
An Efficient Parallel Implementation of the Runge–Kutta Discontinuous Galerkin Method with Weighted Essentially Non-Oscillatory Limiters on Three-Dimensional Unstructured Meshes


Abstract
:1. Introduction
2. Methods
2.1. Spatial Discretization
- represent , respectively;
- is a matrix of unknowns, each row of which is a scalar function depending on position and time t;
- (where ) is also a matrix, which is the dot-product of the flux (whose value depends on ) and (which is an unit vector along the positive direction of the -axis);
- is a matrix of 0’s.
2.2. Limiting Procedures
2.2.1. The ScalarWeno Limiter
2.2.2. The EigenWeno Limiter
2.2.3. The LazyWeno Limiter
2.3. Temporal Discretization
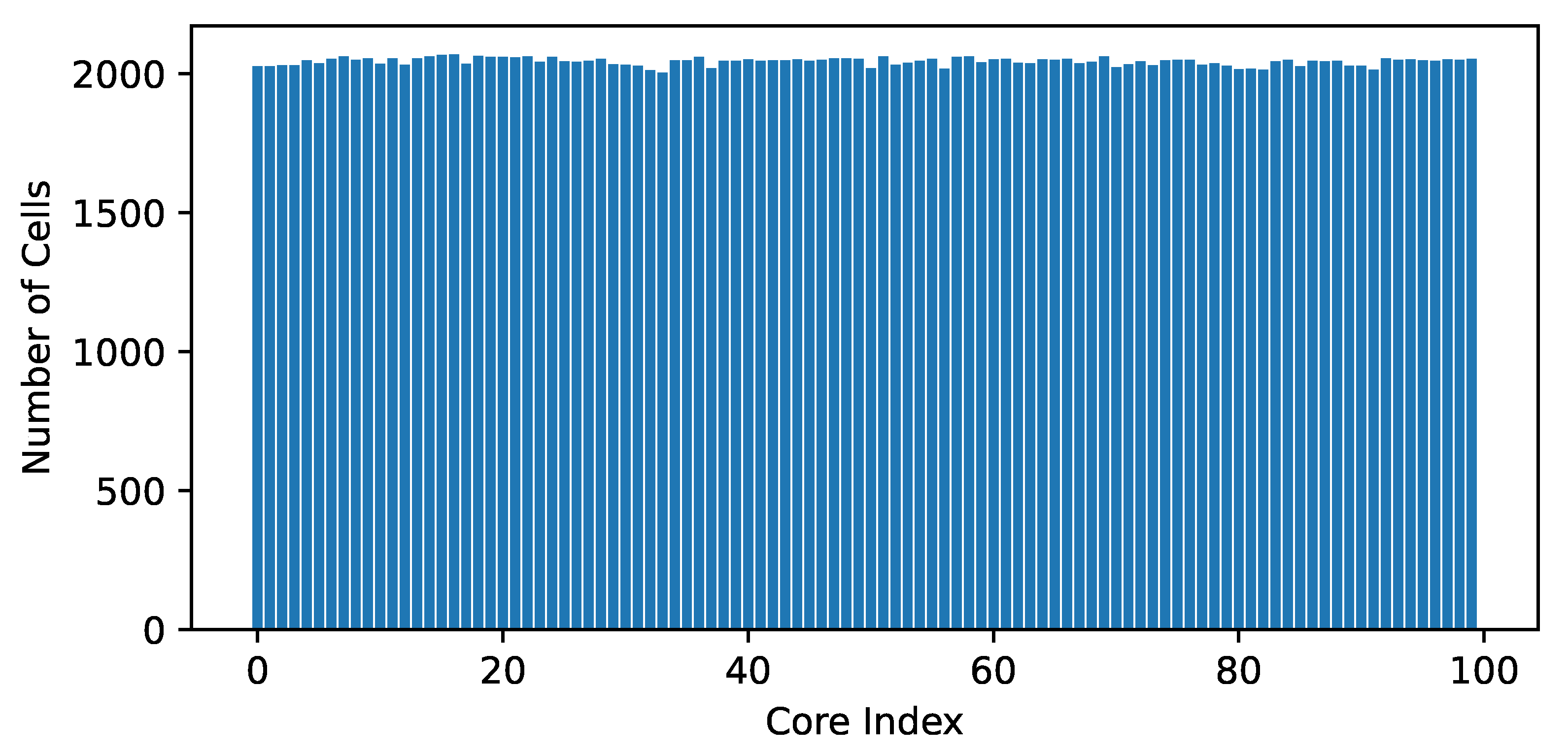
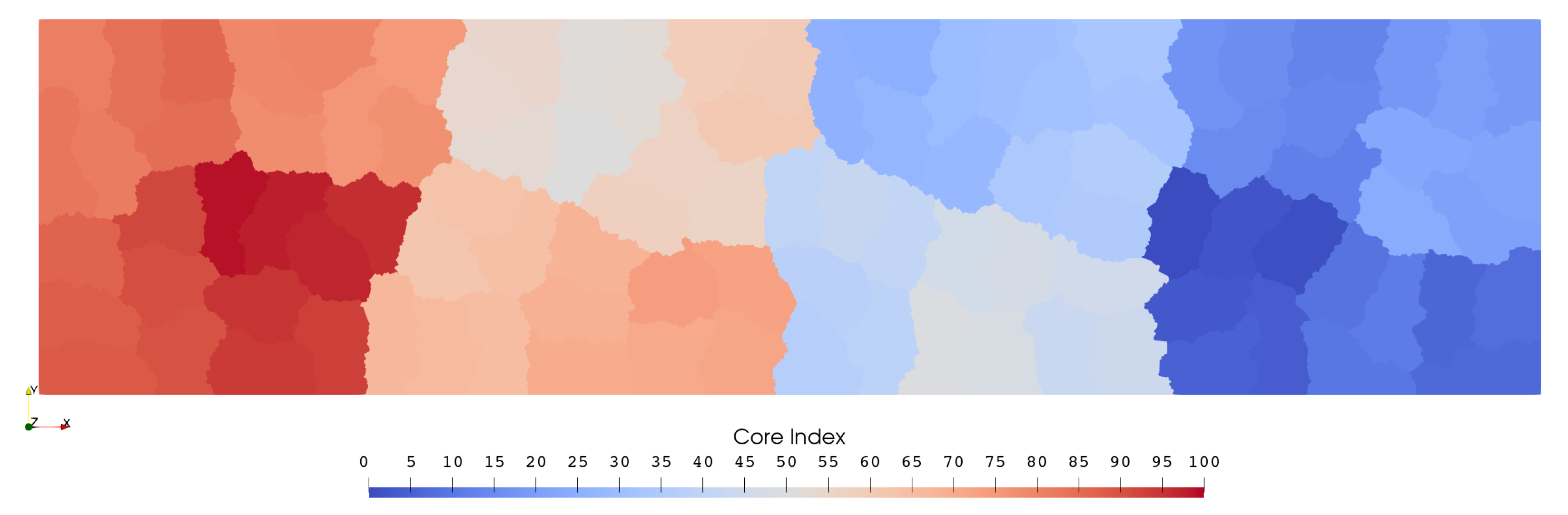
2.4. Parallel Programming
- For each destination, put the data to be sent into a sending buffer and register a request of sending by calling the MPI_Isend(...) function.
- For each source, allocate a receiving buffer for the data to be received and register a request of receiving by calling the MPI_Irecv(...) function.
- Performed other computations that can be conducted without communications.
- Block the process until all its requests complete by calling the the MPI_Waitall(...) function.
3. Results
3.1. Linear Conservation Laws
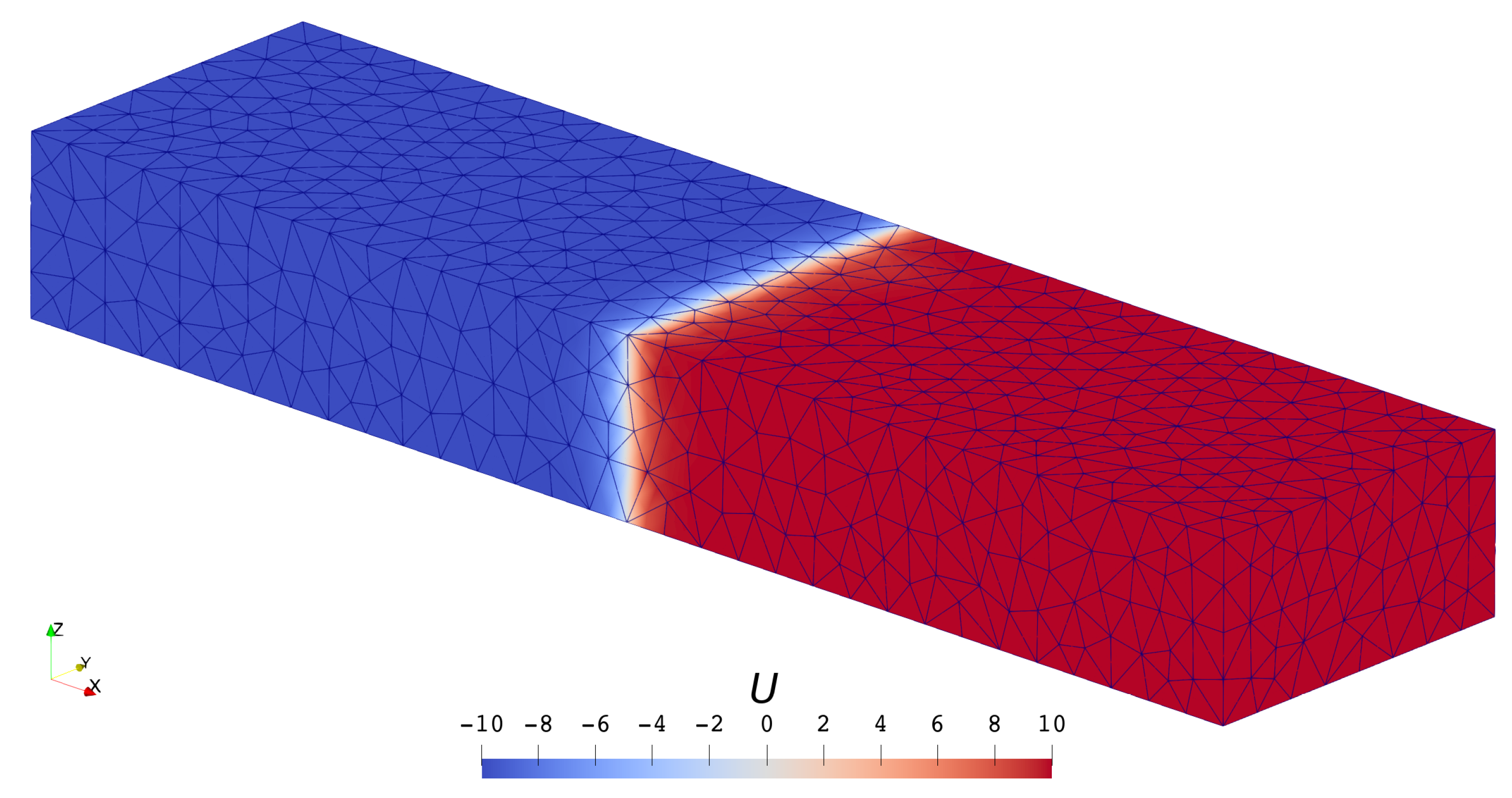
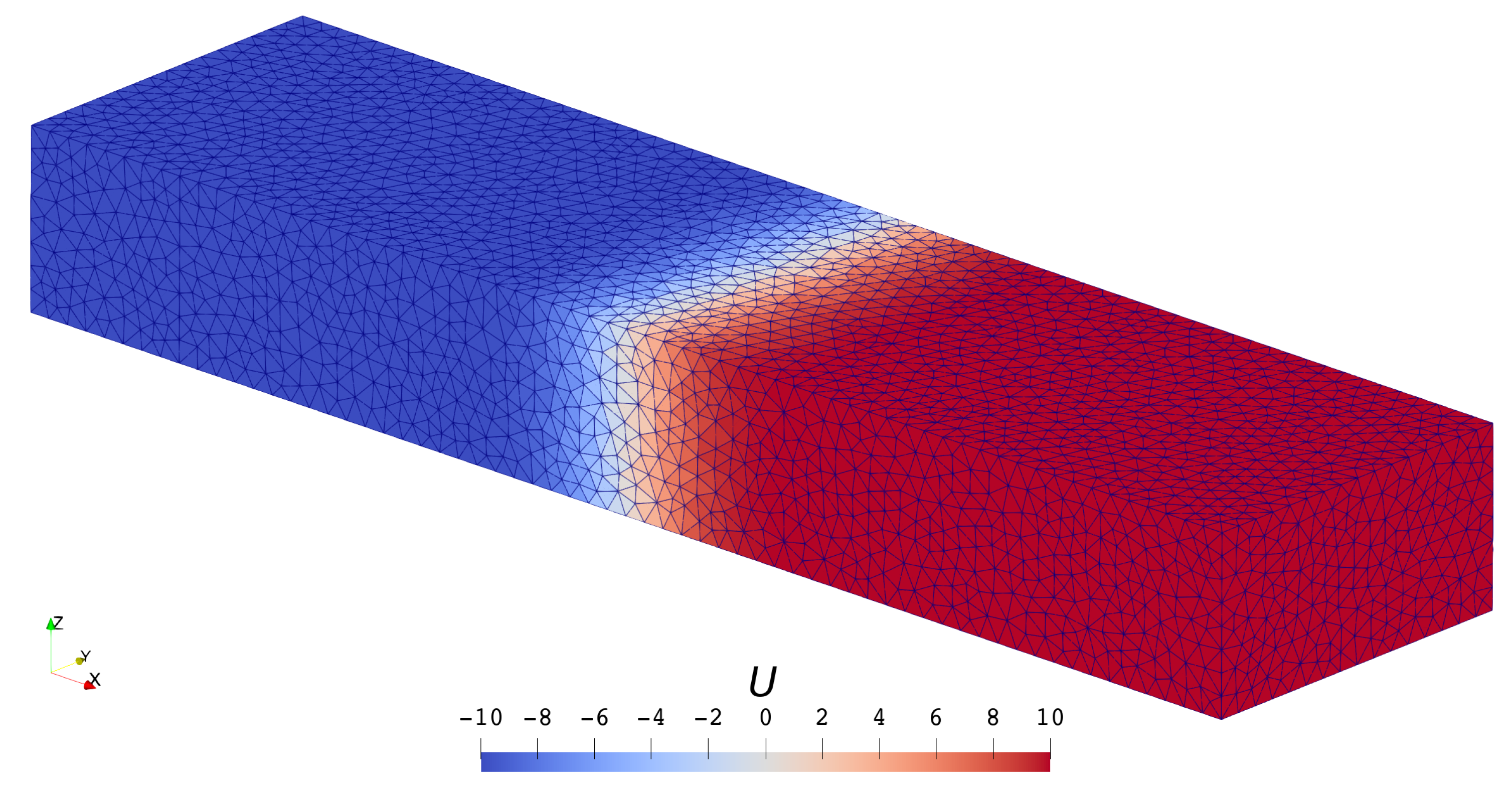
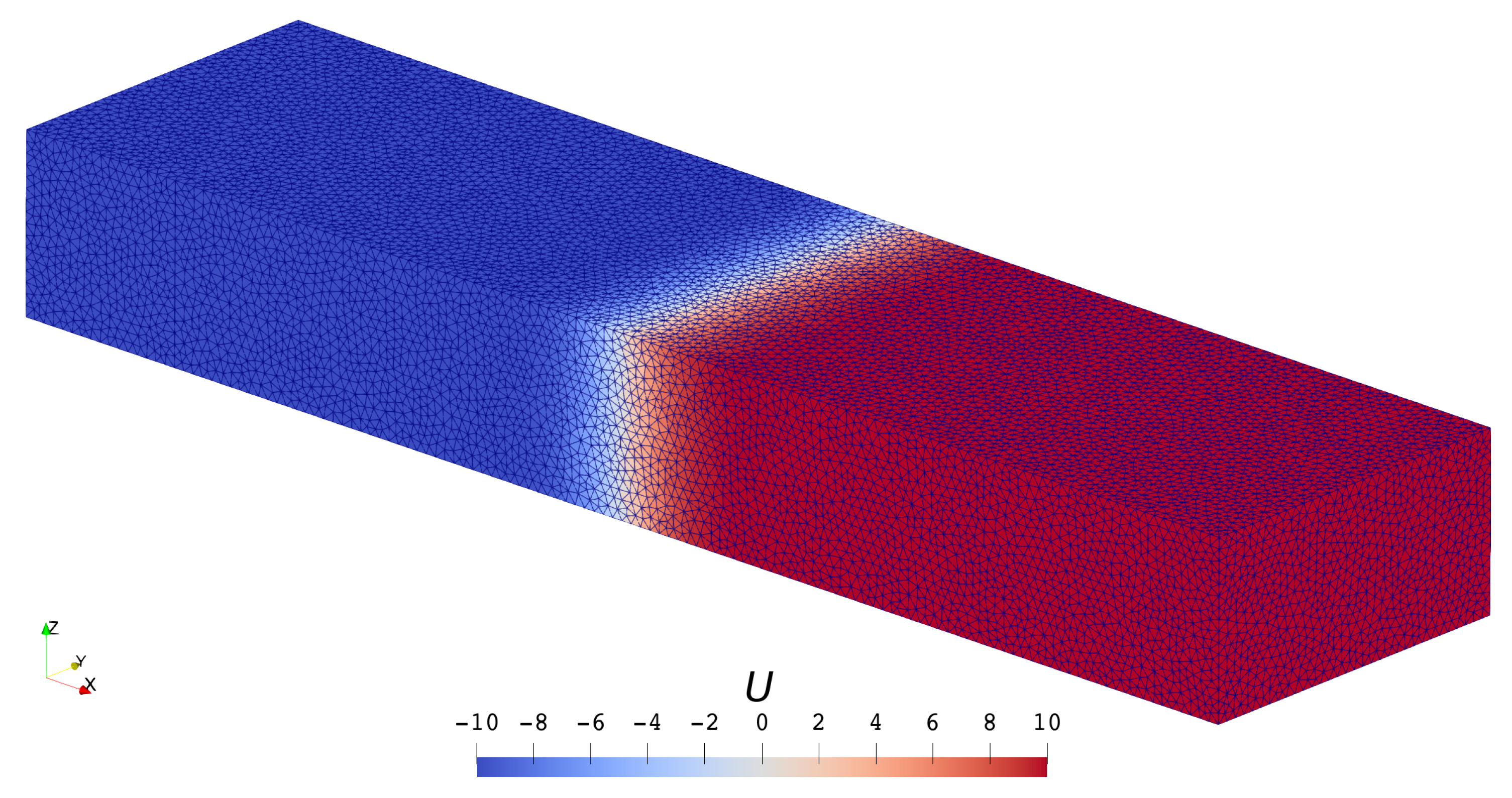
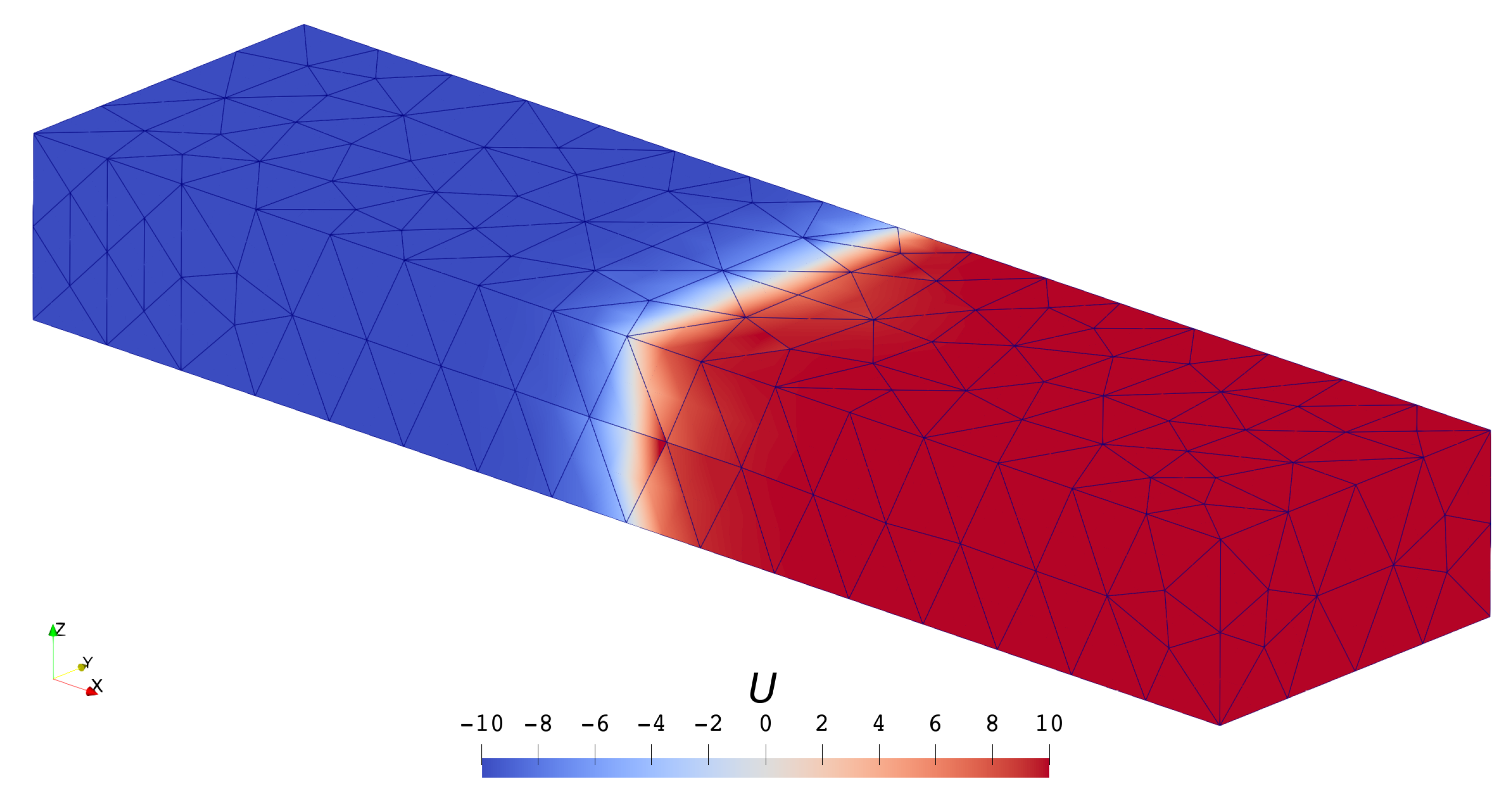
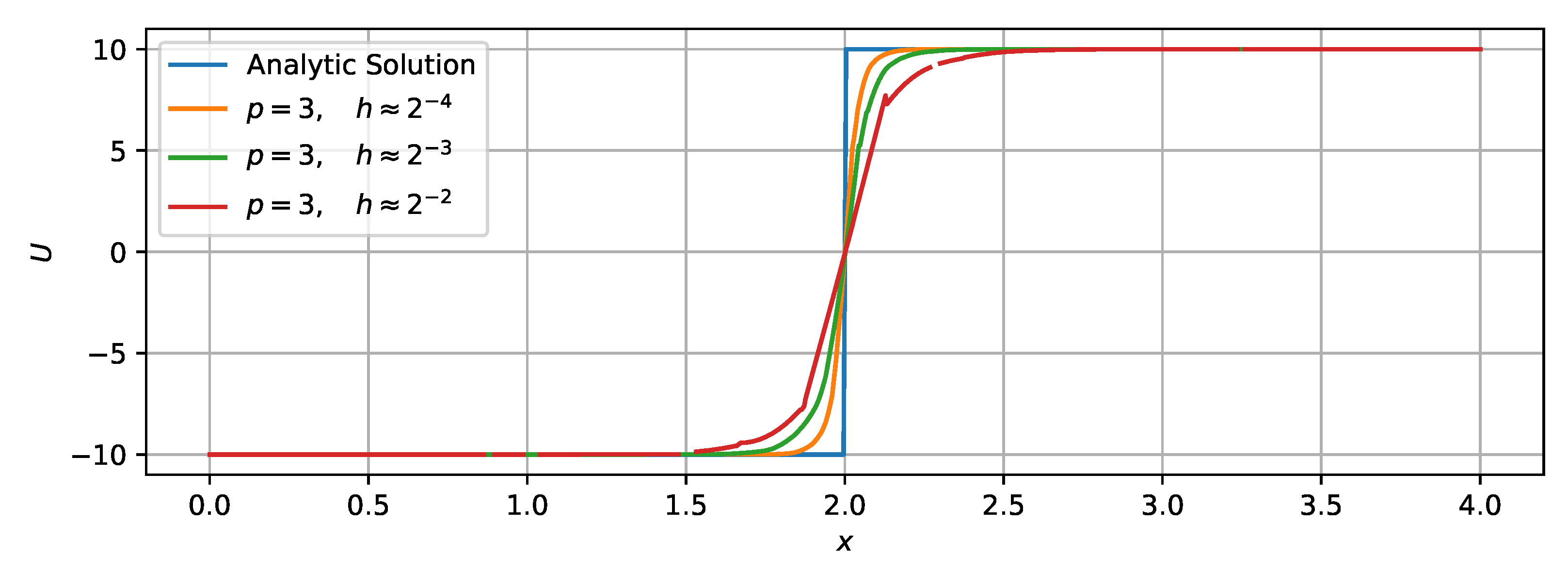
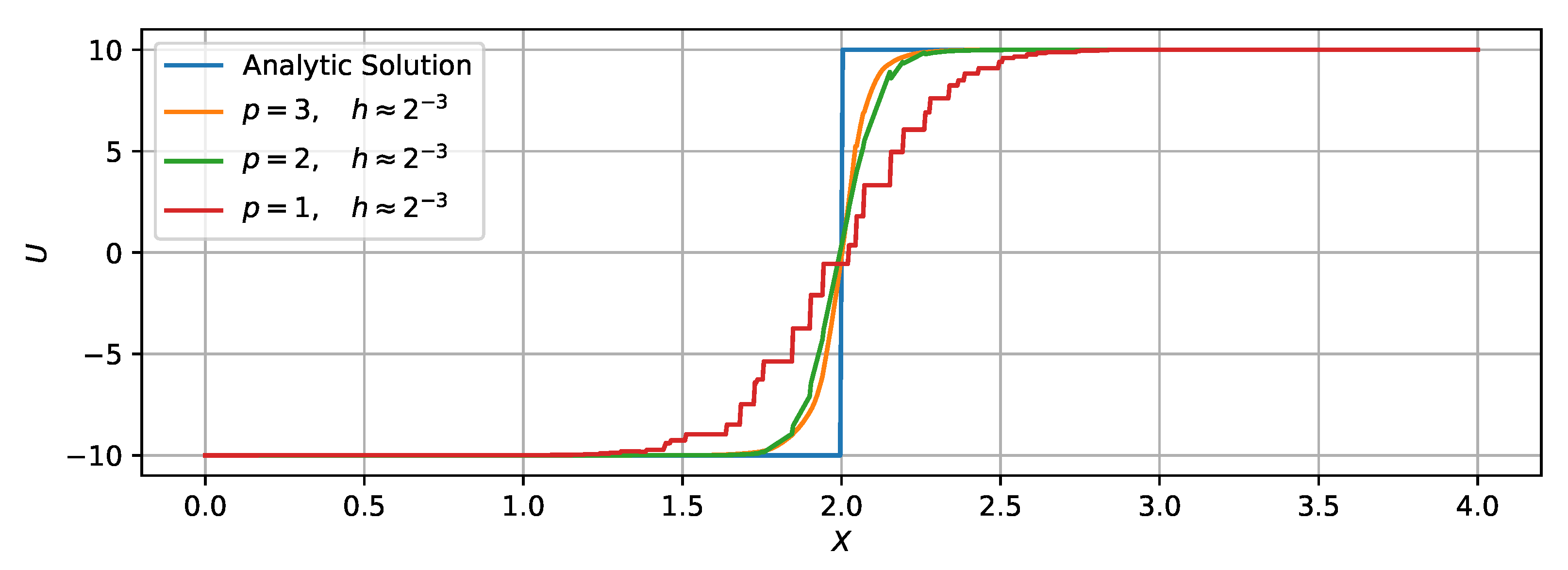
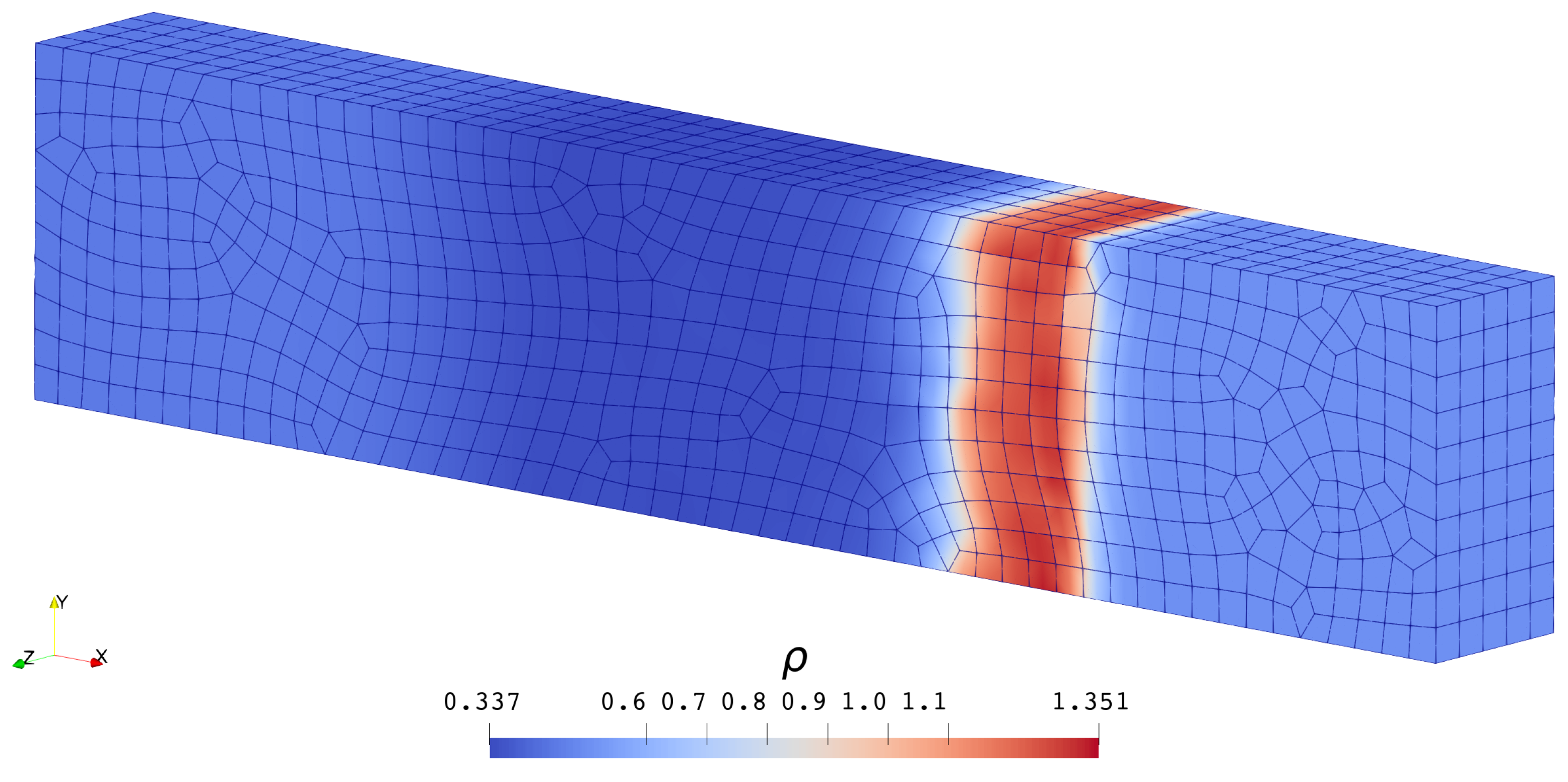
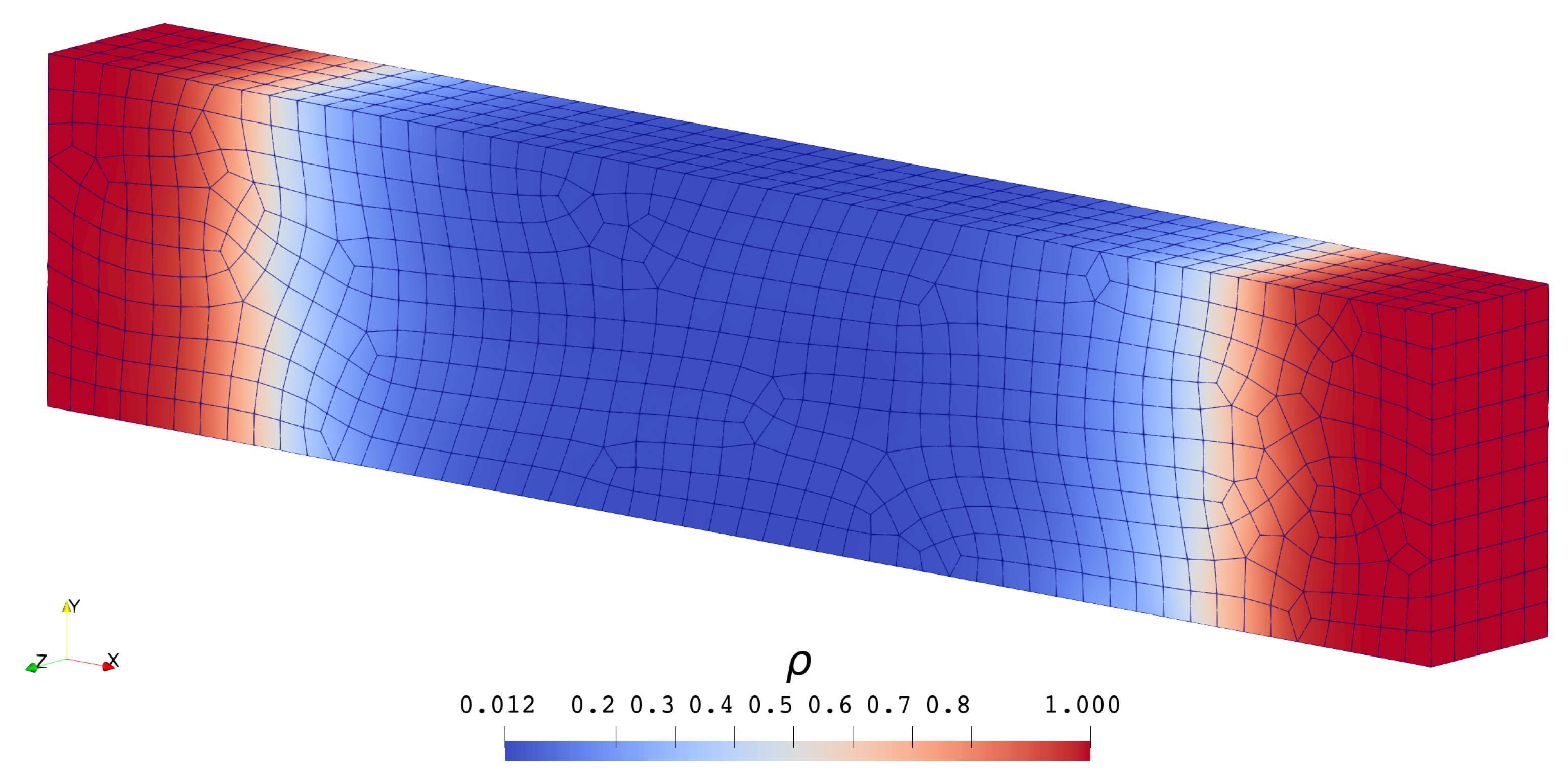
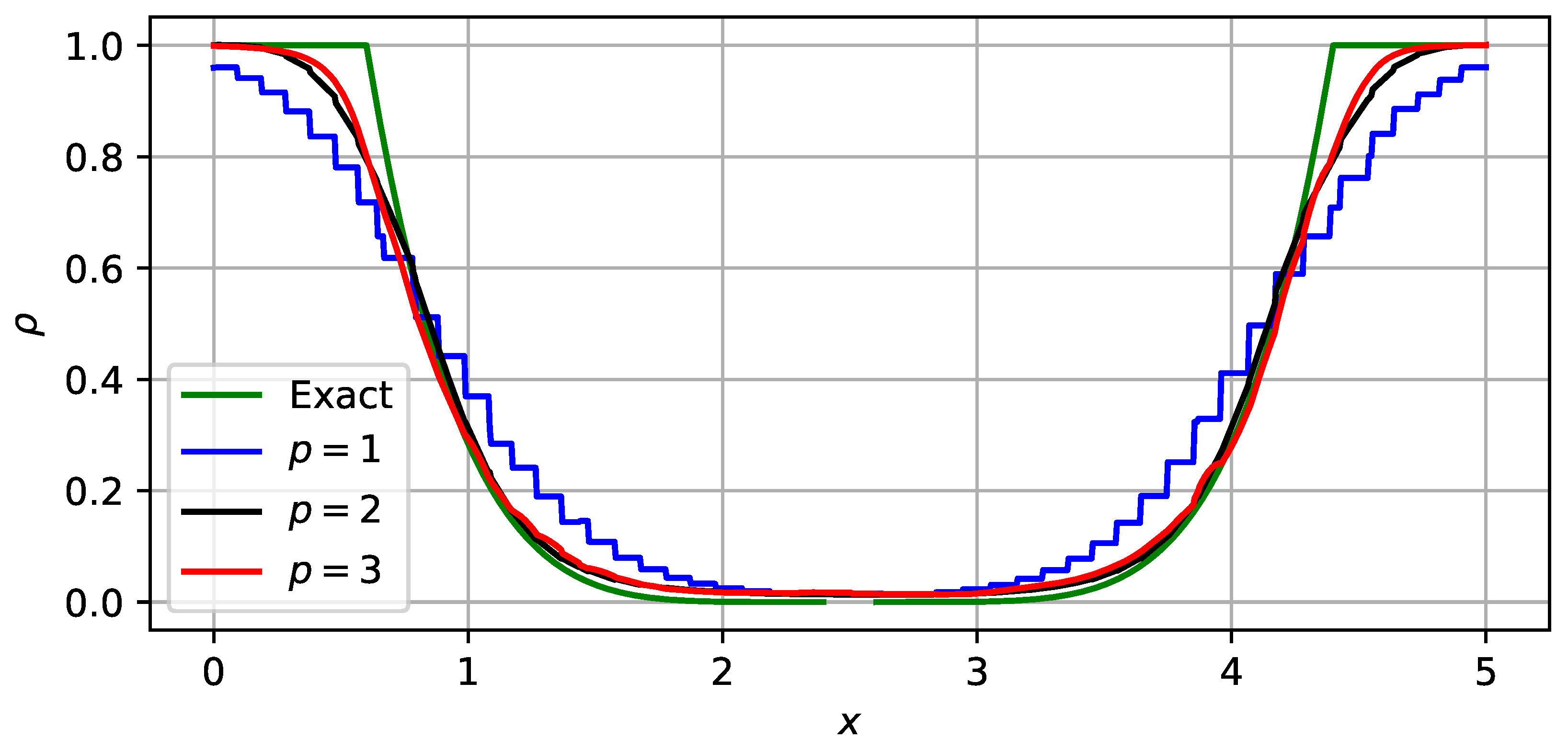
3.1.1. Scalar Case
- Both mesh refinement (decreasing h) and order increment (increasing p) can help to improve accuracy.
- The solver of the highest order () on the coarsest () mesh defeats the solver of the lowest order () on the finest () mesh in accuracy but saves quite a lot of time.
- High-order schemes are better than low-order ones in the sense of getting the same level of accuracy with less time cost.
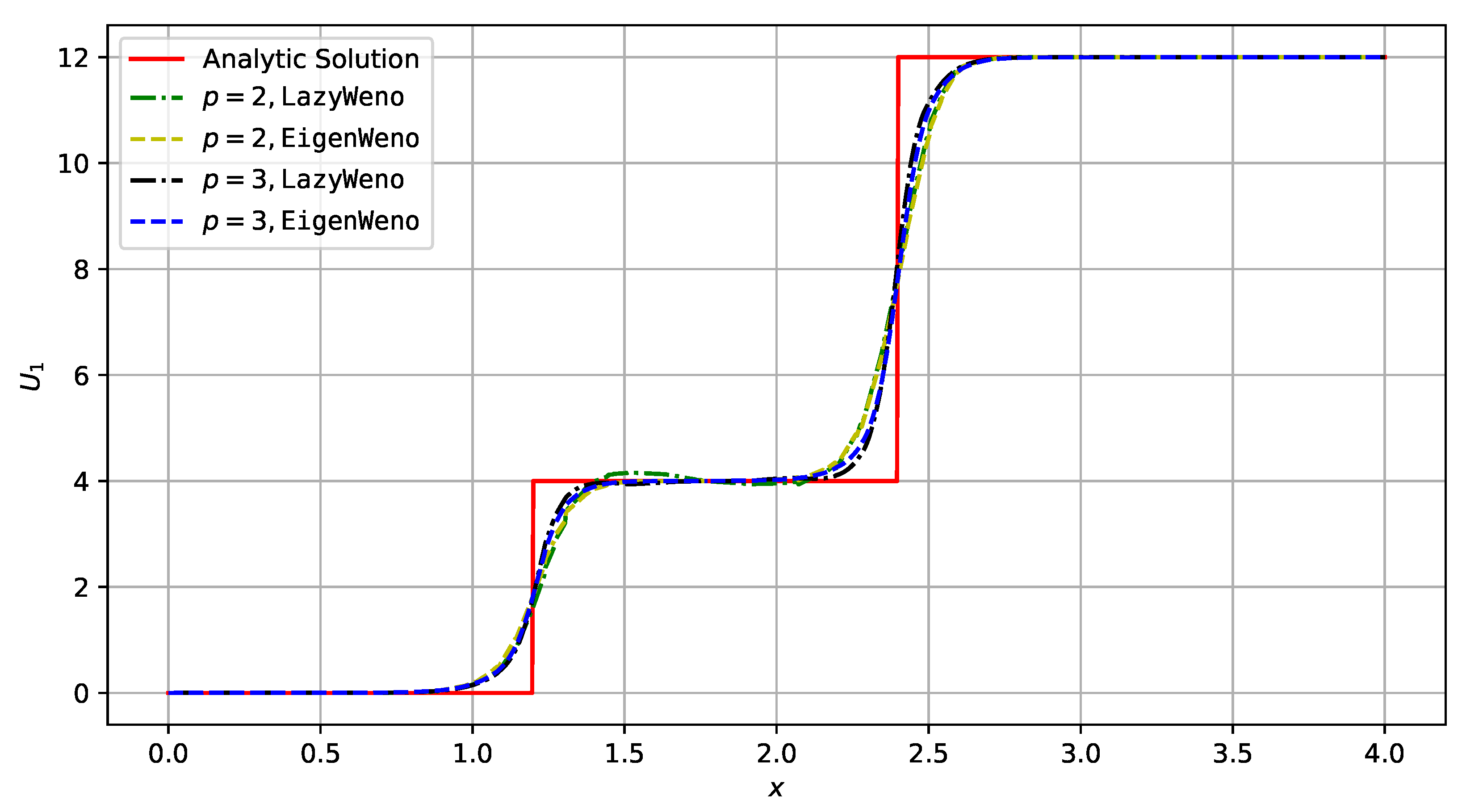
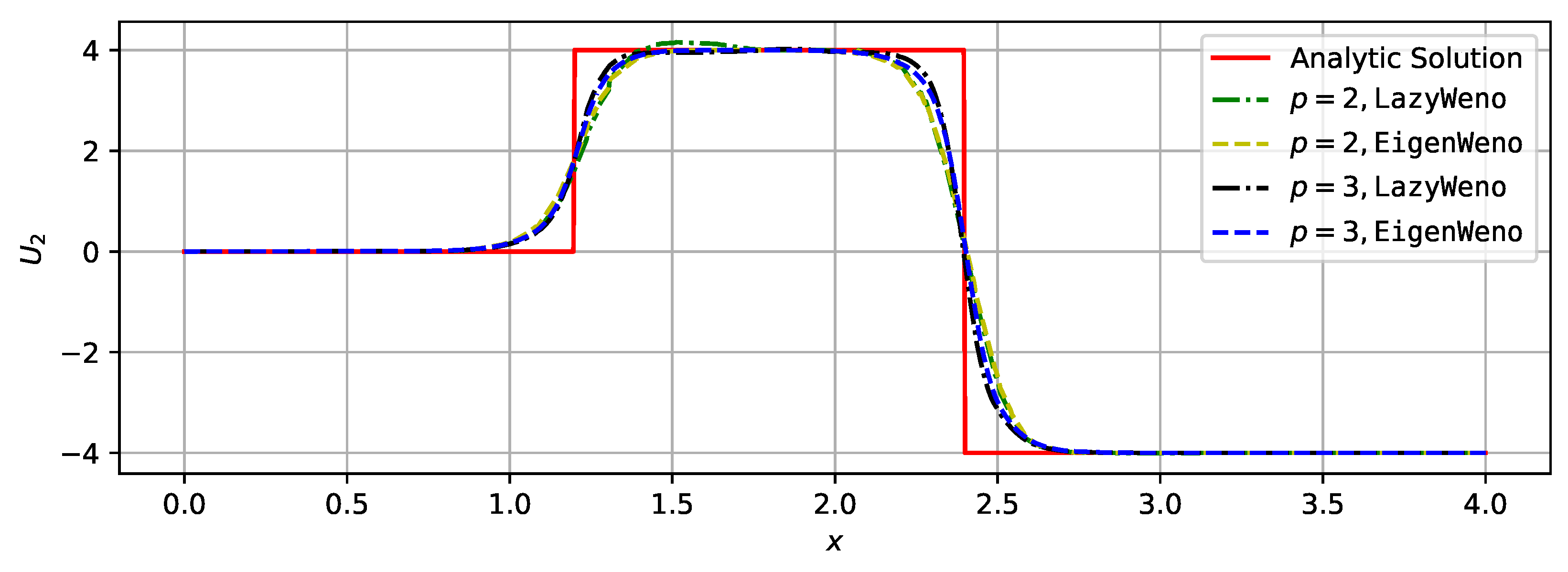
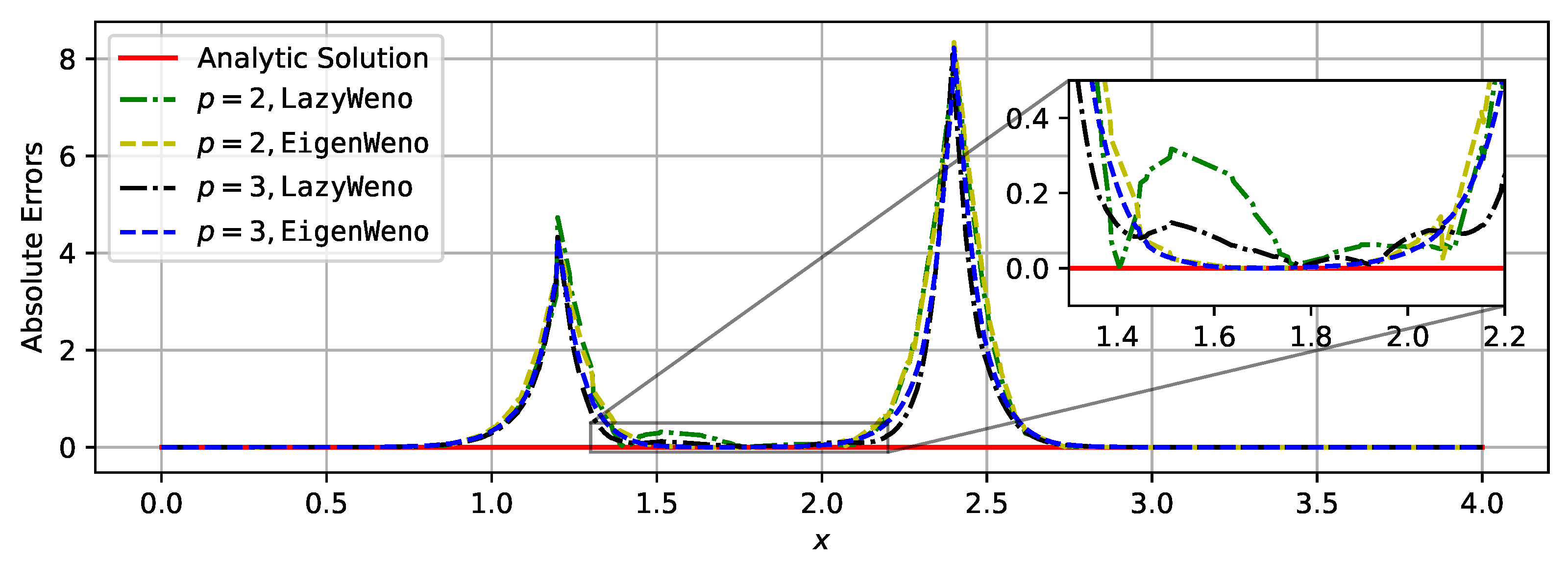
3.1.2. System Case
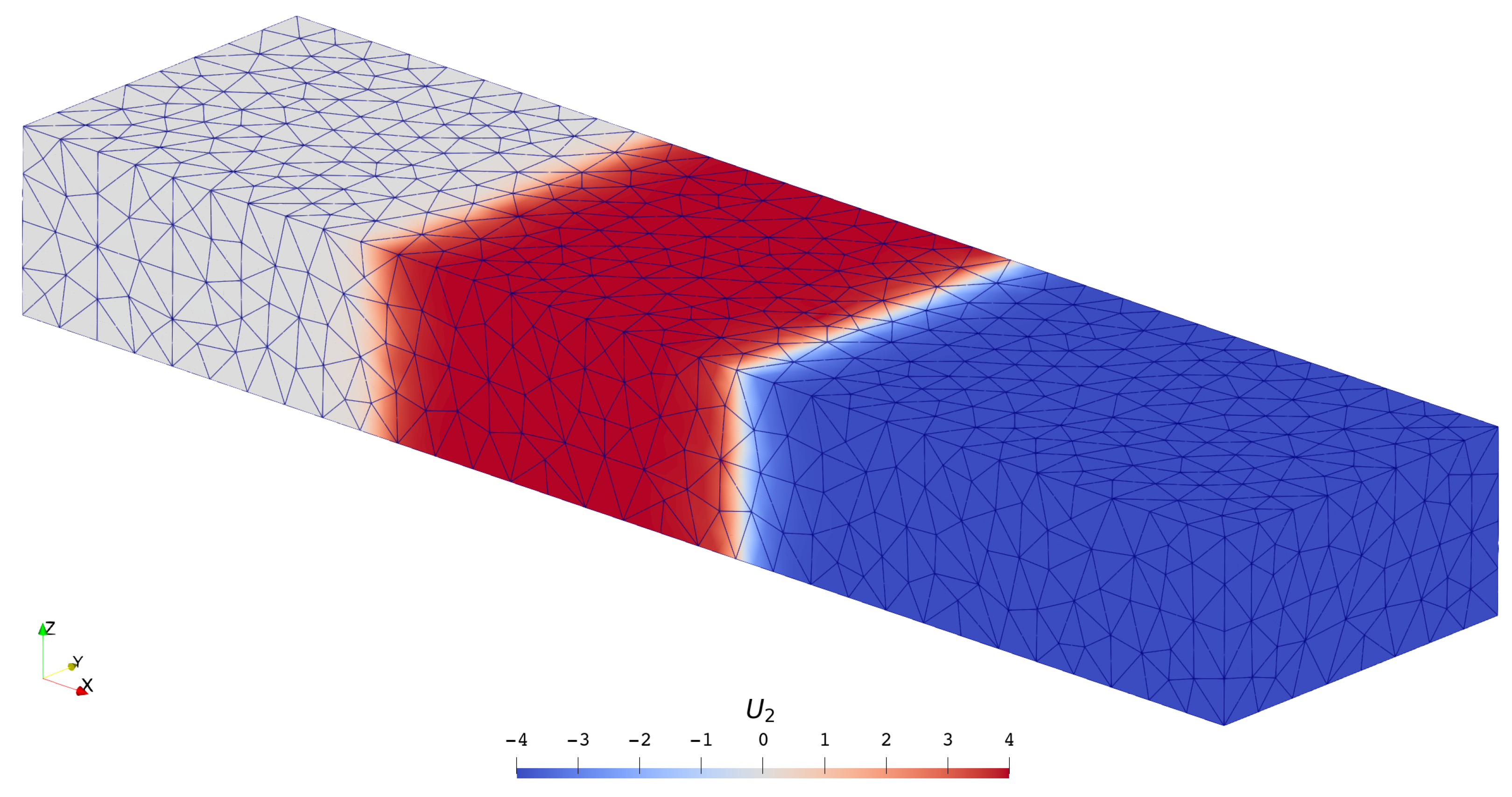
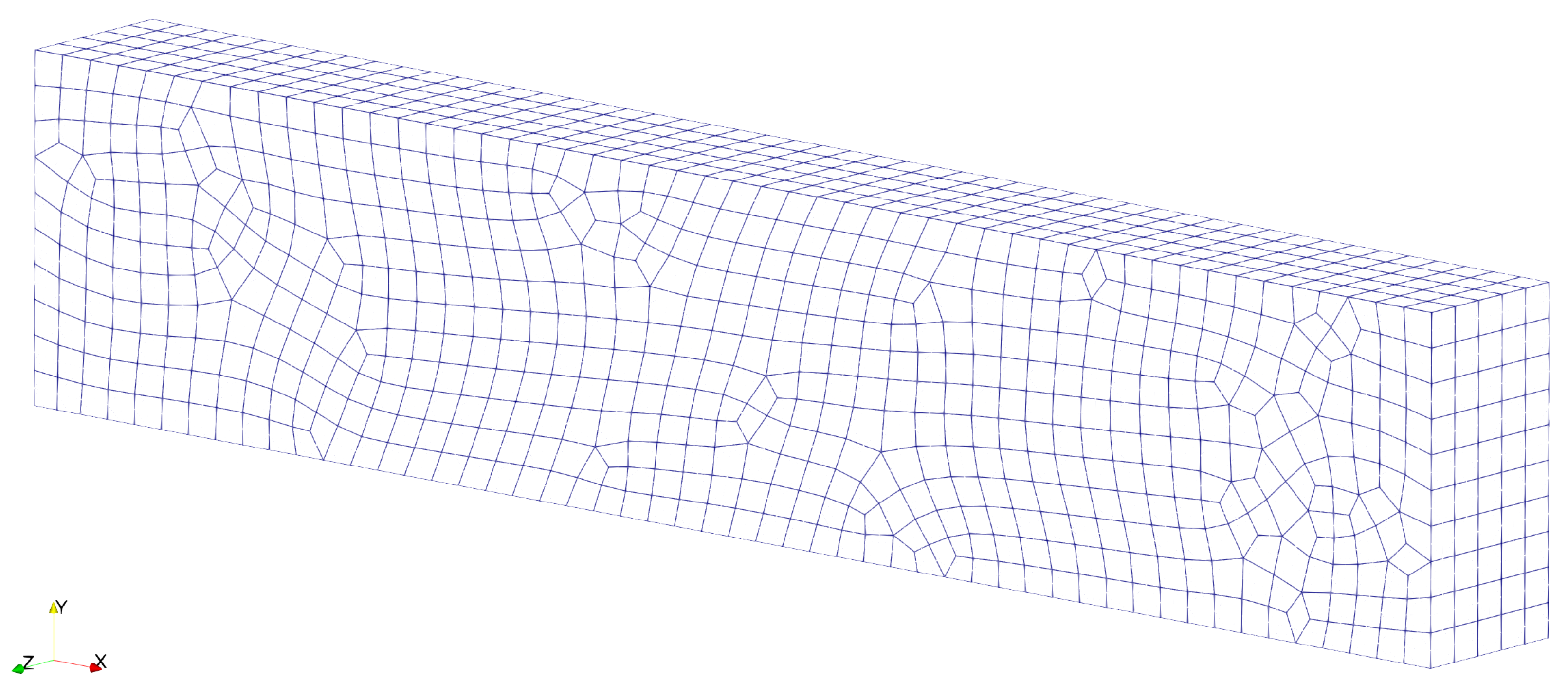
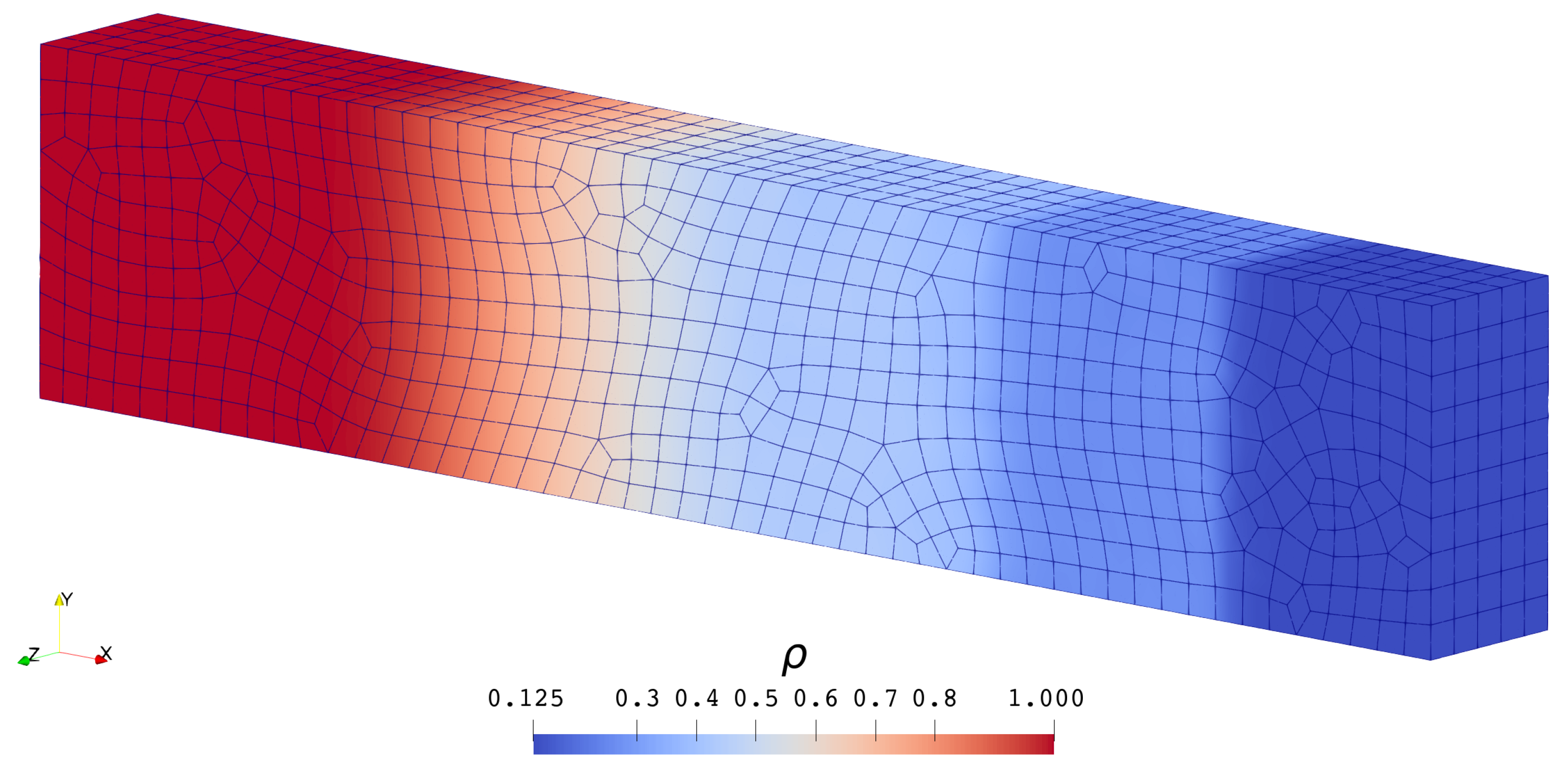
3.2. Inviscid Compressible Flows
3.2.1. Shock Tube Problems
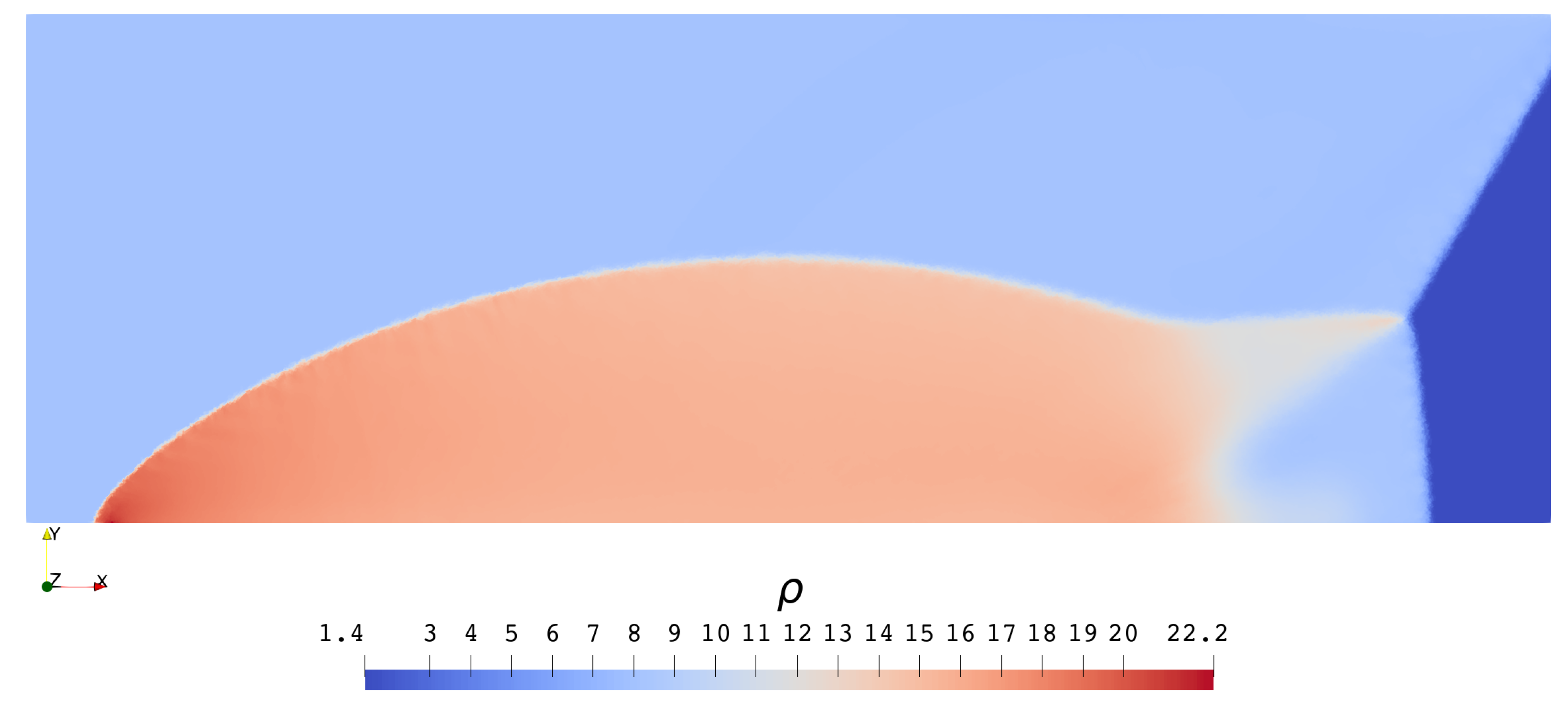
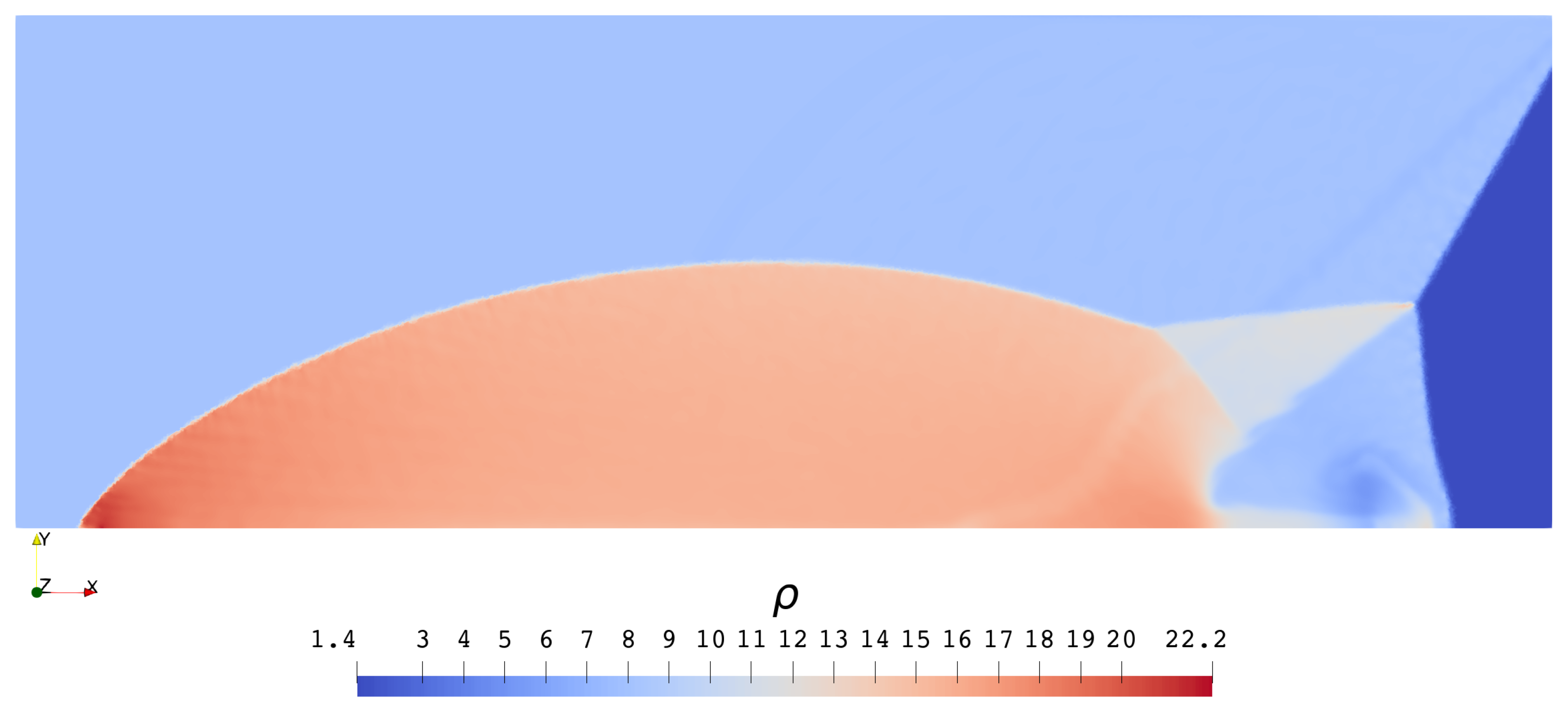
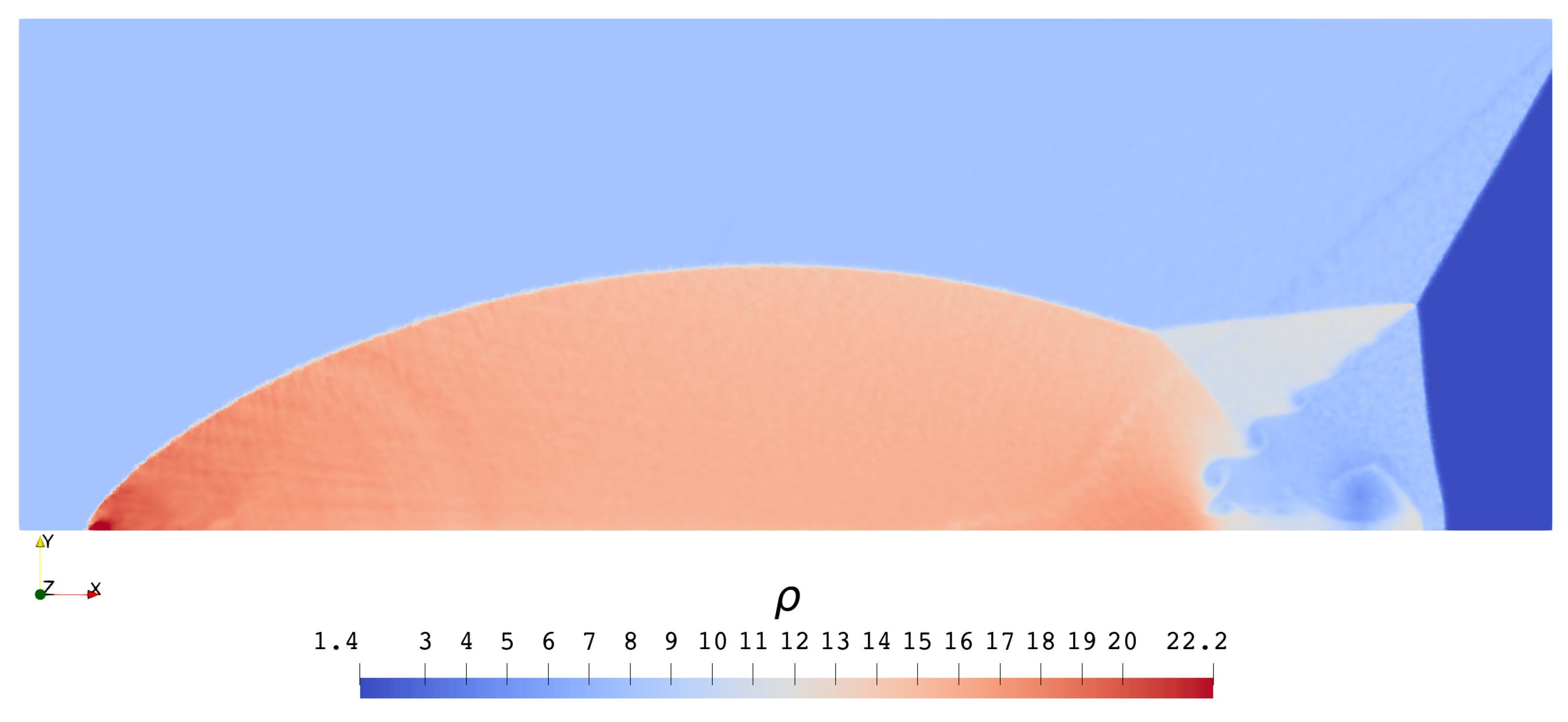
3.2.2. Double Mach Reflection Problem
- The surface is open as an inlet;
- The surface and the part of the surface are open as outlets;
- The part of the surface is closed as a solid wall;
- The surface has the following prescribed state:
- P means the number of processes (one process per core).
- means the wall clock time to finish the first n step.
- is the core time per step. The total core time of all steps is often used as an index for charging by high performance computing centers.
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hesthaven, J.S.; Warburton, T. Nodal Discontinuous Galerkin Methods; Springer: New York, NY, USA, 2008. [Google Scholar] [CrossRef] [Green Version]
- Reed, W.H.; Hill, T.R. Triangular Mesh Methods for the Neutron Transport Equation; Technical Report LA-UR-73-479; Los Alamos Scientific Lab.: Los Alamos, NM, USA, 1973. [Google Scholar]
- Chavent, G.; Salzano, G. A finite-element method for the 1-D water flooding problem with gravity. J. Comput. Phys. 1982, 45, 307–344. [Google Scholar] [CrossRef]
- Cockburn, B.; Shu, C.W. The Runge-Kutta local projection P1-discontinuous-Galerkin finite element method for scalar conservation laws. In Proceedings of the 1st National Fluid Dynamics Conference, Cincinnati, OH, USA, 25–28 July 1988; American Institute of Aeronautics and Astronautics: Reston, VA, USA, 1988. [Google Scholar] [CrossRef] [Green Version]
- Shu, C.W.; Osher, S. Efficient implementation of essentially non-oscillatory shock-capturing schemes. J. Comput. Phys. 1988, 77, 439–471. [Google Scholar] [CrossRef] [Green Version]
- Shu, C.W.; Osher, S. Efficient implementation of essentially non-oscillatory shock-capturing schemes, II. J. Comput. Phys. 1989, 83, 32–78. [Google Scholar] [CrossRef]
- Cockburn, B.; Lin, S.Y.; Shu, C.W. TVB Runge-Kutta local projection discontinuous Galerkin finite element method for conservation laws III: One-dimensional systems. J. Comput. Phys. 1989, 84, 90–113. [Google Scholar] [CrossRef] [Green Version]
- Cockburn, B.; Hou, S.; Shu, C.W. The Runge-Kutta local projection discontinuous Galerkin finite element method for conservation laws. IV. The multidimensional case. Math. Comput. 1990, 54, 545–581. [Google Scholar] [CrossRef] [Green Version]
- Cockburn, B. An introduction to the Discontinuous Galerkin method for convection-dominated problems. In Lecture Notes in Mathematics; Springer: Berlin/Heidelberg, Germany, 1998; pp. 150–268. [Google Scholar] [CrossRef]
- Bassi, F.; Rebay, S. A High-Order Accurate Discontinuous Finite Element Method for the Numerical Solution of the Compressible Navier–Stokes Equations. J. Comput. Phys. 1997, 131, 267–279. [Google Scholar] [CrossRef]
- Cockburn, B.; Shu, C.W. The Local Discontinuous Galerkin Method for Time-Dependent Convection-Diffusion Systems. SIAM J. Numer. Anal. 1998, 35, 2440–2463. [Google Scholar] [CrossRef]
- Cockburn, B.; Shu, C.W. Runge–Kutta Discontinuous Galerkin Methods for Convection-Dominated Problems. J. Sci. Comput. 2001, 16, 173–261. [Google Scholar] [CrossRef]
- Gottlieb, D.; Shu, C.W. On the Gibbs Phenomenon and Its Resolution. SIAM Rev. 1997, 39, 644–668. [Google Scholar] [CrossRef] [Green Version]
- Leer, B.V. Towards the ultimate conservative difference scheme III. Upstream-centered finite-difference schemes for ideal compressible flow. J. Comput. Phys. 1977, 23, 263–275. [Google Scholar] [CrossRef]
- Leer, B.V. Towards the ultimate conservative difference scheme. IV. A new approach to numerical convection. J. Comput. Phys. 1977, 23, 276–299. [Google Scholar] [CrossRef]
- van Leer, B. Towards the ultimate conservative difference scheme. V. A second-order sequel to Godunov’s method. J. Comput. Phys. 1979, 32, 101–136. [Google Scholar] [CrossRef]
- van Leer, B.; Nishikawa, H. Towards the ultimate understanding of MUSCL: Pitfalls in achieving third-order accuracy. J. Comput. Phys. 2021, 446, 110640. [Google Scholar] [CrossRef]
- Harten, A.; Engquist, B.; Osher, S.; Chakravarthy, S.R. Uniformly High Order Accurate Essentially Non-oscillatory Schemes, III. J. Comput. Phys. 1997, 131, 3–47. [Google Scholar] [CrossRef]
- Jiang, G.S.; Shu, C.W. Efficient Implementation of Weighted ENO Schemes. J. Comput. Phys. 1996, 126, 202–228. [Google Scholar] [CrossRef] [Green Version]
- Hu, C.; Shu, C.W. Weighted Essentially Non-oscillatory Schemes on Triangular Meshes. J. Comput. Phys. 1999, 150, 97–127. [Google Scholar] [CrossRef] [Green Version]
- Qiu, J.; Shu, C.W. Runge–Kutta Discontinuous Galerkin Method Using WENO Limiters. SIAM J. Sci. Comput. 2005, 26, 907–929. [Google Scholar] [CrossRef]
- Zhu, J.; Qiu, J.; Shu, C.W.; Dumbser, M. Runge–Kutta discontinuous Galerkin method using WENO limiters II: Unstructured meshes. J. Comput. Phys. 2008, 227, 4330–4353. [Google Scholar] [CrossRef]
- Zhong, X.; Shu, C.W. A simple weighted essentially nonoscillatory limiter for Runge–Kutta discontinuous Galerkin methods. J. Comput. Phys. 2013, 232, 397–415. [Google Scholar] [CrossRef]
- Zhu, J.; Zhong, X.; Shu, C.W.; Qiu, J. Runge–Kutta discontinuous Galerkin method using a new type of WENO limiters on unstructured meshes. J. Comput. Phys. 2013, 248, 200–220. [Google Scholar] [CrossRef]
- Mazaheri, A.; Shu, C.W.; Perrier, V. Bounded and compact weighted essentially nonoscillatory limiters for discontinuous Galerkin schemes: Triangular elements. J. Comput. Phys. 2019, 395, 461–488. [Google Scholar] [CrossRef]
- Biswas, R.; Devine, K.D.; Flaherty, J.E. Parallel, adaptive finite element methods for conservation laws. Appl. Numer. Math. 1994, 14, 255–283. [Google Scholar] [CrossRef]
- Bey, K.S.; Patra, A.; Oden, J.T. hp-version discontinuous Galerkin methods for hyperbolic conservation laws: A parallel adaptive strategy. Int. J. Numer. Methods Eng. 1995, 38, 3889–3908. [Google Scholar] [CrossRef]
- Chalmers, N.; Agbaglah, G.; Chrust, M.; Mavriplis, C. A parallel hp-adaptive high order discontinuous Galerkin method for the incompressible Navier-Stokes equations. J. Comput. Phys. X 2019, 2, 100023. [Google Scholar] [CrossRef]
- Karypis, G.; Kumar, V. A Fast and High Quality Multilevel Scheme for Partitioning Irregular Graphs. SIAM J. Sci. Comput. 1998, 20, 359–392. [Google Scholar] [CrossRef]
- Message Passing Interface Forum. MPI: A Message-Passing Interface Standard, 4th ed.; University of Tennessee: Knoxville, TN, USA, 2021. [Google Scholar]
- Toro, E.F. Riemann Solvers and Numerical Methods for Fluid Dynamics; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar] [CrossRef]
- Zhang, L.; Cui, T.; Liu, H. A Set of Symmetric Quadrature Rules on Triangles and Tetrahedra. J. Comput. Math. 2009, 27, 89–96. [Google Scholar]
- Quarteroni, A.; Sacco, R.; Saleri, F. Numerical Mathematics; Springer: New York, NY, USA, 2007. [Google Scholar] [CrossRef] [Green Version]
- Gottlieb, S.; Shu, C.W. Total variation diminishing Runge-Kutta schemes. Math. Comput. 1998, 67, 73–85. [Google Scholar] [CrossRef] [Green Version]
- Meyers, S. Effective Modern C++; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2015. [Google Scholar]
- Woodward, P.; Colella, P. The numerical simulation of two-dimensional fluid flow with strong shocks. J. Comput. Phys. 1984, 54, 115–173. [Google Scholar] [CrossRef]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| -Error with Respect to the Analytic Solution | |||||
|---|---|---|---|---|---|
| 1 | 2.858 | 2.095 | 1.524 | 1.108 | |
| 2 | 1.258 | 0.771 | 0.463 | 0.275 | |
| 3 | 1.021 | 0.590 | 0.341 | ||
| Time Cost (in Seconds) Measured on a Single Core Whose Main Frequency Is 2.7 GHz | |||||
| 1 | 0.373 | 1.129 | 16.533 | 306.293 | |
| 2 | 1.580 | 14.894 | 253.821 | 4986.391 | |
| 3 | 4.147 | 61.425 | 906.914 | ||
| P | |||||
|---|---|---|---|---|---|
| 1 | 17,652.2 | 35,324.5 | 35,519.3 | 178.508 | 178.671 |
| 20 | 960.443 | 1912.365 | 1926.584 | 192.307 | 193.228 |
| 40 | 491.070 | 971.710 | 983.933 | 194.198 | 197.145 |
| 60 | 335.651 | 666.548 | 676.930 | 200.544 | 204.767 |
| 80 | 251.548 | 494.541 | 504.951 | 196.358 | 202.722 |
| 100 | 202.789 | 397.641 | 408.126 | 196.820 | 205.337 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pei, W.; Jiang, Y.; Li, S. An Efficient Parallel Implementation of the Runge–Kutta Discontinuous Galerkin Method with Weighted Essentially Non-Oscillatory Limiters on Three-Dimensional Unstructured Meshes. Appl. Sci. 2022, 12, 4228. https://doi.org/10.3390/app12094228
Pei W, Jiang Y, Li S. An Efficient Parallel Implementation of the Runge–Kutta Discontinuous Galerkin Method with Weighted Essentially Non-Oscillatory Limiters on Three-Dimensional Unstructured Meshes. Applied Sciences. 2022; 12(9):4228. https://doi.org/10.3390/app12094228
Chicago/Turabian StylePei, Weicheng, Yuyan Jiang, and Shu Li. 2022. "An Efficient Parallel Implementation of the Runge–Kutta Discontinuous Galerkin Method with Weighted Essentially Non-Oscillatory Limiters on Three-Dimensional Unstructured Meshes" Applied Sciences 12, no. 9: 4228. https://doi.org/10.3390/app12094228