
Processing Analytical Queries over Polystore System for a Large Astronomy Data Repository



Abstract
:1. Introduction
- Utilize URIs to identify objects;
- Utilize HTTP URIs to enable users to look up those names;
- When someone searches for a URI, give relevant information by utilizing industry standards (RDF, SPARQL);
- Include hyperlinks to additional URIs, so that users can continue to learn new things.
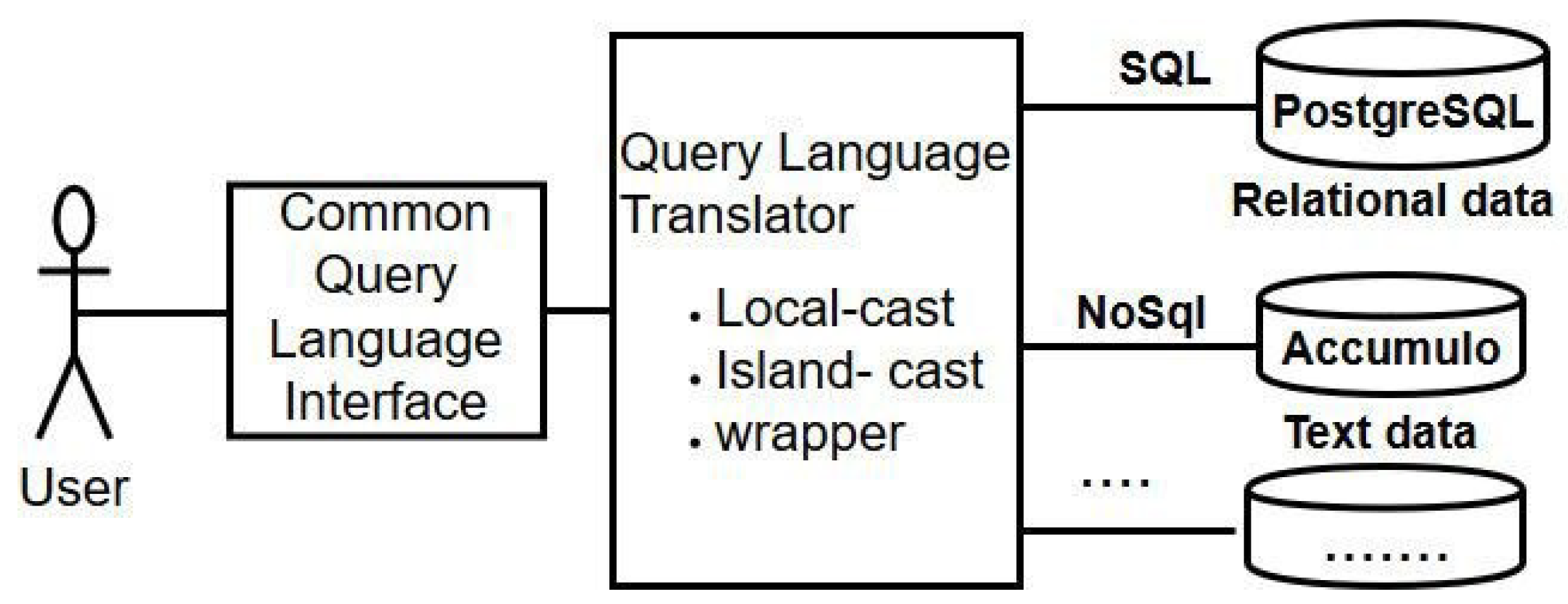
1.1. Polystore
1.2. Motivating Example of Linked Open Data in ZTF Repository
- Create an effective multidatabase architecture for managing heterogeneous astronomical data;
- Provide a query language that federates data, transforms it, and migrates it effectively inside the underlying data repositories;
- Incorporate a completely automated workflow-based query management system to manage heterogeneous data.
2. Related Work
2.1. Polystore System—Datawnt0 (Existing Work)
- A limitation of Datawnt0 is that users can access only single-exposure (sci) images form PTF data archive;
- Another main drawback of Datawnt0 is that recursive queries do not work in this system as there is a loss of data. If a user needs to search entire fields and galaxies or search by position (galactic coordinates), the cDatawnt0 interface does not support this option at this time.
3. ZTF Data Processing Overview
3.1. IRSA Archive
- /raw = raw image data file;
- /cal = calibration product file;
- /sci = epochal science product file and difference images;
- /ref = reference image (co-adds) and catalog files;
- <fff> = first three (leftmost) digits of <fieldID>;
- <caltype> = calibration type, e.g., “bias”, “hifreqflat”;
- <imgtype> = single character label in raw camera image file;
- <ptype> = product type suffix string from pipeline;
- YYYY = year;
- MMDD = month and day (all UT-based);
- dddddd = fractional time of day of exposure (all UT-based);
- fieldID = 6-digit survey field ID if targeted science (on-sky) exposure, otherwise “000000” for calibrations;
- filterID = 2-letter filter code:zg, zr, zi for exposure acquired in g, R, or i respectively (for on-sky & flat-fields) bi, dk for bias and dark images, respectively (filter neutral);
- ccdID = 2-digit detector chip ID: 01, 02, … 16;
- quadID = 1-digit quadrant ID in ccd: 1, 2, 3, or 4 imgtype o: on-sky object observation or science exposure, b: bias calibration image, d: dark calibration image, f: dome/screen flatfield calibration image, c: focus image, g: guider image;
- ptype = fits, txt format image product type.
3.2. ZTF Released Products
3.3. Access to ZTF Data
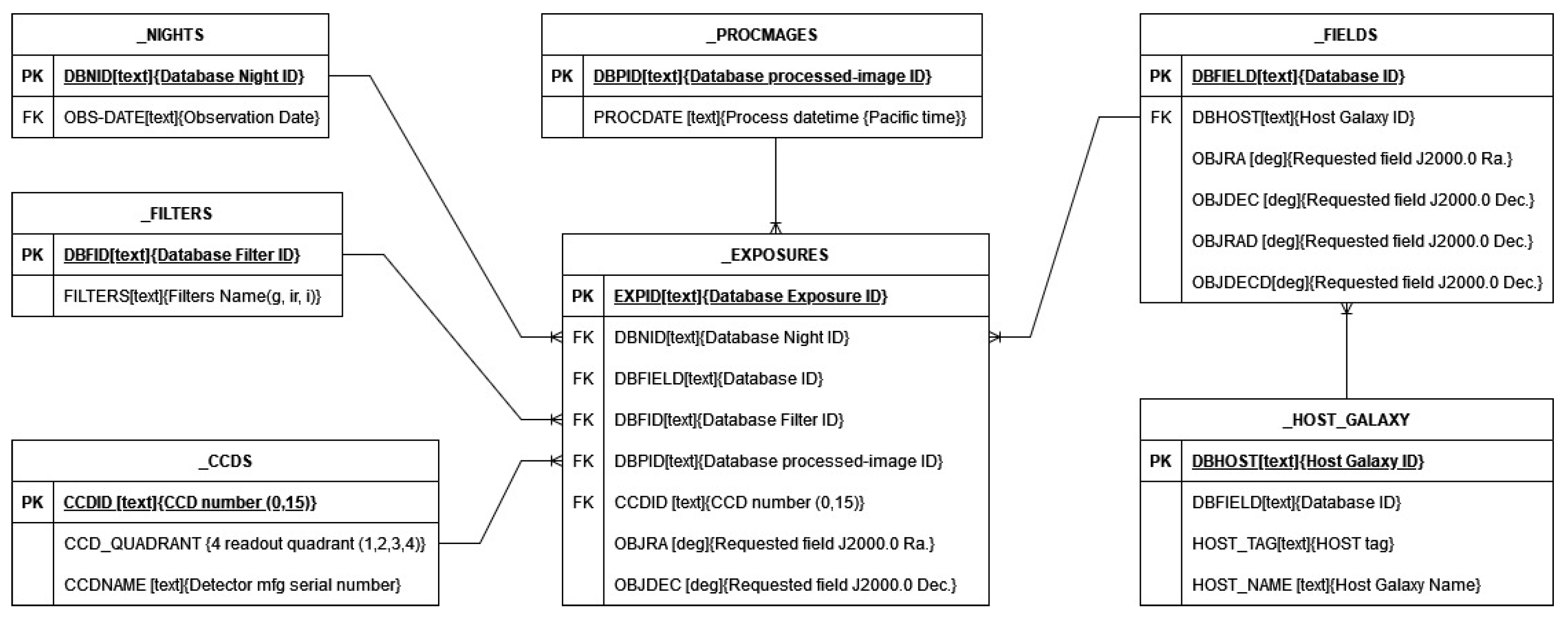
3.4. Retrieving the Catalog File from IRSA Remote Resource
- Nights: Nights contain the date or time of the images taken, with the unique index nid and alternative key—nightdate.
- Fields: Fields database table stores images according to the X and Y coordinate and assigned identification ID. In this table, fieldid is a unique index and field is an alternative key.
- Exposures: Exposure tables contain information from both night database table and fields database table. Exposure tables also contain detailed information on CCD, such as CCD ID, exposure time, image type, etc. The expid is a unique index and obsdate is an alternative key.
- Procimages: Procimages contains processed-images metadata, i.e., image file names. The unique index is processed-images number pid.
- Filters: Filters includes a record for each camera filter that was used to acquire the exposures. The unique index is fid.
- CCDS: CCD (16 charge-coupled devices) contains the camera details numbered CCDID 1, … 16. The unique index is ccdid.
- Host_galaxy: Host galaxy consists of the names of the galaxies.
4. Proposed System Overview and Use of Open Link Data Integration for Polystore Databases
4.1. Existing IPAC Sources
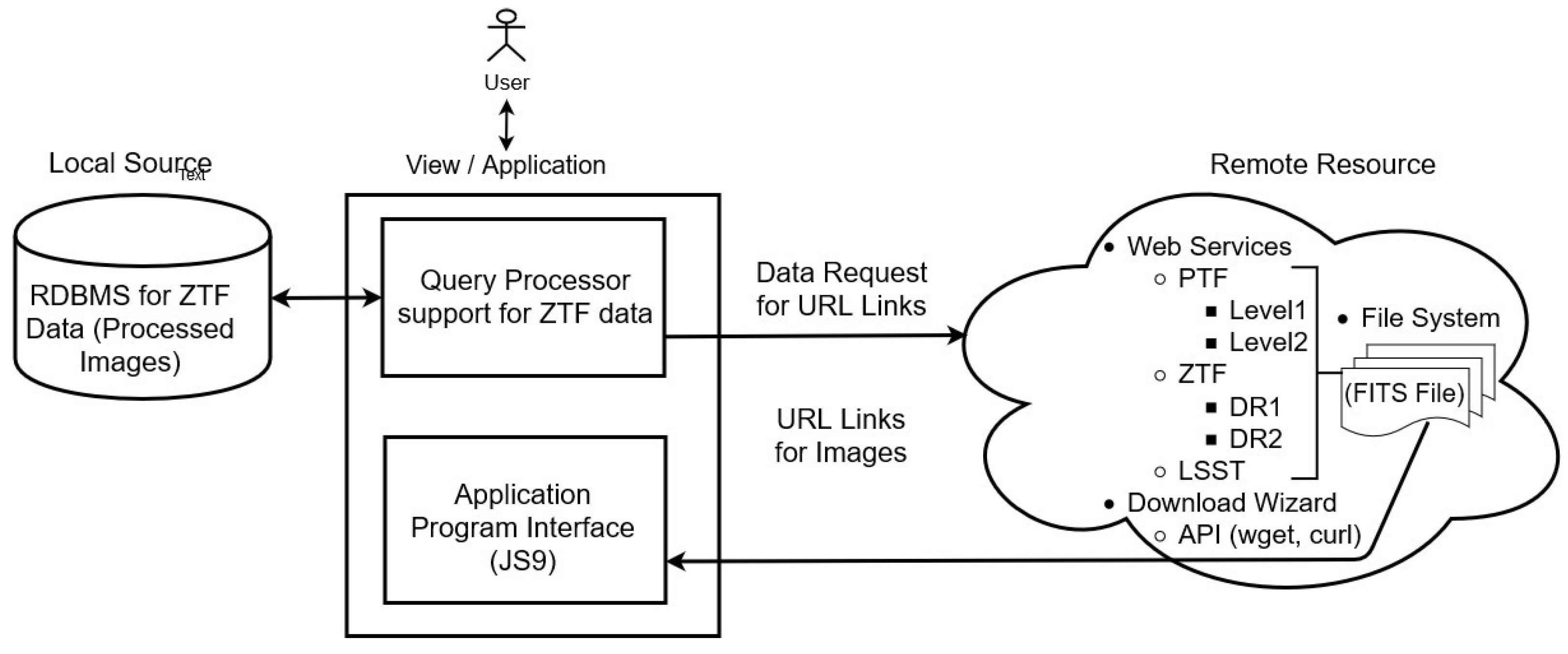
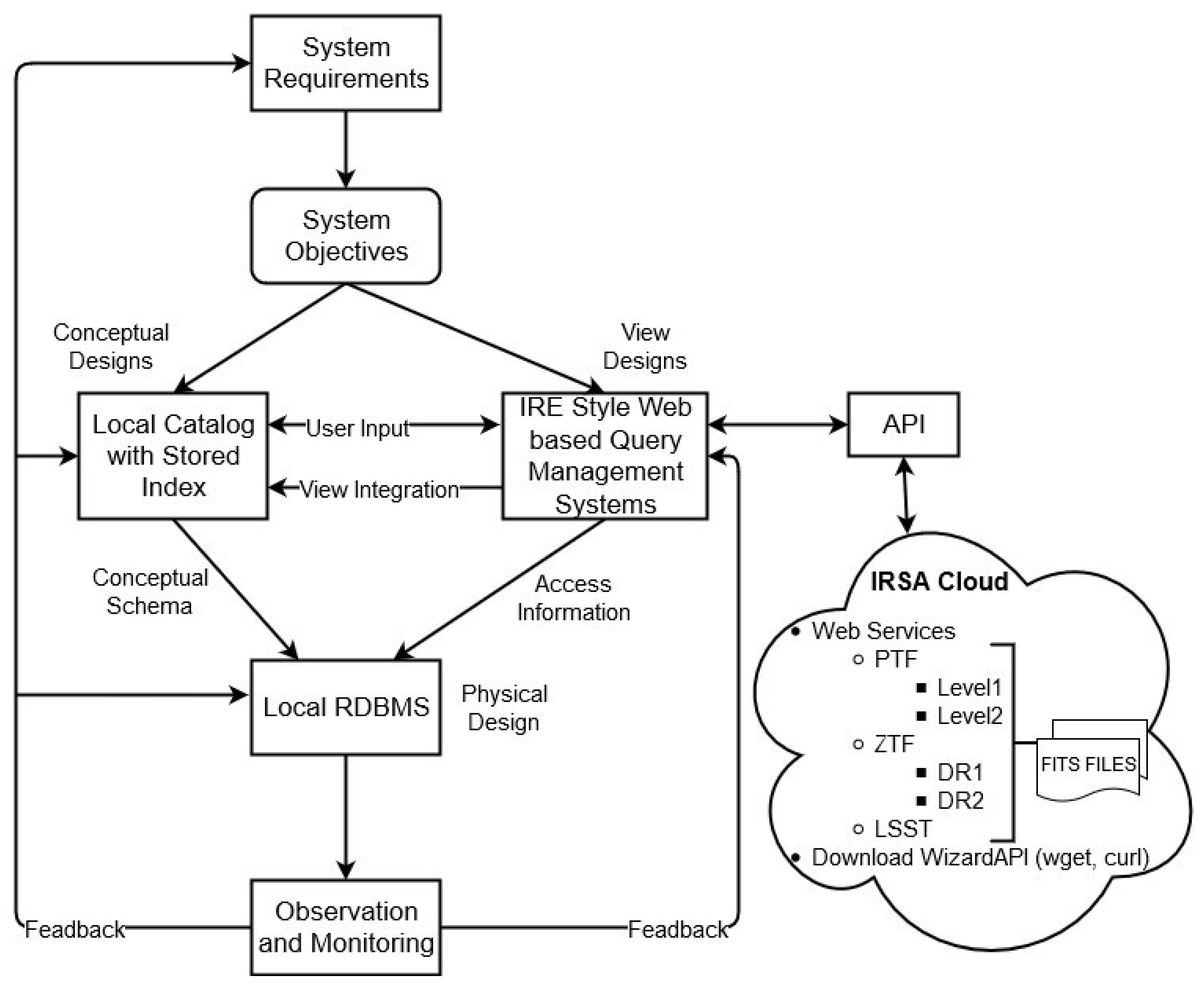
4.2. Proposed System
4.3. Workflow Web-Based Query Management System with Top-Down Approach
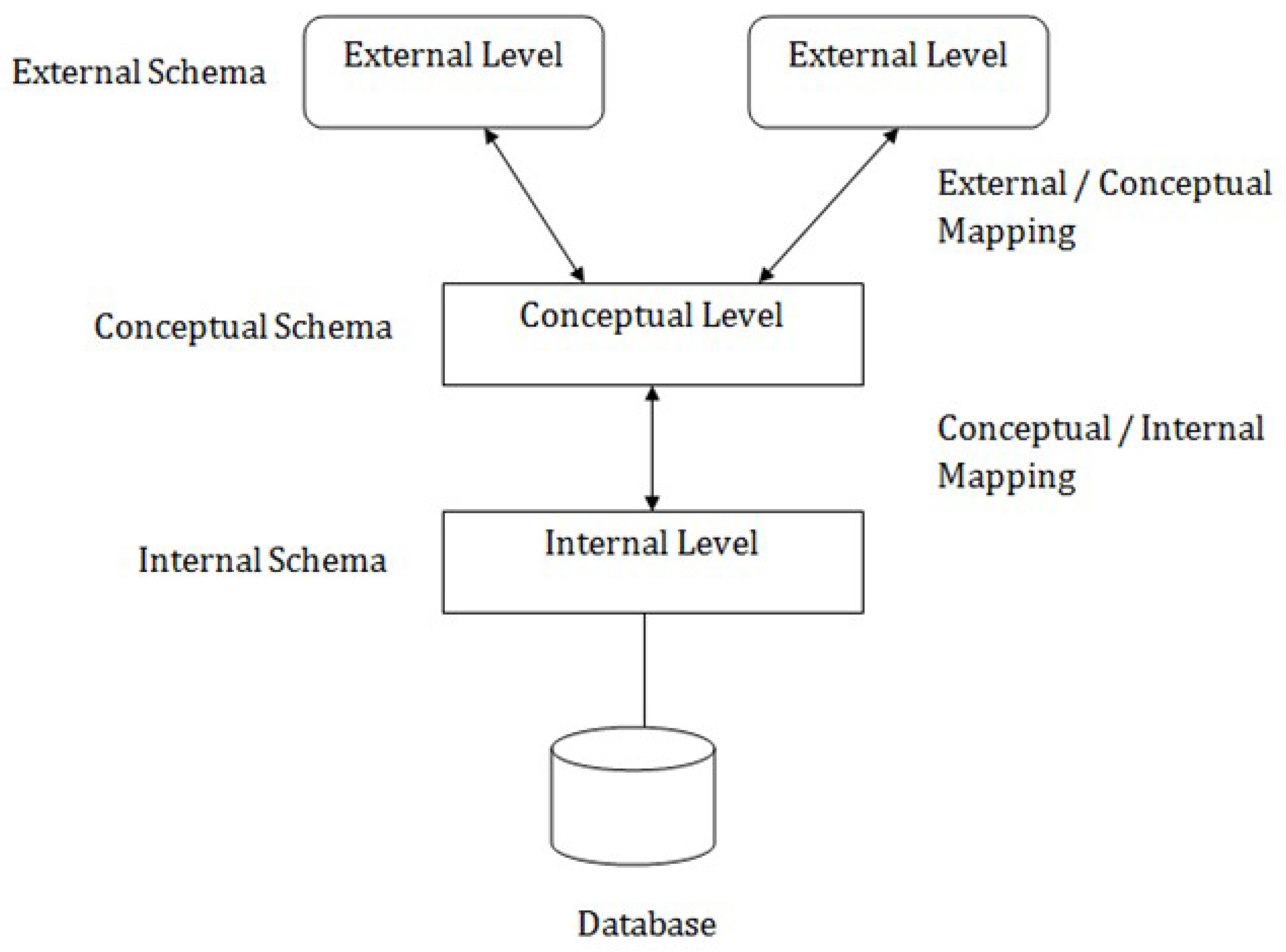
4.3.1. Schema Mapping
4.3.2. Proposal for Top-Down Polystore Systems Approach
4.3.3. Query Processor
| Algorithm 1: Query Workflow across the multiple data sources. |
 |
- Query 1: Find the information of image from a Fields where user select example records from object list (e.g., fields, nights, exposures, procimages, ccd, etc.)SQL for Query 1:select distinct on (A."DBFIELD") A.* from "_FIELDS" A\\Image SQL for Query 1:select A.*,B.* from "_Exposures" A, "_PROCIMAGES" B,(select distinct on (A."DBFIELD") A.* from "_FIELDS" A)C where A."DBFIELD" = C."DBFIELD" and A."DBRID"= B."DBRID"order by B."DBPID" offset 0 limit 10
- Query 2: Find the information of image from a certain place field and exposures.SQL for Query 2:select distinct on (A."DBEXPID") A.* from "_exposures" A,(select distinct on (A."DBFIELD") A.* from "_FIELDS" A)B where A."DBFIELD"=B."DBFIELD"Image SQL for Query 2:select A.*,B.* from "_PROCIMAGES" B,(select distinct on (A."DBRID") A.* from "_exposures" A,(select distinct on (A."DBFIELD") A.* from "_FIELDS" A)B where A."DBFIELD"=B."DBFIELD" ) A where A."DBEXPID"= B."DBEXPID"order by B."DBPID" offset 0 limit 10;
- Query 3: Find the information of image where field, night exposure is exactly the same in the tables.SQL for Query 3:select distinct on (A."DBNID") A.* from "_NIGHTS" A,(select distinct on (A."DBEXPID") A.* from "_EXPOSURES" A,(select distinct on (A."DBFIELD") A.* from "_FIELDS" A)B where A."DBFIELD"=B."DBFIELD" ) B where A."DBNID"=B."DBNID" ;Image SQL for Query 3:select A.*,B.* from "_EXPOSURES" A, "_PROCIMAGES" B,(select distinct on (A."DBNID") A.* from "_NIGHTS" A,(select distinct on (A."DBEXPID") A.* from "_EXPOSURES" A,(select distinct on (A."DBFIELD") A.* from "_FIELDS" A)B where A."DBFIELD"=B."DBFIELD" ) B where A."DBNID"=B."DBNID" )C where A."DBNID" = C."DBNID" and A."DBEXPID"= B."DBEXPID"order by B."DBPID" offset 0 limit 10;
5. Evaluation and Discussion
5.1. Evaluation Based on Existing Work
5.2. Evaluation Based on Features of Polystore System
5.3. Experimental Setup
- Query by positions: Uses galactic coordinates to specify the exact position to map the exact fields of galactic plane.
- Find all the objects in a certain galactic position.
- Query by observational date and time: Uses built-in calendar input function (OBJ-DATE) details and Night details which include the date (DD:MM:YYYY) and time (HH:MM:SS) per observed astronomical bodies.
- Find all the objects from a certain time period.
- Query by host galaxies: Uses target search for catalogs of nearby galaxies
- Find all the objects related to the specific galaxies.
- Query by camera details: Uses 16ccds cameras as per the different object filters used by ZTF, namely, zg, zr, zi for exposure acquired in g, R, I, respectively, and bi, dk for bias and dark images, respectively.
- Find all the object from camera filters;
- Find all the object from camera name.
5.4. Query Comparison Analysis
- Find all the images where Fields ID = 841;
- Find all the images where Exposures ID = 44316126;
- Find all images from fields where OBSJD = 2458197.6612616;
- Find all the images where Night ID = 443;
- Find all the images where Host galaxies where HOSTTAG = m81;
- Find all images by observation date between 2018-04-01 and 2018-04-30;
- Find all the images where Filters = 2;
- Find all the images with R-band filters = zr;
- Find all the images with CCD ID = 16;
- Find all the images with Night ID = 443 and Fields ID = 809;
- Find all the images with Night ID = 443 and CCD ID = 5;
- Find all the images with Night ID = 443 and filtercode = zg;
- Find all the images with Field ID = 841 and Exposure ID = 44316126;
- Find all the images with Field ID = 809 and filtercode zg;
- Find all the images where Exposures ID = 44316126 and Filters ID = 2;
- Find all the images from date 2018-04-01 and 2018-04-30 and Field ID = 841 and CCD ID = 5 with R-band filters;
- Find all the images with Night ID = 443 and Fields ID = 809 and CCD ID = 12 with g-band filter;
- Find all the images from the Fields table or exposures tables;
- Find all the Science Exposures images where Host galaxies name = m81;
- Find all the References Images and Science Images where Host Galaxies name = ngc 13.
5.5. Discussion
6. Summary and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- European Commission. What Is Open Data? 2007. Available online: https://data.europa.eu/elearning/en/module1/#/id/co-01 (accessed on 15 December 2021).
- Handbook, O.D. What is Open Data? 2022. Available online: https://opendatahandbook.org/guide/en/what-is-open-data/ (accessed on 19 December 2021).
- Nentwig, M.; Soru, T.; Ngonga Ngomo, A.C.; Rahm, E. Linklion: A link repository for the web of data. In Proceedings of the European Semantic Web Conference, Heraklion, Crete, Greece, 10–12 May 2014; pp. 439–443. [Google Scholar]
- Berners-Lee, T. Linked Data. 2009. Available online: https://www.w3.org/DesignIssues/LinkedData.html (accessed on 1 January 2022).
- Stonebraker, M. The Case for Polystores. 2015. Available online: http://wp.sigmod.org/?p=1629 (accessed on 11 December 2021).
- Shrestha, S.; Bhalla, S. A Survey on the Evolution of Models of Data Integration. Int. J. Knowl. Based Comput. Syst. 2020, 8, 11–16. [Google Scholar]
- Miller, R.J. Open data integration. Proc. Vldb Endow. 2018, 11, 2130–2139. [Google Scholar] [CrossRef] [Green Version]
- Hai, R.; Quix, C.; Jarke, M. Data lake concept and systems: A survey. arXiv 2021, arXiv:2106.09592. [Google Scholar]
- Izquierdo, Y.T.; García, G.M.; Menendez, E.; Leme, L.A.P.; Neves, A.; Lemos, M.; Finamore, A.C.; Oliveira, C.; Casanova, M.A. Keyword search over schema-less RDF datasets by SPARQL query compilation. Inf. Syst. 2021, 102, 101814. [Google Scholar] [CrossRef]
- Hota, L.; Dash, P.K. An Insight into Big Data and Its Pertinence. In Handbook of Research for Big Data: Concepts and Techniques; Apple Academic Press: New York, NY, USA, 2022; p. 137. [Google Scholar]
- Duggan, J.; Elmore, A.J.; Stonebraker, M.; Balazinska, M.; Howe, B.; Kepner, J.; Madden, S.; Maier, D.; Mattson, T.; Zdonik, S. The bigdawg Polystore system. ACM Sigmod Rec. 2015, 44, 11–16. [Google Scholar] [CrossRef]
- Valduriez, P. An Overview of Polystores. 2021. Available online: https://slideplayer.com/slide/13365730/ (accessed on 13 November 2021).
- Doan, A.; Halevy, A.; Ives, Z. Principles of Data Integration; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar]
- Law, N.M.; Kulkarni, S.R.; Dekany, R.G.; Ofek, E.O.; Quimby, R.M.; Nugent, P.E.; Surace, J.; Grillmair, C.C.; Bloom, J.S.; Kasliwal, M.M.; et al. The Palomar Transient Factory: System overview, performance, and first results. Publ. Astron. Soc. Pac. 2009, 121, 1395. [Google Scholar] [CrossRef] [Green Version]
- Bryant, A.; Raja, U. In the realm of Big Data. First Monday 2014, 19. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Zhao, Y. Astronomy in the big data era. Data Sci. J. 2015, 14, 11. [Google Scholar] [CrossRef] [Green Version]
- Portela, F. Data science and knowledge discovery. Future Internet 2021, 13, 178. [Google Scholar] [CrossRef]
- Shrestha, S.; Poudel, M.; Sarode, R.P.; Chu, W.; Bhalla, S. Open data integration model using a Polystore system for large scale scientific data archives in astronomy. Int. J. Comput. Sci. Eng. 2021, 24, 116–127. [Google Scholar] [CrossRef]
- Bellm, E. The Zwicky transient facility. In Third Hot-Wiring the Transient Universe Workshop; IOP: Santa Fe, NM, USA, 2014; Volume 27. [Google Scholar]
- Masci, F.J.; Laher, R.R.; Rusholme, B.; Shupe, D.L.; Groom, S.; Surace, J.; Jackson, E.; Monkewitz, S.; Beck, R.; Flynn, D.; et al. The zwicky transient facility: Data processing, products, and archive. Publ. Astron. Soc. Pac. 2018, 131, 018003. [Google Scholar] [CrossRef]
- Kulkarni, S. The intermediate palomar transient factory (iptf) begins. Astron. Telegr. 2013, 4807, 1. [Google Scholar]
- Bianco, F.B.; Ivezić, Ž.; Jones, R.L.; Graham, M.L.; Marshall, P.; Saha, A.; Strauss, M.A.; Yoachim, P.; Ribeiro, T.; Anguita, T.; et al. The Impact of Observing Strategy on Reliable Classification of Standard Candle Stars: Detection of Amplitude, Period, and Phase Modulation (Blazhko Effect) of RR Lyrae Stars with LSST. arXiv 2021, arXiv:2108.01683. [Google Scholar]
- Wells, D.C.; Greisen, E.W. FITS-a flexible image transport system. In Image Processing in Astronomy; Osservatorio Astronomico di Trieste: Trieste, Italy, 1979; p. 445. [Google Scholar]
- Jiang, H.; Shen, F.; Chen, S.; Li, K.C.; Jeong, Y.S. A secure and scalable storage system for aggregate data in IoT. Future Gener. Comput. Syst. 2015, 49, 133–141. [Google Scholar] [CrossRef]
- Elmore, A.J.; Duggan, J.; Stonebraker, M.; Balazinska, M.; Cetintemel, U.; Gadepally, V.; Heer, J.; Howe, B.; Kepner, J.; Kraska, T.; et al. A demonstration of the bigdawg Polystore system. Proc. VLDB Endow. 2015, 8, 1908. [Google Scholar] [CrossRef] [Green Version]
- Clifford, G.D.; Scott, D.J.; Villarroel, M. User guide and documentation for the MIMIC II database. In MIMIC-II Database Version; Free Software Foundation: Cambridge, MA, USA, 2009; Volume 2. [Google Scholar]
- Gadepally, V.; Chen, P.; Duggan, J.; Elmore, A.; Haynes, B.; Kepner, J.; Madden, S.; Mattson, T.; Stonebraker, M. The bigdawg Polystore system and architecture. In Proceedings of the 2016 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 13–15 September 2016; pp. 1–6. [Google Scholar]
- Kolev, B.; Valduriez, P.; Bondiombouy, C.; Jiménez-Peris, R.; Pau, R.; Pereira, J. CloudMdsQL: Querying heterogeneous cloud data stores with a common language. Distrib. Parallel Databases 2016, 34, 463–503. [Google Scholar] [CrossRef] [Green Version]
- Zheng, X.; Dasgupta, S.; Kumar, A.; Gupta, A. Processing Analytical Queries in the AWESOME Polystore [Information Systems Architectures]. arXiv 2021, arXiv:2112.00833. [Google Scholar]
- Rezig, E.K.; Bhandari, A.; Fariha, A.; Price, B.; Vanterpool, A.; Gadepally, V.; Stonebraker, M. DICE: Data discovery by example. Proc. Vldb Endow. 2021, 14, 2819–2822. [Google Scholar] [CrossRef]
- Poudel, M.; Shrestha, S.; Sarode, R.P.; Chu, W.; Bhalla, S. Query Languages for Polystore Databases for Large Scientific Data Archives. In Proceedings of the 2019 9th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 10–11 January 2019; pp. 185–190. [Google Scholar]
- Patidar, R.G.; Shrestha, S.; Bhalla, S. Polystore Data Management Systems for Managing Scientific Data-sets in Big Data Archives. In Proceedings of the International Conference on Big Data Analytics, Warangal, India, 18–21 December 2018; pp. 217–227. [Google Scholar]
- Duev, D.A.; Mahabal, A.; Masci, F.J.; Graham, M.J.; Rusholme, B.; Walters, R.; Karmarkar, I.; Frederick, S.; Kasliwal, M.M.; Rebbapragada, U.; et al. Real-bogus classification for the Zwicky Transient Facility using deep learning. Mon. Not. R. Astron. Soc. 2019, 489, 3582–3590. [Google Scholar] [CrossRef] [Green Version]
- Caltech. NASA/IPAC Infrared Science Archive. 2021. Available online: https://irsa.ipac.caltech.edu/frontpage/ (accessed on 28 November 2021).
- Caltech. Zwicky Transient Facility—Public Data Release 2. 2021. Available online: https://www.ztf.caltech.edu/news/public-data-release-2 (accessed on 25 November 2021).
- Poudel, M.; Shrestha, S.; Yilang, W.; Wanming, C.; Bhalla, S. Polystore Database Systems for Managing Large Scientific Dataset Archives. In Proceedings of the 2018 7th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 29–31 August 2018; pp. 1–6. [Google Scholar]
- Bellm, E.C.; Kulkarni, S.R.; Graham, M.J.; Dekany, R.; Smith, R.M.; Riddle, R.; Masci, F.J.; Helou, G.; Prince, T.A.; Adams, S.M.; et al. The Zwicky Transient Facility: System overview, performance, and first results. Publ. Astron. Soc. Pac. 2018, 131, 018002. [Google Scholar] [CrossRef]
- De, K.; Kasliwal, M.M.; Tzanidakis, A.; Fremling, U.C.; Adams, S.; Aloisi, R.; Andreoni, I.; Bagdasaryan, A.; Bellm, E.C.; Bildsten, L.; et al. The Zwicky Transient Facility census of the local universe. I. Systematic search for calcium-rich gap transients reveals three related spectroscopic subclasses. Astrophys. J. 2020, 905, 58. [Google Scholar] [CrossRef]
- Laher, R.R.; Surace, J.; Grillmair, C.J.; Ofek, E.O.; Levitan, D.; Sesar, B.; van Eyken, J.C.; Law, N.M.; Helou, G.; Hamam, N.; et al. IPAC image processing and data archiving for the Palomar Transient Factory. Publ. Astron. Soc. Pac. 2014, 126, 674. [Google Scholar] [CrossRef] [Green Version]
- Caltech. Zwicky Transient Facility—Mission Characteristics. 2021. Available online: https://www.ztf.caltech.edu/ (accessed on 23 November 2021).
- Caltech. IPAC Table Format. 2021. Available online: https://irsa.ipac.caltech.edu/applications/DDGEN/Doc/ipac_tbl.html (accessed on 22 November 2021).
- Wu, Y.; Chu, W. Query languages for domain specific information from ptf astronomical repository. In International Workshop on Databases in Networked Information Systems; Springer: Aizu-Wakamatsu, Japan, 2015; pp. 237–243. [Google Scholar]
- OmniSci, I. Data Exploration—A Complete Introduction. 2021. Available online: https://www.omnisci.com/learn/data-exploration (accessed on 20 November 2021).
- Shrestha, S.; Poudel, M.; Wu, Y.; Chu, W.; Bhalla, S.; Kupfer, T.; Kulkarni, S. PDSPTF: Polystore database system for scalability and access to PTF time-domain astronomy data archives. In Heterogeneous Data Management, Polystores, and Analytics for Healthcare; Springer: Rio De Janeiro, Brazil, 2018; pp. 78–92. [Google Scholar]
- Madaan, A.; Bhalla, S. Domain specific multistage query language for medical document repositories. Proc. Vldb Endow. 2013, 6, 1410–1415. [Google Scholar] [CrossRef]
- JS9. JS9: Astronomical Image Display Everywheret. 2021. Available online: https://js9.si.edu/ (accessed on 24 November 2021).
- Koleoso, T. Integrating with jOOQ. In Beginning jOOQ; Springer: New York, NY, USA, 2022; pp. 145–172. [Google Scholar]
- Poudel, M.; Sarode, R.P.; Shrestha, S.; Wu, Y.; Chu, W.; Bhalla, S. Development of a Polystore Data Management System for an Evolving Big Scientific Data Archive. In Heterogeneous Data Management, Polystores, and Analytics for Healthcare; Springer: Los Angeles, CA, USA, 2019; pp. 167–182. [Google Scholar]
- Özsu, M.T.; Valduriez, P. Principles of Distributed Database Systems; Springer: New York, NY, USA; Dordrecht, The Netherlands; Heidelberg, Germany; London, UK, 1999; Volume 2. [Google Scholar]
- Li, T.; Lockett, H.; Lawson, C. Using requirement-functional-logical-physical models to support early assembly process planning for complex aircraft systems integration. J. Manuf. Syst. 2020, 54, 242–257. [Google Scholar] [CrossRef]
- Ponce, A.; Ponce Rodriguez, R.A. An analysis of the supply of open government data. Future Internet 2020, 12, 186. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Project Name | Duration | Data Download | No. of FITS File | Product |
|---|---|---|---|---|
| PTF (Level 0, Level 1) | 2009–2012 | 0.1 TB per night | Around 3 million | Epochal images, photometric catalogs |
| iPTF (Level 2) | 2013–2017 | 0.3 TB per night | Around 5 million | Deep reference, light curves |
| ZTF (Data release 1 to 8) | 2017–2021 | 1.4 TB per night | Around 50 million | New reference, lightcurves, transient candidates, catalog |
| LSST (Data release 1 to 8) | 2022–2024 | 3 TB per night | Around 500 million | Calibrated images, measure of position, flux and shapes, and light curves |
| Header | Data Unit | |
|---|---|---|
| , Size and index for the data (1, … 50 million) | ||
| Name, size of Data | Data type | |
| Night, field, etc. | FITS, Log … | |
| ZTF Public Data Released | Date of Releases | Data Acquired |
|---|---|---|
| Data Released 1 (DR1) | 8 May 2019 | ZTF-g and ZTF-r filters |
| Data Released 2 (DR2) | 11 December 2019 | ZTF-g, ZTF-r and ZTF-i filters |
| Data Released 3 (DR3) | 24 June 2020 | ZTF-g, ZTF-r and ZTF-i filters |
| Data Released 4 (DR4) | 9 December 2020 | ZTF-g, ZTF-r and ZTF-i filters |
| Data Released 5 (DR5) | 31 March 2021 | ZTF-g, ZTF-r and ZTF-i filters |
| Data Released 6 (DR6) | 30 June 2021 | ZTF-g, ZTF-r and ZTF-i filters |
| Data Released 7 (DR7) | 8 September 2021 | ZTF-g, ZTF-r and ZTF-i filters |
| Data Released 8 (DR8) | 3 November 2021 | ZTF-g, ZTF-r and ZTF-i filters |
| Entities | Nights | Fields | Filters | Exposures | CCD | Host Galaxy | Procimages |
|---|---|---|---|---|---|---|---|
| Nights | - | - | - | 1:N | - | - | - |
| Fields | - | - | - | 1:N | - | 1:N | - |
| Filters | - | - | - | 1:N | - | - | - |
| Exposures | 1:N | 1:N | 1:N | - | 1:N | - | 1:N |
| CCD | - | - | - | 1:N | - | - | - |
| Host Galaxy | - | 1:N | - | - | - | - | - |
| Procimages | - | - | - | 1:N | - | - | - |
| Evaluation Framework | IRSA ZTF Images GUI | Datawnt0 GUI (Past Work) | Proposed Systems GUI |
|---|---|---|---|
| Data support |
|
|
|
| Query Support Function |
|
|
|
| Architecture Flexibility |
|
|
|
| Users |
|
|
|
| Evaluation Framework | BigDAWG | CloudMdsQL | Proposed System |
|---|---|---|---|
| Heterogeneity |
|
|
|
| Autonomy |
|
|
|
| Transparency |
|
|
|
| Flexibility |
|
|
|
| Optimality |
|
|
|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Poudel, M.; Sarode, R.P.; Watanobe, Y.; Mozgovoy, M.; Bhalla, S. Processing Analytical Queries over Polystore System for a Large Astronomy Data Repository. Appl. Sci. 2022, 12, 2663. https://doi.org/10.3390/app12052663
Poudel M, Sarode RP, Watanobe Y, Mozgovoy M, Bhalla S. Processing Analytical Queries over Polystore System for a Large Astronomy Data Repository. Applied Sciences. 2022; 12(5):2663. https://doi.org/10.3390/app12052663
Chicago/Turabian StylePoudel, Manoj, Rashmi P. Sarode, Yutaka Watanobe, Maxim Mozgovoy, and Subhash Bhalla. 2022. "Processing Analytical Queries over Polystore System for a Large Astronomy Data Repository" Applied Sciences 12, no. 5: 2663. https://doi.org/10.3390/app12052663