1. Introduction
Recently, a tremendous advance has been achieved in the development of social media platforms, which largely encourage people to express their emotional states online [
1,
2]. Furthermore, it has become popular to publish users’ comments or opinions about services and products on specific electronic platforms in a timely manner. These perspectives expressed directly by consumers are extremely important for merchants to improve their service while in a dealing. Thus, how to extract the exact aspect terms, opinion terms, and their corresponding sentiment from a specific sentence is a significant Natural Language Processing (NLP) subtask [
3,
4,
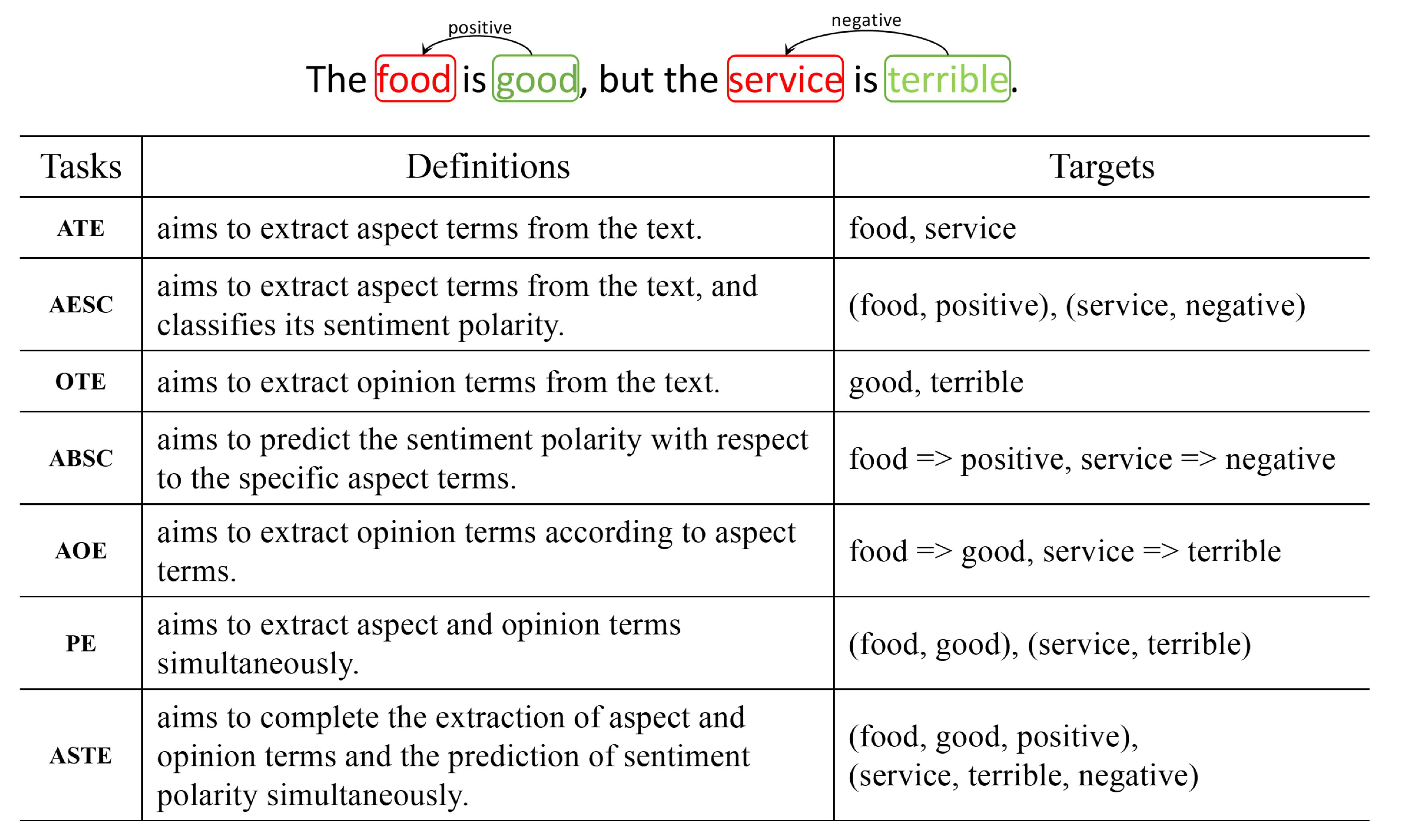
5]. The recent developing task, Aspect-Based Sentiment Analysis (ABSA), aims to mine the explicit or implicit sentiment information about the opinion terms with regard to the specific aspect terms, which implements sentiment analysis about consumers’ reviews effectively. Generally, the ABSA task contains seven fundamental subtasks (
Figure 1), which are Aspect Term Extraction (ATE) [
6], Aspect Term Extraction and Sentiment Classification (AESC) [
7], Opinion Term Extraction (OTE) [
6], Aspect-Based Sentiment Classification (ABSC) [
8], Aspect-Oriented Opinion Term Extraction (AOE) [
9], Pair Extraction (PE) [
10], and Aspect Sentiment Triplets Extraction (ASTE) [
11]. In particular, as the fine-grained subtask in ABSA, the ASTE task takes aspect terms, opinion terms, and sentiment polarities into consideration simultaneously, which is challenging but significant. For example, as shown in
Figure 1, the review “The food is good, but the service is terrible”. contains two triplets, (food, good, positive) and (service, terrible, negative). Unlike the other subtasks, such triplets extracted by the ASTE task can better reflect multiple emotional factors (aspect, opinion, sentiment) from the user reviews and are more proper for practical application scenarios.
In previous studies, the pipeline manner is widely applied in the approaches to ASTE. Peng et al. [
12] first introduced the ASTE task and extracted the triplet {aspect, opinion, sentiment} via utilizing a pipeline method, which contains a two-stage framework. The first stage provided predictions about aspect, opinion, and sentiment, respectively. Furthermore, the second stage was designed to pair up the predictions achieved from the first stage and output triplets. However, the interactions among them were totally ignored, and the potential error was propagated between these two stages [
13,
14]. To take the dependencies among the multiple subtasks into consideration, the multi-turn machine reading comprehension (MRC) manner [
15,
16] was utilized to jointly train multiple subtasks together, and it has achieved significant results. In addition, the fashion of end-to-end [
17,
18] also attracts many researchers’ attentions, which is constructed based on the new tagging scheme.
Although the paradigm of the framework is important to enhance the performance of the ASTE task, the effective utilization of various linguistic relations between words is also decisive to the task’s success [
19]. Specifically, the syntactic dependency tree is widely used to present the structure of a sentence, which tends to depict the syntactic relations among words. Zhao et al. [
20] adopted the dependency tree as the support to capture relations between aspect and opinion terms. Furthermore, the work [
21] directly employed an interactive attention mechanism to integrate syntactic and semantic relations between words. In addition, the contribution of part-of-speech categories to ASTE is also noticed, which straightly impacts the semantic representation of sentences. Except for the dependency tree, relative position also largely influences the expression of the sentence. Xu et al. [
22] applied a position-aware tagging scheme to mark the relative position between words in a sentence. Furthermore, the semantic features in this work are represented by Long Short-term Memory (LSTM) with the pre-trained Glove, which cannot handle contextual ambiguity comprehensively. Moreover, the tree-based distance and relative position distance of each word pair in the sentence also contribute a lot to the improvement in the ASTE task [
23], and the utilization of Bidirectional Encoder Representation from Transformers (BERT) can largely enhance the feature representation from the semantic perspective. However, although significant progress has been achieved by previous studies, there are still remaining limitations: the effective optimization of semantic features is not enough, and the powerful utilization of multi-type textual features is unsolved yet.
To address these two problems, motivated by the impressive performance achieved by BERT, we propose a novel BERT- and Graph Convolutional Network-based (GCN-based) model Multi-branch Graph Convolutional Network (MBGCN) for the ASTE task. In detail, in our model, to evacuate the potential capability of BERT and obtain a more exquisite contextual representation, a structure-biased BERT [
24] is firstly utilized as the semantic feature encoder. Subsequently, depending on the generated representations, aspect-oriented and opinion-oriented feature maps are extracted by two multi-layer perceptions (MLP). Then, before incorporating other relations of words, a biaffine attention module is applied to unify the aspect-oriented and opinion-oriented semantic features effectively. Unlike fusing textual features via a single GCN, an MBGCN employs four branch GCNs to integrate semantic representation with syntactic dependency type, part-of-speech combination, tree-based distance, and relative position distance among each word pair, respectively. Through the complementary of these four branches, a more precise textual representation is achieved. Finally, a shallow interaction strategy is designed to complete the work of information fusion before the triplet decoding layer. To validate the effectiveness of the MBGCN, a series of experiments are conducted on four widely used and available datasets. The experimental results prove that MBGCNs can efficiently deal with the complex relations among sentences and outperform the state-of-the-art (SOTA) ASTE approaches.
The main contributions of this work can be summarized as follows:
We propose a framework MBGCN to extract the aspect, opinion, and sentiment triplet from review sentences in an end-to-end fashion, which can avoid error propagation among different subtasks;
We utilize a structure-biased BERT to improve the ability to extract abundant contextual information, which provides rich textual features for subsequent task-oriented operations;
Our proposed MBGCN adopts four branch GCNs to integrate the semantic feature with four types of linguistic relations, including syntactic dependency type, part-of-speech combination, tree-based distance, and relative position distance of each word pair. Furthermore, a shallow interaction layer is introduced to output the final textual representation;
The extensive experiments conducted on multiple ASTE datasets prove that the proposed MBGCN outperforms the mentioned SOTA baselines.
The remainder of this article is organized as follows. In
Section 2, we present a brief overview of the development of ABSA, previous research about ASTE, and the application of GCNs. The proposed framework MBGCN is introduced in detail in
Section 3. In
Section 4, we provide detailed experimental studies and performance analyses. Finally,
Section 5 provides a conclusion of this study and an outlook for future work.
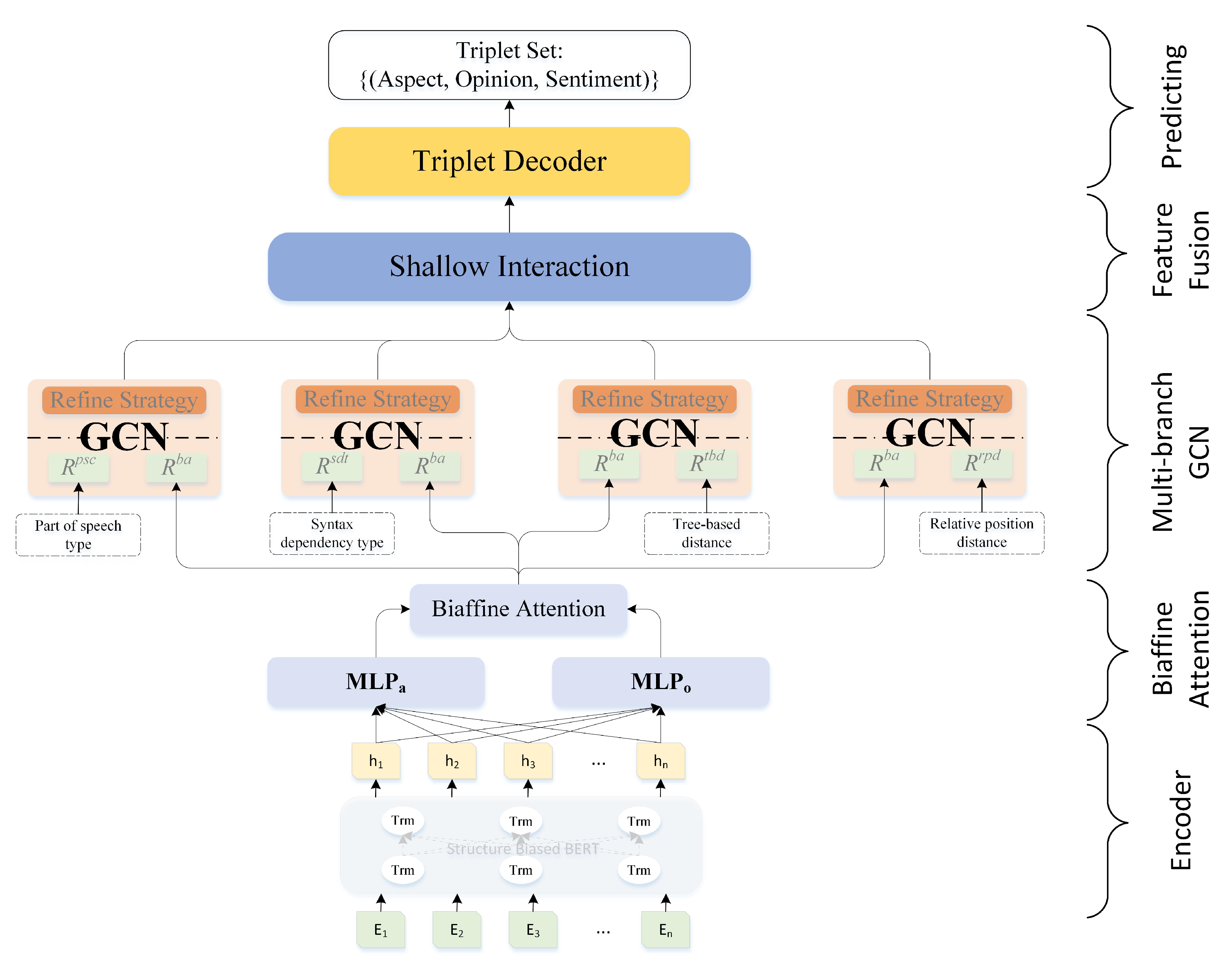
3. Framework of MBGCN
In this section, the detailed framework of the MBGCN is described. Firstly, the definition of the ASTE task is introduced briefly. Then, the mechanism of feature generation through the backbone structure-biased BERT is depicted, and this step is utilized to generate semantic features. After that, multi-branch GCNs are employed to integrate semantic features with the other four types of linguistic feature representations. Lastly, the shallow interaction, output layer, and training are introduced shortly. Additionally, the overall architecture of the MBGCN is described in detail in
Figure 2.
3.1. Task Formulation
Given a sentence with a sequence of words
X =
as input, where
n is the number of words, the goal of the ASTE task is to extract and output a set of triplets
, where
a,
o, and
s are the aspect term, opinion term, and the corresponding sentiment polarity, respectively, and
m is the number of triplets. Concretely, the aspect
a can be decomposed into two or more elements, i.e.,
, where
b and
e mean the start and end positions. The opinion
o can be decomposed as
similarly. Furthermore,
s is selected from the set (position, netural, negative) to represent the sentiment polarity of the corresponding opinion term on the aspect term. For the sentence shown in
Figure 1, the triplets are collected as (food, good, positive) and (service, terrible, negative).
Specifically, to make the target of our ASTE task more explicit, ten types of relations between words in a review are defined, which are collected in
Table 1. Similarly, the mentioned relations also can be seen as the labels, and these labels are introduced to present the relations in the word pairs, which are also the eventual predictions of our MBGCN.
3.2. Embedding via Structure-Biased BERT
As aforementioned, BERT has an impressive performance in modeling contextual representation in various NLP tasks [
46,
47,
48,
49]. Therefore, in our proposed Multi-branches Graph Convolutional Netwrok (MBGCN),we also utilize it to generate the semantic features by the version of the
. To be precise, before feeding the review
X into the MBGCN, the input is always formulated in three formats: segment embedding
, position embedding
, and tokens embedding
. Then, these three aspects of embedding are summarized as the input to the selective feature generator, which is shown in Equation (
1),
where
is the input of self-attention (Equation (
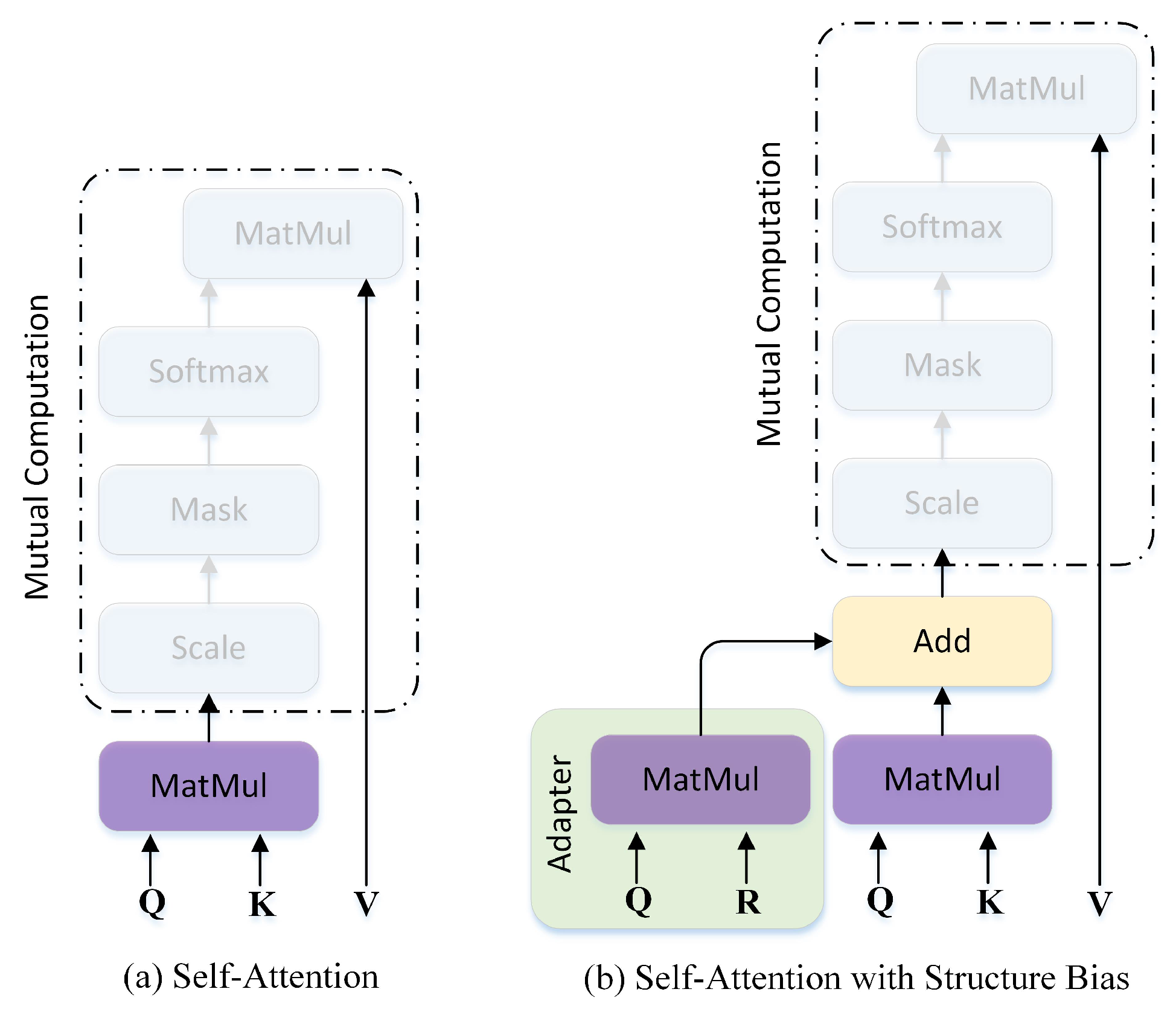
2)). In detail, BERT is a PLM with the structure of a stacked transformer, which has 12 transformer layers in total. Furthermore, in each transformer layer, the feature representations are transformed by multi-head self-attention with a residual structure (
Figure 3a). Furthermore, this transformation can be formulated as follows:
where
is the
l-th layer transformer, and
means the input embedding of BERT, which is built from
E with a liner function. The outputs of 12-layer transformers are denoted as
.
includes two linear functions with a
activation function between.
is the core of the transformer, which has a stacked structure with 12 heads of self-attention. Thus, we can formulate the architecture of attention as follows:
where parameters
,
, and
are the learnable weights for query
, key
, and value
, and
d is the head dimensionality.
is the single attention, and
denotes the sum of
N heads attention (MHSA).
Inspired by the structure-biased BERT utilized in [
24,
50], we also introduce it into our MBGCN for generating more informative feature maps. In the optimized approach, self-attention is re-constructed by inserting the relative distance or the dependency between words. Furthermore, the effectiveness of this modification has been obviously proven by the NLP task [
51]. Thus, we describe this change in our model as Equation (
8), which can be implemented in Equation (
6) directly. Additionally, the procedure is depicted below:
where
indicates the relative distance embedding between the word pairs of the
k-th sentence in
-th transformer layer. Note that each dependency embedding is independent from one layer to another layer, but it can be transformed across different heads as an entirety. Additionally, the sketch of the difference between raw self-attention (a) and biased self-attention (b) is shown in
Figure 3.
With the backbone encoder of structure-biased BERT, the semantic features is obtained, which provides more accurate contextual information to the module of biaffine attention.
3.3. Biaffine Attention
Biaffine attention has been proven to have the ability to capture the relationship among the different words or word pairs [
23,
52]. Thus, in this paper, we also apply it to predict the relation probability of word pairs in a sentence. To present the process of biaffine attention, the hidden states
and
of
and
in
X are extracted from
. With the aforementioned
and
, the aspect-specific feature
(Equation (
9)) and opinion-specific feature
(Equation (
10)) are obtained, which are adopted into the processing of biaffine attention directly.
and the transformation of biaffine attention can be formulated as
where
,
, and
are the trainable weights and biases, and ⊕ denotes the operation of concatenation. The relations between
and
are modeled as
.
is the number of relation types. Furthermore, we use
to represent the relations obtained in this manner in the following sections.
With the aspect-oriented and opinion-oriented processing of biaffine attention, the probability of relation between the word pairs in a sentence can be modeled effectively. Furthermore, this relation will be integrated with the other four types of linguistic features via GCNs adequately.
3.4. Multi-Branch GCN
Except for encoding text as semantic feature maps, it also can be represented in the linguistic feature types. Furthermore, the most widely utilized type is the syntax dependency graph, where the feature is formed in a graph
.
V is the vertex (i.e., node or word), and
E is the edge (i.e., dependency or syntactic relation) between two nodes. Generally, we usually denote this kind of relation through a matrix, namely adjacent matrix
A.
if the relation between
and
exists, and
otherwise. In addition, in this paper, we also introduce three other types of linguistic features for each word pair to enhance the contextual representation of the sentence, which are the part-of-speech combination, tree-based distance, and relative position distance (
Figure 4). Before feeding them into the GCN, they are all encoded in the fashion of adjacency matrices. Then, these four types of linguistic features are integrated with semantic features, respectively. For instance, we apply the GCN to integrate the
with
encoded from syntactic dependency type tensor
, and the process is depicted as follows:
where
is obtained from the original contextual representation
through a dense layer and a
activation layer;
is the function
. Furthermore,
is an average pooling function applied on the node hidden representations of all channels. To make the extracted relations more accurate, a refining strategy is employed to enhance the relations among words, which can be described as
we use ⊕ to concatenate contextual representation
and syntactic dependency type tensor
. Furthermore, in Equation (
16),
and
are the main diagonal and vice diagonal, which are used to refine the representation
. Finally, with the operations of a linear layer and a softmax layer, the distribution of probabilities on ten defined relations between
and
is obtained, which is denoted as
.
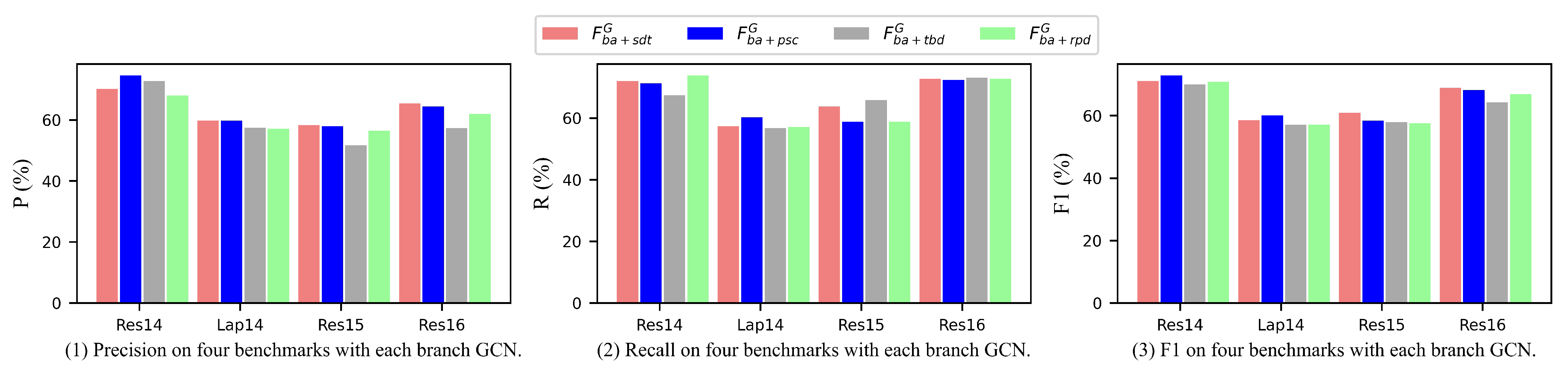
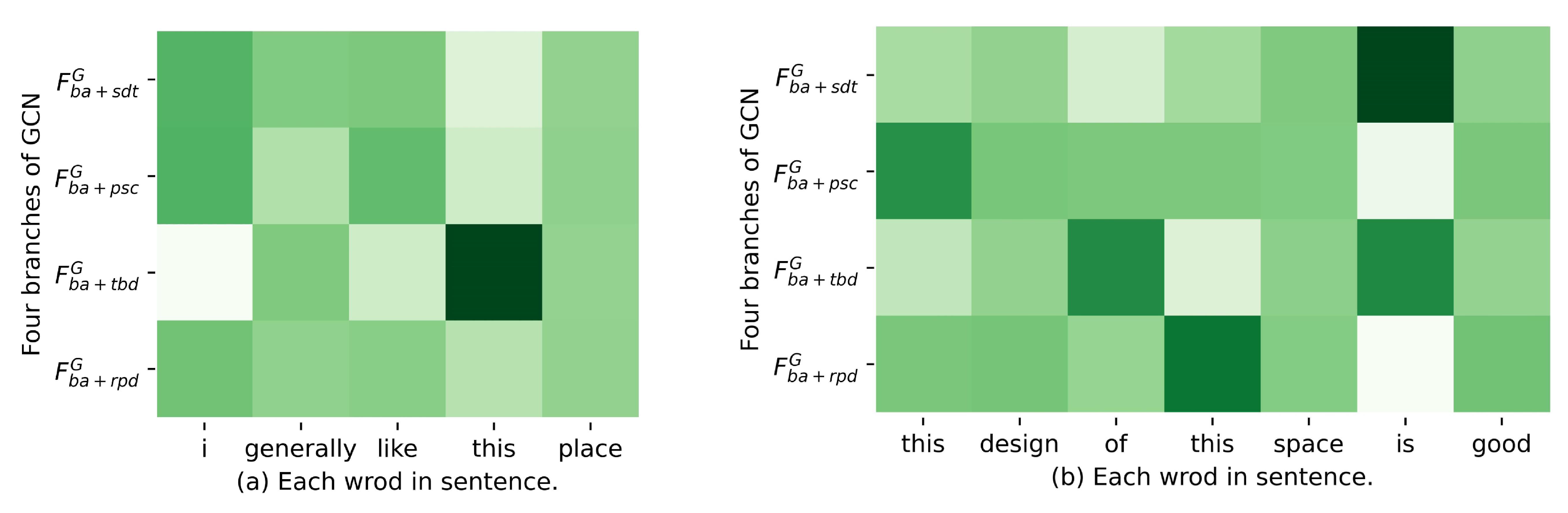
Similarly, we integrate with , , and via different branches of the GCN to obtain the refined feature representations , and , respectively. Through the operations described in this part, we enhance the contextual feature with four types linguistic features, respectively.
3.5. Shallow Interaction and Output Layer
To further enhance the performance of our MBGCN, we apply a shallow interaction layer to fuse the four types of integrated feature representations, which can be depicted as follows:
where
,
,
and
are manually selective hyper-parameters to control the weights of different feature representations. Furthermore, ⊤ is the transposition operation for the related matrix. With this layer, the MBGCN achieves the final textual representation fused from four branches of the GCN, which take five types of textual features into consideration simultaneously.
3.6. Training
Generally, the deep learning models are always optimized by minimizing a loss function, and cross entropy is usually applied to complete this work. Without simply applying cross entropy in the proposed MBGCN, due to various contextual information involved, it is necessary to take these into the final fine tuning. For instance, the separated loss
to measure the influence of
is modeled as
where
is the indicator function,
is the ground truth relation of word pair
. Furthermore,
denotes the whole relations set. With a similar operation, the other four separated linguistic features’ losses
,
,
, and
are all obtained likewise. Thus, with the prediction, the final loss function
in the paper is designed as
where
and
are the manual hyper-parameters to control the influence of each part on the final loss function. Through this manner, our MBGCN can adjust its fine-tuning from six aspects simultaneously.
5. Conclusions
In this work, we propose an end-to-end model MBGCN for the ASTE task, which processes Aspect Term Extraction, Opinion Term Extraction, and sentiment polarity prediction in a sentence, simultaneously. For modeling the textual semantic feature more accurately, an optimized attention module is inserted into BERT, namely structure-biased BERT, which is employed to enhance the representation of the specific sentence. In addition, to emphasize the key features in the generated representation, biaffine attention is utilized to absorb the crucial components from both aspect-oriented and opinion-oriented feature maps. Furthermore, a novel fusion architecture with a multi-branch GCN is proposed to integrate the semantic feature with the linguistic feature. In this part, through each branch GCN, attentive semantic representation is integrated with syntactic dependency types, part-of-speech combination, relative positive distance, and tree-based distance, respectively. Eventually, four branch features are synthesized as an entirety via a designed shallow interaction layer. To validate the effectiveness of our proposed model, we conduct extensive experiments on the benchmark datasets, and the results show that the MBGCN achieves SOTA performances.
Although outstanding performances were achieved by our proposed MBGCN, several limitations still exist, which are the working aims of our future study. First, the working mechanism of prompt learning should be optimized to be more proper for our current task. Second, a more robust integration strategy is essential in our future study for feature fusion.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}