
One-Class LSTM Network for Anomalous Network Traffic Detection

 , and
, and
Abstract
:1. Introduction
- (1)
- In this paper we propose an unsupervised anomaly detection algorithm based on the one-class long short-term memory (OC-LSTM) network. The model is an end-to-end single-class neural network with a specially designed loss function equivalent to the optimization objective of a single-class SVM.
- (2)
- By directly adopting the objective of representation learning for anomaly detection, OC-LSTM can directly process raw data without using unsupervised transfer learning for further feature extraction. This will help to discern complex anomalies in large datasets, especially when the decision boundary between normal and anomalous data is highly nonlinear.
2. Background and Related Work
2.1. Anomaly Detection
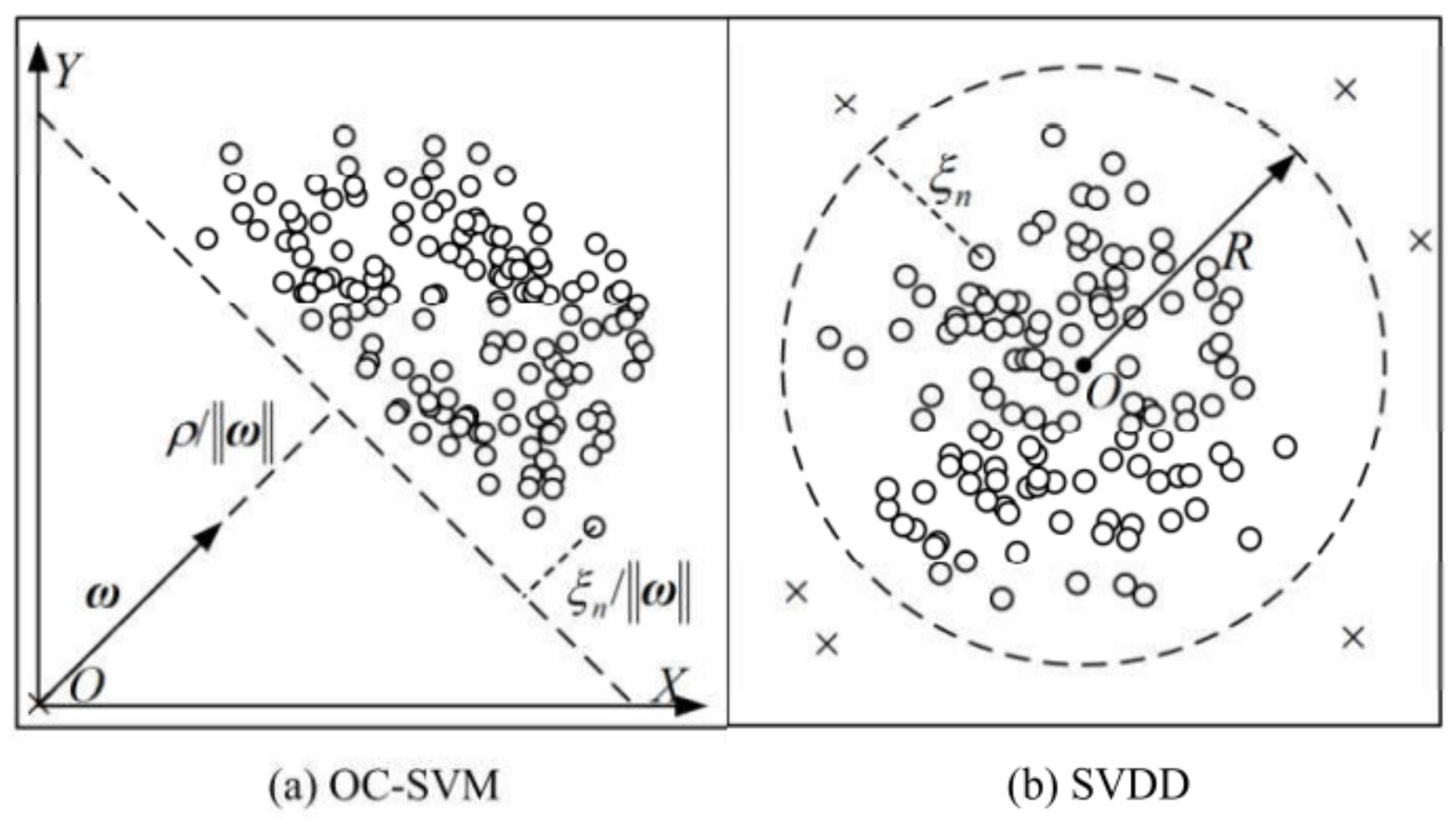
2.2. One-Class Classification
2.3. Deep Learning for Unsupervised Anomaly Detection
3. Materials and Methods
3.1. OC-LSTM Objective and Optimization Process
3.2. OC-LSTM Algorithm
| Algorithm 1 OC-LSTM algorithm | |
| 1: | Input: |
| 2: | Output: |
| 3: | =1.0 |
| 4: | |
| 5: | While (convergence not achieved) do |
| 6: | |
| 7: | |
| 8: | |
| 9: | End while |
| 10: | |
| 11: | Ifthen |
| 12: | is the normal data |
| 13: | else |
| 14: | is the anomalous data |
| 15: | Return |
4. Experimental Setup
4.1. Compared Methods
4.1.1. Shallow Baseline Models
- (1)
- OC-SVM/SVDD as per the formulation in [6]. When the Gaussian kernel function is used, these two methods are equivalent and are asymptotically consistent density-level set estimators. For the OC-SVM/SVDD models, the kernel size is the reciprocal of the number of features, and the fraction of outliers is set according to the obtained outlier proportions.
- (2)
- (3)
- Kernel Density Estimation (KDE) as per the formulation in [28]. The bandwidth of the Gaussian kernel is selected from using the log-likelihood score, and the best result is reported.
4.1.2. Deep Baseline Models
- (1)
- Deep Convolution Autoencoder (DCAE) as per the formulation in [29]. The encoder part and decoder part of the DCAE architecture contain four portions. Every portion contains a convolutional layer, a batch normalization (BN) layer, an exponential linear unit (ELU) layer, and a down-sampling/up-sampling layer, which can provide a better representation of the convolutional filters. The DCAE is trained using a mean-squared error (MSE) loss function to enable the hidden layers to encode high-quality, nonlinear feature representations of the input data.
- (2)
- One-class neural network (OC-NN) as per the formulation in [21]. A feed-forward neural network consisting of a single hidden layer with linear activation functions is trained with the OC-NN objective. The optimal value of the parameter , which is equivalent to the percentage of anomalies in each dataset, is set according to the respective outlier proportions.
- (3)
4.1.3. One-Class LSTM (OC-LSTM)
4.2. Datasets
- (1)
- The NSL-KDD dataset is the benchmark dataset in the field of network security, and it can provide consistent and comparable evaluation results for different research works [30]. Furthermore, the number of records in the NSL-KDD datasets is reasonable, and each record contains 41-dimensional features. The anomaly data mainly include thirty-nine types of network attacks across four categories.
- (2)
- The CIC-IDS2017 dataset contains benign data and the most up-to-date common attacks, so it resembles true real-world data [31]. The data contain a total of five days of network traffic in July 2017. The implemented attacks include Brute-Force FTP, Brute Force SSH, DoS, Heartbleed, Web Attack, PortScan, Infiltration, Botnet, and DDoS. In this study we randomly selected Friday’s traffic as the experimental dataset, which contained two types of abnormalities, DDoS and PortScan.
- (3)
- MAWILab is a database that assists researchers in evaluating traffic anomaly detection methods [32,33]. The dataset has been updated daily since 2001 to include new traffic from upcoming applications and anomalies; this has been ongoing for over 20 years. In this study, the data collected on the first collection day in January and December 2020 were selected as the experimental dataset. We used the code provided in [1] to process the original network traffic and extract the inherent features. The processed data contained 109-dimensional features, and the data distribution is shown in the table above.
4.3. Evaluation Criteria
5. Experimental Results and Discussion
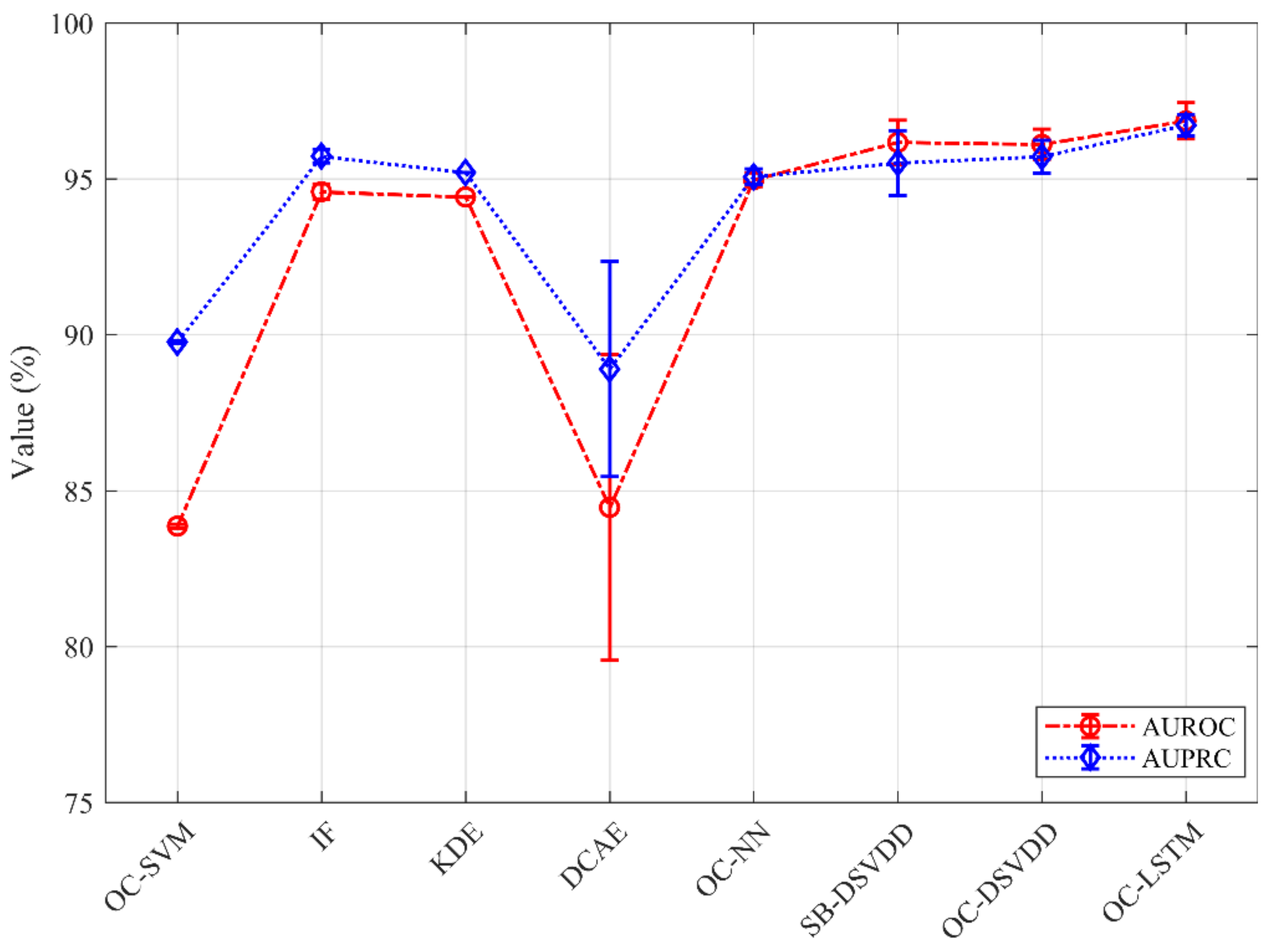
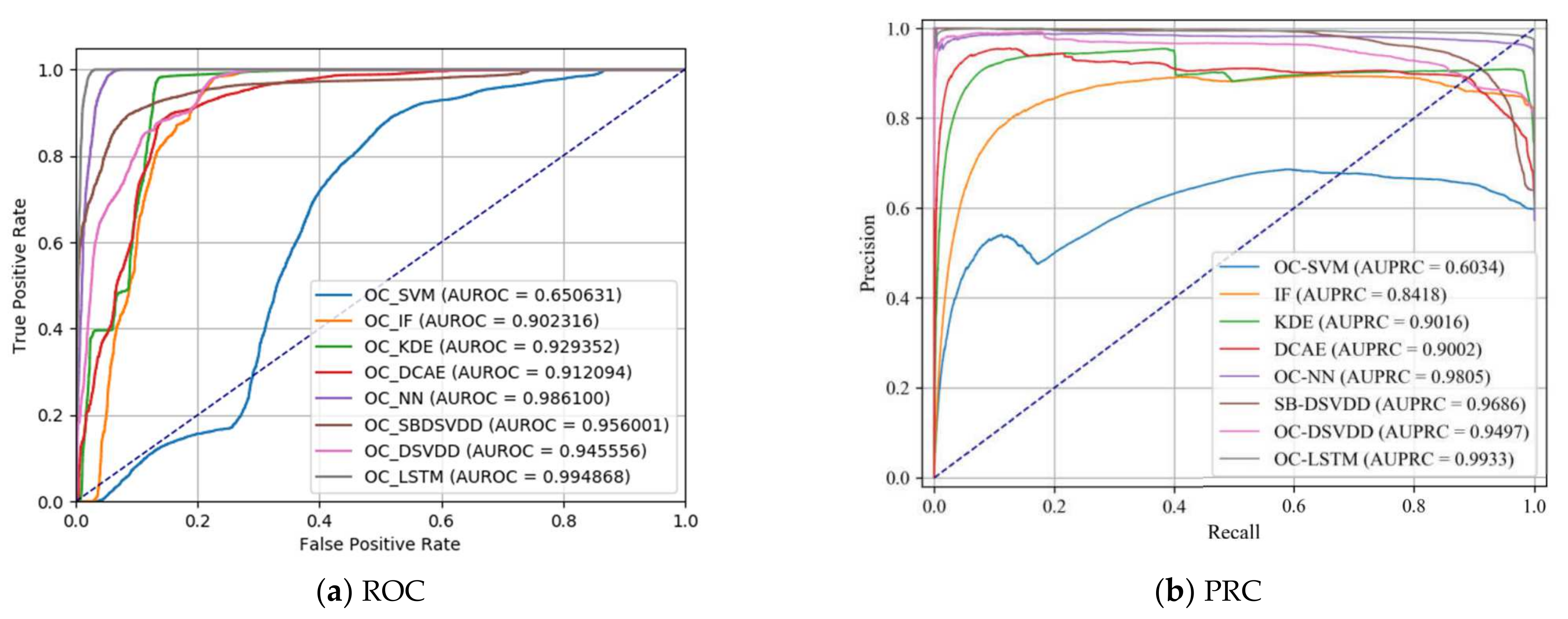
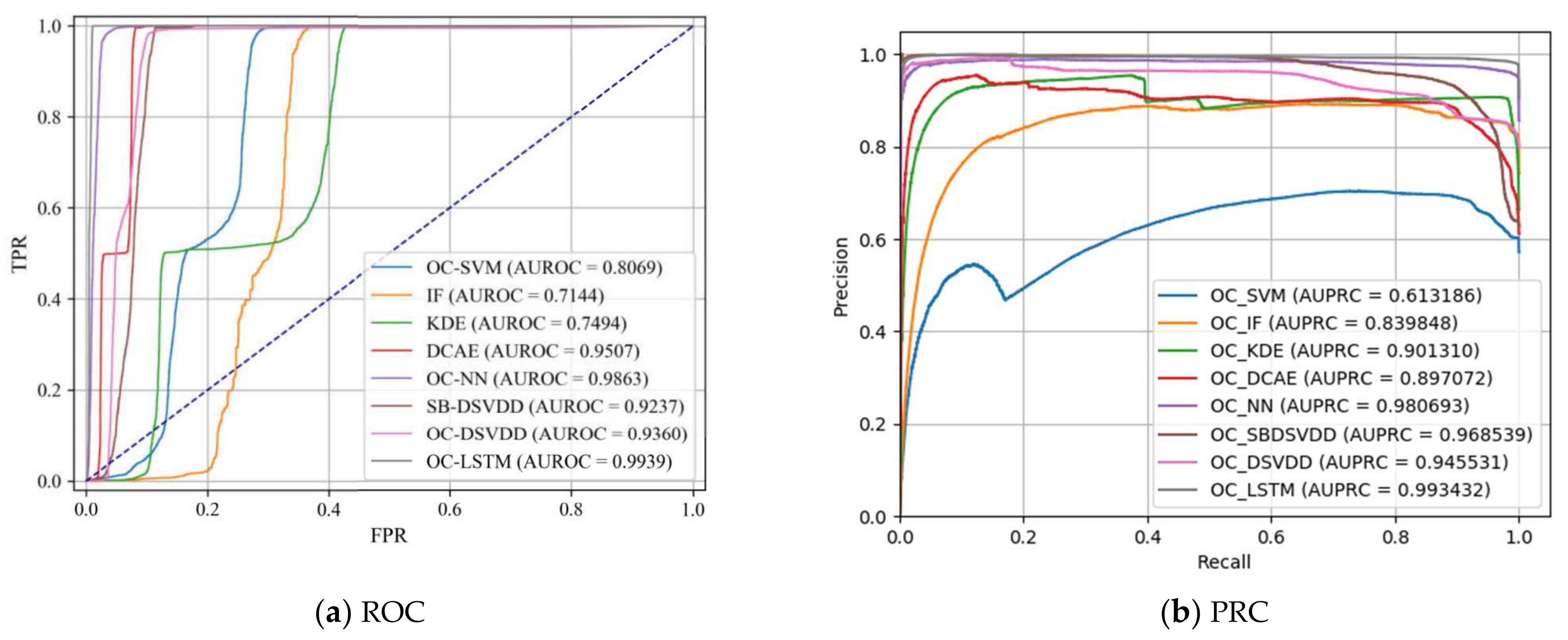
5.1. One-Class Classification on NSL-KDD
5.2. One-Class Classification on CIC-IDS2017
5.3. One-Class Classification on MAWILab
5.4. The Anomaly Detection System
5.5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chandola, V.; Banerjee, A.; Kumar, V. Outlier detection: A survey. ACM Comput. Surv. 2007, 14, 15. [Google Scholar]
- Zhou, C.R.; Paffenroth, C. Anomaly detection with robust deep autoencoders. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 665–674. [Google Scholar]
- Rodríguez-Ruiz, J.; Mata-Sánchez, J.I.; Monroy, R.; Loyola-González, O.; López-Cuevas, A. A one-class classification approach for bot detection on Twitter. Comput. Secur. 2020, 91, 101715. [Google Scholar] [CrossRef]
- Perera, P.; Patel, V.M. Learning deep features for one-class classification. IEEE Trans. Image Process. 2019, 28, 5450–5463. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, D.; Deng, L.; Lee, M.; Wang, H. IoT data feature extraction and intrusion detection system for smart cities based on deep migration learning. Int. J. Inf. Manag. 2019, 49, 533–545. [Google Scholar] [CrossRef]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the support of a high-dimensional distribution. Neural. Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef] [PubMed]
- Tax, D.M.; Duin, R.P. Support vector data description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef] [Green Version]
- Mishra, P.; Varadharajan, V.; Tupakula, U.; Pilli, E.S. A Detailed Investigation and Analysis of Using Machine Learning Techniques for Intrusion Detection. IEEE Commun. Surv. Tutor. 2019, 21, 686–728. [Google Scholar] [CrossRef]
- Nisioti, A.; Mylonas, A.; Yoo, P.D.; Katos, V. From Intrusion Detection to Attacker Attribution: A Comprehensive Survey of Unsupervised Methods. IEEE Commun. Surv. Tutor. 2018, 20, 3369–3388. [Google Scholar] [CrossRef]
- Cui, Z.; Xue, F.; Cai, X.; Cao, Y.; Wang, G.; Chen, J. Detection of Malicious Code Variants Based on Deep Learning. IEEE Trans. Ind. Inform. 2018, 14, 3187–3196. [Google Scholar] [CrossRef]
- Li, Y.; Xu, Y.; Liu, Z.; Hou, H.; Zheng, Y.; Xin, Y.; Zhao, Y.; Xin, Y.; Zhao, Y.; Cui, L. Robust detection for network intrusion of industrial IoT based on multi-CNN fusion. Measurement 2020, 154, 107450. [Google Scholar] [CrossRef]
- Chalapathy, R.; Chawla, S. Deep learning for anomaly detection: A survey. arXiv 2019, arXiv:1901.03407. [Google Scholar]
- Aldweesh, A.; Derhab, A.; Emam, A.Z. Deep learning approaches for anomaly-based intrusion detection systems: A survey, taxonomy, and open issues. Knowl. Based Syst. 2020, 189, 105124. [Google Scholar] [CrossRef]
- Khan, S.S.; Madden, M.G. One-class classification: Taxonomy of study and review of techniques. Knowl. Eng. Rev. 2014, 29, 345–374. [Google Scholar] [CrossRef] [Green Version]
- Krawczyk, B.; Galar, M.; Woźniak, M.; Bustince, H.; Herrera, F. Dynamic ensemble selection for multi-class classification with one-class classifiers. Pattern Recogn. 2018, 83, 34–51. [Google Scholar] [CrossRef]
- Wan, M.; Shang, W.; Zeng, P. Double Behavior Characteristics for One-Class Classification Anomaly Detection in Networked Control Systems. IEEE Trans. Inf. Forensics Secur. 2017, 12, 3011–3023. [Google Scholar] [CrossRef]
- Chalapathy, R.; Khoa, N.L.D.; Chawla, S. Robust Deep Learning Methods for Anomaly Detection. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 6–10 July 2020; pp. 3507–3508. [Google Scholar]
- Xu, Y.; Liu, Z.; Li, Y.; Hou, H.; Cao, Y.; Zhao, Y.; Guo, W.; Cui, L. Feature data processing: Making medical data fit deep neural networks. Future Gener. Comput. Syst. 2020, 109, 149–157. [Google Scholar] [CrossRef]
- Muhammad, S.; Cheol-Hong, K.; Jong-Myon, K. A hybrid feature model and deep-learning-based bearing fault diagnosis. Sensors 2017, 17, 2876. [Google Scholar]
- Erfani, S.M.; Rajasegarar, S.; Karunasekera, S.; Leckie, C. High-dimensional and large-scale anomaly detection using a linear one-class SVM with deep learning. Pattern Recogn. 2016, 58, 121–134. [Google Scholar] [CrossRef]
- Chalapathy, R.; Menon, A.K.; Chawla, S. Anomaly detection using one-class neural networks. arXiv 2018, arXiv:1802.06360. [Google Scholar]
- Chalapathy, R.; Menon, A.K.; Chawla, S. Robust, deep and inductive anomaly detection. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases Springer, Skopje, Macedonia, 18–22 September 2017; pp. 36–51. [Google Scholar]
- Chen, J.; Sathe, S.; Aggarwal, C.; Turaga, D. Outlier detection with autoencoder ensembles. In Proceedings of the 2017 SIAM International Conference on Data Mining, Houston, TX, USA, 27–29 April 2017; pp. 90–98. [Google Scholar]
- Ruff, L.; Vandermeulen, R.; Goernitz, N.; Deecke, L.; Siddiqui, S.A.; Binder, A.; Kloft, M. Deep one-class classification. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 10–15 July 2018; pp. 4393–4402. [Google Scholar]
- Oza, P.; Patel, V.M. One-Class Convolutional Neural Network. IEEE Signal Proc. Let. 2019, 26, 277–281. [Google Scholar] [CrossRef] [Green Version]
- Schlachter, P.; Liao, Y.; Yang, B. Deep one-class classification using intra-class splitting. arXiv 2019, arXiv:1902.01194. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z. Isolation Forest; IEEE: Piscataway, NJ, USA, 2008; pp. 413–422. [Google Scholar]
- Parzen, E. On estimation of a probability density function and mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Masci, J.; Meier, U.; Cireşan, D.; Schmidhuber, J. Stacked Convolutional Auto-Encoders for Hierarchical Feature Extraction; Springer: Berlin/Heidelberg, Germany, 2011; pp. 52–59. [Google Scholar]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A Detailed Analysis of the KDD CUP 99 Data Set; IEEE: Piscataway, NJ, USA, 2009; pp. 1–6. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. ICISSp 2018, 1, 108–116. [Google Scholar]
- Fontugne, R.; Borgnat, P.; Abry, P.; Fukuda, K. Mawilab: Combining diverse anomaly detectors for automated anomaly labeling and performance benchmarking. In Proceedings of the 6th International Conference; Springer: Berlin/Heidelberg, Germany, 2010; pp. 1–12. [Google Scholar]
- Kim, C.; Sim, J.; Choi, J. Generating labeled flow data from MAWILab traces for network intrusion detection. In Proceedings of the ACM Workshop on Systems and Network Telemetry and Analytics, Phoenix, AZ, USA, 25 June 2019; pp. 45–48. [Google Scholar]
- Abadi, M. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Instances | Anomalies | Features | |
|---|---|---|---|---|
| NSL-KDD | KDDTrain+ | 67,343 (53.46%) | 58,630 (46.54%) | 41 |
| KDDTest+ | 9711 (43.08%) | 12,833 (56.92%) | 41 | |
| CIC-IDS 2017 | CIC-DDoS | 97,718 (43.29%) | 128,027 (56.71%) | 78 |
| CIC-PortScan | 127,537 (44.52%) | 158,930 (55.48%) | 78 | |
| MAWILab | MAWILab-20200102 | 22,228,204 (97.06%) | 673,825 (2.94%) | 109 |
| MAWILab-20201203 | 25,195,651 (96.80%) | 832,028 (3.20%) | 109 | |
| Anomaly Class | OC-SVM/ SVDD | IF | KDE | DCAE | OC-NN | Soft-Bound Deep SVDD | One-Class Deep SVDD | OC-LSTM |
|---|---|---|---|---|---|---|---|---|
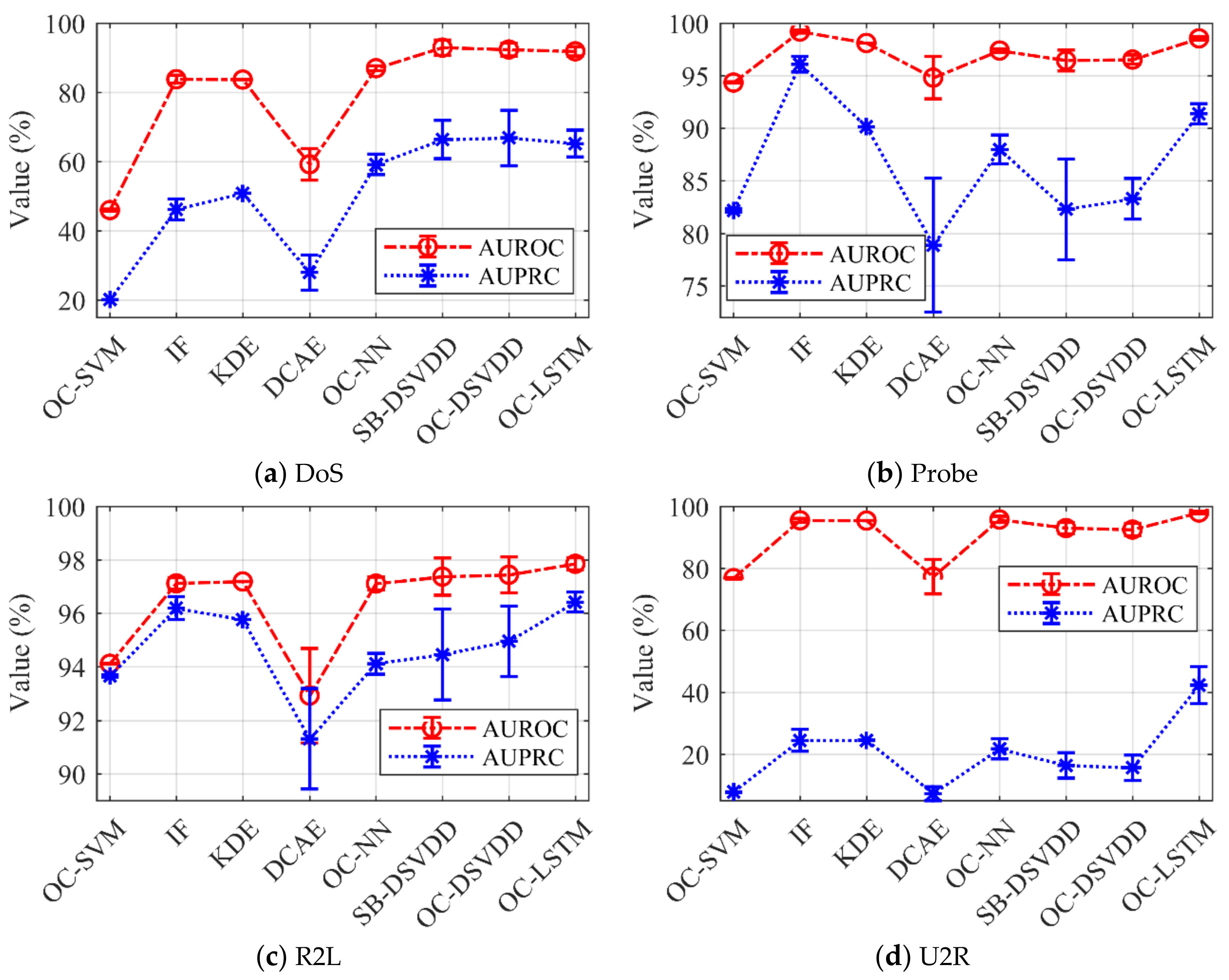
| DoS | 94.11 ± 0.02 | 97.12 ± 0.22 | 97.19 ± 0.00 | 92.92 ± 1.76 | 97.11 ± 0.24 | 97.37 ± 0.70 | 97.44 ± 0.67 | 97.85 ± 0.23 |
| Probe | 94.34 ± 0.07 | 99.20 ± 0.13 | 98.11 ± 0.00 | 94.81 ± 2.02 | 97.39 ± 0.16 | 96.44 ± 0.99 | 96.53 ± 0.44 | 98.55 ± 0.15 |
| R2L | 45.95 ± 0.28 | 83.80 ± 1.20 | 83.68 ± 0.03 | 59.19 ± 4.57 | 86.97 ± 0.70 | 92.92 ± 2.22 | 92.39 ± 1.86 | 91.86 ± 1.33 |
| U2R | 76.82 ± 0.17 | 95.51 ± 0.64 | 95.41 ± 0.01 | 77.29 ± 5.53 | 95.77 ± 1.00 | 93.00 ± 1.78 | 92.50 ± 2.05 | 98.01 ± 0.34 |
| Total | 83.86 ± 0.06 | 94.59 ± 0.25 | 94.42 ± 0.01 | 84.46 ± 4.91 | 94.97 ± 0.22 | 96.17 ± 0.71 | 96.11 ± 0.48 | 96.86 ± 0.58 |
| Anomaly Class | OC-SVM/ SVDD | IF | KDE | DCAE | OC-NN | Soft-Bound Deep SVDD | One-Class Deep SVDD | OC-LSTM |
|---|---|---|---|---|---|---|---|---|
| DoS | 93.65 ± 0.04 | 96.19 ± 0.43 | 95.76 ± 0.00 | 91.31 ± 1.88 | 94.11 ± 0.39 | 94.45 ± 1.70 | 94.95 ± 1.32 | 96.42 ± 0.37 |
| Probe | 82.16 ± 0.18 | 96.08 ± 0.74 | 90.13 ± 0.01 | 78.88 ± 6.36 | 87.97 ± 1.37 | 82.28 ± 4.78 | 83.27 ± 1.94 | 91.38 ± 0.96 |
| R2L | 20.14 ± 0.09 | 46.14 ± 3.00 | 50.80 ± 0.06 | 28.00 ± 5.10 | 59.13 ± 2.97 | 66.34 ± 5.56 | 66.82 ± 8.01 | 65.18 ± 3.84 |
| U2R | 7.83 ± 0.06 | 24.42 ± 3.56 | 24.42 ± 0.04 | 7.20 ± 2.20 | 21.68 ± 3.28 | 16.34 ± 4.13 | 15.57 ± 4.10 | 42.24 ± 5.98 |
| Total | 89.77 ± 0.03 | 95.73 ± 0.22 | 95.20 ± 0.00 | 88.90 ± 3.45 | 95.07 ± 0.25 | 95.51 ± 1.04 | 95.71 ± 0.53 | 96.72 ± 0.34 |
| Method | CIC-DDoS | CIC-PortScan | ||
|---|---|---|---|---|
| AUROC | AUPRC | AUROC | AUPRC | |
| OC-SVM/SVDD | 66.46 ± 0.90 | 61.56 ± 0.79 | 71.92 ± 0.08 | 62.32 ± 0.06 |
| IF | 90.75 ± 1.92 | 84.95 ± 2.35 | 74.64 ± 5.42 | 67.11 ± 4.74 |
| KDE | 92.81 ± 0.34 | 89.78 ± 0.69 | 74.98 ± 0.20 | 67.79 ± 0.15 |
| DCAE | 90.62 ± 2.51 | 89.10 ± 5.12 | 94.75 ± 4.29 | 90.62 ± 7.37 |
| OC-NN | 99.07 ± 0.26 | 98.90 ± 0.41 | 98.53 ± 0.71 | 97.35 ± 1.48 |
| Soft-Bound Deep SVDD | 95.94 ± 2.83 | 96.56 ± 1.93 | 88.49 ± 7.78 | 82.47 ± 9.59 |
| One-Class Deep SVDD | 97.59 ± 1.12 | 97.72 ± 0.92 | 85.50 ± 4.91 | 79.25 ± 6.20 |
| OC-LSTM | 99.24 ± 0.14 | 99.15 ± 0.16 | 99.66 ± 0.19 | 99.07 ± 0.39 |
| Method | MAWILab-20200102 | MAWILab-20201203 | ||
|---|---|---|---|---|
| AUROC | AUPRC | AUROC | AUPRC | |
| OC-SVM/SVDD | 90.66 ± 0.23 | 83.59 ± 0.41 | 87.58 ± 0.30 | 80.19 ± 0.51 |
| IF | 94.58 ± 0.42 | 90.43 ± 0.86 | 89.35 ± 1.04 | 86.51 ± 1.29 |
| KDE | 92.17 ± 0.21 | 86.81 ± 0.55 | 89.81 ± 0.24 | 85.17 ± 0.31 |
| DCAE | 94.78 ± 1.04 | 92.49 ± 1.40 | 92.50 ± 1.31 | 90.45 ± 1.53 |
| OC-NN | 96.42 ± 0.30 | 94.90 ± 0.48 | 93.96 ± 0.21 | 92.71 ± 0.51 |
| Soft-Bound Deep SVDD | 94.89 ± 0.73 | 91.49 ± 1.46 | 90.96 ± 2.90 | 88.53 ± 1.60 |
| One-Class Deep SVDD | 95.00 ± 0.73 | 91.70 ± 1.26 | 91.79 ± 2.30 | 90.04 ± 1.80 |
| OC-LSTM | 97.36 ± 0.49 | 96.70 ± 0.72 | 94.58 ± 0.47 | 93.23 ± 0.64 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Xu, Y.; Cao, Y.; Hou, J.; Wang, C.; Guo, W.; Li, X.; Xin, Y.; Liu, Z.; Cui, L. One-Class LSTM Network for Anomalous Network Traffic Detection. Appl. Sci. 2022, 12, 5051. https://doi.org/10.3390/app12105051
Li Y, Xu Y, Cao Y, Hou J, Wang C, Guo W, Li X, Xin Y, Liu Z, Cui L. One-Class LSTM Network for Anomalous Network Traffic Detection. Applied Sciences. 2022; 12(10):5051. https://doi.org/10.3390/app12105051
Chicago/Turabian StyleLi, Yanmiao, Yingying Xu, Yankun Cao, Jiangang Hou, Chun Wang, Wei Guo, Xin Li, Yang Xin, Zhi Liu, and Lizhen Cui. 2022. "One-Class LSTM Network for Anomalous Network Traffic Detection" Applied Sciences 12, no. 10: 5051. https://doi.org/10.3390/app12105051