



Efficient Weighted Ensemble Method for Predicting Peak-Period Postal Logistics Volume: A South Korean Case Study

Abstract
:1. Introduction
2. Proposed Method
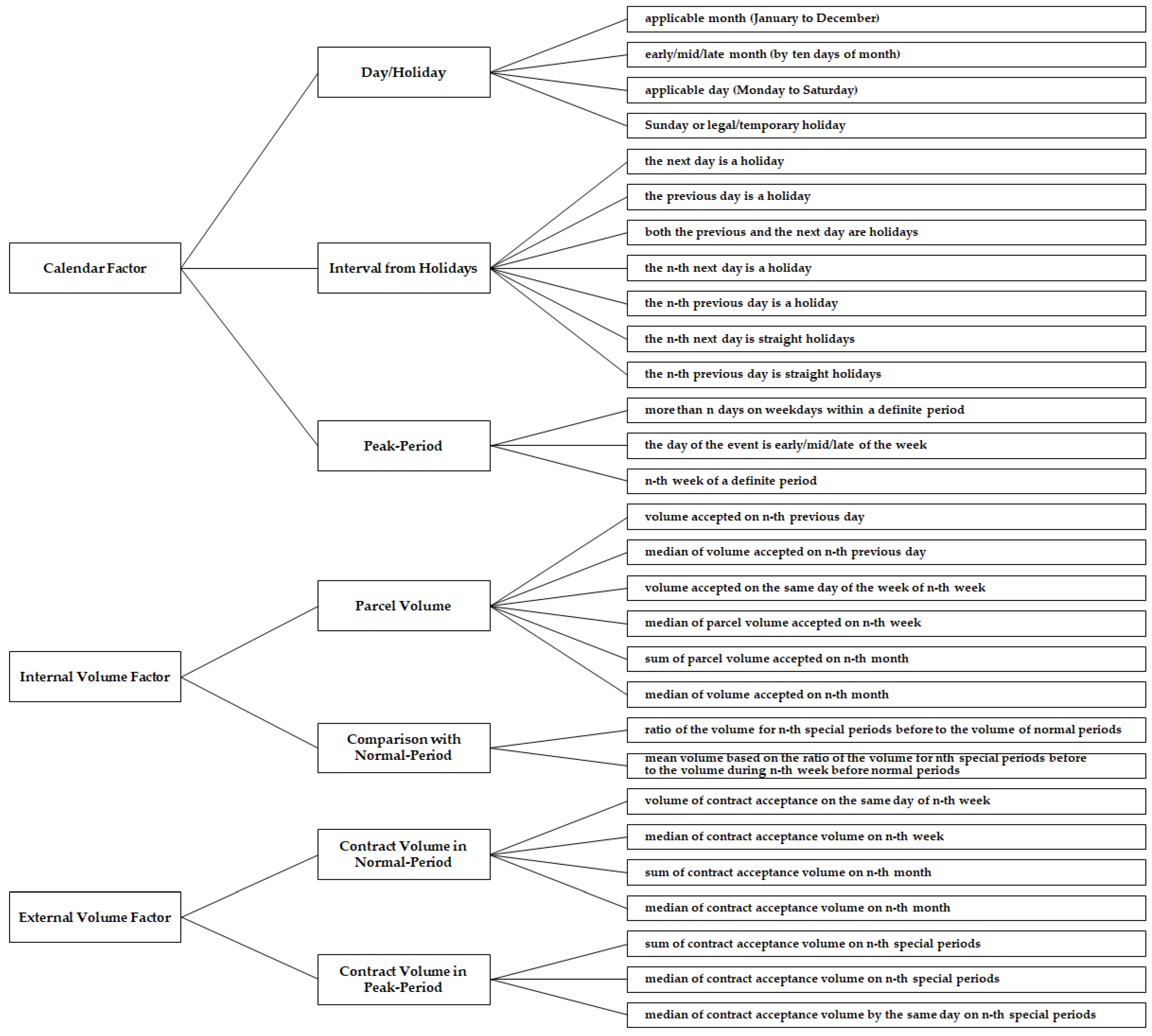
2.1. Feature Engineering
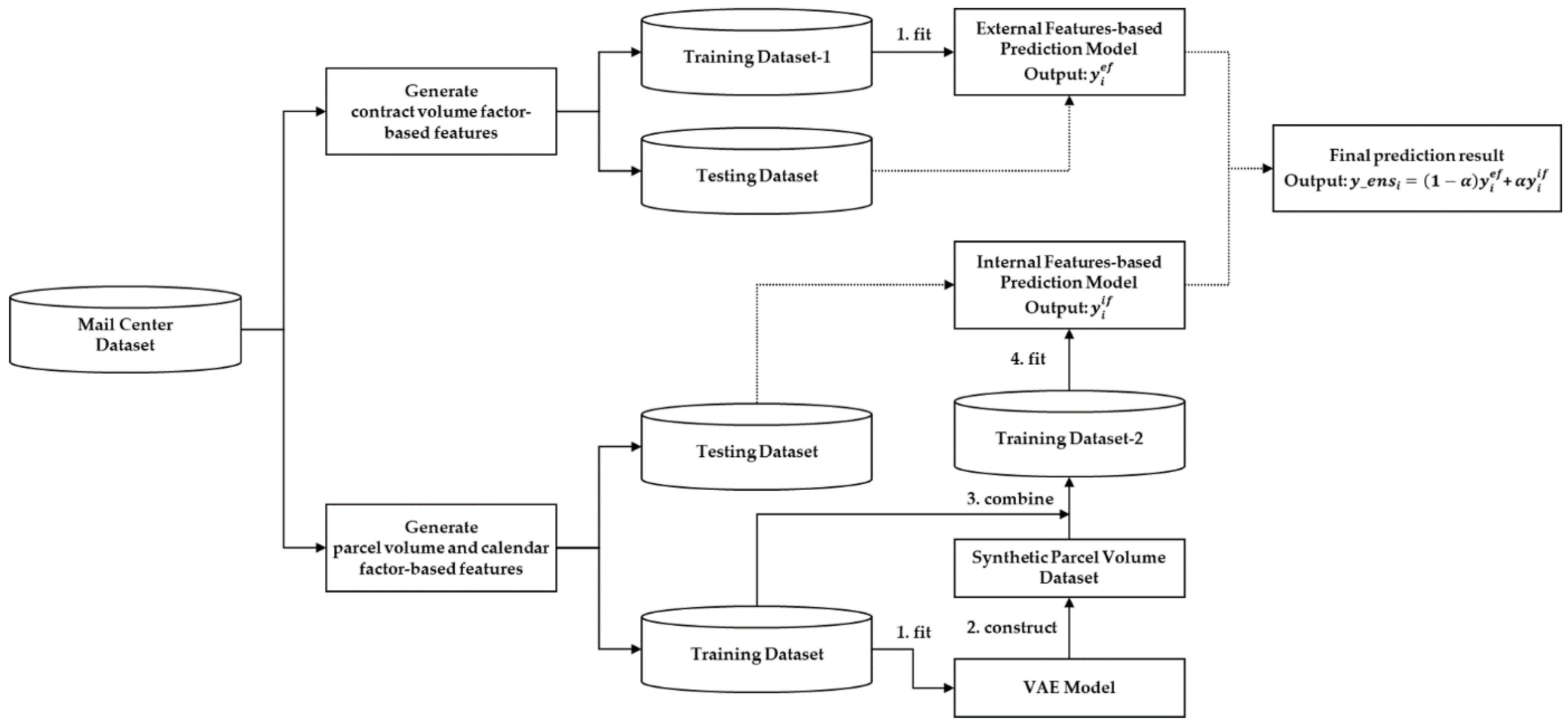
2.2. MLP-Based Weighted Ensemble Method
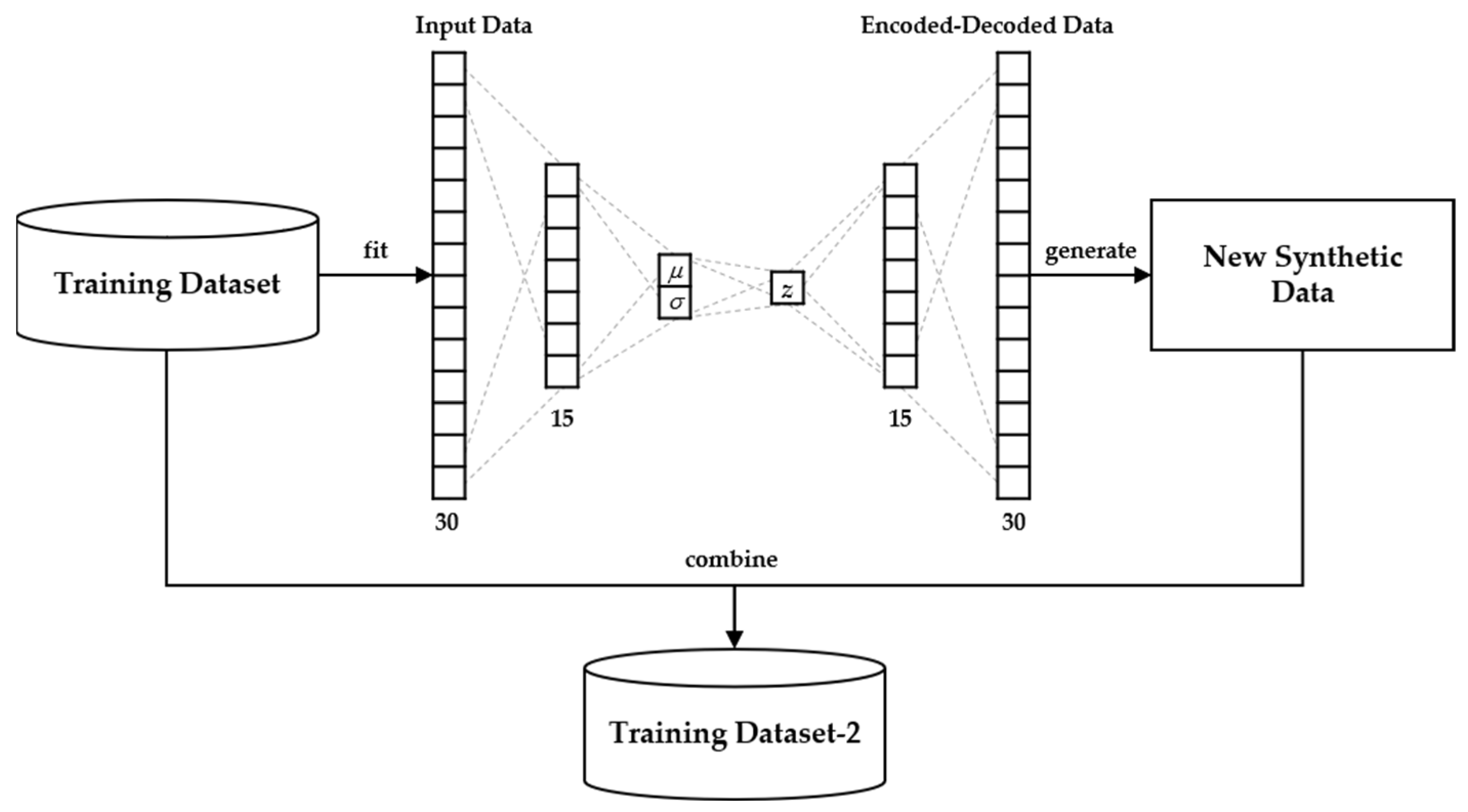
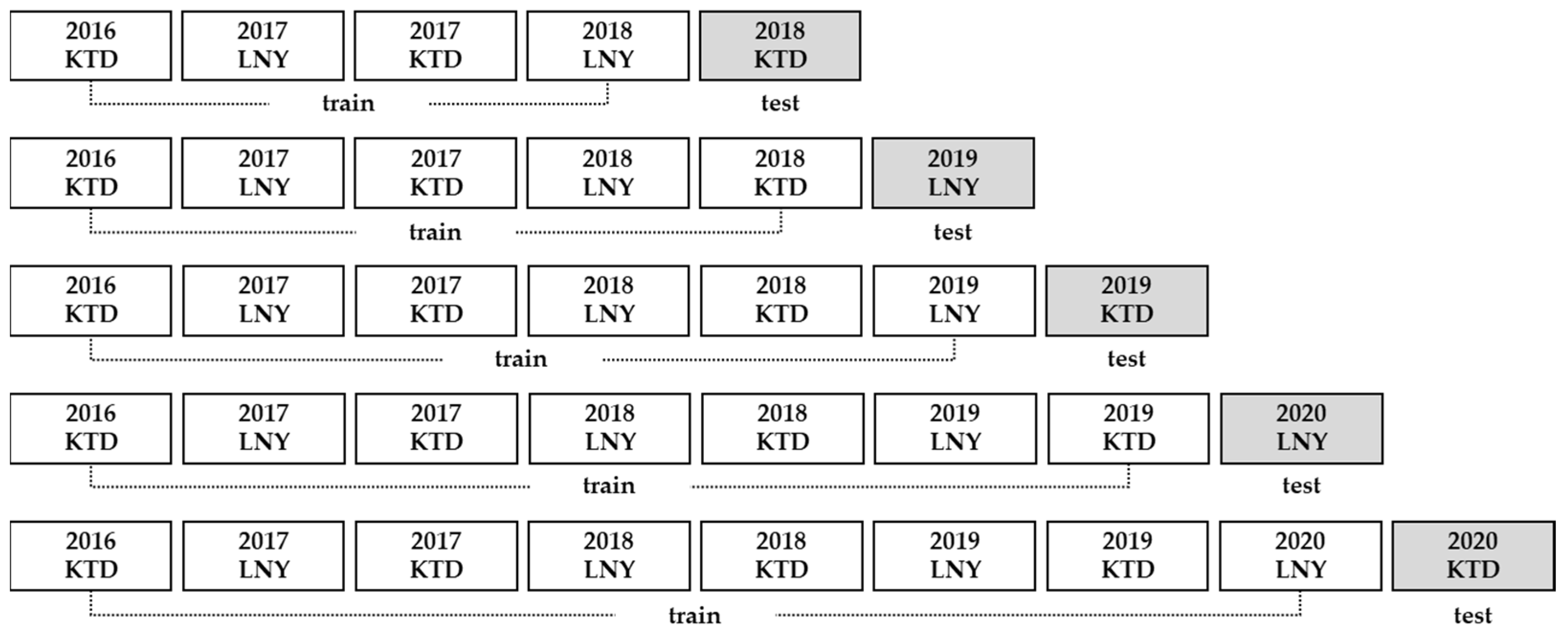
2.2.1. Construction of Training Datasets
2.2.2. Ensembling MLP Models
3. Experimental Study
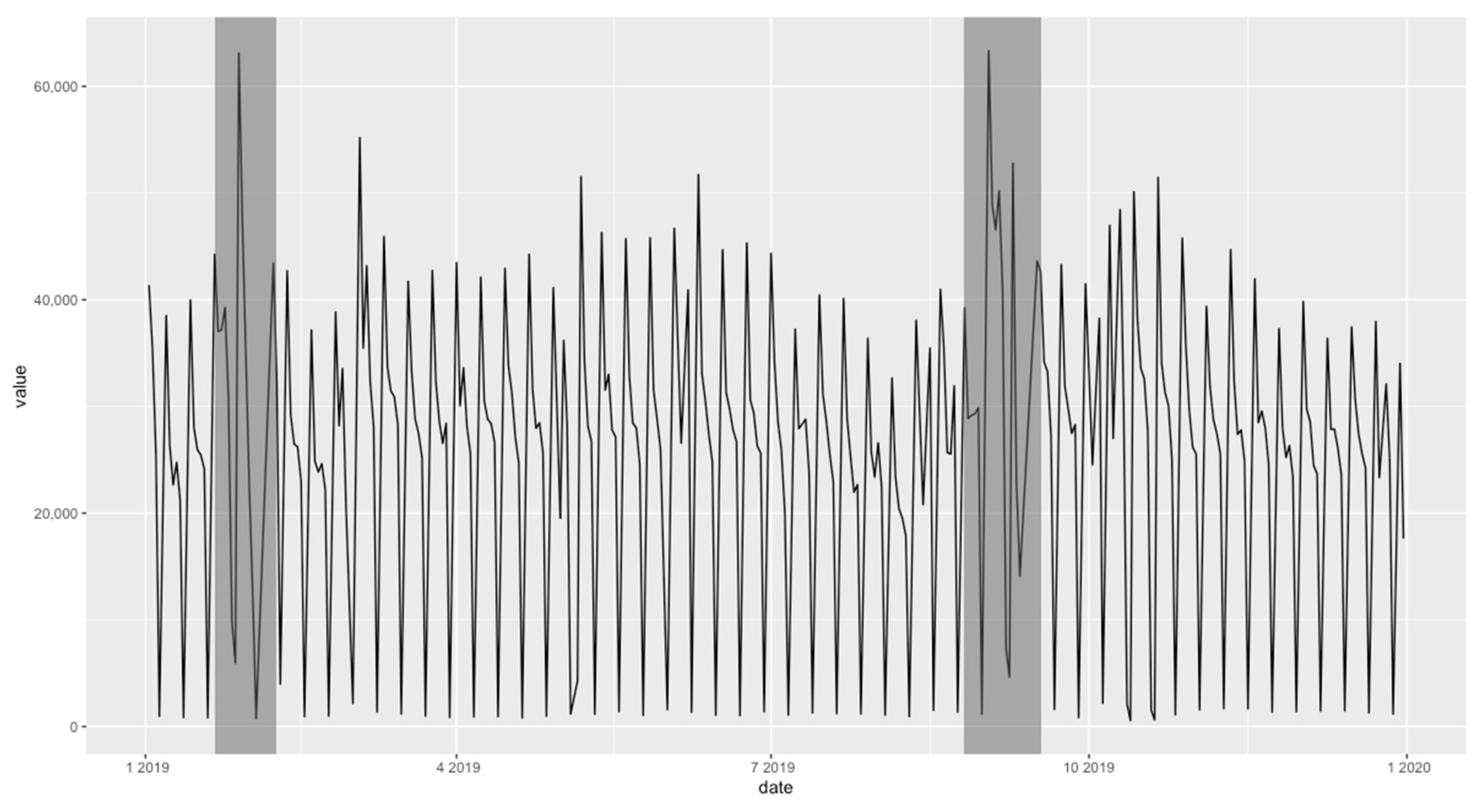
3.1. Experimental Dataset
3.2. Evaluation Metrics
3.3. Compared Methods
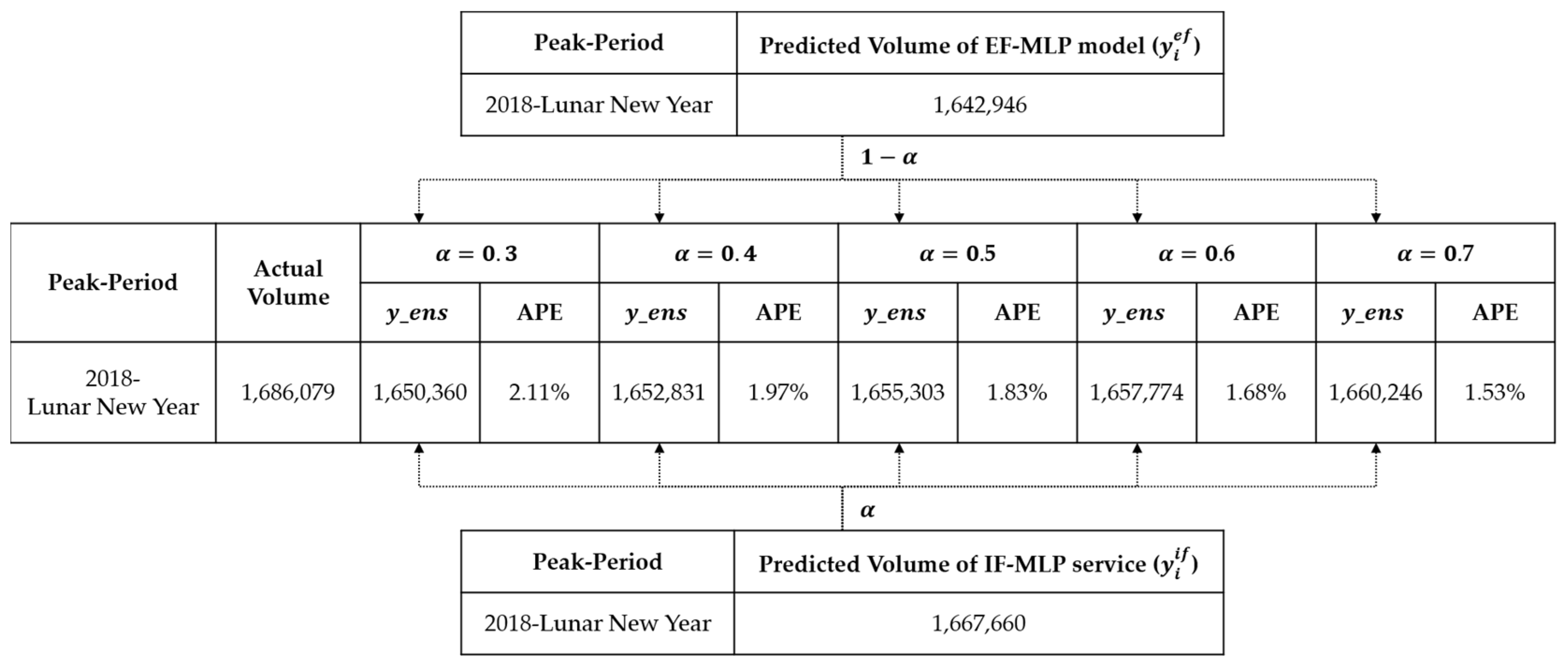
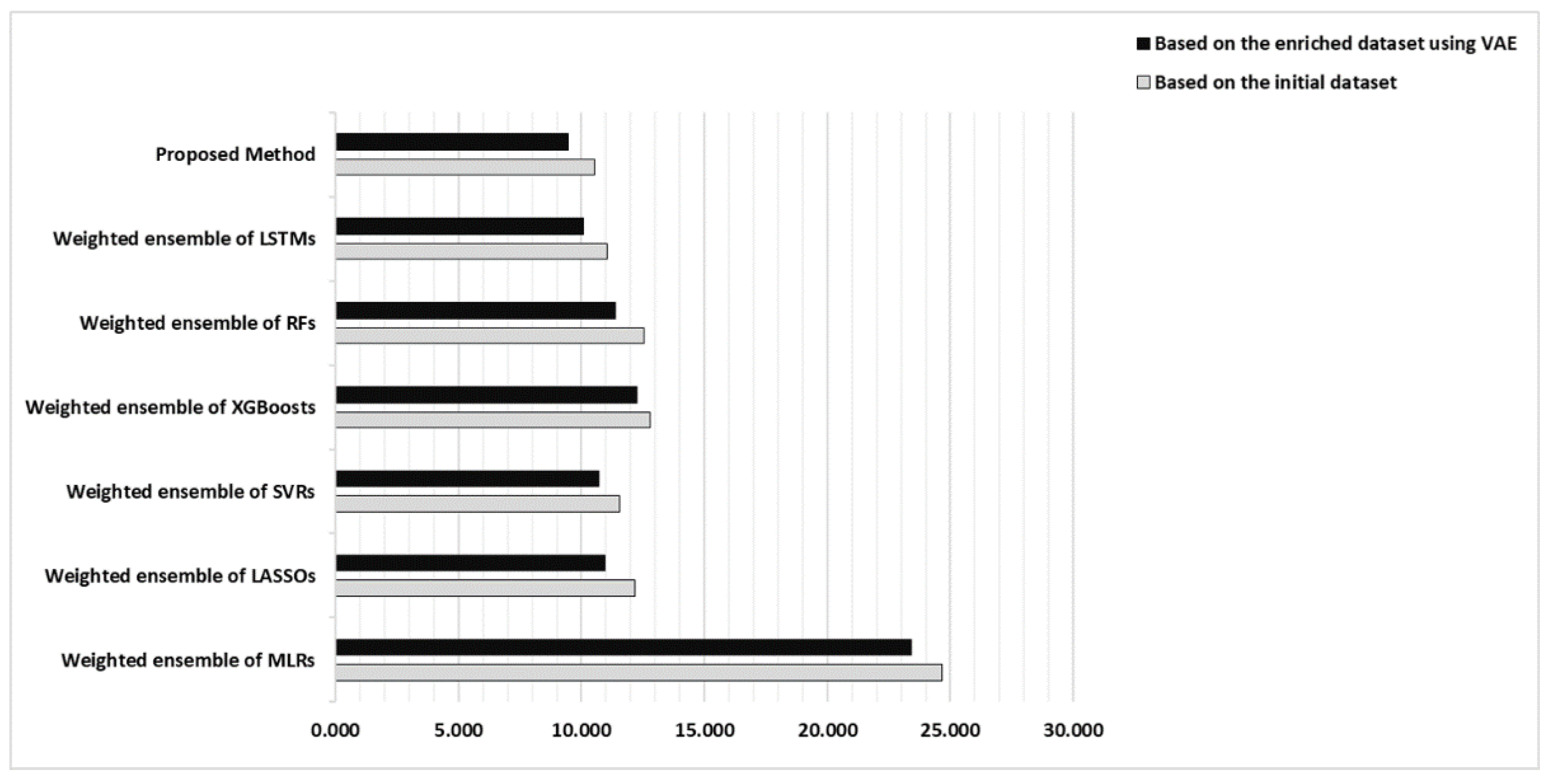
3.4. Prediction Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fève, F.; Floren, J.P.; Rodriguez, F.; Soteri, S. Forecasting mail volumes in an evolving market environment. In Heightening Competition in the Postal and Delivery Sector, 1st ed.; Edward Elgar: Northampton, MA, USA, 2010; pp. 116–134. [Google Scholar] [CrossRef] [Green Version]
- Toshkollari, O.; Sota, F.; Shtino, V.; Bozhiqi, K. Analysis and prediction of city postal services in Albania. A case study. In Proceedings of the UBT International Conference, Durres, Albania, 28–30 October 2016. [Google Scholar] [CrossRef] [Green Version]
- Ebbesson, M. Mail Volume Forecasting an Evaluation of Machine Learning Models. Master’s Thesis, Uppsala University, Uppsala, Sweden, 2016. [Google Scholar]
- Huang, L.; Xie, G.; Zhao, W.; Gu, Y.; Huang, Y. Regional logistics demand forecasting: A BP neural network approach. Complex Intell. Syst. 2021, 7, 1–16. [Google Scholar] [CrossRef]
- Kim, E.; Jung, H. Feature Engineering-based Short-Term Prediction Model for Postal Parcel Logistics. In Proceedings of the 6th International Conference on Machine Learning Technologies, Jeju Island, Republic of Korea, 23–25 April 2021. [Google Scholar] [CrossRef]
- Trinkner, U.; Grossmann, M. Forecasting Swiss mail demand. In Progress Toward Liberalization of the Postal and Delivery Sector, 1st ed.; Springer: Boston, MA, USA, 2006; Volume 49, pp. 267–280. [Google Scholar] [CrossRef]
- Nguyen, T.Y. Research on logistics demand forecast in southeast Asia. World J. Eng. Technol. 2020, 8, 249–256. [Google Scholar] [CrossRef]
- Rogan, I.D.; Pronić-Rančić, O.R. Forecasting the volume of postal services using Savitzky-Golay filter modification. In Proceedings of the 56th International Scientific Conference on Information, Communication and Energy Systems and Technologies, Sozopol, Bulgaria, 16–18 June 2021. [Google Scholar] [CrossRef]
- Machado, C.; Silva, F. Postal Traffic in Portugal: Applying Time Series Modeling. In The Changing Postal Environment, 1st ed.; Springer: Cham, Switzerland, 2020; pp. 197–212. [Google Scholar] [CrossRef]
- Pu, Z.; Yang, L.; Guo, Z.G. Applied Research on Logistics Demand Prediction Based on Support Vector Machine of Genetic Algorithm. In Proceedings of the International Conference on Computational and Information Sciences, Chengdu, China, 21–23 October 2011. [Google Scholar] [CrossRef]
- Yu, N.; Xu, W.; Yu, K.L. Research on regional logistics demand forecast based on improved support vector machine: A case study of Qingdao city under the New Free Trade Zone Strategy. IEEE Access 2020, 8, 9551–9564. [Google Scholar] [CrossRef]
- Rogan, I.D.; Pronić-Rančić, O.R. SARIMA and ANN Approaches in Forecasting the Volume of Postal Services. In Proceedings of the 15th International Conference on Advanced Technologies, Systems and Services in Telecommunications, Nis, Serbia, 20–22 October 2021. [Google Scholar] [CrossRef]
- Lin, Y.S.; Zhang, Y.; Lin, I.C.; Chang, C.J. Predicting logistics delivery demand with deep neural networks. In Proceedings of the 7th International Conference on Industrial Technology and Management, Oxford, UK, 7–9 March 2018. [Google Scholar] [CrossRef]
- Kim, E.; Jung, H. Extreme Event Forecasting for Postal Logistics Service. In Proceedings of the 8th International Conference on Management of e-Commerce and e-Government, Jeju, Republic of Korea, 4–6 July 2021. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Biswal, S.; Ghosh, S.; Duke, J.; Malin, B.; Stewart, W.; Sun, J. EVA: Generating Longitudinal Electronic Health Records Using Conditional Variational Autoencoders. arXiv 2020, arXiv:2012.10020. [Google Scholar]
- Amarbayasgalan, T.; Pham, V.H.; Theera-Umpon, N.; Piao, Y.; Ryu, K.H. An efficient prediction method for coronary heart disease risk based on two deep neural networks trained on well-ordered training datasets. IEEE Access 2021, 9, 135210–135223. [Google Scholar] [CrossRef]
- Wan, Z.; Zhang, Y.; He, H. Variational autoencoder based synthetic data generation for imbalanced learning. In Proceedings of the IEEE Symposium Series on Computational Intelligence (SSCI) 2017, Honolulu, HI, USA, 27 November 2017–1 December 2017. [Google Scholar] [CrossRef]
- Jain, A.K.; Mao, J.; Mohiuddin, K.M. Artificial neural networks: A tutorial. Computer 1996, 29, 31–44. [Google Scholar] [CrossRef] [Green Version]
- Otter, D.W.; Medina, J.R.; Kalita, J.K. A survey of the usages of deep learning for natural language processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 604–624. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; Van Der Laak, J.A.; Van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep learning based recommender system: A survey and new perspectives. ACM Comput. Sur. 2019, 52, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Kleinbaum, D.G.; Kupper, L.L.; Muller, K.E.; Nizam, A. Applied Regression Analysis and Other Multivariable Methods, 4th ed.; Cengage Learning: Boston, MA, USA, 2007. [Google Scholar]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B Stat. Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory, 2nd ed.; Springer: Berlin, Germany, 2013. [Google Scholar]
- Awad, M.; Khanna, R. Support vector regression. In Efficient Learning Machines, 1st ed.; Apress: Berkeley, CA, USA, 2015; pp. 67–80. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mail Center | Q1 | Q2 | Q3 | Q4 | Max | Avg | Stdev | 95% CI | CV |
|---|---|---|---|---|---|---|---|---|---|
| Mail Center #1 | 52,842.5 | 120,541.0 | 149,959.0 | 225,370.0 | 225,370 | 104,943.7 | 63,352.7 | 95,096.4–114,790.9 | 0.60 |
| Mail Center #2 | 2180.0 | 20,477.0 | 29,992.0 | 79,048.0 | 79,048 | 23,705.5 | 17,073.4 | 76,377.3–81,718.7 | 0.72 |
| Mail Center #3 | 9889.0 | 28,064.0 | 38,370.0 | 77,927.0 | 77,927 | 26,459.0 | 16,882.7 | 23,814.6–29,103.4 | 0.64 |
| Mail Center #4 | 27,063.0 | 47,586.0 | 58,418.0 | 139,060.0 | 139,060 | 45,200.8 | 26,463.4 | 40,973.9–49,427.7 | 0.59 |
| Mail Center #5 | 24,075.5 | 41,184.5 | 51,461.3 | 94,285.0 | 94,285 | 37,884.1 | 22,435.9 | 34,288.6–41,479.6 | 0.59 |
| Mail Center #6 | 6267.3 | 10,545.0 | 15,723.5 | 29,372.0 | 29,372 | 10,982.2 | 6737.3 | 8405.9–13,558.5 | 0.61 |
| Mail Center #7 | 25,117.5 | 64,168.0 | 84,739.5 | 135,408.0 | 135,408 | 57,270.0 | 33,229.3 | 52,297.9–62,242.1 | 0.58 |
| Mail Center #8 | 10,982.0 | 24,748.0 | 34,520.0 | 71,813.0 | 71,813 | 23,914.4 | 15,760.3 | 19,387.5–28,441.3 | 0.66 |
| Mail Center #9 | 27,461.5 | 58,678.0 | 75,437.5 | 121,475.0 | 121,475 | 51,902.1 | 30,383.5 | 47,127.7–56,676.5 | 0.59 |
| Mail Center #10 | 25,940.0 | 45,000.0 | 58,127.5 | 94,897.0 | 94,897 | 41,943.5 | 24,780.3 | 38,011.5–45,875.5 | 0.59 |
| Mail Center #11 | 37,859.0 | 70,448.0 | 85,492.8 | 138,841.0 | 138,841 | 63,427.3 | 35,386.0 | 53,950.9–72,903.7 | 0.56 |
| Mail Center #12 | 40,217.0 | 89,316.0 | 119,860.8 | 237,143.0 | 237,143 | 82,019.7 | 51,102.6 | 73,989.6–90,049.8 | 0.62 |
| Mail Center #13 | 42,016.8 | 69,176.5 | 95,636.8 | 156,706.0 | 156,706 | 67,975.5 | 51,102.6 | 61,594.2–74,356.8 | 0.75 |
| Mail Center #14 | 16,935.5 | 30,181.5 | 46,781.3 | 74,552.0 | 74,552 | 31,479.3 | 20,162.7 | 28,226.2–34,732.4 | 0.64 |
| Mail Center #15 | 12,599.8 | 19,316.0 | 28,208.0 | 48,345.0 | 48,345 | 19,804.8 | 11,208.1 | 17,945.4–21,664.2 | 0.57 |
| Mail Center #16 | 10,828.0 | 41,718.0 | 62,952.0 | 117,847.0 | 117,847 | 40,518.9 | 28,092.7 | 36,146.4–44,891.4 | 0.69 |
| Mail Center #17 | 24,916.3 | 68,523.0 | 98,665.5 | 176,951.0 | 176,951 | 67,183.7 | 42,668.3 | 60,521.6–73,845.8 | 0.64 |
| Mail Center #18 | 10,243.3 | 15,970.5 | 22,504.8 | 48,978.0 | 48,978 | 16,187.6 | 10,150.5 | 17,945.4–21,664.2 | 0.63 |
| Mail Center #19 | 8630.0 | 18,777.0 | 33,069.0 | 70,283.0 | 70,283 | 21,526.0 | 15,927.7 | 18,911.5–24,140.5 | 0.74 |
| Mail Center #20 | 11,396.8 | 21,525.0 | 29,665.8 | 54,976.0 | 54,976 | 20,651.3 | 12,261.1 | 18,699.4–22,603.2 | 0.59 |
| Mail Center #21 | 11,008.0 | 20,151.0 | 30,727.0 | 69,885.0 | 69,885 | 21,959.8 | 15,357.4 | 19,473.6–24,446.0 | 0.70 |
| Mail Center #22 | 25,305.0 | 70,339.0 | 85,875.0 | 151,727.0 | 151,727 | 62,182.4 | 38,329.0 | 19,473.6–24,446.0 | 0.62 |
| Mail Center #23 | 13,141.5 | 24,884.5 | 46,106.0 | 89,609.0 | 89,609 | 29,871.5 | 22,499.3 | 26,265.8–33,477.2 | 0.75 |
| Mail Center #24 | 7191.8 | 14,144.0 | 20,541.0 | 43,956.0 | 43,956 | 14,001.7 | 9061.1 | 12,529.8–15,473.6 | 0.65 |
| Mail Center #25 | 40,091.5 | 91,905.0 | 147,942.5 | 222,904.0 | 222,904 | 93,499.4 | 62,742.8 | 83,794.9–03,203.9 | 0.67 |
| Mail Centers | MLP (Baseline) | EF-MLP | IF-MLP | Proposed | ||||
|---|---|---|---|---|---|---|---|---|
| MAPE | MAE | MAPE | MAE | MAPE | MAE | MAPE | MAE | |
| SMAPE | RMSE | SMAPE | RMSE | SMAPE | RMSE | SMAPE | RMSE | |
| Mail Center #1 | 8.245 | 166,430.0 | 9.237 | 201,634.5 | 5.923 | 128,320.7 | 6.076 | 131,779.3 |
| 8.679 | 187,880.7 | 10.055 | 274,179.0 | 6.211 | 166,883.6 | 6.386 | 172,273.1 | |
| Mail Center #2 | 24.860 | 129,159.6 | 23.368 | 121,265.9 | 25.401 | 132,437.6 | 24.108 | 269,291.7 |
| 63.978 | 454,463.6 | 72.296 | 432,934.8 | 63.379 | 421,951.1 | 62.094 | 394,716.5 | |
| Mail Center #3 | 12.122 | 55,555.2 | 10.705 | 53,918.7 | 7.528 | 34,675.2 | 10.090 | 50,429.3 |
| 11.689 | 58,175.8 | 11.085 | 68,097.4 | 7.262 | 45,449.9 | 10.348 | 62,254.3 | |
| Mail Center #4 | 10.864 | 84,690.7 | 11.847 | 77,226.4 | 7.503 | 64,445.3 | 8.931 | 56,224.0 |
| 10.838 | 98,681.0 | 10.530 | 110,427.5 | 7.844 | 88,154.4 | 8.060 | 85,958.8 | |
| Mail Center #5 | 12.212 | 85,184.9 | 8.209 | 60,226.8 | 8.672 | 58,807.0 | 7.868 | 54,813.0 |
| 13.121 | 96,738.0 | 8.865 | 81,912.7 | 9.201 | 67,044.5 | 8.287 | 60,962.6 | |
| Mail Center #6 | 13.931 | 26,250.5 | 8.827 | 16,598.3 | 8.060 | 14,978.9 | 3.225 | 6180.1 |
| 15.186 | 28,240.1 | 8.571 | 20,286.1 | 8.683 | 19,855.1 | 3.287 | 6711.9 | |
| Mail Center #7 | 15.890 | 184,636.9 | 7.939 | 110,440.1 | 12.971 | 157,518.5 | 7.661 | 101,561.9 |
| 15.703 | 203,238.7 | 8.842 | 189,087.5 | 12.821 | 185,911.8 | 8.362 | 167,814.1 | |
| Mail Center #8 | 12.959 | 53,347.1 | 9.084 | 39,366.6 | 15.951 | 63,867.6 | 8.424 | 36,017.7 |
| 12.982 | 65,448.9 | 9.669 | 47,857.7 | 14.375 | 76,470.0 | 8.795 | 42,160.4 | |
| Mail Center #9 | 8.944 | 88,769.8 | 12.547 | 115,290.7 | 6.324 | 63,180.8 | 11.263 | 104,454.8 |
| 9.109 | 94,215.5 | 12.226 | 145,732.4 | 6.763 | 89,717.9 | 11.098 | 122,761.0 | |
| Mail Center #10 | 8.126 | 66,934.4 | 12.113 | 106,297.9 | 2.663 | 22,661.2 | 7.382 | 64,424.7 |
| 8.322 | 70,176.0 | 13.241 | 128,728.4 | 2.738 | 34,506.1 | 7.788 | 78,741.3 | |
| Mail Center #11 | 8.173 | 93,854.9 | 3.635 | 41,706.9 | 5.980 | 66,280.8 | 3.171 | 35,222.8 |
| 7.895 | 109,198.8 | 3.609 | 48,269.8 | 5.919 | 73,963.2 | 3.105 | 48,512.5 | |
| Mail Center #12 | 12.548 | 213,895.2 | 15.592 | 291,748.6 | 12.500 | 216,383.2 | 13.304 | 231,382.9 |
| 13.530 | 239,177.6 | 17.471 | 353,703.2 | 13.598 | 262,091.1 | 14.478 | 271,213.8 | |
| Mail Center #13 | 11.340 | 132,817.0 | 9.589 | 120,317.4 | 10.735 | 134,590.5 | 8.539 | 106,148.2 |
| 10.696 | 182,117.9 | 9.891 | 144,527.3 | 10.522 | 155,959.6 | 8.692 | 122,585.5 | |
| Mail Center #14 | 11.617 | 68,646.8 | 7.010 | 44,892.1 | 10.772 | 64,262.8 | 6.926 | 44,347.8 |
| 12.077 | 86,639.6 | 7.668 | 77,396.3 | 15.118 | 89,138.0 | 7.580 | 76,730.7 | |
| Mail Center #15 | 9.665 | 30,503.0 | 4.042 | 12,698.1 | 7.798 | 24,605.1 | 3.733 | 11,624.5 |
| 9.519 | 33,665.8 | 3.965 | 13,690.6 | 7.868 | 27,276.8 | 3.669 | 12,610.5 | |
| Mail Center #16 | 8.135 | 63,139.3 | 6.866 | 52,967.8 | 4.185 | 32,533.2 | 3.398 | 26,809.2 |
| 7.801 | 72,776.7 | 6.964 | 61,500.6 | 4.359 | 43,777.2 | 3.478 | 31,514.6 | |
| Mail Center #17 | 18.482 | 210,939.7 | 10.730 | 113,781.4 | 11.529 | 126,172.2 | 10.083 | 105,712.6 |
| 18.849 | 232,308.3 | 9.736 | 150,959.2 | 10.877 | 156,001.1 | 9.175 | 145,372.9 | |
| Mail Center #18 | 29.400 | 74,301.1 | 16.129 | 39,864.5 | 14.355 | 36,356.8 | 11.235 | 27,723.7 |
| 24.262 | 96,851.9 | 13.851 | 57,401.9 | 14.867 | 41,707.7 | 10.197 | 37,596.3 | |
| Mail Center #19 | 15.222 | 52,095.2 | 4.648 | 15,539.0 | 11.379 | 38,471.7 | 4.545 | 15,262.0 |
| 13.964 | 74,066.8 | 4.461 | 22,703.4 | 10.739 | 48,963.5 | 4.319 | 24,065.9 | |
| Mail Center #20 | 6.375 | 23,599.9 | 8.152 | 34,187.4 | 5.291 | 19,475.2 | 5.249 | 19,756.7 |
| 6.319 | 33,965.6 | 8.957 | 53,419.3 | 5.198 | 25,839.9 | 5.202 | 23,838.8 | |
| Mail Center #21 | 16.660 | 54,886.0 | 49.398 | 169,356.8 | 11.771 | 39,135.7 | 13.203 | 44,925.5 |
| 16.030 | 61,489.4 | 35.081 | 246,618.6 | 11.418 | 49,462.3 | 12.227 | 52,351.9 | |
| Mail Center #22 | 14.900 | 183,708.7 | 9.093 | 106,237.1 | 11.342 | 133,792.7 | 10.739 | 126,154.0 |
| 16.069 | 221,819.3 | 8.774 | 130,242.2 | 11.524 | 136,342.5 | 10.790 | 130,241.2 | |
| Mail Center #23 | 29.869 | 146,433.4 | 21.777 | 99,925.7 | 17.243 | 77,933.3 | 15.276 | 69,954.8 |
| 30.531 | 179,673.1 | 20.077 | 119,480.9 | 15.575 | 94,092.7 | 13.882 | 91,474.5 | |
| Mail Center #24 | 12.186 | 30,362.3 | 17.649 | 47,736.3 | 10.314 | 27,247.0 | 10.688 | 28,141.9 |
| 13.265 | 34,953.7 | 20.052 | 56,824.1 | 10.893 | 30,520.6 | 11.518 | 32,974.8 | |
| Mail Center #25 | 28.113 | 403,099.3 | 9.804 | 145,090.0 | 23.176 | 333,733.9 | 21.303 | 306,970.0 |
| 22.685 | 539,578.5 | 9.232 | 186,659.0 | 19.928 | 407,434.7 | 18.459 | 379,725.5 | |
| Mail Centers | MLR | LASSO | SVR | XGBoost | RF | LSTM | Proposed | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAPE | MAE | MAPE | MAE | MAPE | MAE | MAPE | MAE | MAPE | MAE | MAPE | MAE | MAPE | MAE | |
| SMAPE | RMSE | SMAPE | RMSE | SMAPE | RMSE | SMAPE | RMSE | SMAPE | RMSE | SMAPE | RMSE | SMAPE | RMSE | |
| Mail Center #1 | 8.700 | 176,927.2 | 8.800 | 183,267.9 | 8.300 | 168,968.4 | 7.000 | 143,238.6 | 5.960 | 120,928.2 | 9.581 | 198,052.7 | 8.200 | 166,430.0 |
| 9.145 | 196,286.1 | 9.189 | 197,004.6 | 8.583 | 185,988.8 | 7.259 | 165,407.9 | 6.064 | 129,216.5 | 10.096 | 216,752.1 | 8.679 | 187,880.7 | |
| Mail Center #2 | 25.567 | 133,309.2 | 23.104 | 120,387.0 | 24.855 | 125,101.1 | 21.061 | 109,000.7 | 29.904 | 154,773.0 | 23.854 | 120,888.3 | 24.860 | 129,159.6 |
| 63.978 | 454,463.6 | 61.039 | 436,652.9 | 62.794 | 404,836.7 | 58.927 | 432,818.1 | 68.399 | 338,071.0 | 62.385 | 457,488.2 | 63.129 | 470,150.7 | |
| Mail Center #3 | 13.210 | 59,803.5 | 8.622 | 37,953.7 | 9.632 | 44,434.8 | 8.357 | 37,345.6 | 15.507 | 73,843.5 | 11.806 | 55,294.1 | 12.122 | 55,555.2 |
| 12.248 | 70,960.9 | 7.859 | 58,173.2 | 9.507 | 54,156.0 | 7.701 | 53,794.7 | 15.200 | 85,141.4 | 11.572 | 60,555.8 | 11.689 | 58,175.8 | |
| Mail Center #4 | 8.718 | 55,153.8 | 4.745 | 35,652.1 | 13.292 | 96,957.7 | 6.313 | 46,961.0 | 8.498 | 61,704.6 | 11.704 | 86,176.1 | 10.864 | 84,690.7 |
| 8.321 | 71,366.8 | 4.780 | 38,827.4 | 14.301 | 110,275.6 | 6.456 | 53,920.5 | 8.428 | 64,974.4 | 12.633 | 98,993.6 | 10.838 | 98,681.0 | |
| Mail Center #5 | 9.194 | 65,580.1 | 11.130 | 80,354.2 | 12.606 | 88,449.8 | 11.616 | 84,341.6 | 11.833 | 81,396.0 | 10.640 | 71,789.6 | 12.212 | 85,184.9 |
| 9.783 | 77,081.5 | 11.384 | 84,720.1 | 12.808 | 93,646.0 | 11.523 | 87,613.7 | 12.706 | 90,280.7 | 11.585 | 86,332.0 | 13.121 | 96,738.0 | |
| Mail Center #6 | 8.670 | 16,416.9 | 10.357 | 19,485.0 | 16.509 | 31,091.2 | 11.469 | 21,543.6 | 7.841 | 14,572.3 | 14.307 | 27,009.9 | 13.931 | 26,250.5 |
| 9.083 | 16,707.0 | 11.063 | 21,319.8 | 18.438 | 34,405.9 | 12.406 | 24,283.3 | 8.501 | 20,282.9 | 15.657 | 29,265.2 | 15.186 | 28,240.1 | |
| Mail Center #7 | 15.614 | 194,105.6 | 15.764 | 193,784.9 | 14.380 | 172,578.1 | 14.595 | 178,457.5 | 17.170 | 206,847.0 | 16.436 | 200,644.4 | 15.890 | 184,636.9 |
| 16.107 | 230,523.0 | 16.147 | 223,426.7 | 14.253 | 201,953.4 | 14.725 | 203,967.5 | 17.928 | 239,378.5 | 16.463 | 237,349.5 | 15.703 | 203,238.7 | |
| Mail Center #8 | 12.150 | 47,857.8 | 14.685 | 58,537.6 | 14.172 | 58,134.2 | 16.385 | 66,464.3 | 9.754 | 39,491.3 | 8.216 | 33,513.9 | 12.959 | 53,347.1 |
| 11.680 | 57,534.7 | 13.697 | 67,064.5 | 12.934 | 69,725.4 | 14.565 | 82,339.2 | 9.778 | 45,368.2 | 8.014 | 38,377.6 | 12.982 | 65,448.9 | |
| Mail Center #9 | 15.475 | 154,923.6 | 13.724 | 139,705.0 | 11.173 | 112,467.8 | 13.898 | 139,276.6 | 10.044 | 96,345.6 | 9.106 | 94,373.0 | 8.944 | 88,769.8 |
| 16.323 | 172,577.8 | 13.677 | 154,132.8 | 11.662 | 137,145.2 | 13.838 | 155,917.5 | 10.461 | 107,908.6 | 9.363 | 107,343.3 | 9.109 | 94,215.5 | |
| Mail Center #10 | 9.718 | 84,693.5 | 7.865 | 66,159.7 | 3.734 | 31,769.3 | 6.467 | 51,486.4 | 9.532 | 76,688.4 | 6.447 | 58,445.7 | 8.126 | 66,934.4 |
| 10.324 | 106,016.5 | 7.804 | 74,191.2 | 3.768 | 41,944.2 | 6.381 | 59,493.8 | 10.090 | 86,767.4 | 6.801 | 79,742.1 | 8.322 | 70,176.0 | |
| Mail Center #11 | 7.684 | 86,461.5 | 6.946 | 78,909.5 | 10.479 | 120,436.2 | 8.428 | 97,234.5 | 8.207 | 94,408.1 | 4.796 | 52,858.0 | 8.173 | 93,854.9 |
| 7.624 | 89,752.8 | 6.777 | 84,003.9 | 10.117 | 129,083.6 | 8.114 | 110,128.6 | 8.001 | 113,977.8 | 4.792 | 65,940.2 | 7.895 | 109,198.8 | |
| Mail Center #12 | 10.909 | 198,019.9 | 11.528 | 185,539.0 | 11.335 | 198,073.9 | 8.060 | 150,602.6 | 16.509 | 274,021.5 | 15.502 | 262,408.4 | 12.548 | 213,895.2 |
| 11.772 | 246,448.9 | 12.531 | 218,863.7 | 12.257 | 245,098.6 | 8.656 | 215,053.7 | 18.237 | 301,877.6 | 16.933 | 282,917.5 | 13.530 | 239,177.6 | |
| Mail Center #13 | 10.859 | 129,566.8 | 6.434 | 74,832.8 | 9.337 | 113,476.0 | 9.281 | 114,457.0 | 7.296 | 85,524.0 | 8.080 | 98,972.2 | 11.340 | 132,817.0 |
| 11.120 | 138,456.2 | 6.335 | 99,743.8 | 9.057 | 133,681.6 | 8.935 | 136,944.4 | 7.062 | 107,624.9 | 7.967 | 120,164.5 | 10.696 | 182,117.9 | |
| Mail Center #14 | 16.932 | 96,731.0 | 18.979 | 107,594.1 | 19.794 | 110,870.1 | 20.317 | 114,463.1 | 11.588 | 66,490.6 | 13.838 | 78,714.7 | 11.617 | 68,646.8 |
| 16.959 | 118,159.9 | 18.727 | 127,884.7 | 18.542 | 146,544.5 | 19.714 | 137,958.4 | 11.370 | 84,755.5 | 13.502 | 99,496.8 | 12.077 | 86,639.6 | |
| Mail Center #15 | 8.754 | 27,941.4 | 11.134 | 35,581.8 | 13.548 | 43,346.5 | 14.943 | 47,741.2 | 15.315 | 48,570.3 | 11.348 | 35,829.2 | 9.665 | 30,503.0 |
| 8.690 | 32,400.6 | 11.092 | 41,586.6 | 13.484 | 52,510.2 | 14.895 | 54,839.4 | 14.685 | 54,990.4 | 10.834 | 40,745.5 | 9.519 | 33,665.8 | |
| Mail Center #16 | 3.698 | 28,663.5 | 5.464 | 43,052.0 | 6.492 | 51,490.9 | 6.490 | 51,788.5 | 6.349 | 47,643.9 | 7.297 | 56,151.7 | 8.135 | 63,139.3 |
| 3.816 | 36,871.1 | 5.561 | 46,735.1 | 6.427 | 55,291.6 | 6.305 | 61,412.2 | 7.075 | 83,335.8 | 7.355 | 61,467.2 | 7.801 | 72,776.7 | |
| Mail Center #17 | 14.733 | 158,789.7 | 16.539 | 183,795.1 | 16.429 | 186,916.6 | 14.200 | 161,566.7 | 19.331 | 161,566.7 | 16.563 | 183,237.2 | 18.482 | 210,939.7 |
| 13.463 | 196,929.1 | 15.824 | 220,976.3 | 16.195 | 207,466.2 | 13.491 | 190,206.8 | 18.517 | 240,885.5 | 15.926 | 204,504.1 | 18.849 | 232,308.3 | |
| Mail Center #18 | 20.435 | 51,450.7 | 21.996 | 55,775.9 | 25.215 | 64,258.0 | 19.346 | 49,369.6 | 15.841 | 40,561.3 | 21.873 | 55,301.3 | 29.400 | 74,301.1 |
| 28.192 | 79,467.2 | 26.368 | 70,379.0 | 22.703 | 69,386.8 | 18.473 | 56,735.1 | 14.867 | 47,297.2 | 25.580 | 68,735.8 | 24.262 | 96,851.9 | |
| Mail Center #19 | 15.019 | 51,420.0 | 15.848 | 54,138.4 | 14.909 | 50,633.0 | 18.489 | 62,803.5 | 12.916 | 44,291.3 | 13.166 | 44,567.9 | 15.222 | 52,095.2 |
| 13.911 | 65,230.5 | 14.368 | 73,624.5 | 13.558 | 69,627.7 | 16.082 | 87,969.5 | 12.076 | 56,959.1 | 12.230 | 56,548.1 | 13.964 | 74,066.8 | |
| Mail Center #20 | 11.547 | 45,280.7 | 11.540 | 45,856.9 | 10.177 | 40,072.3 | 11.494 | 45,175.6 | 7.627 | 28,476.7 | 7.115 | 26,853.6 | 6.375 | 23,599.9 |
| 11.300 | 54,913.2 | 10.861 | 57,032.3 | 9.892 | 47,984.0 | 10.965 | 55,129.5 | 7.344 | 37,455.5 | 6.967 | 32,726.6 | 6.319 | 33,965.6 | |
| Mail Center #21 | 16.681 | 60,290.4 | 16.351 | 57,179.8 | 13.080 | 44,519.4 | 16.823 | 61,666.8 | 24.834 | 92,035.0 | 12.517 | 39,110.7 | 16.660 | 54,886.0 |
| 14.947 | 72,309.0 | 15.399 | 67,283.7 | 13.021 | 49,189.5 | 15.435 | 70,936.8 | 24.361 | 115,086.2 | 11.942 | 50,038.0 | 16.030 | 61,489.4 | |
| Mail Center #22 | 13.315 | 156,021.0 | 12.662 | 145,766.2 | 13.516 | 157,752.1 | 13.456 | 156,104.2 | 9.676 | 112,407.9 | 12.311 | 144,273.1 | 14.900 | 183,708.7 |
| 13.954 | 176,387.5 | 12.670 | 173,683.7 | 13.815 | 171,023.6 | 13.699 | 174,139.7 | 9.571 | 124,694.2 | 12.691 | 161,564.8 | 16.069 | 221,819.3 | |
| Mail Center #23 | 20.367 | 93,087.6 | 21.404 | 98,199.6 | 17.038 | 78,316.0 | 20.242 | 91,943.1 | 24.992 | 111,352.3 | 17.995 | 80,754.6 | 29.869 | 146,433.4 |
| 18.357 | 105,324.3 | 19.417 | 105,831.9 | 15.795 | 89,847.6 | 18.188 | 102,284.2 | 21.546 | 130,080.3 | 16.291 | 95,857.8 | 30.531 | 179,673.1 | |
| Mail Center #24 | 9.957 | 26,785.1 | 11.388 | 30,247.6 | 10.294 | 27,316.7 | 12.451 | 33,483.7 | 10.569 | 26,705.3 | 9.116 | 23,761.7 | 12.186 | 30,362.3 |
| 10.261 | 30,556.2 | 11.716 | 32,659.0 | 10.588 | 29,210.4 | 12.606 | 35,745.9 | 11.103 | 27,769.1 | 9.721 | 28,603.8 | 13.265 | 34,953.7 | |
| Mail Center #25 | 26.521 | 380,001.1 | 27.421 | 393,419.5 | 28.329 | 404,349.9 | 29.513 | 415,541.1 | 26.655 | 386,851.2 | 22.264 | 323,511.7 | 28.113 | 403,099.3 |
| 22.250 | 469,426.9 | 22.883 | 485,654.4 | 22.995 | 527,813.4 | 23.557 | 550,621.2 | 23.253 | 456,895.5 | 19.459 | 391,006.8 | 22.685 | 539,578.5 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, E.; Amarbayasgalan, T.; Jung, H. Efficient Weighted Ensemble Method for Predicting Peak-Period Postal Logistics Volume: A South Korean Case Study. Appl. Sci. 2022, 12, 11962. https://doi.org/10.3390/app122311962
Kim E, Amarbayasgalan T, Jung H. Efficient Weighted Ensemble Method for Predicting Peak-Period Postal Logistics Volume: A South Korean Case Study. Applied Sciences. 2022; 12(23):11962. https://doi.org/10.3390/app122311962
Chicago/Turabian StyleKim, Eunhye, Tsatsral Amarbayasgalan, and Hoon Jung. 2022. "Efficient Weighted Ensemble Method for Predicting Peak-Period Postal Logistics Volume: A South Korean Case Study" Applied Sciences 12, no. 23: 11962. https://doi.org/10.3390/app122311962