

DISubNet: Depthwise Separable Inception Subnetwork for Pig Treatment Classification Using Thermal Data
 ,
,  ,
,  ,
,  and
and
Abstract
:Simple Summary
Abstract
1. Introduction
- 1.
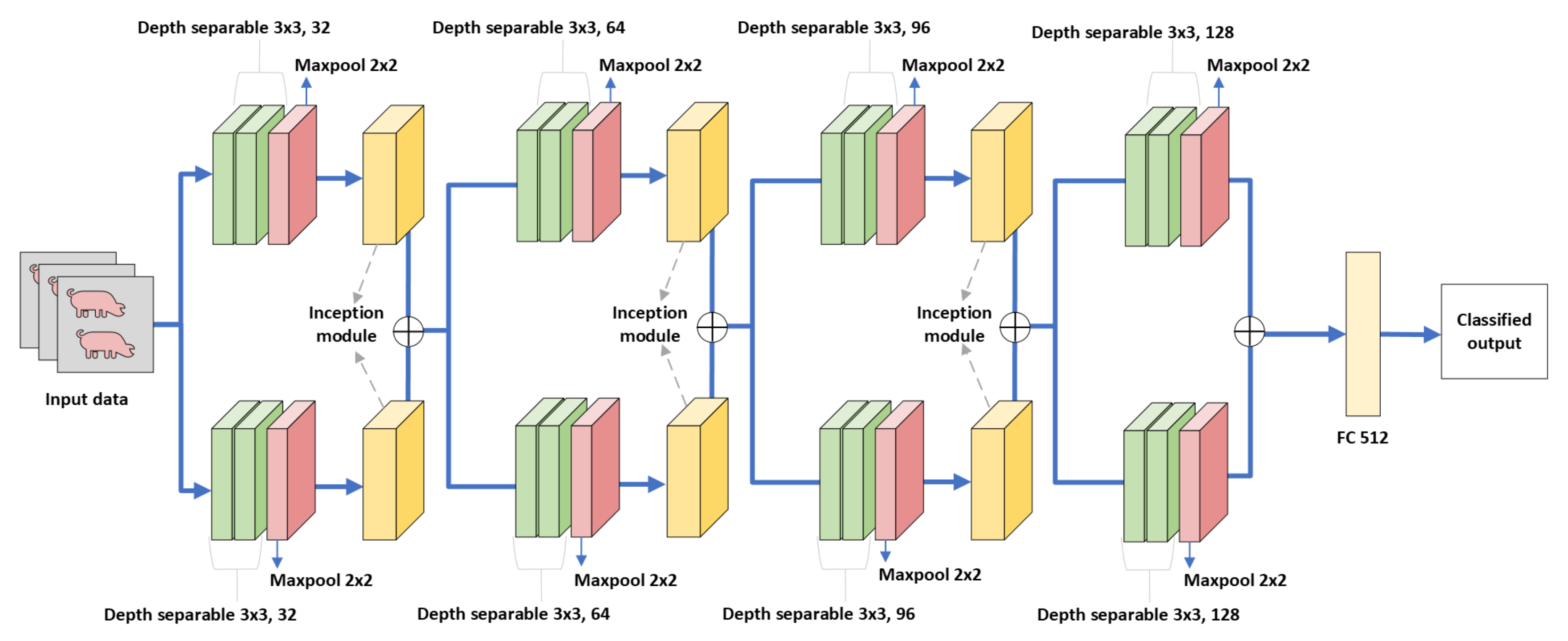
- We propose a depthwise separable inception subnetwork (DISubNet), a lightweight model for pig treatment classifications that consist of depthwise separable layers and an inception module.
- 2.
- We propose two versions of DISubNet: DISubNetV1 and DISubNetV2. The models are modified based on the concatenation of depthwise layers and inception modules.
- 3.
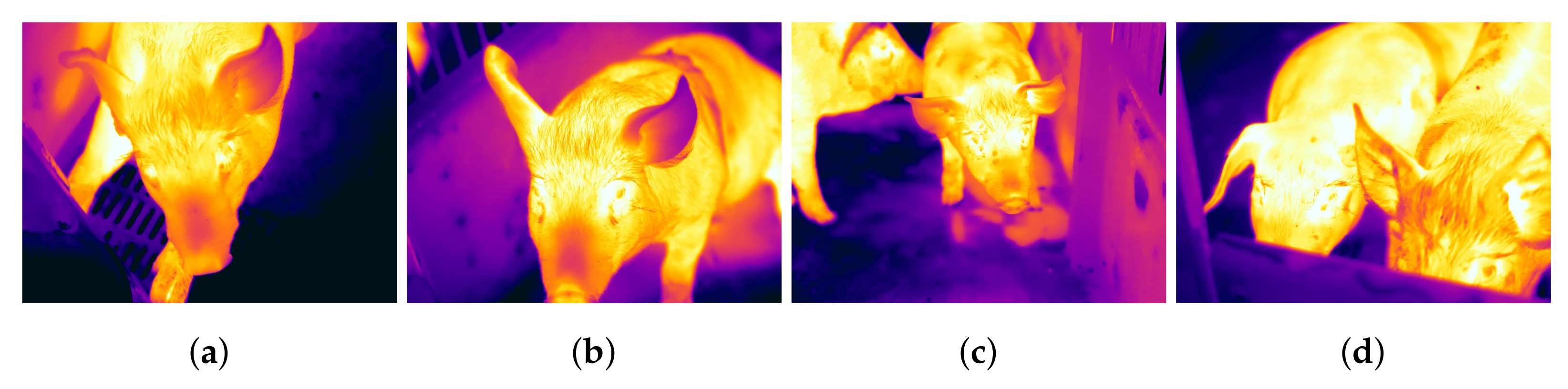
- Experiments are carried out on the pig image thermal dataset collected from the FLIR camera. The collected dataset consists of four pig treatment categories, such as isolation after feeding (IAF), isolation before feeding (IBF), paired after feeding (PAF), and paired before feeding (PBF).
- 4.
- Detailed experiments are conducted on both versions of DISubNet models with other image classification models using various evaluation metrics.
2. Related Work
2.1. Image Classification Methods
2.2. Model Design and Efficiency
3. Materials and Methods
3.1. Image Classifcation Models
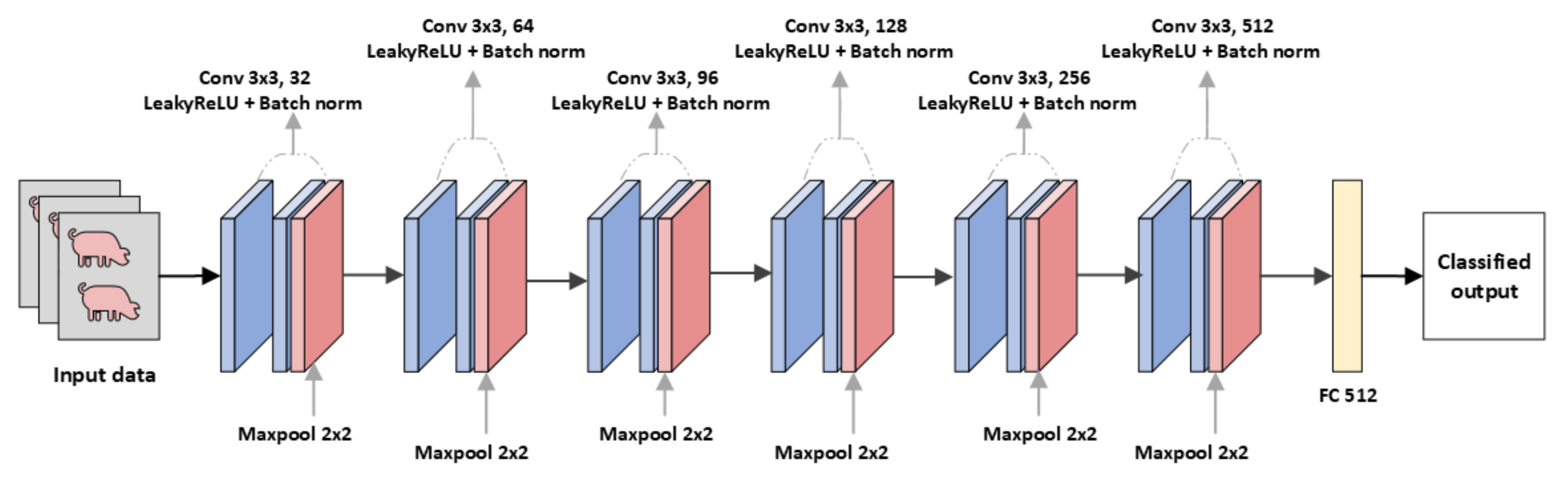
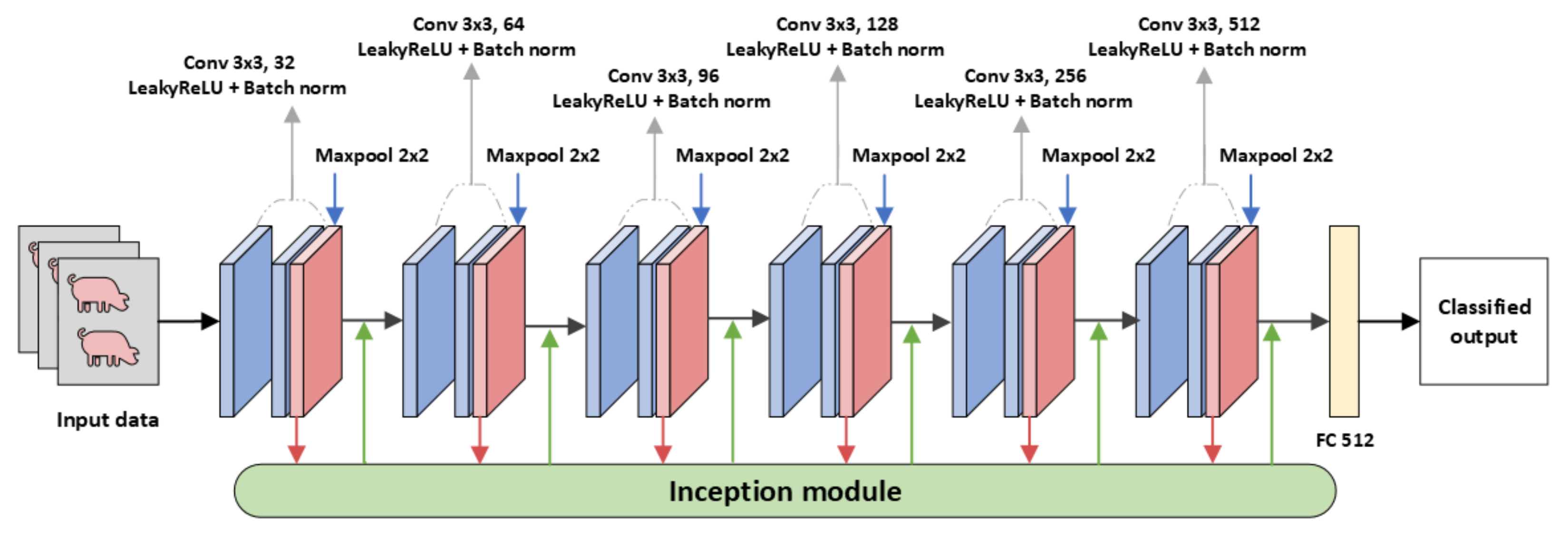
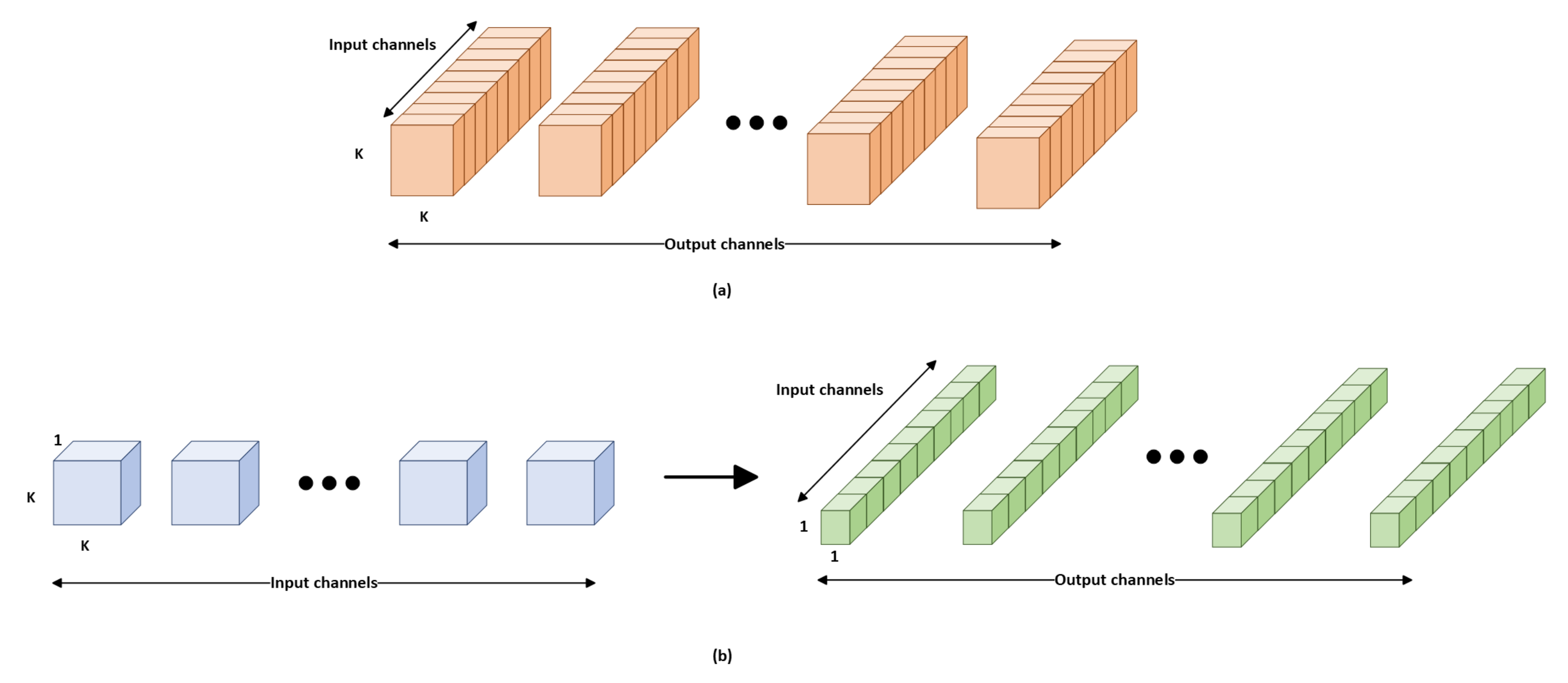
3.2. Modified CNN Models
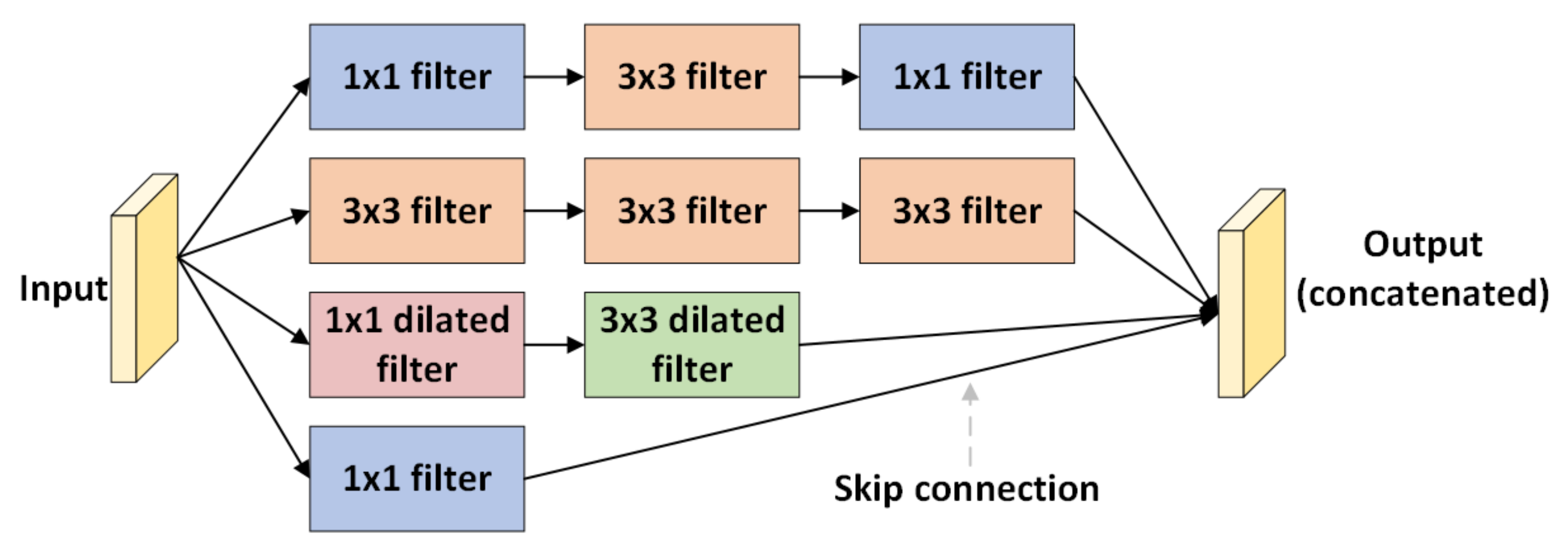
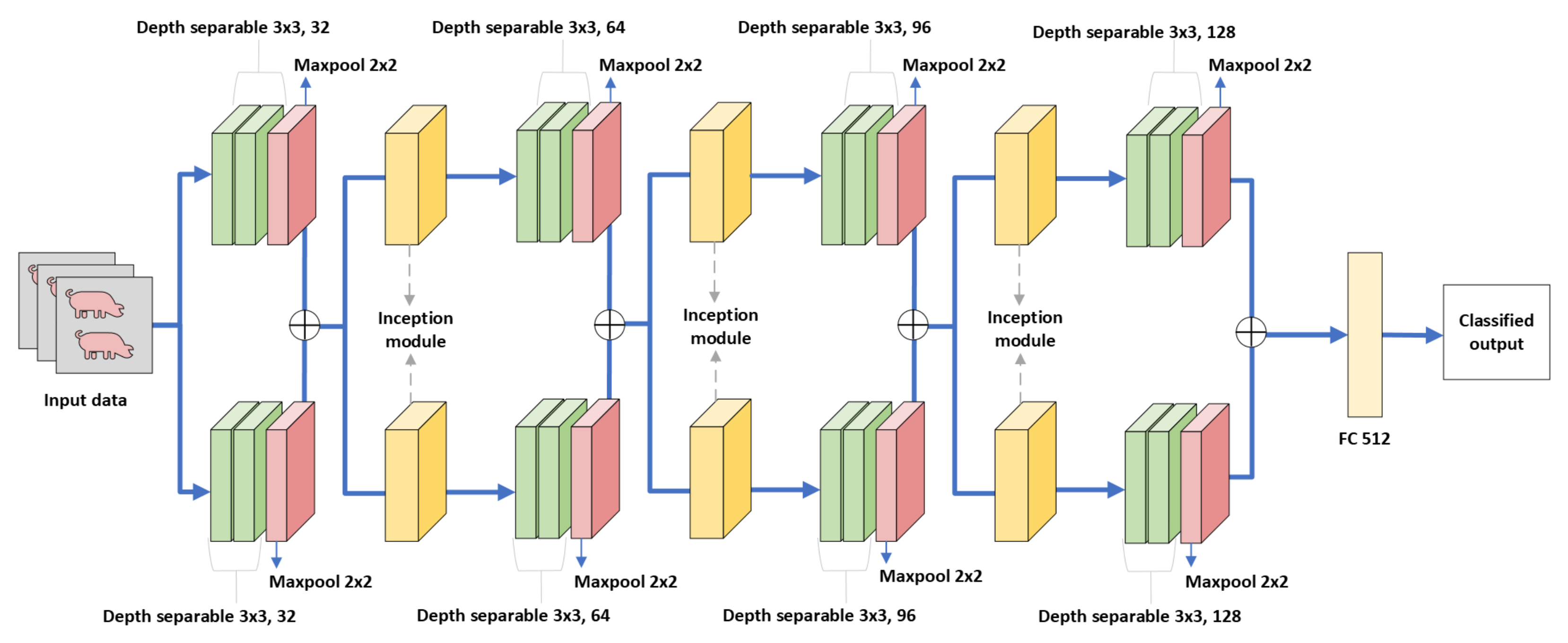
3.3. Proposed Model for Pig Treatment Classification
4. Experimental Setup
4.1. Dataset
4.2. Implementation Details
4.3. Loss Function
4.4. Activation Function
4.5. Evaluation Metrics
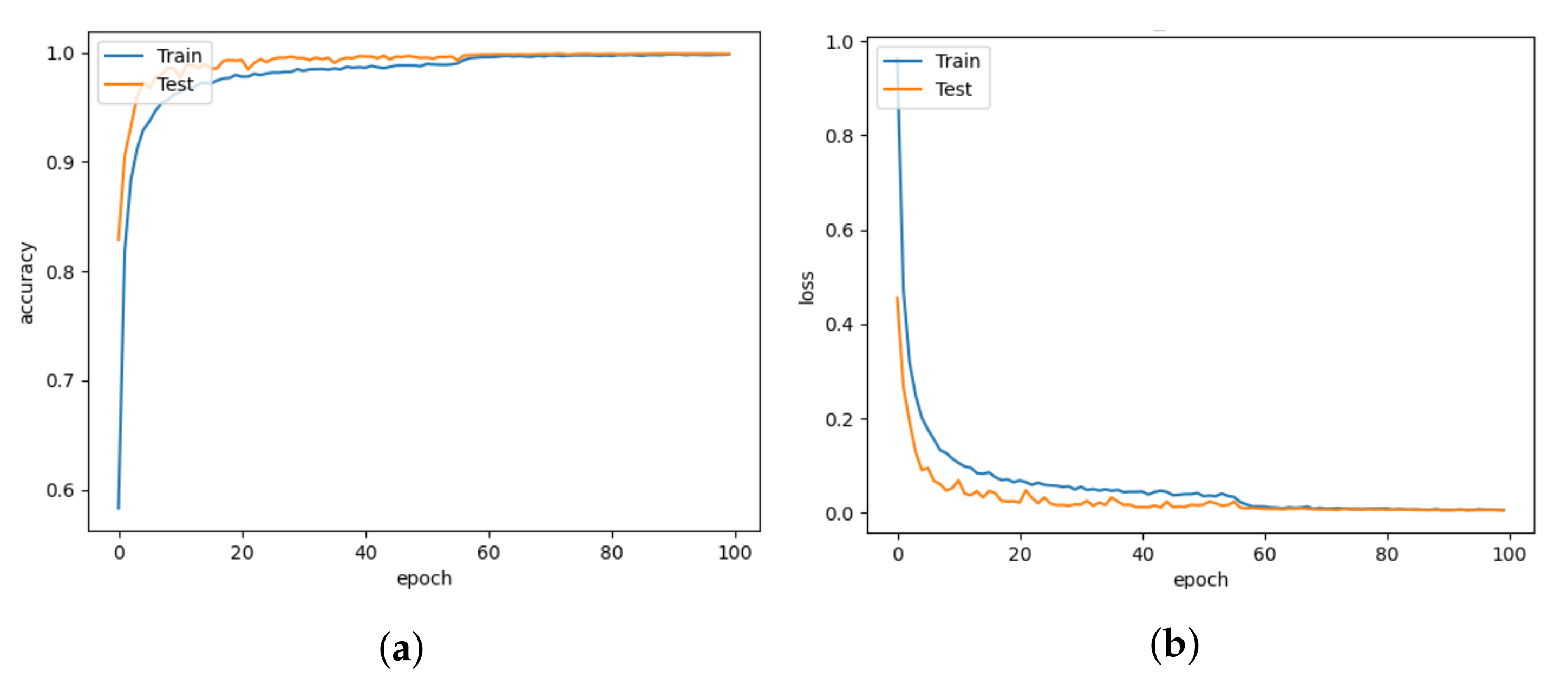
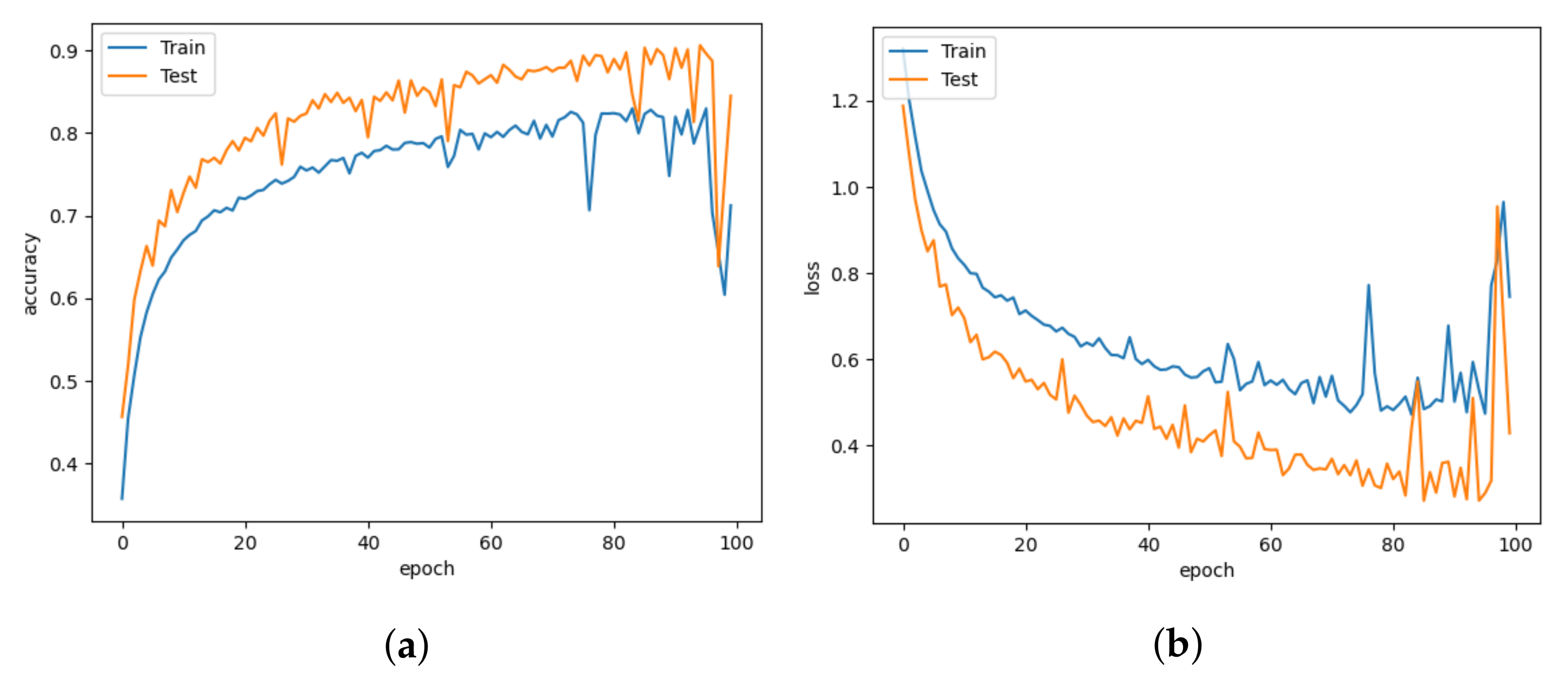
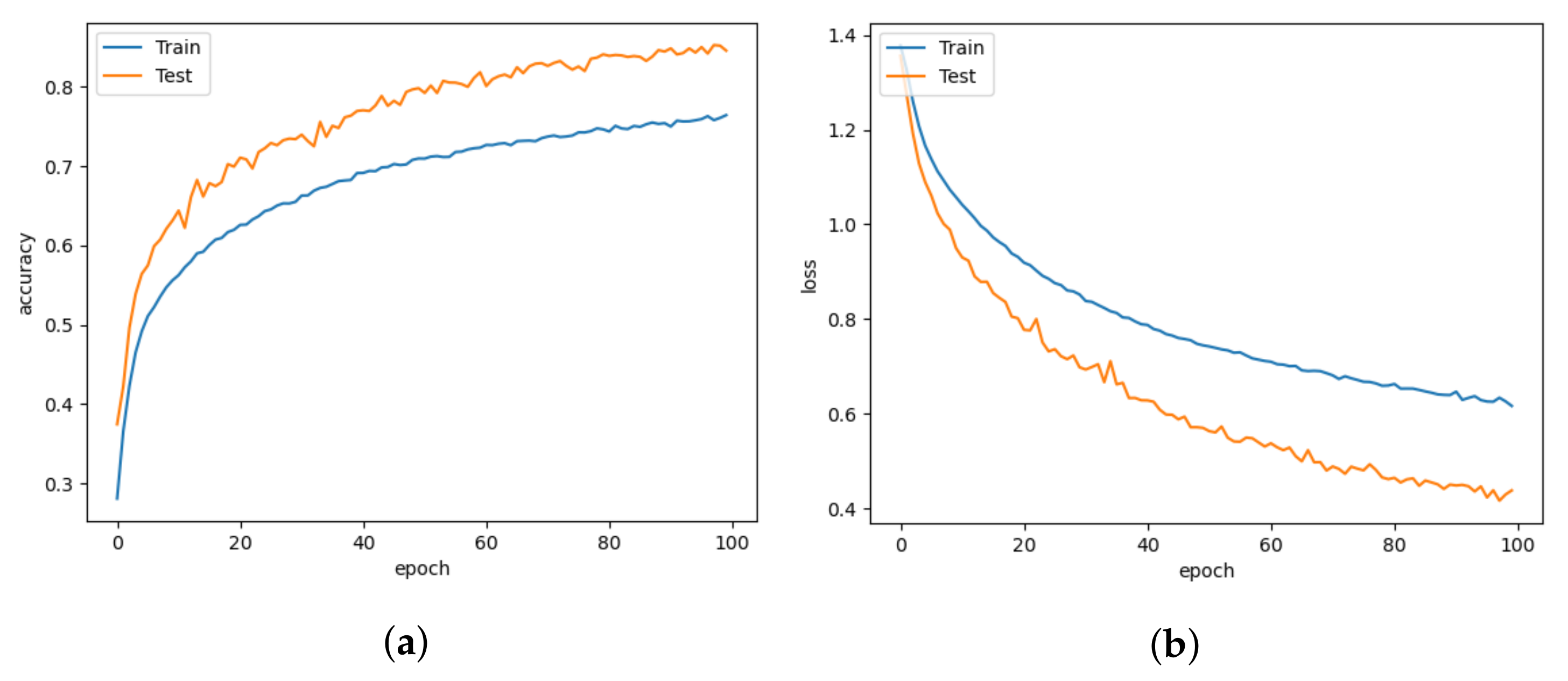
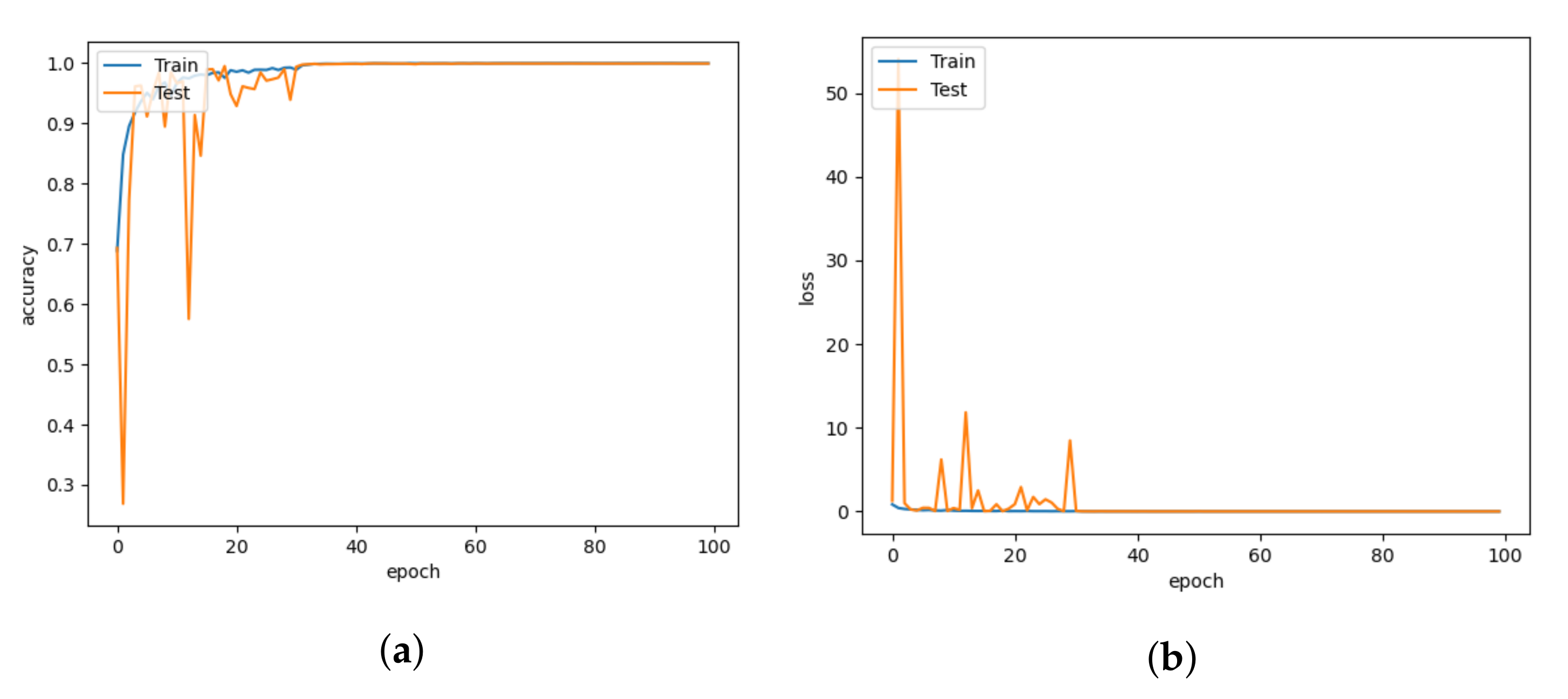
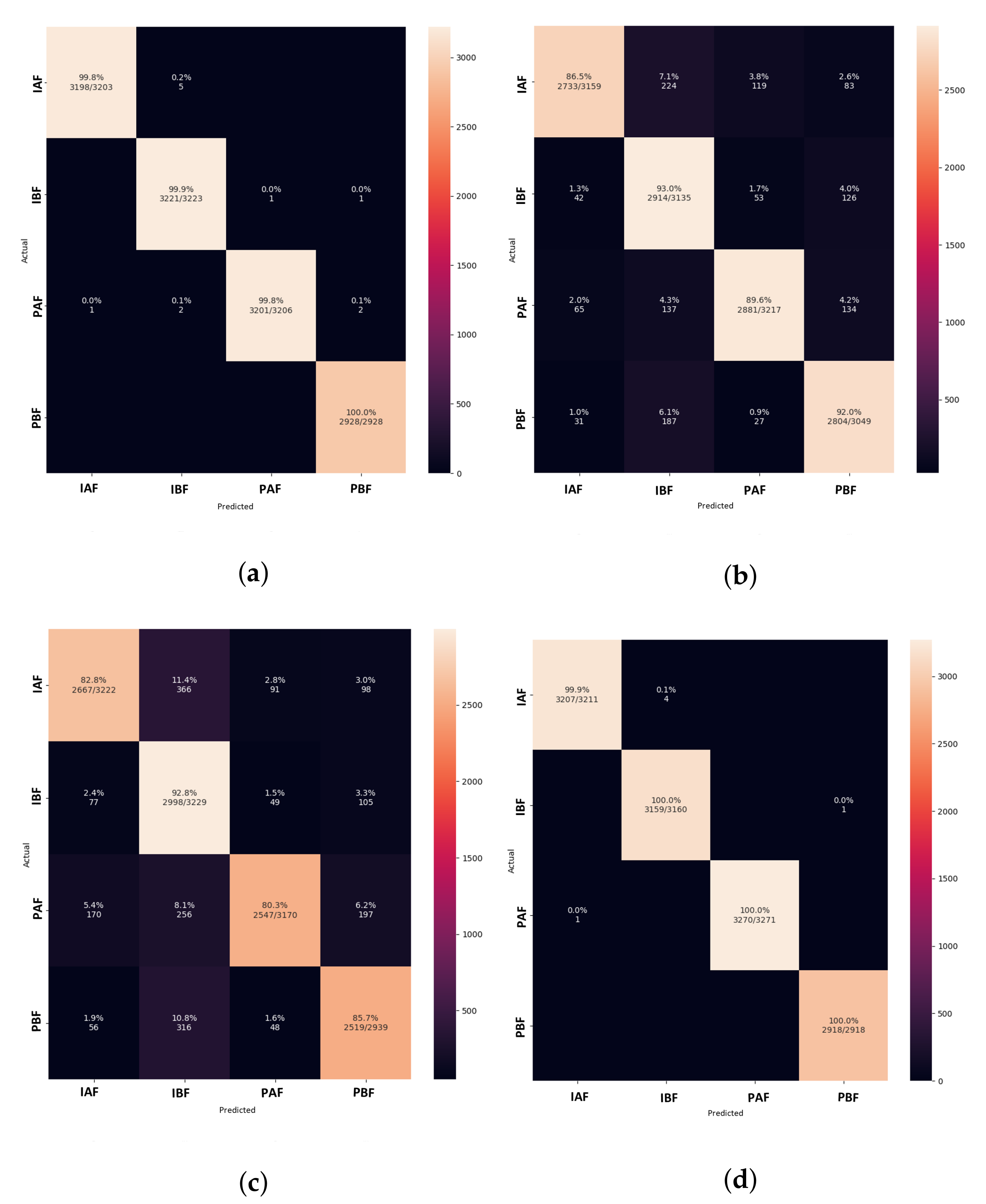
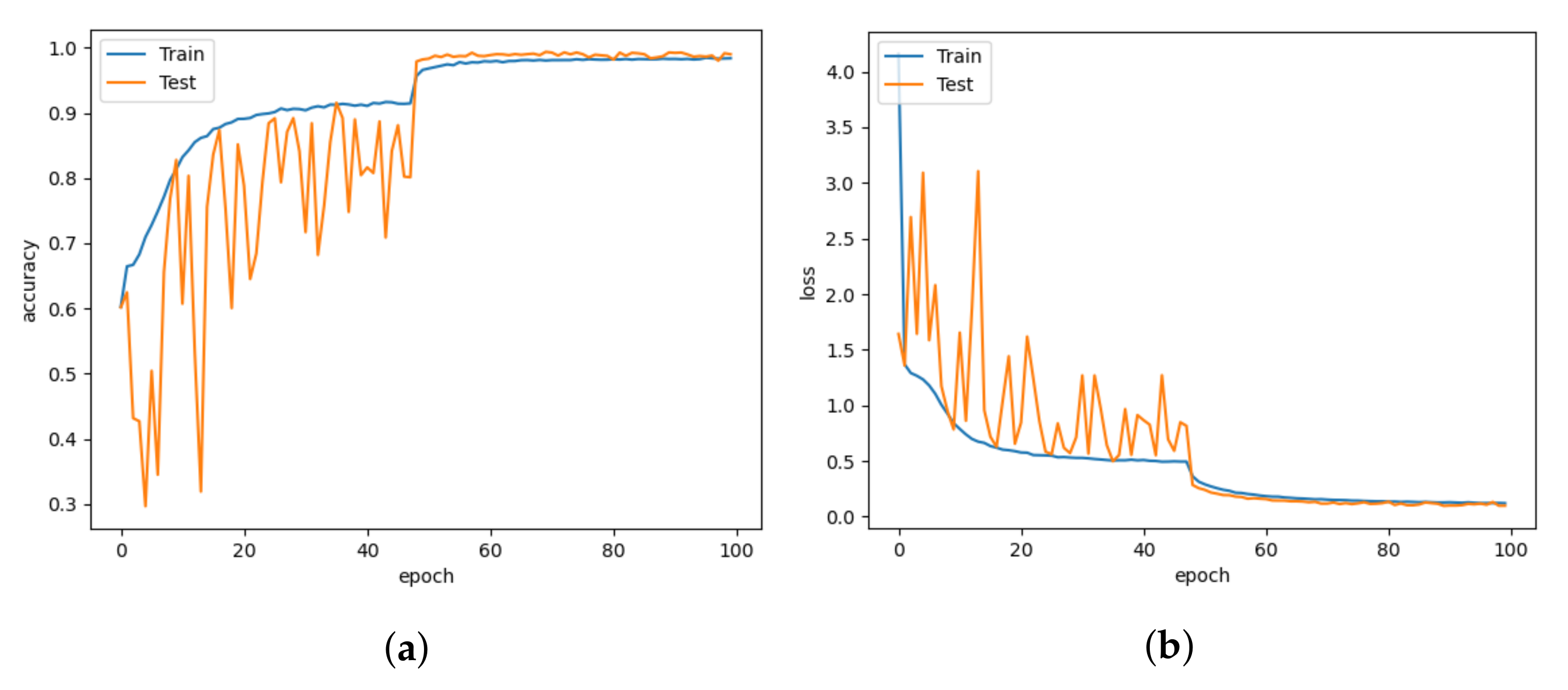
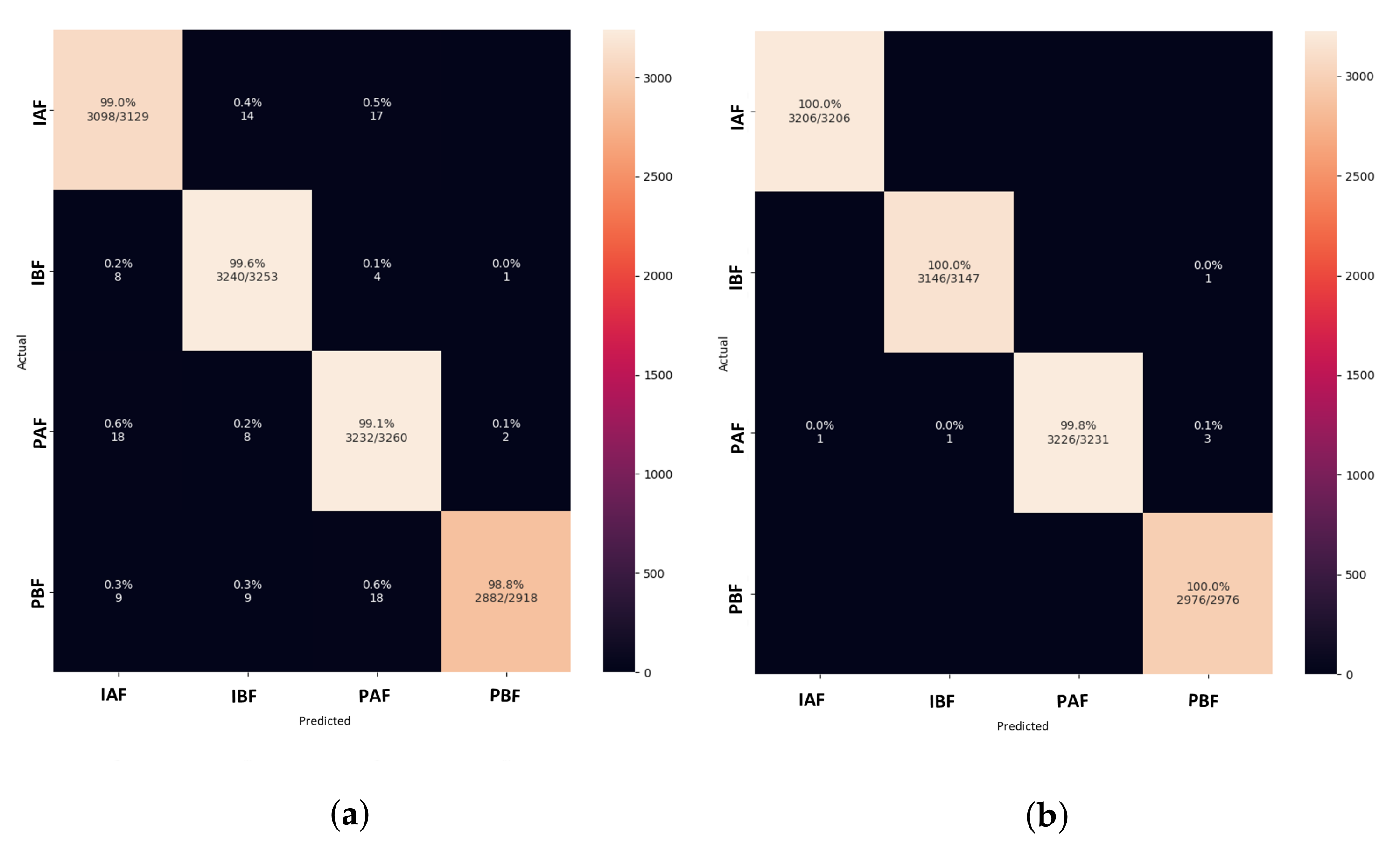
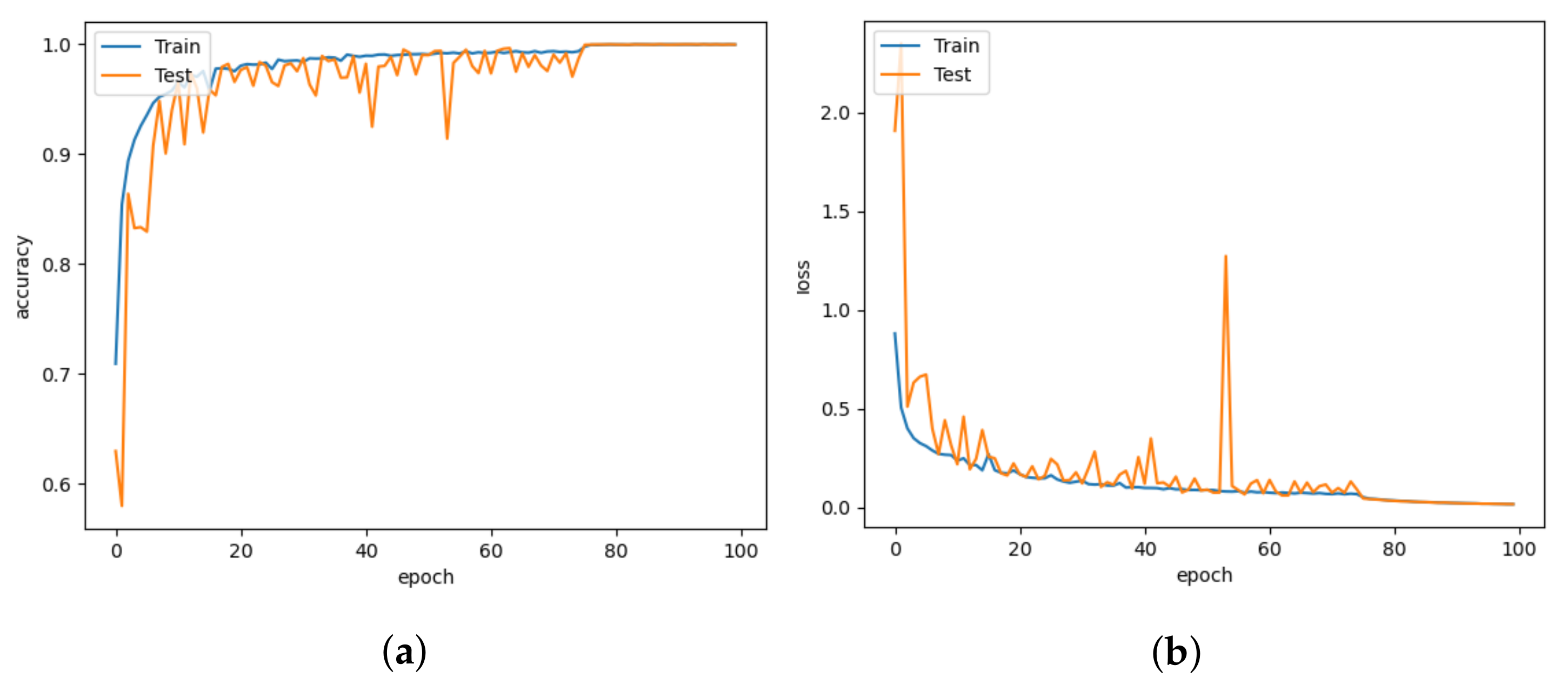
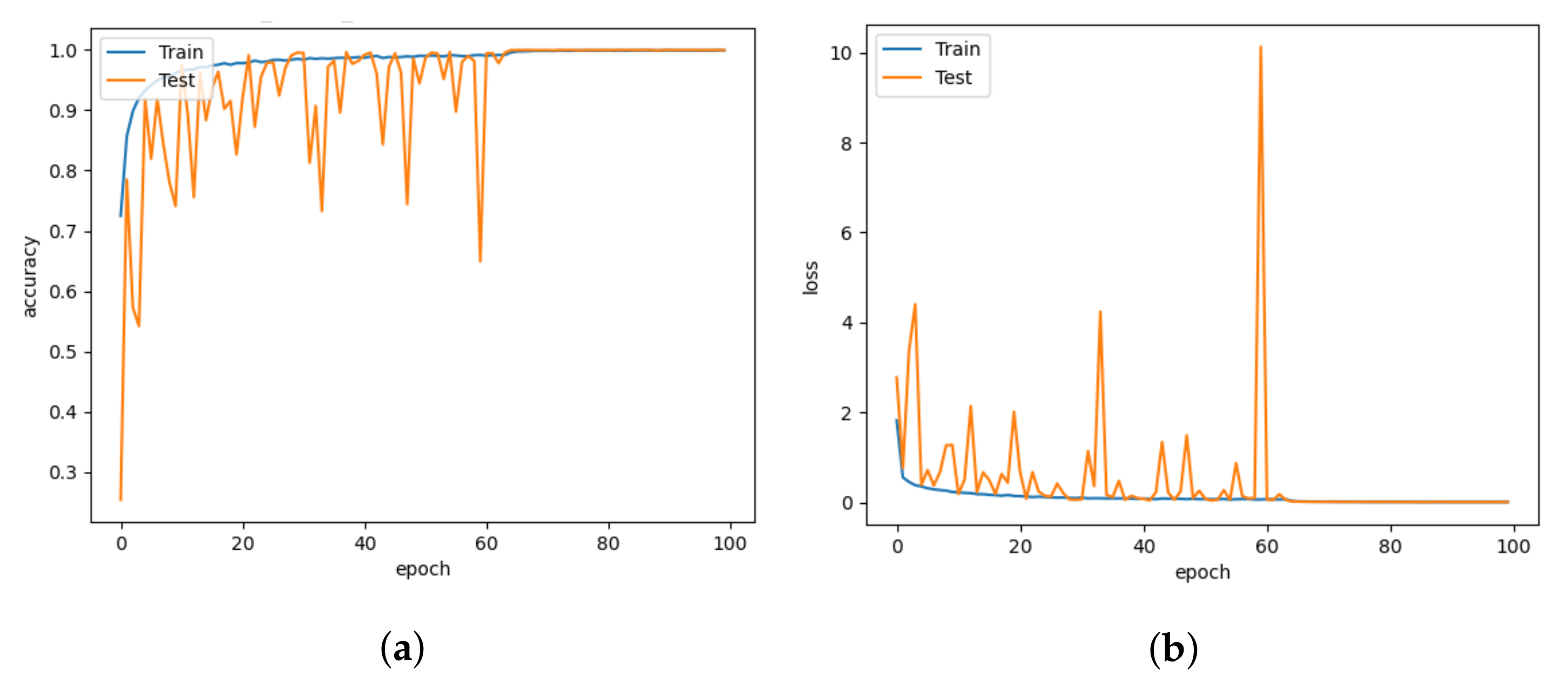
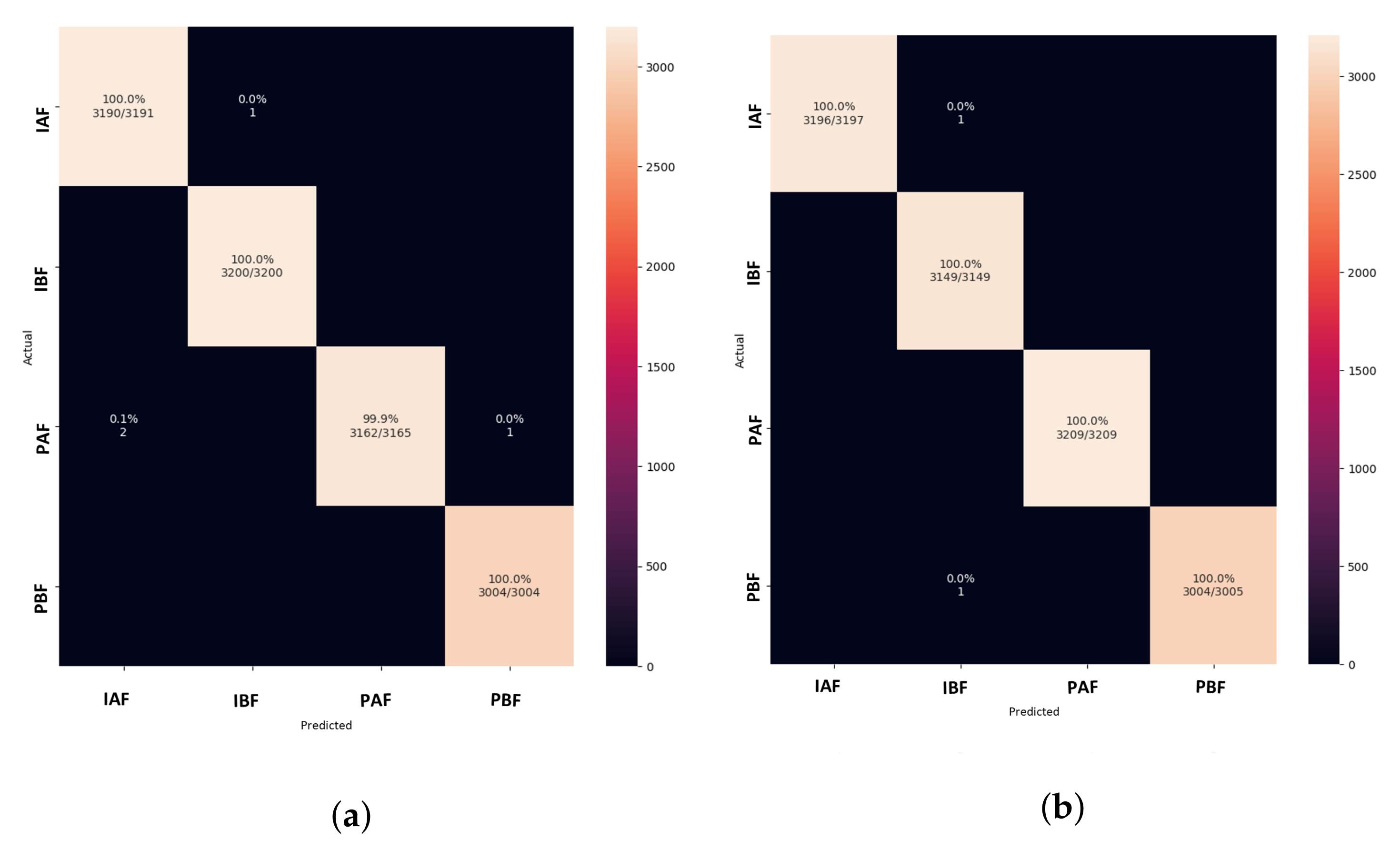
5. Results and Discussion
5.1. Model Comparison
5.2. Comparison with Different Learning Rates
5.3. Comparison with Number of Parameters and Model Size
5.4. Importance of Pig Treatment Classification in Animal Welfare
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xing, F.; Xie, Y.; Su, H.; Liu, F.; Yang, L. Deep learning in microscopy image analysis: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 4550–4568. [Google Scholar] [CrossRef] [PubMed]
- Stewart, M.; Webster, J.; Schaefer, A.; Cook, N.; Scott, S. Infrared thermography as a non-invasive tool to study animal welfare. Anim. Welf. 2005, 14, 319–325. [Google Scholar] [CrossRef]
- Cangar, Ö.; Aerts, J.-M.; Buyse, J.; Berckmans, D. Quantification of the spatial distribution of surface temperatures of broilers. Poult. Sci. 2008, 87, 2493–2499. [Google Scholar] [CrossRef] [PubMed]
- Warriss, P.; Pope, S.; Brown, S.; Wilkins, L.; Knowles, T. Estimating the body temperature of groups of pigs by thermal imaging. Vet Rec. 2006, 158, 331–334. [Google Scholar] [CrossRef]
- Weschenfelder, A.V.; Saucier, L.; Maldague, X.; Rocha, L.M.; Schaefer, A.L.; Faucitano, L. Use of infrared ocular thermography to assess physiological conditions of pigs prior to slaughter and predict pork quality variation. Meat Sci. 2013, 95, 616–620. [Google Scholar] [CrossRef]
- Rodriguez-Baena, D.S.; Gomez-Vela, F.A.; García-Torres, M.; Divina, F.; Barranco, C.D.; Daz-Diaz, N.; Jimenez, M.; Montalvo, G. Identifying livestock behavior patterns based on accelerometer dataset. J. Comput. Sci. 2020, 41, 101076. [Google Scholar] [CrossRef]
- Dutta, R.; Smith, D.; Rawnsley, R.; Bishop-Hurley, G.; Hills, J.; Timms, G.; Henry, D. Dynamic cattle behavioural classification using supervised ensemble classifiers. Comput. Electron. Agric. 2015, 111, 18–28. [Google Scholar] [CrossRef]
- Phung Cong Phi, K.; Nguyen Thi, K.; Nguyen Dinh, C.; Tran Duc, N.; Tran Duc, T. Classification of cow’s behaviors based on 3-DoF accelerations from cow’s movements. Int. J. Electr. Comput. Eng. 2019, 9, 1656–1662. [Google Scholar]
- Becciolini, V.; Ponzetta, M.P. Inferring behaviour of grazing livestock: Opportunities from GPS telemetry and activity sensors applied to animal husbandry. Eng. Rural Dev. 2018, 17, 192–198. [Google Scholar]
- Decandia, M.; Giovanetti, V.; Acciaro, M.; Mameli, M.; Molle, G.; Cabiddu, A.; Manca, C.; Cossu, R.; Serra, M.; Rassu, S. Monitoring grazing behaviour of Sarda cattle using an accelerometer device. In Grassland Resources for Extensive Farming Systems in Marginal Lands: Major Drivers and Future Scenarios, Proceedings of the 19th Symposium of the European Grassland Federation, Alghero, Italy, 7–10 May 2017; Istituto Sistema Produzione Animale Ambiente Mediterraneo: Sassari, Italy, 2017; Volume 22, p. 143. [Google Scholar]
- McManus, R.; Boden, L.A.; Weir, W.; Viora, L.; Barker, R.; Kim, Y.; McBride, P.; Yang, S. Thermography for disease detection in livestock: A scoping review. Front. Vet. Sci. 2022, 1163, 1163. [Google Scholar] [CrossRef]
- Sykes, D.; Couvillion, J.; Cromiak, A.; Bowers, S.; Schenck, E.; Crenshaw, M.; Ryan, P. The use of digital infrared thermal imaging to detect estrus in gilts. Theriogenology 2012, 78, 147–152. [Google Scholar] [CrossRef] [PubMed]
- Pacheco, V.M.; de Sousa, R.V.; da Silva Rodrigues, A.V.; de Souza Sardinha, E.J.; Martello, L.S. Thermal imaging combined with predictive machine learning based model for the development of thermal stress level classifiers. Livest. Sci. 2020, 241, 104244. [Google Scholar] [CrossRef]
- Arulmozhi, E.; Basak, J.K.; Sihalath, T.; Park, J.; Kim, H.T.; Moon, B.E. Machine learning-based microclimate model for indoor air temperature and relative humidity prediction in a swine building. Animals 2021, 11, 222. [Google Scholar] [CrossRef] [PubMed]
- Oliveira, D.A.B.; Pereira, L.G.R.; Bresolin, T.; Ferreira, R.E.P.; Dorea, J.R.R. A review of deep learning algorithms for computer vision systems in livestock. Livest. Sci. 2021, 253, 104700. [Google Scholar] [CrossRef]
- Boileau, A.; Farish, M.; Turner, S.P.; Camerlink, I. Infrared thermography of agonistic behaviour in pigs. Physiol. Behav. 2019, 210, 112637. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Alameer, A.; Kyriazakis, I.; Dalton, H.A.; Miller, A.L.; Bacardit, J. Automatic recognition of feeding and foraging behaviour in pigs using deep learning. Biosyst. Eng. 2020, 197, 91–104. [Google Scholar] [CrossRef]
- Alameer, A.; Kyriazakis, I.; Bacardit, J. Automated recognition of postures and drinking behaviour for the detection of compromised health in pigs. Sci. Rep. 2020, 10, 1–15. [Google Scholar] [CrossRef]
- Peng, S.; Zhu, J.; Liu, Z.; Hu, B.; Wang, M.; Pu, S. Prediction of Ammonia Concentration in a Pig House Based on Machine Learning Models and Environmental Parameters. Animals 2022, 13, 165. [Google Scholar] [CrossRef]
- Tusell, L.; Bergsma, R.; Gilbert, H.; Gianola, D.; Piles, M. Machine learning prediction of crossbred pig feed efficiency and growth rate from single nucleotide polymorphisms. Front. Genet. 2020, 11, 567818. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Trnovszky, T.; Kamencay, P.; Orjesek, R.; Benco, M.; Sykora, P. Animal recognition system based on convolutional neural network. Adv. Electr. Electron. Eng. 2017, 15, 517–525. [Google Scholar] [CrossRef]
- Kernel (Image Processing). Available online: https://en.wikipedia.org/wiki/Kernel_(image_processing) (accessed on 23 September 2019).
- Mouloodi, S.; Rahmanpanah, H.; Burvill, C.; Davies, H.M. Prediction of displacement in the equine third metacarpal bone using a neural network prediction algorithm. Biocybern. Biomed. Eng. 2020, 40, 849–863. [Google Scholar] [CrossRef]
- Hamilton, A.W.; Davison, C.; Tachtatzis, C.; Andonovic, I.; Michie, C.; Ferguson, H.J.; Somerville, L.; Jonsson, N.N. Identification of the rumination in cattle using support vector machines with motion-sensitive bolus sensors. Sensors 2019, 19, 1165. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rahman, A.; Smith, D.; Hills, J.; Bishop-Hurley, G.; Henry, D.; Rawnsley, R. A comparison of autoencoder and statistical features for cattle behaviour classification. In Proceedings of IEEE International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 2954–2960. [Google Scholar]
- Rahman, A.; Smith, D.; Little, B.; Ingham, A.; Greenwood, P.; Bishop-Hurley, G. Cattle behaviour classification from collar, halter, and ear tag sensors. Inf. Process. Agric. 2018, 5, 124–133. [Google Scholar] [CrossRef]
- Riaboff, L.; Poggi, S.; Madouasse, A.; Couvreur, S.; Aubin, S.; Bédère, N.; Goumand, E.; Chauvin, A.; Plantier, G. Development of a methodological framework for a robust prediction of the main behaviours of dairy cows using a combination of machine learning algorithms on accelerometer data. Comput. Electron. Agric. 2020, 169, 105179. [Google Scholar] [CrossRef]
- Benaissa, S.; Tuyttens, F.A.; Plets, D.; Cattrysse, H.; Martens, L.; Vandaele, L.; Joseph, W.; Sonck, B. Classification of ingestive-related cow behaviours using RumiWatch halter and neck-mounted accelerometers. Appl. Anim. Behav. Sci. 2019, 211, 9–16. [Google Scholar] [CrossRef] [Green Version]
- Williams, L.R.; Bishop-Hurley, G.J.; Anderson, A.E.; Swain, D.L. Application of accelerometers to record drinking behaviour of beef cattle. Anim. Prod. Sci. 2017, 59, 122–132. [Google Scholar] [CrossRef]
- Smith, D.; Little, B.; Greenwood, P.I.; Valencia, P.; Rahman, A.; Ingham, A.; Bishop-Hurley, G.; Shahriar, M.S.; Hellicar, A. A study of sensor derived features in cattle behaviour classification models. In Proceedings of IEEE SENSORS, Busan, Republic of Korea, 1–4 November 2015; pp. 1–4. [Google Scholar]
- Villa, A.G.; Salazar, A.; Vargas, F. Towards automatic wild animal monitoring: Identification of animal species in camera-trap images using very deep convolutional neural networks. Ecol. Inform. 2017, 41, 24–32. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Nguyen, H.; Maclagan, S.J.; Nguyen, T.D.; Nguyen, T.; Flemons, P.; Andrews, K.; Ritchie, E.G.; Phung, D. Animal recognition and identification with deep convolutional neural networks for automated wildlife monitoring. In Proceedings of IEEE International Conference on Data Science and Advanced Analytics (DSAA), Tokyo, Japan, 19–21 October 2017; pp. 40–49. [Google Scholar]
- Brown, G.V.; Warrell, D.A. Venomous bites and stings in the tropical world. Med. J. Aust. 1993, 159, 773–779. [Google Scholar] [CrossRef]
- Giraldo-Zuluaga, J.-H.; Salazar, A.; Gomez, A.; Diaz-Pulido, A. Automatic recognition of mammal genera on camera-trap images using multi-layer robust principal component analysis and mixture neural networks. arXiv 2017, arXiv:1705.02727. [Google Scholar]
- Neethirajan, S. The role of sensors, big data and machine learning in modern animal farming. Sens.-Bio-Sens. Res. 2020, 29, 100367. [Google Scholar] [CrossRef]
- Neethirajan, S. Happy cow or thinking pig? Wur wolf—facial coding platform for measuring emotions in farm animals. AI 2021, 2, 342–354. [Google Scholar] [CrossRef]
- Neethirajan, S. ChickTrack–a quantitative tracking tool for measuring chicken activity. Measurement 2022, 191, 110819. [Google Scholar] [CrossRef]
- Heuvel, H.v.d.; Graat, L.; Youssef, A.; Neethirajan, S. Quantifying the Effect of an Acute Stressor in Laying Hens using Thermographic Imaging and Vocalizations. bioRxiv 2022. [Google Scholar] [CrossRef]
- Jin, J.; Dundar, A.; Culurciello, E. Flattened convolutional neural networks for feedforward acceleration. arXiv 2014, arXiv:1412.5474. [Google Scholar]
- Wang, M.; Liu, B.; Foroosh, H. Factorized convolutional neural networks. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 545–553. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Hassibi, B.; Stork, D. Second order derivatives for network pruning: Optimal brain surgeon. Adv. Neural. Inf. Process. Syst. 1992, 5, 164–171. [Google Scholar]
- Ahmed, K.; Torresani, L. Connectivity learning in multi-branch networks. arXiv 2017, arXiv:1709.09582. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. In Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- LeCun, Y. LeNet-5, Convolutional Neural Networks. Available online: http://yann.lecun.com/exdb/lenet (accessed on 26 January 2023).
- Chollet, F. In Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Colaco, S.J.; Kim, J.H.; Poulose, A.; Van, Z.S.; Neethirajan, S.; Han, D.S. Pig Treatment Classification on Thermal Image Data using Deep Learning. In Proceedings of 13th IEEE International Conference on Ubiquitous and Future Networks (ICUFN), Barcelona, Spain, 5–8 July 2022; pp. 8–11. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop, Coursera: Neural Networks for Machine Learning; Technical Report; University of Toronto: Toronto, ON, Canada, 2012; Volume 6. [Google Scholar]
- Brandt, P.; Rousing, T.; Herskin, M.; Olsen, E.; Aaslyng, M. Development of an index for the assessment of welfare of finishing pigs from farm to slaughter based on expert opinion. Livest. Sci. 2017, 198, 65–71. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy | Precision | Recall | F1 Score | Loss |
|---|---|---|---|---|---|
| (%) | (%) | (%) | (%) | ||
| LeNet5 | 99.9045 | 99.9045 | 99.9045 | 99.9045 | 0.0061 |
| AlexNet | 90.2229 | 90.2581 | 90.2581 | 90.2229 | 0.2716 |
| VGGNet | 85.4379 | 86.3148 | 85.5091 | 85.4379 | 0.4164 |
| Xception | 99.9522 | 99.9522 | 99.9522 | 99.9522 | 0.0043 |
| CNN-LeakyReLU | 99.1401 | 99.1426 | 99.1401 | 99.1403 | 0.0976 |
| CNN-inception | 99.9761 | 99.9761 | 99.9761 | 99.9761 | 0.0179 |
| DISubNetV1 | 99.9682 | 99.9682 | 99.9682 | 99.9682 | 0.0014 |
| DISubNetV2 | 99.9841 | 99.9841 | 99.9841 | 99.9841 | 0.0036 |
| Model | Learning | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| Rate | (%) | (%) | (%) | (%) | |
| LeNet5 | 0.01 | 25.3025 | 6.4022 | 25.3025 | 10.2188 |
| 0.0001 | 99.9124 | 99.9125 | 99.9124 | 99.9124 | |
| AlexNet | 0.01 | 24.8885 | 6.1944 | 24.8885 | 9.9199 |
| 0.0001 | 99.9602 | 99.9602 | 99.9602 | 99.9602 | |
| VGGNet | 0.01 | 25.6528 | 6.5806 | 25.6528 | 10.4744 |
| 0.0001 | 99.9840 | 99.9840 | 99.9840 | 99.9840 | |
| Xception | 0.01 | 99.9682 | 99.9682 | 99.9682 | 99.9682 |
| 0.0001 | 99.9920 | 99.9920 | 99.9920 | 99.9920 | |
| CNN-LeakyReLU | 0.01 | 25.8996 | 6.7079 | 25.8996 | 10.6560 |
| 0.0001 | 99.9601 | 99.9601 | 99.9601 | 99.9601 | |
| CNN-inception | 0.01 | 37.7388 | 50.2383 | 37.7388 | 32.1467 |
| 0.0001 | 99.9681 | 99.9681 | 99.9681 | 99.9681 | |
| DISubNetV1 | 0.01 | 25.1433 | 6.3218 | 25.1433 | 10.1034 |
| 0.0001 | 99.9682 | 99.9682 | 99.9682 | 99.9682 | |
| DISubNetV2 | 0.01 | 25.2229 | 6.3619 | 25.2229 | 10.1610 |
| 0.0001 | 99.9920 | 99.9920 | 99.9920 | 99.9920 |
| Model | Number of Parameters | Model Size |
|---|---|---|
| LeNet5 | 19,628,074 | 224 MB |
| AlexNet | 23,392,580 | 267 MB |
| VGGNet | 17,075,396 | 195 MB |
| Xception | 20,991,980 | 240 MB |
| CNN-LeakyReLU | 7,255,332 | 83.2 MB |
| CNN-inception | 7,419,812 | 85.8 MB |
| DISubNetV1 | 4,591,574 | 53.7 MB |
| DISubNetV2 | 4,591,574 | 53.7 MB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Colaco, S.J.; Kim, J.H.; Poulose, A.; Neethirajan, S.; Han, D.S. DISubNet: Depthwise Separable Inception Subnetwork for Pig Treatment Classification Using Thermal Data. Animals 2023, 13, 1184. https://doi.org/10.3390/ani13071184
Colaco SJ, Kim JH, Poulose A, Neethirajan S, Han DS. DISubNet: Depthwise Separable Inception Subnetwork for Pig Treatment Classification Using Thermal Data. Animals. 2023; 13(7):1184. https://doi.org/10.3390/ani13071184
Chicago/Turabian StyleColaco, Savina Jassica, Jung Hwan Kim, Alwin Poulose, Suresh Neethirajan, and Dong Seog Han. 2023. "DISubNet: Depthwise Separable Inception Subnetwork for Pig Treatment Classification Using Thermal Data" Animals 13, no. 7: 1184. https://doi.org/10.3390/ani13071184