
An Efficient Boosting-Based Windows Malware Family Classification System Using Multi-Features Fusion


Abstract
:1. Introduction
- (i)
- Combined plausible binary and assembly malware features using a forward feature stepwise selection method to produce the most efficient fused features. Experimental findings demonstrate that the XGBoost classifier’s classification accuracy using the proposed fused features is 99.87%, which is higher than most existing malware classification models.
- (ii)
- Using a limited number of 5530 features makes the system much faster with high accuracy and easier to use for large-scale malware classification tasks.
- (iii)
- The LightGBM and CatBoost-based models were applied for the first time to process malware classification tasks. Both models obtained over 99.7% accuracy.
2. Related Work
2.1. Portable Executable (PE)
2.2. Gradient Boosting Decision Tree (GBDT)
- (I)
- Dividing the training samples into random subsets.
- (II)
- Converting label values into integers.
- (III)
- Iterating through each sample in turn and converting the category features to the data type according to the following formula.
2.3. Forward Selection Algorithm
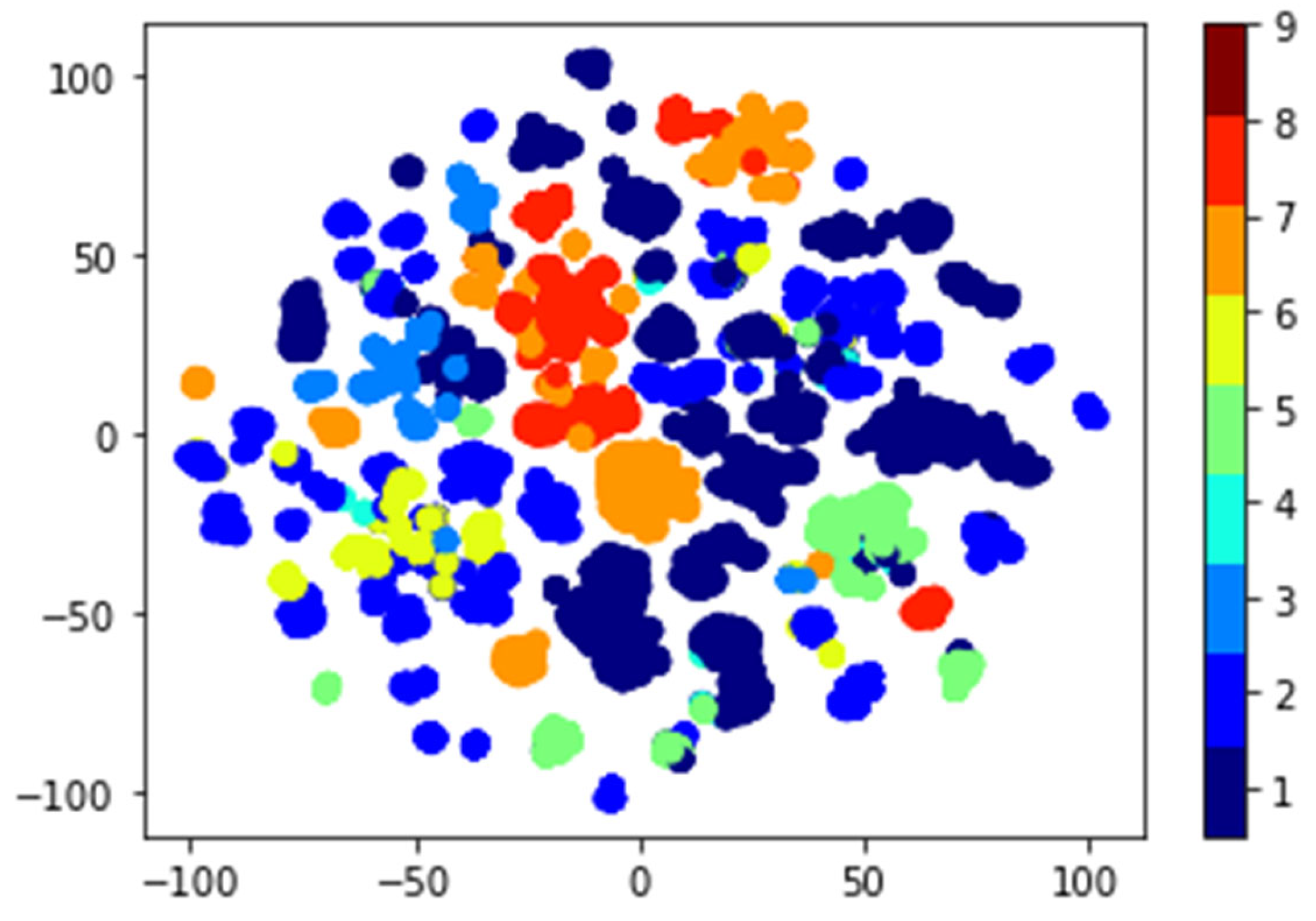
2.4. Visualizing Malware as an Image
2.5. Malware Detection and Classification
3. The Proposed System
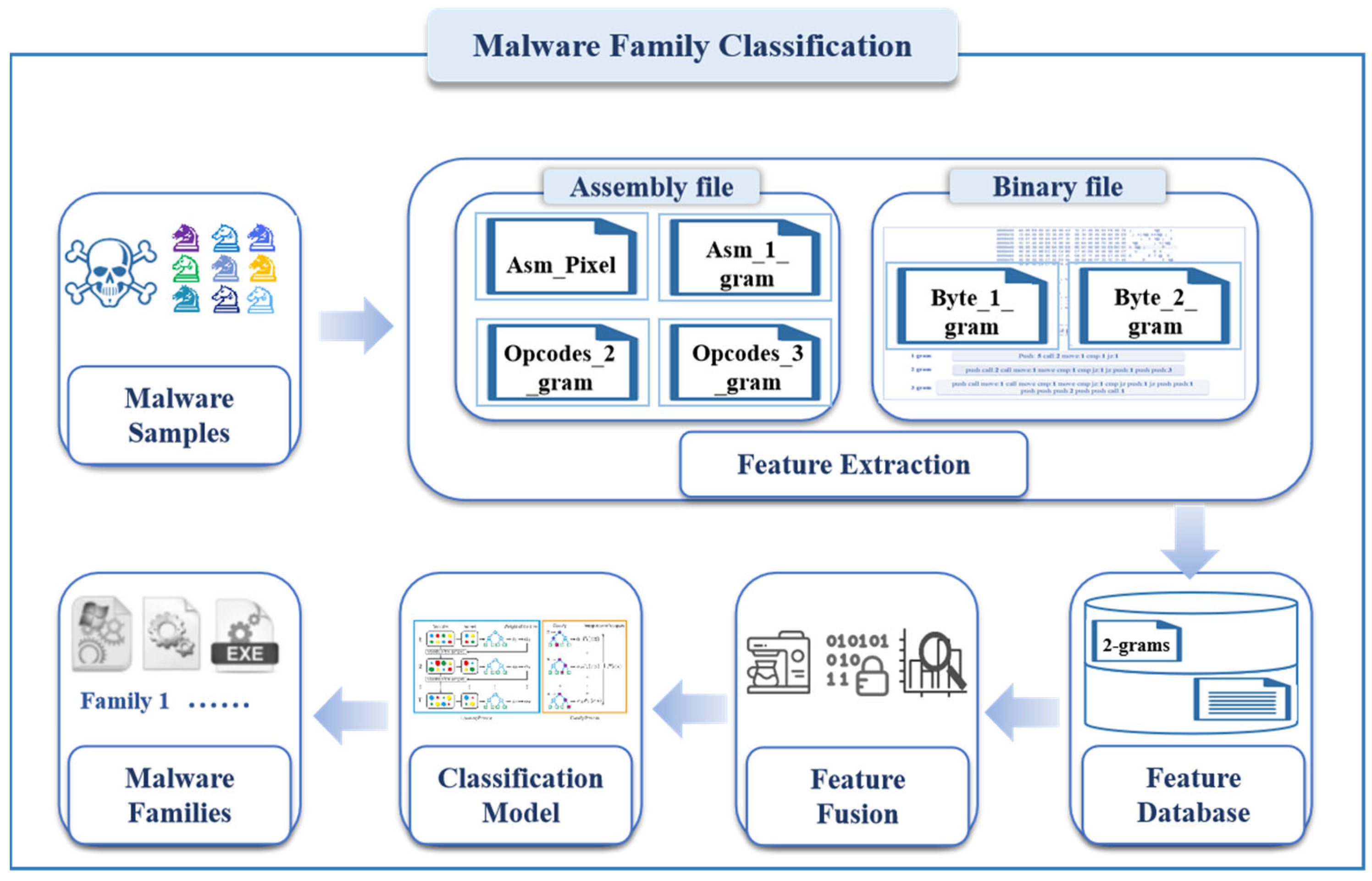
3.1. Overview of the Proposed System
3.2. Malware Representation
3.3. Feature Extraction
3.3.1. Binary File
3.3.2. Assembly File
- (a)
- Segments: The preset sections in PE (.text, .data, .bss, .rdata, .edata, .idata, .rsrc, etc.). We selected 13 commonly used segments, and the experiments prove that these segments benefit the classification results;
- (b)
- Opcodes: The machine code, which represents the assembly instruction, is represented by the opcode as a helper. The full list of ×86 instruction sets is vast and complex, so we chose a subset of 26 opcodes based on how frequently they are used in malware samples. We measured how frequently these 26 opcodes were used in each malware sample;
- (c)
- Keywords: Extracted three keyword features: .dll, std::, and :dword;
- (d)
- Registers: Extracted the features of registers edx, esi, eax, ebx, ecx, edi, ebp, esp, and eip and experimentally demonstrated that the frequency of register usage is a helpful feature for assigning malware samples to a family.
3.4. Feature Fusion
3.5. Classification Model
3.6. Measures for Evaluation
4. Experimental Results and Discussion
4.1. Data
4.2. Feature Selection
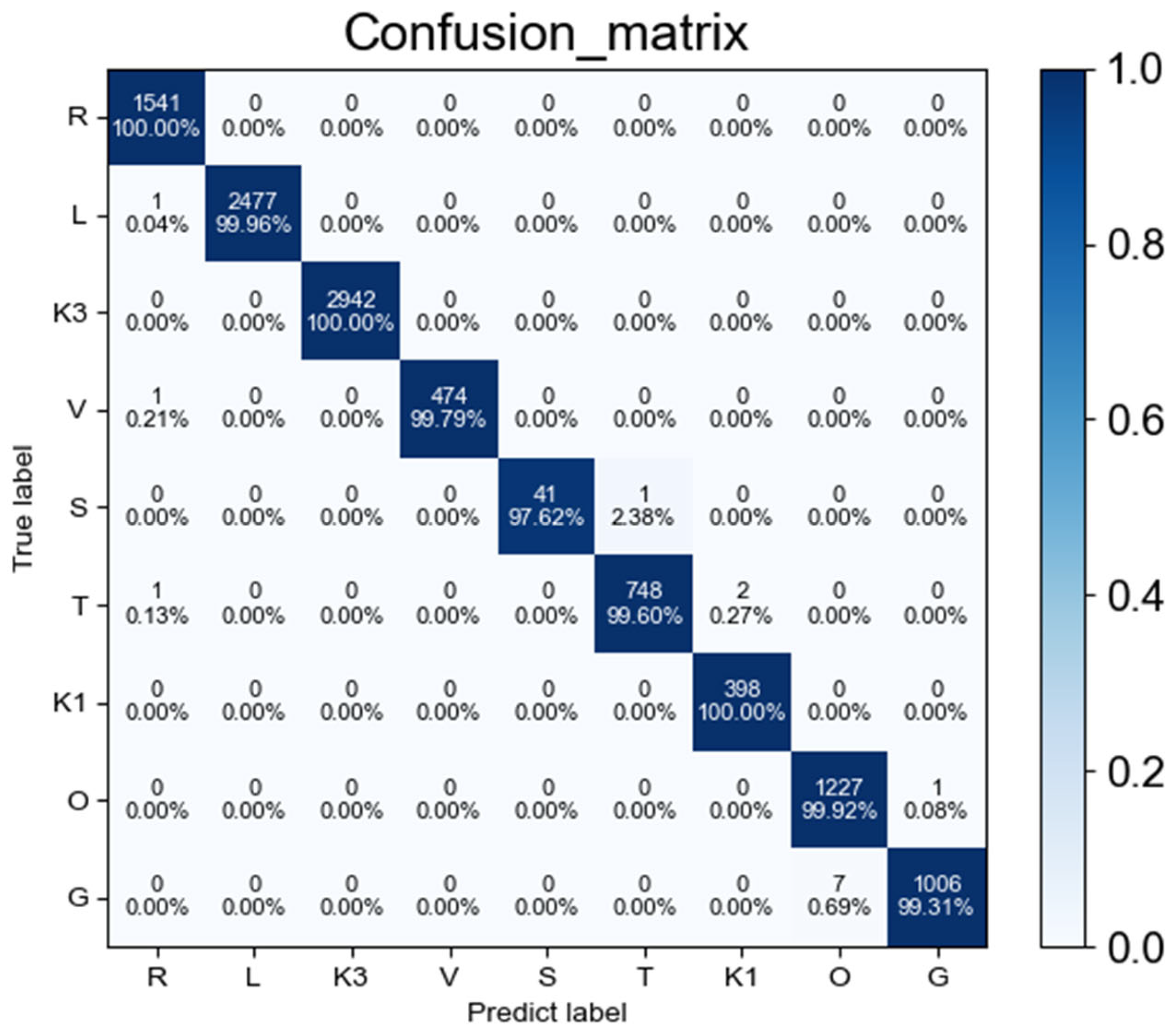
4.3. Experimental Results Analysis
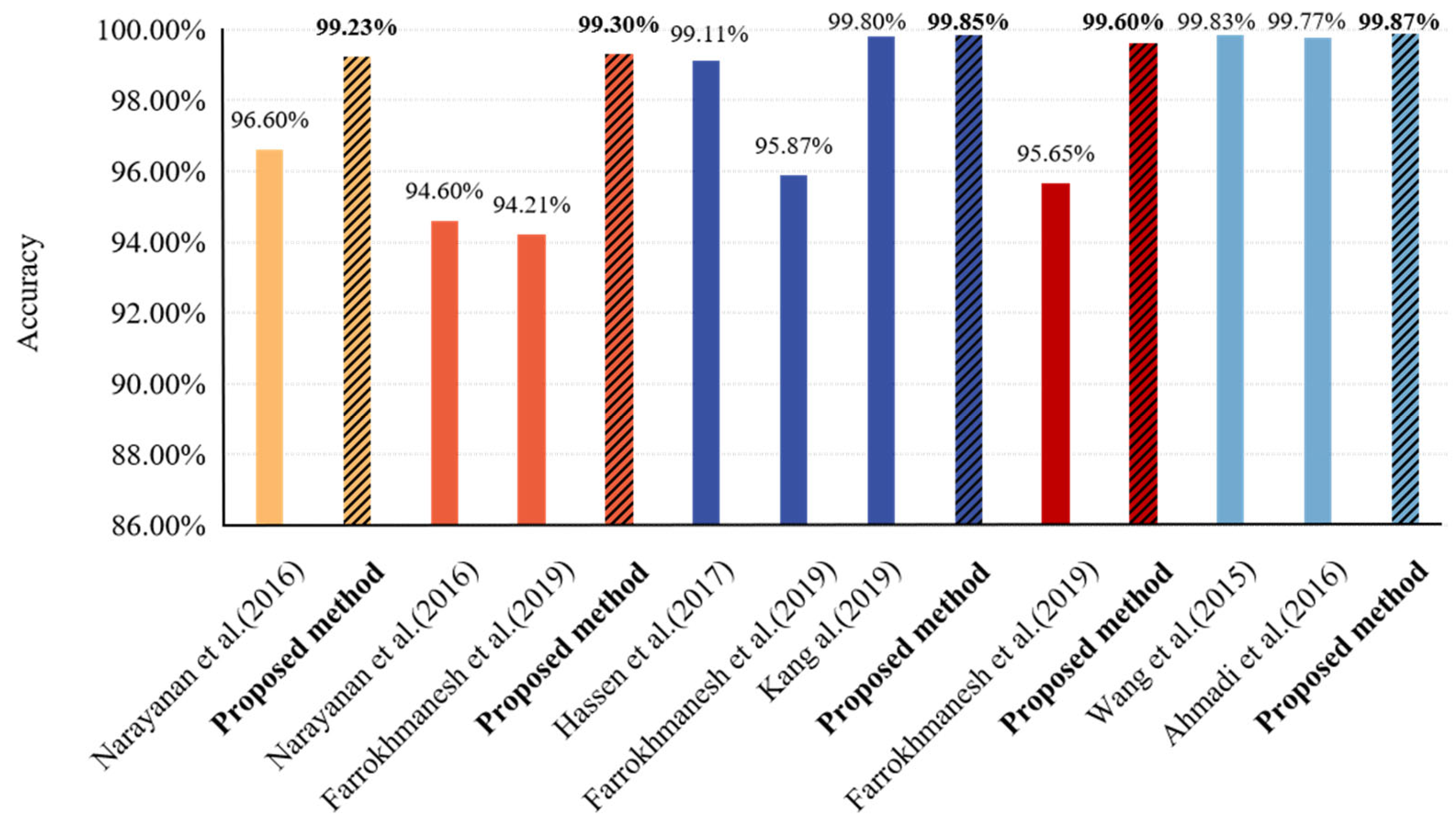
4.4. Comparison and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Said, V.; Eelly, E.; Zag, E.; Murat, O. The Dangerous Combo: Fileless Malware and Cryptojacking. J. SoutheastCon 2022, 125–132. [Google Scholar] [CrossRef]
- Greengard, S. Cybersecurity gets smart. Commun. ACM 2016, 59, 29–31. [Google Scholar] [CrossRef]
- Rizvi, S.K.J.; Aslam, W.; Shahzad, M.; Saleem, S.; Fraz, M. PROUD-MAL: Static analysis-based progressive framework for deep unsupervised malware classification of windows portable executable. Complex Intell. Syst. 2022, 8, 673–685. [Google Scholar] [CrossRef]
- Johnson, S.; Gowtham, R.; Nair, A.R. Ensemble Model Ransomware Classification: A Static Analysis-based Approach. Inventive Comput. Inf. Technol. 2022, 336, 153–167. [Google Scholar]
- Loi, N.; Borile, C.; Ucci, D. Towards an Automated Pipeline for Detecting and Classifying Malware through Machine Learning. 2021. Available online: https://arxiv.org/abs/2106.05625 (accessed on 5 December 2022).
- Jeon, J.; Kim, J.; Jeon, S.; Lee, S.; Jeong, Y.S. Static Analysis for Malware Detection with Tensorflow and GPU. In Advances in Computer Science and Ubiquitous Computing; Springer: Singapore, 2021; Volume 715, pp. 537–546. [Google Scholar]
- Barbi, S.; Barbieri, F.; Marinelli, S.; Rimini, B.; Merchiori, S.; Larwa, B.; Bottarelli, M.; Montorsi, M. Phase change material-sand mixtures for distributed latent heat thermal energy storage: Interaction and performance analysis. Renew. Energy 2021, 169, 1066–1076. [Google Scholar] [CrossRef]
- Chanajitt, R.; Pfahringer, B.; Gomes, H.M.; Yogarajan, V. Multiclass Malware Classification Using Either Static Opcodes or Dynamic API Calls. In Proceedings of the AI 2022: Advances in Artificial Intelligence, Perth, WA, Australia, 3 December 2022; pp. 427–441. [Google Scholar]
- Jing, C.; Wu, Y.; Cui, C. Ensemble dynamic behavior detection method for adversarial malware. Future Gener. Comput. Syst. 2022, 30, 193–206. [Google Scholar] [CrossRef]
- Li, C.; Lv, Q.; Li, N.; Wang, Y.; Sun, D. A novel deep framework for dynamic malware detection based on API sequence intrinsic features. Comput. Secur. 2022, 116, 102686. [Google Scholar] [CrossRef]
- Anderson, B.; Quist, D.; Neil, J.; Storlie, C.; Lane, T. Graph-based malware detection using dynamic analysis. J. Comput. Virol. 2020, 52, 247–258. [Google Scholar] [CrossRef]
- Alshamrani, S.S. Design and Analysis of Machine Learning Based Technique for Malware Identification and Classification of Portable Document Format Files. Secur. Commun. Netw. 2022, 2022, 7611741. [Google Scholar] [CrossRef]
- Wang, W.; Ren, C.; Song, H.; Zhang, S.; Liu, P. FGL_Droid: An Efficient Android Malware Detection Method Based on Hybrid Analysis. Secur. Commun. Netw. 2022, 2022, 8398591. [Google Scholar] [CrossRef]
- Catak, F.O.; Yazı, A.F. A Benchmark API Call Dataset for Windows PE Malware Classification. 2019. Available online: https://arxiv.org/abs/1905.01999 (accessed on 11 December 2022).
- Afianian, A.; Niksefat, S.; Sadeghiyan, B.; Baptiste, D. Malware dynamic analysis evasion techniques: A survey. ACM Comput. Surv. (CSUR) 2020, 52, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Lebbie, M.; Prabhu, S.; Agrawal, A.K. Comparative Analysis of Dynamic Malware Analysis Tools. In Proceedings of the International Conference on Paradigms of Communication, Computing and Data Sciences, Kurukshetra, India, 1 January 2022; pp. 359–368. [Google Scholar]
- Du, J.; Raza, S.H.; Ahmad, M.; Alam, I.; Hanif, S.; Habib, M.A. Digital Forensics as Advanced Ransomware Pre-Attack Detection Algorithm for Endpoint Data Protection. Secur. Commun. Netw. 2022, 2022, 1424638. [Google Scholar] [CrossRef]
- Gu, Z.; Nazir, S.; Hong, C.; Khan, S. Convolution Neural Network-Based Higher Accurate Intrusion Identification System for the Network Security and Communication. Secur. Commun. Netw. 2020, 2020, 8830903. [Google Scholar] [CrossRef]
- Ahmadi, M.; Ulynaov, D.; Semenov, S.; Trofimov, M.; Giacinto, G. Novel Feature Extraction, Selection and Fusion for Effective Malware Family Classification. In Proceedings of the Sixth ACM Conference on Data and Application Security and Privacy, New Orleans, LA, USA, 9–11 March 2016; pp. 183–194. [Google Scholar]
- Anderson, H.S.; Roth, P. Ember: An Open Dataset for Training Static pe Malware Machine Learning Models. 2018. Available online: https://arxiv.org/abs/1804.04637 (accessed on 12 December 2022).
- Zhang, Y.; Haghani, A. A gradient boosting method to improve travel time prediction. Transp. Res. Part C Emerg. Technol. 2015, 58, 308–324. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3149–3157. [Google Scholar]
- Dorogu, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient Boosting with Categorical Features Support. 2018. Available online: https://arxiv.org/abs/1810.11363 (accessed on 16 December 2022).
- Mao, K.Z. Orthogonal forward selection and backward elimination algorithms for feature subset selection. IEEE Trans. Syst. Man Cybern. 2004, 34, 629–634. [Google Scholar] [CrossRef] [PubMed]
- Nataraj, L.; Karthikeyan, S.; Jacob, G.; Manjunath, B.S. Malware images: Visualization and automatic classification. In Proceedings of the 8th International Symposium on Visualization for Cyber Security, Pittsburgh, PA, USA, 20 July 2011; pp. 1–7. [Google Scholar]
- Tekerek, A.; Yapici, M. A novel malware classification and augmentation model based on convolutional neural network. Comput. Secur. 2022, 112, 102515. [Google Scholar] [CrossRef]
- Dai, Y.; Li, H.; Qian, Y.; Lu, X. A malware classification method based on memory dump grayscale image. Digit. Investig. 2018, 27, 30–37. [Google Scholar] [CrossRef]
- Gibert, D.; Mateu, C.; Planes, J.; Vicens, R. Using convolutional neural networks for classification of malware represented as images. J. Comput. Virol. Hacking Tech. 2019, 15, 15–28. [Google Scholar] [CrossRef] [Green Version]
- Sun, Z.; Rao, Z.; Chen, J.; Xu, R.; He, D.; Yang, H.; Liu, J. An Opcode Sequences Analysis Method For Unknown Malware Detection. In Proceedings of the 2019 2nd International Conference on Geoinformatics and Data Analysis, Prague, Czech Republic, 15–17 March 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 15–19. [Google Scholar]
- Ijaz, M.; Durad, M.H.; Ismail, M. Static and Dynamic Malware Analysis Using Machine Learning. In Proceedings of the 2019 16th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 8–12 January 2019; pp. 687–691. [Google Scholar]
- Hemalatha, J.; Roseline, S.A.; Geetha, S.; Damasevicius, R. An Efficient DenseNet-Based Deep Learning Model for Malware Detection. Entropy 2021, 23, 3. [Google Scholar] [CrossRef] [PubMed]
- Sun, G.; Qian, Q. Deep Learning and Visualization for Identifying Malware Families. IEEE Trans. Dependable Secur. Comput. 2021, 18, 283–295. [Google Scholar] [CrossRef]
- Li, L.; Ding, Y.; Li, B.; Qiao, M.; Ye, B. Malware classification based on double byte feature encoding. Alex. Eng. J. 2022, 61, 91–99. [Google Scholar] [CrossRef]
- Kumar, S.; Janet, B.; Neelakantan, S. Identification of malware families using stacking of textural features and machine learning. Expert Syst. Appl. 2022, 208, 118073. [Google Scholar] [CrossRef]
- Jadvani, N.; Agarwal, M.; Leelasankar, K. Malware Detection Based on Portable Executable File Features. In Proceedings of the International Conference on Computing, Communication, Electrical and Biomedical Systems, Cham, Switzerland, 28 February 2022; pp. 377–384. [Google Scholar]
- Shankarapani, M.K.; Ramamoorthy, S.; Movva, R.S.; Mukkamala, S. Malware detection using assembly and API call sequences. J. Comput. Virol. 2011, 7, 107–119. [Google Scholar] [CrossRef]
- Narayanan, B.N.; Djaneye-Boundjou, O.; Kebede, T.M. Performance analysis of machine learning and pattern recognition algorithms for Malware classification. In Proceedings of the 2016 IEEE National Aerospace and Electronics Conference (NAECON) and Ohio Innovation Summit (OIS), Dayton, OH, USA, 25–29 July 2016; pp. 338–342. [Google Scholar]
- Farrokhmanesh, M.; Hamzeh, A. Music classification as a new approach for malware detection. J. Comput. Virol. Hacking Tech. 2019, 5, 77–96. [Google Scholar] [CrossRef]
- Hassen, M.; Carvalho, M.M.; Chan, P.K. Malware classification using static analysis-based features. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November 2017; pp. 1–7. [Google Scholar]
- Kang, J.; Won, Y. Malware Classification Using Machine Learning. Adv. Comput. Sci. Ubiquitous Comput. 2019, 536, 279–284. [Google Scholar]
- Wang, X.; Liu, J.; Chen, X. First Place Team: Say No to Overfitting. 2015. Available online: https://github.com/xiaozhouwang/kaggle_Microsoft_Malware/blob/master/Saynotooverfitting.pdf (accessed on 21 December 2022).
- Sudhakra; Kumar, S. MCFT-CNN: Malware classification with fine-tune convolution neural networks using traditional and transfer learning in Internet of Things. Future Gener. Comput. Syst. 2021, 125, 334–351. [Google Scholar] [CrossRef]
- Çayır, A.; Ünal, U.; Dağ, H. Random CapsNet forest model for imbalanced malware type classification task. Comput. Secur. 2021, 102, 102133. [Google Scholar] [CrossRef]
- Jian, Y.; Kuang, H.; Ren, C.; Ma, Z.; Wang, H. A novel framework for image-based malware detection with a deep neural network. Comput. Secur. 2021, 109, 102400. [Google Scholar] [CrossRef]
- Yuan, B.; Wang, J.; Liu, D.; Guo, W.; Wu, P.; Bao, X. Byte-level malware classification based on markov images and deep earning. Comput. Secur. 2020, 92, 101740. [Google Scholar] [CrossRef]
- Liu, X.; Lin, Y.; Li, H.; Zhang, J. A novel method for malware detection on ML-based visualization technique. Comput. Secur. 2020, 89, 101682. [Google Scholar] [CrossRef]
- Gibert, D.; Mateu, C.; Planes, J. HYDRA: A multimodal deep learning framework for malware classification. Comput. Secur. 2020, 95, 101873. [Google Scholar] [CrossRef]
- Gao, X.W.; Hu, C.; Shan, C.; Liu, B.; Niu, Z.; Xie, H. Malware classification for the cloud via semi-supervised transfer learning. J. Inf. Secur. Appl. 2020, 55, 102661. [Google Scholar] [CrossRef]
- Le, Q.; Boydell, O.; Namee, B.M.; Scanlon, M. Deep learning at the shallow end: Malware classification for non-domain experts. Digit. Investig. 2018, 26, S118–S126. [Google Scholar] [CrossRef]
- Kattamuri, S.J.; Penmatsa, R.K.V.; Chakravarty, S.; Madabathula, V.S.P. Swarm Optimization and Machine Learning Applied to PE Malware Detection towards Cyber Threat Intelligence. Electron 2023, 12, 342. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Authors | Types Det Class | Features Header Body | Models | ||
|---|---|---|---|---|---|---|
| 2019 | Sun et al. [29] | √ | - | OP | Machine Learning | |
| 2020 | Ijaz et al. [30] | √ | STC | STC | Gradient Boosting | |
| 2021 | Loi et al. [5] | √ | √ | BYT | STC | Automated Pipeline |
| 2021 | Hemalatha et al. [31] | √ | BYT | BYT | DenseNet | |
| 2021 | Sun et al. [32] | √ | - | OP | RMVC | |
| 2022 | Li et al. [33] | √ | BYT | BYT | SAE | |
| 2022 | Kumar et al. [34] | √ | BYT | BYT | SVM | |
| 2022 | Jadvani et al. [35] | √ | STC | - | Random Forest | |
| 2022 | Greengard et al. [2] | √ | API | - | Machine Learning | |
| 2022 | Johnson et al. [4] | √ | - | OP | Ensemble Learning | |
| 2022 | Rizvi et al. [3] | √ | STC | - | FANN | |
| Hex view |
| 00401000 00 00 80 40 40 28 00 1C 02 42 00 C4 00 20 |
| 00401010 00 00 20 09 2A 02 00 70 00 03 5E 10 31 0A |
| 00401020 40 00 02 01 00 90 21 00 32 40 00 1C 01 40 |
| Assembly view |
| .text:00401000 56 push esi |
| .text:00401005 50 push eax |
| .text:00401005 50 assume es: nothing |
| Class ID | Family Name | Train Samples | Type |
|---|---|---|---|
| 1 | Ramnit | 1541 | Worm |
| 2 | Lollipop | 2478 | Adware |
| 3 | Kelihos_ver3 | 2942 | Backdoor |
| 4 | Vundo | 475 | Trojan |
| 5 | Simda | 42 | Backdoor |
| 6 | Tracur | 751 | TrojanDownloader |
| 7 | Kelihos_ver1 | 398 | Backdoor |
| 8 | Obfuscator.ACY | 1228 | Any kind of obfuscated malware |
| 9 | Gatak | 1013 | Backdoor |
| Feature | Number | Time (Seconds) | Number (Chi-Square) | Time (Seconds) |
|---|---|---|---|---|
| Byte_2_gram | 2000 | 1013.15 | 360 | 1011.78 |
| Asm_Pixel | 5000 | 966.77 | 2300 | 944.75 |
| Opcodes_2_gram | 625 | 0.67 | 565 | 0.56 |
| Opcodes_3_gram | 10,000 | 69.21 | 2000 | 68.89 |
| Category of Feature | Numbers | Train | 5-CV | ||
|---|---|---|---|---|---|
| Accuracy | Logloss | Accuracy | Logloss | ||
| Hex dump file | |||||
| Byte_1_gram | 257 | 1.0 | 0.0007 | 0.9873 | 0.0477 |
| Byte_2_gram | 360 | 1.0 | 0.0005 | 0.9940 | 0.0234 |
| Disassembled file | |||||
| Asm_Pixel | 2300 | 0.9999 | 0.0010 | 0.9902 | 0.0399 |
| Asm_1_gram | 48 | 0.9982 | 0.0054 | 0.9945 | 0.0207 |
| Opcodes_2_gram | 565 | 0.9971 | 0.0082 | 0.9914 | 0.0335 |
| Opcodes_3_gram | 2000 | 0.9971 | 0.0083 | 0.9921 | 0.0307 |
| Category of Feature | Numbers | Train | 5-CV | ||
|---|---|---|---|---|---|
| Accuracy | Logloss | Accuracy | Logloss | ||
| C1: Asm_1_gram + Asm_Pixel | 2348 | 1.0 | 0.00042 | 0.9959 | 0.0163 |
| C2: C1 + Byte_1_gram | 2605 | 1.0 | 0.00036 | 0.9966 | 0.0129 |
| C3: C2 + Opcodes_2_gram | 3170 | 1.0 | 0.00035 | 0.9976 | 0.0097 |
| C4: C3 + Opcodes_3_gram | 5170 | 1.0 | 0.00035 | 0.9978 | 0.0092 |
| C5: C4 + Byte_2_gram | 5530 | 1.0 | 0.00035 | 0.9979 | 0.0090 |
| Category of Feature | Numbers | 5-CV | |
|---|---|---|---|
| Accuracy | Logloss | ||
| C5 (Parameter optimization) | 5530 | 0.9987 | 0.007 |
| C5 (No parameter optimization) | 5530 | 0.9979 | 0.009 |
| Approaches | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| RMVC [32] | 99.50 | - | - | - |
| MCFT and CNN [42] | 98.63 | 98.56 | 96.00 | 97.22 |
| RCNF [43] | 99.56 | - | - | 98.20 |
| SERLA [44] | 98.31 | 98.68 | 97.93 | 98.30 |
| MDMC [45] | 99.26 | - | - | - |
| ML and VT [46] | 97.73 | - | - | - |
| HYDRA [47] | 99.75 | - | - | 99.51 |
| XGBoost and RNN [48] | 96.90 | - | - | - |
| CNN and BILSTM [49] | 98.20 | - | - | 96.05 |
| ACO-DT [50] | 99.37 | |||
| CatBoost | 99.76 | 99.66 | 98.93 | 99.28 |
| LightGBM | 99.84 | 99.77 | 98.55 | 99.66 |
| XGBoost | 99.87 | 99.87 | 99.58 | 99.70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Ren, X. An Efficient Boosting-Based Windows Malware Family Classification System Using Multi-Features Fusion. Appl. Sci. 2023, 13, 4060. https://doi.org/10.3390/app13064060
Chen Z, Ren X. An Efficient Boosting-Based Windows Malware Family Classification System Using Multi-Features Fusion. Applied Sciences. 2023; 13(6):4060. https://doi.org/10.3390/app13064060
Chicago/Turabian StyleChen, Zhiguo, and Xuanyu Ren. 2023. "An Efficient Boosting-Based Windows Malware Family Classification System Using Multi-Features Fusion" Applied Sciences 13, no. 6: 4060. https://doi.org/10.3390/app13064060