
A Study on Reversible Data Hiding Technique Based on Three-Dimensional Prediction-Error Histogram Modification and a Multilayer Perceptron



Abstract
:1. Introduction
1.1. Background
1.2. Prediction-Error Expansion
1.3. Our Contribution
2. Related Work and Comparisons between the Methods
- Lossless compression-based methods.Most early RDH was implemented based on lossless compression [35,36,37,38,39,40,41,42]. Partial space is released by lossless compressing a feature set of the original image, and the data is embedded using the released space to achieve RDH. The performance of this method depends on the lossless compression algorithm used and the selection of compressed feature sets. The experimental results suggest that the algorithm based on lossless compression will result in greater distortion and poorer embedding effect than the subsequent RDH method.
- Integer-transform-based methods.Integer-transform-based methods can be seen in [36,39,41]. In this type of method, the original image is initially divided, so that multiple adjacent pixels can form an embedding unit. Subsequently, the secret information is embedded into each unit using integer transform. However, this type of method usually uses the average value of a pixel block to predict each pixel in the block, so that the image redundancy cannot be well utilized. Moreover, its algorithm cannot control the maximum modification range of each pixel so that the embedded distortion cannot be controlled effectively. Due to two defects mentioned above, the embedding performance of the integer transform-based methods is limited. The performance of this type of method has been significantly improved compared to the lossless compression-based methods; however, it still cannot achieve good embedding performance.
- Two-phase embedding with location maps.There are RDH schemes proceeds with two-phases (e.g., [43,44,45]) using location maps which map each pixel to a certain value and also ensure the reversibility of the cover image. In [44], Malik et al. considered even-valued and odd-valued pixels separately and embed the secret data bit for each pixel of the cover image by changing its value by at most 1. Their work improves previous complementary embedding strategy by Chang and Kieu [43] which uses vertical embedding and horizontal embedding separately in two phases. Kumar et al. considered even-valued and odd-valued pixels with location maps as well while the cover image is divided into non-overlapping 2-by-2 blocks of pixels and the secret bits are converted into 2-bit segments and embedded into the blocks by increasing or decreasing the pixel value of the corresponding block by at most 1. Since the second phase embedding has the affect as complement of the first phase embedding, this kind of approach persist the stego-image’s quality while doubling the EC.
- Histogram modification-based methods.In this type of method, the original image is mapped to space with a lower dimension at the beginning by using the redundancy of the image. Then generate a histogram by counting the distribution of the low-dimensional space. Finally, the reversible embedding is realized by modifying the histogram. The earliest method having a great impact is proposed by Ni et al. in 2006 [46]. In this method, the secret data is embedded into the pixels with the highest frequency in the image histogram by expanding the histogram. The stego-image with this method maintains high image quality, but the embedding rate is low. Therefore, Lee et al. [47] improved the method of [46], which uses the image difference histogram that the shape rule is similar to Laplace distribution. The histogram of the method experiences a very high peak and rapidly dropping; therefore, it can have a better embedding capacity while maintaining image quality.
2.1. Further Discussion on Histograph Modification-Based Approaches
- Using histograms, especially PEHs, can effectively utilize image redundancy.
- Modifying the histogram by expansion or shifting can control the maximum modification range of each pixel and the embedding distortion effectively.
- Generation method of histogram.
- Modification method of histogram.Different from the early expansion methods [8,9,16,24] using a peak in histogram, several authors [15,25,26,27] proposed methods to expand the histogram by adaptively selecting with the frequency of pixels in the image histogram. These methods can significantly reduce the embedding distortion of PEE.
- Selection of embedding location.This type of method firstly selects the image area that is more suitable for reversible embedding (usually smooth areas), and then uses the selected area as a new carrier for RDH. The effect of these methods are remarkable. Combining with PEE can effectively reduce the embedding distortion of PEE. Its idea was first proposed by Kamstra et al. [18], and many subsequent works have also applied this method as an auxiliary means to further optimize the embedding performance.
- High-dimensional histogram modification.Several authors [10,21] proposed the methods based on high-dimensional histogram modification. They map high-dimensional redundant features of images to two-dimensional space, and then modify the two-dimensional histogram to achieve reversible embedding. In recent works [5,14,17], the methods based on three-dimensional or high-dimensional histogram modification are proposed. By mapping the redundant features of the image to a higher-dimensional space, the embedding capacity is increased and the image quality is maintained. This type of method can greatly improve the embedding performance of existing PEE algorithms.
- Multi-histogram modification.
- PEH for color images.In [51], Zhan et al. applied 3D-PEH to color images. Their approach is to predict the pixel values of each RGB channel of a color image and establish the 3D prediction-error histogram. Their results yield low distortion for color images.
- Histogram-shifting-imitated technique based on human visual system (HVS).Kumar et al. take human visual system into consideration [52] and improves previous work using histogram-shifting-imitated reversible data hiding method in [53]. Since human eyes are more sensitive to the changes in lower intensity pixels than higher ones, this approach divide the intensity levels into four groups of equal size and embed less bits in the low intensity pixels for less conceived distortion of the stego-image so that the visual imperceptibility is improved.
- Pixel Value Ordering (PVO).Li et al. [20] proposed the pixel value ordering (PVO) technique which is an advancement of PEE. When the cover images are divided into blocks, PVO first sorts pixel values in each block and then computes minimum, maximum, second-minimum and second maximum pixels which are used for data embedding depending on the minimum and maximum prediction errors in the blocks. PVO changes the pixel values only by at most 1; hence, it generates high quality stego-images. Kaur et al. [54] propose RDH technique using PVO and pairwise PEE to improve EC while retain the quality of the stego image. The embedding strategy is performed in two-phases on three-pixel blocks. Pixels are traversed in a zig-zag way and then sorted based on their rhombus means. The key of PVO for increasing EC is that smaller prediction errors are derived after pixels are sorted. Kaur et al. [55] also considered RDH based on PVO for roughly texture images. For more thorough survey on RDH approaches based on PVO can refer to the survey in [54].
2.2. Comparisons and Highlight of Our Approach
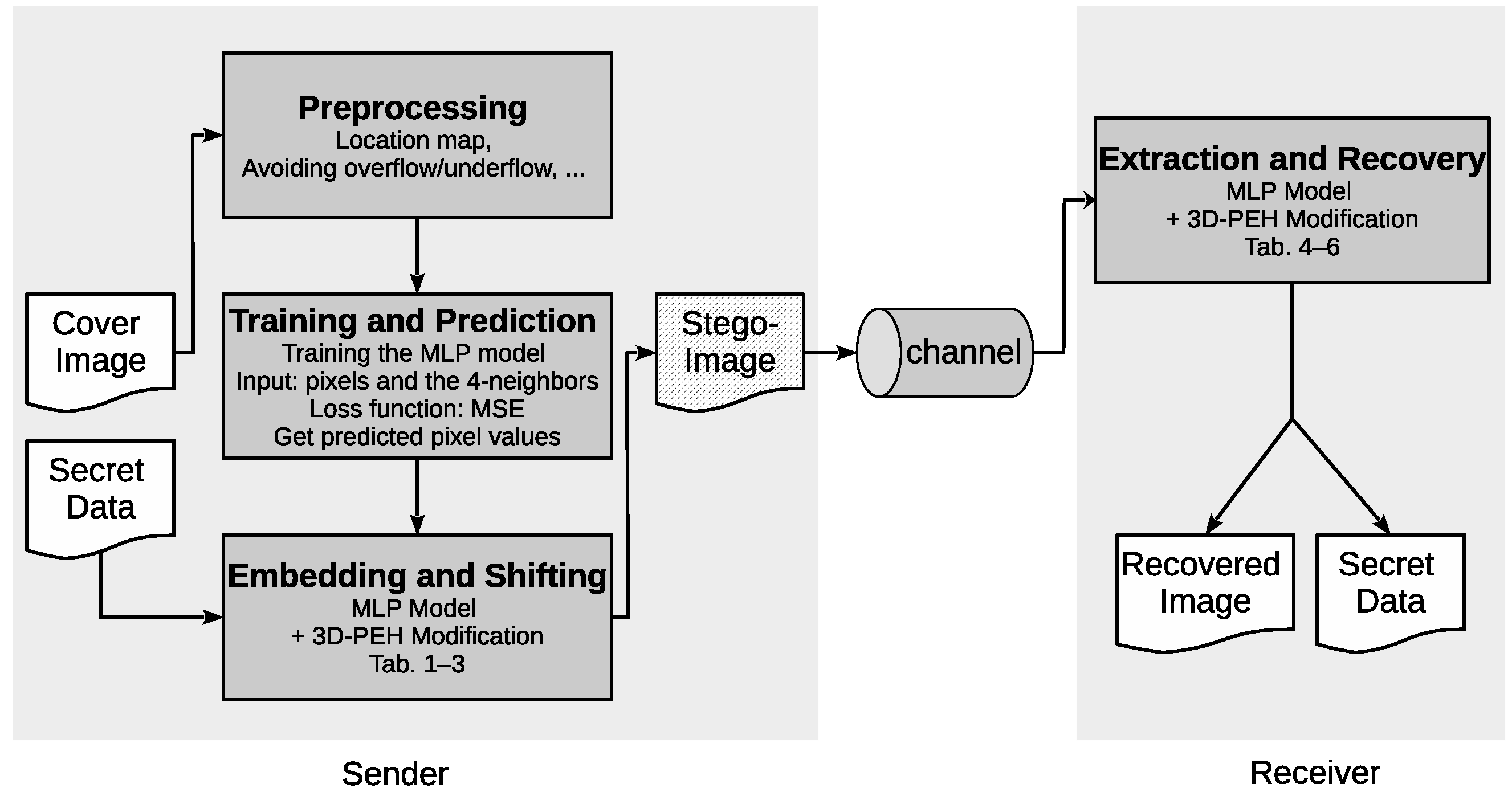
3. The Proposed Approach
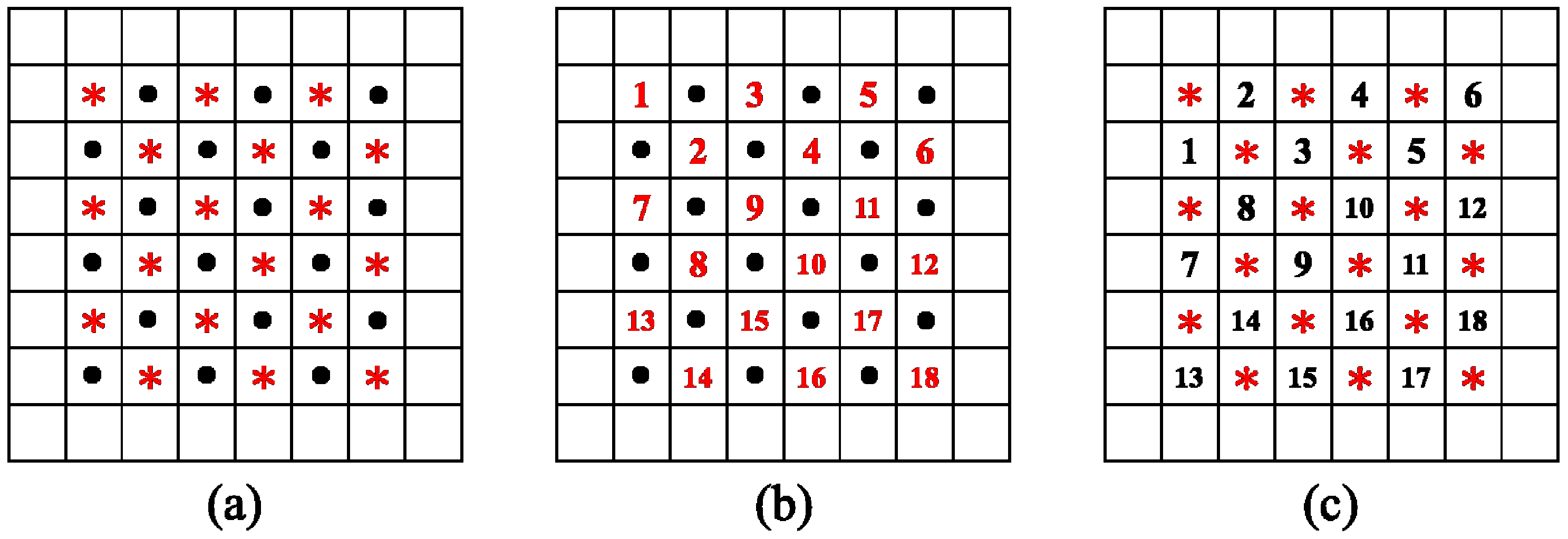
3.1. The Pre-Processing Phase
3.2. The Training and Prediction Phase
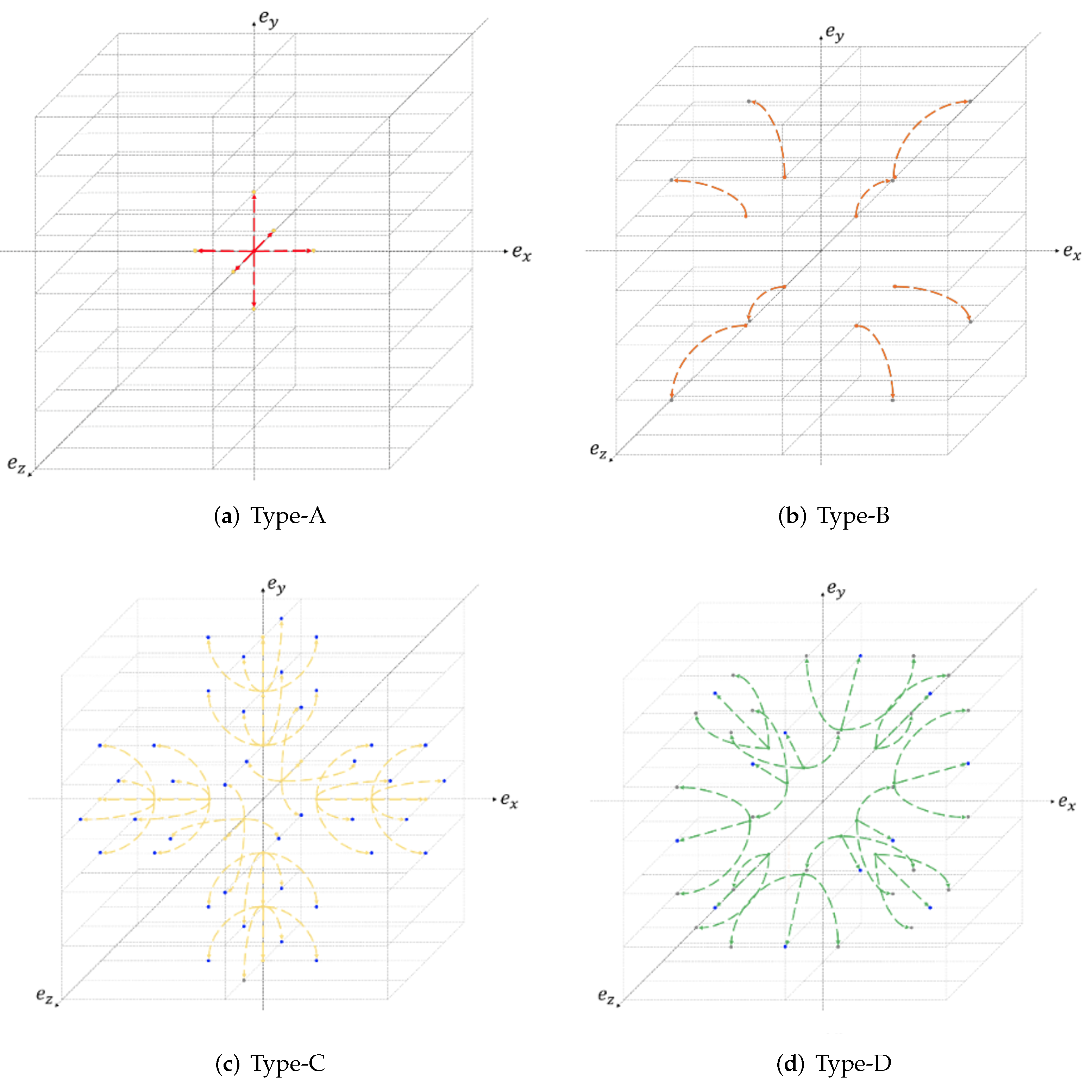
3.3. The Embedding and Shifting Phase
- Step 1:
- 1.
- Get the three bits from : . This is a Type-A case.
- 2.
- Get three bits from if the first two bits are . Since the secret bits are , we have .
- 3.
- Get three units from and derive .
The results of this step are and . - Step 2:
- 1.
- Get three bits from : . This is a Type-A case.
- 2.
- Get two bits from . Since the secret bits are , we have .
- 3.
- Get three units from . and derive .
The results of this step are and . - Step 3:
- 1.
- Get three bits from : . This is a Type-B case.
- 2.
- Get one bit from . Since the secret bit is , we have .
- 3.
- Get three units from and derive = .
The results of this step are and . - Step 4:
- 1.
- Get three bits from : . This is a Type-C case.
- 2.
- Get three bits from if the secret bits are . Since the secret bit is , we have .
- 3.
- Get three units from . and derive
The results of this step are and . - Step 5:
- 1.
- Get three bits from : . This is a Type-C case.
- 2.
- Get two bits from if the secret bits are not . Since the secret bit is , we have .
- 3.
- Get three units from . and derive .
The results of this step are and .
3.4. The Extraction and Recovery Phase
- Step 1:
- 1.
- Get the three bits from : . This is a Type- case. The extracted secret bits are .
- 2.
- Get three bits from . Then, we can derive .
The results of this step are and . - Step 2:
- 1.
- Get the three bits from : . This is a Type- case. The extracted secret bits are .
- 2.
- Get three bits from . Then, we can derive .
The results of this step are and . - Step 3:
- 1.
- Get the three bits from : . This is a Type- case. The extracted secret bits are .
- 2.
- Get three bits from . Then, we can derive .
The results of this step are and . - Step 4:
- 1.
- Get the three bits from : . This is a Type- case. The extracted secret bits are .
- 2.
- Get three bits from . Then, we can derive .
The results of this step are and . - Step 5:
- 1.
- Get the three bits from : . This is a Type- case. The extracted secret bits are .
- 2.
- Get three bits from . Then, we can derive .
The results of this step are and .
4. Computational Complexity
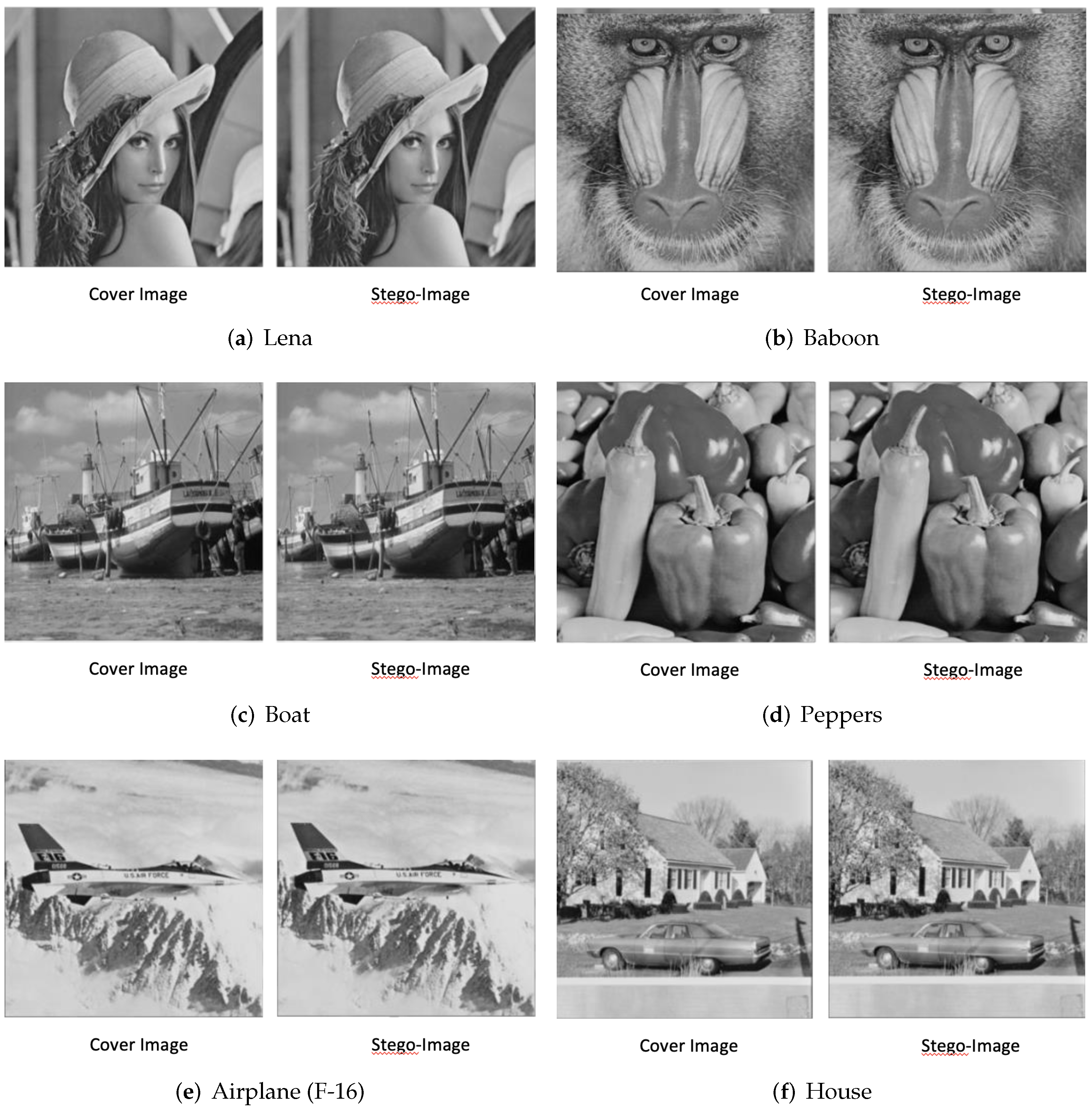
5. Experimental Results
5.1. Performance Comparison between the Proposed Method and Baseline Approaches
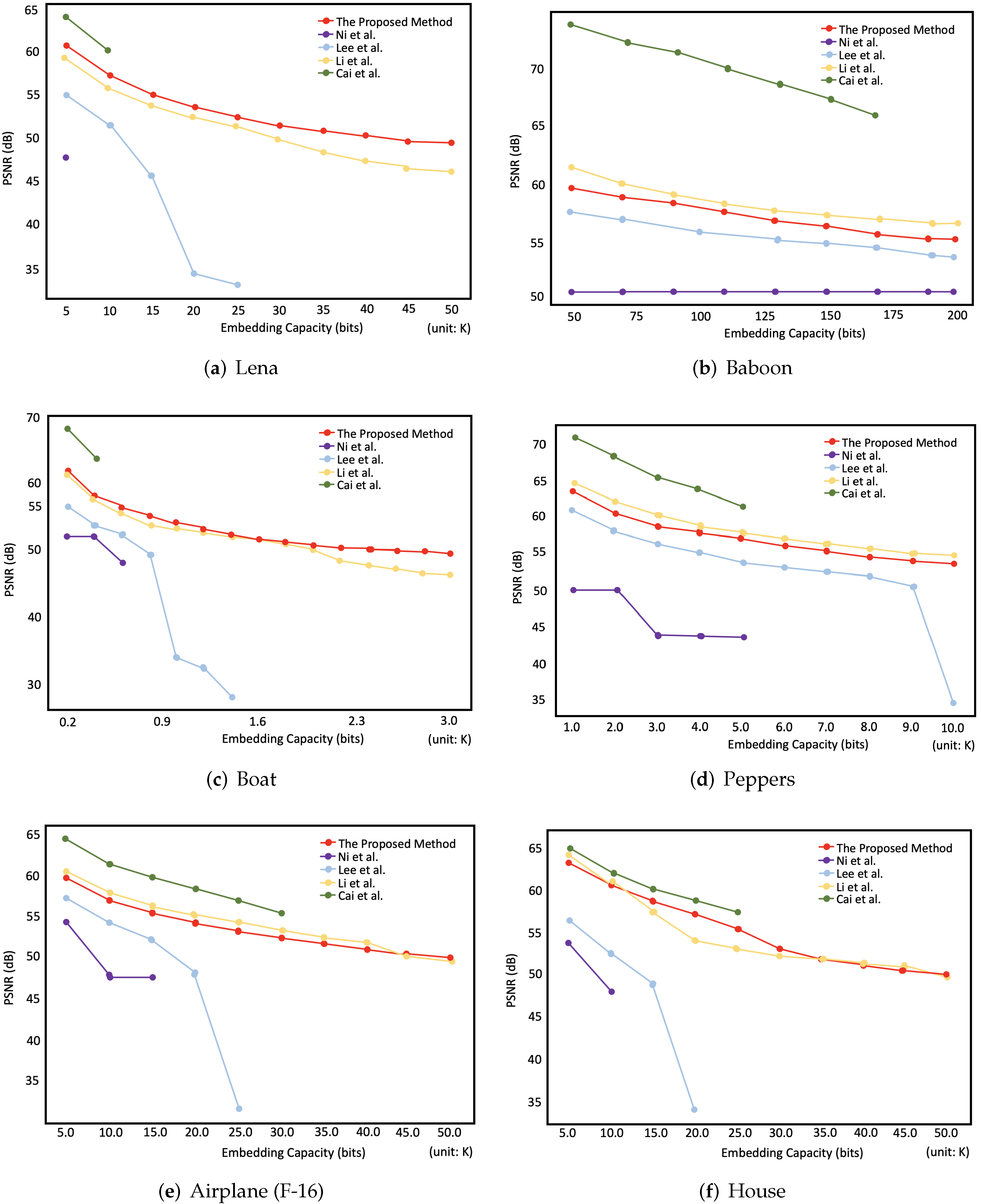
5.1.1. Maximum Embedding Capacity
5.1.2. Embedding Capability in Different Embedding Capacities
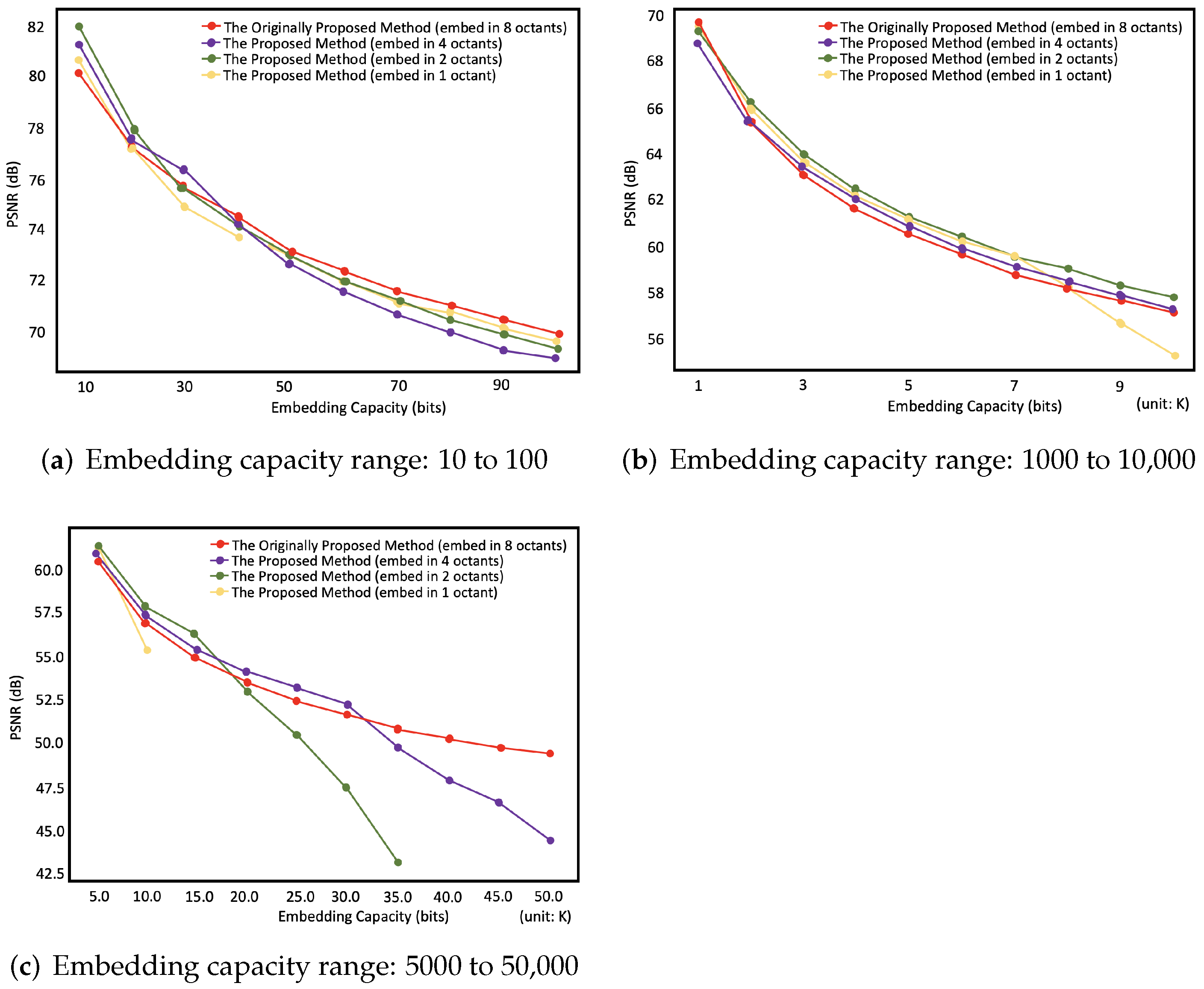
5.2. Comparison between the Proposed Method and the Different Embedding Methods with Different Octant Embed Number
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yu, J.; Zhang, J. Recent progress on high-speed optical transmission. Digit. Commun. Netw. 2016, 2, 65–76. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Wu, N.; Tsai, C.; Hwang, M. A high quality steganographic method with pixel-value differencing and modulus function. J. Syst. Softw. 2008, 81, 150–158. [Google Scholar] [CrossRef]
- Alattar, A.M. Reversible watermark using the difference expansion of a generalized integer transformation. IEEE Trans. Image Process. 2004, 13, 1147–1156. [Google Scholar] [CrossRef] [PubMed]
- Shi, Y.Q. Reversible data hiding. In Proceedings of the International Workshop on Digital Watermarking (IWDW’04), Seoul, Korea, 30 October–1 November 2004; pp. 1–12. [Google Scholar]
- Cai, S.; Li, X.; Liu, J.; Guo, Z. A new reversible data hiding scheme exploiting high-dimensional prediction-error histogram. In Proceedings of the IEEE International Conference on Image Processing (ICIP’16), Phoenix, AZ, USA, 25–28 September 2016; pp. 2732–2736. [Google Scholar]
- Shi, Y.Q.; Li, X.; Zhang, X.; Wu, H.T.; Ma, B. Reversible data hiding: Advances in the past two decades. IEEE Access 2016, 4, 3210–3237. [Google Scholar] [CrossRef]
- Almohammad, A.; Ghinea, G. Stego image quality and the reliability of PSNR. In Proceedings of the 2nd International Conference on Image Processing Theory, Tools and Applications (IPTA’10), Paris, France, 7–10 July 2010; pp. 215–220. [Google Scholar]
- Thodi, D.M.; Rodriguez, J.J. Expansion embedding techniques for reversible watermarking. IEEE Trans. Image Process. 2007, 16, 721–730. [Google Scholar] [CrossRef] [PubMed]
- Honga, W.; Chen, T.S.; Shiua, C.W. Reversible data hiding for high quality images using modification of prediction errors. J. Syst. Softw. 2009, 82, 1833–1842. [Google Scholar] [CrossRef]
- Ou, B.; Li, X.; Zhao, Y.; Ni, R.; Shi, Y.Q. Pairwise prediction-error expansion for efficient reversible data hiding. IEEE Trans. Image Process. 2013, 22, 5010–5021. [Google Scholar] [CrossRef] [PubMed]
- Caciula, I.; Coltuc, D. Improved control for low bit-rate reversible watermarking. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP’14), Florence, Italy, 4–9 May 2014; pp. 7425–7429. [Google Scholar]
- Dragoi, I.C.; Coltuc, D. Local-prediction-based difference expansion reversible watermarking. IEEE Trans. Image Process. 2014, 23, 1779–1790. [Google Scholar] [CrossRef]
- Dragoi, I.; Coltuc, D. On local prediction based reversible watermarking. IEEE Trans. Image Process. 2015, 24, 1244–1246. [Google Scholar] [CrossRef]
- Gui, X.; Li, X.; Yang, B. High-dimensional histogram utilization for reversible data hiding. In Proceedings of the International Workshop on Digital Watermarking (IWDW’14), Taipei, Taiwan, 1–4 October 2014; pp. 243–253. [Google Scholar]
- Hwang, H.J.; Kim, H.J.; Sachnev, V.; Joo, S.H. Reversible watermarking method using optimal histogram pair shifting based on prediction and sorting. KSII Trans. Internet Inf. Syst. 2010, 4, 655–670. [Google Scholar] [CrossRef]
- Hu, Y.; Lee, H.K.; Li, J. DE-based reversible data hiding with improved overflow location map. IEEE Trans. Circuits Syst. Video Technol. 2008, 19, 250–260. [Google Scholar]
- Jiang, R.; Zhang, W.; Hou, D.; Wang, H.; Yu, N. Reversible data hiding for 3D mesh models with three-dimensional prediction-error histogram modification. Multimed. Tools Appl. 2018, 77, 5263–5280. [Google Scholar] [CrossRef]
- Kamstra, L.; Heijmans, H.J.A.M. Reversible data embedding into images using wavelet techniques and sorting. IEEE Trans. Image Process. 2005, 14, 2082–2090. [Google Scholar] [CrossRef]
- Luo, L.; Chen, Z.; Chen, M.; Zeng, X.; Xiong, Z. Reversible image watermarking using interpolation technique. IEEE Trans. Inf. Forensics Secur. 2009, 5, 187–193. [Google Scholar]
- Li, X.; Li, J.; Li, B.; Yang, B. High-fidelity reversible data hiding scheme based on pixel-value-ordering and prediction-error expansion. Signal Process. 2013, 93, 198–205. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Gui, X.; Yang, B. A novel reversible data hiding scheme based on two-dimensional difference-histogram modification. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1091–1110. [Google Scholar]
- Li, X.; Zhang, W.; Gui, X.; Yang, B. Efficient reversible data hiding based on multiple histograms modification. IEEE Trans. Inf. Forensics Secur. 2015, 10, 2016–2027. [Google Scholar] [CrossRef]
- Qin, C.; Chang, C.C.; Huang, Y.H.; Liao, L.T. An inpainting-assisted reversible steganographic scheme using a histogram shifting mechanism. IEEE Trans. Circuits Syst. Video Technol. 2012, 23, 1109–1118. [Google Scholar] [CrossRef]
- Sachnev, V.; Kim, H.J.; Nam, J.; Suresh, S.; Shi, Y.Q. Reversible watermarking algorithm using sorting and prediction. IEEE Trans. Circuits Syst. Video Technol. 2009, 19, 989–999. [Google Scholar] [CrossRef]
- Xuan, G.; Shi, Y.Q.; Chai, P.; Cui, X.; Ni, Z.C.; Tong, X.F. Optimum histogram pair based image lossless data embedding. In Proceedings of the International Workshop on Digital Watermarking (IWDW’07), Guangzhou, China, 3–5 December 2007; pp. 264–278. [Google Scholar]
- Xuan, G.; Tong, X.; Teng, J.; Zhang, X.; Shi, Y.Q. Optimal histogram-pair and prediction-error based image reversible data hiding. In Proceedings of the International Workshop on Digital Watermarking (IWDW’12), Shanghai, China, 31 October–3 November 2012; pp. 368–383. [Google Scholar]
- Wang, J.; Ni, J.; Zhang, X.; Shi, Y.Q. Rate and distortion optimization for reversible data hiding using multiple histogram shifting. IEEE Trans. Cybern. 2016, 47, 315–326. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Schalkoff, R.J. Pattern Recognition: Statistical. Structural and Neural Approaches; Wiley: New York, NY, USA, 2007. [Google Scholar]
- Salgado, C.M.; Dam, R.S.F.; Salgado, W.L.; Werneck, R.R.A.; Pereira, C.M.N.A.; Schirru, R. The comparison of different multilayer perceptron and general regression neural networks for volume fraction prediction using MCNPX code. Appl. Radiat. Isot. 2020, 162, 109170. [Google Scholar] [CrossRef] [PubMed]
- Sharifzadeh, F.; Akbarizadeh, G.; Kavian, Y.S. Ship classification in SAR images using a new hybrid CNN–MLP classifier. J. Indian Soc. Remote Sens. 2019, 47, 551–562. [Google Scholar] [CrossRef]
- Heidari, A.A.; Faris, H.; Aljarah, I.; Mirjalili, S. An efficient hybrid multilayer perceptron neural network with grasshopper optimization. Soft Comput. 2019, 23, 7941–7958. [Google Scholar] [CrossRef]
- Fath, A.H.; Madanifar, F.; Abbasi, M. Implementation of multilayer perceptron (MLP) and radial basis function (RBF) neural networks to predict solution gas-oil ratio of crude oil systems. Petroleum 2020, 6, 80–91. [Google Scholar] [CrossRef]
- Janani, V.; Maadhuryaa, N.; Pavithra, D.; Sree, S.R. Dengue prediction using (MLP) multilayer perceptron—A machine learning approach. Int. J. Res. Eng. Sci. Manag. 2020, 3, 226–231. [Google Scholar]
- Fridrich, J.; Goljan, M.; Du, R. Invertible authentication. In Security and Watermarking of Multimedia Contents III; SPIE: Bellingham, WA, USA, 2001; Volume 4314, pp. 197–208. [Google Scholar]
- Goljan, M.; Fridrich, J.; Du, R. Distortion-free data embedding for images. In Proceedings of the International Workshop on Information Hiding (IHW’01), Pittsburgh, PA, USA, 25–27 April 2001; pp. 27–41. [Google Scholar]
- Goljan, M.; Fridrich, J.; Du, R. Lossless data embedding: New paradigm in digital watermarking. EURASIP J. Adv. Signal Process. 2002, 2002, 185–196. [Google Scholar]
- Xuan, G.; Chen, J.; Zhu, J.; Shi, Y.Q.; Ni, Z.; Su, W. Lossless data hiding based on integer wavelet transform. In Proceedings of the IEEE Workshop on Multimedia Signal Processing (MMSP’02), St. Thomas, VI, USA, 9–11 December 2002; pp. 312–315. [Google Scholar]
- Xuan, G.; Zhu, J.; Chen, J.; Shi, Y.Q.; Ni, Z.; Su, W. Distortionless data hiding based on integer wavelet transform. Electron. Lett. 2002, 38, 1646–1648. [Google Scholar] [CrossRef]
- Celik, M.U.; Sharma, G.; Tekalp, A.M.; Saber, E. Reversible data hiding. In Proceedings of the IEEE International Conference on Image Processing (ICIP’02), Rochester, NY, USA, 22–25 September 2002; pp. 157–160. [Google Scholar]
- Celik, M.; Sharma, G.; Tekalp, A.; Saber, E. Lossless generalized-LSB data embedding. IEEE Trans. Image Process. 2005, 14, 253–266. [Google Scholar] [CrossRef] [PubMed]
- Celik, M.U.; Sharma, G.; Tekalp, A.M. Lossless watermarking for image authentication: A new framework and an implementation. IEEE Trans. Image Process. 2006, 15, 1042–1049. [Google Scholar] [CrossRef] [PubMed]
- Chang, C.C.; Kieu, T.D. A reversible data hiding scheme using complementary embedding strategy. Inf. Sci. 2010, 180, 3045–3058. [Google Scholar] [CrossRef]
- Malik, A.; Singh, S.; Kumar, R. Recovery based high capacity reversible data hiding scheme using even-odd embedding. Multimed. Tools Appl. 2018, 77, 15803–15827. [Google Scholar] [CrossRef]
- Kumar, R.; Chand, S.; Singh, S. A reversible data hiding scheme using pixel location. Int. Arab J. Inf. Technol. 2018, 15, 763–768. [Google Scholar]
- Ni, Z.; Shi, Y.Q.; Ansari, N.; Su, W. Reversible data hiding. IEEE Trans. Circuits Syst. Video Technol. (TCSVT’06) 2006, 16, 354–362. [Google Scholar]
- Lee, S.K.; Suh, Y.H.; Ho, Y.S. Reversible image authentication based on watermarking. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME’06), Toronto, ON, Canada, 9–12 July 2006; pp. 1321–1324. [Google Scholar]
- Lin, S.J.; Chung, W.H. The scalar scheme for reversible information-embedding in gray-scale signals: Capacity evaluation and code constructions. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1155–1167. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X. Reversible data hiding with optimal value transfer. IEEE Trans. Multimed. 2012, 15, 316–325. [Google Scholar] [CrossRef]
- Zhang, W.; Hu, X.; Li, X.; Yu, N. Recursive histogram modification: Establishing equivalency between reversible data hiding and lossless data compression. IEEE Trans. Image Process. 2013, 22, 2775–2785. [Google Scholar] [CrossRef]
- Zhan, Y.; Su, Y.; Wang, X.; Pei, Q. Three-dimensional prediction-error histograms based reversible data hiding algorithm for color images. Multimed. Tools Appl. 2019, 78, 35289–35311. [Google Scholar] [CrossRef]
- Kumar, R.; Chand, S.; Singh, S. An improved histogram-shifting-imitated reversible data hiding based on HVS characteristics. Multimed. Tools Appl. 2018, 77, 13445–13457. [Google Scholar] [CrossRef]
- Wang, Z.H.; Lee, C.F.; Chang, C.Y. Histogram-shifting-imitated reversible data hiding. J. Syst. Softw. 2013, 86, 315–323. [Google Scholar] [CrossRef]
- Kaur, G.; Singh, S.; Rani, R.; Kumar, R. A comprehensive study of reversible data hiding (RDH) schemes based on pixel value ordering (PVO. Arch. Comput. Methods Eng. 2020, 28, 3517–3568. [Google Scholar] [CrossRef]
- Kaur, G.; Singh, S.; Rani, R. PVO based reversible data hiding technique for roughly textured images. Multidimens. Syst. Signal Process. 2021, 32, 533–558. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RDH Method Types | Image Quality | Embedding Capacity |
|---|---|---|
| Lossless-compression | × | × |
| Integer-transform | ||
| Two-phased embedding+location maps | ∘ | ∘ |
| Histogram modification | ∘ | ⊚ |
| Methods | Characteristics | Image Quality (PSNR (dB)) | Embedding Capacity (bits) |
|---|---|---|---|
| Ni et al. [46] | first histogram modification/baseline | ||
| Lee et al. [47] | image-difference histogram | ||
| Li et al. [21] | 2D-PEH modification | 24,612.50 | |
| Cai et al. [5] | 3D-PEH modification (1st octant) | ||
| Our method | 3D-PEH + MLP Prediction (8 octants) | 48.55 | 48,344.17 |
| Type | Secret Bits | EC (bits) | |||
|---|---|---|---|---|---|
| A | 3 | ||||
| A | 2 | ||||
| B | 1 | ||||
| C | , | 3 | |||
| C | , | 2 | |||
| C | , | 3 | |||
| C | , | 2 | |||
| C | , | 3 | |||
| C | , | 2 |
| Type | Secret Bits | EC (bits) | |||
|---|---|---|---|---|---|
| D | 2 | ||||
| D | 2 | ||||
| D | 2 | ||||
| E | , | 2 | |||
| E | , | 1 | |||
| E | , | 2 | |||
| E | , | 1 | |||
| E | , | 2 | |||
| E | , | 1 | |||
| F | , | 1 | |||
| F | , | 1 | |||
| F | , | 1 |
| Type | Secret Bits | EC (bits) | |||
|---|---|---|---|---|---|
| G | , and | – | – |
| Type | Extracted Secret Bits | |||
|---|---|---|---|---|
| , , , , , | , , | |||
| , , , , , | , , | |||
| , , , , , | , , |
| Type | Extracted Secret Bits | |||
|---|---|---|---|---|
| , , , | ||||
| , , , | ||||
| , , , | ||||
| , , | ||||
| , , | ||||
| , , |
| Type | Extracted Secret Bits | |||
|---|---|---|---|---|
| , , , | no embedded data bit |
| Image | Ni et al. | Lee et al. | Li et al. | Cai et al. | Our Method |
|---|---|---|---|---|---|
| Lena | 2785 | 10,139 | 24,255 | 7964 | 59,751 |
| Baboon | 2717 | 4069 | 9885 | 990 | 19,136 |
| Boat | 5796 | 7193 | 17,295 | 2923 | 37,938 |
| Peppers | 2753 | 8591 | 19,687 | 3040 | 35,402 |
| Aiprplain (F-16) | 8155 | 15,797 | 39,843 | 21,300 | 66,465 |
| House | 7336 | 12,585 | 36,710 | 20,448 | 71,373 |
| Average | 4923.67 | 9729.00 | 24,612.50 | 9444.17 | 48,344.17 |
| Image | Ni et al. | Lee et al. | Li et al. | Cai et al. | Our Method |
|---|---|---|---|---|---|
| Lena | 53.70 | 51.72 | 51.60 | 62.16 | 48.64 |
| Baboon | 51.96 | 51.35 | 51.34 | 70.84 | 48.26 |
| Boat | 51.97 | 51.52 | 51.47 | 66.26 | 48.41 |
| Peppers | 52.49 | 51.60 | 51.51 | 65.92 | 48.39 |
| Aiprplain (F-16) | 54.21 | 52.16 | 51.90 | 58.27 | 48.75 |
| House | 53.91 | 52.14 | 51.83 | 58.86 | 48.84 |
| Average | 53.04 | 51.75 | 51.07 | 63.72 | 48.55 |
| Image | Ni et al. | Lee et al. | Li et al. | Cai et al. | Our Method |
|---|---|---|---|---|---|
| Lena | 53.75 | 63.17 | 66.84 | 71.30 | 69.62 |
| Baboon | 50.47 | 55.81 | 58.59 | 70.78 | 57.90 |
| Boat | 52.07 | 60.28 | 64.63 | 70.96 | 64.97 |
| Peppers | 50.14 | 61.14 | 64.93 | 70.94 | 63.61 |
| Aiprplain (F-16) | 54.46 | 63.29 | 66.68 | 71.28 | 66.21 |
| House | 54.11 | 67.52 | 72.41 | 72.32 | 68.51 |
| Average | 52.50 | 61.87 | 65.68 | 71.26 | 65.14 |
| Image | Ni et al. | Lee et al. | Li et al. | Cai et al. | Our Method |
|---|---|---|---|---|---|
| Lena | 47.81 | 55.14 | 59.50 | 54.14 | 60.59 |
| Baboon | 44.41 | 47.23 | 53.89 | – | 52.52 |
| Boat | 51.99 | 52.98 | 56.55 | – | 57.27 |
| Peppers | 44.08 | 53.96 | 57.82 | 61.52 | 57.00 |
| Airplane (F-16) | 54.31 | 57.34 | 60.50 | 64.29 | 59.86 |
| House | 53.98 | 56.60 | 64.53 | 65.28 | 63.48 |
| Average | 49.43 | 53.88 | 58.80 | 63.81 | 58.45 |
| Image | Ni et al. | Lee et al. | Li et al. | Cai et al. | Our Method |
|---|---|---|---|---|---|
| Lena | – | 51.79 | 55.90 | 60.32 | 57.15 |
| Baboon | – | – | 50.93 | – | 50.62 |
| Boat | 48.24 | 46.25 | 53.35 | – | 54.00 |
| Peppers | – | 48.66 | 54.53 | – | 54.11 |
| Airplane (F-16) | 48.10 | 54.47 | 57.87 | 61.43 | 57.18 |
| House | 48.35 | 52.80 | 61.09 | 62.25 | 60.68 |
| Average | 48.23 | 50.79 | 55.61 | 61.33 | 55.62 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hung, C.-C.; Lin, C.-C.; Wu, H.-C.; Lin, C.-W. A Study on Reversible Data Hiding Technique Based on Three-Dimensional Prediction-Error Histogram Modification and a Multilayer Perceptron. Appl. Sci. 2022, 12, 2502. https://doi.org/10.3390/app12052502
Hung C-C, Lin C-C, Wu H-C, Lin C-W. A Study on Reversible Data Hiding Technique Based on Three-Dimensional Prediction-Error Histogram Modification and a Multilayer Perceptron. Applied Sciences. 2022; 12(5):2502. https://doi.org/10.3390/app12052502
Chicago/Turabian StyleHung, Chih-Chieh, Chuang-Chieh Lin, Hsien-Chu Wu, and Chia-Wei Lin. 2022. "A Study on Reversible Data Hiding Technique Based on Three-Dimensional Prediction-Error Histogram Modification and a Multilayer Perceptron" Applied Sciences 12, no. 5: 2502. https://doi.org/10.3390/app12052502