
An Application of Statistical Methods in Data Mining Techniques to Predict ICT Implementation of Enterprises



Abstract
:1. Introduction
2. Research Background
2.1. Modern Business Environment
2.2. Knowledge Gap and Hypotheses
- H1a: Manager/director age positively affects intentions to implement and apply ICTs within an enterprise.
- H1b: Manager/director gender positively affects intentions to implement and apply ICTs within an enterprise.
- H1c: Manager/director education positively affects intentions to implement and apply ICTs within an enterprise.
- H1d: Enterprise size positively affects intentions to implement and apply ICTs within an enterprise.
- H2: Business performance positively affects intentions to implement and apply ICTs within an enterprise.
- H3: Awareness of ICT importance positively affects intentions to implement and apply ICTs within an enterprise.
- H4: Intellectual capital positively affects intentions to implement and apply ICTs within an enterprise.
- H5: Market assessment positively affects intentions to implement and apply ICTs within an enterprise.
3. Methodology
3.1. Research Framework and Dataset
- Identifying the primary goal of the research (which is to present the application of data mining algorithms and attempt to predict enterprises’ intentions of implementing and applying ICTs with multiple potential predictors);
- Literature review (obtaining and concisely presenting a theoretical background in the domain of modern business environments);
- Data acquisition (developing a structured survey, survey distribution, data collection, and creating an integrated dataset for data mining via various statistical methods);
- Statistical methods (including descriptive statistics, linear regression, binary logistic regression, multicollinearity test, heteroscedasticity test, QUEST classification tree algorithm, support-vector machine–SVM);
- Information extraction and discussion (presenting and determining whether it is possible to predict intentions of ICT implementation and application with different statistical methods).
3.2. QUEST Algorithm for Data Mining
- Its accuracy is not compromised by its increased speed;
- It uses imputations instead of surrogate splits for missing values, making it better than the CART algorithm;
- It can handle categorical predictor variables with multiple categories;
- It does not have a bias toward variable selection before splitting [68];
- Its lack of bias is controlled through variation levels in the observed predictor variables [69].
- It can be applied for nominal, ordinal, and continuous values (ANOVA for ordinal and continuous values, and Pearson’s χ2 for categorical values);
- Cross-validation is used for pruning;
- It can be used with variate splits as well as for a combination of linear splits [66].
| Algorithm 1. Pseudocode for the QUEST algorithm |
|
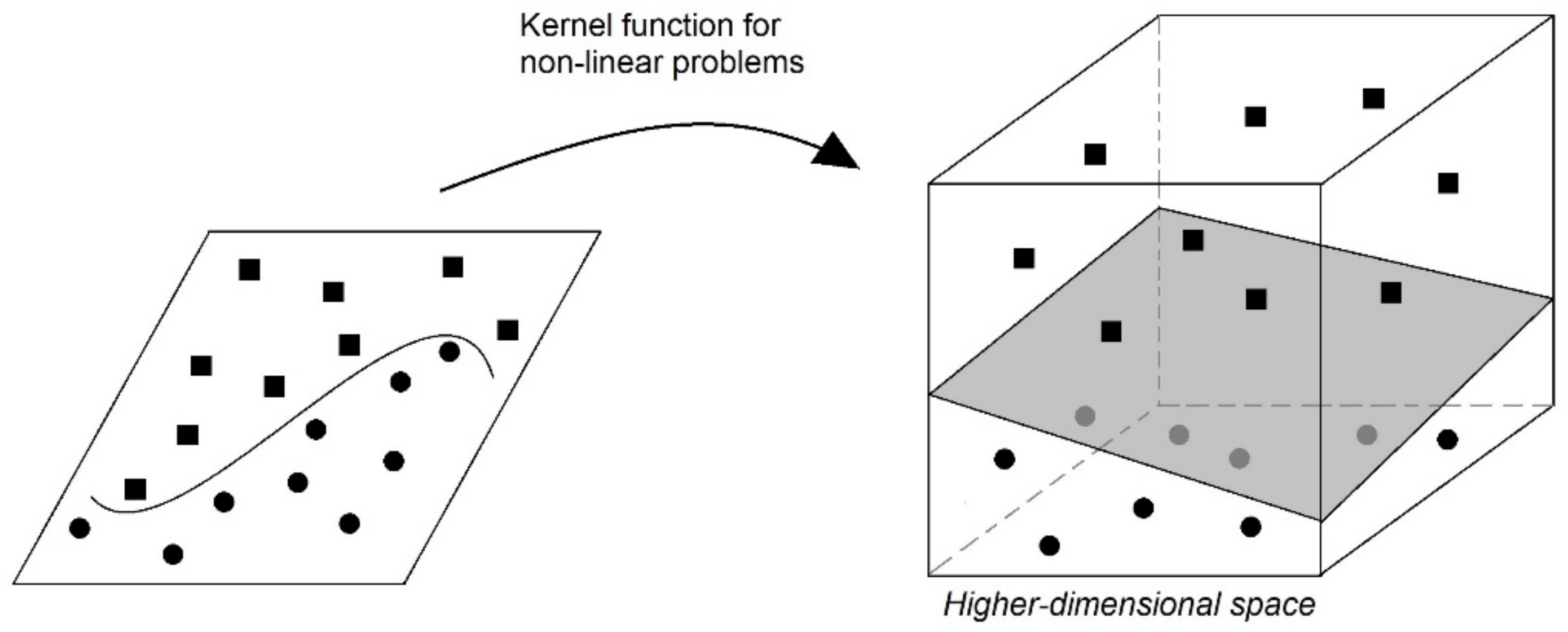
3.3. SVM Algorithm for Data Mining
| Algorithm 2. Pseudocode for the SVM. |
|
3.4. Feed-Forward Neural Network
| Algorithm 3. Python Cozde for Neural Network Training. |
|
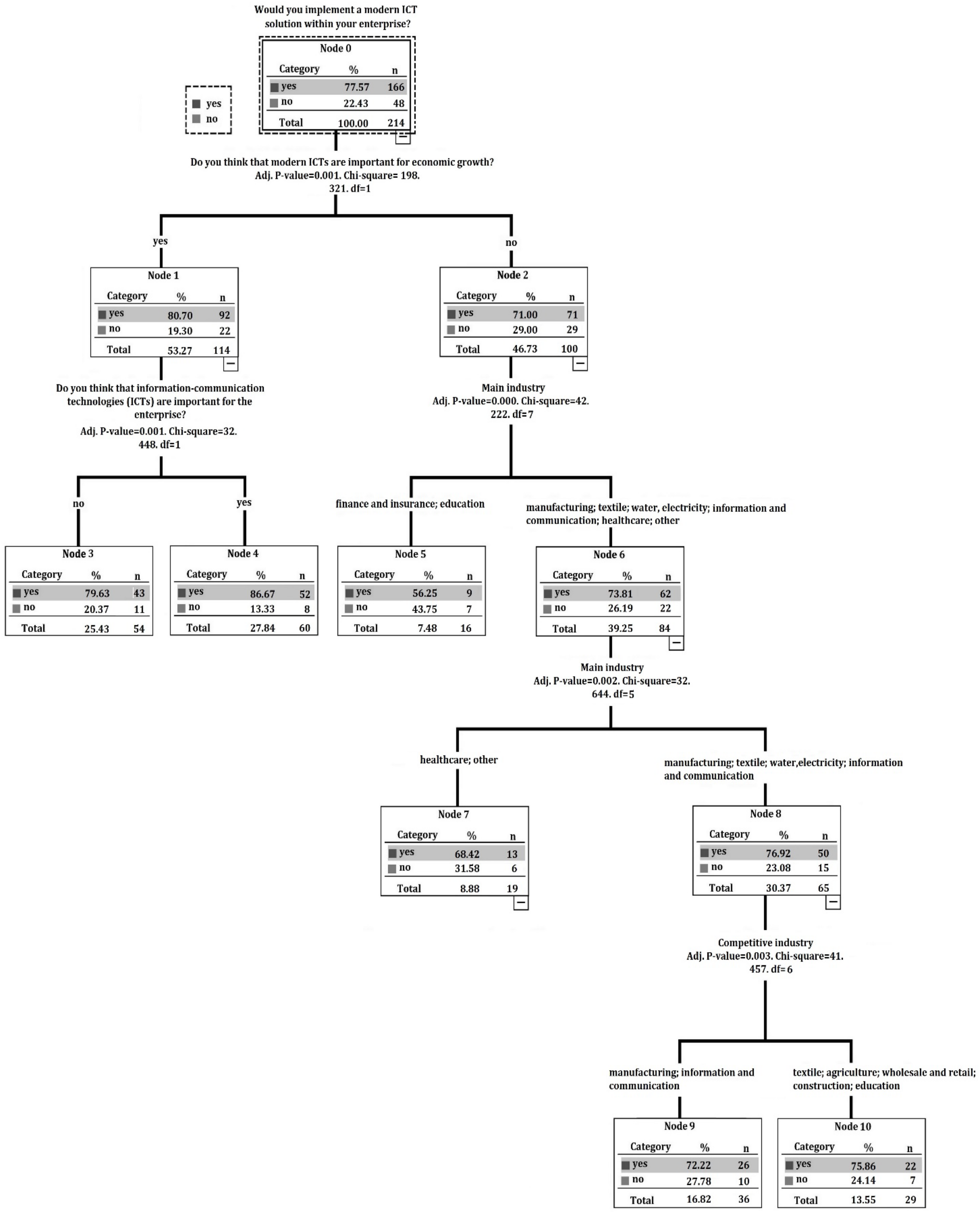
4. Results
- Awareness of ICT importance (Do you think that modern ICTs are important for economic growth-ICTECO); (Do you think that information-communication technologies (ICTs) are important for the enterprise? (ICTIM));
- Market assessment (Main industry in which the enterprise conducts business-INDENT); (In your opinion, what industry is the most competitive? (INDCOMP));
- N1: if (ICTECO = y),then class y = 80.70% and class n = 19.30%;
- N2: if (ICTECO = n),then class y = 71.00% and class n = 29.00%;
- N3: if (ICTIM = n),then class y = 79.63% and class n = 20.37%;
- N4: if (ICTIM = y),then class y = 86.67% and class n = 13.33%;
- N5: if (INDENT = [finance and insurance] OR [education]),then class y = 56.25% and class n = 43.75%;
- N6: if (INDENT = [manufacturing] OR [textile] OR [water electricity] OR [information and communication] OR [healthcare] OR [other]),then class y = 73.81% and class n = 26.19%;
- N7: if (INDENT = [healthcare] OR [other]),then class y = 68.42% and class n = 31.58%;
- N8: if (INDENT = [manufacturing] OR [textile] OR [water electricity] OR [information and communication]),then class y = 76.92% and class n = 23.08%;
- N9: if (INDCOMP = [manufacturing] OR [information and communication])),then class y = 72.22% and class n = 27.78%;
- N10: if (INDCOMP = [textile] OR [agriculture] OR [wholesale and retail] OR [construction] OR [education]),then class y = 75.86% and class n = 24.14%.
5. Discussion
5.1. Assessing the Results of the Linear Regression Analysis
- H1a: Manager/director age positively affects intentions to implement and apply ICTs within an enterprise. Did not gain support.
- H1b: Manager/director gender positively affects intentions to implement and apply ICTs within an enterprise. Did not gain support.
- H1c: Manager/director education positively affects intentions to implement and apply ICTs within an enterprise. Did not gain support.
- H1d: Enterprise size positively affects intentions to implement and apply ICTs within an enterprise. Did not gain support.
- H2: Business performance positively affects intentions to implement and apply ICTs within an enterprise. Did not gain support.
- H3: Awareness of ICT importance positively affects intentions to implement and apply ICTs within an enterprise. Did not gain support.
- H4: Intellectual capital positively affects intentions to implement and apply ICTs within an enterprise. Did not gain support.
- H5: Market assessment positively affects intentions to implement and apply ICTs within an enterprise. Failed to be rejected.
5.2. Assessing the Results of the Binary Logistic Regression Analysis
- H1a: Manager/director age positively affects intentions to implement and apply ICTs within an enterprise. Did not gain support.
- H1b: Manager/director gender positively affects intentions to implement and apply ICTs within an enterprise. Did not gain support.
- H1c: Manager/director education positively affects intentions to implement and apply ICTs within an enterprise. Did not gain support.
- H1d: Enterprise size positively affects intentions to implement and apply ICTs within an enterprise. Did not gain support.
- H2: Business performance positively affects intentions to implement and apply ICTs within an enterprise. Failed to be rejected.
- H3: Awareness of ICT importance positively affects intentions to implement and apply ICTs within an enterprise. Did not gain support.
- H4: Intellectual capital positively affects intentions to implement and apply ICTs within an enterprise. Did not gain support.
- H5: Market assessment positively affects intentions to implement and apply ICTs within an enterprise. Failed to be rejected.
5.3. Assessing the Results of the QUEST Algorithm
- H1a: Manager/director age positively affects intentions to implement and apply ICTs within an enterprise. Did not gain support.
- H1b: Manager/director gender positively affects intentions to implement and apply ICTs within an enterprise. Did not gain support.
- H1c: Manager/director education positively affects intentions to implement and apply ICTs within an enterprise. Did not gain support.
- H1d: Enterprise size positively affects intentions to implement and apply ICTs within an enterprise. Did not gain support.
- H2: Business performance positively affects intentions to implement and apply ICTs within an enterprise. Did not gain support.
- H3: Awareness of ICT importance positively affects intentions to implement and apply ICTs within an enterprise. Failed to be rejected.
- H4: Intellectual capital positively affects intentions to implement and apply ICTs within an enterprise. Did not gain support.
- H5: Market assessment positively affects intentions to implement and apply ICTs within an enterprise. Failed to be rejected.
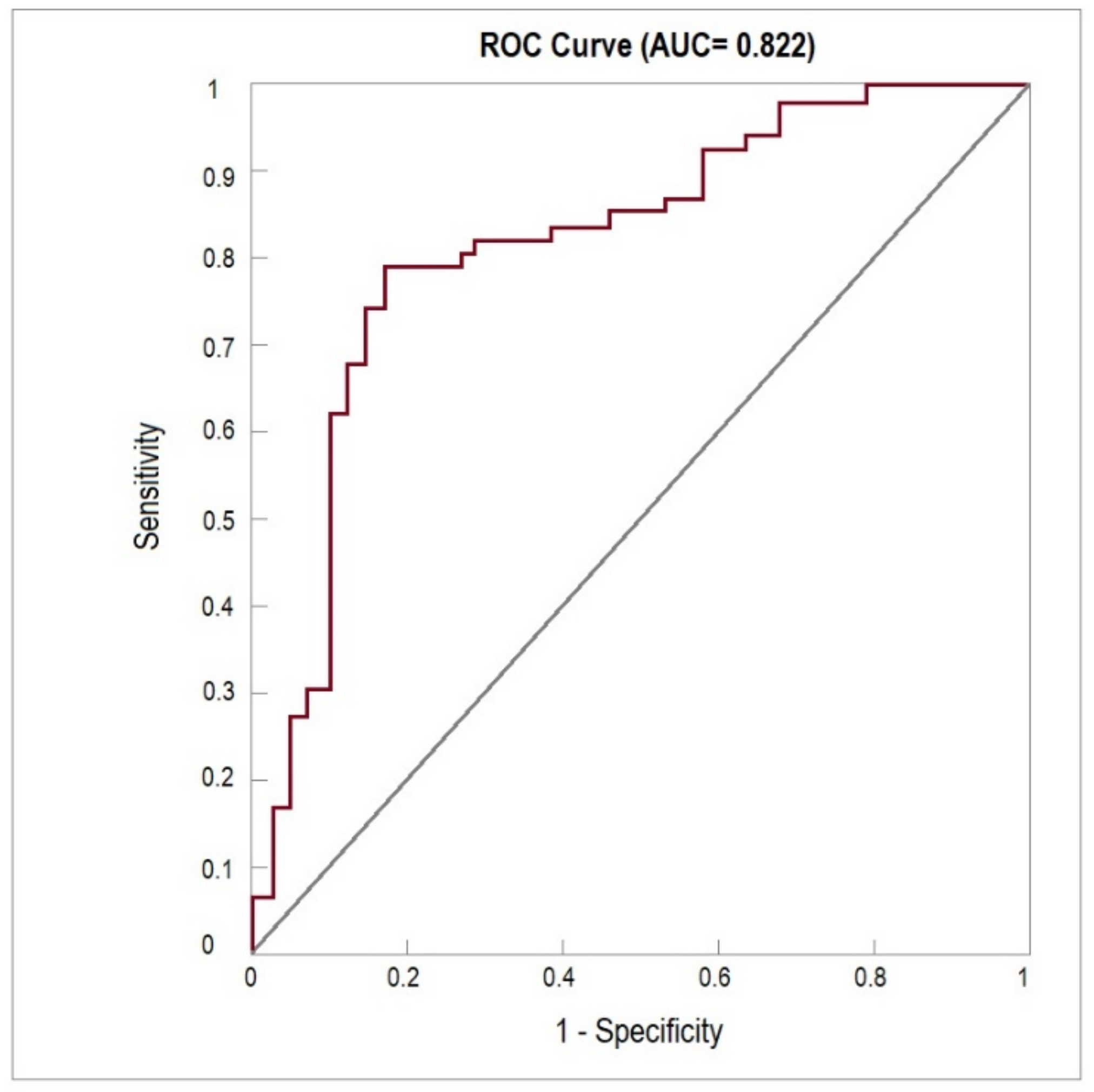
5.4. Assessing the Results of the SVM Classifier
- H1a: Manager/director age positively affects intentions to implement and apply ICTs within an enterprise. Failed to be rejected.
- H1b: Manager/director gender positively affects intentions to implement and apply ICTs within an enterprise. Failed to be rejected.
- H1c: Manager/director education positively affects intentions to implement and apply ICTs within an enterprise. Failed to be rejected.
- H1d: Enterprise size positively affects intentions to implement and apply ICTs within an enterprise. Failed to be rejected.
- H2: Business performance positively affects intentions to implement and apply ICTs within an enterprise. Failed to be rejected.
- H3: Awareness of ICT importance positively affects intentions to implement and apply ICTs within an enterprise. Failed to be rejected.
- H4: Intellectual capital positively affects intentions to implement and apply ICTs within an enterprise. Failed to be rejected.
- H5: Market assessment positively affects intentions to implement and apply ICTs within an enterprise. Failed to be rejected.
5.5. Assessing the Results of the Feed-Forward Neural Network
5.6. Other Studies
5.7. Limitations, Future Research, and Implications
- Mainly English literature in the theoretical background section;
- Unexplained variance in the results, which indicates that there may be other factors that affect the dependent variable (this is expected with social studies);
- Pie charts and histograms were not developed;
- Analysis was conducted only on enterprises within Serbia. However, transitional economies tend to have the same issues when it comes to competitiveness.
- Extensive equations were not included (the methods derive from well-established equations).
- Consider the limitations noted above;
- Use a structured approach to future research;
- Introduce additional predictor factors such as human resource management, employee productivity, and marketing management;
- Analyze datasets consisting of enterprises from other countries and compare them to this current paper’s findings;
- Conduct meta-analysis when similar studies are published;
- Apply CHART, CHAID, and other classifiers in future studies.
- Governments (increasing strategic incentive programs for ICT adoption across industries would improve national competitiveness).
- Schools and universities can address this paper by presenting the necessity and imperative role of ICTs in the modern global economy.
- Fellow scholars can address this study for their own research. This paper provides an adequate basis and guidelines for future analysis in this domain.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| First Predictor Group: Sample Size and Structure (Demographic Information) | ||
|---|---|---|
| Label | Variable | Available Answers |
| GEND | Gender |
|
| AGE | Age | every age is observed individually |
| EDU | Education (acquaired) |
|
| ENSI | Enterprise size |
|
| Second predictor group: Business performance | ||
| Code | Attribute | Available answers |
| ENBU | Do you think that the enterprise’s business performance is satisfactory? |
|
| QPS | Quality of products is satisfactory. |
|
| FIG | Financial goals are easily achieved. |
|
| PROS | Strategic long-term profitability is sustainable. |
|
| GROS | Growth of new customers and customer retention is adequate. |
|
| Third predictor group: Awareness of ICT importance | ||
| Code | Attribute | Available answers |
| ICTIM | Do you think that information-communication technologies (ICTs) are important for the enterprise? |
|
| ICTCO | Do you think enterprises that implement modern ICTs are more competitive compared to enterprises that don’t? |
|
| ICTECO | Do you think that modern ICTs are important for economic growth? |
|
| ICTEX | Do you think ICTs are expensive compared to what improvements they offer to the enterprise? |
|
| ICTSOL | What kind of ICT solution do you think can help an enterprise when it comes to conducting business? |
|
| Fourth predictor group: Intellectual capital | ||
| Code | Attribute | Available answers |
| ICEN | Intellectual capital is effectively applied in the enterprise. |
|
| ICSD | Intellectual capital is applied to make strategic decisions. |
|
| ICRP | Intellectual capital is reported periodically within the enterprise. |
|
| ICCB | Intellectual capital is regarded as an important part of conducting business. |
|
| Fifth predictor group: Market assessment | ||
| CODE | Attribute | Available answers |
| INDENT | Main industry within the enterprise conducts business |
|
| INDCOMP | In your opinion, what industry is the most competitive? |
|
| MARCOMP | Do you think the market is competitive within your enterprise’s industry? |
|
| FINDCHAL | Do you think the fourth industrial revolution has brought additional challenges to enterprises? |
|
| COVMP | Do you think the COVID-19 pandemic has negatively affected the enterprise’s market performance? |
|
| Dependent variable: Intention to implement and modern ICT solution | ||
| CODE | Attribute | Available answers |
| IMPICT (dependent variable) | Would you implement a modern ICT solution within your enterprise? |
|
Appendix B
| Sample Size and Structure (Demographic Information) | |
|---|---|
| Gender | Male (135 answers; 63.08%) Female (79 answers; 36.92%) |
| Age | Mean 43.47 Variance 52.27 Standard deviation 7.23 Median 41 Mode 40 Percentages: 29 (2 answers; 0.93%) 32 (7 answers; 3.27%) 33 (5 answers; 2.34%) 36 (11 answers; 5.14%) 37 (15 answers; 7.01%) 38 (22 answers; 10.28%) 40 (31 answers; 14.49%) 41 (28 answers; 13.08%) 42 (11 answers; 5.14%) 45 (17 answers; 7.79%) 49 (14 answers; 6.54%) 50 (2 answers; 0.93%) 51 (8 answers; 3.74%) 52 (5 answers; 2.34%) 53 (14 answers; 6.54%) 55 (3 answers; 1.40%) 56 (6 answers; 2.80%) 57 (4 answers; 1.87%) 58 (4 answers; 1.87%) 59 (4 answers; 1.87%) 61 (1 respondent; 0.47%) |
| Education (completed) | HS (5 answers; 2.34%) BSc (159 answers; 74.30%) MSc (42 answers; 19.63%) PhD (8 answers, 3.74%) |
| Enterprise size | micro (<10 employees) (78 answers, 36.45%) small (10–49 employees) (105 answers, 49.07%) medium (50–249 employees) (25 answers, 11.68%) large (250 > employees) (6 answers, 2.80%) |
| Business performance | |
| Do you think that the enterprise’s business performance is satisfactory? | Yes (85 answers; 39.5%) No (129 answers; 60.5%) |
| Quality of products is satisfactory. | Agree (52 answers; 24.1%) Mostly agree (43 answers; 20.3%) Don’t know (35 answers; 16.4%) Mostly disagree (60 answers; 28%) Disagree (24 answers; 11.2%) |
| Financial goals are easily achieved. | Agree (17 answers; 7.9%) Mostly agree (42 answers; 19.4%) Don’t know (39 answers; 18.4%) Mostly disagree (82 answers; 38.5%) Disagree (34 answers; 15.8%) |
| Strategic long-term profitability is sustainable. | Agree (52 answers; 24.4%) Mostly agree (13 answers; 6.1%) Don’t know (38 answers; 17.7%) Mostly disagree (41 answers; 19.1%) Disagree (70 answers; 32.7%) |
| Growth of new customers and customer retention is adequate. | Agree (90 answers; 41.9%) Mostly agree (30 answers; 14%) Don’t know (10 answers; 4.7%) Mostly disagree (42 answers; 19.8%) Disagree (42 answers; 19.6%) |
| Awareness of ICT importance | |
| Do you think that information-communication technologies (ICTs) are important for the enterprise? | Yes (100 responses; 46.4%) No (114 responses; 53.6%) |
| Do you think enterprises that implement modern ICTs are more competitive compared to enterprises that don’t? | Yes (95 responses; 44.6%) No (119 responses; 55.4%) |
| Do you think that modern ICTs are important for economic growth? | Yes (113 responses; 52.7%) No (101 responses; 47.3%) |
| Do you think ICTs are expensive compared to what improvements they offer to the enterprise? | Yes (120 responses; 56.2%) No (94 responses; 43.8%) |
| What kind of ICT solution do you think can help an enterprise when it comes to conducting business? | Cloud-based solution (131 responses; 61.2%) ERP system (10 responses; 4.7%) Management information system (27 responses; 12.7%) Decision making support system (18 responses; 8.3%) Other (28 responses; 13.1%) |
| Would you implement a modern ICT solution within your enterprise? | Yes 166 (166 responses; 77.6%) No 48 (48 responses; 22.4%) |
| Intellectual capital | |
| Intellectual capital is effectively applied in the enterprise. | Agree (52 answers; 24.5%) Mostly agree (25 answers; 11.4%) Don’t know (30 answers; 13.9%) Mostly disagree (80 answers; 37.5%) Disagree (27 answers; 12.7%) |
| Intellectual capital is applied to make strategic decisions. | Agree (53 answers; 24.7%) Mostly agree (24 answers; 11.6%) Don’t know (79 answers; 36.9%) Mostly disagree (27 answers; 12.5%) Disagree (31 answers; 14.3%) |
| Intellectual capital is reported periodically within the enterprise. | Agree (69 answers; 32.14%) Mostly agree (54 answers; 25.4%) Don’t know (25 answers; 11.6%) Mostly disagree (48 answers; 22.5%) Disagree (18 answers; 8.36%) |
| Intellectual capital is regarded as an important part of conducting business. | Yes (57 answers; 26.6%) No (157 answers; 73.4%) |
| Market assessment | |
| Main industry within the enterprise conducts business |
|
| In your opinion, what industry is the most competitive? |
|
| Do you think the market is competitive within your enterprise’s industry? | Yes (90 answers; 42.3%) No (124 answers; 57.7%) |
| Do you think the fourth industrial revolution has brought additional challenges to enterprises? | Yes (127 answers; 59.4%) No (87 answers; 40.6%) |
| Do you think the COVID-19 pandemic has negatively affected the enterprise’s market performance? | Yes (144 answers; 67.45%) No (70 answers; 32.55%) |
References
- Ulutaş, A.; Meidute-Kavaliauskiene, I.; Topal, A.; Demir, E. Assessment of Collaboration-Based and Non-Collaboration-Based Logistics Risks with Plithogenic SWARA Method. Logistics 2021, 5, 82. [Google Scholar] [CrossRef]
- Özdemir, L. Testing for Asymmetric Causality Between Developed and Emerging Markets. In Uncertainty and Challenges in Contemporary Economic Behaviour; Emerald Studies in Finance, Insurance, and Risk Management; Emerald Publishing Limited: Bingley, UK, 2020; pp. 145–158. [Google Scholar] [CrossRef]
- Bakator, M.; Đorđević, D.; Ćoćkalo, D. Developing a model for improving business and competitiveness of domestic enterprises. J. Eng. Manag. Compet. 2019, 9, 287–296. [Google Scholar] [CrossRef]
- Surya, B.; Menne, F.; Sabhan, H.; Suriani, S.; Abubakar, H.; Idris, M. Economic Growth, Increasing Productivity of SMEs, and Open Innovation. J. Open Innov. Technol. Mark. Complex. 2021, 7, 20. [Google Scholar] [CrossRef]
- Ćoćkalo, D.; Đorđević, D.; Bogetić, S.; Bakator, M. Youth entrepreneurship development: A review of literature and ten-year research results. J. Eng. Manag. Competitiveness 2020, 10, 151–161. [Google Scholar] [CrossRef]
- Fani, V.; Antomarioni, S.; Bandinelli, R.; Ciarapica, F.E. Data Mining and Augmented Reality: An Application to the Fashion Industry. Appl. Sci. 2023, 13, 2317. [Google Scholar] [CrossRef]
- Barba-Sánchez, V.; Calderón-Milán, M.J.; Atienza-Sahuquillo, C. A Study of the Value of ICT in Improving Corporate Performance: A Corporate Competitiveness View. Technol. Econ. Dev. Econ. 2018, 24, 1388–1407. [Google Scholar] [CrossRef] [Green Version]
- Alam, M.M.D.; Al Karim, R.; Habiba, W. The relationship between CRM and customer loyalty: The moderating role of customer trust. Int. J. Bank Mark. 2021, 39, 1248–1272. [Google Scholar] [CrossRef]
- Hamby, A.; Brinberg, D. Cause-Related Marketing Persuasion Knowledge: Measuring Consumers’ Knowledge and Ability to Interpret CrM Promotions. J. Consum. Aff. 2017, 52, 373–392. [Google Scholar] [CrossRef]
- Zand, J.D.; Keramati, A.; Shakouri, F.; Noori, H. Assessing the impact of customer knowledge management on organizational performance. Knowl. Process. Manag. 2018, 25, 268–278. [Google Scholar] [CrossRef]
- Rua, O.; França, A.; Ortiz, R.F. Key drivers of SMEs export performance: The mediating effect of competitive advantage. J. Knowl. Manag. 2018, 22, 257–279. [Google Scholar] [CrossRef]
- Djalic, N.; Nikolic, M.; Bakator, M.; Erceg, Z. Modeling the Influence of Information Systems on Sustainable Business Performance and Competitiveness. Sustainability 2021, 13, 9619. [Google Scholar] [CrossRef]
- Nurqamarani, A.S.; Sogiarto, E.; Nurlaeli, N. Technology Adoption in Small-Medium Enterprises based on Technology Ac-ceptance Model: A Critical Review. J. Info. Sys. Eng. Bus. Intel. 2021, 7, 2, 162–172. [Google Scholar] [CrossRef]
- Molero, G.D.; Santarremigia, F.E.; Poveda-Reyes, S.; Mayrhofer, M.; Awad-Núñez, S.; Kassabji, A. Key factors for the implementation and integration of innovative ICT solutions in SMEs and large companies involved in the multimodal transport of dangerous goods. Eur. Transp. Res. Rev. 2019, 11, 28. [Google Scholar] [CrossRef]
- Ghobakhloo, M. Industry 4.0, digitization, and opportunities for sustainability. J. Clean. Prod. 2019, 252, 119869. [Google Scholar] [CrossRef]
- Javaid, M.; Haleem, A.; Vaishya, R.; Bahl, S.; Suman, R.; Vaish, A. Industry 4.0 technologies and their applications in fighting COVID-19 pandemic. Diabetes Metab. Syndr. Clin. Res. Rev. 2020, 14, 419–422. [Google Scholar] [CrossRef]
- Bai, C.; Dallasega, P.; Orzes, G.; Sarkis, J. Industry 4.0 technologies assessment: A sustainability perspective. Int. J. Prod. Econ. 2020, 229, 107776. [Google Scholar] [CrossRef]
- Kumar, R.; Singh, R.K.; Dwivedi, Y.K. Application of industry 4.0 technologies in SMEs for ethical and sustainable operations: Analysis of challenges. J. Clean. Prod. 2020, 275, 124063. [Google Scholar] [CrossRef] [PubMed]
- Trzaska, R.; Sulich, A.; Organa, M.; Niemczyk, J.; Jasiński, B. Digitalization Business Strategies in Energy Sector: Solving Problems with Uncertainty under Industry 4.0 Conditions. Energies 2021, 14, 7997. [Google Scholar] [CrossRef]
- Aslam, F.; Aimin, W.; Li, M.; Ur Rehman, K. Innovation in the Era of IoT and Industry 5.0: Absolute Innovation Management (AIM) Framework. Information 2020, 11, 124. [Google Scholar] [CrossRef] [Green Version]
- Maddikunta, P.K.R.; Pham, Q.-V.; Prabadevi, B.; Deepa, N.; Dev, K.; Gadekallu, T.R.; Ruby, R.; Liyanage, M. Industry 5.0: A survey on enabling technologies and potential applications. J. Ind. Inf. Integr. 2021, 26, 100257. [Google Scholar] [CrossRef]
- Quintero-Quintero, W.; Blanco-Ariza, A.B.; Garzón-Castrillón, M.A. Intellectual Capital: A Review and Bibliometric Analysis. Publications 2021, 9, 46. [Google Scholar] [CrossRef]
- Ali, M.A.; Hussin, N.; Haddad, H.; Al-Araj, R.; Abed, I.A. Intellectual Capital and Innovation Performance: Systematic Literature Review. Risks 2021, 9, 170. [Google Scholar] [CrossRef]
- Secundo, G.; Ndou, V.; Del Vecchio, P.; De Pascale, G. Sustainable development, intellectual capital and technology policies: A structured literature review and future research agenda. Technol. Forecast. Soc. Chang. 2020, 153, 119917. [Google Scholar] [CrossRef]
- Alvino, F.; Di Vaio, A.; Hassan, R.; Palladino, R. Intellectual capital and sustainable development: A systematic literature review. J. Intellect. Cap. 2020, 22, 76–94. [Google Scholar] [CrossRef]
- Juergensen, J.; Guimón, J.; Narula, R. European SMEs amidst the COVID-19 crisis: Assessing impact and policy responses. J. Ind. Bus. Econ. 2020, 47, 499–510. [Google Scholar] [CrossRef]
- Mubarak, M.F.; Petraite, M. Industry 4.0 technologies, digital trust and technological orientation: What matters in open in-novation? Technol Forecast. Soc. Chang. 2020, 161, 120332. [Google Scholar] [CrossRef]
- Zheng, T.; Ardolino, M.; Bacchetti, A.; Perona, M. The applications of Industry 4.0 technologies in manufacturing context: A systematic literature review. Int. J. Prod. Res. 2020, 59, 1922–1954. [Google Scholar] [CrossRef]
- Amoako, T.; Sheng, Z.H.; Dogbe, C.S.K.; Pomegbe, W.W.K. Effect of internal integration on SMEs’ performance: The role of external integration and ICT. Int. J. Prod. Perform. Manag. 2020, 71, 643–665. [Google Scholar] [CrossRef]
- Cataldo, A.; Pino, G.; McQueen, R.J. Size matters: The impact of combinations of ICT assets on the performance of Chilean micro, small and medium enterprises. Inf. Technol. Dev. 2019, 26, 292–315. [Google Scholar] [CrossRef]
- Arsawan, I.W.E.; Koval, V.; Rajiani, I.; Rustiarini, N.W.; Supartha, W.G.; Suryantini, N.P.S. Leveraging knowledge sharing and innovation culture into SMEs sustainable competitive advantage. Int. J. Prod. Perform. Manag. 2020, 71, 405–428. [Google Scholar] [CrossRef]
- Abdissa, G.; Ayalew, A.; Illés, C.B.; Dunay, A. Effects of Corporate Entrepreneurship Dimensions on Organizational Performance: Case of Small and Medium Enterprises in Holeta Town, Ethiopia. J. Open Innov. Technol. Mark. Complex. 2021, 7, 234. [Google Scholar] [CrossRef]
- Stroumpoulis, A.; Kopanaki, E.; Karaganis, G. Examining the Relationship between Information Systems, Sustainable SCM, and Competitive Advantage. Sustainability 2021, 13, 11715. [Google Scholar] [CrossRef]
- Yoon, J.; Sung, S.; Ryu, D. The Role of Networks in Improving International Performance and Competitiveness: Perspective View of Open Innovation. Sustainability 2020, 12, 1269. [Google Scholar] [CrossRef]
- Liñán, F.; Paul, J.; Fayolle, A. SMEs and entrepreneurship in the era of globalization: Advances and theoretical approaches. Small Bus. Econ. 2019, 55, 695–703. [Google Scholar] [CrossRef]
- Gujrati, R. Trends toward globalization: Challenges & issues. Splint Int. J. Prof. 2019, 6, 63–72. [Google Scholar]
- Wen, Y. Remote sensing image land type data mining based on QUEST decision tree. Clust. Comput. 2018, 22, 8437–8443. [Google Scholar] [CrossRef]
- Kahraman, C.; Cevik Onar, S.; Oztaysi, B.; Sari, I.U.; Cebi, S.; Tolga, A.C. (Eds.) Intelligent and Fuzzy Techniques: Smart and Innovative Solutions. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar] [CrossRef]
- Djordjevic, D.; Cockalo, D.; Bogetic, S.; Bakator, M. Predicting Entrepreneurial Intentions among the Youth in Serbia with a Classification Decision Tree Model with the QUEST Algorithm. Mathematics 2021, 9, 1487. [Google Scholar] [CrossRef]
- Acioli, C.; Scavarda, A.; Reis, A. Applying Industry 4.0 technologies in the COVID–19 sustainable chains. Int. J. Prod. Perform. Manag. 2021, 70, 988–1016. [Google Scholar] [CrossRef]
- Cyfert, S.; Glabiszewski, W.; Zastempowski, M. Impact of Management Tools Supporting Industry 4.0 on the Importance of CSR during COVID-19. Generation Z. Energies 2021, 14, 1642. [Google Scholar] [CrossRef]
- Nahavandi, S. Industry 5.0—A Human-Centric Solution. Sustainability 2019, 11, 4371. [Google Scholar] [CrossRef] [Green Version]
- Sachs, J.D.; Schmidt-Traub, G.; Mazzucato, M.; Messner, D.; Nakicenovic, N.; Rockström, J. Six Transformations to achieve the Sustainable Development Goals. Nat. Sustain. 2019, 2, 805–814. [Google Scholar] [CrossRef]
- De Felice, F.; Travaglioni, M.; Petrillo, A. Innovation Trajectories for a Society 5.0. Data 2021, 6, 115. [Google Scholar] [CrossRef]
- Santoro, G.; Usai, A. Knowledge exploration and ICT knowledge exploitation through human resource management: A study of Italian firms. Manag. Res. Rev. 2018, 41, 701–715. [Google Scholar] [CrossRef]
- Chatterjee, S.; Chaudhuri, R.; Vrontis, D.; Thrassou, A.; Ghosh, S.K. ICT-enabled CRM system adoption: A dual Indian qualitative case study and conceptual framework development. J. Asia Bus. Stud. 2020, 15, 257–277. [Google Scholar] [CrossRef]
- Salau, O.; Osibanjo, A.; Adeniji, A.; Igbinoba, E. An integrated dataset on organisational retention attributes and commitment of selected ICT and accounting firms. Data Brief 2018, 18, 1930–1936. [Google Scholar] [CrossRef]
- Minashkina, D.; Happonen, A. A Systematic Literature Mapping of Current Academic Research Connecting Sustainability into the Warehouse Management Systems Context. Curr. Approaches Sci. Technol. Res. 2021, 5, 52–80. [Google Scholar]
- Dolan-Canning, R. Sensor-based and cognitive assistance systems in industry 4.0: Big data analytics, smart production, and sustainable value creation. Econ. Manag. Financ. Mark. 2019, 14, 3, 16–22. [Google Scholar]
- Karunagaran, S.; Mathew, S.K.; Lehner, F. Differential cloud adoption: A comparative case study of large enterprises and SMEs in Germany. Inf. Syst. Front. 2017, 21, 861–875. [Google Scholar] [CrossRef]
- Shen, H.; Fu, M.; Pan, H.; Yu, Z.; Chen, Y. The Impact of the COVID-19 Pandemic on Firm Performance. Emerg. Mark. Finance Trade 2020, 56, 2213–2230. [Google Scholar] [CrossRef]
- Caballero-Morales, S.-O. Innovation as recovery strategy for SMEs in emerging economies during the COVID-19 pandemic. Res. Int. Bus. Finance 2021, 57, 101396. [Google Scholar] [CrossRef]
- Fukuyama, M. Society 5.0: Aiming for a New Human-Centered Society. Jpn. Spotlight 2018, 1, 47–50. [Google Scholar]
- Potočan, V.; Mulej, M.; Nedelko, Z. Society 5.0: Balancing of Industry 4.0, economic advancement and social problems. Kybernetes 2020, 50, 794–811. [Google Scholar] [CrossRef]
- Onday, O. Japan’s society 5.0: Going beyond Industry 4.0. Bus. Econ. J. 2019, 10, 1–6. [Google Scholar]
- Skobelev, P.O.; Borovik, S.Y. On the way from Industry 4.0 to Industry 5.0: From digital manufacturing to digital society. Industry 4.0 2017, 2, 307–311. [Google Scholar]
- Zengin, Y.; Naktiyok, S.; Kaygın, E.; Kavak, O.; Topçuoğlu, E. An Investigation upon Industry 4.0 and Society 5.0 within the Context of Sustainable Development Goals. Sustainability 2021, 13, 2682. [Google Scholar] [CrossRef]
- Ahmed, S.S.; Guozhu, J.; Mubarik, S.; Khan, M.; Khan, E. Intellectual capital and business performance: The role of dimensions of absorptive capacity. J. Intellect. Cap. 2019, 21, 23–39. [Google Scholar] [CrossRef]
- McDowell, W.C.; Peake, W.O.; Coder, L.A.; Harris, M.L. Building small firm performance through intellectual capital development: Exploring innovation as the “black box”. J. Bus. Res. 2018, 88, 321–327. [Google Scholar] [CrossRef]
- Varadarajan, R. Customer information resources advantage, marketing strategy and business performance: A market resources based view. Ind. Mark. Manag. 2020, 89, 89–97. [Google Scholar] [CrossRef]
- Kwan, S.H.; Mertens, T.M. Market assessment of COVID-19. FRBSF Econ. Lett. 2020, 14, 1–5. [Google Scholar]
- Mahmoud, M.A.; Blankson, C.; Owusu-Frimpong, N.; Nwankwo, S.; Trang, T.P. Market orientation, learning orientation and business performance: The mediating role of innovation. Int. J. Bank Mark. 2016, 34, 623–648. [Google Scholar] [CrossRef]
- Edvinsson, L.; Mas, F.D.; Pablos, P.O.D.; Massaro, M.; Dumay, J. From a value-based knowledge economy to a worth economy. New reflections and perspectives on intellectual capital research. Int. J. Learn. Intellect. Cap. 2021, 19, 83–101. [Google Scholar] [CrossRef]
- Nailevich, I.R. Ways to Increase the Competitiveness of Enterprises. Cent. Asian J. Innov. Tour. Manag. Financ. 2023, 4, 174–177. [Google Scholar] [CrossRef]
- Chatterjee, S.; Chaudhuri, R. Adoption of Artificial Intelligence Integrated Customer Relationship Management in Organizations for Sustainability. In Business Under Crisis, Volume III: Avenues for Innovation, Entrepreneurship and Sustainability; Palgrave Macmillan: Cham, Switzerland, 2022; pp. 137–156. [Google Scholar] [CrossRef]
- Alam, K.; Ali, M.A.; Erdiaw-Kwasie, M.; Shahiduzzaman; Velayutham, E.; Murray, P.A.; Wiesner, R. Impact of ICTs on Innovation and Performance of Firms: Do Start-ups, Regional Proximity and Skills Matter? Sustainability 2022, 14, 5801. [Google Scholar] [CrossRef]
- Liñán, F.; Chen, Y.-W. Development and Cross–Cultural Application of a Specific Instrument to Measure Entrepreneurial Intentions. Entrep. Theory Pract. 2009, 33, 593–617. [Google Scholar] [CrossRef]
- Martínez-González, J.A.; Kobylinska, U.; García-Rodríguez, F.J.; Nazarko, L. Antecedents of Entrepreneurial Intention among Young People: Model and Regional Evidence. Sustainability 2019, 11, 6993. [Google Scholar] [CrossRef] [Green Version]
- Shirokova, G.; Tsukanova, T.; Morris, M.H. The Moderating Role of National Culture in the Relationship Between University Entrepreneurship Offerings and Student Start-Up Activity: An Embeddedness Perspective. J. Small Bus. Manag. 2017, 56, 103–130. [Google Scholar] [CrossRef]
- Loh, W.; Shih, Y. Split selection methods for classification trees. Stat. Sin. 1997, 7, 815–840. [Google Scholar]
- Díaz-Casero, J.C.; Fernández-Portillo, A.; Sánchez-Escobedo, M.-C.; Hernández-Mogollón, R. The Influence of University Context on Entrepreneurial Intentions. In Entrepreneurial Universities; Springer: Berlin/Heidelberg, Germany, 2016; pp. 65–81. [Google Scholar]
- Gunduz, M.; Lutfi, H. Go/No-Go Decision Model for Owners Using Exhaustive CHAID and QUEST Decision Tree Algorithms. Sustainability 2021, 13, 815. [Google Scholar] [CrossRef]
- Guo, Y.; Logan, H.L.; Glueck, D.H.; Muller, K.E. Selecting a sample size for studies with repeated measures. BMC Med Res. Methodol. 2013, 13, 100. [Google Scholar] [CrossRef] [Green Version]
- Chittam, S.; Gokaraju, B.; Xu, Z.; Sankar, J.; Roy, K. Big Data Mining and Classification of Intelligent Material Science Data Using Machine Learning. Appl. Sci. 2021, 11, 8596. [Google Scholar] [CrossRef]
- Shao, J.; Liu, X.; He, W. Kernel Based Data-Adaptive Support Vector Machines for Multi-Class Classification. Mathematics 2021, 9, 936. [Google Scholar] [CrossRef]
- Huang, Y.; Zhao, L. Review on landslide susceptibility mapping using support vector machines. Catena 2018, 165, 520–529. [Google Scholar] [CrossRef]
- Zhang, Z.; Feng, F.; Huang, T. FNNS: An Effective Feedforward Neural Network Scheme with Random Weights for Processing Large-Scale Datasets. Appl. Sci. 2022, 12, 12478. [Google Scholar] [CrossRef]
- Aldakheel, F.; Satari, R.; Wriggers, P. Feed-Forward Neural Networks for Failure Mechanics Problems. Appl. Sci. 2021, 11, 6483. [Google Scholar] [CrossRef]
- Ling, C.; Lei, J.; Kuo, W. Support Vector Machine-Assisted Importance Sampling for Optimal Reliability Design. Appl. Sci. 2022, 12, 12750. [Google Scholar] [CrossRef]
- Zhao, M.; Li, Z.; He, W. Classifying Four Carbon Fiber Fabrics via Machine Learning: A Comparative Study Using ANNs and SVM. Appl. Sci. 2016, 6, 209. [Google Scholar] [CrossRef] [Green Version]
- Cemiloglu, A.; Zhu, L.; Arslan, S.; Xu, J.; Yuan, X.; Azarafza, M.; Derakhshani, R. Support Vector Machine (SVM) Application for Uniaxial Compression Strength (UCS) Prediction: A Case Study for Maragheh Limestone. Appl. Sci. 2023, 13, 2217. [Google Scholar] [CrossRef]





| Information | Detail |
|---|---|
| Number of participants | 214 |
| Participants |
|
| Enterprise | The majority of enterprises are micro-sized (36.45%) and small-sized (49.07%). This is expected as the majority of enterprises in the Republic of Serbia are micro- and small-sized enterprises. Industries in which the enterprises conduct their business: manufacturing (58); textile (28); agriculture (4); mining and quarrying (2); information and communication (41); wholesale and retail (9); construction (9); finance and insurance (26); healthcare and social work (9); water, electricity, gas supply (12); education (10); other (6). |
| Note: | Additional details are presented in the Appendix A. |
| Methodology Aspects | Info |
|---|---|
| Number of completed surveys | 214 (n = 214) |
| Study length | Less than a year (finalized in 2021) |
| Sample structure | Managers/directors/owners of micro-, small-, medium-, and large-sized enterprises |
| Study research instrument | Survey (attached as an Appendix A) |
| Conducted data analysis |
|
| Predictor groups | Demographic and basic information (gender, age, education, enterprise size)
|
| Dependent variable | Intention to implement and apply ICT within the enterprise |
| Independent Variables (Viewed as Predictor Groups) | Dependent Variable | Standardized Coefficients | p |
|---|---|---|---|
| Business performance | ICT implementation intentions | −0.158 | 0.000 |
| Awareness of ICT importance | 0.112 | 0.722 | |
| Intellectual capital | 0.057 | 0.602 | |
| Market assessment | 0.166 | 0.000 |
| Feature Item | Feature Group | β | p | 95% CI | |
|---|---|---|---|---|---|
| Financial goals are easily achieved. | Business performance | 1.20 | 0.001 | 1.17 | 1.54 |
| Strategic long-term profitability is sustainable. | Business performance | 0.74 | 0.000 | 0.68 | 0.78 |
| Quality of products is satisfactory. | Business performance | 0.94 | 0.001 | 1.01 | 0.99 |
| Do you think that information-communication technologies (ICTs) are important for the enterprise? | Awareness ICT importance | 0.96 | 0.000 | 0.68 | 0.96 |
| Do you think that enterprises that implement modern ICTs are more competitive compared to enterprises that don’t? | Awareness of ICT importance | 0.38 | 0.01 | 0.44 | 1.01 |
| Intellectual capital is effectively applied in the enterprise. | Intellectual capital | 1.14 | 0.000 | 1.02 | 1.33 |
| Intellectual capital is reported periodically within the enterprise. | Intellectual capital | 0.80 | 0.188 | 0.83 | 1.02 |
| Do you think the COVID-19 pandemic has negatively affected the enterprise’s market performance? | Market assessment | 0.81 | 0.055 | 0.81 | 0.94 |
| Do you think the market is competitive within your enterprise’s industry? | Market assessment | 0.79 | 0.006 | 0.72 | 1.08 |
| Business Performance | Awareness of ICT Importance | Intellectual Capital | Market Assessment | |
|---|---|---|---|---|
| Tolerance | 0.454 | 0.422 | 0.351 | 0.490 |
| Variance Inflation Factor (VIF) | 1.955 | 1.947 | 1.844 | 2.505 |
| Breusch–Pagan Test | White Test | |
|---|---|---|
| LM (Observed value) | 0.745 | 6.02 |
| LM (Critical Value) | 2.995 | 6.147 |
| DF | 1 | 2 |
| p-value (Two-tailed) | 0.034 | 0.04 |
| alpha | 0.05 | 0.05 |
| Positive class | 1 |
| Number of observations in the training set | 157 |
| Bias | 0.000 |
| Number of support vectors | 76 |
| Features used (the features were selected based on the structured survey). The features are the independent variables. | Manager Age Manager Gender Manager Education Enterprise Size Business Performance Awareness of ICT Importance Intellectual Capital Market Assessment |
| From/To | 0 | 1 | Total | % Correct |
|---|---|---|---|---|
| 0 | 27 | 6 | 33 | 81.82 |
| 1 | 4 | 13 | 17 | 76.47 |
| Total | 31 | 19 | 50 | 79.14 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bakator, M.; Cockalo, D.; Kavalić, M.; Terek Stojanović, E.; Gluvakov, V. An Application of Statistical Methods in Data Mining Techniques to Predict ICT Implementation of Enterprises. Appl. Sci. 2023, 13, 4055. https://doi.org/10.3390/app13064055
Bakator M, Cockalo D, Kavalić M, Terek Stojanović E, Gluvakov V. An Application of Statistical Methods in Data Mining Techniques to Predict ICT Implementation of Enterprises. Applied Sciences. 2023; 13(6):4055. https://doi.org/10.3390/app13064055
Chicago/Turabian StyleBakator, Mihalj, Dragan Cockalo, Mila Kavalić, Edit Terek Stojanović, and Verica Gluvakov. 2023. "An Application of Statistical Methods in Data Mining Techniques to Predict ICT Implementation of Enterprises" Applied Sciences 13, no. 6: 4055. https://doi.org/10.3390/app13064055