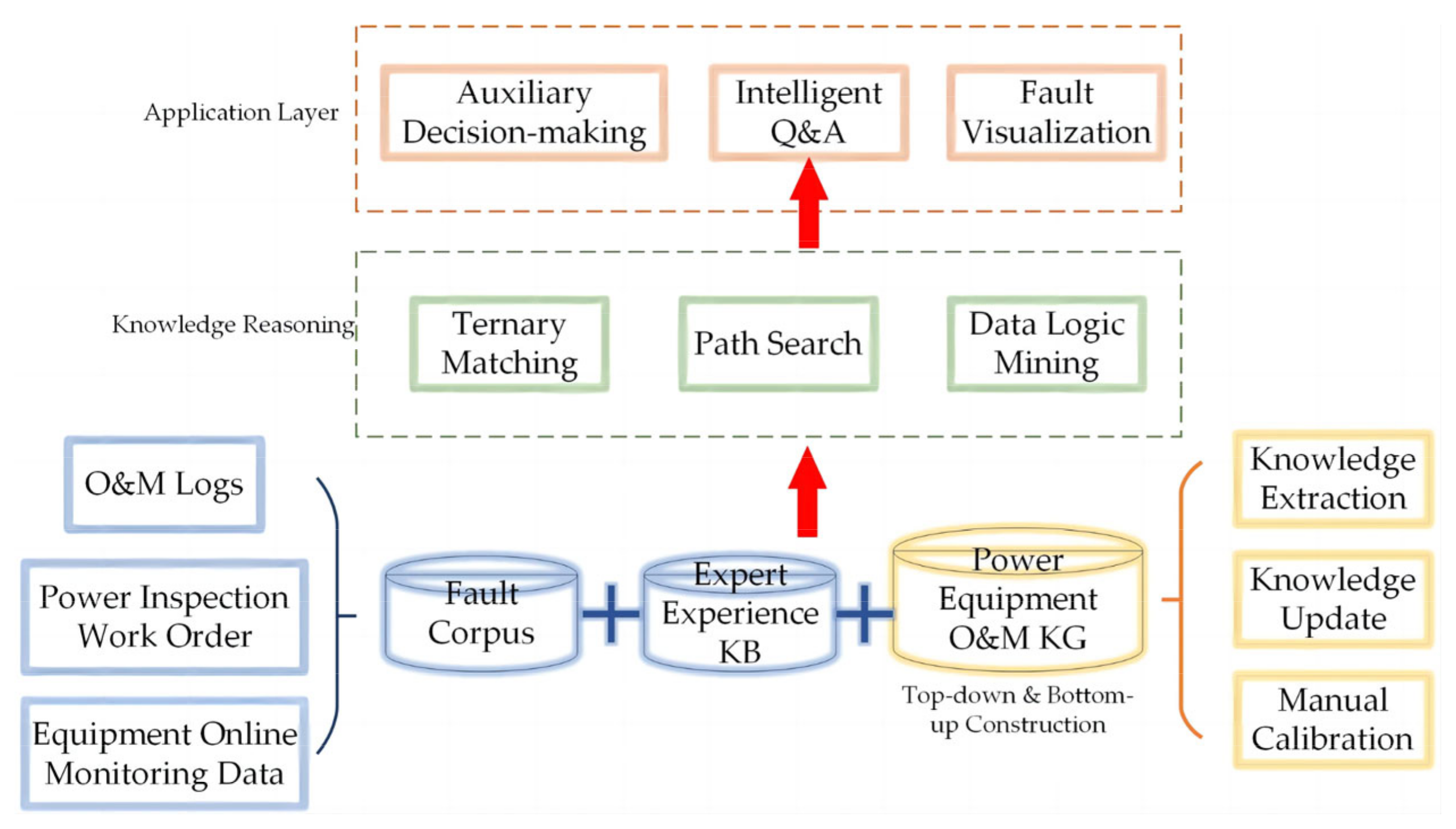{kind=link}
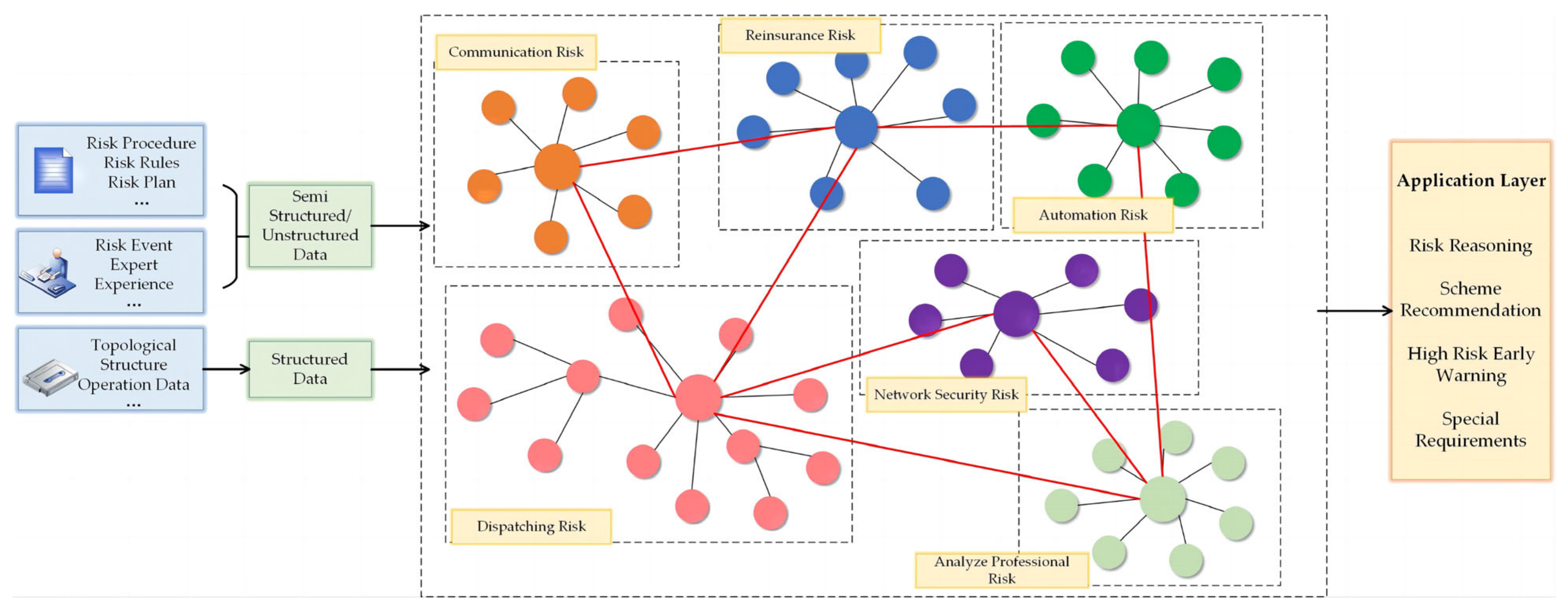{kind=link}
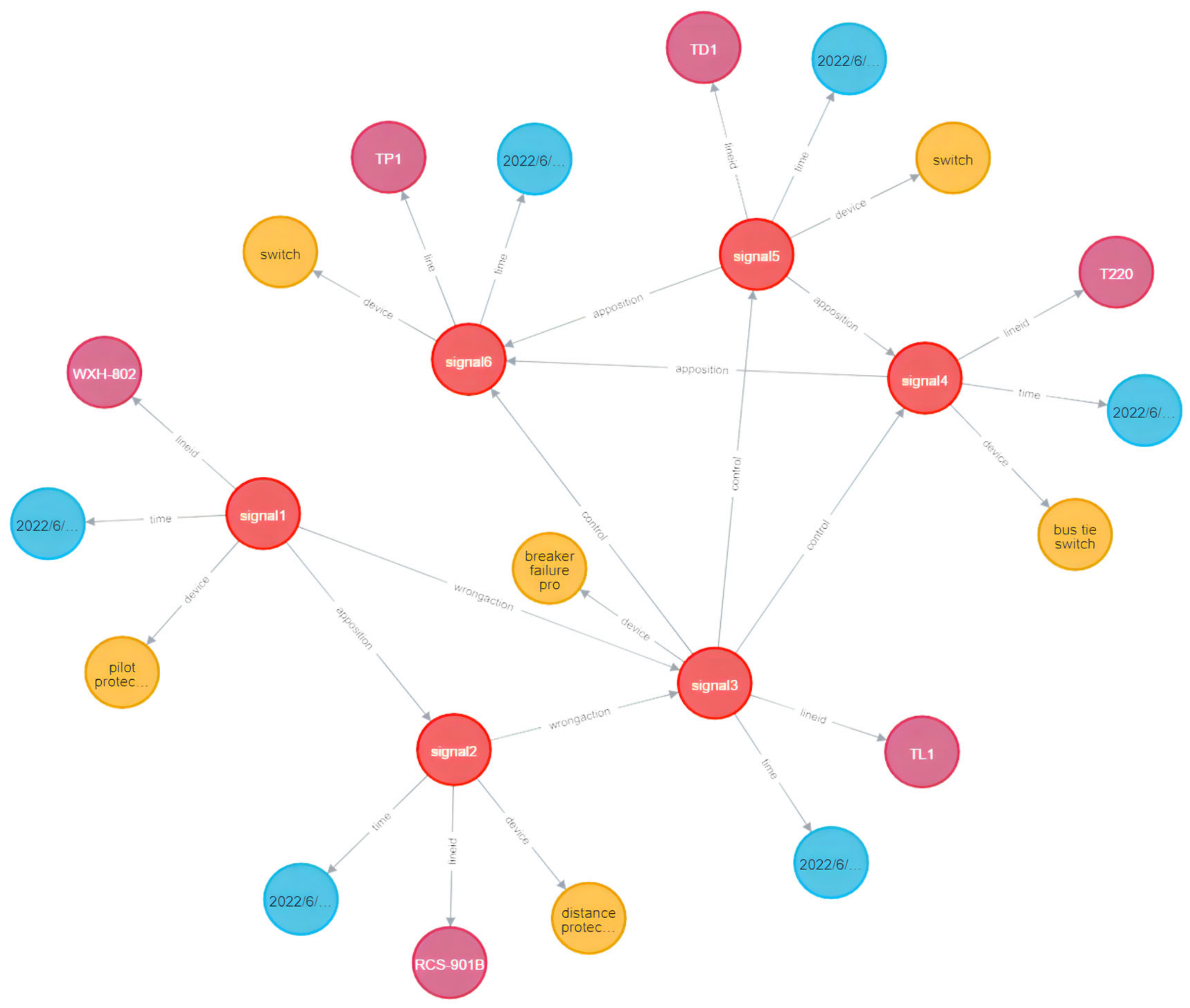{kind=link}
 TransE |  TransH |
 Entity representation spaces Relationship representation spaces TransR | |
 Entity representation spaces Relationship representation spaces TransD | |
Table 2.
Some common large-scale knowledge bases.
| Name | Start Date | Main Knowledge Source | Scale (Entity/Concept/Relation/Fact) |
|---|---|---|---|
| WordNet [81] | 1985 | Expert Knowledge | 155,287/117,659/18/- |
| YAGO [82] | 2007 | WordNet + Wikipedia | 4,595,906/488,469/77/- ≈ 40 M |
| Dbpedia [83] | 2007 | Wikipedia + Expert Knowledge | 17,315,785/754/2843/79,030,098 |
| Freebase [84] | 2008 | Wikipedia + Domain Knowledge + Swarm Intelligence | 58,726,427/2209/39,151/3,197,653,841 |
| NELL [85] | 2010 | WordNet + Wikipedia(Multilingual) | 9,671,518/6,117,108/1,307,706,673/- |
| Wikidata [86] | 2012 | Freebase + Swarm Intelligence | 45,766,755/-/-/- |
Table 3.
Representation methods: comparison and evaluation.
| Representation Method | Precision/% | Recall/% | F1-Score/% |
|---|---|---|---|
| KG | 93.62 | 92.77 | 93.19 |
| VSM with tf-idf | 50.94 | 69.18 | 58.68 |
| LSI | 44.81 | 63.68 | 52.60 |
| LDA | 47.59 | 63.85 | 54.53 |
Table 4.
Model evaluation of LSTM, Bi-LSTM, Bi-LSTM-CRF.
| Model | Precision/% | Recall/% | F1/% |
|---|---|---|---|
| LSTM | 70.8 | 69.1 | 70.0 |
| Bi-LSTM | 71.3 | 74.1 | 72.7 |
| Bi-LSTM-CRF | 74.2 | 76.3 | 75.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Liu, R.; Fu, R.; Xu, K.; Shi, X.; Ren, X. A Review of Knowledge Graph-Based Reasoning Technology in the Operation of Power Systems. Appl. Sci. 2023, 13, 4357. https://doi.org/10.3390/app13074357
AMA Style
Liu R, Fu R, Xu K, Shi X, Ren X. A Review of Knowledge Graph-Based Reasoning Technology in the Operation of Power Systems. Applied Sciences. 2023; 13(7):4357. https://doi.org/10.3390/app13074357
Chicago/Turabian StyleLiu, Rui, Rong Fu, Kang Xu, Xuanzhe Shi, and Xiaoning Ren. 2023. "A Review of Knowledge Graph-Based Reasoning Technology in the Operation of Power Systems" Applied Sciences 13, no. 7: 4357. https://doi.org/10.3390/app13074357
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.