
Statistical Power Analysis in Reliability Demonstration Testing: The Probability of Test Success


Abstract
:1. Introduction
1.1. Motivation
1.2. Assessment of Recent Work
1.3. Research Gaps
- A metric for objectively assessing reliability tests based solely on their ability to demonstrate the frequentist reliability target must be established;
- A holistic approach to assessing all possible reliability tests needs to be developed;
- A procedure for efficient reliability demonstration test planning considering all possible reliability tests needs to be worked out;
- The calculation effort involved in reliability test planning needs to be reduced.
1.4. Outline
2. Probability of Test Success
3. Calculation of the Probability of Test Success
- A.
- A general calculation method
- B.
- An analytic and exact calculation method for SR tests
- C.
- An analytic and approximate calculation method for failure-based tests
- D.
- A calculation method using test simulation.
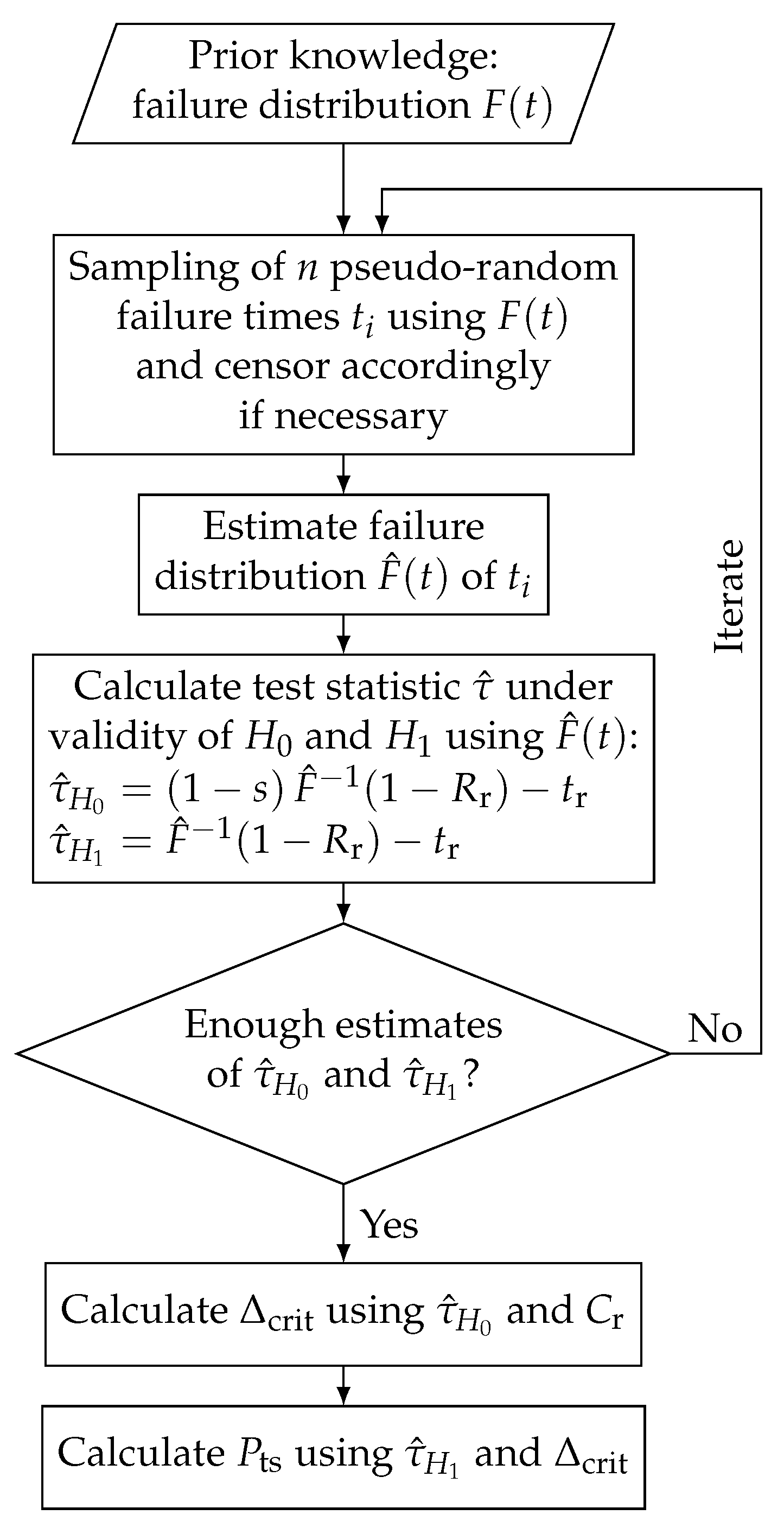
3.1. General Calculation Procedure
3.1.1. General Calculation for Failure-Based Tests
3.1.2. General Calculation for the Success Run Test
3.2. Exact Calculation for the Success Run Test
3.3. Approximate Calculation for Failure-Based Tests
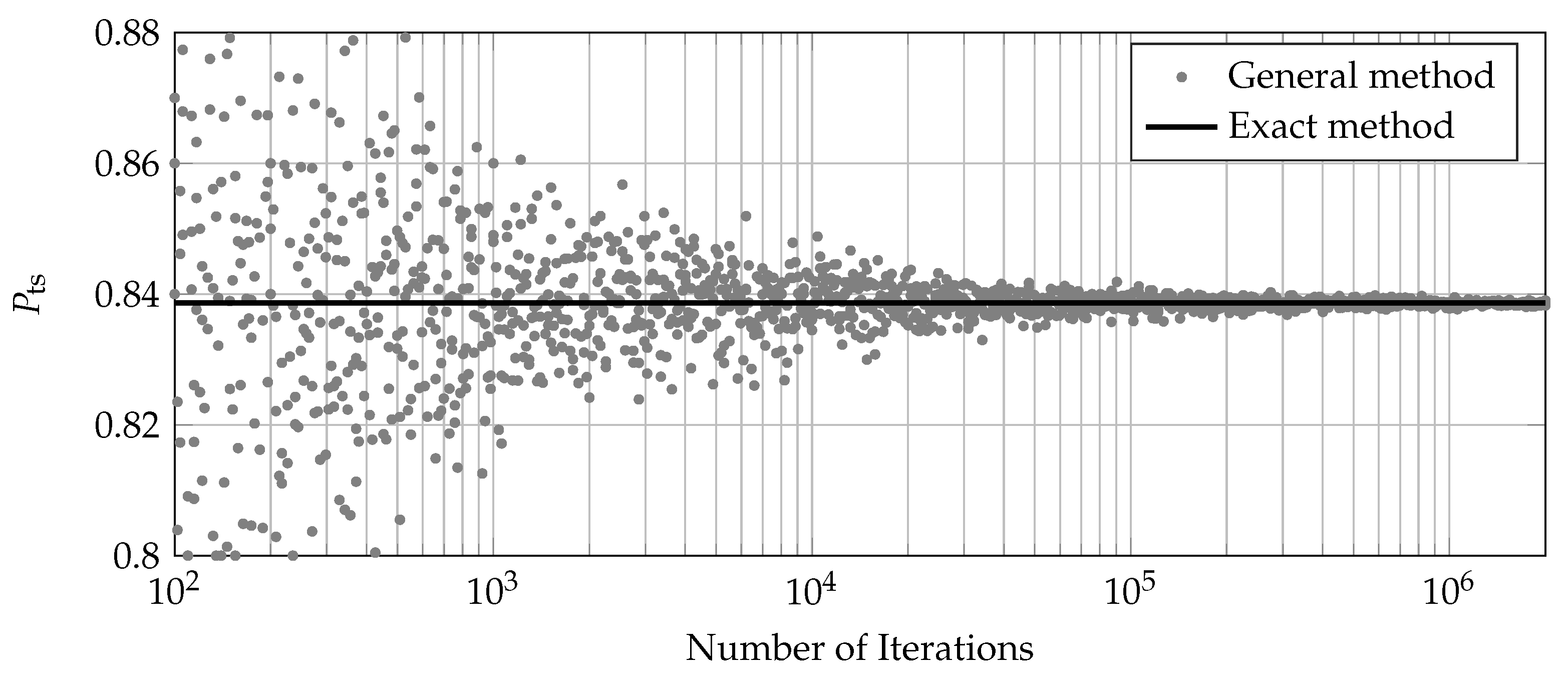
3.4. Calculation by Test Simulation
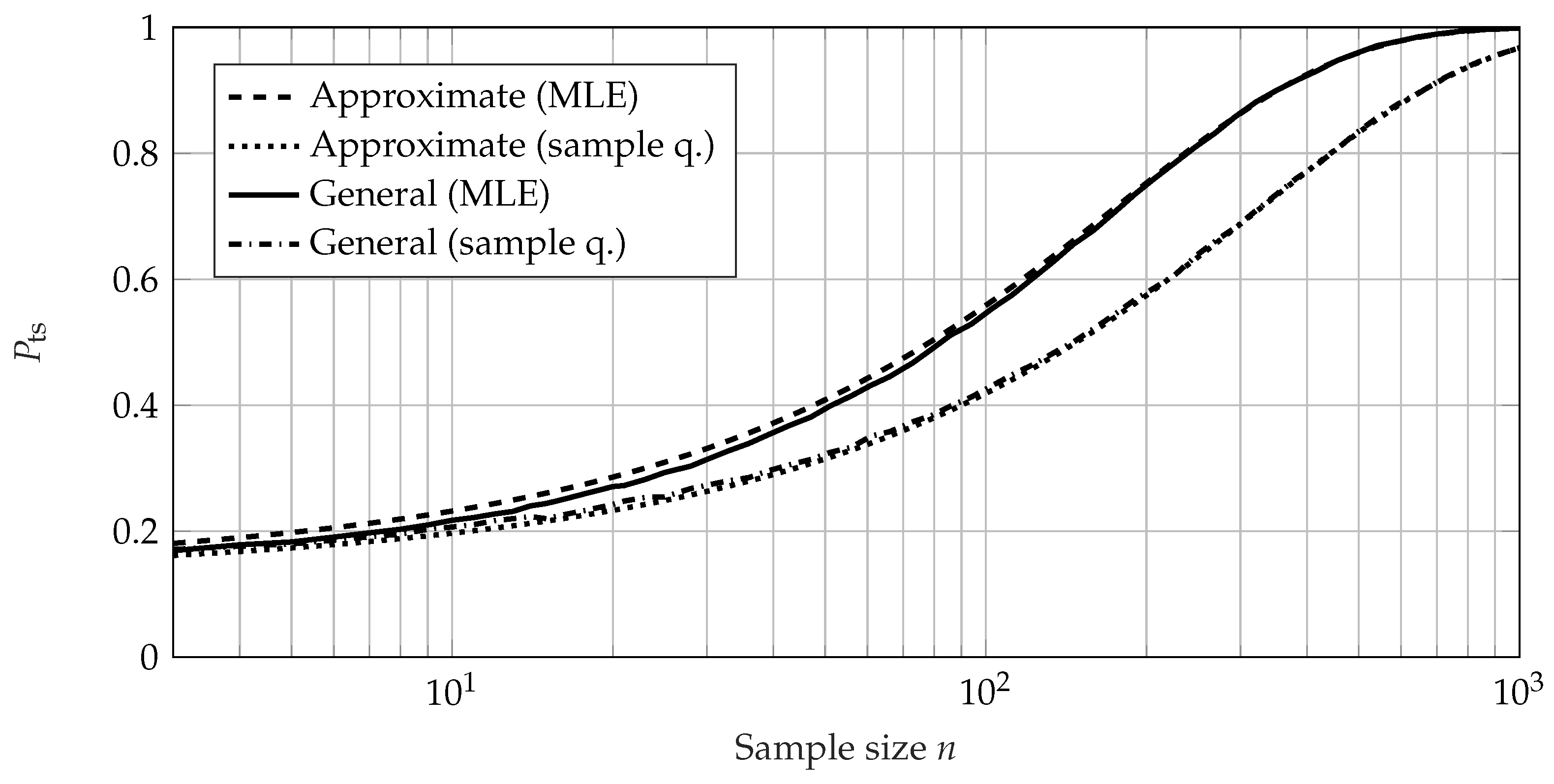
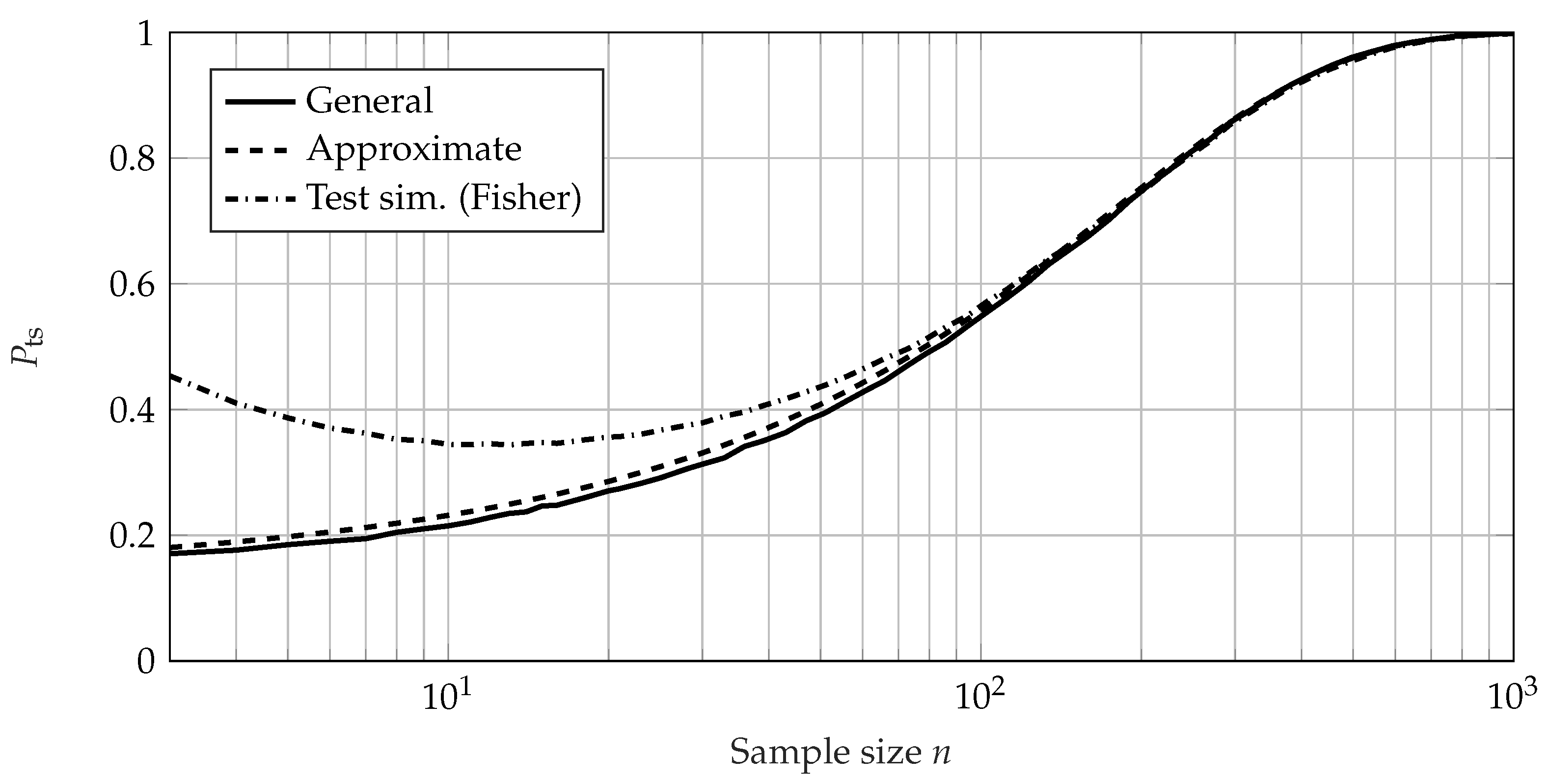
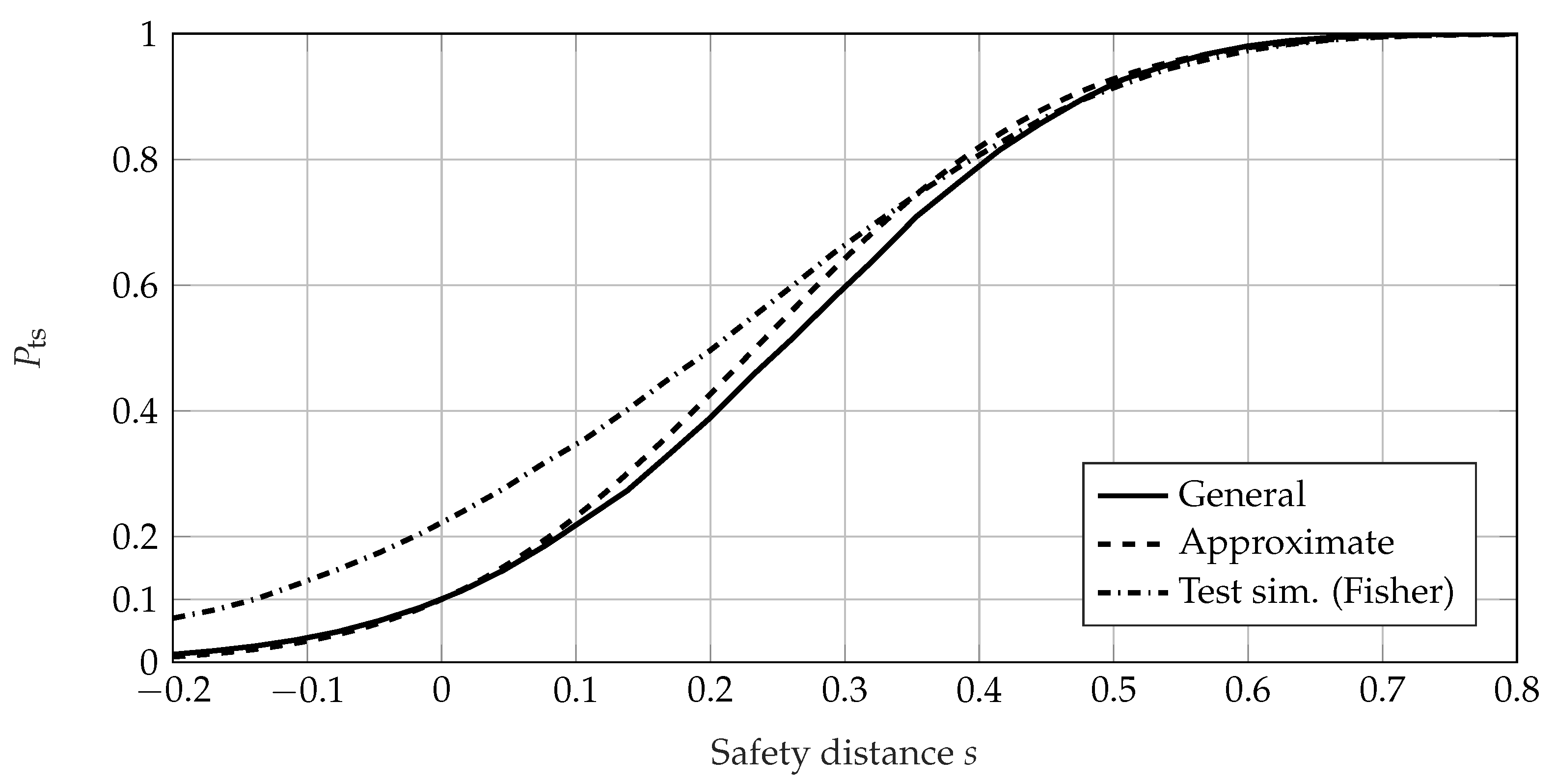
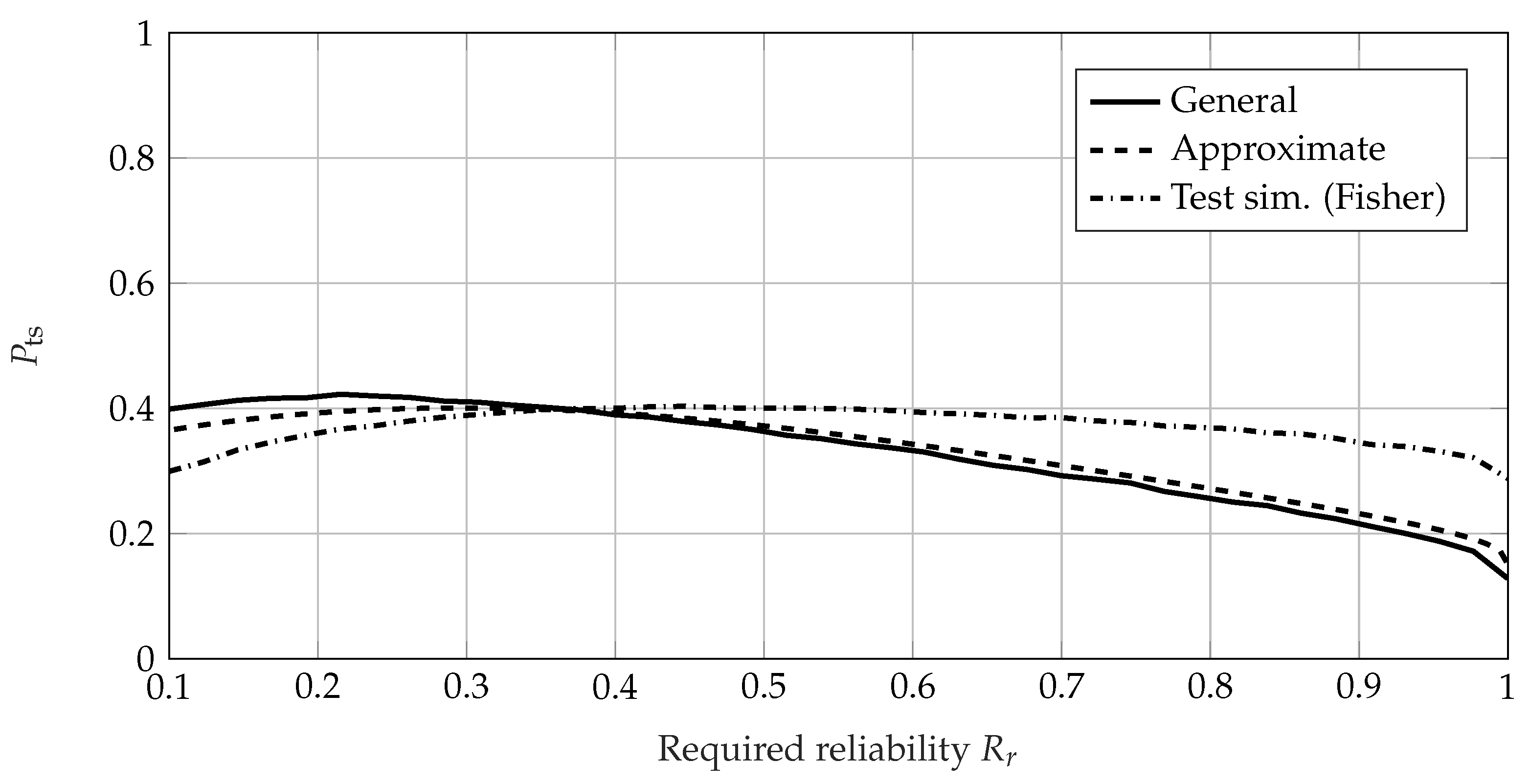
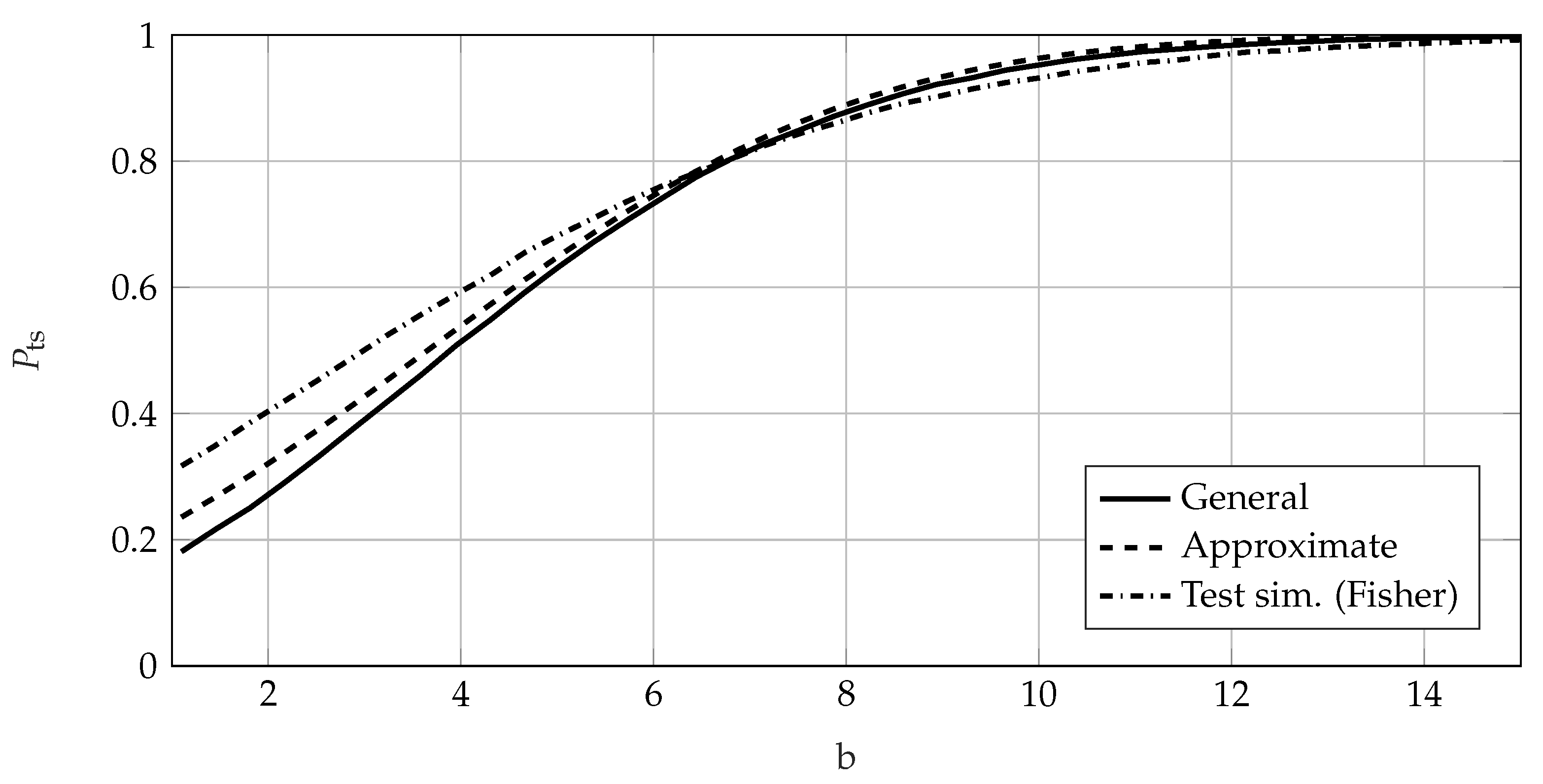
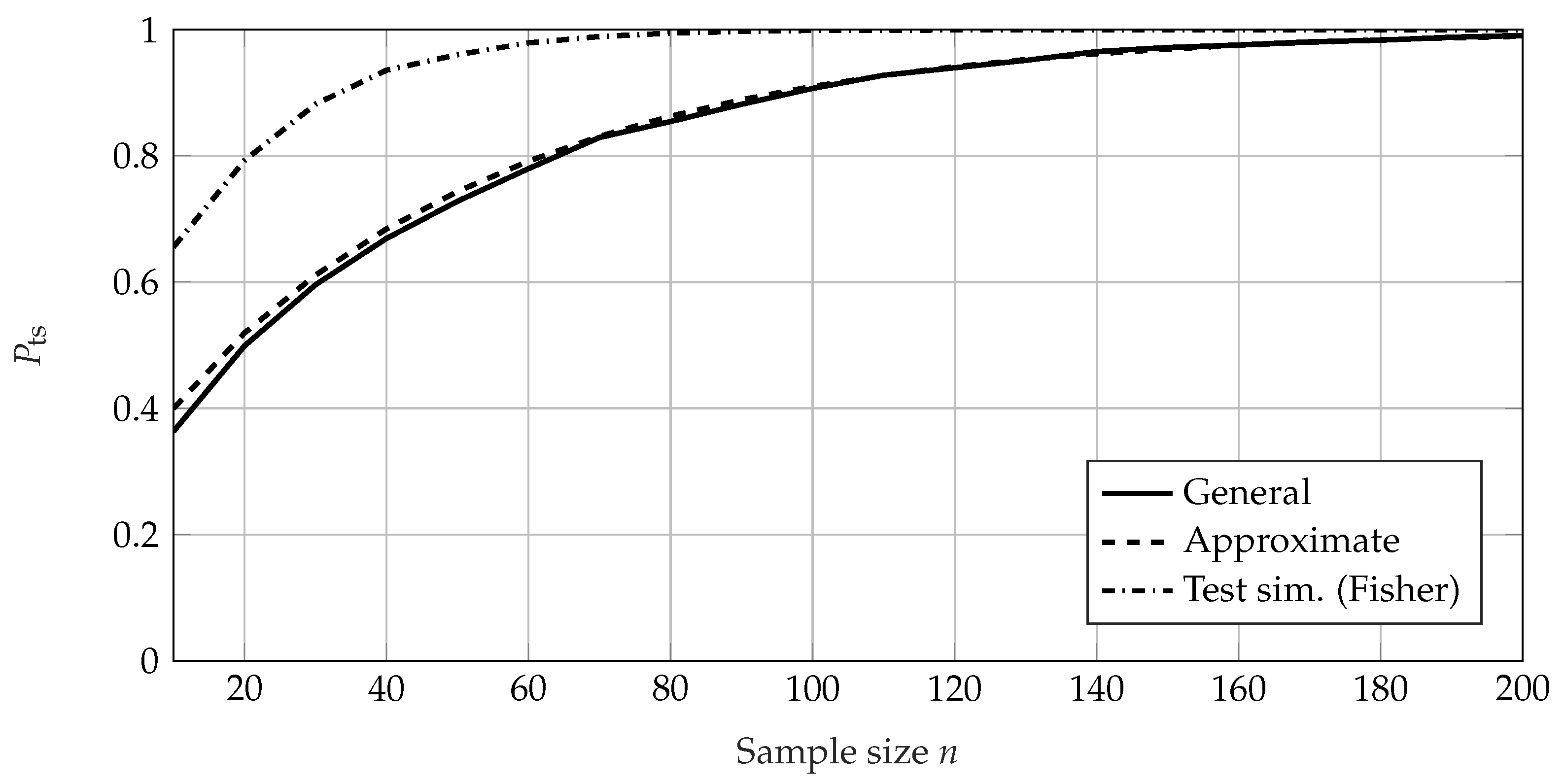
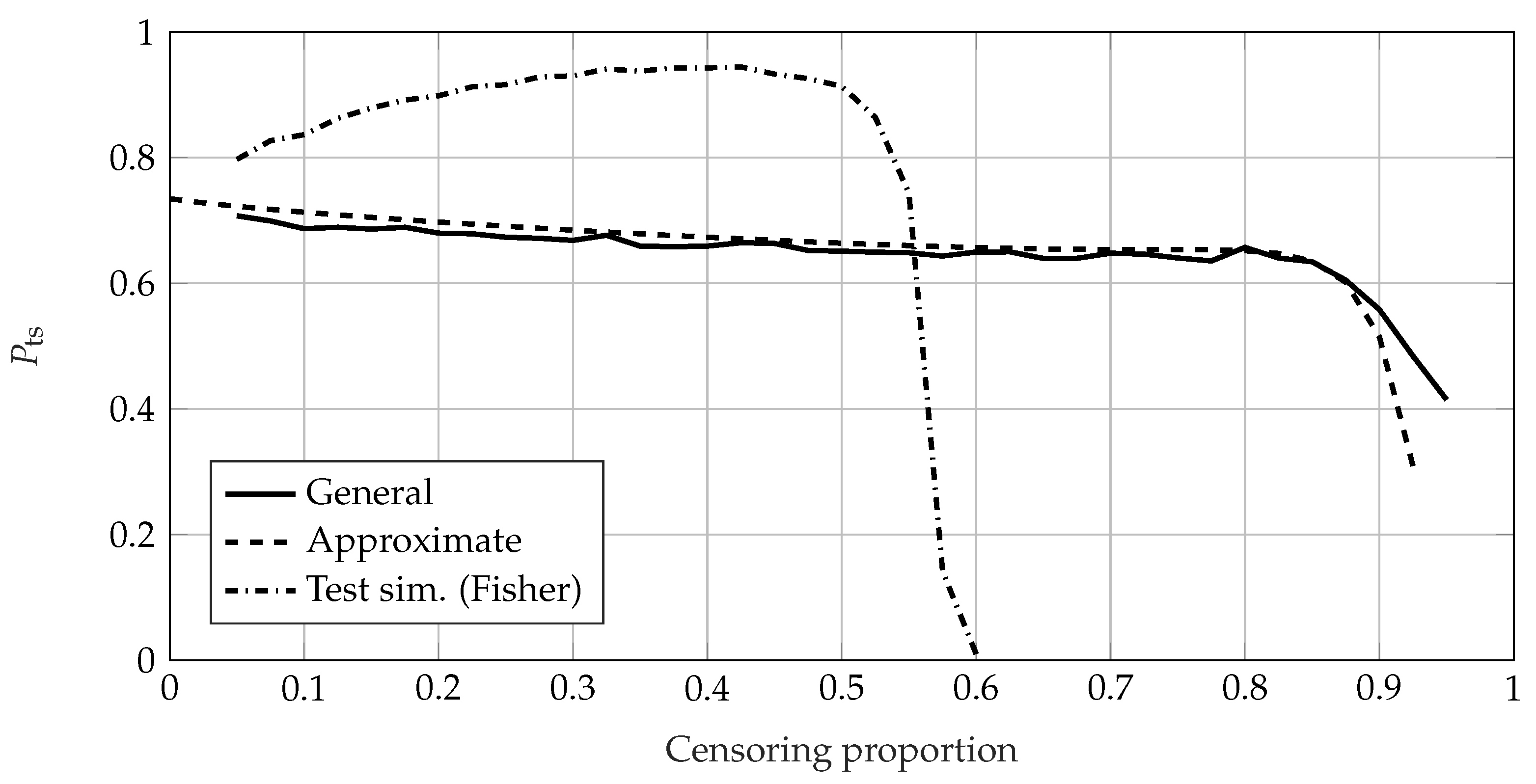
4. Comparison of the Calculation Methods for the Probability of Test Success
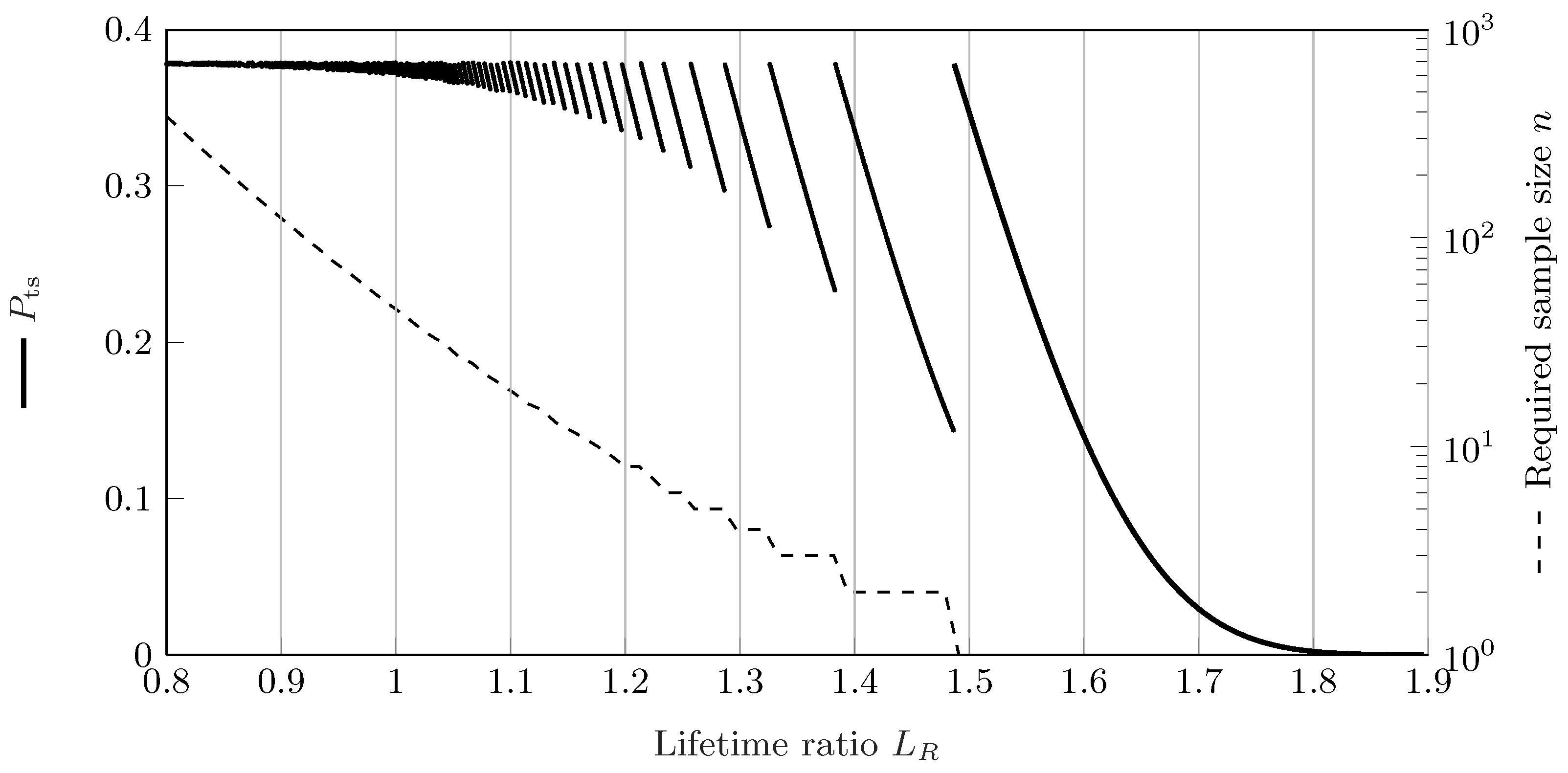
4.1. Comparison Using Success Run Tests
4.2. Comparison Using Failure-Based Tests
- General method (General);
- Approximate method (Approximate);
- Test simulation method (Test sim.).
4.3. Conclusion of the Comparison
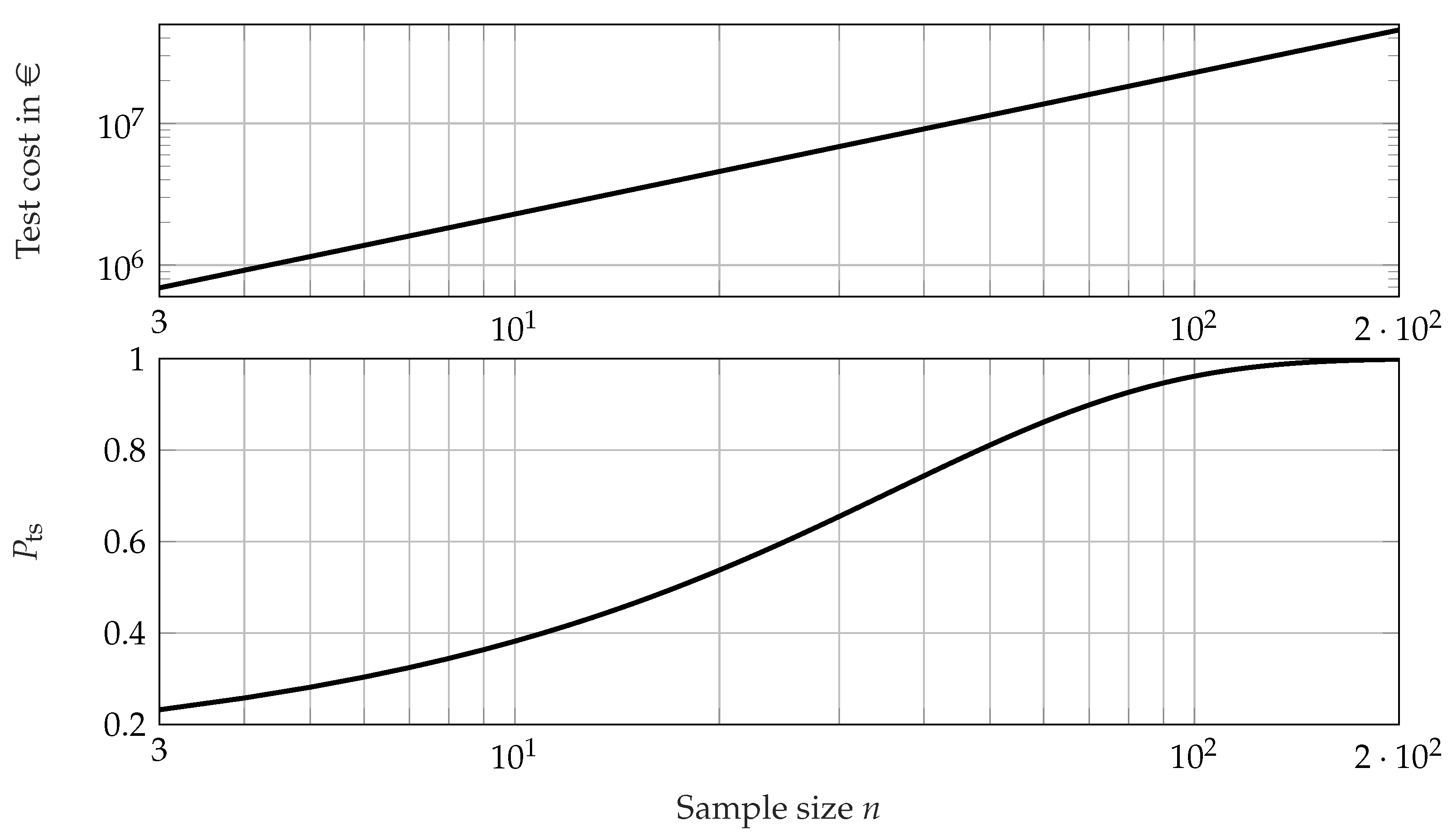
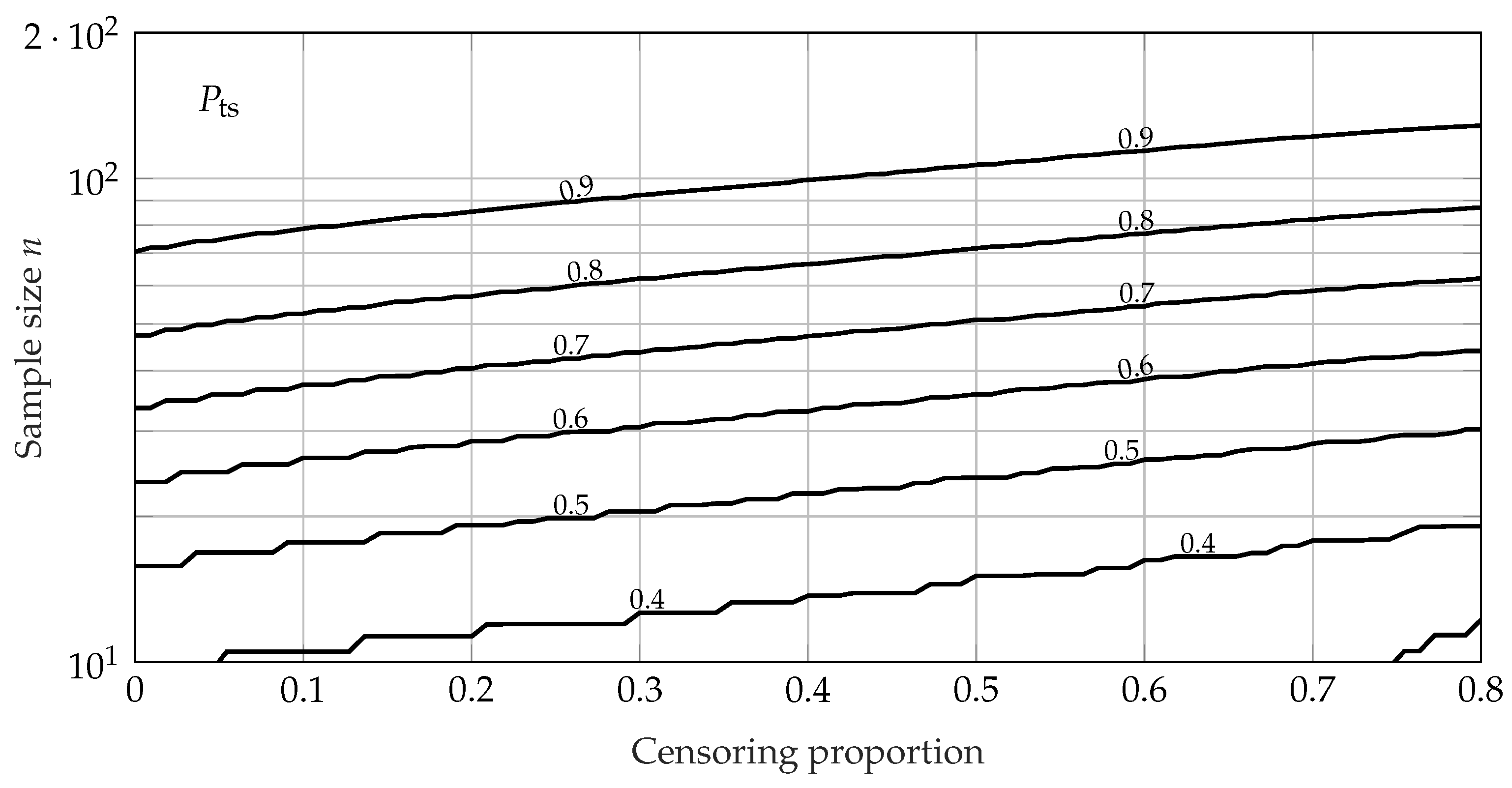
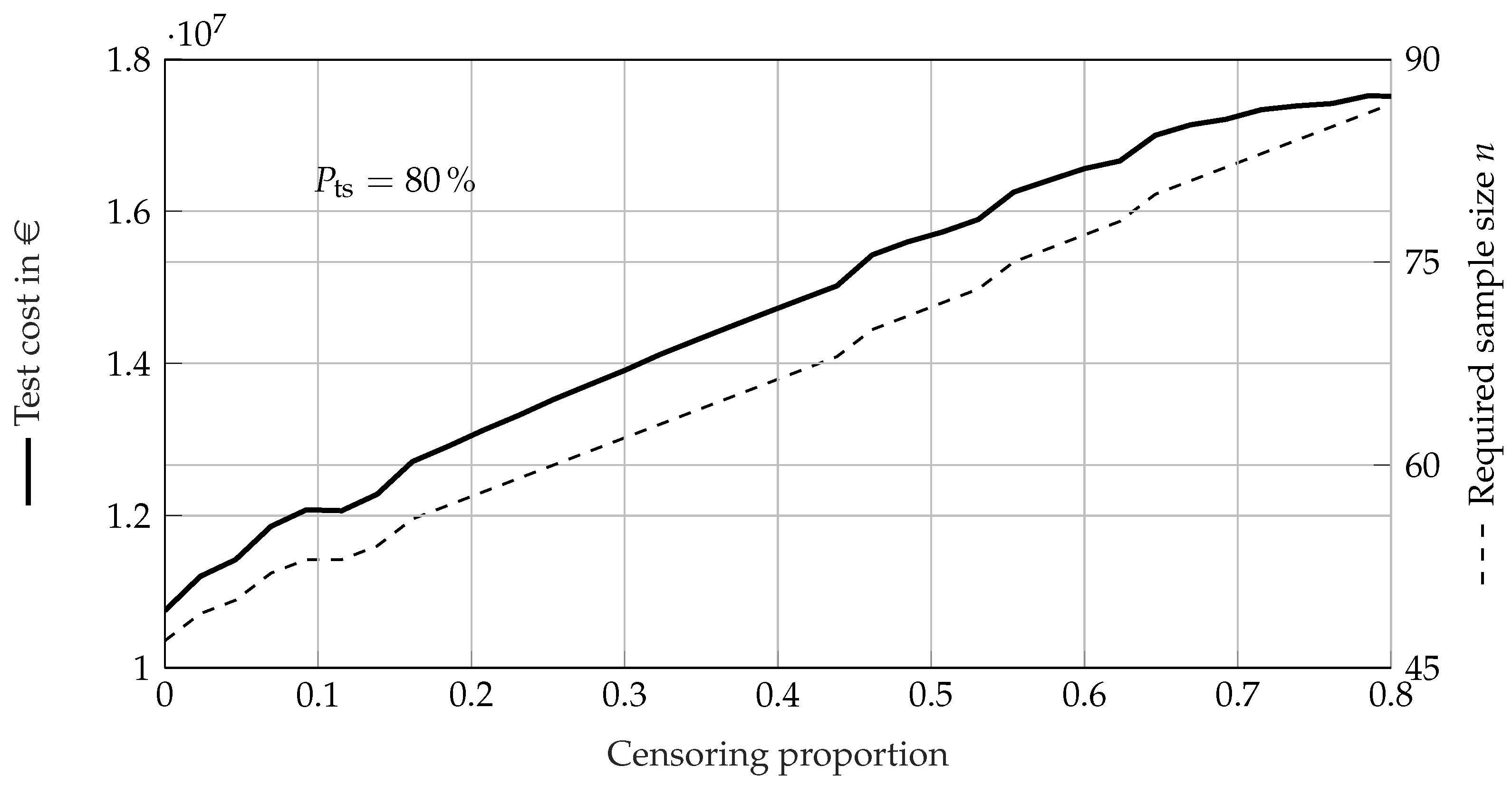
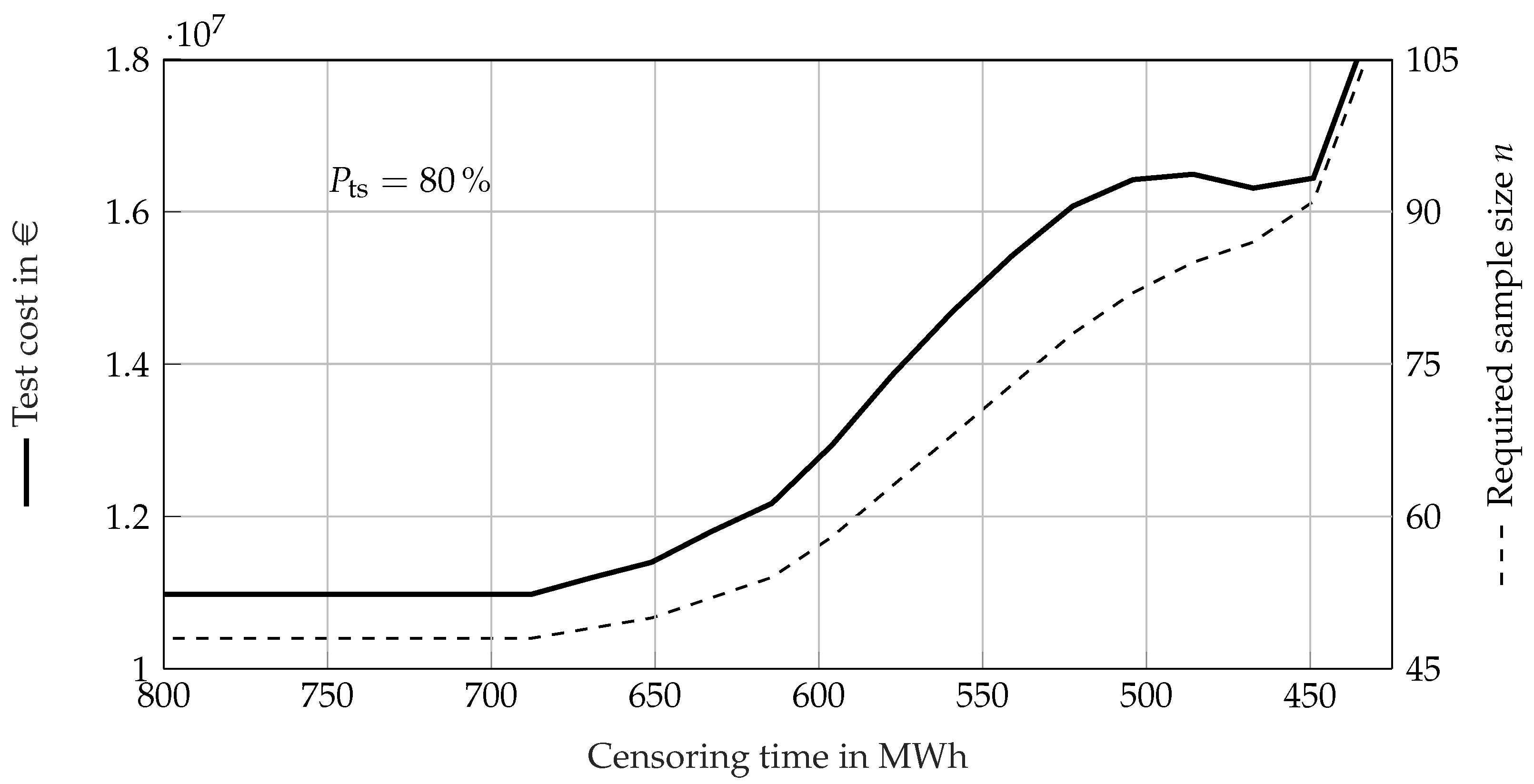
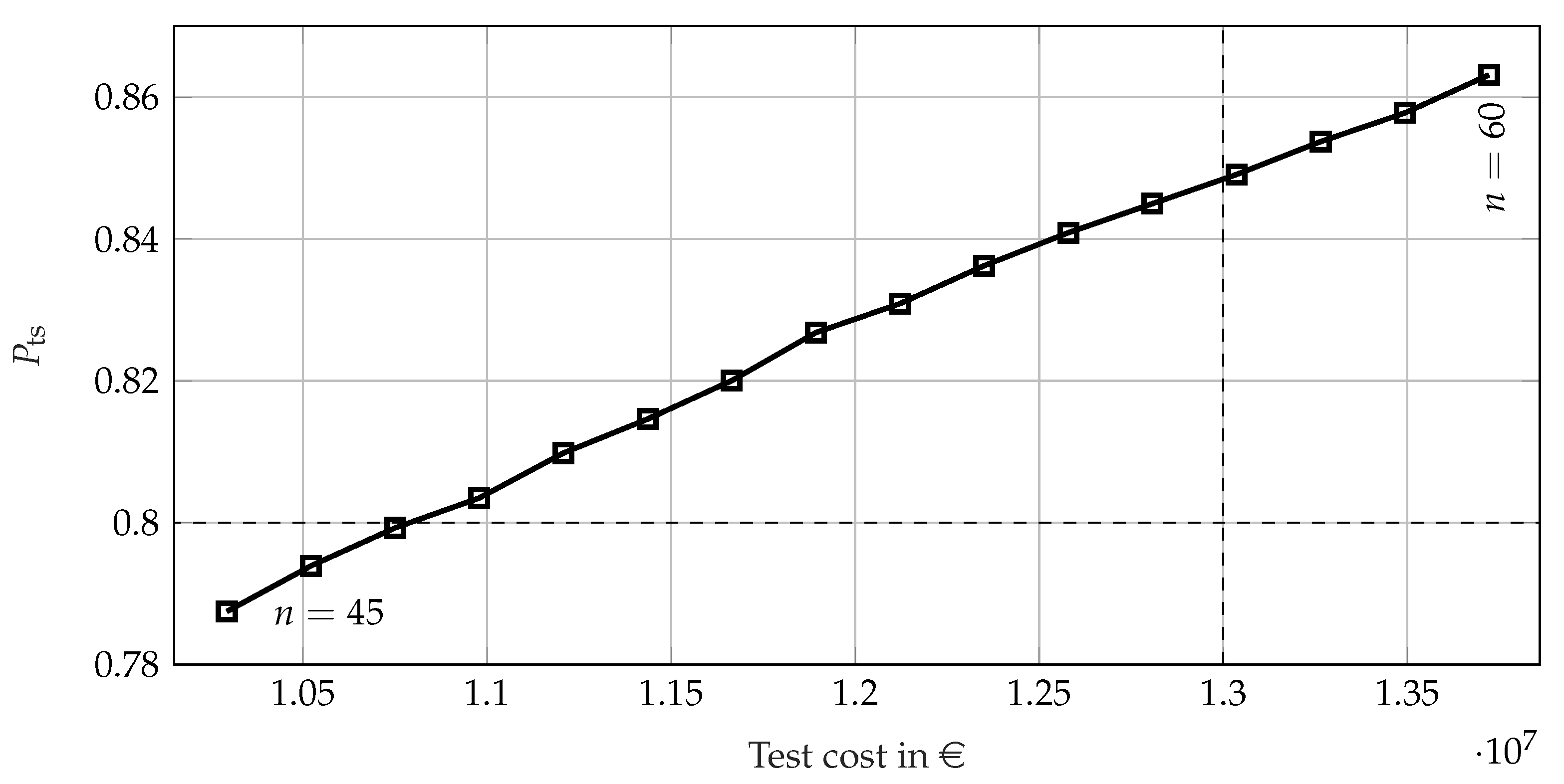
5. Case Study
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DOE | Design of experiments |
| SR | Success run |
| SD | Sudden death |
| MCS | Monte Carlo simulation |
| MTTF | Mean time to failure |
| EoL | End of life |
| MLE | Maximum likelihood estimation |
| CLT | Central limit theorem |
| ETP | Accumulated energy throughput |
| Probability density function | |
| cdf | Cumulative distribution function |
| pmf | Probability mass function |
References
- Montgomery, D.C. Design and Analysis of Experiments, 10th ed.; John Wiley & Sons: Hoboken, NJ, USA, 2020. [Google Scholar]
- Siebertz, K.; van Bebber, D.; Hochkirchen, T. Statistische Versuchsplanung; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar] [CrossRef]
- McPherson, K. On choosing the number of interim analyses in clinical trials. Stat. Med. 1982, 1, 25–36. [Google Scholar] [CrossRef]
- Choi, S.C.; Smith, P.J.; Becker, D.P. Early Decision in Clinical Trials When the Treatment Differences Are Small. Experience of a Controlled Trial in Head Trauma. Control. Clin. Trials 1985, 6, 280–288. [Google Scholar] [CrossRef]
- Trzaskoma, B.; Sashegyi, A. Predictive Probability of Success and the Assessment of Futility in Large Outcomes Trials. J. Biopharm. Stat. 2007, 17, 45–63. [Google Scholar] [CrossRef]
- Rufibach, K.; Burger, H.U.; Abt, M. Bayesian predictive power: Choice of prior and some recommendations for its use as probability of success in drug development. Pharm. Stat. 2016, 15, 438–446. [Google Scholar] [CrossRef] [PubMed]
- Squeglia, N.L. Zero Acceptance Number Sampling Plans, 5th ed.; ASQ Quality Press: Milwaukee, WI, USA, 2008. [Google Scholar] [CrossRef]
- Meeker, W.Q.; Escobar, L.A. Statistical Methods for Reliabillity Data; John Wiley & Sons: New York, NY, USA; Chichester, UK; Weinheim, Germany; Brisbane, Australia; Singapore; Toronto, ON, Canada, 1998; p. 680. [Google Scholar]
- Nelson, W.B. Applied Life Data Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Bertsche, B. Reliability in Automotive and Mechanical Engineering; Springer: Berlin, Germany, 2008. [Google Scholar] [CrossRef]
- Bayes, M.; Price, M. An Essay Towards Solving a Problem in the Doctrine of Chances. By the Late Rev. Mr. Bayes, F. R. S. Communicated by Mr. Price, in a Letter to John Canton, AMFR S. Philos. Trans. R. Soc. Lond. 1763, 53, 370–418. [Google Scholar] [CrossRef]
- Beyer, R.; Lauster, E. Statistische Lebensdauerprüfpläne bei Berücksichtigung von Vorkenntnissen. Qualität und Zuverlässigkeit 1990, 35, 93–98. [Google Scholar]
- Grundler, A.; Bartholdt, M.; Bertsche, B. Statistical test planning using prior knowledge—Advancing the approach of Beyer and Lauster. In Proceedings of the Safety and Reliability—Safe Societies in a Changing World, Trondheim, Norway, 17–21 June 2018; pp. 809–814. [Google Scholar] [CrossRef]
- Guida, M.; Pulcini, G. Automotive reliability inference based on past data and technical knowledge. Reliab. Eng. Syst. Saf. 2002, 76, 129–137. [Google Scholar] [CrossRef]
- Kleyner, A.; Bhagath, S.; Gasparini, M.; Robinson, J.; Bender, M. Bayesian techniques to reduce the sample size in automotive electronics attribute testing. Microelectron. Reliab. 1997, 37, 879–883. [Google Scholar] [CrossRef]
- Kleyner, A.; Elmore, D.; Boukai, B. A Bayesian Approach to Determine Test Sample Size Requirements for Reliability Demonstration Retesting after Product Design Change. Qual. Eng. 2015, 27, 289–295. [Google Scholar] [CrossRef]
- Krolo, A.; Rzepka, B.; Bertsche, B. Application of Bayes statistics to reduce sample-size, considering a lifetime-ratio. In Proceedings of the Annual Reliability and Maintainability Symposium, Seattle, WA, USA, 28–31 January 2002; pp. 577–583. [Google Scholar] [CrossRef]
- Krolo, A.; Rzepka, B.; Bertsche, B. The Use of the Bayes Theorem to Accelerated Life Tests. In Proceedings of the European Conference on Safety and Reliability ESREL, Lyon, France, 18–21 March 2002. [Google Scholar]
- Krolo, A. Planung von Zuverlässigkeitstests mit Weitreichender Berücksichtigung von Vorkenntnissen. Ph.D. Thesis, University of Stuttgart, Stuttgart, Germany, 2004. [Google Scholar]
- Savchuk, V.P.; Martz, H.F. Bayes Reliability Estimation Using Multiple Sources of Prior Information: Binomial Sampling. IEEE Trans. Reliab. 1994, 43, 138–144. [Google Scholar] [CrossRef]
- Grundler, A.; Bollmann, M.; Obermayr, M.; Bertsche, B. Berücksichtigung von Lebensdauerberechnungen als Vorkenntnis im Zuverlässigkeitsnachweis. In Proceedings of the VDI-Fachtagung Technische Zuverlässigkeit 2019, Mannheim, Germany, 2–3 July 2019. [Google Scholar]
- Genest, C.; Zidek, J.V. Combining Probability Distributions: A Critique and an Annotated Bibliography. Stat. Sci. 1986, 1, 114–148. [Google Scholar]
- Hitziger, T.; Bertsche, B. An approach to determine uncertainties of prior information—The transformation factor. In Proceedings of the European Conference on Safety and Reliability ESREL, Tri City, Poland, 27–30 June 2005; Volume 1, pp. 843–849. [Google Scholar]
- Lu, L.; Li, M.; Anderson-Cook, C.M. Multiple objective optimization in reliability demonstration tests. J. Qual. Technol. 2016, 48, 326–342. [Google Scholar] [CrossRef]
- Hamada, M.S.; Wilson, A.G.; Reese, C.S.; Martz, H.F. Bayesian Reliability; Springer: New York, NY, USA, 2008. [Google Scholar] [CrossRef] [Green Version]
- Lindley, D.V.; Singpurwalla, N.D. Adversarial Life Testing. J. R. Stat. Soc. Ser. B (Methodol.) 1993, 55, 837–847. [Google Scholar] [CrossRef]
- Wilson, K.J.; Farrow, M. Assurance for Sample Size Determination in Reliability Demonstration Testing. Technometrics 2021, 63, 523–535. [Google Scholar] [CrossRef]
- Guo, H.; Pohl, E.; Gerokostopoulos, A. Determining the Right Sample Size for Your Test: Theory and Application. In Proceedings of the 2013 Annual Reliability and Maintainability Symposium, Orlando, FL, USA, 28–31 January 2013. [Google Scholar]
- Arizono, I.; Kawamura, Y.; Takemoto, Y. Reliability tests for Weibull distribution with variational shape parameter based on sudden death lifetime data. Eur. J. Oper. Res. 2008, 189, 570–574. [Google Scholar] [CrossRef]
- Huang, S.R.; Wu, S.J. Reliability sampling plans under progressive type-I interval censoring using cost functions. IEEE Trans. Reliab. 2008, 57, 445–451. [Google Scholar] [CrossRef]
- Vlcek, B.L.; Hendricks, R.C.; Zaretsky, E.V. Monte Carlo simulation of sudden death bearing testing. Tribol. Trans. 2004, 47, 188–199. [Google Scholar] [CrossRef] [Green Version]
- Hsieh, H.K. Average Type-II Censoring Times for the 2-Parameter Weibull Distribution. IEEE Trans. Reliab. 1994, 43, 91–96. [Google Scholar] [CrossRef]
- Tsai, T.R.; Lu, Y.T.; Wu, S.J. Reliability sampling plans for Weibull distribution with limited capacity of test facility. Comput. Ind. Eng. 2008, 55, 721–728. [Google Scholar] [CrossRef]
- Kirchner, E. Werkzeuge und Methoden der Produktentwicklung: Von der Idee zum Erfolgreichen Produkt; Springer: Berlin, Germany, 2020. [Google Scholar]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences, 2nd ed.; Lawrence Erlbaum Associates: New York, NY, USA, 1988. [Google Scholar]
- Neyman, J.; Pearson, E.S. On the Use and Interpretation of Certain Test Criteria for Purposes of Statistical Inference: Part I. Biometrika 1928, 20A, 175–240. [Google Scholar]
- Neyman, J.; Pearson, E.S., IX. On the problem of the most efficient tests of statistical hypotheses. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 1933, 231, 289–337. [Google Scholar] [CrossRef] [Green Version]
- Grundler, A.; Dazer, M.; Bertsche, B. Reliability-Test Planning Considering Multiple Failure Mechanisms and System Levels. In Proceedings of the Annual Reliability and Maintainability Symposium, Palm Springs, CA, USA, 27–30 January 2020. [Google Scholar]
- Grundler, A.; Dazer, M.; Herzig, T.; Bertsche, B. Considering Multiple Failure Mechanisms in Optimal Test Design. In Proceedings of the Proceedings IRF2020: 7th International Conference Integrity-Reliability-Failure, Funchal, Portugal, 6–10 September 2020; pp. 673–682. [Google Scholar]
- Grundler, A.; Dazer, M.; Bertsche, B. Effect of Uncertainty in Prior Kowledge on Test Planning for a Brake Caliper using the Probability of Test Success. In Proceedings of the Proceedings—Annual Reliability and Maintainability Symposium, Orlando, FL, USA, 24–27 May 2021. [Google Scholar]
- Grundler, A.; Dazer, M.; Herzig, T.; Bertsche, B. Efficient System Reliability Demonstration Tests Using the Probability of Test Success. In Proceedings of the Proceedings of the 31st European Safety and Reliability Conference ESREL 2021, Angers, France, 19–23 September 2021; pp. 1654–1661. [Google Scholar] [CrossRef]
- MIL-STD-1916; Department of Defense Test Method Standard; Department of Defense: Washington, DC, USA, 1996.
- John, P.W.M. Statistical Methods in Engineering and Quality Assurance; Chapman and Hall/CRC: London, UK, 1990. [Google Scholar]
- Pyzdek, T. Quality Engineering Handbook, 2nd ed.; Marcel Dekker, Inc.: New York, NY, USA; Basel, Switzerland, 2003. [Google Scholar] [CrossRef]
- Dazer, M. Zuverlässigkeitstestplanung mit Berücksichtigung von Vorwissen aus Stochastischen Lebensdauerberechnungen. Ph.D. Thesis, University of Stuttgart, Stuttgart, Germany, 2019. [Google Scholar]
- Dazer, M.; Brautigam, D.; Leopold, T.; Bertsche, B. Optimal Planning of Reliability Life Tests Considering Prior Knowledge. In Proceedings of the 2018 Annual Reliability and Maintainability Symposium (RAMS), Reno, NV, USA, 22–25 January 2018 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Dazer, M.; Herzig, T.; Grundler, A.; Bertsche, B. R-OPTIMA: Optimal Planning of Reliability Tets. In Proceedings of the Proceedings IRF2020: 7th International Conference Integrity-Reliability-Failure, Funchal, Portugal, 6–10 September 2020; pp. 695–702. [Google Scholar]
- Neyman, J. Outline of a Theory of Statistical Estimation Based on the Classical Theory of Probability. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 1937, 236, 333–380. [Google Scholar] [CrossRef]
- Efron, B.; Tibshirani, R.J. An Introduction to the Bootstrap; Chapman & Hall: London, UK; CRC Press LLC: Boca Raton, FL, USA, 1998. [Google Scholar]
- Pearson, K. On the Systematic Fitting of Curves to Observations and Measurments: Part II. Biometrika 1902, 2, 1–23. [Google Scholar] [CrossRef]
- Nelson, W.B. Accelerated Testing: Statistical Models, Test Plans and Data Analyses; John Wiley & Sons: Hoboken, NJ, USA, 2004; p. 624. [Google Scholar]
- Fisher, R.A. On the mathematical foundations of theoretical statistics. Philos. Trans. R. Soc. Lond. Ser. A Contain. Pap. Math. Phys. Character 1922, 222, 309–368. [Google Scholar]
- Etemadi, N. An elementary proof of the strong law of large numbers. Z. Für Wahrscheinlichkeitstheorie Und Verwandte Geb. 1981, 55, 119–122. [Google Scholar] [CrossRef]
- David, H.A.; Nagaraja, H.N. Order Statistics, 3rd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2003. [Google Scholar]
- Whittaker, E.T.; Watson, G.N. A Course of Modern Analysis, 3rd ed.; Cambridge University Press: Cambridge, UK, 1920. [Google Scholar]
- von Mises, R. Fundamentalsätze der Wahrscheinlichkeitsrechnung. Math. Z. 1919, 4, 1–97. [Google Scholar] [CrossRef] [Green Version]
- DasGupta, A. Asymptotic Theory of Statistics and Probability; Springer: New York, NY, USA, 2008. [Google Scholar]
- Fisher, R. Frequency Distribution of the Values of the Correlation Coefficients in Samples from an Indefinitely large Population. Biometrika 1915, 10, 507–521. [Google Scholar] [CrossRef]
- Taylor, B. Methodus Incrementorum: Directa & Inversa; Typis Pearsonianis Prostant Apud Gul; Innys ad Insignia Principis in Coemeterio Paulino: London, UK, 1715. [Google Scholar]
- Benard, A.; Bos-Levenbach, E.C. Het uitzetten van waarnemingen op waarschijnlijkheids-papier. Stat. Neerl. 1953, 7, 163–173. [Google Scholar] [CrossRef] [Green Version]
- Dazer, M.; Stohrer, M.; Kemmler, S.; Bertsche, B. Planning of reliability life tests within the accuracy, time and cost triangle. In Proceedings of the 2016 IEEE Accelerated Stress Testing & Reliability Conference (ASTR), Pensacola Beach, FL, USA, 28–30 September 2016; pp. 1–9. [Google Scholar] [CrossRef]
- Grundler, A.; Göldenboth, M.; Stoffers, F.; Dazer, M.; Bertsche, B. Effiziente Zuverlässigkeitsabsicherung durch Berücksichtigung von Simulationsergebnissen am Beispiel einer Hochvolt-Batterie. In 30. VDI-Fachtagung Technische Zuverlässigkeit 2021; VDI-Berichte 2377; VDI Verlag: Düsseldorf, Germany, 2021; ISBN 978-3-18-092377-2. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Null hypothesis | The reliability requirement is not met | ||
| Alternative hypothesis | The reliability requirement is met | ||
| Confidence level | Probability of correctly accepting | Probability of the reliability statement of the test to be correct | |
| Probability of Test Success | Probability of correctly accepting | Probability of the test to be successful in demonstrating the reliability requirement | |
| Calculation Method | Key Findings |
|---|---|
| General method | • Applicable for all tests • Most precise • Most flexible • Test costs and test time can be calculated • High calculation effort due to bootstrap • Though precise, calculation effort is unnecessary for SR tests • Only an approximation |
| Approximate method (only for EoL tests) | • Fastest calculation • Simple to implement • Easy to calculate • Very good approximation for large sample sizes • (can replace general method) • Good approximation for small sample sizes • Good approximation for both censored and uncensored tests |
| Exact method (only for SR tests) | • Exact, thus no approximation • Very fast calculation • Easiest to implement • Should always be used for SR tests |
| Test simulation method | • Good for very large sample sizes • Suffers from bias amplification • Very good for SR tests (coincides with general method) • Should only be used in special cases • Not usable for strongly censored EoL tests |
| Requirement | Prior Knowledge |
|---|---|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Grundler, A.; Dazer, M.; Herzig, T. Statistical Power Analysis in Reliability Demonstration Testing: The Probability of Test Success. Appl. Sci. 2022, 12, 6190. https://doi.org/10.3390/app12126190
Grundler A, Dazer M, Herzig T. Statistical Power Analysis in Reliability Demonstration Testing: The Probability of Test Success. Applied Sciences. 2022; 12(12):6190. https://doi.org/10.3390/app12126190
Chicago/Turabian StyleGrundler, Alexander, Martin Dazer, and Thomas Herzig. 2022. "Statistical Power Analysis in Reliability Demonstration Testing: The Probability of Test Success" Applied Sciences 12, no. 12: 6190. https://doi.org/10.3390/app12126190