
Discriminating Pattern Mining for Diagnosing Reading Disorders †


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Preliminaries
2.1. Tachistoscope
2.2. Encoded Pathologies
2.3. Input Data, Feature Extraction
2.3.1. Structural Features
2.3.2. Contextual Features
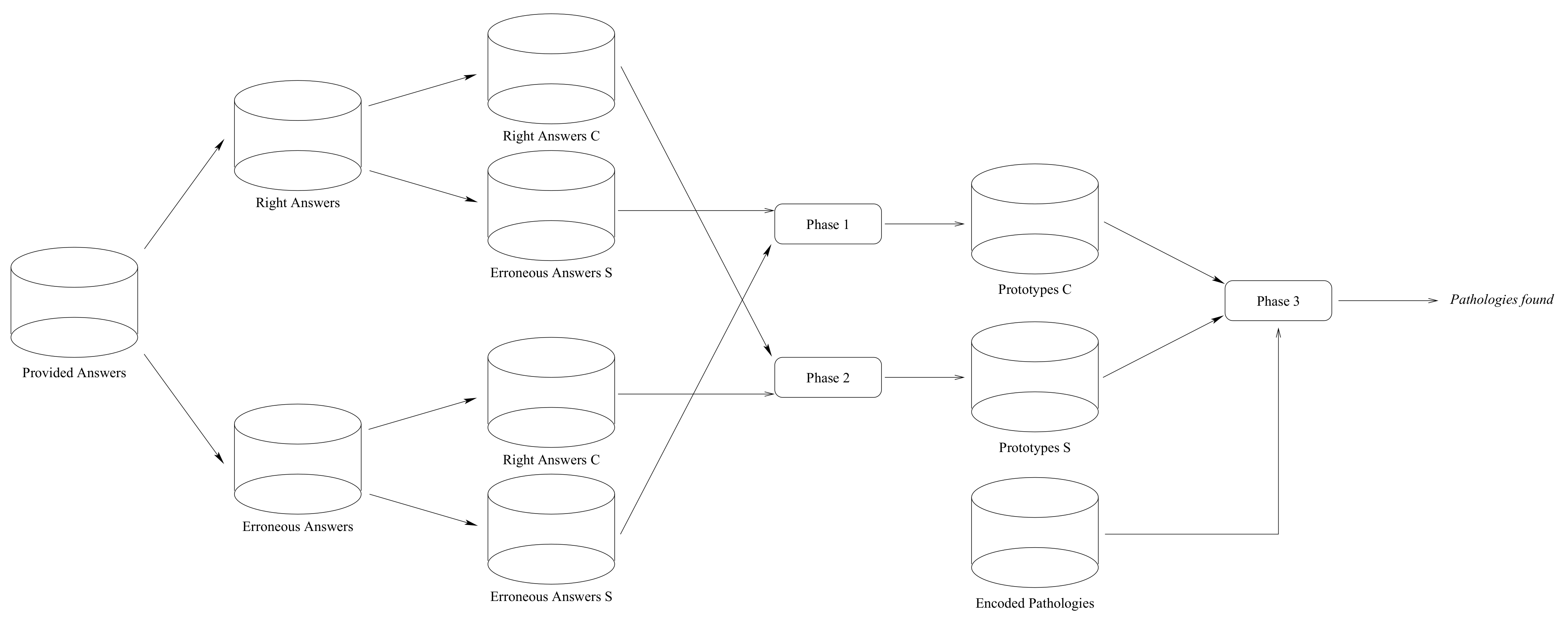
2.3.3. Phases of the Method
- Phase 1: Discriminating Pattern Search
- Phase 2: Context Analysis
- Phase 3: Encoded Pathology Detection
3. Technique
3.1. Preliminaries
3.1.1. Session Vectorization
- the set of words with right answers ;
- the set of words with erroneous answers .
3.1.2. Contextual Features
- time:
- the time in milliseconds of the trial associated with w;
- masking:
- a binary value stating whether the “masking” is active or not;
- existence:
- a binary value stating whether the word is in the dictionary or not;
- length:
- the number of characters of the word;
- frequency:
- a binary value stating whether the word is of common use or not;
- easiness:
- a binary value stating whether the structure of the word is simple.
3.1.3. Structural Features
3.1.4. Test Vectorization
3.2. Phase 1: Discriminating Prototype Search
- ;
- ;
- the prototype words should be able to discriminate between and .
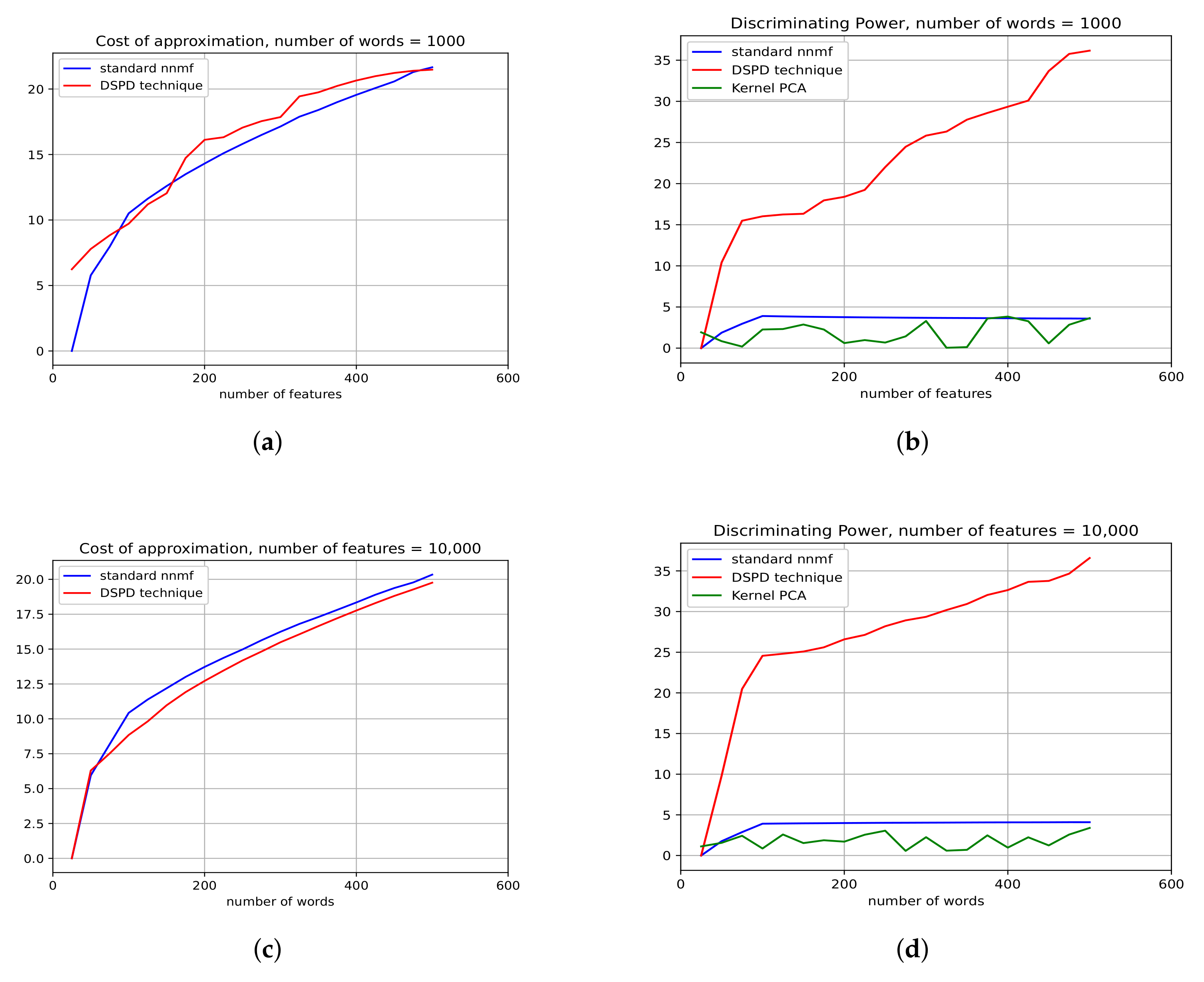
3.2.1. Discriminating Power
3.2.2. Computational Issues
Recall on Trace Derivative Computation
3.3. Phase 2: Context Analysis
3.4. Phase 3: Known and New Pathology Identification
Computational Issues
4. Experiments
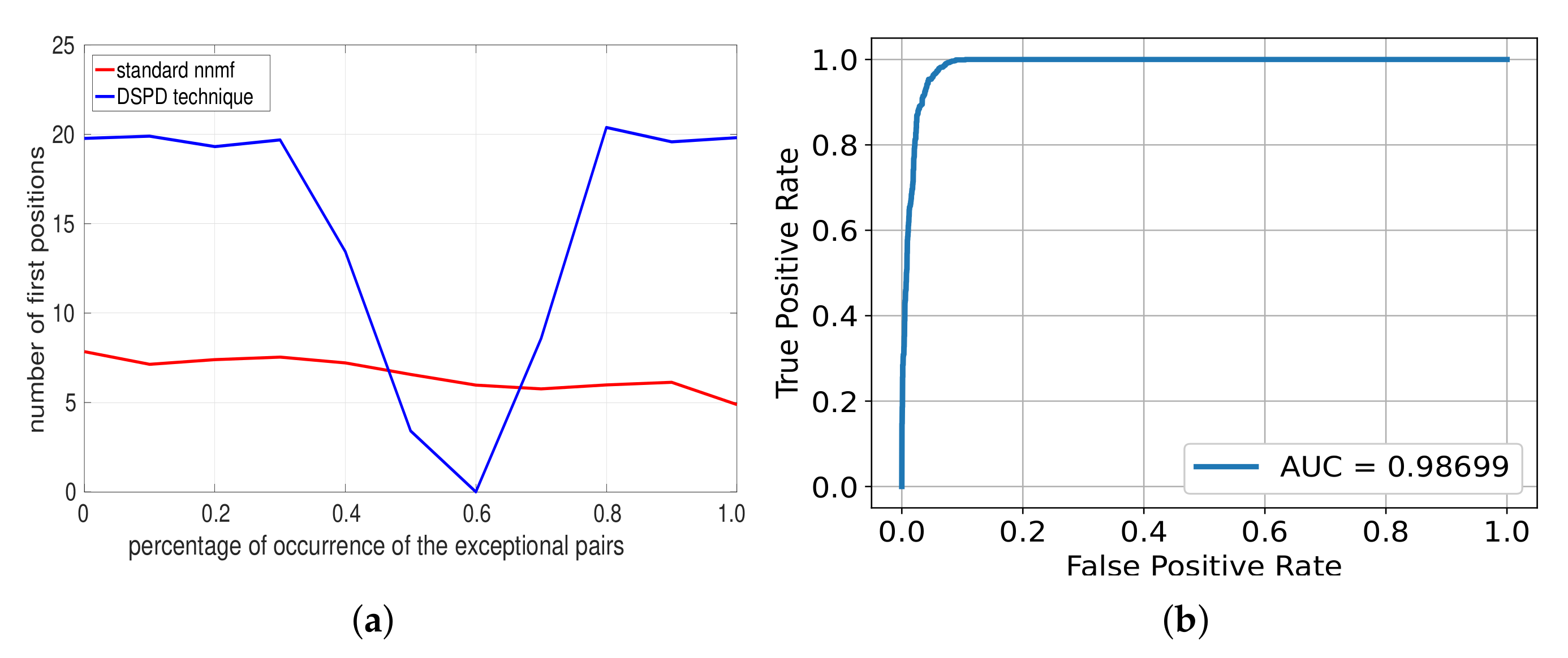
4.1. Synthetic Data
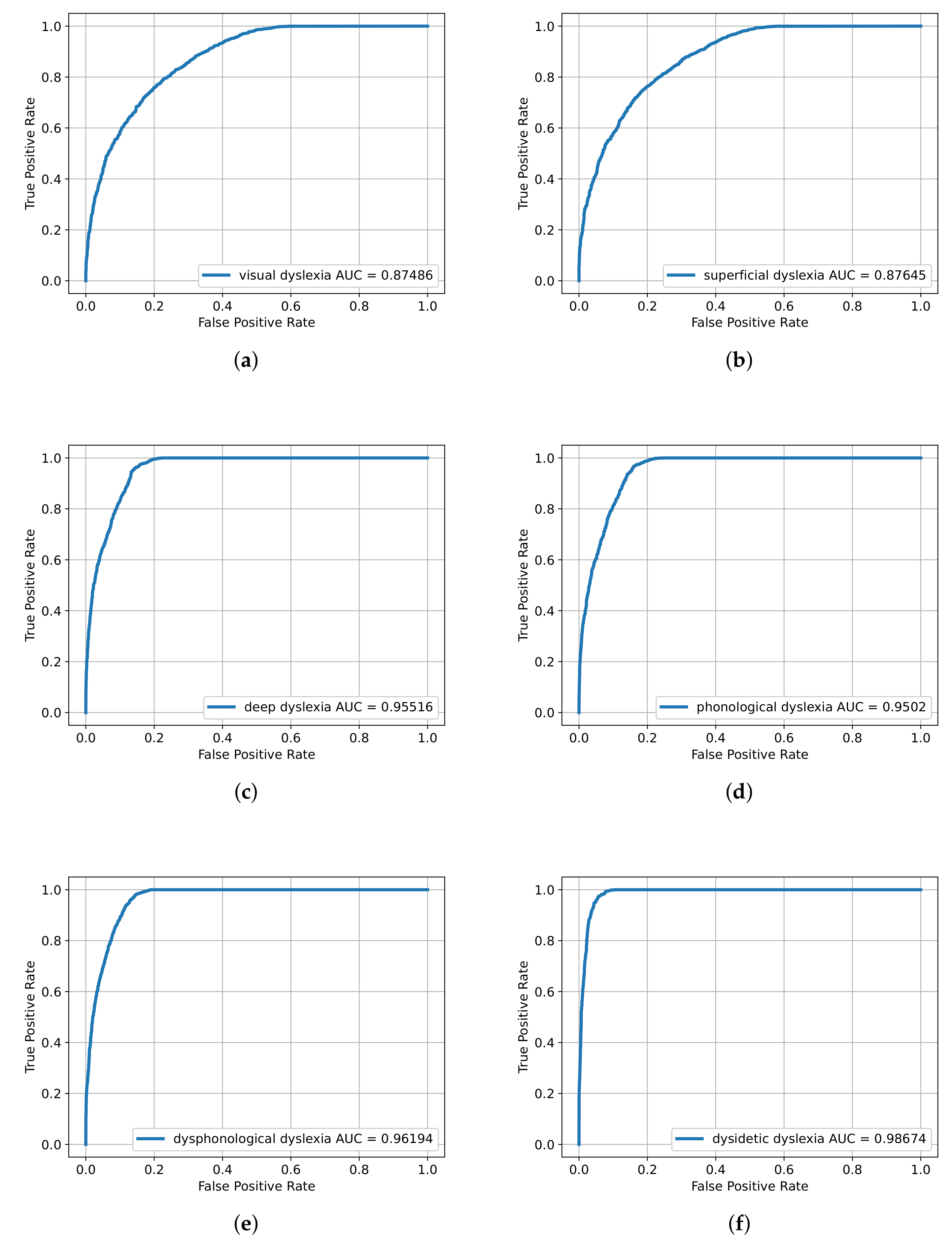
4.2. Real Data
- visual dyslexia;
- superficial dyslexia where lexical pathways are compromised, but reading, although difficult, is possible;
- phonological dyslexia where a phonological path is compromised since a correct association between grapheme and phoneme is missing;
- deep dyslexia where the semantic path is compromised, and semantic paraphasias are performed.
- dysidetic dyslexia where the representation of the word in its variations is difficult, and the new words are not understandable;
- dysphonological dyslexia concerning a deficit at the level of grapheme phoneme mappings.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Benschop, R. What Is a Tachistoscope? Historical Explorations of an Instrument. Sci. Context 1998, 11, 23–50. [Google Scholar] [CrossRef] [PubMed]
- Lorusso, M.L.; Facoetti, A.; Toraldo, A.; Molteni, M. Tachistoscopic treatment of dyslexia changes the distribution of visual–spatial attention. Brain Cogn. 2005, 57, 135–142. [Google Scholar] [CrossRef]
- Lorusso, M.L.; Facoetti, A.; Bakker, D.J. Neuropsychological Treatment of Dyslexia: Does Type of Treatment Matter? J. Learn. Disabil. 2011, 44, 136–149. [Google Scholar] [CrossRef] [Green Version]
- Mafioletti, S.; Pregliasco, R.; Ruggeri, L. Il bambino e le abilità di Lettura. Il Ruolo Della Visione; Franco Angeli: Milan, Italy, 2005. [Google Scholar]
- Benso, F.; Berriolo, S.; Marinelli, M.; Guida, P.; Conti, G.; Francescangeli, E. Stimolazione Integrata dei Sistemi Specifi ci per la Lettura e Delle Risorse Attentive Dedicate e del Sistema Attentivo Supervisore; Edizioni Erickson: Trento, Italy, 2008; Volume 5, pp. 167–181. [Google Scholar]
- Nippold, M.A.; Schwartz, I.E. Reading disorders in stuttering children. J. Fluen. Disord. 1990, 15, 175–189. [Google Scholar] [CrossRef]
- Gori, S.; Facoetti, A. Is the language transparency really that relevant for the outcome of the action video games training? Curr. Biol. 2013, 23, 00258-3. [Google Scholar]
- Benso, F. Teoria e Trattamenti nei Disturbi di Apprendimento; Tirrenia (Pisa) Del Cerro: Pisa, Italy, 2004. [Google Scholar]
- Benso, F. Sistema Attentivo-Esecutivo e Lettura. Un Approccio Neuropsicologico alla Dislessia; Il leone verde: Torino, Italy, 2010. [Google Scholar]
- Sharma, M.; Purdy, S.; Kelly, A. Comorbidity of Auditory Processing, Language, and Reading Disorders. J. Speech Lang. Hear. Res. JSLHR 2009, 52, 706–722. [Google Scholar] [CrossRef] [Green Version]
- Yadav, N.; Poellabauer, C.; Daudet, L.; Collins, T.; McQuillan, S.; Flynn, P. Portable Neurological Disease Assessment Using Temporal Analysis of Speech. In Proceedings of the 6th ACM Conference on Bioinformatics, Computational Biology and Health Informatics, Atlanta, GA, USA, 9–12 September 2015; Association for Computing Machinery: New York, NY, USA, 2015. BCB ’15. pp. 77–85. [Google Scholar]
- Cagatay, M.; Ege, P.; Tokdemir, G.; Cagiltay, N.E. A serious game for speech disorder children therapy. In Proceedings of the 2012 7th International Symposium on Health Informatics and Bioinformatics, Nevsehir, Turkey, 19–22 April 2012; pp. 18–23. [Google Scholar]
- Pervaiz, M.; Patel, R. SpeechOmeter: Heads-up monitoring to improve speech clarity. In Proceedings of the 16th International ACM SIGACCESS Conference on Computers and Accessibility, Rochester, NY, USA, 20–22 October 2014; pp. 319–320. [Google Scholar]
- Wang, Y.X.; Zhang, Y.J. Nonnegative Matrix Factorization: A Comprehensive Review. IEEE Trans. Knowl. Data Eng. 2013, 25, 1336–1353. [Google Scholar] [CrossRef]
- Kim, J.; He, Y.; Park, H. Algorithms for nonnegative matrix and tensor factorizations: A unified view based on block coordinate descent framework. J. Glob. Optim. 2014, 58, 285–319. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.; Choo, J.; Kim, J.; Reddy, C.K.; Park, H. Simultaneous Discovery of Common and Discriminative Topics via Joint Nonnegative Matrix Factorization. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 567–576. [Google Scholar]
- Berry, M.W.; Castellanos, M. Survey of Text Mining II: Clustering, Classification, and Retrieval, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Long, Y.H.; Dai, L.R.; Wang, E.Y.; Ma, B.; Guo, W. Non-negative matrix factorization based discriminative features for speaker verification. In Proceedings of the International Symposium on Chinese Spoken Language Processing, Tainan, Taiwan, 10 January 2010; pp. 291–295. [Google Scholar]
- Zhang, Z.Y. Nonnegative Matrix Factorization: Models, Algorithms and Applications. In Data Mining: Foundations and Intelligent Paradigms: Volume 2: Statistical, Bayesian, Time Series and Other Theoretical Aspects; Holmes, D.E., Jain, L.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 99–134. [Google Scholar]
- Hulme, C.; Snowling, M.J. Reading disorders and dyslexia, Current Opinion in Pediatrics. Neurology 2016, 28, 731–735. [Google Scholar]
- Schölkopf, B.; Smola, A.J.; Müller, K.R. Nonlinear Component Analysis as a Kernel Eigenvalue Problem. Neural Comput. 1998, 10, 1299–1319. [Google Scholar] [CrossRef] [Green Version]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fassetti, F.; Fassetti, I. Discriminating Pattern Mining for Diagnosing Reading Disorders. Appl. Sci. 2022, 12, 7540. https://doi.org/10.3390/app12157540
Fassetti F, Fassetti I. Discriminating Pattern Mining for Diagnosing Reading Disorders. Applied Sciences. 2022; 12(15):7540. https://doi.org/10.3390/app12157540
Chicago/Turabian StyleFassetti, Fabio, and Ilaria Fassetti. 2022. "Discriminating Pattern Mining for Diagnosing Reading Disorders" Applied Sciences 12, no. 15: 7540. https://doi.org/10.3390/app12157540