Analysis of Fluid Velocity inside an Agricultural Sprayer Using Generalized Linear Mixed Models

 , ,
, ,
Abstract
:1. Introduction
1.1. Theoretical Sequencing of the Model
1.2. Objective
2. Material and Methods
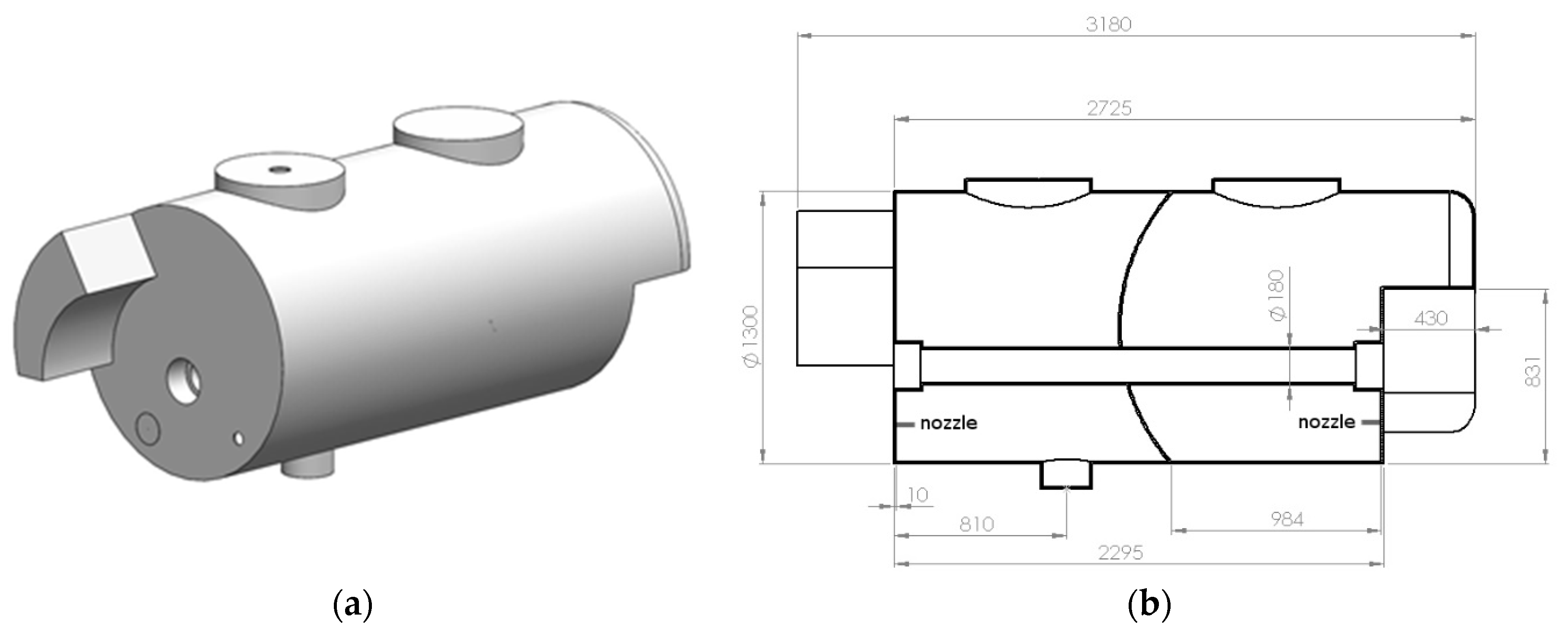
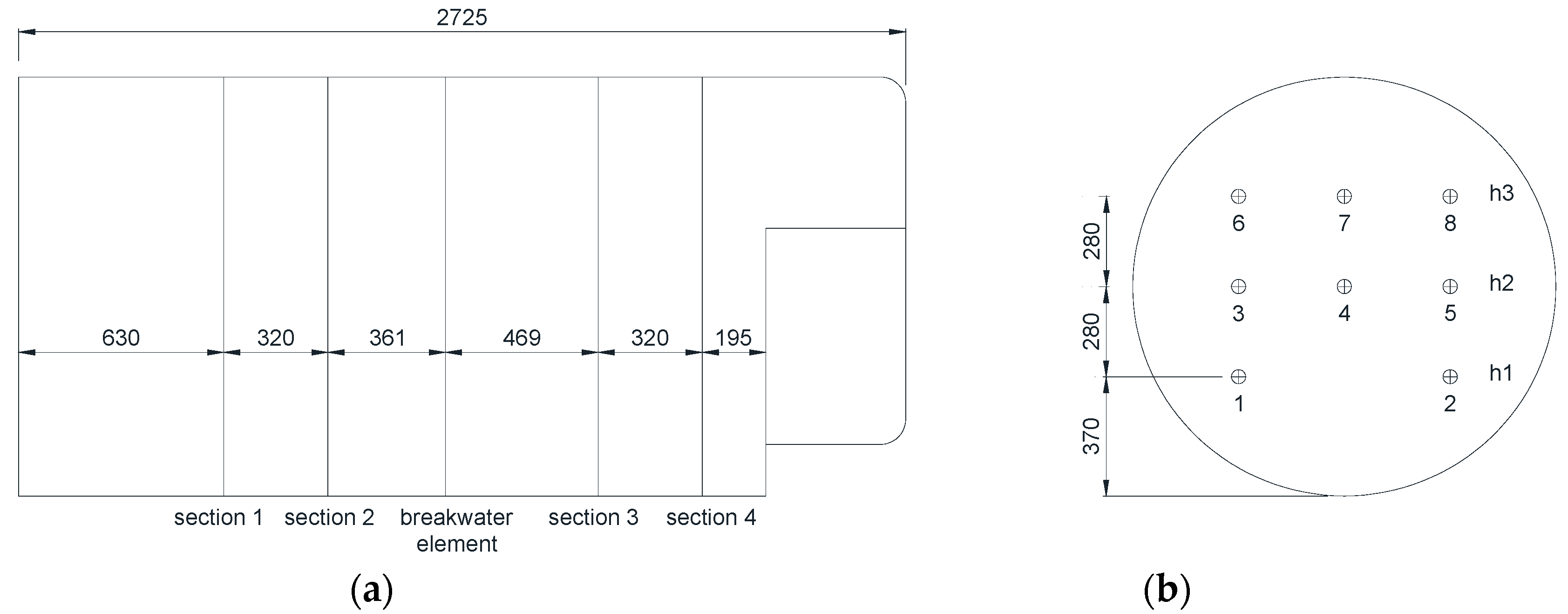
2.1. Source of the Data
2.2. Software Used
2.3. Useful Sequencing of the Best Model
3. Results and Discussion
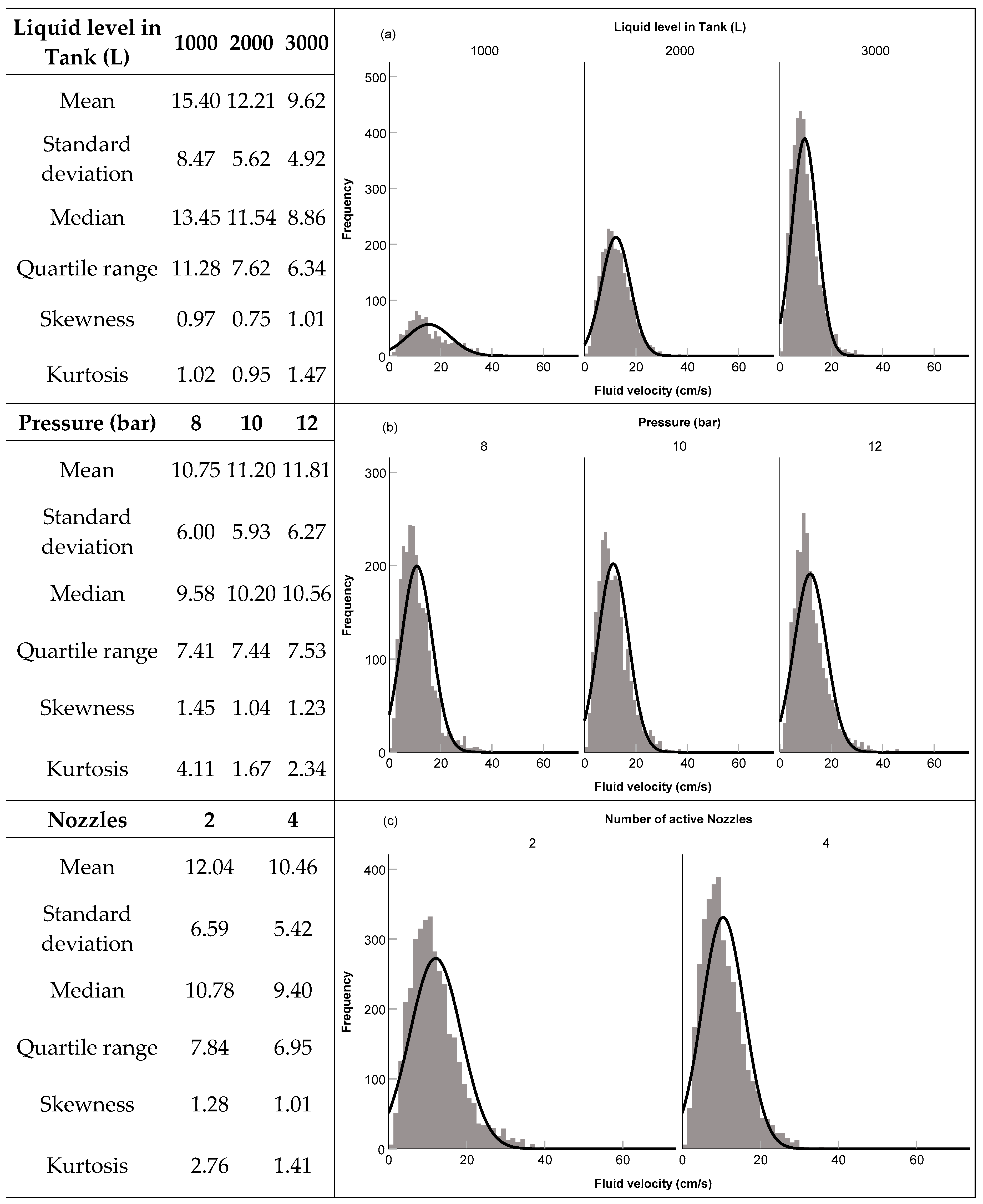
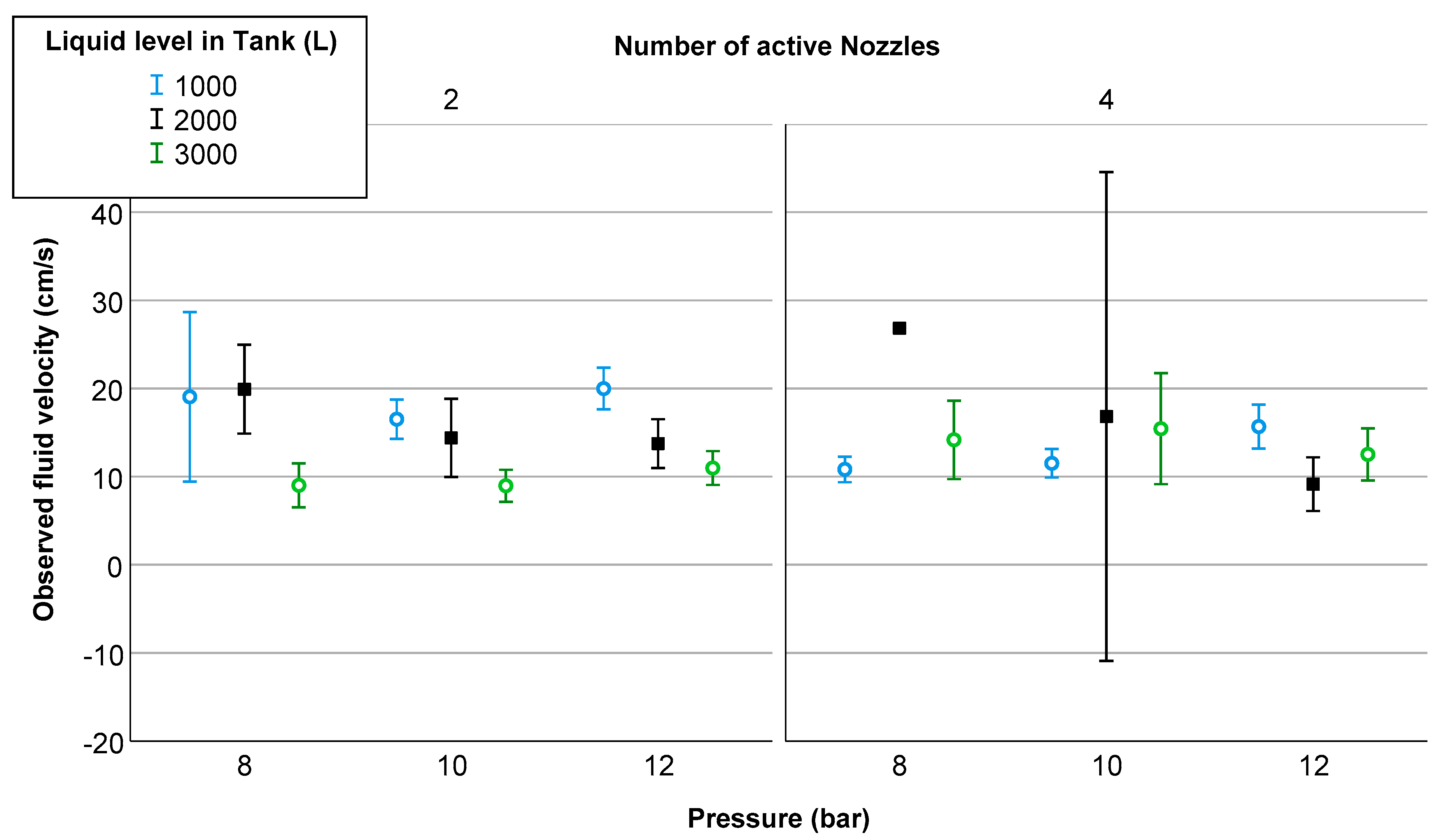
3.1. Distribution Analysis of the Targeted Variable: Fluid Velocity
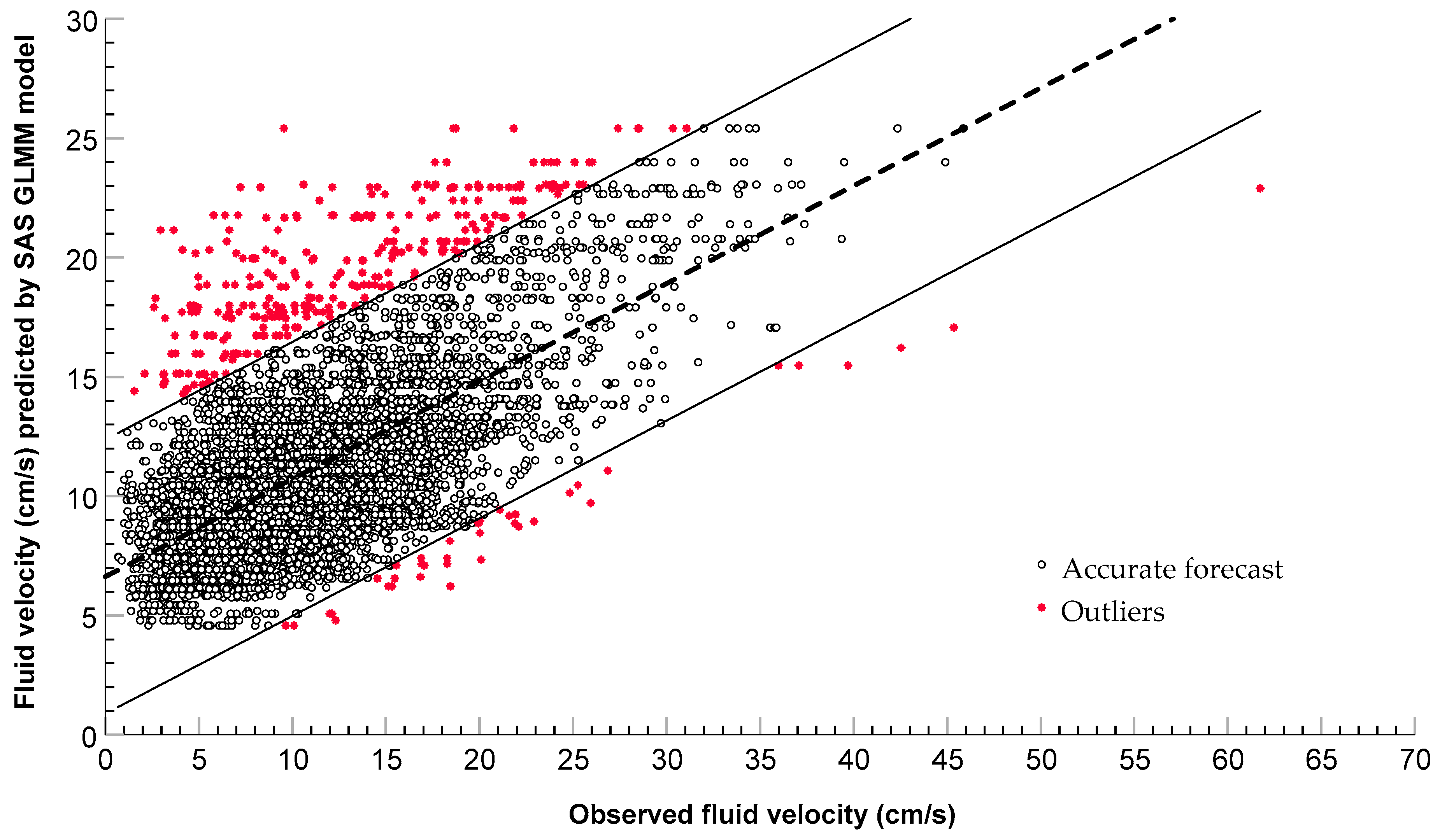
3.2. Model Comparison
3.3. Best Model Description
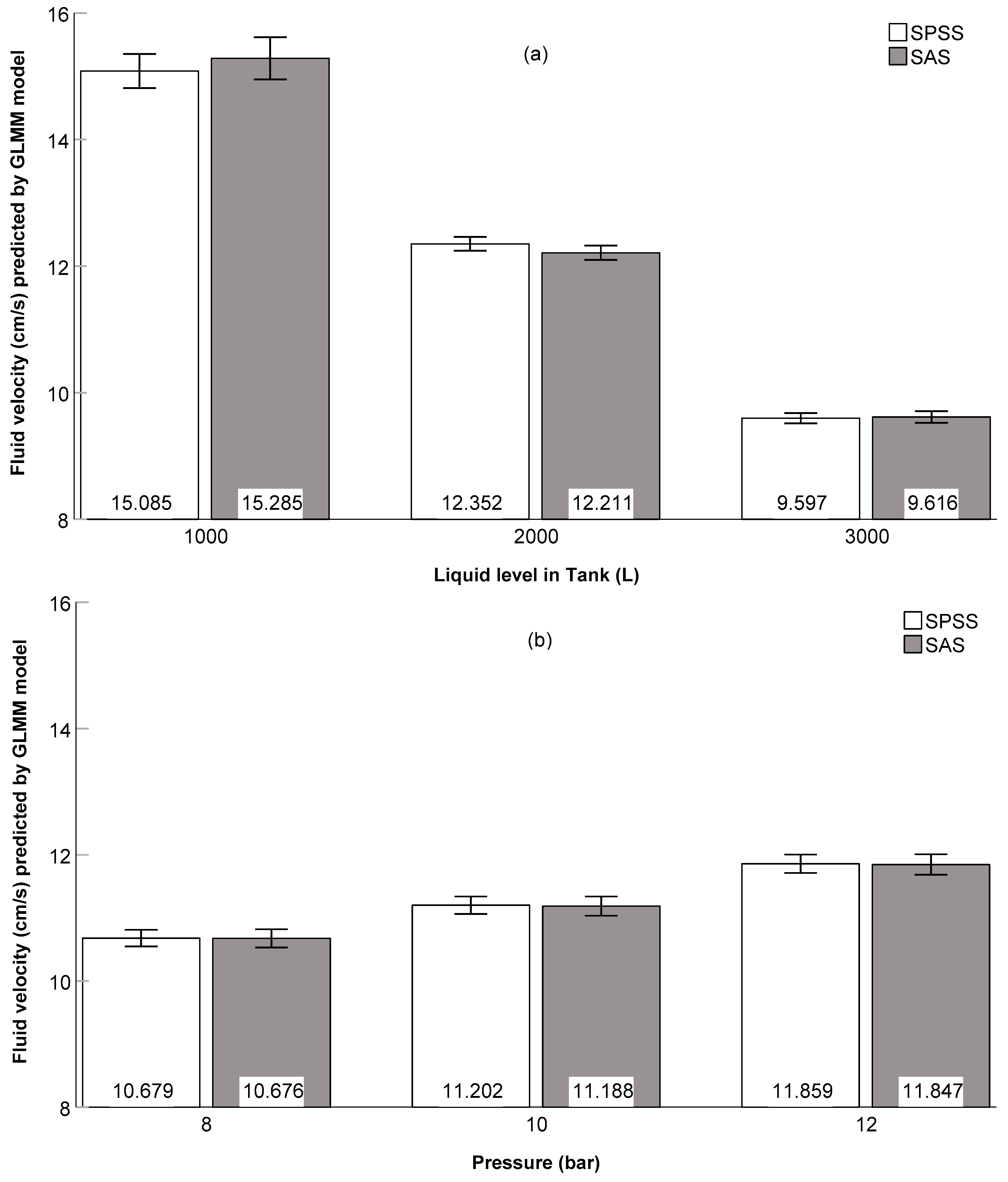
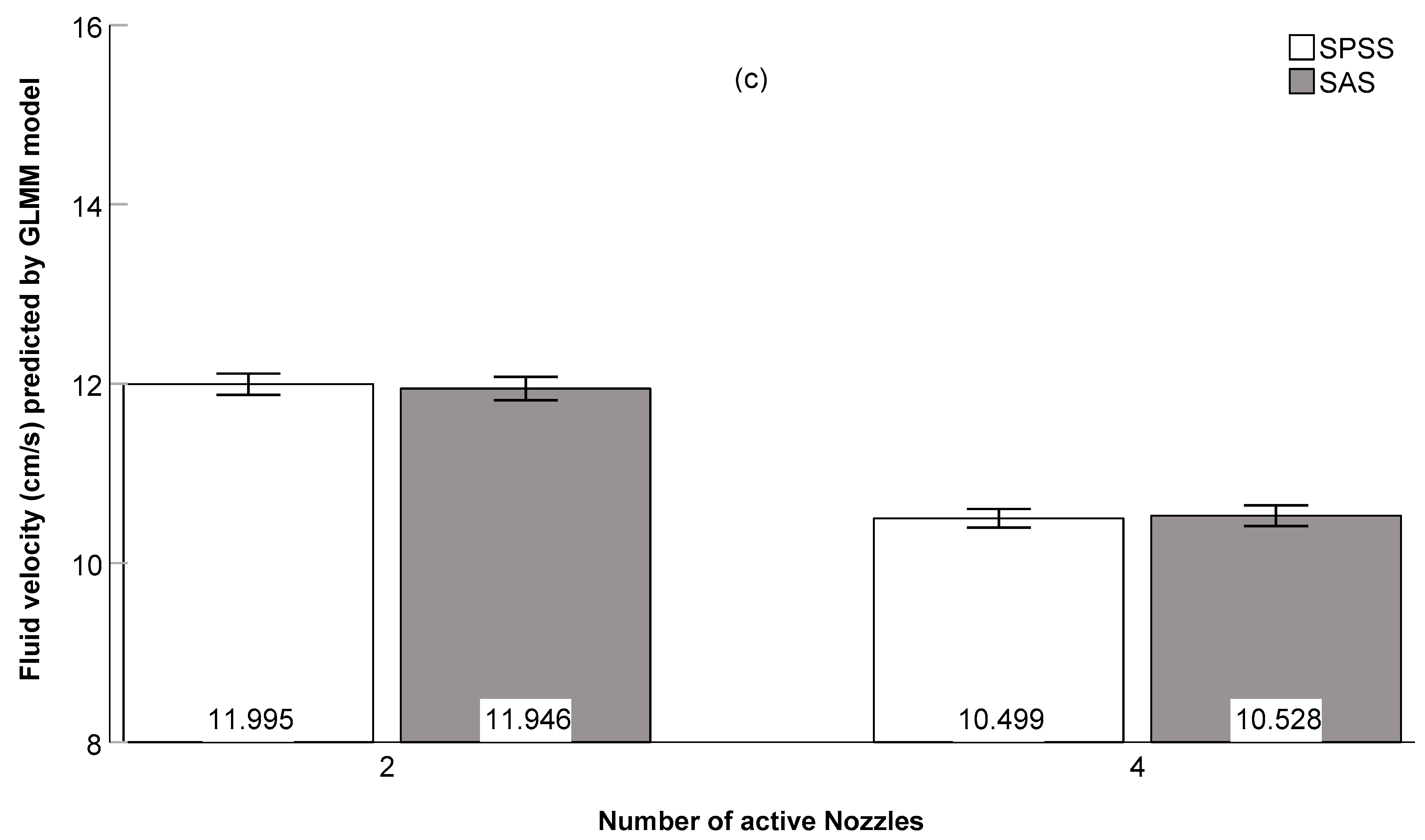
3.4. Comparison of IBM SPSS and SAS Model Results
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. SPSS Scripts to Compute the Best Model
Appendix A.2. SAS Scripts to Compute the Best Model
Appendix B

References
- Armenante, P.M.; Luo, C.; Chou, C.-C.; Fort, I.; Medek, J. Velocity profiles in a closed, unbaffled vessel: Comparison between experimental LDV data and numerical CFD predictions. Chem. Eng. Sci. 1997, 52, 3483–3492. [Google Scholar] [CrossRef]
- Xiongkui, H.; Kleisinger, S.; Luoluo, W.; Bingli, L. Influences of dynamic factors and filling level of spray in the tank on the efficacy of hydraulic agitation of the sprayer. Trans. CSAE 1999, 15, 131–134. [Google Scholar]
- Tamagnone, M.; Balsari, P.; Bozzer, C.; Marucco, P. Assessment of parameters needed to design agitation systems for sprayer tanks. Asp. Appl. Biol. 2011, 114, 167–174. [Google Scholar]
- García-Ramos, F.J.; Badules, J.; Boné, A.; Gil, E.; Aguirre, A.J.; Vidal, M. Application of an Acoustic Doppler Velocimeter to Analyse the Performance of the Hydraulic Agitation System of an Agricultural Sprayer. Sensors 2018, 18, 3715. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, N.; Liao, B.; Pan, J.; Li, Q.; Gao, C. Improvement of the flow rate distribution in quench tank by measurement and computer simulation. Mater. Lett. 2006, 60, 1659–1664. [Google Scholar] [CrossRef]
- Badules, J.; Vidal, M.; Boné, A.; Gil, E.; García-Ramos, F.J. CFD Models as a Tool to Analyze the Performance of the Hydraulic Agitation System of an Air-Assisted Sprayer. Agronomy 2019, 9, 769. [Google Scholar] [CrossRef] [Green Version]
- McCulloch, C.E.; Searle, S.R. Generalized, Linear, and Mixed Models; John Wiley & Sons, Inc.: New York, NY, USA, 2001; p. 358. [Google Scholar]
- McCullagh, P.; Nelder, J.A. Generalized Linear Models, 2nd ed.; Chapman & Hall/CRC: New York, NY, USA, 1989; p. 532. [Google Scholar]
- Fitzmaurice, G.M.; Laird, N.M.; Ware, J.H. Applied Longitudinal Analysis, 2nd ed.; John Wiley and Sons: Boston, MA, USA, 2011; p. 752. [Google Scholar]
- Harville, D.A. Maximum Likelihood Approaches to Variance Component Estimation and to Related Problems. J. Am. Stat. Assoc. 1977, 72, 320–338. [Google Scholar] [CrossRef]
- Laird, N.M.; Ware, J.H. Random-Effects Models for Longitudinal Data. Biometrics 1982, 38, 963–974. [Google Scholar] [CrossRef]
- McCulloch, C.E.; Neuhaus, J.M. Generalized Linear Mixed Models. In Encyclopedia of Biostatistics; Armitage, P., Colton, T., Eds.; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2005; pp. 1–5. [Google Scholar] [CrossRef] [Green Version]
- Gad, A.M.; El Kholy, R.B. Generalized Linear Mixed Models for Longitudinal Data. Int. J. Probab. Stat. 2012, 1, 41–47. [Google Scholar] [CrossRef] [Green Version]
- Verbeke, G.; Molenberghs, G. The gradient function as an exploratory goodness-of-fit assessment of the random-effects distribution in mixed models. Biostatistics 2013, 14, 477–490. [Google Scholar] [CrossRef] [Green Version]
- Gbur, E.E.; Stroup, W.W.; McCarter, K.S.; Durham, S.; Young, L.J.; Christman, M.; West, M.; Kramer, M. Analysis of Generalized Linear Mixed Models in the Agricultural and Natural Resources Sciences; American Society of Agronomy; Crop Science Society of America; Soil Science Society of America: Madison, WI, USA, 2012; p. 277. [Google Scholar] [CrossRef]
- Bolker, B.M.; Brooks, M.E.; Clark, C.J.; Geange, S.W.; Poulsen, J.R.; Stevens, M.H.H.; White, J.-S.S. Generalized linear mixed models: A practical guide for ecology and evolution. Trends Ecol. Evol. 2009, 24, 127–135. [Google Scholar] [CrossRef] [PubMed]
- Schall, R. Estimation in Generalized Linear Models with Random Effects. Biometrika 1991, 78, 719–727. [Google Scholar] [CrossRef]
- Wolfinger, R.D.; O’Connell, M. Generalized linear mixed models a pseudo-likelihood approach. J. Stat. Comput. Simul. 1993, 48, 233–243. [Google Scholar] [CrossRef]
- Breslow, N.E.; Clayton, D.G. Approximate Inference in Generalized Linear Mixed Models. J. Am. Stat. Assoc. 1993, 88, 9–25. [Google Scholar] [CrossRef]
- Goldstein, H. Nonlinear multilevel models, with an application to discrete response data. Biometrika 1991, 78, 45–51. [Google Scholar] [CrossRef]
- Raudenbush, S.W.; Yang, M.-L.; Yosef, M. Maximum likelihood for generalized linear models with nested random effects via high-order, multivariate Laplace approximation. J. Comput. Graph. Stat. 2000, 9, 141–157. [Google Scholar] [CrossRef]
- Pinheiro, J.C.; Chao, E.C. Efficient Laplacian and adaptive Gaussian quadrature algorithms for multilevel generalized linear mixed models. J. Comput. Graph. Stat. 2006, 15, 58–81. [Google Scholar] [CrossRef]
- Gilks, W.R.; Richardson, S.; Spiegelhalter, D.J. Introducing Markov chain Monte Carlo. In Markov chain Monte Carlo in practice; Gilks, W.R., Richardson, S., Spiegelhalter, D.J., Eds.; Chapman and Hall/CRC: Boca Raton, FL, USA, 1996; pp. 1–19. [Google Scholar]
- Pinheiro, J.C.; Bates, D.M. Approximations to the Log-Likelihood Function in the Nonlinear Mixed-Effects Model. J. Comput. Graph. Stat. 1995, 4, 12–35. [Google Scholar] [CrossRef]
- Littell, R.C.; Milliken, G.A.; Stroup, W.W.; Wolfinger, R.D.; Schabenberger, O. SAS® for Mixed Models, 2nd ed.; SAS Institute Inc.: Cary, NC, USA, 2006; p. 834. [Google Scholar]
- Schaalje, G.B.; McBride, J.B.; Fellingham, G.W. Approximations to distributions of test statistics in complex mixed linear models using SAS proc mixed. In Proceedings of the twenty-sixth annual SAS ® Users Group International Conference; SAS Institute Inc.: Long Beach, CA, USA, 2001; Volume 26, p. 6. [Google Scholar]
- Wolfinger, R.D. Covariance structure selection in general mixed models. Commun. Stat. Simul. Comput. 1993, 22, 1079–1106. [Google Scholar] [CrossRef]
- Wolfinger, R.D. Heterogeneous variance: Covariance structures for repeated measures. J. Agric. Biol. Environ. Stat. 1996, 1, 205–230. [Google Scholar] [CrossRef]
- Moore, K.J.; Dixon, P.M. Analysis of Combined Experiments Revisited. Agron. J. 2015, 107, 763–771. [Google Scholar] [CrossRef]
- Kincaid, C. Guidelines for Selecting the Covariance Structure in Mixed Model Analysis. In Proceedings of the Thirtieth Annual SAS® Users Group International Conference; SAS Institute Inc.: Cary, NC, USA, 2005; Volume 30, p. 8. [Google Scholar]
- Montgomery, D.C.; Runger, G.C. Applied Statistics and Probability for Engineers, 3rd ed.; John Wiley & Sons, Inc.: New York, NY, USA, 2003; p. 976. [Google Scholar]
- Krishnaiah, P.R. Handbook of Statistics 1: Analysis of Variance; North-Holland Publishing Company: Amsterdam, The Netherlands, 1980; p. 991. [Google Scholar]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Burnham, K.P.; Anderson, D.R. Practical Use of the Information-Theoretic Approach. In Model Selection and Inference; Burnham, K.P., Anderson, D.R., Eds.; Springer: New York, NY, USA, 1998; pp. 75–117. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the Dimension of a Model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Bozdogan, H. Model selection and Akaike’s information criterion (AIC): The general theory and its analytical extensions. Psychometrika 1987, 52, 345–370. [Google Scholar] [CrossRef]
- Litière, S.; Alonso, A.; Molenberghs, G. The impact of a misspecified random-effects distribution on the estimation and the performance of inferential procedures in generalized linear mixed models. Stat. Med. 2008, 27, 3125–3144. [Google Scholar] [CrossRef]
- Ucar, T.; Fox, R.D.; Ozkan, H.E.; Brazee, R.D. Simulation of jet agitation in sprayer tanks: Comparison of predicted and measured water velocities. Trans. ASAE 2001, 44, 223–230. [Google Scholar] [CrossRef]
- Abad, A.A.; Litière, S.; Molenberghs, G. Testing for misspecification in generalized linear mixed models. Biostatistics 2010, 11, 771–786. [Google Scholar] [CrossRef] [Green Version]
- Tsonaka, R.; Rizopoulos, D.; Verbeke, G.; Lesaffre, E. Nonignorable models for intermittently missing categorical longitudinal responses. Biometrics 2010, 66, 834–844. [Google Scholar] [CrossRef]
- Xiang, L.; Yau, K.K.W.; Lee, A.H. The robust estimation method for a finite mixture of Poisson mixed-effect models. Comput. Stat. Data Anal. 2012, 56, 1994–2005. [Google Scholar] [CrossRef]
- Huang, X. Diagnosis of Random-Effect Model Misspecification in Generalized Linear Mixed Models for Binary Response. Biometrics 2009, 65, 361–368. [Google Scholar] [CrossRef]
- Komárek, A.; Lesaffre, E. Generalized linear mixed model with a penalized Gaussian mixture as a random effects distribution. Comput. Stat. Data Anal. 2008, 52, 3441–3458. [Google Scholar] [CrossRef]
- Goldstein, H. Multilevel mixed linear model analysis using iterative generalized least squares. Biometrika 1986, 73, 43–56. [Google Scholar] [CrossRef]
- Keselman, H.J.; Algina, J.; Kowalchuk, R.K.; Wolfinger, R.D. A comparison of two approaches for selecting covariance structures in the analysis of repeated measurements. Commun. Stat.-Simul. Comput. 1998, 27, 591–604. [Google Scholar] [CrossRef]
- Kenward, M.G.; Roger, J.H. An improved approximation to the precision of fixed effects from restricted maximum likelihood. Comput. Stat. Data Anal. 2009, 53, 2583–2595. [Google Scholar] [CrossRef]
- Satterthwaite, F.E. An Approximate Distribution of Estimates of Variance Components. Biom. Bull. 1946, 2, 110–114. [Google Scholar] [CrossRef]
- Schaalje, G.B.; McBride, J.B.; Fellingham, G.W. Adequacy of Approximations to Distributions of Test Statistics in Complex Mixed Linear Models. J. Agric. Biol. Environ. Stat. 2002, 7, 512–524. [Google Scholar] [CrossRef]
- Schluchter, M.D.; Elashoff, J.T. Small-sample adjustments to tests with unbalanced repeated measures assuming several covariance structures. J. Stat. Comput. Simul. 1990, 37, 69–87. [Google Scholar] [CrossRef]
- Kramer, C.Y. Extension of multiple range tests to group means with unequal numbers of replications. Biometrics 1956, 12, 307–310. [Google Scholar] [CrossRef]
- White, H. A Heteroskedasticity-Consistent covariance matrix estimator and a direct test for heteroskedasticity. Econometrica 1980, 48, 817–838. [Google Scholar] [CrossRef]
- Long, J.S.; Ervin, L.H. Using heteroscedasticity consistent standard errors in the linear regression model. Am. Stat. 2000, 54, 217–224. [Google Scholar] [CrossRef]
- MacKinnon, J.G.; White, H. Some heteroskedasticity-consistent covariance matrix estimators with improved finite sample properties. J. Econom. 1985, 29, 305–325. [Google Scholar] [CrossRef] [Green Version]
- Mancl, L.A.; DeRouen, T.A. A covariance estimator for GEE with improved small-sample properties. Biometrics 2001, 57, 126–134. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Meaning |
|---|---|
| yij | Observation of the jth individual (j = 1; 2; …; ni) within the ith set (i = 1; 2; …; p) |
| Ŝ2r | Estimated residual variance |
| I | Identity covariance matrix structure |
| AR(1) | First-order autoregressive covariance matrix structure |
| ARH(1) | Heterogeneous first-order autoregressive covariance matrix structure |
| ARMA(1,1) | First-order autoregressive moving-average covariance matrix structure |
| CS | Compound-symmetry covariance matrix structure |
| CSH | Heterogeneous compound-symmetry covariance matrix structure |
| D | Diagonal covariance matrix structure |
| Toep | Toeplitz covariance matrix structure |
| UN | Unstructured covariance matrix structure |
| and | Estimated linear regression intercept and slope (computed from ) |
| Error in prediction of linear regression |
| N | Model | AICc | BIC |
|---|---|---|---|
| 1 | FV = f(none variable) | 46,439.09 | 46,445.98 |
| 2 | FV = f(FE(LT)) | 45,613.44 | 45,620.32 |
| 3 | FV = f(FE(NN)) | 46,318.66 | 46,325.54 |
| 4 | FV = f(FE(P)) | 46,406.36 | 46,413.24 |
| 5 | FV = f(FE(LT, NN)) | 45,478.07 | 45,484.95 |
| 6 | FV = f(FE(LT, P)) | 45,576.50 | 45,583.38 |
| 7 | FV = f(FE(NN, P)) | 46,285.34 | 46,292.22 |
| 8 | FV = f(FE(LT, NN, P)) | 45,440.38 | 45,447.26 |
| 9 | FV = f(FE(LT, NN, P, SC)) | 44,656.55 | 44,663.43 |
| 10 | FV = f(FE(LT, NN, P, SC) + RE(H, S)) | 44,314.36 | 44,328.12 |
| 11 | FV = f(FE(LT, NN, P) + RE(SC)) | 43,681.51 | 43,695.27 |
| 12 | FV = f(FE(LT, NN, P) + RE(SC, H)) | 43,684.51 | 43,698.27 |
| 13 | FV = f(FE(LT, NN, P) + RE(SC, H, S)) | 43,687.52 | 43,701.28 |
| 14 | FV = f(FE(LT, NN, P) + RE(H, S)) | 45,137.79 | 45,151.55 |
| Model | Δi = AICi − AICmin | wi = exp(−0.5·Δi)/Σ(exp(−0.5·Δi)) |
|---|---|---|
| 1 | 2757.59 | 0.00 × 100 |
| 2 | 1931.94 | 0.00 × 100 |
| 3 | 2637.15 | 0.00 × 100 |
| 4 | 2724.86 | 0.00 × 100 |
| 5 | 1796.56 | 0.00 × 100 |
| 6 | 1895.00 | 0.00 × 100 |
| 7 | 2603.83 | 0.00 × 100 |
| 8 | 1758.88 | 0.00 × 100 |
| 9 | 975.04 | 1.47 × 10−212 |
| 10 | 632.85 | 2.97 × 10−138 |
| 11 | 0.00 | 7.86 × 10−1 |
| 12 | 3.00 | 1.75 × 10−1 |
| 13 | 6.02 | 3.88 × 10−2 |
| 14 | 1456.29 | 0.00 × 100 |
| Model | Ŝ2r | Standard Error | z | Lower Limit | Upper Limit |
|---|---|---|---|---|---|
| 1 | 37.02 | 0.62 | 59.996 | 35.83 | 38.24 |
| 2 | 33.00 | 0.55 | 59.987 | 31.94 | 34.09 |
| 3 | 36.39 | 0.61 | 59.992 | 35.23 | 37.61 |
| 4 | 36.84 | 0.61 | 59.987 | 35.66 | 38.06 |
| 5 | 32.38 | 0.54 | 59.983 | 31.34 | 33.45 |
| 6 | 32.82 | 0.55 | 59.979 | 31.77 | 33.91 |
| 7 | 36.22 | 0.60 | 59.983 | 35.06 | 37.42 |
| 8 | 32.20 | 0.54 | 59.975 | 31.17 | 33.27 |
| 9 | 28.87 | 0.49 | 59.962 | 27.94 | 29.83 |
| 10 | 27.40 | 0.46 | 59.933 | 26.52 | 28.31 |
| 11, 12, 13 | 24.76 | 0.41 | 59.845 | 23.96 | 25.58 |
| 14 | 30.74 | 0.51 | 59.945 | 29.75 | 31.76 |
| Structure | AICc | wi (AICc) | BIC | wi (BIC) | SC | p |
|---|---|---|---|---|---|---|
| I | 8371.42 | 0.084 | 8385.18 | 0.353 | 0.056 | <0.001 |
| AR(1) | 8371.59 | 0.077 | 8392.23 | 0.010 | 0.057 | <0.001 |
| ARH(1) | 8373.66 | 0.027 | 8414.94 | 0.000 | 0.214 0.355 0.209 0.159 | <0.001 <0.001 <0.001 0.001 |
| ARMA(1,1) | 8368.55 | 0.353 | 8396.07 | 0.001 | 0.057 | <0.001 |
| CS | 8373.33 | 0.032 | 8393.97 | 0.004 | 0.051 | 0.001 |
| CSH | 8376.04 | 0.008 | 8417.31 | 0.000 | 0.051 0.138 0.037 0.024 | <0.001 “ “ “ |
| D | 8374.09 | 0.022 | 8408.48 | 0.000 | 0.050 0.129 0.037 0.023 | 0.061 0.065 0.059 0.087 |
| Toep | 8368.94 | 0.291 | 8403.34 | 0.000 | 0.060 | 0.001 |
| UN | 8374.29 | 0.020 | 8449.95 | 0.000 | 0.046 0.071 0.064 0.054 | 0.073 0.154 0.187 0.256 |
| Structure | R2ad | Intercept “ ” | Slope “ ” | SEE | Ŝ2pr | |
|---|---|---|---|---|---|---|
| I | 0.34044 | 7.459 | 0.336 | 2.8493 | 0.99753 | −6.68 × 10−10 |
| AR(1) | 0.34045 | 7.459 | 0.336 | 2.8494 | 0.99753 | −6.10 × 10−10 |
| ARH(1) | 0.34038 | 7.452 | 0.337 | 2.8558 | 0.99755 | −2.34 × 10−11 |
| ARMA(1,1) | 0.34057 | 7.458 | 0.337 | 2.8491 | 0.99755 | −1.00 × 10−11 |
| CS | 0.34042 | 7.459 | 0.336 | 2.8493 | 0.99753 | −9.31 × 10−10 |
| CSH | 0.34035 | 7.452 | 0.337 | 2.8554 | 0.99755 | −3.14 × 10−11 |
| D | 0.34038 | 7.453 | 0.337 | 2.8548 | 0.99755 | −2.39 × 10−11 |
| Toep | 0.34060 | 7.455 | 0.337 | 2.8513 | 0.99757 | −9.60 × 10−10 |
| UN | 0.34075 | 7.450 | 0.337 | 2.8549 | 0.99770 | −2.77 × 10−10 |
| Software | AICc | BIC | Ŝ2r | Chi-Square/df | Ŝ2pr |
|---|---|---|---|---|---|
| SPSS | 8368.94 | 8403.34 | 0.1828 | - | 0.995 |
| SAS | 7703.14 | 7758.17 | 0.1637 | 0.16 | 0.991 |
| Fixed-Effect Adjustments | Least Square Means of Fluid Velocity (cm/s) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Fixed Effects Levels | ||||||||||
| SPSS (df: Satterthwaite) | ||||||||||
| FE | F | p | 1000 L | 8 bars | 2 | 2000 L | 10 bars | 4 | 3000 L | 12 bars |
| LT | 38.64 | 0.0015 | 15.17c | 12.80b | 9.37a | |||||
| P | 27.94 | <0.0001 | 11.60a | 12.17a | 12.88b | |||||
| NN | 6.43 | 0.0501 | 13.05 | 11.42 | ||||||
| SAS (df: Between-Within) | ||||||||||
| LT | 17.01 | <0.0001 | 17.79c | 12.23b | 9.31a | |||||
| P | 9.99 | <0.0001 | 12.03a | 12.61a | 13.35b | |||||
| NN | 8.42 | 0.0052 | 13.48b | 11.88a | ||||||
| Software | R2ad | Intercept “ ” | Slope “ ” | Residual Skewness | Residual Kurtosis | Rho |
|---|---|---|---|---|---|---|
| SPSS | 0.341 | 7.455 | 0.337 | 0.544 | 0.410 | 0.515 |
| SAS | 0.419 | 6.629 | 0.409 | 0.465 | 0.343 | 0.584 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aguirre, Á.J.; Guevara-Viera, G.E.; Torres-Inga, C.S.; Guevara-Viera, R.V.; Boné, A.; Vidal, M.; García-Ramos, F.J. Analysis of Fluid Velocity inside an Agricultural Sprayer Using Generalized Linear Mixed Models. Appl. Sci. 2020, 10, 5029. https://doi.org/10.3390/app10155029
Aguirre ÁJ, Guevara-Viera GE, Torres-Inga CS, Guevara-Viera RV, Boné A, Vidal M, García-Ramos FJ. Analysis of Fluid Velocity inside an Agricultural Sprayer Using Generalized Linear Mixed Models. Applied Sciences. 2020; 10(15):5029. https://doi.org/10.3390/app10155029
Chicago/Turabian StyleAguirre, Ángel Javier, Guillermo E. Guevara-Viera, Carlos S. Torres-Inga, Raúl V. Guevara-Viera, Antonio Boné, Mariano Vidal, and Francisco Javier García-Ramos. 2020. "Analysis of Fluid Velocity inside an Agricultural Sprayer Using Generalized Linear Mixed Models" Applied Sciences 10, no. 15: 5029. https://doi.org/10.3390/app10155029