
Attention V-Net: A Modified V-Net Architecture for Left Atrial Segmentation

Abstract
:1. Introduction
2. Related Work
2.1. Left Atrial Segmentation
2.1.1. Supervised Segmentation
2.1.2. Semi-Supervised Segmentation
Regularization Based Methods
Multi-Task Frameworks
2.2. Attention Model
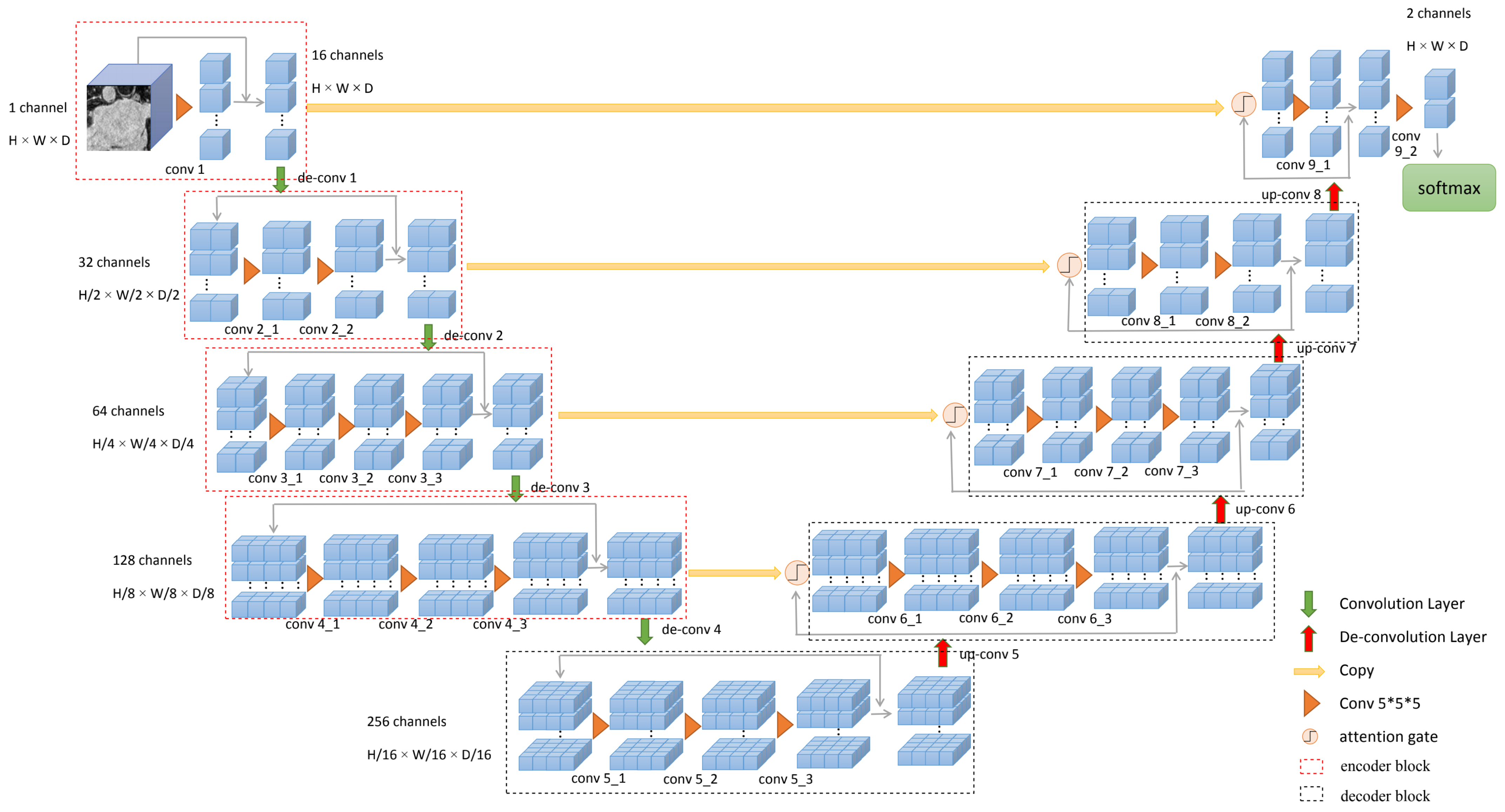
3. Methodology
3.1. The Proposed Framework
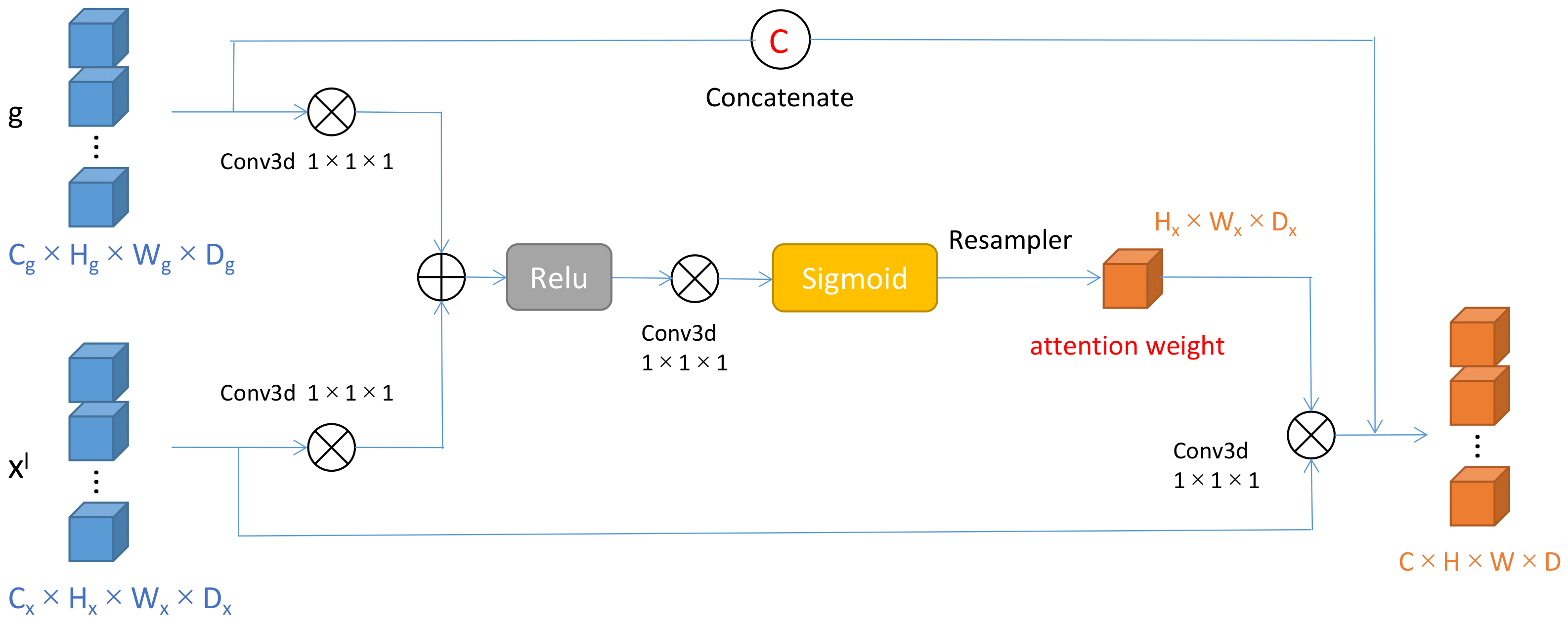
3.2. Attention Gates
4. Experiments and Results
4.1. Datasets and Pre-Processing
4.2. Implementation Details and Evaluation Metrics
4.2.1. Implementation Details
4.2.2. Evaluation Metrics
4.3. Results and Analysis
4.3.1. Comparison with Other Semi-Supervised Methods
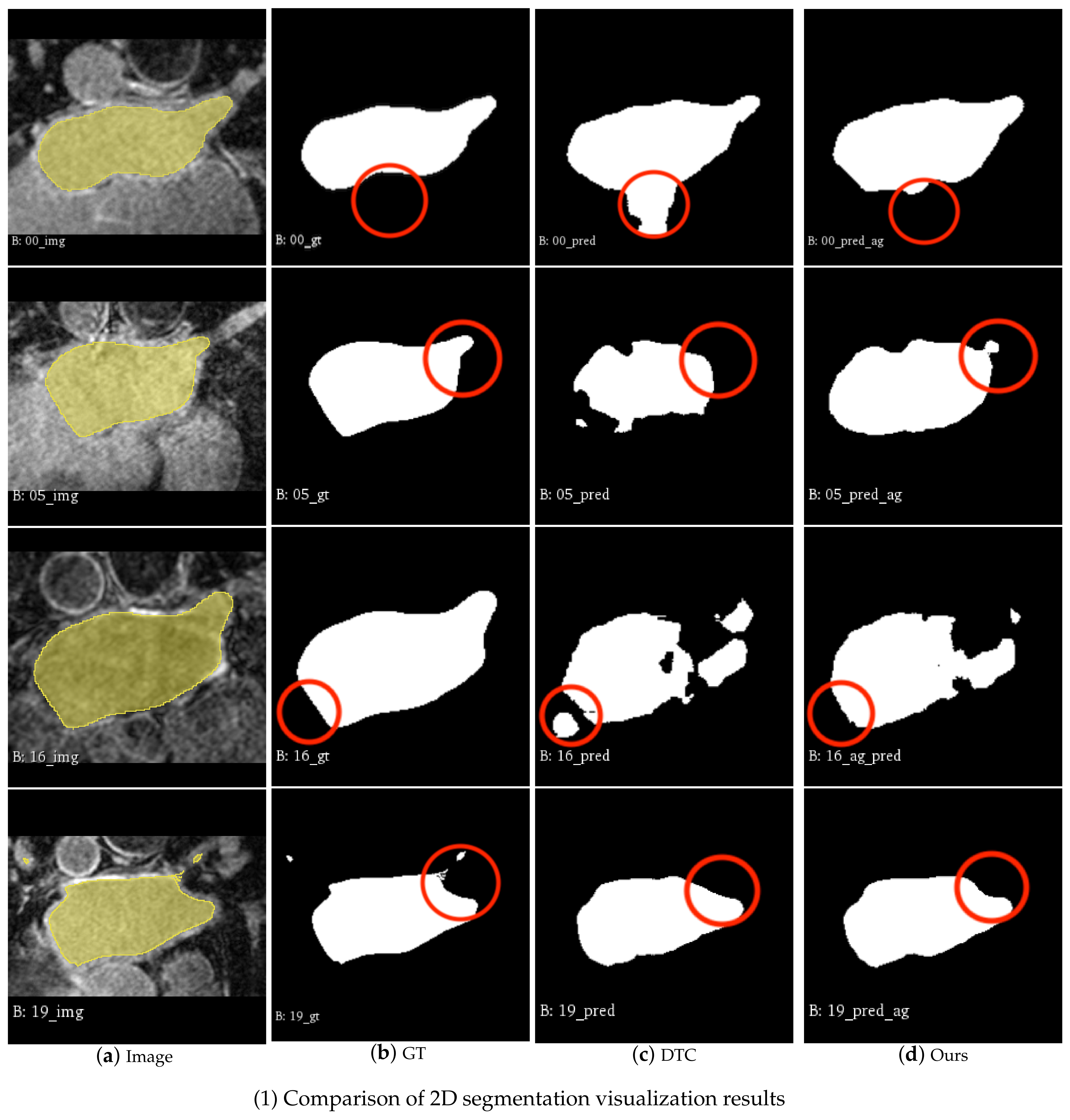
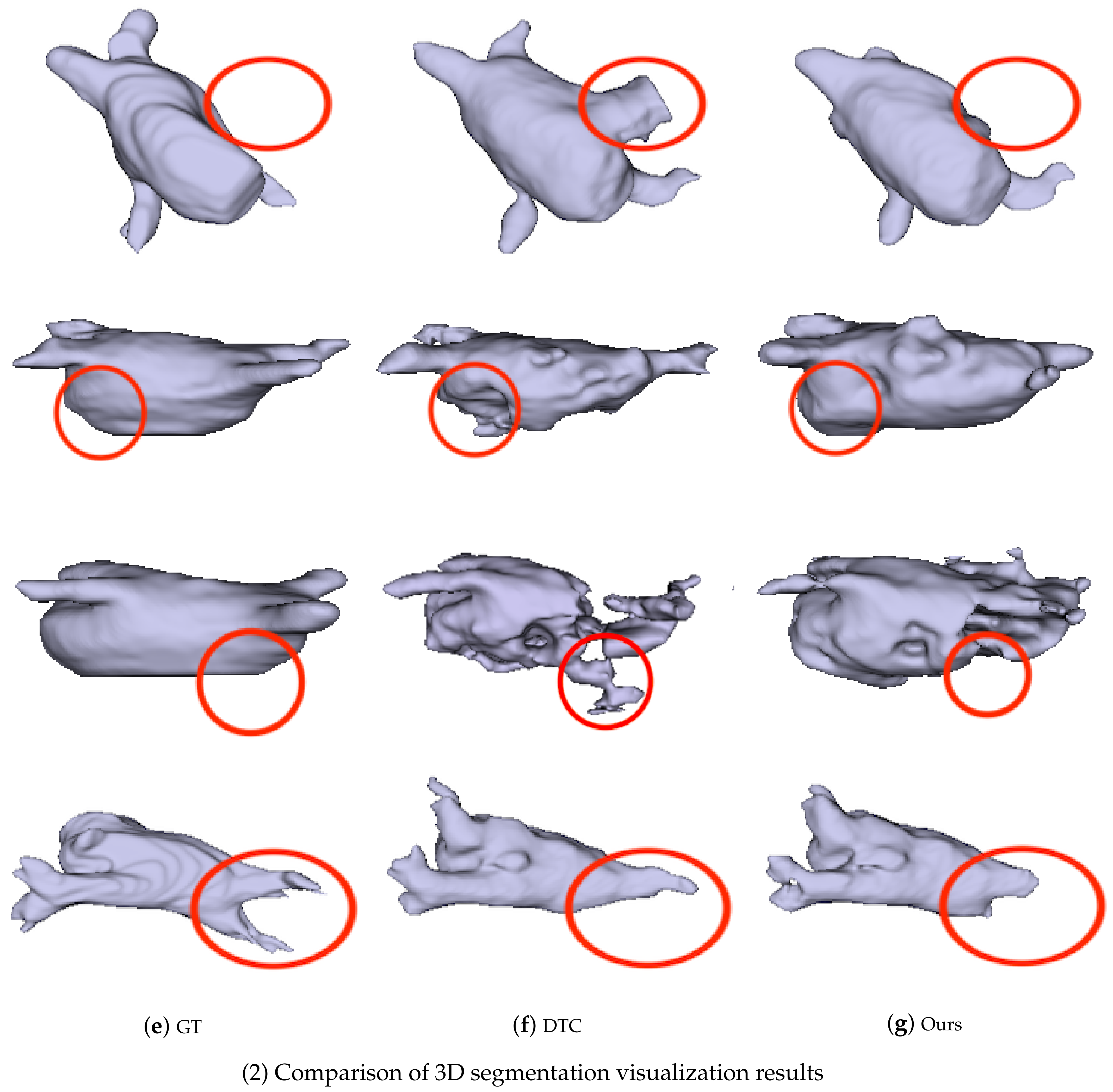
4.3.2. Visualization
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Narayan, S.M.; Rodrigo, M.; Kowalewski, C.A.; Shenasa, F.; Meckler, G.L.; Vishwanathan, M.N.; Baykaner, T.; Zaman, J.A.B.; Paul, J.; Wang, P.J. Ablation of focal impulses and rotational sources: What can be learned from differing procedural outcomes. Curr. Cardiovasc. Risk Rep. 2017, 11, 27. [Google Scholar] [CrossRef]
- Hansen, B.J.; Zhao, J.; Csepe, T.A.; Moore, B.T.; Li, N.; Jayne, L.A.; Kalyanasundaram, A.; Lim, P.; Bratasz, A.; Powell, K.A.; et al. Atrial fibrillation driven by micro-anatomic intramural re-entry revealed by simultaneous sub-epicardial and sub-endocardial optical mapping in explanted human hearts. Eur. Heart J. 2015, 36, 2390–2401. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Njoku, A.; Kannabhiran, M.; Arora, R.; Reddy, P.; Gopinathannair, R.; Lakkireddy, D.; Dominic, P. Left atrial volume predicts atrial fibrillation recurrence after radiofrequency ablation: A meta-analysis. EP Eur. 2017, 20, 33–42. [Google Scholar] [CrossRef] [PubMed]
- Higuchi, K.; Cates, J.; Gardner, G.; Morris, A.; Burgon, N.S.; Akoum, N.; Marrouche, N.F. The spatial distribution of late gadolinium enhancement of left atrial mri in patients with atrial fibrillation. JACC Clin. Electrophysiol. 2017, 4, 49–58. [Google Scholar] [CrossRef] [PubMed]
- Ciresan, D.; Giusti, A.; Gambardella, L.M.; Schmidhuber, J. Deep neural networks segment neuronal membranes in electron microscopy images. Adv. Neural Inf. Process. Syst. 2012, 25, 1–9. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 fourth international conference on 3D vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Li, X.; Yu, L.; Chen, H.; Fu, C.W.; Heng, P.A. Semi-supervised skin lesion segmentation via transformation consistent self-ensembling model. arXiv 2018, arXiv:1808.03887. [Google Scholar]
- Yu, L.; Wang, S.; Li, X.; Fu, C.-W.; Heng, P.-A. Uncertainty-aware self-ensembling model for semi-supervised 3D left atrium segmentation. In Proceedings of the International Conference on Medical Imaging Computing for Computer Assisted Intervention, Shenzhen, China, 13–17 October 2019. [Google Scholar]
- Li, S.; Zhang, C.; He, X. Shape-aware semi-supervised 3D semantic segmentation for medical images. In Proceedings of the International Conference on Medical Imaging Computing for Computer Assisted Intervention, Lima, Peru, 4–8 October 2020; pp. 552–561. [Google Scholar]
- Luo, X.; Chen, J.; Song, T.; Wang, G. Semi-supervised medical image segmentation through dual-task consistency. arXiv 2020, arXiv:2009.04448. [Google Scholar]
- Xia, Q.; Yao, Y.; Hu, Z.; Hao, A. Automatic 3D atrial segmentation from GE-MRIs using volumetric fully convolutional networks. In Proceedings of the International Workshop on Statistical Atlases and Computational Models of the Heart, Granada, Spain, 16 September 2018; pp. 211–220. [Google Scholar]
- Isensee, F.; Jäger, P.F.; Kohl, S.A.; Petersen, J.; Maier-Hein, K.H. Automated design of deep learning methods for biomedical image segmentation. arXiv 2019, arXiv:1904.08128. [Google Scholar]
- Ahmad, I.; Hussain, F.; Khan, S.A.; Akram, U.; Jeon, G. CPS-based fully automatic cardiac left ventricle and left atrium segmentation in 3D MRI. J. Intell. Fuzzy Syst. 2019, 36, 4153–4164. [Google Scholar] [CrossRef]
- Laine, S.; Aila, T. Temporal ensembling for semi-supervised learning. arXiv 2016, arXiv:1610.02242. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Adv. Neural Inf. Process. Syst. 2017, 30, 1–10. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6077–6086. [Google Scholar]
- Banerjee, S.; Lyu, J.; Huang, Z.; Leung, H.F.F.; Lee, T.T.-Y.; Yang, D.; Su, S.; Zheng, Y.; Ling, S.-H. Light-Convolution Dense Selection U-Net (LDS U-Net) for Ultrasound Lateral Bony Feature Segmentation. Appl. Sci. 2021, 11, 180. [Google Scholar] [CrossRef]
- Xiao, T.J.; Xu, Y.C.; Yang, K.Y.; Zhang, J.X.; Peng, Y.X.; Zhang, Z. The application of two-level attention models in deep convolutional neural network for fine-grained image classification. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 842–850. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Xiong, Z.; Xia, Q.; Hu, Z.; Huang, N.; Bian, C.; Zheng, Y.; Vesal, S.; Ravikumar, N.; Maier, A.; Yang, X.; et al. A global benchmark of algorithms for segmenting late gadolinium-enhanced cardiac magnetic resonance imaging. Med. Image Anal. 2020, 67, 101832. [Google Scholar] [CrossRef] [PubMed]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 1–12. [Google Scholar]
- Vu, T.-H.; Jain, H.; Bucher, M.; Cord, M. Advent: Adversarial entropy minimization for domain adaptation in semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2517–2526. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Block Name | Layer Name | Layer Configuration | Remark |
|---|---|---|---|
| Encoder Block (1) | conv 1 | , 16 | Down-sampling path |
| de-conv 1 | , stride 2 | ||
| Encoder Block (2) | conv 2_1 | , 32 | |
| conv 2_2 | , 32 | ||
| de-conv 2 | , stride 2 | ||
| Encoder Block (3) | conv 3_1 | , 64 | Down-sampling path |
| conv 3_2 | , 64 | ||
| conv 3_3 | , 64 | ||
| de-conv 3 | , stride 2 | ||
| Encoder Block (4) | conv 4_1 | , 128 | |
| conv 4_2 | , 128 | ||
| conv 4_3 | , 128 | ||
| de-conv 4 | , stride 2 | ||
| Decoder Block (5) | conv 5_1 | , 256 | Up-sampling path |
| conv 5_2 | , 256 | ||
| conv 5_3 | , 256 | ||
| up-conv 5 | , stride 2 | ||
| Decoder Block (6) | conv 6_1 | , 128 | |
| conv 6_2 | , 128 | ||
| conv 6_3 | , 128 | ||
| up-conv 6 | , stride 2 | ||
| Decoder Block (7) | conv 7_1 | , 64 | |
| conv 7_2 | , 64 | ||
| conv 7_3 | , 64 | ||
| up-conv 7 | , stride 2 | ||
| Decoder Block (8) | conv 8_1 | , 32 | |
| conv 8_2 | , 32 | ||
| up-conv 8 | , stride 2 | ||
| conv 9_1 | , 16 | ||
| conv 9_2 | , 2 |
| Method | Metrics | |||
|---|---|---|---|---|
| Dice (%) | Jaccard (%) | ASD (Voxel) | 95HD (Voxel) | |
| Entropy Mini (CVPR 2019) | 88.45 | 79.51 | 3.72 | 14.14 |
| UA-MT (MICCAI 2019) | 88.88 | 80.21 | 2.26 | 7.32 |
| SASSnet (MICCAI 2020) | 88.78 | 80.04 | 2.96 | 10.30 |
| DTC (AAAI 2021) | 88.52 | 79.74 | 2.08 | 8.54 |
| Attention V-Net | 89.08 | 80.48 | 1.94 | 8.22 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Yin, R.; Yin, J. Attention V-Net: A Modified V-Net Architecture for Left Atrial Segmentation. Appl. Sci. 2022, 12, 3764. https://doi.org/10.3390/app12083764
Liu X, Yin R, Yin J. Attention V-Net: A Modified V-Net Architecture for Left Atrial Segmentation. Applied Sciences. 2022; 12(8):3764. https://doi.org/10.3390/app12083764
Chicago/Turabian StyleLiu, Xiaoli, Ruoqi Yin, and Jianqin Yin. 2022. "Attention V-Net: A Modified V-Net Architecture for Left Atrial Segmentation" Applied Sciences 12, no. 8: 3764. https://doi.org/10.3390/app12083764