
Progress of Process Monitoring for the Multi-Mode Process: A Review


{kind=link}
Abstract
:1. Introduction
2. Definition, Data Characteristics and Causes of Multi-Mode Processes
2.1. Definition, Data Characteristics of the Multi-Mode Process
- Multi-mode: multiple operation states and stages in industrial production processes are referred to as multi-mode. Modes and physical phases do not necessarily closely correspond to each other.
- Multi-mode process: a process with multiple stable mode states in the same production process affected by changes in the external environment and other conditions, or by changes in the production scheme or inherent characteristics of the process itself, is referred to as a multi-mode process. Depending on the different production modes adopted, multi-mode processes can be divided into multi-mode continuous processes and batch processes. A multi-mode system will continuously switch between the following modes: steady-state mode 1—transition mode—steady-state mode 2. The data characteristics corresponding to each mode will be different, such as shifts in the mean value of variables and changes in the covariance structure.
- Continuous process: a continuous process is a mode that works stably according to the state. Its characteristic variables change slowly.
- Batch process: batch processes involve a cyclic mode of work. There are multiple steady-state modes in batch processes and their time characteristics change with progress of the process; there are also short-term transition modes in adjacent batch processes.
- Steady-state mode: a steady-state mode is a mode in which the operating state of the system is relatively stable during production. The variables characterizing the steady-state mode, such as the mean, variance, and correlation, do not change with operation time. In the production process, a system will usually operate in a steady-state mode, which is the crucial mode that determines product quality.
- Transition mode: when a production process goes from one steady-state mode to another, it cannot do so suddenly. A gradual and dynamic transition mode is required to connect two steady-state modes. In the transition mode, the process variables and operation modes can change greatly over a short period, and the running track is generally different each time. The characteristic variables of the transition mode show strong time-varying, dynamic and non-linear characteristics and have a considerable impact on the production process.
2.2. Causes of the Multi-Mode Process
- Changes in raw material properties, the occurrence of chemical reactions, changes in the external environment, and changes in the operational task and production scheme, can cause the normal mode area of the process to drift over time, such as in chemical distillation processes and other multi-mode processes.
- Changes in the process parameters or loads, equipment reorganization, and equipment aging, can lead to changes in the relationships between process variables, thus showing obvious multi-mode characteristics. For example, reciprocating mechanical steam turbines show variable working modes during startup, shutdown and load changes. During the operation of mills, steel balls are constantly worn, resulting in slow changes in modes [10]. With different loads, an engine can respond using several speeds, or different gears to influence power, resulting in multi-mode processes.
- The inherent characteristics of a production process mean that it will include multiple operation periods. For example, the injection-molding of plastic products is divided into five operational stages for an injection batch: mold closing, injection, pressure maintenance, cooling and mold opening. It represents a typical batch process [11].
- In the start-up and shutdown stages of a process, operation modes, such as mode adjustment and mode switching, inevitably involve a transition mode. The transition mode usually lasts for a short time with less easy access to process data. Therefore, a transition mode will not only require the intervention of many operators but often also results in the production of unassessed products, which can greatly impact both safety of production and product quality [12].
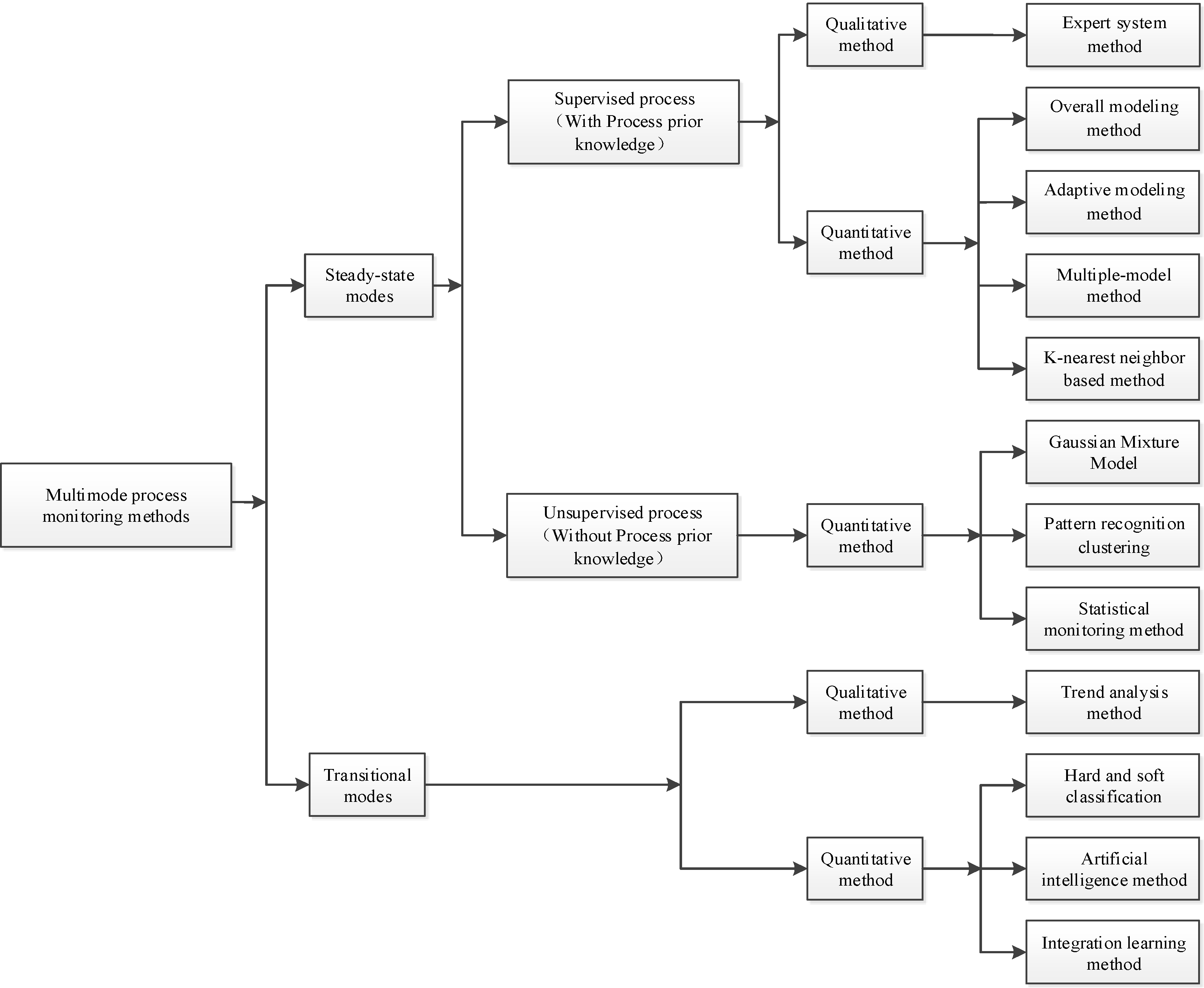
3. Multi-Mode Process Monitoring Methods
4. Steady-State Mode Process Monitoring Methods
4.1. Supervised Process Monitoring Method
4.1.1. Expert System Method
4.1.2. Overall Modeling Method
4.1.3. Adaptive Modeling Method
4.1.4. Multiple-Model Method
4.1.5. K-Nearest Neighbor (KNN) Based Method
4.2. Unsupervised Process Monitoring Method
4.2.1. GMM
4.2.2. Pattern Recognition Clustering Method
4.2.3. Statistical Monitoring Analysis Methods
5. Transition Modes Process Monitoring Method
5.1. Trend Analysis Method
5.2. Hard Classification and Soft Classification
5.3. Artificial Intelligence Method
5.3.1. Neural Network Method
5.3.2. Autoencoder Model-Based Method
5.3.3. Dirichlet Process-Based Method
5.3.4. Hidden Markov Model (HMM)-Based Method
5.3.5. Just-In-Time Learning (JITL) Method
5.4. Integrated Learning Method
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tan, S.; Wang, F.L.; Chang, Y.Q.; Wang, S.; Zhou, H. Fault detection of multi-mode process using segmented PCA based on differential transform. Acta Autom. Sin. 2010, 36, 1626–1636. [Google Scholar] [CrossRef]
- Xie, X. Multimode Industrial Process Modeling and Monitoring Method Based on Statistical Theory. Ph.D. Thesis, East China University of Technology, Shanghai, China, 2012. [Google Scholar]
- Gao, Y.; Gong, Z.H.; Huang, H. Energy saving through centralized air conditioners control and implementation of expert system. J. Beijing Univ. Technol. 1997, 17, 393–396. [Google Scholar]
- Zhang, Q.J. Study on Multi-Mode Switching Fuzzy Control Method and Logic Management of Unmanned Helicopter. Master’s Thesis, University of Defense Science and Technology, Beijing, China, 2006. [Google Scholar]
- Qian, M.Y. Optimal Control of Fermentation Engineering; Jiangsu Science and Technology Press: Nanjing, China, 1998. [Google Scholar]
- Guo, J.Y.; Yuan, T.M.; Li, Y. Fault detection method for uneven-length multimode batch processes. CIESC J. 2016, 67, 2916–2924. [Google Scholar]
- Peng, K.X.; Ma, L.; Zhang, K. Review of quality-related detection and diagnosis technology for complex industrial process. Acta Autom. Sin. 2017, 3, 349–365. [Google Scholar]
- Xu, L. Research on Statistical Monitoring of Multimode Process Based on PCA Mixture Model. Master’s Thesis, Zhejiang University, Hangzhou, China, 2010. [Google Scholar]
- Ge, Z.Q. Statistical Process Monitoring Methods for Complex Processes. Ph.D. Thesis, Zhejiang University, Hangzhou, China, 2009. [Google Scholar]
- He, M.; Zhi, E.W.; Cheng, L.; Yan, G.W. Soft sensor of ball mill load parameters based on multi-mode transfer learning. Control Eng. China 2019, 26, 1994–1999. [Google Scholar]
- Zhao, F. Study on Some Key Issues in Product Quality Control of Injection Molding Process. Master’s Thesis, Nanjing University of Aeronautics and Astronautics, Nanjing, China, 2014. [Google Scholar]
- Tan, S.; Wang, F.L.; Peng, J.; Shi, H.T. Modeling algorithm for new mode process. Control. Decis. 2012, 27, 1241–1246. [Google Scholar]
- Chang, Y.Q.; Ma, R.X.; Wang, F.L.; Zheng, W.; Wang, S. Multimode process mode identifification with coexistence of quantitative information and qualitative information. Trans. Autom. Sci. Eng. 2020, 3, 1516–1527. [Google Scholar]
- Xie, L. Research on Statistical Performance Monitoring of Batch Process. Ph.D. Thesis, Zhejiang University, Hangzhou, China, 2005. [Google Scholar]
- Marcos, Q.; Alberto, P.; Cristina, V.; Orestes, L. Data-driven monitoring of multimode continuous processes: A review. Chemom. Intell. Lab. Syst. 2019, 189, 56–71. [Google Scholar]
- Lee, Y.H.; Jin, H.D.; Han, C.H. On-line process state classification for adaptive monitoring. Ind. Eng. Chem. Res. 2006, 45, 3095–3107. [Google Scholar] [CrossRef]
- Yu, J.B. Local and global Principle Component Analysis for process monitoring. J. Process Control. 2012, 22, 1358–1373. [Google Scholar] [CrossRef]
- Lane, S.; Martin, E.B.; Kooijmans, R.; Morris, A.J. Performance monitoring of a multiproduct Semi-batch process. J. Process Control 2001, 11, 1–11. [Google Scholar] [CrossRef]
- Xie, Y.H.; Xue, Z.Q.; Feng, L.W.; Zhang, C.; Li, Y. Research on application of fault detection based on ILNS-SVDD in multi-state process. Comput. Appl. Chem. 2019, 36, 1–8. [Google Scholar]
- Xie, Y.H.; Liu, W.J.; Li, Y. Application of dynamic weighted SVDD based on difference in multi-modal process. Appl. Research. Compu. 2019, 36, 3777–3780. [Google Scholar]
- Li, W.H.; Yue, H.H.; Sergio, V.; Qin, S.J. Recursive PCA for adaptive process monitoring. J. Process Control 2000, 10, 471–486. [Google Scholar] [CrossRef]
- Kano, M.; Hasebe, S.; Hashimoto, I. Evolution of multivariate statistical process control: Application of Independent Component Analysis and external analysis. Compu. Chem. Eng. 2004, 14, 467–485. [Google Scholar] [CrossRef]
- Ge, Z.Q.; Song, Z.H. New online monitoring method for multiple operating modes process. CIESC J. 2008, 59, 135–141. [Google Scholar]
- Wang, X.Y. Study of Monitoring Methods for Process with Multiple Operation Modes and Its Application of Process. Master’s Thesis, East China University of Technology, Shanghai, China, 2013. [Google Scholar]
- Hwang, D.H.; Han, C. Real-time monitoring for a process with multiple operating modes. Control. Eng. Pract. 1999, 7, 891–902. [Google Scholar] [CrossRef]
- Choi, S.W.; Martin, E.B.; Morris, A.J.; Lee, I.B. Adaptive multivariate statistical process control for monitoring time-varying processes. Ind. Eng. Chem. Res. 2006, 45, 3108–3118. [Google Scholar] [CrossRef]
- Cheng, C.; Chiu, M.S. Nonlinear process monitoring using JITL-PCA. Chemoetrics Intell. Lab. Syst. 2005, 76, 1–13. [Google Scholar] [CrossRef]
- Ge, Z.Q.; Song, Z.H. Online monitoring of nonlinear multiple mode processes based on adaptive local model approach. Control. Eng. Pract. 2008, 16, 1427–1437. [Google Scholar] [CrossRef]
- Huang, K.K.; Wei, K.; Zhou, L.F.; Li, Y.G.; Yang, C.H. Multimode process monitoring and mode identification based on multiple Dictionary learning. IEEE Trans. Instrumentation. Meas. 2021, 70, 1–12. [Google Scholar] [CrossRef]
- Huang, K.K.; Wu, Y.M.; Wang, C.; Xie, Y.F.; Yang, C.H.; Gui, W.J. A projective and Discriminative Dictionary learning for High-Dimensional process monitoring with industrial applications. IEEE Trans. Ind Inform. 2021, 17, 558–568. [Google Scholar] [CrossRef]
- Huang, K.K.; Wu, Y.M.; Yang, C.H.; Peng, G.Z.; Shen, W.M. Structure Dictionary Learning-Based multimode process monitoring and its application to Aluminum Electrolysis process. IEEE Trans. Autom. Sci. Eng. 2020, 17, 1989–2003. [Google Scholar] [CrossRef]
- Xiao, Y.T.; Tao, Y.; Shi, H.B. Distribution Adaptation Local Outlier Factor for Multimode Process Monitoring. In Proceedings of the 39th Chinese Control Conference, Shenyang, China, 27–29 July 2020; pp. 2294–2300. [Google Scholar]
- Zhao, S.J.; Zhang, J.; Xu, Y.M. Monitoring of processes with multiple operating modes through multiple Principle Component Analysis models. Ind. Eng. Chem. Res. 2004, 43, 7025–7035. [Google Scholar] [CrossRef]
- Guo, J.Y.; Liu, Y.C.; Li, Y. PCA based on probability density for fault detection of multimodal processes. Appl. Res. Comput. 2019, 36, 1397–1408. [Google Scholar]
- Yu, J.; Qin, S.J. Multimode process monitoring with Bayesian inference-based finite Gaussian Mixture Models. AIChE J. 2008, 54, 1811–1829. [Google Scholar] [CrossRef]
- Zhang, J.M.; Xu, L.; Xu, X.Z.; Xie, L. Multi-mode process monitoring method based on PCA mixture model. Control Eng. China 2010, 17, 553–558. [Google Scholar]
- Guo, X.G.; Xiong, W.L.; Xu, B.G. Multimode monitoring based on local neighborhood standardization and Bayesian inference. Inf. Control. 2017, 46, 113–121. [Google Scholar]
- Xie, X.; Shi, H.B. A novel integrated statistical monitoring index for multimode industrial processes. J. East China Univ. Sci. Technol. (Nat. Sci. Ed.) 2012, 38, 488–494. [Google Scholar]
- He, Q.P.; Wang, J. Fault detection using the K-Nearest Neighbor rule for semiconductor manufacturing processes. IEEE Trans. Semicond. Manuf. 2007, 20, 345–354. [Google Scholar] [CrossRef]
- Guo, X.P.; Liu, S.Y.; Li, Y. Fault detection of multi-mode process employing sparse residual distance. Acta Autom. Sin. 2019, 45, 617–625. [Google Scholar]
- Zhang, C.C.; Deng, X.G.; Xu, Y. Improved multiway Kernel Entropy Component Analysis based fault detection for batch process. Control. Eng. 2018, 25, 636–642. [Google Scholar]
- Feng, L.W.; Zhang, C.; Li, Y.; Xie, Y.H. Fault detection strategy of standard-distance-based K-nearest neighbor rule in multimode. Control. Theory Appl. 2019, 36, 553–560. [Google Scholar]
- Zhang, S.M. Mode Identification and Process Monitoring of Complex Multimode Process Based on Data-Driven Methods. Ph.D. Thesis, Northeast University, Liaoning, China, 2016. [Google Scholar]
- Zhong, N.; Deng, X.G.; Xu, Y. Fault detection method based on LECA for multimode process. CIESC J. 2015, 66, 4929–4940. [Google Scholar]
- Zhang, C.; Guo, Q.X.; Li, Y. Fault detection in the Tennessee Eastman Benchmark process using principal component difference based on K-Nearest Neighbors. IEEE Access 2020, 8, 49999–50009. [Google Scholar] [CrossRef]
- Feng, L.W.; Zhang, C.; Li, Y. Study on PC-WKNN-based fault detection method in multimode batch process. Comput. Appl. Res. 2018, 35, 1130–1134. [Google Scholar]
- Guo, J.Y.; Liu, Y.C.; Li, Y. Multimodal process fault detection based on local relative probability density KNN. J. Chem. Eng. Chinese Univ. 2019, 33, 159–166. [Google Scholar]
- Ma, H.H.; Hu, Y.; Shi, H.B. Unsupervised fault detection of multimode processes using distance space statistics analysis. CIESC J. 2012, 63, 873–880. [Google Scholar]
- Wu, H.M. Robot Multimodal Introspection and Learning based on Nonparametric Bayesian Model. Ph.D. Thesis, Guangdong University of Technology, Guangzhou, China, 2019. [Google Scholar]
- Jing, H.; Zhao, C.H.; Gao, F.R. Non-stationary data reorganization for weighted wind turbine icing monitoring with Gaussian Mixture Model. Comput. Chem. Eng. 2021, 147, 107241. [Google Scholar] [CrossRef]
- Choi, S.W.; Park, J.H.; Lee, I.B. Process monitoring using a Gaussian Mixture Model via Principle Component Analysis and discriminate analysis. Comput. Chem. Eng. 2004, 28, 1377–1387. [Google Scholar] [CrossRef]
- Xu, X.Z.; Xie, L.; Wang, S.Q. A multimode process monitoring method based GMM. Comput. Appl Chem. 2010, 27, 17–22. [Google Scholar]
- Zou, X.Y.; Chang, Y.Q.; Wang, F.L.; Zhou, Y. Operation performance assessment for multimode processes based on GMM and Bayesian inference. Control. Theory Appl. 2016, 33, 164–171. [Google Scholar]
- Guo, Q.X.; Liu, J.C.; Tan, S.B.; Yang, D.S.; Li, Y.; Zhang, C. A Multimode process monitoring strategy via improved variational inference Gaussian Mixture Model based on Locality Preserving Projections. Trans. Inst. Meas. Control. 2022, 44, 1732–1743. [Google Scholar] [CrossRef]
- Gao, J.F.; Zhou, L.K. Process monitoring research based on multimode mixture model. Control. Instrum. Chem. Ind. 2015, 3, 263–266. [Google Scholar]
- Tang, P.; Peng, K.X.; Dong, J.; Zhang, K.; Zhao, S.S. Monitoring of nonlinear processes with multiple operating modes through a Novel Gaussian Mixture variational autoencoder model. IEEE Access 2020, 8, 114487–114500. [Google Scholar] [CrossRef]
- Tan, S.; Chang, Y.Q.; Wang, F.L.; Wang, S. Mode identification and process monitoring of multiple mode process based on GMM. Control. Decis. 2014, 28, 1626–1636. [Google Scholar]
- Xie, X.; Shi, H.B. Global monitoring strategy for multimodal chemical processes. J. Chem. Eng. 2012, 63, 2156–2162. [Google Scholar]
- Niu, Z.; Liu, J.Z.; Niu, Y.G. Fault detection under varying load conditions based on dynamic multi-principal component models. Power Eng. 2005, 25, 554–558,598. [Google Scholar]
- Zhang, Z.Y.; Hu, Y.; Shi, H.B. Multi-stage batch process monitoring based on clustering method. CIESC J. 2013, 64, 4522–4528. [Google Scholar]
- Liang, S.J.; Zhang, S.R.; Zheng, X.; Lin, D.S. Online Fault Detection of Fixed-Wing UAV based on DKPCA algorithm with multiple operation conditions considered. J. Northwestern. Polytech. Univ. 2020, 38, 619–626. [Google Scholar] [CrossRef]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Plenum Press: New York, NY, USA, 1981. [Google Scholar]
- Wang, X.Y.; Wang, X.; Xu, P.L.; Wang, Z.L.; Qian, F. Self-adaptive fuzzy cluster based multiple models process monitoring and its application. Comput. Appl Chem. 2011, 28, 1509–1513. [Google Scholar]
- Liu, J.L. Fault detection and classification for a process with multiple production grades. Ind. Eng Chem. Res. 2008, 47, 8250–8262. [Google Scholar] [CrossRef]
- Luo, J. Study on Modal Identification and Fault Monitoring of Multimodal Chemical Process. Master’s Thesis, China University of Petroleum (Beijing), Beijing, China, 2017. [Google Scholar]
- Xie, X.; Shi, H.B. Multimode process monitoring based on Fuzzy C-means in Locality Preserving Projection Subspace. Chin. J. Chem. Eng. 2012, 20, 1174–1179. [Google Scholar] [CrossRef]
- Deng, X.G.; Xu, Y. Multimode Non-Gaussian Process Fault Detection Based on Bayesian-ICA. Control. Eng. China 2018, 25, 402–407. [Google Scholar]
- Xu, Y. Multimode Industrial Process Fault Diagnosis Method Based on Bayesian Independent Component Analysis. Master’s Thesis, China University of Petroleum (East China), Qingdao, China, 2016. [Google Scholar]
- Jiang, Q.C.; Yan, X.F. Multimode Process Monitoring Using Variational Bayesian Inference and Canonical Correlation Analysis. Trans. Autom Sci. Eng. 2019, 16, 1814–1824. [Google Scholar] [CrossRef]
- Zhang, H.X. The Application of Multivariate Process Control Charts. Master’s Thesis, Sichuan Normal University, Chengdu, China, 2018. [Google Scholar]
- Laion, L.B.; Paulo, H.F.; Rosemeire, L.F. On flexible Statistical Process Control with Artificial Intelligence: Classification control charts. Expert Systems. Appl. 2022, 194, 116492. [Google Scholar]
- Sanchez-Fernandez, A.; Baldan, F.J.; Sainz-Palmero, G.I.; Benítez, J.M.; Fuente, M.J. Fault detection based on time series modeling and multivariate statistical process control. Chemom. Intel. Labor. Syst. 2018, 182, 57–69. [Google Scholar] [CrossRef]
- Guo, H.J.; Xu, C.L.; Shi, H.B. Multimode process monitoring based on local neighborhood standardization strategy. J. Shanghai Jiaotong Univ. 2015, 49, 868–875+883. [Google Scholar]
- Xu, Y.Y.; Yang, J.; Tan, S.; Shi, H.B. Multimode process monitoring based on local features. J. East China Univ. Sci. Technol (Nat. Sci. Ed.) 2017, 43, 260–265. [Google Scholar]
- Liu, B.L.; Ma, Y.X.; Shi, H.B. A Multimodal process fault detection method based on weighted distance neighborhood selection strategy. J. East China Univ. Sci. Technol (Nat. Sci. Ed.) 2015, 41, 192–197+215. [Google Scholar]
- Gu, X.S.; Zhou, B.Q. Multimodal industrial process fault detection based on LNS-DEWKECA. Control. Decis. 2020, 35, 1879–1885. [Google Scholar]
- Sundarraman, A.; Srinivasan, R. Monitoring transitions in chemical plants using enhanced trend analysis. Comput. Chem. Eng. 2003, 27, 1455–1472. [Google Scholar] [CrossRef]
- Lu, N.Y.; Gao, F.R.; Wang, F. A sub-PCA modeling and on-line monitoring strategy for batch processes. AIChE J. 2004, 50, 255. [Google Scholar] [CrossRef]
- Zhao, C.H.; Wang, F.L.; Lu, N.Y.; Jia, M.X. Stage-based soft-transition multiple PCA modeling and On-line monitoring strategy for batch processes. J. Process Control. 2007, 17, 728–741. [Google Scholar] [CrossRef]
- Yao, Y.; Gao, F.R. Phase and transition based batch modeling and Online monitoring. J. Process Control. 2009, 19, 816–826. [Google Scholar] [CrossRef]
- Ng, Y.S.; Srinivasan, R. Multivariate temporal data analysis using Self Organization Maps monitoring and diagnosis of multistate operations. Ind. Eng. Chem. Res. 2008, 47, 7758–7771. [Google Scholar] [CrossRef]
- Han, S.F.; Yu, Y.; Tang, T.; Chen, M.; Wang, L.; Xia, Y.L. Measurement of Weld Pool Oscillation for pulsed GTAW based on laser vision. Microcomput. Appl. 2019, 35, 4–9. [Google Scholar]
- Ma, J.; Li, S.L.; Wang, X.Y. Condition Monitoring of Rolling Bearing Based on Multi-Order FRFT and SSA-DBN. Symmetry 2022, 14, 320. [Google Scholar]
- Lv, F.Y.; Wen, C.L.; Liu, M.Q. Representation learning based adaptive multimode process monitoring. Chemom. Intell. Lab. Syst. 2018, 181, 95–104. [Google Scholar] [CrossRef]
- Lv, F.Y.; Fan, X.N.; Wen, C.L.; Bao, Z.J. Stacked Sparse Autoencoder Network based multimode process monitoring. In Proceedings of the 2018 International Conference On Control Automation & Information Sciences, Hangzhou, China, 24–27 October 2018; pp. 227–232. [Google Scholar]
- Jiang, L. Nonlinear Process Monitoring Based on Autoencoder Model. Ph.D. Thesis, Zhejiang University, Hangzhou, China, 2017. [Google Scholar]
- Lee, S.; Kwak, M.; Tsui, K.; Seoung, B.K. Process monitoring using variational autoencoder for high-dimensional nonlinear processes. Eng. Appl. Artif. Intell. 2019, 83, 13–27. [Google Scholar] [CrossRef]
- Wu, H.; Zhao, J. Self-adaptive deep learning for multimode process monitoring. Comput. Chem. Eng. 2020, 141, 107024. [Google Scholar] [CrossRef]
- Ma, J.P.; Li, C.W.; Zhang, G.Z. Rolling bearing fault diagnosis based on deep learning and autoencoder information fusion. Symmetry 2022, 14, 13. [Google Scholar] [CrossRef]
- Tan, R.M.; Cong, T.; Nina, F.T.; James, R.O.; Jerzy, B. Statistical monitoring of processes with multiple operating modes. IFAC papersOnLine 2020, 52, 635–642. [Google Scholar] [CrossRef]
- Wang, B.; Li, Z.C.; Dai, Z.W.; Neil, L.; Yan, X.F. Data-Driven mode identification and unsupervised fault detection for nonlinear multimode processes. IEEE Trans. Ind. Inform. 2020, 16, 3651–3661. [Google Scholar] [CrossRef]
- Tan, R.M.; Cong, T.; James, R.O.; Jerzy, B.; Nina, F.T. An on-line framework for monitoring nonlinear processes with multiple operating modes. J. Process Control. 2020, 89, 119–130. [Google Scholar] [CrossRef]
- Dong, J.; Zhang, C.; Peng, K.X. A new multimode process monitoring method based on a hierarchical Dirichlet process-Hidden semi-Markov model with application to the hot steel strip mill process. Control. Eng. Pract. 2021, 110, 104764. [Google Scholar] [CrossRef]
- Peng, P.; Zhao, J.X.; Zhang, Y.; Zhang, H.M. Hidden Markov Model Combined with Kernel Principal Component Analysis for Nonlinear Multimode Process Fault Detection. In Proceedings of the 2019 IEEE 15th International Conference on Automation Science and Engineering (CASE), Vancouver, BC, Canada, 22–26 August 2019; pp. 1586–1591. [Google Scholar]
- Wang, L. Hidden Markov Model-Based Industrial Process Monitoring. Ph.D. Thesis, Zhejiang University, Hangzhou, China, 2018. [Google Scholar]
- Wu, D.H.; Zhou, D.H.; Zhang, J.X.; Chen, M.Y. Multimode process monitoring based on fault dependent variable selection and moving window-negative log likelihood probability. Comput. Chem. Eng. 2020, 136, 106787. [Google Scholar] [CrossRef]
- Jiang, Q.C.; Yan, S.F.; Yan, X.F.; Chen, S.T.; Sun, J.G. Data-driven individual-joint learning framework for nonlinear process monitoring. Control. Eng. Pract. 2020, 95, 104235. [Google Scholar] [CrossRef]
- He, Y.C. Data-Driven Modeling and Monitoring of Transient Phases in Continuous Industrial Processes. Ph.D. Thesis, Zhejiang University, Hangzhou, China, 2016. [Google Scholar]
- Chen, Z.W.; Liu, C.; Steven, X.D.; Peng, T.; Yang, C.H.; Gui, W.H.; Yuri, A.W. Shardt. A Just-In-Time-Learning-Aided Canonical Correlation Analysis method for multimode process monitoring and fault detection. IEEE Trans. Ind. Electr. 2021, 68, 5259–5270. [Google Scholar] [CrossRef]
- Zhang, H.Y.; Tian, X.M.; Deng, X.G.; Cao, Y.P. Multiphase batch process with transitions monitoring based on global preserving Statistics Slow Feature Analysis. Neurocomputing 2018, 293, 64–86. [Google Scholar] [CrossRef]
- Zhu, Z.B. Integrating Cluster Analysis for Fault Detection and Classification. Ph.D. Thesis, Zhejiang University, Hangzhou, China, 2012. [Google Scholar]
- Li, Y.; Liu, N.; Tang, X.C. Clustering for multi-mode process based on K-ICA-PCA. Control. Eng. China 2015, 22, 501–504. [Google Scholar]
- Li, S.; Zhou, X.F.; Shi, H.B. Fault Detection Using Common and Specific Variable Decomposition for Nonlinear Multimode Process. In Proceedings of the 2020 Chinese Automation Congress (CAC), Shanghai, China, 6–8 November 2020; pp. 5052–5056. [Google Scholar]
- Guo, L.L.; Wu, P.; Lou, S.W.; Gao, J.F.; Liu, Y.C. A multi-feature extraction technique based on Principal Component Analysis for nonlinear dynamic process monitoring. J. Process Control. 2020, 85, 159–172. [Google Scholar] [CrossRef]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, J.; Zhang, J. Progress of Process Monitoring for the Multi-Mode Process: A Review. Appl. Sci. 2022, 12, 7207. https://doi.org/10.3390/app12147207
Ma J, Zhang J. Progress of Process Monitoring for the Multi-Mode Process: A Review. Applied Sciences. 2022; 12(14):7207. https://doi.org/10.3390/app12147207
Chicago/Turabian StyleMa, Jie, and Jinkai Zhang. 2022. "Progress of Process Monitoring for the Multi-Mode Process: A Review" Applied Sciences 12, no. 14: 7207. https://doi.org/10.3390/app12147207