1. Introduction
Convolutional neural networks (CNNs) are essential types of deep learning models that have found wide applications in artificial intelligence. CNNs have achieved remarkable success in various fields, including image recognition [
1,
2,
3], speech recognition [
4,
5,
6], and natural language processing [
7,
8,
9]. However, the performance of a CNN is heavily reliant on the selection of its hyperparameters. During the CNN training process, a range of hyperparameters needs to be predetermined, such as the size of the convolution kernel, the type of pooling layer, and the activation function. Different choices of hyperparameters can significantly impact the model’s performance. The size of the convolution kernel determines the size of the features extracted by the model, the type of pooling layer determines the way the model reduces the size of the feature map, and the kind of activation function affects the expressiveness of the network. Since the CNN hyperparameter settings are specific to the problem, the optimal hyperparameters for the different situations will likely differ. Therefore, efficiently selecting the optimal CNN hyperparameters is currently a hot research topic.
Early in the research, Bergstra et al. [
10] proposed the grid and random search methods for hyperparameter optimization. The grid search method is an exhaustive trial-and-error approach that requires the appropriate expertise. This method can be effective when the number of hyperparameters is small. However, as the hyperparameter search space increases, the time consumed by the grid search method increases exponentially. The random search method uses sampled parameters for randomly selecting the optimal hyperparameters. The search results have some level of uncertainty, and each sampling point does not consider the previous effects, which may result in the problem of repeated searches.
In order to overcome the time-consuming and laborious task of the manual selection of the hyperparameters, researchers have recently achieved promising results using metaheuristic algorithms for hyperparameter optimization. Metaheuristic algorithms have become a research trend in CNN hyperparameter optimization due to their evolutionary features. These algorithms are usually classified into nine different categories, including swarm-based algorithms, chemical-based algorithms, biology-based algorithms, physics-based algorithms, sport-based algorithms, music-based algorithms, social-based algorithms, mathematics-based algorithms, and hybrid methods [
11]. Among these categories, swarm-based algorithms are the most widely used in the field of CNN hyperparameter optimization.
Yamasaki et al. [
12] were the first to apply PSO to the field of CNN hyperparameter tuning and proposed the PSO-CNN algorithm. Their experiments on five different image datasets showed that the proposed algorithm significantly improved the model’s accuracy compared to the original AlexNet model. To improve the algorithm’s global and local search capabilities, Serizawa et al. [
13] introduced a linear decreasing inertia weighting strategy. They proposed the LDWPSO-CNN algorithm, which obtained a better LeNet-5 image classification accuracy on the MNIST and CIFAR-10 datasets. Guo et al. [
14] proposed the DPSO-CNN model, which combines distributed techniques with PSO-CNN to reduce the time required for algorithm operation. Singh et al. [
15] addressed the problem of the algorithm runtime by proposing a multi-level particle swarm optimization (MPSO-CNN) algorithm, which combined the hierarchical ideas with the hyperparameter optimization problems by simultaneously searching for the structure and hyperparameters of the CNN using multiple levels of particle swarms. Lee et al. [
16] applied a genetic algorithm to the hyperparameter optimization problem of convolutional neural networks and achieved superior results in their experiments on an amyloid brain dataset for Alzheimer’s diagnosis by searching for an excellent CNN network structure and hyperparameters. Rasmiranjan et al. [
17] used the gray wolf optimization algorithm to select the suitable CNN hyperparameters by searching for them in a skin lesion multiclass dataset. They conducted experiments with GA-CNN model, which showed an excellent competitiveness for the proposed algorithm.
The cited studies in the references [
12,
13,
14,
15,
16,
17] demonstrated the effective outcomes in hyperparameter optimization of convolutional neural networks by applying evolutionary algorithms. Nonetheless, CNN hyperparameter optimization is a complex optimization problem with multiple locally optimal solutions, and these studies have disregarded the limitations of evolutionary algorithms in solving intricate optimization problems. Specifically, evolutionary algorithms converge on locally optimal solutions and have a limited solution accuracy when confronted with complex issues. The advantages and disadvantages of the mentioned hyperparametric optimization methods are shown in
Table 1.
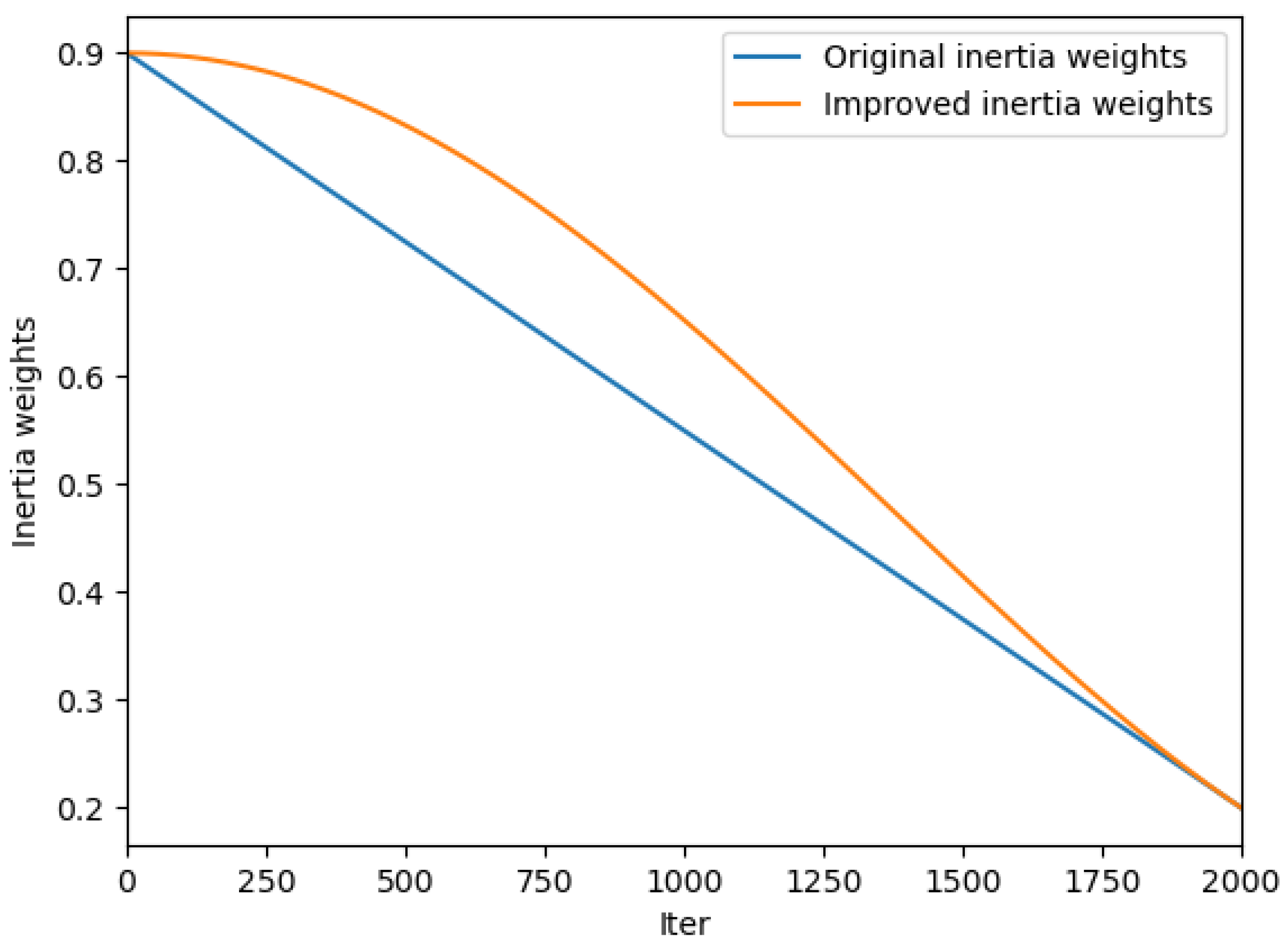
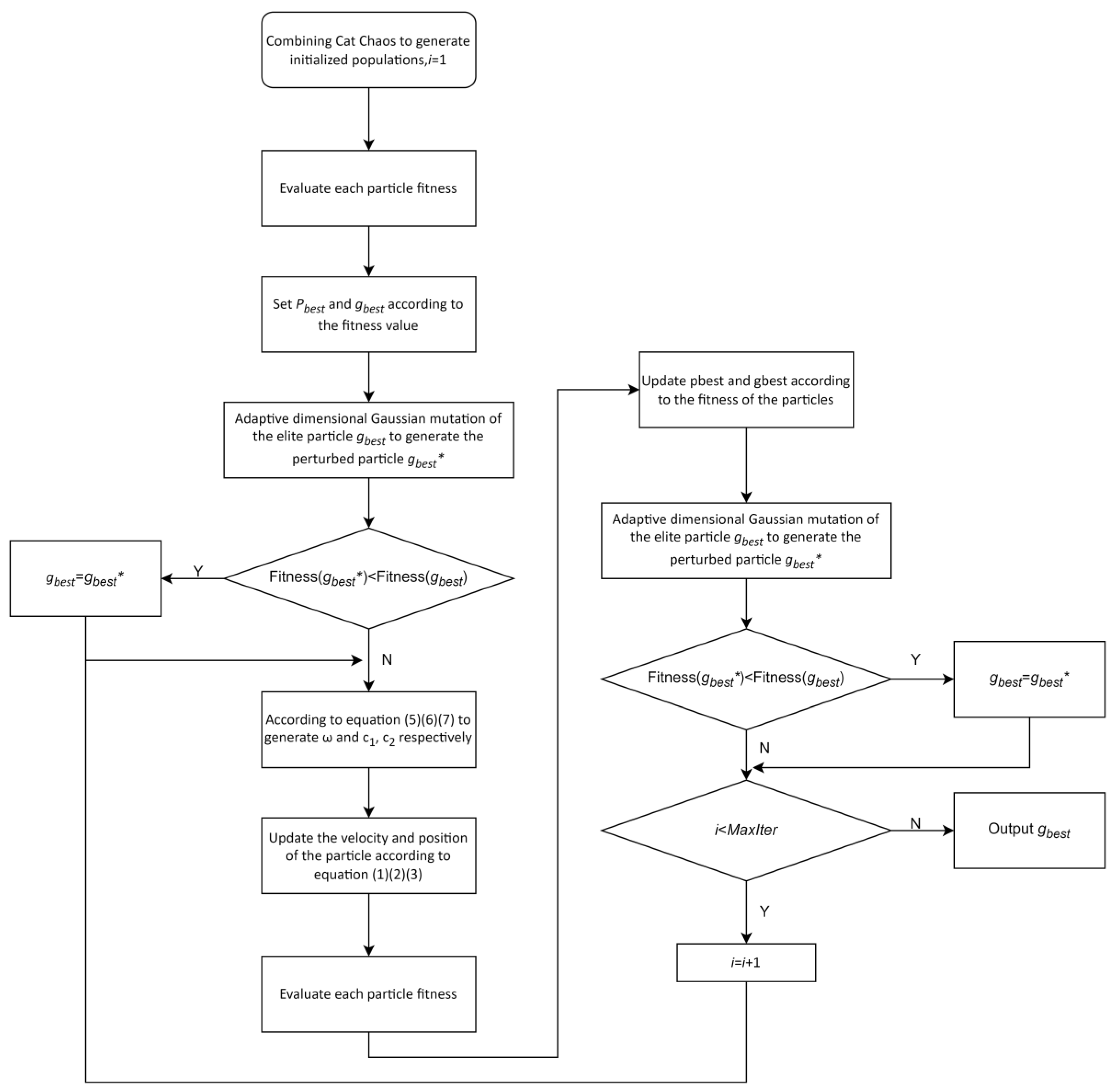
To address the challenges mentioned above and improve the automatic discovery of the optimal hyperparameter configurations, this paper presents a particle swarm algorithm with an adaptive dimensional Gaussian mutation. Compared to the original PSO, this method offers three key advantages: (1) the initialization of the population using cat chaos mapping, which enhances the uniformity of the initial population; (2) the introduction of a sine-based nonlinear decreasing inertia weight and a heterogeneous learning factor strategy that balances the pre-exploration and post-exploitation capabilities; and (3) the proposal of a strategy for an adaptive dimensional Gaussian mutation for the elite particles to increase the optimal global particle, which enhances the search range and facilitates the escape from local optimal solutions. The elite particles’ dimensionality is adaptively reduced later to preserve most of their information and improve the algorithmic convergence accuracy. The experimental results demonstrate the superiority of the proposed algorithm over the standard CNN models and the PSO-CNN, LDWPSO-CNN, and GA-CNN methods.
The main contributions of this paper are as follows:
This paper proposes an adaptive dimensional Gaussian mutation particle swarm algorithm to enhance the algorithm’s performance by addressing the limitations of the standard PSO method. The proposed approach leverages a cat chaotic initial population, a sine-based nonlinear decreasing inertia weight, an asynchronous learning factor strategy, and an elite particle adaptive dimensional Gaussian mutation strategy.
The performance of the proposed algorithm is evaluated through benchmark function comparisons with the mainstream evolutionary algorithms. Additionally, a single policy ablation experiment is conducted to demonstrate the effectiveness of the proposed improvements.
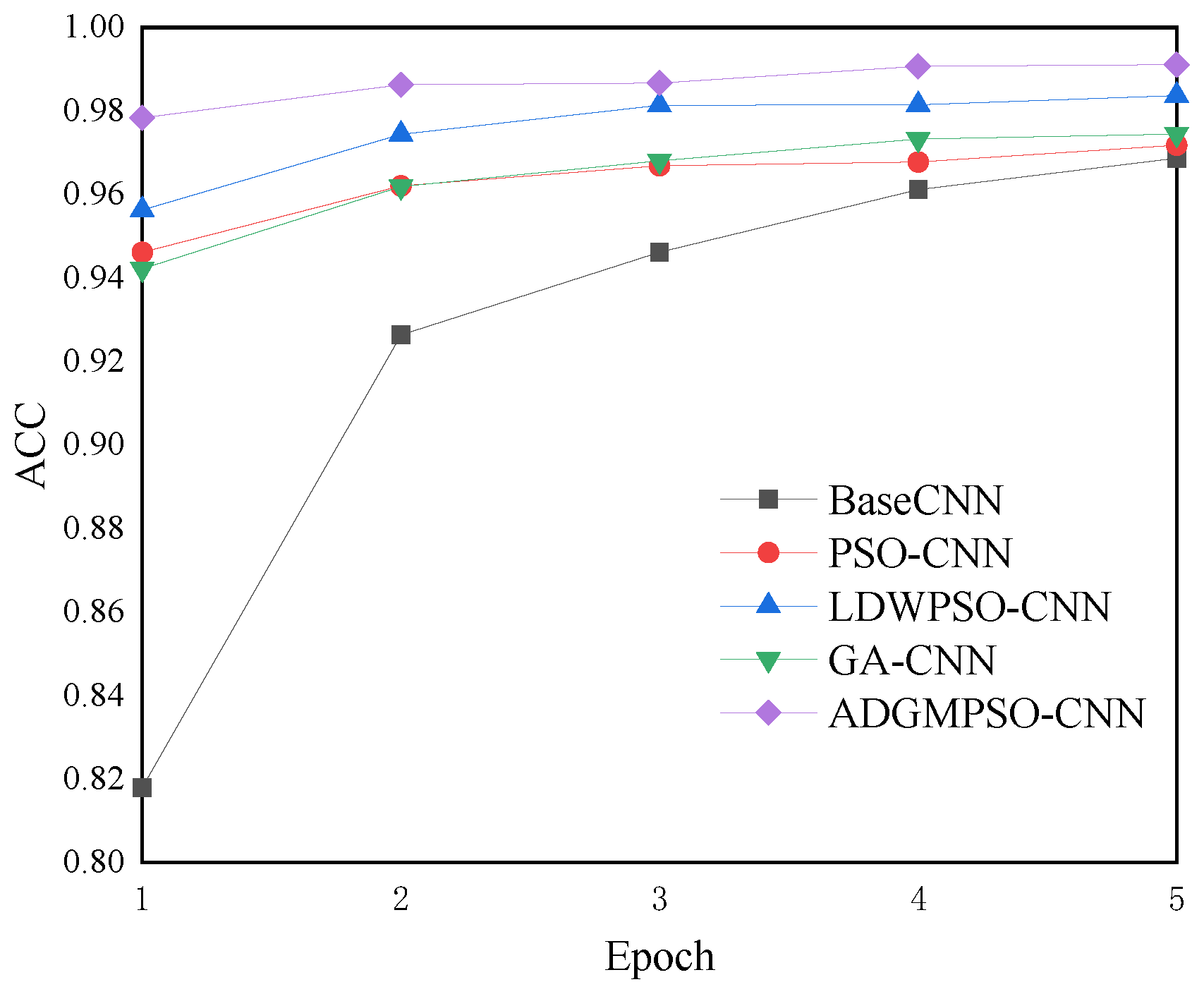
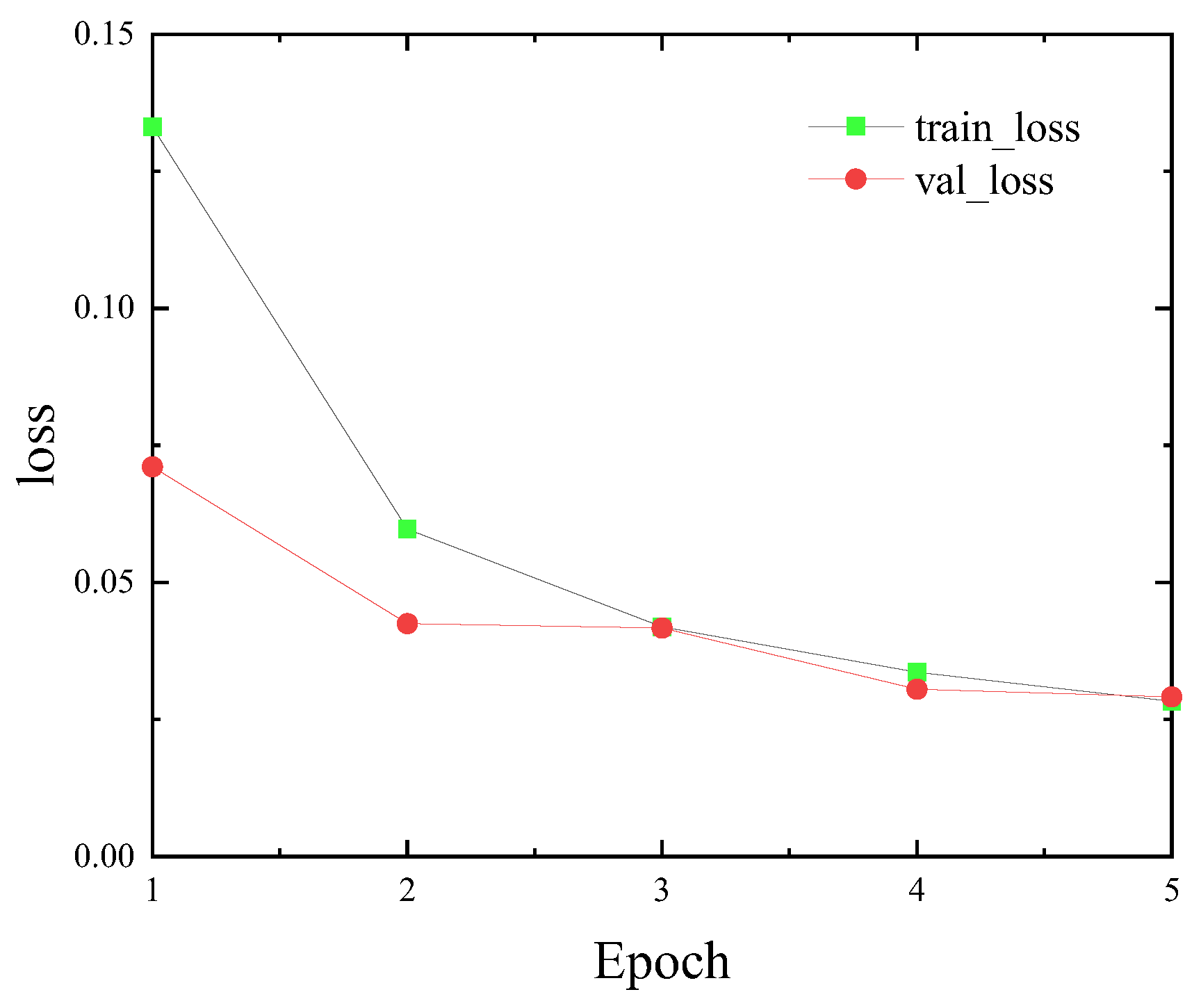
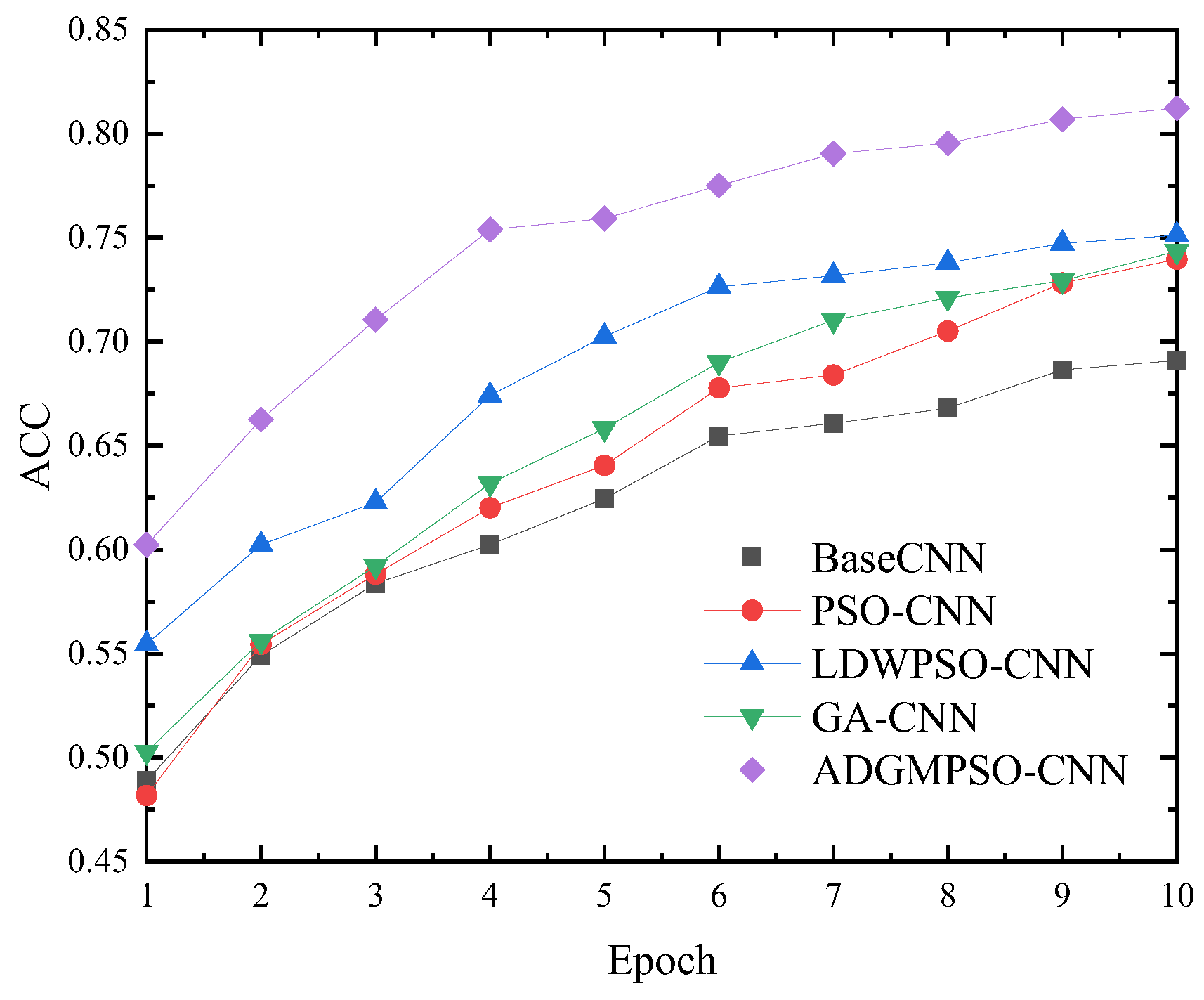
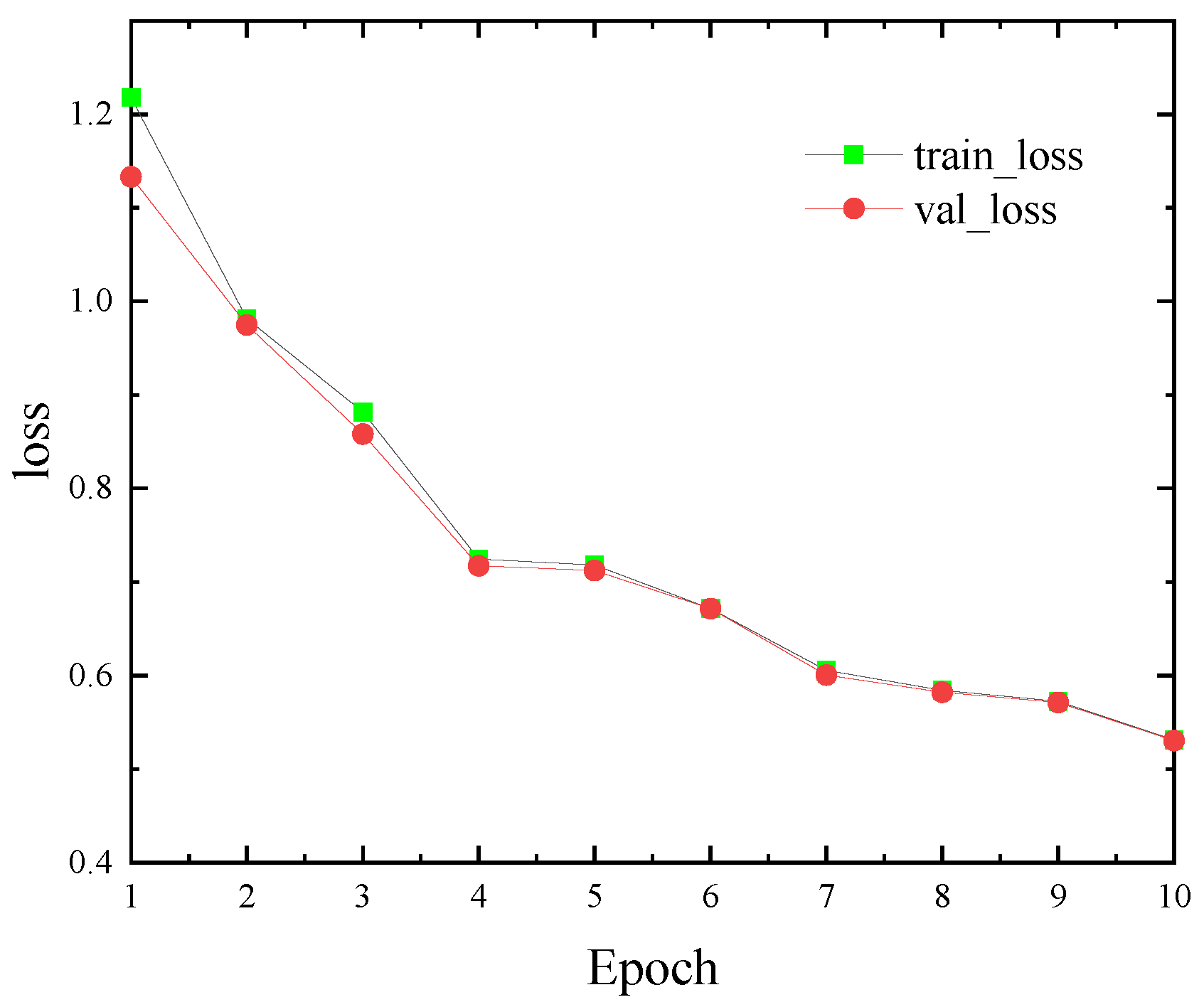
The proposed algorithm is applied to the hyperparameter optimization for the classical CNN models LeNet-5 and ResNet-18 on the MNIST and CIFAR10 datasets, respectively. The experimental results demonstrate that the optimized network model achieved a 99.11% accuracy after only five epochs on the MNIST dataset and 81.23% after ten epochs on the CIFAR10 dataset. The accuracy achieved on the CIFAR10 dataset after ten epochs, 81.23%, was significantly higher than that of the standard CNN model and the related hyperparameter optimization algorithms, such as the PSO-CNN, LDWPSO-CNN, and GA-CNN.
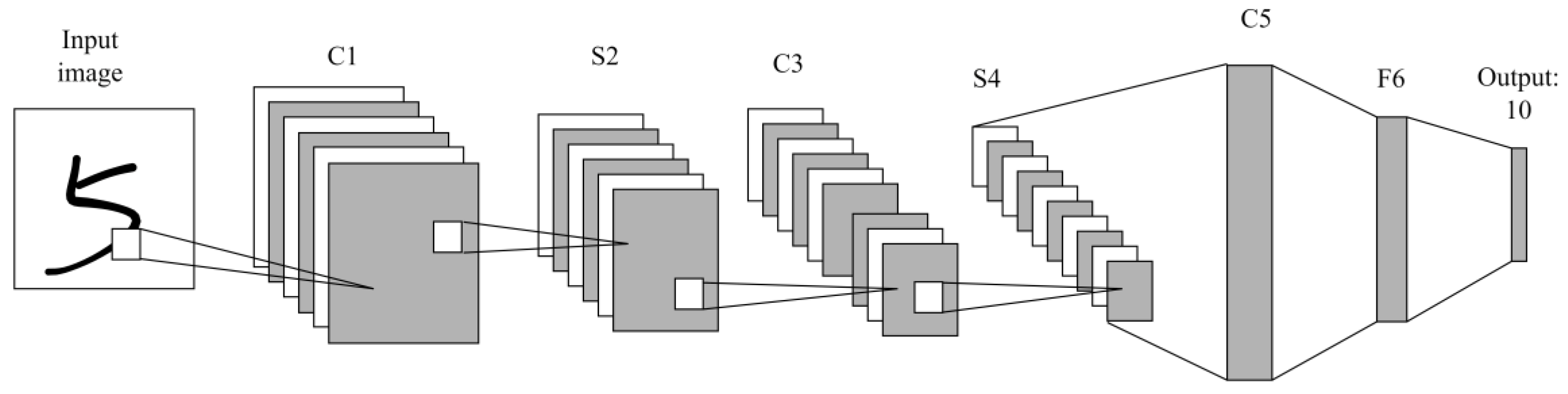
The essay is organized as follows. The convolutional neural network-related theories and demonstrative CNN models are introduced in
Section 2 of this paper as well as the underlying theory and equations of the PSO algorithm.
Section 3 details the improvement strategies related to the proposed improved algorithm ADGMPSO.
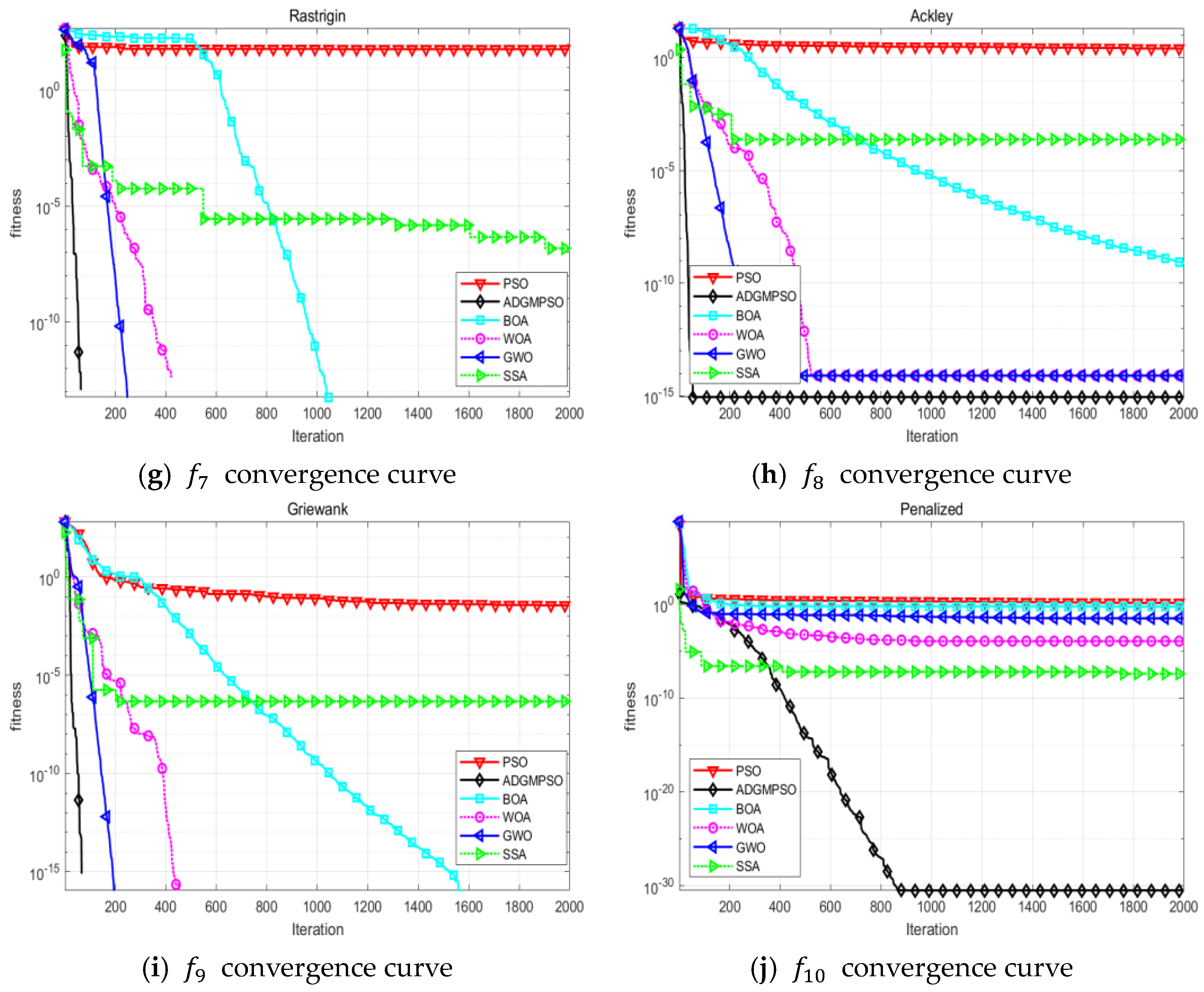
Section 4 tests the proposed algorithm against five mainstream evolutionary algorithms using benchmark test functions and examines the effectiveness of the improved strategy.
Section 5 combines the ADGMPSO with two typical CNN models, LeNet-5 and ResNet-18, to perform hyperparameter tuning experiments on the MNIST and CIFAR-10 datasets. Finally,
Section 6 provides a summary of the main findings and the conclusions of the study while also identifying the potential avenues for future research.
6. Conclusions and Future Work
In this paper, we proposed an adaptive dimensional Gaussian mutation PSO (ADGMPSO) algorithm that incorporated three improvement strategies to enhance the performance of PSO in identifying optimal solutions. The experimental results comparing the proposed algorithm with mainstream evolutionary algorithms using ten benchmark functions demonstrated its advantages in the convergence speed, evading locally optimal solutions, and the convergence accuracy. The hyperparameter tuning experiments on the LeNet-5 and ResNet-18 models for the MNIST and CIFAR10 datasets further showed the superiority and generalization ability of the proposed algorithm.
Despite the positive impact of our study, its limitations must be acknowledged. Firstly, since ADGMPSO aimed to improve the PSO algorithm’s ability to avoid locally optimal solutions and convergence accuracy, it did not optimize the algorithm’s running time and, therefore, did not reduce the algorithm’s running time compared to the original algorithm. Secondly, when conducting the hyperparameters optimization experiments for more complex convolutional neural networks, this paper optimized the hyperparameters of only the first few layers, given the computational resources and time constraints, without optimizing the whole network structure.
To overcome these limitations, our future research will first focus on considering both the algorithm’s performance improvement and time complexity, propose a new multi-objective hyperparameter optimization improvement algorithm, conduct a more comprehensive hyperparameter optimization for more complex network structures to demonstrate the algorithm’s superiority, and finally, carry out more extensive hyperparameter tuning of CNNs for other fields, such as speech recognition and natural language processing to demonstrate the algorithm’s generalization capability.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
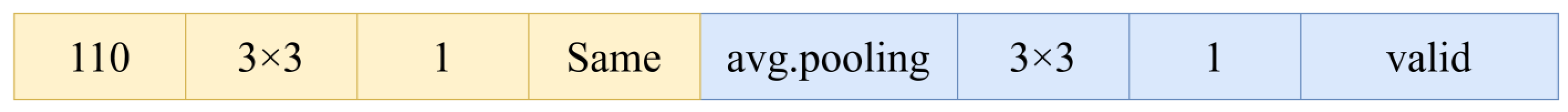{kind=link}
{kind=link}
{kind=link}