
Research on Fault Diagnosis Algorithm of Ship Electric Propulsion Motor

Abstract
:1. Introduction
2. Theoretical Background
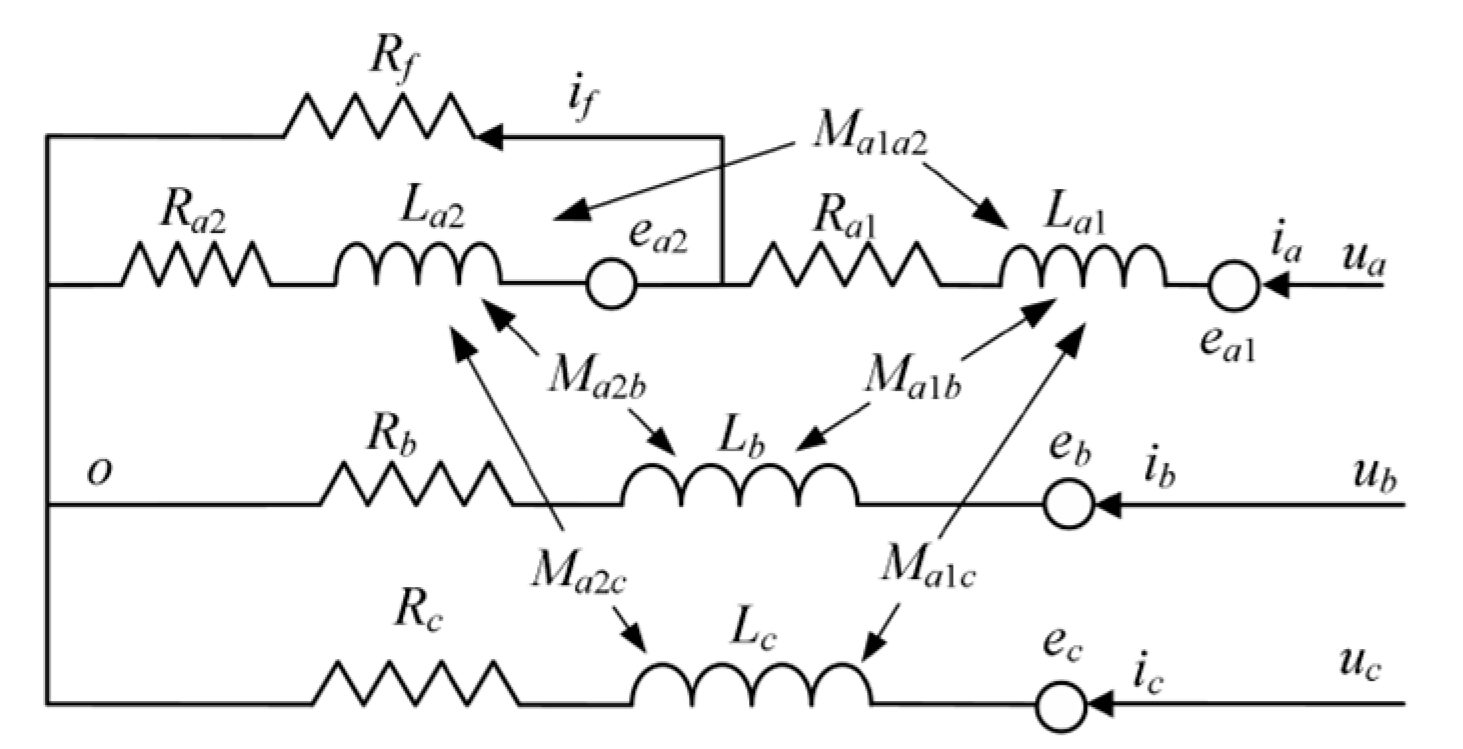
2.1. Mathematical Model of PMSM under Interturn Short-Circuit Fault
2.2. Variational Mode Decomposition
2.3. Constructing Multi-Scale Features
2.4. Principal Component Analysis
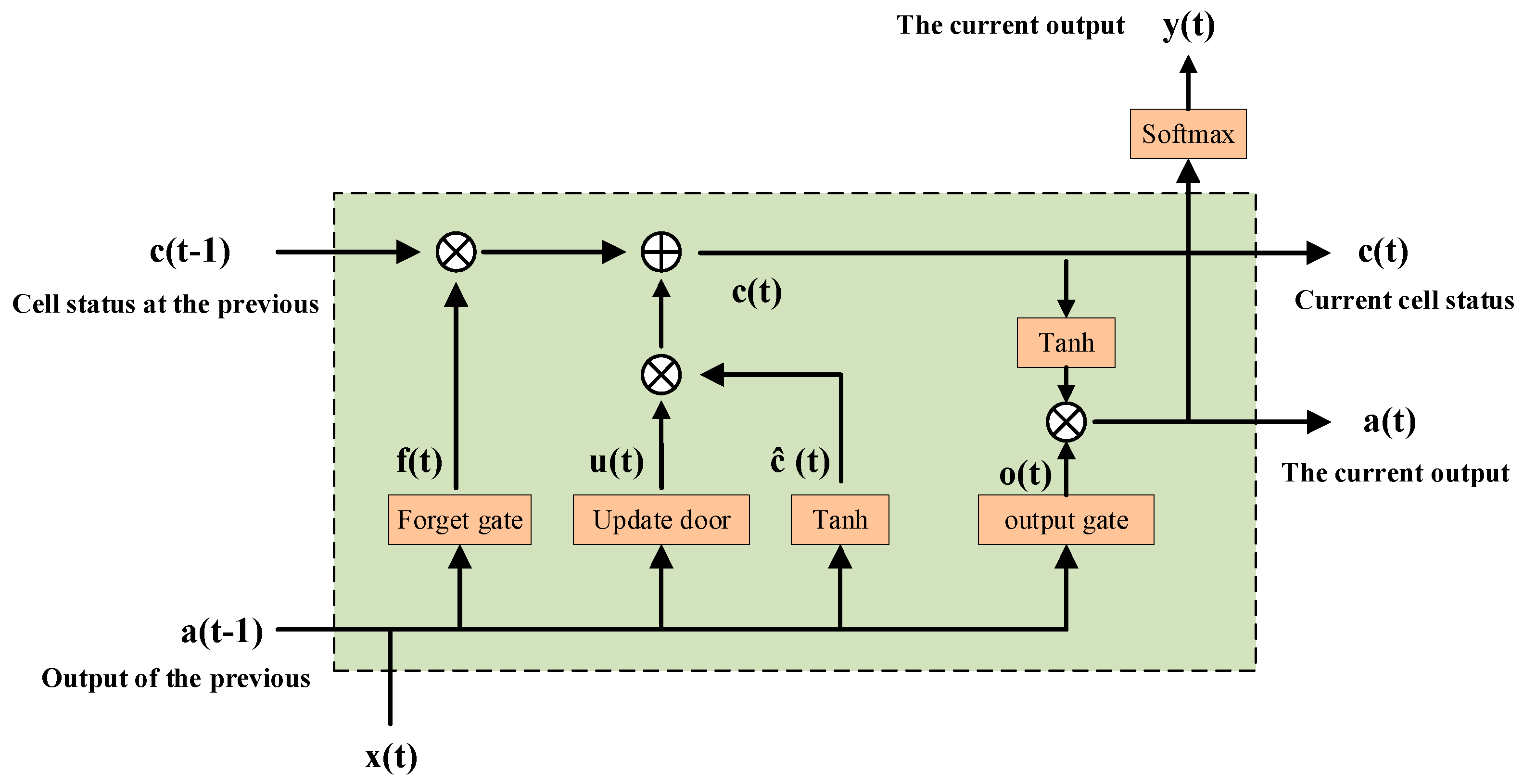
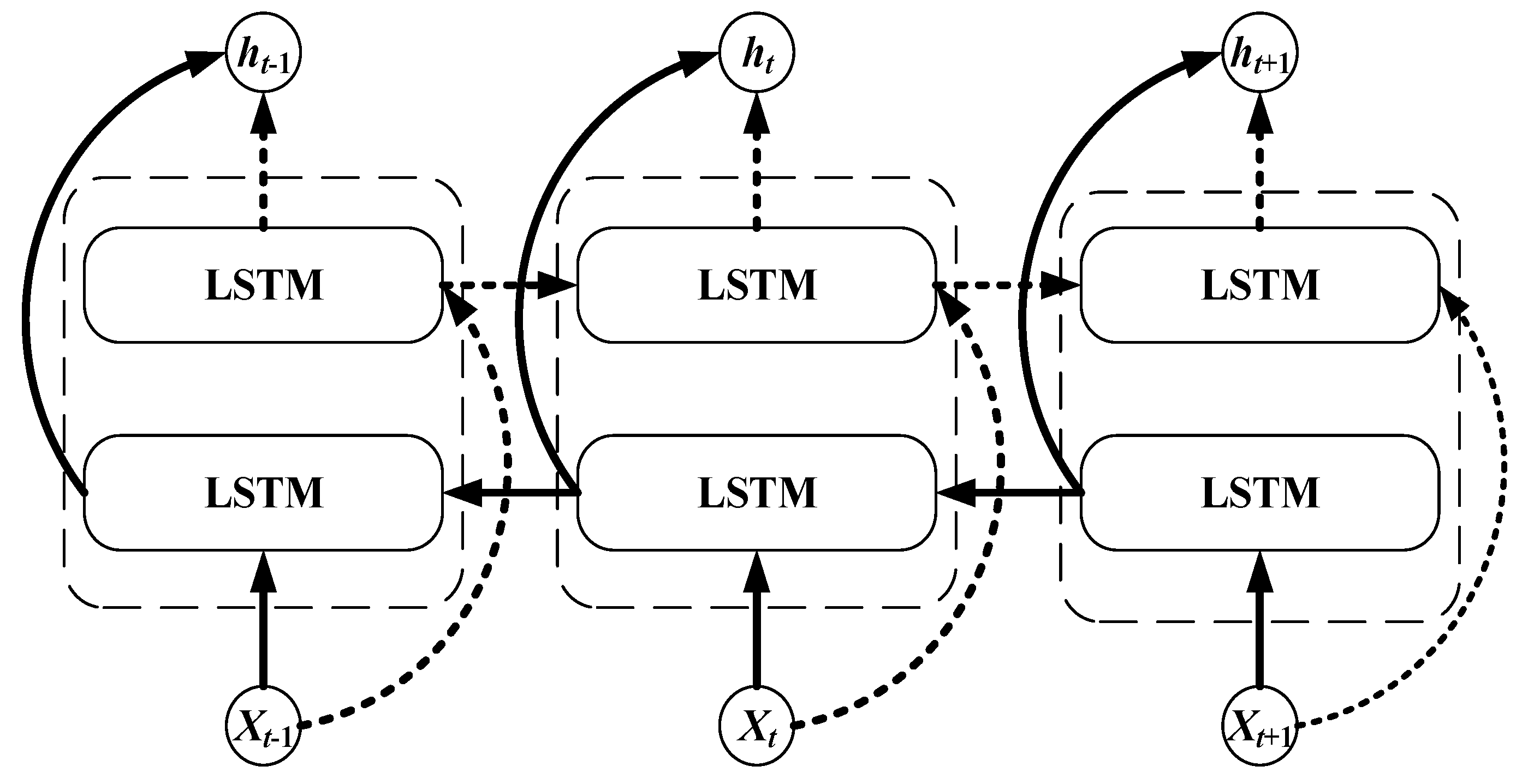
2.5. Long Short-Term Memory Neural Network
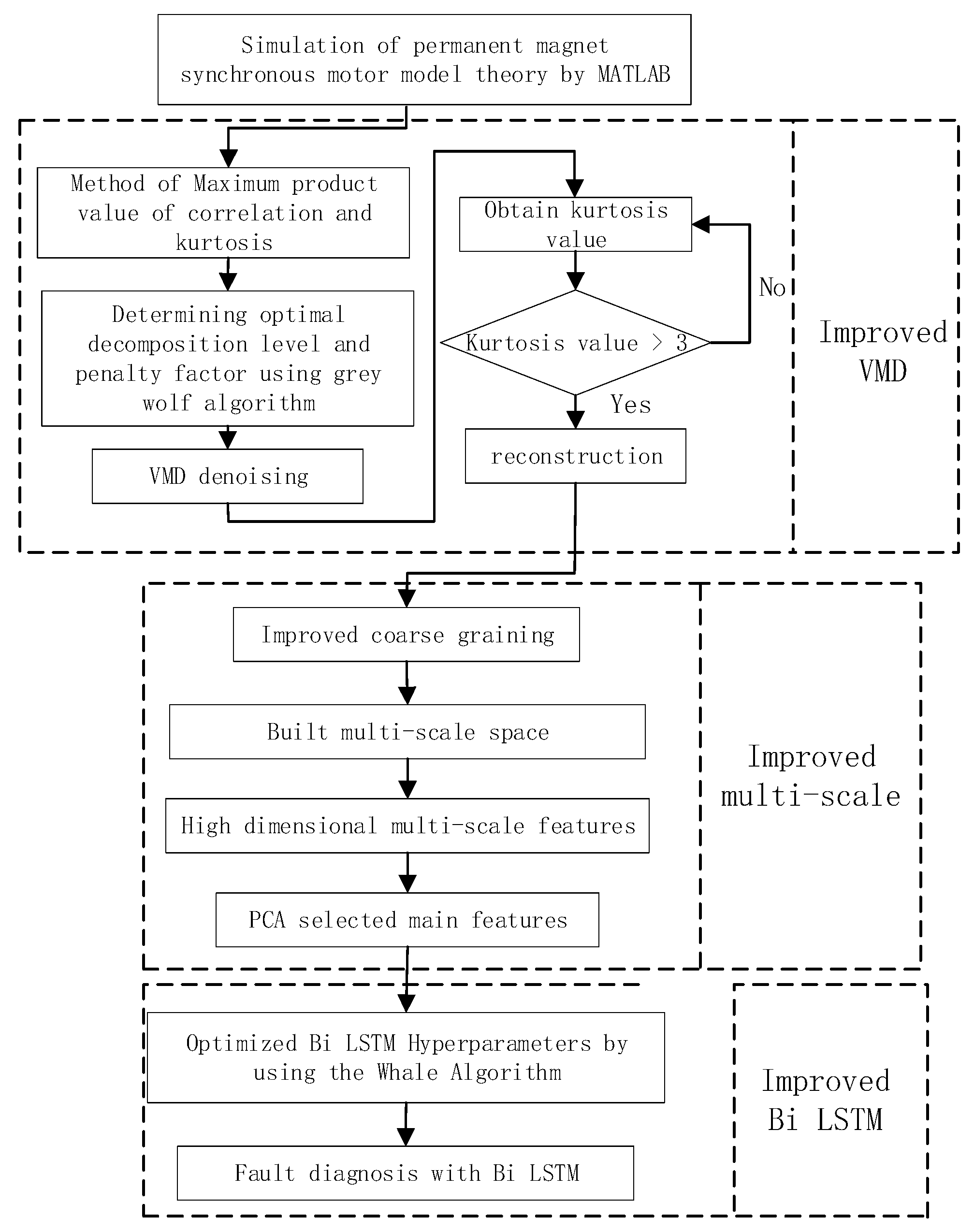
3. The Proposed Method
3.1. Model Optimization of Variational Mode Decomposition
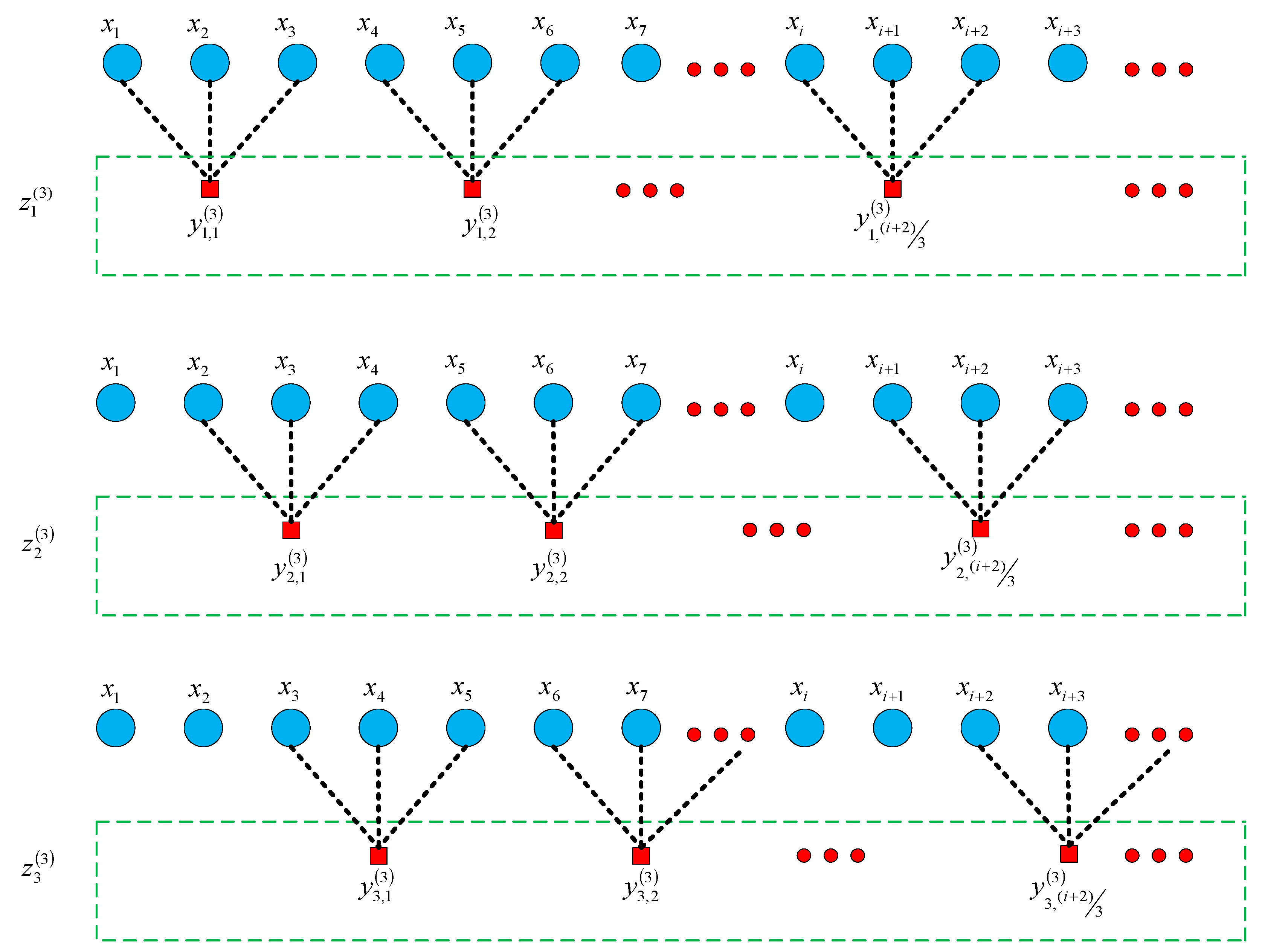
3.2. Multi-Scale Feature Optimization Based on Improved Coarse-Graining
- The given signal is processed by the improved coarse-grained process to obtain sets of time series:
- For each set of new coarse-grained time series , its characteristic value in time and frequency domains are obtained, and then the average value of τ time series eigenvalues is calculated to obtain the eigenvalues under the time scale .

3.3. Parameter Optimization of Long Short-Term Memory Neural Network
4. Experiments and Results
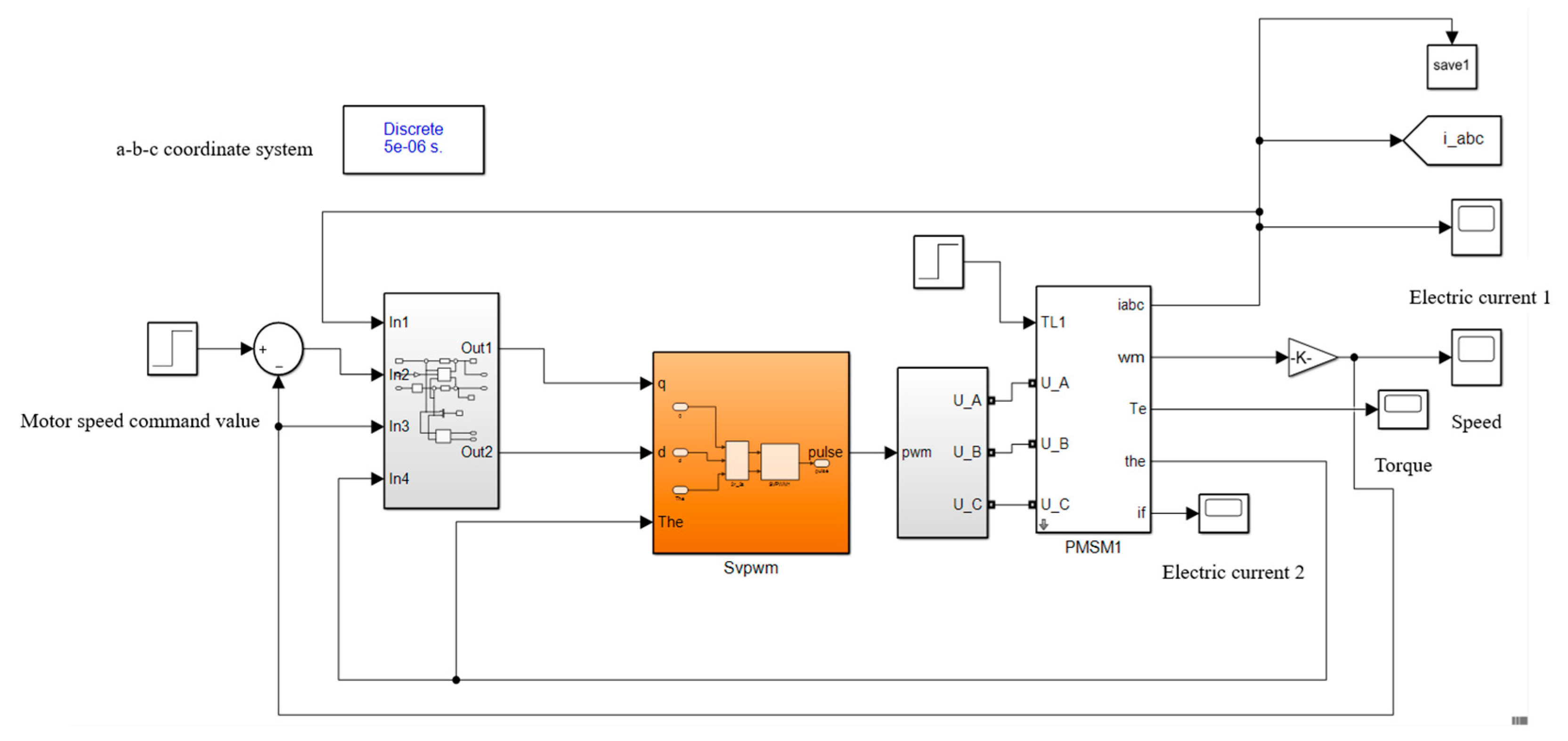
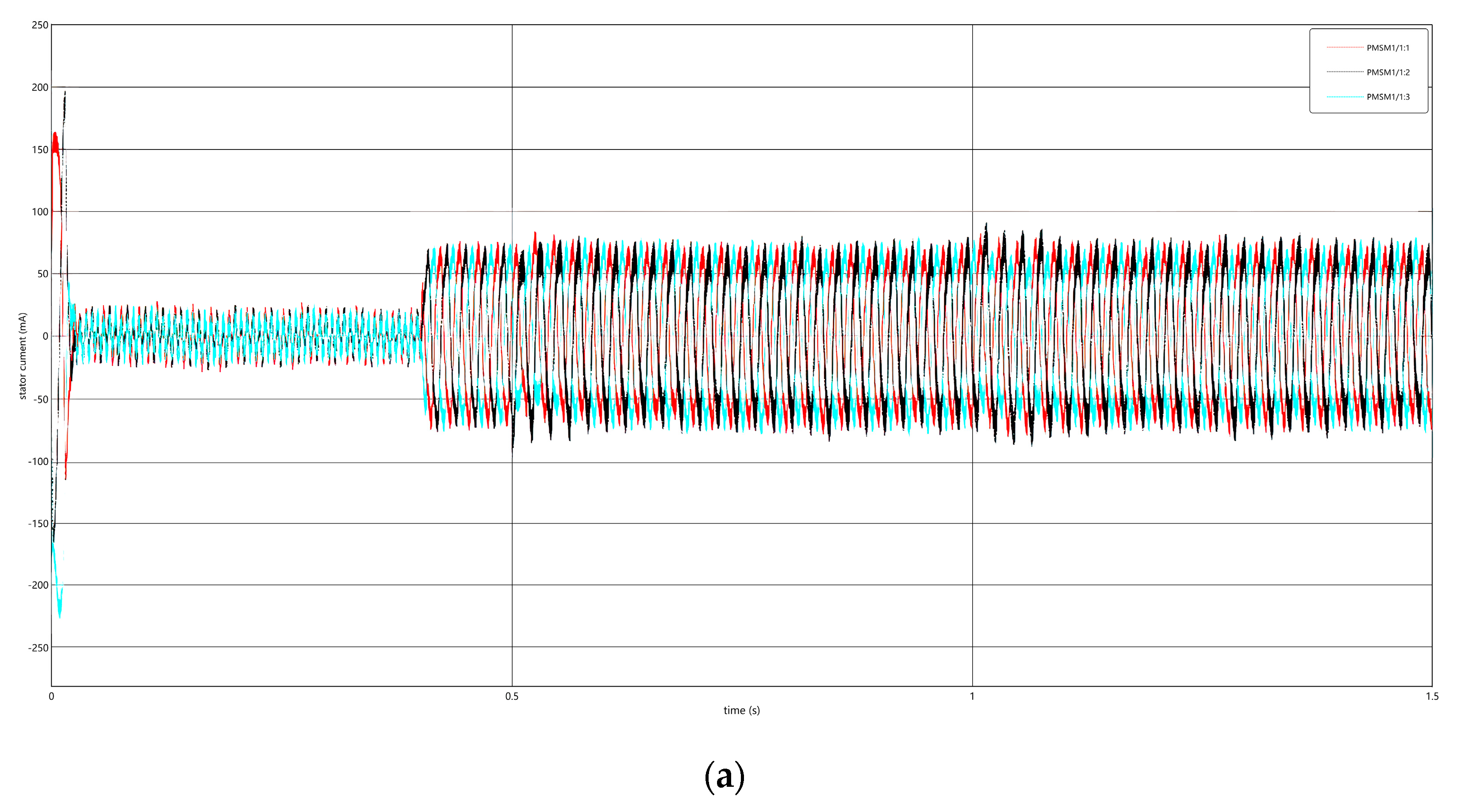
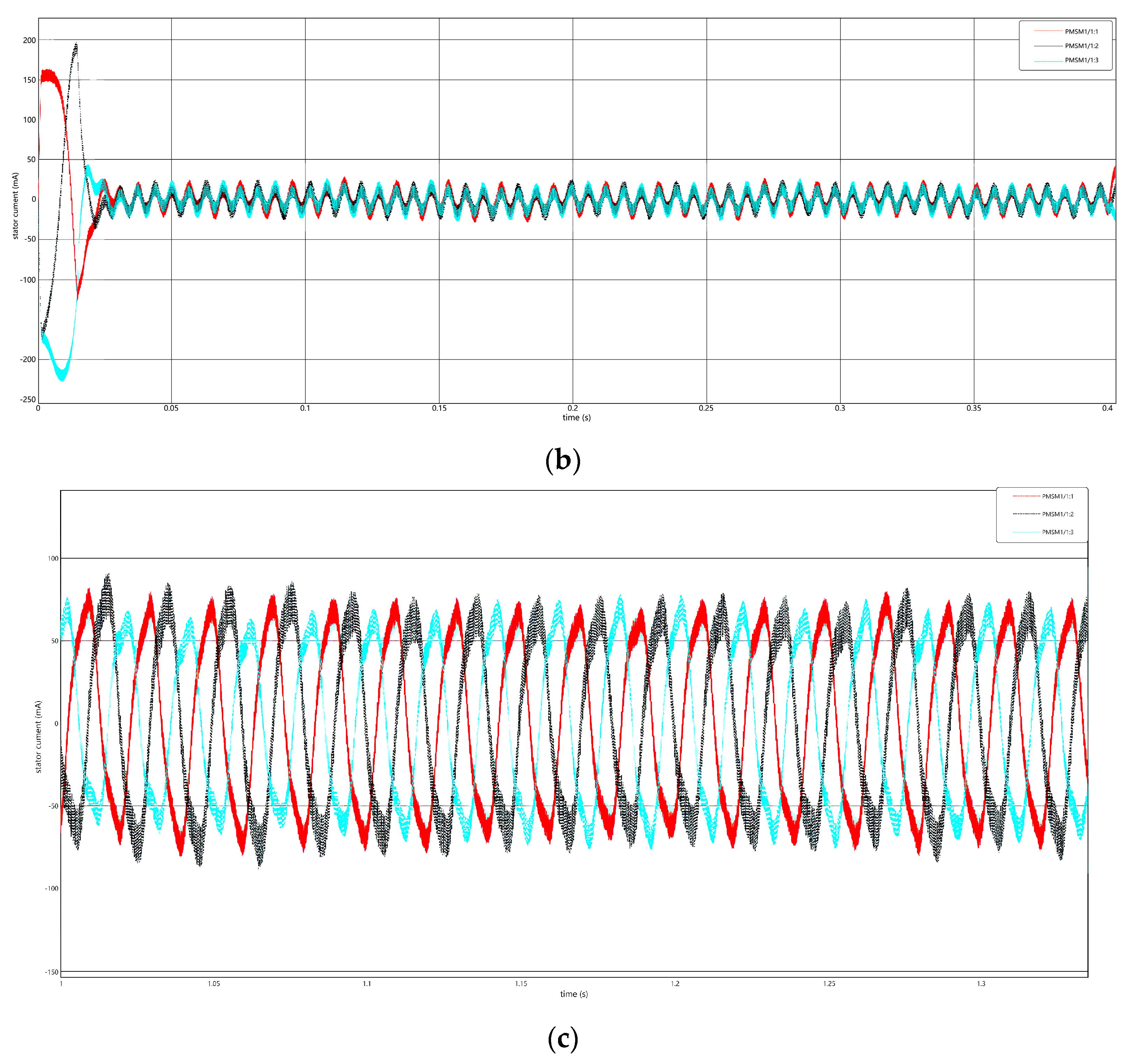
4.1. Data Acquisition
4.2. Ablation Experiments
4.2.1. The Effectiveness of the VMD Algorithm Based on GWO Optimization
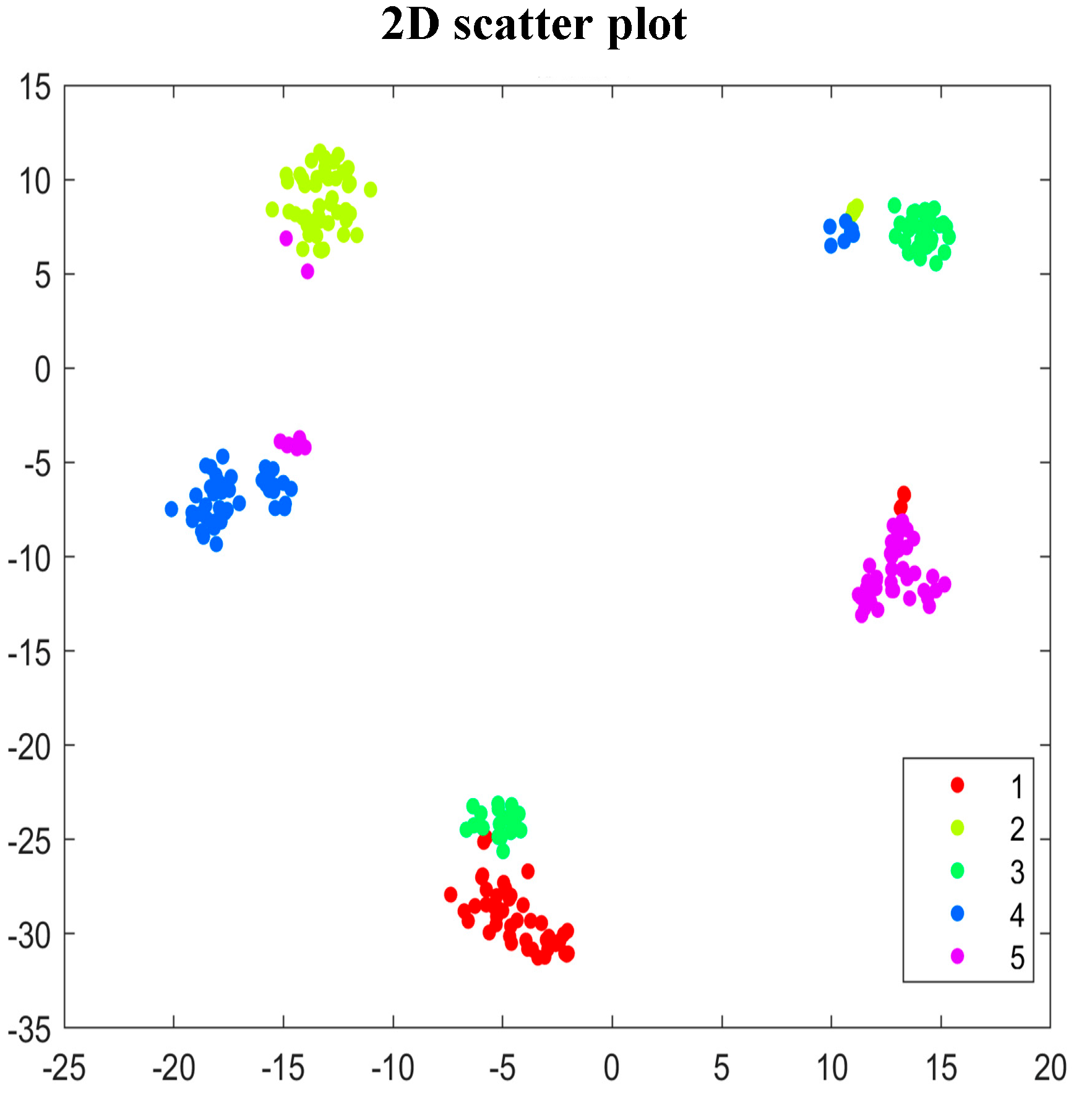
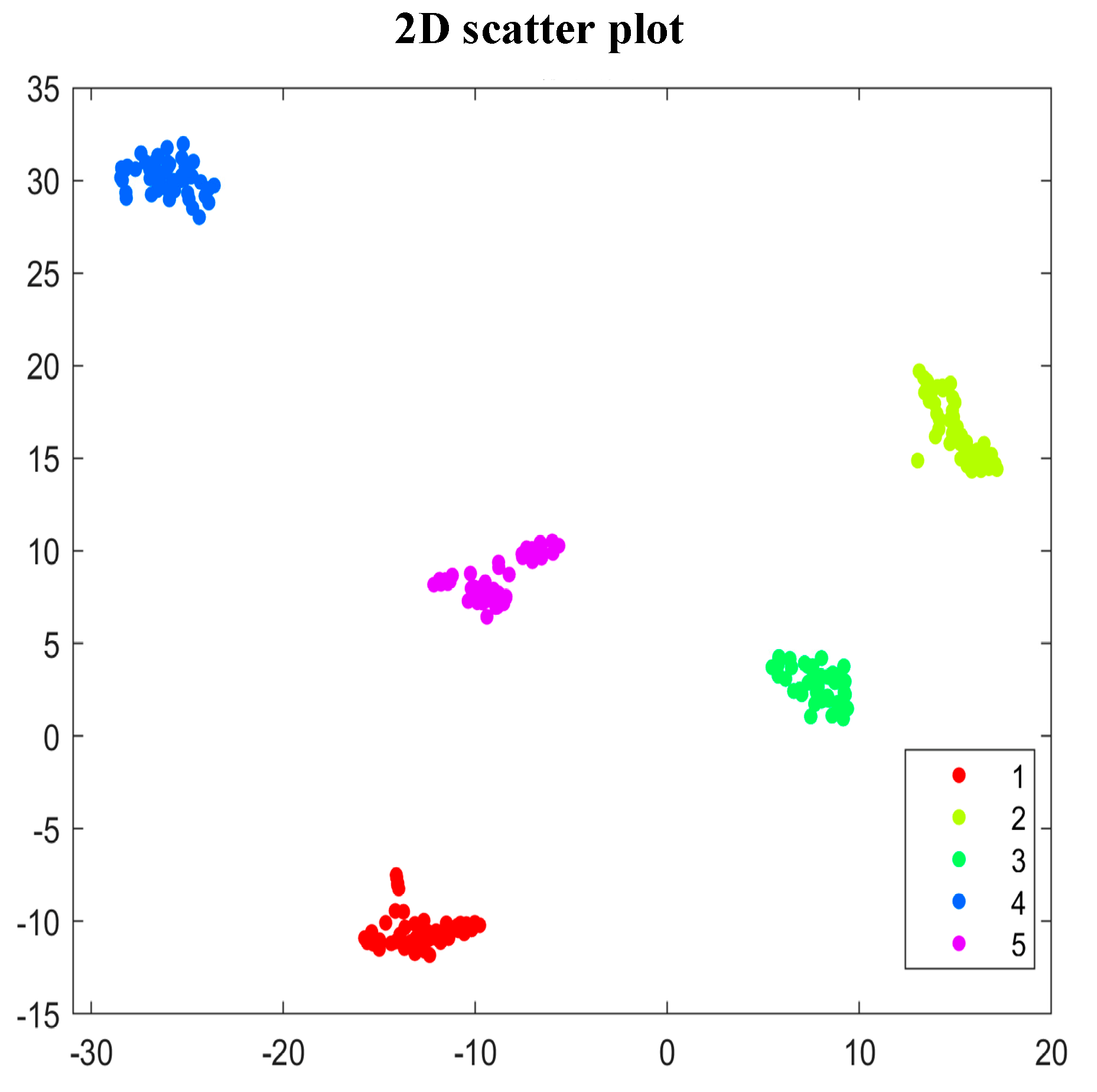
4.2.2. The Effectiveness of the Improved Coarse-Grained Multi-Scale Feature Extraction Method
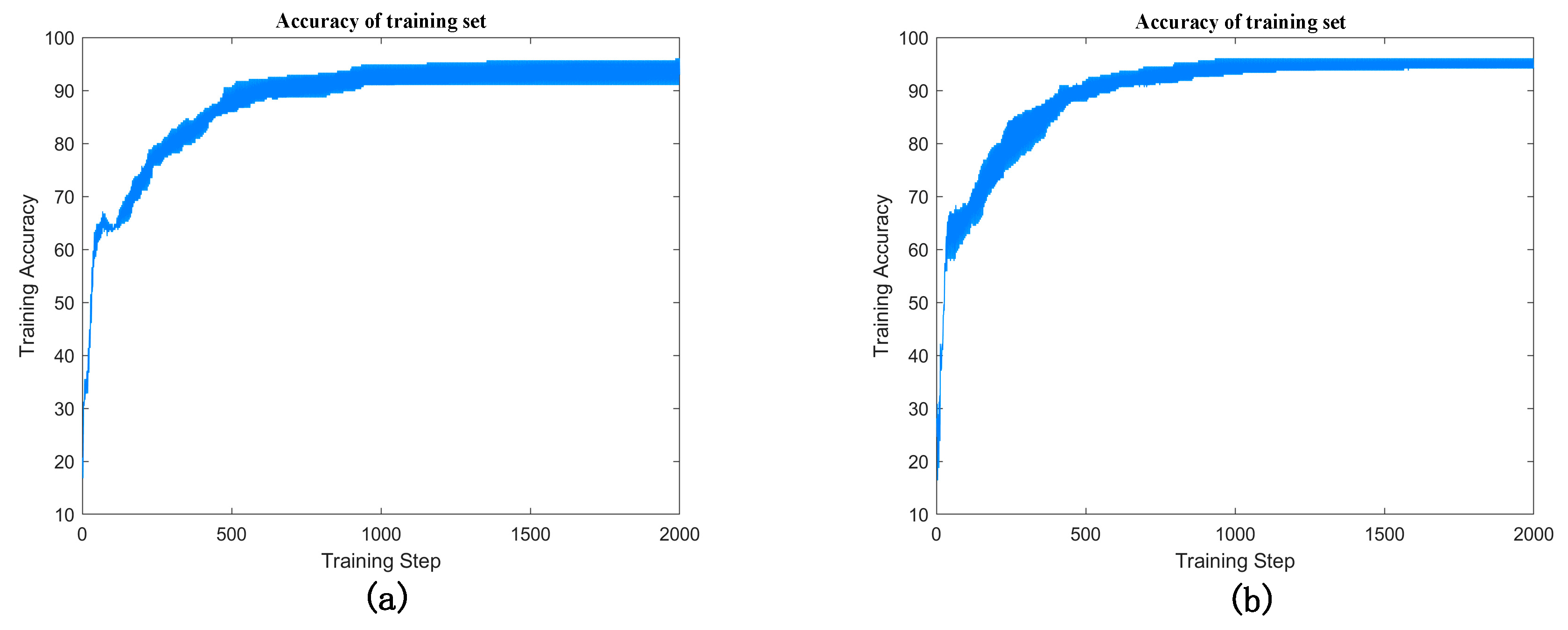
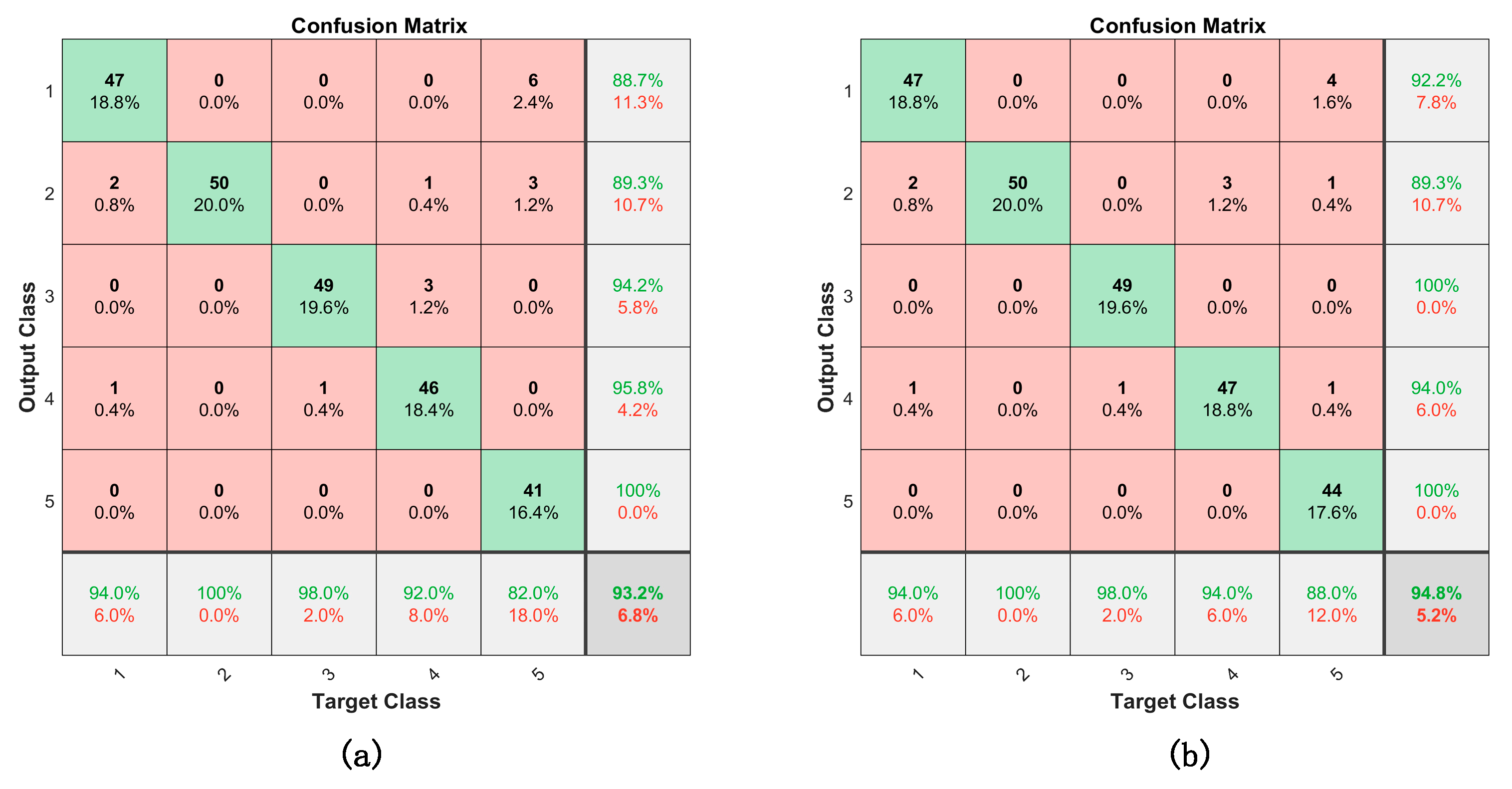
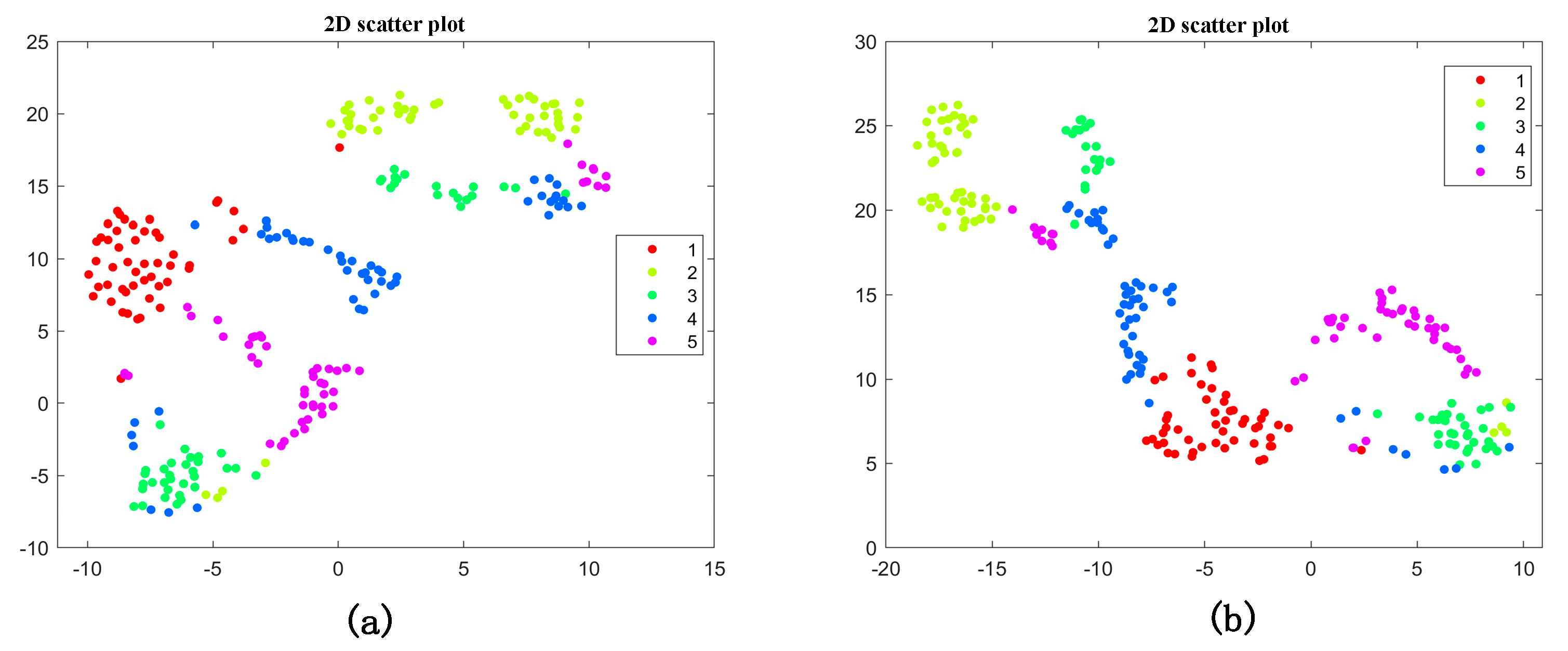
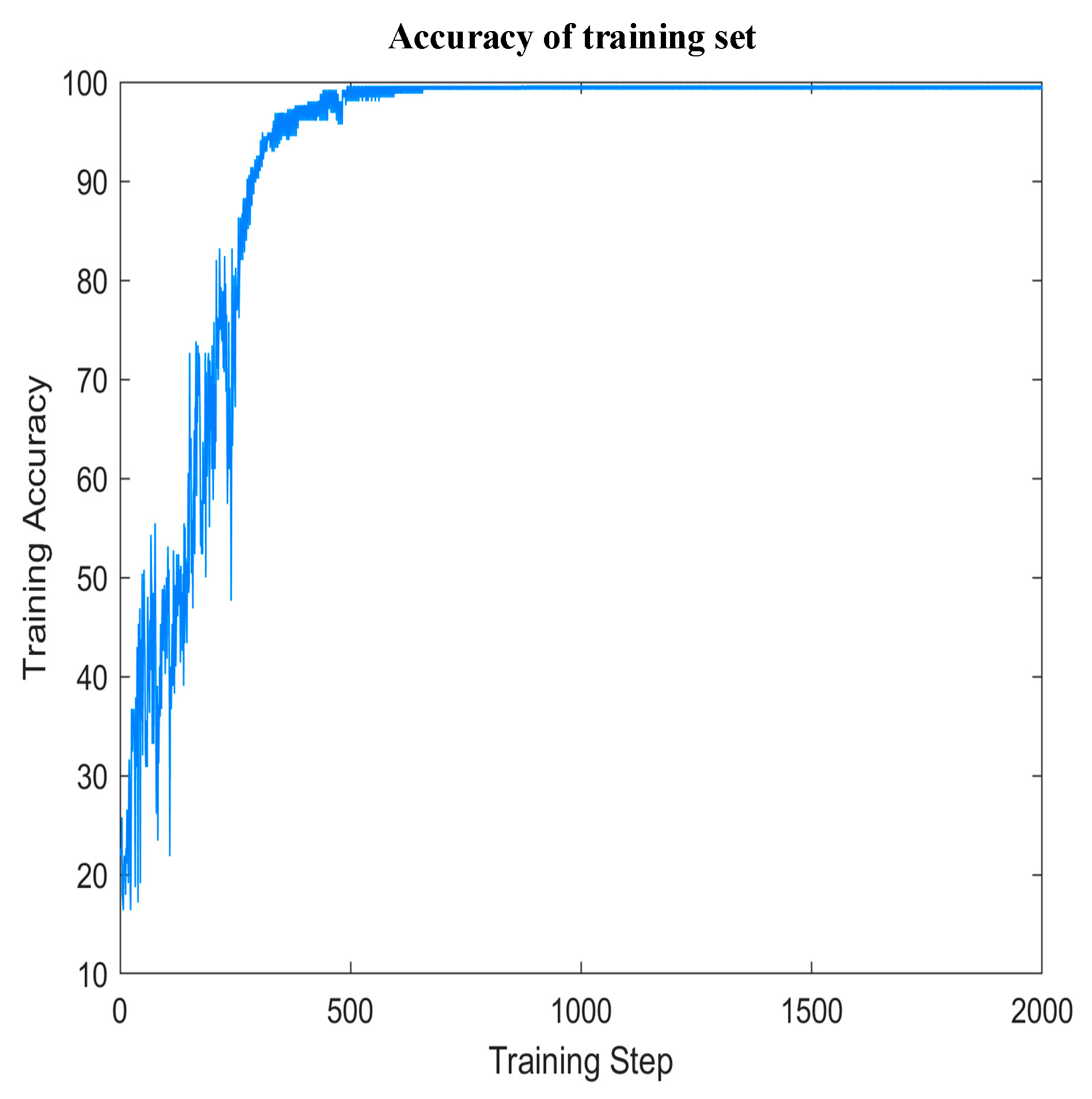
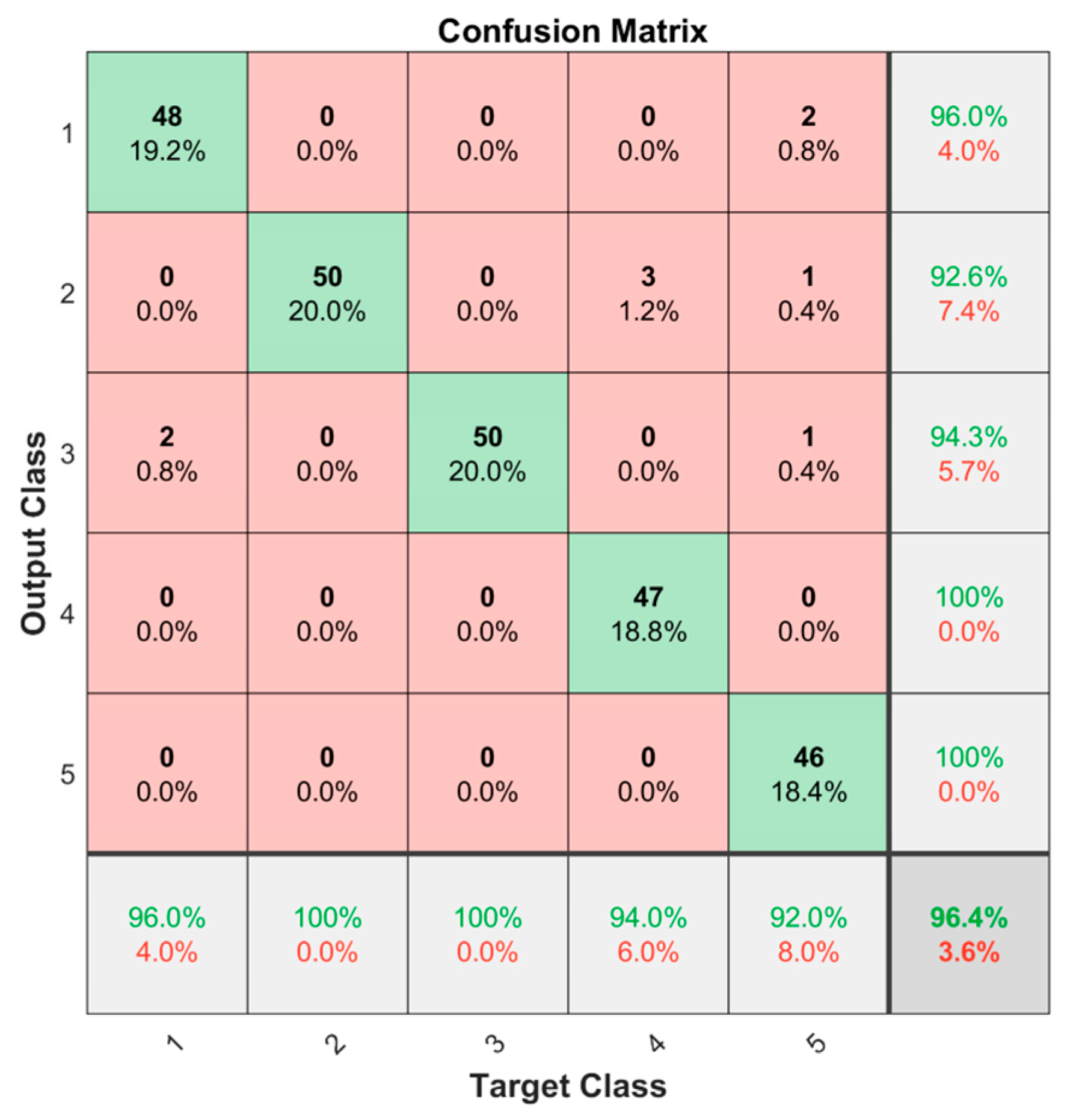
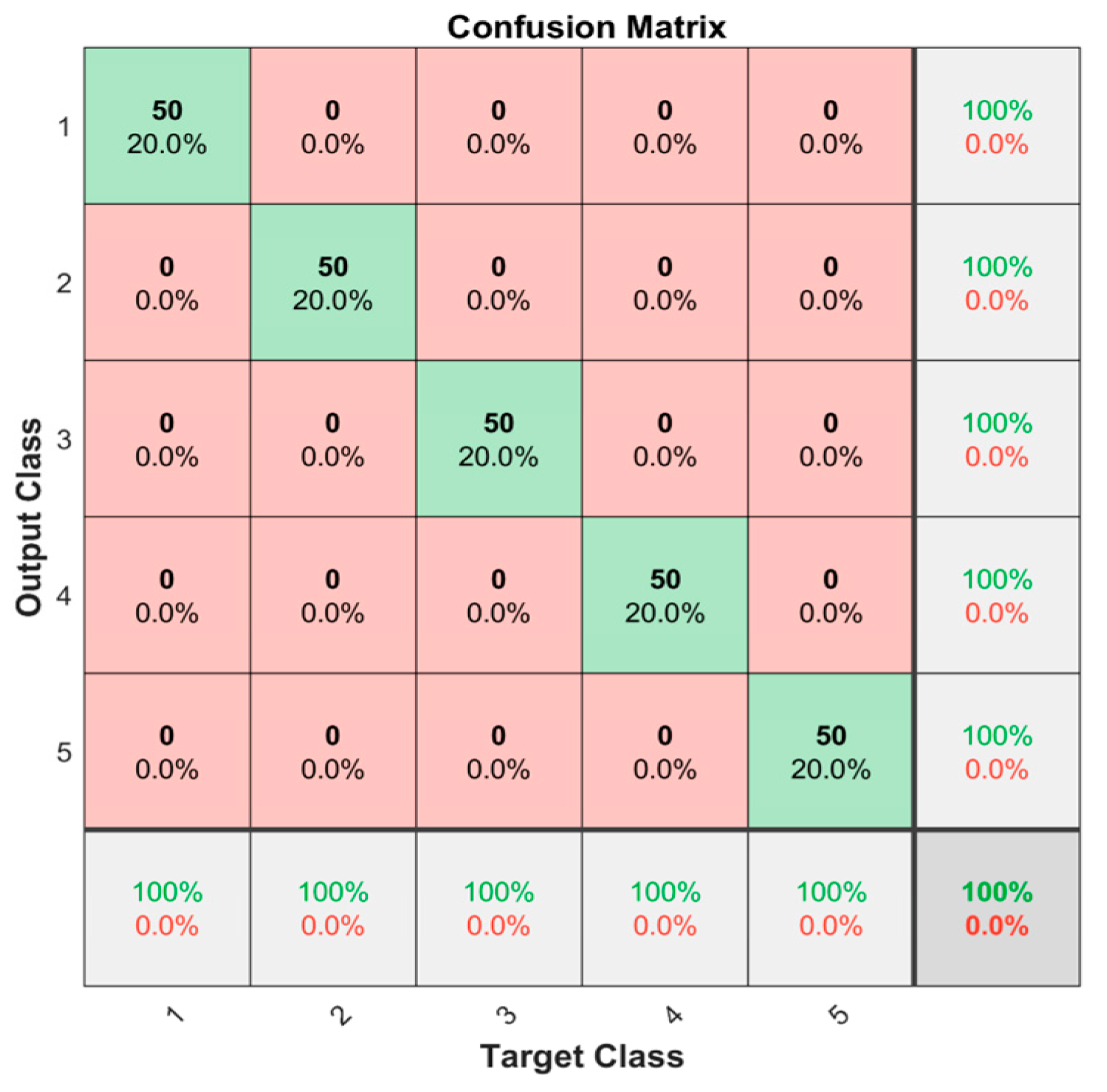
4.2.3. The Effectiveness of the Fault Diagnosis Model Based on the Improved Bi-LSTM Neural Network
5. Conclusions and Future Works
- The GWO algorithm is used to adaptively select the k value and α value in VMD decomposition, and the maximum value of the product of Pearson correlation p and kurtosis value is taken as the optimized objective function value, to realize the extraction of weak signals in inter-turn short circuit faults.
- The improved coarse-grained multi-scale feature extraction improves the performance of traditional multi-scale arrangement features.
- The WOA is adopted to optimize the number of hidden-layer nodes and the learning rate of the Bi-LSTM network, which improves the diagnostic accuracy and solves the problem of the hyper-parameter configuration of the deep learning model.
- In practical engineering applications, a new fault diagnosis method is proposed to make fault diagnosis more intelligent.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hu, Y. Model Predictive Torque Control Strategy for Marine Permanent Magnet Synchronous Propulsion Motor. Master’s Thesis, Wuhan University of Technology, Wuhan, China, 2019. (In Chinese). [Google Scholar]
- Yu, C.; Qi, L.; Sun, J.; Jiang, C.; Su, J.; Shu, W. Fault diagnosis technology for ship electrical power system. Energies 2022, 15, 1287. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, Y.; Zhao, X.; Hu, Q.; Liu, D. Fuzzy wavelet network intelligent predictive controller for vacuum injection molding. Comput. Integr. Manuf. Syst. 2010, 16, 2647–2652. (In Chinese) [Google Scholar]
- Zhang, L.; Yang, M. Fault diagnosis of permanent magnet synchronous motor based on mixup-LSTM. Electr. Switch. 2022, 60, 58–62. (In Chinese) [Google Scholar]
- Xue, S.; He, Q.; Pan, J.; Huang, X. Research on dynamic eccentricity fault diagnosis method of permanent magnet synchronous motor based on GA-SVM. Zuhe Jichuang Yu Zidonghua Jiagong Jishu 2022, 99–103. (In Chinese) [Google Scholar]
- Zhao, S.; Song, Q.; Zhang, Y.; Zhang, W. Mechanical fault detection of permanent magnet synchronous motor based on improved DFA and LDA. J. Beijing Inst. Technol. 2023, 43, 61–69. (In Chinese) [Google Scholar]
- Huang, W.; Du, J.; Hua, W.; Fan, Q. An open-circuit fault diagnosis method for PMSM drives using symmetrical and DC components. Chin. J. Electr. Eng. 2021, 7, 124–135. [Google Scholar] [CrossRef]
- Tang, S.; Chen, X.; Zheng, S. Fault diagnosis method of motor bearing based on attention and multi-scale convolution neural network. Electr. Technol. 2020, 21, 32–38. (In Chinese) [Google Scholar]
- Li, F.; Honglin, L.; Shuiqing, X. Research on open circuit fault diagnosis of PMSM Inverter with SDAE-FFNN network. Chongqing Ligongxue Xuebao 2013, 1–9. (In Chinese) [Google Scholar]
- Chen, Z.; Liang, K.; Peng, T.; Wang, Y. Multi-condition PMSM fault diagnosis based on convolutional neural network phase tracker. Symmetry 2022, 14, 295. [Google Scholar] [CrossRef]
- Zhang, Y.; Lei, Y. Data anomaly detection of bridge structures using convolutional neural network based on structural vibration signals. Symmetry 2021, 13, 1186. [Google Scholar] [CrossRef]
- Lee, H.; Jeong, H.; Kim, S.W. Detection of interturn short-circuit fault and demagnetization fault in IPMSM by 1-D convolutional neural network. In Proceedings of the 2019 IEEE PES Asia-Pacific Power and Energy Engineering Conference (APPEEC), Macao, China, 1–4 December 2019; pp. 1–5. [Google Scholar]
- Man, Y.; Yang, L.; Yan, L.; Cui, G. Detection method of incipient inter-turn short circuit fault of PMSM based on VMD. Electr. Mechines Control Appl. 2022, 49, 66–74. (In Chinese) [Google Scholar]
- Wang, Y. Fault Diagnosis of Interturn Short Circuit in Permanent Magnet Synchronous Motor Based on Stacked Sparse Autoencoder. Master’s Thesis, Jiangsu University of Science and Technology, Zhenjiang, China, 2021. (In Chinese). [Google Scholar]
- Gu, J.; Jiang, T.; Zhu, H. Multi-objective discrete grey wolf optimization algorithm for job shop energy saving scheduling. Comput. Integr. Manuf. Syst. 2021, 27, 2295–2306. (In Chinese) [Google Scholar]
- Xu, F.; Fang, Y.; Zhang, R. Cluster fault diagnosis of PCA-GG rolling bearing based on EEMD fuzzy entropy. Comput. Integr. Manuf. Syst. 2016, 22, 2631–2642. (In Chinese) [Google Scholar]
- Liu, J.; Ma, Y.; Li, Y. Improved whale algorithm for solving engineering design optimization problems. Comput. Integr. Manuf. Syst. 2021, 27, 1884–1897. (In Chinese) [Google Scholar]
- Wang, J.; Li, F. Review of signal processing methods in fault diagnosis for machinery. Noise Vib. Control. 2013, 33, 128–132. (In Chinese) [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Failure Mode | Sample Label | Kurtosis Value after VMD | |||||
|---|---|---|---|---|---|---|---|
| 1 | S1 | 6.24 | 1.52 | 25.71 | 1.53 | 23.65 | 8.96 |
| S2 | 3.18 | 3.38 | 1.52 | 12.87 | 1.51 | 23.94 | |
| S3 | 3.42 | 3.08 | 1.52 | 12.38 | 1.52 | 16.32 | |
| 2 | S4 | 3.05 | 3.40 | 1.52 | 12.13 | 1.51 | 29.16 |
| S5 | 2.89 | 1.52 | 22.57 | 1.54 | 24.08 | 13.42 | |
| S6 | 2.98 | 1.53 | 20.10 | 1.54 | 20.91 | 16.10 | |
| 3 | S7 | 3.03 | 3.39 | 1.53 | 11.95 | 1.52 | 31.91 |
| S8 | 3.44 | 2.98 | 1.53 | 11.97 | 1.52 | 38.54 | |
| S9 | 3.46 | 2.81 | 1.53 | 11.44 | 1.52 | 30.73 | |
| 4 | S10 | 3.57 | 1.53 | 19.02 | 1.55 | 15.55 | 21.01 |
| S11 | 3.18 | 1.53 | 17.95 | 1.55 | 16.87 | 19.15 | |
| S12 | 3.02 | 3.36 | 1.53 | 12.25 | 1.52 | 21.24 | |
| 5 | S13 | 5.20 | 1.52 | 52.68 | 9.03 | 1.54 | 21.00 |
| S14 | 6.42 | 1.53 | 48.69 | 9.23 | 1.54 | 20.98 | |
| S15 | 2.38 | 1.53 | 54.71 | 9.05 | 1.54 | 21.98 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, F.; Qi, L.; Ye, S.; Chen, Y.; Xiao, H.; Li, S. Research on Fault Diagnosis Algorithm of Ship Electric Propulsion Motor. Appl. Sci. 2023, 13, 4064. https://doi.org/10.3390/app13064064
Ma F, Qi L, Ye S, Chen Y, Xiao H, Li S. Research on Fault Diagnosis Algorithm of Ship Electric Propulsion Motor. Applied Sciences. 2023; 13(6):4064. https://doi.org/10.3390/app13064064
Chicago/Turabian StyleMa, Fengxin, Liang Qi, Shuxia Ye, Yuting Chen, Han Xiao, and Shankai Li. 2023. "Research on Fault Diagnosis Algorithm of Ship Electric Propulsion Motor" Applied Sciences 13, no. 6: 4064. https://doi.org/10.3390/app13064064