


Applying Deep Learning Methods for Mammography Analysis and Breast Cancer Detection

Abstract
:1. Introduction
2. Review of Medical Imaging Techniques for BC Detection
2.1. Medical Imaging Techniques for BC Diagnosis
2.1.1. Mammography
2.1.2. Ultrasound
2.1.3. Magnetic Resonance Imaging (MRI)
2.1.4. Histopathology
2.1.5. Thermography
2.2. Deep Learning Methods for BC Detection and Classification
2.2.1. Transfer Learning and Data Augmentation
2.2.2. Feature Extraction and Multiple Model-Based Architectures
2.2.3. Generative Adversarial Networks
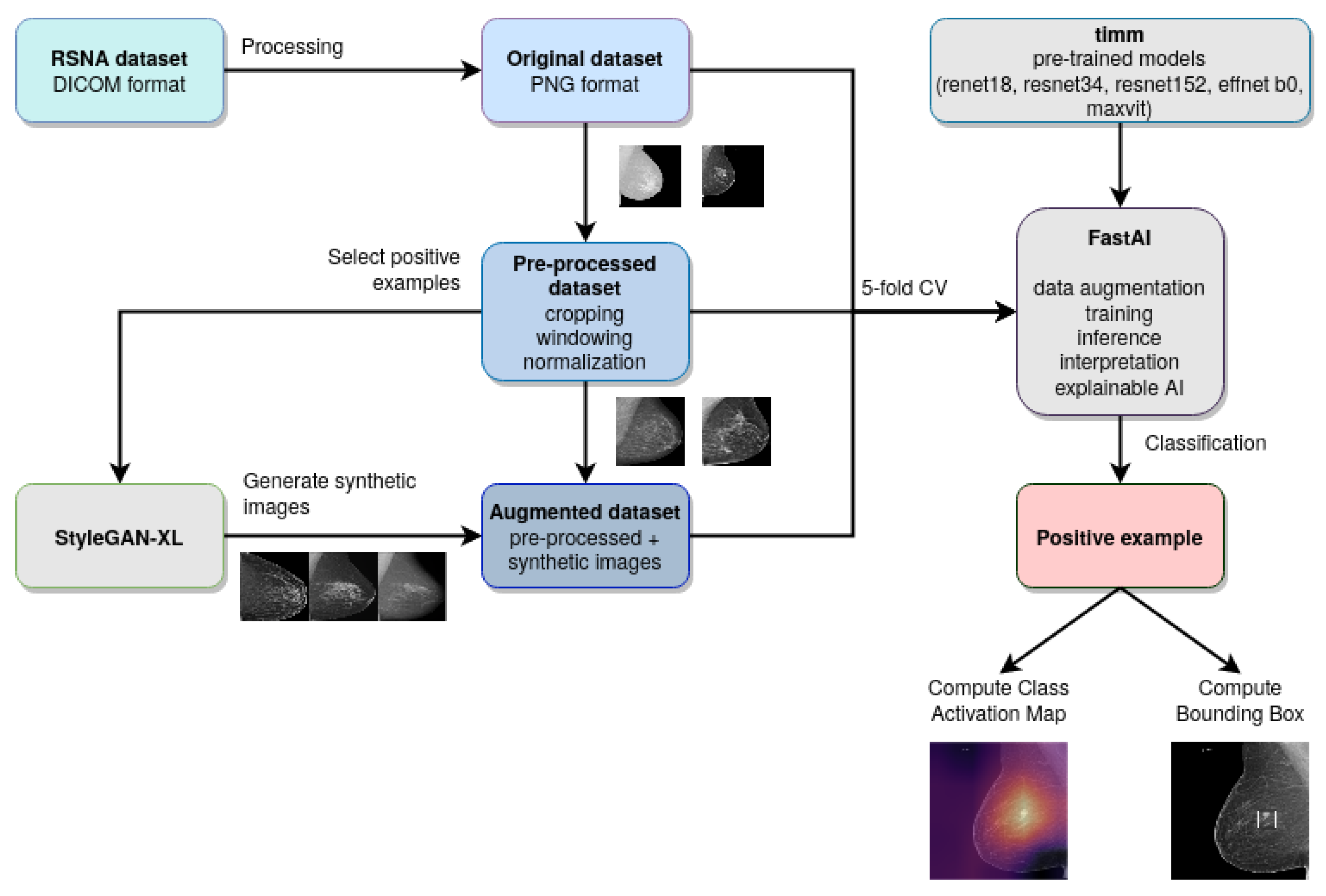
3. Materials and Methods
| Algorithm 1: Experimental methodology |
 |
3.1. Computer Vision Models
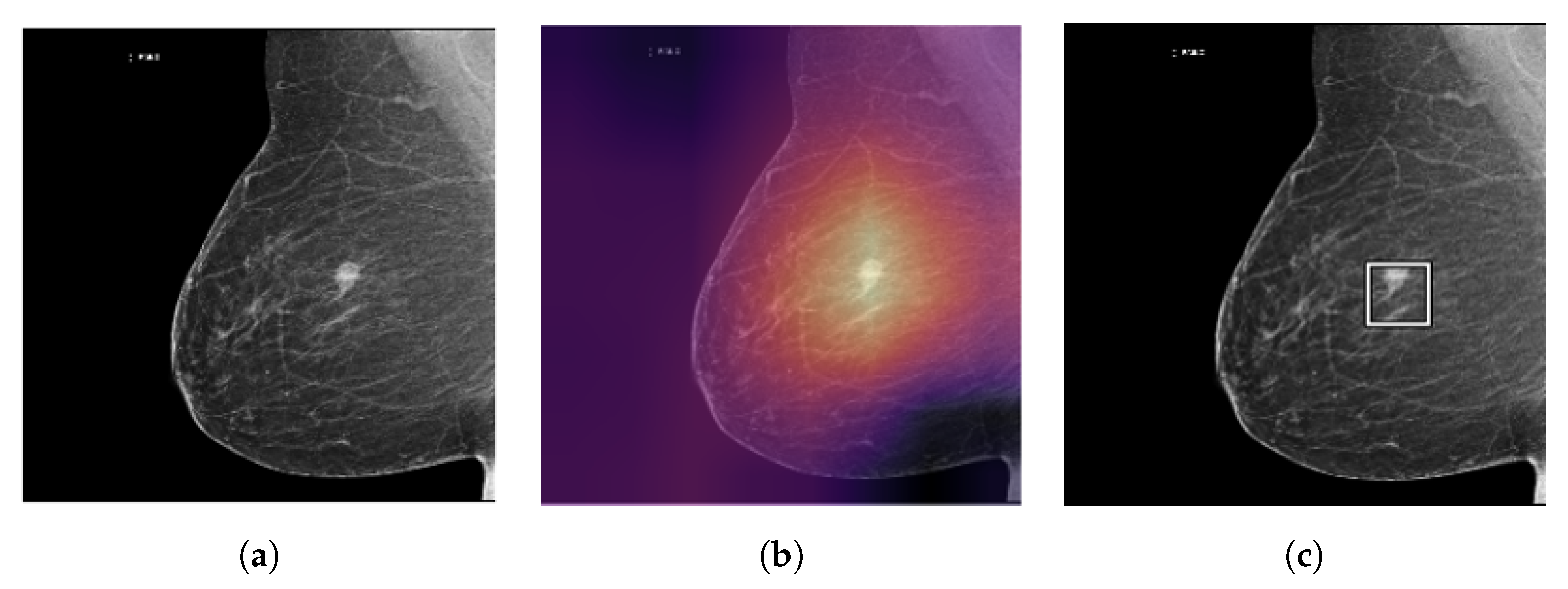
3.2. Explainable AI
- Saliency maps: Saliency maps highlight the regions of an input image that are most important for the model’s prediction. These maps can be generated using techniques such as gradient-based methods or activation maximization, which analyze the gradients or activations of the model’s layers to determine which parts of the image are most relevant;
- Class activation maps: Class activation maps (CAM) are a type of saliency map that focuses specifically on the regions of an image that correspond to a specific class label. CAMs can be used to visualize which parts of the image are most responsible for the model’s classification decision.
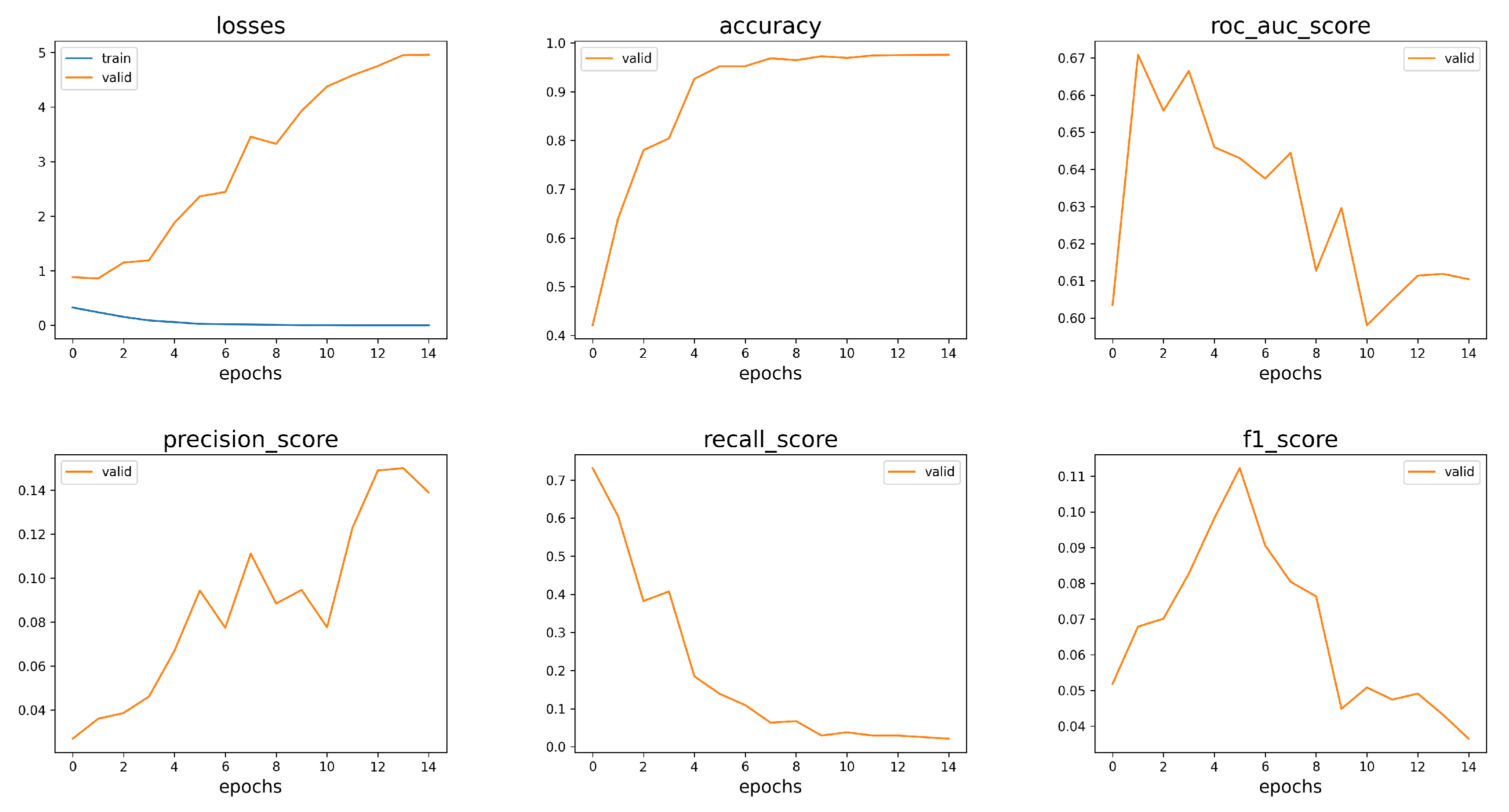
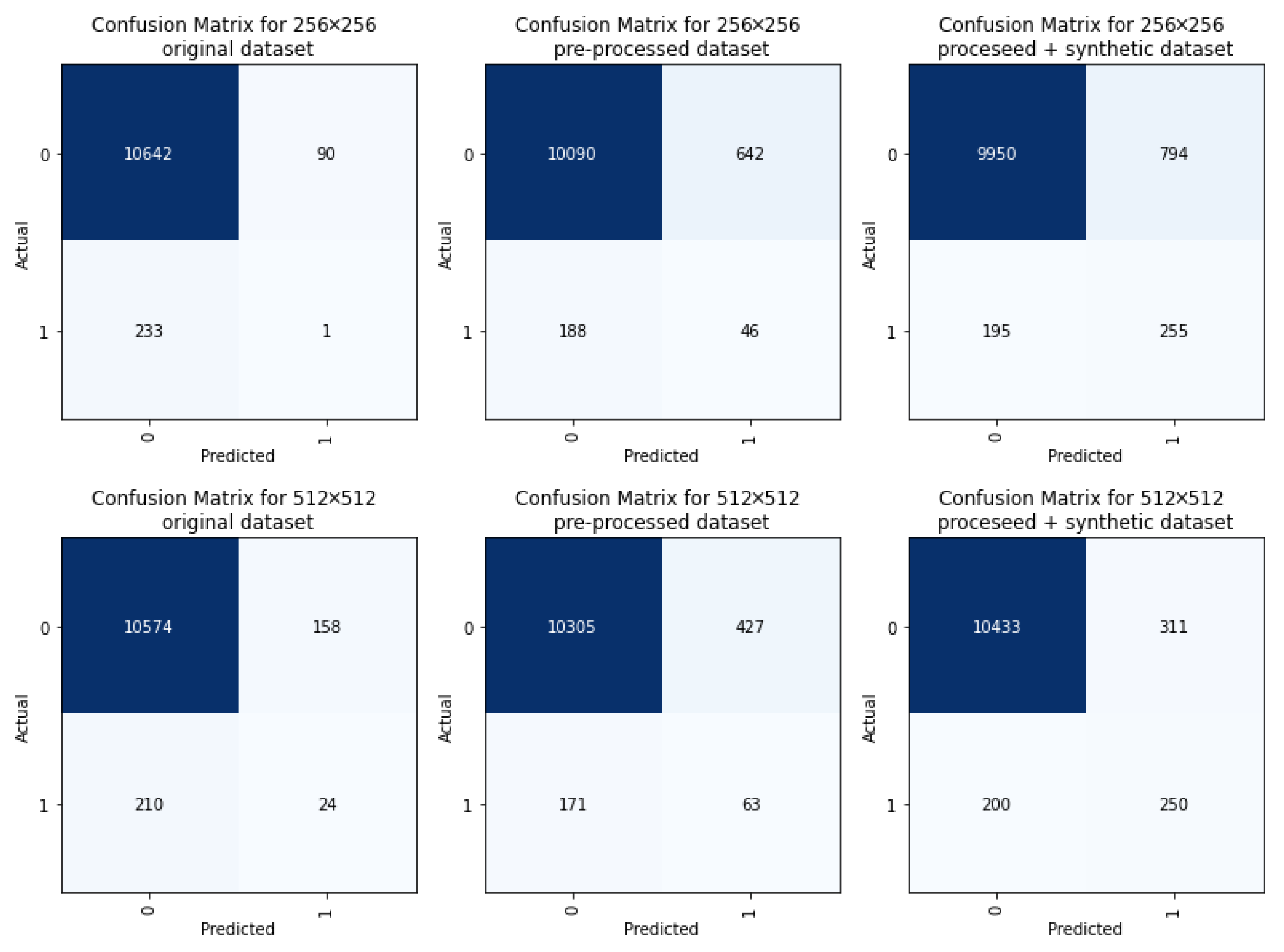
4. Results
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Arnold, M.; Morgan, E.; Rumgay, H.; Mafra, A.; Singh, D.; Laversanne, M.; Vignat, J.; Gralow, J.R.; Cardoso, F.; Siesling, S.; et al. Current and future burden of breast cancer: Global statistics for 2020 and 2040. Breast 2022, 66, 15–23. [Google Scholar] [CrossRef] [PubMed]
- WHO. Breast Cancer. Available online: https://www.who.int/news-room/fact-sheets/detail/breast-cancer. (accessed on 27 February 2023).
- Clinic, M. Breast Calcifications: When to See a Doctor. Available online: https://www.mayoclinic.org/symptoms/breast-calcifications/basics/definition/sym-20050834. (accessed on 27 February 2023).
- Altameem, A.; Mahanty, C.; Poonia, R.C.; Saudagar, A.K.J.; Kumar, R. Breast Cancer Detection in Mammography Images Using Deep Convolutional Neural Networks and Fuzzy Ensemble Modeling Techniques. Diagnostics 2022, 12, 1812. [Google Scholar] [CrossRef] [PubMed]
- Health, U. Breast Cancer Diagnosis. Available online: https://www.ucsfhealth.org/Conditions/BreastCancer/Diagnosis. (accessed on 27 February 2023).
- Case, A. Differences between Screening & Diagnostic Mammograms. 2020. Available online: https://www.midstateradiology.com/blog/breast-imaging/screening-diagnostic-mammograms/, (accessed on 27 February 2023).
- Michailovich, O.; Tannenbaum, A. Despeckling of medical ultrasound images. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 2006, 53, 64–78. [Google Scholar] [CrossRef] [PubMed]
- Rulaningtyas, R.; Hyperastuty, A.S.; Rahaju, A.S. Histopathology Grading Identification of Breast Cancer Based on Texture Classification Using GLCM and Neural Network Method. J. Physics: Conf. Ser. 2018, 1120, 012050. [Google Scholar] [CrossRef]
- Boudouh, S.S.; Bouakkaz, M. Breast Cancer: Breast Tumor Detection Using Deep Transfer Learning Techniques in Mammogram Images. In Proceedings of the 2022 International Conference on Computer Science and Software Engineering (CSASE), Duhok, Iraq, 15–17 March 2022; IEEE: Duhok, Iraq, 2022; pp. 289–294. [Google Scholar] [CrossRef]
- Shen, L.; Margolies, L.R.; Rothstein, J.H.; Fluder, E.; McBride, R.; Sieh, W. Deep Learning to Improve Breast Cancer Detection on Screening Mammography. Sci. Rep. 2019, 9, 12495. [Google Scholar] [CrossRef]
- Moreira, I.C.; Amaral, I.; Domingues, I.; Cardoso, A.; Cardoso, M.J.; Cardoso, J.S. INbreast. Acad. Radiol. 2012, 19, 236–248. [Google Scholar] [CrossRef]
- Salama, W.M.; Aly, M.H. Deep learning in mammography images segmentation and classification: Automated CNN approach. Alex. Eng. J. 2021, 60, 4701–4709. [Google Scholar] [CrossRef]
- Oza, P.; Sharma, P.; Patel, S.; Adedoyin, F.; Bruno, A. Image Augmentation Techniques for Mammogram Analysis. J. Imaging 2022, 8, 141. [Google Scholar] [CrossRef]
- Maqsood, S.; Damaševičius, R.; Maskeliūnas, R. TTCNN: A Breast Cancer Detection and Classification towards Computer-Aided Diagnosis Using Digital Mammography in Early Stages. Appl. Sci. 2022, 12, 3273. [Google Scholar] [CrossRef]
- Montaha, S.; Azam, S.; Rafid, A.K.M.R.H.; Ghosh, P.; Hasan, M.Z.; Jonkman, M.; De Boer, F. BreastNet18: A High Accuracy Fine-Tuned VGG16 Model Evaluated Using Ablation Study for Diagnosing Breast Cancer from Enhanced Mammography Images. Biology 2021, 10, 1347. [Google Scholar] [CrossRef]
- Lee, R.S.; Gimenez, F.; Hoogi, A.; Miyake, K.K.; Gorovoy, M.; Rubin, D.L. A curated mammography data set for use in computer-aided detection and diagnosis research. Sci. Data 2017, 4, 170177. [Google Scholar] [CrossRef]
- Mahmood, T.; Li, J.; Pei, Y.; Akhtar, F. An Automated In-Depth Feature Learning Algorithm for Breast Abnormality Prognosis and Robust Characterization from Mammography Images Using Deep Transfer Learning. Biology 2021, 10, 859. [Google Scholar] [CrossRef]
- Tsai, K.J.; Chou, M.C.; Li, H.M.; Liu, S.T.; Hsu, J.H.; Yeh, W.C.; Hung, C.M.; Yeh, C.Y.; Hwang, S.H. A High-Performance Deep Neural Network Model for BI-RADS Classification of Screening Mammography. Sensors 2022, 22, 1160. [Google Scholar] [CrossRef]
- Dang, L.A.; Chazard, E.; Poncelet, E.; Serb, T.; Rusu, A.; Pauwels, X.; Parsy, C.; Poclet, T.; Cauliez, H.; Engelaere, C.; et al. Impact of artificial intelligence in breast cancer screening with mammography. Breast Cancer 2022, 29, 967–977. [Google Scholar] [CrossRef]
- din, N.M.u.; Dar, R.A.; Rasool, M.; Assad, A. Breast cancer detection using deep learning: Datasets, methods, and challenges ahead. Comput. Biol. Med. 2022, 149, 106073. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, L.; Shu, X.; Feng, Y.; Yi, Z.; Lv, Q. Feature-Sensitive Deep Convolutional Neural Network for Multi-Instance Breast Cancer Detection. IEEE/ACM Trans. Comput. Biol. Bioinform. 2022, 19, 2241–2251. [Google Scholar] [CrossRef]
- Melekoodappattu, J.G.; Dhas, A.S.; Kandathil, B.K.; Adarsh, K.S. Breast cancer detection in mammogram: Combining modified CNN and texture feature based approach. J. Ambient Intell. Humaniz. Comput. 2022. [Google Scholar] [CrossRef]
- Altan, G. Deep Learning-based Mammogram Classification for Breast Cancer. Int. J. Intell. Syst. Appl. Eng. 2020, 8, 171–176. [Google Scholar] [CrossRef]
- Frazer, H.M.; Qin, A.K.; Pan, H.; Brotchie, P. Evaluation of deep learning-based artificial intelligence techniques for breast cancer detection on mammograms: Results from a retrospective study using a BreastScreen Victoria dataset. J. Med Imaging Radiat. Oncol. 2021, 65, 529–537. [Google Scholar] [CrossRef]
- Eroğlu, Y.; Yildirim, M.; Çinar, A. Convolutional Neural Networks based classification of breast ultrasonography images by hybrid method with respect to benign, malignant, and normal using mRMR. Comput. Biol. Med. 2021, 133, 104407. [Google Scholar] [CrossRef]
- Zhai, D.; Hu, B.; Gong, X.; Zou, H.; Luo, J. ASS-GAN: Asymmetric semi-supervised GAN for breast ultrasound image segmentation. Neurocomputing 2022, 493, 204–216. [Google Scholar] [CrossRef]
- Haq, I.U.; Ali, H.; Wang, H.Y.; Cui, L.; Feng, J. BTS-GAN: Computer-aided segmentation system for breast tumor using MRI and conditional adversarial networks. Eng. Sci. Technol. Int. J. 2022, 36, 101154. [Google Scholar] [CrossRef]
- Lee, J.; Nishikawa, R.M. Identifying Women With Mammographically- Occult Breast Cancer Leveraging GAN-Simulated Mammograms. IEEE Trans. Med Imaging 2022, 41, 225–236. [Google Scholar] [CrossRef] [PubMed]
- Guan, S. Breast cancer detection using synthetic mammograms from generative adversarial networks in convolutional neural networks. J. Med Imaging 2019, 6, 1. [Google Scholar] [CrossRef] [PubMed]
- Oyelade, O.N.; Ezugwu, A.E.; Almutairi, M.S.; Saha, A.K.; Abualigah, L.; Chiroma, H. A generative adversarial network for synthetization of regions of interest based on digital mammograms. Sci. Rep. 2022, 12, 6166. [Google Scholar] [CrossRef]
- Zakka, C.; Saheb, G.; Najem, E.; Berjawi, G. MammoGANesis: Controlled Generation of High-Resolution Mammograms for Radiology Education. arXiv 2020, arXiv:2010.05177. [Google Scholar]
- Wu, E.; Wu, K.; Cox, D.; Lotter, W. Conditional Infilling GANs for Data Augmentation in Mammogram Classification. In Image Analysis for Moving Organ, Breast, and Thoracic Images; Stoyanov, D., Taylor, Z., Kainz, B., Maicas, G., Beichel, R.R., Martel, A., Maier-Hein, L., Bhatia, K., Vercauteren, T., Oktay, O., Eds.; Series Title: Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11040, pp. 98–106. [Google Scholar] [CrossRef]
- Carr, C.; Kitamura, F.; Kalpathy-Cramer, J.; Mongan, J.; Andriole, K.; Vazirabad, M.; Riopel, M.; Ball, R.; Dane, S. RSNA Screening Mammography Breast Cancer Detection. 2022. Available online: https://kaggle.com/competitions/rsna-breast-cancer-detection (accessed on 27 February 2023).
- Frazer, H.M.L.; Tang, J.S.N.; Elliott, M.S.; Kunicki, K.M.; Hill, B.; Karthik, R.; Kwok, C.F.; Peña-Solorzano, C.A.; Chen, Y.; Wang, C.; et al. ADMANI: Annotated Digital Mammograms and Associated Non-Image Datasets. Radiol. Artif. Intell. 2023, 5, e220072. [Google Scholar] [CrossRef]
- Cadrin-Chênevert, A. Unleashing the Power of Deep Learning for Breast Cancer Detection through Open Mammography Datasets. Radiol. Artif. Intell. 2023, 5, e220294. [Google Scholar] [CrossRef]
- Sauer, A.; Schwarz, K.; Geiger, A. StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets. arXiv 2022, arXiv:2202.00273. [Google Scholar]
- Targ, S.; Almeida, D.; Lyman, K. Resnet in Resnet: Generalizing Residual Architectures. arXiv 2016, arXiv:1603.08029. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2020, arXiv:1905.11946. [Google Scholar]
- Tu, Z.; Talebi, H.; Zhang, H.; Yang, F.; Milanfar, P.; Bovik, A.; Li, Y. MaxViT: Multi-Axis Vision Transformer. arXiv 2022, arXiv:2204.01697. [Google Scholar]
- Howard, J.; Gugger, S. Fastai: A Layered API for Deep Learning. Information 2020, 11, 108. [Google Scholar] [CrossRef]
- Howard, J.; Gugger, S. Deep Learning for Coders with Fastai and Pytorch: AI Applications Without a PhD. 2020. Available online: https://github.com/fastai/fastbook (accessed on 27 February 2023).
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Wightman, R.; Raw, N.; Soare, A.; Arora, A.; Ha, C.; Reich, C.; Guan, F.; Kaczmarzyk, J.; MrT23; Mike; et al. Pytorch Image Models. 2023. Available online: https://zenodo.org/record/4414861 (accessed on 27 February 2023). [CrossRef]
- Sriram, A.; Muckley, M.; Sinha, K.; Shamout, F.; Pineau, J.; Geras, K.J.; Azour, L.; Aphinyanaphongs, Y.; Yakubova, N.; Moore, W. COVID-19 Prognosis via Self-Supervised Representation Learning and Multi-Image Prediction. arXiv 2021, arXiv:2101.04909. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| cbase | 16,384 |
| cmax | 256 |
| syn_layers | 7 |
| head_layers | 4 |
| Mammograms with 256 × 256 resolution | |||||
|---|---|---|---|---|---|
| Model | Accuracy | AUC | Precision | Recall | F1 |
| Original images | |||||
| ResNet18 | 0.96 | 0.61 | 0.06 | 0.04 | 0.04 |
| ResNet34 | 0.96 | 0.63 | 0.08 | 0.06 | 0.06 |
| ResNet152 | 0.89 | 0.58 | 0.03 | 0.17 | 0.06 |
| EfficientNetB0 | 0.96 | 0.59 | 0.03 | 0.02 | 0.02 |
| MaxViT | 0.95 | 0.66 | 0.09 | 0.15 | 0.11 |
| Processed images | |||||
| ResNet18 | 0.92 | 0.67 | 0.07 | 0.22 | 0.11 |
| ResNet34 | 0.93 | 0.67 | 0.09 | 0.21 | 0.13 |
| ResNet152 | 0.82 | 0.64 | 0.04 | 0.33 | 0.07 |
| EfficientNetB0 | 0.95 | 0.63 | 0.08 | 0.11 | 0.09 |
| MaxViT | 0.93 | 0.67 | 0.09 | 0.21 | 0.13 |
| Processed images + synthetic images | |||||
| ResNet18 | 0.92 | 0.83 | 0.26 | 0.58 | 0.36 |
| ResNet34 | 0.94 | 0.82 | 0.34 | 0.56 | 0.42 |
| ResNet152 | 0.84 | 0.8 | 0.15 | 0.63 | 0.24 |
| EfficientNetB0 | 0.95 | 0.8 | 0.39 | 0.52 | 0.45 |
| MaxViT | 0.9 | 0.85 | 0.23 | 0.63 | 0.34 |
| Mammograms with 512 × 512 resolution | |||||
| Model | Accuracy | AUC | Precision | Recall | F1 |
| Original images | |||||
| ResNet18 | 0.97 | 0.66 | 0.16 | 0.09 | 0.12 |
| ResNet34 | 0.97 | 0.66 | 0.16 | 0.09 | 0.12 |
| ResNet152 | 0.83 | 0.59 | 0.03 | 0.26 | 0.06 |
| EfficientNetB0 | 0.96 | 0.64 | 0.1 | 0.06 | 0.08 |
| MaxViT | 0.95 | 0.69 | 0.11 | 0.18 | 0.14 |
| Processed images | |||||
| ResNet18 | 0.93 | 0.72 | 0.1 | 0.26 | 0.15 |
| ResNet34 | 0.94 | 0.71 | 0.13 | 0.24 | 0.16 |
| ResNet152 | 0.83 | 0.69 | 0.05 | 0.4 | 0.09 |
| EfficientNetB0 | 0.95 | 0.69 | 0.12 | 0.18 | 0.14 |
| MaxViT | 0.89 | 0.77 | 0.08 | 0.43 | 0.14 |
| Processed images + synthetic images | |||||
| ResNet18 | 0.94 | 0.85 | 0.35 | 0.59 | 0.44 |
| ResNet34 | 0.95 | 0.84 | 0.4 | 0.58 | 0.47 |
| ResNet152 | 0.83 | 0.82 | 0.14 | 0.66 | 0.23 |
| EfficientNetB0 | 0.95 | 0.84 | 0.47 | 0.55 | 0.51 |
| MaxViT | 0.89 | 0.88 | 0.22 | 0.72 | 0.34 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prodan, M.; Paraschiv, E.; Stanciu, A. Applying Deep Learning Methods for Mammography Analysis and Breast Cancer Detection. Appl. Sci. 2023, 13, 4272. https://doi.org/10.3390/app13074272
Prodan M, Paraschiv E, Stanciu A. Applying Deep Learning Methods for Mammography Analysis and Breast Cancer Detection. Applied Sciences. 2023; 13(7):4272. https://doi.org/10.3390/app13074272
Chicago/Turabian StyleProdan, Marcel, Elena Paraschiv, and Alexandru Stanciu. 2023. "Applying Deep Learning Methods for Mammography Analysis and Breast Cancer Detection" Applied Sciences 13, no. 7: 4272. https://doi.org/10.3390/app13074272