
Quantitative Assessment and Grading of Hardware Trojan Threat Based on Rough Set Theory


Abstract
:1. Introduction
- We leverage RST and TOPSIS for the quantitative assessment of HT threat. Based on the attributes of the relevant HTs in an existing HT library, Trust-hub, we measure HT threat, adopting rough set theory for weight calculation and TOPSIS for quantitative assessment. The closeness coefficient is used to characterize the threat.
- In order to address the lack of decision attributes in the corresponding information system, we introduce information content to calculate the weight of each attribute. Based on the information content and the significance of the attribute, the weights of both core and non-core attributes are obtained.
- K-means is used to discretize threat data. Aiming at the unstable clustering results in the preliminary work, we propose the EFD method to preprocess the data and obtain the initial cluster center. Compared with other initial center optimization methods, this is more efficient and accurate.
- We use BWP to characterize the effectiveness of clustering in order to solve the problem of the number of clusters being unavailable in advance. The number of clusters with the largest BWP is taken as the optimal choice for HT threat grading.
2. System Model and Assessment Formulation
2.1. Information System and Attributes
2.1.1. Insertion Phase
2.1.2. Abstraction Level
2.1.3. Activation Mechanism
2.1.4. Effect
2.1.5. Location
2.2. Weight Calculation and Quantitative Assessment
2.2.1. Core Attribute
2.2.2. Information Content
2.2.3. Significance of Attribute
2.2.4. Weight of Attributes
2.2.5. Quantitative Assessment Algorithm Based on TOPSIS
| Algorithm 1 Quantitative Assessment Algorithm |
|
3. Assessment of Grade Division and Grade Quantity
3.1. EFD-Based K-Means for Grade Division
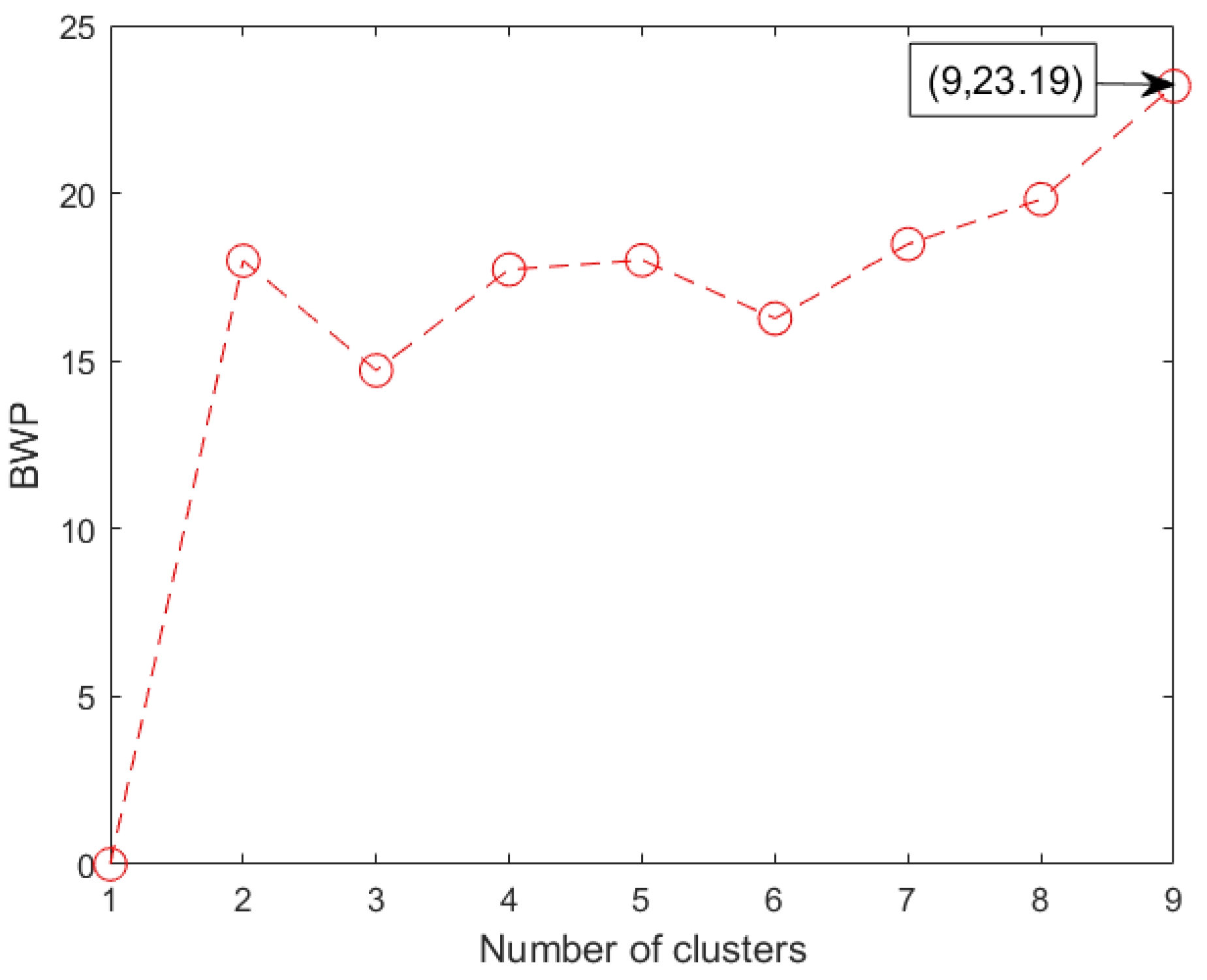
3.2. Determination of Grade Quantity Based on BWP
4. Case Study
4.1. Test Setup
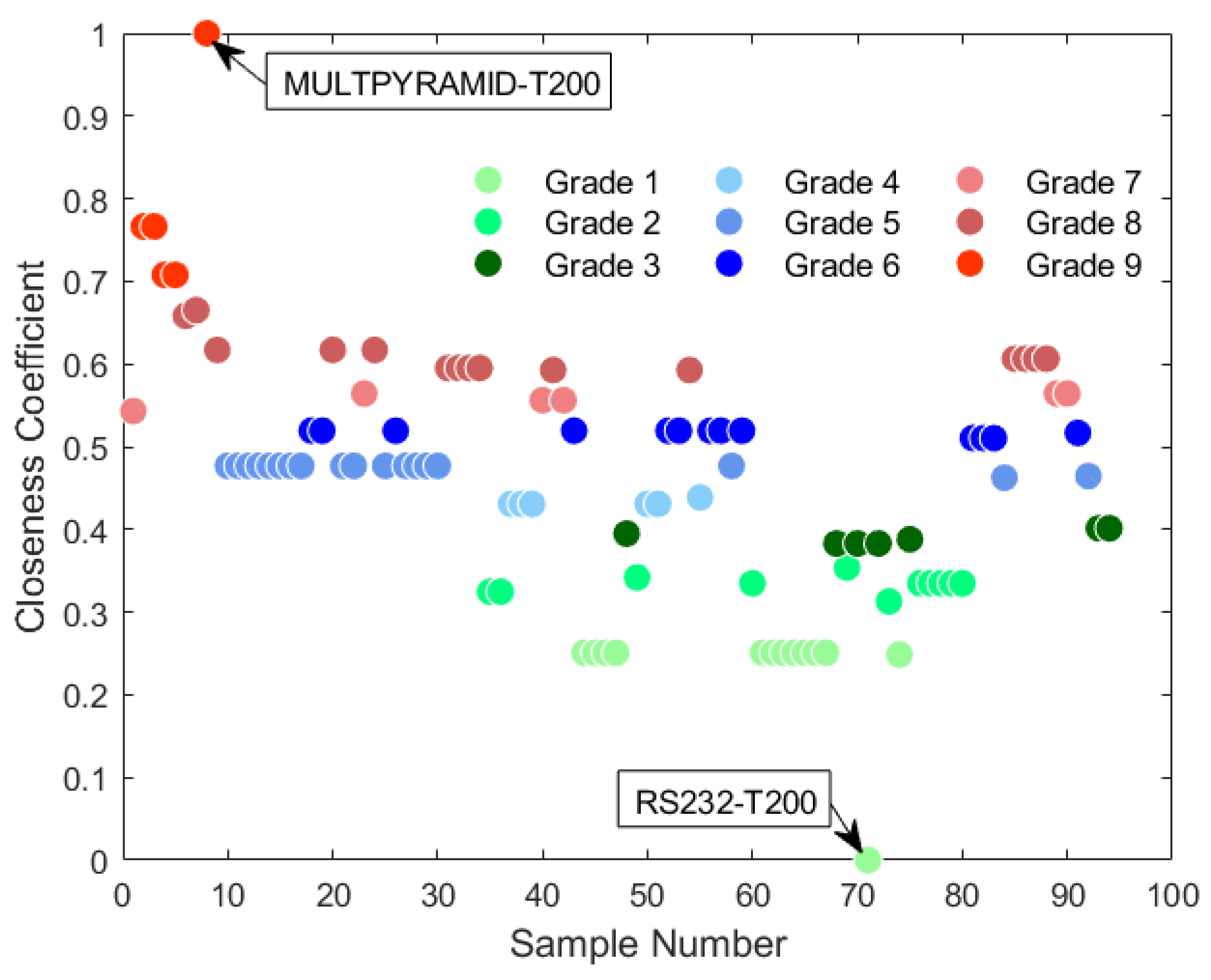
4.2. Quantitative Assessment Results
4.3. Preliminary Experiment of Threat Discretization
4.4. Clustering Results and Optimal Cluster Selection
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Karri, R.; Rajendran, J.; Rosenfeld, K.; Tehranipoor, M. Trustworthy Hardware: Identifying and Classifying Hardware Trojans. Computer 2010, 43, 39–46. [Google Scholar] [CrossRef]
- Tehranipoor, M.; Koushanfar, F. A Survey of Hardware Trojan Taxonomy and Detection. Des. Test Comput. IEEE 2010, 27, 10–25. [Google Scholar] [CrossRef]
- Kim, L.; Villasenor, J. Dynamic Function Replacement for System-on-Chip Security in the Presence of Hardware-Based Attacks. IEEE Trans. Reliab. 2014, 63, 661–675. [Google Scholar] [CrossRef]
- Rudra, M.; Daniel, N.; Nagoorkar, V.; Hoe, D. Designing Stealthy Trojans with Sequential Logic: A Stream Cipher Case Study. Proc.-Des. Autom. Conf. 2014, 1, 1–4. [Google Scholar] [CrossRef]
- Yang, K.; Hicks, M.; Dong, Q.; Austin, T.; Sylvester, D. A2: Analog Malicious Hardware. IEEE Symp. Secur. Priv. 2016, 5, 18–37. [Google Scholar] [CrossRef]
- Bhunia, S.; Abramovici, M.; Agrawal, D.; Bradley, P.; Hsiao, M.; Plusquellic, J.; Tehranipoor, M. Protection against Hardware Trojan Attacks: Towards a Comprehensive Solution. Des. Test IEEE 2013, 30, 6–17. [Google Scholar] [CrossRef]
- Chakraborty, R.; Wolff, F.; Paul, S.; Papachristou, C.; Bhunia, S. MERO: A Statistical Approach for Hardware Trojan Detection. In Cryptographic Hardware and Embedded Systems—CHES. Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5747, pp. 396–410. [Google Scholar] [CrossRef] [Green Version]
- Graf, J. Trust games: How game theory can guide the development of hardware Trojan detection methods. In Proceedings of the IEEE International Symposium on Hardware Oriented Security & Trust, McLean, VA, USA, 3–5 May 2016; pp. 91–96. [Google Scholar] [CrossRef]
- Kamhoua, C.; Zhao, H.; Rodriguez, M.; Kwiat, K. A Game-Theoretic Approach for Testing for Hardware Trojans. IEEE Trans.-Multi-Scale Comput. Syst. 2016, 2, 199–210. [Google Scholar] [CrossRef]
- Yang, D.; Gao, C.; Huang, J. Dynamic Game for Strategy Selection in Hardware Trojan Attack and Defense. IEEE Access 2020, 8, 213094–213103. [Google Scholar] [CrossRef]
- Saha, S.; Chakraborty, R.; Mukhopadhyay, D. Testability Based Metric for Hardware Trojan Vulnerability Assessment. In Proceedings of the Euromicro Conference on Digital System Design, Limassol, Cyprus, 31 August–2 September 2016; pp. 503–510. [Google Scholar] [CrossRef]
- Guo, X.; Dutta, R.; He, J.; Tehranipoor, M.; Jin, Y. QIF-Verilog: Quantitative Information-Flow based Hardware Description Languages for Pre-Silicon Security Assessment. In Proceedings of the IEEE International Symposium on Hardware Oriented Security and Trust, McLean, VA, USA, 5–10 May 2019; pp. 91–100. [Google Scholar] [CrossRef]
- Gao, C.L.; Li, S.C.; Wang, J.; Li, L.; Lin, P. The Risk Assessment of Tunnels Based on Grey Correlation and Entropy Weight Method. Geotech. Geol. Eng. 2018, 36, 1621–1631. [Google Scholar] [CrossRef]
- Wei, J.; Zhou, L.; Wang, F.; Wu, D. Work safety evaluation in Mainland China using grey theory. Appl. Math. Model. 2015, 39, 924–933. [Google Scholar] [CrossRef]
- Shi, H.; Li, W.; Meng, W. A New Approach to Construction Project Risk Assesment Based on Rough Set and Information Entropy. In Proceedings of the International Conference on Information Management, Innovation Management and Industrial Engineering, Taipei, Taiwan, 19–21 December 2008; Volume 1, pp. 187–190. [Google Scholar] [CrossRef]
- Hatefi, S.; Tamosaitiene, J. Construction Projects Assessment Based on the Sustainable Development Criteria by an Integrated Fuzzy AHP and Improved GRA Model. Sustainability 2018, 10, 991. [Google Scholar] [CrossRef] [Green Version]
- Shakya, B. Benchmarking of Hardware Trojans and Maliciously Affected Circuits. J. Hardw. Syst. Secur. 2017, 1, 85–102. [Google Scholar] [CrossRef]
- Jin, Y.; Makris, Y. Hardware Trojans in Wireless Cryptographic ICs. Des. Test Comput. IEEE 2010, 27, 26–35. [Google Scholar] [CrossRef]
- Banga, M.; Hsiao, M. A Region Based Approach for the Identification of Hardware Trojans. In Proceedings of the IEEE International Workshop on Hardware-Oriented Security and Trust, Anaheim, CA, USA, 9 June 2008; pp. 40–47. [Google Scholar] [CrossRef]
- Wolff, F.; Papachristou, C.; Bhunia, S.; Chakraborty, R. Towards Trojan-Free Trusted ICs: Problem Analysis and Detection Scheme. In Proceedings of the Conference on Design, Automation and Test in Europe, Munich, Germany, 10–14 March 2008; pp. 1362–1365. [Google Scholar] [CrossRef]
- Liu, S.; Forrest, J. On measures of information content of grey numbers. Kybernetes 2006, 35, 899–904. [Google Scholar] [CrossRef]
- Zhou, S.B.; Xu, Z.Y.; Tang, X.Q. Method for determining optimal number of clusters in K -means clustering algorithm. J. Comput. Appl. 2010, 30, 1995–1998. [Google Scholar] [CrossRef]
- Yang, J.Y.; Zhang, L.L. Fuzzy Comprehensive Evaluation Method on Water Environmental Quality Based on Entropy Weight with Consideration of Toxicology of Evaluation Factors. Adv. Mater. Res. 2012, 356, 2383–2388. [Google Scholar] [CrossRef]
- Sun, Z.J.; Liang, Y.Q.; Fan, J. Optimization Study and Application on the K Value of K-Means Algorithm. J. Bioinform. Intell. Control. 2013, 2, 223–227. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. K-Means++: The Advantages of Careful Seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; Volume 8, pp. 1027–1035. [Google Scholar]
- Li, G.; Tang, J. A New K-Neighbor Search Algorithm Based on Variable Incremental Dynamic Grid Division. In Proceedings of the International Symposium on Computational Intelligence and Design, Hangzhou, China, 11–12 December 2010; pp. 167–170. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Attribute | Class | Value |
|---|---|---|
| Insertion Phase | Design | 1 |
| Fabrication | 2 | |
| Abstraction Level | Register Transfer | 1 |
| Gate | 2 | |
| Layout | 3 | |
| Physical | 4 | |
| Activation Mechanism | Always On | 4 |
| Time-Based | 2 | |
| Physical-Condition-Based | 1 | |
| User Input | 3 | |
| Effect | Change Functionality | 2 |
| Degrade Performance | 1 | |
| Information Leakage | 3 | |
| Denial of Service | 4 | |
| Location | Processor | 6 |
| Memory | 5 | |
| I/O | 4 | |
| Power Supply | 2 | |
| Clock Grid | 3 | |
| Others | 1 |
| Category | Insertion Phase | Abstraction Level | Activation Mechanism | Effect | Location |
|---|---|---|---|---|---|
| Core Attribute | No | Yes | Yes | Yes | Yes |
| Weight for RST | 0 | 0.588 | 0.607 | 0.701 | 0.592 |
| Weight for EWM | 0.057 | 0.125 | 0.219 | 0.395 | 0.202 |
| Category | Number of Errors | Running Time (s) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| K = 2 | K = 3 | K = 4 | K = 5 | K = 6 | K = 7 | K = 8 | K = 9 | ||
| k-means | 4986 | 3706 | 5840 | 6220 | 8197 | 9214 | 9497 | 9632 | 259.355 |
| k-means++ | 0 | 244 | 7546 | 8204 | 7976 | 7816 | 4971 | 6229 | 303.718 |
| ED-based k-means | 0 | 446 | 2974 | 3842 | 5538 | 5134 | 4984 | 5211 | 283.319 |
| EFD-based k-means | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 245.997 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, D.; Gao, C.; Huang, J. Quantitative Assessment and Grading of Hardware Trojan Threat Based on Rough Set Theory. Appl. Sci. 2022, 12, 5576. https://doi.org/10.3390/app12115576
Yang D, Gao C, Huang J. Quantitative Assessment and Grading of Hardware Trojan Threat Based on Rough Set Theory. Applied Sciences. 2022; 12(11):5576. https://doi.org/10.3390/app12115576
Chicago/Turabian StyleYang, Daming, Cheng Gao, and Jiaoying Huang. 2022. "Quantitative Assessment and Grading of Hardware Trojan Threat Based on Rough Set Theory" Applied Sciences 12, no. 11: 5576. https://doi.org/10.3390/app12115576