1. Introduction
Named entity recognition aims to identify entities such as names, places and organizations from unstructured texts. As the basic task of information extraction, NER will directly affect the downstream tasks such as relation extraction [
1], entity linking [
2] and the question answering system [
3]. NER is often treated as a sequence labeling task; that is, each unit in the text is labeled with a predefined entity label [
4]. In recent years, NER models based on deep learning have shown outstanding performance and gradually become the mainstream method [
5].
Compared with English, Chinese texts lack natural word separators and explicit word boundaries. Therefore, Chinese NER needs to recognize the boundaries and types of entities at the same time, which is more difficult than English NER [
6]. One way to implement Chinese NER is to segment sentences into word sequences first, and then recognize entities based on word sequences. However, the recognition effect of this method is vulnerable to the negative impact of segmentation errors. In order to avoid entity prediction failure caused by word segmentation errors, Chinese NER tasks generally model based on characters.
In English, words with the same prefix or suffix can often be classified into one category. For example, words such as geologist, pianist and physicist have the suffix “-ist”, which can represent entities engaged in a certain occupation. Chiu and Ma et al. [
7,
8] used a convolutional neural network (CNN) to capture the spelling features of prefixes and suffixes in English words; experiments showed that these spelling features can enhance the model’s understanding of word semantics and improve the recognition performance of the NER model. Large-scale pre-trained language models, such as BERT [
9] and GPT [
10], use the word-piece method to split a word into multiple pieces, which can effectively express out-of-vocabulary words while reducing the size of the vocabulary, thus improving the semantic representation ability of the model. Different from English, Chinese characters are ideographic characters and have no prefix, suffix, root and other characteristics of English words. Chinese characters evolved from hieroglyphs, and their glyph structure contains rich semantic information. For example, “花 (flower)”, “荷 (lotus)” and “茶 (tea)” all contain the radical “艹 (grass)”, indicating that these three characters are related to herbaceous plants. This means that when there are characters out-of-vocabulary, we can deduce the approximate semantics of out-of-vocabulary characters from the glyph features of Chinese characters, such as radicals. At the same time, in Chinese naming culture, it is also preferred to use radicals with Wu-Xing (five elements) or positive meanings as part of the name. For example, radicals such as “火 (fire)” and “日 (sum)” often appear in names, while radicals such as “疒 (epilepsy)”, which represent diseases, rarely appear in names. These patterns may be useful for identifying the Chinese names of people and businesses. Moreover, Chinese characters are mostly polysemous, meaning that one Chinese character has multiple meanings, and most of them need to be combined with other Chinese characters into words to have a more clear semantic representation. For example, the Chinese character “行” in “银行 (bank)” and “爬行 (crawling)” have completely different semantics. In “银行”, “行” is a noun, indicating an institution, while in “爬行”, “行” is a verb, indicating walking. Moreover, the potential word formation knowledge between the glyphs of adjacent characters can enrich the semantic information of Chinese characters and alleviate the problem of polysemy. For instance, in “爪” (often representing an action related to the hand), the radical of “爬”, can help to express that “行” is a verb, indicating the meaning of walking. However, most of the existing Chinese NER models focus on the contextual semantic features of the character, and ignore the rich semantic information contained in the Chinese character glyph.
In addition, the simple concatenation of contextual semantic features from text and glyph features from images can easily cause information redundancy, and the model cannot make full use of the complementary information between different modal features. This multimodal feature fusion problem mainly focuses on video question answering [
11], multimodal sentiment analysis [
12], etc. In order to fully fuse features from different modals, Zadeh et al. successively proposed a tensor fusion network [
13], memory fusion network [
14] and dynamic fusion graph [
15]. Further, Tsai et al. [
16] proposed MulT, which uses multiple crossmodal Transformers to fuse the three modal features of text, audio and vision. At the heart of MulT is the use of a crossmodal attention mechanism to repeatedly strengthen the features from two modals, so that MulT can fully learn useful and complementary information from different modals. However, these methods focus on the fusion of sentence-level features, while the Chinese NER task needs to complete the fusion of character-level features.
The questions of how to better utilize the semantic knowledge contained in Chinese character glyphs and their sequences, and how to better integrate contextual semantic features from text and glyph features from images, are two of the main challenges facing Chinese NER currently. Therefore, in order to make full use of the semantic knowledge contained in Chinese character glyphs and fuse the extracted semantic features of glyphs into the character-based Chinese NER model to improve the recognition performance of the model, this paper proposes a novel Chinese NER model based on contextual representation and glyph representation, named CGR-NER. First, for the contextual representation, CGR-NER uses BERT to dynamically generate contextual semantic representations of characters to solve the polysemy problem; for the glyph representation, a hybrid neural network CBHNN, which combines a three-dimensional convolutional neural network and bi-directional long short-term memory network, is proposed to extract the semantic information contained in a Chinese character glyph, the potential word formation knowledge between adjacent glyphs and the contextual semantic and global dependent features of glyph sequences from the perspective of images. Second, to make the representations from different modals complement each other and dynamically adjust the contributions of different representations in different contexts, an interactive fusion method with a crossmodal attention and gate mechanism is proposed, so as to realize the information interaction between the contextual representation and glyph representation and generate a fusion representation. Finally, the fusion representation is input into the BiLSTM-CRF network for Chinese named entity recognition. In summary, the main tasks and contributions of this paper are as follows:
A novel hybrid neural network CBHNN is proposed to extract and utilize the rich semantic knowledge contained in Chinese character glyphs and glyph sequences.
An interactive fusion method with a crossmodal attention and gate mechanism is proposed to realize the feature complementarity among different modal representations and dynamically control the fusion of contextual representation and glyph representation.
Sufficient experiments are conducted on two mainstream Chinese NER datasets, and the results show the advantages and effectiveness of our model. The results of several ablation experiments show that our model still has good recognition performance in the case of insufficient training data or out-of-vocabulary character interference.
The rest of this paper is organized as follows:
Section 2 describes the work related to the Chinese NER task;
Section 3 introduces the architecture of CGR-NER;
Section 4 presents our experimental details and ablation studies; finally,
Section 5 gives the conclusions and future works.
2. Related Work
In traditional NER work, rule-based, dictionary-based and statistical machine learning methods are mainly used, such as the hidden Markov model [
17], conditional random field (CRF) [
18], etc. Such traditional NER models strongly rely on manual features. When facing different fields, manual features often need to be redesigned, resulting in poor model migration performance. With the development of deep learning, the end-to-end neural network model not only has better performance in NER tasks, but is also independent of manual features, so it has become the mainstream method in NER tasks. Huang et al. [
19] proposed an end-to-end BiLSTM-CRF model by combining BiLSTM and CRF, and achieved excellent performance in sequence labeling tasks such as NER. Based on BiLSTM-Attention-CRF and a contextual representation combining the character level and word level, Ali et al. [
20] proposed CaBiLSTM for Sindhi named entity recognition, achieving the best results on the SiNER dataset without relying on additional language-specific resources.
2.1. Chinese NER Based on External Resource Enhancement
In order to further improve the recognition performance of NER models, researchers try to integrate external knowledge such as a lexicon or syntactic characteristics into the model. Zhu et al. [
21] proposed SDI-NER, which uses a graph neural network to learn syntactic dependency knowledge and integrates it into the BiLSTM-CRF model, so as to enhance the understanding of sentence semantics by the NER model. Li et al. [
22] proposes FLAT, which causes potential matching words to interact with characters directly by improving the position encoding and attention mechanism, and improves the parallel computing efficiency of the NER model. Nie et al. [
23] proposed AESINER, which integrates part-of-speech labels, syntactic constituents and dependency relations in sentences into an NER model through a key-value memory network. Xue et al. [
24] proposed PLTE, which models all characters and matched words in parallel with batch processing by extending the Transformer encoder. Hu et al. [
25] proposed KGNER, a model that incorporates a knowledge graph into the Chinese NER task, and uses a new position encoding method and masking matrix to limit the impact of knowledge graph information on the original semantic meaning of sentences. Liu et al. [
26] proposed LEBERT, a model that integrates the matched lexicon knowledge into the underlying layer of BERT through a lexicon adapter, achieving the deep fusion of character and vocabulary knowledge. Liu et al. [
27] proposed MW-NER, which integrates word embeddings and n-gram embeddings through two independent attention networks to obtain multi-granular word information. It also attempts different fusion strategies to integrate character information and multi-granular word information, reducing the interference of word segmentation errors and noise in model performance. However, the performance of such methods is easily affected by the quality of external resources, such as the accuracy of parsing tools. At the same time, for entity recognition tasks in some special fields, it is necessary to build the corresponding lexicon or knowledge graph first, and then provide these methods for entity recognition.
2.2. Chinese NER Based on Chinese Character Glyph Enhancement
Chinese characters evolved from hieroglyphs, and their glyphs also contain rich semantic information. The work of extracting this semantic information to enhance the recognition performance of Chinese NER models can be divided into two methods, including the decomposition of Chinese characters and image processing.
2.2.1. The Decomposition of Chinese Characters
The decomposition of Chinese characters is to use radicals, wu-bi or structural components to represent Chinese character glyphs. For example, for Chinese character “茶”, its radical is “艹”; wu-bi are “AWSU” and structural components are “艹人木”. A typical method is ME-CNER [
28], which improves the NER performance by using a CNN to capture potential glyph information in a radical sequence. Wu et al. [
29] proposed MECT, which introduces the structural components of Chinese characters into FLAT, and designs a Cross-Transformer network to fuse the information of characters, radicals and words. Li et al. [
30] proposed MFE-NER, which uses wu-bi to help generate a glyph embedding, and combines it with character and phonetic features to generate multi-feature fusion embedding, so as to improve the performance of the Chinese NER model and reduce the influence caused by character substitution. Lv et al. [
31] proposed StyleBERT to improve the semantic expression ability of a Chinese pre-training language model by integrating word, pinyin, wu-bi and chaizi information. However, the method based on the decomposition of Chinese characters ignores the overall structure and spatial characteristics of Chinese characters, because the structural components of Chinese characters are not all horizontally distributed as with English words, and the distribution of structural components of Chinese characters can be vertical, surrounding, half-surrounding, etc., with obvious spatial characteristics. For example, “叶 (leaf)” and “困 (trap)” have the same radical “口” and structural components “口十”, but the spatial distribution of the structural components is different.
2.2.2. Image Processing
In the work based on image processing, the semantic information of Chinese character glyphs is learned by extracting the visual features of Chinese character images, which avoids the shortcomings of the decomposition of Chinese characters method. Meng et al. [
32] proposed Glyce, a representation vector of Chinese character glyphs. Glyce uses Chinese character images of different periods and writing styles to enrich the visual features of Chinese character glyphs; it also designs the Tianzige-CNN network to extract the semantic information contained in the glyph images, and updates the best records of multiple Chinese NER datasets. Song et al. [
33] treat the problem of extracting semantic information from Chinese character glyph images as an image classification problem and propose the GlyNN network to encode Chinese character images. Then, the glyph feature obtained is used as an additional representation of the NER model. Sun et al. [
34] proposed ChineseBERT, which integrates Chinese character images with different writing styles and Chinese character pinyin into the pre-training of the language model, effectively enhancing the semantic expression ability of the Chinese pre-training language model. However, these methods encode each Chinese character glyph independently, ignoring the potential word formation knowledge between adjacent glyphs. Moreover, the representation sequences of different modals have their unique contextual semantics and global dependency information, and the above methods do not explicitly extract this semantic information from the glyph representation sequences. In addition, the above methods simply concatenate the contextual representation and glyph representation from different modals, ignoring the interactive information between the two representations.
In comparison, our approach fully excavates and makes use of the semantic knowledge contained in Chinese character glyphs. First, we propose CBHNN, which uses the characteristics of 3DCNN, which simultaneously extracts spatial and temporal dimension information, to learn the semantic knowledge contained in Chinese character glyphs and the potential word formation knowledge between adjacent glyphs, and explicitly captures the contextual semantics and global dependence features of a glyph sequence through BiLSTM to generate the glyph representation. Second, an interactive fusion method with a crossmodal attention and gate mechanism is proposed to realize the feature complementarity among the contextual representation and glyph representation, reducing the information redundancy and improving the recognition performance of the model.
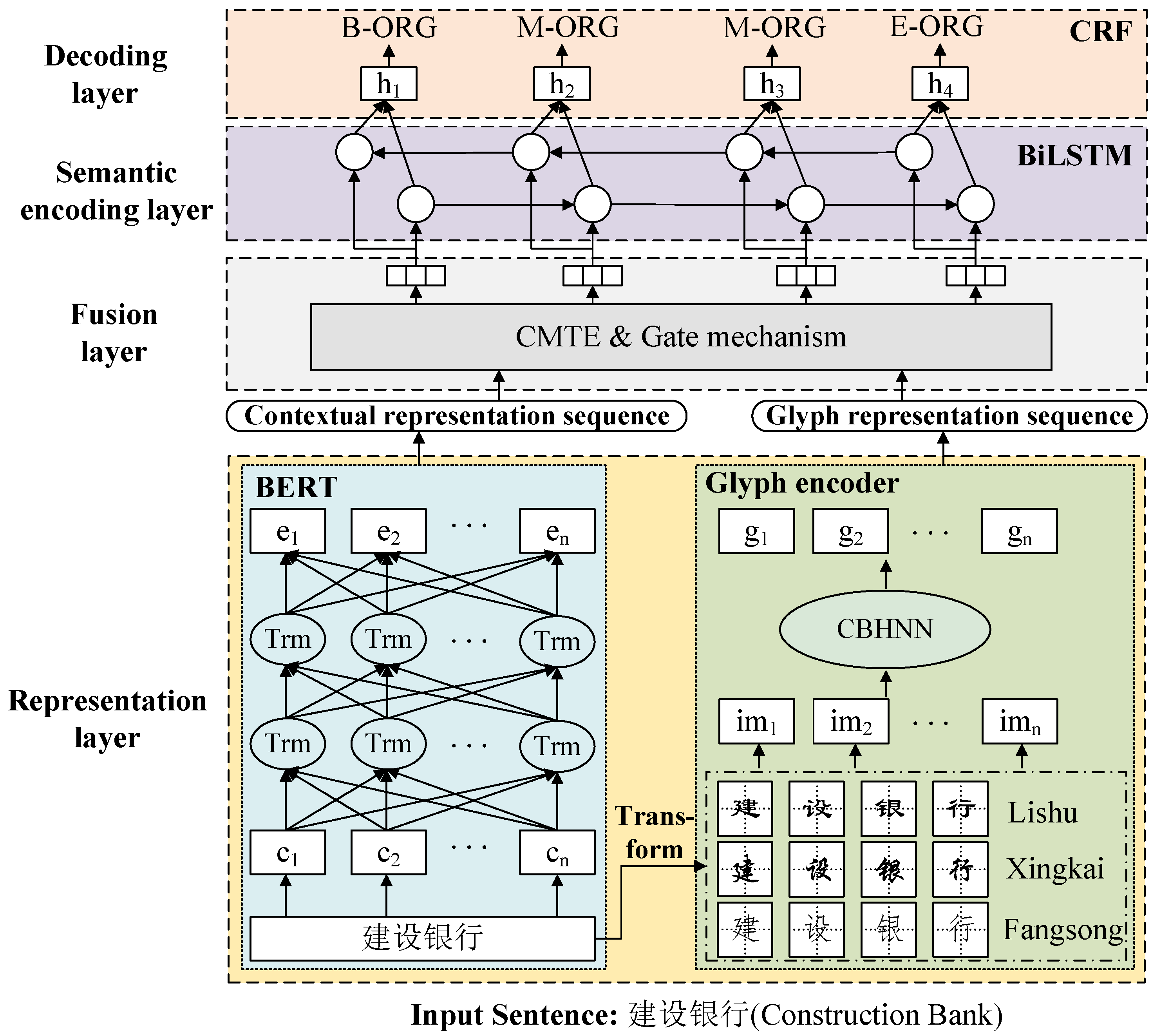
3. CGR-NER Architecture
Chinese NER is conventionally regarded as a typical sequence labeling task: for an input sentence
with
n tokens, we output its corresponding named entity label sequence
in the same length. Following this paradigm, the CGR-NER architecture mentioned in this paper is shown in
Figure 1. It is composed of four layers: a representation layer, fusion layer, semantic encoding layer and decoding layer. We will introduce CGR-NER in detail in this section.
3.1. Representation Layer
In the representation layer, each character of the sentence S will be converted into the corresponding contextual representation and glyph representation.
3.1.1. Contextual Representation
In previous studies, Word2Vec [
35] was often used to generate a contextual representation. However, the contextual representation generated by Word2Vec was context-independent and could not effectively represent polysemy words. To solve this problem, CGR-NER uses BERT to dynamically generate a contextual representation. BERT is a pre-trained language representation model, which is stacked by multiple layers of Transformer encoders. It no longer uses the traditional one-way language model or shallow concatenation of two one-way language models for training, but uses the masked language model to train the two-way Transformer encoder, and finally generates a deep two-way language representation that can fuse contextual semantic information. The process of generating the contextual representation sequence
corresponding to sentence
S can be denoted as
where
is the contextual representation corresponding to the
ith character of sentence
S, and
n is the sentence length.
,
is the dimension of the contextual representation.
3.1.2. Glyph Representation
From the perspective of image processing, we propose a hybrid neural network named CBHNN that combines 3DCNN and BiLSTM to learn the semantic information contained in Chinese character glyphs and obtain the glyph representation of each character, as shown in
Figure 2. The input of CBHNN is a sequence of glyph images
, for which the characters of the sentence S need to be converted into corresponding glyph images first. In order to enrich the visual features of Chinese character glyphs, three glyph images with different styles, Lishu, Xingkai and Fangsong, were used to concatenate the dimensions of the image channel. Therefore, the glyph image size of CBHNN input was 3 × 24 × 24. Then, three 3DCNN blocks were used to capture the glyph feature contained in the glyph image. Each 3DCNN block contains a 3DCNN, ReLU function and 3D max-pooling operation. The number of output channels of each block was 64, 128, 256, and the output of the last block was batch-normalized and reshaped to obtain the glyph feature vector of 256 dimensions. Different from 2DCNN, 3DCNN can simultaneously extract the feature information of spatial and temporal dimensions, which means that CBHNN can not only extract the glyph visual feature in the Chinese character image, but also capture the glyph visual features of adjacent characters at the same time, so that the model can learn the potential word formation knowledge between glyphs. It makes the same Chinese character dynamically generate different glyph feature vectors in different contexts, which is beneficial to alleviate the problem of polysemy. Finally, CBHNN uses BiLSTM to extract contextual semantics and global dependency features from the glyph feature vector sequence, to obtain the glyph representation sequence
. The process of obtaining the glyph representation sequence corresponding to the sentence
S can be denoted as
where
is the glyph representation corresponding to the
ith character of sentence
S.
,
are the dimensions of the glyph representation.
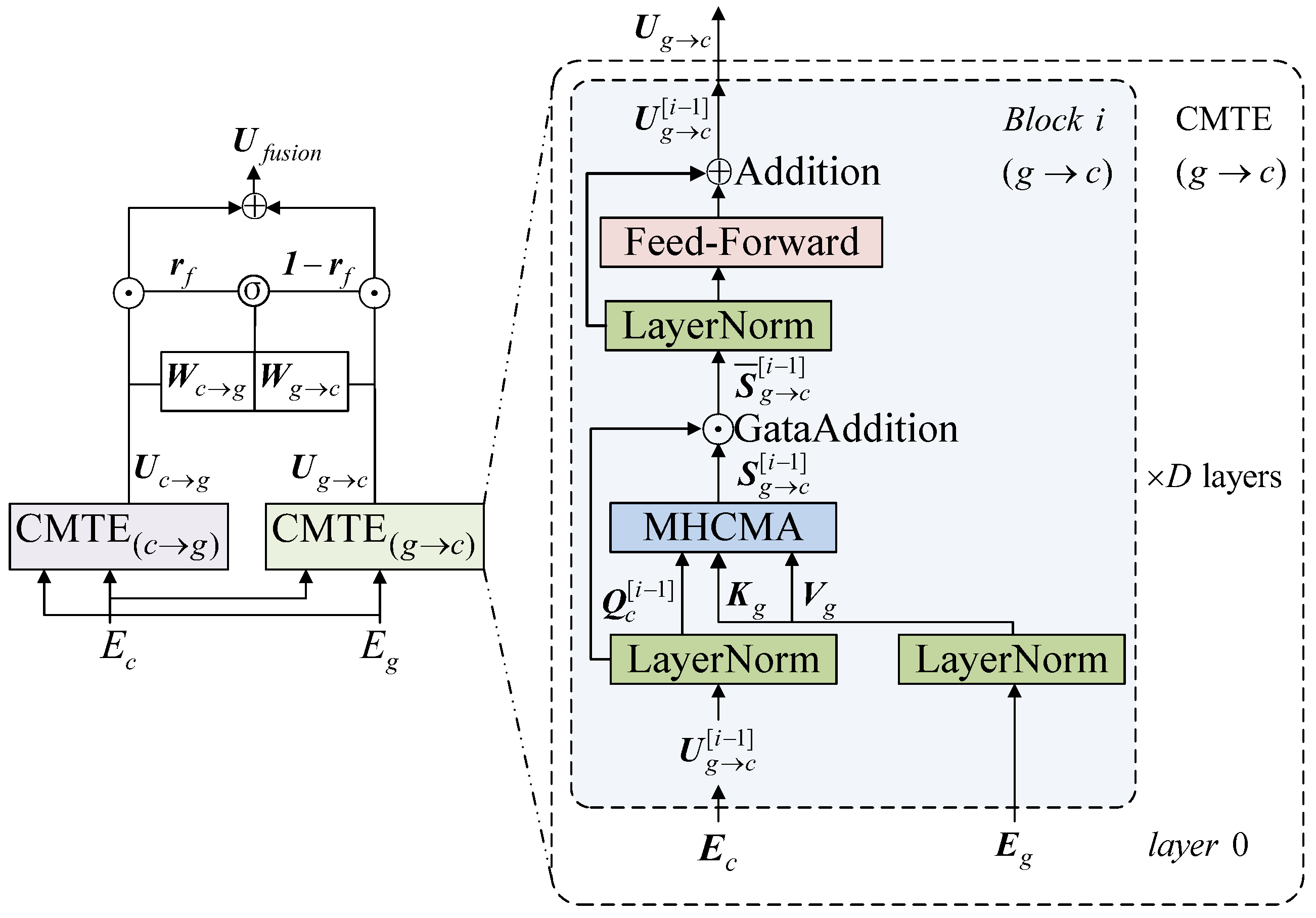
3.2. Fusion Layer
After obtaining the contextual representation sequence and glyph representation sequence, we further propose an interactive fusion method with a crossmodal attention and gate mechanism to obtain a semantic enhanced fusion representation sequence, as shown in
Figure 3. We first use two crossmodal Transformer encoders (CMTE) to complete the feature complementarity between the two modal representations, and then use a gate mechanism to dynamically adjust the contributions of different modal representations in different contexts.
At the heart of CMTE to realize the interaction between different modal features is that the source modal feature can adaptively learn the complementary information from the target modal feature through the crossmodal attention mechanism. In the following, we take the contextual representation adaptively learning potential complementary information from the glyph representation as an example, which is denoted as
(see
in
Figure 3). In this example, the contextual representation sequence
is used as the source modal feature sequence, and the glyph representation sequence
is the target modal feature sequence. Formally,
computes feed-forwardly for
layers of crossmodal attention blocks. In the crossmodal attention block of each layer, the crossmodal attention is calculated first:
where
,
are transformation matrices, and
means layer normalization.
represents multi-head crossmodal attention, which is the key to achieving crossmodal interaction. To enhance the direction and distance perception ability of the model in the interaction process, we adopt the relative positional encoding scheme proposed by TENER [
36], so
can be calculated as follows:
where
n is the number of heads,
h is the index of heads,
.
,
,
,
,
are learnable parameters.
is the part of
allocated to each head.
is the relative positional encoding,
in Equation (
9).
t,
j is the index of the target token and context token, respectively.
is the query vector of token
t,
is the key vector of token
j.
is the attention score between token
t,
j;
is the bias of the token
t in the relative position;
is the bias of the token
j;
is the bias term for distance and direction between tokens
t,
j.
Then, a reset function
is used to dynamically control the residual connection of
and
:
where
is the sigmoid function,
,
are trainable parameters and
is the bias term.
represents the element-wise multiplication operation and
is a 1-matrix with its dimension matching
.
After this, the position-wise feed-forward can be calculated as follows:
where
represents the position-wise feed-forward network parameterized by
.
In this process, constantly interacts with through multi-layer crossmodal attention blocks, and updates its representation sequence by learning the potential complementary feature in . The process of the glyph representation adaptively learning complementary information from the contextual representation () is similar to , except that the source modal feature sequence is and the target modal feature sequence is .
After using CMTE to complete the interaction between the two modal representations, we propose a gate mechanism to dynamically adjust the contributions of different modal representations in different contexts to enhance the performance of the model. In detail, we use a gated threshold
to evaluate the outputs from the
and the
by
where
,
are trainable parameters and
is the bias term.
is the output of
and
is the output of
.
is a 1-matrix with its dimension matching
. ⊕ denotes the concatenation operation.
Finally, we obtain the semantic enhanced fusion representation sequence .
3.3. Semantic Encoding Layer
BiLSTM is suitable for modeling sequence problems. It not only effectively solves the problem of gradient disappearance and explosion when traditional recurrent neural networks deal with long-distance dependency information, but also captures more dependency features from the forward and backward direction of the sequence and outputs hidden feature vectors with both forward and backward sequence dependency information. CGR-NER uses BiLSTM to encode the glyph feature sequence and fusion representation sequence and extract their contextual semantics and global dependency features.
For the fusion representation sequence
output from the fusion layer, the process of BiLSTM to calculate the corresponding hidden state of each representation is as follows:
where
and
denote the hidden state of the forward and backward for
. The final output hidden state sequence is
.
3.4. Decoding Layer
The conditional random field can effectively alleviate the label bias problem and is often used as the decoder for sequence labeling tasks. For the output
of the semantic encoding layer, assuming that its predicted label sequence is
, the probability of label
is calculated by
where
is the set with all named entity labels, and
and
are trainable parameters. In the process of decoding, we use the Viterbi algorithm to generate the optimal label sequence
.
4. Experiments and Analyses
We conduct extensive experiments on two mainstream Chinese NER datasets to evaluate the entity recognition performance of CGR-NER and compare it with the mainstream Chinese NER model. We present the experimental datasets, parameter setting, experimental results and analysis in this section.
4.1. Datasets
The effectiveness of CGR-NER is evaluated on two datasets from different fields, namely Weibo [
37] and OntoNotes 4 [
38]. The corpus of the Weibo dataset is collected from Chinese social media site Sina Weibo, and labeled with four entity labels: PER (person), ORG (organization), LOC (location) and GEO (geography). The corpus of the OntoNotes 4 dataset is collected from a news domain, including four entity labels: PER, ORG, LOC and GEO. The statistics of these datasets are shown in
Table 1.
4.2. Parameter Setting and Evaluation Metrics
In our experiment, precision (P), recall (R) and F1 score (F1) are used as evaluation metrics. Only when the model correctly recognizes the boundary and type of entities at the same time can it represent correct recognition. In order to avoid experimental error and contingency, we tested each experiment ten times, and calculated the average values of the evaluation metrics as the final experimental results.
We manually adjusted the hyperparameters according to the recognition performance of the model on the development set. At the representation layer, we used BERT, a pre-trained language model released by Google, to generate a contextual representation and follow its default Settings. For CBHNN, we follow the settings in
Section 3.1.2. For CMTE,
is set to 64, and the numbers of crossmodal attention heads and layers are set to 8 and 2, respectively. The hidden size of BiLSTM in the semantic encoding layer is set to 512. The maximum sentence length is 200, the batch size is 32 and the dropout rate is 0.4 for all datasets. The training epoch is set to 100 for the Weibo dataset, and 20 for OntoNotes 4. Adam is adopted to optimize the model, with a learning rate of 0.0004. The model with the highest F1 score on the development set will be the best, and the performance evaluation will be conducted on the test set. All the experiments are conducted on an NVIDIA 3090 GPU.
Table 2 shows the selection range of hyperparameters.
Table 3 shows the evaluation results on the development set of different kernel sizes (context window size) in CBHNN and different hidden sizes in the semantic encoding layer. We can find that the kernel size is set to 3 and the hidden size is set to 512, which are superior to other optional parameters. Therefore, our model selects the kernel size of 3 in CBHNN and the hidden size of 512 in the semantic encoding layer as the final parameters.
4.3. Model Training
To demonstrate the training situation and computational cost of our model, we reimplement BERT-BiLSTM-CRF because it is the mainstream base model in the NER task, and we take it as the baseline.
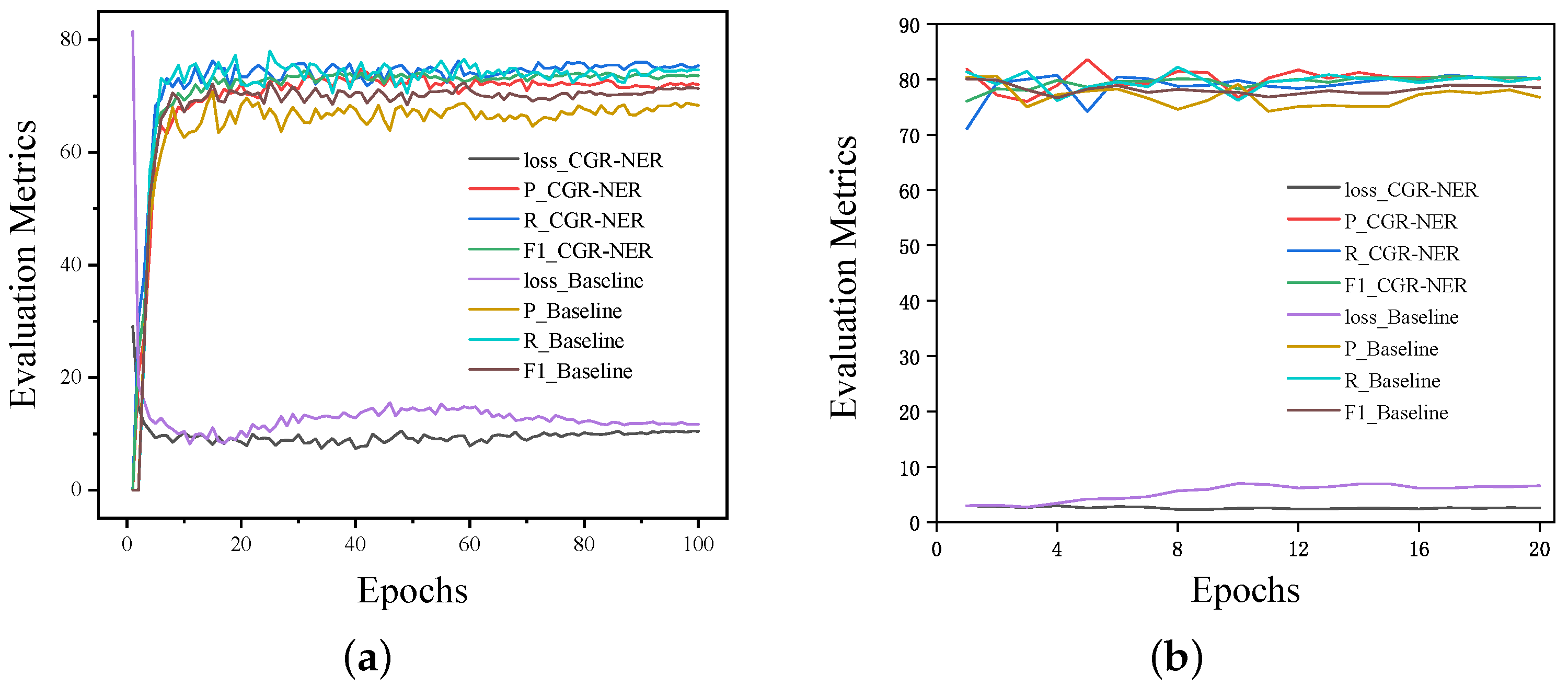
Figure 4 shows the variation tendency of evaluation metrics and loss value on the development set with the training epoch. As can be seen from
Figure 4, on the Weibo dataset, the evaluation metrics and loss value exhibit significant fluctuations during the early stages of training. This is because the Weibo dataset has a relatively small amount of data, approximately one twelfth of the OntoNotes 4 dataset, so the model requires more training time to learn and adjust before it can stably demonstrate good performance. Meanwhile, compared with BERT-BiLSTM-CRF, the loss curve of CGR-NER is lower and smoother, indicating the better fit of the CGR-NER model. Moreover, to demonstrate the computational cost of CGR-NER, we also report the total number of parameters and the average time per epoch during training for both BERT-BiLSTM-CRF and CGR-NER in
Table 4.
4.4. Effectiveness Study
We compare CGR-NER with several classic and recently published NER models introduced in the related work. Among them, SDI-NER, FLAT+BERT, AESINER, PLTE+BERT, LEBERT, KGNER and MW-NER enhance the recognition performance of the NER model by introducing a lexicon, syntax knowledge and a knowledge graph; MECT, StyleBERT, GlyNN, Glyce, MFE-NER and ChineseBERT enhance the recognition performance of the NER model by fusing the unique language features of Chinese characters, such as radical, wu-bi, the structural components of Chinese characters and pinyin. The experimental results are shown in
Table 5 and
Table 6.
For the OntoNotes 4 dataset, the precision, recall and F1 score of our model surpass the baseline (i.e., BERT-BiLSTM-CRF) by 1.65%, 1.56% and 1.63%, respectively, indicating that the semantic information contained in the Chinese character glyphs can significantly improve the recognition performance of the model. For the second-best model, MECT, which fuses the lexicon and the structural information of Chinese characters, our model surpasses it by 0.4% for the F1 score. In addition, compared with Glyce, which also utilizes a CNN to extract semantic information from the visual features of glyphs, our model significantly improves by 1.34% for the F1 score. We attribute this improvement to the fact that CGR-NER fully utilizes the potential word formation knowledge between adjacent glyphs and the interaction information between the character representation and glyph representation.
For the Weibo dataset, the precision, recall and F1 score of our model surpass the baseline by 0.37%, 3.97% and 2.3%, respectively. KGNER and LEBERT achieved the first and second highest F1 scores, respectively. We speculate that this is because the corpus of the Weibo dataset is collected from social media, and the corpus is messy and noisy, which makes the NER task more challenging. Meanwhile, KGNER and LEBERT supplement additional semantic information for the NER model with the help of a knowledge graph and lexicon, respectively, so as to have better performance in the Weibo dataset. It should be noted that in some special fields, such as industrial robot entity recognition, the performance of these models may be limited due to the lack of corresponding knowledge graphs or lexicons. However, CGR-NER still achieved the third highest F1 score without the help of external knowledge, which proves that our model has a strong entity recognition ability. At the same time, CGR-NER does not rely on external knowledge, so it can be applied to a wider range of scenarios.
4.5. Ablation Study
4.5.1. Effect of Model Hyperparameters
In order to explore the effect of the kernel size in CBHNN and the number of crossmodal attention layers in CMTE on the performance of CGR-NER, we select different parameter values and evaluate them. The experimental results are shown in
Table 7 and
Table 8.
Table 7 shows the impact of different kernel sizes on model performance. It can be seen that three different kernel sizes have achieved better performance than BERT-BiLSTM-CRF, indicating that different kernel sizes have positive effects on model performance. However, the F1 score does not increase as the kernel size increases. One possible reason is that the small kernel size is more focused on extracting local details, so the glyph features have richer semantic information.
It can be seen from
Table 8 that the three different layer sizes have achieved better performance than BERT-BiLSTM-CRF. When the number of layers is set to 2, the F1 score on the two datasets reaches the best value. When the number of layers increases to 3, the performance of CGR-NER does not continue to be improved. One possible reason is that the excessive number of layers may cause the model to over-fit or even learn noise, resulting in reduced recognition performance.
4.5.2. Effect of Model Components
We conducted experiments on the Weibo and OntoNotes 4 datasets to evaluate the impact of various components contained in CGR-NER on model performance. As shown in
Table 9, after removing the Chinese character glyph (‘-w/o Glyph’) from CGR-NER, the F1 scores on the Weibo and OntoNotes 4 datasets are significantly reduced by 2.3% and 1.63%, respectively, which verifies the effectiveness of the Chinese character glyph in improving the recognition performance of our model. When the gate mechanism is removed (‘-w/o GM’) and the contextual representation and glyph representation after CMTE interaction are directly concatenated, the F1 scores on Weibo and OntoNotes 4 are decreased by 0.6% and 0.22%, respectively, which indicates that the importance of the representation from different modals varies, and the gate mechanism could effectively balance them. After removing the CMTE (‘-w/o CMTE’) from the fusion layer, the F1 scores on the Weibo and OntoNotes 4 datasets are reduced by 0.54% and 0.28%, respectively, which indicates that the interaction information between different modal representations could help the model to learn more semantic knowledge, thus improving the recognition performance of the model. When CMTE and the gate mechanism are removed at the same time (‘-w/o CMTE+GM’), and the contextual representation is directly concatenated with the glyph representation, the F1 scores on the Weibo and OntoNotes 4 datasets are reduced by 0.85% and 0.55%, respectively, verifying the necessity of CMTE and the gate mechanism.
4.5.3. Effect of CBHNN
To verify the effectiveness of CBHNN in capturing the semantic information contained in Chinese character glyphs, we used glyph encoders with different structures to generate a glyph representation, and conducted experiments on the Weibo and OntoNotes 4 datasets, as shown in
Table 10. Among them, ‘character’ represents BERT-BiLSTM-CRF, which only has a contextual representation as input. Tianzige is Tianzige-CNN proposed by Glyce [
32]. Tianzige-BiLSTM represents that BiLSTM is used to capture the hidden state of Tianzige output, which is used as the glyph representation input of the model. CBHNN
represents the CBHNN with no BiLSTM. Other settings of CGR-NER remained unchanged.
According to
Table 10, the model based only on the contextual representation as input achieves the worst result because it ignores the semantic information contained in the Chinese character glyphs. Compared with Tianzige, the F1 scores of CBHNN
on Weibo and OntoNotes 4 are improved by 0.6% and 0.34%, respectively, for the reason that the CBHNN
can not only capture the semantic information in Chinese character glyphs, but also learns the potential word formation knowledge between adjacent glyphs through 3D convolution, thus enriching the semantic information of the representation. After Tianzige and CBHNN
are combined with BiLSTM, respectively, the performance of the NER model is further improved, indicating that the context semantics and global dependency features in the glyph sequence are helpful for entity recognition. In contrast, CBHNN, which combines 3DCNN and BiLSTM, achieves the best F1 scores with 70.70% and 82.97% on the Weibo and OntoNotes 4 datasets, respectively. Hence, the experimental results show that CBHNN can effectively learn the semantic information contained in Chinese character glyphs, the potential word formation knowledge between adjacent glyphs and the context semantics and global dependency features of glyph sequences, thus improving the recognition performance of our proposed model.
4.5.4. Influence of Training Set Size
To verify the performance of CGR-NER under the condition of insufficient training data, we randomly select 10∼90% samples from the training sets of the Weibo and OntoNotes 4 datasets as the training set, respectively, while keeping the development set and test set unchanged, and we use BERT-BiLSTM-CRF as the baseline to compare with CGR-NER. As can be seen from
Figure 5, the performance of CGR-NER surpasses that of BERT-BiLSTM-CRF under different training set sizes, indicating that CGR-NER has a stronger learning ability. In addition, we can find that CGR-NER has a more obvious improvement effect on the Weibo dataset. When the training data amount is 10%, the F1 score of CGR-NER on the Weibo dataset is improved by around 10% compared with BERT-BiLSTM-CRF. This is because the corpus of the Weibo dataset is collected from social media, the total amount of data is small, and the text format is chaotic, making entity recognition more challenging. At the same time, the glyphs of Chinese characters can be used as a data supplement to provide additional semantic knowledge for CGR-NER, so that CGR-NER can still have an excellent fitting ability in the case of insufficient training data.
4.5.5. Influence of Out-of-Vocabulary Characters
To verify the recognition performance of the NER model under the condition of out-of-vocabulary characters, we divided the test set of each dataset into two parts: one containing out-of-vocabulary characters and the other containing no out-of-vocabulary characters. The experimental results are shown in
Table 11. It can be found that the results of the model on the subset without out-of-vocabulary characters are better than those on the subset with out-of-vocabulary characters, indicating that it is still challenging for the NER model to recognize entities correctly in the presence of out-of-vocabulary characters. In addition, our CGR-NER outperforms BERT-BiLSTM-CRF, regardless of whether the subsets contain out-of-vocabulary characters. For the subset containing out-of-vocabulary characters, the F1 score of our model surpasses that of BERT-BiLSTM-CRF by 3.32% and 3.9% on Weibo and OntoNotes 4, respectively. One possible reason is that CGR-NER can infer the approximate semantics of out-of-vocabulary characters by extracting the semantic information contained in the Chinese character glyph structure, so that the model can better understand the text semantics and improve the recognition performance.
4.6. Case Study
Last but not least, we intuitively demonstrate the effectiveness of CGR-NER through two cases from the test set of the Weibo dataset.
Table 12 shows the recognition results of CGR-NER and BERT-BiLSTM-CRF. In sentence 1, BERT-BiLSTM-CRF failed to identify the entity “萌萌 (Mengmeng)”, but CGR-NER made a correct identification. In sentence 2, BERT only recognized the entity “哥 (brother)”, but failed to recognize the entities “林日曦 (Lin Rixi)”, “姗日曦 (Shan Rixi)” and “曉囈 (Xiao yi)”, while CGR-NER correctly recognized all entities. We attribute the correct recognition of CGR-NER to the following reasons. First, entities such as “林日曦”, “姗日曦”, “曉囈” and “萌萌” have radicals such as “木 (wood)”, “日 (sun)”, “艹 (grass)” and “明 (bright)”. The combination of these radicals often appears in Chinese naming, which is very consistent with the naming style of Chinese culture. Consequently, by capturing such features in Chinese character glyphs, CGR-NER can more accurately identify entities such as Chinese people and enterprise names. Secondly, although “曉” and “囈” belong to out-of-vocabulary characters, “曉” and “晓 (dawn)”, “囈” and “呓 (balderdash)” have the same radical and a similar glyph structure, respectively. As a result, CGR can infer that they have similar semantics through their similar visual features, thereby reducing the impact of out-of-vocabulary characters on the model recognition performance and correctly identifying the entity “曉囈”.
5. Conclusions
In order to make full use of the rich semantic information contained in Chinese character glyphs and improve the recognition performance of Chinese NER, this paper proposes a novel Chinese NER model named CGR-NER. In CGR-NER, a hybrid neural network CBHNN is applied to capture the semantic information contained in Chinese character glyphs, the potential word formation knowledge between adjacent glyphs and the unique contextual semantics and global dependencies of glyph sequences. In addition, a fusion method with a crossmodal attention and gate mechanism is proposed to dynamically fuse the contextual representation from text and the glyph representation from images, so that the model can learn the complementary information between different modal representations. We conducted sufficient experiments on two mainstream Chinese NER datasets. The experimental results showed that CGR-NER achieved 70.70% and 82.97% F1 scores on the Weibo dataset and OntoNotes 4 dataset, which were increased by 2.3% and 1.63% compared with the baseline, respectively. At the same time, we conducted multiple groups of ablation experiments, proving that CGR-NER can still maintain good recognition performance in the condition of insufficient training data and out-of-vocabulary characters.
In addition, our model also has some limitations. Since CGR-NER carries out Chinese NER at the character level, it may lack the word-level features. In the future, we will consider how to more effectively integrate characters, glyphs and word-level information into the Chinese NER model, and continue to study the entity recognition effect of our model in specific domains to verify its robustness and generalization ability.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}