Recommendation Systems: Algorithms, Challenges, Metrics, and Business Opportunities


Abstract
:1. Introduction
2. Recommendation System Categories
2.1. Collaborative-Filtering Recommendation Systems
2.2. Content-Based Recommendation Systems
2.3. Demographic-Based Recommendation Systems
2.4. Utility-Based Recommendation Systems
2.5. Knowledge-Based Recommendation Systems
2.6. Hybrid-Based Recommendation Systems
2.6.1. Weighted
2.6.2. Switching
2.6.3. Mixed
2.6.4. Feature Combination
2.6.5. Cascade
2.6.6. Feature Augmentation
2.6.7. Meta-Level
3. Challenges in Recommendation Systems
3.1. Cold-Start
3.2. Data Sparsity
3.3. Scalability
3.4. Diversity
3.5. Habituation Effect
4. Evaluation Metrics
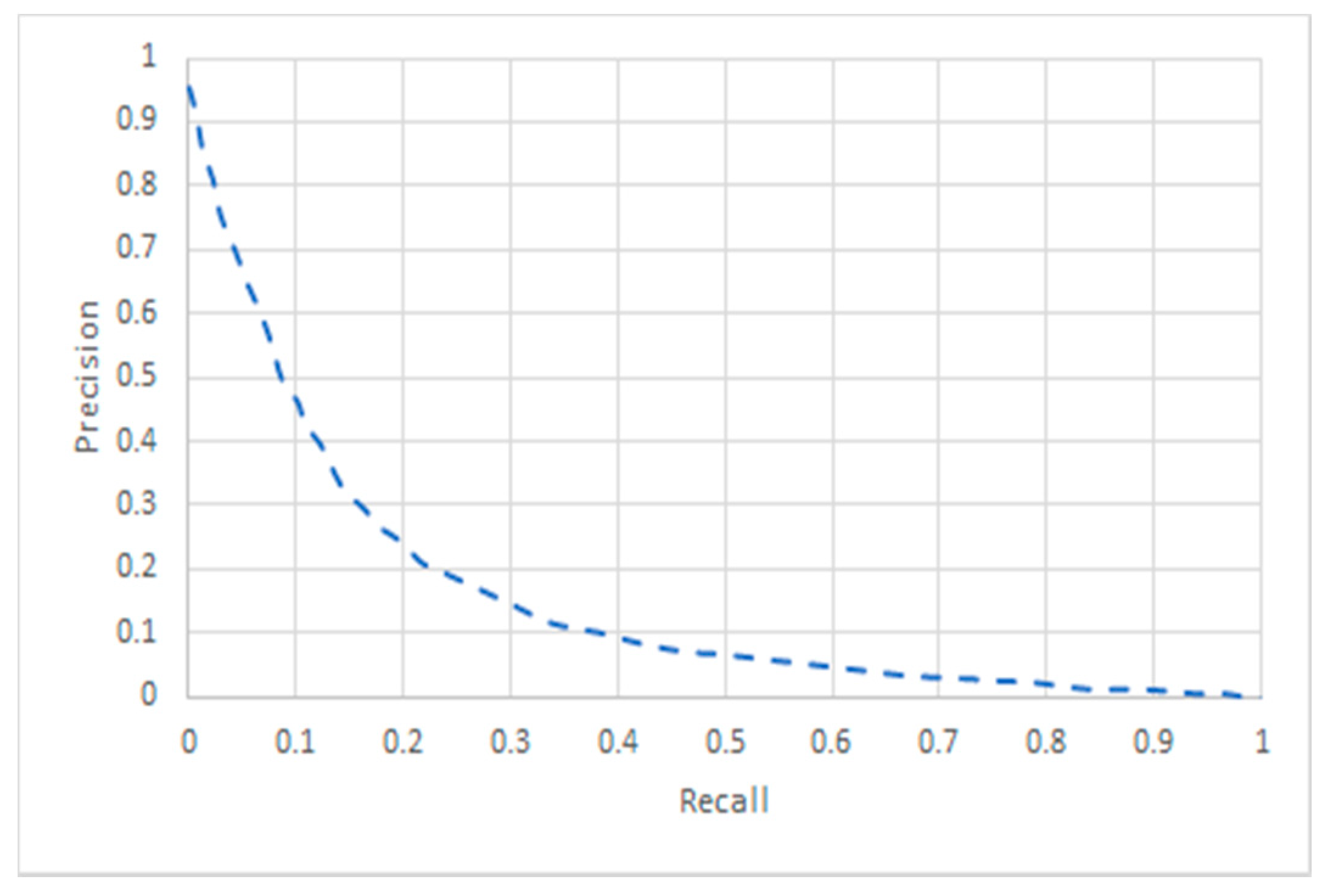
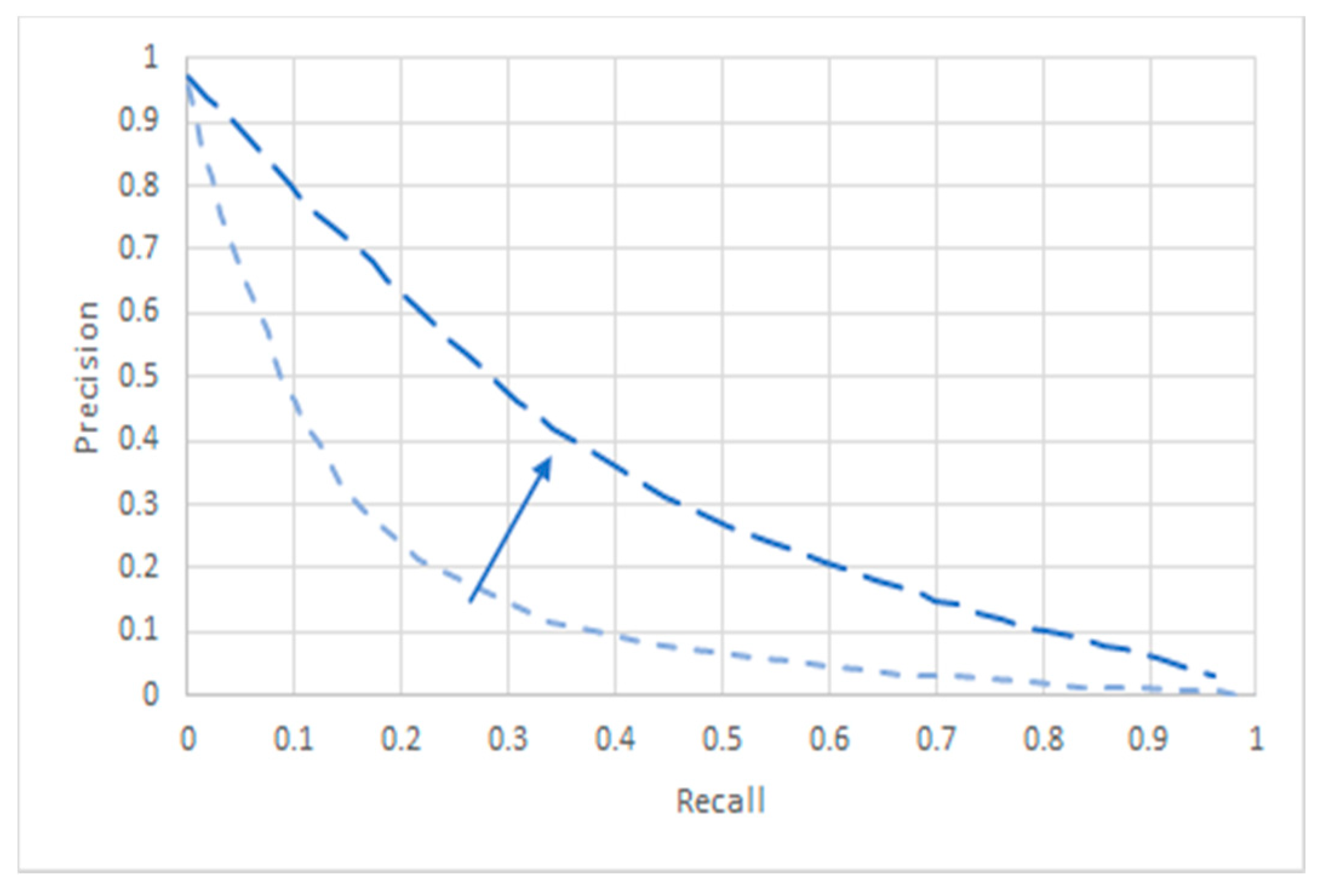
4.1. Recall and Precision
4.2. Accuracy
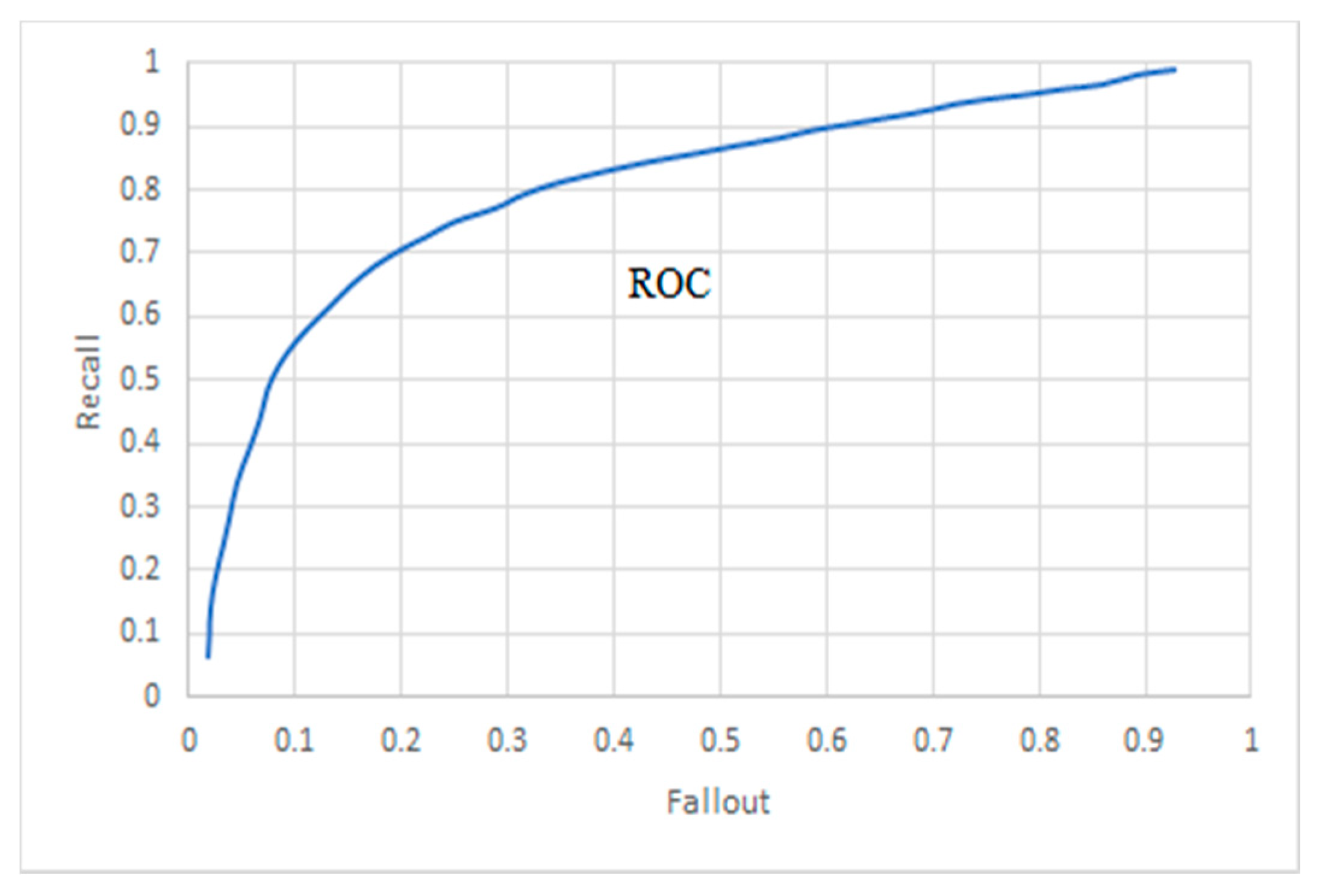
4.3. ROC Curve
4.4. F-Measure
5. Business Adoption and Applications
5.1. Recommendation Systems in e-Commerce
5.2. Recommendation Systems in Transportation
- Recommending trip
- Recommending path
- Recommending popular activities in a location
- Recommending popular locations (restaurants)
- Recommending transporters (goods transporter, bus lines, drivers)
5.3. Recommendation Systems in the e-Health Domain
5.4. Recommendation Systems in Agriculture
5.5. Recommendation Systems in Media and Beyond
6. Conclusions and Future Directions
Author Contributions
Funding
Conflicts of Interest
References
- Beel, J.; Langer, S.; Genzmehr, M.; Gipp, B.; Breitinger, C.; Nürnberger, A. Research paper recommender system evaluation: A quantitative literature survey. In Proceedings of the International Workshop on Reproducibility and Replication in Recommender Systems Evaluation, Hong Kong, China, 12 October 2013; pp. 15–22. [Google Scholar]
- Resnick, P.; Varian, H.R. Recommender systems. Commun. ACM 1997, 40, 56–59. [Google Scholar] [CrossRef]
- Ricci, F.; Rokach, L.; Shapira, B. Introduction to recommender systems handbook. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2011; pp. 1–35. [Google Scholar]
- Schafer, J.B.; Konstan, J.A.; Riedl, J. E-commerce recommendation applications. Data Min. Knowl. Discov. 2001, 5, 115–153. [Google Scholar] [CrossRef]
- Smith, B.; Linden, G. Two decades of recommender systems at Amazon.com. IEEE Internet Comput. 2017, 21, 12–18. [Google Scholar] [CrossRef]
- Mustaqeem, A.; Anwar, S.M.; Majid, M. A modular cluster-based collaborative recommender system for cardiac patients. Artif. Intell. Med. 2019, 102. [Google Scholar] [CrossRef]
- Archana, K.; Saranya, K.G. Crop Yield Prediction, Forecasting and Fertilizer Recommendation using Voting Based Ensemble Classifier. SSRG Int. J. Comput. Sci. Eng. 2020, 7. [Google Scholar] [CrossRef]
- Gheraibia, M.Y.; Gouin-Vallerand, C. Intelligent mobile-based recommender system framework for smart freight transport. In Proceedings of the 5th EAI International Conference on Smart Objects and Technologies for Social Good, Valencia, Spain, 25–27 September 2019; pp. 219–222. [Google Scholar]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutiérrez, A. Recommender systems survey. Knowl. Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Yang, X.; Guo, Y.; Liu, Y.; Steck, H. A survey of collaborative filtering based social recommender systems. Comput. Commun. 2014, 41, 1–10. [Google Scholar] [CrossRef]
- Ding, Z.; Li, X.; Jiang, C.; Zhou, M. Objectives and state-of-the-art of location-based social network recommender systems. ACM Comput. Surv. CSUR 2018, 51, 1–28. [Google Scholar] [CrossRef]
- Lu, J.; Wu, D.; Mao, M.; Wang, W.; Zhang, G. Recommender system application developments: A survey. Decis. Support Syst. 2015, 74, 12–32. [Google Scholar] [CrossRef]
- Ricci, F.; Rokach, L.; Shapira, B. Recommender Systems: Introduction and Challenges. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2015. [Google Scholar] [CrossRef]
- Aggarwal, C.C. An Introduction to Recommender Systems. In Recommender Systems; Springer: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Kardan, A.A.; Ebrahimi, M. A novel approach to hybrid recommendation systems based on association rules mining for content recommendation in asynchronous discussion groups. Inf. Sci. 2013, 219, 93–110. [Google Scholar] [CrossRef]
- Herlocker, J.L.; Konstan, J.A.; Terveen, L.G.; Riedl, J.T. Evaluating collaborative filtering recommender systems. ACM Trans. Inf. Syst. TOIS 2004, 22, 5–53. [Google Scholar] [CrossRef]
- Sarwar, B.M.; Karypis, G.; Konstan, J.A.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In WWW ’01, Proceedings of the 10th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; Association for Computing Machinery: New York, NY, USA, 2001; Volume 1, pp. 285–295. [Google Scholar]
- Gong, S.; Cheng, G. Mining user interest change for improving collaborative filtering. In Proceedings of the 2008 Second International Symposium on Intelligent Information Technology Application, Shanghai, China, 21–22 December 2008; Volume 3, pp. 24–27. [Google Scholar]
- Schafer, J.B.; Frankowski, D.; Herlocker, J.; Sen, S. Collaborative filtering recommender systems. In The Adaptive Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 291–324. [Google Scholar]
- Vozalis, M.; Margaritis, K.G. Collaborative filtering enhanced by demographic correlation. In Proceedings of the AIAI Symposium on Professional Practice in AI, Part of the 18th World Computer Congress, Toulouse, France, 22–27 August 2004. [Google Scholar]
- Al-Shamri, M.Y.H. User profiling approaches for demographic recommender systems. Knowl. Based Syst. 2016, 100, 175–187. [Google Scholar] [CrossRef]
- Deng, F. Utility-based recommender systems using implicit utility and genetic algorithm. In Proceedings of the 2015 International Conference on Mechatronics, Electronic, Industrial and Control Engineering (MEIC-15), Shenyang, China, 1–3 April 2015; Atlantis Press: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Burke, R. Integrating knowledge-based and collaborative-filtering recommender systems. In Proceedings of the Workshop on AI and Electronic Commerce, Orlando, FL, USA, 18–22 July 1999; pp. 69–72. [Google Scholar]
- Burke, R. Knowledge-based recommender systems. In Encyclopedia of Library and Information Systems; CRC Press: Boca Raton, FL, USA, 2000; Volume 69, (Suppl. 32), pp. 175–186. [Google Scholar]
- Lillegraven, T.N.; Wolden, A.C. Design of a Bayesian Recommender System for Tourists Presenting a Solution to the Cold-Start User Problem. Master’s Thesis, Norwegian University of Science and Technology, Trondheim, Norway, 2010. [Google Scholar]
- Schein, A.I.; Popescul, A.; Ungar, L.H.; Pennock, D.M. Methods and metrics for cold-start recommendations. In Proceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval, Tampere, Finland, 11–15 August 2002; Association for Computing Machinery: New York, NY, USA, 2002. [Google Scholar]
- Al-Bakri, N.F.; Hashim, S.H. Reducing data sparsity in recommender systems. Al Nahrain J. Sci. 2018, 21, 138–147. [Google Scholar] [CrossRef]
- Chen, Y.; Wu, C.; Xie, M.; Guo, X. Solving the sparsity problem in recommender systems using association retrieval. J. Comput. 2011, 6, 1896–1902. [Google Scholar] [CrossRef]
- Massa, P.; Bhattacharjee, B. Using trust in recommender systems: An experimental analysis. In Proceedings of the International Conference on Trust Management (iTrust), Oxford, UK, 29 March–1 April 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 221–235. [Google Scholar]
- Guo, G. Integrating trust and similarity to ameliorate the data sparsity and cold start for recommender systems. In Proceedings of the 7th ACM conference on Recommender systems, Hong Kong, China, 12–16 October 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 451–454. [Google Scholar]
- O’Donovan, J.; Smyth, B. Trust in recommender systems. In Proceedings of the 10th international conference on Intelligent user interfaces, San Diego, CA, USA, 10–13 January 2005; Association for Computing Machinery: New York, NY, USA, 2005; pp. 167–174. [Google Scholar]
- Guo, G.; Zhang, J.; Thalmann, D. Merging trust in collaborative filtering to alleviate data sparsity and cold start. Knowl. Based Syst. 2014, 57, 57–68. [Google Scholar] [CrossRef]
- Takács, G.; Pilászy, I.; Németh, B.; Tikk, D. Scalable collaborative filtering approaches for large recommender systems. J. Mach. Learn. Res. 2009, 10, 623–656. [Google Scholar]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Incremental singular value decomposition algorithms for highly scalable recommender systems. In Proceedings of the Fifth International Conference on Computer and Information Science, Dhaka, Bangladesh, 27–28 December 2002; Volume 27, p. 28. [Google Scholar]
- Sarwar, B.M.; Karypis, G.; Konstan, J.; Riedl, J. Recommender systems for large-scale ecommerce: Scalable neighborhood formation using clustering. In Proceedings of the Fifth International Conference on Computer and Information Technology, Shanghai, China, 21–23 September 2005; Volume 1, pp. 291–324. [Google Scholar]
- Zhou, T.; Kuscsik, Z.; Liu, J.; Medo, M.; Wakeling, J.R.; Zhang, Y. Solving the apparent diversity-accuracy dilemma of recommender systems. Proc. Natl. Acad. Sci. USA 2010, 107, 4511–4515. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Manikanta, B.K. Tackling the Problems of Diversity in Recommender Systems. Ph.D. Thesis, Kansas State University, Manhattan, KS, USA, 2010. [Google Scholar]
- Bortko, K.; Bartków, P.; Jankowski, J.; Kuras, D.; Sulikowski, P. Multi-criteria Evaluation of Recommending Interfaces towards Habituation Reduction and Limited Negative Impact on User Experience. Procedia Comput. Sci. 2019, 159, 2240–2248. [Google Scholar] [CrossRef]
- Hu, R.; Pu, P. Enhancing recommendation diversity with organization interfaces. In Proceedings of the 16th International Conference on Intelligent User Interfaces, Palo Alto, CA, USA, 13–16 February 2011; pp. 347–350. [Google Scholar]
- Lee, J.; Ahn, J.H.; Park, B. The effect of repetition in internet banner ads and the moderating role of animation. Comput. Hum. Behav. 2015, 46, 202–209. [Google Scholar] [CrossRef]
- Jankowski, J.; Hamari, J.; Watróbski, J. A gradual approach for maximising user conversion without compromising experience withhigh visual intensity website elements. Internet Res. 2019, 29, 194–217. [Google Scholar] [CrossRef]
- Vaishnavi, S.; Jayanthi, A.; Karthik, S. Ranking technique to improve diversity in recommender systems. Int. J. Comput. Appl. 2013, 68, 2. [Google Scholar]
- Ge, M.; Delgado-Battenfeld, C.; Jannach, D. Beyond accuracy: Evaluating recommender systems by coverage and serendipity. In Proceedings of the Fourth ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 257–260. [Google Scholar]
- Gunawardana, A.; Shani, G. A survey of accuracy evaluation metrics of recommendation tasks. J. Mach. Learn. Res. 2009, 10, 2935–2962. [Google Scholar]
- del Olmo, F.H.; Gaudioso, E. Evaluation of recommender systems: A new approach. Expert Syst. Appl. 2008, 35, 790–804. [Google Scholar] [CrossRef]
- Cremonesi, P.; Turrin, R.; Lentini, E.; Matteucci, M. An evaluation methodology for collaborative recommender systems. In Proceedings of the 2008 International Conference on Automated Solutions for Cross Media Content and Multi-Channel Distribution, Florence, Italy, 17–19 November 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 224–231. [Google Scholar]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (roc) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.Y.; Kuo, F.-C.; Merkel, R. On the statistical properties of testing effectiveness measures. J. Syst. Softw. 2006, 79, 591–601. [Google Scholar] [CrossRef]
- Rodriguez-Carrion, A.; Garcia-Rubio, C.; Campo, C.; Cortés-Martín, A.; Garcia-Lozano, E.; Noriega-Vivas, P. Study of LZ-based location prediction and its application to transportation recommender systems. Sensors 2012, 12, 7496–7517. [Google Scholar] [CrossRef]
- Madhusree, K.; Rath, B.K.; Mohanty, S.N. Crop Recommender System for the Farmers using Mamdani Fuzzy Inference Model. Int. J. Eng. Technol. 2018, 7, 277–280. [Google Scholar]
- Sezgin, E.; Sevgi, Ö. A systematic literature review on Health Recommender Systems. In Proceedings of the 2013 E-Health and Bioengineering Conference (EHB), Iasi, Romania, 21–23 November 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1–4. [Google Scholar]
- Zhang, M.; Yi, C.; Xiaohong, Z.; Junyong, L. Study on the recommendation technology for tourism information service. In Proceedings of the 2009 Second International Symposium on Computational Intelligence and Design, Changsha, China, 12–14 December 2009; IEEE: Piscataway, NJ, USA, 2009; Volume 1, pp. 410–415. [Google Scholar]
- Panagiotis, S.; Nanopoulos, A.; Manolopoulos, Y. MoviExplain: A recommender system with explanations. In Proceedings of the Third ACM Conference on Recommender Systems, New York, NY, USA, 22–25 October 2009; pp. 317–320. [Google Scholar]
- Geuens, S.; Coussement, K.; De Bock, K.W. A framework for configuring collaborative filtering-based recommendations derived from purchase data. Eur. J. Oper. Res. 2017, 265, 208–218. [Google Scholar] [CrossRef]
- Sulikowski, P.; Zdziebko, T. Deep Learning-Enhanced Framework for Performance Evaluation of a Recommending Interface with Varied Recommendation Position and Intensity Based on Eye-Tracking Equipment Data Processing. Electronics 2020, 9, 266. [Google Scholar] [CrossRef] [Green Version]
- Srifi, M.; Oussous, A.; Ait Lahcen, A.; Mouline, S. Recommender Systems Based on Collaborative Filtering Using Review Texts—A Survey. Information 2020, 11, 317. [Google Scholar] [CrossRef]
- Szabó, R.; Farkas, K.; Ispany, M.; Benczúr, A.A.; Bátfai, N.; Jeszenszky, P.; Laki, S.; Vágner, A.; Kollár, L.; Sidló, C.; et al. Framework for smart city applications based on participatory sensing. In Proceedings of the 2013 IEEE 4th International Conference on Cognitive Infocommunications (CogInfoCom), Budapest, Hungary, 2–5 December 2013; pp. 295–300. [Google Scholar]
- Ricci, F. Mobile recommender systems. Inf. Technol. Tour. 2011, 12, 205–231. [Google Scholar] [CrossRef]
- Park, M.H.; Hong, J.; Cho, S. Location-based recommendation system using bayesian user’s preference model in mobile devices. In Proceedings of the 4th International Conference on Ubiquitous Intelligence and Computing, Hong Kong, China, 11–13 July 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 1130–1139. [Google Scholar]
- Brown, B.; Chalmers, M.; Bell, M.; Hall, M.; MacColl, I.; Rudman, P. Sharing the square: Collaborative leisure in the city streets. In Proceedings of the Ninth European Conference on Computer-Supported Cooperative Work (ECSW), Paris, France, 18–22 September 2005; Springer: Dordrecht, The Netherlands, 2005; pp. 427–447. [Google Scholar]
- Yin, H.; Sun, Y.; Cui, B.; Hu, Z.; Chen, L. LCARS: A location-content-aware recommender system. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–13 August 2013; pp. 221–229. [Google Scholar]
- Horozov, T.; Narasimhan, N.; Vasudevan, V. Using location for personalized POI recommendations in mobile environments. In Proceedings of the International Symposium on Applications and the Internet (SAINT’06), Phoenix, AZ, USA, 23–27 January 2006; IEEE: Piscataway, NJ, USA, 2006; p. 6. [Google Scholar]
- Gao, H.; Tang, J.; Liu, H. Exploring temporal effects for location recommendation on location based social networks. In Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 93–100. [Google Scholar]
- Yuan, Q.; Cong, G.; Ma, Z.; Sun, A.; Magnenat-Thalmann, N. Time-aware point-of-interest recommendation. In Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 28 July–1 August 2013; pp. 363–372. [Google Scholar]
- Hamid, K. Personalized Healthcare System Based on Ontologies. In Proceedings of the International Conference on Advanced Intelligent Systems for Sustainable Development (AI2SD ’2018), Tangiers, Morocco, 12–14 July 2018; Volume 4, p. 185. [Google Scholar]
- Sung, Y.-S.; Dravenstott, R.W.; Darer, J.D.; Devapriya, P.D.; Kumara, S. SuperOrder: Provider order recommendation system for outpatient clinics. Health Inform. J. 2019, 26, 999–1016. [Google Scholar] [CrossRef]
- Frittelli, D.M.V. An Architecture for e-Health Recommender Systems Based on Similarity of Patients’ Symptoms. In Blockchain Technology for Smart Cities; Springer: Singapore, 2020. [Google Scholar]
- Mezei, J.; Nikou, S. Fuzzy optimization to improve mobile health and wellness recommendation systems. Knowl. Based Syst. 2018, 142, 108–116. [Google Scholar] [CrossRef]
- Sahoo, A.K.; Pradhan, C.; Barik, R.K.; Dubey, H. DeepReco: Deep learning based health recommender system using collaborative filtering. Computation 2019, 7, 25. [Google Scholar] [CrossRef] [Green Version]
- Hors-Fraile, S.; Núñez Benjumea, F.J.; Hernández, L.C.; Ruiz, F.O.; Fernandez-Luque, L. Design of two combined health recommender systems for tailoring messages in a smoking cessation app. arXiv 2016, arXiv:1608.07192. [Google Scholar]
- Iwendi, C.; Khan, S.; Anajemba, J.H.; Bashir, A.K.; Noor, F. Realizing an Efficient IoMT-Assisted Patient Diet Recommendation System through Machine Learning Model. IEEE Access 2020, 8, 28462–28474. [Google Scholar] [CrossRef]
- Amelie Gyrard, A.S. IAMHAPPY: Towards an IoT knowledge-based cross-domain well-being recommendation system for everyday happiness. Smart Health 2020, 15, 100083. [Google Scholar] [CrossRef]
- Almeida, J.R.; Monteiro, E.; Silva, L.B.; Sierra, A.P.; Oliveira, J.L. A Recommender System to Help Discovering Cohorts in Rare Diseases. In Proceedings of the 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS), Rochester, MN, USA, 28–30 July 2020. [Google Scholar]
- Lacasta, J.; Lopez-Pellicer, F.J.; Espejo-García, B.; Nogueras-Iso, J.; Zarazaga, F.J.-S. Agricultural recommendation system for crop protection. Comput. Electron. Agric. 2018, 152, 82–89. [Google Scholar] [CrossRef] [Green Version]
- Jaiswal, S.; Kharade, T.; Kotambe, N.; Shinde, S. Collaborative Recommendation System For Agriculture Sector. ITM Web Conf. 2020, 32, 03034. [Google Scholar] [CrossRef]
- Santosh Kumar, M.B.; Balakrishnan, K. Development of a Model Recommender System for Agriculture Using Apriori Algorithm. In Cognitive Informatics and Soft Computing; Springer: Singapore, 2019; pp. 153–163. [Google Scholar]
- Pudumalar, S.; Ramanujam, E.; Harine Rajashree, R.; Kavya, C.; Kiruthika, T.; Nisha, J. Crop recommendation system for precision agriculture. In Proceedings of the 2016 Eighth International Conference on Advanced Computing (ICoAC), Chennai, India, 19–21 January 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 32–36. [Google Scholar]
- Bangaru Kamatchi, R.S. Improvement of Crop Production Using Recommender System by Weather Forecasts. Procedia Comput. Sci. 2019, 165, 724–732. [Google Scholar] [CrossRef]
- Kulkarni, N.H.; Srinivasan, G.N.; Sagar, B.M.; Cauvery, N.K. Improving Crop Productivity through a Crop Recommendation System Using Ensembling Technique. In Proceedings of the 2018 3rd International Conference on Computational Systems and Information Technology for Sustainable Solutions (CSITSS), Bangalore, India, 20–22 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 114–119. [Google Scholar]
- Hong, M.; Jung, J.J.; Piccialli, F.; Chianese, A. Social recommendation service for cultural heritage. Pers. Ubiquitous Comput. 2017, 21, 191–201. [Google Scholar] [CrossRef]
- Pavlidis, G. Recommender systems, cultural heritage applications, and the way forward. J. Cult. Herit. 2019, 35, 183–196. [Google Scholar] [CrossRef]
- Su, X.; Sperlì, G.; Moscato, V.; Picariello, A.; Esposito, C.; Choi, C. An edge intelligence empowered recommender system enabling cultural heritage applications. IEEE Trans. Ind. Inform. 2019, 15, 4266–4275. [Google Scholar] [CrossRef]
- Yang, J.; Wang, H.; Lv, Z.; Wei, W.; Song, H.; Erol-Kantarci, M.; Kantarci, B.; He, S. Multimedia recommendation and transmission system based on cloud platform. Future Gener. Comput. Syst. 2017, 70, 94–103. [Google Scholar] [CrossRef]
- Mwinyi, I.H.; Narman, H.S.; Fang, K.; Yoo, W. Predictive self-learning content recommendation system for multimedia contents. In Proceedings of the 2018 Wireless Telecommunications Symposium (WTS), Phoenix, AZ, USA, 18–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Baek, J.-W.; Chung, K.-Y. Multimedia recommendation using Word2Vec-based social relationship mining. Multimed. Tools Appl. 2020, 1–17. [Google Scholar] [CrossRef]
- Aysha, K.; Ali, R. Recommender System Based on OSN Data Analytics. In Information and Communication Technology for Intelligent Systems, Proceedings of ICTIS 2018, Padang, Indonesia, 25–26 July 2018; Springer: Singapore, 2018; Volume 2, p. 2. [Google Scholar]
- Moscato, V.; Picariello, A.; Sperli, G. An Emotional Recommender System for music. IEEE Intell. Syst. 2020, 1. [Google Scholar] [CrossRef]
- Yang, X.; Dong, M.; Chen, X.; Ota, K. Recommender System-Based Diffusion Inferring for Open Social Networks. IEEE Trans. Comput. Soc. Syst. 2020, 7, 24–34. [Google Scholar] [CrossRef]
- Sperlì, G.; Amato, F.; Mercorio, F.; Mezzanzanica, M. A Social Media Recommender System. Int. J. Multimed. Data Eng. Manag. 2018, 9, 36–50. [Google Scholar] [CrossRef]
- Ma, X.; Jianfeng, M.; Li, H.; Jiang, Q.; Gao, S. ARMOR: A trust-based privacy-preserving framework for decentralized friend recommendation in online social networks. Future Gener. Comput. Syst. 2017, 79, 82–94. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Successful Recommendation | Not a Successful Recommendation | |
|---|---|---|
| Recommended | a | b |
| Not Recommended | c | d |
| Area | Application | Reference |
|---|---|---|
| e-commerce | Items recommendations to buyers | [4,5] |
| Movie or video recommendations | [43] | |
| Transportation | Path Recommendation for transporting goodOr passengers | [8,49,39] |
| Recommendations to Tourists | [50,51,52] | |
| Venue recommendation | [53,54,55] | |
| e-health | Medical advice or treatment plan recommendation | [6,46,63,64] |
| Recommending Personalized services to patients | [44] | |
| Appointments recommendation to clinicians | [45] | |
| Health recommendations in mobile systems | [59] | |
| Healthy behavioral recommendations | [61] | |
| Diet recommendation | [62] | |
| Agriculture | Fertilizer recommendation to farmers | [7] |
| Crops issue recommendation | [47] | |
| Assisting farmers inquiries | [48] | |
| Agricultural products recommendation | [65] | |
| Crop cultivation suggestion | [40,66,67,68] | |
| Media | Event recommendations | [80] |
| Museum recommendations | [81,82] | |
| Multimedia recommendations | [83,84,85] | |
| Open Social Networks recommendations | [86,87,88,89,90] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fayyaz, Z.; Ebrahimian, M.; Nawara, D.; Ibrahim, A.; Kashef, R. Recommendation Systems: Algorithms, Challenges, Metrics, and Business Opportunities. Appl. Sci. 2020, 10, 7748. https://doi.org/10.3390/app10217748
Fayyaz Z, Ebrahimian M, Nawara D, Ibrahim A, Kashef R. Recommendation Systems: Algorithms, Challenges, Metrics, and Business Opportunities. Applied Sciences. 2020; 10(21):7748. https://doi.org/10.3390/app10217748
Chicago/Turabian StyleFayyaz, Zeshan, Mahsa Ebrahimian, Dina Nawara, Ahmed Ibrahim, and Rasha Kashef. 2020. "Recommendation Systems: Algorithms, Challenges, Metrics, and Business Opportunities" Applied Sciences 10, no. 21: 7748. https://doi.org/10.3390/app10217748