1. Introduction
In the era of big data, the amount of information on the Internet has increased dramatically, including a large number of reviews posted by users on the Web. Most of these reviews express users’ opinions and evaluations of products and services, which contain a lot of potential value [
1]. The purpose of sentiment analysis techniques is to uncover the emotions and attitudes expressed in them, but due to the complex nature of comment data, which is diverse, colloquial and abbreviated, it is particularly important to use computational techniques to achieve automatic, in-depth and accurate analysis and processing [
2].
The development of sentiment analysis has had a significant impact on the field of natural language processing. Natural language processing techniques and text analysis methods are used to mine text and extract sentiment polarity from it [
3]. Sentiment analysis has a wide range of applications, such as reputation management, market research, customer service, brand monitoring, and so on.
Based on the above, sentiment analysis is important in various fields such as business, politics and society to help people better understand and respond to different emotions and attitudes in society. Sentiment analysis has developed through three main stages: sentiment lexicons, machine learning and deep learning [
4].
Sentiment lexicon-based approaches: The earliest approaches to sentiment analysis were mainly based on sentiment lexicons, which typically contained a large number of words, each of which was tagged with a sentiment polarity such as positive, negative or neutral. The main use of sentiment lexicons in sentiment analysis is to automatically identify and classify the sentiment polarity of texts. The creation of a sentiment lexicon typically involves two aspects: word selection and sentiment annotation. For word selection, a large number of words are usually collected from different sources (e.g., network texts, human written texts, annotated datasets, etc.). The annotators have to annotate each vocabulary with a positive, negative or neutral sentiment polarity according to predefined sentiment classification criteria [
5].
Several sentiment lexicons have been developed and are widely used in natural language processing. In the early years of research, Sebastiani Fabrizio et al. in [
6,
7,
8] proposed the SentiWordNet sentiment lexicon, a WordNet-based sentiment lexicon that associates each word with a set of sentiment strengths, including positive sentiment, negative sentiment, and neutral sentiment. After a few years, Wu Xing et al. in [
9], inspired by social cognitive theories, combined basic sentiment value lexicon and social evidence lexicon to improve the traditional polarity lexicon. In 2016, Wang Shih-Ming et al. in [
10] presented the ANTU (Augmented NTU) Sentiment Dictionary, which was constructed by collecting sentiment statistics for words from several sentiment annotation exercises. A total of 26,021 Chinese words were collected in ANTUSD. In 2020, Yang Li et al. in [
11] proposes a new sentiment analysis model SLCABG based on a sentiment lexicon that combines a convolutional neural network (CNN) with a bi-directional gated recurrent unit (BiGRU) based on an attention mechanism. The sentiment lexicon was used to enhance the sentiment features in the comments. CNN and BiGRU networks are used to extract the main sentiment and contextual features from the comments and weight them using the attention mechanism.
The advantage of sentiment dictionary-based methods is that they are simple and fast, but they require manual construction and updating of sentiment dictionaries, and they do not work well for some special texts (e.g., texts with complex semantics such as irony and metaphor).
Machine learning based approaches: With the development of machine learning techniques, models such as RNN, LSTM, CRF and GRU are gradually being proposed by researchers and people are using machine learning algorithms for text sentiment analysis.
LSTM (Long Short-Term Memory) [
12] is a recurrent neural network (RNN) model commonly used to process sequential data. LSTM can effectively solve the long-term dependency problem in RNN by introducing a special memory unit. The BiLSTM model can be thought of as processing the input sequence from left to right for one LSTM model and from right to left for another LSTM model, and finally merging their outputs. The advantage of this is that not only the previous information but also the subsequent information can be considered when processing the input at the current time step. Xiao Zheng et al. in [
13] used a bidirectional LSTM (BiLSTM) model for sentiment analysis. The experimental results show that BiLSTM outperforms CRF and LSTM for Chinese sentiment analysis. Similarly, Gan Chenquan et al. in [
14] proposed a scalable multi-channel extended CNN-BiLSTM model with attention mechanism for Chinese text sentiment analysis, in which the convolutional model CNN based on bridging the BiLSTM model and achieved better result on several public Chinese sentiment analysis datasets.
In addition to LSTM, some researchers select GRU (Gated Recurrent Unit) to handle sentiment analysis tasks. As a variant of LSTM, GRU has fewer parameters than LSTM, requires less training data and has a faster training speed. Miao YaLin et al. in [
15] proposed the adoption of the application of CNN-BiGRU model in Chinese short text sentiment analysis, which introduced the BiGRU model based on CNN. Zhang Binlong et al. in [
16] proposed Transformer-Encoder-GRU (T-E-GRU) to solve the problem of transformer being naturally insufficient compared to the recurrent model in capturing the sequence features in the text through positional encoding. Both have achieved good experimental results in the field of Chinese sentiment analysis.
To leverage the affective dependencies of the sentence, in 2020, Liang Bin et al. in [
17] proposed a graph convolutional network based on SenticNet [
18] according to the specific aspect, called Sentic GCN, and explored a novel solution to construct the graph neural networks via integrating the affective knowledge from SenticNet to enhance the dependency graphs of sentences. Experimental results illustrate that SenticNet can beat state-of-the-art methods. In the same year, Jain Deepak Kumar et al. in [
19] proposed BBSO-FCM model for sentiment analysis, used Binary Brain Storm Optimization (BBSO) algorithm for the Feature Selection process and thereby achieved improved classification performance, and Fuzzy Cognitive Maps (FCMs) were used as a classifier to classify the incidence of positive or negative sentiments. Experimental values highlight the improved performance of BBSO-FCM model in terms of different measures. In 2021, Sitaula Chiranjibi et al. in [
20] proposed three different feature extraction methods and three different CNNs (Convolutional Neural Networks) to implement the features using a low resource dataset called NepCOV19Tweets, which contains COVID-19-related tweets in Nepali language. By using ensemble CNN, they ensemble the three CNNs models. Experimental results show that proposed feature extraction methods possess the discriminating characteristics for the sentiment classification, and the proposed CNN models impart robust and stable performance on the proposed features.
However, machine learning-based methods require large amounts of annotated data to train the classifier, and require manual selection of features and algorithms. There is a degree of subjectivity in feature extraction and algorithm selection, with good or bad feature extraction directly affecting classification results [
21] and not easily generalized to a new corpus.
Deep learning-based approaches: In recent years, the rise of deep learning techniques has brought new breakthroughs in text sentiment analysis. In particular, the use of pre-trained language models (e.g., BERT, RoBERTa, XLNet, etc.) for fine-tuning to solve sentiment analysis problems has yielded very good results. This approach does not require manual feature construction and can handle complex semantic relationships, and therefore has very promising applications in the field of text sentiment analysis.
BERT (Bidirectional Encoder Representations from Transformers) is a pre-trained language model based on the transformer structure proposed by Google in 2018, and is currently one of the most representative and influential models in the field of natural language processing [
22]. Due to the excellent performance of the BERT model, various variants derived from it are also widely used in the field of natural language processing, such as RoBERTa [
23], ALBERT [
24], ELECTRA [
25], etc. The emergence of the BERT model has greatly promoted the development of the field of natural language processing and has achieved leading scores in several benchmark tests, becoming an important milestone in the field of natural language processing. Li Mingzheng et al. in [
26] proposed a novel sentiment analysis model for Chinese stock reviews based on BERT. This model relies on a pre-trained model to improve the classification accuracy. The model uses a BERT pre-training language model to perform sentence-level representation of stock reviews, and then feeds the obtained feature vector into the classifier layer for classification. In the experiments, we demonstrate that our method has higher precision, recall and F1 than TextCNN, TextRNN, Att-BLSTM and TextCRNN. Our model can achieve the best results, which indicates its effectiveness in Chinese stock review sentiment analysis. Meanwhile, our model has strong generalization ability and can perform sentiment analysis in many fields.
In 2019, Google proposed XLNet [
27], which uses the Permuted Language Model (PLM) with a two-stream self-attention mechanism to outperform the BERT model in 20 natural language processing tasks, achieving the best results in 18 tasks. Currently, XLNet is widely used in natural language processing, covering tasks such as classification and named entity recognition [
28,
29].
As part of text classification, sentiment analysis was also an important application of XLNet. Gong Xin-Rong et al. in [
30] proposed a Broad Autoregressive Language Model (BroXLNet) to automatically process the sentiment analysis task. BroXLNet integrates the advantage of generalized autoregressive language modeling and broad learning system, which has the ability of extracting deep contextual features and randomly searching high-level contextual representation in broad spaces. BroXLNet achieved the best result of 94.0% in sentiment analysis task of binary Stanford Sentiment Treebank.
XLNet was trained on different languages. Alduailej Alhanouf et al. in [
31] proposed AraXLNet model, which pre-trained XLNet model in Arabic language for sentiment analysis. For Chinese language, Cui Yiming et al. in [
32] published an unofficial XLNet Chinese pre-training model, which was trained from the Chinese Wikipedia corpus, but its word segmentation model still suffers from the defects of excessively long word segmentation length, infrequent use of word segmentation, and incomplete coverage of the word list.
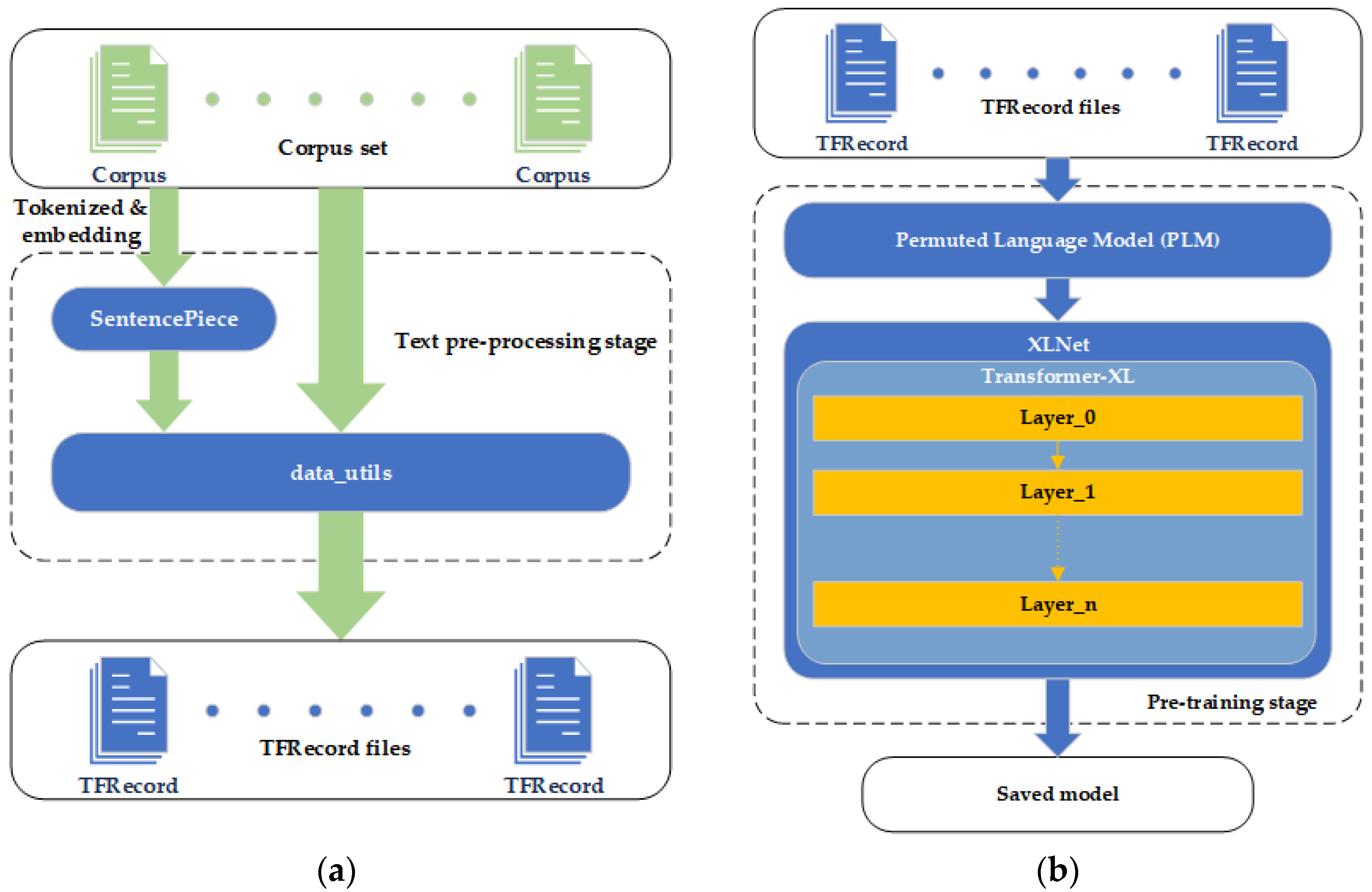
To address the above problems, this paper proposes the CWSXLNet (Chinese Word Segmentation XLNet) model, which improves the XLNet model. First, the original corpus is segmented in the text pre-processing stage and the corresponding segmentation codes are generated; in the pre-training stage, the corresponding segmentation mask codes are generated according to the random sequence of PLM. Combined with the two-stream self-attention mechanism and the attention mask with the segmentation mask codes, thus realising the improvement of Chinese sub-word location information while using the single Chinese character as the granularity. It is designed to solve the problem of the XLNet model for Chinese language processing in terms of character-to-word granularity.
For the Chinese sentiment analysis tasks, this paper combines the above researches and uses the BiGRU model in the downstream task, which can further extract the feature information of the context. In addition, the CWSXLNet-BiGRU-Attention model is proposed by introducing the self-attention mechanism in the model to increase its attention to sentiment-weighted words. It can further capture the sentiment keywords in the text and achieve better results in Chinese sentiment analysis tasks.
3. CWSXLNet
3.1. Deficiencies of XLNet Model in Handling Chinese
When the XLNet model is used to process Chinese, because it uses SentencePiece for text segmentation, and SentencePiece tends to split longer sub-words when using the BPE method for word segmentation, these longer words, when separated from the original corpus, tend to be used less frequently in other text, causing the waste of the limited positional space of the word table. Furthermore, because SentencePiece tends to segment longer words rather than individual Chinese character, the required word list is unusually large. With a limited word list length of 32,000, there are still many commonly used Chinese words not included in the word list, which can only be represented by <UNK> during word embedding, affecting the model’s understanding of semantics and sentiment analysis.
Figure 6 shows the sub-words of the word list in [
31], which proposed Chinese pre-trained XLNet model. The numbers in
Figure 6 indicate the weights. It can be seen that SentencePiece prefers to split out longer sub-words, which are less frequently used in the detached pre-trained corpus and waste space in the word list.
The basic unit of the Chinese language is the Chinese character. Several Chinese characters make up words. Several Chinese words form sentences. Unlike English, Chinese words are not separated by spaces, and there are approximately 55,000 commonly used Chinese words. For comparison, the length of XLNet’s word list is 32,000. To avoid problems caused by long word lists, we reduce the granularity to the Chinese character instead of the Chinese word. However, this approach creates another problem: the relationship between characters from the same word is lost. To avoid this, we discovered a way to improve the connection between characters from the same word.
First, we want to use a tokenized tool to separate Chinese words from sentences, and use spaces to separate Chinese words like in English. Secondly, we reduce the granularity to the Chinese character. Finally, we need to improve the relationship between characters that form the same word, and make sure that the improvement fits perfectly to the XLNet model. This is a brief introduction to our CWSXLNet model; we explain the model in more detail below.
3.2. CWSXLNet Model
In this paper, we propose the CWSXLNet model, which aims to solve the natural non-adaptation problem of the SentencePiece model used in the XLNet model for Chinese. Improvements are made in the data pre-processing phase and the pre-training phase of XLNet.
In the data pre-processing stage, the model used the LTP [
35] as a word separation tool to separate the original corpus with spaces between words. The following
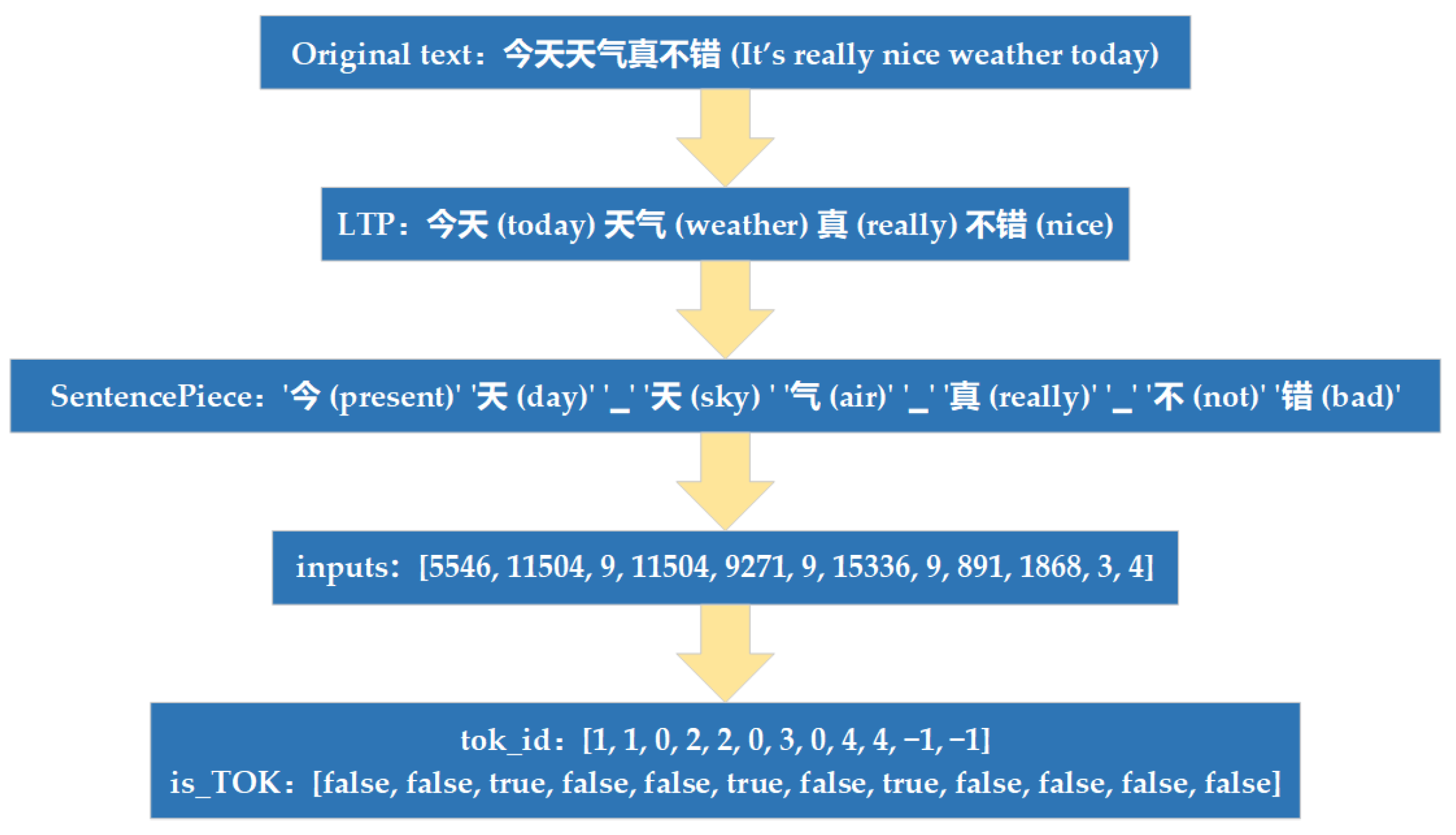
Figure 7 shows an example of the text after word separation using the LTP word separation tool.
In order to reduce the training granularity to words while retaining the word separation information in the original text, CWSXLNet trains the SentencePiece model at the granularity of a single Chinese character. First, a total of 14,516 Chinese characters in the dictionary book are crawled using a crawler tool. These are fed into the SentencePiece model as training text for character-based partitioning training. Finally, the SentencePiece model is trained to segment Chinese texts as single characters.
The original corpus is fed into the SentencePiece model, which is trained as described above. In the subsequent training phase, the proposed model also uses the character “▁” as a word separation marker and refers to the character “▁” as a <TOK> marker, which is used to detect the boundary between words.
When the original text is processed to generate Features, the <TOK> token is used as a word delimiter to determine the position of each word. The tok_id vector of each data is generated to determine which word of the data the current character belongs to, where the tok_id of the <TOK> token is 0 and the tok_id of the control characters <SEP> and <CLS> is −1; the is_TOK vector of the data is generated at the same time, where the position of the TOK token is true and the rest position is false, which is used to determine whether the current token is a TOK token or not. The above two pieces of data are stored with input, tgt, label, seg_id and is_masked in the TFRecord files.
Figure 8 shows the process of generating the corresponding tok_id of a text with is_TOK. For illustration purposes, the lengths of reuse_len and the vector B are set to 0. The original text is “今天天气真不错 (It’s really nice weather today)”. The LTP separated the text to “今天 (today)”, “天气 (weather)”, “真 (really)”, “不错 (nice)”.
Inputs is the result of vectorizing the text by adding the <SEP> and <CLS> flags to the end of the original text, where 9 is <TOK>, 3 is <SEP> and 4 is <CLS>.
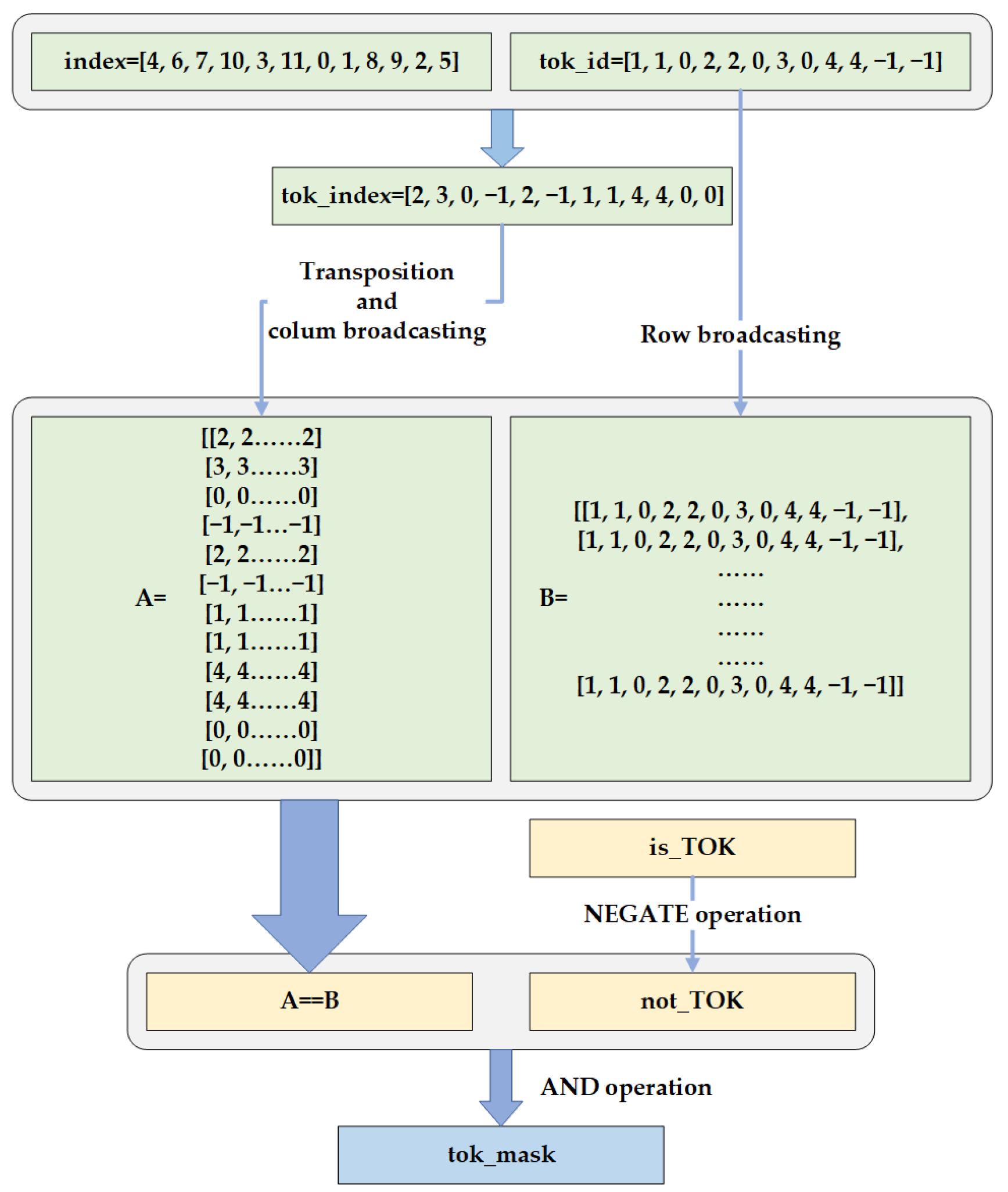
In the pre-training phase, the tok_mask matrix is computed using the same random sequence, while the random sequence is used to generate the perm_mask. Following the example in
Figure 8, at this point, assuming the random sequence index = [4, 6, 7, 10, 3, 11, 0, 1, 8, 9, 2, 5], then the tok_index = [2, 3, 0, −1, 2, −1, 1, 1, 4, 4, 0, 0], which is how reordered version of tok_id by index is obtained.
Matrix A is obtained by transposing tok_index and broadcasting the columns, and matrix B is obtained by broadcasting the rows of tok_id. Elements in tok_mask matrix are set to 1 if Matrix A and B’s corresponding elements are equal and 0 if they are not. The calculation flowchart is shown in
Figure 9.
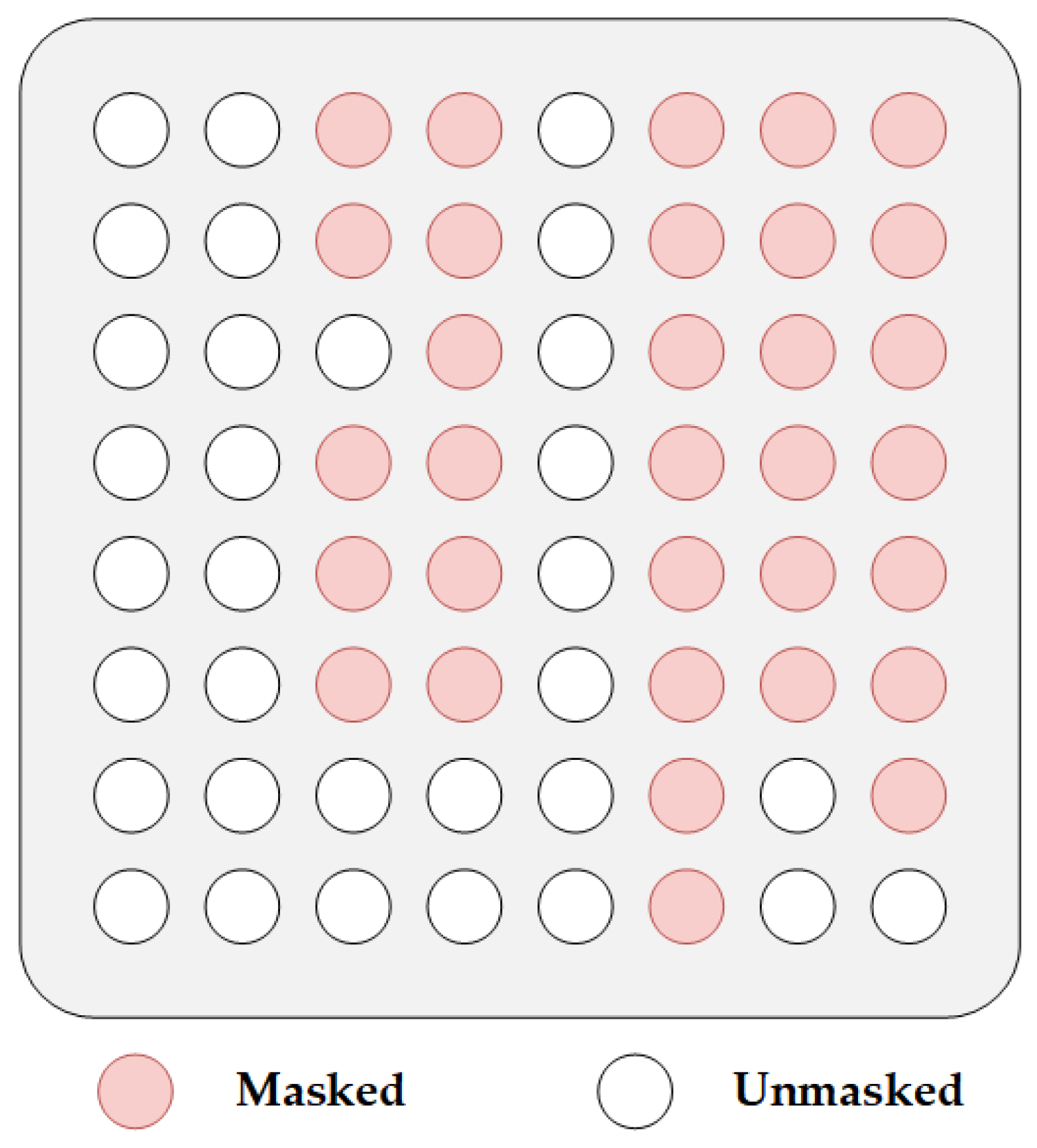
The structure of the tok_mask matrix is shown in
Figure 10. tok_mask[i][j] = 1 (diagonal circle) means that the ith token belongs to the same Chinese word as the jth token after disordering, and conversely tok_mask[i][j] = 0 (hollow circle) means that the ith token does not belong to the same Chinese word as the jth token.
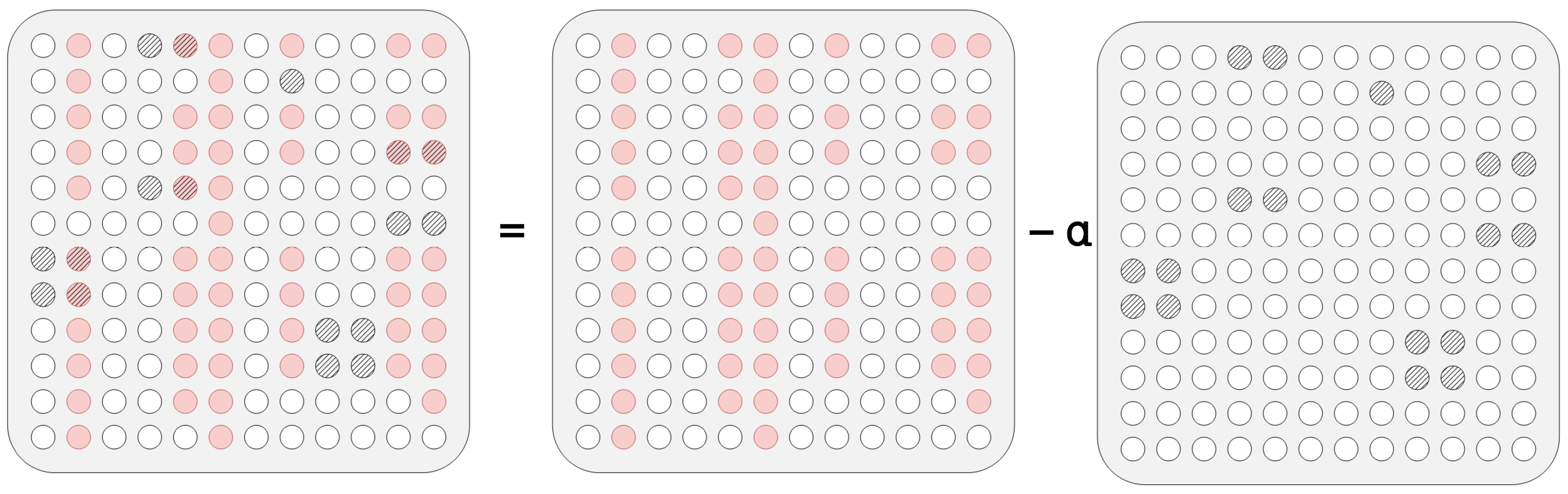
After generating tok_mask, the following operations are performed on perm_mask:
where α is the masking argument of tok_mask in the range (0,1), which is used to control the degree of “masking” of the mask, and clip is the clipping operation, which sets the range of each element in the perm_mask matrix from the original (−α,1) to (α − 1,1).
After the above operation, the degree of masking of some originally masked words in perm_mask is “reduced”, while the degree of unmasking of some non-masked words is “enhanced” (as shown in
Figure 11).
This is reflected in Equation (1), which calculates the attn_score.
At this point, the element values in the attn_mask matrix can be one of the four cases 1, 0, 1 − α, α − 1, as shown in
Figure 12.
As we see in
Figure 8, the LTP shows that Chinese word “天气 (weather)” is separated by a space. It indicates that Chinese character “天 (sky)” and “气 (air)” belong to Chinese word “天气 (weather)”, and we hope to enhance the relationship between “天 (sky)” to “气 (air)”, and, conversely, “气 (air)” and “天 (sky)”. From the perm_mask matrix in the middle of
Figure 10, we know that “天 (sky)” is masked; to enhance the relationship, we use the tok_mask matrix to reduce the degree of mask from “气 (air)” to “天 (sky)” and increase attention from “天 (sky)” to “气 (air)”.
If the element in attn_mask[i][j] is 1-α (solid diagonal circle), this means that originally i could not notice j, but since i and j belong to the same Chinese word, the attentional masking of j by i is “reduced” and the probability of attn_score[i][j] is reduced compared to the original one, which increases the probability of the subsequent softmax prediction. For example, the element in row 1 and column 5 in
Figure 12 means that the first element “气 (air)” would not be able to notice the unordered fifth element “天 (sky)” after disordering, because “天 (sky)” is masked for “气 (air)”. However, since “天 (sky)” and “气 (air)” belong to the same Chinese word “天气 (weather)”, the extent of mask from “气 (air)” to “天 (sky)” is “reduced”. Since “气 (air)” is not masked for “天 (sky)”, the attention is increased from “气 (air)” to “天 (sky)”.
As we see in
Figure 8, the LTP shows that Chinese word “不错 (nice)” is separated by space. It indicates that Chinese character “不 (not)” and “错 (bad)” belong to Chinese word “不错 (nice)”, and we hope to enhance the relationship between “不 (not)” and “错 (bad)”, and, conversely, “错 (bad)” and “不 (not)”. From the perm_mask matrix in the middle of
Figure 10, we know that both “不 (not)” and “错 (bad)” are unmasked; to enhance the relationship, we use the tok_mask matrix to increase attention from “不 (not)” to “错 (bad)” and “错 (bad)” to “不 (not)”.
If attn_mask[i][j] is α−1 (hollow diagonal circle), this means that originally i can notice j, but because i and j belong to the same phrase, i’s attention to j is “increased” compared to the original, attn_score[i][j] is increased, which also increases the probability of softmax prediction. For example, the elements in row 9 and column 10 in
Figure 12 indicate that the ninth element “不 (not)” after disordering is able to detect the tenth element “错 (bad)”, which is not disordered. Since “不 (not)” and “错 (bad)” belong to the same Chinese word, we increase the attention from “不 (not)” to “错 (bad)” and “错 (bad)” to “不 (not)”.
In summary, we have reduced the granularity of Chinese natural language processing from Chinese sub-word to single Chinese character. To solve the problem of information loss by splitting Chinese words into characters, we proposed a method to enhance the relationship between characters from the same word. The embodiment of this approach in the XLNet model is the tok_mask matrix. To further enhance the sentiment analysis capability, we combined BIGRU and self-attention to form CWSXLNet. In
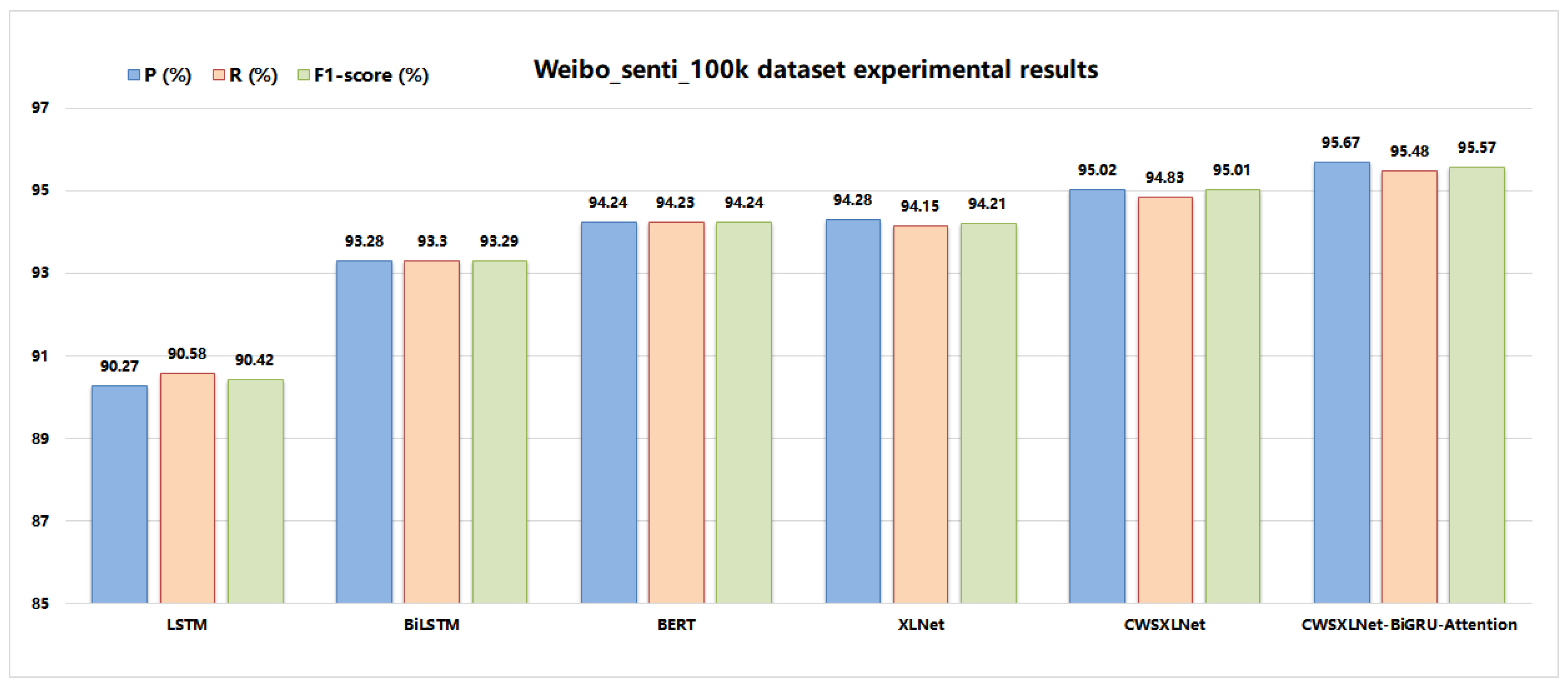
Section 4, the experimental result shows that it definitely improves the ability of Chinese sentiment analysis.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}