
Fusing Context Features and Spatial Attention to Improve Object Detection


Abstract
:1. Introduction
- Improving the YOLO-v3 model to better extract the features of small objects;
- Adding context features to improve the detection accuracy of overlapping objects;
- Integrating an attention mechanism to better detect difficult targets.
2. Related Works
3. Attention Mechanism
4. Context Feature
5. Proposed Methods
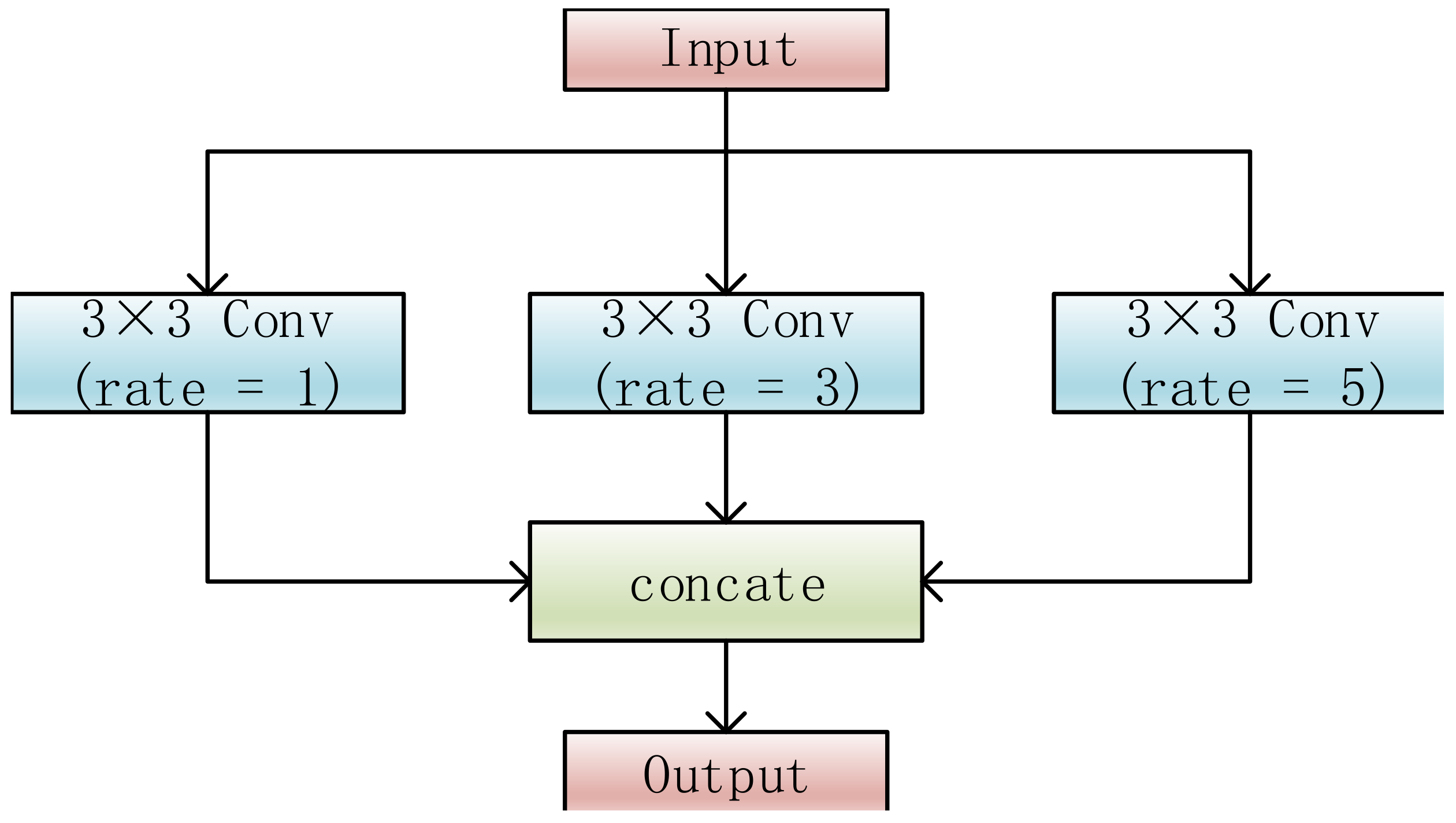
5.1. Context Features
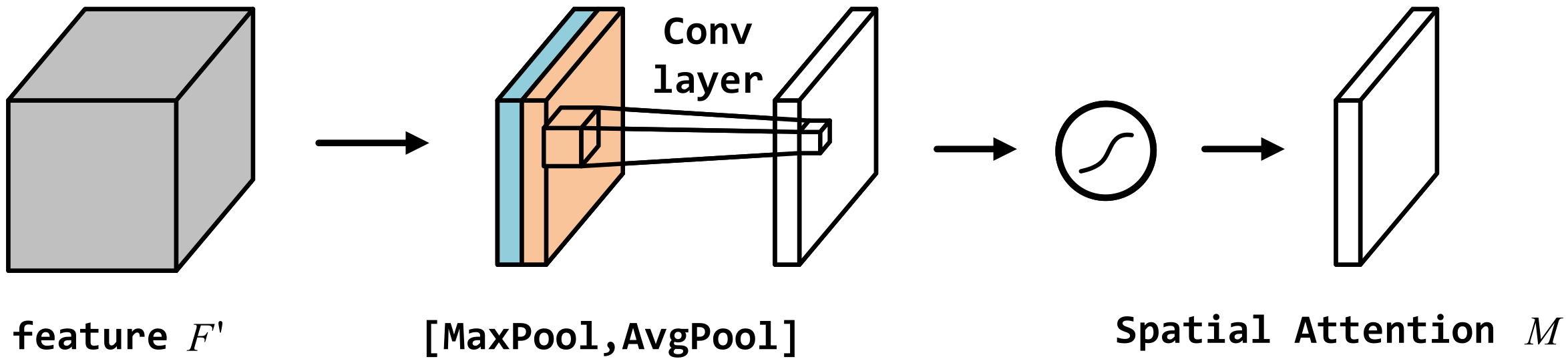
5.2. Spatial Attention Mechanism
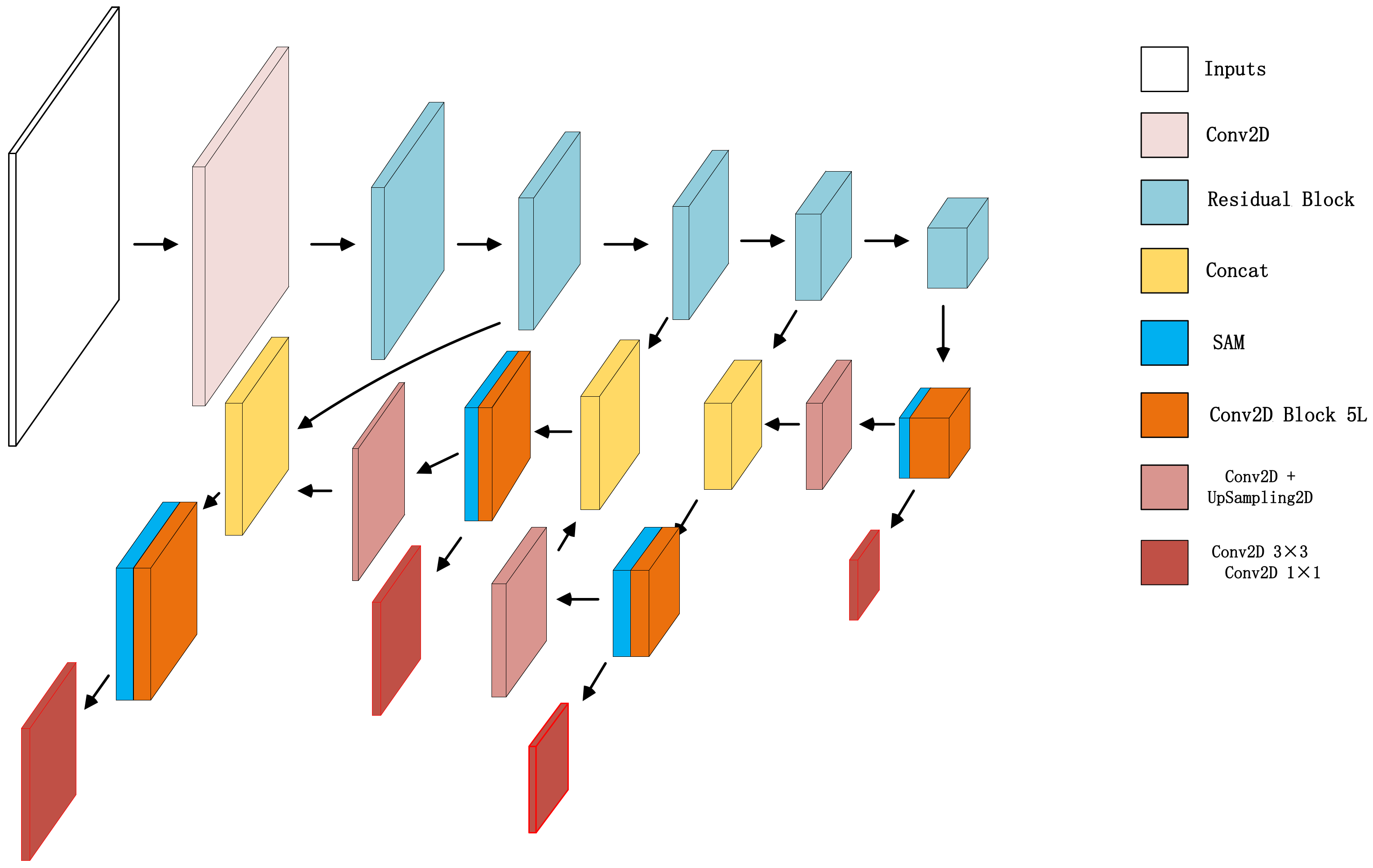
5.3. Improved YOLO-v3
6. Performance
6.1. Evaluation Metrics
6.2. Experimental Settings
6.3. Experiments
6.4. Ablation Study
6.5. Example Visualization of Experimental Results
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Annual Conference on Neural Information Processing Systems 2015 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified Real-Time Object Detection. arXiv 2015, arXiv:1506.02640. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLO-v6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLO-v7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Fan, D.P.; Li, T.; Lin, Z.; Ji, G.P.; Zhang, D.; Cheng, M.M.; Fu, H.; Shen, J. Re-thinking co-salient object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4339–4354. [Google Scholar] [CrossRef] [PubMed]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Lin, L.; Lin, W.; Huang, S. Group object detection and tracking by combining RPCA and fractal analysis. Soft Comput. 2018, 22, 231–242. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the darkness: A practical low-light image enhancer. In Proceedings of the 27th ACM international conference on multimedia, Nice, France, 21–25 October 2019; pp. 1632–1640. [Google Scholar]
- Loh, Y.P.; Liang, X.; Chan, C.S. Low-light image enhancement using Gaussian Process for features retrieval. Signal Process. Image Commun. 2019, 74, 175–190. [Google Scholar] [CrossRef]
- Kaya, E.C.; Alatan, A.A. Improving proposal-based object detection using convolutional context features. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 1308–1312. [Google Scholar]
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An empirical study of spatial attention mechanisms in deep networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 6688–6697. [Google Scholar]
- Zhou, X.; Zhuo, J.; Krahenbuhl, P. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 850–859. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Li, L.; Shi, J. Foveabox: Beyound anchor-based object detection. IEEE Trans. Image Process. 2020, 29, 7389–7398. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Wang, J.; Chen, K.; Yang, S.; Loy, C.C.; Lin, D. Region proposal by guided anchoring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2965–2974. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 1314–1324. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Fan, Q.; Fan, D.P.; Fu, H.; Tang, C.K.; Shao, L.; Tai, Y.W. Group collaborative learning for co-salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12288–12298. [Google Scholar]
- Liu, Y.; Han, J.; Zhang, Q.; Shan, C. Deep salient object detection with contextual information guidance. IEEE Trans. Image Process. 2019, 29, 360–374. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detection Result | Abbreviation | Definition |
|---|---|---|
| true positive | TP | correctly predicted positive samples |
| false positive | FP | incorrectly predicted positive samples |
| true negative | TN | correctly predicted negative samples |
| false negative | FN | incorrectly predicted negative samples |
| Evaluation Metric | Abbreviation | Computing Method | Definition |
|---|---|---|---|
| Accuracy | A | The proportion of correct predictions made by the model among all predictions. | |
| Precision | P | The proportion of true-positive samples among all samples predicted as positive by the model. | |
| Recall | R | The proportion of samples correctly predicted by the model among all positive samples. | |
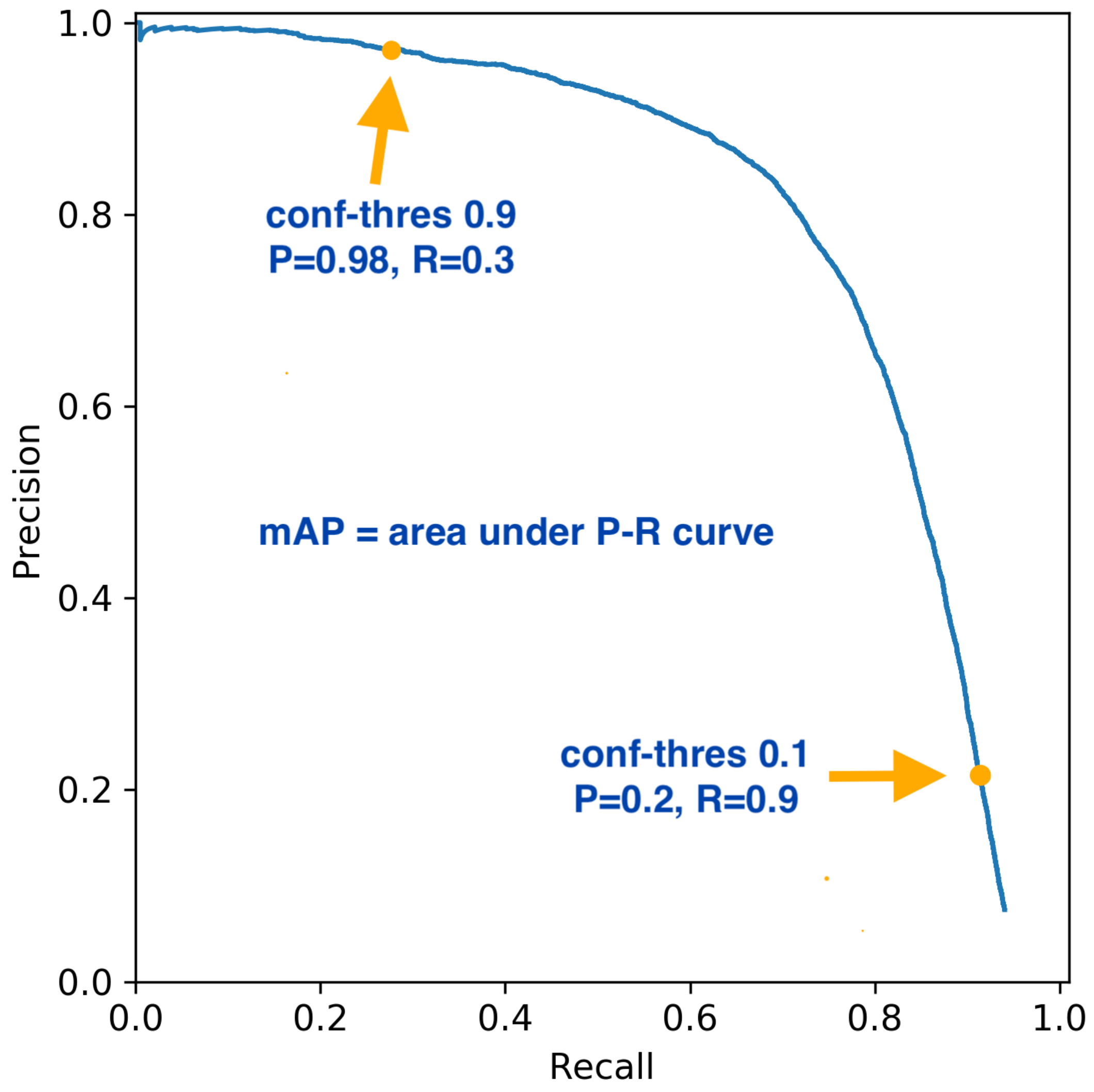
| Average precision | AP | Area under the precision–recall curve. | |
| Mean average precision | mAP | The average of AP for all classes. | |
| Frames per second | FPS | - | The number of pictures that can be processed per second. |
| Method | Backbone | Input Size | Precision | Recall | mAP | FPS |
|---|---|---|---|---|---|---|
| Faster RCNN | ResNet-101 | 600 × 600 | 77.10 | 64.63 | 73.41 | 10.31 |
| FCOS | Normal Convolution | 600 × 600 | 76.38 | 67.06 | 74.53 | 14.53 |
| SSD512 | VGG16 | 512 × 512 | 84.15 | 67.58 | 76.80 | 17.21 |
| CenterNet | Hourglass-104 Convolution | 600 × 600 | 85.88 | 70.11 | 80.23 | 12.80 |
| YOLO-v3 | ResNet53 | 412 × 412 | 90.26 | 73.83 | 82.34 | 16.95 |
| Our model | ResNet53+ | 412 × 412 | 91.67 | 76.97 | 85.68 | 19.89 |
| Class | Airplane | Bicycle | Bird | Boat | Bottle | Bus | Car | Cat | Chair | Cow |
|---|---|---|---|---|---|---|---|---|---|---|
| R | 83.33 | 85.92 | 73.17 | 61.47 | 54.09 | 83.06 | 82.17 | 83.61 | 59.37 | 53.16 |
| P | 99.01 | 96.83 | 96.77 | 95.71 | 85.00 | 100 | 93.81 | 95.03 | 79.74 | 58.33 |
| Class | Dining Table | Dog | Horse | Motorbike | Person | Potted Plant | Sheep | Sofa | Train | TV Monitor |
| R | 63.89 | 88.70 | 86.47 | 86.05 | 82.98 | 40.44 | 28.42 | 76.47 | 83.47 | 80.45 |
| P | 80.23 | 87.80 | 95.83 | 97.37 | 93.86 | 88.10 | 100 | 85.71 | 91.82 | 91.45 |
| ResNet53+ | Depthwise Separable Convolution | Context feature | SAM | mAP | FPS |
|---|---|---|---|---|---|
| ✓ | × | × | × | 82.34 | 16.95 |
| ✓ | ✓ | × | × | 82.13 | 22.01 |
| ✓ | ✓ | ✓ | × | 83.73 | 20.60 |
| ✓ | ✓ | ✓ | ✓ | 85.68 | 19.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, T.; Wu, J.; Luo, X.; Xu, G. Fusing Context Features and Spatial Attention to Improve Object Detection. Appl. Sci. 2023, 13, 4250. https://doi.org/10.3390/app13074250
Liu T, Wu J, Luo X, Xu G. Fusing Context Features and Spatial Attention to Improve Object Detection. Applied Sciences. 2023; 13(7):4250. https://doi.org/10.3390/app13074250
Chicago/Turabian StyleLiu, Tianjia, Jinsong Wu, Xuze Luo, and Guangquan Xu. 2023. "Fusing Context Features and Spatial Attention to Improve Object Detection" Applied Sciences 13, no. 7: 4250. https://doi.org/10.3390/app13074250