

SFCA: A Scalable Formal Concepts Driven Architecture for Multi-Field Knowledge Graph Completion

Abstract
:1. Introduction
1.1. Limitations
- (1)
- For the DBpedia-related KGs, only some famous KGs have their commonsense knowledge base, and the number of including commonsense concepts is not large. In general, the commonsense concepts from the DBpedia KGs are hard to share with other verticals KGs because commonsense concepts are mainly appropriate for the corresponding KGs (The greater the difference between common sense concepts in the more specialized fields, the more difficult it is to reuse).
- (2)
- For the specific KGs, such as industrial KGs, do not even have a commonsense knowledge base. Meanwhile, the commonsense concepts of specific KGs are hard to collect since they are commonly defined by corresponding researchers or experts. For the same reason, the previous models or algorithms [23,24] performed poorly on automatic commonsense extraction (The more specialized domains rely more on human-defined commonsense concepts).
1.2. Motivation
- (1)
- Formal concepts can be efficient and automatically generated, while commonsense concepts require expensive manual annotation. The formal concept is derived from the KG itself and belongs to the information of the KGs. On the contrary, the commonsense concept must be manually annotated for information outside the KG.
- (2)
- Formal concepts are not subject to KGs, while commonsense concepts are limited to the corresponding KGs. To be detailed, the formal concept can be applied to any KG, including a commonsense KG, while the commonsense concept is only applicable to the KG that has corresponding commonsense in theory and has artificially annotated commonsense concepts.
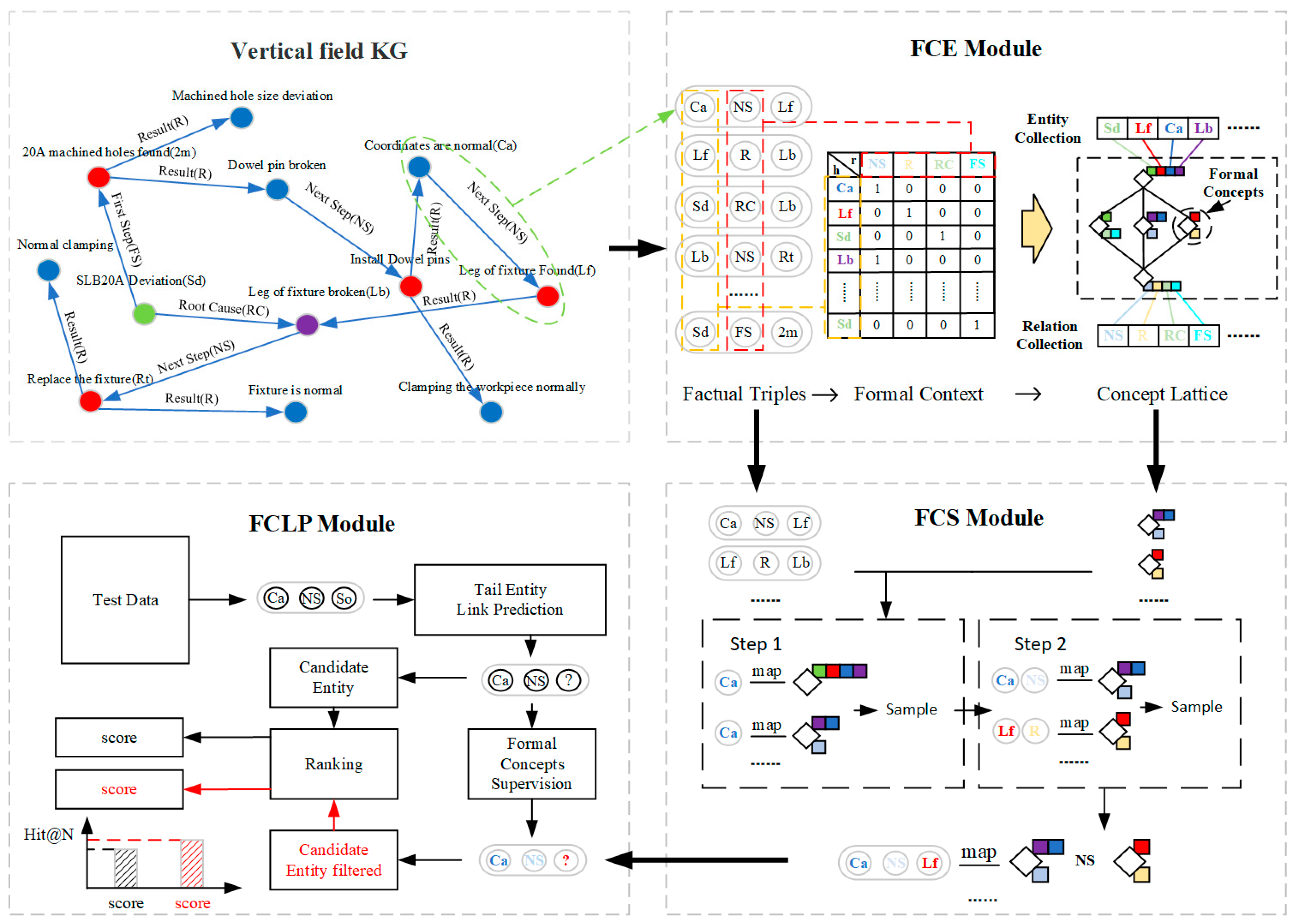
1.3. Architecture for KGC
- (1)
- Formal concept extraction module (FCE) extracts the formal concepts in triples and links the formal concepts with the entities.
- (2)
- Formal concept sampling module (FCS) sifting streamlined formal concepts from redundant formal concepts.
- (3)
- Formal concept-driven link prediction module (FCLP)leverages sampled formal concepts to improve KGC performance.
- (1)
- We propose a scalable KGC architecture based on formal concept analysis to generate formal concepts from KG. In comparison, existing methods either perform poorly or require commonsense concepts of manual extraction. To our knowledge, we are the first to apply formal concepts to KGC.
- (2)
- We design a coarser-to-fine formal concept extraction strategy to choose streamlined formal concepts of entities in the KG that can be used to improve the computational efficiency of the model.
- (3)
- Comprehensive experiments on four public datasets demonstrate the effectiveness and robustness of the proposed architecture with each module. Furthermore, the results show that SFCA helps generate KG’s formal concepts, which greatly supplements the existing methods.
- (4)
- Extensive experiments on real data of industrial proving the practicality of the proposed model. The results show that SFCA is effective and robust in various fields of KGC tasks.
2. Related Works
2.1. KGE Models
- (1)
- The KG structural information-based methods include translation-based and semantic matching models. Translation-based models [10,12,15] are models that utilize entity and relation embeddings to compute translation scores, where relations represent the translation operations between entities. Translating embeddings for modeling multi-relational data (TransE) [10] is the pioneer of the translation-based model, which embeds entities and relations into the space with the same dimension, and regards relations as translation operations between entity vectors. The advantage of TransE is that it is simple and efficient, while it cannot model various relation patterns. Knowledge graph embedding by relational rotation in complex space (RotatE) [15] embeds entities and relations in a complex vector space, treats relations as rotation operations between entity vectors, effectively models and infers various relational patterns, and refreshes the best results of the KGC task. Learning hierarchy-aware knowledge graph embeddings for link prediction (HAKE) [12] effectively embeds the semantic hierarchy by mapping the entity to the polar coordinate system, achieving the STOA result of the KGC task. Semantic matching models [11,13,14,16] compute semantic matching scores for entity and relation embeddings in the latent space. A three-way model for collective learning on multi-relational data (RESCAL) [16] treats entities as vectors and relations as matrices and calculates scores with bilinear functions. Embedding entities and relations for learning and inference in knowledge bases (DistMult) [13] simplifies RESCAL by restricting the relation matrix to be a diagonal matrix. Complex embeddings for simple link prediction (ComplEx) [14] extend DistMult to embed entities and relations into complex space. Quaternion knowledge graph embeddings (QuatE) [11] embed a hypercomplex value with three imaginary components to represent entities and model the relation as a rotation on a 4-dimensional space (hypercomplex space), thus unifying ComplEx [14] and RotatE [15].
- (2)
- External information-based methods focus on adding extra information to enrich the KGE models. Most models that add external information [18,20,21] utilize the logic rules mined from the knowledge graph to improve the link prediction results. Fast rule mining in ontological knowledge bases with AMIE + + (AMIE+) [20], End-to-end differentiable rule mining on knowledge graphs (DRUM) [21], and Knowledge graph embedding with iterative guidance from soft rules (RUGE) [18] automatically mine the logic rules in KG and apply the logic rules to KGC tasks. A considerable part of the models that add internal information [17,19,22] use the known concept information corresponding to the entity to improve the link prediction outcomes. Representation learning of knowledge graphs with hierarchical types (TKRL) [17] uses the type information of the entity to design a scoring function with a hierarchical projection matrix for the entity, which improves the performance of the KGC task, Type-based multiple embedding representations for knowledge graph completion (TransT) [22] adopts entity types to construct relation types and takes the similarity between relative entities and relations as prior knowledge, and utilizes prior knowledge to improve the KGC task results. A scalable commonsense-aware framework for multi-view knowledge graph completion (CAKE) [19] leverages commonsense concepts of entities to improve the quality of negative sampling and the accuracy of link prediction candidate entities. Ontology-guided Entity Alignment via Joint Knowledge Graph Embedding (OntoEA) [25] embeds ontology and knowledge graphs together to get better entity embedding.
2.2. KG Embedding with Ontology
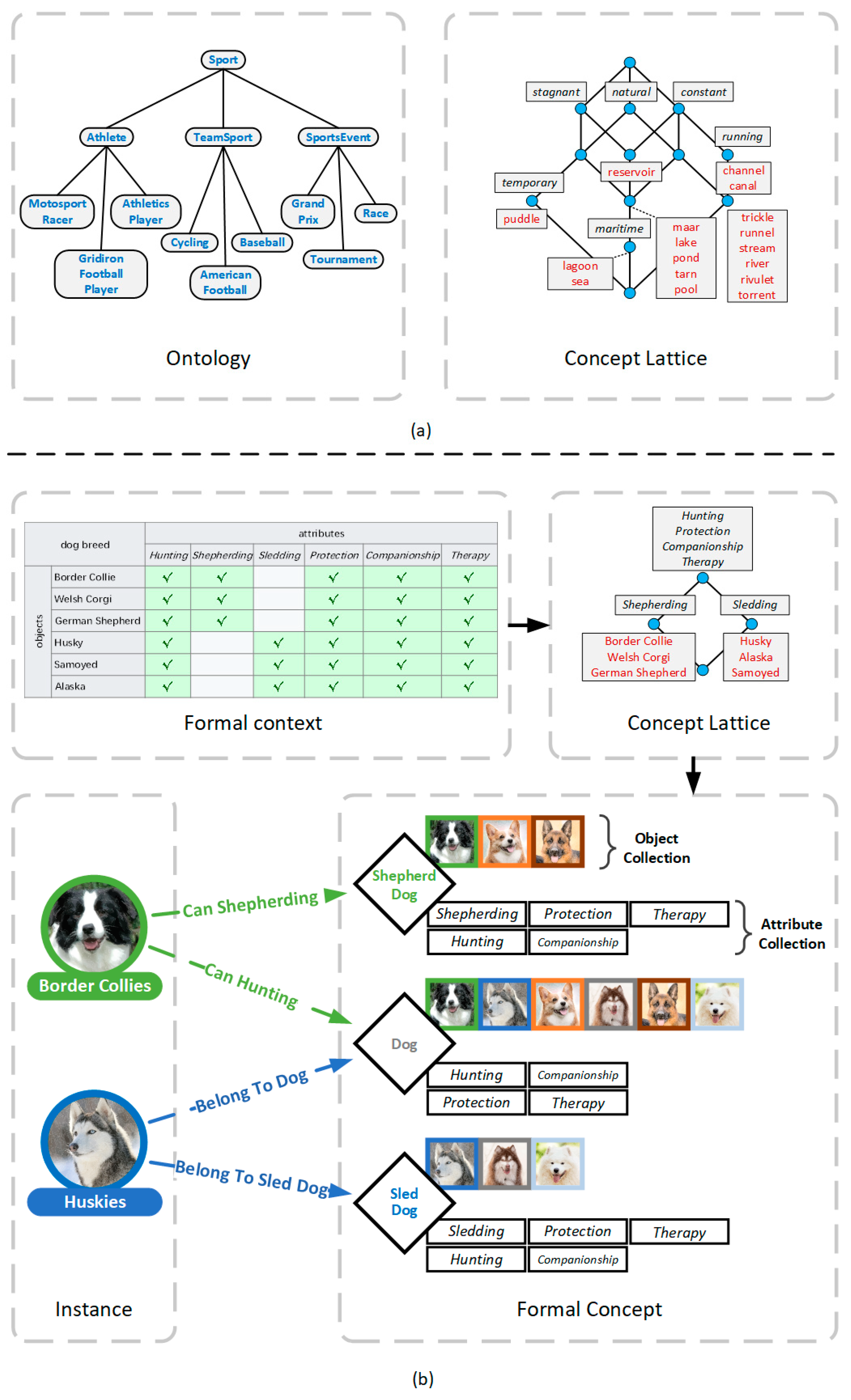
2.3. Formal Concept Analysis
3. Methodology
3.1. Notations and Problem Formalization
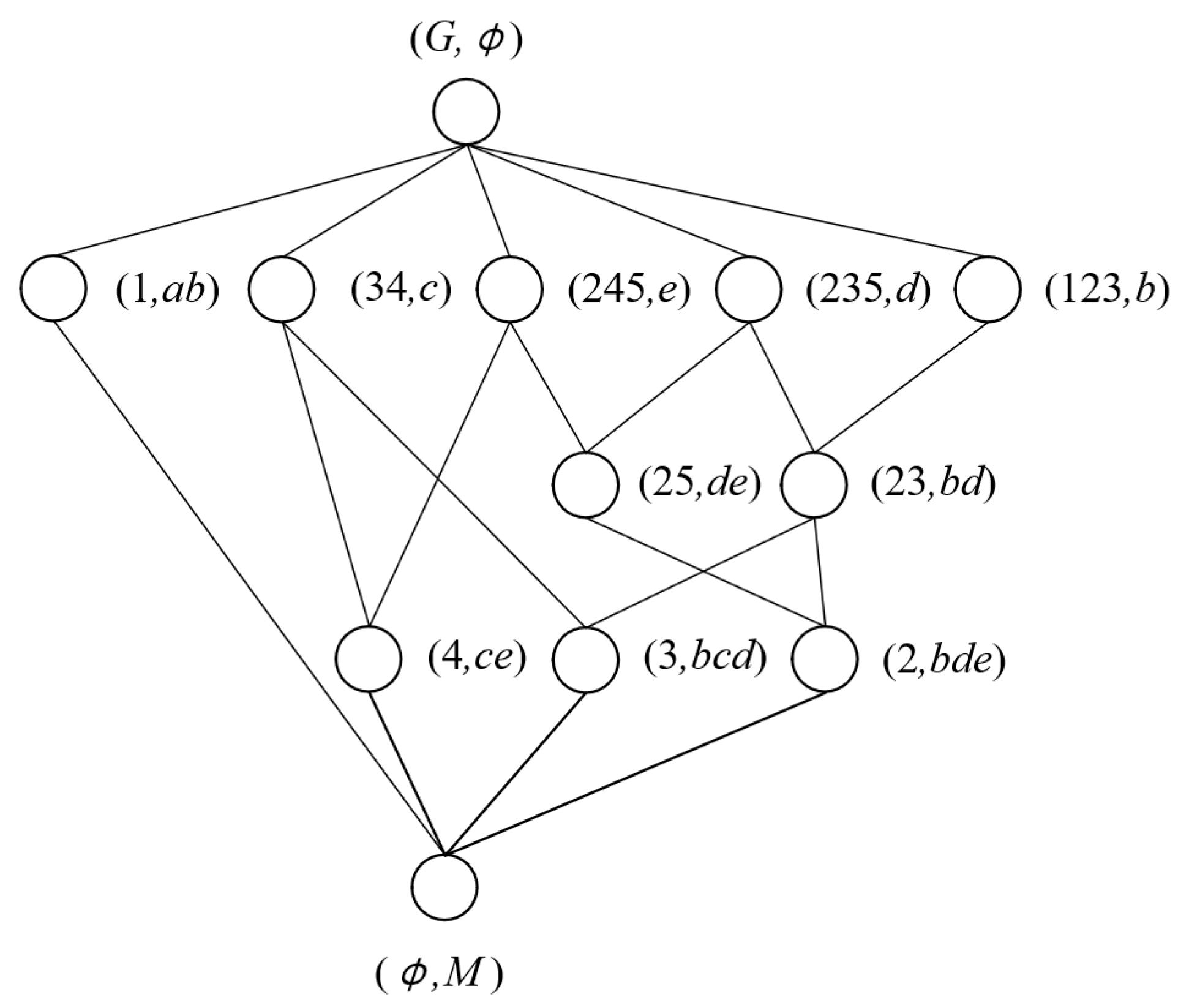
3.1.1. Preliminary Knowledge of FCA
3.1.2. KGE Score Function
3.1.3. KGC
3.2. Formal Concept Extraction Module
3.3. Formal Concept Sampling Module
3.4. Formal Concept-Driven Link Prediction Module
4. Experiments
4.1. Experiment Settings
4.1.1. Datasets
4.1.2. Baselines
4.1.3. Implementation Details
4.1.4. Evaluation Protocol
4.2. Evaluation of Public KGs
4.3. Common Sense Concepts vs. Formal Concepts
4.4. Evaluation of Actual Industrial KGs
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, X.; Luo, F.; Wu, Q.; Bao, Z. How Context or Knowledge Can Benefit Healthcare Question Answering? IEEE Trans. Knowl. Data Eng. 2021, 35, 575–588. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, S.; Xu, Y.; Miao, C.; Wu, M.; Zhang, J. Contextualized graph attention network for recommendation with item knowledge graph. IEEE Trans. Knowl. Data Eng. 2021, 35, 181–195. [Google Scholar] [CrossRef]
- Kang, S.; Shi, L.; Zhang, Z. Knowledge Graph Double Interaction Graph Neural Network for Recommendation Algorithm. Appl. Sci. 2022, 12, 12701. [Google Scholar] [CrossRef]
- Zhong, M.; Zheng, Y.; Xue, G.; Liu, M. Reliable keyword query interpretation on summary graphs. IEEE Trans. Knowl. Data Eng. 2022, 35, 5187–5202. [Google Scholar] [CrossRef]
- Sun, Y.; Chun, S.-J.; Lee, Y. Learned semantic index structure using knowledge graph embedding and density-based spatial clustering techniques. Appl. Sci. 2022, 12, 6713. [Google Scholar] [CrossRef]
- Gu, R.; Wang, T.; Deng, J.; Cheng, L. Improving Chinese Named Entity Recognition by Interactive Fusion of Contextual Representation and Glyph Representation. Appl. Sci. 2023, 13, 4299. [Google Scholar] [CrossRef]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 10–12 June 2008; pp. 1247–1250. [Google Scholar]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A core of semantic knowledge. In Proceedings of the 16th international conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; Van Kleef, P.; Auer, S. Dbpedia–a large-scale, multilingual knowledge base extracted from wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar] [CrossRef] [Green Version]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. Adv. Neural Inf. Process. Syst. 2013, 26, 2787–2795. [Google Scholar]
- Zhang, S.; Tay, Y.; Yao, L.; Liu, Q. Quaternion knowledge graph embeddings. Adv. Neural Inf. Process. Syst. 2019, 32, 2735–2745. [Google Scholar]
- Zhang, Z.; Cai, J.; Zhang, Y.; Wang, J. Learning hierarchy-aware knowledge graph embeddings for link prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 3065–3072. [Google Scholar]
- Yang, B.; Yih, W.-t.; He, X.; Gao, J.; Deng, L. Embedding entities and relations for learning and inference in knowledge bases. arXiv 2014, arXiv:1412.6575. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex embeddings for simple link prediction. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2071–2080. [Google Scholar]
- Sun, Z.; Deng, Z.-H.; Nie, J.-Y.; Tang, J. Rotate: Knowledge graph embedding by relational rotation in complex space. arXiv 2019, arXiv:1902.10197. [Google Scholar]
- Nickel, M.; Tresp, V.; Kriegel, H.-P. A three-way model for collective learning on multi-relational data. In Proceedings of the Icml, Bellevue, WC, USA, 28 June–2 July 2011; pp. 3104482–3104584. [Google Scholar]
- Xie, R.; Liu, Z.; Sun, M. Representation learning of knowledge graphs with hierarchical types. In Proceedings of the IJCAI, New York, NY, USA, 9–15 July 2016; pp. 2965–2971. [Google Scholar]
- Guo, S.; Wang, Q.; Wang, L.; Wang, B.; Guo, L. Knowledge graph embedding with iterative guidance from soft rules. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018. [Google Scholar]
- Niu, G.; Li, B.; Zhang, Y.; Pu, S. CAKE: A scalable commonsense-aware framework for multi-view knowledge graph completion. arXiv 2022, arXiv:2202.13785. [Google Scholar]
- Galárraga, L.; Teflioudi, C.; Hose, K.; Suchanek, F.M. Fast rule mining in ontological knowledge bases with AMIE+. VLDB J. 2015, 24, 707–730. [Google Scholar] [CrossRef] [Green Version]
- Sadeghian, A.; Armandpour, M.; Ding, P.; Wang, D.Z. Drum: End-to-end differentiable rule mining on knowledge graphs. Adv. Neural Inf. Process. Syst. 2019, 32, 1–13. [Google Scholar]
- Ma, S.; Ding, J.; Jia, W.; Wang, K.; Guo, M. Transt: Type-based multiple embedding representations for knowledge graph completion. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2017, Proceedings, Part I 10. Skopje, North Macedonia, 18–22 September 2017; pp. 717–733. [Google Scholar]
- Liu, J.; Chen, T.; Wang, C.; Liang, J.; Chen, L.; Xiao, Y.; Chen, Y.; Jin, K. VoCSK: Verb-oriented commonsense knowledge mining with taxonomy-guided induction. Artif. Intell. 2022, 310, 103744. [Google Scholar] [CrossRef]
- Li, C.; Liang, J.; Xiao, Y.; Jiang, H. Towards Fine-Grained Concept Generation. IEEE Trans. Knowl. Data Eng. 2021, 35, 986–997. [Google Scholar] [CrossRef]
- Xiang, Y.; Zhang, Z.; Chen, J.; Chen, X.; Lin, Z.; Zheng, Y. OntoEA: Ontology-guided entity alignment via joint knowledge graph embedding. arXiv 2021, arXiv:2105.07688. [Google Scholar]
- Guo, S.; Wang, Q.; Wang, B.; Wang, L.; Guo, L. SSE: Semantically smooth embedding for knowledge graphs. IEEE Trans. Knowl. Data Eng. 2016, 29, 884–897. [Google Scholar] [CrossRef]
- Lv, X.; Hou, L.; Li, J.; Liu, Z. Differentiating concepts and instances for knowledge graph embedding. arXiv 2018, arXiv:1811.04588. [Google Scholar]
- Li, Z.; Liu, X.; Wang, X.; Liu, P.; Shen, Y. Transo: A knowledge-driven representation learning method with ontology information constraints. World Wide Web 2023, 26, 297–319. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhuang, F.; Qu, M.; Lin, F.; He, Q. Knowledge graph embedding with hierarchical relation structure. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3198–3207. [Google Scholar]
- Zhang, F.; Wang, X.; Li, Z.; Li, J. TransRHS: A representation learning method for knowledge graphs with relation hierarchical structure. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021. [Google Scholar]
- Hao, J.; Chen, M.; Yu, W.; Sun, Y.; Wang, W. Universal representation learning of knowledge bases by jointly embedding instances and ontological concepts. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1709–1719. [Google Scholar]
- Wang, P.; Zhou, J. JECI++: A Modified Joint Knowledge Graph Embedding Model for Concepts and Instances. Big Data Res. 2021, 24, 100160. [Google Scholar] [CrossRef]
- Ganter, B.; Wille, R. Formal Concept Analysis: Mathematical Foundations; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Toutanova, K.; Chen, D. Observed versus latent features for knowledge base and text inference. In Proceedings of the 3rd Workshop on Continuous Vector Space Models and Their Compositionality, Beijing, China, 31 July 2015; pp. 57–66. [Google Scholar]
- Mahdisoltani, F.; Biega, J.; Suchanek, F. Yago3: A knowledge base from multilingual wikipedias. In Proceedings of the 7th Biennial Conference on Innovative Data Systems Research, Asilomar, CA, USA, 4–7 January 2015. [Google Scholar]
- Shang, C.; Tang, Y.; Huang, J.; Bi, J.; He, X.; Zhou, B. End-to-end structure-aware convolutional networks for knowledge base completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Hilton, HI, USA, 27 January–1 February 2019; pp. 3060–3067. [Google Scholar]
- Xiong, W.; Hoang, T.; Wang, W.Y. Deeppath: A reinforcement learning method for knowledge graph reasoning. arXiv 2017, arXiv:1707.06690. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| a | b | c | d | e | |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 |
| 2 | 0 | 1 | 0 | 1 | 1 |
| 3 | 0 | 1 | 1 | 1 | 0 |
| 4 | 0 | 0 | 1 | 0 | 1 |
| 5 | 0 | 0 | 0 | 1 | 1 |
| Model | Score Function | Parameters |
|---|---|---|
| TransE | ||
| DistMult | ||
| ComplEx | ||
| RotatE | ||
| HAKE |
| Dataset | #Rel | #Ent | #Train | #Valid | #Test |
|---|---|---|---|---|---|
| FB15K237 | 237 | 14,541 | 272,115 | 17,535 | 20,466 |
| YAGO3-10 | 37 | 123,182 | 1,079,040 | 5000 | 5000 |
| WN18RR | 11 | 40,943 | 86,835 | 3034 | 3134 |
| NELL-995 | 200 | 75,492 | 123,370 | 15,000 | 15,843 |
| Dbpedia-242 | 298 | 99,744 | 529,654 | 35,850 | 30,000 |
| Industrial KG | 15 | 57,373 | 78,787 | 3000 | 3000 |
| Metrics | Computing Formula | Notation Definition |
|---|---|---|
| MRR | ||
| MR | ||
| Hits@n |
| Model | FB15K237 | YAGO3-10 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MR | MRR | Hits@1 | Hits@3 | Hits@10 | MR | MRR | Hits@1 | Hits@3 | Hits@10 | |
| TransE | 175 | 0.331 | 0.234 | 0.369 | 0.526 | 1124 | 0.504 | 0.411 | 0.563 | 0.672 |
| TransE * | 110 | 0.371 | 0.275 | 0.410 | 0.563 | 648 | 0.535 | 0.452 | 0.583 | 0.688 |
| DistMult | 216 | 0.284 | 0.223 | 0.310 | 0.447 | 1723 | 0.130 | 0.084 | 0.135 | 0.219 |
| DistMult * | 145 | 0.320 | 0.240 | 0.346 | 0.482 | 1110 | 0.174 | 0.116 | 0.185 | 0.287 |
| ComplEx | 181 | 0.308 | 0.220 | 0.337 | 0.486 | 1118 | 0.198 | 0.131 | 0.214 | 0.325 |
| ComplEx * | 119 | 0.344 | 0.258 | 0.372 | 0.518 | 660 | 0.253 | 0.181 | 0.276 | 0.393 |
| RotatE | 177 | 0.336 | 0.240 | 0.374 | 0.530 | 1859 | 0.497 | 0.406 | 0.553 | 0.665 |
| RotatE * | 108 | 0.376 | 0.280 | 0.413 | 0.567 | 795 | 0.542 | 0.469 | 0.591 | 0.694 |
| HAKE | 184 | 0.343 | 0.246 | 0.380 | 0.537 | 1384 | 0.531 | 0.444 | 0.586 | 0.687 |
| HAKE * | 112 | 0.380 | 0.285 | 0.417 | 0.572 | 613 | 0.562 | 0.485 | 0.605 | 0.703 |
| Model | WN18RR | NELL-995 | ||||||||
| MR | MRR | Hits@1 | Hits@3 | Hits@10 | MR | MRR | Hits@1 | Hits@3 | Hits@10 | |
| TransE | 5081 | 0.191 | 0.004 | 0.343 | 0.478 | 2238 | 0.239 | 0.079 | 0.348 | 0.508 |
| TransE * | 4209 | 0.221 | 0.029 | 0.382 | 0.500 | 353 | 0.325 | 0.202 | 0.394 | 0.548 |
| DistMult | 6043 | 0.406 | 0.358 | 0.437 | 0.490 | 2523 | 0.348 | 0.268 | 0.385 | 0.500 |
| DistMult * | 4935 | 0.414 | 0.364 | 0.444 | 0.503 | 472 | 0.398 | 0.311 | 0.435 | 0.564 |
| ComplEx | 6394 | 0.457 | 0.416 | 0.481 | 0.526 | 3664 | 0.369 | 0.289 | 0.405 | 0.518 |
| ComplEx * | 5274 | 0.463 | 0.421 | 0.488 | 0.535 | 727 | 0.417 | 0.331 | 0.453 | 0.582 |
| RotatE | 5648 | 0.466 | 0.435 | 0.480 | 0.527 | 2327 | 0.358 | 0.269 | 0.404 | 0.526 |
| RotatE * | 4597 | 0.473 | 0.440 | 0.488 | 0.539 | 337 | 0.405 | 0.313 | 0.450 | 0.580 |
| HAKE | 4132 | 0.492 | 0.450 | 0.509 | 0.574 | 2419 | 0.313 | 0.205 | 0.374 | 0.514 |
| HAKE * | 3325 | 0.504 | 0.463 | 0.519 | 0.585 | 348 | 0.373 | 0.270 | 0.427 | 0.567 |
| Model | FB15K237 | NELL-995 | Dbpedia-242 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MR | MRR | Hits@1 | Hits@3 | Hits@10 | MR | MRR | Hits@1 | Hits@3 | Hits@10 | MR | MRR | Hits@1 | Hits@3 | Hits@10 | |
| TransE + U | 167 | 0.309 | 0.215 | 0.340 | 0.496 | 1261 | 0.249 | 0.153 | 0.288 | 0.428 | 1332 | 0.281 | 0.123 | 0.393 | 0.538 |
| TransE + S | 172 | 0.303 | 0.208 | 0.337 | 0.494 | 1212 | 0.255 | 0.156 | 0.295 | 0.436 | 1302 | 0.302 | 0.132 | 0.427 | 0.573 |
| TransE + C | 177 | 0.295 | 0.199 | 0.330 | 0.484 | 485 | 0.310 | 0.187 | 0.374 | 0.532 | 901 | 0.331 | 0.159 | 0.461 | 0.596 |
| TransE + U * | 29 | 0.756 | 0.709 | 0.779 | 0.850 | 232 | 0.344 | 0.248 | 0.386 | 0.527 | 635 | 0.316 | 0.170 | 0.415 | 0.557 |
| TransE + S * | 28 | 0.754 | 0.704 | 0.780 | 0.849 | 226 | 0.351 | 0.253 | 0.392 | 0.536 | 606 | 0.336 | 0.182 | 0.446 | 0.586 |
| RotatE + U | 188 | 0.316 | 0.221 | 0.351 | 0.507 | 1389 | 0.342 | 0.249 | 0.379 | 0.522 | 1935 | 0.337 | 0.197 | 0.434 | 0.560 |
| RotatE + S | 190 | 0.324 | 0.230 | 0.357 | 0.514 | 1357 | 0.351 | 0.260 | 0.385 | 0.533 | 1788 | 0.372 | 0.239 | 0.464 | 0.592 |
| RotatE + C | 192 | 0.318 | 0.226 | 0.348 | 0.503 | 503 | 0.404 | 0.305 | 0.455 | 0.593 | 1049 | 0.419 | 0.310 | 0.486 | 0.605 |
| RotatE + U * | 34 | 0.761 | 0.712 | 0.784 | 0.853 | 223 | 0.433 | 0.343 | 0.469 | 0.611 | 772 | 0.366 | 0.236 | 0.454 | 0.576 |
| RotatE + S * | 32 | 0.760 | 0.711 | 0.784 | 0.855 | 220 | 0.433 | 0.341 | 0.470 | 0.611 | 718 | 0.413 | 0.299 | 0.485 | 0.607 |
| Model | Industrial KG | ||||
|---|---|---|---|---|---|
| MR | MRR | Hits@1 | Hits@3 | Hits@10 | |
| TransE | 5949 | 0.353 | 0.143 | 0.505 | 0.758 |
| TransE * | 1000 | 0.681 | 0.609 | 0.741 | 0.796 |
| DistMult | 6811 | 0.545 | 0.492 | 0.572 | 0.671 |
| DistMult * | 847 | 0.636 | 0.574 | 0.680 | 0.744 |
| ComplEx | 6246 | 0.557 | 0.498 | 0.591 | 0.685 |
| ComplEx * | 835 | 0.630 | 0.562 | 0.678 | 0.752 |
| RotatE | 7086 | 0.588 | 0.510 | 0.634 | 0.760 |
| RotatE * | 1061 | 0.672 | 0.602 | 0.726 | 0.788 |
| HAKE | 3538 | 0.584 | 0.521 | 0.610 | 0.728 |
| HAKE * | 448 | 0.699 | 0.629 | 0.756 | 0.819 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, X.; Wu, C.; Yang, S. SFCA: A Scalable Formal Concepts Driven Architecture for Multi-Field Knowledge Graph Completion. Appl. Sci. 2023, 13, 6851. https://doi.org/10.3390/app13116851
Sun X, Wu C, Yang S. SFCA: A Scalable Formal Concepts Driven Architecture for Multi-Field Knowledge Graph Completion. Applied Sciences. 2023; 13(11):6851. https://doi.org/10.3390/app13116851
Chicago/Turabian StyleSun, Xiaochun, Chenmou Wu, and Shuqun Yang. 2023. "SFCA: A Scalable Formal Concepts Driven Architecture for Multi-Field Knowledge Graph Completion" Applied Sciences 13, no. 11: 6851. https://doi.org/10.3390/app13116851