
Assessment of the Critical Defect in Additive Manufacturing Components through Machine Learning Algorithms





Abstract
:1. Introduction
2. Machine Learning and Defect Size: Algorithms
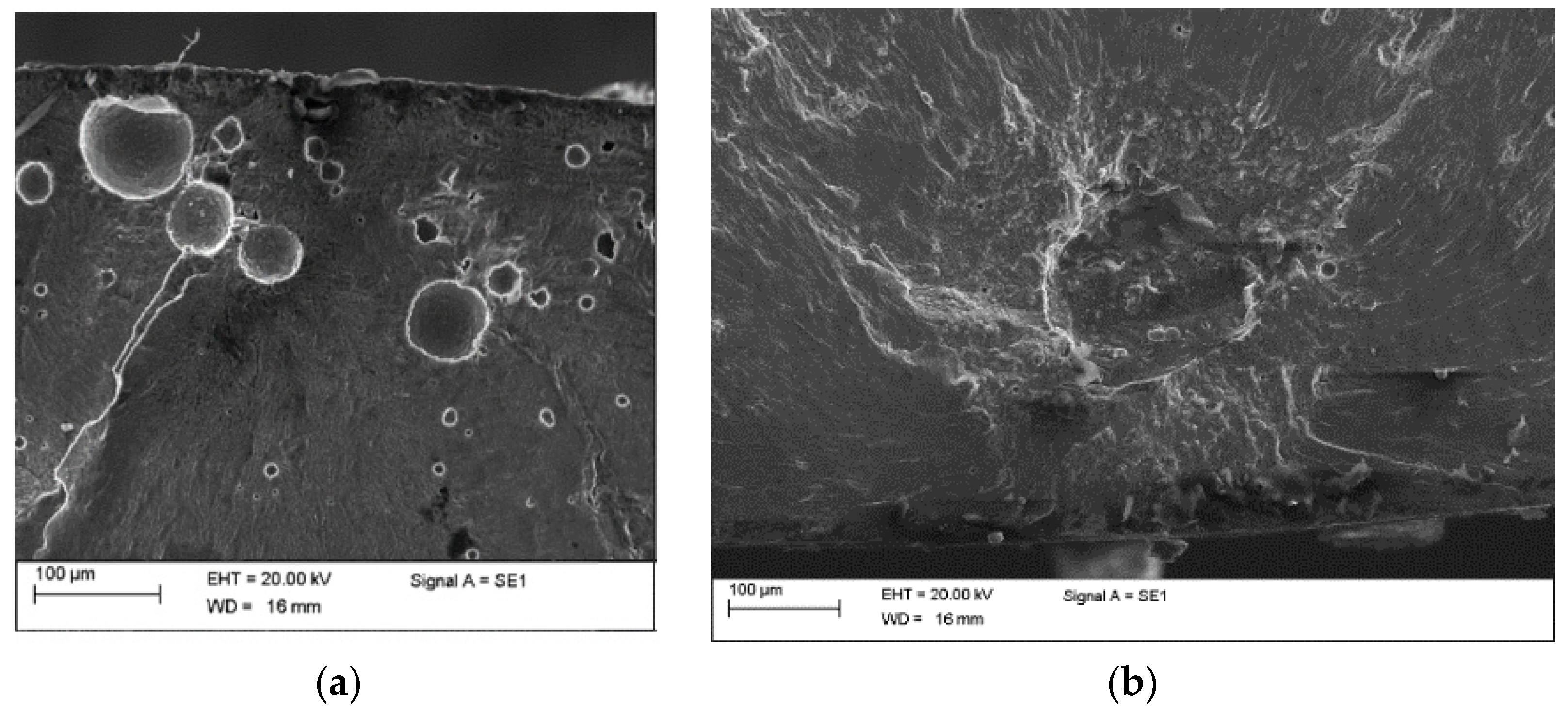
2.1. Defects in AM Components
2.2. Process Parameters and Defects in AM Components
- Building orientation: several experimental results have proved the influence of the building orientation on the defect size and, accordingly, on the fatigue strength. In the following, with 0° and 90° the authors refer to a building orientation with the specimen axis parallel and perpendicular to the building platform (horizontal and vertical building orientation), respectively [23,24].
- Power and scan speed: these two parameters are strongly correlated, since the energy per unit length, dependent on both input power and scan speed, controls the formation of pores or lack of fusion defects [25].
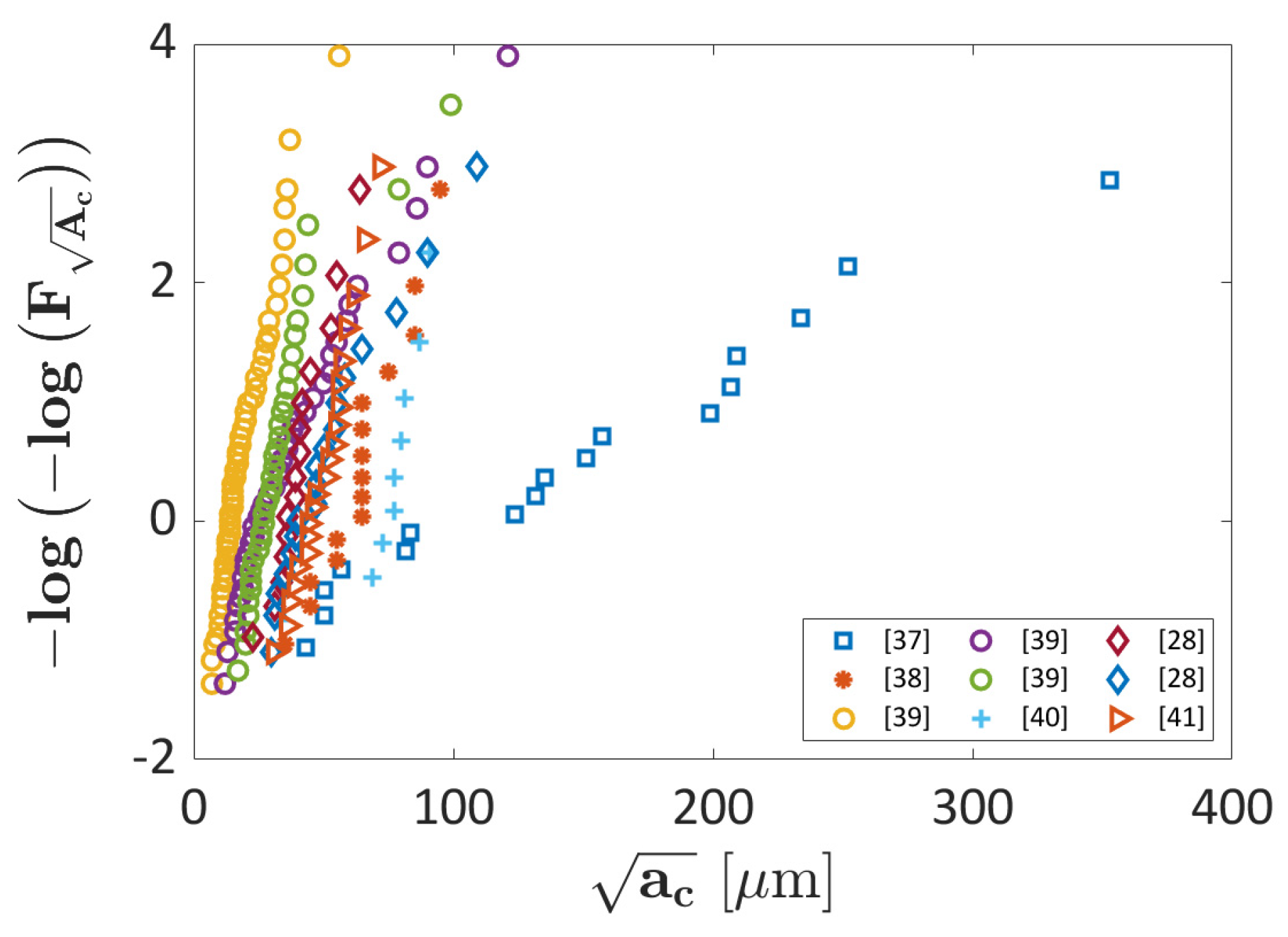
- Powder size: the powder size affects the defect formation. For example, in [28,29], it has been shown that defects tend to be larger in parts produced with smaller powder, thus affecting the fatigue response. In the following analysis, the average powder size has been considered as the input parameter for the developed ML algorithms.
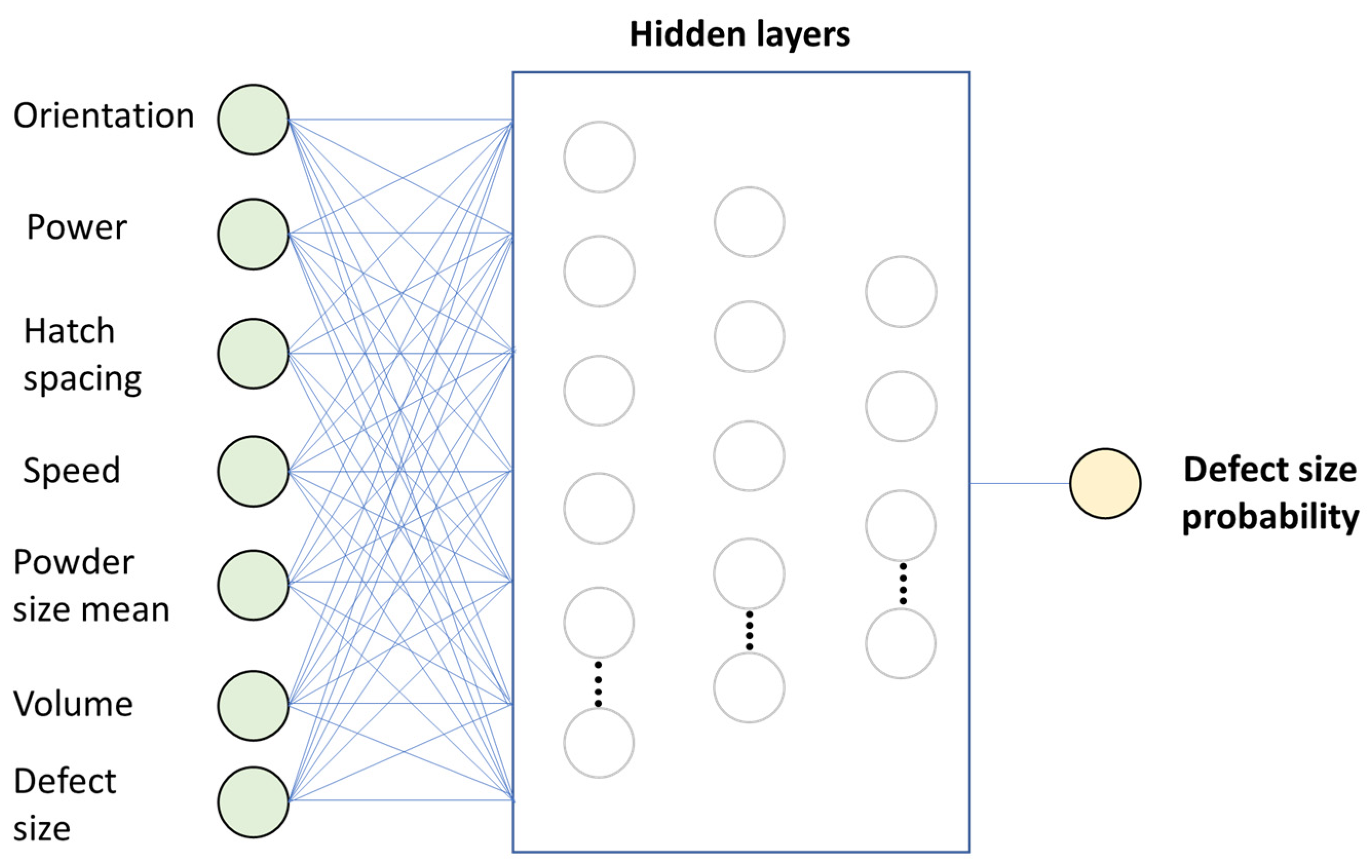
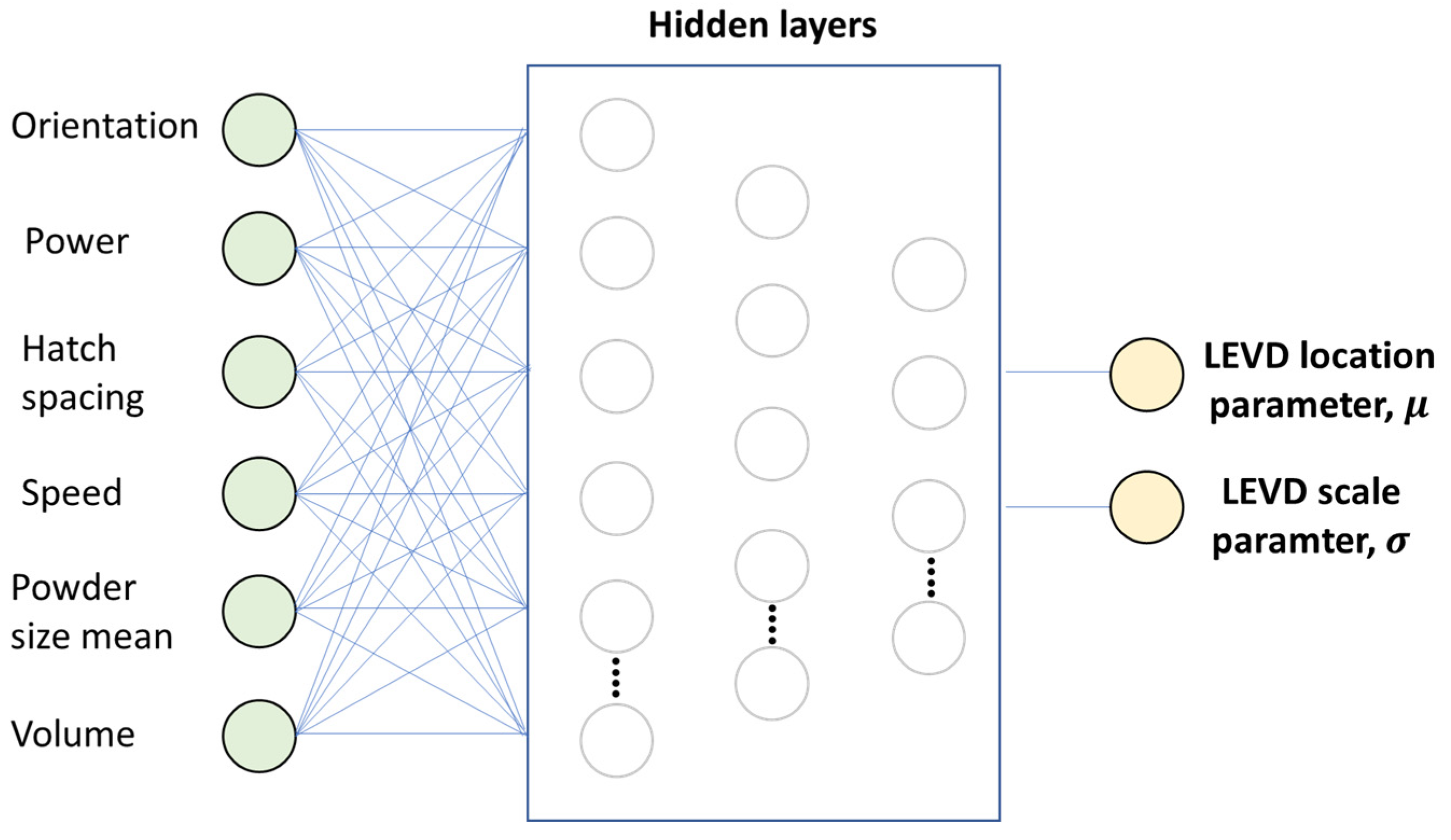
2.3. Neural Networks Architecture
2.3.1. NN Architecture: Probability of a Specific Defect Size (Probability ML)
2.3.2. NN Architecture: LEVD Distribution Parameters (LEVD ML)
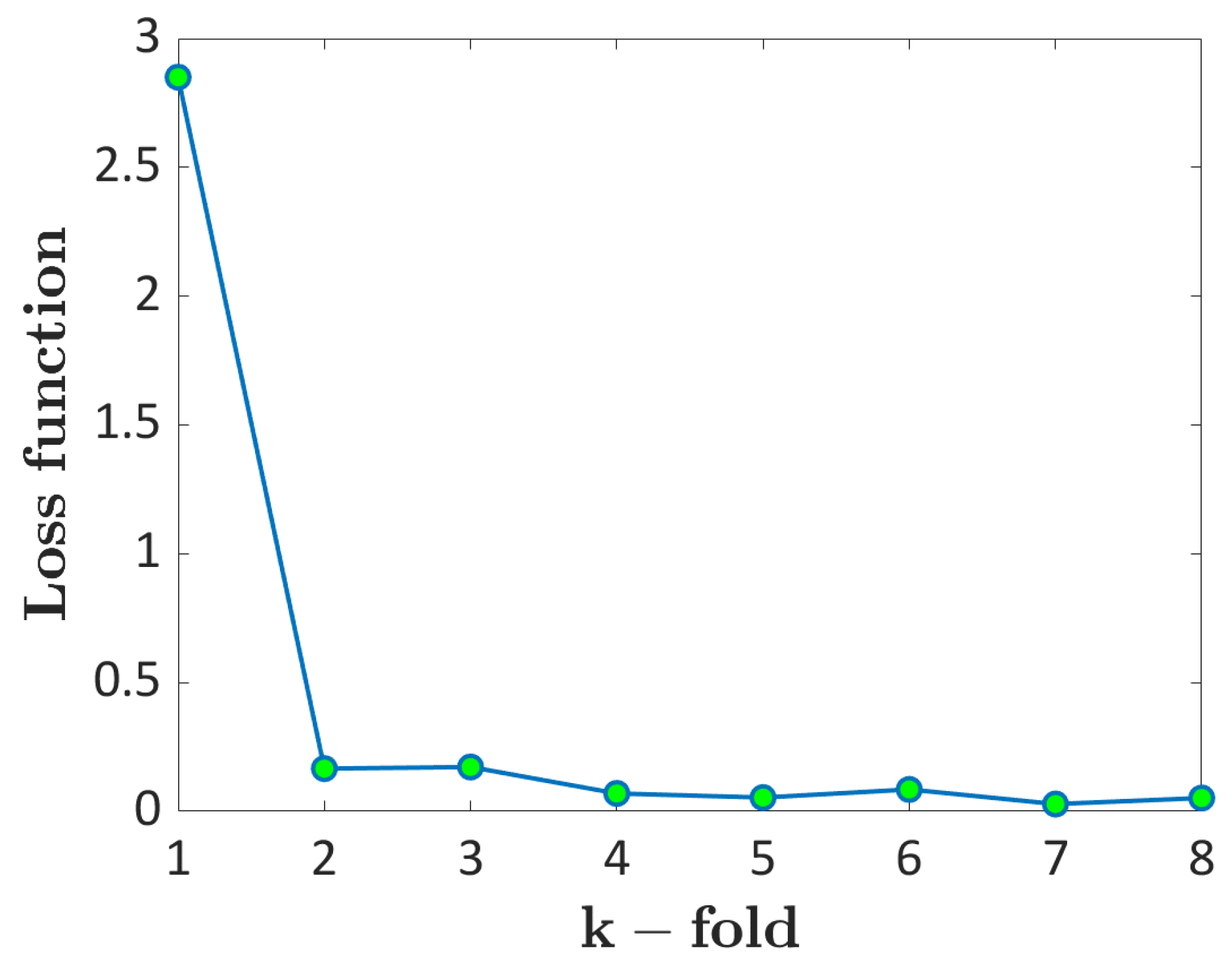
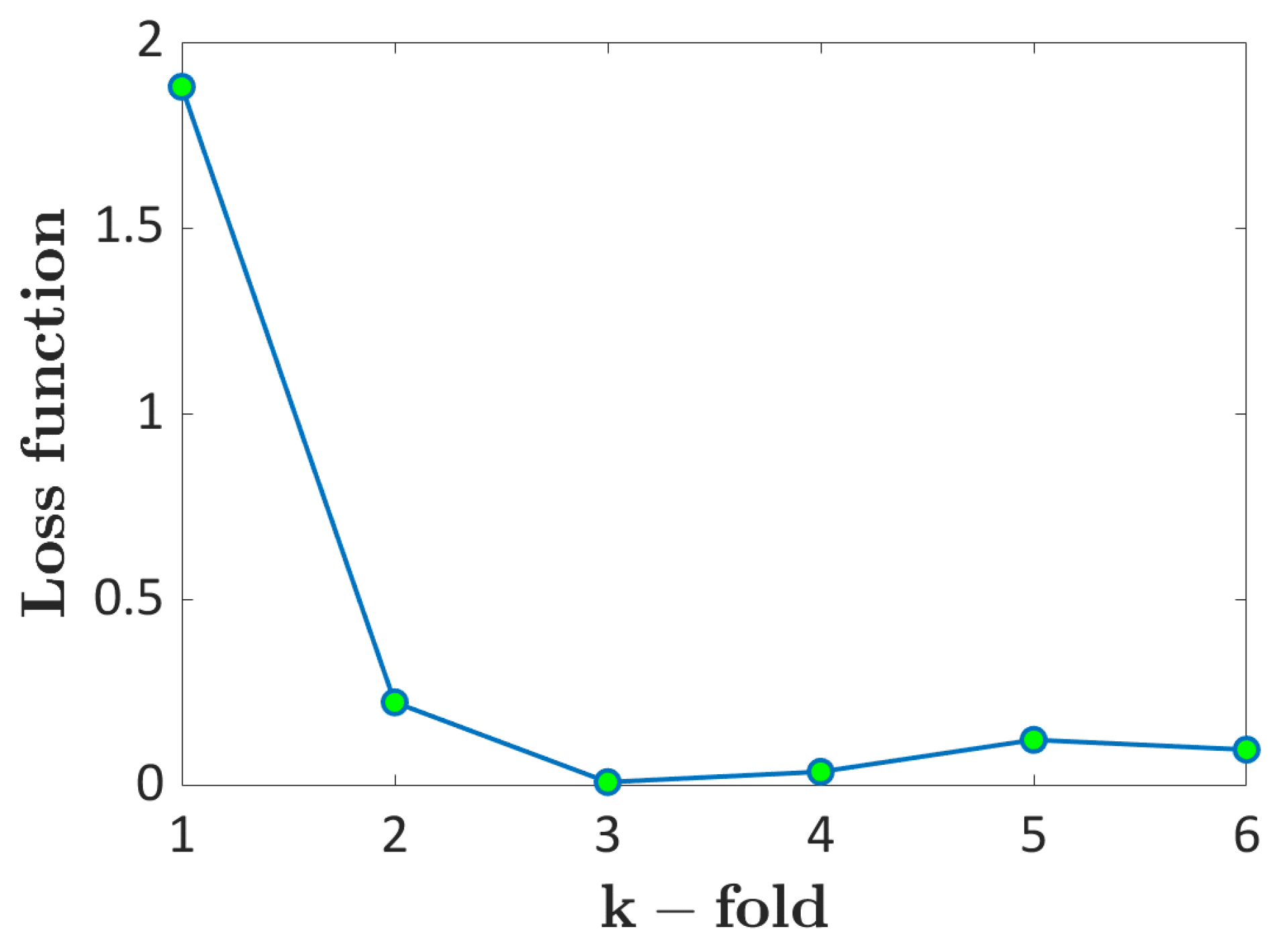
2.4. k-Fold Cross Validation
3. Experimental Validation
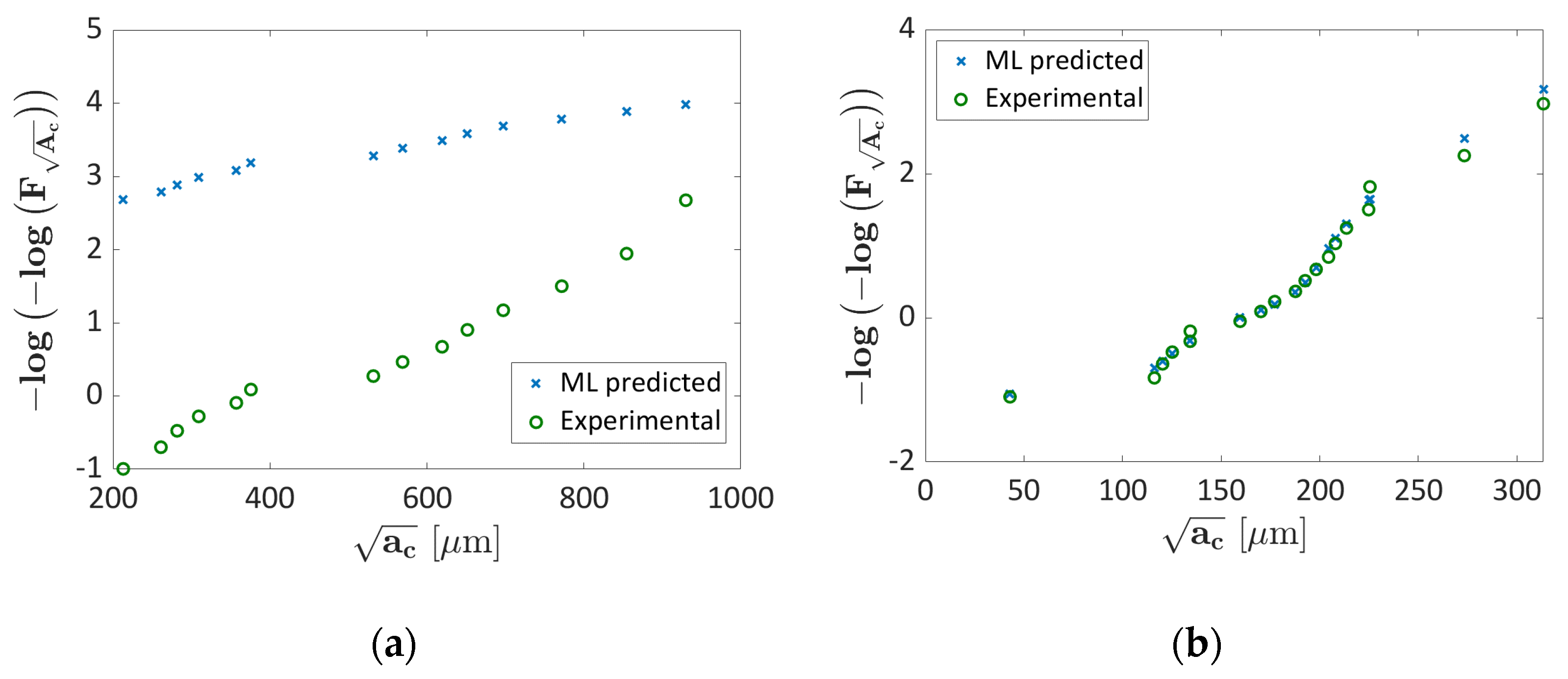
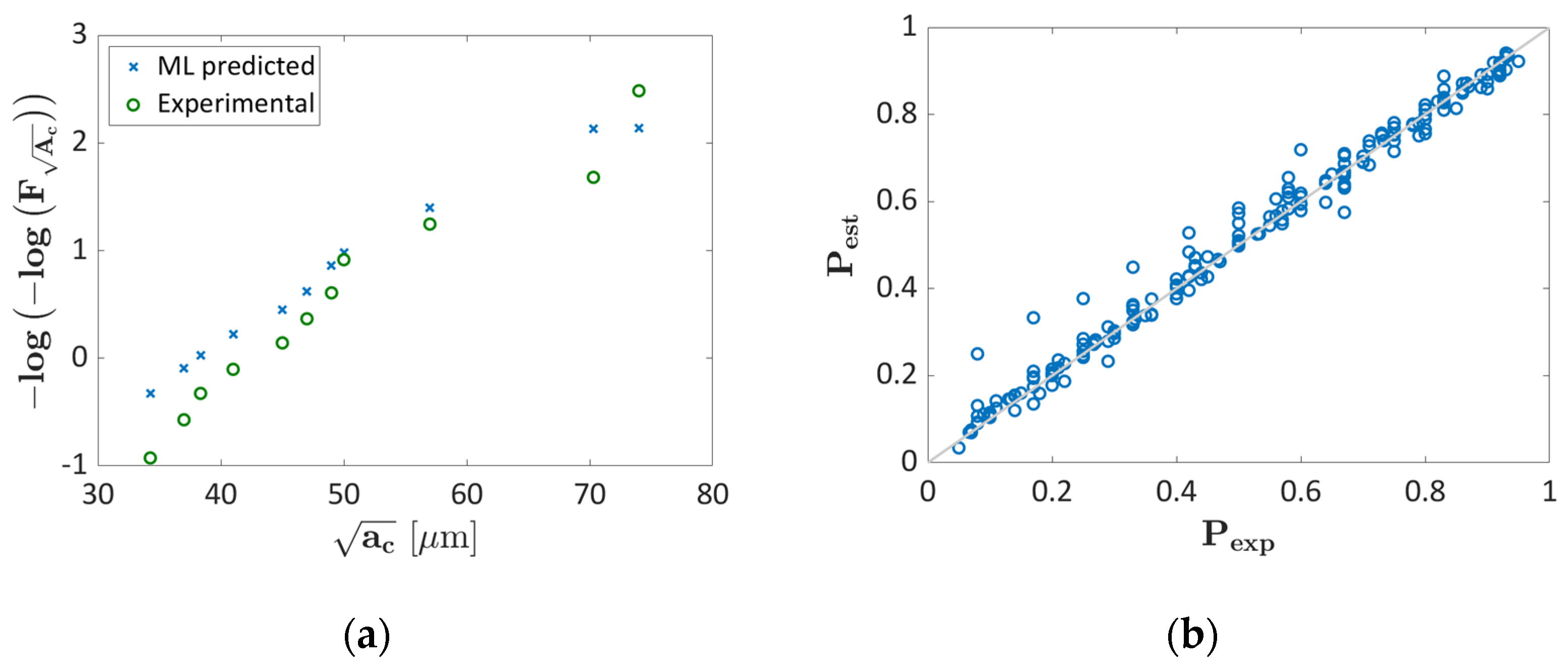
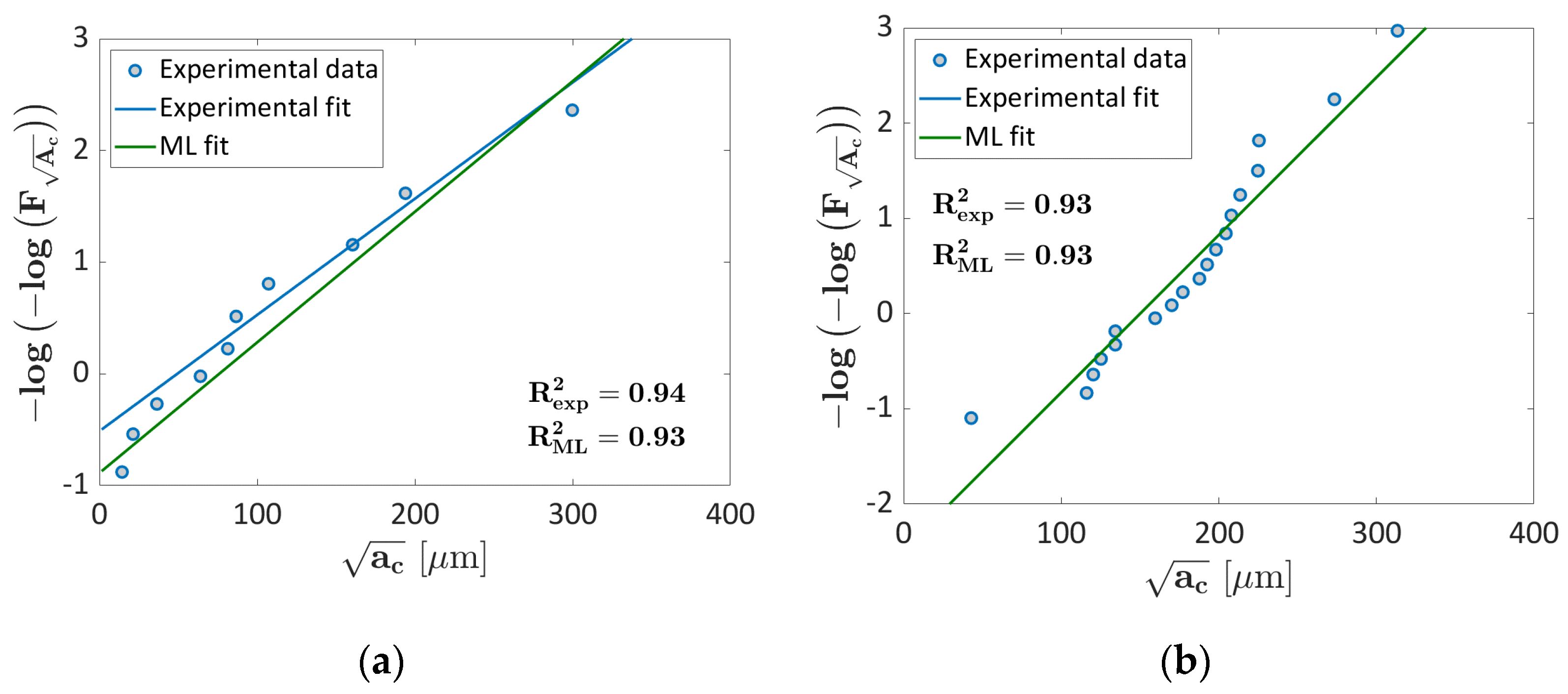
3.1. AlSi10Mg Validation
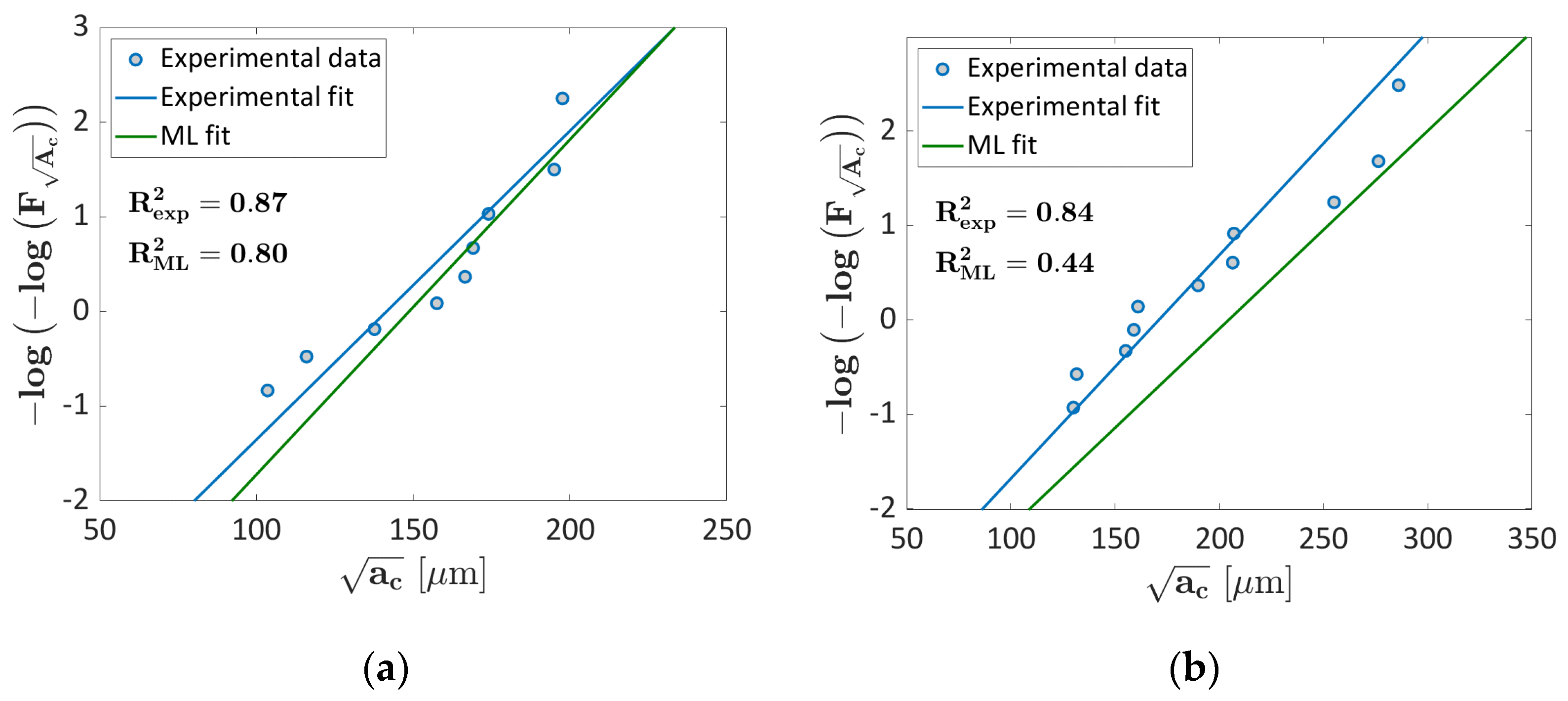
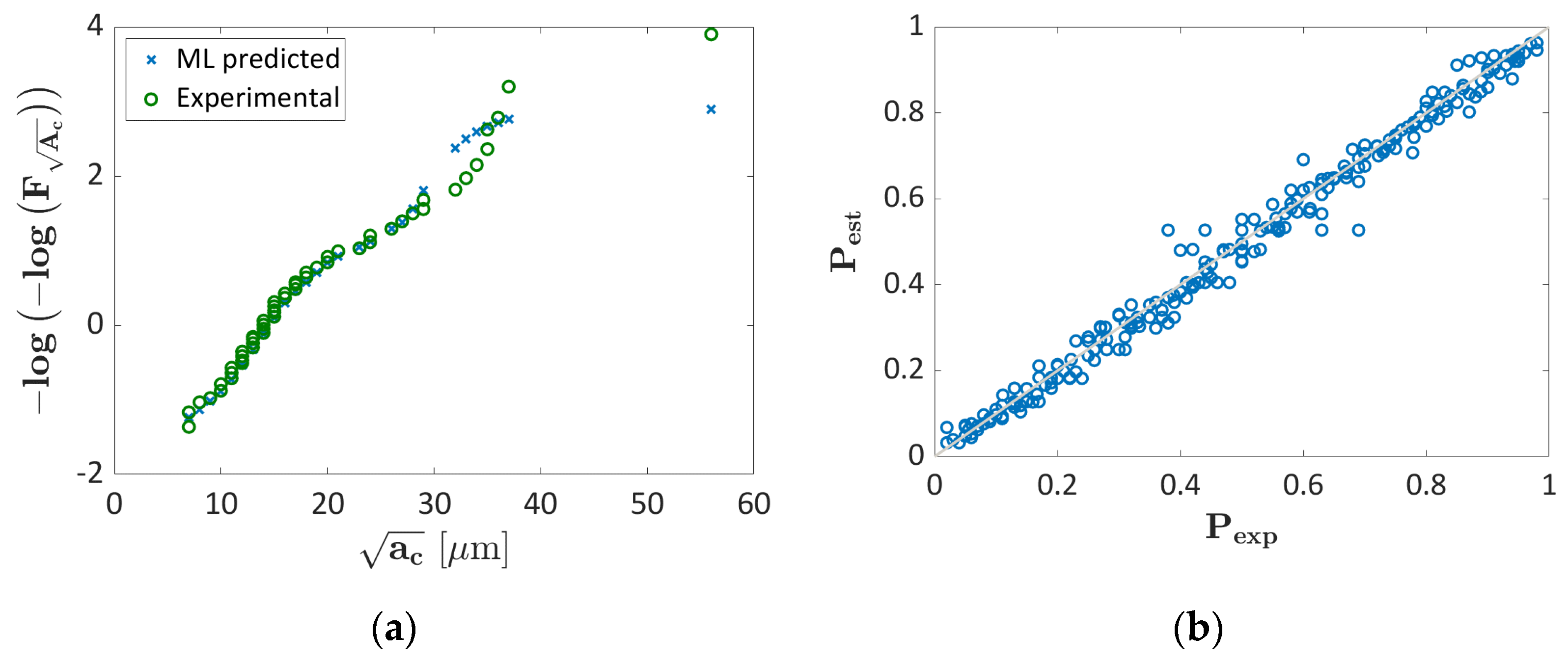
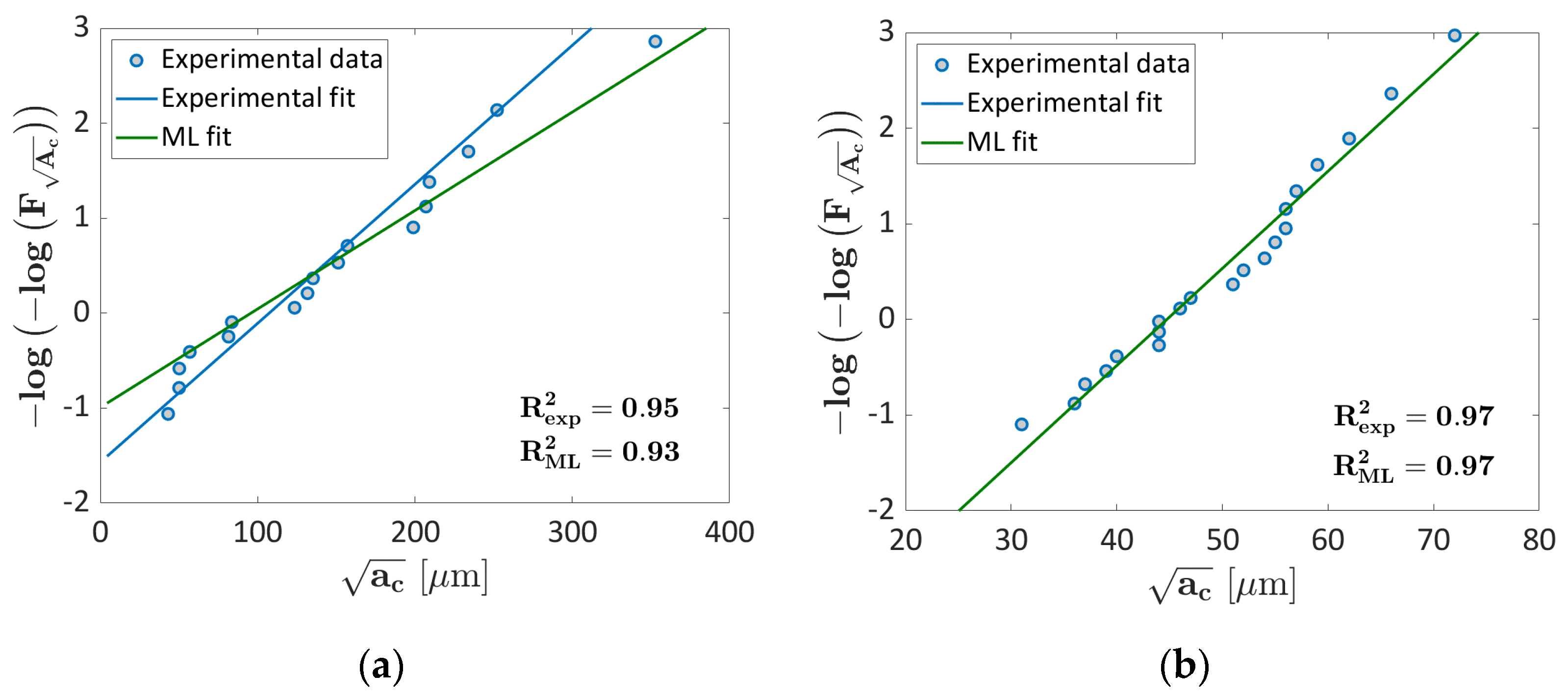
3.1.1. Probability ML Validation
3.1.2. LEVD ML Algorithm: Validation
3.2. Ti6Al4V Validation
3.2.1. Probability ML Validation
3.2.2. LEVD ML Algorithm Validation
4. Discussion
5. Conclusions
- Probability ML and LEVD ML have shown a high predicting capability for both AlSi10Mg and Ti6Al4V datasets. A k-fold cross-validation scheme has been used for the validation, proving that both approaches can be reliably used for the analysis of defects in SLM components. The loss functions with respect to the fold considered for the validation were almost constant, thus confirming the good performances of both architectures.
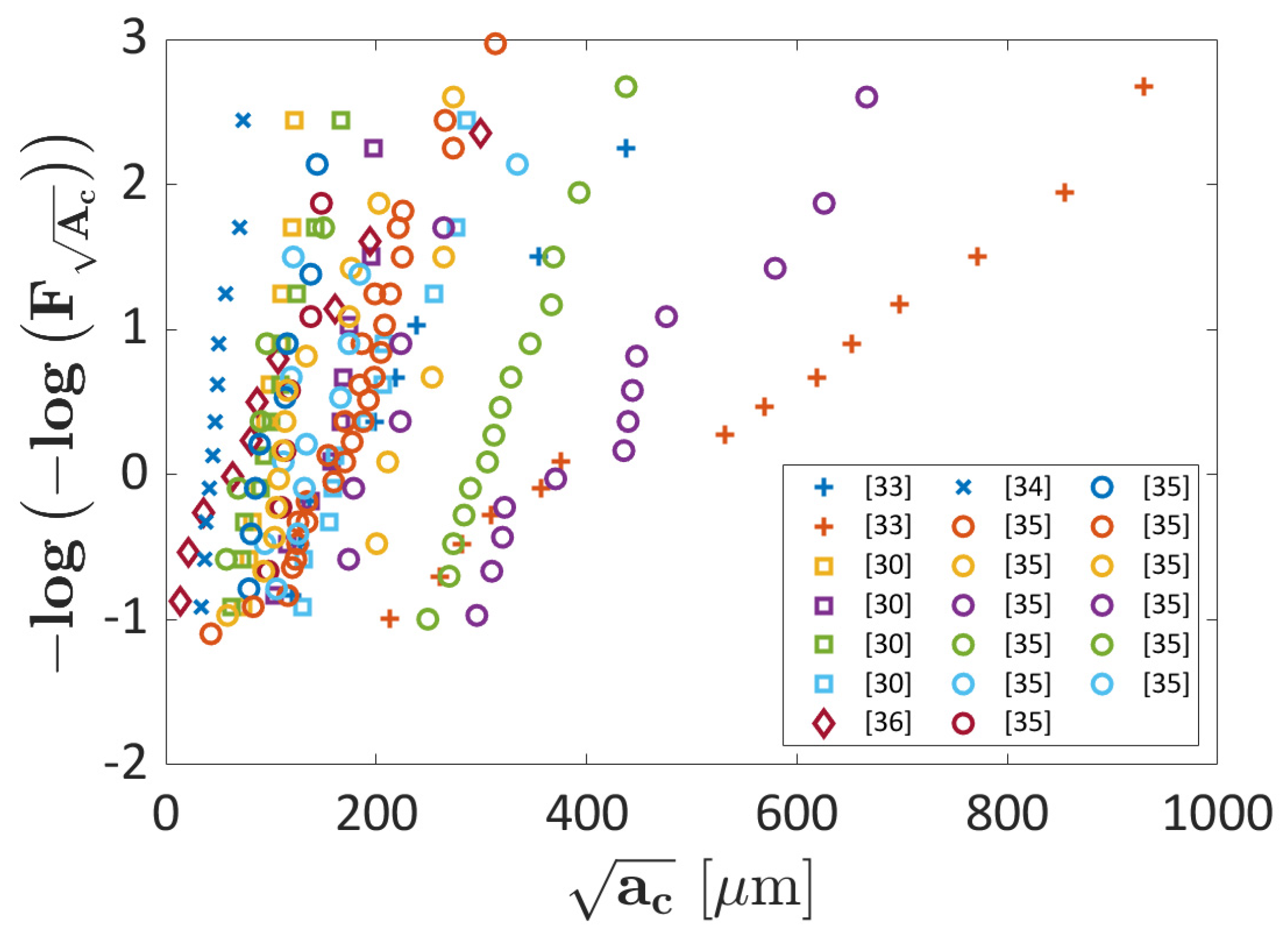
- LEVD ML has been shown to work well even for datasets with a trend significantly different from that of the other datasets considered for the training process. On the other hand, the Probability ML algorithm tends to overestimate the probability associated with each defect, being less conservative.
- The trend in the Gumbel Plot estimated with the Probability ML algorithm can show a large scatter and, for the same process parameters, it is not ensured that larger defects are characterized by larger probabilities. This can be solved by increasing the number of training data. On the other hand, the LEVD ML “embeds” the LEVD statistical model based on the experimental evidence, thus overcoming this criticality.
- The predicting capability of both developed ML algorithms may be enhanced by adding more input factors, whose influence on the defect size population is still debated in the literature, such as heat treatment temperature, the building platform heating temperature, the powder size ranges and the SLM production system. However, the number of available datasets for the training process should be significantly increased.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yadollahi, A.; Shamsaei, N. Additive Manufacturing of Fatigue Resistant Materials: Challenges and Opportunities. Int. J. Fatigue 2017, 98, 14–31. [Google Scholar] [CrossRef] [Green Version]
- Mower, T.M.; Long, M.J. Mechanical Behavior of Additive Manufactured, Powder-Bed Laser-Fused Materials. Mater. Sci. Eng. A 2016, 651, 198–213. [Google Scholar] [CrossRef]
- Uzan, N.E.; Shneck, R.; Yeheskel, O.; Frage, N. Fatigue of AlSi10Mg Specimens Fabricated by Additive Manufacturing Selective Laser Melting (AM-SLM). Mater. Sci. Eng. A 2017, 704, 229–237. [Google Scholar] [CrossRef]
- Murakami, Y. Metal Fatigue: Effects of Small Defects and Nonmetallic Inclusions; Elsevier: Amsterdam, The Netherlands, 2002; ISBN 9780128138779. [Google Scholar]
- Masuo, H.; Tanaka, Y.; Morokoshi, S.; Yagura, H.; Uchida, T. Influence of Defects, Surface Roughness and HIP on the Fatigue Strength of Ti-6Al-4V Manufactured by Additive Manufacturing. Int. J. Fatigue 2018, 117, 163–179. [Google Scholar] [CrossRef]
- Sanaei, N.; Fatemi, A. Defects in Additive Manufactured Metals and Their Effect on Fatigue Performance: A State-of-the-Art Review. Prog. Mater. Sci. 2021, 117, 100724. [Google Scholar] [CrossRef]
- Beretta, S.; Romano, S. A Comparison of Fatigue Strength Sensitivity to Defects for Materials Manufactured by AM or Traditional Processes. Int. J. Fatigue 2017, 94, 178–191. [Google Scholar] [CrossRef]
- Romano, S.; Brückner-Foit, A.; Brandão, A.; Gumpinger, J.; Ghidini, T.; Beretta, S. Fatigue Properties of AlSi10Mg Obtained by Additive Manufacturing: Defect-Based Modelling and Prediction of Fatigue Strength. Eng. Fract. Mech. 2018, 187, 165–189. [Google Scholar] [CrossRef]
- Tridello, A.; Boursier Niutta, C.; Berto, F.; Qian, G.; Paolino, D.S. Fatigue Failures from Defects in Additive Manufactured Components: A Statistical Methodology for the Analysis of the Experimental Results. Fatigue Fract. Eng. Mater. Struct. 2021, 44, 1944–1960. [Google Scholar] [CrossRef]
- Zhang, M.; Sun, C.N.; Zhang, X.; Wei, J.; Hardacre, D.; Li, H. Predictive Models for Fatigue Property of Laser Powder Bed Fusion Stainless Steel 316L. Mater. Des. 2018, 145, 42–54. [Google Scholar] [CrossRef]
- Du, L.; Qian, G.; Zheng, L.; Hong, Y. Influence of Processing Parameters of Selective Laser Melting on High-Cycle and Very-High-Cycle Fatigue Behaviour of Ti-6Al-4V. Fatigue Fract. Eng. Mater. Struct. 2021, 44, 240–256. [Google Scholar] [CrossRef]
- Zhan, Z.; Li, H. A Novel Approach Based on the Elastoplastic Fatigue Damage and Machine Learning Models for Life Prediction of Aerospace Alloy Parts Fabricated by Additive Manufacturing. Int. J. Fatigue 2021, 145, 106089. [Google Scholar] [CrossRef]
- Maleki, E.; Bagherifard, S.; Razavi, S.M.J.; Bandini, M.; du Plessis, A.; Berto, F.; Guagliano, M. On the Efficiency of Machine Learning for Fatigue Assessment of Post-Processed Additively Manufactured AlSi10Mg. Int. J. Fatigue 2022, 160, 106841. [Google Scholar] [CrossRef]
- Chen, J.; Liu, Y. Fatigue Property Prediction of Additively Manufactured Ti-6Al-4V Using Probabilistic Physics-Guided Learning. Addit. Manuf. 2021, 39, 101876. [Google Scholar] [CrossRef]
- Schneller, W.; Leitner, M.; Maier, B.; Grün, F.; Jantschner, O.; Leuders, S.; Pfeifer, T. Artificial Intelligence Assisted Fatigue Failure Prediction. Int. J. Fatigue 2022, 155, 106580. [Google Scholar] [CrossRef]
- Salvati, E.; Tognan, A.; Laurenti, L.; Pelegatti, M.; De Bona, F. A Defect-Based Physics-Informed Machine Learning Framework for Fatigue Finite Life Prediction in Additive Manufacturing. Mater. Des. 2022, 222, 111089. [Google Scholar] [CrossRef]
- Awd, M.; Münstermann, S.; Walther, F. Effect of Microstructural Heterogeneity on Fatigue Strength Predicted by Reinforcement Machine Learning. Fatigue Fract. Eng. Mater. Struct. 2022, 45, 3267–3287. [Google Scholar] [CrossRef]
- Wang, H.; Li, B.; Xuan, F.Z. Fatigue-Life Prediction of Additively Manufactured Metals by Continuous Damage Mechanics (CDM)-Informed Machine Learning with Sensitive Features. Int. J. Fatigue 2022, 164, 107147. [Google Scholar] [CrossRef]
- Ciampaglia, A.; Tridello, A.; Paolino, D.S.; Berto, F. Data Driven Method for Predicting the Effect of Process Parameters on the Fatigue Response of Additive Manufactured AlSi10Mg Parts. Int. J. Fatigue 2023, 170, 107500. [Google Scholar] [CrossRef]
- Shi, T.; Sun, J.; Li, J.; Qian, G.; Hong, Y. Machine Learning Based Very-High-Cycle Fatigue Life Prediction of Ti-6Al-4V Alloy Fabricated by Selective Laser Melting. Int. J. Fatigue 2023, 173, 107585. [Google Scholar] [CrossRef]
- Cutolo, A.; Lammens, N.; Vanden Boer, K.; Erdelyi, H.; Schulz, M.; Muralidharan, G.K.; Thijs, L.; Elangeswaran, C.; Van Hooreweder, B. Fatigue Life Prediction of a L-PBF Component in Ti-6Al-4V Using Sample Data, FE-Based Simulations and Machine Learning. Int. J. Fatigue 2023, 167, 107276. [Google Scholar] [CrossRef]
- Colombo, C.; Tridello, A.; Pagnoncelli, A.P.; Biffi, C.A.; Fiocchi, J.; Tuissi, A.; Vergani, L.M.; Paolino, D.S. Efficient Experimental Methods for Rapid Fatigue Life Estimation of Additive Manufactured Elements. Int. J. Fatigue 2023, 167, 107345. [Google Scholar] [CrossRef]
- Tridello, A.; Fiocchi, J.; Biffi, C.A.; Chiandussi, G.; Rossetto, M.; Tuissi, A.; Paolino, D.S. Effect of Microstructure, Residual Stresses and Building Orientation on the Fatigue Response up to 109 Cycles of an SLM AlSi10Mg Alloy. Int. J. Fatigue 2020, 137, 105659. [Google Scholar] [CrossRef]
- Qian, G.; Li, Y.; Paolino, D.S.; Tridello, A.; Berto, F.; Hong, Y. Very-High-Cycle Fatigue Behavior of Ti-6Al-4V Manufactured by Selective Laser Melting: Effect of Build Orientation. Int. J. Fatigue 2020, 136, 105628. [Google Scholar] [CrossRef]
- Mukherjee, S.; Kar, S.K.; Sivaprasad, S.; Tarafder, S.; Viswanathan, G.B.; Fraser, H.L. Creep-Fatigue Response, Failure Mode and Deformation Mechanism of HAYNES 282 Ni Based Superalloy: Effect of Dwell Position and Time. Int. J. Fatigue 2022, 159, 106820. [Google Scholar] [CrossRef]
- Tang, M.; Pistorius, P.C. Fatigue Life Prediction for AlSi10Mg Components Produced by Selective Laser Melting. Int. J. Fatigue 2019, 125, 479–490. [Google Scholar] [CrossRef]
- Fischer, C.; Schweizer, C. Lifetime Assessment of the Process-Dependent Material Properties of Additive Manufactured AlSi10Mg under Low-Cycle Fatigue Loading. MATEC Web Conf. 2020, 326, 07003. [Google Scholar] [CrossRef]
- Soltani-Tehrani, A.; Habibnejad-Korayem, M.; Shao, S.; Haghshenas, M.; Shamsaei, N. Ti-6Al-4V Powder Characteristics in Laser Powder Bed Fusion: The Effect on Tensile and Fatigue Behavior. Addit. Manuf. 2022, 51, 102584. [Google Scholar] [CrossRef]
- Jian, Z.M.; Qian, G.A.; Paolino, D.S.; Tridello, A.; Berto, F.; Hong, Y.S. Crack Initiation Behavior and Fatigue Performance up to Very-High-Cycle Regime of AlSi10Mg Fabricated by Selective Laser Melting with Two Powder Sizes. Int. J. Fatigue 2021, 143, 106013. [Google Scholar] [CrossRef]
- Tridello, A.; Fiocchi, J.; Biffi, C.A.; Rossetto, M.; Tuissi, A.; Paolino, D.S. Size-Effects Affecting the Fatigue Response up to 109 Cycles (VHCF) of SLM AlSi10Mg Specimens Produced in Horizontal and Vertical Directions. Int. J. Fatigue 2022, 160, 106825. [Google Scholar] [CrossRef]
- Paolino, D.S. Very High Cycle Fatigue Life and Critical Defect Size: Modeling of Statistical Size Effects. Fatigue Fract. Eng. Mater. Struct. 2021, 44, 1209–1224. [Google Scholar] [CrossRef]
- Benard, A.; Bos-Levenbach, E.C. The Plotting of Observations on Probability Paper. Stat. Afd. 1953, 7, 163–173. [Google Scholar]
- Wu, Z.; Wu, S.; Bao, J.; Qian, W.; Karabal, S.; Sun, W.; Withers, P.J. The Effect of Defect Population on the Anisotropic Fatigue Resistance of AlSi10Mg Alloy Fabricated by Laser Powder Bed Fusion. Int. J. Fatigue 2021, 151, 106317. [Google Scholar] [CrossRef]
- Muhammad, M.; Nezhadfar, P.D.; Thompson, S.; Saharan, A.; Phan, N.; Shamsaei, N. A Comparative Investigation on the Microstructure and Mechanical Properties of Additively Manufactured Aluminum Alloys. Int. J. Fatigue 2021, 146, 106165. [Google Scholar] [CrossRef]
- Rhein, R.K.; Shi, Q.; Arjun Tekalur, S.; Wayne Jones, J.; Carroll, J.W. Effect of Direct Metal Laser Sintering Build Parameters on Defects and Ultrasonic Fatigue Performance of Additively Manufactured AlSi10Mg. Fatigue Fract. Eng. Mater. Struct. 2021, 44, 295–305. [Google Scholar] [CrossRef]
- Sausto, F.; Tezzele, C.; Beretta, S. Analysis of Fatigue Strength of L-PBF AlSi10Mg with Different Surface Post-Processes: Effect of Residual Stresses. Metals 2022, 12, 898. [Google Scholar] [CrossRef]
- Günther, J.; Krewerth, D.; Lippmann, T.; Leuders, S.; Tröster, T.; Weidner, A.; Biermann, H.; Niendorf, T. Fatigue Life of Additively Manufactured Ti–6Al–4V in the Very High Cycle Fatigue Regime. Int. J. Fatigue 2017, 94, 236–245. [Google Scholar] [CrossRef]
- Hu, Y.N.; Wu, S.C.; Withers, P.J.; Zhang, J.; Bao, H.Y.X.; Fu, Y.N.; Kang, G.Z. The Effect of Manufacturing Defects on the Fatigue Life of Selective Laser Melted Ti-6Al-4V Structures. Mater. Des. 2020, 192, 108708. [Google Scholar] [CrossRef]
- Le, V.D.; Pessard, E.; Morel, F.; Edy, F. Interpretation of the Fatigue Anisotropy of Additively Manufactured TA6V Alloys via a Fracture Mechanics Approach. Eng. Fract. Mech. 2019, 214, 410–426. [Google Scholar] [CrossRef] [Green Version]
- Alegre, J.M.; Díaz, A.; García, R.; Peral, L.B.; Cuesta, I.I. Effect of HIP Post-Processing at 850 °C/200 MPa in the Fatigue Behavior of Ti-6Al-4V Alloy Fabricated by Selective Laser Melting. Int. J. Fatigue 2022, 163, 107097. [Google Scholar] [CrossRef]
- Hu, Y.N.; Wu, S.C.; Wu, Z.K.; Zhong, X.L.; Ahmed, S.; Karabal, S.; Xiao, X.H.; Zhang, H.O.; Withers, P.J. A New Approach to Correlate the Defect Population with the Fatigue Life of Selective Laser Melted Ti-6Al-4V Alloy. Int. J. Fatigue 2020, 136, 105584. [Google Scholar] [CrossRef]
- Siddique, S.; Imran, M.; Walther, F. Very High Cycle Fatigue and Fatigue Crack Propagation Behavior of Selective Laser Melted AlSi12 Alloy. Int. J. Fatigue 2017, 94, 246–254. [Google Scholar] [CrossRef]
- Schneller, W.; Leitner, M.; Leuders, S.; Sprauel, J.M.; Grün, F.; Pfeifer, T.; Jantschner, O. Fatigue Strength Estimation Methodology of Additively Manufactured Metallic Bulk Material. Addit. Manuf. 2021, 39, 101688. [Google Scholar] [CrossRef]
- Tenkamp, J.; Awd, M.; Siddique, S.; Starke, P.; Walther, F. Fracture–Mechanical Assessment of the Effect of Defects on the Fatigue Lifetime and Limit in Cast and Additively Manufactured Aluminum–Silicon Alloys from Hcf to Vhcf Regime. Metals 2020, 10, 943. [Google Scholar] [CrossRef]
- Santos Macías, J.G.; Douillard, T.; Zhao, L.; Maire, E.; Pyka, G.; Simar, A. Influence on Microstructure, Strength and Ductility of Build Platform Temperature during Laser Powder Bed Fusion of AlSi10Mg. Acta Mater. 2020, 201, 231–243. [Google Scholar] [CrossRef]
- Zhuang, L.; Xu, A.; Wang, X.L. A Prognostic Driven Predictive Maintenance Framework Based on Bayesian Deep Learning. Reliab. Eng. Syst. Saf. 2023, 234, 109181. [Google Scholar] [CrossRef]
- Jiao, Z.; Wang, H.; Xing, J.; Yang, Q.; Yang, M.; Zhou, Y.; Zhao, J. A LightGBM Based Framework for Lithium-Ion Battery Remaining Useful Life Prediction Under Driving Conditions. IEEE Trans. Ind. Inform. 2023. [Google Scholar] [CrossRef]
- Luo, C.; Shen, L.; Xu, A. Modelling and Estimation of System Reliability under Dynamic Operating Environments and Lifetime Ordering Constraints. Reliab. Eng. Syst. Saf. 2022, 218, 108136. [Google Scholar] [CrossRef]
- Chen, Z.; Zhou, D.; Zio, E.; Xia, T.; Pan, E. A Deep Learning Feature Fusion Based Health Index Construction Method for Prognostics Using Multiobjective Optimization. IEEE Trans. Reliab. 2022, 1–15. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Orientation | Power | Speed | Hatch Distance | Layer Thickness | Average Powder Size | Risk Volume |
|---|---|---|---|---|---|---|
| [W] | [mm/s] | [ | [ | [] | [mm3] | |
| [0, 90] | [220, 380] | [600, 1650] | [130, 190] | [30, 60] | [30, 41.5] | [250, 2300] |
| Orientation | Power | Speed | Hatch Distance | Layer Thickness | Average Powder Size | Risk Volume |
|---|---|---|---|---|---|---|
| [W] | [mm/s] | [ | [ | [] | [mm3] | |
| [0, 90] | [175, 400] | [150, 1400] | [120, 140] | [30, 60] | [34, 45] | [84, 1204] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tridello, A.; Ciampaglia, A.; Berto, F.; Paolino, D.S. Assessment of the Critical Defect in Additive Manufacturing Components through Machine Learning Algorithms. Appl. Sci. 2023, 13, 4294. https://doi.org/10.3390/app13074294
Tridello A, Ciampaglia A, Berto F, Paolino DS. Assessment of the Critical Defect in Additive Manufacturing Components through Machine Learning Algorithms. Applied Sciences. 2023; 13(7):4294. https://doi.org/10.3390/app13074294
Chicago/Turabian StyleTridello, Andrea, Alberto Ciampaglia, Filippo Berto, and Davide Salvatore Paolino. 2023. "Assessment of the Critical Defect in Additive Manufacturing Components through Machine Learning Algorithms" Applied Sciences 13, no. 7: 4294. https://doi.org/10.3390/app13074294