1. Introduction
The goal of bioequivalence (BE) testing is to determine the in vivo “equivalence” of two drug products containing the same active moiety, namely the test (T) and the innovator’s formulation of the same active substance known as the reference (R) product [
1,
2]. In turn, showing bioequivalence is needed to make sure that the therapeutic effects of the two products under consideration are the same. The idea behind bioequivalence is that a product’s therapeutic profile is a function of the concentration of the active ingredient in the effect site, which relies on the concentration of drug in the general circulation. Thus, two drugs (T and R) are termed bioequivalent if their time-concentration profiles are similar enough to assure comparable clinical performance [
3]. Formally, a T product is considered bioequivalent to the original R product if it has the same active ingredient and, when taken at the same molar dose, there are no significant differences in the rate and amount of absorption compared to the R formulation [
1,
2]. To standardize and clarify the BE assessment procedure, regulatory health agencies around the world have issued many guidelines with a focus on pharmacokinetic (PK) issues, such as the type of PK parameters to be estimated, statistical analysis, and the selection of the appropriate clinical design that will allow the reliable estimation of the PK parameters [
4].
In the case of immediate-release formulations, it is now widely accepted that the rate of absorption should be assessed by the peak plasma concentration (Cmax), whereas the extent of absorption is expressed by the area under the time-concentration curve (AUC) from time zero to the last sampling point [
1,
2]. Other PK metrics are also utilized to provide further information. These include the area under the plasma time-concentration curve extrapolated to infinity (AUCinf), the time (Tmax) at which Cmax occurs, and the time-concentration curve’s terminal slope (lambda). Other PK characteristics, such as the highest and lowest drug concentrations at steady state, the AUC at each interval of administration, and the peak-to-trough fluctuation, are used for modified release products [
4,
5,
6,
7,
8,
9,
10].
Even though Cmax is routinely used in BE assessment worldwide, it has been questioned as a metric that expresses the extent of absorption in addition to the rate of absorption [
6,
11,
12]. In this vein, several studies [
13,
14,
15,
16,
17] have revealed similar problems concerning the use of Cmax as a parameter of absorption rate. Other pharmacokinetic metrics, such as the Cmax/AUC ratio, Tmax, and partial AUCs, have been proposed to address some of the shortcomings of Cmax [
12,
14,
18]. However, even though much work has been done towards the statistical assessment (e.g., scaled bioequivalence limits) and the clinical designs (e.g., replicate, two-stage adaptive), the problematic Cmax is still used, and the inherent problems that it carries seem to have been neglected. This means that despite the fact that in BE assessment there is a detailed and carefully specified framework, the rate of absorption is not actually evaluated.
The use of machine learning (ML) approaches, a subfield of artificial intelligence, is a useful tool for addressing this question [
19,
20]. ML techniques enable data to be trained, followed by statistical analysis to provide values that fall inside a particular range. ML enables the creation of models from sample data in order to automate decision-making processes based on data inputs. ML tasks are often divided into broad categories based on how the system learns or receives feedback on what it learns. The two most common ML methods are “supervised learning,” in which algorithms are taught using labeled input and output data, and “unsupervised learning,” in which the algorithm is not given labeled data and must identify structure in the input data [
19,
20].
Despite the fact that the limitations of Cmax as an absorption rate parameter have been recognized since its inception, Cmax has been used in BE studies for more than 30 years. The aim of this study is to use the modern tool of machine learning in order to address, from a new perspective, the old problem of setting the most appropriate rate of absorption for use in BE assessment. Two machine learning algorithms (principal component analysis and random forest) are utilized to explore the relationships among the PK parameters and to identify the most suitable metric for absorption rate. Moreover, among the PK metrics evaluated, a novel metric, the Cmax/Tmax ratio, is introduced and explored for its utility in describing absorption rate alongside the other measurements.
In order to accomplish this task, the computation approach included three steps: (a) First, the two ML algorithms are applied to the actual bioequivalence dataset of donepezil. To validate the findings obtained in the previous step and to address additional questions, simulated bioequivalence datasets were generated. (b) Since a population pharmacokinetic model would be necessary for the simulations, non-linear mixed effect modeling was applied to the actual concentration-time (C-t) data of donepezil. (c) Simulated BE datasets were then generated for three different types of absorption kinetics (slow, intermediate, and fast). (d) Machine learning was applied again to the simulated data.
2. Materials and Methods
2.1. Strategy of the Analysis
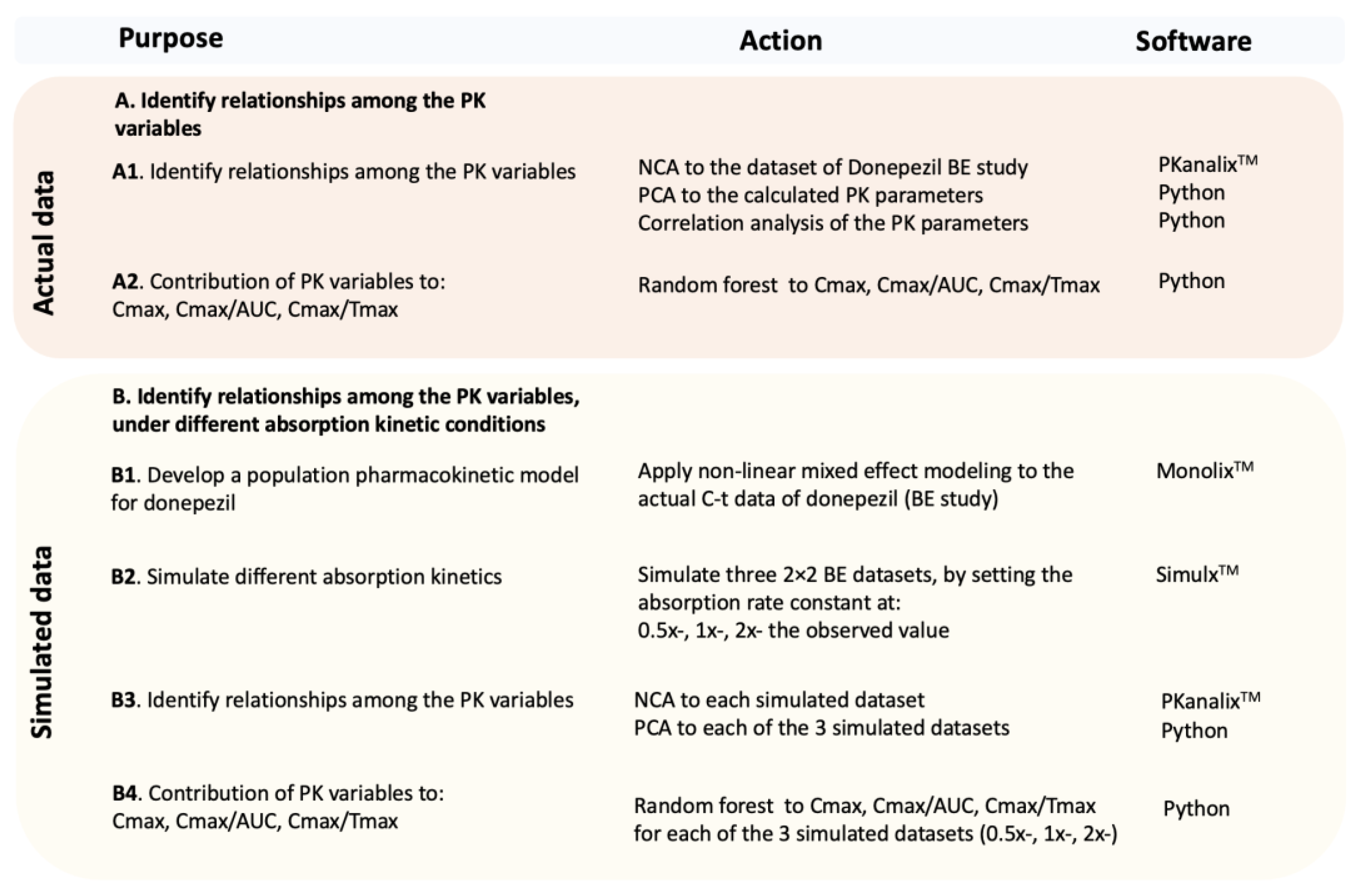
In this study, a two-step procedure is used where the ML algorithms are applied to actual and simulated BE data.
Figure 1 shows an outline of the strategy that was used in order to address to the questions posed in this study, namely to identify how the PK parameters relate to each other and find the best possible metric for absorption rate.
Initially, from the actual concentration (C) and time (t) data of the donepezil BE study, pharmacokinetic parameters were estimated using the classic non-compartmental (NCA) approach (
Figure 1). Then, principal component analysis (PCA) was applied to the previously calculated PK data. Afterwards, correlation analysis was used to explore the bivariate relationships in the original scale of the PK variables. In order to uncover the contribution of PK characteristics into each possible absorption rate metric (Cmax, Cmax/AUC, and Cmax/Tmax), the second ML technique, random forest (RF), was applied.
Aiming to explore more conditions with faster or slower absorption rates and identify the performance of PK metrics, further simulations were performed (
Figure 1). To fulfill this task, the first step was to develop a PK model to describe the kinetics of donepezil. Non-linear mixed effect modeling (NLME) was employed on the actual C-t data, and a population PK model for donepezil was developed. In a subsequent step, using the population estimates (and all variabilities calculated from the NLME analysis), three scenarios were simulated: (a) slower absorption by adjusting the absorption rate constant (Ka) to be half of the original (0.5x-), (b) equal to the original Ka (i.e., 1x-), and (c) faster absorption where Ka was set to be twice the original (2x-). Thus, three BE datasets of donepezil were simulated, and the two ML techniques (PCA and RF) were re-applied. The latter allows detecting the relationships among the PK variables and the contribution of each one to another, under different absorption rates. In other words, it was an effort to isolate the impact of absorption rate and elaborate on it.
2.2. Bioequivalence Data-Noncompartmental Analysis
Donepezil is a widely used drug for symptomatic relief of Alzheimer’s disease. The actual C-t data used in this study were obtained from a two-sequence, two-period, crossover BE study in 26 healthy volunteers who received a single dose of donepezil 10 mg tablets (Verisfield SA) and donepezil (Aricept®) from Pfizer, separated by a 21-day washout period. The pharmaceutical company (Verisfield SA) kindly provided the blind C-t data of the study participants in order to perform this computational study. According to the BE study protocol, the blood samples were obtained at 0.5, 1, 2, 3, 4, 6, 8, 12, 24, 48, 96, 144, and 192 h after the treatment. Overall, there were 14 observations per subject and 26 subjects per period of the study. Taking into consideration that the data come from a 2 × 2 crossover study and there was no discrimination between the two medicinal products, there are 52 subjects with 14 observations each. As a result, 52·14 = 728 measurement points.
Following the appropriate clinical and analytical procedures, the blood samples were finally analyzed to quantify donepezil concentration using a validated high-performance liquid chromatography/tandem mass spectrometry (LC-MS/MS). The analytical approach demonstrated great sensitivity, specificity, accuracy, and speed. The linearity of the curve was reported at concentrations ranging from 0.1 to 100 ng/mL. The lower limit of quantitation for donepezil was equal to 0.1 ng/mL.
In the BE study, participated male and female volunteers between the ages of 18 and 45 with a BMI of 18.5 to 24.9 kg/m2. To confirm that they were healthy volunteers, a comprehensive medical history was collected, and a physical examination and laboratory tests were performed 21 days before enrollment in the study. After an overnight fast, the medication was taken orally with roughly 240 mL of water. Subjects fasted for 4 h, 8 h, 12 h, 24 h, 28 h, 32 h, 36 h, and 48 h following administration before eating regular meals. All the participants signed a written consent form, and the study was performed according to the ethical rules of the Helsinki Declaration.
Non-compartmental approaches (PKanalix
TM, MonolixSuite
TM 2021R2, and Simulation Plus) were used to calculate the PK parameters of donepezil. These parameters were AUC, Cmax, Tmax, lambda, and the area under the C-t curve extrapolated from time zero to infinity (AUCinf). The linear trapezoidal rule was used to determine AUC and AUCinf. The Cmax/AUC and Cmax/Tmax ratios were calculated for each subject based on these estimates. The term “lambda” refers to the apparent terminal elimination rate constant, which is found by applying a least squares regression analysis to the terminal log-linear phase of the C-t curve, in line with the regulatory guidelines [
1,
2].
2.3. Principal Component Analysis
A well-established method for transforming a high-dimensional set of features into a low-dimensional set is principal component analysis [
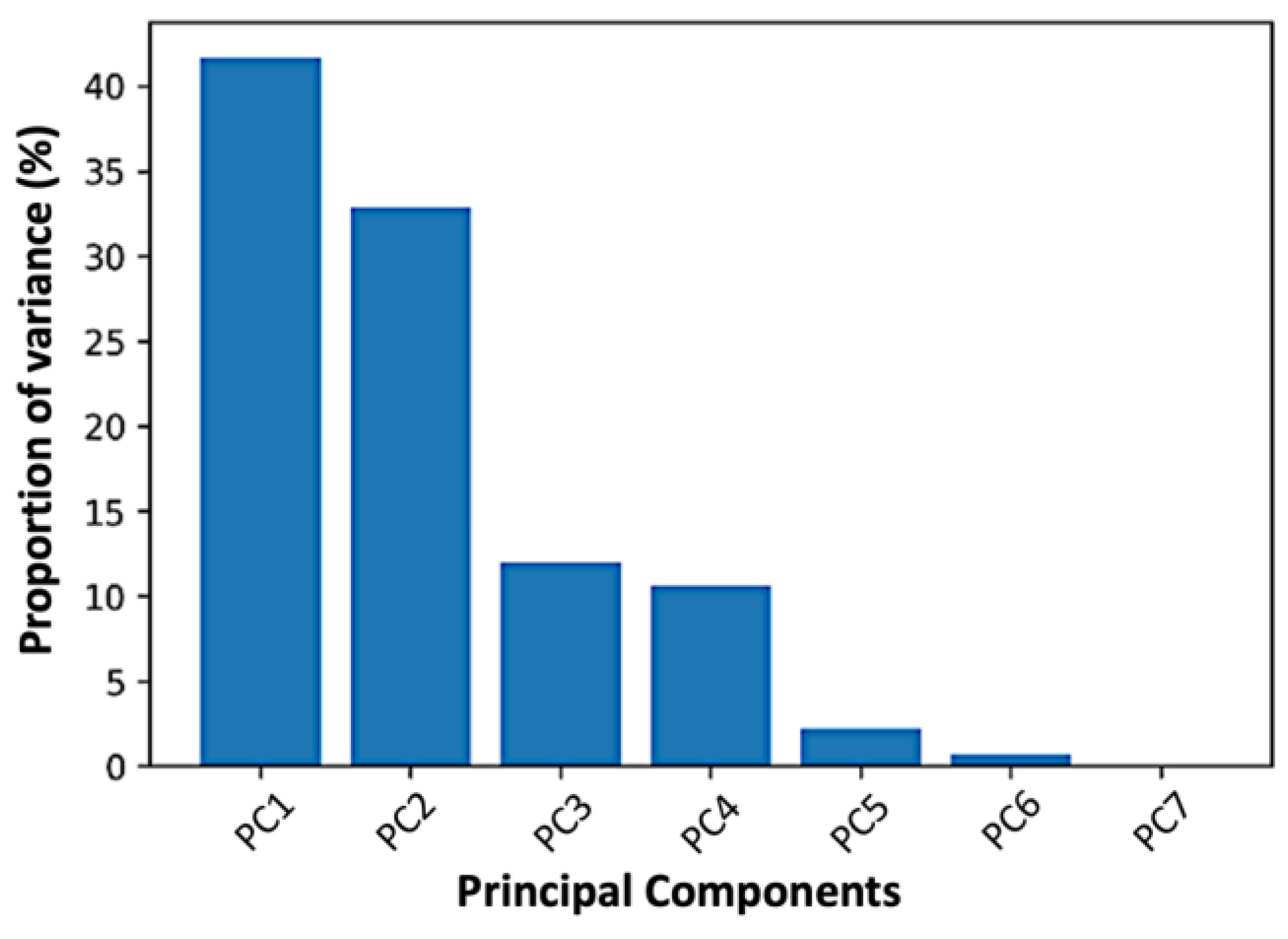
20]. PCA seeks the lowest dimensional representation of the data, while preserving as much information/variance as possible. In order to capture as much variability as possible, PCA converts the original space, produced from the original dataset, into a new space that is a linear combination of the dataset dimensions. Each dimension that is created is referred to as a principal component (PC). The new coordinates of the data are referred to as “scores.” Each PC accounts for a part of the variation in the original data set. The first principal component’s direction is the direction in which the data varies the most. The contribution of each original dimension to the new dimension is expressed by the “loadings”. The closer the loading value is to +1 (or −1), the greater the feature’s positive (or negative) impact on this PC.
The “biplot” is the usual approach to examine the loadings and scores combined. The biplot is a two-dimensional scatter plot in which the two axes reflect the two most important PCs in terms of explained variance. The loadings of the first two PCs of each characteristic are shown over the data points in this two-dimensional coordinate system, utilizing the scores as coordinates. Scree plots are used to identify the fewest number of primary components required to reflect the original data adequately. A scree plot main aim is to display the findings of the component analysis and to locate the apparent change in slope (elbow). The eigenvalue is shown against the major components in a scree plot. The proportion of variance explained by a component is its eigenvalue divided by the sum of its eigenvalues. The first component typically explains a substantial proportion of the variability, the subsequent components explain a moderate proportion, and the final components explain just a small proportion of the total variability.
The data linear dimensionality was reduced using singular value decomposition (SVD). The latter was employed in order to project data into a lower dimensional space. Before applying the SVD, the input data were centered and scaled for each feature. Since the features (i.e., PK parameters) used in the PCA differed in scale (e.g., Tmax vs. AUC), feature scaling was required prior to conducting the PCA. Using the
StandardScaler of “Scikit-learn” from the preprocessing submodule, z-score standardization was used to get all features into the same scale. Because the dataset was constrained, the actual full SVD was computed and then reduced [
21]. Because we are interested in finding relationships among all PK parameters, PCA was implemented using the original number of dimensions. As a result, the number of components hyperparameter was set to “none” in order to keep all components. A one-dimensional “numpy” array was used to calculate the percentage of variance explained by each of the selected components. Then, the principal components were ordered by decreasing explained variance and the two first principal components were kept. The entire PCA analysis was implemented in Python v. 3.10.8.
2.4. Correlation Analysis
Correlation analysis is a statistical tool used in research to determine and quantify the strength of a linear association between two variables. The correlation coefficient quantifies the linear relationship between two sets of data. It is the product of the covariances of two variables and their standard deviations. Consequently, it is essentially a standardized measurement of covariance, with the result always falling between +1 and −1. The measure, like covariance, can only indicate a linear connection of variables and ignores numerous other forms of linkages or correlations. In this study, the Pearson correlation coefficient was used as a surrogate measure of the bivariate association between two PK variables. The analysis was performed in Python v. 3.10.8.
2.5. Random Forest
Bagging is a machine learning approach in which many “copies” of the training data are created, where each “copy” is somewhat different from the others. Each copy is then subjected to a weak learner, such as a “decision tree.” This generates a large number of weak models, which are subsequently merged. Random forest is a supervised learning bagging strategy in which a large number of decorrelated trees are produced and then averaged to generate a more precise and consistent prediction of the target variable [
20]. It is usual practice to partition the initial dataset into two pieces, “training” and “testing,” to make the algorithm more robust. The training set is used to build the model, and the testing set is used to assess the model’s performance.
Random forest is a supervised machine learning technique for either classification or regression tasks. An RF classifier operates on data with discrete labels, namely classes. Also, RF can be used for regression tasks in addition to classification. Even though RF cannot be used for extrapolation tasks, RF’s nonlinear nature gives it an advantage over linear methods. The response variable in the case of an RF regressor should have numerical values. For the purposes of this study, RF was used for classification. Thus, prior to using RF, the response variable had to be in the form of an ordinal scale. Thus, Cmax, Cmax/AUC, and Cmax/Tmax were transformed into ordinal scales from their original continuous scales.
For the implementation of RF, the hyper-parameters must be defined before training. In general, the hyper-parameter tuning was based on trial-and-error. These hyper-parameters may refer to the number of decision trees in the forest and the number of classes into which the response variable was classified. Bootstrap samples were utilized to construct trees, while the number of trees in the forest was equal to 500. To get all features into the same scale, z-score standardization was employed with the StandardScaler of sklearn from the preprocessing submodule. The number of random states, which affects the randomness of sample bootstrapping when creating trees, was set to 42. No warm was used, but a completely new forest was built every time. The number of parallel jobs was set to one. The utilized criterion (loss function), to determine model classification, was the default of the sklearn library, the Gini impurity. The max depth of each tree was set to 5. It should be stated that several settings were tested, but the final used are those presented above.
The dataset was divided into training and test sets, with the latter accounting for 33% of the data (the remaining 67% referring to the training set). Following the split, the model was trained on the training set and predictions were made on the test set. The feature significance scores were generated and shown using the Matplotlib tool once the random forest model was developed. The “confusion matrix” is employed to assess the performance of a model in a classification task (i.e., where the dependent variable is categorical). The confusion matrix is a M × M matrix, where M refers to the number of classes in the response variable. The matrix compares the expected and true classes. This provides a detailed perspective of the categorization model’s overall performance and the types of errors it makes. The correctness and misinterpretation of the predictions are measured in order to reflect the classification’s performance. When utilizing random forest, it is also feasible to determine the contribution of each variable to the prediction of the response variable by studying the feature importance.
Initially, the response variable was divided into four classes in order to express the conditions of “low”, “intermediate”, “high”, and “very high” values. This hyper-parameter (i.e., number of classes) tuning was based on a trial-and-error rationale; two-, three-, and five- groups were also investigated. The classification results, obtained from the 4-group sorting were at least equal to those from the 3-group. The two other cases (e.g., two or five groups) led to worse classifications. Thus, the 4-group classification was finally selected. Besides, the latter, based on the distribution quartiles, allowed the balanced participation of all attributes. The distribution of each response variable between the four classes was compared by assessing the inter-quartile range (within each group) and applying the Kolmogorov–Smirnov test (at the significance level of 5%). In all cases of the analysis presented below, no statistically significant differences were observed.
The random forest algorithm was implemented in Python v. 3.10.8.
2.6. Non-Linear Mixed Effect Modeling
Individual plasma C-t measurements were collected from the donepezil BE dataset. For nonlinear mixed effects modeling, the stochastic approximation of the expectation maximization algorithm was used, followed by importance sampling approaches [
22]. For the final population parameter values, the value of the objective function (OVF) was computed using the important Monte Carlo sampling method.
One-, two-, and three-compartment models with first-order elimination were investigated, with initial parameter estimations based on the literature [
23]. All pharmacokinetic parameters were assumed to have a lognormal distribution. Many residual error models were examined, e.g., constant, proportional, and combinations of constant and proportional error models. The selection of the final best model was based on goodness-of-fit plots and OVF comparisons. Visual analysis of the resulting goodness of fit plots enabled the detection of potential biases or issues in the structural model, random effects, and statistical techniques. Plots of observed values versus individual projected values, individual weighted residuals versus time, and individual weighted residuals versus concentration were used to assess goodness of fit.
One of the advantages of non-linear mixed effect modeling relies on the fact that relatively small numbers of subjects are required and sparse sample size. In this study, 26 subjects participated in a 2 × 2 clinical design. This sample size allows the reliable estimation of the population estimates as well as their variabilities; either between-subject (i.e., the omega estimates) or the residual error [
24,
25].
MonolixTM 2021R2 (Simulation Plus) was used for the population pharmacokinetic analysis.
2.7. Simulated Bioequivalence Datasets
Using the population PK estimates from the NLME analysis, three BE datasets (2 × 2 crossover) of 26 subjects each were simulated: (a) slower absorption by setting the absorption rate constant to be half of the original (0.5x-), (b) equal to the original Ka (i.e., 1x-), and (c) quicker absorption by setting Ka to be twice the original (2x-). As a result, three donepezil BE datasets were simulated and the two ML approaches (PCA and RF) were re-applied. The latter allowed the investigation of relationships between the PK variables and the contribution of each to another, under varying absorption rates. The sampling schedule was set every 15 min in order to avoid adding bias to the estimations of the PK parameters.
4. Discussion
The objective of this study was to explore the relationships among the PK parameters used in BE assessment and identify the most appropriate metric for characterizing absorption rate. This task was accomplished using two machine learning algorithms (PCA and RF) and the use of actual BE data from 26 healthy volunteers, as well as three simulated BE studies. To the best of knowledge, this is the first study that utilizes machine learning in the field of bioequivalence assessment.
Over the last few years, it has been agreed that AUC indicates the extent of exposure, whereas Cmax (the maximum plasma concentration or peak exposure) and Tmax refer to absorption rate-dependent characteristics [
1,
2,
4]. Even though there are no doubts about the use of AUC as a measure of the extent of absorption, the choice of Cmax as a metric for the rate of absorption has raised many concerns [
6,
11,
12,
14,
16,
17]. First of all, it has to be reminded why Cmax was preferred over other PK metrics, e.g., Tmax, partial AUC areas, or mean residence time for reflecting the kinetic aspects of absorption. The requirement to evaluate “rate” in bioequivalence tests using indirect metrics comes from the ambiguity about whether such testing is meant to ensure pharmaceutical quality (in terms of drug release characteristics) as well as clinical safety and efficacy [
12]. Thirty years ago, scientists using simple simulations demonstrated the danger of evaluating the performance of several indirect rate measures using a fixed universal acceptability interval for bioequivalence [
12]. However, because rate, as indicated by a rate constant, cannot be accurately assessed using indirect metrics and may have little clinical relevance, regulatory guidelines supported the use of Cmax as an empirical index of safety and efficacy.
However, Cmax inherently carries two problems: first, the fact that concentration measurements are only taken at discrete time intervals complicates the direct determination of Cmax (as well as Tmax). Secondly, and most importantly, Cmax is known to be greatly influenced by the extent of absorption. Hence, Cmax should be better used to measure high drug exposure rather than absorption rate. This implies that the ineffective use of Cmax as an indirect parameter for absorption rate contributes to the unpredictable and uncertain outcome of BE studies [
11]. In this context, Tmax and the ratio Cmax/AUC have been proposed as possible alternatives to Cmax for assessing the absorption rate characteristics of immediate-release formulations [
14]. Studies comparing the absorption rates of two drug formulations have shown that Tmax and the Cmax/AUC ratio share similar features [
14]. This observation provided a compelling justification for using the observed Cmax/AUC ratio as a measure of absorption rate rather than Tmax because Cmax/AUC was easier to handle statistically and could be measured with more precision than Tmax [
14,
18].
Even though the limitations of Cmax as an absorption rate metric have been acknowledged since its initial adoption, the use of Cmax in BE studies has been traditionally used for more than 30 years. In this study, the modern tool of machine learning is used to address an old problem from another perspective. Two ML methods, principal component analysis and random forest, are used to identify the relationships between the PK parameters. The underlying meaning of this task was to unveil the relationships among all possible pharmacokinetic measures used in bioequivalence studies. In general, in bioequivalence testing, pharmacokinetic parameters are calculated to express two characteristics: extent and rate of absorption. The traditional way in pharmacokinetics to explore the properties of a pharmacokinetic parameter is to find its relationships with the bioavailable fraction and absorption rate constant assuming a certain type of kinetics (e.g., a one-compartment model with first-order absorption and elimination) and using simple simulations. In this study, for the first time, ML algorithms are applied instead of a simple simulation exercise, and all pharmacokinetic features are explored together. The PCA analysis identifies proximities between PK characteristics, whereas the RF analysis identifies the nature of each parameter, specifically whether it is influenced by the extent or rate of absorption.
In addition, a new metric, the ratio Cmax/Tmax, is introduced and explored together with the traditional PK parameters. We assess the contribution of PK characteristics to each one of the potential absorption rate metrics (i.e., Cmax, Cmax/AUC, and Cmax/Tmax). In this analysis, ML techniques were applied to two different types of data (
Figure 1): (a) actual data on donepezil obtained from a 2 × 2 BE study in 26 volunteers, and (b) simulated donepezil BE data assuming a slower (0.5x-), similar (1x-), and faster (2x-) absorption rate. An overview of the analyses taken in this study and the main findings are summarized in
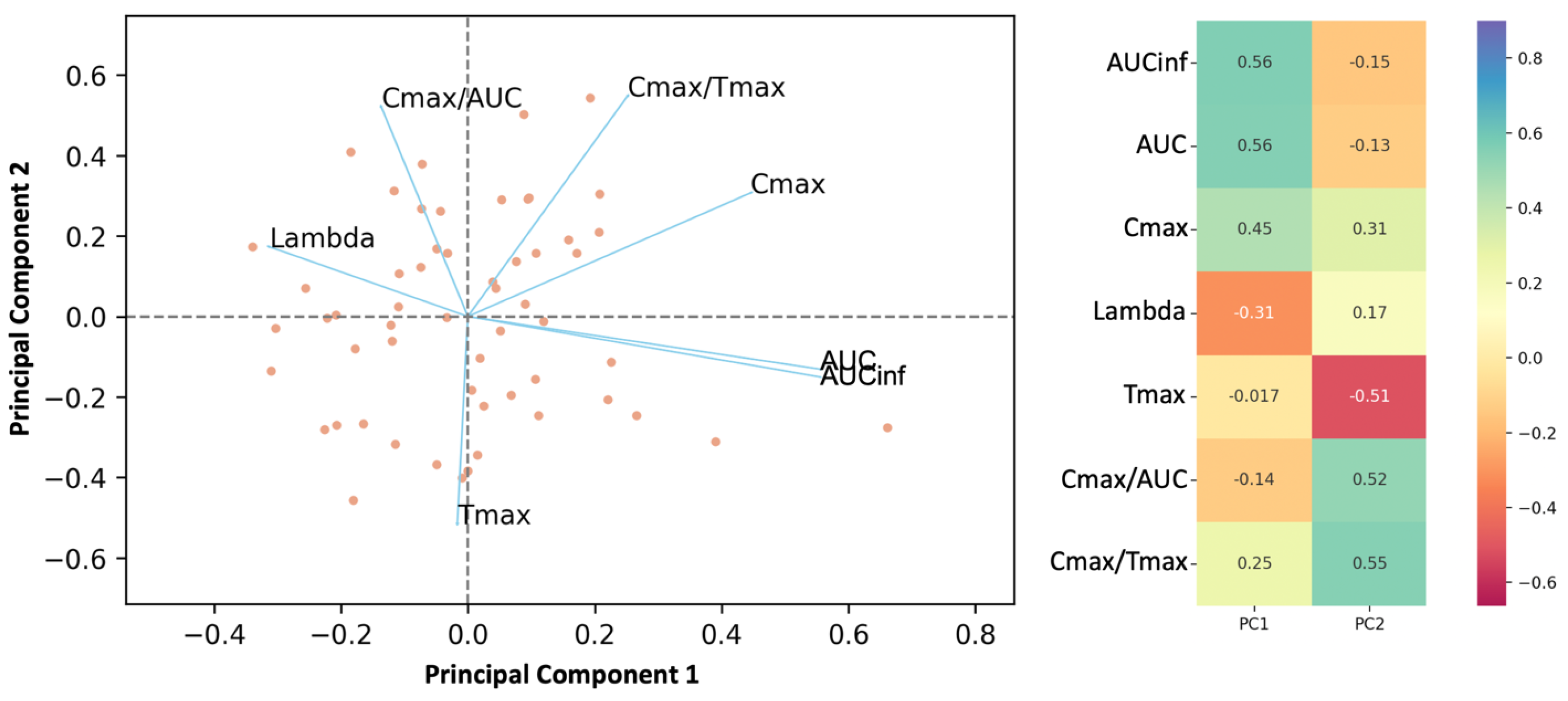
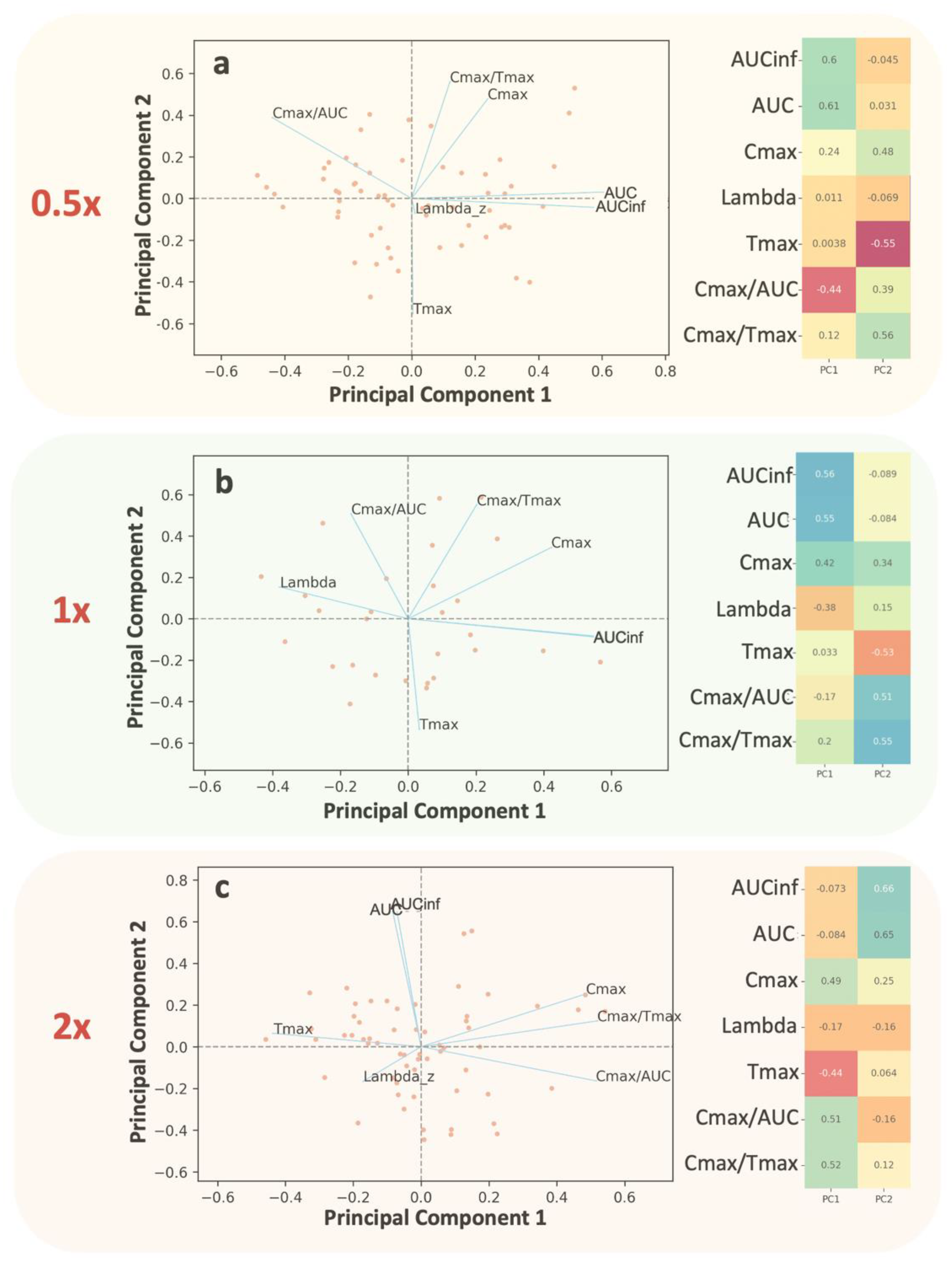
Table 3. Initially, it was shown, as was expected, that AUC and AUCinf show almost identical behavior. Moreover, Cmax is strongly related to AUC and AUCinf, while Cmax/AUC and Cmax/Tmax are not much related to AUC or AUCinf. Besides, Cmax/AUC and Cmax/Tmax have opposite behavior compared to Tmax because they are spotted in opposite directions relevant to the second principal component (
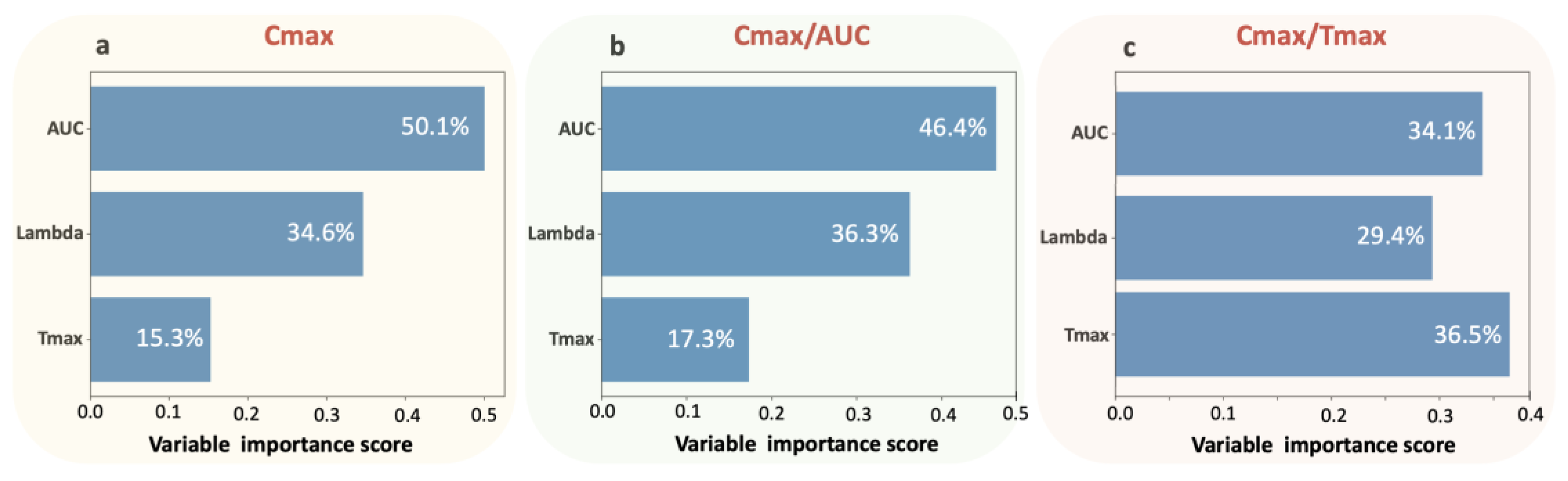
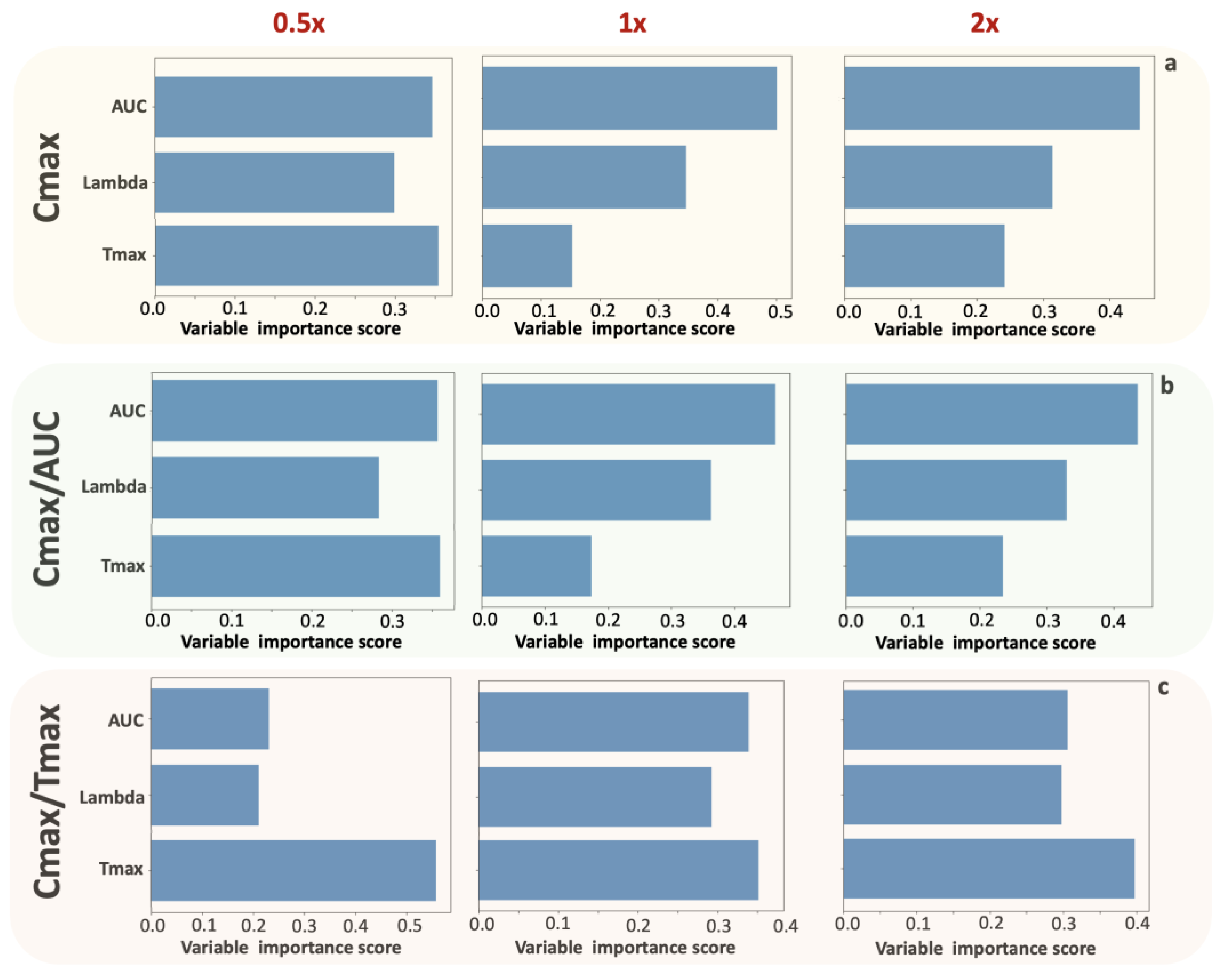
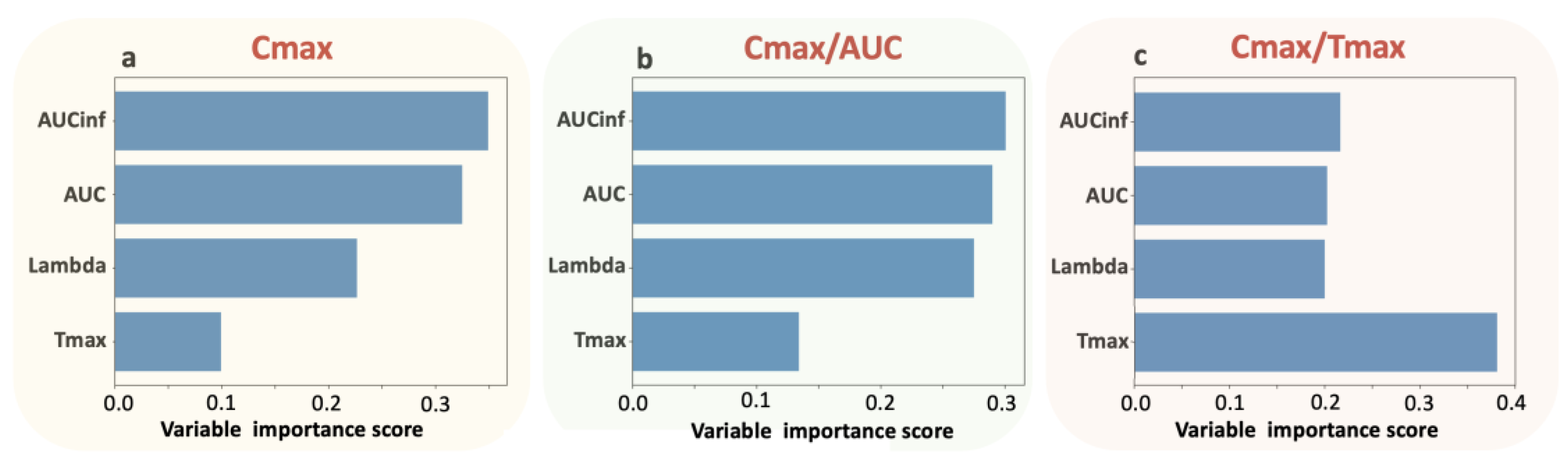
Figure 2). The application of the random forest algorithm showed that the contribution of Tmax properties to the parameters is the least for Cmax, slightly higher for Cmax/AUC, and highest for Cmax/Tmax (
Table 3 and
Figure 3). The latter implies the “kinetic nature” of the Cmax/Tmax ratio as it better reflects the kinetic properties of absorption rate.
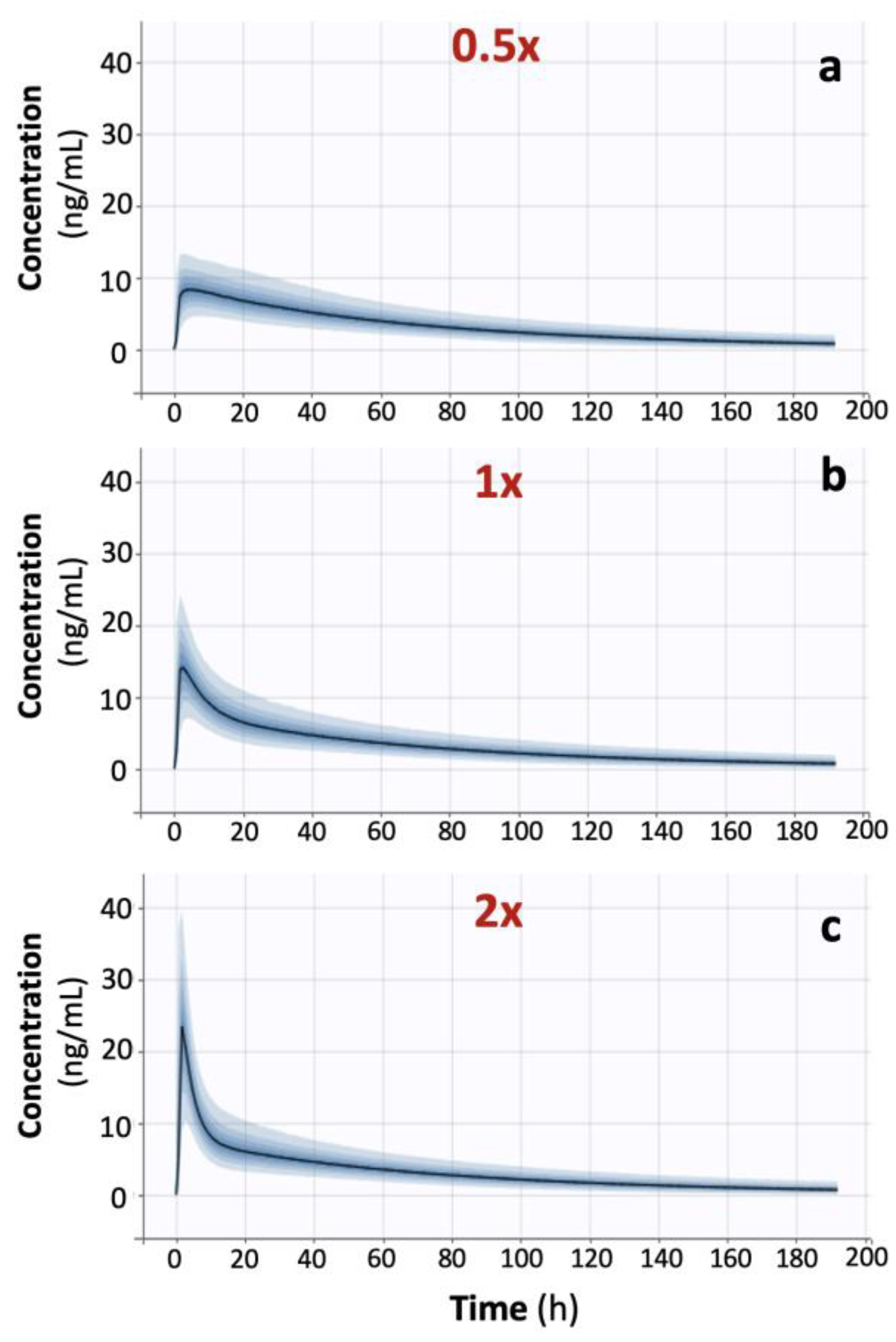
In order to validate the findings from the analysis of actual BE data, simulations were also performed using scenarios with faster or slower absorption rates than those originally estimated from the donepezil BE data. As a result, three donepezil BE datasets were simulated, with N = 26 for each study. All pharmacokinetic properties of donepezil were kept unaltered, except for the absorption rate, and NCA was applied to each simulated dataset (
Table 3). The impact of absorption kinetics on the choice of the most suitable PK metric was assessed. The application of PCA to each of the three simulated datasets verified the findings identified in the case of actual BE data (
Figure 6). Especially for the simulations in the “1x-” case (
Figure 6b), the obtained results are quite similar to those derived from analyzing the actual dataset (
Figure 2). Moreover, it was possible to observe that as absorption kinetics became faster, the relationship between AUC (or AUCinf) and the three other metrics (Cmax, Cmax/AUC, and Cmax/Tmax) became less strong (
Table 3 and
Figure 6). The use of the RF algorithm (
Figure 7) verified the findings found in the simple case of actual donepezil data. In addition, RF uncovered the pattern where the contribution of Tmax into Cmax or Cmax/AUC becomes less as absorption kinetics get faster. Similarly, the contribution of Tmax to Cmax/Tmax remains the predominant characteristic under all kinetic conditions.
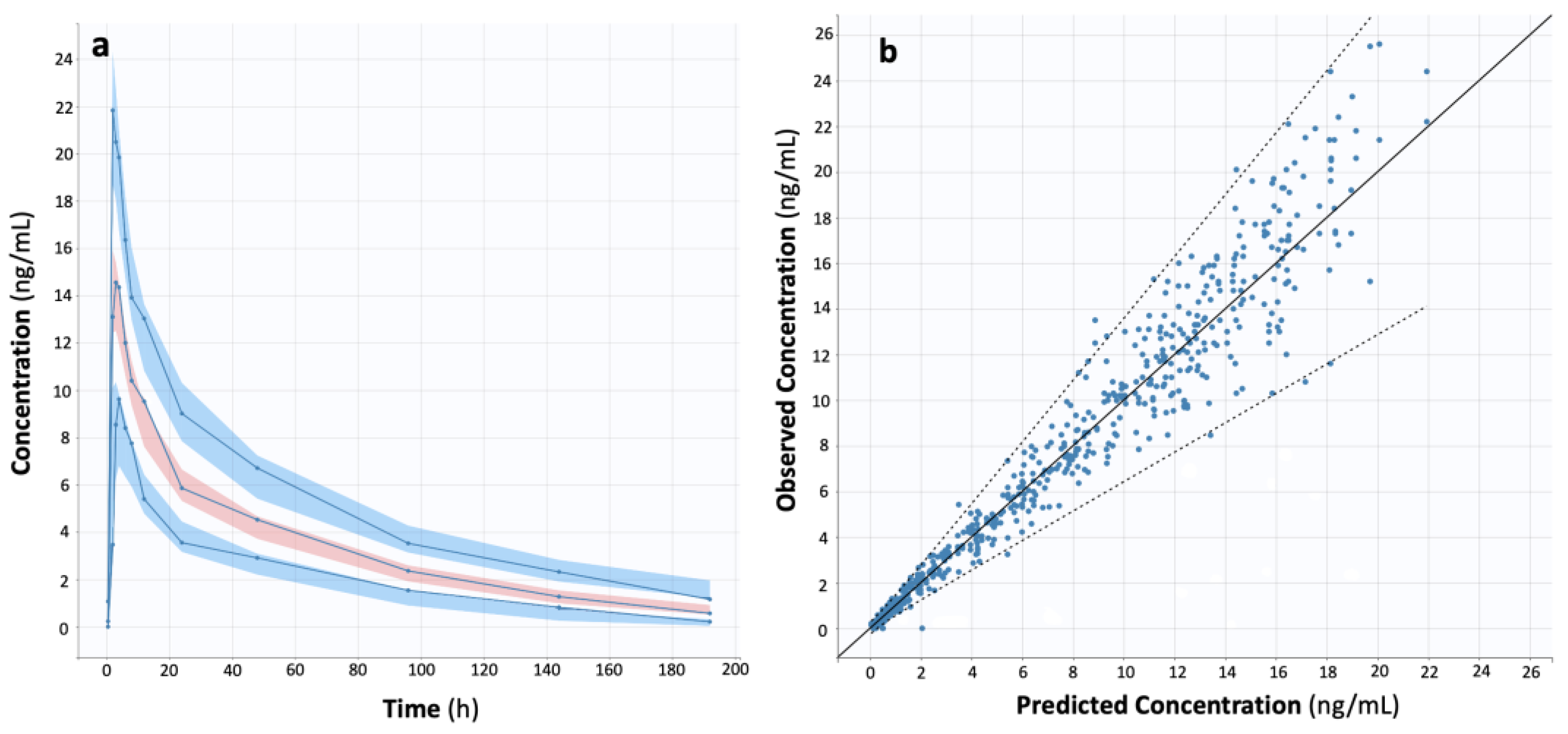
It should be stated that for the needs of this study, a population PK model of donepezil was developed as an intermediate step (
Table 2,
Figure 4). Even though the development of a population PK model was not the primary goal of this study, it was necessary in order to simulate BE datasets with different absorption kinetic characteristics and provide additional evidence. The use of ML approaches in the actual data allowed identifying the relationships among the PK variables and the contribution of each one to another. However, the additional use of simulated BE datasets offered the opportunity to verify the previous results and explore the role of absorption rate. Because the donepezil BE data were already available, the rationale way was to create a population model characterizing donepezil kinetics (
Table 2,
Figure 4) and then use this model to simulate different absorption conditions. This method has the advantage of retaining all donepezil PK parameters from the original dataset in the simulated datasets, whereas only the absorption rate constant was changed. As a result, the absorption rate’s impact could be isolated and assessed in the ML analysis. Setting the absorption rate constant to be “0.5x” and “2x” of what was originally estimated from the NLME analysis was considered a rational choice for slower and faster absorption, respectively. Slower or faster absorption kinetics, compared to those above, would not offer any advantage or alter the results. Moreover, the use of simulated conditions for the actual data (i.e., the “1x-” scenario) allowed to verify the findings obtained from the original dataset.
From the analysis made in this study, it was shown that the metric best reflecting the rate of absorption, among those examined, is the Cmax/Tmax ratio. The latter was found to better reflect the absorption rate, regardless of the absolute kinetic properties of absorption. It should be underlined that Cmax/Tmax is not proposed to be the best measure for absorption rate, but the two machine learning algorithms uncovered its better suitability compared to the other PK metrics explored (e.g., Cmax, Cmax/AUC).
A possible argument against the use of Cmax/Tmax could arise from the fact that the latter relies on Tmax, which is known to have some limitations due to the fact that it is measured on a discrete scale and can be highly variable due to insufficient sampling. For this reason, it was actually stated in the EMA 2001 guideline that Tmax should be analyzed as a discrete attribute using the non-parametric 90% confidence interval [
26]. The existing EMA guideline states that a statistical analysis of Tmax, which is only necessary when a rapid release is clinically relevant for the initiation of action or linked to adverse events, should compare the median values and its variability between test and reference products [
1]. However, the possible problems due to sampling are counterbalanced with a frequent sampling schedule at early time points, before Tmax, which is actually required by the guidelines [
1,
2]. In this study, the simulated BE datasets were generated assuming a sampling interval of 15 min in order to avoid adding bias to the estimations of the PK parameters. The frequency of this sampling scheme was adequate not only for the typical case (“1x-”) and the slow absorption (“0.5x-”), but also for the fast absorption scenario (“2x-”). It should be reminded that typically the Tmax of donepezil is anticipated to appear between 3–4 h post dose [
27]. The fact that Tmax is a discrete variable, since it is dependent on sampling, has already been addressed in the literature [
11,
28]. It has been reported that Tmax defines a count process that encompasses the rate of absorption if it is acquired at equally spaced sample periods during the suspected absorption phase. Furthermore, such count data appear to follow the single parameter Poisson distribution, which characterizes the rate of many discrete processes and so provides the appropriate theoretical foundation for comparing two or more formulations for differences in absorption rate. Besides, the sampling schedule at early time points is already frequent, so Tmax can be easily converted into a count variable. These observations have revealed the usefulness of Tmax as an absorption rate measure [
11,
28].
This study has some limitations, one of which was the application of the machine learning algorithms to one actual dataset. In order to overcome this drawback, the two simulated datasets were generated and analyzed. However, further investigation is required into the performance of the PK metrics in drugs with different pharmacokinetics and in particular different absorption kinetics. Another possible future exploration refers to the analysis of additional PK metrics, either existing or newly proposed, as potential measures for the rate of absorption. The newly proposed Cmax/Tmax ratio was found to have the optimal behavior among those investigated. However, this finding does not exclude the fact that other pharmacokinetic metrics might be more suitable.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








