

Enhanced Multiple Speakers’ Separation and Identification for VOIP Applications Using Deep Learning

Abstract
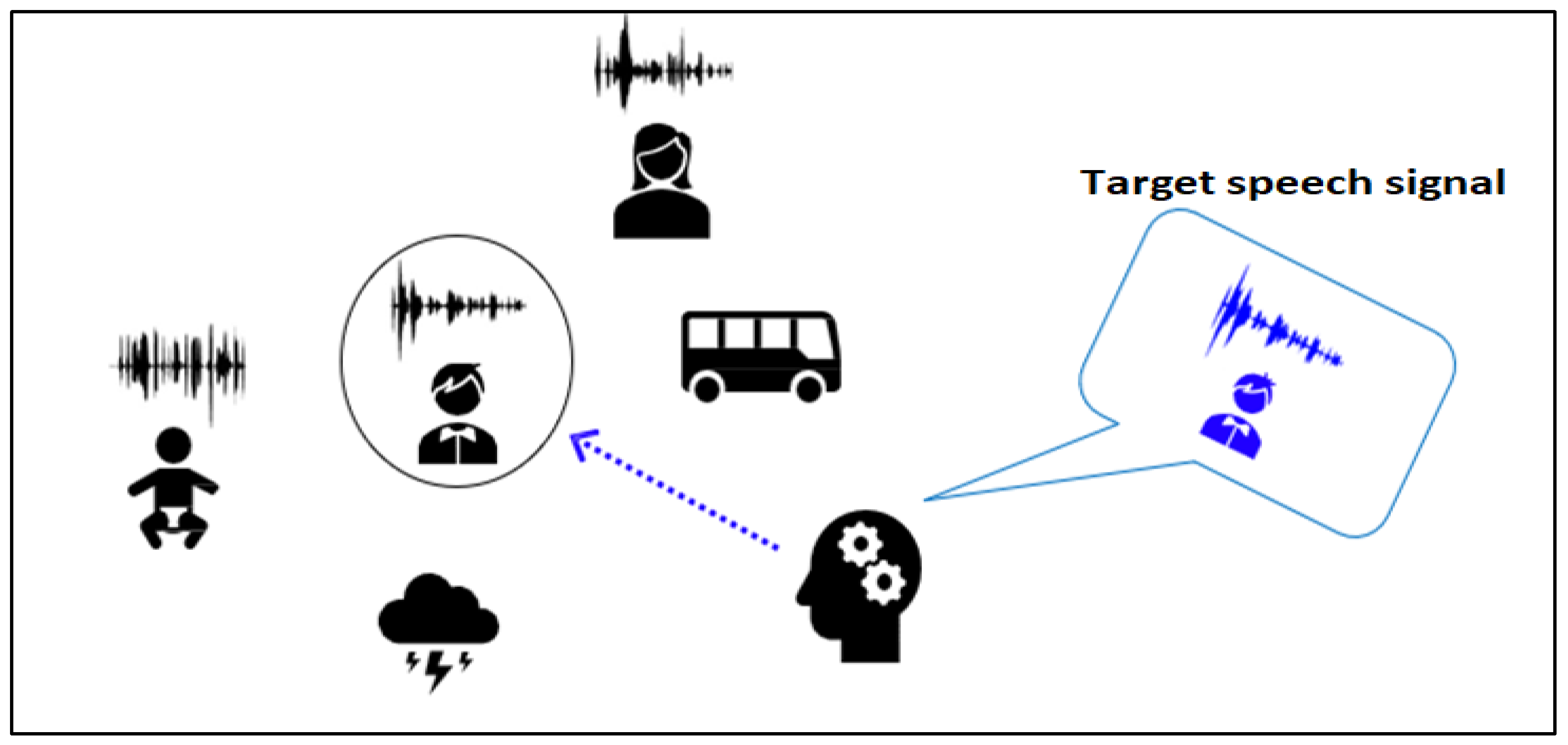
:1. Introduction
2. Literature Review
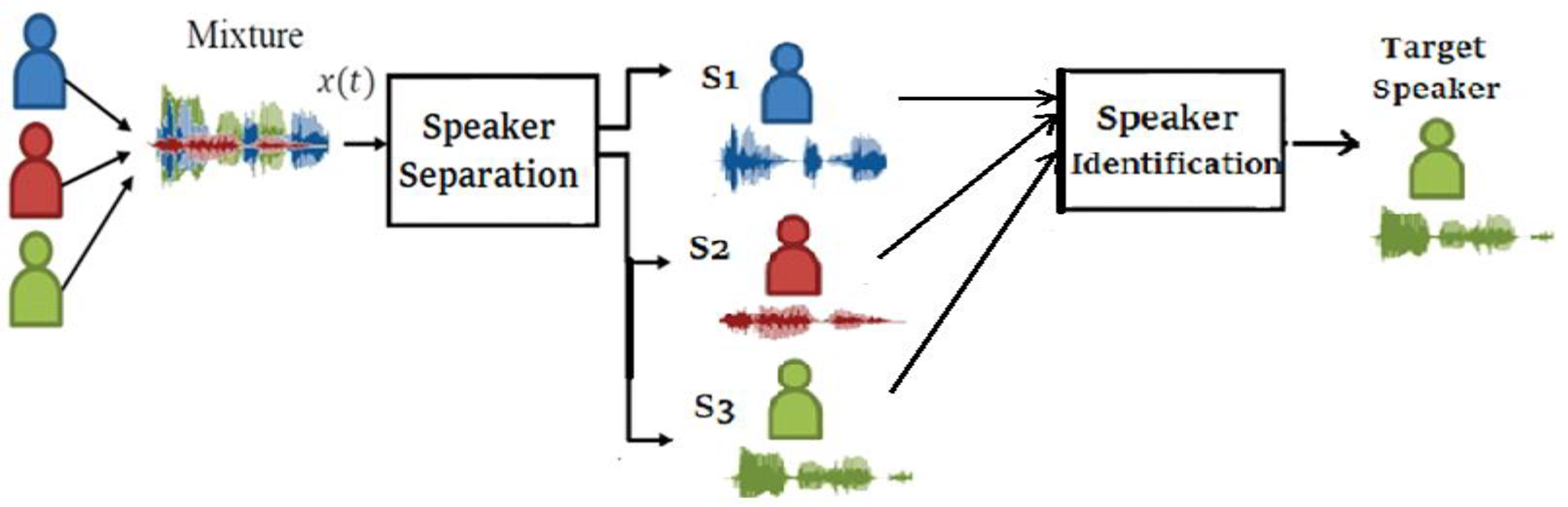
3. Model Description
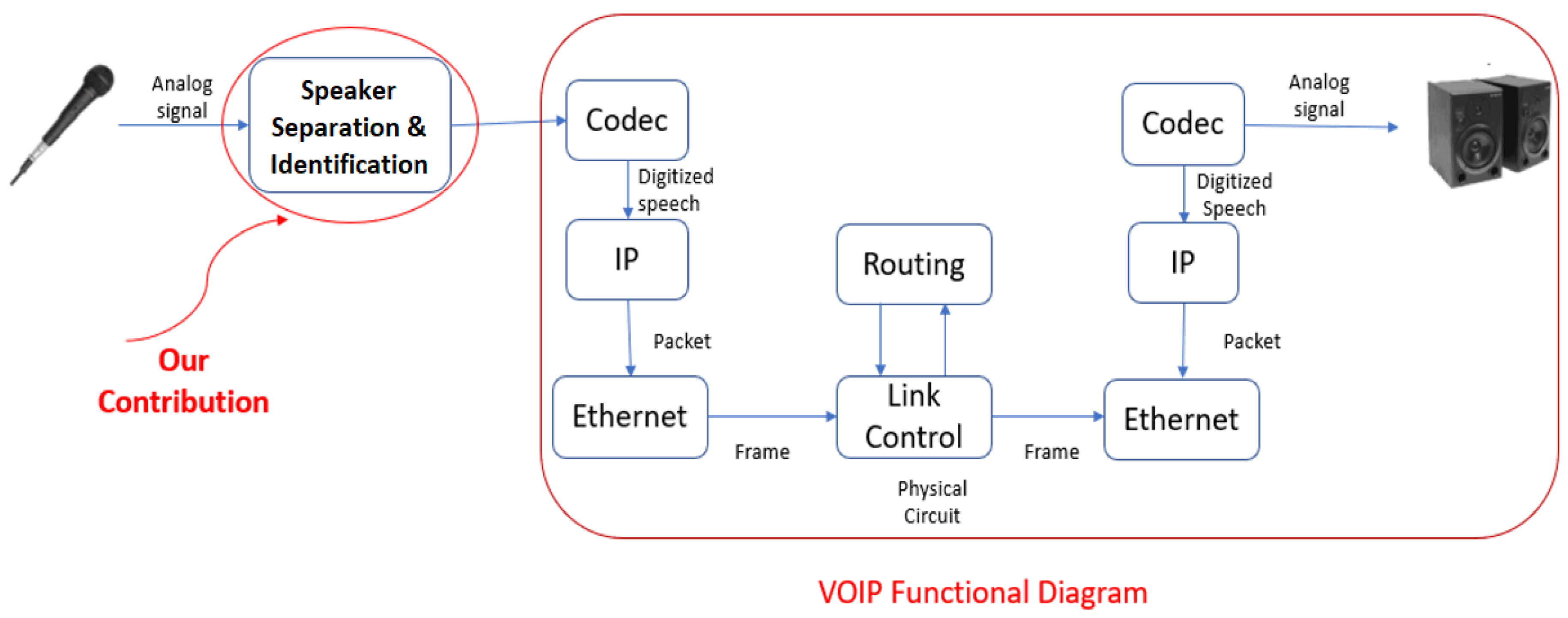
3.1. Real-Time Audio Pre-Processing
3.2. Voice Separation for Multiple Speakers
3.2.1. Speaker Separation Model
3.2.2. Separation Training Objective
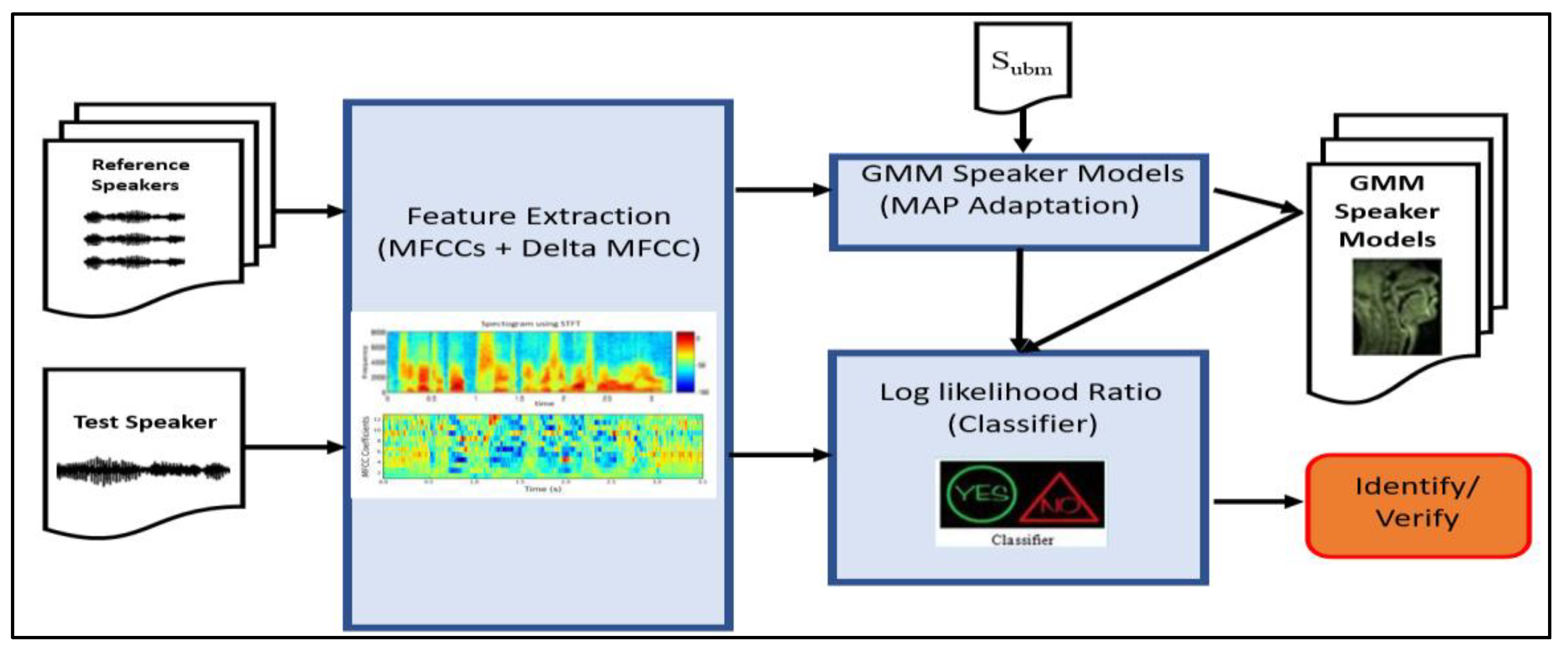
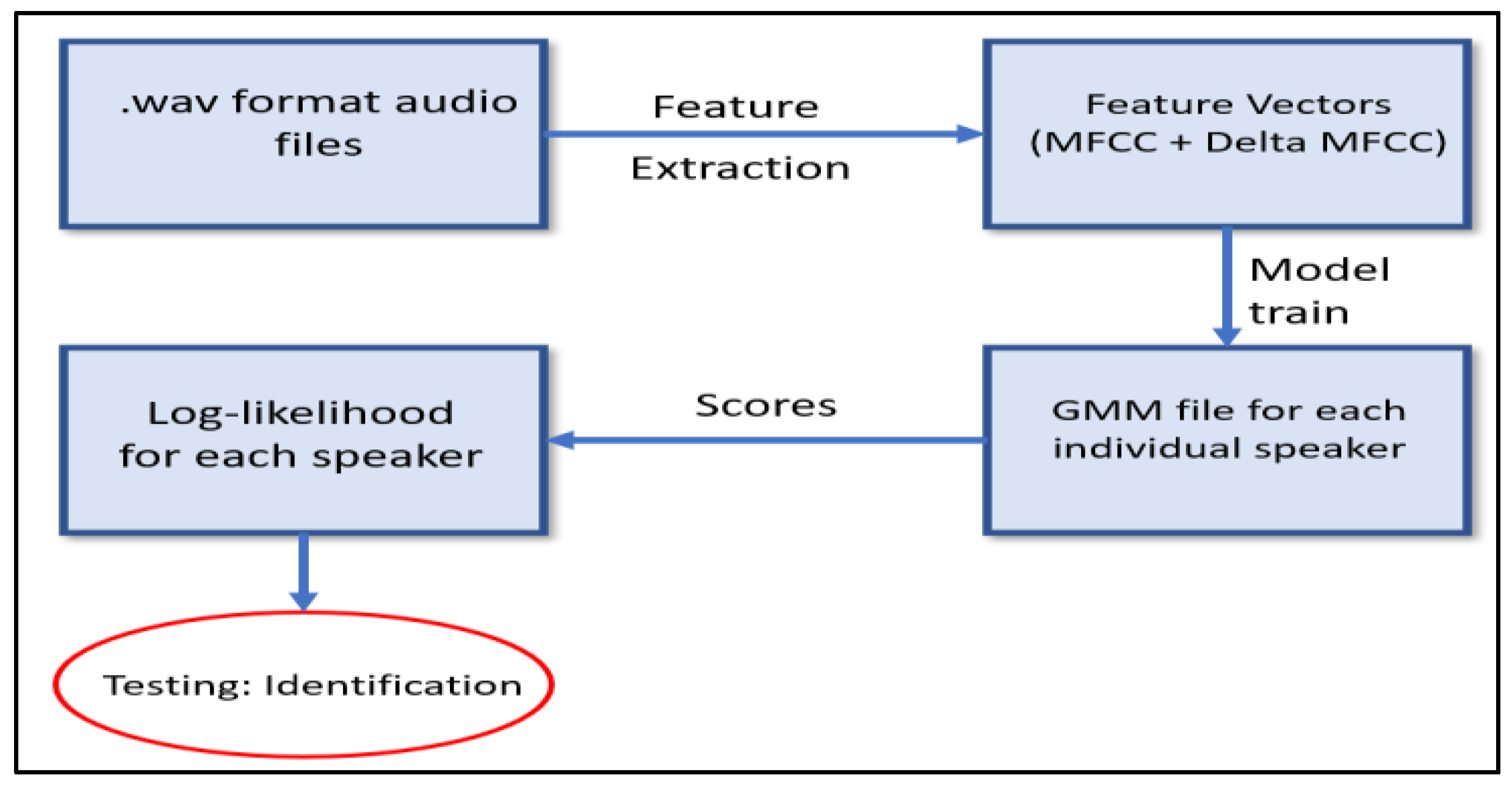
3.3. Speaker Identification Process
3.3.1. Speaker Identification Model
3.3.2. Identification Training Objective
4. Experiments
4.1. Dataset
4.1.1. For Separation
4.1.2. For Identification
4.2. Network Configuration
4.2.1. For Separation
4.2.2. For Identification
4.3. Evaluation Metrics
4.3.1. For Separation
4.3.2. For Identification
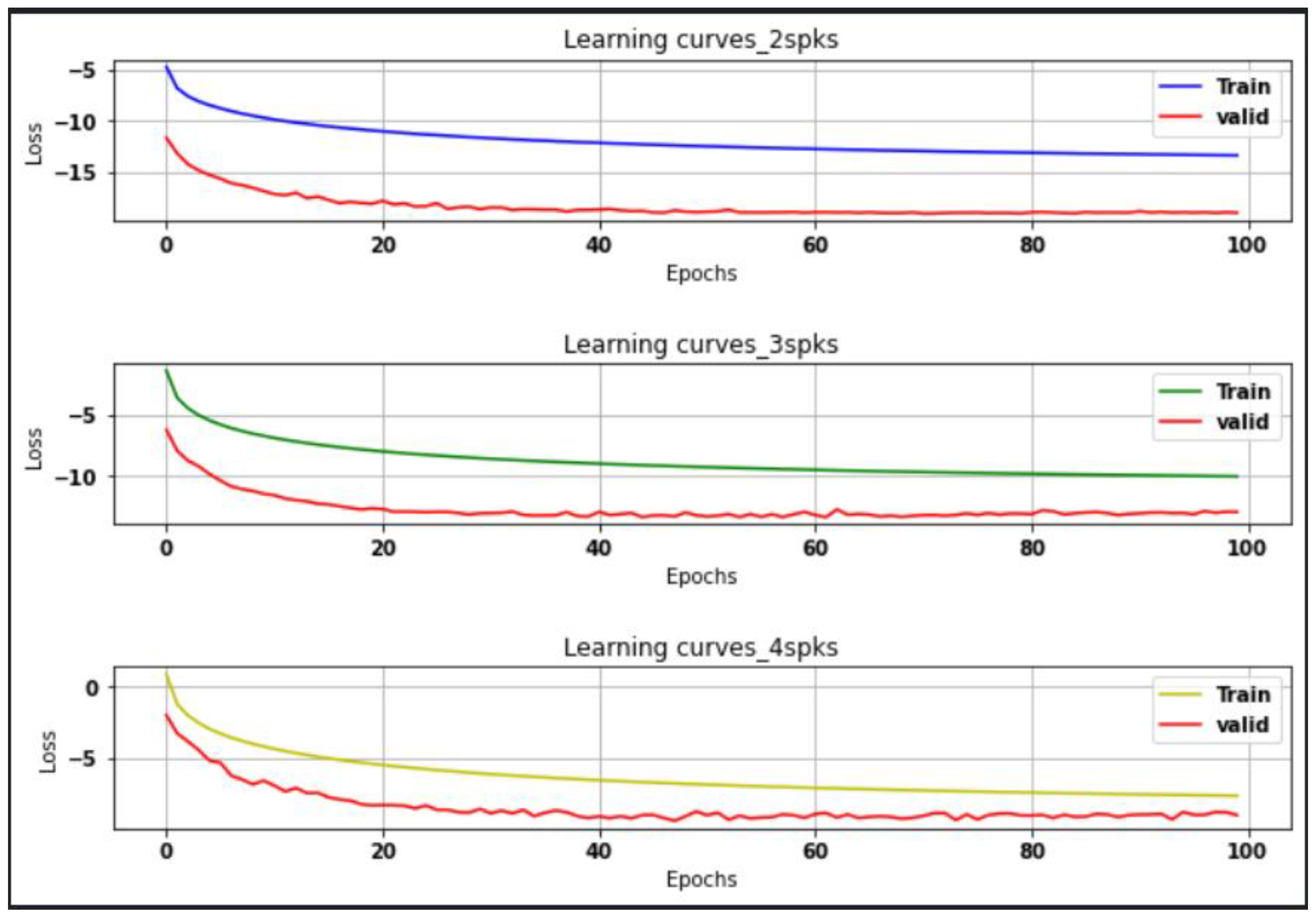
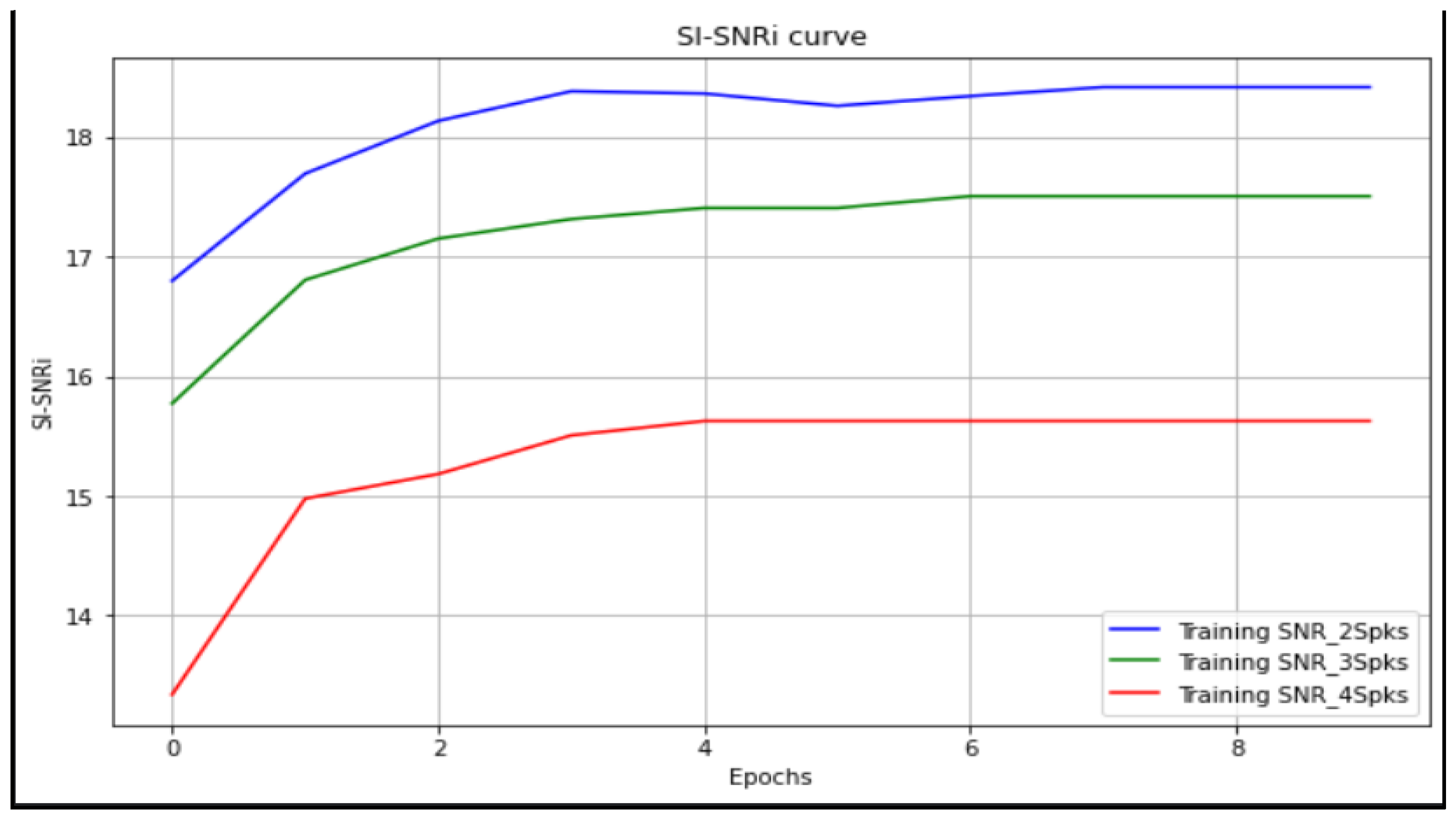
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mahmoud, M.A. Assessment and Improvement of the Quality of Voice-over-IP Communications. Master’s Thesis, Waterford Institute of Technology, Waterford, Ireland, August 2013. [Google Scholar]
- Adhilaksono, B.; Setiawan, B. A study of Voice-over-Internet Protocol quality metrics. Procedia Comput. Sci. 2022, 197, 377–384. [Google Scholar] [CrossRef]
- Campbell, W.M.; Sturim, D.E.; Reynolds, D.A. Support vector machines using GMM supervectors for speaker verification. IEEE Signal Process. Lett. 2006, 13, 308–311. [Google Scholar] [CrossRef]
- Wang, D.; Chen, J. Supervised Speech Separation Based on Deep Learning: An Overview. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1702–1726. [Google Scholar] [CrossRef] [PubMed]
- Wijayakusuma, A.; Gozali, D.R.; Widjaja, A.; Ham, H. Implementation of Real-Time Speech Separation Model Using Time-Domain Audio Separation Network (TasNet) and Dual-Path Recurrent Neural Network (DPRNN). Procedia Comput. Sci. 2021, 179, 762–772. [Google Scholar] [CrossRef]
- Lee, H. Speech Separation, Deep Clustering. Available online: https://blog.csdn.net/qq_45866407/article/details/106878854 (accessed on 22 November 2022).
- Dehak, N.; Kenny, P.; Dehak, R.; Dumouchel, P.; Ouellet, P. Front-End Factor Analysis for Speaker Verification. IEEE Trans. Audio Speech Lang. Process. 2010, 19, 788–798. [Google Scholar] [CrossRef]
- Tsujikawa, M.; Nishikawa, T.; Matsui, T. I-vector-based speaker identification with extremely short utterances for both training and testing. In Proceedings of the 2017 IEEE 6th Global Conference on Consumer Electronics (GCCE), Nagoya, Japan, 24–27 October 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Travadi, R.; Van Segbroeck, M.; Narayanan, S. Modified-prior i-vector estimation for language identification of short duration utterances. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014; pp. 3037–3041. [Google Scholar] [CrossRef]
- Huang, P.S.; Kim, M.; Hasegawa-Johnson, M.; Smaragdis, P. Joint Optimization of Masks and Deep Recurrent Neural Networks for Monaural Source Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 2136–2147. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.L.; Wang, D. A Deep Ensemble Learning Method for Monaural Speech Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 967–977. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Isik, Y.; Le Roux, J.; Chen, Z.; Watanabe, S.; Hershey, J.R. Single-Channel Multi-Speaker Separation Using Deep Clustering. Proc. Interspeech 2016 2016, 545–549. [Google Scholar] [CrossRef] [Green Version]
- Kolbæk, M.; Yu, D.; Tan, Z.H.; Jensen, J. Multitalker Speech Separation with Utterance-Level Permutation Invariant Training of Deep Recurrent Neural Networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1901–1913. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Luo, Y.; Mesgarani, N. Deep attractor network for single-microphone speaker separation. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 246–250. [Google Scholar] [CrossRef] [Green Version]
- Luo, Y.; Chen, Z.; Mesgarani, N. Speaker-Independent Speech Separation with Deep Attractor Network. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 787–796. [Google Scholar] [CrossRef]
- Erdogan, H.; Hershey, J.R.; Watanabe, S.; Le Roux, J. Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Queensland, Australia, 19–24 April 2015; pp. 708–712. [Google Scholar]
- Williamson, D.S.; Wang, Y.; Wang, D.L. Complex Ratio Masking for Monaural Speech Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 24, 483–492. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Luo, Y.; Chen, Z.; Hershey, J.R.; Le Roux, J.; Mesgarani, N. Deep clustering and conventional networks for music separation: Stronger together. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 61–65. [Google Scholar] [CrossRef] [Green Version]
- Luo, Y.; Mesgarani, N. TaSNet: Time-Domain Audio Separation Network for Real-Time, Single-Channel Speech Separation. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 696–700. [Google Scholar] [CrossRef] [Green Version]
- Sainath, T.N.; Weiss, R.J.; Senior, A.; Wilson, K.W.; Vinyals, O. Learning the speech front-end with raw waveform CLDNNs. In Proceedings of the INTERSPEECH, Dresden, Germany, 6–10 September 2015; pp. 1–5. [Google Scholar]
- Ghahremani, P.; Manohar, V.; Povey, D.; Khudanpur, S. Acoustic modelling from the signal domain using CNNs. In Proceedings of the INTERSPEECH, San Francisco, CA, USA, 8–12 September 2016; pp. 3434–3438. [Google Scholar] [CrossRef] [Green Version]
- Oord, A.V.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. 2016, pp. 1–15. Available online: http://arxiv.org/abs/1609.03499 (accessed on 7 May 2022).
- Mehri, Y.B.S.; Kumar, K.; Gulrajani, I.; Kumar, R.; Jain, S.; Sotelo, J.; Courville, A. SampleRNN: An unconditional end-to-end neural audio generation model. arXiv 2017, arXiv:1612.07837. [Google Scholar]
- Pascual, S.; Bonafonte, A.; Serra, J. SEGAN: Speech Enhancement Generative Adversarial Network. In Proceedings of the 18th Annual Conference of the International Speech Communication Association (INTERSPEECH 2017), Stockholm, Sweden, 20–24 August 2017; pp. 3642–3646. [Google Scholar] [CrossRef] [Green Version]
- Nachmani, E.; Adi, Y.; Wolf, L. Voice separation with an unknown number of multiple speakers. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; Volume PartF16814, pp. 7121–7132. [Google Scholar]
- Défossez, A.; Usunier, N.; Bottou, L.; Bach, F. Music Source Separation in the Waveform Domain. 2019. Available online: http://arxiv.org/abs/1911.13254 (accessed on 11 May 2022).
- Luo, Y.; Mesgarani, N. Conv-TasNet: Surpassing Ideal Time–Frequency Magnitude Masking for Speech Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1256–1266. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Singh, B.P.; Jha, S.K.; Khurmi, R.; Yadav, N.K. Live Speaker Identification Using MFCC and Delta-MFCC. IJSRD—Int. J. Sci. Res. Dev. 2020, 8, 465–470. Available online: https://www.ijsrd.com/articles/IJSRDV8I30362.pdf (accessed on 11 May 2022).
- Campbell, J.P. Linear Prediction Residual based Short-term Cepstral Features for Replay Attacks Detection. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 1437–1462. [Google Scholar] [CrossRef] [Green Version]
- Yong, F.; Xinyuan, C.; Ruifang, J. Evaluation of the deep nonlinear metric learning based speaker identification on the large scale of voiceprint corpus. In Proceedings of the 2016 10th International Symposium on Chinese Spoken Language Processing (ISCSLP), Tianjin, China, 17–20 October 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Ye, F.; Yang, J. A Deep Neural Network Model for Speaker Identification. Appl. Sci. 2021, 11, 3603. [Google Scholar] [CrossRef]
- Pan, Y.; Wang, Y.; Wu, Y.; Yang, C.; Owens, J.D. Multi-GPU Graph Analytics. In Proceedings of the 2017 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Orlando, FL, USA, 29 May–2 June 2017; pp. 479–490. [Google Scholar] [CrossRef] [Green Version]
- Schaetz, S.; Uecker, M. A multi-GPU programming library for real-time applications. In Algorithms and Architectures for Parallel Processing; Springer Nature: Berlin/Heidelberg, Germany, 2012; Volume 7439, pp. 114–128. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 2 spk | 3 spk | 4 spk | |
|---|---|---|---|
| Self-Made | 18.4168 | 17.5052 | 15.6260 |
| WSJ0-mix | 20.12 | 16.85 | 12.88 |
| Separation Time | Identification Time | Total Processing Time | Estimated Processing Time after GPU | |
|---|---|---|---|---|
| 2 Spk | 6.60 s | 1.03 s | 6.63 s | 1.71 s |
| 3 Spk | 6.53 s | 1.04 s | 7.57 s | 1.96 s |
| 4 Spk | 6.782 s | 1.06 s | 7.743 s | 2.00 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohamed, A.A.; Eltokhy, A.; Zekry, A.A. Enhanced Multiple Speakers’ Separation and Identification for VOIP Applications Using Deep Learning. Appl. Sci. 2023, 13, 4261. https://doi.org/10.3390/app13074261
Mohamed AA, Eltokhy A, Zekry AA. Enhanced Multiple Speakers’ Separation and Identification for VOIP Applications Using Deep Learning. Applied Sciences. 2023; 13(7):4261. https://doi.org/10.3390/app13074261
Chicago/Turabian StyleMohamed, Amira A., Amira Eltokhy, and Abdelhalim A. Zekry. 2023. "Enhanced Multiple Speakers’ Separation and Identification for VOIP Applications Using Deep Learning" Applied Sciences 13, no. 7: 4261. https://doi.org/10.3390/app13074261