1. Introduction
Machine learning integration in the medical field, especially image analysis for histopathology and cancer research could make a huge impact due to the possibility of rapid and more accurate results. In recent years, advancements in technology have revolutionized the health system enabling it to use digitized imaging in order review patient data through computer systems and applications. Digital content can be simply stored without losing its quality and reshared between health specialists, especially because of the increasing number of image analysis applications and large image compression tools [
1,
2,
3]. Unfortunately, switching from glass to digital analysis requires new expensive hardware, extensive memory size and especially trained technicians [
4]. To this day a legitimate comparison research method using accepted Al techniques that could be used for histopathology does not exist, especially because of expensive hardware and eligible access to patient data. Additionally, the main challenge is that different WSI’s scanners lower the results, and the most significant barrier to the widespread use of Al approaches in the clinic is undoubtedly the limited generalizability of algorithms [
5]. Despite this, medical professionals might help develop new techniques that could be applied in clinical practice as the start of implementing Al in histology [
4].
A cancer, also called tumor, is a formation of altered, unregulated, unlimitedly proliferating but not clearly defined clusters of abnormal cells that lead to terminal illnesses. There are three main types of tumors: benign, premalignant, and malignant. Benign tumors are defined as less dangerous and harmful due to the fact of being noninvasive, however, certain cases declare that they can become malignant. Malignant tumors usually grow rapidly, penetrating and destroying healthy tissues, spreading to distant organs and finally, metastasize [
6,
7]. There is a variety tumor identification methods: magnetic resonance imaging (MRI), computed tomography (CT), Single-Photon-Emission Computed Tomography (SPECT), and other medical imaging technologies are used to determine the exact type, location, and level of threat that cancer-damaged tissue has [
8,
9]. International research for cancer statistics in 2020 showed over 19.3 million new cancer cases from all over the world. Even though the medical field is rapidly growing and progressing, the World Health Organization (WHO) declared that cancer is the main leading cause of death, unfortunately reflecting the size of population [
10].
In histopathology analysis, specialists must focus on objective and accurate identification of diagnosis due to the complexity of diseases. Digital imaging allows to analyze histopathological specimens with a quantification of slides technique using machine learning methods as deep learning. Such promising technology of multi-layered artificial neural networks allows to perform a quantity of tasks adapting consistent tasks. Other studies have suggested that using digital histopathological images makes it possible to identify cancer cells [
11,
12,
13]. To increase the efficiency of tumor identification research with the reduction in errors, automatization using mathematical methods could be a solution. Taking into consideration this relevant case, Al experts [
14,
15,
16,
17] have already developed a variety of fully exploitable technologies that take place in the medical field. For instance, to detect or identify a brain, spine and chest tumor, the following methods are applicable: K-means, SVM, Level Set, Adaboost, Naive Bayes classifier, ANN classifier, convolutional neural networks, multilayer perceptron neural networks for analyzing magnetic resonance, and computed tomography type data analysis [
18,
19,
20,
21,
22].
In this article, we use machine learning for recognizing cancer cells that are applied over histopathological images consisting immense number of pixels. We are aware of deep learning methods that can benefit the identification and recognition of tumor cells. The machine learning algorithm goes over the given data, or as in our cases an image, or an image that shows cancer affected tissue, following an algorithm mode to ascertain from the training data and assign to make a prediction for further work. If this algorithm advances and increases the number of executions of improved and correct diagnosis—then we consider it as a learned task [
23]. To explain machine learning, we use certain terms: supervised, unsupervised, semi-supervised, and reinforcement learning [
24] algorithms [
25]. Furthermore, deep learning gives us opportunities to explore wide-ranging data [
26]. To gain the best possible accuracy, we must use an artificial neural network (ANN) as one of the machine learning techniques that allows to remove the artifacts (errors) that naturally appear in different types of data. Such errors, especially in the medical field, are one of the most common issues for misinterpretation. An ANN can be explained as assembly of neurons that are arranged in a sequence of multiple layers. The activation of an ANN begins from an input layer whose main aim is to correctly choose the format and transfer data to different layers until it reaches the last or the output layer. Fascinatingly, all other layers have different numbers of neurons and are identified as hidden because they play an important role allowing to learn data structure and give the ability to classify its type. In general, the operation of neural networks is very similar to linear regression, which means that each individual neuron is just like a linear regression model consisting of input data, its weights, bias and finally the output [
27,
28]. Medical image analysis empowered by deep learning, especially using a convolutional neural network (CNN), and its significant results for different types of cancer detection in histopathology scans (two-dimensional data), has drawn attention from scientists all over the world [
29,
30,
31]. The main reason is that it gives the ability to clinicians to make correct health diagnoses and receive precise analysis of illnesses that can be compared with previous samples. Training deep learning models, including CNN, demand significant training size and computing resources due to the profuse number of pixels in an image [
1,
32]. One of the subtypes of CNN, called the residual convolutional neural network (ResNet), can work with large datasets (the training and test material) even if the neural network increases in depth (extend in number of stacked layers), benefiting in a reduction in error rate [
33,
34]. Another subtype of CNN is the DenseNet, that reduces the vanishing gradient effect in DNN. This network is formed of dense blocks that are detached by a transition layer that minimizes the size of the delivered feature maps that will be transferred to the following layers. To compare ResNet and DenseNet we must understand how data are being directed between the layers. A transition layer, which aims to minimize the size of the generated feature maps that will be sent to the following layers, separates each dense block in a DenseNet network [
35]. A residual learning unit is a feature of ResNet, which was created to counteract deep neural network degeneration. This system is built as a feed-forward network with a shortcut link that enables the addition of new inputs and outputs. The main benefit is that it increases the classification accuracy without complicating the model’s actual design [
36].
Following reviews of different tumor identification systems, it became obvious that selecting the machine learning system that is best suited to produce the desired result based on the current data comes only after the data has been properly analyzed and processed [
37,
38,
39]. There is a lot of space for improvement because most of the systems that have been presented only process very small amounts of data using straightforward neural networks [
40,
41]. Applying more recent advancements in data collection and processing, which have been successfully used in other scientific fields, along with a new generation of convolutional neural networks with a more complex structure, guarantees the most accurate outcome for tumor detection.
In this research, we applied machine learning to histopathological images that consisted of immense numbers of pixels to recognize cancer cells. Automatic systems can solve complex problems that require an extremely fast response, accuracy, or take place on tasks that require both a fast and accurate response at the same time. Such systems and image pre-processing that are based on machine learning algorithms can be adapted to work with medical images, especially whole slide images (WSIs), that will allow clinicians to review a much larger number of health cases in a shorter time and give the ability to identify the preliminary stages of cancer or other diseases, thereby improving health monitoring strategies.
The main contributions of this paper are as follows:
Modern augmentation and image preprocessing methods to analyze WSIs,
Creating an adaptive U-Net model architecture,
Adding different optimizers for best outcoming result in AUC.
The paper is organized as follows:
In
Section 2, we did a review of machine learning models, architectures, algorithms, and other techniques that can be used for histopathological WSIs,
Section 3 outlines the methodology, that step by step describes the machine learning model, dataset, and accuracy requirements for further experiments,
Section 4 consists of the design of the experiments, the main values, graphical and statistical results,
In
Section 5, we list the major accomplishments and talk about the outcomes,
In
Section 6, we conclude our work and identify potential work directions.
4. Experiments and Results
4.1. Experimental Setup
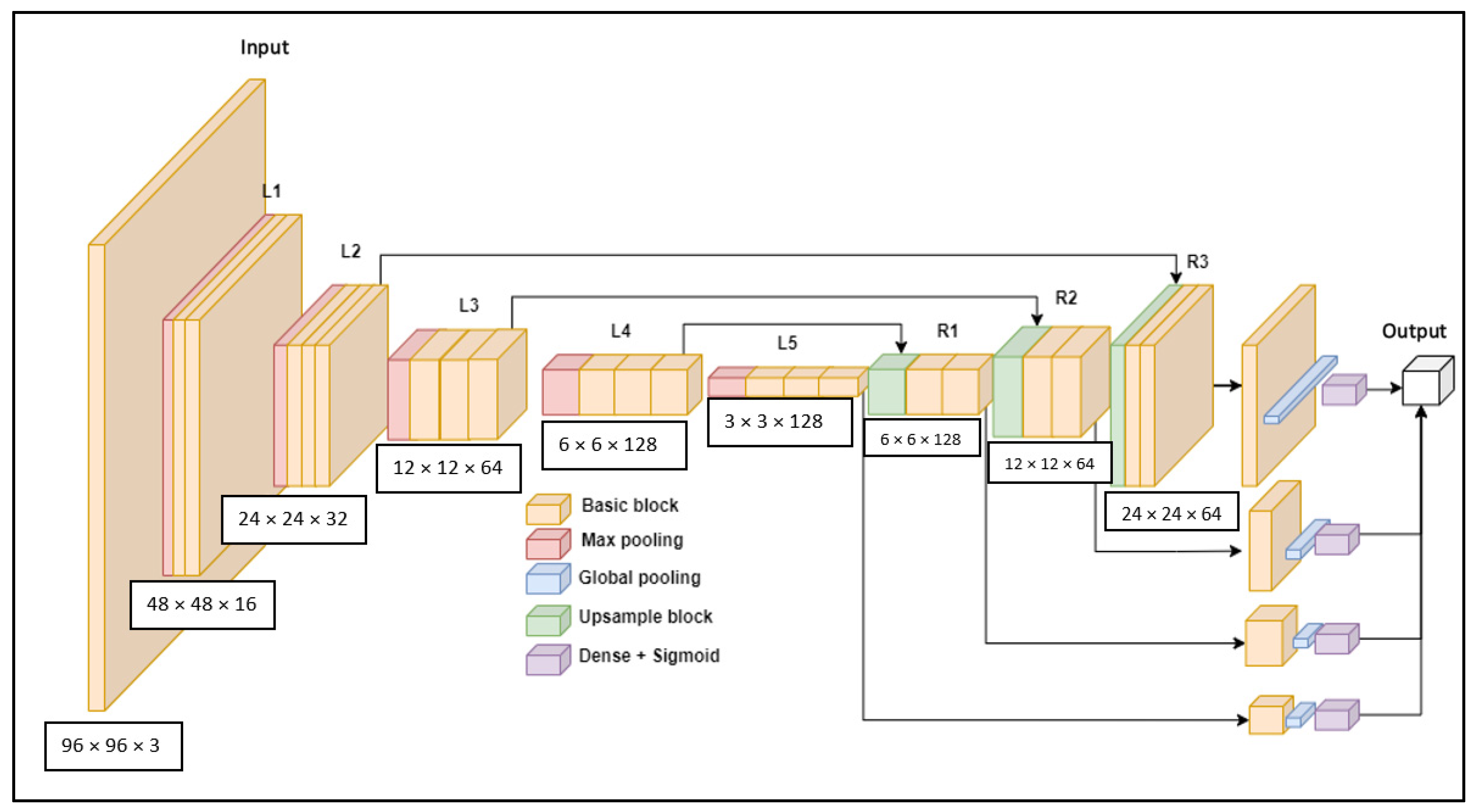
As we stated previously, the U-Net type architecture is currently one of the most popular templates to search for a suitable architecture. It allows you to easily check the signal information of different levels individually and by combining high and low frequency signals in separate levels; in our work, we called it the M-model, shown in
Figure 4.
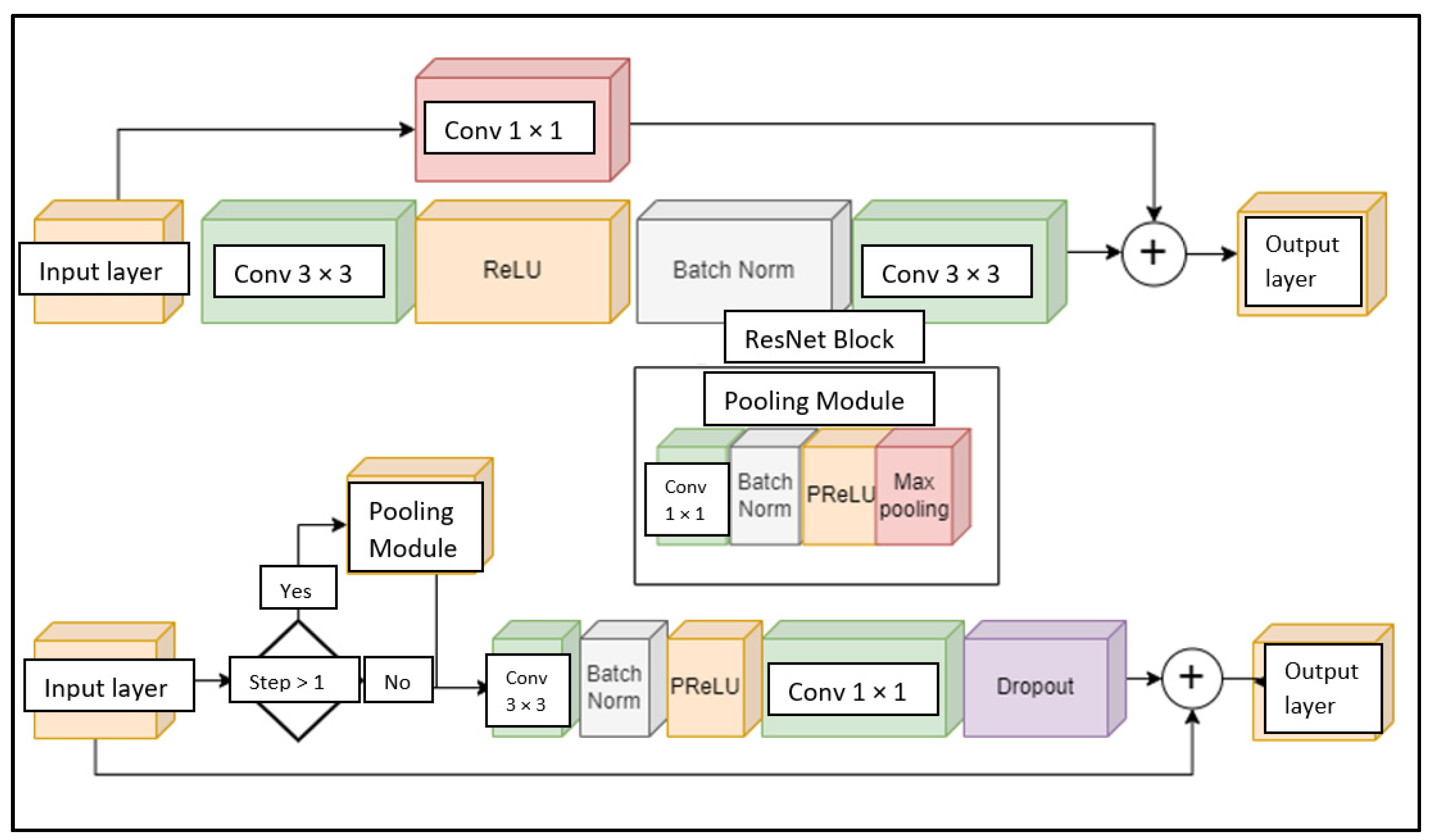
By default, U-Net networks form a complete U-shape—they transmit the entire input signal to the output of the model, which is applicable in this work due to efficiency and the type of task itself. Higher resolution output is usually used for image reproduction or segmentation tasks. In this research, classification was performed from low-resolution images, so the high-resolution output will not be superior. The following changes were made to the intermediate modules of the network structure, that we will call the E-Module, shown in
Figure 5. Compared to the commonly used standard ResNet module, the E module was more efficient and faster—two 3 × 3 convolutions were changed to one compressed 3 × 3 convolution and one 1 × 1 convolution, with the same number of channels as the number of input layer channels. Furthermore, the typical ReLU (rectified linear unit) activation was changed to PReLU (parametric rectified linear unit) [
75]. In this way, the model will be able to apply the best activation for each layer according to the direction of the gradient. Together with this activation function, it was possible to see the behavior of the model by analyzing the values of the activation coefficients. Finally, a Dropout layer was added at the end of the module, which performs a dual regularization: it reduces the signal bandwidth and allows the dropout factor to be increased to 1 at the end of training to discard supposedly unnecessary parts of the model.
Additionally, the entire network structure was reworked into a dynamic format. Based on the principle of the EfficientNet architecture [
76], the rules for growing the width and length of the network were established and adaptive regularization were applied with Equations (5)–(9) shown below:
L2 regularization (8):
where
f is the base number of filters,
F is the filter multiplier,
s is the filter multiplier,
h is the height of the network in pixels,
g is the number of convolutional groups of the network. The number of blocks indicates how many internal blocks will make up the mesh module after each decrease or increase in height and width of the mesh. Exclusion factor—indicates how many neurons will be turned off in percentage in each block, where m indicates the maximum possible number of filters. The L2 regularization [
77,
78] specifies the value of the L2 regularization constant for all network convolutions.
To understand whether all the changes made to the model gave advantages compared to ResNet50 or DenseNet121 models, the following experiments were performed. According to the already presented formula for changing the structure of the model, three sizes for f were selected: 8, 16, 32. Sizing allows us to see the areas where the network performs too poorly, overlearns, and where it performs optimally. It is additionally important to find out from which part of the network the best result can be obtained. Therefore, five output layers were added to the already existing network. Accordingly, we noticed a trend while comparing the results of all outputs. All models gave their best performance from the outputs of L5 and R1. This suggests that using a model with such a structure for this task, a higher resolution not only does not provide additional benefits, but also spoils the result. We can be assured that the most suitable model size for this task is f = 16, as in the first test, models where f = 8 and f = 32 performed worse. Among the model outputs, it can also be seen that higher resolution did not provide enough benefits.
Overall, compared to the first experiment, most of the results have improved, especially the output AUC of L5 has increased from 0.95279 to 0.95341. According to these results, it can be confidently stated that the U-Net type architecture did not provide enough benefits for this task. Moreover, comparing the obtained results with ResNet50 and Densenet121, the new model was already superior in terms of accuracy and learning speed—the new model reached the maximum result in eight epochs, which none of the previously described models was able to do when learning with newly initialized weights. According to the results of the first tests, the U-Net model was modified. We removed the right part of U-Net layers and all intermediate connection, also fixed size multiplier f = 16. Such pruning not only provided speed, but also allowed to gain greater accuracy due to less information reuse, this improved model will be called the MS-model.
4.2. Results
First, we made additional training validation performed on the artificially augmented and non-augmented datasets. The ResNet and DenseNet networks with ImageNet weights were applied for the test. Both models performed with more than 1% greater accuracy with augmented data than with non-augmented data (
Table 1). It can be assumed that these models were too large for such a task and most probably overlearned as a result, however the AUC value on the training data set shown in
Table 2 confirmed this. Without augmentation, the AUC was almost at unity at 0.993, while with augmented data it was only 0.975 with the ResNet50 model. Although retraining has occurred, the results show that the data generated for training was fine, and the selected augmentations were useful.
After making sure that the training environment and data were correct and everything was working as it should, further analysis was performed. Each selected model was trained twice. First, using ImageNet weights and then applying Xavier weights with initialization according to the training protocol, results are shown in
Table 3.
Comparing with ImageNet weights, DenseNet achieved the best result. According to the learning graph, it exceeded the AUC value of 0.95 after only two epochs. The next best was ResNet50, although it did not show the second result according to the table, but it also exceeded the AUC value of 0.95 after two epochs. Collectively, this means that these two architectures were the most suitable for this task. Furthermore, the ResNetV1 and ResNetV2 models excelled the most. Although their results were not the best, they exceeded 0.94 AUC in just five epochs. This shows that the ResNet-type blocks and persistent connections were well suited for this task due to their fine gradient feedback.
A new training session was performed with the trimmed model called the MS-model. Two tests were selected. The first was by extending the training using the best weights, as shown in
Table 4 and gave better results after reusing weights. As the original structure of the network remained the same, weights could easily be transferred from one network to another. The second was to train the same network with ever new weights initialization.
A popular way to get a better result is to change the optimization algorithm. Although all training was done with the SGD optimizer, which should potentially be the best for this problem, other methods could potentially find a better solution simply because of the difference in the optimization Hyper parameters. As a result, shown in
Table 5, we learned that of several optimizers, the best result was achieved with the AdamW optimizer.
Based on the results of the last test that adding more regularization is better, changes were made to the model and training code. The L2 regularization of the convolutional weights used so far was increased to 1 × 10−4, and the learning frequency cycle used in the SGD optimizer was converted to cosine. As expected, this teaching principle worked very well. After the fifth iteration, we managed to achieve an AUC of 0.95911, which was almost 0.4% better than the last best model trained with the AdamW optimizer.
In addition to that, we added the TTA [
79,
80] method, as the training data were adjusted very flexibly—we selected certain featuring: color channel change, vertical flip, horizontal flip, rotate −90 degrees, rotate +90 degrees, lighten the image by 5%, darken the image by 25%; unfortunately, the individually processed images results gained only 0.9590 AUC.
Another approach that did not require model retraining, reengineering, or other changes was model ensemble. This can be done in several ways. We proposed two methods for it. The first one, which combines the outputs of the different models according to the arithmetic mean and returns a single result, and the next one, which combines the weights of the different models into one common list of weight matrices.
5. Discussion
After all strategies and methods, we observed that different training optimizers, more heavily augmented data, learning step graph, or even a well-chosen learning starting point of the model, all influence the overall result when using them combined in an ensemble; it can be argued that the models or weights will converge if their individual performance does not overlap. This means that the models must make different errors among themselves. Therefore, it is obvious that by combining the ensemble methods of the last two experiments, it will be possible to achieve even higher accuracy.
It can be seen in
Table 6 that all used methods are models that lead our MS-model to be improved from 0.95918 to 0.96675 AUC.
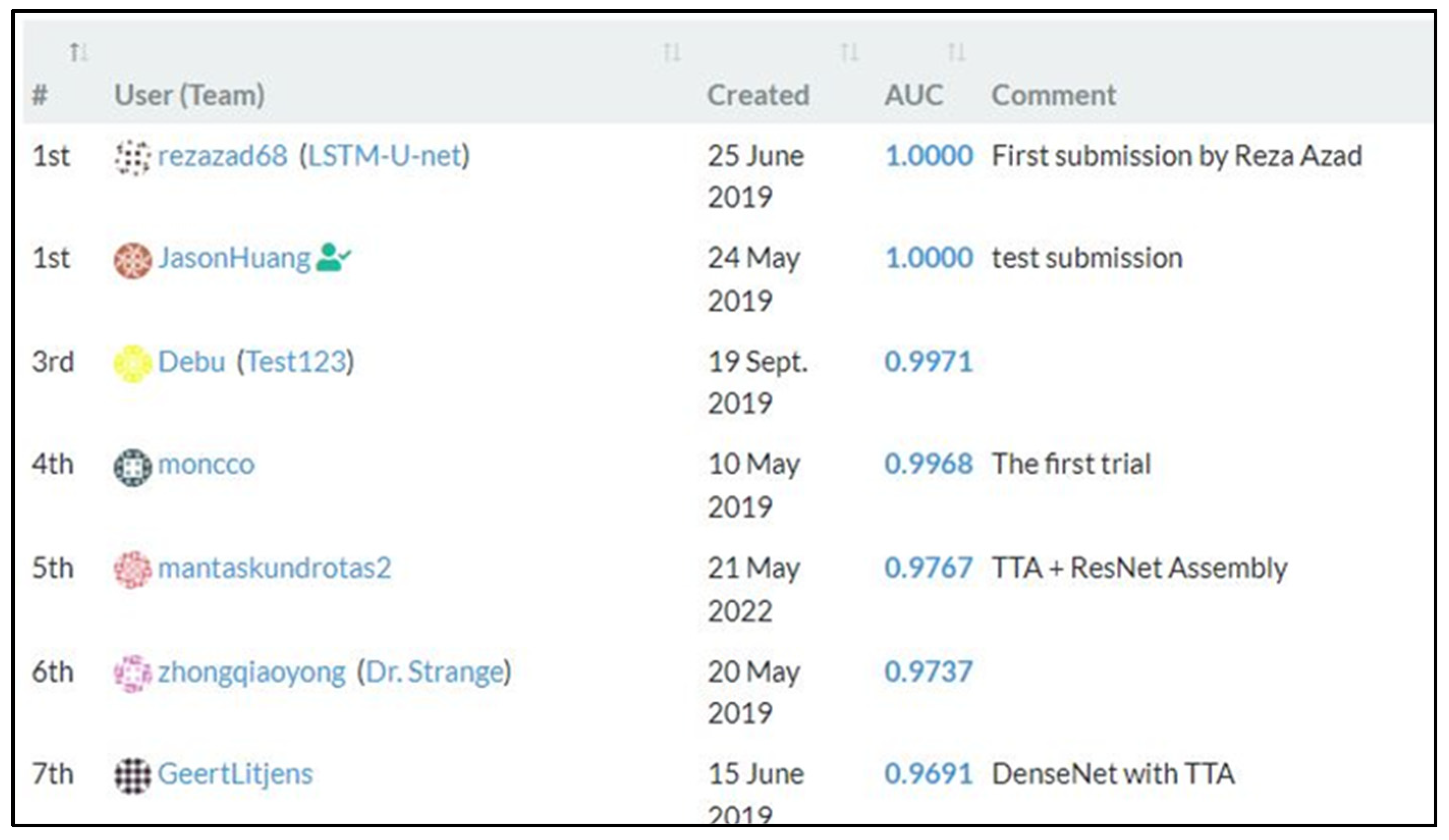
To sum up, it can be stated that artificial neural networks are able to distinguish tissue areas affected by cancer quite well. The developed MS-model is more accurate and faster than most of the models presented in the “Patch Chameleon” standings as shown in
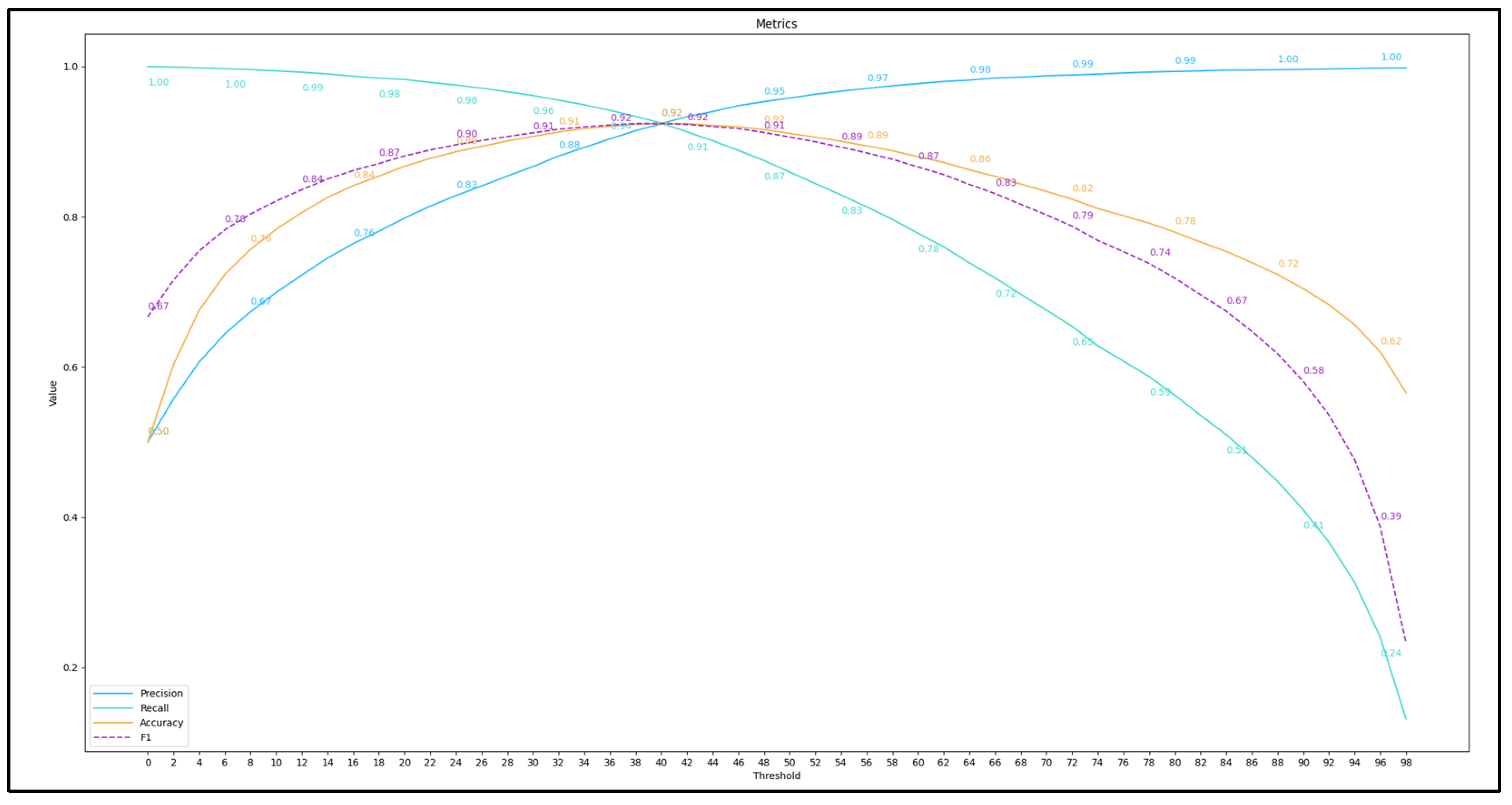
Figure 6. It can be said that such accuracy was most influenced by the effective architecture of the neural network and research on combining and assembling models. As shown in
Figure 7, we have reached a maximum
F1 score of 0.924 with a threshold of
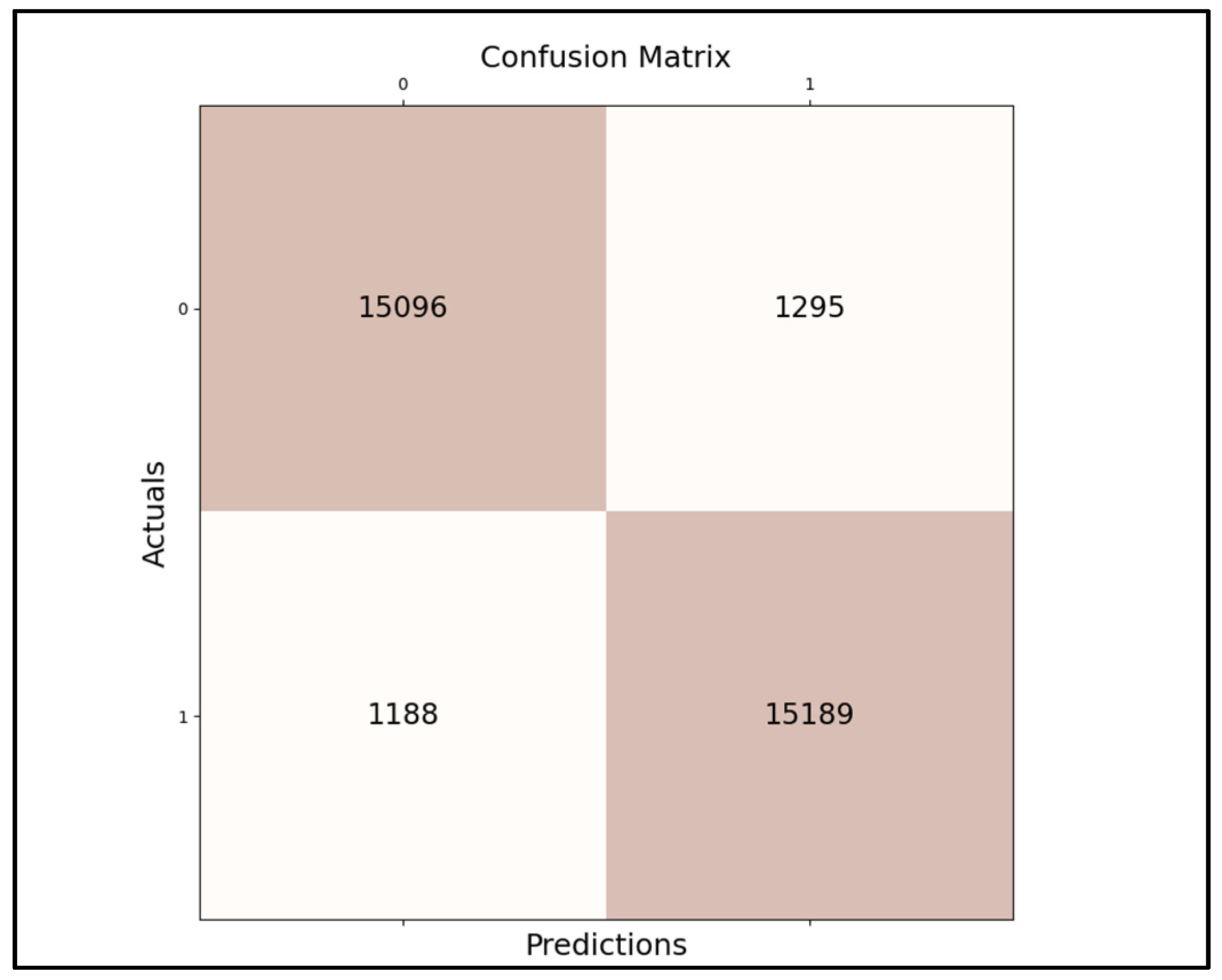
0.393; this score measured on our last best model’s accuracy (that is evaluated from precision and recall), as long as the confusion matrix is that shown in
Figure 8, giving us a result of meaning how many times our best model gave us correct predictions: true positives—15,096, true negatives—15,189, false negatives—1295, and false positives—1188. According to experiments, even with less-than-ideally prepared training data, the last ensemble method managed to exceed
0.9691 AUC.
6. Conclusions
In this work, we proposed to use ML and different neural network techniques to find a solution to WSIs histopathological data analysis. Our extensive experiments showed that the application of artificial deep neural networks for the classification of medical images, compared to other classical methods, are superior in almost all criteria. First, the CNN generalize well and perform similarly well on unseen data, even with additional constraints. From the obtained experiments, the AUC difference between the training and testing datasets was about one percent. Second, these models were highly flexible, allowing the size and architecture of the model to be experimentally tailored to the type of task. Using the M-model in several training iterations, we managed to reduce the model size by almost twice and increase the accuracy from 0.95491 to 0.95515 AUC. Third, when properly trained, convolutional models perform well on groups of various sizes. The result increased to 0.96870 with the TTA method, and 0.96977 with the addition of the multi-model ensemble. Fourth, by applying special analysis methods, it was possible to identify the shortcomings of the models and correct them. After finding that excessive and inappropriate image augmentation was detrimental to learning, a correction of the image processing parameters was sufficient to increase the AUC by almost 0.3%. Moreover, after additional training data preparation, the result of the individual model increased to 0.96664 AUC.
Due to the complexity of histopathological images, current image classification methods still lack accuracy and stability, and even the final model ensemble result of 0.97673 was not sufficient for the system to work autonomously. The results are too unpredictable, so this type of system can only be used as a guide as an image analysis tool for the physician.
Nevertheless, even such an achievement is important—it is a step closer to the ideal accuracy that would exceed human resolution.
In future work, not only another optimizing, and DNN techniques and architectures, but also imaging improving unsupervised methods could be used to gain best accurate results that further diagnostics tools for faster and more accurate cancer detection in histopathology imaging.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}