When deciding whether or not to make a film, a filmmaker must consider several factors, the most prominent of which is the film’s potential box office take. The film’s success can be measured by how well it does at the box office. Many things affect a movie’s performance at the box office, such as its genre, writers, directors, actors, length, year of release, producers, and production company. The firms that sell, promote, and market the film are crucial to its overall success [
10]. There are too many variables at play for anyone to accurately predict the status of the market or the profit of a particular film. Many scientific papers have employed machine learning algorithms to predict how a movie will do at the box office, how popular it will be, and how it will be rated. In [
11], the researchers suggested a methodology for predicting movie success that incorporates machine learning, social network analysis, and text mining approaches. Their model extracts many sorts of characteristics, such as “who”, “what”, “when”, and “hybrid”. They examined movie success from three perspectives: audience, release, and movie. Their data was obtained from IMDB and Box Office Mojo. In [
12], the researchers compared the performance and outcomes of three supervised learning approach models to forecast revenue: the linear regression model, the logistic regression model, and the support vector machine regression model. Their data comes from IMDB, Rotten Tomatoes, and Wikipedia. The researchers suggested machine learning strategies to predict movie popularity [
13]. They used and compared the following classifiers: Logistic Regression, Simple Logistic, Multilayer Perceptron, J48, Nave Bayes, and PART. Their data source is IMDB, and they categorized the movies as Terrible, Poor, Average, and Excellent based on their IMDB rating, which is the same technique used by [
14]. In [
14], they offered a machine learning strategy based on intrinsic features, employing C4.5, PART, and correlation coefficients to predict movie popularity categorization, whereas [
15] proposed a data mining approach to assess and forecast movie ratings. Using data mining techniques, such as neural networks, regression, and decision trees, researchers devised a way to predict how much money a movie will make at the box office and estimate its profit [
16]. Opus Data gathered the dataset used in this article. The dataset was then supplemented with IMDB, IDMB, Metacritic, and Mojo information. They created a mathematical model [
17] to predict movie ratings and success for Hollywood and Bollywood films. The films were categorized as Flop, Neutral, or Hit. For classification, the KNN method was utilized. The information was gathered from IMDB and social media networks, such as Facebook, Instagram, and Twitter. In [
18], the writers projected a film’s profitability to aid early-stage production finance decisions. Using social network analysis and text mining techniques, the team presents a system that can automatically extract information on a movie’s cast, narrative, and release date from several data sources. In comparison to other methods, their data confirmed the system’s effectiveness. The feature selection strategy they employed considerably improved the forecast’s accuracy. Through an analysis of the industry’s most influential driving forces, they wanted to create a decision-making tool that may be utilized. Using a mathematical model, in [
19], they could accurately anticipate the performance of upcoming films at the box office. Budget, cast, director, producer, set location, narrative writer, movie release date, competing movies released simultaneously, music, release location, and target audience are just a few factors considered when evaluating a film’s success. They developed a model by evaluating how distinct traits interact with one another. Each important component was assigned a weight, and the prediction was developed based on them. In addition, they illustrated the approach’s prescriptive potential by demonstrating how it may be used to select a set of income-maximizing actors. Instead of depending on the opinions of critics and others, the researchers in [
20] provide a method for forecasting a film’s performance at the box office before its release. This paper presents an approach for estimating an IMDb rating using the IMDb Movie Dataset. Several algorithms were included in the study’s analysis, but Random forest generated the most accurate predictions. It was discovered that the number of individuals who voted for the picture, the number of critics who reviewed it, the number of Facebook likes it earned, the film’s running length, and its overall box office profits all had a substantial impact on the film’s IMDb rating. Dramas and biopics are often the highest-quality examples of their respective film genres. In [
21], researchers employed regression techniques to develop a model that considers multiple factors, assigns a weight to each element, and predicts the success or failure of forthcoming films based on the factor’s value. In [
22], models were created to forecast the performance and ratings of a new film before its premiere. A revenue threshold was established based on heuristics to classify the film as successful or unsuccessful. The comments on teasers and trailers were collected from YouTube since they are quite helpful when rating a film. Natural Language Processing (NLP) was used to extract keywords from user evaluations, and those reviews were evaluated as positive or negative based on emotional analysis. A detailed comparison of the various machine learning models used to estimate the success rate of a movie was made in [
23]. These models’ accuracy and statistical significance were examined to determine which is the best predictor. There are also some observations about aspects that impact the success of movies. The analyzed models include regression models, machine learning models, a time series model, and a neural network, with the neural network exhibiting the highest accuracy at about 86%. In addition, as part of the testing, statistics regarding 2020′s film releases were evaluated. The authors of [
24] made sure that the success of casting a movie depends on many things, such as the type of movie, when it comes out, who is in it, and how much money it makes in total. Understanding the risks associated with a film’s release, which might affect its success or failure, can be an important step in expanding the film industry. As a result, they offered an ensemble learning technique to assess such comprehension, in which predictions from previously guided attribute computations may be utilized to improve future success/failure accuracy. Diverse methods are employed in the literature to examine and compare the generated data. The dataset is used with the machine learning algorithms SVM, KNN, Naive Bayes, Boosting Ensemble Technique, Stacking Ensemble Technique, Voting Ensemble Technique, and MLP Neural Network to guess how well a movie will do at the box office. In [
24], they used many algorithms and their trends to predict the outcome of a movie and showed that the suggested method is better than the current research when these algorithms and trends are used. In [
25], their study uses ML to forecast a movie’s performance before its release, reducing risk. The Twitter sentimental analysis calculates the movie’s polarity and subjectivity from user evaluations. Machine learning systems anticipate IMDb ratings using those data. Decision tree regression, SVR, and random forest regression create a predictive model. The study compared three methods to anticipate movie success [
25] accurately. They created two models in [
26] to achieve their prediction goals. The first model, the rate prediction model (RPM), predicts user satisfaction with the product using an ensemble regression model. The second model is a temporal-product popularity model (T-PPM) that predicts the product’s temporal popularity using a random forest classifier. They gathered a new dataset, TweetAMovie, to test the IMDb and Twitter model proposals [
26]. In [
27], multiple classification algorithms based on machine learning are used in our movie dataset for multiclassification. The primary purpose of this research is to compare the efficacy of various machine learning techniques. This study compared Multinomial Logistic Regression (MLR), Support Vector Machine (SVM), Bagging (BAG), Naive Bayes (NBS), and K-Nearest Neighbor (KNN). At the same time, the noise was reduced using All KEdited Nearest Neighbors (AKNNs) (AENNs). These techniques predict the net profit of a film using the prior IMDb dataset. The algorithms anticipate the box office earnings for each of these five methods. In [
28], they developed a method for predicting movie success rates based on tweets about movie trailers. The results show the film’s rating as several stars (1–5). We collected tweets on several films following the release of their trailers using the hashtag approach (#Hash). They have trained and tested our models using four main algorithms (Naive Bayes, SVM, decision trees, and KNN) on the NLTK movie review corpora. Training datasets for machine learning were not readily available for movie ratings, so they turned to a lexicon-based method. These three dictionaries have various word counts; each is assigned a score indicating its polarity. Finally, they compared their results with those of other movie rating websites, such as IMDB, and found them satisfactory [
28].
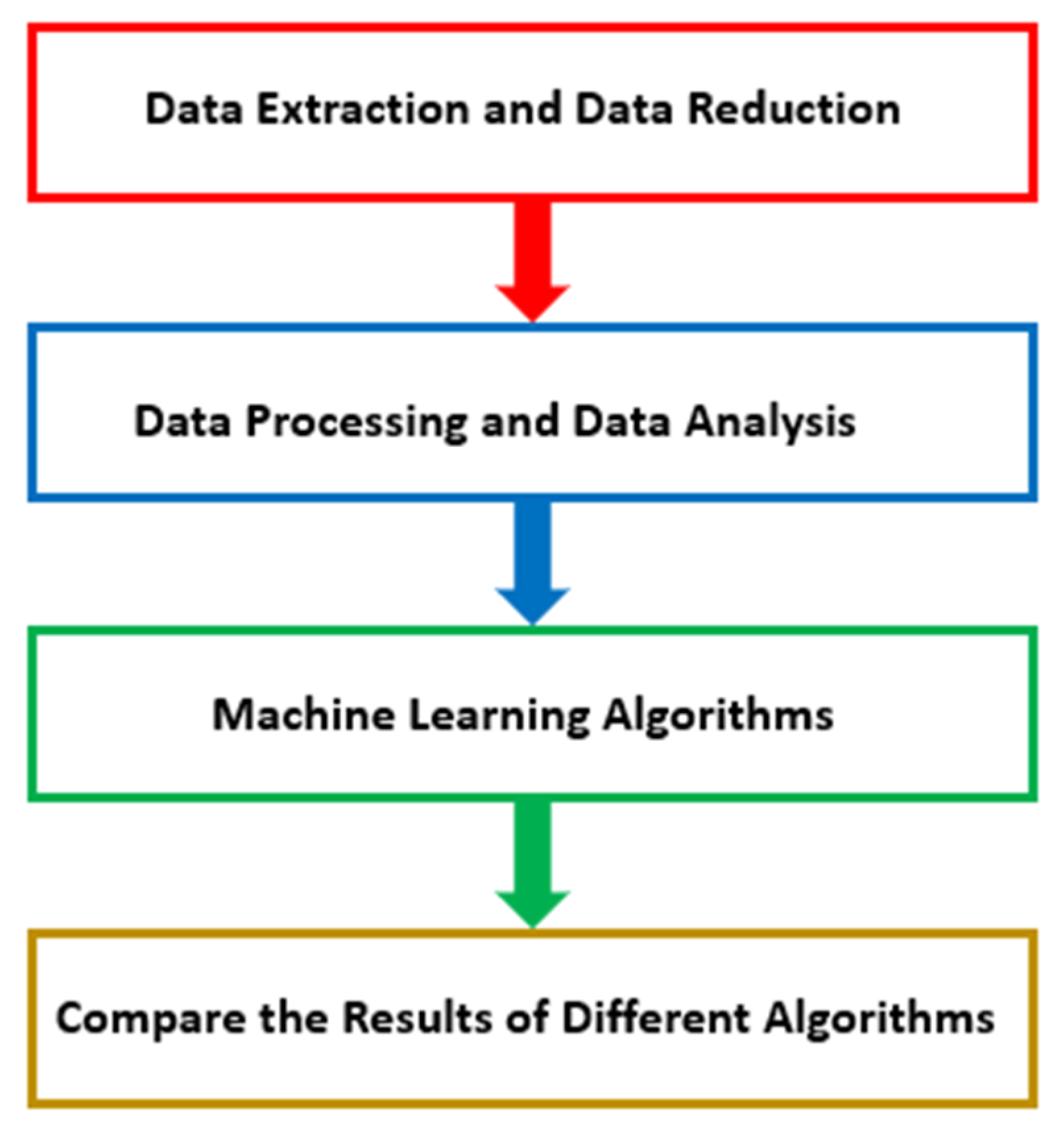
This study primarily assists with two primary outcomes by developing a viable method for predicting a film’s early success. This work demonstrates how diverse types of freely accessible data, including structured data, network data, and unstructured data, may be collected, merged, and analyzed to train machine learning algorithms. During the design and development of information system artifacts, these data-driven methodologies can assist firms with decision making by providing insightful predictions and recommendations. It is the most precise recommendation among the algorithms and actions that may be taken to obtain optimal results from these data and algorithms. Second, this research offers numerous innovative approaches for predicting the early success of movies. Included are the film’s plot, release date, producers, and directors, and we introduce a feature scoring approach that reduces the complexity of the optimization algorithm of the ML method. These elements demonstrated that each component substantially impacted the system’s performance and explained why movies are so popular. Contrary to the previous ML algorithms, this paper provides a modified KNN-ML approach as an alternate approach to open-space risk reduction that employs k-nearest neighbor approaches to discover discriminative characteristics of the feature set. This study aims to make a machine learning algorithm that improves on what we already know and gives a reasonable estimate of the success rate based on what we know, how we act, and how well the algorithm works. We will also show that our method has predictive value by showing how it can be used to suggest a group of agents that will bring in the most money. This study shows how predictive and prescriptive data analytics could help the science fiction movie industry in the future. However, it may be possible to create a model that can anticipate how a movie will do by analyzing box office returns and critic scores. This research uses 14 machine learning algorithms to make predictions about a film’s box office performance. These algorithms and their performance are evaluated and contrasted. The article is set up as follows. The next section lays out the theoretical basis for the proposed algorithm, the data collection process, the analysis, and the implementation of the machine learning algorithms. The implementation results are tabulated, and their outcomes are further monitored and thoroughly discussed. Finally, the conclusions are presented.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
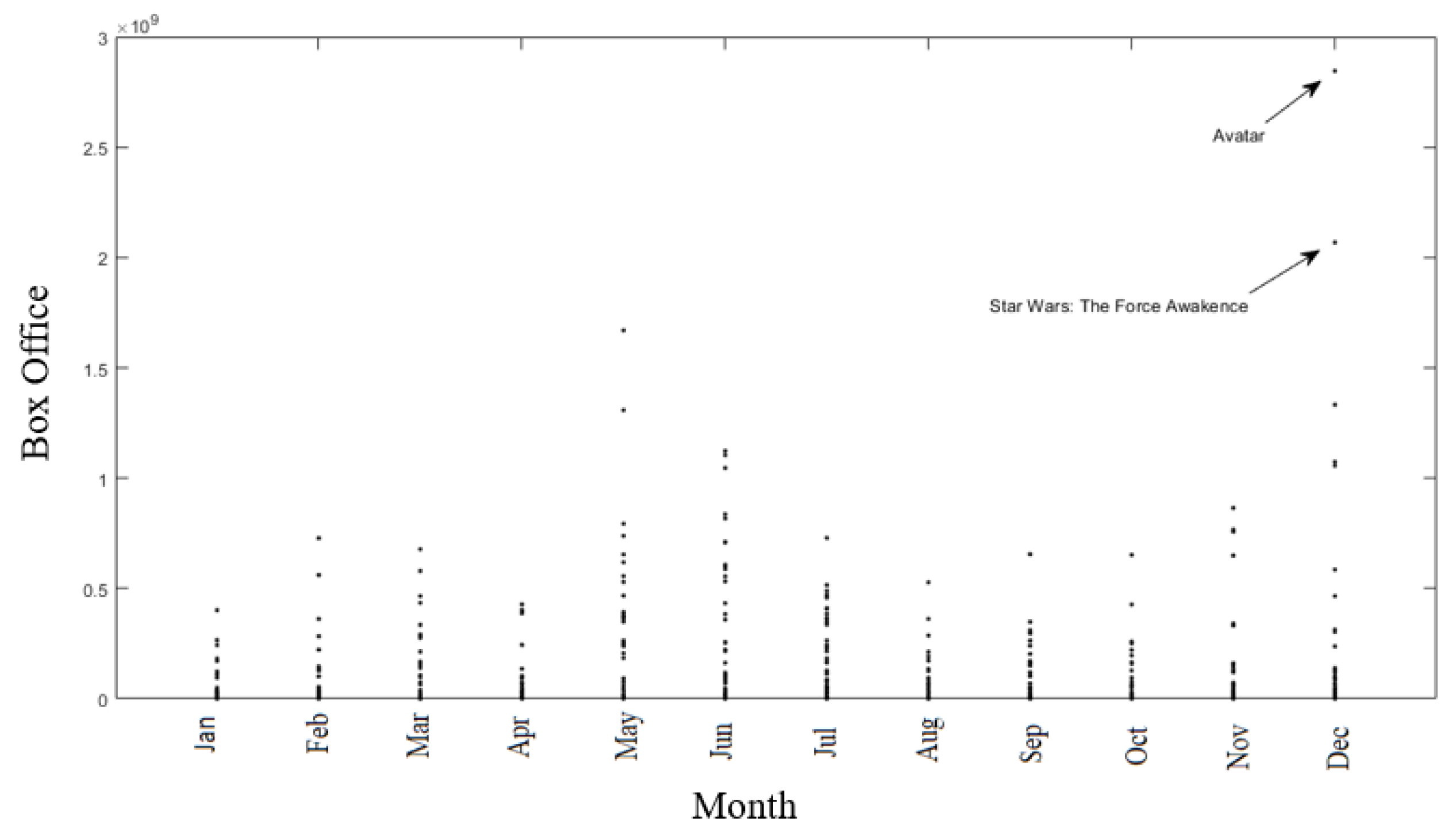{kind=link}
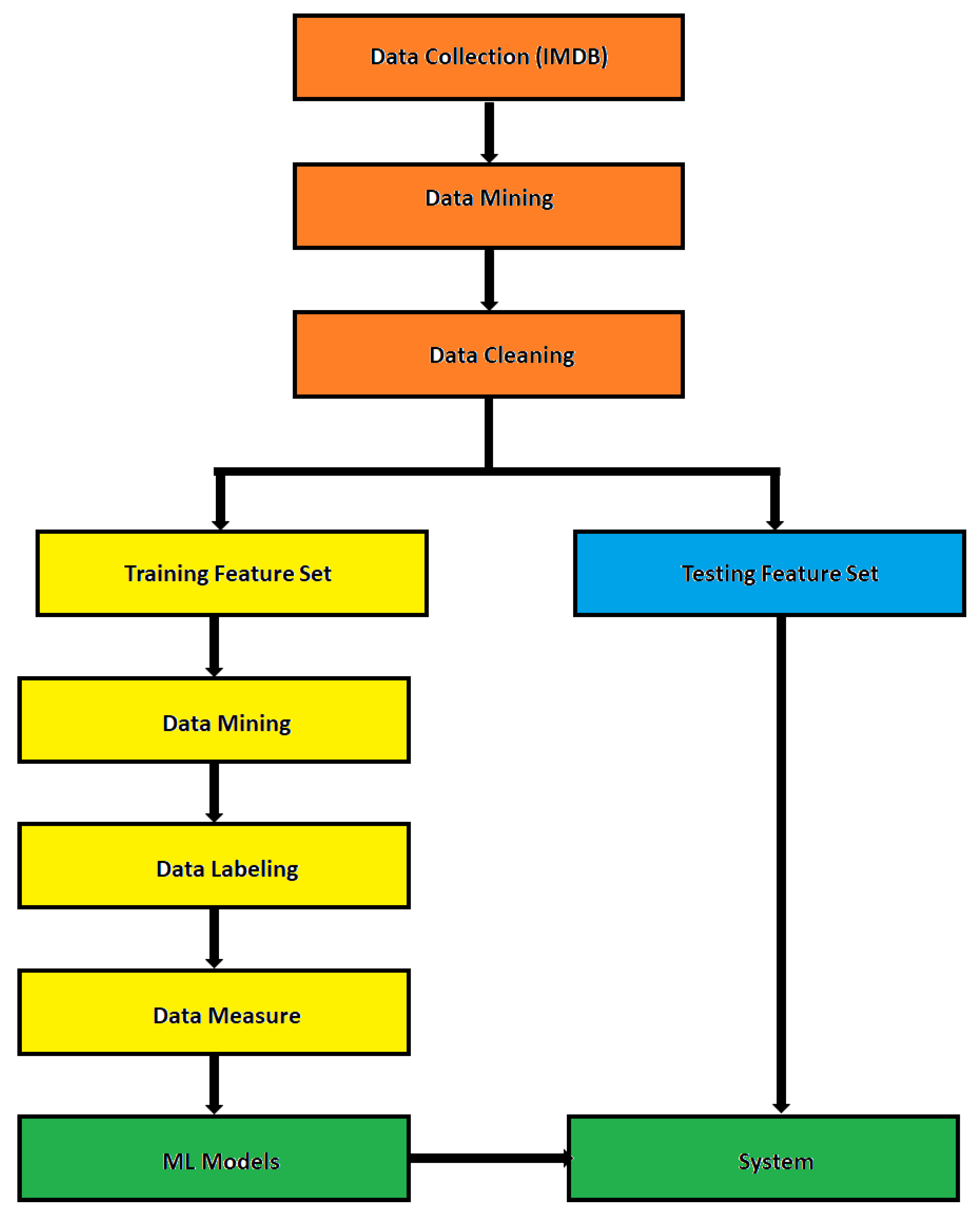{kind=link}
{kind=link}
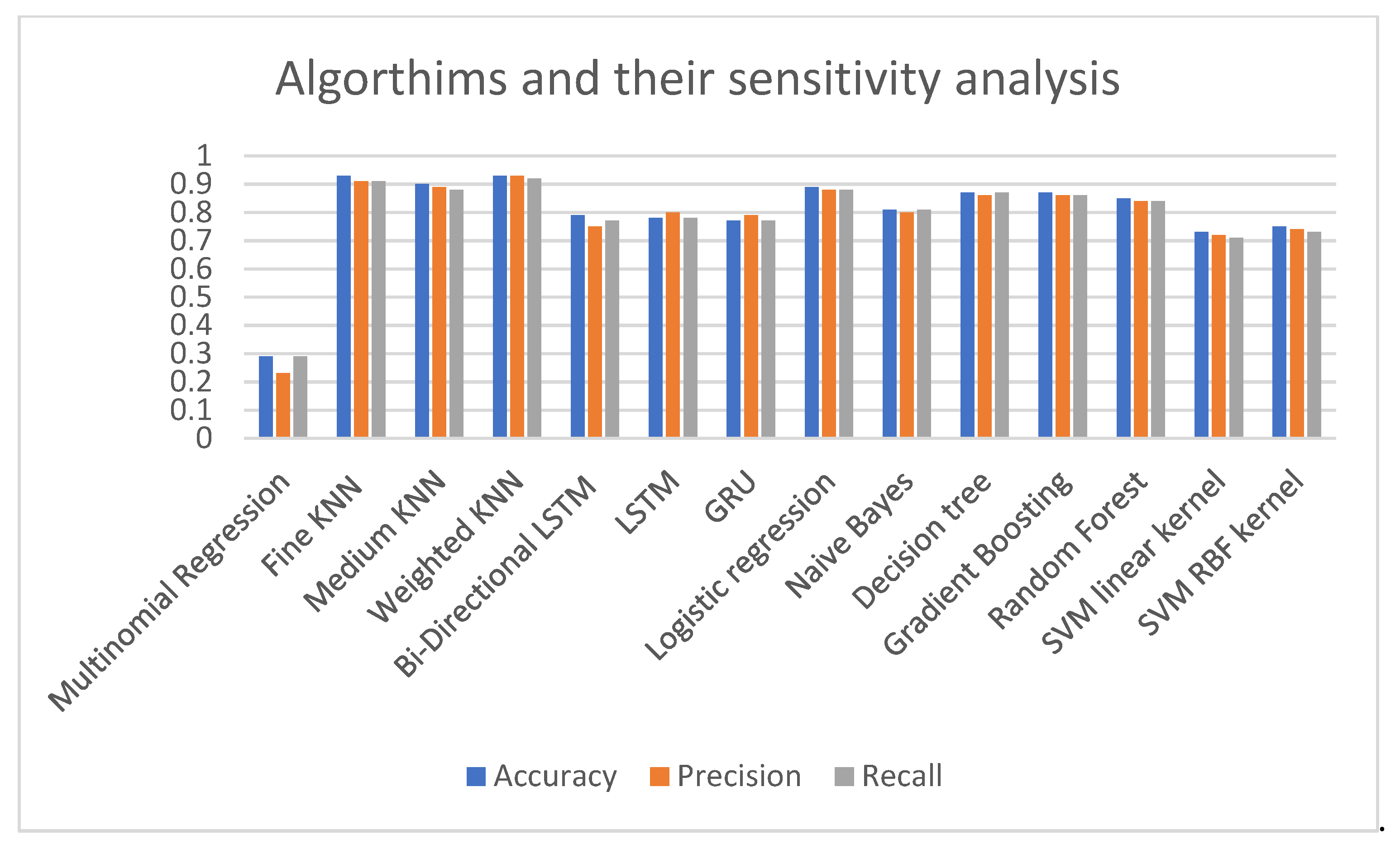{kind=link}