
Local Differential Privacy-Based Federated Learning under Personalized Settings

Abstract
:1. Introduction
- Different model perturbation methods are proposed for IID and non-IID data. For IID data, the Gaussian mechanism is applied, to achieve local differential privacy preserving. For non-IID data, the symbolized function is used, to perturb the local model of the client.
- In order to obtain a federated model under the premise of personalized privacy settings, two model aggregation methods are proposed, namely a weighted average method and a probability-based selection method. The proposed methods can help to reduce the impact of privacy-conscious clients on the federated model, thus can preserve the accuracy of the model.
- Experiments are conducted on real-world datasets. The experimental results show that, compared with the arithmetic average aggregation method, the proposed aggregation methods can achieve better accuracy on both IID data and non-IID data.
2. Preliminaries
2.1. Local Differential Privacy
2.2. Federated Learning
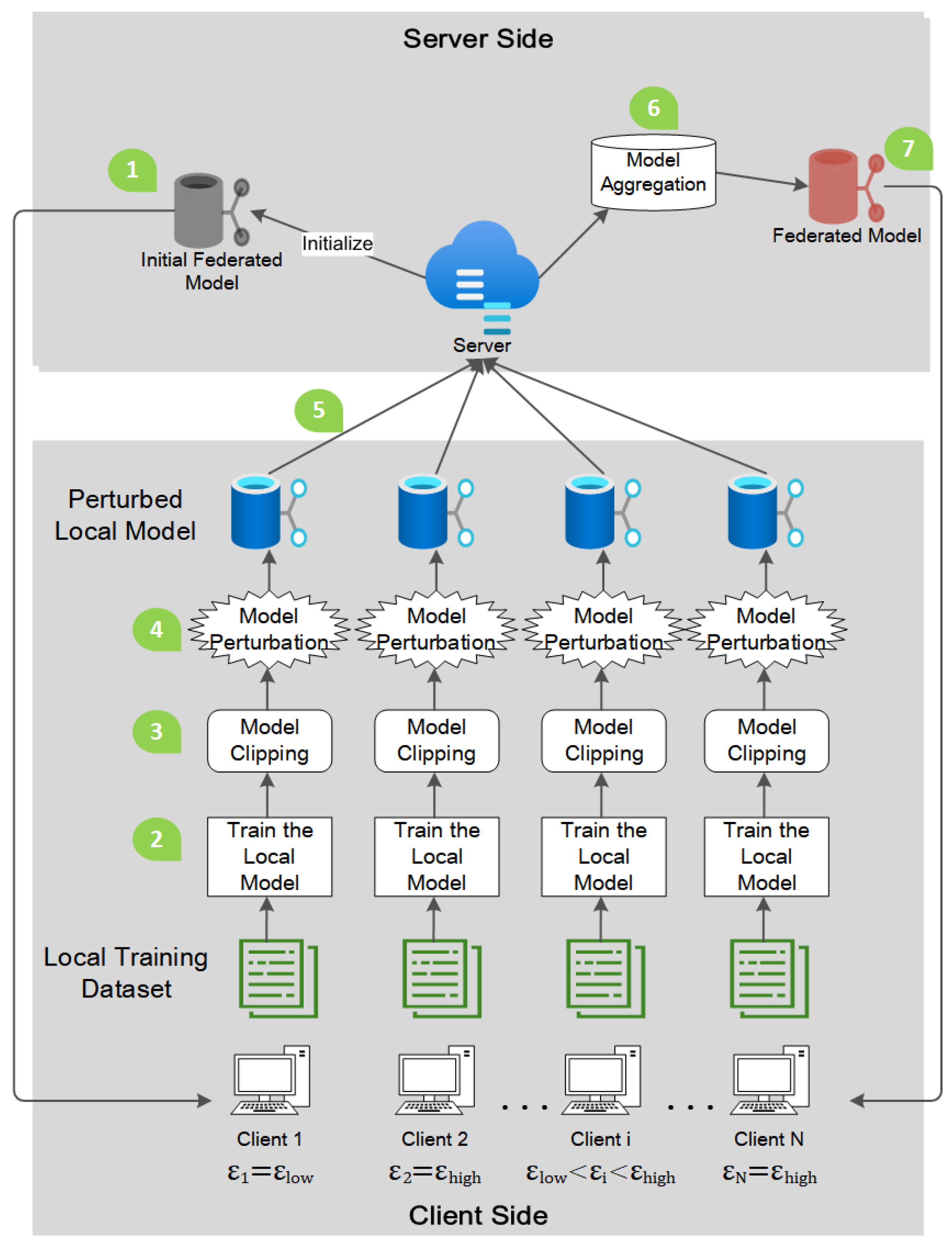
3. System Model
3.1. Client Side
- For IID data, the perturbation mechanism M, is to add Gaussian noise to each element p, in . Firstly, the client i, calculates the standard deviation [28], of the Gaussian distribution:where denotes the privacy budget set by the client i, q denotes the probability of randomly sampling the samples in clients i’s dataset, and , denotes the inverse of the dataset size. Secondly, random noise is generated according to the Gaussian distribution . The probability density function is given byFor each element p, in , the perturbed result , is given by . Finally, the client i sends to the server.
- For non-IID data, the perturbation mechanism M, is to symbolize . By symbolize, we mean that only the sign of each element in is retained, making a vector consisting of only or . As described in [19], each client i, uses the privacy-symbolization function to perturb , and obtain . Specifically, for each element p, in the vector , the perturbed result , is given byIn the above equation, denotes the cumulative distribution function of the normalized Gaussian distribution, and denotes the standard deviation. The standard deviation is computed as:where denotes the -sensitivity [11], and denotes the inverse of the dataset size.
3.2. Server Side
| Algorithm 1 Federated learning with personalized local differential privacy on independent identically distributed data. |
| Input: The total number of clients N, the maximum number of training rounds R, the maximum number of logistic regression rounds U, the clipping threshold of client i, the learning rate of SGD, the standard deviation of client i. |
|
| Algorithm 2 Federated learning with personalized local differential privacy on non-independent identically distributed data. |
| Input: The total number of clients N, the maximum number of training rounds R, the maximum number of logistic regression rounds U, the clipping threshold of client i, the learning rate of SGD, the standard deviation of client i. |
|
4. Improved Aggregation Method
4.1. Weighted Average Method
4.2. Probability-Based Selection Method
5. Experiments
5.1. Datasets
5.2. Experiments on Independent Identically Distributed Data
5.2.1. Experiment Setting
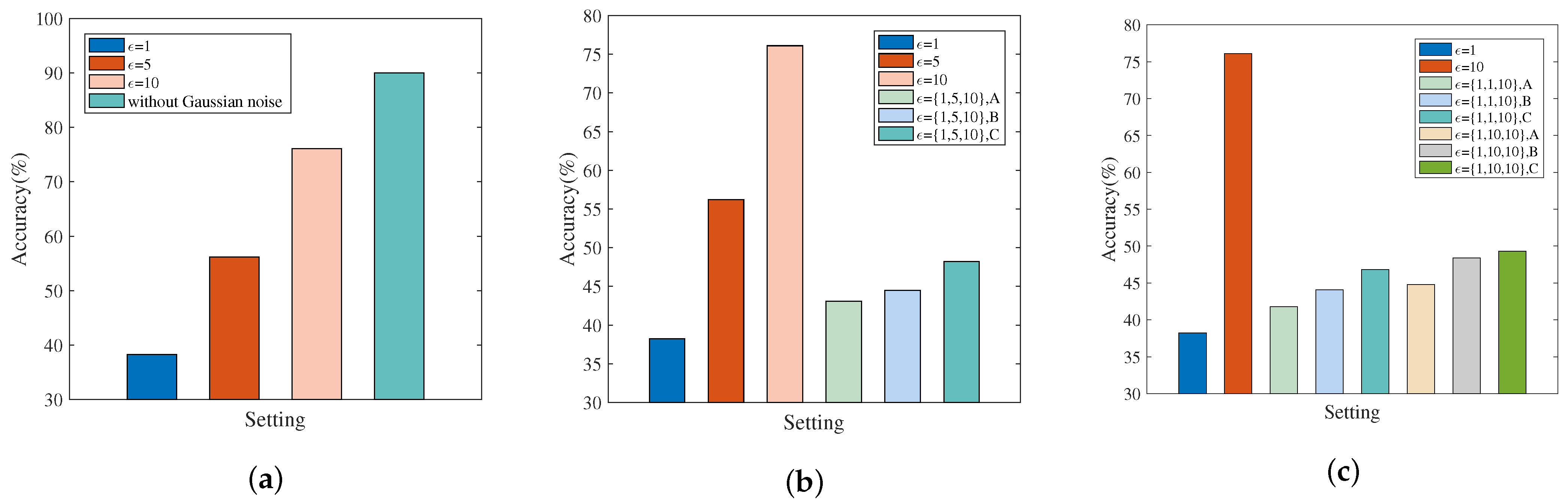
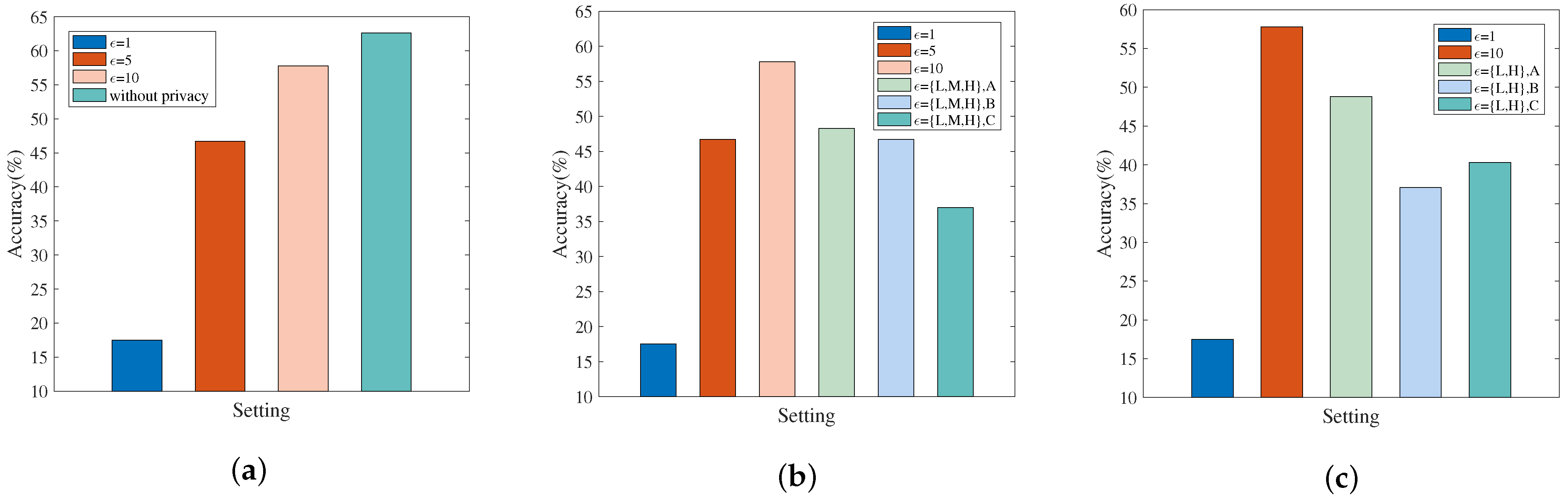
- MNIST: Experiments are configured with , , , , , , . When simulating the non-personalized scenario, each client’s privacy budget , is set to 1, 5, or 10. When simulating the personalized scenario, the privacy budgets of the three clients are set as , , or .
- Fashion-MNIST: Experiments are configured with , , , , , , . When simulating the non-personalized scenario, each client’s privacy budget , is set to 0.05, 0.5, or 1. When simulating the personalized scenario, the privacy budgets of the three clients are set as , , or .
- Forest cover-types: Experiments are configured with , , , , , , . When simulating the non-personalized scenario, each client’s privacy budget , is set to 1, 5, or 10. When simulating the personalized scenario, the privacy budgets of the ten clients are set as or .
5.2.2. Results Discussion
5.3. Experiments on Non-Independent Identically Distributed Data
5.3.1. Experiment Setting
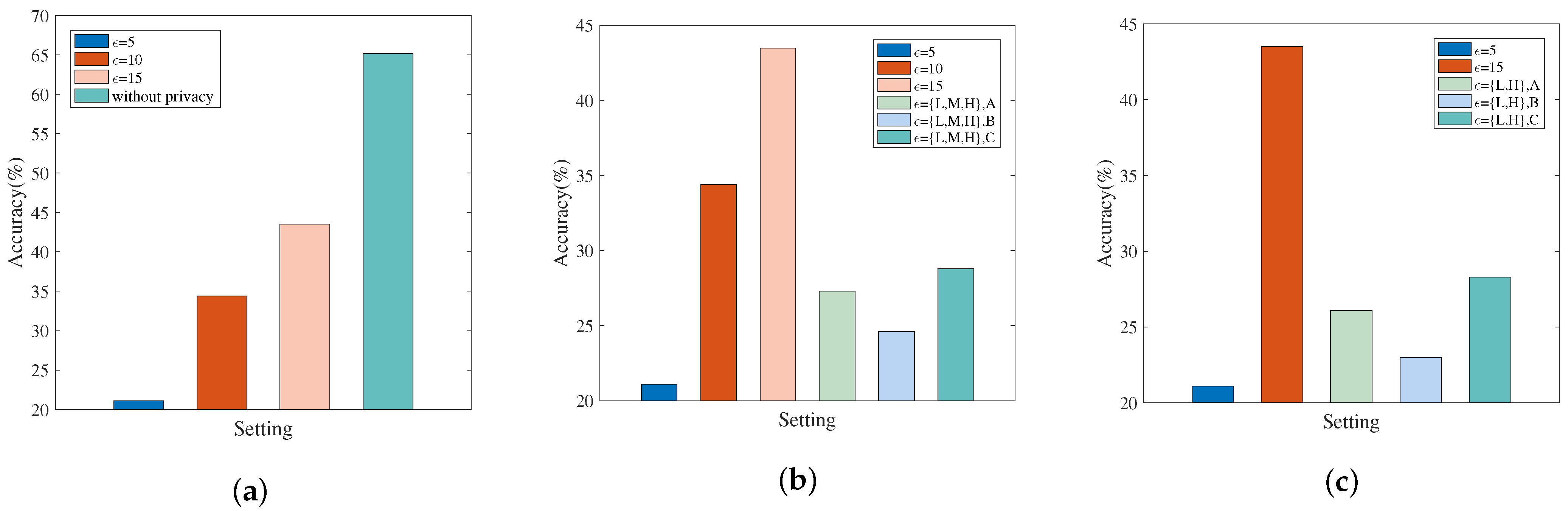
- MNIST: Experiments are configured with , , , , , , . When simulating the non-personalized scenario, each client’s privacy budget , is set to 5, 10, or 15. When simulating the personalized scenario, the privacy budgets of the ten clients are set as or .
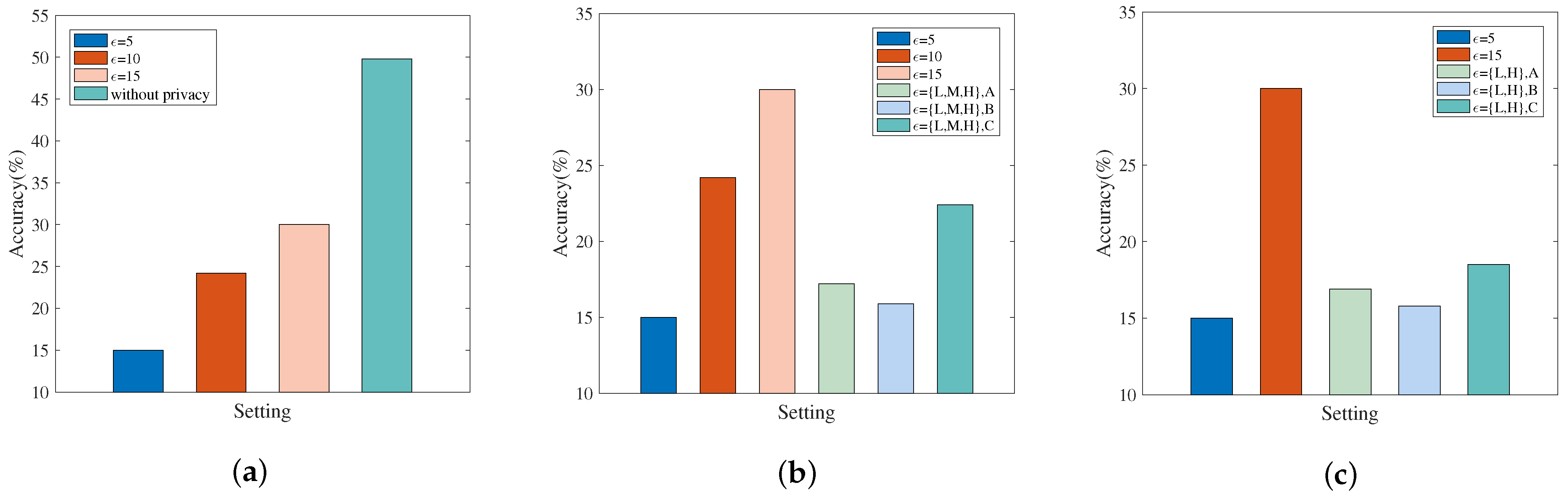
- Fashion-MNIST: Experiments are configured with , , , , , , . When simulating the non-personalized scenario, each client’s privacy budget , is set to 5, 10, or 15. When simulating the personalized scenario, the privacy budgets of the ten clients are set as or .
- Forest cover-types: Experiments are configured with , , , , , , . When simulating the non-personalized scenario, each client’s privacy budget , is set to 1, 5, or 10. When simulating the personalized scenario, the privacy budgets of the ten clients are set as or .
5.3.2. Results Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Abdulrahman, S.; Tout, H.; Ould-Slimane, H.; Mourad, A.; Guizani, M. A Survey on Federated Learning: The Journey From Centralized to Distributed On-Site Learning and Beyond. IEEE IoT 2020, 8, 5476–5497. [Google Scholar] [CrossRef]
- Fu, Y.; Luo, S.; Shu, J. Survey of Secure Cloud Storage System and Key Technologies. J. Comput. Res. Dev. 2013, 50, 136–145. [Google Scholar]
- General Data Protection Regulation. Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46. Off. J. Eur. Union 2016. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient Learning of Deep Networks from Decentralized Data. Artif. Intell. Stat. 2017, 54, 1273–1282. [Google Scholar]
- Shokri, M.N.R.; Houmansadr, A. Comprehensive Privacy Analysis of Deep Learning: Passive and Active White-box Inference Attacks against Centralized and Federated Learning. In Proceedings of the IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 16 September 2019. [Google Scholar] [CrossRef]
- Mothukuri, V.; Parizi, R.M.; Pouriyeh, S.; Huang, Y.; Dehghantanha, A.; Srivastava, G. A Survey on Security and Privacy of Federated Learning. FGCS 2021, 115, 619–640. [Google Scholar] [CrossRef]
- Yao, A.C. Protocols for Secure Computations. In Proceedings of the 23rd Annual IEEE Symposium on Foundations of Computer Science, Chicago, IL, USA, 18 July 2008. [Google Scholar] [CrossRef]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; Seth, K. Practical Secure Aggregation for Federated Learning on User-Held Data. arXiv 2016, arXiv:1611.04482. [Google Scholar]
- Abrego, L. On Data Banks and Privacy Homomorphisms. Found. Secur. Comput. 1978, 76, 169–179. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Chen, B.; Yu, S.; Deng, H. PEFL: A Privacy-Enhanced Federated Learning Scheme for Big Data Analytics. In Proceedings of 2019 IEEE Global Communications Conference, Waikoloa, HI, USA, 9–13 December 2019. [Google Scholar] [CrossRef]
- Dwork, C.; Roth, A. The Algorithmic Foundations of Differential privacy. Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Kasiviswanathan, S.P.; Lee, H.K.; Nissim, K.; Raskhodnikova, S.; Smith, A.D. What Can We Learn Privately? In Proceedings of the 49th Annual IEEE Symposium on Foundations of Computer Science, Philadelphia, PA, USA, 2 December 2008. [Google Scholar] [CrossRef] [Green Version]
- Duchi, J.C.; Jordan, M.I.; Wainwright, M.J. Local Privacy and Statistical Minimax Rates. In Proceedings of the 54th IEEE Annual Symposium on Foundations of Computer Science, Berkeley, CA, USA, 19 December 2013. [Google Scholar] [CrossRef]
- McMahan, H.B.; Ramage, D.; Talwar, K.; Zhang, L. Learning Differentially Private Recurrent Language Models. arXiv 2018, arXiv:1710.06963. [Google Scholar]
- Wang, N.; Xiao, X.; Yang, Y.; Zhao, J.; Hui, S.C.; Shin, H.; Shin, J.; Yu, G. Collecting and Analyzing Multidimensional Data with Local Differential Privacy. In Proceedings of the 35th IEEE International Conference on Data Engineering, Macao, China, 6 June 2019. [Google Scholar] [CrossRef] [Green Version]
- Truex, S.; Liu, L.; Chow, K.H.; Gursoy, M.E.; Wei, W. LDP-Fed: Federated Learning with Local Differential Privacy. arXiv 2020, arXiv:2006.03637. [Google Scholar]
- Mugunthan, V.; Peraire-Bueno, A.; Kagal, L. PrivacyFL: A Simulator for Privacy-preserving and Secure Federated Learning. arXiv 2020, arXiv:2002.08423. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated Machine Learning: Concept and Applications. ACM TIST 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Jin, R.; Huang, Y.; He, X.; Dai, H.; Wu, T. Stochastic-Sign SGD for Federated Learning with Theoretical Guarantees. arXiv 2020, arXiv:2002.10940. [Google Scholar]
- Warner, S.L. Randomized Response: A Survey Technique for Eliminating Evasive Answer Bias. JASA 1965, 60, 63–69. [Google Scholar] [CrossRef] [PubMed]
- Dwork, C.; Kenthapadi, K.; McSherry, F.; Mironov, I.; Naor, M. Our Data, Ourselves: Privacy Via Distributed Noise Generation, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 486–503. [Google Scholar] [CrossRef]
- Liu, R.; Cao, Y.; Chen, H.; Guo, R.; Yoshikawa, M. FLAME: Differentially Private Federated Learning in the Shuffle Model. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021. [Google Scholar]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated Learning with Non-IID Data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Robbins, H.; Monro, S. A Stochastic Approximation Method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Kim, M.; Gunlu, O.; Schaefer, R.F. Federated Learning with Local Differential Privacy: Trade-offs between Privacy, Utility, and Communication. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, ON, Canada, 13 May 2021. [Google Scholar] [CrossRef]
- Sun, L.; Qian, J.; Chen, X. LDP-FL: Practical Private Aggregation in Federated Learning with Local Differential Privacy. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–27 August 2021. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, X.; Hong, M.; Wu, S.; Yi, J. Understanding Clipping for Federated Learning: Convergence and Client-Level Differential Privacy. arXiv 2021, arXiv:2106.13673. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep Learning with Differential Privacy. In Proceedings of the ACM Conference on Compututer and Communication Security, Vienna, Austria, 24–28 October 2016. [Google Scholar] [CrossRef] [Green Version]
- Hosmer, D.W. Stanley Lemeshow. In Applied Logistic Regression, 1st ed.; Wiley: Hoboken, NJ, USA, 2000. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description | Symbol | Description |
|---|---|---|---|
| Real number field | M | Perturbation mechanism | |
| f | Aggregation rule | N | Total number of clients |
| m | Number of selected clients by using probability parameter | i | The i-th client |
| R | Maximum number of training rounds | r | The r-th round () |
| d | Dimension of model parameter | Learning rate of SGD | |
| U | Maximum number of logistic regression rounds | q | Random sampling probability |
| A uniformly distributed random number between 0 and 1, generated by the server | Training dataset of the i-th client | ||
| Privacy budget of the i-th client | Clipping threshold of the i-th client | ||
| Inverse of training dataset size (default: ) | Standard deviation of the i-th client | ||
| Weighting coefficient of the i-th client in the weighted average method | Inverse of the standard deviation of the Gaussian distribution of the i-th client | ||
| Probability parameter of the i-th client | Initial federated model parameter | ||
| Federated model parameter generated in the r-th round | Gradient of the i-th client in the r-th round | ||
| Local model update of the i-th client in the r-th round | Local model parameter of the i-th client generated in the r-th round | ||
| Clipped local model parameter of the i-th client generated in the r-th round | Perturbed local model parameter of the i-th client generated in the r-th round |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, X.; Xu, L.; Zhu, L. Local Differential Privacy-Based Federated Learning under Personalized Settings. Appl. Sci. 2023, 13, 4168. https://doi.org/10.3390/app13074168
Wu X, Xu L, Zhu L. Local Differential Privacy-Based Federated Learning under Personalized Settings. Applied Sciences. 2023; 13(7):4168. https://doi.org/10.3390/app13074168
Chicago/Turabian StyleWu, Xia, Lei Xu, and Liehuang Zhu. 2023. "Local Differential Privacy-Based Federated Learning under Personalized Settings" Applied Sciences 13, no. 7: 4168. https://doi.org/10.3390/app13074168