
Greenhouse Temperature Prediction Based on Time-Series Features and LightGBM

Abstract
:1. Introduction
2. Related Work
3. Proposed Methodology
4. Experiment
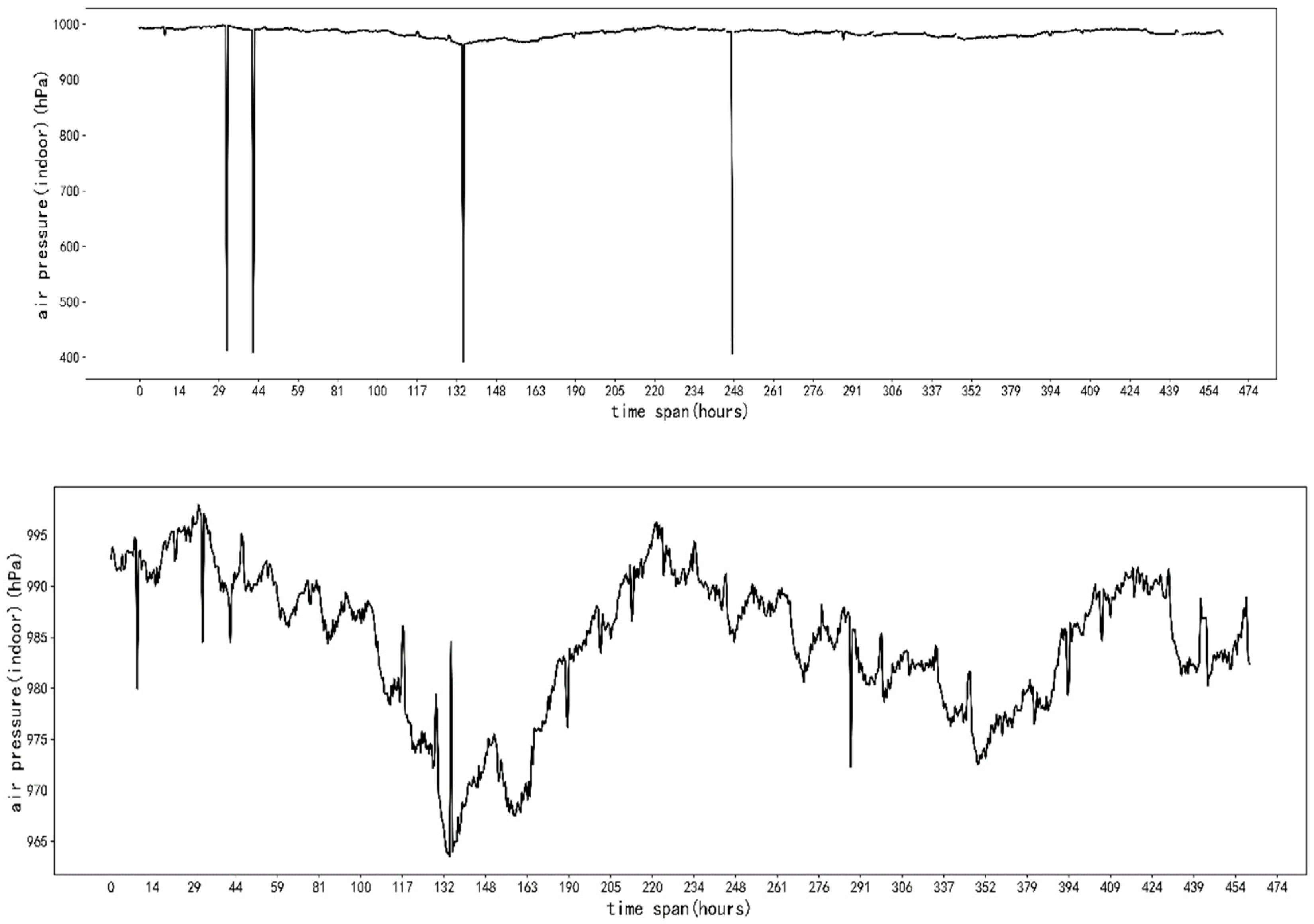
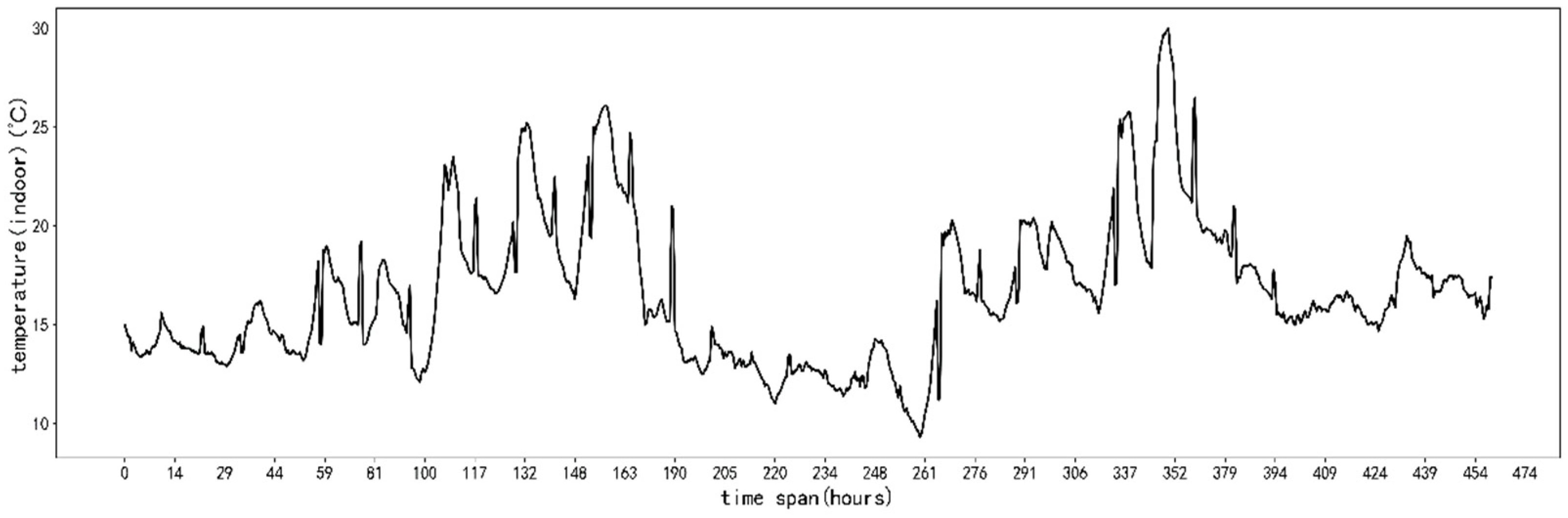
4.1. Data Description
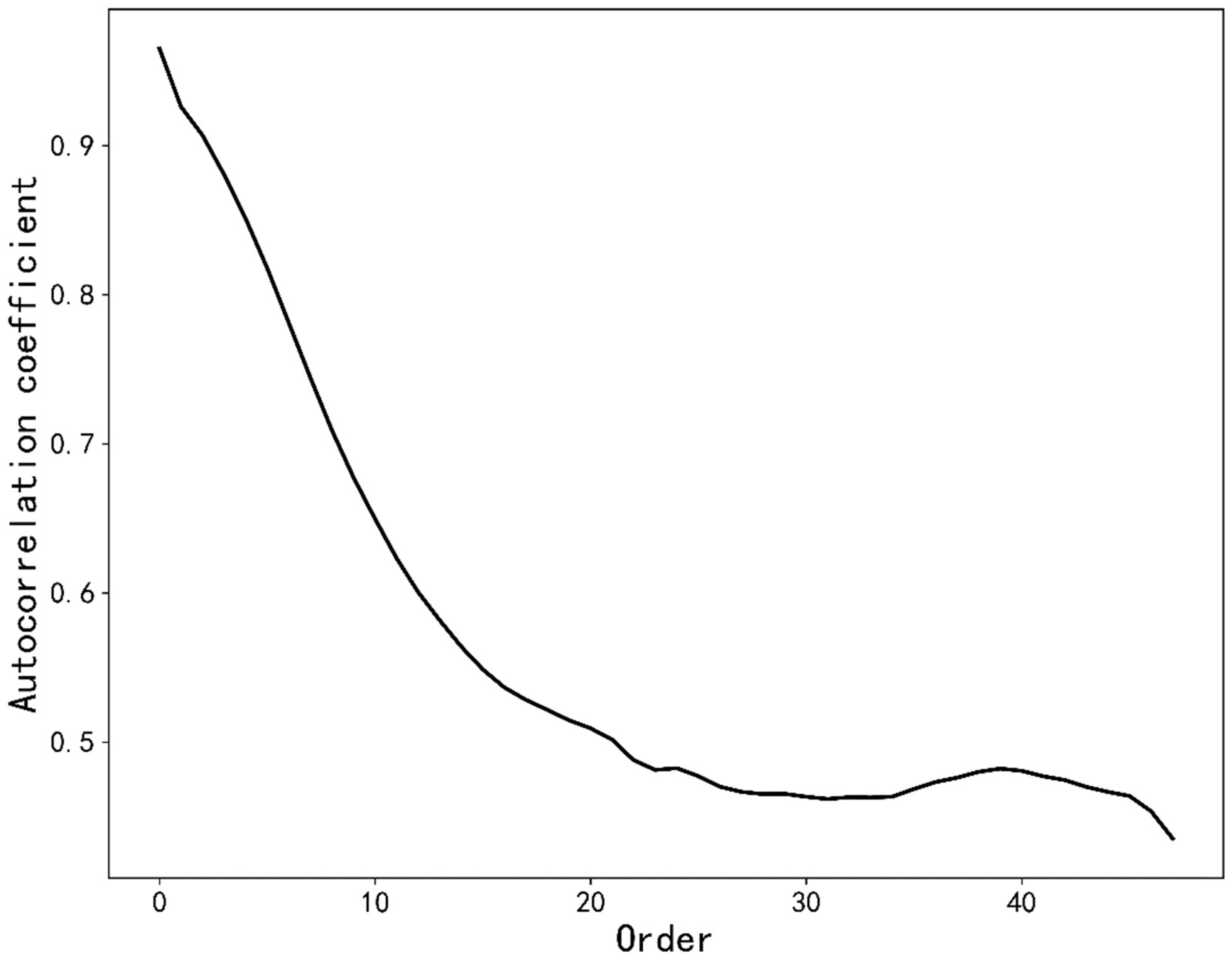
4.2. Data Preprocessing
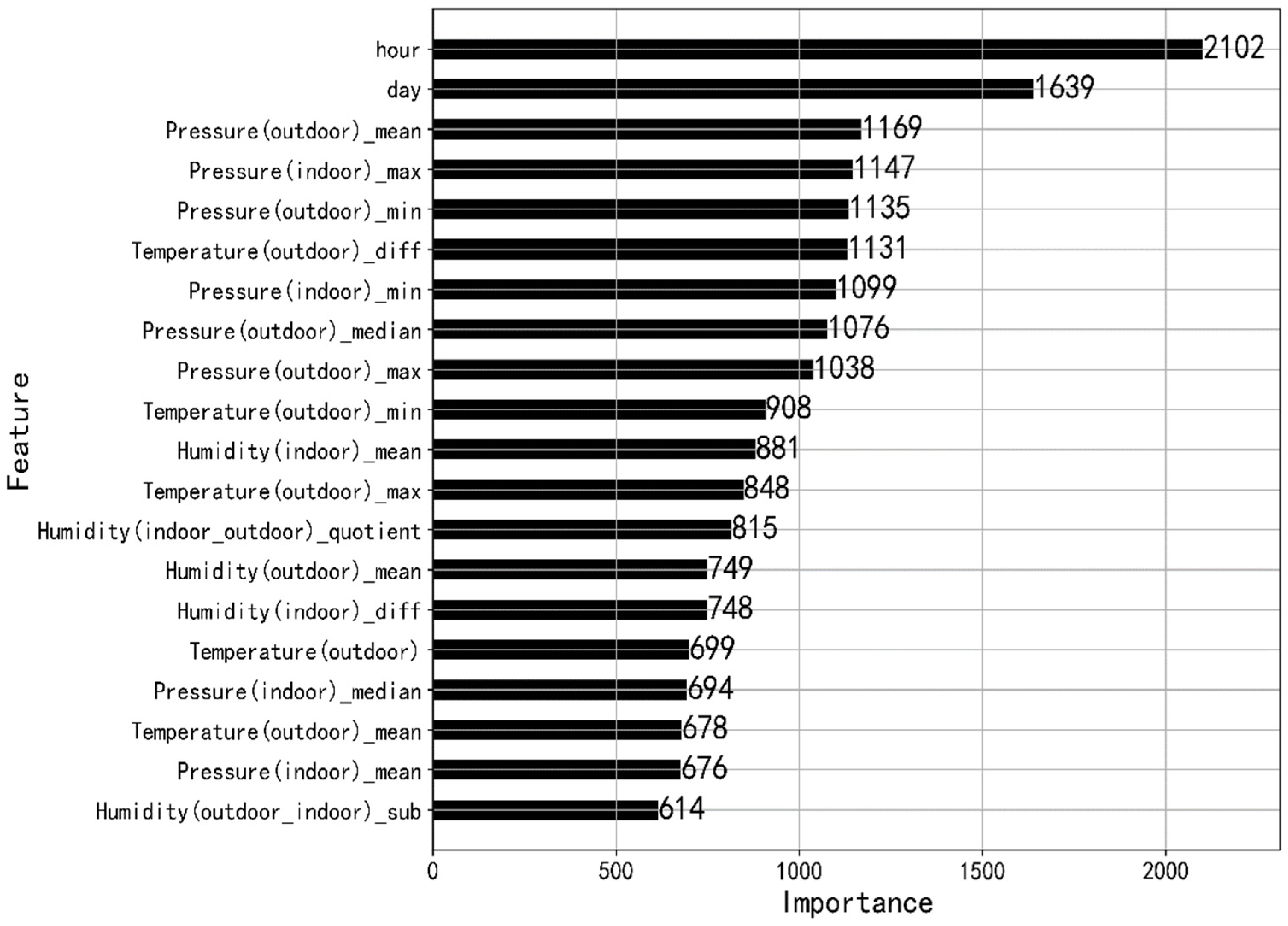
4.3. Feature Engineering
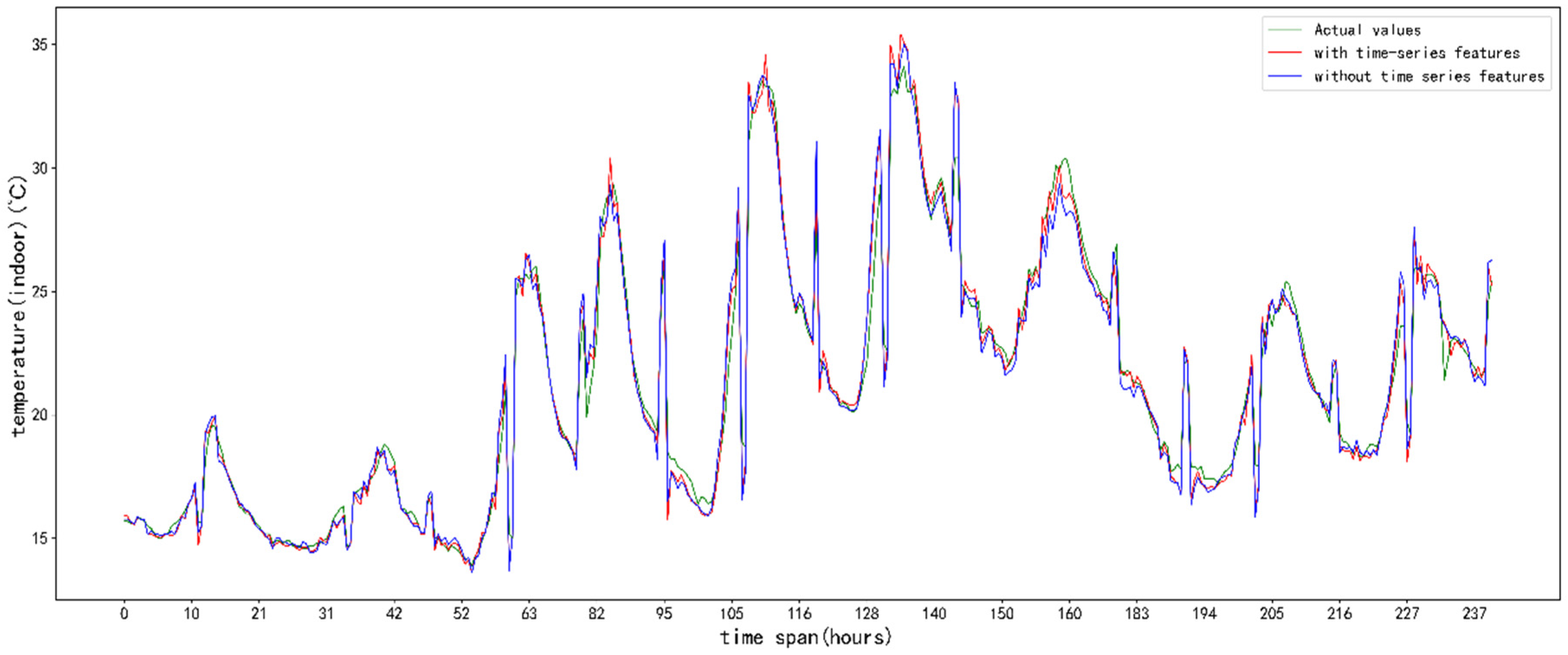
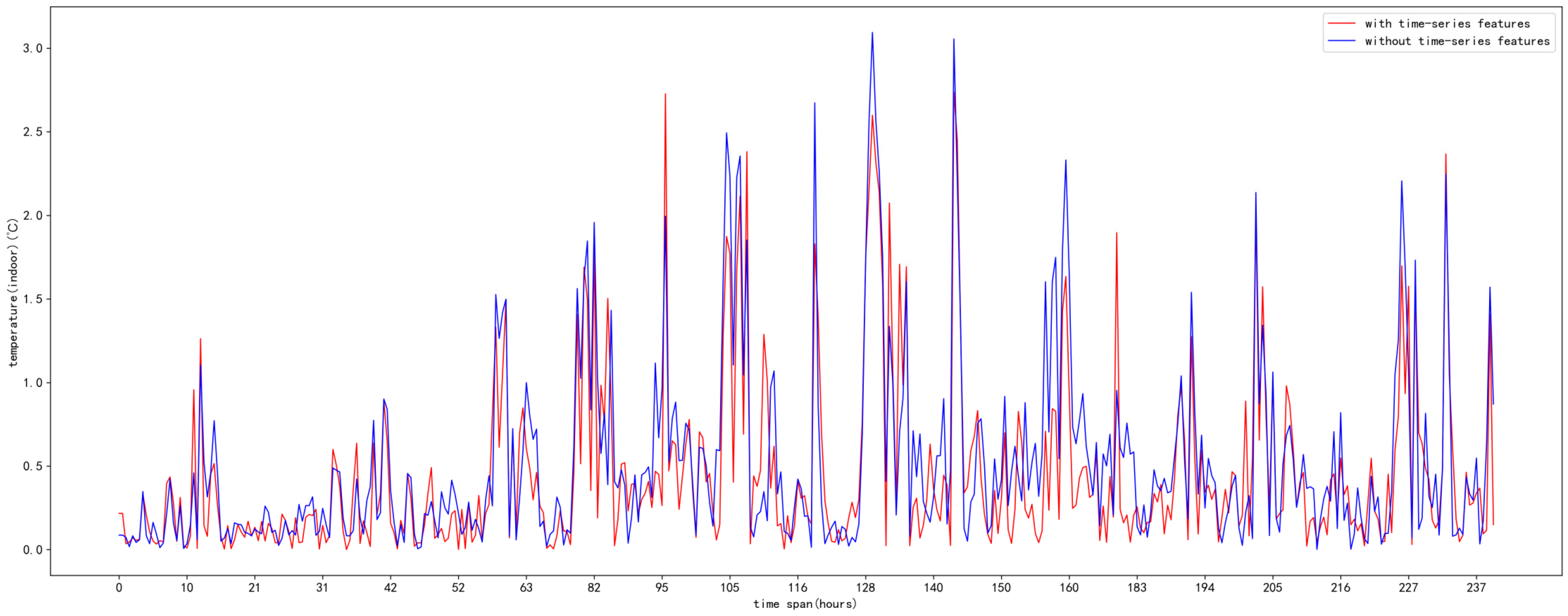
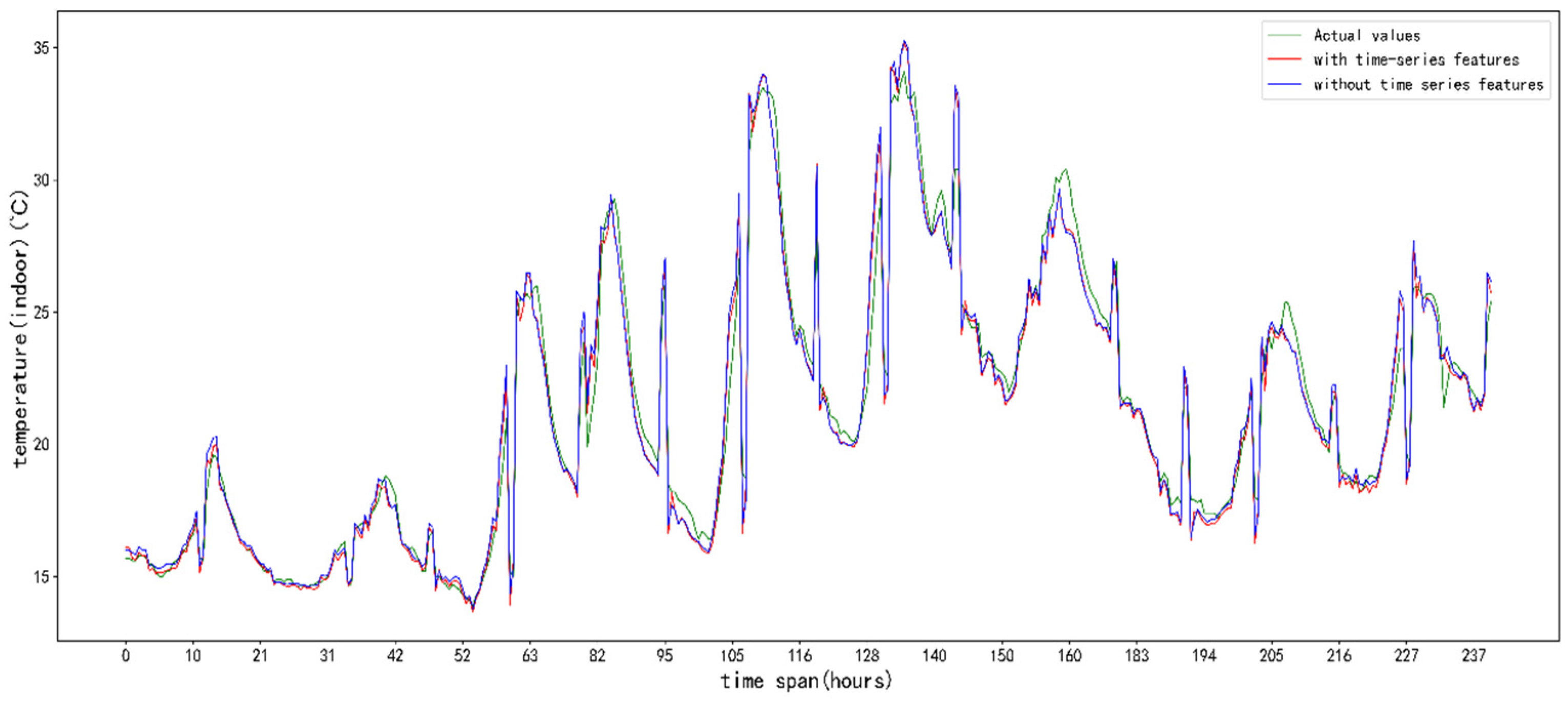
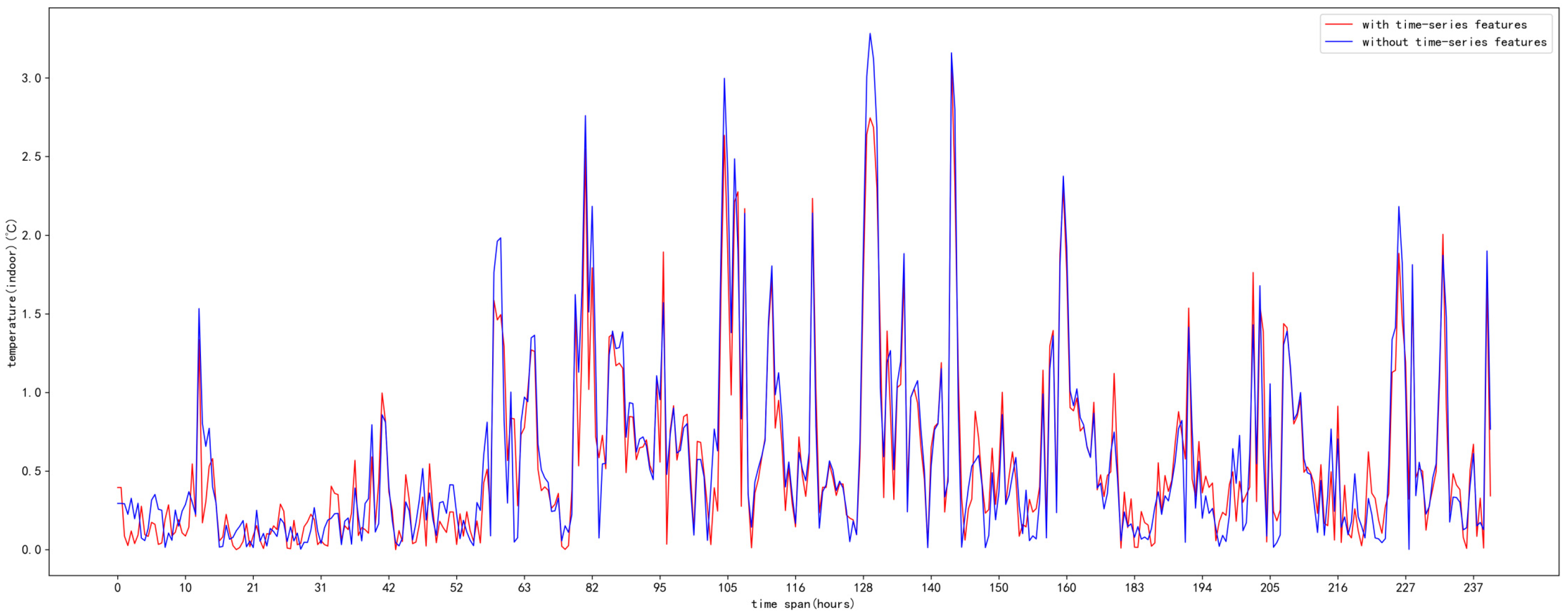
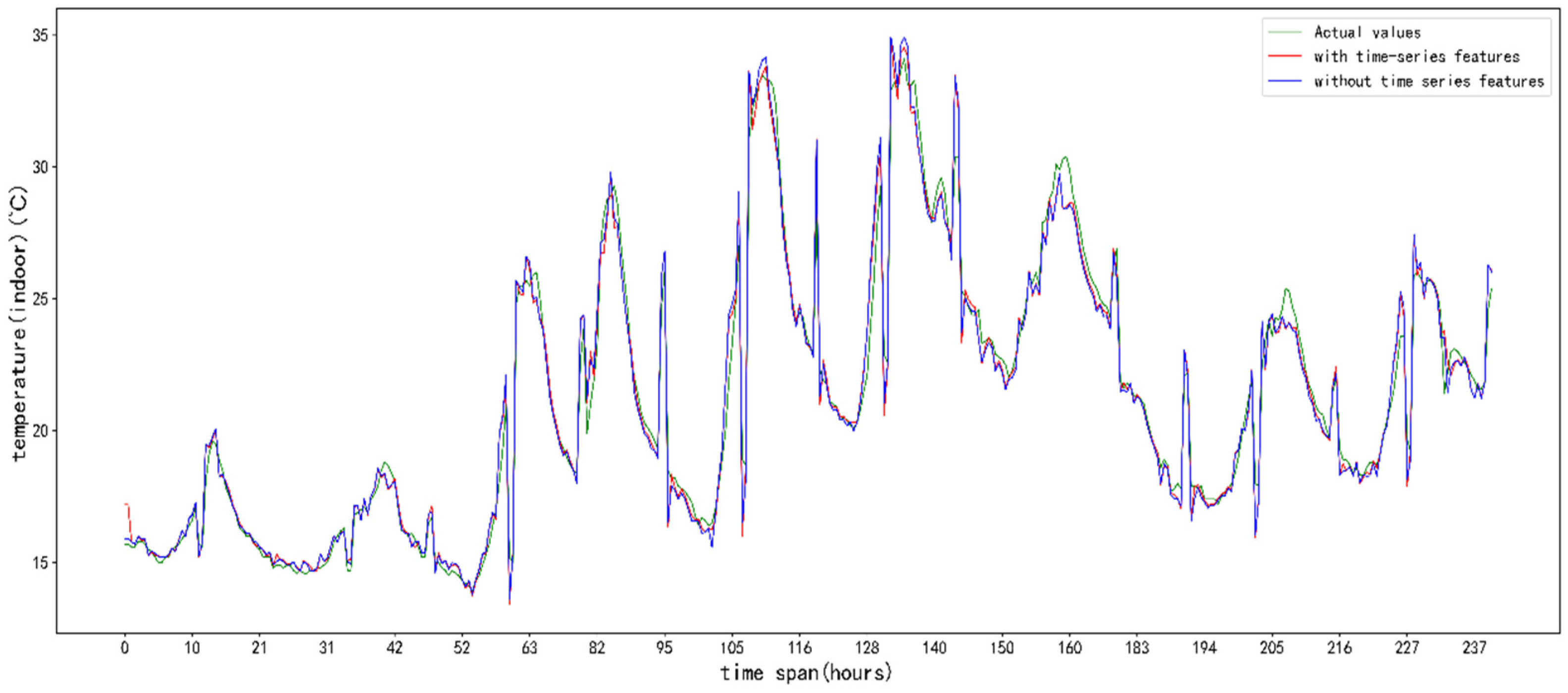
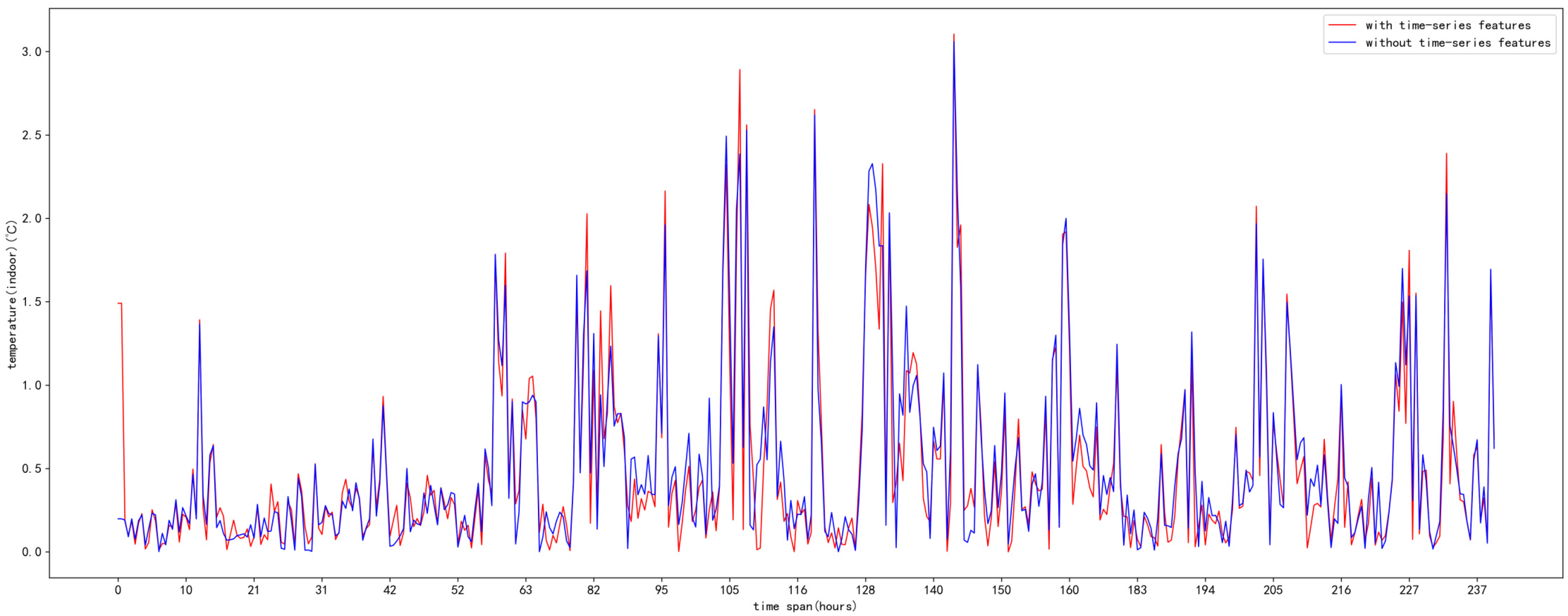
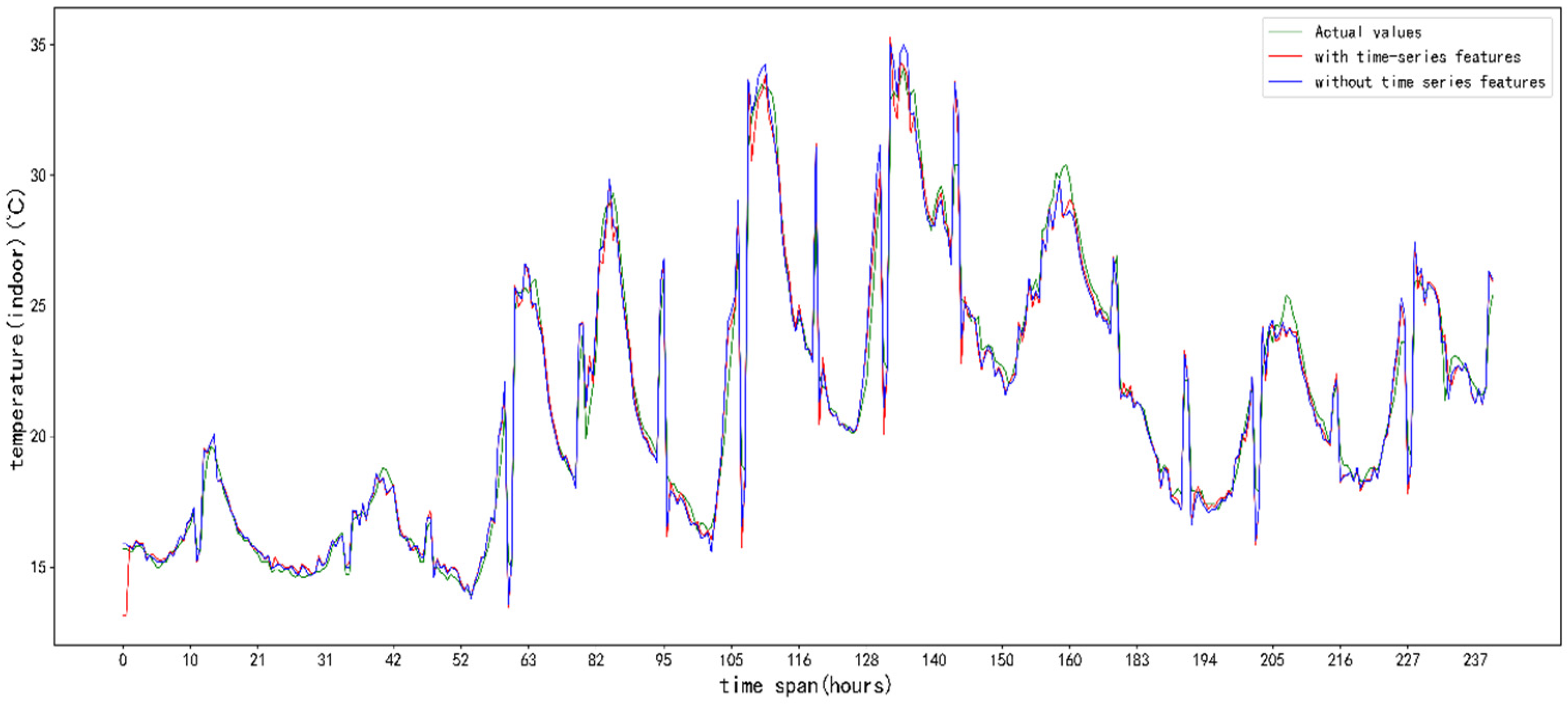
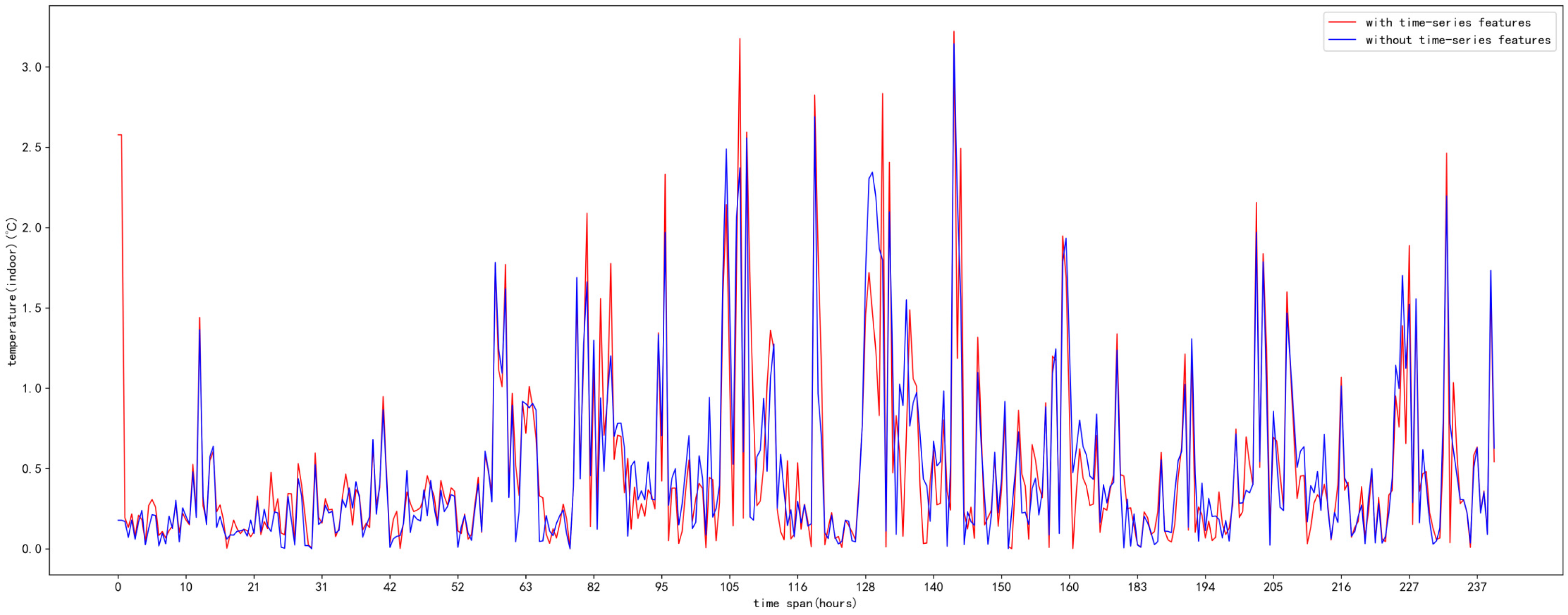
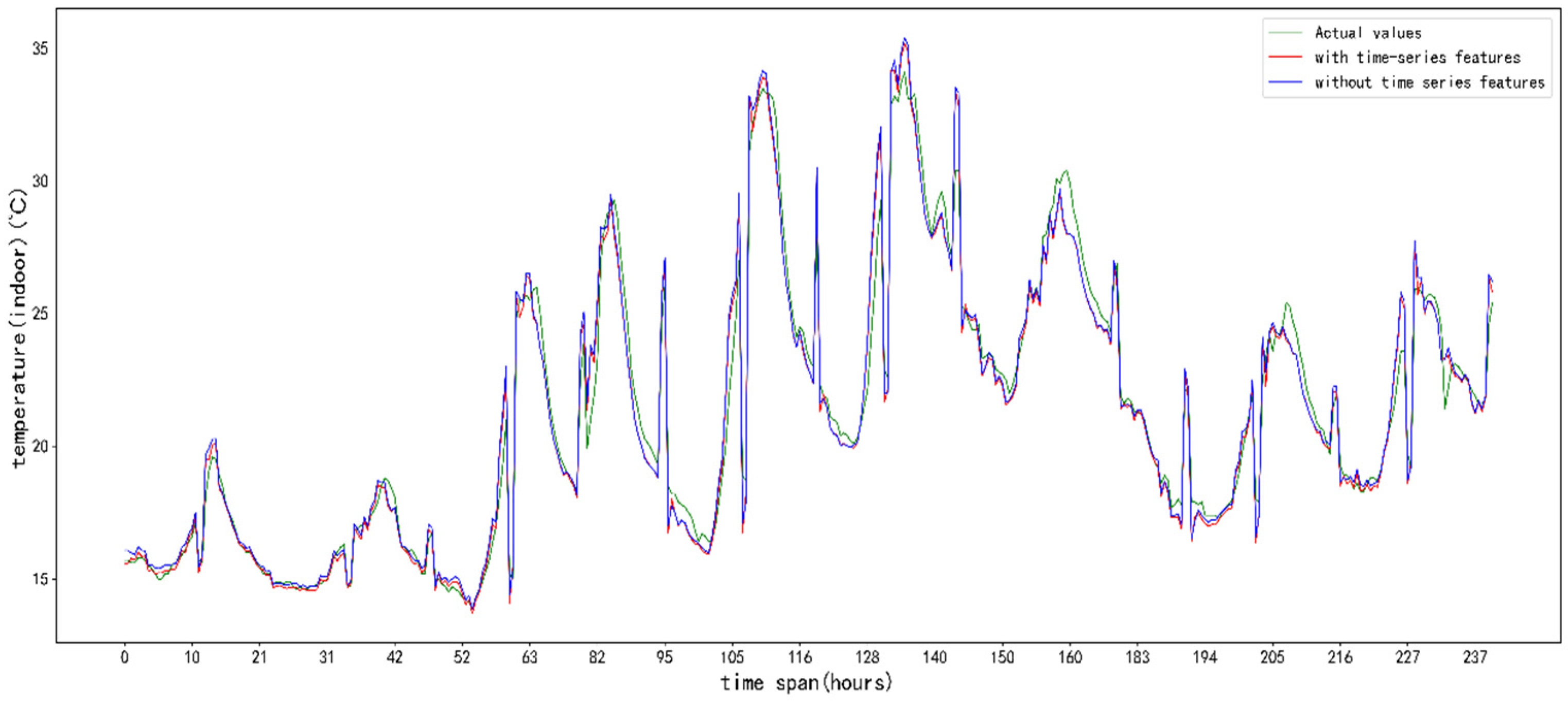
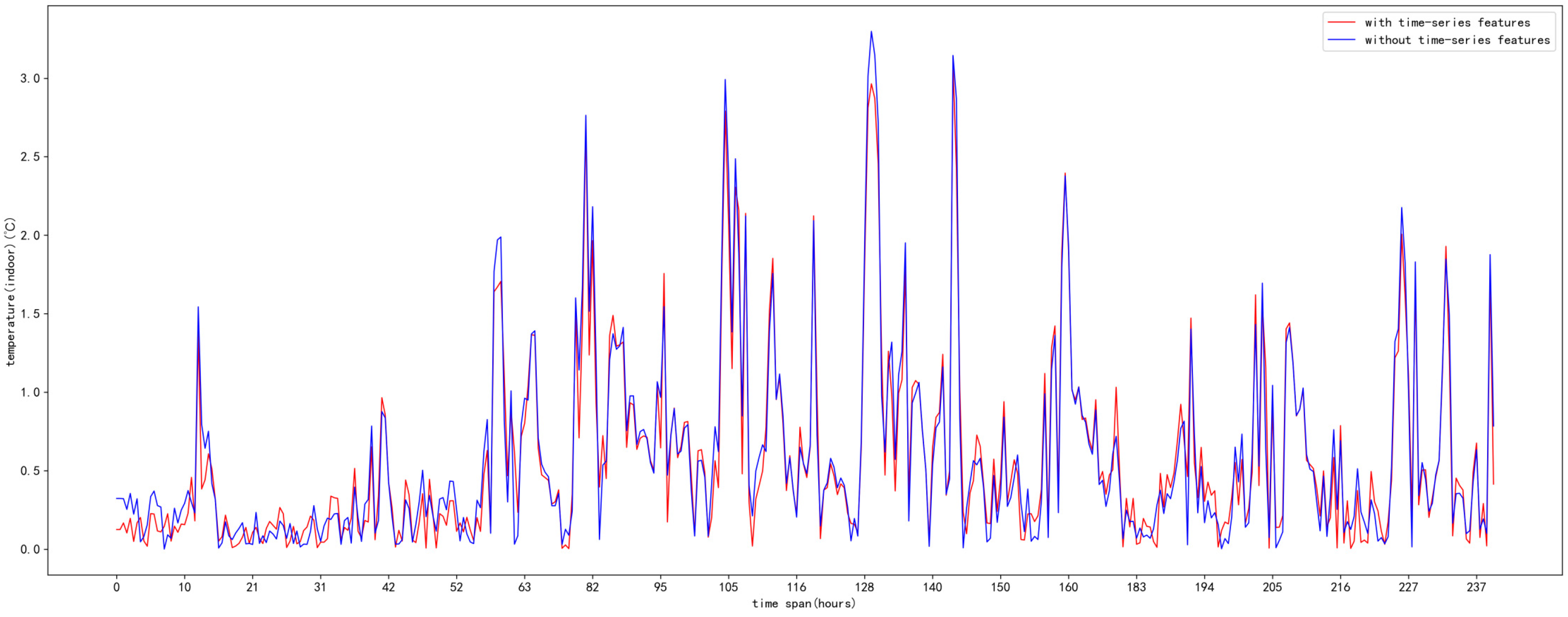
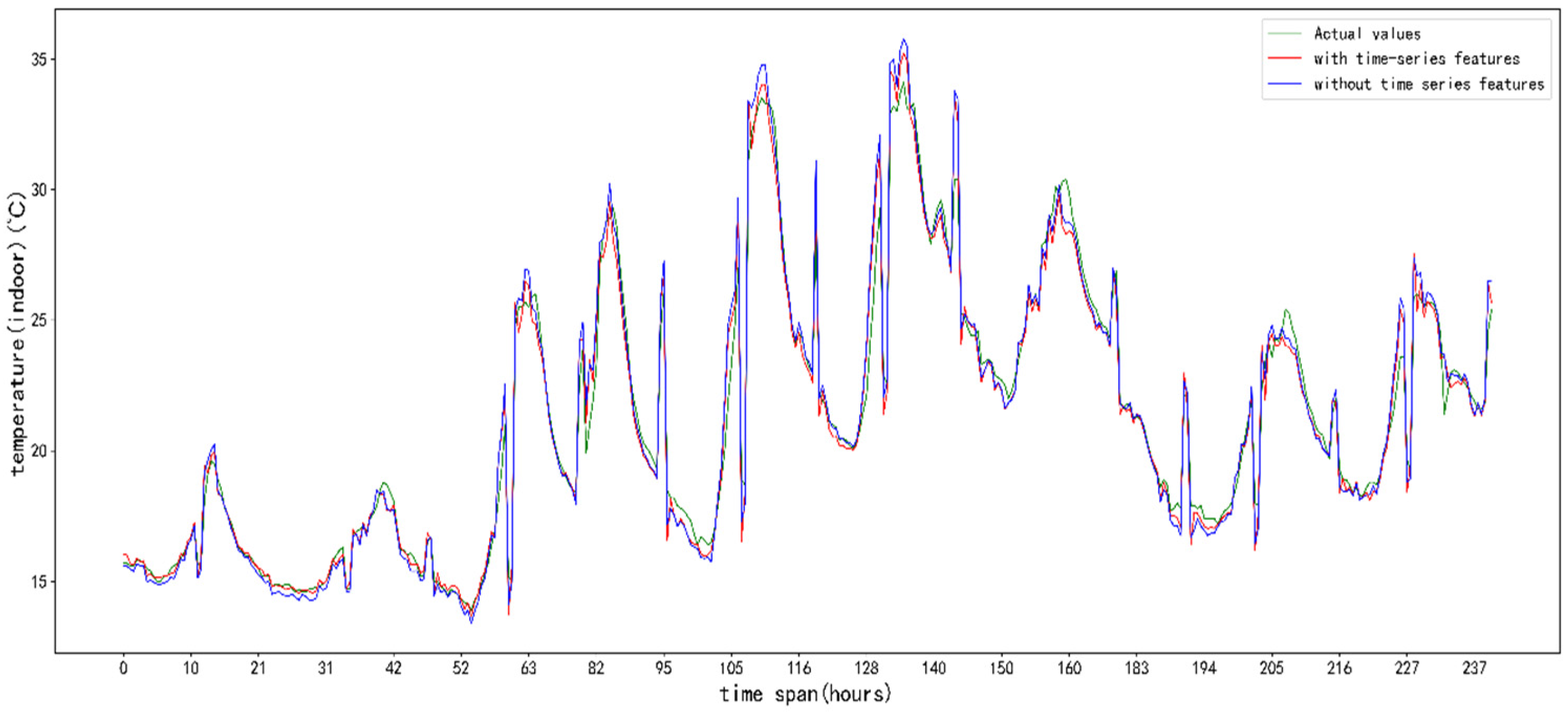
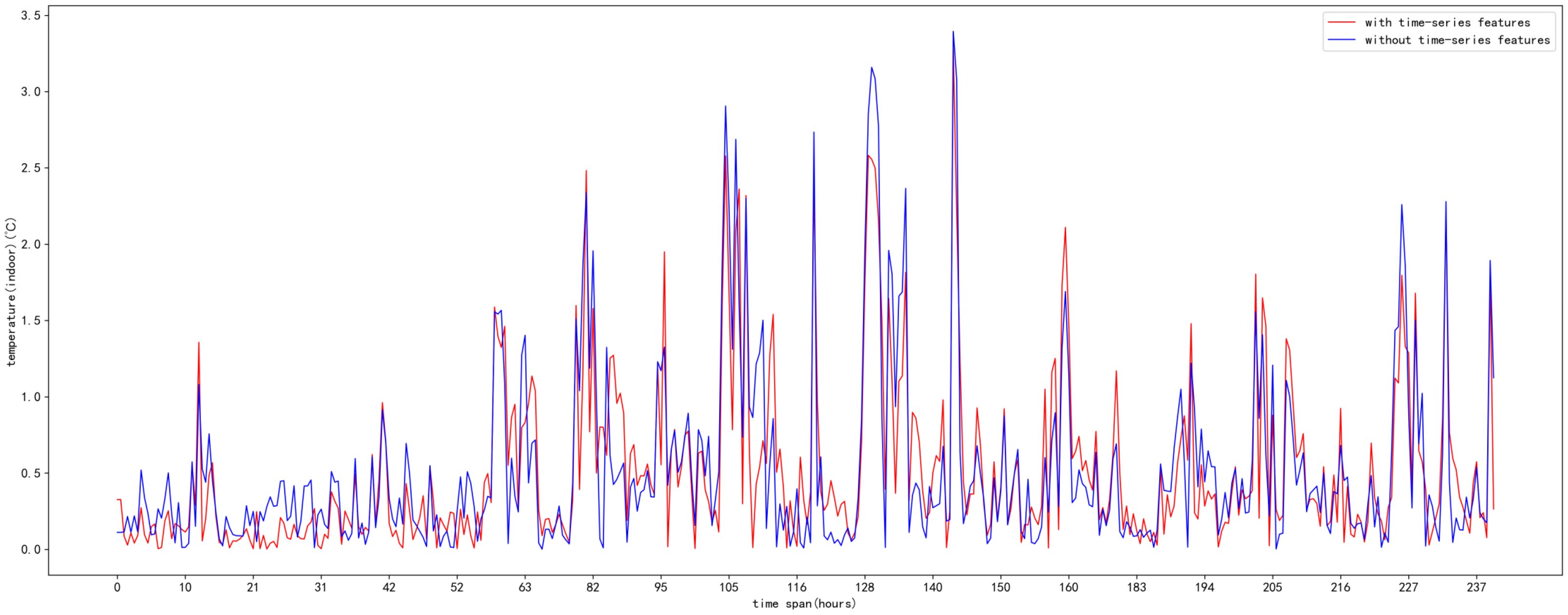
5. Results and Analysis
5.1. Evaluation Indicator
5.2. Hyperparameter Selection
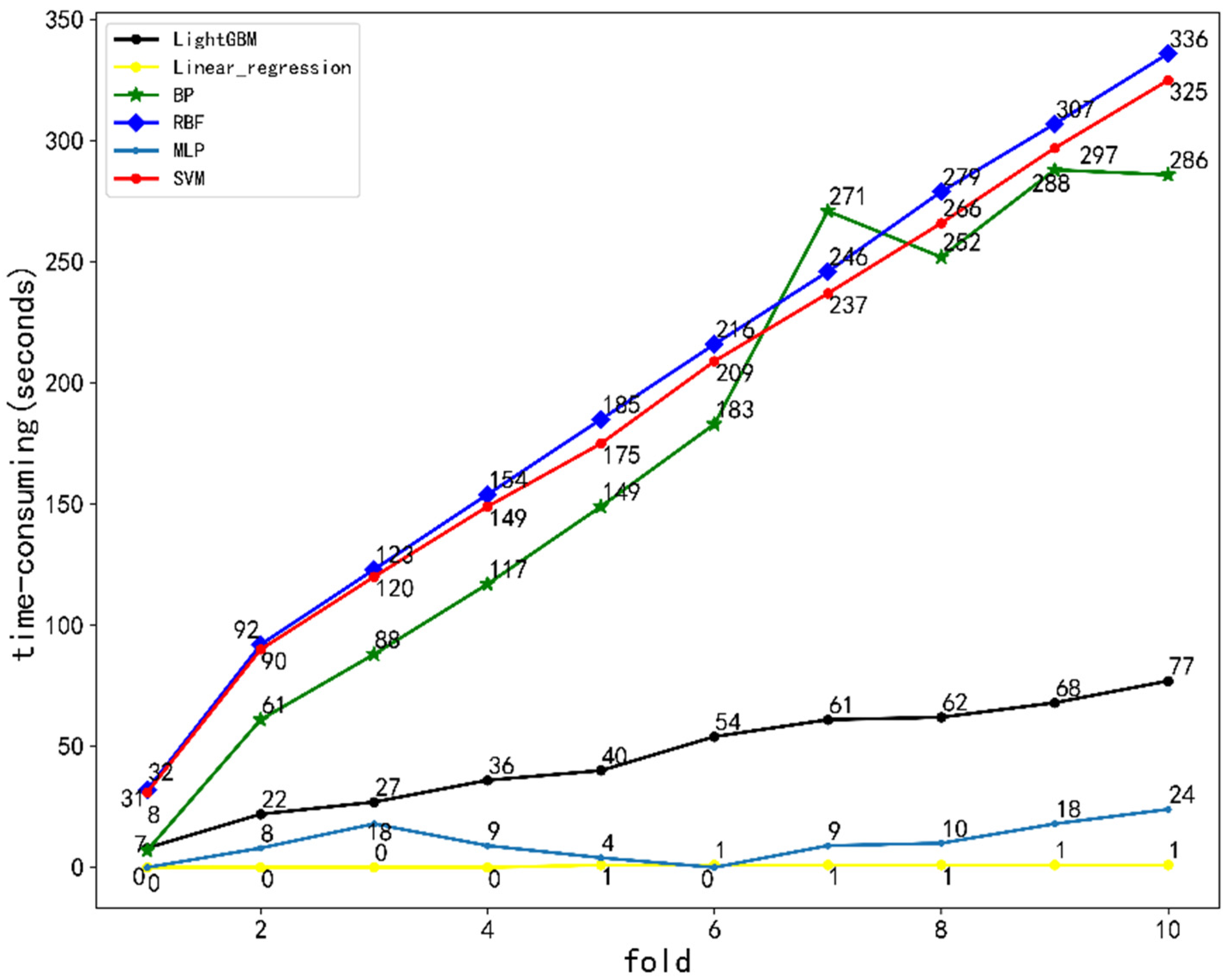
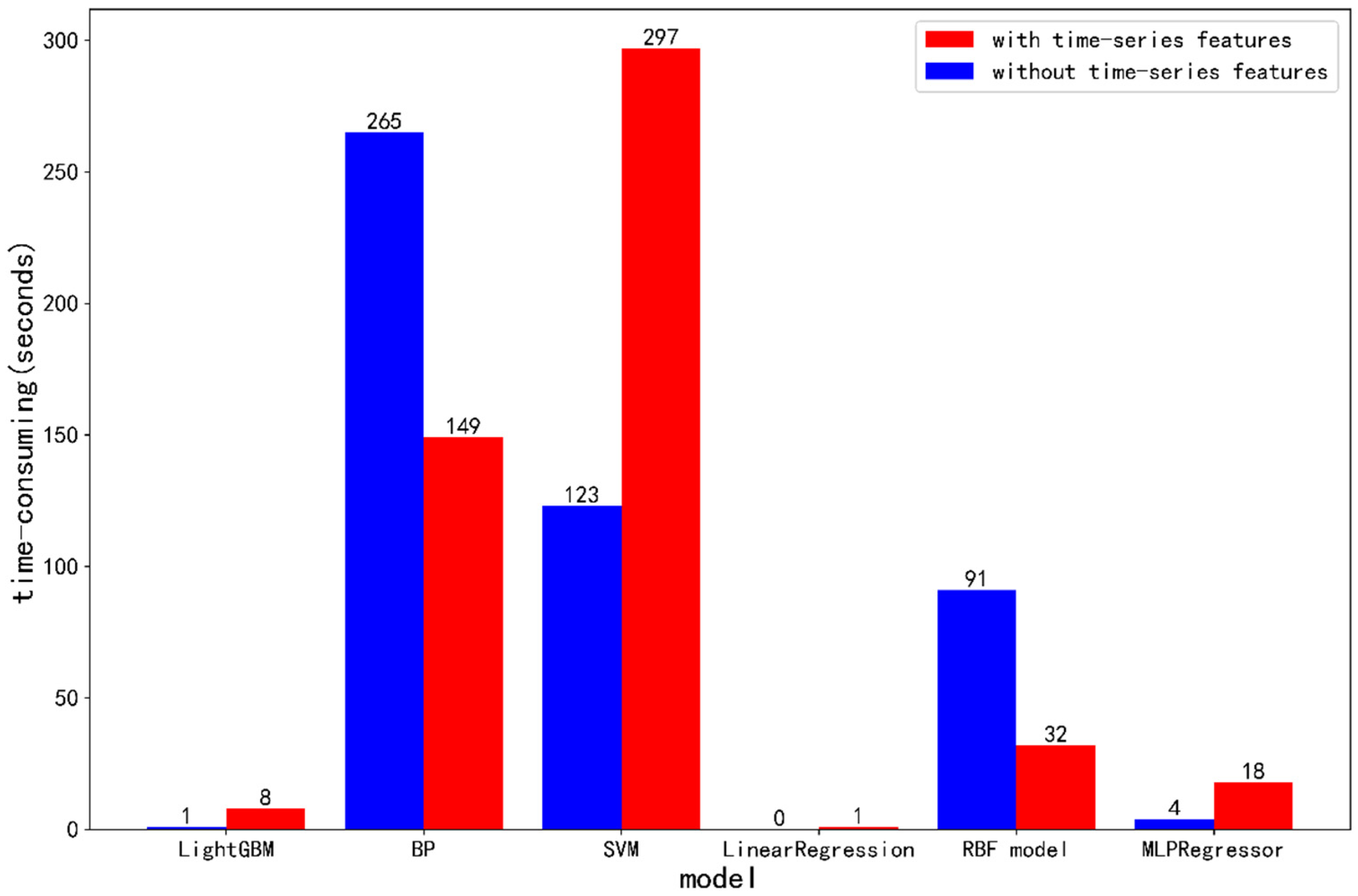
5.3. Analysis of Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, X.; Luo, J.; Li, X. Study on Temperature and Humidity Prediction Model of Plastic Greenhouse Environment. Water Sav. Irrig. 2013, 10, 23–26. [Google Scholar]
- Li, Y.; Wu, D.; Yu, Z. Simulation and Test Research of Micrometeorology Environment in a Sun-Light Greenhouse. Trans. Chin. Soc. Agric. Eng. 1994, 1, 130–136. [Google Scholar]
- Cui, L.; Bian, Z. Temperature Prediction Model Based on Improved Support Vector Machine. Technol. Innov. Appl. 2020, 10, 101–102. [Google Scholar]
- Peng, X.; Bai, B.; Wang, F.; Zhou, G. Layout of Environmental Science Data Monitoring Sensors in Sunlight Greenhouse. Jiangsu Agric. Sci. 2017, 45, 167–170. [Google Scholar]
- Shi, Y.; Guo, Q.; Xu, C. Temperature Field Analysis of Greenhouse Based on Moving Least Square Method. Agric. Res. Appl. 2015, 2, 37–41. [Google Scholar]
- Yu, C.; Wang, J.; Ying, Y. Greenhouse Temperature Prediction Model Based on Radial Basias Function Neural Networks. J. Biomath. 2006, 4, 549–553. [Google Scholar]
- Shen, C.; Yang, J. RBF Neural Network PID Control for Greenhouse Temperature Control System. Control Eng. China 2017, 24, 361–364. [Google Scholar]
- Zhang, K.; Zhao, K. Greenhouse Temperature Prediction Based on Improved CFA PSO-RBF Neural Network. Comput. Appl. Softw. 2020, 37, 95–99. [Google Scholar]
- Xia, S.; Li, L. Application of Greenhouse Temperature Prediction Based on PSO-RBF Neutral Network. Comput. Eng. Des. 2017, 38, 744–748. [Google Scholar]
- Mohammadi, B.; Ranjbar, S.F.; Ajabshirchi, Y. Application of dynamic model to predict some inside environment variables in a semi-solar greenhouse. Inf. Process. Agric. 2018, 5, 279–288. [Google Scholar] [CrossRef]
- Nguyen-Xuan, S.; Nhat, N.L. A dynamic model for temperature prediction in glass greenhouse. In Proceedings of the 2019 6th NAFOSTED Conference on Information and Computer Science (NICS), Hanoi, Vietnam, 12–13 December 2019; pp. 274–278. [Google Scholar]
- Li, X.; Zhang, X.; Wang, Y.; Zhang, K.; Chen, Y.-F. Temperature prediction model for solar greenhouse based on improved BP neural network. J. Phys. Conf. Ser. 2020, 1639, 012036. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, L.R.; Wang, H.J. Sunlight Greenhouse Temperature Prediction Model Based on Bayesian Regularization BP Neural Network. Appl. Mech. Mater. 2015, 740, 871–874. [Google Scholar] [CrossRef]
- Papacharalampous, G.; Tyralis, H.; Papalexiou, S.M.; Langousis, A.; Khatami, S.; Volpi, E.; Grimaldi, S. Global-scale massive feature extraction from monthly hydroclimatic time series: Statistical characterizations, spatial patterns and hydrological similarity. Sci. Total Environ. 2021, 767, 144612. [Google Scholar] [CrossRef] [PubMed]
- Jia, Z.; Lin, Y.; Liu, Y.; Jiao, Z.; Wang, J. Refined nonuniform embedding for coupling detection in multivariate time series. Phys. Rev. E 2020, 101, 062113. [Google Scholar] [CrossRef] [PubMed]
- Jia, Z.; Lin, Y.; Jiao, Z.; Ma, Y.; Wang, J. Detecting causality in multivariate time series via non-uniform embedding. Entropy 2019, 21, 1233. [Google Scholar] [CrossRef] [Green Version]
- Li, H. Statistic Learning Method, 2nd ed.; Tsinghua University Press: Beijing, China, 2019. [Google Scholar]
- Learn, S. Ensemble Methods—Gradient Boosting. 2019. Available online: https://scikit-learn.org/stable/modules/ensemble.html#gradient-tree-boosting (accessed on 1 July 2022).
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Ser. KDD’16, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. Lightgbm: A highly efficient gradient boosting decision tree. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 3146–3154. [Google Scholar]
- Leevy, J.L.; Hancock, J.; Zuech, R.; Khoshgoftaar, T.M. Detecting Cybersecurity Attacks Using Different Network Features with LightGBM and XGBoost Learners. In Proceedings of the 2020 IEEE Second International Conference on Cognitive Machine Intelligence (CogMI), Atlanta, GA, USA, 28–31 October 2020; pp. 190–197. [Google Scholar] [CrossRef]
- Xia, H.; Wei, X.; Gao, Y.; Lv, H. Traffic Prediction Based on Ensemble Machine Learning Strategies with Bagging and LightGBM. In Proceedings of the 2019 IEEE International Conference on Communications Workshops (ICC Workshops), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Machado, M.R.; Karray, S.; de Sousa, I.T. LightGBM: An Effective Decision Tree Gradient Boosting Method to Predict Customer Loyalty in the Finance Industry. In Proceedings of the 2019 14th International Conference on Computer Science & Education (ICCSE), Toronto, ON, Canada, 19–21 August 2019; pp. 1111–1116. [Google Scholar] [CrossRef]
- Do, D.T.; Le, N.Q.K. Using extreme gradient boosting to identify origin of replication in Saccharomyces cerevisiae via hybrid features. Genomics 2020, 112, 2445–2451. [Google Scholar] [CrossRef]
- Zhao, X.; Zhao, Q. Stock Prediction Using Optimized LightGBM Based on Cost Awareness. In Proceedings of the 2021 5th IEEE International Conference on Cybernetics (CYBCONF), Sendai, Japan, 8–10 June 2021; pp. 107–113. [Google Scholar] [CrossRef]
- Mestre, G.; Portela, J.; Rice, G.; Roque, A.M.S.; Alonso, E. Functional time series model identification and diagnosis by means of auto- and partial autocorrelation analysis. Comput. Stat. Data Anal. 2021, 155, 107108. [Google Scholar] [CrossRef]
- Kokoszka, P.; Rice, G.; Shang, H.L. Inference for the autocovariance of a functional time series under conditional heteroscedasticity. J. Multivar. Anal. 2017, 162, 32–50. [Google Scholar] [CrossRef] [Green Version]
- Guan, B.; Zhao, Y.; Yin, Y.; Li, Y. A differential evolution based feature combination selection algorithm for high-dimensional data. Inf. Sci. 2021, 547, 870–886. [Google Scholar] [CrossRef]
- Gu, J.; Mao, H. A Mathematical Model on Intelligent Control of Greenhouse Environment. Trans. Chin. Soc. Agric. Mach. 2001, 32, 63–65. [Google Scholar]
- Yu, Q.; Huang, X.; Li, W.; Wang, C.; Chen, Y.; Ge, Y. Using Features Extracted From Vital Time Series for Early Prediction of Sepsis. In Proceedings of the 2019 Computing in Cardiology (CinC), Singapore, 8–11 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Li, Y.; Yang, C.; Sun, Y. Dynamic time features expanding and extracting method for prediction model of sintering process quality index. IEEE Trans. Ind. Inform. 2021, 18, 1737–1745. [Google Scholar] [CrossRef]
- Shi, S. Temporal Characteristic of Climatic, Soil, and Hydrological Elements and Their Influencing Factors in The Upper Reaches of The Heihe River. Acta Geod. Cartogr. Sin. 2020, 49, 1508. [Google Scholar]
- Tao, L.; Jeong, D.; Wang, J.; Adams, Z.; Bryan, P.; Levin, C.S. Simulation studies to understand sensitivity and timing characteristics of an optical property modulation-based radiation detection concept for PET. Phys. Med. Biol. 2020, 65, 215021. [Google Scholar] [CrossRef] [PubMed]
- Varma, S.; Simon, R. Bias in error estimation when using cross-validation for model selection. BMC Bioinforma. 2006, 7, 1–8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Roberts, D.R.; Bahn, V.; Ciuti, S.; Boyce, M.S.; Elith, J.; Guillera-Arroita, G.; Hauenstein, S.; Lahoz-Monfort, J.J.; Schröder, B.; Thuiller, W.; et al. Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure. Ecography 2017, 40, 913–929. [Google Scholar] [CrossRef] [Green Version]
- Bergmeir, C.; Hyndman, R.J.; Koo, B. A note on the validity of cross-validation for evaluating autoregressive time series prediction. Comput. Stat. Data Anal. 2018, 120, 70–83. [Google Scholar] [CrossRef]
- Bergmeir, C.; Benítez, J.M. On the use of cross-validation for time series predictor evaluation. Inf. Sci. 2012, 191, 192–213. [Google Scholar] [CrossRef]
- Snijders, T.A.B. On cross-validation for predictor evaluation in time series. In On Model Uncertainty and Its Statistical Implications; Springer: Berlin/Heidelberg, Germany, 1988; pp. 56–69. [Google Scholar]
- Racine, J. Consistent cross-validatory model-selection for dependent data: Hv-block cross-validation. J. Econ. 2000, 99, 39–61. [Google Scholar] [CrossRef]
- McQuarrie, A.D.; Tsai, C.-L. Regression and Time Series Model Selection; World Scientific: Singapore, 1998. [Google Scholar]
- Cerqueira, V.; Torgo, L.; Smailović, J.; Mozetič, I. A comparative study of performance estimation methods for time series forecasting. In Proceedings of the 2017 IEEE international conference on data science and advanced analytics (DSAA), Tokyo, Japan, 19–21 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 529–538. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Description |
|---|---|
| Collection time | Data collection time |
| Temperature (indoor) | Temperature inside greenhouse (Label) |
| Humidity (indoor) | Humidity inside greenhouse |
| Air pressure (indoor) | Air pressure inside greenhouse |
| Temperature (outdoor) | Temperature outside greenhouse |
| Humidity (outdoor) | Humidity outside greenhouse |
| Air pressure (outdoor) | Air pressure outside greenhouse |
| Indoor Temperature (°C) | Indoor Humidity (%) | Indoor Air Pressure (hPa) | Outdoor Temperature (°C) | Outdoor Humidity (%) | Outdoor Air Pressure (hPa) | |
|---|---|---|---|---|---|---|
| count | 24,807 | 24,807 | 24,807 | 25,241 | 24,837 | 24,837 |
| mean | 16.63 | 72.60 | 981.26 | 16.61 | 74.36 | 983.64 |
| SD | 3.69 | 14.05 | 43.90 | 4.32 | 16.35 | 22.99 |
| min | 9.3 | 25 | 392.5 | 8.9 | 23 | 400.2 |
| 25% | 13.8 | 64 | 980 | 13.4 | 64 | 979.9 |
| 50% | 16.1 | 76 | 985.9 | 16 | 78 | 986.1 |
| 75% | 18.4 | 84 | 989.9 | 18.7 | 88 | 990.4 |
| max | 30.1 | 91 | 1013.7 | 36.7 | 96 | 1082.5 |
| Indicators | Without Time-Series Features | With Time-Series Features | |||||
|---|---|---|---|---|---|---|---|
| Model | Max | Mean | SD | Max | Mean | SD | |
| LightGBM | 3.0942 | 0.5177 | 0.5652 | 2.7378 | 0.4491 | 0.5259 | |
| BP | 3.2832 | 0.5852 | 0.6146 | 3.1263 | 0.5617 | 0.5640 | |
| SVM | 3.0594 | 0.5111 | 0.5374 | 3.1045 | 0.4917 | 0.5476 | |
| Linear Regression | 3.1440 | 0.4988 | 0.5414 | 3.2217 | 0.5030 | 0.5732 | |
| RBF | 3.2983 | 0.5901 | 0.6148 | 3.0887 | 0.5749 | 0.5867 | |
| MLP | 3.3944 | 0.5229 | 0.6028 | 3.2793 | 0.5141 | 0.5583 | |
| Indicators | Without Time-Series Features | With Time-Series Features | (MSE1i-MSE2i)/ MSE1i | (MSE2i-MSE2LightGBM)/MSE2i | |||||
|---|---|---|---|---|---|---|---|---|---|
| Model | MSE1 | MAE2 | R2_score1 | MSE2 | MAE2 | R2_score2 | |||
| LightGBM | 0.5868 | 0.5177 | 0.9760 | 0.4776 | 0.4491 | 0.9805 | 18.61% | - | |
| BP | 0.7193 | 0.5852 | 0.9706 | 0.6329 | 0.5617 | 0.9742 | 12.01% | 24.54% | |
| SVM | 0.5494 | 0.5111 | 0.9776 | 0.5409 | 0.4917 | 0.9779 | 1.55% | 11.70% | |
| Linear Regression | 0.5413 | 0.4988 | 0.9779 | 0.5808 | 0.5030 | 0.9763 | −7.30% | 17.77% | |
| RBF | 0.7254 | 0.5901 | 0.9704 | 0.6739 | 0.5749 | 0.9725 | 7.10% | 29.13% | |
| MLP | 0.6360 | 0.5229 | 0.9740 | 0.5753 | 0.5141 | 0.9765 | 9.54% | 16.98% | |
| 0.95 Confidence Interval | Without Time-Series Features | With Time-Series Features | |
|---|---|---|---|
| Model | |||
| LightGBM | [−0.5901, 1.6256] | [−0.5816, 1.4799] | |
| BP | [−0.6194, 1.7898] | [−0.5436, 1.6672] | |
| SVM | [−0.5422, 1.5645] | [−0.5815, 1.5650] | |
| Linear Regression | [−0.5624, 1.5601] | [−0.6204, 1.6266] | |
| RBF | [−0.6150, 1.7952] | [−0.5750, 1.7249] | |
| MLP | [−0.6586, 1.7045] | [−0.5801, 1.6085] | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, Q.; Wu, Y.; Yang, J.; Yin, J. Greenhouse Temperature Prediction Based on Time-Series Features and LightGBM. Appl. Sci. 2023, 13, 1610. https://doi.org/10.3390/app13031610
Cao Q, Wu Y, Yang J, Yin J. Greenhouse Temperature Prediction Based on Time-Series Features and LightGBM. Applied Sciences. 2023; 13(3):1610. https://doi.org/10.3390/app13031610
Chicago/Turabian StyleCao, Qiong, Yihang Wu, Jia Yang, and Jing Yin. 2023. "Greenhouse Temperature Prediction Based on Time-Series Features and LightGBM" Applied Sciences 13, no. 3: 1610. https://doi.org/10.3390/app13031610