1. Introduction
Cyber defense is a continuous process that entails tasks, such as prevention, detection, and recovery, which are applied at various system levels. Network intrusion detection is a branch of cyber security that deals with the detection of attacks at the network layer level.
Network intrusion detection techniques can be broadly divided into two types: signature-based and anomaly-based methods [
1]. Signature-based methods operate by matching incoming network traffic against a predefined set of known attack signatures. Thus, they perform well in detecting previously known attack signatures; however, signature-based methods fail to detect novel attacks [
2]. On the other hand, anomaly-based methods, which entail machine learning methods, operate by modeling normal network traffic data and then flag any network traffic that deviates from the model pattern as an anomaly. However, these approaches sometimes lead to too many false alarm rates (FARs).
Network intrusion detection using machine learning methods has been studied for a long time, with many commercial intrusion detection systems (IDSs) using machine learning algorithms as part of their detection engines [
3].
Recently, technologies such as cloud computing, IoT, and 5G have led to an explosion in the volume and diversity of network traffic, which provide fertile ground for applying deep learning (DL) techniques. Deep learning techniques are end-to-end learning models, capable of learning highly complex non-linear functions, which enable them to learn powerful representations directly from input data [
4]. Thus, recent research on intrusion detection system (IDS) methods are mostly focused on this area [
5].
However, network IDSs based on supervised deep learning techniques require huge amounts of labeled data in order to generalize well. Collecting a large-scale malicious sample to train DL classifiers is prohibitively expensive, and subject to obsolescence as the landscape is constantly evolving. Regardless, unsupervised anomaly-based methods provide an alternative towards generalization of an unseen malicious sample, and these approaches are highly susceptible to false alarm rates [
6]. Hence, there has been an increase in interest from the research community towards approaches that require a handful of samples to achieve detection. Since collecting a few samples of malicious traffic is more realistic in a practical settings, which, for instance, can be realized from a few successfully detected intrusions from a deployed detection system, few-shot learning is emerging as an alternative to conventional supervised learning methods to simulate more realistic settings.
Few-shot learning measures the challenging issue of a model’s ability to generalize new tasks using limited data [
7]. This was addressed recently, based on the idea of meta-learning or “learning to learn” [
8,
9,
10,
11,
12]. The meta-learning paradigm consist of two disjointed stages: meta-training and meta-testing. Each of the meta stages consists of a number of classification tasks with limited training data that require fast adaptability by the learner. The goal is to leverage the meta-training stage to learn transferable knowledge from a set of tasks that will enable fast adaptability to novel tasks in the testing stage.
However, recently, it has been established that good learned representations are very powerful for few-shot classification tasks, and perform on par with, or slightly worse than, the current set of complicated meta-learning algorithms [
13,
14,
15]. Therefore, in this paper we propose a simple framework that relies on learning good representations to achieve few-shot intrusion detection. Our approach consists of a linear model trained on top of a pre-trained feature extractor model. The feature extractor model is trained to learn good representations using a discriminative autoencoder.
In contrast to conventional autoencoders, which are purely unsupervised representation learning methods, discriminative autoencoders are a form of supervised autoencoders that leverages the class information of their inputs. Thus, they combine both reconstruction and classification errors in their objective functions. This makes the representations learned by discriminative autoencoders more discriminative and more suitable for classification tasks [
16,
17].
The remainder of the paper is organized as follows:
Section 2 presents the related work,
Section 3 presents our problem formulation of few-shot intrusion detection using discriminative autoencoders,
Section 4 presents the results and discussion of our experiments, and
Section 5 concludes the paper.
2. Related Works
Traditionally, networks are defended against intrusion using signature-based techniques, whereby incoming network traffic is compared against commonly known attack patterns. These approaches perform well against previously known attacks, but fail to detect novel attacks.
Classical machine learning (ML) methods provide an upgrade over traditional signature-based techniques. These methods exploit various features of network traffic, which enable them to detect attack signatures without explicit rule specifications [
18]. Thus, popular classical ML approaches, such as K-nearest neighbor (KNN) [
19], support vector machines (SVM) [
20], decision tree (DT) [
21], and random forest (RF) [
22], have all been employed as network-based IDSs.
For example, Kutrannont et al. [
23] proposed a KNN-based IDS. KNN operates based on the assumption that a sample belongs to the class where most of its top K-neighbors reside. Therefore, parameter K affects the performance of the model. In their work, Kutrannont et al. proposed the integration of a simplified neighborhood classification using a percentage instead of group rankings. Taking into account the unevenness of data distribution, the improve rule selects a fixed percentage (50%) of neighboring samples as neighbors and its efficiency is enhanced via parallel processing using a graphical processing unit (GPU). The algorithm performs well on sparse data, achieving an accuracy of 99.30%.
Goeschel et al. [
24] employed a combination of SVM, decision tree (DT), and naïve Bayes classifiers. The SVM was first trained to perform a binary classification to separate data instances into benign and malicious classes. The malicious classes are then categorized into specific classes of attacks using a DT classifier. However, since DT can only separate known classes of attacks, they further employed a naïve Bayes classifier to identify unknown attacks types. This hybrid method achieved an accuracy of 99.62% and a false alarm rate of 1.57%.
Malik et al. [
25] proposed an IDS using random forest (RF) and particle swarm optimization (PSO). They trained the IDS in two stages: feature selection and classification. The PSO serves as feature selection algorithm, which is used to select appropriate features for classifying attacks, while the RF is used as a classifier. They evaluated their approach using the KDD cup99 dataset, and achieved detection rates of 99.92%, 99.49%, and 88.46% on DoS, Probe, and U2R attack classes.
Recently, there has been widespread adoption of DL techniques for network-based IDSs for sizeable numbers of datasets. These techniques can operate directly on raw data, learn features, and perform classifications. Hence, they achieve better performances when compared to classical machine learning methods [
26]. Deep learning models, such as multi-layer perceptron (MLP), convolutional neural network (CNN), autoencoders (AE), recurrent neural network (RNN), as well as deep generative networks, such as the deep belief network (DBN) and generative adversarial networks (GANs) have all been applied in the context of network-intrusion detection [
27,
28].
Min et al. [
29] proposed an IDS named TR-IDS, which leverages both statistical features as well as payload features. They employed a CNN to extract important features from the payload. To accomplish this, they first encoded each byte in the payload in to a word vector using skip-gram word embedding, and then applied the CNN to extract the features. The extracted features were then combined with the statistical features generated from each network flow, which included fields from the packet header and statistical attributes of the entire flow. The features were then used to train a random forest classifier, which achieves an accuracy of 99.13%.
In the work by Yin et al. [
30], a recurrent neural network (RNN) was directly applied for intrusion detection tasks. The RNN model achieved better performance on a NSL-KDD dataset when compared with classical ML techniques consisting of support vector machines and random forest.
Wang et al. employed a combination of CNN and long short-term memory (LSTM). Intuitively, the CNN learns the low-level spatial features of network traffic, while the LSTM learns the high-level temporal features of the data. The learned features enable the model to improve the false alarm rate of an IDS [
31].
In another work, Al Qatf et al. employed a sparse autoencoder (AE) for dimensionality reduction and the reduced features are then retrained using the SVM classifier. This enables the model to outperform classical machine learning methods [
32].
Similarly, in a recent work by Narayana et al., a hybrid methodology involving a sparse autoencoder, DNN, and LSTM was employed. In the first stage, the autoencoder is trained in an unsupervised fashion with smoothed l1 regularization to enforce sparsity. This enables the autoencoder to learn sparse representations, which are then used to train the MLP and LSTM classifiers in the second stage. The model performs better than conventional deep learning classifiers in terms of detection rates and low false positive rates [
33].
Another hybrid intrusion detection method that employs both classical machine learning and deep learning techniques was proposed by Le, et al. They first built a feature selection model termed a sequence forward selection (SFS) algorithm (SFSD) and a decision tree. The SFSD algorithm selects the best subset of features, which are then used in the second part to train various forms of RNN (traditional RNN, LSTM and gated recurrent neural network (GRU)). The model achieves significant improvements in detection rates when compared with classical methods [
34].
However, these techniques require huge amounts of labeled data during training in order to generalize well. The dynamic nature of the modern-day cyber-threat landscape makes it unfeasible or prohibitively expensive to acquire sufficient enough malicious samples to train deep learning classifiers. Therefore, a trend is developing towards techniques that require only a few shot of malicious examples to achieve detection.
For example, Hindy et al. proposed an intrusion detection model using one-shot learning. The main idea of one-shot learning is to learn patterns and similarities from previously seen classes that enable classifying unseen classes using only one instance. Thus, one-shot learning is an instance of few-shot learning, whereby the number of examples is restricted to only a single example [
35]. To model an IDS using one-shot learning, Hindy et al. employed a Siamese neural network, a form of neural network consisting of twin networks. The Siamese network is trained using two pairs of instances to learn patterns and similarities instead of fitting the model to fixed classes. Therefore, during the training stage, the Siamese network learns patterns and discriminate between benign traffic and different classes of a known cyber-attacks. At the evaluation stage, a new traffic instance is compared against all known classes (used during training) without any form of additional training. Although the approach provides a simple framework for one-shot learning, in general, they achieve lower detection rates relative to other works [
36].
In another work, Xu et al. proposed an intrusion detection method using few-shot learning. They employed a deep neural network architecture (DNN) named FC-Net, which is composed of two parts: a feature extraction network and a comparison network. FC-Net is trained using a meta-learning approach consisting of two disjointed stages of meta-training and meta-testing. In the meta-training phase, the feature extraction network of FC-Net is trained using several meta-tasks, where a meta-task is comprised of a binary classification between an attack category and benign traffic. This enables FC-Net to learn a pair of feature maps, which are then used by the comparison network in the meta-testing stage to determine whether a new traffic instance belongs to the different classes of attacks learned during training [
37]. However, one drawback with their approach is it requires a complex DNN architecture and computationally intensive optimization procedures.
3. Our Proposed Few-Shot Intrusion Detection Method
Supervised learning approaches for network intrusion detection require all categories of attacks to be known in advance, with a sufficient number of training examples available for each category. The basic task is to use a classifier, , to infer labels for network traffic samples, . The number of samples, , is often very large and is simply composed of two groups: a training set and a test set. Contrary to this, in real-world settings, new attacks frequently emerge, and only subset of categories are known beforehand, with few examples per category. Therefore, in such scenarios, where the number of samples, , is small, the problem is considered as a few-shot classification. Applying the conditions of a supervised learning method to this problem will encounter overfitting.
Few-shot learning is popularly addressed based on the meta-learning paradigm, which is composed of meta-training and meta-testing. Each one of the meta stages consists of a number of classification tasks, where each task describes a pair: training (support) and testing (query). The meta-training set is described as and the meta-testing set is , with each dataset containing pairs of data points and their ground-truth labels, i.e., and , which are sampled from the same distribution. The objective is to leverage the meta-training stage to learn good representations, which will enable it to adapt quickly to unseen tasks in the meta-testing stage, using powerful optimization techniques.
In a network intrusion detection context, a task, , can be simply defined as a binary classification between a normal network traffic sample and a category of malicious samples. Supposing that there are five different network traffic samples, and such that, sample is a benign network traffic, samples indicate known categories of attacks with sufficient examples, while the remaining sample, , refers to a newly found category of attack with a few examples. The goal is to identify the new attack sample, S, with as few examples as possible. Then, three different tasks can be constructed, and where and define a binary classification task between a normal sample and attack categories and . and constitute the meta-training set, while the meta-test set consists of a normal sample, , and the novel class, , which has few examples. The idea is to leverage the meta-training stage to learn transferable knowledge from and that will enable a classifier to accomplish task (a binary classification between normal sample and attack category ) with as few examples as possible during the meta-testing phase. Thus, in our case, a discriminative autoencoder was employed to acquire such transferable knowledge.
4. Evaluation
4.1. Evaluation Metrics
Accuracy, recall (detection rate) and precision are common metrics normally used when evaluating a classifier. Accuracy, which indicates the percentage of correctly classified data items, is a poor metric for a task where the dataset is largely skewed in favor of normal samples. Similarly, a high detection rate implies fewer chances of a model missing alarming anomalies, while a high precision highlights the ability of a model to classify normal data. We consider detection rate (DR) to be more significant in our case than precision; for example, if a model predicts a normal sample as an attack, it is easier to correct the prediction of the model through domain knowledge, since there are few attack samples. However, if the model fails to detect an attack, it is difficult to find the attack in such a huge dataset. Nonetheless, we consider all three metrics; when comparing our approach with baseline models, we only considered DR since it is more significant in our situation.
4.2. Datasets
We evaluated the performance of our approach against baseline models using the following network intrusion detection datasets: CIC-IDS2017 and NSL-KDD. The CIC-IDS2017 dataset reflects recent attacks, and, to some extent, it satisfies the criteria for reliable intrusion detection datasets proposed by [
39], which are anonymity, attack diversity, complete capture, complete interaction, complete network configuration, available protocol, complete traffic feature set, meta data, heterogeneity, and labeling.
The dataset was developed at the Canadian Institute of Cybersecurity of the University of New Brunswick (UNB) in 2017. The dataset comprises raw PCAP files, as well as 80 statistical features generated from the PCAP files, which were captured on different days of a week (from Monday to Friday). The dataset considers several attacks and sub-attacks, as depicted in
Table 1.
The NSL-KDD dataset was also generated at the Canadian Institute of Cybersecurity. This dataset was purposely created to solve the problem of the original KDDcup’99 dataset, which has about 78% and 75% of the training and testing set duplicated, respectively [
40]. The NSL-KDD rectifies this problem and still retains the original 41 features.
Table 2 depicts a breakdown of some of the attacks that exist in the dataset with more than five samples.
4.3. Implementation
We employed tensorflow 2.6 as the deep learning framework to implement our approach. We implemented the feature extractor module (discriminative autoencoder), and the classifier was a standard multi-layer perceptron (MLP) neural network.
Table 3 present the architectural details of the modules.
4.4. Experiments and Results
We conducted the following experiments to evaluate our few-shot detection approach.
4.4.1. Experiment 1: Detecting Mutants of Existing Attacks
The objective of this experiment was to evaluate our approach in detecting mutants of existing attacks. Malicious users develop mutants of existing attacks to evade detection, as conventional supervised learning models detect such mutants poorly, especially when there is significant variation with the known existing attack.
To accomplish this, we extracted categories of attacks, which we believed to comprise variants of one another in both the NSL-KDD and CIC-2017IDS datasets.
Table 1 and
Table 2 depict the compositions of such attack mutants.
To evaluate our approach in detecting a particular mutant, we utilized all the other mutants of the attack as a data source for the meta-training stage. For instance, if the attack mutant we wanted to detect was DoS hulk, then our meta-training data source will comprise all the other DoS subclasses (golden eye, slow loris, slow http test). The DoS hulk would then serve as the data source for the meta-testing stage. We then trained our feature extractor using the meta-training set. Thereafter, in the few-shot detection stage, we selected 10 samples of the meta-testing set and trained our classifier on top of our feature extractor. We applied the same logic to all attacks in both the NSL-KDD and CIC-IDS2017 datasets. However, we conducted this experiment on classes with sufficient numbers of samples. Therefore, on the NSL-KDD set we were able to perform the experiment on DoS and probe classes. While on the CIC-IDS2017 dataset, only the DoS class has a sufficient number of samples.
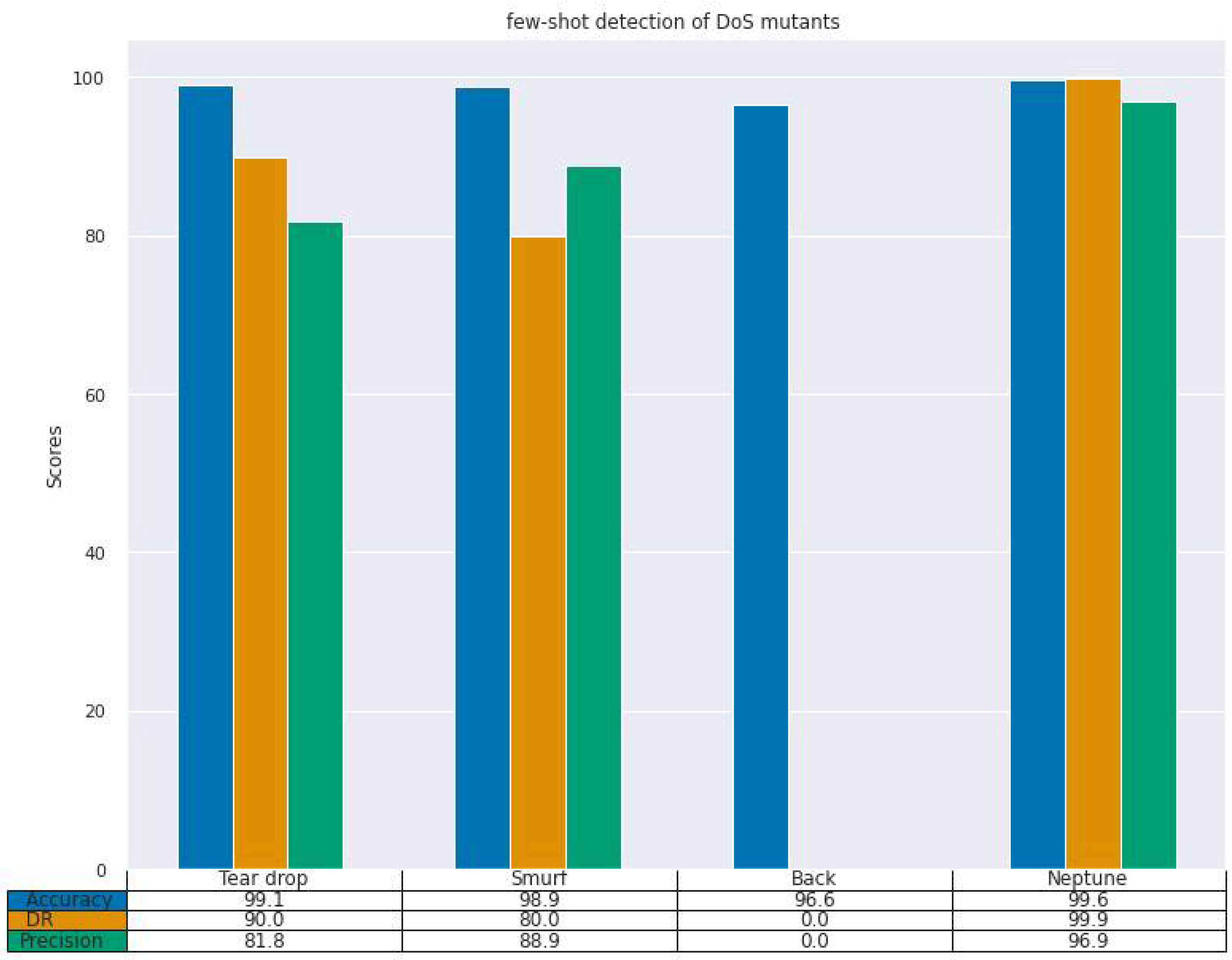
Figure 1,
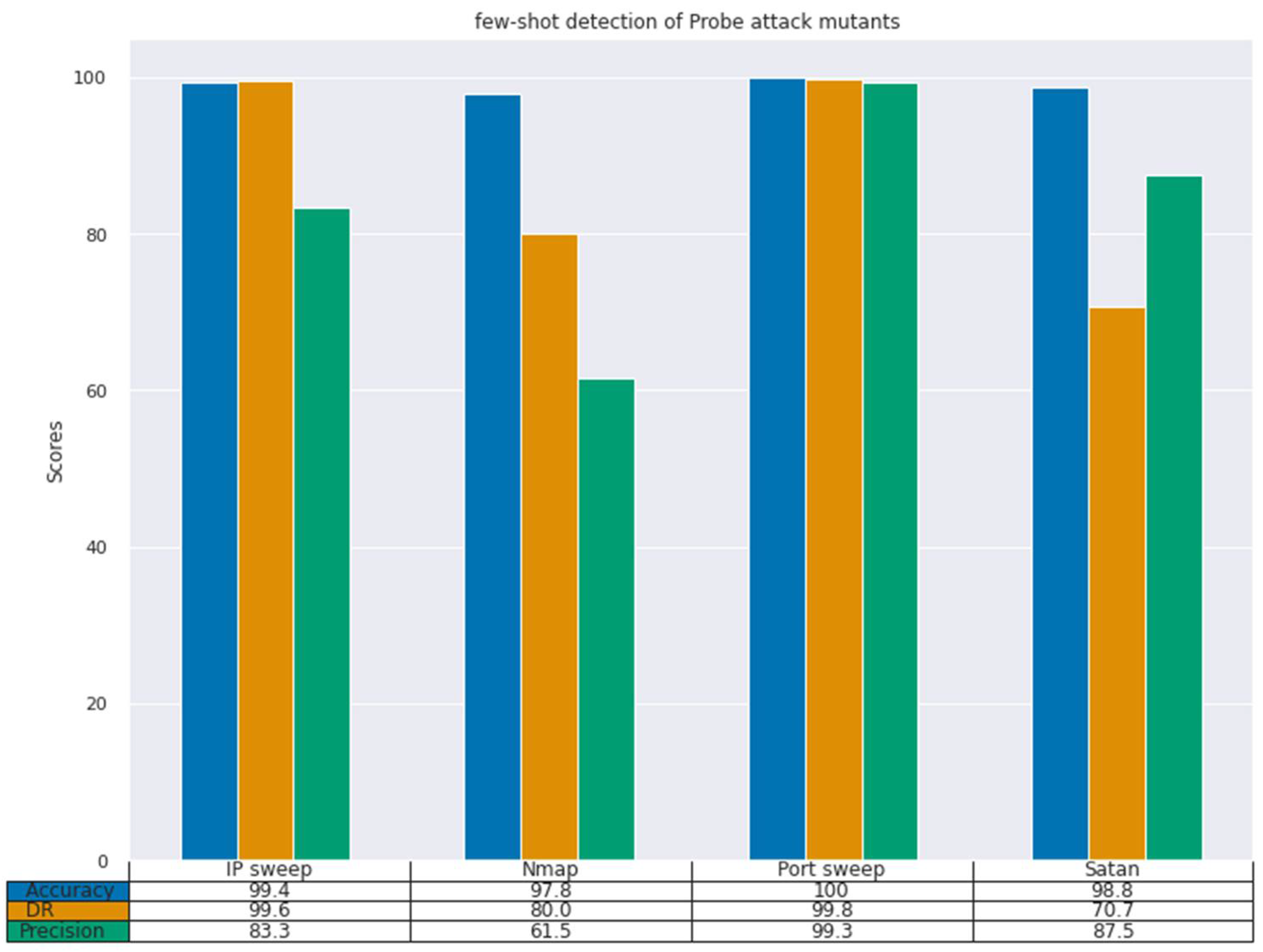
Figure 2 and
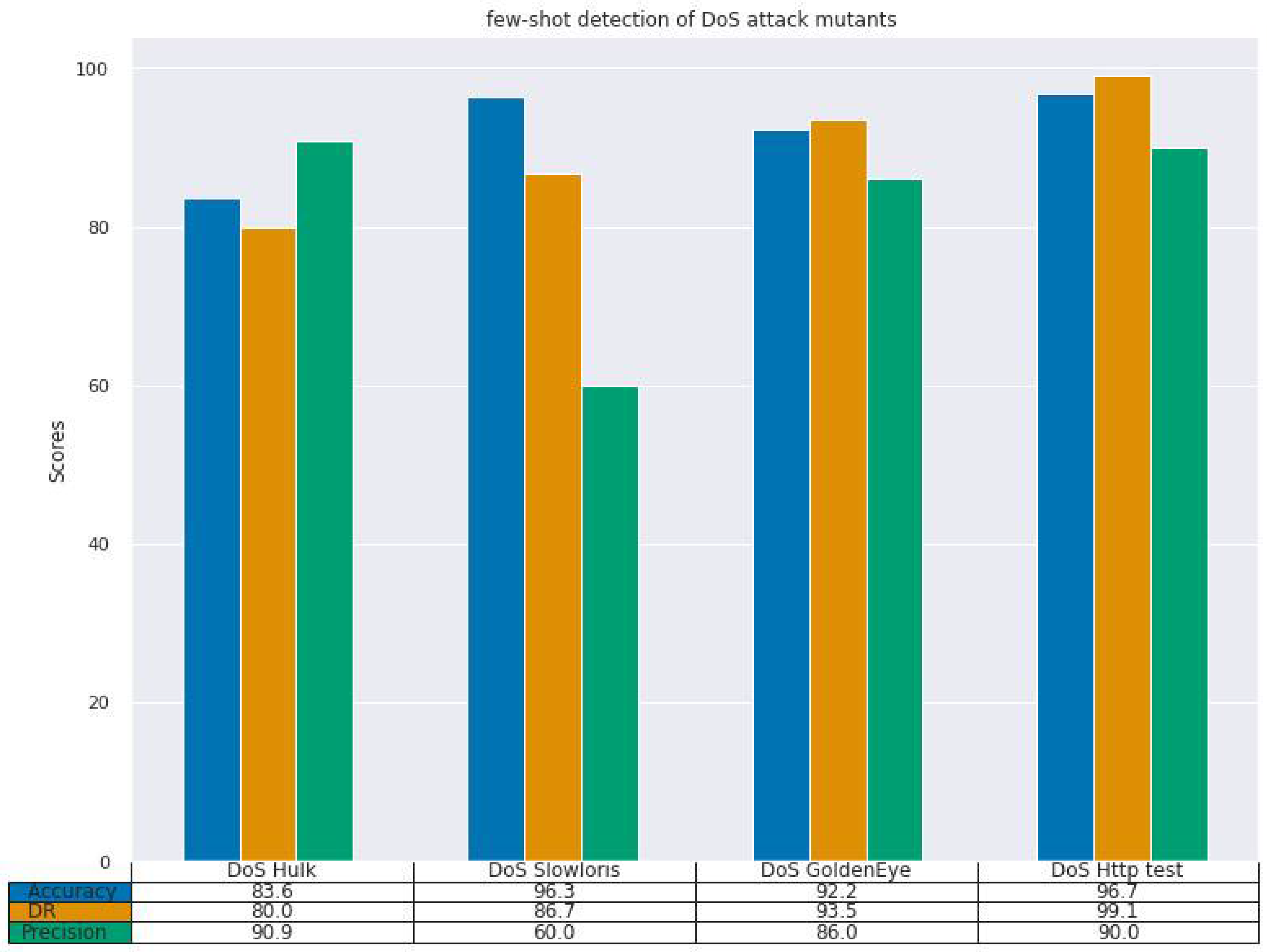
Figure 3 display the results of our experiment on both the CIC-IDS2017 and NSL-KDD datasets. As can be seen from the results, our model achieves the highest detection rate of 99.9% on DoS attack mutant Neptune (
Figure 1), followed by 90.0% and 80.0% on tear drop and smurf attack, respectively. These are good results, considering that we employed few-shots examples to train our classifier. However, our model achieves a DR of 0.0% on DoS attack mutant back. In fact, our model scores 0.0% on all the other performance metrics (accuracy and precision). This indicates that the DoS attack mutant back has significant variations with other DoS attack subclasses.
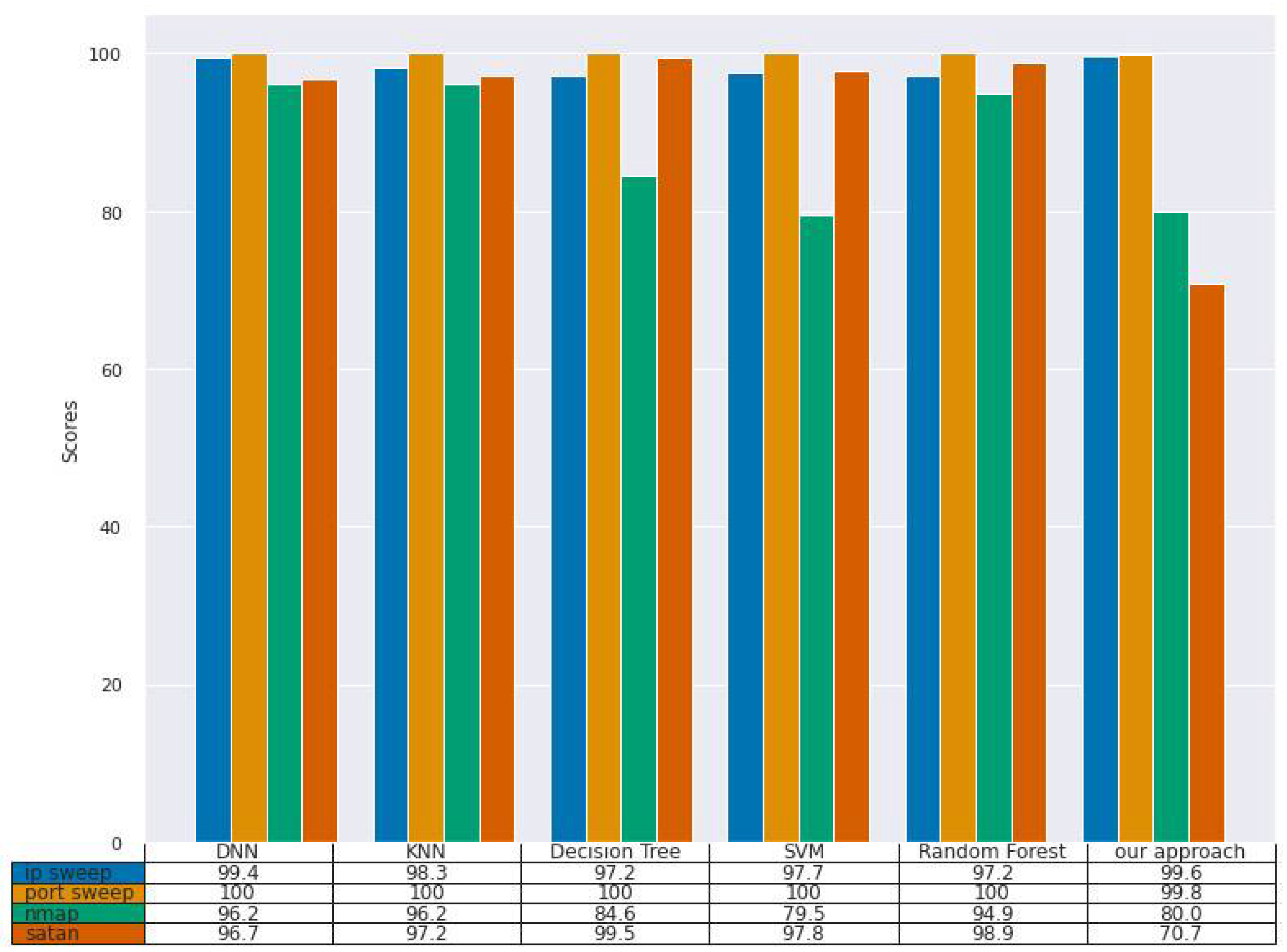
For the probe attack mutants (
Figure 2), our model also performs well, achieving the highest DR score of 99.8% on the port sweep attack, and a DR score of 99.6%, 80.0%, and 70.7% for the port sweep, Nmap and Satan, respectively. All the attack mutants achieved a good DR, which indicated that the attack mutants had many attributes in common, which our feature extractor model was able to discover.
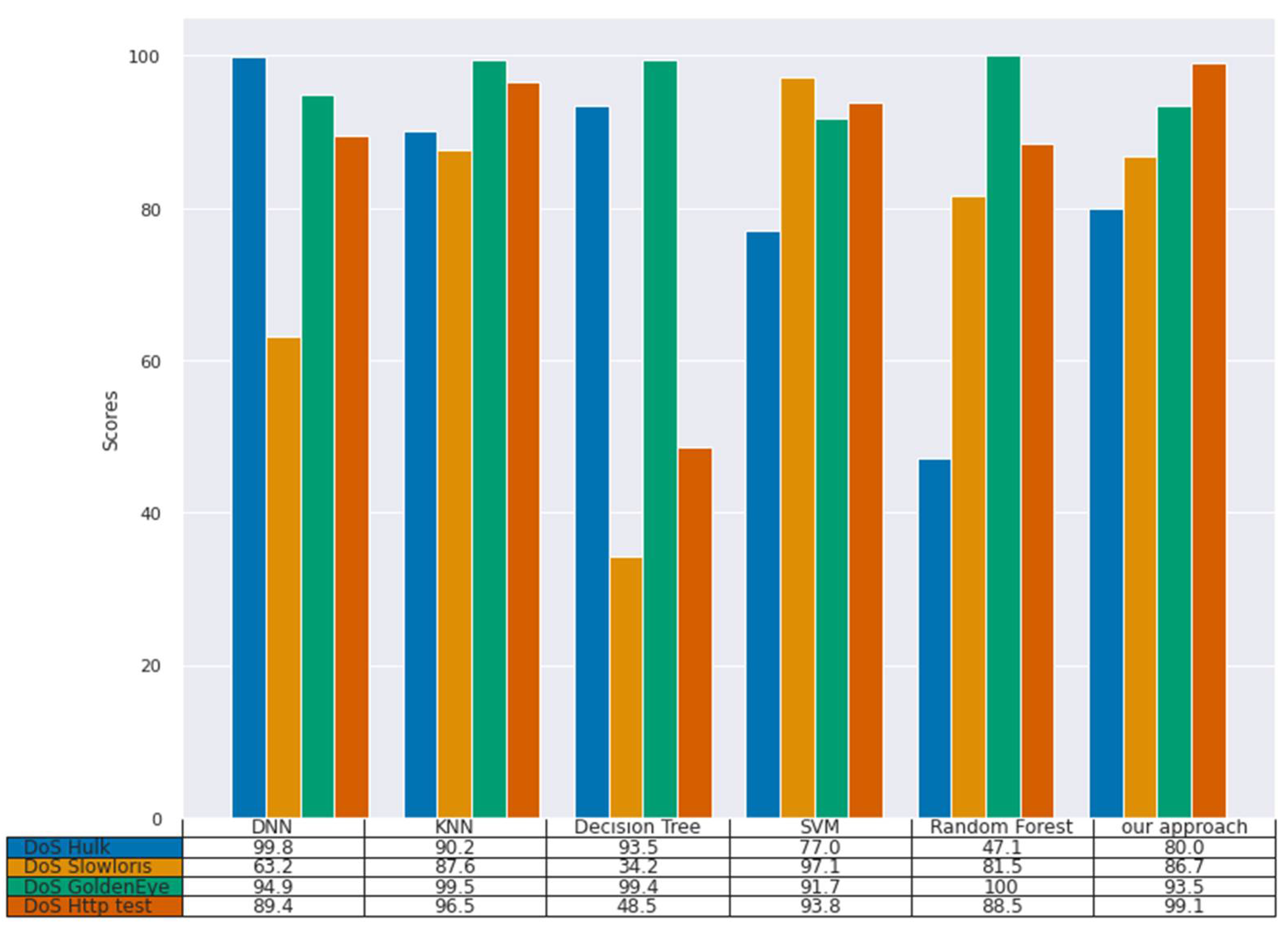
Similarly, with the CIC-IDS2017 dataset, our model’s performance was good. We achieved the highest DR score of 99.1% on DoS http test attack (
Figure 3), and DR scores of 93.5%, 86.7%, and 80.0% on DoS golden eye, DoS slow loris and DoS hulk attacks, respectively. The results follow a similar trend as in the NSL-KDD dataset.
We also compared our model’s DR with baseline models, and we employed a combination of classical and deep learning algorithms as our baselines. For deep learning, we employed a multi-layer perceptron (MLP), while for the classical ML models we employed K-nearest neighbor (KNN), decision tree, support vector machine (SVM) and random forest. All the baseline models were trained using the full dataset.
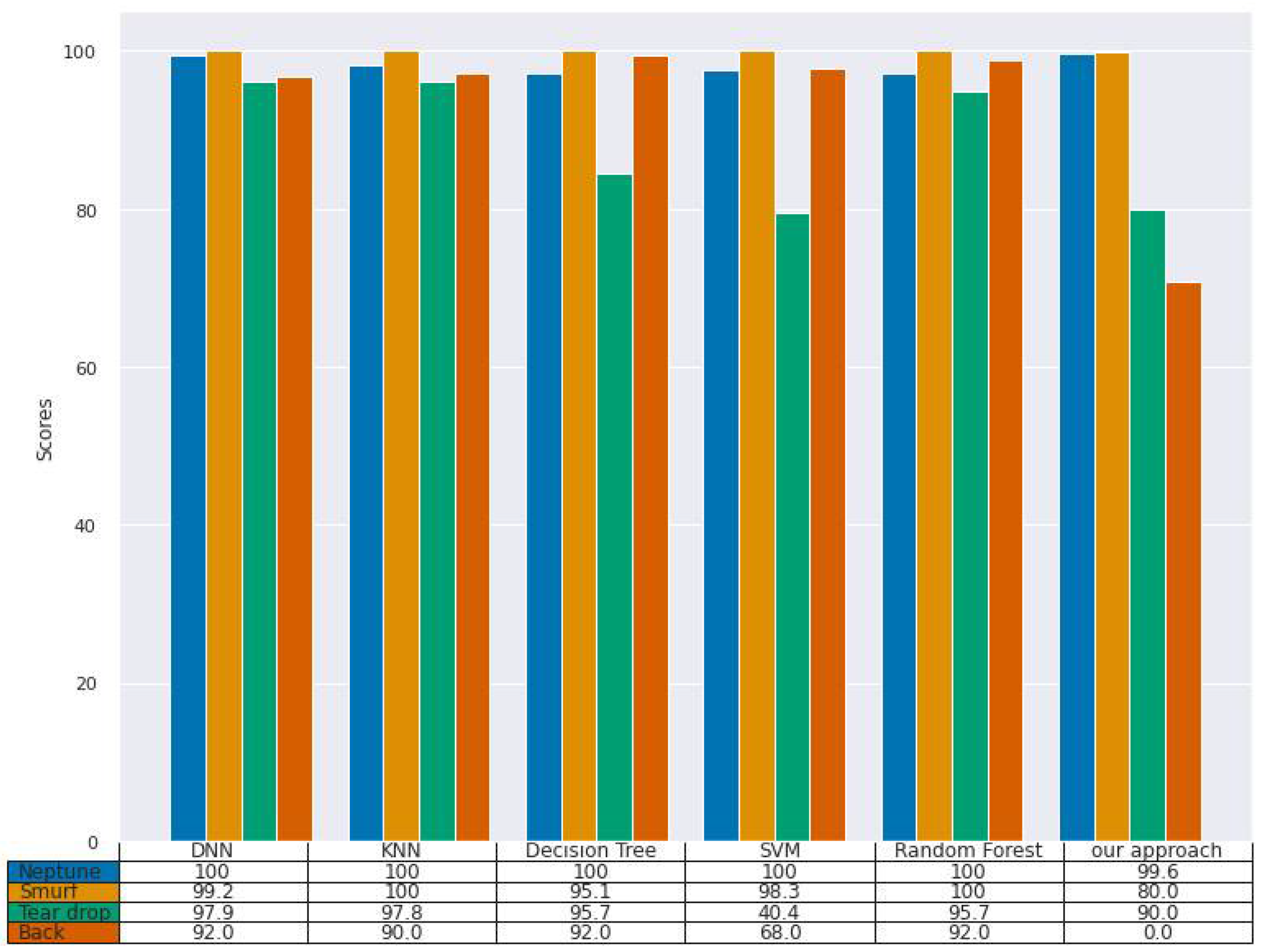
Figure 4,
Figure 5 and
Figure 6 depict the results of such comparisons. As can be seen from results, there was not much of a difference in terms of performance between the DL models, ML models, and our model. It is well known that classical ML models perform well on small and medium datasets. The highest DR score was 100% on the Neptune DoS mutant (
Figure 4), which was achieved by all baselines, while our model scored 99.6% (despite having been trained with only 10 examples), which is quite on par with the baselines results. The lowest DR score was for the back attack mutant, where our model’s DR score as 0.0%. However, the lowest DR score from the baselines was achieved by SVM, which scored 40.4% on the tear drop attack.
In addition, for the probe attack class, the result followed similar trend, the highest DR score achieved was 100%, which was achieved by the baseline models on the port sweep attack mutant (
Figure 5), while our model was slightly worse with a DR score of 99.8% on the same attack class.
Our model also recorded the lowest DR score, 70.7%, on the Satan attack mutant, while the lowest DR score achieved by the baselines was 79.5%, which was scored by SVM on the Nmap attack mutant. Overall, there was no significant difference in performance with our model; our model was either slightly worse or on par with the baselines.
Similarly,
Figure 6 presents the results of the comparison with baselines models for the CIC-IDS2017 dataset. The highest performing model was random forest, which achieved a DR of 100% for the DoS golden eye attack mutant. The lowest DR score was 48.5% which was achieved by the decision tree model for the DoS http test attack mutant. Similar to the NSL-KDD dataset, our model performed competitively with the baseline models, where it achieved DRs of 99.6%, 99.8%, 80.0%, and 70.7% on IP sweep, port sweep, Nmap and Satan, respectively.
4.4.2. Experiment: General Anomaly Detection
The objective here was to evaluate our approach in detecting broader classes of attacks that were not seen before. For example, the NSL-KDD dataset can be broadly categorized into the following classes: DoS, Probe, R2L and U2R. Similarly, the CIC-IDS2017 dataset, when classified broadly, is made up of the following classes: DoS, port scan, heart bleed, Botnet, SSH-Patator, FTP-Patator, and web-based attacks
To perform the experiment, we applied a similar logic as in experiment 1. For instance, to detect the probe class of attack in the NSL-KDD dataset, our meta-training set consisted of all other attack classes (DoS, R2L, and U2R). While the meta-testing set comprised the attack we wanted to classify, which was the probe attack in this case. We applied the same procedure as for the CIC-IDS2017 dataset.
Figure 7 and
Figure 8 present the results of our experiments when the number of samples selected to train our classifier was limited 10 for both NSL-KDD and CIC-IDS2017, respectively.
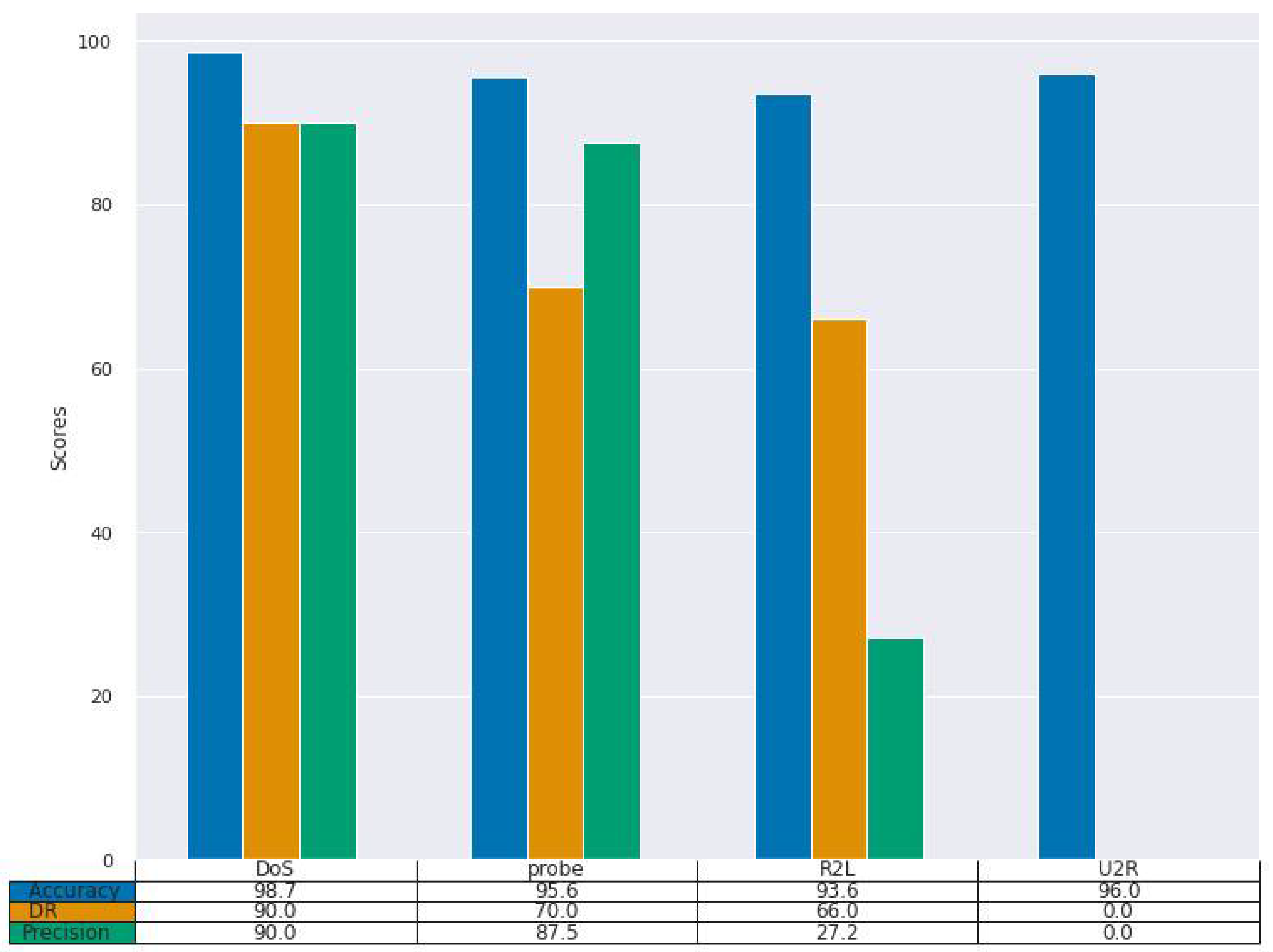
For the NSL-KDD dataset, (
Figure 7), our approach performed reasonably well, especially for DoS and probe classes. Our model achieved the highest DR score of 90% with the DoS class and 70% on probe class. However, overall, our model’s performance was low compared to the results of experiment 1. Some attacks were poorly detected. For example, our model’s DR scores was 66% for the R2L class, and it completely failed to detect the U2R attack class, scoring a DR of 0.0%.
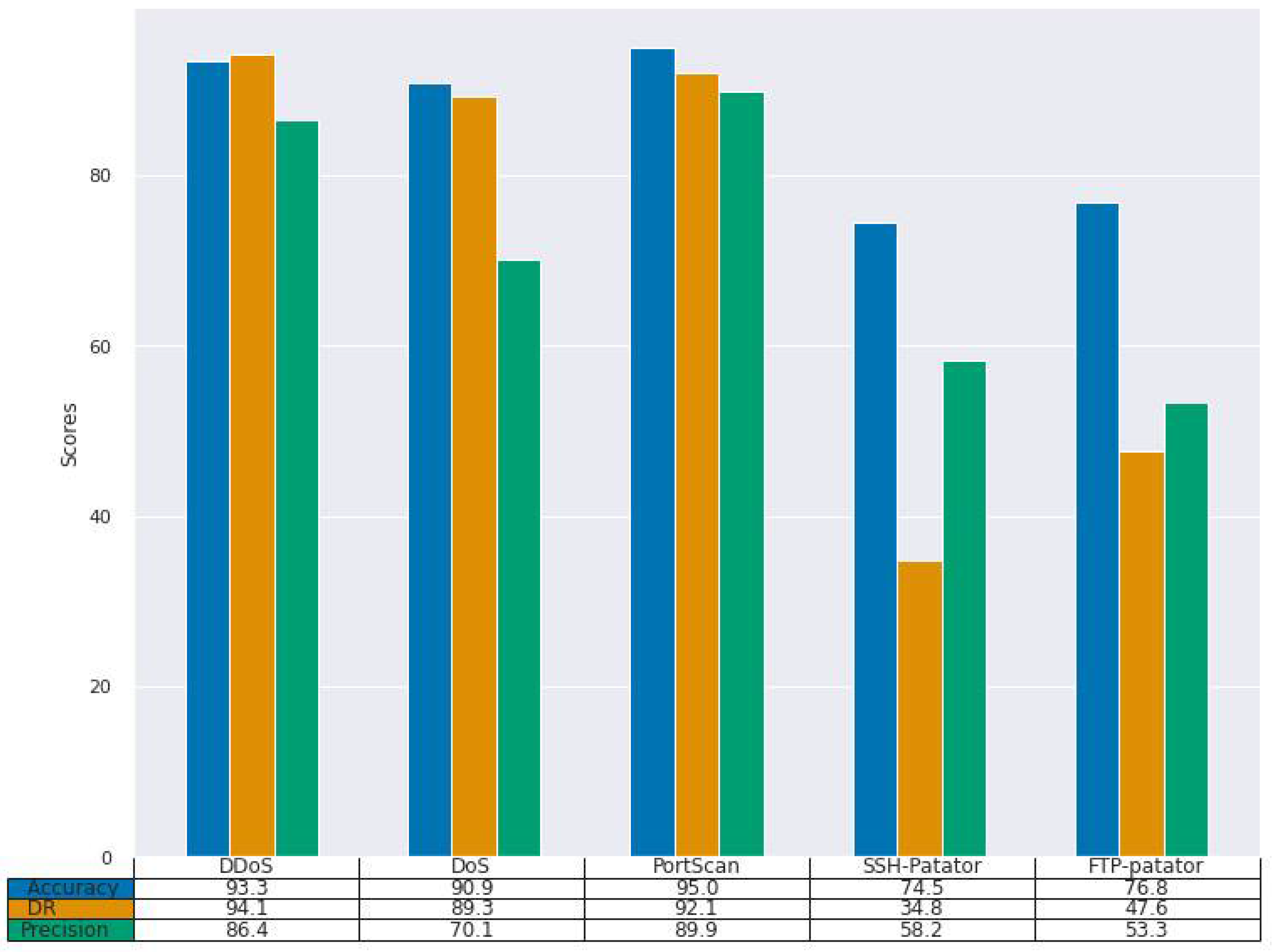
Similarly, the result of our experiment on CIC-IDS2017 (
Figure 8) follows similar trend. There is drop in performance, our model performance was not as good as that of experiment 1. The highest DR score was 94.1%, which was achieved for the DDoS attack class. Our model poorly detects the Patator attack classes, scoring 34.8% and 47.6%, respectively.
4.5. Discussion
Section 4.4 presents a performance evaluation of our approach. We designed two different experiments to evaluate our approach. The first experiment was designed to evaluate detecting mutants of existing attacks (subclasses of attacks). This was designed to addresses situations where attackers introduce some variations of a known existing attack to evade detection. We hypothesized that finding good representations using existing known similar attacks will enable the model to detect a novel mutant of that attack by using a few examples since attack mutants share similar attributes. Thus, our feature extractor would be able to discover the manifold of a broader class of such attacks.
Figure 1,
Figure 2 and
Figure 3 in
Section 4.4 present the results of our experiment, which prove our hypothesis. As we were able to detect several mutants with an excellent detection rate using only a few shot examples. We achieved up to 99.9% DR on the Neptune DoS mutant (
Figure 1), and, overall, we achieved an excellent detection rate. This shows that our feature extractor was able to discover the manifold of optimal representations of such a class.
To further validate the efficacy of our feature extractor model, we increased the number of samples required to train our classifier in the few-shot detection stage from 10 to 20 samples. However, as can be seen in
Table 4,
Table 5 and
Table 6, respectively, the DR varies slightly, despite doubling the number of samples. This is contrary to conventional supervised learning approaches, where the DR increases significantly with an increase in the number of training examples.
The more powerful the representations, the smaller the number of training samples required. This concludes that our feature extractor model is able to discover the manifold of optimal representations, which causes the DR to slightly depends on the number of examples.
We also compared our approach with the baseline models, which comprised the DL model and the classical ML, as shown in
Figure 4,
Figure 5 and
Figure 6. The baseline models were trained on the full dataset.
As can be observed from the results, our approach performed competitively with the baseline models. On all the datasets, our model was on par with, or slightly worse than, the baseline models, despite being trained on few-shot examples.
The second experiment was designed to discover whether it was possible to learn representations that would be useful in detecting any class of attack, when re-trained with few-shot examples of that attack. The results of the experiment are presented in
Figure 6 and
Figure 7. Our model performed reasonably well in detecting certain classes of attacks. For instance, our model achieved detection rates of 90% and 89% for DoS classes in both the NSL-KDD and CIC-IDS2017 datasets. This shows that our feature extractor still learns some useful representations to detect these classes of attacks. However, it performs poorly in detecting other classes, such as R2L and U2R, from NSL-KDD (
Figure 7), where the detection rate was 66% and 0.0%, respectively. Similarly, it failed to achieve good detection rates for both FTP-Patator and SSH-Patator attack classes for the CIC-IDS2017 dataset (
Figure 8), scoring 34.8% and 47.6%, respectively. Therefore, as expected, there was a drop in overall performance for our model compared to the results of experiment 1. This was due to the fact that our feature extractor tries to discover a singular representation for identification, based on the different classes of attacks observed in the meta-training stage. However, it is difficult to discover such representations due to the diverse nature of the attacks in the meta-training set. Since attacks differ in purpose and implementation, for instance, the DoS attack class tries to shut down traffic flow to and from a target system, a U2R attack tries to gain access to the system or network, an R2L attack tries to gain access to the remote machine, while attacks such as probe try to get information from a network, we assumed that these attack types are too diverse to allow our feature extractor to learn singular representations for identification that can enable excellent detection when trained with a few examples.
5. Conclusions
Network intrusion detection using machine learning methods has been studied for a long time, with many commercial intrusion detection systems (IDSs) using machine learning algorithms as part of their detection engines. However, machine learning-based IDSs are susceptible to false alarm rates, which makes the field an active area of research.
Recently, DL methods have been widely applied in network-based IDSs due to their success in fields such as natural language processing (NLP) and computer vision. However, to achieve a better detection rate, DL methods require sizeable volumes of datasets. Collecting large-scale datasets is non-trivial, especially in the cybersecurity domain where the landscape is constantly changing. Hence, few-shot network intrusion detection is emerging as an alternative to conventional supervised DL methods. The concept is popularly addressed based on a meta-learning paradigm, whereby transferable knowledge is learned in some related tasks using complex optimization techniques, which enables generalization at test time with limited examples.
However, in this paper, we propose a simple framework for few-shot network intrusion detection. Our approach relies on learning powerful representations, and is implemented in two stages. We first train a feature extractor model using discriminative representation learning with a supervised autoencoder, and we then train a classifier on top of the feature extractor, which is able to generalize with a few examples.
To validate our approach, we evaluated our model using two publicly available intrusion detection datasets. Our proposed method achieved excellent detection rates in detecting mutants of existing attacks. However, though our approach achieves good detection rates for certain classes of attacks in the general anomaly detection scenario it performs poorly for others. This is due to the diverse nature of attacks, and it is difficult to learn singular representations that can enable generalization with only a few examples.
Therefore, based on the results of the experiments conducted, our approach is more suited for detecting specific classes of attack or mutants of an existing attack. In addition, it is safe to say that our model can be used in situations like zero-day attacks, since, even in such a scenario, a few samples of attacks can be obtained, which will be sufficient enough to train our model to detect similar occurrences of the same attack or its variants in the future.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}