

Minimizing Maximum Feature Space Deviation for Visible-Infrared Person Re-Identification
Abstract
:1. Introduction
2. Related Work
2.1. Metric Learning-Based Method
2.2. Feature Extraction-Based Method
2.3. Generation-Based Method
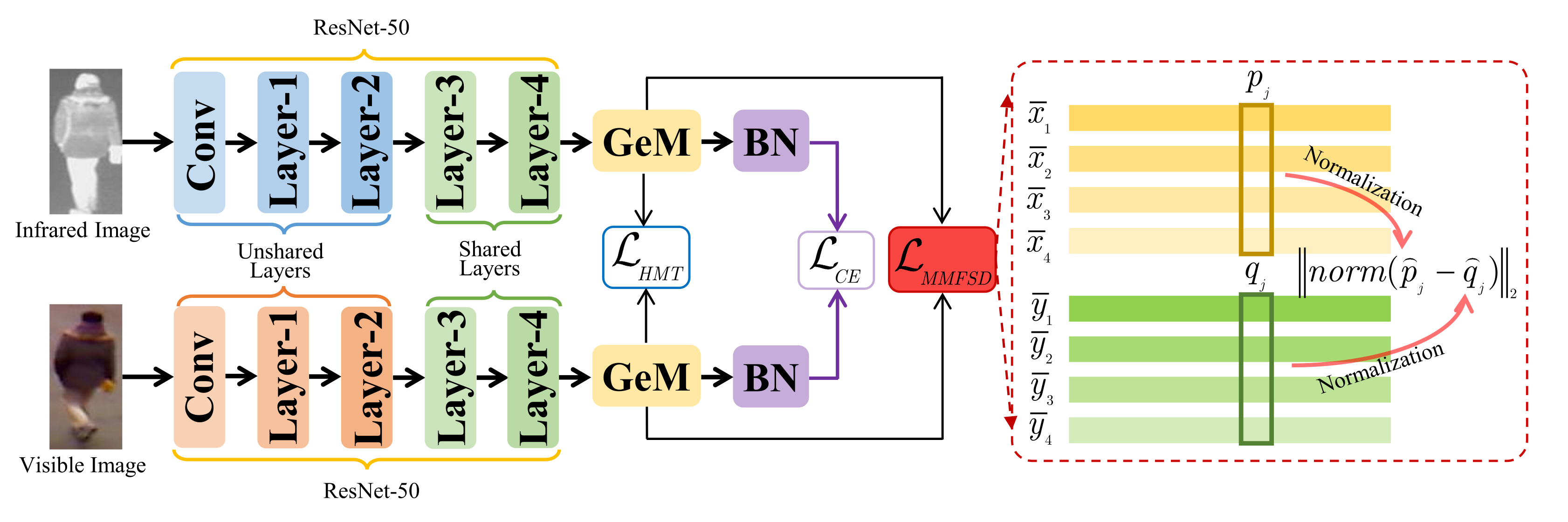
3. Proposed Method
3.1. Feature Space Deviation Modeling
3.2. Feature Learning Architecture
3.3. Total Loss Function Design
4. Experiments and Analysis
4.1. Datasets
4.2. Implementation Details
4.3. Comparison with State-of-the-Arts Methods
4.3.1. Comparison on SYSU-MM01
4.3.2. Comparison on RegDB
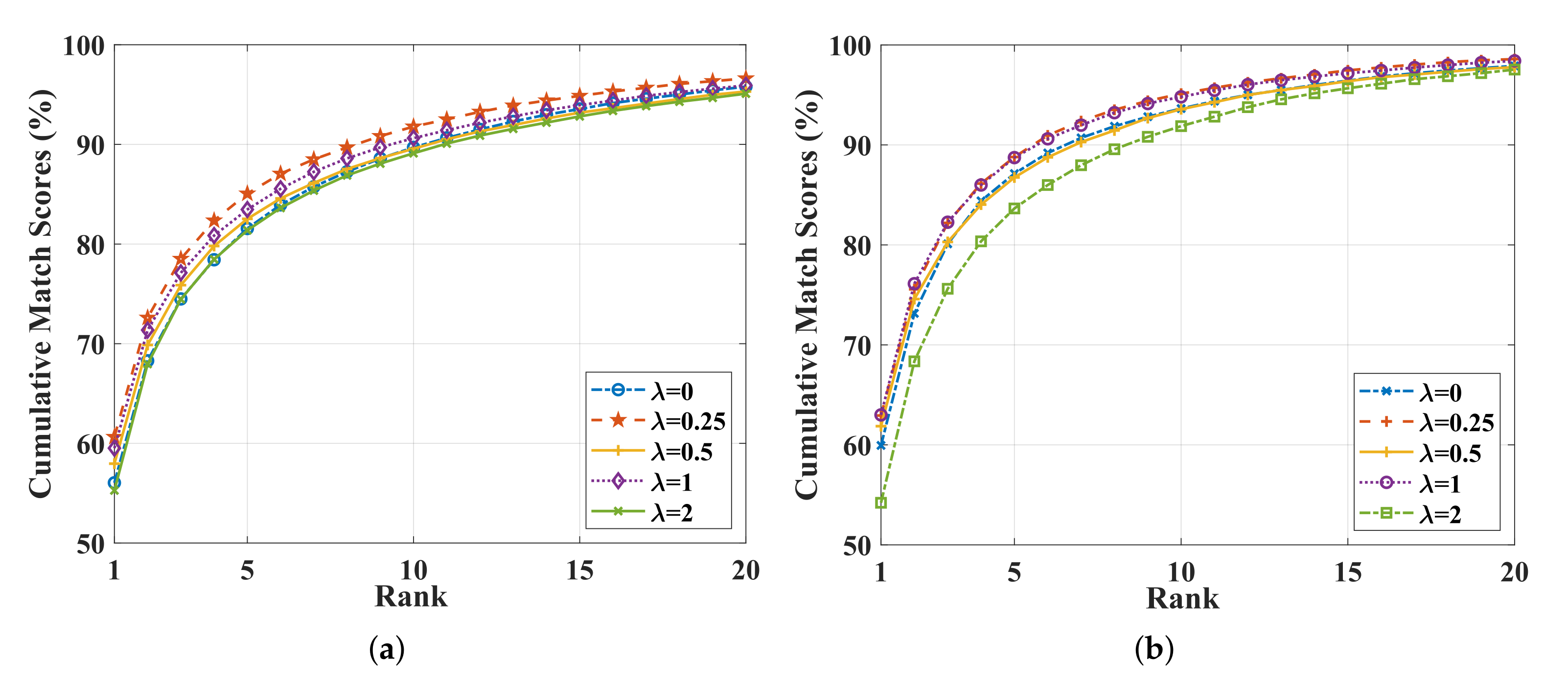
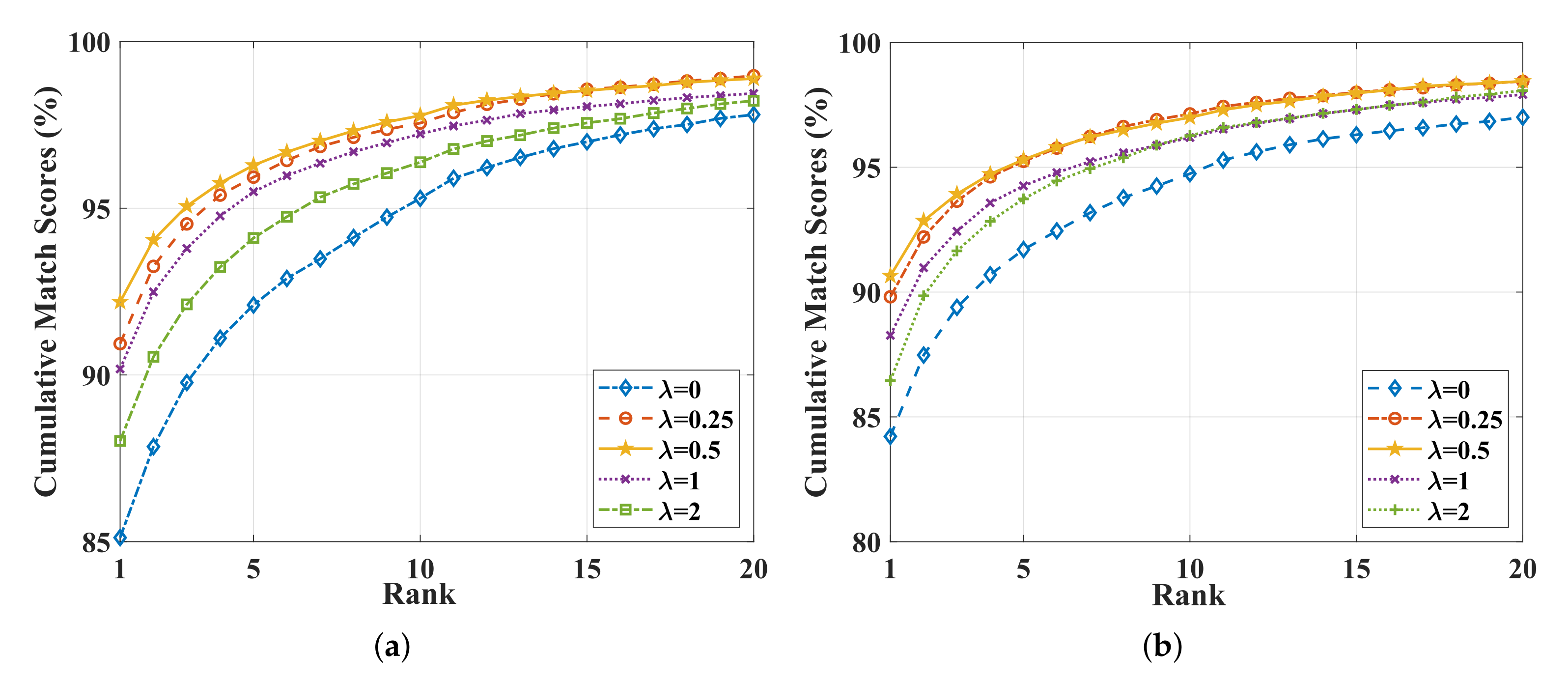
4.4. Role of Minimizing Feature Space Maximum Deviation Loss Function
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| VIPR | Visible-infrared person re-identification |
| FSD | Feature space deviation |
| MMFSD | Minimizing maximum feature space deviation |
| GAN | Genaration adversarial network |
| Conv | Convolutional layer |
| GeM | Generalized-mean pooling |
| BN | Batch normalization |
| HMT | Hard-mining triplet |
| CE | Cross-entropy |
| BNNeck | Batch normalization neck |
| mAP | Mean average precision |
| CMC | Cumulative match characteristic |
| Rank1 | rank-1 accuracy |
| SGD | Stochastic gradient descent |
References
- Ye, M.; Shen, J.; Crandall, D.; Shao, L.; Luo, J. Dynamic Dual-Attentive Aggregation Learning for Visible-Infrared Person Re-identification. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 229–247. [Google Scholar]
- Ye, M.; Lan, X.; Li, J.; Yuen, P. Hierarchical Discriminative Learning for Visible Thermal Person Re-Identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 7501–7508. [Google Scholar]
- Ye, M.; Wang, Z.; Lan, X.; Yuen, P.C. Visible Thermal Person Re-Identification via Dual-Constrained Top-Ranking. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 1092–1099. [Google Scholar]
- Dai, H.; Xie, Q.; Ma, Y.; Liu, Y.; Xiong, S. RGB-Infrared Person Re-identification via Image Modality Conversion. In Proceedings of the International Conference on Pattern Recognition, Milan, Italy, 10–15 January 2021; pp. 592–598. [Google Scholar]
- Liu, H.; Tan, X.; Zhou, X. Parameter Sharing Exploration and Hetero-center Triplet Loss for Visible-Thermal Person Re-Identification. IEEE Trans. Multimed. 2021, 23, 4414–4425. [Google Scholar]
- Dai, P.; Ji, R.; Wang, H.; Wu, Q.; Huang, Y. Cross-Modality Person Re-Identification with Genertive Adversarial Training. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 677–683. [Google Scholar]
- Wu, A.; Zheng, W.S.; Yu, H.X.; Gong, S.; Lai, J. RGB-Infrared Cross-Modality Person Re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5390–5399. [Google Scholar]
- Nguyen, D.T.; Hong, H.G.; Kim, K.W.; Park, K.R. Person Recognition System Based on a Combination of Body Images from Visible Light and Thermal Cameras. Sensors 2017, 17, 605. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.; Liu, L.; Zhu, X.; Zeng, H. A spatial structural similarity triplet loss for auxiliary vehicle re-identification. Sciece China Inf. Sci. 2021, 64, 179104. [Google Scholar] [CrossRef]
- Zhu, J.; Huang, J.; Zeng, H.; Ye, X.; Li, B.; Lei, Z.; Zheng, L. Object reidentification via joint quadruple decorrelation directional deep networks in smart transportation. IEEE Internet Things J. 2020, 7, 2944–2954. [Google Scholar] [CrossRef]
- Zhu, J.; Zeng, H.; Huang, J.; Zhu, X.; Lei, Z.; Cai, C.; Zheng, L. Body symmetry and part-locality-guided direct nonparametric deep feature enhancement for person reidentification. IEEE Internet Things J. 2019, 7, 2053–2065. [Google Scholar]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep Learning for Person Re-identification: A Survey and Outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2872–2893. [Google Scholar]
- Liu, H.; Tan, X.; Zhou, X. Bi-Directional Center-Constrained Top-Ranking for Visible Thermal Person Re-Identification. IEEE Trans. Inf. Forensics Secur. 2020, 15, 407–419. [Google Scholar]
- Liu, S.; Zhang, J. Local Alignment Deep Network for Infrared-Visible Cross-Modal Person Re-identification in 6G-Enabled Internet of Things. IEEE Internet Things J. 2021, 8, 15259–15266. [Google Scholar]
- Lu, Y.; Wu, Y.; Liu, B.; Zhang, T.; Li, B.; Chu, Q.; Yu, N. Cross-Modality Person Re-Identification With Shared-Specific Feature Transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13376–13386. [Google Scholar]
- Zhang, L.; Du, G.; Liu, F.; Tu, H.; Shu, X. Global-Local Multiple Granularity Learning for Cross-Modality Visible-Infrared Person Reidentification. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–11. [Google Scholar] [CrossRef]
- Wei, Z.; Yang, X.; Wang, N.; Gao, X. Flexible Body Partition-Based Adversarial Learning for Visible Infrared Person Re-Identification. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–12. [Google Scholar] [CrossRef]
- Can, Z.; Hong, L.; Wei, G.; Mang, Y. Multi-Scale Cascading Network with Compact Feature Learning for RGB-Infrared Person Re-Identification. In Proceedings of the International Conference on Pattern Recognition, Milan, Italy, 10–15 January 2021; pp. 8679–8686. [Google Scholar]
- Liu, H.; Ma, S.; Xia, D.; Li, S. SFANet: A Spectrum-Aware Feature Augmentation Network for Visible-Infrared Person Reidentificatione. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–14. [Google Scholar] [CrossRef]
- Li, D.; Wei, X.; Hong, X.; Gong, Y. Infrared-Visible Cross-Modal Person Re-Identification with an X Modality. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 4610–4617. [Google Scholar]
- Miao, Z.; Liu, H.; Shi, W.; Xu, W.; Ye, H. Modality-aware Style Adaptation for RGB-Infrared Person Re-Identification. In Proceedings of the International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–27 August 2021; pp. 916–922. [Google Scholar]
- Zhong, X.; Lu, T.; Huang, W.; Ye, M.; Jia, X.; Lin, C.W. Grayscale Enhancement Colorization Network for Visible-infrared Person Re-identification. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1418–1430. [Google Scholar]
- Wang, G.A.; Zhang, T.; Yang, Y.; Cheng, J.; Chang, J.; Liang, X.; Hou, Z. Cross-Modality Paired-Images Generation for RGB-Infrared Person Re-Identification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12144–12151. [Google Scholar]
- Hu, B.; Liu, J.; Zha, Z.j. Adversarial Disentanglement and Correlation Network for Rgb-Infrared Person Re-Identification. In Proceedings of the IEEE International Conference on Multimedia and Expo, Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Seokeon, C.; Lee, S.; Kim, Y.; Kim, C. Hi-CMD:Hiererchical Cross-Modality Disentanglement for Visible-Infrared Person Re-Identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10254–10263. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, Z.; Wang, Z.; Zheng, Y.; Chuang, Y.Y.; Satoh, S. Learning to Reduce Dual-Level Discrepancy for Infrared-Visible Person Re-Identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 618–626. [Google Scholar]
- Wang, G.A.; Zhang, T.; Cheng, J.; Liu, S.; Yang, Y.; Hou, Z. RGB-Infrared Cross-Modality Person Re-Identification via Joint Pixel and Feature Alignment. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 3622–3631. [Google Scholar]
- Luo, H.; Gu, Y.; Liao, X.; Lai, S.; Jiang, W. Bag of Tricks and a Strong Baseline for Deep Person Re-Identification. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 1487–1495. [Google Scholar]
- Feng, Y.; Xu, J.; Ji, Y.m.; Wu, F. LLM: Learning Cross-Modality Person Re-Identification via Low-Rank Local Matching. IEEE Signal Process. Lett. 2021, 28, 1789–1793. [Google Scholar]
- Zhu, X.; Li, Z.; Lou, J.; Shen, Q. Video Super-Resolution Based on a Spatio-Temporal Matching Network. Pattern Recognit. 2020, 110, 107619. [Google Scholar]
- Zhu, X.; Li, Z.; Li, X.; Li, S.; Dai, F. Attention-aware Perceptual Enhancement Nets for Low-Resolution Image Classification. Inf. Sci. 2020, 515, 233–247. [Google Scholar]
- Bianco, V.; Mazzeo, P.L.; Paturzo, M.; Distante, C.; Ferraro, P. Deep learning assisted portable IR active imaging sensor spots and identifies live humans through fire. Opt. Lasers Eng. 2020, 124, 105818. [Google Scholar]
- Ye, M.; Chen, C.; Shen, J.; Shao, L. Dynamic Tri-Level Relation Mining with Attentive Graph for Visible Infrared Re-Identification. IEEE Trans. Inf. Forensics Secur. 2022, 17, 386–398. [Google Scholar]
- Zhao, J.; Wang, H.; Zhou, Y.; Yao, R.; Chen, S.; El Saddik, A. Spatial-Channel Enhanced Transformer for Visible-Infrared Person Re-Identification. IEEE Trans. Multimed. 2022, 1. [Google Scholar] [CrossRef]
- Hou, J.B.; Zhu, X.; Liu, C.; Yang, C.; Yin, X.C. Detecting Text in Scene and Traffic Guide Panels with Attention Anchor Mechanism. IEEE Trans. Intell. Transp. Syst. 2021, 22, 6890–6899. [Google Scholar]
- Ye, M.; Lan, X.; Leng, Q.; Shen, J. Cross-Modality Person Re-Identification via Modality-Aware Collaborative Ensemble Learning. IEEE Trans. Image Process. 2020, 29, 9387–9399. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In Defense of the Triplet Loss for Person Re-Identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Unlabeled Samples Generated by GAN Improve the Person Re-identification Baseline in Vitro. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3774–3782. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Annual Conference on Neural Information Processing Systems, South Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Hao, Y.; Wang, N.; Li, J.; Gao, X. HSME: Hypersphere Manifold Embedding for Visible Thermal Person Re-Identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8385–8392. [Google Scholar]
- Feng, Z.; Lai, J.; Xie, X. Learning Modality-Specific Representations for Visible-Infrared Person Re-Identification. IEEE Trans. Image Process. 2020, 29, 579–590. [Google Scholar]
- Hu, W.; Liu, B.; Zeng, H.; Hu, H. Adversarial Decoupling and Modality-invariant Representation Learning for Visible-Infrared Person Re-identification. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5095–5109. [Google Scholar] [CrossRef]
- Qiong, W.; Pingyang, D.; Jie, C.; Chia-Wei, L.; Yongjian, W.; Feiyue, H.; Bineng, Z.; Rongrong, J. Discover Cross-Modality Nuances for Visible-Infrared Person Re-Identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4328–4337. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | All-Search Mode | Indoor-Search Mode | Reference | ||
|---|---|---|---|---|---|
| Rank1 (%) | mAP (%) | Rank1 (%) | mAP (%) | ||
| BDTR [3] | 17.01 | 19.66 | N/A | N/A | IJCAI 2018 |
| cmGAN [6] | 26.97 | 27.80 | 31.63 | 42.19 | IJCAI 2018 |
| D-HSME [43] | 20.68 | 23.12 | N/A | N/A | AAAI 2019 |
| DRL [27] | 28.9 | 29.2 | N/A | N/A | CVPR 2019 |
| AlignGAN [28] | 42.4 | 40.7 | 45.9 | 54.3 | ICCV 2019 |
| eBDTR [13] | 27.82 | 28.42 | N/A | N/A | TIFS 2020 |
| CEL [4] | 29.52 | 28.4 | N/A | N/A | ICPR 2020 |
| Hi-CMD [25] | 34.9 | 35.9 | N/A | N/A | CVPR 2020 |
| DGD+MSR [44] | 37.35 | 38.11 | 39.64 | 50.88 | TIP 2020 |
| JSIA-ReID [23] | 38.1 | 36.9 | 43.8 | 52.9 | AAAI 2020 |
| MSPAC-MeCen [18] | 46.62 | 47.26 | 51.63 | 61.54 | ICPR 2020 |
| X modality [20] | 49.92 | 50.73 | N/A | N/A | AAAI 2020 |
| MACE [37] | 51.64 | 50.11 | 57.35 | 64.79 | TIP 2020 |
| LAND [14] | 53.6 | 52.0 | 57.0 | 63.2 | IOT 2020 |
| DDAG [1] | 54.75 | 53.02 | 61.02 | 68.0 | ECCV 2020 |
| FBP-AL [17] | 43.78 | 42.91 | N/A | N/A | TNNLS 2021 |
| AGW [12] | 47.50 | 47.65 | 54.17 | 62.97 | TPAMI 2021 |
| LLM [30] | 55.25 | 52.96 | 59.65 | 65.46 | SPL 2021 |
| ADCNet [24] | 55.9 | 59.6 | 58.8 | 65.6 | ICME 2021 |
| DMiR [45] | 50.54 | 49.29 | 53.92 | 62.49 | TCSVT 2022 |
| GECNet [22] | 53.37 | 51.83 | 60.60 | 62.89 | TCSVT 2022 |
| DFLN-ViT [35] | 59.84 | 57.70 | 62.13 | 69.03 | TMM 2022 |
| MMFSD | 60.64 | 57.54 | 62.93 | 69.27 | Ours |
| Method | Visible-to-Infrared Retrieval | Infrared-to-Visible Retrieval | Reference | ||
|---|---|---|---|---|---|
| Rank1 (%) | mAP (%) | Rank1 (%) | mAP (%) | ||
| BDTR [3] | 33.47 | 31.83 | N/A | N/A | IJCAI 2018 |
| DRL [27] | 43.3 | 44.1 | N/A | N/A | CVPR 2019 |
| D-HSME [43] | 50.85 | 47.00 | 50.15 | 46.16 | AAAI 2019 |
| AlignGAN [28] | 57.9 | 53.6 | 56.3 | 53.4 | ICCV 2019 |
| eBDTR [13] | 31.83 | 33.18 | N/A | N/A | TIFS 2020 |
| CEL [4] | 47.50 | 44.21 | N/A | N/A | ICPR 2020 |
| DGD+MSR [44] | 48.43 | 48.67 | N/A | N/A | TIP 2020 |
| JSIA-ReID [23] | 48.5 | 49.3 | 48.1 | 48.9 | AAAI 2020 |
| MSPAC-MeCen [18] | 49.61 | 53.64 | N/A | N/A | ICPR 2020 |
| X modality [20] | 62.21 | 60.18 | N/A | N/A | AAAI 2020 |
| DDAG [1] | 69.34 | 63.46 | 68.06 | 61.80 | ECCV 2020 |
| Hi-CMD [25] | 70.93 | 66.04 | N/A | N/A | CVPR 2020 |
| cm-SSFT [15] | 72.3 | 72.9 | 71.0 | 71.7 | CVPR 2020 |
| MACE [37] | 72.37 | 69.09 | 72.12 | 68.57 | TIP 2020 |
| LADN [14] | 75.7 | 72.9 | 75.3 | 73.0 | IoT 2020 |
| AGW [12] | 70.05 | 66.37 | N/A | N/A | TPAMI 2021 |
| ADCNet [24] | 72.9 | 66.5 | 72.4 | 65.3 | ICME 2021 |
| FBP-AL [17] | 73.98 | 68.24 | 70.05 | 66.61 | TNNLS 2021 |
| LLM [30] | 74.85 | 71.32 | N/A | N/A | SPL 2021 |
| SFANet [19] | 76.31 | 68.00 | 70.15 | 63.77 | TNNLS 2021 |
| GECNet [22] | 82.33 | 78.45 | 78.93 | 75.58 | TCSVT 2021 |
| MPANet [46] | 83.7 | 80.9 | 82.8 | 80.7 | CVPR 2021 |
| MSA [21] | 84.86 | 82.16 | N/A | N/A | IJCAI 2021 |
| HC-Triplet [5] | 91.05 | 83.28 | 89.30 | 81.46 | TMM 2021 |
| GLMC [16] | 91.84 | 81.42 | 91.12 | 81.06 | TNNLS 2021 |
| DMiR [45] | 75.79 | 69.97 | 73.93 | 68.22 | TCSVT 2022 |
| DTRM [34] | 79.09 | 70.09 | 78.02 | 69.56 | TIFS 2022 |
| DFLN-ViT [35] | 92.10 | 82.11 | 91.21 | 81.62 | TMM 2022 |
| MMFSD | 92.19 | 85.95 | 90.65 | 84.38 | Ours |
| All Search | Indoor Search | |||||
|---|---|---|---|---|---|---|
| Rank1 (%) | mAP (%) | mINP (%) | Rank1 (%) | mAP (%) | mINP (%) | |
| 0 | 56.04 | 54.71 | 41.96 | 59.95 | 67.23 | 63.35 |
| 0.25 | 60.64 | 57.54 | 43.31 | 62.93 | 69.27 | 64.89 |
| 0.5 | 57.96 | 54.64 | 40.15 | 61.87 | 67.66 | 62.82 |
| 1 | 59.52 | 55.97 | 41.31 | 63.00 | 69.08 | 64.32 |
| 2 | 55.27 | 51.42 | 35.66 | 54.21 | 61.92 | 57.09 |
| Visible to Infrared | Infrared to Visible | |||||
|---|---|---|---|---|---|---|
| Rank1 (%) | mAP (%) | mINP (%) | Rank1 (%) | mAP (%) | mINP (%) | |
| 0 | 85.12 | 80.44 | 68.67 | 84.22 | 79.16 | 65.75 |
| 0.25 | 90.94 | 85.25 | 73.26 | 89.81 | 83.72 | 69.58 |
| 0.5 | 92.19 | 85.95 | 73.86 | 90.65 | 84.38 | 70.73 |
| 1 | 90.18 | 81.49 | 65.46 | 88.27 | 79.23 | 61.65 |
| 2 | 88.02 | 79.71 | 63.97 | 86.45 | 78.48 | 61.48 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Z.; Wen, T. Minimizing Maximum Feature Space Deviation for Visible-Infrared Person Re-Identification. Appl. Sci. 2022, 12, 8792. https://doi.org/10.3390/app12178792
Wu Z, Wen T. Minimizing Maximum Feature Space Deviation for Visible-Infrared Person Re-Identification. Applied Sciences. 2022; 12(17):8792. https://doi.org/10.3390/app12178792
Chicago/Turabian StyleWu, Zhixiong, and Tingxi Wen. 2022. "Minimizing Maximum Feature Space Deviation for Visible-Infrared Person Re-Identification" Applied Sciences 12, no. 17: 8792. https://doi.org/10.3390/app12178792