

Mouth Sounds: A Review of Acoustic Applications and Methodologies

 , , , and
, , , and
Abstract
:1. Introduction
2. Mouth Sounds and Their Acoustic Features
2.1. Which Are the Mouth Sounds?
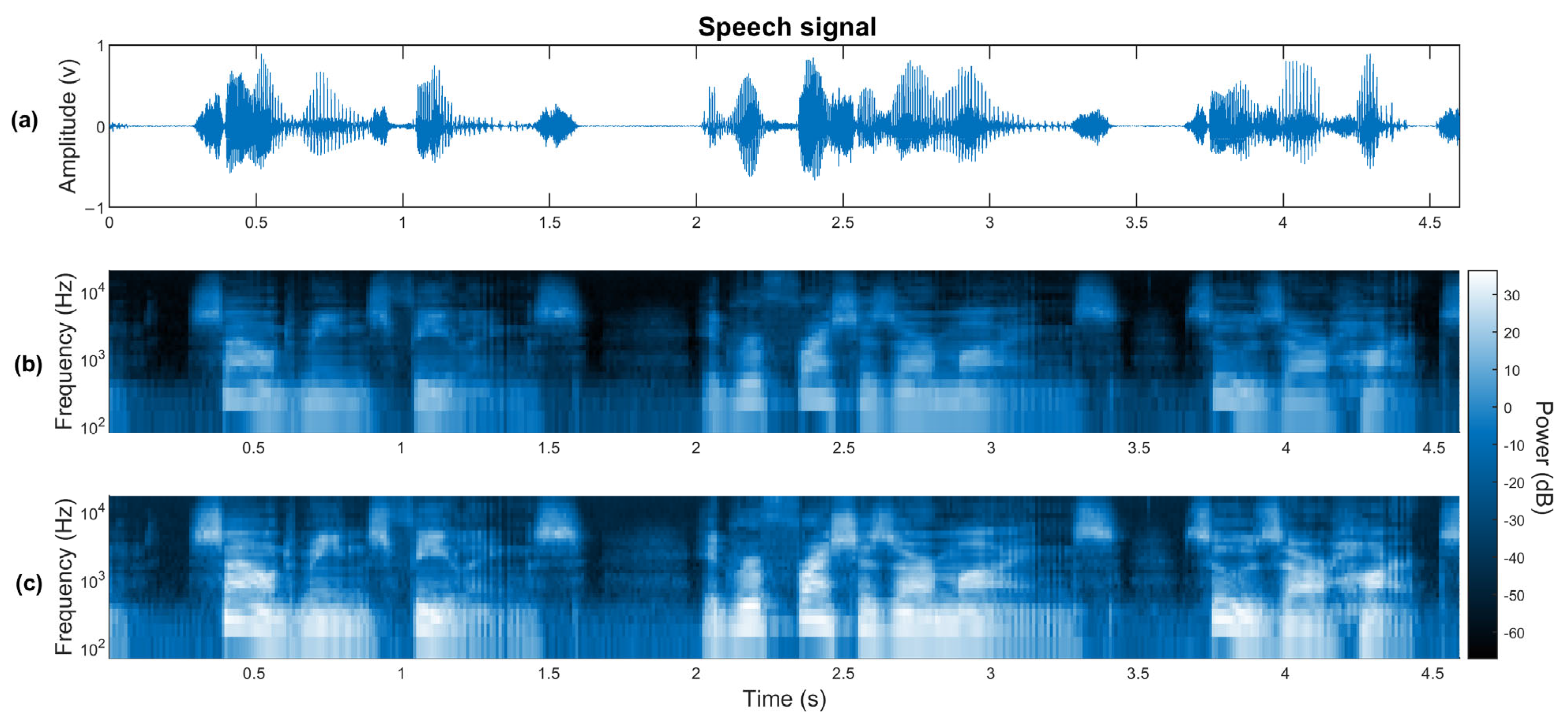
2.1.1. Speech
2.1.2. Singing
2.1.3. Babbling
2.1.4. Whistling
2.1.5. Breathing Sounds
2.1.6. Cough
2.1.7. Snoring
2.1.8. Crying
2.2. Acoustic Features of Mouth Sounds
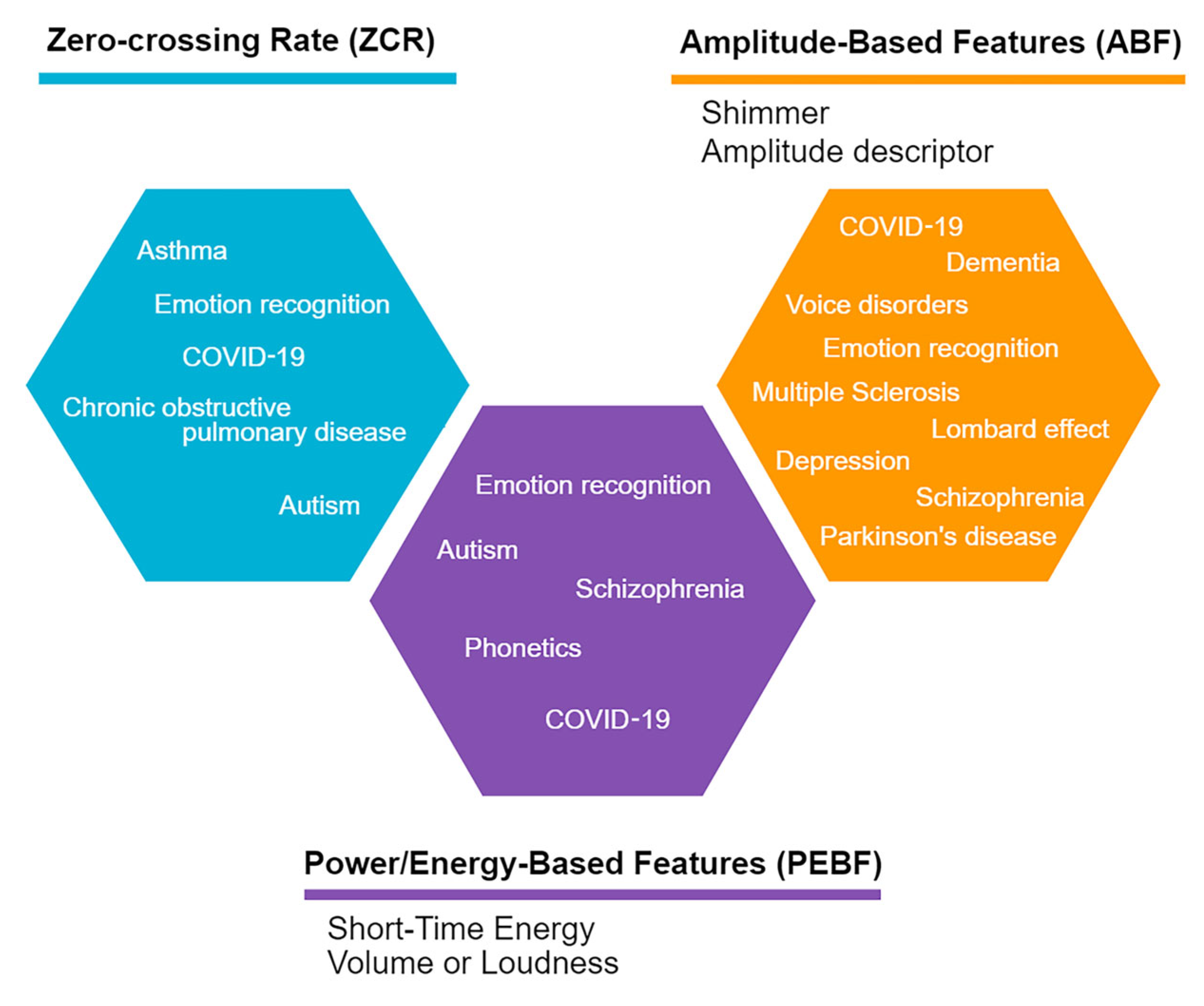
2.2.1. Time Domain Features
- A.
- Zero-Crossing Rate (ZCR)
- B.
- Power/Energy-Based Features (PEBF)
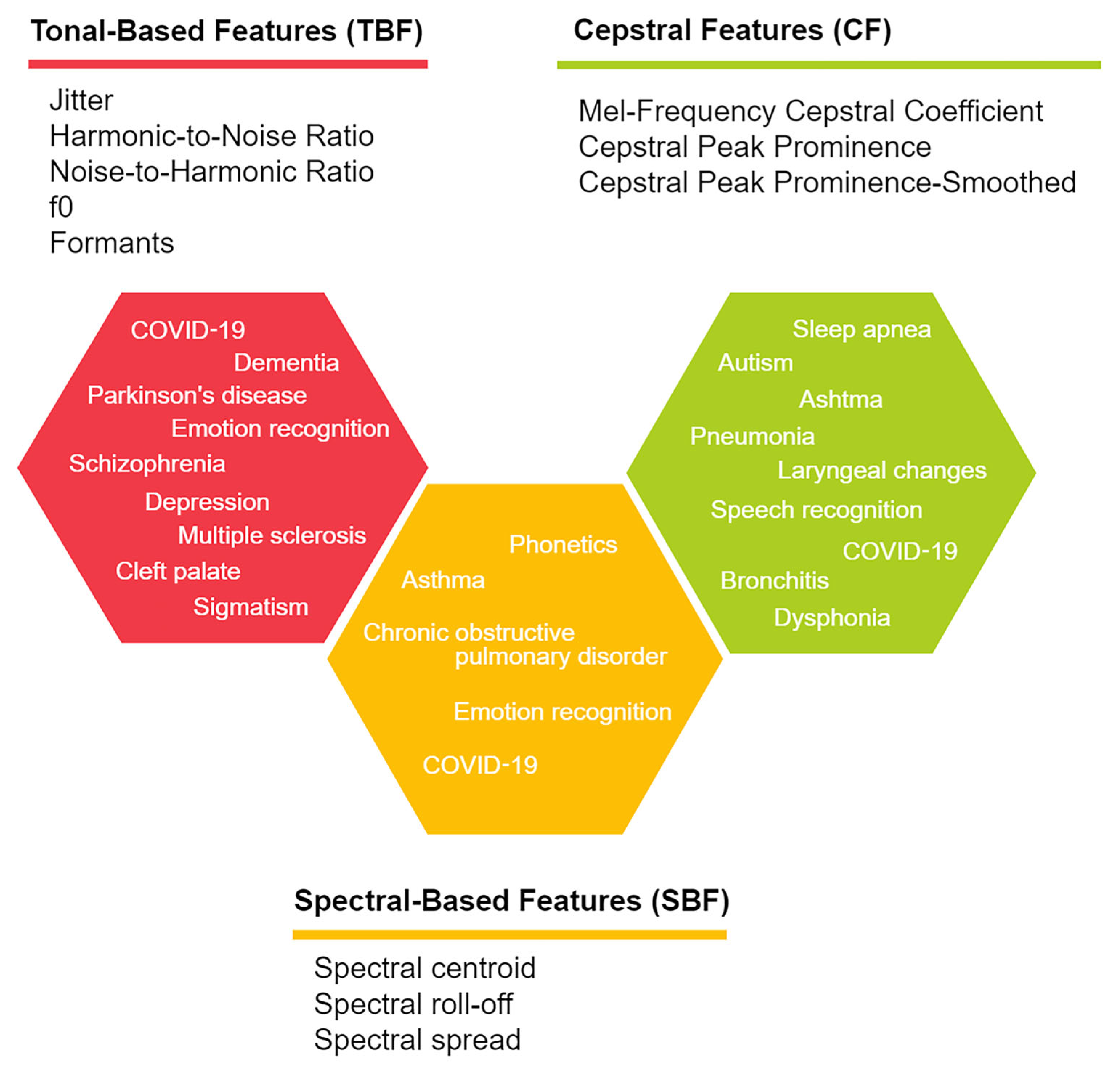
2.2.2. Frequency Domain Features
- C.
- Cepstral Features (CF)
3. Materials and Methods
3.1. Databases
3.2. Inclusion Criteria
3.3. Boolean Operators and Keywords
4. Main Findings
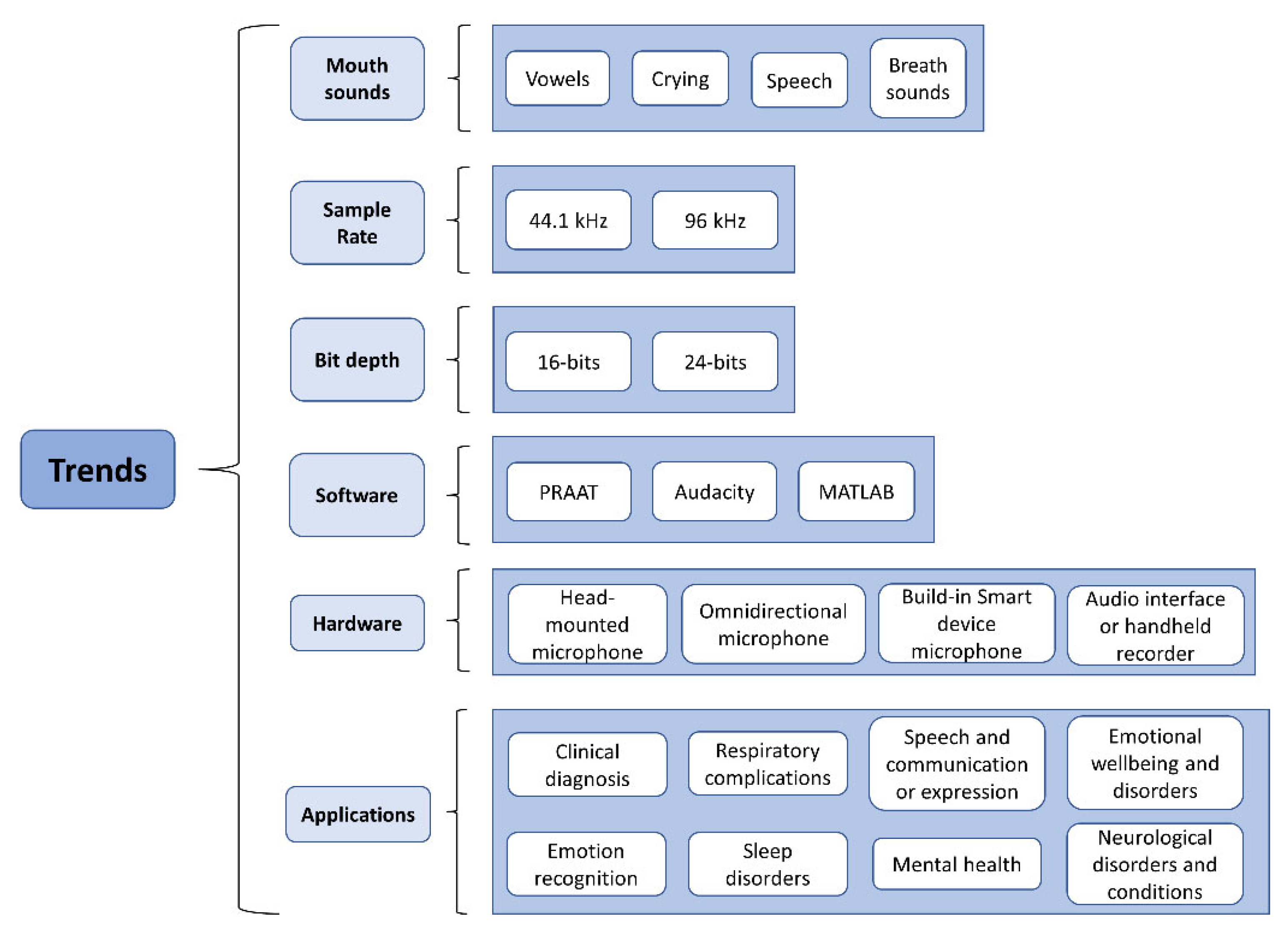
4.1. Recording Conditions
4.2. Acoustic Signal Processing Techniques
4.2.1. Time Domain
4.2.2. Frequency Domain
4.2.3. Spatial Filtering
4.3. Acoustic Feature Analysis
4.3.1. Statistical Analyses for Evaluation
4.3.2. Machine Learning (ML) Techniques for Pattern Recognition
4.3.3. Beyond ML Strategies
4.4. Applications
4.4.1. Physical Health Monitoring
- A.
- Clinical Diagnosis
- B.
- Respiratory Complications
- C.
- Coronavirus Disease 2019 (COVID-19)
- D.
- Neurological Disorders and Conditions
4.4.2. Mental Condition Monitoring
- A.
- Emotional Well-Being and Disorders
- B.
- Emotion Recognition
- C.
- Mental Health
4.4.3. Other Applications
- A.
- Sleep Disorders
- B.
- Speech and Communication/Expression
5. Discussion
5.1. Recording Conditions
5.2. Acoustic Signal Processing Techniques
5.3. Acoustic Feature Analysis
5.4. Applications
6. Conclusions
7. Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Time-Domain Feature Definitions

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Definition |
|---|---|
| Power/Energy-Based Features (PEBF) | |
| Volume or Loudness | It is used in the discrimination and segmentation of speech signals [144], and it is calculated as the root-mean-square (RMS) of the amplitude in a waveform for each time frame [34]. |
| Amplitude-Based Features (ABF) | |
| Shimmer | Based on the waveform, shimmer computes the cycle-to-cycle differences in the amplitude [35]. It is used to discriminate between vocal and non-vocal sound regions [144] and in the recognition and verification of speakers [34]. |
| Amplitude descriptor | This feature allows differentiating between diverse envelopes, focusing on collecting the energy, length, and duration [34,144] |
| Linear Predictive Coding | It intends to model human speech by considering the formants of the vocal tract [145]. It intends to predict future values with previous information [34]. |
| Maximum Phonation Time | It estimates the longest period one person can sustain the phonation of a vowel sound [146] and it is used to estimate vocal function. |
| Speech Intensity Prominence | It is used to estimate the overall loss of speech–sound intensity or attenuation effect. It is calculated by subtracting the floor intensity from the average intensity [53]. |
Appendix B. Frequency-Domain Feature Definitions
| Features | Definition |
|---|---|
| Tonality-Based Features (TBF) | |
| Jitter | It computes f0 variations [35] and reflects the periodicity of vocal fold vibration [144]. It helps to analyze pathological voices and determine vocal and non-vocal sounds [34,144]. |
| Harmonic-to-Noise Ratio (HNR) | It is a measure reflecting the amount of additive noise in a voice signal [144], and it is computed as the ratio between the harmonic part to the rest of the signal. It is used to analyze pathological voices [34]. |
| Noise-to-Harmonic Ratio (NHR) | It is the inverse of HNR and refers to the ratio of noise to the harmonic energy of a signal [147]. |
| Fundamental frequency (f0) or pitch | In simple terms, f0, also denoted as pitch, is the lowest frequency of a waveform [34] and is calculated by evaluating the periodicity of it in the time domain [144]. |
| Formants | Formants are resonances produced by the vocal tract. Formants can be seen as peaks in the spectrum signal and are usually significant in the pronunciation of vowels [35]. |
| Spectral-Based Features (SBF) | |
| Spectral centroid or spectral brightness. | It is defined as the center of ‘gravity’ of the spectrum [32], describing the brightness of a sound, and helps to measure timbre [34]. Moreover, it has a relation with the subjective intensity perception of a sound. |
| Spectral roll-off | It is the frequency below which the spectral magnitude is concentrated at 85% [144], 90% [32], and 95% [34] of the maximum spectral magnitude. Spectral roll-off is used in speech classification [34] and discriminates between voiced and unvoiced sounds [32]. |
| Spectral spread | This feature is closely related to the bandwidth of the signal [34] and measures how the spectrum is distributed around its centroid [32]. Generally, it is narrow for speech sounds [34]. |
| Spectrum envelope | It is a feature obtained with the log-frequency power spectrum, used chiefly in music genre classification [34]. |
| Spectral flux | It measures the change in the spectral content over time [32] by the frame-to-frame difference in the spectral amplitude [34]. |
| Spectral kurtosis | It is related to the flatness of the signal around the mean value; it has been used in Parkinson’s disease (PD) detection [34]. |
| Entropy | It measures the flatness of a signal; it is used in automatic speech recognition [34]. |
| Cepstral Features (CF) | |
| Linear prediction cepstral coefficients | Derived directly from linear predictive coding, it uses the recursion technique, rather than applying inverse Fourier transformation of the logarithms of the spectrum of the original signal [148]. It is used to capture emotion-specific information manifested through vocal tract features. |
| Cepstral Peak Prominence (CPP) | CPP measures the amplitude of the cepstral peak normalized to the overall amplitude. Having a higher CPP would imply a less periodic signal [149]. |
| Cepstral Peak Prominence-Smoothed (CPPS) | CPPS is similar to CPP, but uses different algorithms because it smooths the cepstral feature before extracting the peak [150]. |
| Linear Frequency Cepstral Coefficients (LFCC) | LFCC is similar to MFCC, but the difference is found in the filter bank, as the coefficients of this filter are distributed with the same size throughout all the frequencies and have the same importance; in contrast, MFCC put more emphasis on low frequencies [151]. |
| Rasta-PLP | It is used in speech recognition to reduce noise variations [34]. |
| Teager energy cepstral coefficient | It is similar to MFCC—the difference is that MFCC uses the standard energy instead of the non-linear Teager energy that is used for this feature [152]. |
| Teager energy-based Mel-frequency cepstral coefficient. | It is a feature used for speech recognition when there are high noise levels. It uses the Teager energy, warping it to the MFCC [153]. |
References
- Tortora, G.J.; Derrickson, B. Principles of Anatomy & Physiology; John Wiley and Sons: Hoboken, NJ, USA, 2017; ISBN 9781119320647. [Google Scholar]
- Woodson, G.E. Laryngeal and Pharyngeal Function, 7th ed.; Elsevier Inc.: Amsterdam, The Netherlands, 2010. [Google Scholar]
- Wang, X.; Jiang, W.; Zheng, X.; Xue, Q. A computational study of the effects of vocal fold stiffness parameters on voice production. J. Voice 2021, 35, 327.e1–327.e11. [Google Scholar] [CrossRef] [PubMed]
- Giovanni, A.; Ghio, A.; Mattei, A. Estudio clínico de la fonación. EMC Otorrinolaringol. 2021, 50, 1–16. [Google Scholar] [CrossRef]
- Hirano, M. Vocal mechanisms in singing: Laryngological and phoniatric aspects. J. Voice 1988, 2, 51–69. [Google Scholar] [CrossRef]
- Blythe, S.G. Appendix 2: Frequency Range of Vocals and Musical Instruments. In Attention, Balance and Coordination: The A.B.C. of Learning Success; John Wiley and Sons Inc.: Hoboken, NJ, USA, 2017; ISBN 9781119964148. [Google Scholar]
- Lewis, A.; Philip, K.E.J.; Lound, A.; Cave, P.; Russell, J.; Hopkinson, N.S. The physiology of singing and implications for ‘Singing for Lung Health’ as a therapy for individuals with chronic obstructive pulmonary disease. BMJ Open Respir. Res. 2021, 8, e000996. [Google Scholar] [CrossRef] [PubMed]
- Rvachew, S.; Alhaidary, A. The Phonetics of Babbling. In Oxford Research Encyclopedia of Linguistics; Oxford University Press: Oxford, UK, 2018. [Google Scholar]
- Bedford, R.; Saez de Urabain, I.R.; Cheung, C.H.M.; Karmiloff-Smith, A.; Smith, T.J. Toddlers’ Fine Motor Milestone Achievement Is Associated with Early Touchscreen Scrolling. Front. Psychol. 2016, 7, 1108. [Google Scholar] [CrossRef] [Green Version]
- Daffern, H.; Keren-Portnoy, T.; DePaolis, R.A.; Brown, K.I. BabblePlay: An app for infants, controlled by infants, to improve early language outcomes. Appl. Acoust. 2020, 162, 107183. [Google Scholar] [CrossRef] [PubMed]
- Meyer, J. Whistle Production and Physics of the Signal. In Whistled Languages; Springer: Berlin/Heidelberg, Germany, 2015; pp. 69–90. [Google Scholar]
- Azola, A.; Palmer, J.; Mulheren, R.; Hofer, R.; Fischmeister, F.; Fitch, W.T. The physiology of oral whistling: A combined radiographic and MRI analysis. J. Appl. Physiol. 2018, 124, 34–39. [Google Scholar] [CrossRef] [Green Version]
- Aloui, S.; Khirani, S.; Ramirez, A.; Colella, M.; Louis, B.; Amaddeo, A.; Fauroux, B. Whistle and cough pressures in children with neuromuscular disorders. Respir. Med. 2016, 113, 28–36. [Google Scholar] [CrossRef] [Green Version]
- Ball, M.; Hossain, M.; Padalia, D. Anatomy, Airway; StatPearls: Treasure Island, FL, USA, 2022. [Google Scholar]
- Sarkar, M.; Madabhavi, I.; Niranjan, N.; Dogra, M. Auscultation of the respiratory system. Ann. Thorac. Med. 2015, 10, 158. [Google Scholar] [CrossRef]
- Forgacs, P.; Nathoo, A.R.; Richardson, H.D. Breath sounds. Thorax 1971, 26, 288–295. [Google Scholar] [CrossRef] [Green Version]
- Andrani, F.; Aiello, M.; Bertorelli, G.; Crisafulli, E.; Chetta, A. Cough, a vital reflex. mechanisms, determinants and measurements. Acta Biomed. 2019, 89, 477–480. [Google Scholar] [CrossRef] [PubMed]
- Sykes, D.L.; Morice, A.H. The Cough Reflex: The Janus of Respiratory Medicine. Front. Physiol. 2021, 12, 684080. [Google Scholar] [CrossRef] [PubMed]
- Chung, K.F.; Widdicombe, J.G.; Boushey, H.A. (Eds.) Cough: Causes, Mechanisms and Therapy; Wiley: Hoboken, NJ, USA, 2003; ISBN 9781405116343. [Google Scholar]
- Korpáš, J.; Sadloňová, J.; Vrabec, M. Analysis of the Cough Sound: An Overview. Pulm. Pharmacol. 1996, 9, 261–268. [Google Scholar] [CrossRef] [PubMed]
- Jadcherla, S.R.; Hasenstab, K.A.; Shaker, R.; Castile, R.G. Mechanisms of cough provocation and cough resolution in neonates with bronchopulmonary dysplasia. Pediatr. Res. 2015, 78, 462–469. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Korpas, J.; Vrabec, M.; Sadlonova, J.; Salat, D.; Debreczeni, L.A. Analysis of the cough sound frequency in adults and children with bronchial asthma. Acta Physiol. Hung. 2003, 90, 27–34. [Google Scholar] [CrossRef] [PubMed]
- Pevernagie, D.; Aarts, R.M.; De Meyer, M. The acoustics of snoring. Sleep Med. Rev. 2010, 14, 131–144. [Google Scholar] [CrossRef]
- Alencar, A.M.; da Silva, D.G.V.; Oliveira, C.B.; Vieira, A.P.; Moriya, H.T.; Lorenzi-Filho, G. Dynamics of snoring sounds and its connection with obstructive sleep apnea. Phys. A Stat. Mech. Appl. 2013, 392, 271–277. [Google Scholar] [CrossRef] [Green Version]
- Gračanin, A.; Bylsma, L.M.; Vingerhoets, A.J.J.M. Is crying a self-soothing behavior? Front. Psychol. 2014, 5, 502. [Google Scholar] [CrossRef] [Green Version]
- Rothgänger, H. Analysis of the sounds of the child in the first year of age and a comparison to the language. Early Hum. Dev. 2003, 75, 55–69. [Google Scholar] [CrossRef]
- Shinya, Y.; Kawai, M.; Niwa, F.; Imafuku, M.; Myowa, M. Fundamental frequency variation of neonatal spontaneous crying predicts language acquisition in preterm and term infants. Front. Psychol. 2017, 8, 2195. [Google Scholar] [CrossRef] [Green Version]
- Gabrieli, G.; Scapin, G.; Bornstein, M.; Esposito, G. Are Cry Studies Replicable? An Analysis of Participants, Procedures, and Methods Adopted and Reported in Studies of Infant Cries. Acoustics 2019, 1, 866–883. [Google Scholar] [CrossRef] [Green Version]
- Mahmoudian, S.; Aminrasouli, N.; Ahmadi, Z.Z.; Lenarz, T.; Farhadi, M. Acoustic Analysis of Crying Signal in Infants with Disabling Hearing Impairment. J. Voice 2019, 33, 946.e7–946.e13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ballou, G. Handbook for Sound Engineers, 5th ed.; Focal Press: Waltham, MA, USA, 2015; ISBN 978-0-203-75828-1. [Google Scholar]
- Duville, M.M.; Alonso-Valerdi, L.M.; Ibarra-Zarate, D.I. Electroencephalographic Correlate of Mexican Spanish Emotional Speech Processing in Autism Spectrum Disorder: To a Social Story and Robot-Based Intervention. Front. Hum. Neurosci. 2021, 15, 626146. [Google Scholar] [CrossRef] [PubMed]
- Giannakopoulos, T.; Pikrakis, A. Audio Features. In Introduction to Audio Analysis; Elsevier: Amsterdam, The Netherlands, 2014; pp. 59–103. [Google Scholar]
- Lee, J.; Ali, H.; Ziaei, A.; Tobey, E.A.; Hansen, J.H.L. The Lombard effect observed in speech produced by cochlear implant users in noisy environments: A naturalistic study. J. Acoust. Soc. Am. 2017, 141, 2788–2799. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sharma, G.; Umapathy, K.; Krishnan, S. Trends in audio signal feature extraction methods. Appl. Acoust. 2020, 158, 107020. [Google Scholar] [CrossRef]
- Abhang, P.A.; Gawali, B.W.; Mehrotra, S.C. Introduction to EEG- and Speech-Based Emotion Recognition; Elsevier: Amsterdam, The Netherlands, 2016; ISBN 9780128045312. [Google Scholar]
- Kumar, P.; Biswas, A.; Mishra, A.N.; Chandra, M. Spoken Language Identification Using Hybrid Feature Extraction Methods. arXiv 2010, arXiv:1003.5623. [Google Scholar]
- Compton, M.T.; Lunden, A.; Cleary, S.D.; Pauselli, L.; Alolayan, Y.; Halpern, B.; Broussard, B.; Crisafio, A.; Capulong, L.; Balducci, P.M.; et al. The aprosody of schizophrenia: Computationally derived acoustic phonetic underpinnings of monotone speech. Schizophr. Res. 2018, 197, 392–399. [Google Scholar] [CrossRef]
- Baird, A.; Amiriparian, S.; Berschneider, M.; Schmitt, M.; Schuller, B. Predicting Biological Signals from Speech: Introducing a Novel Multimodal Dataset and Results. In Proceedings of the 2019 IEEE 21st International Workshop on Multimedia Signal Processing (MMSP), Kuala Lumpur, Malaysia, 27–29 September 2019; IEEE: New York, NY, USA, 2019; Volume 3346632, pp. 1–5. [Google Scholar]
- Krecichwost, M.; Mocko, N.; Badura, P. Automated detection of sigmatism using deep learning applied to multichannel speech signal. Biomed. Signal Process. Control 2021, 68, 102612. [Google Scholar] [CrossRef]
- Liao, S.; Song, C.; Wang, X.; Wang, Y. A classification framework for identifying bronchitis and pneumonia in children based on a small-scale cough sounds dataset. PLoS ONE 2022, 17, e0275479. [Google Scholar] [CrossRef]
- Tracey, B.; Patel, S.; Zhang, Y.; Chappie, K.; Volfson, D.; Parisi, F.; Adans-Dester, C.; Bertacchi, F.; Bonato, P.; Wacnik, P. Voice Biomarkers of Recovery From Acute Respiratory Illness. IEEE J. Biomed. Health Inform. 2022, 26, 2787–2795. [Google Scholar] [CrossRef]
- Vahedian-azimi, A.; Keramatfar, A.; Asiaee, M.; Atashi, S.S.; Nourbakhsh, M. Do you have COVID-19? An artificial intelligence-based screening tool for COVID-19 using acoustic parameters. J. Acoust. Soc. Am. 2021, 150, 1945–1953. [Google Scholar] [CrossRef] [PubMed]
- Despotovic, V.; Ismael, M.; Cornil, M.; Call, R.M.; Fagherazzi, G. Detection of COVID-19 from voice, cough and breathing patterns: Dataset and preliminary results. Comput. Biol. Med. 2021, 138, 104944. [Google Scholar] [CrossRef] [PubMed]
- Costantini, G.; Cesarini, V.; Robotti, C.; Benazzo, M.; Pietrantonio, F.; Di Girolamo, S.; Pisani, A.; Canzi, P.; Mauramati, S.; Bertino, G.; et al. Deep learning and machine learning-based voice analysis for the detection of COVID-19: A proposal and comparison of architectures. Knowl. Based Syst. 2022, 253, 109539. [Google Scholar] [CrossRef] [PubMed]
- Suppa, A.; Asci, F.; Saggio, G.; Marsili, L.; Casali, D.; Zarezadeh, Z.; Ruoppolo, G.; Berardelli, A.; Costantini, G. Voice analysis in adductor spasmodic dysphonia: Objective diagnosis and response to botulinum toxin. Park. Relat. Disord. 2020, 73, 23–30. [Google Scholar] [CrossRef] [PubMed]
- Mou, Z.; Teng, W.; Ouyang, H.; Chen, Y.; Liu, Y.; Jiang, C.; Zhang, J.; Chen, Z. Quantitative analysis of vowel production in cerebral palsy children with dysarthria. J. Clin. Neurosci. 2019, 66, 77–82. [Google Scholar] [CrossRef]
- Thies, T.; Mücke, D.; Lowit, A.; Kalbe, E.; Steffen, J.; Barbe, M.T. Prominence marking in parkinsonian speech and its correlation with motor performance and cognitive abilities. Neuropsychologia 2020, 137, 107306. [Google Scholar] [CrossRef]
- Vashkevich, M.; Azarov, E.; Petrovsky, A.; Rushkevich, Y. Features extraction for the automatic detection of ALS disease from acoustic speech signals. In Proceedings of the 2018 Signal Processing: Algorithms, Architectures, Arrangements, and Applications (SPA), Poznan, Poland, 19–21 September 2018; pp. 321–326. [Google Scholar] [CrossRef]
- Jing, S.; Mao, X.; Chen, L. Prominence features: Effective emotional features for speech emotion recognition. Digit. Signal Process. Rev. J. 2018, 72, 216–231. [Google Scholar] [CrossRef]
- Di Natale, V.; Cantarella, G.; Manfredi, C.; Ciabatta, A.; Bacherini, C.; DeJonckere, P.H. Semioccluded Vocal Tract Exercises Improve Self-Perceived Voice Quality in Healthy Actors. J. Voice 2020, 36, 584.e7–584.e14. [Google Scholar] [CrossRef]
- Abou-Abbas, L.; Tadj, C.; Fersaie, H.A. A fully automated approach for baby cry signal segmentation and boundary detection of expiratory and inspiratory episodes. J. Acoust. Soc. Am. 2017, 142, 1318–1331. [Google Scholar] [CrossRef] [Green Version]
- Robotti, C.; Costantini, G.; Saggio, G.; Cesarini, V.; Calastri, A.; Maiorano, E.; Piloni, D.; Perrone, T.; Sabatini, U.; Ferretti, V.V.; et al. Machine Learning-based Voice Assessment for the Detection of Positive and Recovered COVID-19 Patients. J. Voice 2021. [Google Scholar] [CrossRef]
- Magee, M.; Lewis, C.; Noffs, G.; Reece, H.; Chan, J.C.S.; Zaga, C.J.; Paynter, C.; Birchall, O.; Rojas Azocar, S.; Ediriweera, A.; et al. Effects of face masks on acoustic analysis and speech perception: Implications for peri-pandemic protocols. J. Acoust. Soc. Am. 2020, 148, 3562–3568. [Google Scholar] [CrossRef] [PubMed]
- McLoughlin, I.V.; Perrotin, O.; Sharifzadeh, H.; Allen, J.; Song, Y. Automated Assessment of Glottal Dysfunction Through Unified Acoustic Voice Analysis. J. Voice 2020, 36, 743–754. [Google Scholar] [CrossRef]
- Lu, R.; Duan, Z.; Zhang, C. Audio-Visual Deep Clustering for Speech Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1697–1712. [Google Scholar] [CrossRef]
- Yerigeri, V.V.; Ragha, L.K. Speech stress recognition using semi-eager learning. Cogn. Syst. Res. 2021, 65, 79–97. [Google Scholar] [CrossRef]
- González Hautamäki, R.; Sahidullah, M.; Hautamäki, V.; Kinnunen, T. Acoustical and perceptual study of voice disguise by age modification in speaker verification. Speech Commun. 2017, 95, 1–15. [Google Scholar] [CrossRef]
- Hariharan, M.; Sindhu, R.; Vijean, V.; Yazid, H.; Nadarajaw, T.; Yaacob, S.; Polat, K. Improved binary dragonfly optimization algorithm and wavelet packet based non-linear features for infant cry classification. Comput. Methods Programs Biomed. 2018, 155, 39–51. [Google Scholar] [CrossRef] [PubMed]
- Gutz, S.E.; Rowe, H.P.; Tilton-Bolowsky, V.E.; Green, J.R. Speaking with a KN95 face mask: A within-subjects study on speaker adaptation and strategies to improve intelligibility. Cogn. Res. Princ. Implic. 2022, 7, 73. [Google Scholar] [CrossRef]
- Zealouk, O.; Satori, H.; Hamidi, M.; Laaidi, N.; Salek, A.; Satori, K. Analysis of COVID-19 Resulting Cough Using Formants and Automatic Speech Recognition System. J. Voice 2021. [Google Scholar] [CrossRef]
- Bartl-Pokorny, K.D.; Pokorny, F.B.; Batliner, A.; Amiriparian, S.; Semertzidou, A.; Eyben, F.; Kramer, E.; Schmidt, F.; Schönweiler, R.; Wehler, M.; et al. The voice of COVID-19: Acoustic correlates of infection in sustained vowels. J. Acoust. Soc. Am. 2021, 149, 4377–4383. [Google Scholar] [CrossRef]
- Maor, E.; Tsur, N.; Barkai, G.; Meister, I.; Makmel, S.; Friedman, E.; Aronovich, D.; Mevorach, D.; Lerman, A.; Zimlichman, E.; et al. Noninvasive Vocal Biomarker is Associated With Severe Acute Respiratory Syndrome Coronavirus 2 Infection. Mayo Clin. Proc. Innov. Qual. Outcomes 2021, 5, 654–662. [Google Scholar] [CrossRef]
- Balamurali, B.T.; Hee, H.I.; Teoh, O.H.; Lee, K.P.; Kapoor, S.; Herremans, D.; Chen, J.-M. Asthmatic versus healthy child classification based on cough and vocalised /ɑ:/ sounds. J. Acoust. Soc. Am. 2020, 148, EL253–EL259. [Google Scholar] [CrossRef]
- Chen, H.; Lin, Y.; Li, Y.; Wang, W.; Wang, P.; Lei, Y. Hybrid Feature Embedded Sparse Stacked Autoencoder and Manifold Dimensionality Reduction Ensemble for Mental Health Speech Recognition. IEEE Access 2021, 9, 28729–28741. [Google Scholar] [CrossRef]
- Jeancolas, L.; Benali, H.; Benkelfat, B.E.; Mangone, G.; Corvol, J.C.; Vidailhet, M.; Lehericy, S.; Petrovska-Delacretaz, D. Automatic detection of early stages of Parkinson’s disease through acoustic voice analysis with mel-frequency cepstral coefficients. In Proceedings of the 2017 International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Fez, Morocco, 22–24 May 2017. [Google Scholar] [CrossRef]
- Chong, A.J.; Risdal, M.; Aly, A.; Zymet, J.; Keating, P. Effects of consonantal constrictions on voice quality. J. Acoust. Soc. Am. 2020, 148, EL65–EL71. [Google Scholar] [CrossRef] [PubMed]
- Korvel, G.; Treigys, P.; Kostek, B. Highlighting interlanguage phoneme differences based on similarity matrices and convolutional neural network. J. Acoust. Soc. Am. 2021, 149, 508–523. [Google Scholar] [CrossRef] [PubMed]
- Castillo-Escario, Y.; Ferrer-Lluis, I.; Montserrat, J.M.; Jane, R. Entropy analysis of acoustic signals recorded with a smartphone for detecting apneas and hypopneas: A comparison with a commercial system for home sleep apnea diagnosis. IEEE Access 2019, 7, 128224–128241. [Google Scholar] [CrossRef]
- Cesari, U.; De Pietro, G.; Marciano, E.; Niri, C.; Sannino, G.; Verde, L. A new database of healthy and pathological voices. Comput. Electr. Eng. 2018, 68, 310–321. [Google Scholar] [CrossRef]
- Vizza, P.; Mirarchi, D.; Tradigo, G.; Redavide, M.; Bossio, R.B.; Veltri, P. Vocal signal analysis in patients affected by Multiple Sclerosis. Procedia Comput. Sci. 2017, 108, 1205–1214. [Google Scholar] [CrossRef]
- Oshana, R. Overview of Digital Signal Processing Algorithms. In DSP Software Development Techniques for Embedded and Real-Time Systems; Newnes: Burlington, MA, USA, 2006; pp. 59–121. [Google Scholar] [CrossRef]
- Fang, S.H.; Tsao, Y.; Hsiao, M.J.; Chen, J.Y.; Lai, Y.H.; Lin, F.C.; Wang, C. Te Detection of Pathological Voice Using Cepstrum Vectors: A Deep Learning Approach. J. Voice 2019, 33, 634–641. [Google Scholar] [CrossRef]
- Sampaio, M.C.; Bohlender, J.E.; Brockmann-Bauser, M. Fundamental Frequency and Intensity Effects on Cepstral Measures in Vowels from Connected Speech of Speakers with Voice Disorders. J. Voice 2019, 35, 422–431. [Google Scholar] [CrossRef]
- Selamtzis, A.; Castellana, A.; Salvi, G.; Carullo, A.; Astolfi, A. Effect of vowel context in cepstral and entropy analysis of pathological voices. Biomed. Signal Process. Control 2019, 47, 350–357. [Google Scholar] [CrossRef] [Green Version]
- Phadke, K.V.; Laukkanen, A.M.; Ilomäki, I.; Kankare, E.; Geneid, A.; Švec, J.G. Cepstral and Perceptual Investigations in Female Teachers With Functionally Healthy Voice. J. Voice 2018, 34, 485.e33–485.e43. [Google Scholar] [CrossRef] [PubMed]
- Aichinger, P.; Hagmuller, M.; Schneider-Stickler, B.; Schoentgen, J.; Pernkopf, F. Tracking of Multiple Fundamental Frequencies in Diplophonic Voices. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 330–341. [Google Scholar] [CrossRef]
- Dar, J.A.; Srivastava, K.K.; Ahmed Lone, S. Design and development of hybrid optimization enabled deep learning model for COVID-19 detection with comparative analysis with DCNN, BIAT-GRU, XGBoost. Comput. Biol. Med. 2022, 150, 106123. [Google Scholar] [CrossRef] [PubMed]
- Gong, Y.; Yatawatte, H.; Poellabauer, C.; Schneider, S.; Latham, S. Automatic Autism Spectrum Disorder Detection Using Everyday Vocalizations Captured by Smart Devices. In Proceedings of the 2018 ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, Washington, DC, USA, 29 August–1 September 2018; pp. 465–473. [Google Scholar] [CrossRef]
- Al-nasheri, A.; Muhammad, G.; Alsulaiman, M.; Ali, Z. Investigation of Voice Pathology Detection and Classification on Different Frequency Regions Using Correlation Functions. J. Voice 2017, 31, 3–15. [Google Scholar] [CrossRef]
- Xie, W.; Gaydecki, P.; Caress, A.L. An Inhaler Tracking System Based on Acoustic Analysis: Hardware and Software. IEEE Trans. Instrum. Meas. 2019, 68, 4472–4480. [Google Scholar] [CrossRef] [Green Version]
- Manfredi, C.; Bandini, A.; Melino, D.; Viellevoye, R.; Kalenga, M.; Orlandi, S. Automated detection and classification of basic shapes of newborn cry melody. Biomed. Signal Process. Control 2018, 45, 174–181. [Google Scholar] [CrossRef]
- Umayahara, Y.; Soh, Z.; Sekikawa, K.; Kawae, T.; Otsuka, A.; Tsuji, T. Estimation of cough peak flow using cough sounds. Sensors 2018, 18, 2381. [Google Scholar] [CrossRef] [Green Version]
- Oliveira, G.; Fava, G.; Baglione, M.; Pimpinella, M. Mobile Digital Recording: Adequacy of the iRig and iOS Device for Acoustic and Perceptual Analysis of Normal Voice. J. Voice 2017, 31, 236–242. [Google Scholar] [CrossRef]
- Madill, C.; Nguyen, D.D. Impact of Instructed Laryngeal Manipulation on Acoustic Measures of Voice–Preliminary Results. J. Voice 2020, 37, 143.e1–143.e11. [Google Scholar] [CrossRef]
- Vizza, P.; Tradigo, G.; Mirarchi, D.; Bossio, R.B.; Lombardo, N.; Arabia, G.; Quattrone, A.; Veltri, P. Methodologies of speech analysis for neurodegenerative diseases evaluation. Int. J. Med. Inform. 2019, 122, 45–54. [Google Scholar] [CrossRef]
- Flego, S. Estimating vocal tract length by minimizing non-uniformity of cross-sectional area. Proc. Meet. Acoust. 2019, 35, 060003. [Google Scholar] [CrossRef]
- Grinstein-Koren, O.; Herzog, N.; Amir, O. Hyposalivation Affecting Womens’ Voice. J. Voice 2021. [Google Scholar] [CrossRef] [PubMed]
- Koo, S.K.; Kwon, S.B.; Koh, T.K.; Ji, C.L.; Park, G.H.; Lee, H.B. Acoustic analyses of snoring sounds using a smartphone in patients undergoing septoplasty and turbinoplasty. Eur. Arch. Oto-Rhino-Laryngol. 2021, 278, 257–263. [Google Scholar] [CrossRef] [PubMed]
- Mirheidari, B.; Blackburn, D.; Walker, T.; Reuber, M.; Christensen, H. Dementia detection using automatic analysis of conversations. Comput. Speech Lang. 2019, 53, 65–79. [Google Scholar] [CrossRef] [Green Version]
- Alghamdi, N.; Maddock, S.; Marxer, R.; Barker, J.; Brown, G.J. A corpus of audio-visual Lombard speech with frontal and profile views. J. Acoust. Soc. Am. 2018, 143, EL523–EL529. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pangputt, P.; Parr, B.; Demidenko, S.; Drain, A. Real-time acoustic analysis for flow rate estimation in a medical aerosol application. In Proceedings of the 2018 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Houston, TX, USA, 14–17 May 2018; IEEE: New York, NY, USA, 2018; pp. 1–6. [Google Scholar]
- Karlsson, F.; Schalling, E.; Laakso, K.; Johansson, K.; Hartelius, L. Assessment of speech impairment in patients with Parkinson’s disease from acoustic quantifications of oral diadochokinetic sequences. J. Acoust. Soc. Am. 2020, 147, 839–851. [Google Scholar] [CrossRef] [Green Version]
- Rahman, M.M.; Ahmed, T.; Nemati, E.; Nathan, V.; Vatanparvar, K.; Blackstock, E.; Kuang, J. ExhaleSense: Detecting High Fidelity Forced Exhalations to Estimate Lung Obstruction on Smartphones. In Proceedings of the 2020 IEEE International Conference on Pervasive Computing and Communications (PerCom), Austin, TX, USA, 23–27 March 2020; IEEE: New York, NY, USA, 2020; pp. 1–10. [Google Scholar]
- Tang, C.; Zheng, W.; Zong, Y.; Qiu, N.; Lu, C.; Zhang, X.; Ke, X.; Guan, C. Automatic identification of high-risk autism spectrum disorder: A feasibility study using video and audio data under the still-face paradigm. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 2401–2410. [Google Scholar] [CrossRef]
- Fujimura, S.; Kojima, T.; Okanoue, Y.; Kagoshima, H.; Taguchi, A.; Shoji, K.; Inoue, M.; Hori, R. Real-Time Acoustic Voice Analysis Using a Handheld Device Running Android Operating System. J. Voice 2020, 34, 823–829. [Google Scholar] [CrossRef]
- Azam, M.A.; Shahzadi, A.; Khalid, A.; Anwar, S.M.; Naeem, U. Smartphone Based Human Breath Analysis from Respiratory Sounds. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; IEEE: New York, NY, USA, 2018; pp. 445–448. [Google Scholar]
- Asiaee, M.; Vahedian-azimi, A.; Atashi, S.S.; Keramatfar, A.; Nourbakhsh, M. Voice Quality Evaluation in Patients With COVID-19: An Acoustic Analysis. J. Voice 2022, 36, 879.e13–879.e19. [Google Scholar] [CrossRef]
- Shang, W.; Stevenson, M. Detection of speech playback attacks using robust harmonic trajectories. Comput. Speech Lang. 2021, 65, 101133. [Google Scholar] [CrossRef]
- Allwood, G.; Du, X.; Webberley, K.M.; Osseiran, A.; Marshall, B.J. Advances in Acoustic Signal Processing Techniques for Enhanced Bowel Sound Analysis. IEEE Rev. Biomed. Eng. 2019, 12, 240–253. [Google Scholar] [CrossRef] [PubMed]
- Lee, G.-T.; Nam, H.; Kim, S.-H.; Choi, S.-M.; Kim, Y.; Park, Y.-H. Deep learning based cough detection camera using enhanced features. Expert Syst. Appl. 2022, 206, 117811. [Google Scholar] [CrossRef] [PubMed]
- Krecichwost, M.; Miodonska, Z.; Badura, P.; Trzaskalik, J.; Mocko, N. Multi-channel acoustic analysis of phoneme /s/ mispronunciation for lateral sigmatism detection. Biocybern. Biomed. Eng. 2019, 39, 246–255. [Google Scholar] [CrossRef]
- Scherer, K.R.; Sundberg, J.; Fantini, B.; Trznadel, S.; Eyben, F. The expression of emotion in the singing voice: Acoustic patterns in vocal performance. J. Acoust. Soc. Am. 2017, 142, 1805–1815. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dropuljic, B.; Mijic, I.; Petrinovic, D.; Jovanovic, T.; Cosic, K. Vocal Analysis of Acoustic Startle Responses. IEEE/ACM Trans. Audio, Speech, Lang. Process. 2018, 26, 318–329. [Google Scholar] [CrossRef]
- Sun, Y.; Ng, M.L.; Lian, C.; Wang, L.; Yang, F.; Yan, N. Acoustic and kinematic examination of dysarthria in Cantonese patients of Parkinson’s disease. In Proceedings of the 2018 11th International Symposium on Chinese Spoken Language Processing, ISCSLP 2018, Taipei, Taiwan, 26–29 November 2018; pp. 354–358. [Google Scholar]
- Hall, R. The mouths of others: The linguistic performance of race in Bermuda. J. Socioling. 2019, 23, 223–243. [Google Scholar] [CrossRef]
- Mięsikowska, M. Analysis of Polish Vowels of Tracheoesophageal Speakers. J. Voice 2017, 31, 263.e5–263.e11. [Google Scholar] [CrossRef]
- Prasada Rao, K.; Chandra Sekhara Rao, M.V.P.; Hemanth Chowdary, N. An integrated approach to emotion recognition and gender classification. J. Vis. Commun. Image Represent. 2019, 60, 339–345. [Google Scholar] [CrossRef]
- Haq, A.U.; Li, J.P.; Memon, M.H.; Khan, J.; Malik, A.; Ahmad, T.; Ali, A.; Nazir, S.; Ahad, I.; Shahid, M. Feature Selection Based on L1-Norm Support Vector Machine and Effective Recognition System for Parkinson’s Disease Using Voice Recordings. IEEE Access 2019, 7, 37718–37734. [Google Scholar] [CrossRef]
- Barreira, R.R.A.; Ling, L.L. Kullback–Leibler divergence and sample skewness for pathological voice quality assessment. Biomed. Signal Process. Control 2020, 57, 101697. [Google Scholar] [CrossRef]
- Grozdić, Đ.T.; Jovičić, S.T.; Subotić, M. Whispered speech recognition using deep denoising autoencoder. Eng. Appl. Artif. Intell. 2017, 59, 15–22. [Google Scholar] [CrossRef]
- Kashyap, B.; Horne, M.; Pathirana, P.N.; Power, L.; Szmulewicz, D. Automated Topographic Prominence based quantitative assessment of speech timing in Cerebellar Ataxia. Biomed. Signal Process. Control 2020, 57, 101759. [Google Scholar] [CrossRef]
- Moro-Velázquez, L.; Gómez-García, J.A.; Godino-Llorente, J.I.; Villalba, J.; Orozco-Arroyave, J.R.; Dehak, N. Analysis of speaker recognition methodologies and the influence of kinetic changes to automatically detect Parkinson’s Disease. Appl. Soft Comput. J. 2018, 62, 649–666. [Google Scholar] [CrossRef]
- Markandeya, M.N.; Abeyratne, U.R. Smart Phone based Snoring Sound analysis to Identify Upper Airway Obstructions. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 4233–4236. [Google Scholar] [CrossRef]
- Koo, S.K.; Kwon, S.B.; Moon, J.S.; Lee, S.H.; Lee, H.B.; Lee, S.J. Comparison of snoring sounds between natural and drug-induced sleep recorded using a smartphone. Auris Nasus Larynx 2018, 45, 777–782. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, Y.; Sun, H.; Shan, H. Parkinson disease detection using energy direction features based on EMD from voice signal. Biocybern. Biomed. Eng. 2021, 41, 127–141. [Google Scholar] [CrossRef]
- Kellermann, W. Beamforming for Speech and Audio Signals. In Handbook of Signal Processing in Acoustics; Springer: New York, NY, USA, 2008; pp. 691–702. [Google Scholar]
- Liu, C.-F.; Ciou, W.-S.; Chen, P.-T.; Du, Y.-C. A Real-Time Speech Separation Method Based on Camera and Microphone Array Sensors Fusion Approach. Sensors 2020, 20, 3527. [Google Scholar] [CrossRef] [PubMed]
- Danayi, A.; Seyedin, S. A novel algorithm based on time-frequency analysis for extracting melody from human whistling. In Proceedings of the 2018 4th Iranian Conference on Signal Processing and Intelligent Systems (ICSPIS), Tehran, Iran, 25–27 December 2018; IEEE: New York, NY, USA, 2018; pp. 135–139. [Google Scholar]
- Kim, G.; Bae, I.; Park, H.; Lee, Y. Comparison of Cepstral Analysis Based on Voiced-Segment Extraction and Voice Tasks for Discriminating Dysphonic and Normophonic Korean Speakers. J. Voice 2021, 35, 328.e11–328.e22. [Google Scholar] [CrossRef] [PubMed]
- Mainka, A.; Platzek, I.; Mattheus, W.; Fleischer, M.; Müller, A.S.; Mürbe, D. Three-dimensional Vocal Tract Morphology Based on Multiple Magnetic Resonance Images Is Highly Reproducible During Sustained Phonation. J. Voice 2017, 31, 504.e11–504.e20. [Google Scholar] [CrossRef] [PubMed]
- Hammami, I.; Salhi, L.; Labidi, S. Voice Pathologies Classification and Detection Using EMD-DWT Analysis Based on Higher Order Statistic Features. IRBM 2020, 41, 161–171. [Google Scholar] [CrossRef]
- Dubey, A.K.; Prasanna, S.R.M.; Dandapat, S. Sinusoidal model-based hypernasality detection in cleft palate speech using CVCV sequence. Speech Commun. 2020, 124, 1–12. [Google Scholar] [CrossRef]
- Xiong, F.; Goetze, S.; Kollmeier, B.; Meyer, B.T. Joint estimation of reverberation time and early-to-late reverberation ratio from single-channel speech signals. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 255–267. [Google Scholar] [CrossRef]
- Fujimura, S.; Kojima, T.; Okanoue, Y.; Shoji, K.; Inoue, M.; Omori, K.; Hori, R. Classification of Voice Disorders Using a One-Dimensional Convolutional Neural Network. J. Voice 2020, 36, 15–20. [Google Scholar] [CrossRef]
- Kurokawa, T.; Miura, T.; Yamashita, M.; Sakai, T.; Matsunaga, S. Emotion-Cluster Classification of Infant Cries Using Sparse Representation. In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018; IEEE: New York, NY, USA, 2018; pp. 1875–1878. [Google Scholar]
- Alimuradov, A.K.; Tychkov, A.Y.; Churakov, P.P. Formant Analysis of Speech Signals Based on Empirical Mode Decomposition to Detect Human Psycho-Emotional Disorder. In Proceedings of the 2019 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus), Saint Petersburg and Moscow, Russia, 28–31 January 2019; IEEE: New York, NY, USA, 2019; pp. 1123–1128. [Google Scholar]
- Liu, L.; Li, W.; Wu, X.; Zhou, B.X. Infant cry language analysis and recognition: An experimental approach. IEEE/CAA J. Autom. Sin. 2019, 6, 778–788. [Google Scholar] [CrossRef]
- Kheddache, Y.; Tadj, C. Identification of diseases in newborns using advanced acoustic features of cry signals. Biomed. Signal Process. Control 2019, 50, 35–44. [Google Scholar] [CrossRef] [PubMed]
- Cornejo, J.; Pedrini, H. Bimodal Emotion Recognition Based on Audio and Facial Parts Using Deep Convolutional Neural Networks. In Proceedings of the 2019 18th IEEE International Conference on Machine Learning and Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; IEEE: New York, NY, USA, 2019; pp. 111–117. [Google Scholar]
- Fernández-Abascal, E.G.; Guerra, P.; Martínez, F.; Domínguez, F.J.; Muñoz, M.Á.; Egea, D.A.; Martín, M.D.; Mata, J.L.; Rodríguez, S.; Vila, J. El Sistema Internacional de Sonidos Afectivos (IADS): Adaptación española. Psicothema 2008, 20, 104–113. [Google Scholar] [PubMed]
- Soares, A.P.; Pinheiro, A.P.; Costa, A.; Frade, C.S.; Comesaña, M.; Pureza, R. Affective auditory stimuli: Adaptation of the International Affective Digitized Sounds (IADS-2) for European Portuguese. Behav. Res. Methods 2013, 45, 1168–1181. [Google Scholar] [CrossRef] [Green Version]
- Guidi, A.; Gentili, C.; Scilingo, E.P.; Vanello, N. Analysis of speech features and personality traits. Biomed. Signal Process. Control 2019, 51, 1–7. [Google Scholar] [CrossRef]
- Deng, B.; Xue, B.; Hong, H.; Fu, C.; Zhu, X.; Wang, Z. Decision tree based sleep stage estimation from nocturnal audio signals. In Proceedings of the 2017 22nd International Conference on Digital Signal Processing (DSP), London, UK, 23–25 August 2017; IEEE: New York, NY, USA, 2017; pp. 1–4. [Google Scholar]
- Xie, J.; Aubert, X.; Long, X.; van Dijk, J.; Arsenali, B.; Fonseca, P.; Overeem, S. Audio-based snore detection using deep neural networks. Comput. Methods Programs Biomed. 2021, 200, 105917. [Google Scholar] [CrossRef]
- Islam, R.; Tarique, M.; Abdel-Raheem, E. A Survey on Signal Processing Based Pathological Voice Detection Techniques. IEEE Access 2020, 8, 66749–66776. [Google Scholar] [CrossRef]
- Naal-Ruiz, N.E.; Alonso-Valerdi, L.M.; Ibarra-Zarate, D.I. Frequency responses of headphones modulate alpha brain oscillations related to auditory processing. Appl. Acoust. 2022, 185, 108415. [Google Scholar] [CrossRef]
- Milanov, N.E.; Milanova, B.E. Proximity Effect of microphone. Audio Eng. Soc. 2001, 1–11. Available online: http://www.aes.org/e-lib/browse.cfm?elib=9940 (accessed on 15 January 2023).
- Black, R. Anti-alias filters: The invisible distortion mechanism in digital audio? In Proceedings of the 106th Convention of the Audio Engineering Society, Amsterdam, The Netherlands, 16–19 May 1998; Volume 966. [Google Scholar]
- Aggarwal, S.G.V.; Selvakanmani, S.; Pant, B.; Kaur, K.; Verma, A.; Binegde, G.N. Audio Segmentation Techniques and Applications Based on Deep Learning. Sci. Program. 2022, 2022, 7994191. [Google Scholar] [CrossRef]
- Alimi, S.; Awodele, O. Voice Activity Detection: Fusion of Time and Frequency Domain Features with A SVM Classifier. Comput. Eng. Intell. Syst. 2022, 13. [Google Scholar] [CrossRef]
- Zhu, H.; Luo, M.-D.; Wang, R.; Zheng, A.-H.; He, R. Deep Audio-visual Learning: A Survey. Int. J. Autom. Comput. 2021, 18, 351–376. [Google Scholar] [CrossRef]
- Sherman, R. Sherman Foundational Data Modeling. In Business Intelligence Guidebook; Elsevier: Amsterdam, The Netherlands, 2015; pp. 173–195. ISBN 9780124114616. [Google Scholar]
- Jiping, Z. Brain Computer Interface System, Performance, Challenges and Applications. J. Comput. Nat. Sci. 2023, 3, 46–57. [Google Scholar] [CrossRef]
- Chaki, J. Pattern Analysis Based Acoustic Signal Processing: A Survey of the State-of-Art; Springer: New York, NY, USA, 2021; Volume 24, ISBN 0123456789. [Google Scholar]
- Mada Sanjaya, W.S.; Anggraeni, D.; Santika, I.P. Speech Recognition using Linear Predictive Coding (LPC) and Adaptive Neuro-Fuzzy (ANFIS) to Control 5 DoF Arm Robot. J. Phys. Conf. Ser. 2018, 1090, 012046. [Google Scholar] [CrossRef]
- Maslan, J.; Leng, X.; Rees, C.; Blalock, D.; Butler, S.G. Maximum phonation time in healthy older adults. J. Voice 2011, 25, 709–713. [Google Scholar] [CrossRef] [Green Version]
- Kreiman, J.; Gerratt, B.R. Perceptual interaction of the harmonic source and noise in voice. J. Acoust. Soc. Am. 2012, 131, 492–500. [Google Scholar] [CrossRef] [Green Version]
- Chia Ai, O.; Hariharan, M.; Yaacob, S.; Sin Chee, L. Classification of speech dysfluencies with MFCC and LPCC features. Expert Syst. Appl. 2012, 39, 2157–2165. [Google Scholar] [CrossRef]
- Hillenbrand, J.; Cleveland, R.A.; Erickson, R.L. Acoustic correlates of breathy vocal quality. J. Speech Lang. Hear. Res. 1994, 37, 769–778. [Google Scholar] [CrossRef]
- Heman-Ackah, Y.D.; Sataloff, R.T.; Laureyns, G.; Lurie, D.; Michael, D.D.; Heuer, R.; Rubin, A.; Eller, R.; Chandran, S.; Abaza, M.; et al. Quantifying the cepstral peak prominence, a measure of dysphonia. J. Voice 2014, 28, 783–788. [Google Scholar] [CrossRef]
- Mohammadi, M.; Sadegh Mohammadi, H.R. Robust features fusion for text independent speaker verification enhancement in noisy environments. In Proceedings of the 2017 Iranian Conference on Electrical Engineering (ICEE), Tehran, Iran, 2–4 May 2017; pp. 1863–1868. [Google Scholar] [CrossRef]
- Khoria, K.; Kamble, M.R.; Patil, H.A. Teager energy cepstral coefficients for classification of normal vs. whisper speech. In Proceedings of the 2020 28th European Signal Processing Conference (EUSIPCO), Amsterdam, The Netherlands, 18–21 January 2021; pp. 371–375. [Google Scholar] [CrossRef]
- Georgogiannis, A.; Digalakis, V. Speech Emotion Recognition using non-linear Teager energy based features in noisy environments. In Proceedings of the 2012 20th European Signal Processing Conference (EUSIPCO), Bucharest, Romania, 27–31 August 2012; pp. 2045–2049. [Google Scholar]






| What Is the Main Objective? | What Was Done to the Signal? | How Was the Signal Acquired? | What Was Used to Process the Signal? | Which Are the Fields of Study? |
|---|---|---|---|---|
| Sound | Processing | Recording | Algorithm | Application |
| Mouth | Analysis | Acquisition | Code | COVID-19 |
| Audio | Extraction | Conditions | Devices | Coronavirus |
| Features | Classification | Instruments | SARS-CoV-2 | |
| Characteristics |
| Mouth Sounds | Acoustic Features | Applications | |
|---|---|---|---|
| Time | Frequency | ||
| Vowels | ZCR | MFCC | Clinical diagnosis |
| Speech | Volume or loudness | CPP | Respiratory complications |
| Breathing sounds | STE | CPPS | Neurological disorders and conditions |
| Crying | Shimmer | Jitter | Emotional wellbeing and disorders |
| Amplitude descriptor | HNR | Emotion recognition | |
| NHR | Mental health | ||
| f0 | Sleep disorders | ||
| Formants | Speech and communication/expression | ||
| Spectral centroid | |||
| Spectral roll-off | |||
| Spectral spread | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naal-Ruiz, N.E.; Gonzalez-Rodriguez, E.A.; Navas-Reascos, G.; Romo-De Leon, R.; Solorio, A.; Alonso-Valerdi, L.M.; Ibarra-Zarate, D.I. Mouth Sounds: A Review of Acoustic Applications and Methodologies. Appl. Sci. 2023, 13, 4331. https://doi.org/10.3390/app13074331
Naal-Ruiz NE, Gonzalez-Rodriguez EA, Navas-Reascos G, Romo-De Leon R, Solorio A, Alonso-Valerdi LM, Ibarra-Zarate DI. Mouth Sounds: A Review of Acoustic Applications and Methodologies. Applied Sciences. 2023; 13(7):4331. https://doi.org/10.3390/app13074331
Chicago/Turabian StyleNaal-Ruiz, Norberto E., Erick A. Gonzalez-Rodriguez, Gustavo Navas-Reascos, Rebeca Romo-De Leon, Alejandro Solorio, Luz M. Alonso-Valerdi, and David I. Ibarra-Zarate. 2023. "Mouth Sounds: A Review of Acoustic Applications and Methodologies" Applied Sciences 13, no. 7: 4331. https://doi.org/10.3390/app13074331