Recovering Microscopic Images in Material Science Documents by Image Inpainting

Abstract
:1. Introduction
2. Related Works and Backgrounds
2.1. Microscopic Images in Material Science Documents
2.2. Image Inpainting Methods
3. Results
3.1. Data Preparation
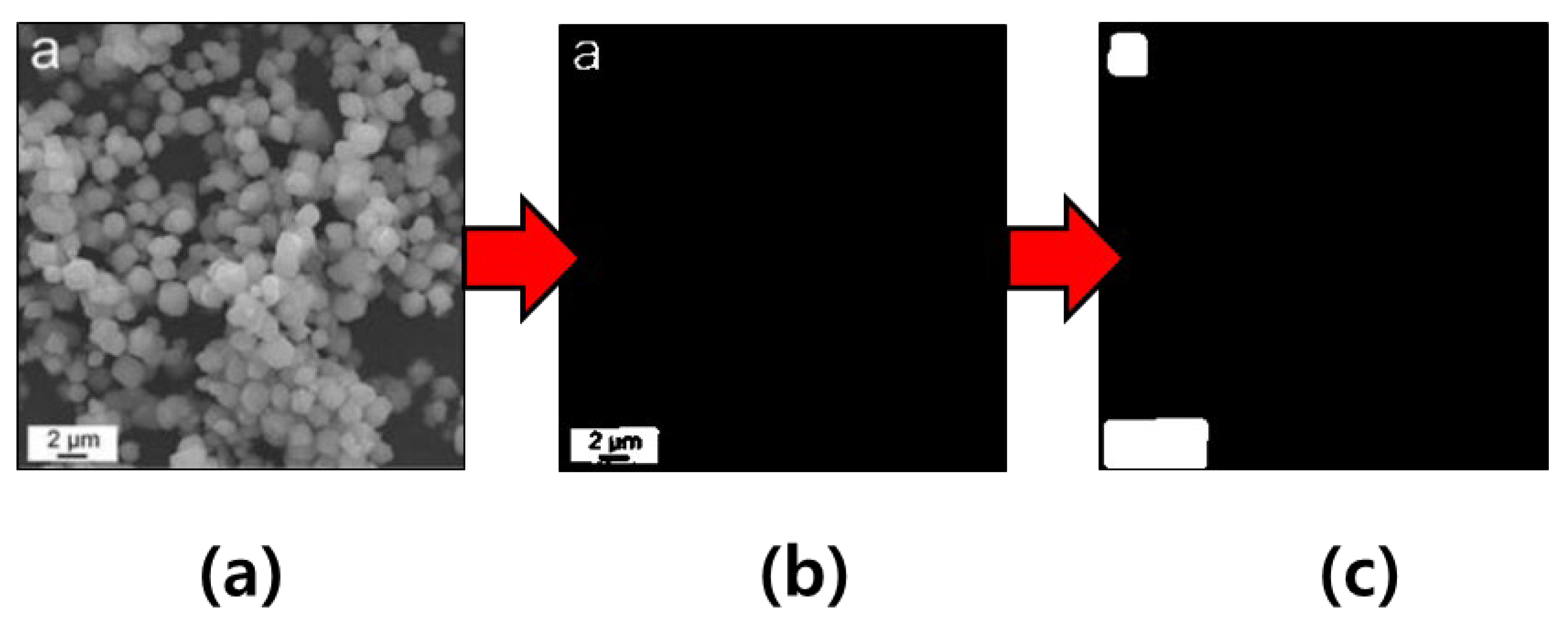
3.2. Generating Inputs Using Masks
3.3. Comparisons of Masks and Models
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Talebian, S.; Rodrigues, T.; Neves, J.; Sarmento, B.; Langer, R.; Conde, J. Facts and Figures on Materials Science and Nanotechnology Progress and Investment. ACS Nano 2021, 15, 15940–15952. [Google Scholar] [CrossRef] [PubMed]
- Williams, D.B.; Carter, C.B. The Transmission Electron Microscope. In Transmission Electron Microscopy; Springer: Boston, MA, USA, 1996; pp. 3–17. [Google Scholar]
- Li, J.; Johnson, G.; Zhang, S.; Su, D. In situ transmission electron microscopy for energy applications. Joule 2019, 3, 4–8. [Google Scholar] [CrossRef] [Green Version]
- Goldstein, J.I.; Newbury, D.E.; Michael, J.R.; Ritchie, N.W.; Scott, J.H.J.; Joy, D.C. Scanning Electron Microscopy and X-ray Microanalysis; Springer: New York, NY, USA, 2017. [Google Scholar]
- Wiesendanger, R.; Roland, W. Scanning Probe Microscopy and Spectroscopy: Methods and Applications; Cambridge University Press: Cambridge, UK, 1994. [Google Scholar]
- Crewe, A.V. Scanning transmission electron microscopy. J. Microsc. 1974, 100, 247–259. [Google Scholar] [CrossRef] [PubMed]
- Himanen, L.; Geurts, A.; Foster, A.S.; Rinke, P. Data-Driven Materials Science: Status, Challenges, and Perspectives. Adv. Sci. 2019, 6, 1900808. [Google Scholar] [CrossRef]
- Zhang, L.; Shao, S. Image-based machine learning for materials science. J. Appl. Phys. 2022, 132, 100701. [Google Scholar] [CrossRef]
- Ge, M.; Su, F.; Zhao, Z.; Su, D. Deep learning analysis on microscopic imaging in materials science. Mat. Today Nano 2020, 11, 100087. [Google Scholar] [CrossRef]
- Nguyen, T.N.M.; Guo, Y.; Qin, S.; Frew, K.S.; Xu, R.; Agar, J.C. Symmetry-aware recursive image similarity exploration for materials microscopy. Npj Comput. Mater. 2021, 7, 166. [Google Scholar] [CrossRef]
- Ma, B.; Wei, X.; Liu, C.; Ban, X.; Huang, H.; Wang, H.; Xue, W.; Wu, S.; Gao, M.; Shen, Q.; et al. Data augmentation in microscopic images for material data mining. Npj Comput. Mater. 2020, 6, 125. [Google Scholar] [CrossRef]
- Chen, F.; Lu, Q.; Fan, T.; Fang, R.; Li, Y. Ionic liquid [Bmim][AuCl4] encapsulated in ZIF-8 as precursors to synthesize N-decorated Au catalysts for selective aerobic oxidation of alcohols. Catal. Today 2020, 351, 94–102. [Google Scholar] [CrossRef]
- Hou, X.; Han, Z.; Xu, X.; Sarker, D.; Zhou, J.; Wu, M.; Liu, Z.; Huang, M.; Jiang, H. Controllable amorphization engineering on bimetallic metal–organic frameworks for ultrafast oxygen evolution reaction. Chem. Eng. J. 2021, 418, 129330. [Google Scholar] [CrossRef]
- Liu, S.; Zhao, T.; Tan, X.; Guo, L.; Wu, J.; Kang, X.; Wang, H.; Sun, L.; Chu, W. 3D pomegranate-like structures of porous carbon microspheres self-assembled by hollow thin-walled highly-graphitized nanoballs as sulfur immobilizers for Li–S batteries. Nano Energy 2019, 63, 103894. [Google Scholar] [CrossRef]
- Liu, G.; Reda, F.A.; Shih, K.J.; Wang, T.-C.; Tao, A.; Catanzaro, B. Image inpainting for irregular holes using partial convolutions. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 85–100. [Google Scholar]
- Simakov, D.; Caspi, Y.; Shechtman, E.; Irani, M. Summarizing visual data using bidirectional similarity. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8. [Google Scholar]
- Bertalmio, M.; Vese, L.; Sapiro, G.; Osher, S. Simultaneous structure and texture image inpainting. IEEE Trans. Image Process. 2003, 12, 882–889. [Google Scholar] [CrossRef]
- Criminisi, A.; Perez, P.; Toyama, K. Object removal by exemplar-based inpainting. In Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003; pp. 1–8. [Google Scholar]
- Barnes, C.; Shechtman, E.; Finkelstein, A.; Goldman, D.B. PatchMatch: A randomized correspondence algorithm for structural image editing. ACM Trans. Graph. 2009, 28, 24. [Google Scholar] [CrossRef]
- Bertalmio, M.; Sapiro, G.; Caselles, V.; Ballester, C. Image inpainting. In Proceedings of the 27th Annual Conference on computer Graphics and Interactive Techniques, SIGGRAPH 2000, New Orleans, LA, USA, 23–28 July 2000; pp. 417–424. [Google Scholar]
- Ballester, C.; Bertalmio, M.; Caselles, V.; Sapiro, G.; Verdera, J. Filling-in by joint interpolation of vector fields and gray levels. IEEE Trans. Image Process. 2001, 10, 1200–1211. [Google Scholar] [CrossRef] [Green Version]
- Levin, A.; Zomet, A.; Weiss, Y. Learning How to Inpaint from Global Image Statistics. In Proceedings of the ICCV, Nice, France, 14–17 October 2003; pp. 305–312. [Google Scholar]
- Yan, Z.; Li, X.; Li, M.; Zuo, W.; Shan, S. Shift-net: Image inpainting via deep feature rearrangement. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 1–17. [Google Scholar]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Globally and locally consistent image completion. ACM Trans. Graph. 2017, 36, 1–14. [Google Scholar] [CrossRef]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5505–5514. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Free-form image inpainting with gated convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4471–4480. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1452–1464. [Google Scholar] [CrossRef] [Green Version]
- Doersch, C.; Singh, S.; Gupta, A.; Sivic, J.; Efros, A. What makes paris look like paris? ACM Trans. Graph. 2012, 31, 103–110. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Tyleček, R.; Šára, R. Spatial pattern templates for recognition of objects with regular structure. In Proceedings of the Pattern Recognition: 35th German Conference (GCPR 2013), Saarbrücken, Germany, 3–6 September 2013; pp. 364–374. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Cimpoi, M.; Maji, S.; Kokkinos, I.; Mohamed, S.; Vedaldi, A. Describing textures in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2014; pp. 3606–3613. [Google Scholar]
- Xie, J.; Xu, L.; Chen, E. Image denoising and inpainting with deep neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 341–349. [Google Scholar]
- Köhler, R.; Schuler, C.; Schölkopf, B.; Harmeling, S. Mask-specific inpainting with deep neural networks. In Proceedings of the Pattern Recognition: 36th German Conference, GCPR 2014, Münster, Germany, 2–5 September 2014; pp. 523–534. [Google Scholar]
- Ren, J.S.; Xu, L.; Yan, Q.; Sun, W. Shepard convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 901–909. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Content-Aware Fill. Available online: https://helpx.adobe.com/photoshop-elements/using/content-aware-fill.html (accessed on 7 June 2022).
- Xu, K.; Shen, X.; Ji, Z.; Yuan, A.; Kong, L.; Zhu, G.; Zhu, J. Highly monodispersed Fe2WO6 micro-octahedrons with hierarchical porous structure and oxygen vacancies for lithium storage. Chem. Eng. J. 2021, 413, 127504. [Google Scholar] [CrossRef]
- Cao, X.; Cheng, S.; You, Y.; Zhang, S.; Xian, Y. Sensitive monitoring and bioimaging intracellular highly reactive oxygen species based on gold nanoclusters@ nanoscale metal-organic frameworks. Anal. Chim. Acta 2019, 1092, 108–116. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]







{kind=link}
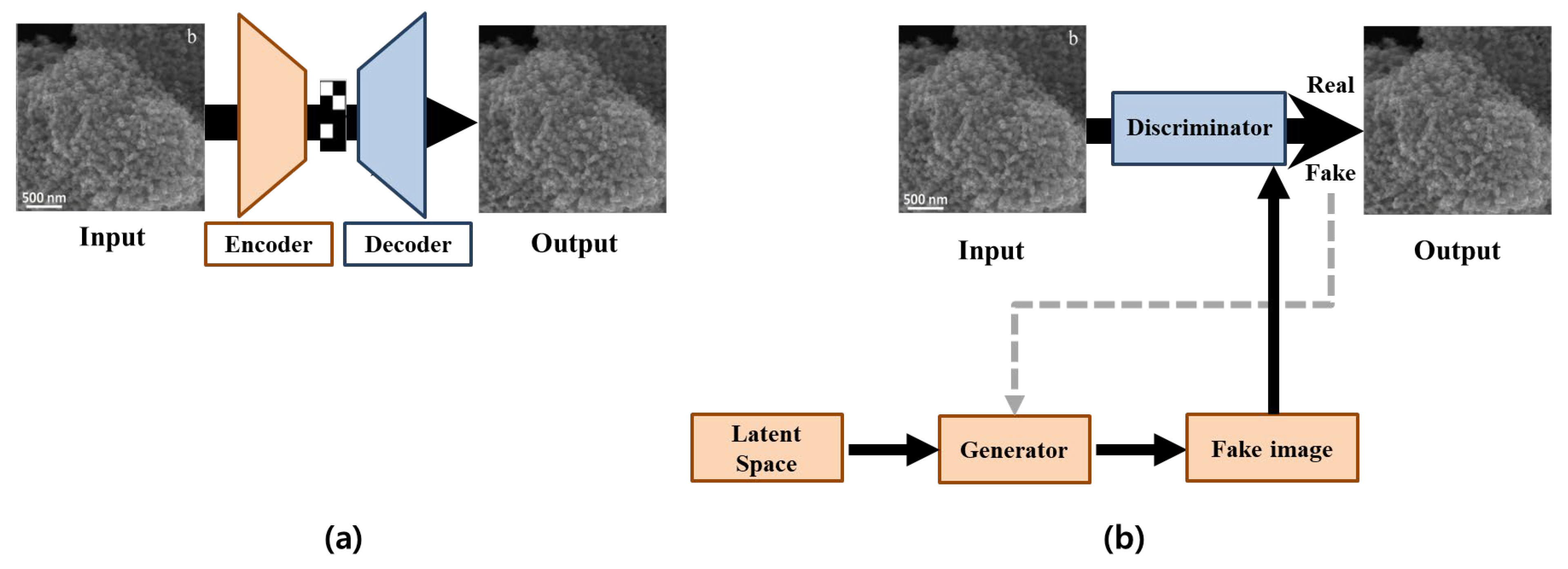{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Type | Method | Dataset |
|---|---|---|---|
| Non-learning approach | Patch-based | Simakov et al. [16] | - |
| Bertalmio et al. [17] | - | ||
| Criminisi et al. [18] | - | ||
| PatchMatch algorithm [19] | - | ||
| Diffusion-based | Baertalmio et al. [20] | - | |
| Ballester et al. [21] | - | ||
| Levin et al. [22] | - | ||
| Deep-learning approach | CNN-based | Shift-Net [23] | Places [27], Paris street View [28] |
| GAN-based | Global and Local [24] | Places2 [27], ImageNet [29], CMP FAcade [30] | |
| Contextual Attention [25] | Places2 [27], ImageNet [29], CelebA [31], CelebA-HQ [32], DTD [33] | ||
| Gated convolution [26] | Places2 [27] |
| Method | SSIM | ||
|---|---|---|---|
| None | 0.29 | 7.85% | 3.94% |
| Shift-Net | 0.80 (0.09) | 4.40% (1.91) | 1.99% (1.08) |
| Global and Local | 0.82 (0.09) | 4.24% (2.03) | 1.85% (0.79) |
| Contextual Attention | 0.89 (0.09) | 3.97% (1.72) | 1.79% (0.79) |
| Gated convolution | 0.94 (0.08) | 3.22% (1.69) | 1.57% (0.83) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, T.; Yeo, B.C. Recovering Microscopic Images in Material Science Documents by Image Inpainting. Appl. Sci. 2023, 13, 4071. https://doi.org/10.3390/app13064071
Kim T, Yeo BC. Recovering Microscopic Images in Material Science Documents by Image Inpainting. Applied Sciences. 2023; 13(6):4071. https://doi.org/10.3390/app13064071
Chicago/Turabian StyleKim, Taeyun, and Byung Chul Yeo. 2023. "Recovering Microscopic Images in Material Science Documents by Image Inpainting" Applied Sciences 13, no. 6: 4071. https://doi.org/10.3390/app13064071