

There You Are! Automated Detection of Indris’ Songs on Features Extracted from Passive Acoustic Recordings

 , , , , , , , ,
, , , , , , , , 
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Collection
2.2. Data Processing
2.3. Data Analysis
3. Results
3.1. Model Performance
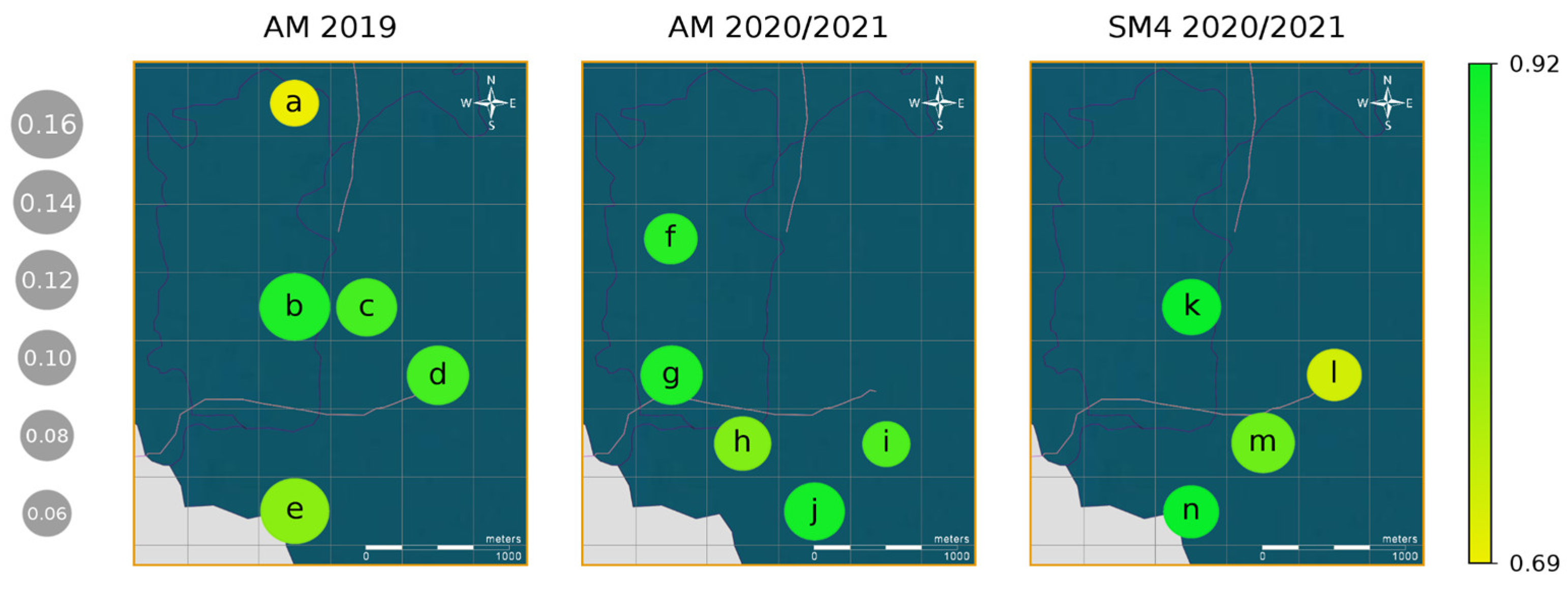
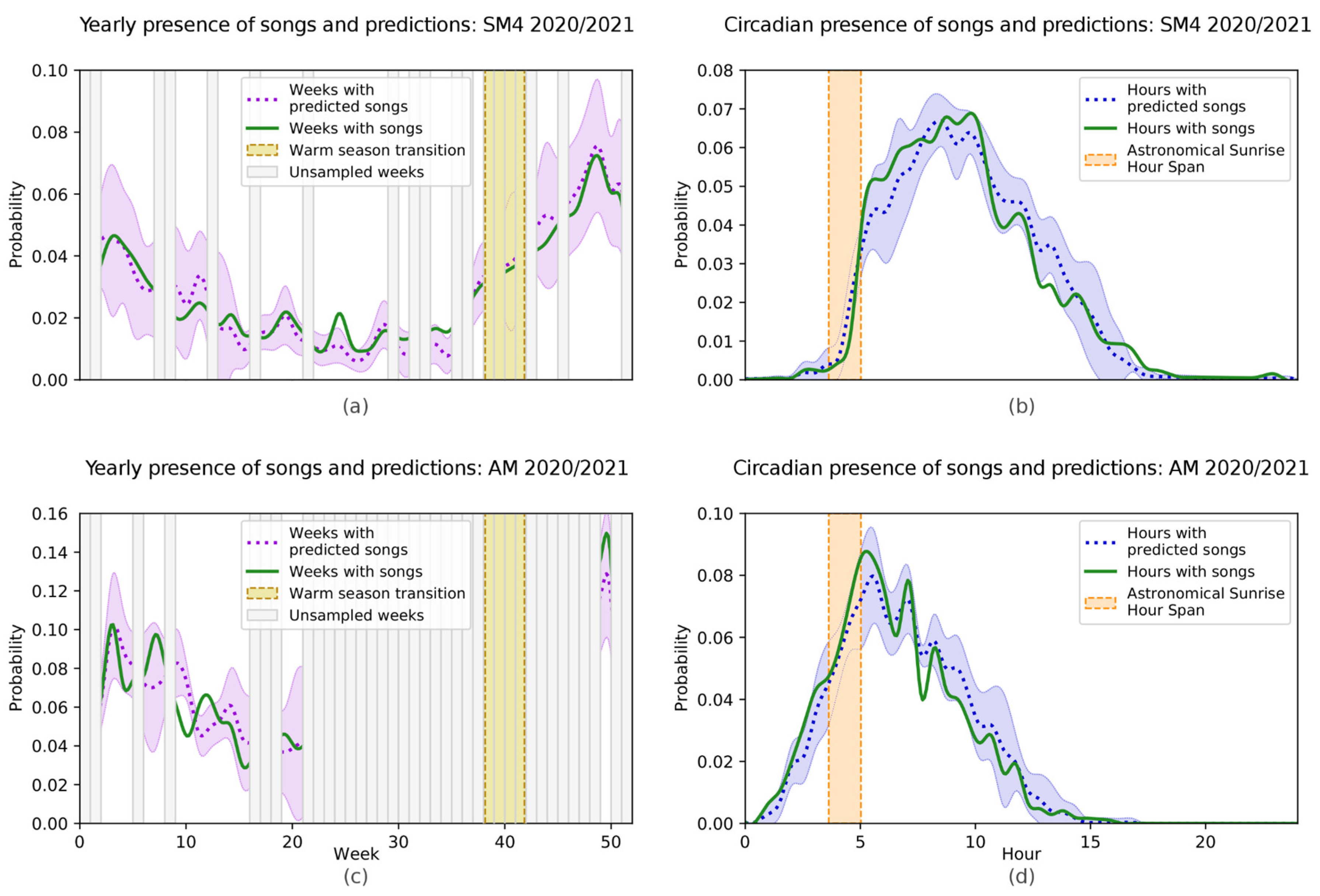
3.2. Indri indri Calling Pattern
4. Discussion
4.1. Model Performance
4.2. Indri indri Calling Pattern
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Anders, F.; Kalan, A.K.; Kühl, H.S.; Fuchs, M. Compensating Class Imbalance for Acoustic Chimpanzee Detection with Convolutional Recurrent Neural Networks. Ecol. Inform. 2021, 65, 101423. [Google Scholar] [CrossRef]
- Escobar-Amado, C.D.; Badiey, M.; Pecknold, S. Automatic Detection and Classification of Bearded Seal Vocalizations in the Northeastern Chukchi Sea Using Convolutional Neural Networks. J. Acoust. Soc. Am. 2022, 151, 299–309. [Google Scholar] [CrossRef] [PubMed]
- Browning, E.; Gibb, R.; Glover-Kapfer, P.; Jones, K.E. Passive Acoustic Monitoring in Ecology and Conservation; WWF-UK: Woking, UK, 2017. [Google Scholar]
- Dufourq, E.; Durbach, I.; Hansford, J.P.; Hoepfner, A.; Ma, H.; Bryant, J.V.; Stender, C.S.; Li, W.; Liu, Z.; Chen, Q.; et al. Automated Detection of Hainan Gibbon Calls for Passive Acoustic Monitoring. Remote Sens. Ecol. Conserv. 2021, 7, 475–487. [Google Scholar] [CrossRef]
- Zhong, M.; Taylor, R.; Bates, N.; Christey, D.; Basnet, H.; Flippin, J.; Palkovitz, S.; Dodhia, R.; Lavista Ferres, J. Acoustic Detection of Regionally Rare Bird Species through Deep Convolutional Neural Networks. Ecol. Inform. 2021, 64, 101333. [Google Scholar] [CrossRef]
- Boddapati, V.; Petef, A.; Rasmusson, J.; Lundberg, L. Classifying Environmental Sounds Using Image Recognition Networks. Procedia Comput. Sci. 2017, 112, 2048–2056. [Google Scholar] [CrossRef]
- Silva, B.; Mestre, F.; Barreiro, S.; Alves, P.J.; Herrera, J.M. SOUND C LASS: An Automatic Sound Classification Tool for Biodiversity Monitoring Using Machine Learning. Methods Ecol. Evol. 2022, 13, 2356–2362. [Google Scholar] [CrossRef]
- Bermant, P.C.; Bronstein, M.M.; Wood, R.J.; Gero, S.; Gruber, D.F. Deep Machine Learning Techniques for the Detection and Classification of Sperm Whale Bioacoustics. Sci. Rep. 2019, 9, 12588. [Google Scholar] [CrossRef] [Green Version]
- Paumen, Y.; Mälzer, M.; Alipek, S.; Moll, J.; Lüdtke, B.; Schauer-Weisshahn, H. Development and Test of a Bat Calls Detection and Classification Method Based on Convolutional Neural Networks. Bioacoustics 2022, 31, 505–516. [Google Scholar] [CrossRef]
- Zhao, Z.; Zhang, S.; Xu, Z.; Bellisario, K.; Dai, N.; Omrani, H.; Pijanowski, B.C. Automated Bird Acoustic Event Detection and Robust Species Classification. Ecol. Inform. 2017, 39, 99–108. [Google Scholar] [CrossRef]
- Pandeya, Y.R.; Kim, D.; Lee, J. Domestic Cat Sound Classification Using Learned Features from Deep Neural Nets. Appl. Sci. 2018, 8, 1949. [Google Scholar] [CrossRef]
- Nanni, L.; Maguolo, G.; Paci, M. Data Augmentation Approaches for Improving Animal Audio Classification. Ecol. Inform. 2020, 57, 101084. [Google Scholar] [CrossRef] [Green Version]
- Oikarinen, T.; Srinivasan, K.; Meisner, O.; Hyman, J.B.; Parmar, S.; Fanucci-Kiss, A.; Desimone, R.; Landman, R.; Feng, G. Deep Convolutional Network for Animal Sound Classification and Source Attribution Using Dual Audio Recordings. J. Acoust. Soc. Am. 2019, 145, 654–662. [Google Scholar] [CrossRef]
- Haimoff, E.H. Convergence in the Duetting of Monogamous Old World Primates. J. Hum. Evol. 1986, 15, 51–59. [Google Scholar] [CrossRef]
- De Gregorio, C.; Carugati, F.; Valente, D.; Raimondi, T.; Torti, V.; Miaretsoa, L.; Gamba, M.; Giacoma, C. Notes on a Tree: Reframing the Relevance of Primate Choruses, Duets, and Solo Songs. Ethol. Ecol. Evol. 2022, 34, 205–219. [Google Scholar] [CrossRef]
- Dufourq, E.; Batist, C.; Foquet, R.; Durbach, I. Passive Acoustic Monitoring of Animal Populations with Transfer Learning. Ecol. Inform. 2022, 70, 101688. [Google Scholar] [CrossRef]
- Geissmann, T.; Mutschler, T. Diurnal Distribution of Loud Calls in Sympatric Wild Indris (Indri indri) and Ruffed Lemurs (Varecia variegata): Implications for Call Functions. Primates 2006, 47, 393–396. [Google Scholar] [CrossRef] [Green Version]
- King, T.; Dolch, R.; Randriahaingo, H.N.T.; Randrianarimanana, L.; Ravaloharimanitra, M. Indri indri. The IUCN Red List of Threatened Species. 2020. Available online:https://dx.doi.org/10.2305/IUCN.UK.2020-2.RLTS.T10826A115565566.en (accessed on 24 November 2022). [CrossRef]
- Markolf, M.; Zinowsky, M.; Keller, J.K.; Borys, J.; Cillov, A.; Schülke, O. Toward Passive Acoustic Monitoring of Lemurs: Using an Affordable Open-Source System to Monitor Phaner Vocal Activity and Density. Int. J. Primatol. 2022, 43, 409–433. [Google Scholar] [CrossRef]
- Torti, V.; Valente, D.; Gregorio, C.D.; Comazzi, C.; Miaretsoa, L.; Ratsimbazafy, J.; Giacoma, C.; Gamba, M. Call and Be Counted! Can We Reliably Estimate the Number of Callers in the Indri’s (Indri indri) Song? PLoS ONE 2018, 13, e0201664. [Google Scholar] [CrossRef] [Green Version]
- Mittermeier, R.A.; Reuter, K.E.; Rylands, A.B.; Jerusalinsky, L.; Schwitzer, C.; Strien, K.B.; Ratsimbazafy, J.; Humle, T. Primates in Peril The World’s 25 Most Endangered Primates 2022–2023, 2022nd ed.; IUCN/SSC Primate Specialist Group (PSG); International Primatological Society (IPS): Washington, DC, USA, 2022. [Google Scholar]
- Vieilledent, G.; Grinand, C.; Rakotomalala, F.A.; Ranaivosoa, R.; Rakotoarijaona, J.-R.; Allnutt, T.F.; Achard, F. Combining Global Tree Cover Loss Data with Historical National Forest Cover Maps to Look at Six Decades of Deforestation and Forest Fragmentation in Madagascar. Biol. Conserv. 2018, 222, 189–197. [Google Scholar] [CrossRef]
- Borgerson, C.; Johnson, S.E.; Hall, E.; Brown, K.A.; Narváez-Torres, P.R.; Rasolofoniaina, B.J.R.; Razafindrapaoly, B.N.; Merson, S.D.; Thompson, K.E.T.; Holmes, S.M.; et al. A National-Level Assessment of Lemur Hunting Pressure in Madagascar. Int. J. Primatol. 2022, 43, 92–113. [Google Scholar] [CrossRef]
- Maretti, G.; Sorrentino, V.; Finomana, A.; Gamba, M.; Giacoma, C. Not Just a Pretty Song: An Overview of the Vocal Repertoire of Indri indri. J. Anthropol. Sci. Riv. Antropol. JASS 2010, 88, 151–165. [Google Scholar]
- Valente, D.; De Gregorio, C.; Torti, V.; Miaretsoa, L.; Friard, O.; Randrianarison, R.M.; Giacoma, C.; Gamba, M. Finding Meanings in Low Dimensional Structures: Stochastic Neighbor Embedding Applied to the Analysis of Indri indri Vocal Repertoire. Anim. Open Access J. MDPI 2019, 9, 243. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Valente, D.; Miaretsoa, L.; Anania, A.; Costa, F.; Mascaro, A.; Raimondi, T.; De Gregorio, C.; Torti, V.; Friard, O.; Ratsimbazafy, J.; et al. Comparative Analysis of the Vocal Repertoires of the Indri (Indri indri) and the Diademed Sifaka (Propithecus diadema). Int. J. Primatol. 2022, 43, 733–751. [Google Scholar] [CrossRef]
- Bonadonna, G.; Zaccagno, M.; Torti, V.; Valente, D.; De Gregorio, C.; Randrianarison, R.M.; Tan, C.; Gamba, M.; Giacoma, C. Intra- and Intergroup Spatial Dynamics of a Pair-Living Singing Primate, Indri indri: A Multiannual Study of Three Indri Groups in Maromizaha Forest, Madagascar. Int. J. Primatol. 2020, 41, 224–245. [Google Scholar] [CrossRef]
- Pollock, J.I. The Song of the Indris (Indri indri; Primates: Lemuroidea): Natural History, Form, and Function. Int. J. Primatol. 1986, 7, 225–264. [Google Scholar] [CrossRef]
- Gamba, M.; Favaro, L.; Torti, V.; Sorrentino, V.; Giacoma, C. Vocal tract flexibility and variation in the vocal output in wild indris. Bioacoustics 2011, 20, 251–265. [Google Scholar] [CrossRef]
- Zanoli, A.; De Gregorio, C.; Valente, D.; Torti, V.; Bonadonna, G.; Randrianarison, R.M.; Giacoma, C.; Gamba, M. Sexually Dimorphic Phrase Organization in the Song of the Indris (Indri indri). Am. J. Primatol. 2020, 82, e23132. [Google Scholar] [CrossRef]
- Pollock, J.I. The Social Behaviour and Ecology of Indri indri. Ph.D. Thesis, University of London, London, UK, 1975. [Google Scholar]
- Melo, I.; Llusia, D.; Pereira Bastos, R.; Signorelli, L. Active or passive acoustic monitoring? Assessing methods to track anuran communities in tropical savanna wetlands. Ecol. Indic. 2021, 132, 108305. [Google Scholar] [CrossRef]
- Pérez-Granados, C.; Schuchmann, K. Passive Acoustic Monitoring of the Diel and Annual Vocal Behavior of the Black and Gold Howler Monkey. Am. J. Primatol. 2021, 83, e23241. [Google Scholar] [CrossRef]
- Do Nascimento, L.A.; Pérez-Granados, C.; Beard, K.H. Passive Acoustic Monitoring and Automatic Detection of Diel Patterns and Acoustic Structure of Howler Monkey Roars. Diversity 2021, 13, 566. [Google Scholar] [CrossRef]
- Randrianarison, R.M.; Lutz, M.; Torti, V.; Tan, C.; Bonadonna, G.; Randrianambinina, B.; Rasoloharijaona, S.; Rabarison, H.; Miaretsoa, L.; Rarojoson, N.J.; et al. Feeding Ecology and Regurgitation–Reingestion Behavior of the Critically Endangered Indri indri in the Maromizaha Protected Area, Eastern Madagascar. Int. J. Primatol. 2022, 43, 584–610. [Google Scholar] [CrossRef]
- OpenAcousticDevices. Available online: https://www.openacousticdevices.info/audiomoth (accessed on 2 December 2022).
- Song Meter SM4 Wildlife Audio Recorder. Available online: https://www.wildlifeacoustics.com/products/song-meter-sm4 (accessed on 7 December 2022).
- Farina, A.; Righini, R.; Fuller, S.; Li, P.; Pavan, G. Acoustic Complexity Indices Reveal the Acoustic Communities of the Old-Growth Mediterranean Forest of Sasso Fratino Integral Natural Reserve (Central Italy). Ecol. Indic. 2021, 120, 106927. [Google Scholar] [CrossRef]
- Boersma, P.; Weenink, D. Praat: Doing Phonetics by Computer [Computer Program]. Glot Int. 2022, 5, 341–345. [Google Scholar]
- Giacoma, C.; Sorrentino, V.; Rabarivola, C.; Gamba, M. Sex Differences in the Song of Indri indri. Int. J. Primatol. 2010, 31, 539–551. [Google Scholar] [CrossRef]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Van Rossum, G.; Drake, F.L. Python 3 Reference Manual; CreateSpace: Scotts Valley, CA, USA, 2009. [Google Scholar]
- Thalmann, U.; Geissmann, T.; Simona, A.; Mutschler, T. The Indris of Anjanaharibe-Sud, Northeastern Madagascar. Int. J. Primatol. 1993, 14, 357–381. [Google Scholar] [CrossRef] [Green Version]
- Torti, V.; Gamba, M.; Rabemananjara, Z.H.; Giacoma, C. The Songs of the Indris (Mammalia: Primates: Indridae): Contextual Variation in the Long-Distance Calls of a Lemur. Ital. J. Zool. 2013, 80, 596–607. [Google Scholar] [CrossRef] [Green Version]
- Long, M. 4-Acoustic Measurements and Noise Metrics. In Architectural Acoustics, 2nd ed.; Long, M., Ed.; Academic Press: Boston, MA, USA, 2014; pp. 129–174. ISBN 978-0-12-398258-2. [Google Scholar]
- Riondato, I.; Gamba, M.; Tan, C.L.; Niu, K.; Narins, P.M.; Yang, Y.; Giacoma, C. Allometric Escape and Acoustic Signal Features Facilitate High-Frequency Communication in an Endemic Chinese Primate. J. Comp. Physiol. A Neuroethol. Sens. Neural. Behav. Physiol. 2021, 207, 327–336. [Google Scholar] [CrossRef]
- Bolgan, M.; O’Brien, J.; Chorazyczewska, E.; Winfield, I.J.; McCullough, P.; Gammell, M. The Soundscape of Arctic Charr Spawning Grounds in Lotic and Lentic Environments: Can Passive Acoustic Monitoring Be Used to Detect Spawning Activities? Bioacoustics 2018, 27, 57–85. [Google Scholar] [CrossRef]
- De Gregorio, C.; Zanoli, A.; Valente, D.; Torti, V.; Bonadonna, G.; Randrianarison, R.M.; Giacoma, C.; Gamba, M. Female Indris Determine the Rhythmic Structure of the Song and Sustain a Higher Cost When the Chorus Size Increases. Curr. Zool. 2019, 65, 89–97. [Google Scholar] [CrossRef] [Green Version]
- Kirk, E.C.; Gosselin-Ildari, A.D. Cochlear Labyrinth Volume and Hearing Abilities in Primates. Anat. Rec. Adv. Integr. Anat. Evol. Biol. 2009, 292, 765–776. [Google Scholar] [CrossRef] [PubMed]
- O’Shea, K.; Nash, R. An Introduction to Convolutional Neural Networks. arXiv 2015, arXiv:1511.08458. [Google Scholar] [CrossRef]
- Ketkar, N. Introduction to Keras. In Deep Learning with Python: A Hands-on Introduction; Ketkar, N., Ed.; Apress: Berkeley, CA, USA, 2017; pp. 97–111. ISBN 978-1-4842-2766-4. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for Simplicity: The All Convolutional Net. arXiv 2014, arXiv:1412.6806. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sunrise and Sunset Times in 18°56′48″ S, 48°27′33″ E. Available online: https://www.timeanddate.com/sun/@-18.9469,48.4592 (accessed on 7 December 2022).
- Blumstein, D.T.; Mennill, D.J.; Clemins, P.; Girod, L.; Yao, K.; Patricelli, G.; Deppe, J.L.; Krakauer, A.H.; Clark, C.; Cortopassi, K.A.; et al. Acoustic monitoring in terrestrial environments using microphone arrays: Applications, technological considerations and prospectus. J. Appl. Ecol. 2011, 48, 758–767. [Google Scholar] [CrossRef]
- Sierro, J.; Schloesing, E.; Pavón, I.; Gil, D. European Blackbirds Exposed to Aircraft Noise Advance Their Chorus, Modify Their Song and Spend More Time Singing. Front. Ecol. Evol. 2017, 5. [Google Scholar] [CrossRef] [Green Version]
- Dominoni, D.M.; Greif, S.; Nemeth, E.; Brumm, H. Airport Noise Predicts Song Timing of European Birds. Ecol. Evol. 2016, 6, 6151–6159. [Google Scholar] [CrossRef] [Green Version]
- Laiolo, P. Characterizing the Spatial Structure of Songbird Cultures. Ecol. Appl. 2008, 18, 1774–1780. [Google Scholar] [CrossRef] [Green Version]
- Torti, V.; Bonadonna, G.; De Gregorio, C.; Valente, D.; Randrianarison, R.M.; Friard, O.; Pozzi, L.; Gamba, M.; Giacoma, C. An Intra-Population Analysis of the Indris’ Song Dissimilarity in the Light of Genetic Distance. Sci. Rep. 2017, 7, 10140. [Google Scholar] [CrossRef] [Green Version]
- Valente, D.; De Gregorio, C.; Favaro, L.; Friard, O.; Miaretsoa, L.; Raimondi, T.; Ratsimbazafy, J.; Torti, V.; Zanoli, A.; Giacoma, C.; et al. Linguistic Laws of Brevity: Conformity in Indri indri. Anim. Cogn. 2021, 24, 897–906. [Google Scholar] [CrossRef]
- De Gregorio, C.; Carugati, F.; Estienne, V.; Valente, D.; Raimondi, T.; Torti, V.; Miaretsoa, L.; Ratsimbazafy, J.; Gamba, M.; Giacoma, C. Born to Sing! Song Development in a Singing Primate. Curr. Zool. 2021, 67, 597–608. [Google Scholar] [CrossRef]
- Clink, D.J.; Hamid Ahmad, A.; Klinck, H. Gibbons Aren’t Singing in the Rain: Presence and Amount of Rainfall Influences Ape Calling Behavior in Sabah, Malaysia. Sci. Rep. 2020, 10, 1282. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| AM 2019 Test Set | AM 2020/2021 Test Set | SM4 2020/2021 Test Set | ||||||
|---|---|---|---|---|---|---|---|---|
| TL | − | − | + | − | + | |||
| DA | − | + | − | − | + | − | − | + |
| Accuracy | 0.94 ± 0.01 | 0.90 ± 0.01 | 0.89 ± 0.01 | 0.96 ± 0.01 | 0.92 ± 0.02 | 0.92 ± 0.01 | 0.95 ± 0.01 | 0.91 ± 0.01 |
| Precision | 0.85 ± 0.04 | 0.59 ± 0.03 | 0.44 ± 0.01 | 0.81 ± 0.04 | 0.56 ± 0.04 | 0.59 ± 0.01 | 0.83 ± 0.02 | 0.52 ± 0.04 |
| Recall | 0.69 ± 0.02 | 0.82 ± 0.04 | 0.89 ± 0.02 | 0.71 ± 0.03 | 0.86 ± 0.02 | 0.75 ± 0.01 | 0.63 ± 0.03 | 0.84 ± 0.02 |
| F1 Score | 0.76 ± 0.02 | 0.69 ± 0.01 | 0.59 ± 0.01 | 0.76 ± 0.01 | 0.68 ± 0.02 | 0.66 ± 0.01 | 0.71 ± 0.01 | 0.64 ± 0.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ravaglia, D.; Ferrario, V.; De Gregorio, C.; Carugati, F.; Raimondi, T.; Cristiano, W.; Torti, V.; Hardenberg, A.V.; Ratsimbazafy, J.; Valente, D.; et al. There You Are! Automated Detection of Indris’ Songs on Features Extracted from Passive Acoustic Recordings. Animals 2023, 13, 241. https://doi.org/10.3390/ani13020241
Ravaglia D, Ferrario V, De Gregorio C, Carugati F, Raimondi T, Cristiano W, Torti V, Hardenberg AV, Ratsimbazafy J, Valente D, et al. There You Are! Automated Detection of Indris’ Songs on Features Extracted from Passive Acoustic Recordings. Animals. 2023; 13(2):241. https://doi.org/10.3390/ani13020241
Chicago/Turabian StyleRavaglia, Davide, Valeria Ferrario, Chiara De Gregorio, Filippo Carugati, Teresa Raimondi, Walter Cristiano, Valeria Torti, Achaz Von Hardenberg, Jonah Ratsimbazafy, Daria Valente, and et al. 2023. "There You Are! Automated Detection of Indris’ Songs on Features Extracted from Passive Acoustic Recordings" Animals 13, no. 2: 241. https://doi.org/10.3390/ani13020241