
Vectorized Representation of Commodities by Fusing Multisource Heterogeneous User-Generated Content with Multiple Models


Abstract
:1. Introduction
2. Related Work
2.1. Fusion of Multisource Heterogeneous Information
2.2. Vectorized Representation of Images and Text
3. Multimodel Fusion-Based Feature Representation of Commodities with Multisource and Heterogeneous User-Generated Content
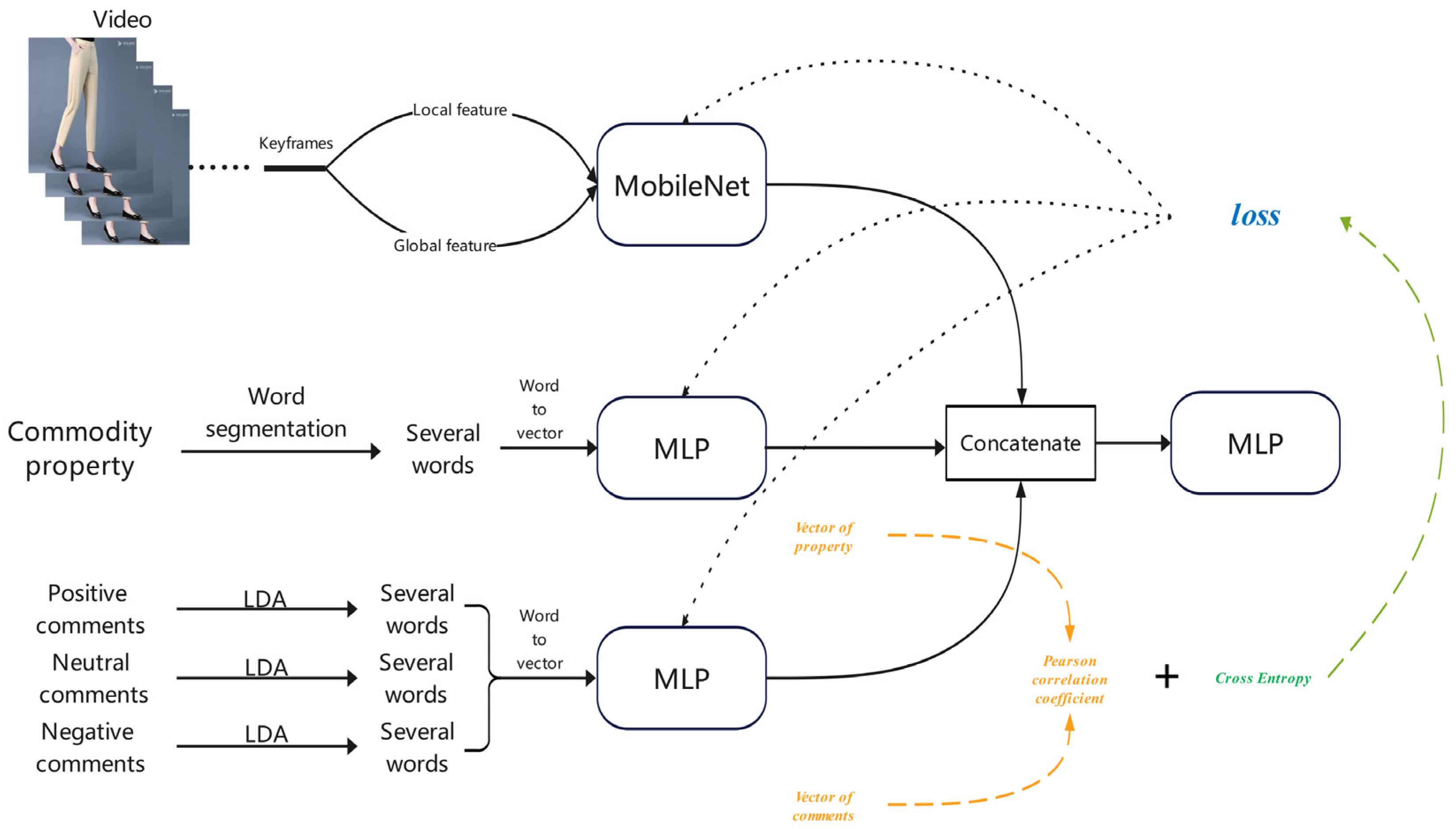
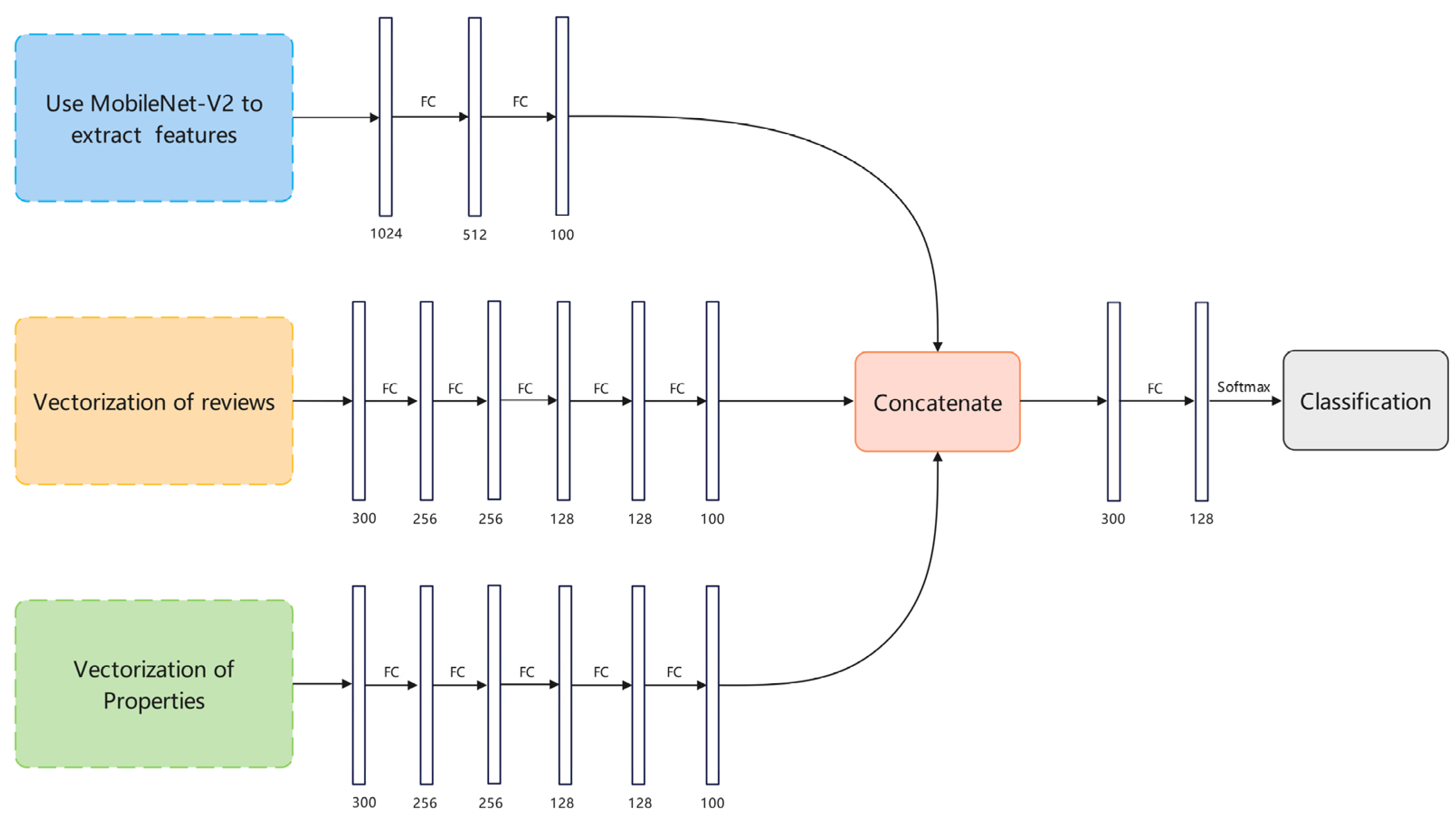
3.1. Framework of the Algorithm
3.2. Vectorized Representation of the Image Subset Using MobileNetV2
3.3. Vectorized Representation of Text Based on LDA and Word2Vec
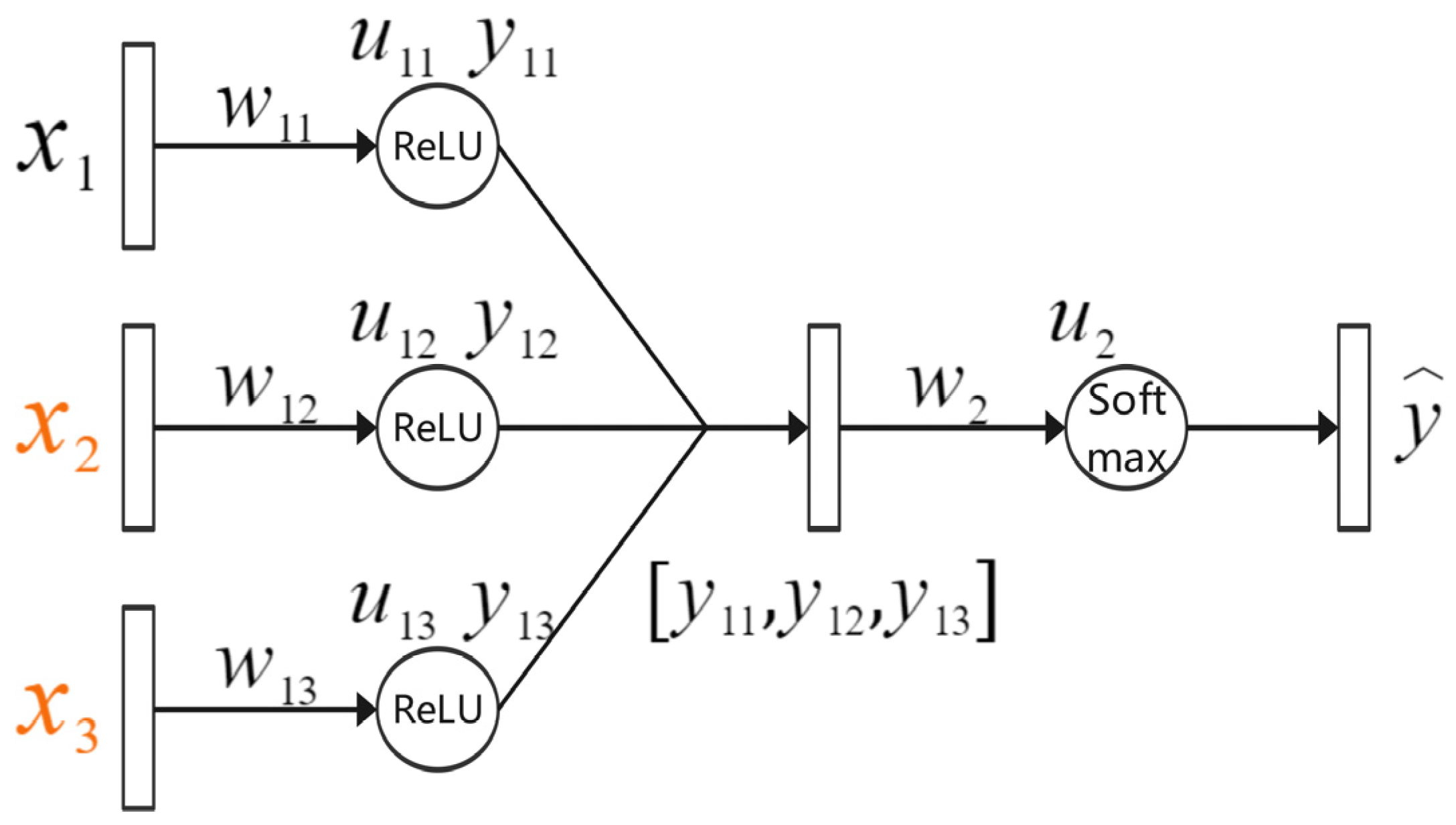
3.4. Improved Loss Function-Assisted Fusion of Commodity Features
| Algorithm 1 The fusion network training process |
| Input: Training data Output: Category Step 1: Select some training data Step 2: The predicted value is obtained by forward propagation Step 3: Loss backpropagates and updates the parameters of MobileNet-V2 and the three MLPS simultaneously Step 4: if not reaching the training times then Redo Step (1) else Finish training |
4. Experiments
4.1. Dataset and Experimental Setup
4.2. Comparison Algorithms and Evaluation Metrics
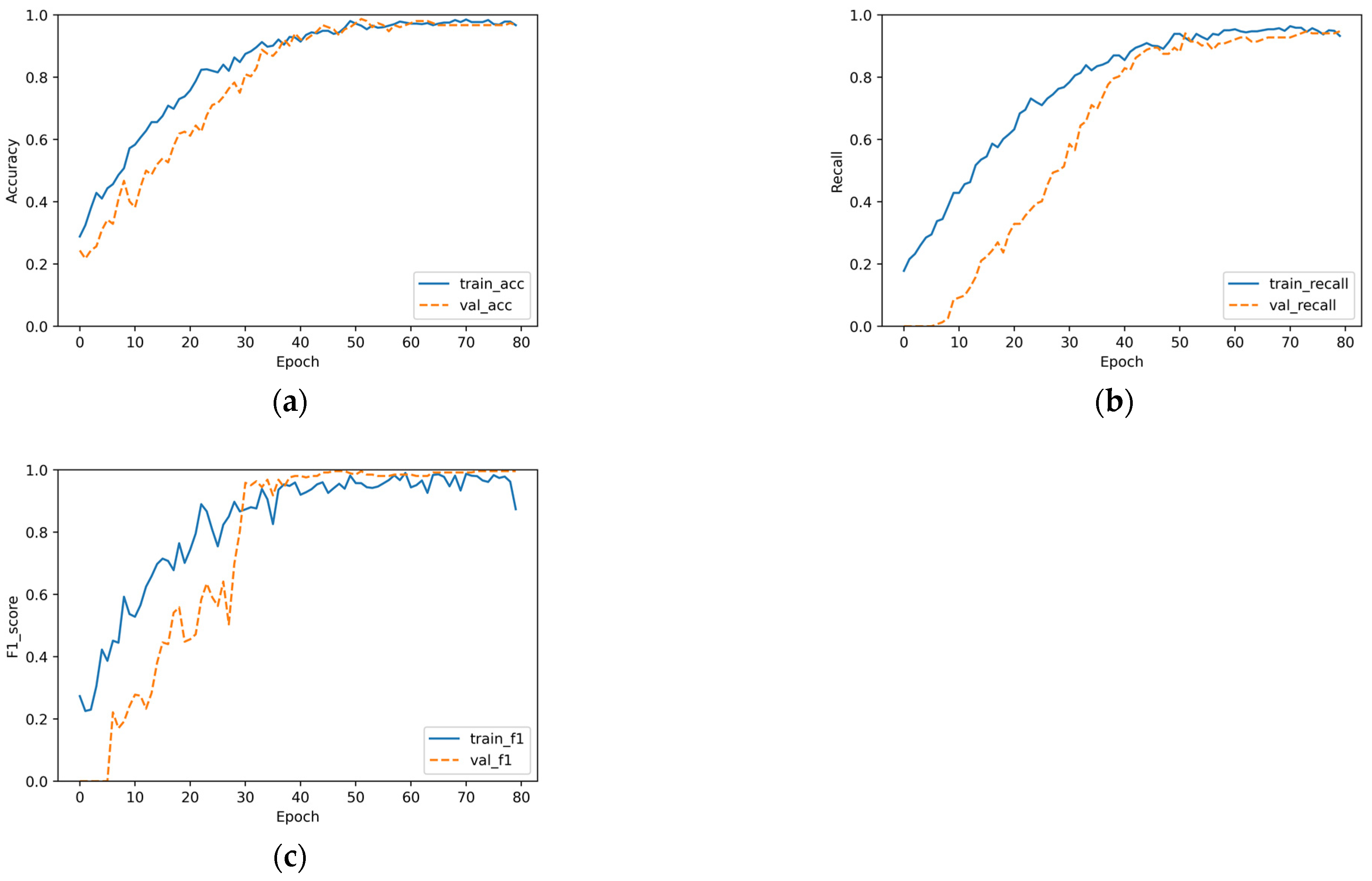
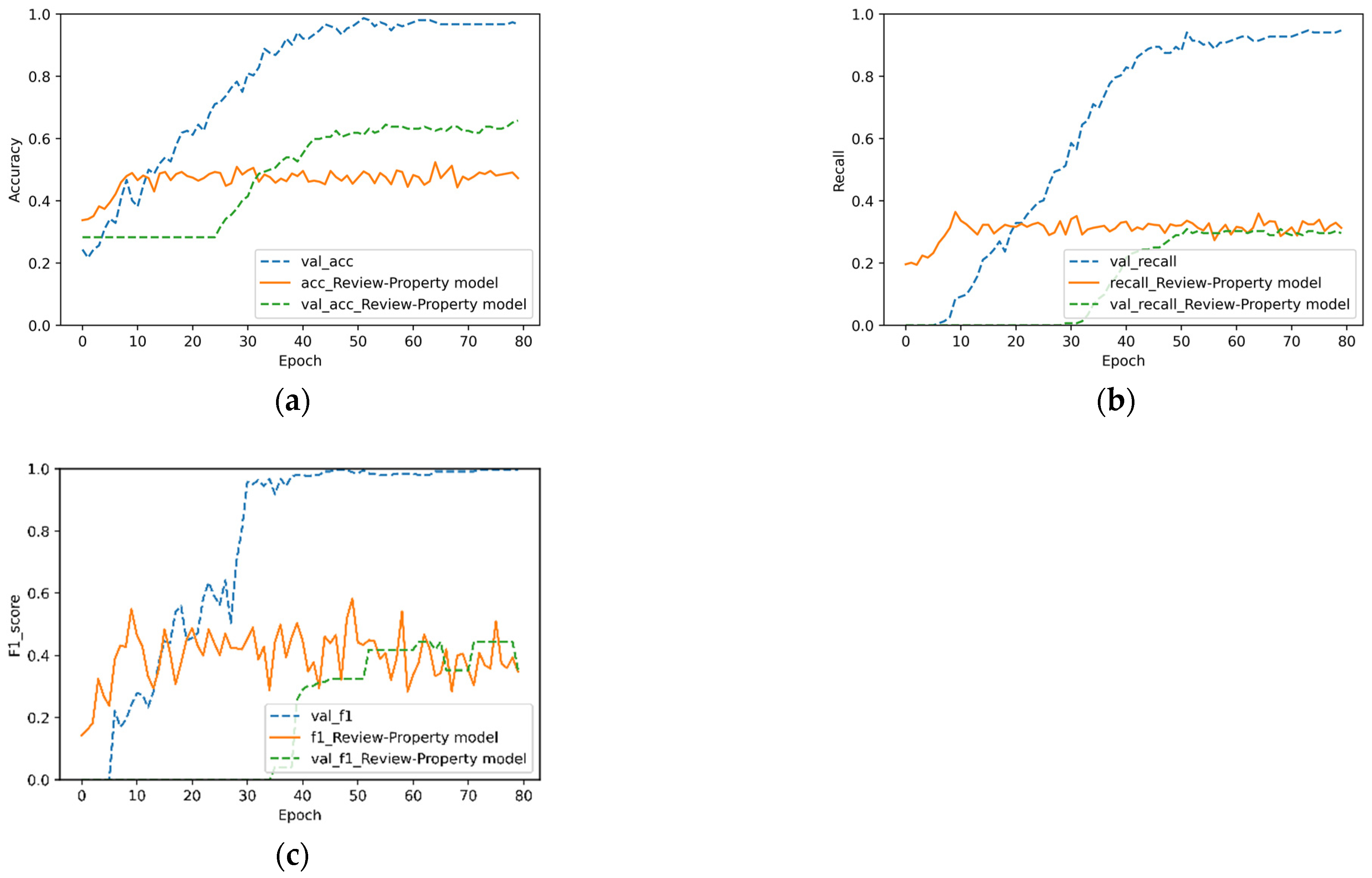
4.3. Performance of Our Algorithm on the Clothes Dataset
4.4. Comparative Experiments
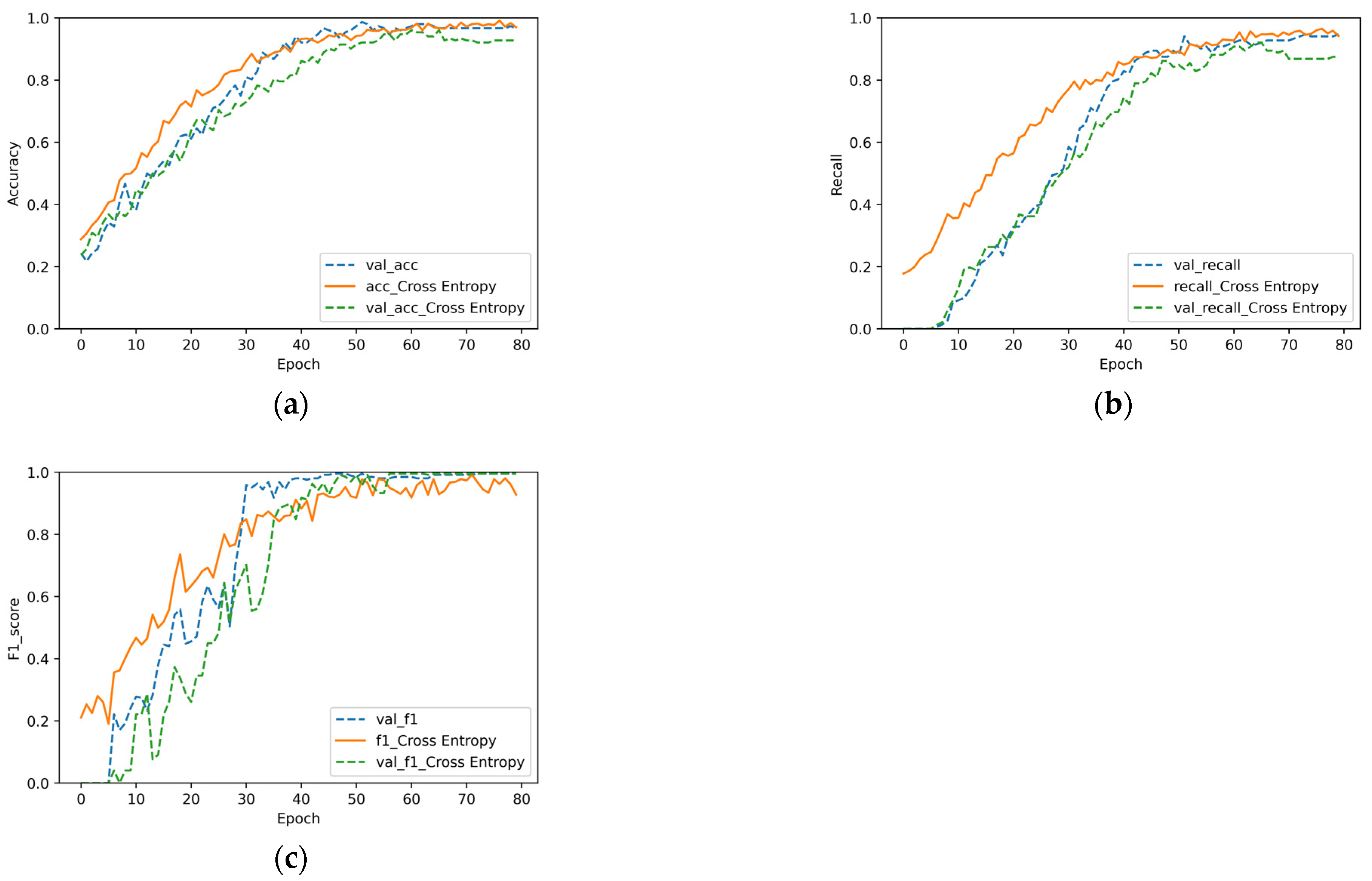
4.5. Validity of the Improved Loss Function
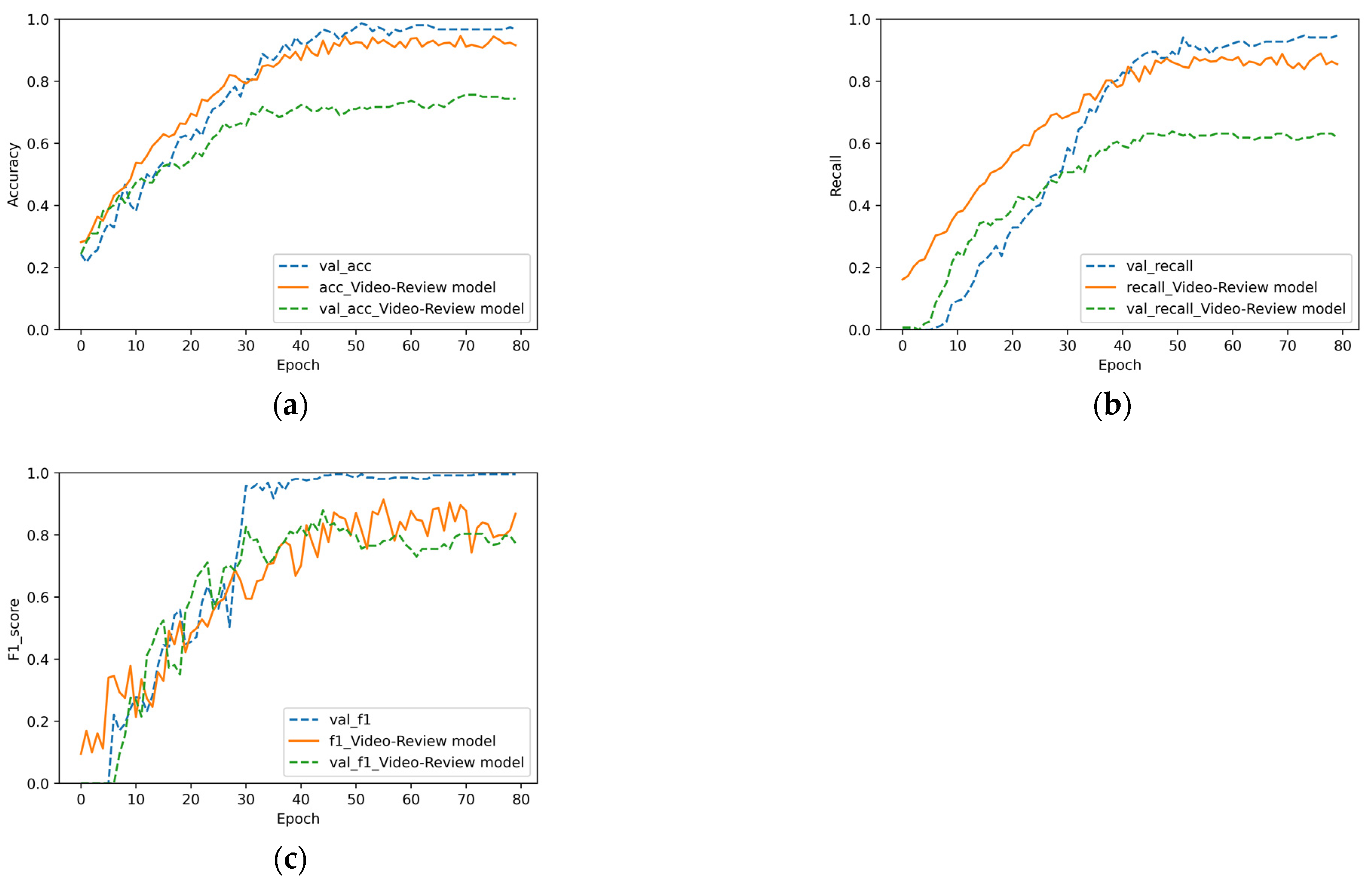
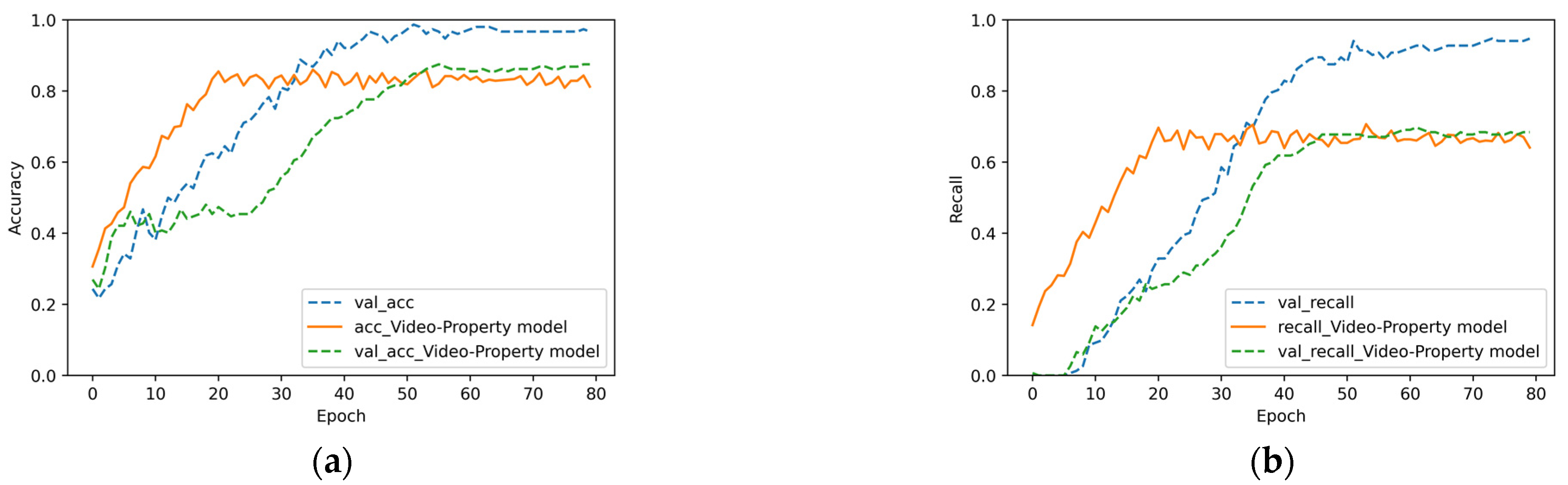
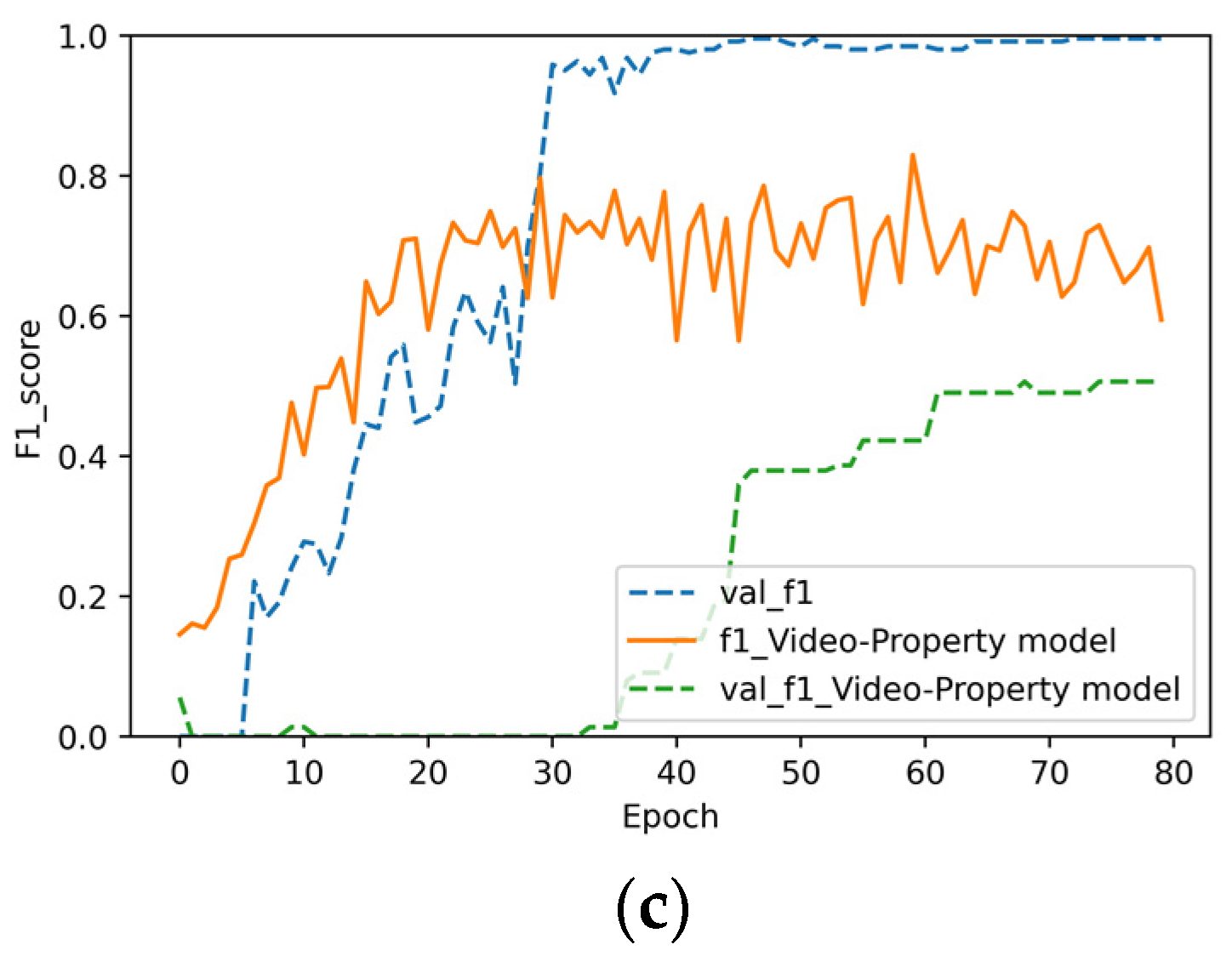
4.6. Value of Multisource Heterogeneous Information
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bramon, R.; Boada, I.; Bardera, A.; Rodriguez, J.; Feixas, M.; Puig, J.; Sbert, M. Multimodal Data Fusion Based on Mutual Information. IEEE Trans. Vis. Comput. Graph. 2012, 18, 1574–1587. [Google Scholar] [CrossRef] [PubMed]
- Bronstein, M.M.; Bronstein, A.M.; Michel, F.; Paragios, N. Data fusion through crossmodality metric learning using similarity-sensitive hashing. In Proceedings of the 2010 IEEE Computer Society Con-ference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3594–3601. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Bajpai, R.; Hussain, A. A review of affective computing: From unimodal analysis to multimodal fusion. Inf. Fusion 2017, 37, 98–125. [Google Scholar] [CrossRef] [Green Version]
- Man, G.; Sun, X. Interested Keyframe Extraction of Commodity Video Based on Adaptive Clustering Annotation. Appl. Sci. 2022, 12, 1502. [Google Scholar] [CrossRef]
- Yu, X.; Ren, X.; Sun, Y.; Gu, Q.; Sturt, B.; Khandelwal, U.; Norick, B.; Han, J. Personalized entity recommendation: A Heterogeneous Information Network Approach. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining, New York, NY, USA, 24–28 February 2014; pp. 283–292. [Google Scholar] [CrossRef]
- Li, Y.; Wang, R.; Nan, G.; Li, D.; Li, M. A personalized paper recommendation method considering diverse user preferences. Decis. Support Syst. 2021, 146, 113546. [Google Scholar] [CrossRef]
- Ishanka, U.A.P.; Yukawa, T. The Prefiltering Techniques in Emotion Based Place Recommendation Derived by User Reviews. Appl. Comput. Intell. Soft Comput. 2017, 2017, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Tang, J.; Wang, K. Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, New York, NY, USA, 5–9 February 2018; pp. 565–573. [Google Scholar] [CrossRef] [Green Version]
- Zhang, F.; Wang, H.; Xie, X.; Guo, M.; Xie, X. DKN: Deep Knowledge-Aware Network for News Recommendation. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1835–1844. [Google Scholar] [CrossRef] [Green Version]
- Hwang, S.; Park, E. Movie Recommendation Systems Using Actor-Based Matrix Computations in South Korea. IEEE Trans. Comput. Soc. Syst. 2021, 9, 1387–1393. [Google Scholar] [CrossRef]
- Cui, Z.; Xu, X.; Xue, F.; Cai, X.; Cao, Y.; Zhang, W.; Chen, J. Personalized Recommendation System Based on Collaborative Filtering for IoT Scenarios. IEEE Trans. Serv. Comput. 2020, 13, 685–695. [Google Scholar] [CrossRef]
- Wang, Z.; Wan, M.; Cui, X.; Liu, L.; Liu, Z.; Xu, W.; He, L. Personalized Recommendation Algorithm Based on Product Reviews. J. Electron. Commer. Organ. 2018, 16, 22–38. [Google Scholar] [CrossRef]
- Islek, I.; Oguducu, S.G. A hierarchical recommendation system for E-commerce using online user reviews. Electron. Commer. Res. Appl. 2022, 52, 101131. [Google Scholar] [CrossRef]
- Ma, L.; Lu, Z.; Shang, L.; Li, H. Multimodal Convolutional Neural Networks for Matching Image and Sentence. In Proceedings of the 2015 IEEE In-ternational Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2623–2631. [Google Scholar] [CrossRef] [Green Version]
- Hou, J.-C.; Wang, S.-S.; Lai, Y.-H.; Tsao, Y.; Chang, H.-W.; Wang, H.-M. Audio-Visual Speech Enhancement Using Multimodal Deep Convolutional Neural Networks. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 2, 117–128. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, T.-L.; Kavuri, S.; Lee, M. A multimodal convolutional neuro-fuzzy network for emotion understanding of movie clips. Neural Netw. 2019, 18, 208–219. [Google Scholar] [CrossRef]
- Gan, M.X.; Zhang, H. DeepFusion: Fusing User-Generated Content and Item Raw Content towards Personalized Product Recommendation. Complexity 2020, 2020, 4780191. [Google Scholar] [CrossRef]
- Zhang, K.; Li, Y.; Wang, J.; Wang, Z.; Li, X. Feature Fusion for Multimodal Emotion Recognition Based on Deep Canonical Correlation Analysis. IEEE Signal Process. Lett. 2021, 28, 1898–1902. [Google Scholar] [CrossRef]
- Wang, H.J.; Zhang, Z.H.; Wang, P.W. A Situation Analysis Method for Specific Domain Based on Multi-source Data Fusion. Intell. Comput. Theor. Appl. 2018, 10954, 160–171. [Google Scholar] [CrossRef]
- Zhang, D.; Yao, L.; Chen, K.; Wang, S.; Chang, X.; Liu, Y. Making Sense of Spatio-Temporal Preserving Representations for EEG-Based Human Intention Recognition. IEEE Trans. Cybern. 2020, 50, 3033–3044. [Google Scholar] [CrossRef]
- Jiang, T.; Wang, H.; Luo, X.; Xie, S.; Wang, J. MIFAS:Multi-sourceheterogeneous information fusion with adaptive importance sampling for link prediction. Expert Syst. 2021, 39, e12888. [Google Scholar] [CrossRef]
- Jiming, H.; Wei, S. An Object-Centric Multi-source Heterogeneous Data Fusion Scheme. In Proceedings of the IEEE International Conference on Information Communication and Software Engineering (ICICSE), Chengdu, China, 19–21 March 2021; pp. 24–29. [Google Scholar] [CrossRef]
- Li, Y.; Li, Q.; Gao, J.; Su, L.; Zhao, B.; Fan, W.; Han, J. Conflicts to Harmony: A Framework for Resolving Conflicts in Heterogeneous Data by Truth Discovery. IEEE Trans. Knowl. Data Eng. 2016, 28, 1986–1999. [Google Scholar] [CrossRef]
- Nti, I.K.; Adekoya, A.F.; Weyori, B.A. A novel multi-source information-fusion predictive framework based on deep neural networks for accuracy enhancement in stock market prediction. J. Big Data 2021, 8, 17. [Google Scholar] [CrossRef]
- Gao, Y.; Ran, L.X. Collaborative Filtering Recommendation Algorithm for Heterogeneous Data Mining in the Internet of Things. IEEE Access 2019, 7, 123583–123591. [Google Scholar] [CrossRef]
- Ji, Z.; Yang, C.; Wang, H.; Armendáriz-Iñigo, J.E.; Arce-Urriza, M. BRS cS: A hybrid recommendation model fusing multi-source heterogeneous data. EURASIP J. Wirel. Commun. Netw. 2020, 2020, 124. [Google Scholar] [CrossRef]
- Zhu, H.; Wang, Z.; Shi, Y.; Hua, Y.; Xu, G.; Deng, L. Multimodal Fusion Method Based on Self-Attention Mechanism. Wirel. Commun. Mob. Comput. 2020, 2020, 1–8. [Google Scholar] [CrossRef]
- Du, P.F.; Gao, Y.L.; Li, X.Y. Bi-attention Modal Separation Network for Multimodal Video Fusion. In Proceedings of the International Conference on Multimedia Modeling, Phu Quoc, Vietnam, 6–10 June 2022; pp. 585–598. [Google Scholar] [CrossRef]
- Zhang, X.; Gong, Y.; Li, Z.; Liu, X.; Pan, S.; Li, J. Multi-Modal Attention Guided Real-Time Lane Detection. In Proceedings of the 6th IEEE International Conference on Advanced Robotics and Mechatronics (ICARM), Chongqing, China, 3–5 July 2021; pp. 146–153. [Google Scholar] [CrossRef]
- Zhang, W.; Yu, J.; Wang, Y.; Wang, W. Multimodal deep fusion for image question answering. Knowl. Based Syst. 2021, 212, 106639. [Google Scholar] [CrossRef]
- Sun, Y.; Fu, Z.; Sun, C.; Hu, Y.; Zhang, S. Deep Multimodal Fusion Network for Semantic Segmentation Using Remote Sensing Image and LiDAR Data. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Zhang, Y.F.; Morel, O.; Seulin, R.; Mériaudeau, F.; Sidibé, D. A central multimodal fusion framework for outdoor scene image segmentation. Multimed. Tools Appl. 2022, 81, 12047–12060. [Google Scholar] [CrossRef]
- Shen, D.; Zareapoor, M.; Yang, J. Multimodal image fusion based on point-wise mutual information. Image Vis. Comput. 2020, 105, 104047. [Google Scholar] [CrossRef]
- Chhabra, P.; Garg, N.K.; Kumar, M. Content-based image retrieval system using ORB and SIFT features. Neural Comput. Appl. 2020, 32, 2725–2733. [Google Scholar] [CrossRef]
- Garg, D.; Garg, N.K.; Kumar, M. Underwater image enhancement using blending of CLAHE and percentile methodologies. Multimed. Tools Appl. 2018, 77, 26545–26561. [Google Scholar] [CrossRef]
- Luo, M.N.; Chang, X.J.; Nie, L.Q.; Yang, Y.; Hauptmann, A.G.; Zheng, Q. An Adaptive Semisupervised Feature Analysis for Video Semantic Recognition. IEEE Trans. Cybern. 2018, 48, 648–660. [Google Scholar] [CrossRef]
- Gupta, S.; Mohan, N.; Kumar, M. A Study on Source Device Attribution Using Still Images. Arch. Comput. Methods Eng. 2021, 28, 2209–2223. [Google Scholar] [CrossRef]
- Shaheed, K.; Mao, A.; Qureshi, I.; Kumar, M.; Hussain, S.; Ullah, I.; Zhang, X. DS-CNN: A pre-trained Xception model based on depth-wise separable convolutional neural network for finger vein recognition. Expert Syst. Appl. 2022, 191, 116288. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A.; Liu, W.; et al. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef] [Green Version]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. arXiv 2014, arXiv:1408.5882. [Google Scholar] [CrossRef]
- Li, S.; Zhao, Z.; Hu, R.; Li, W.; Liu, T.; Du, X. Analogical Reasoning on Chinese Morphological and Semantic Relations; The Association for Computational Linguistics (ACL): Melbourne, Australia, 2018; Volume 2, pp. 138–143. [Google Scholar]
- Chiang, D. Hierarchical Phrase-Based Translation. Comput. Linguist. 2007, 33, 201–228. [Google Scholar] [CrossRef]
- Gupta, A.; Katarya, R. PAN-LDA: A latent Dirichlet allocation based novel feature extraction model for COVID-19 data using machine learning. Comput. Biol. Med. 2021, 138, 104920. [Google Scholar] [CrossRef] [PubMed]
- Doganer, A.; Zhang, Z.J. Evaluating YouTube as a source of information on COVID-19: Analysis with latent Dirichlet allocation method. Bratisl. Med. J. 2021, 122, 325–330. [Google Scholar] [CrossRef]
- Kawai, M.; Sato, H.; Shiohama, T. Topic model-based recommender systems and their applications to cold-start problems. Expert Syst. Appl. 2022, 202, 117129. [Google Scholar] [CrossRef]
- Guo, Y.X.; Wang, F.; Xing, C.; Lu, X.L. Mining multi-brand characteristics from online reviews for competitive analysis: A brand joint model using latent Dirichlet allocation. Electron. Commer. Res. Appl. 2022, 53, 101141. [Google Scholar] [CrossRef]
- Zhao, F.; Ren, X.; Yang, S.; Han, Q.; Zhao, P.; Yang, X. Latent Dirichlet Allocation Model Training With Differential Privacy. IEEE Trans. Inf. Forensics Secur. 2020, 16, 1290–1305. [Google Scholar] [CrossRef]
- Sun, J.; Luo, X.; Gao, H.; Wang, W.; Gao, Y.; Yang, X. Categorizing Malware via A Word2Vec-based Temporal Convolutional Network Scheme. J. Cloud Comput. 2020, 9, 53. [Google Scholar] [CrossRef]
- Byun, Y.C. Extreme Gradient Boosting for Recommendation System by Transforming Product Classification into Regression Based on Multi-Dimensional Word2Vec. Symmetry 2021, 13, 758. [Google Scholar] [CrossRef]
- Xu, D.; Tian, Z.; Lai, R.; Kong, X.; Tan, Z.; Shi, W. Deep learning based emotion analysis of microblog texts. Inf. Fusion 2020, 64, 1–11. [Google Scholar] [CrossRef]
- Wang, Y.C.; Zhu, L.G. Research on improved text classification method based on combined weighted model. Concurr. Comput. Pr. Exp. 2020, 32, e5140. [Google Scholar] [CrossRef]
- Fukui, A.; Park, D.H.; Yang, D.; Rohrbach, A.; Darrell, T.; Rohrbach, M. Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding. In Proceedings of the Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 457–468. [Google Scholar] [CrossRef] [Green Version]
- Kim, W.; Son, B.; Kim, I. Vilt: Vision-And-Language Transformer without Convolution or Region Supervision. In Proceedings of the International Conference on Machine Learning (ICML), Online, 18–24 July 2021; pp. 5583–5594. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Samples | Average Number of Reviews per Item | |
|---|---|---|
| Clothes | 200 | 150 |
| Pants | 225 | 150 |
| Hats | 121 | 150 |
| Shoes | 213 | 150 |
| Number of Samples | Average Number of Reviews per Item | |
|---|---|---|
| Gift cards | 863 | 95 |
| Luxury beauty | 2586 | 47 |
| Magazine subscriptions | 860 | 26 |
| Prime pantry | 2058 | 44 |
| Software | 2233 | 17 |
| True Value | Total | |||||
|---|---|---|---|---|---|---|
| Clothes | Pants | Hats | Shoes | |||
| Predicted value | Clothes | |||||
| Pants | ||||||
| Hats | ||||||
| Shoes | ||||||
| Total | ||||||
| Concatenate | MCB | ViLT | Ours | |
|---|---|---|---|---|
| Accuracy | 0.9951 | 1.0000 | 0.8731 | 0.9786 |
| Val_Accuracy | 0.8750 | 0.2894 | 0.8289 | 0.9671 |
| Precision | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| Val_Precision | 1.0000 | 0.0367 | 1.0000 | 1.0000 |
| Recall | 0.9835 | 1.0000 | 0.6606 | 0.9638 |
| Val_Recall | 0.8487 | 0.1118 | 0.6118 | 0.9474 |
| F1 | 0.9997 | 0.9999 | 0.7584 | 0.9901 |
| Val_F1 | 0.8236 | 0.0206 | 0.5388 | 0.9959 |
| Concatenate | MCB | ViLT | Ours | |
|---|---|---|---|---|
| Accuracy | 0.8889 | 0.9931 | 0.8123 | 0.9998 |
| Val_Accuracy | 0.8286 | 0.2115 | 0.8149 | 0.9982 |
| Precision | 0.9658 | 1.0000 | 0.9561 | 0.9971 |
| Val_Precision | 0.8942 | 0.0698 | 0.9606 | 1.0000 |
| Recall | 0.8596 | 0.9724 | 0.7411 | 0.9946 |
| Val_Recall | 0.7982 | 0.1568 | 0.7381 | 1.0000 |
| F1 | 0.8938 | 0.9772 | 0.6909 | 0.9997 |
| Val_F1 | 0.8221 | 0.0793 | 0.7022 | 0.9963 |
| MCB | ViLT | Ours | |
|---|---|---|---|
| Time | 0.0518 | 0.2842 | 0.0737 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Man, G.; Sun, X.; Wu, W. Vectorized Representation of Commodities by Fusing Multisource Heterogeneous User-Generated Content with Multiple Models. Appl. Sci. 2023, 13, 4217. https://doi.org/10.3390/app13074217
Man G, Sun X, Wu W. Vectorized Representation of Commodities by Fusing Multisource Heterogeneous User-Generated Content with Multiple Models. Applied Sciences. 2023; 13(7):4217. https://doi.org/10.3390/app13074217
Chicago/Turabian StyleMan, Guangyi, Xiaoyan Sun, and Weidong Wu. 2023. "Vectorized Representation of Commodities by Fusing Multisource Heterogeneous User-Generated Content with Multiple Models" Applied Sciences 13, no. 7: 4217. https://doi.org/10.3390/app13074217