

Predicting Astrocytic Nuclear Morphology with Machine Learning: A Tree Ensemble Classifier Study

 , , , and
, , , and 
Abstract
:1. Introduction
1.1. Background
1.2. Related Works
1.3. Aim of the Study
2. Materials and Methods
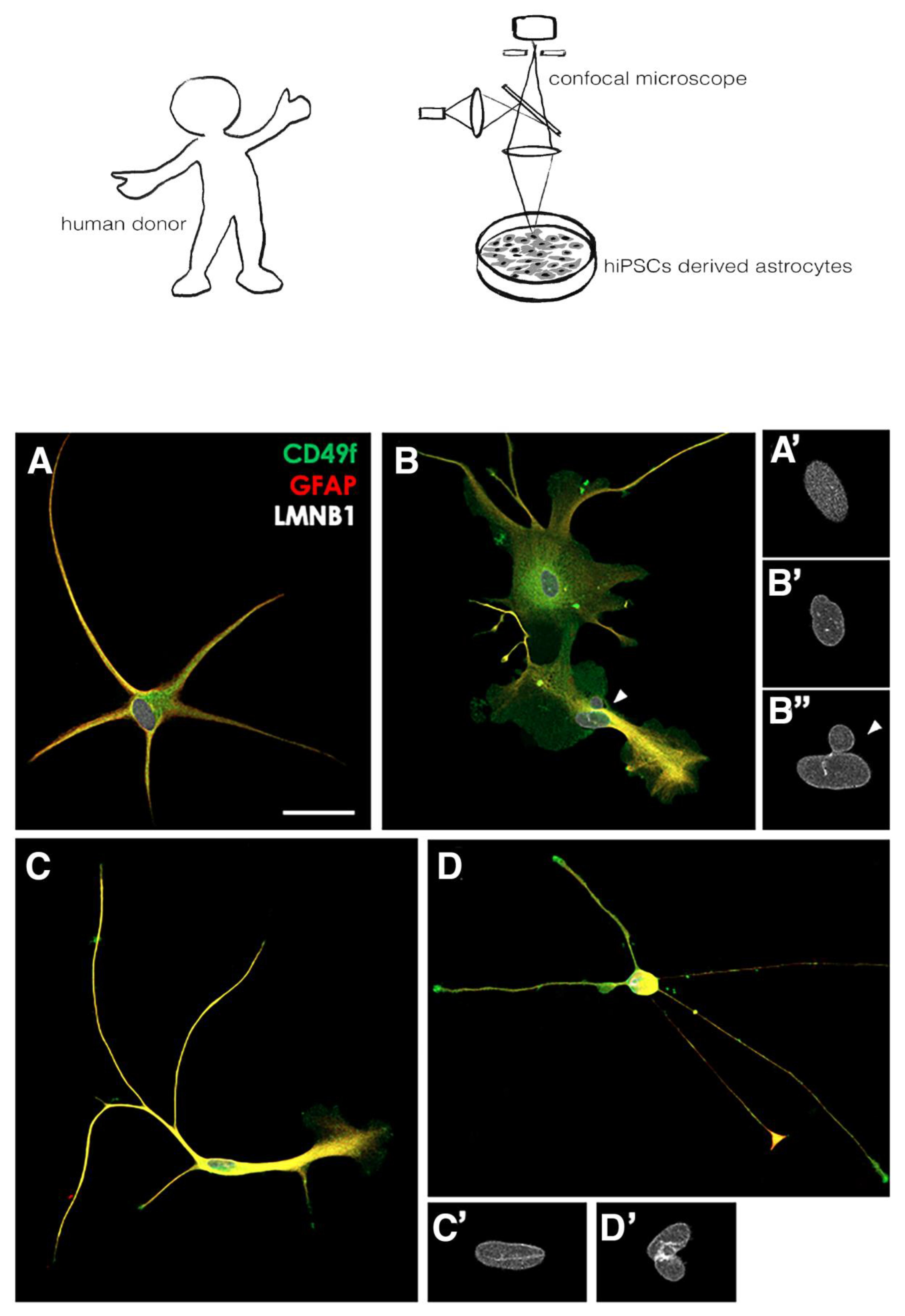
2.1. Human Induced Pluripotent Stem Cell Lines and Cultures
2.2. hiPSCs Neural Commitment and Differentiation into Astrocytes
2.3. Immunofluorescence and Confocal Analysis
2.4. Quantification Analysis
2.5. Classification
3. Results
3.1. Nuclear Patterns of LMNB1 in Astrocytes
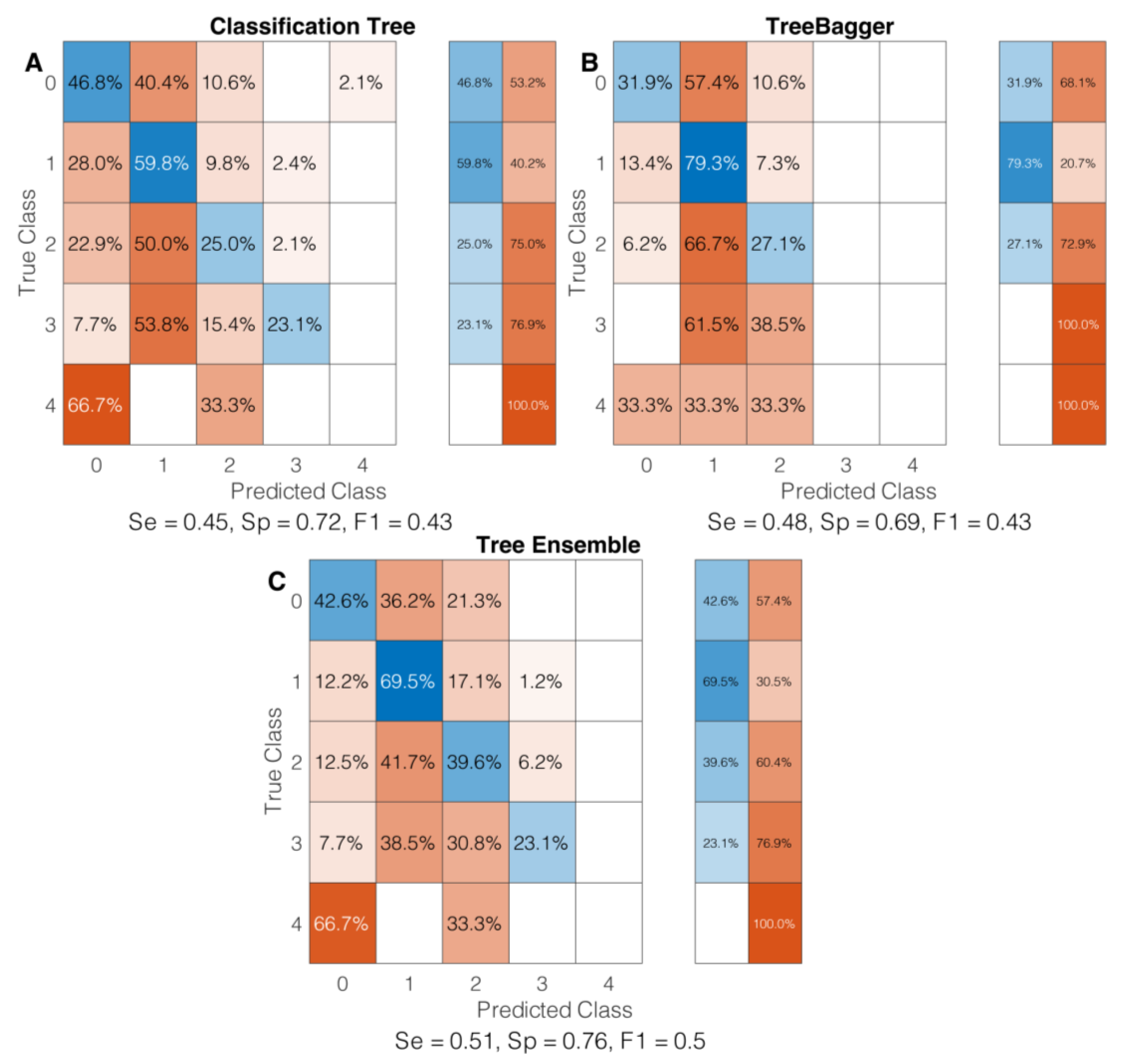
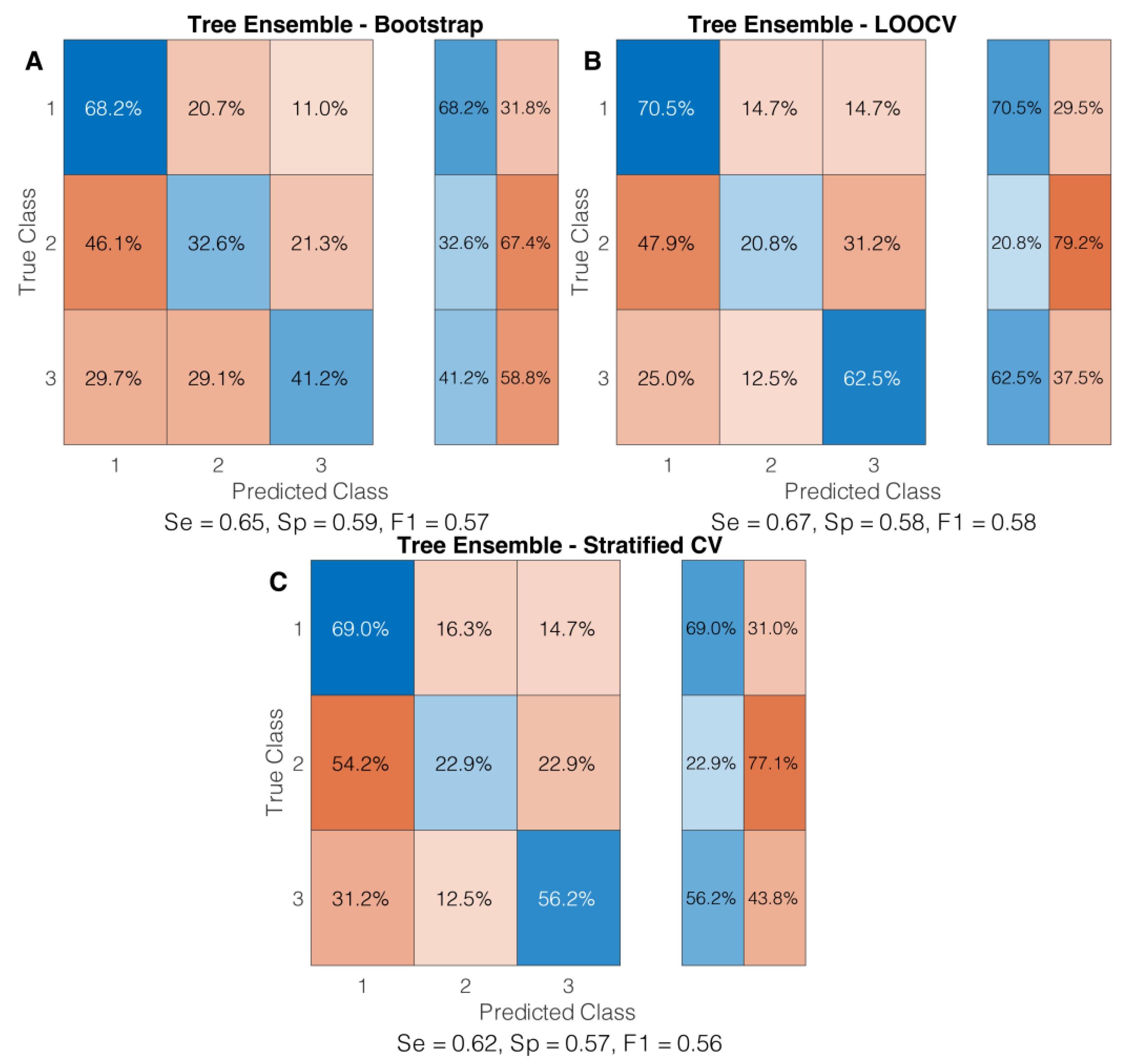
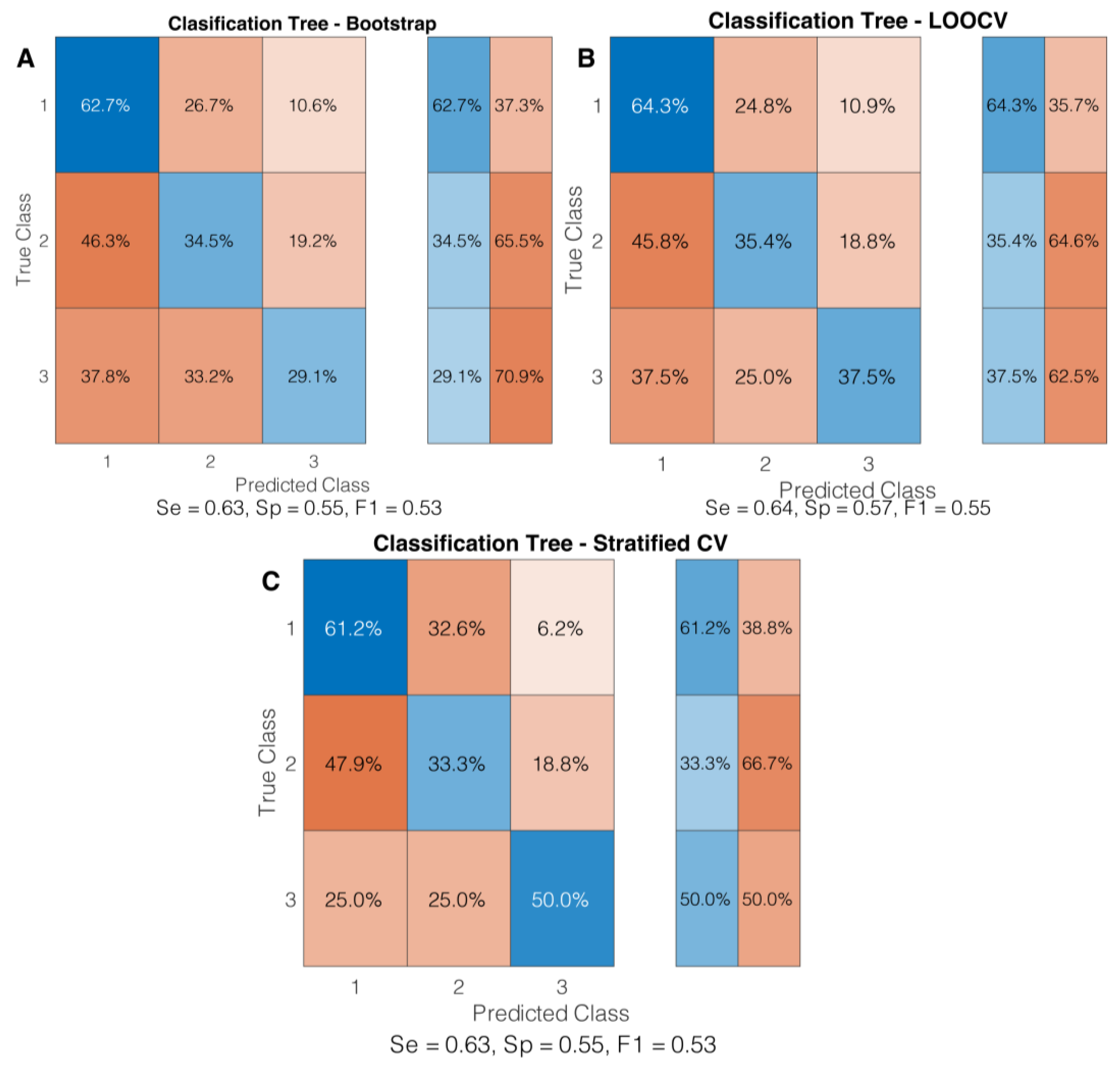
3.2. Classification Algorithm Evaluation
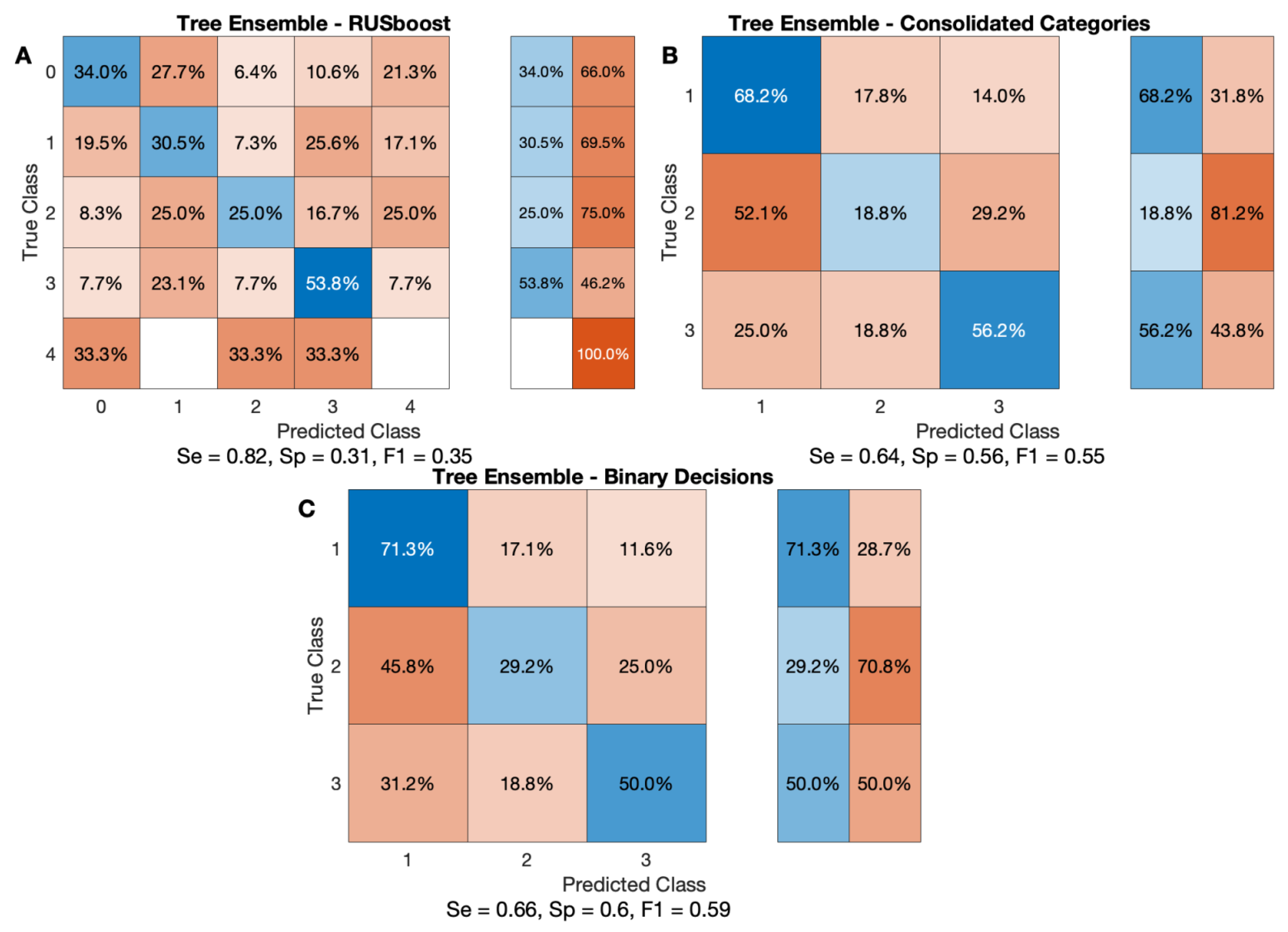
3.3. Cross-Validation Techniques
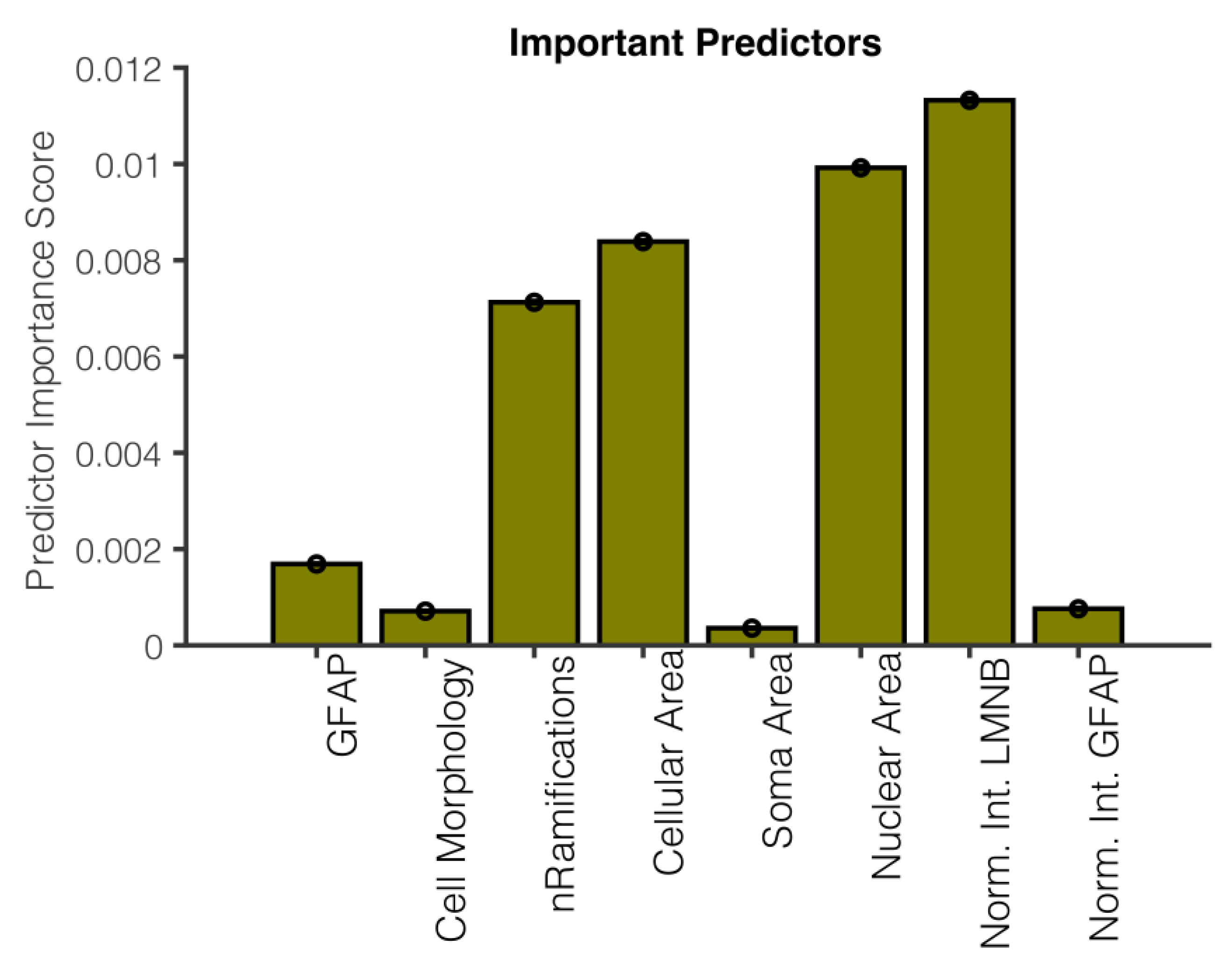
3.4. Important Predictors
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mittal, U.; Chawla, P.; Tiwari, R. EnsembleNet: A Hybrid Approach for Vehicle Detection and Estimation of Traffic Density Based on Faster R-CNN and YOLO Models. Neural Comput. Appl. 2022, 35, 4755–4774. [Google Scholar] [CrossRef]
- Formosa, N.; Quddus, M.; Ison, S.; Abdel-Aty, M.; Yuan, J. Predicting Real-Time Traffic Conflicts Using Deep Learning. Accid. Anal. Prev. 2020, 136, 105429. [Google Scholar] [CrossRef] [PubMed]
- Nam, D.; Lavanya, R.; Jayakrishnan, R.; Yang, I.; Jeon, W.H. A Deep Learning Approach for Estimating Traffic Density Using Data Obtained from Connected and Autonomous Probes. Sensors 2020, 20, 4824. [Google Scholar] [CrossRef] [PubMed]
- Hashad, K.; Gu, J.; Yang, B.; Rong, M.; Chen, E.; Ma, X.; Zhang, K.M. Designing Roadside Green Infrastructure to Mitigate Traffic-Related Air Pollution Using Machine Learning. Sci. Total. Environ. 2021, 773, 144760. [Google Scholar] [CrossRef] [PubMed]
- Verma, P.; Tiwari, R.; Hong, W.-C.; Upadhyay, S.; Yeh, Y.-H. FETCH: A Deep Learning-Based Fog Computing and IoT Integrated Environment for Healthcare Monitoring and Diagnosis. IEEE Access 2022, 10, 12548–12563. [Google Scholar] [CrossRef]
- Rauschert, S.; Raubenheimer, K.; Melton, P.E.; Huang, R.C. Machine Learning and Clinical Epigenetics: A Review of Challenges for Diagnosis and Classification. Clin. Epigenet. 2020, 12, 51. [Google Scholar] [CrossRef] [Green Version]
- Yuan, J.; Ran, X.; Liu, K.; Yao, C.; Yao, Y.; Wu, H.; Liu, Q. Machine Learning Applications on Neuroimaging for Diagnosis and Prognosis of Epilepsy: A Review. J. Neurosci. Methods 2022, 368, 109441. [Google Scholar] [CrossRef]
- Kabade, V.; Hooda, R.; Raj, C.; Awan, Z.; Young, A.S.; Welgampola, M.S.; Prasad, M. Machine Learning Techniques for Differential Diagnosis of Vertigo and Dizziness: A Review. Sensors 2021, 21, 7565. [Google Scholar] [CrossRef]
- Bathla, G.; Singh, P.; Singh, R.K.; Cambria, E.; Tiwari, R. Intelligent Fake Reviews Detection Based on Aspect Extraction and Analysis Using Deep Learning. Neural Comput. Appl. 2022, 34, 20213–20229. [Google Scholar] [CrossRef]
- Nagaraju, M.; Chawla, P.; Upadhyay, S.; Tiwari, R. Convolution Network Model Based Leaf Disease Detection Using Augmentation Techniques. Expert. Syst. 2022, 39, e12885. [Google Scholar] [CrossRef]
- Kokol, P.; Kokol, M.; Zagoranski, S. Machine Learning on Small Size Samples: A Synthetic Knowledge Synthesis. Sci. Prog. 2022, 105, 368504211029777. [Google Scholar] [CrossRef] [PubMed]
- Vu, M.-A.T.; Adalı, T.; Ba, D.; Buzsáki, G.; Carlson, D.; Heller, K.; Liston, C.; Rudin, C.; Sohal, V.S.; Widge, A.S.; et al. A Shared Vision for Machine Learning in Neuroscience. J. Neurosci. 2018, 38, 1601–1607. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vabalas, A.; Gowen, E.; Poliakoff, E.; Casson, A.J. Machine Learning Algorithm Validation with a Limited Sample Size. PLoS ONE 2019, 14, e0224365. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees, 1st ed.; Routledge: Oxford, UK, 2017; ISBN 978-1-315-13947-0. [Google Scholar]
- Das, B. SMOTEBoost 2022. Available online: https://it.mathworks.com/matlabcentral/fileexchange/37311-smoteboost (accessed on 21 March 2023).
- Das, B. RUSBoost 2022. Available online: https://it.mathworks.com/matlabcentral/fileexchange/37315-rusboost (accessed on 21 March 2023).
- Shimi, T.; Butin-Israeli, V.; Adam, S.A.; Hamanaka, R.B.; Goldman, A.E.; Lucas, C.A.; Shumaker, D.K.; Kosak, S.T.; Chandel, N.S.; Goldman, R.D. The Role of Nuclear Lamin B1 in Cell Proliferation and Senescence. Genes. Dev. 2011, 25, 2579–2593. [Google Scholar] [CrossRef] [Green Version]
- Camps, J.; Erdos, M.R.; Ried, T. The Role of Lamin B1 for the Maintenance of Nuclear Structure and Function. Nucleus 2015, 6, 8–14. [Google Scholar] [CrossRef] [Green Version]
- Shah, P.P.; Donahue, G.; Otte, G.L.; Capell, B.C.; Nelson, D.M.; Cao, K.; Aggarwala, V.; Cruickshanks, H.A.; Rai, T.S.; McBryan, T.; et al. Lamin B1 Depletion in Senescent Cells Triggers Large-Scale Changes in Gene Expression and the Chromatin Landscape. Genes. Dev. 2013, 27, 1787–1799. [Google Scholar] [CrossRef] [Green Version]
- Bedrosian, T.A.; Houtman, J.; Eguiguren, J.S.; Ghassemzadeh, S.; Rund, N.; Novaresi, N.M.; Hu, L.; Parylak, S.L.; Denli, A.M.; Randolph-Moore, L.; et al. Lamin B1 Decline Underlies Age-related Loss of Adult Hippocampal Neurogenesis. EMBO J. 2021, 40, e105819. [Google Scholar] [CrossRef]
- Padiath, Q.S.; Saigoh, K.; Schiffmann, R.; Asahara, H.; Yamada, T.; Koeppen, A.; Hogan, K.; Ptáček, L.J.; Fu, Y.-H. Lamin B1 Duplications Cause Autosomal Dominant Leukodystrophy. Nat. Genet. 2006, 38, 1114–1123. [Google Scholar] [CrossRef] [PubMed]
- Giorgio, E.; Lorenzati, M.; Rivetti di Val Cervo, P.; Brussino, A.; Cernigoj, M.; Della Sala, E.; Bartoletti Stella, A.; Ferrero, M.; Caiazzo, M.; Capellari, S.; et al. Allele-Specific Silencing as Treatment for Gene Duplication Disorders: Proof-of-Principle in Autosomal Dominant Leukodystrophy. Brain 2019, 142, 1905–1920. [Google Scholar] [CrossRef] [Green Version]
- Hasel, P.; Liddelow, S.A. Astrocytes. Curr. Biol. 2021, 31, R326–R327. [Google Scholar] [CrossRef]
- Douvaras, P.; Fossati, V. Generation and Isolation of Oligodendrocyte Progenitor Cells from Human Pluripotent Stem Cells. Nat. Protoc. 2015, 10, 1143–1154. [Google Scholar] [CrossRef] [PubMed]
- Douvaras, P.; Wang, J.; Zimmer, M.; Hanchuk, S.; O’Bara, M.A.; Sadiq, S.; Sim, F.J.; Goldman, J.; Fossati, V. Efficient Generation of Myelinating Oligodendrocytes from Primary Progressive Multiple Sclerosis Patients by Induced Pluripotent Stem Cells. Stem Cell. Rep. 2014, 3, 250–259. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barbar, L.; Jain, T.; Zimmer, M.; Kruglikov, I.; Sadick, J.S.; Wang, M.; Kalpana, K.; Rose, I.V.L.; Burstein, S.R.; Rusielewicz, T.; et al. CD49f Is a Novel Marker of Functional and Reactive Human IPSC-Derived Astrocytes. Neuron 2020, 107, 436–453.e12. [Google Scholar] [CrossRef]
- Berg, S.; Kutra, D.; Kroeger, T.; Straehle, C.N.; Kausler, B.X.; Haubold, C.; Schiegg, M.; Ales, J.; Beier, T.; Rudy, M.; et al. Ilastik: Interactive machine learning for (bio)image analysis. Nat. Methods 2019, 16, 1226–1232. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Merk, T.; Peterson, V.; Köhler, R.; Haufe, S.; Richardson, R.M.; Neumann, W.-J. Machine Learning Based Brain Signal Decoding for Intelligent Adaptive Deep Brain Stimulation. Exp. Neurol. 2022, 351, 113993. [Google Scholar] [CrossRef] [PubMed]
- Vyas, S.; Golub, M.D.; Sussillo, D.; Shenoy, K.V. Computation Through Neural Population Dynamics. Annu. Rev. Neurosci. 2020, 43, 249–275. [Google Scholar] [CrossRef]
- Thomas, A.W.; Ré, C.; Poldrack, R.A. Interpreting Mental State Decoding with Deep Learning Models. Trends Cogn. Sci. 2022, 26, 972–986. [Google Scholar] [CrossRef]
- Odegaard, B.; Grimaldi, P.; Cho, S.H.; Peters, M.A.K.; Lau, H.; Basso, M.A. Superior Colliculus Neuronal Ensemble Activity Signals Optimal Rather than Subjective Confidence. Proc. Natl. Acad. Sci. USA 2018, 115, E1588–E1597. [Google Scholar] [CrossRef] [Green Version]
- Boutet, A.; Madhavan, R.; Elias, G.J.B.; Joel, S.E.; Gramer, R.; Ranjan, M.; Paramanandam, V.; Xu, D.; Germann, J.; Loh, A.; et al. Predicting Optimal Deep Brain Stimulation Parameters for Parkinson’s Disease Using Functional MRI and Machine Learning. Nat. Commun. 2021, 12, 3043. [Google Scholar] [CrossRef]
- Li, Y.; Qi, Y.; Wang, Y.; Wang, Y.; Xu, K.; Pan, G. Robust Neural Decoding by Kernel Regression with Siamese Representation Learning. J. Neural Eng. 2021, 18, 056062. [Google Scholar] [CrossRef] [PubMed]
- Chung, K.; Deisseroth, K. CLARITY for Mapping the Nervous System. Nat. Methods 2013, 10, 508–513. [Google Scholar] [CrossRef] [PubMed]
- Yang, B.; Treweek, J.B.; Kulkarni, R.P.; Deverman, B.E.; Chen, C.-K.; Lubeck, E.; Shah, S.; Cai, L.; Gradinaru, V. Single-Cell Phenotyping within Transparent Intact Tissue through Whole-Body Clearing. Cell 2014, 158, 945–958. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vong, C.-M.; Du, J. Accurate and Efficient Sequential Ensemble Learning for Highly Imbalanced Multi-Class Data. Neural Netw. 2020, 128, 268–278. [Google Scholar] [CrossRef] [PubMed]
- Tin Kam Ho The Random Subspace Method for Constructing Decision Forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [CrossRef] [Green Version]
- Efron, B.; Tibshirani, R.J. An Introduction to the Bootstrap; Chapman and Hall/CRC: Boca Raton, FL, USA, 1994; ISBN 978-0-429-24659-3. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LMNB1 Category | N (%) |
|---|---|
| 0 | 47 (24.35) |
| 1 | 82 (42.49) |
| 2 | 48 (24.87) |
| 3 | 13 (6.47) |
| 4 | 3 (1.55) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Grimaldi, P.; Lorenzati, M.; Ribodino, M.; Signorino, E.; Buffo, A.; Berchialla, P. Predicting Astrocytic Nuclear Morphology with Machine Learning: A Tree Ensemble Classifier Study. Appl. Sci. 2023, 13, 4289. https://doi.org/10.3390/app13074289
Grimaldi P, Lorenzati M, Ribodino M, Signorino E, Buffo A, Berchialla P. Predicting Astrocytic Nuclear Morphology with Machine Learning: A Tree Ensemble Classifier Study. Applied Sciences. 2023; 13(7):4289. https://doi.org/10.3390/app13074289
Chicago/Turabian StyleGrimaldi, Piercesare, Martina Lorenzati, Marta Ribodino, Elena Signorino, Annalisa Buffo, and Paola Berchialla. 2023. "Predicting Astrocytic Nuclear Morphology with Machine Learning: A Tree Ensemble Classifier Study" Applied Sciences 13, no. 7: 4289. https://doi.org/10.3390/app13074289