
Using Pruning-Based YOLOv3 Deep Learning Algorithm for Accurate Detection of Sheep Face

 ,
,
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Research Objects
2.2. Experimental Setup
2.3. Data Collection
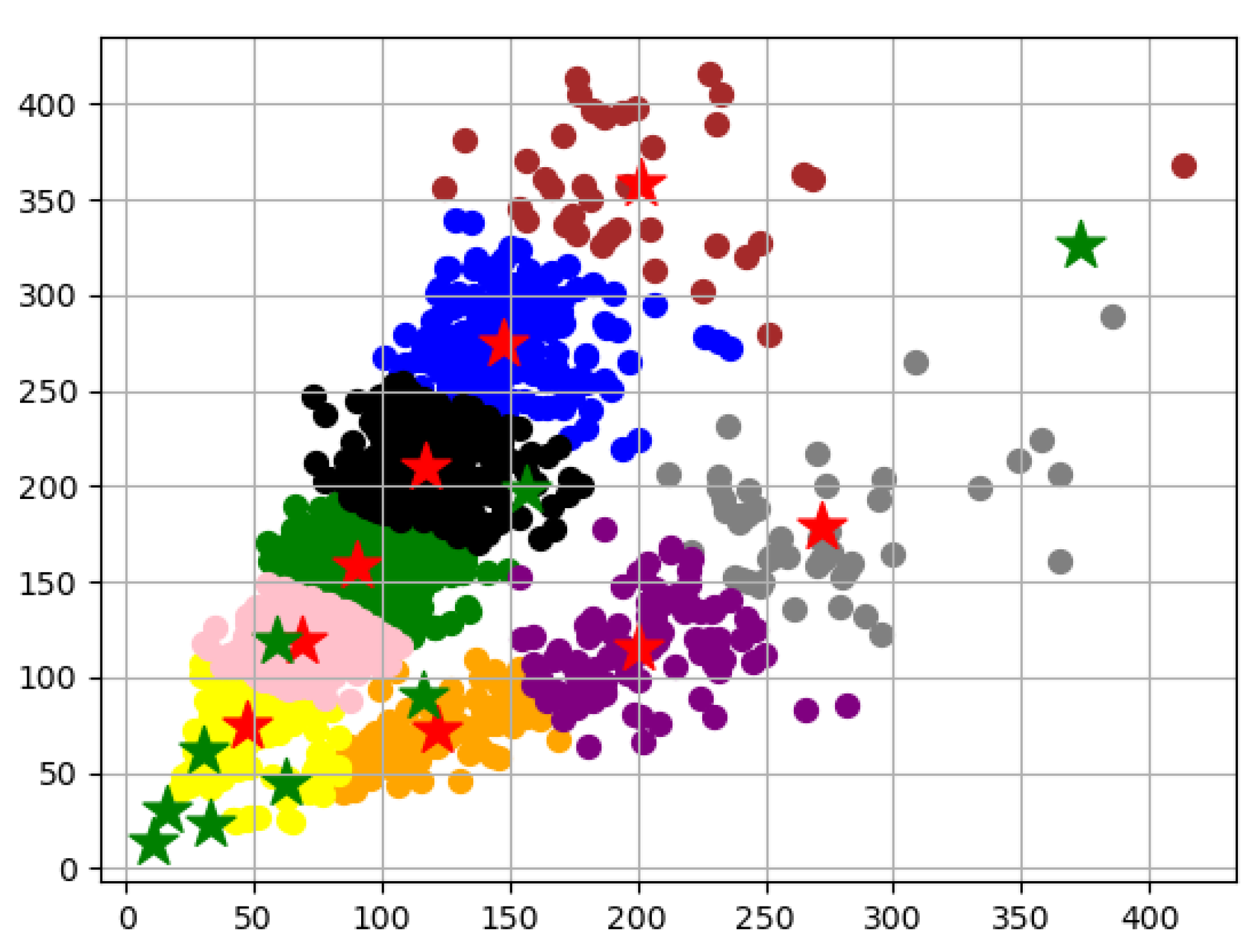
2.4. Dataset Creation and Preprocessing
3. Sheep Face Recognition Based on YOLOv3-P
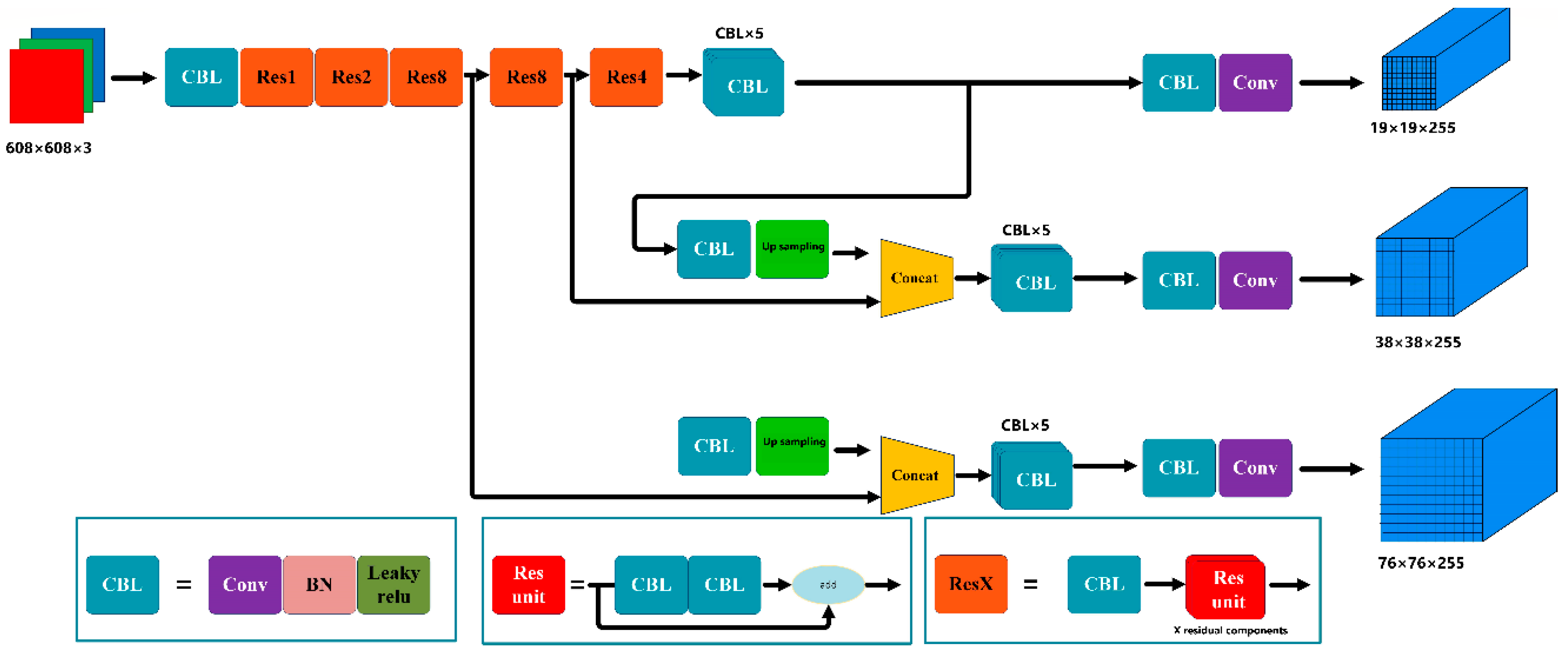
3.1. Overview of the Network Framework
3.2. Sheep Face Detection Based on YOLOv3
3.3. Compress the Model by Pruning
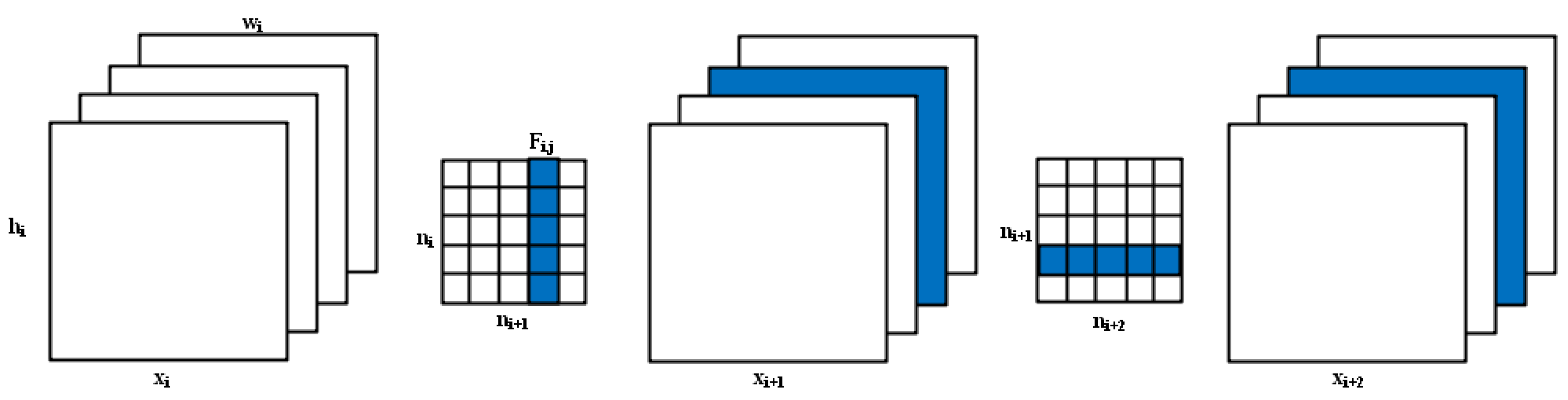
3.3.1. Channel Pruning
3.3.2. Layer Pruning
3.3.3. Combination of Layer Pruning and Channel Pruning
3.4. Experimental Evaluation Index
4. Experimental Results
4.1. Result Analysis
4.1.1. Experiment and Analysis
4.1.2. Comparison of Different Networks
4.1.3. Comparative Analysis of Different Pruning Strategies
4.2. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Scordino, J. Steller Sea Lions (Eumetopias jubatus) of Oregon and Northern California: Seasonal Haulout Abundance Patterns, Movements of Marked Juveniles, and Effects of Hot-Iron Branding on Apparent Survival of Pups at Rogue Reef. Master’s Thesis, Oregon State University, Corvallis, OR, USA, 2006. Available online: https://ir.library.oregonstate.edu/concern/graduate_thesis_or_dissertations/n870zw20m (accessed on 30 May 2021).
- Vestal, M.K.; Ward, C.E.; Doye, D.G.; Lalman, D.L. Beef cattle production and management practices and implications for educators. In Proceedings of the Agricultural and Applied Economics Association (AAEA) Conferences, Annual Meeting, Long Beach, CA, USA, 23–26 July 2006. [Google Scholar] [CrossRef]
- Leslie, E.; Hernández-Jover, M.; Newman, R.; Holyoake, P. Assessment of acute pain experienced by piglets from ear tagging, ear notching and intraperitoneal injectable transponders. Appl. Anim. Behav. Sci. 2010, 127, 86–95. [Google Scholar] [CrossRef]
- Xue, H.; Qin, J.; Quan, C.; Ren, W.; Gao, T.; Zhao, J. Open Set Sheep Face Recognition Based on Euclidean Space Metric. Math. Probl. Eng. 2021, 2021, 3375394. [Google Scholar] [CrossRef]
- Yan, H.; Cui, Q.; Liu, Z. Pig face identification based on improved AlexNet model. INMATEH Agric. Eng. 2020, 61, 97–104. [Google Scholar] [CrossRef]
- Neethirajan, S. The role of sensors, big data and machine learning in modern animal farming. Sens. Bio-Sens. Res. 2020, 29, 100367. [Google Scholar] [CrossRef]
- Schofield, D.; Nagrani, A.; Zisserman, A.; Hayashi, M.; Matsuzawa, T.; Biro, D.; Carvalho, S. Chimpanzee face recognition from videos in the wild using deep learning. Sci. Adv. 2019, 5, eaaw0736. [Google Scholar] [CrossRef] [Green Version]
- Chen, R.; Little, R.; Mihaylova, L.; Delahay, R.; Cox, R. Wildlife surveillance using deep learning methods. Ecol. Evol. 2019, 9, 9453–9466. [Google Scholar] [CrossRef] [Green Version]
- Çevik, K.K.; Mustafa, B. Body condition score (BCS) classification with deep learning. In Proceedings of the IEEE International Conference on Innovations in Intelligent Systems and Applications Conference (ASYU), Izmir, Turkey, 31 October–2 November 2019. [Google Scholar] [CrossRef]
- Guo, Y.; He, D.; Chai, L. A machine vision-based method for monitoring scene-interactive behaviors of dairy calf. Animals 2020, 10, 190. [Google Scholar] [CrossRef] [Green Version]
- Andrew, W.; Greatwood, C.; Burghardt, T. Aerial animal biometrics: Individual friesian cattle recovery and visual identification via an autonomous uav with onboard deep inference. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019. [Google Scholar]
- Halachmi, I.; Guarino, M.; Bewley, J.; Pastell, M. Smart animal agriculture: Application of real-time sensors to improve animal well-being and production. Annu. Rev. Anim. Biosci. 2019, 7, 403–425. [Google Scholar] [CrossRef]
- Hansen, M.F.; Smith, M.L.; Smith, L.N.; Salter, M.G.; Baxter, E.M.; Farish, M.; Grieve, B. Towards on-farm pig face recognition using convolutional neural networks. Comput. Ind. 2018, 98, 145–152. [Google Scholar] [CrossRef]
- Barron, U.G.; Corkery, G.; Barry, B.; Butler, F.; McDonnell, K.; Ward, S. Assessment of retinal recognition technology as a biometric method for sheep identification. Comput. Electron. Agric. 2008, 60, 156–166. [Google Scholar] [CrossRef]
- Andrew, W.; Gao, J.; Mullan, S.; Campbell, N.; Dowsey, A.W.; Burghardt, T. Visual identification of individual Holstein-Friesian cattle via deep metric learning. Comput. Electron. Agric. 2021, 185, 106133. [Google Scholar] [CrossRef]
- Billah, M.; Wang, X.; Yu, J.; Jiang, Y. Real-time goat face recognition using convolutional neural network. Comput. Electron. Agric. 2022, 194, 106730. [Google Scholar] [CrossRef]
- Chen, P.H.; Lin, C.J.; Schölkopf, B. A tutorial on ν-support vector machines. Appl. Stoch. Models Bus. Ind. 2005, 21, 111–136. [Google Scholar] [CrossRef]
- Tharwat, A.; Gaber, T.; Hassanien, A.E. Cattle identification based on muzzle images using gabor features and SVM classifier. In Proceedings of the International Conference on Advanced Machine Learning Technologies and Applications, Cairo, Egypt, 28–30 November 2014. [Google Scholar] [CrossRef]
- Bovik, A.C. The Essential Guide to Image Processing; Academic Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Rusk, C.P.; Blomeke, C.R.; Balschweid, M.A.; Elliot, S.J.; Baker, D. An evaluation of retinal imaging technology for 4-H beef and sheep identification. J. Ext. 2006, 44, 5FEA7. [Google Scholar]
- Hou, J.; Yang, H.; Connor, T.; Gao, J.; Wang, Y.; Zeng, Y.; Zhang, J.; Huang, J.; Zheng, B.; Zhou, S. Identification of animal individuals using deep learning: A case study of giant panda. Biol. Conserv. 2020, 242, 108414. [Google Scholar] [CrossRef]
- Salama, A.; Hassanien, A.E.; Fahmy, A. Sheep identification using a hybrid deep learning and bayesian optimization approach. IEEE Access 2019, 7, 31681–31687. [Google Scholar] [CrossRef]
- Corkery, G.P.; Gonzales-Barron, U.A.; Butler, F.; Mc Donnell, K.; Ward, S. A preliminary investigation on face recognition as a biometric identifier of sheep. Trans. Asabe 2007, 50, 313–320. [Google Scholar] [CrossRef]
- Yang, H.; Zhang, R.; Robinson, P. Human and sheep facial landmarks localization by triplet interpolated features. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016. [Google Scholar] [CrossRef] [Green Version]
- Ma, C.; Sun, X.; Yao, C.; Tian, M.; Li, L. Research on Sheep Recognition Algorithm Based on Deep Learning in Animal Husbandry. J. Phys. Conf. Ser. 2020, 1651, 012129. [Google Scholar] [CrossRef]
- Hitelman, A.; Edan, Y.; Godo, A.; Berenstein, R.; Lepar, J.; Halachmi, I. Biometric identification of sheep via a machine-vision system. Comput. Electron. Agric. 2022, 194, 106713. [Google Scholar] [CrossRef]
- Nasirahmadi, A.; Sturm, B.; Olsson, A.C.; Jeppsson, K.H.; Müller, S.; Edwards, S.; Hensel, O. Automatic scoring of lateral and sternal lying posture in grouped pigs using image processing and Support Vector Machine. Comput. Electron. Agric. 2019, 156, 475–481. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Processing 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–23 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]
- Mozer, M.; Smolensky, P.; Touretzky, D. Advances in Neural Information Processing Systems; Morgan Kaufman: Burlington, MA, USA, 1989. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. arXiv 2016, arXiv:1608.08710. [Google Scholar] [CrossRef]
- Gong, Y.; Liu, L.; Yang, M.; Bourdev, L. Compressing deep convolutional networks using vector quantization. arXiv 2014, arXiv:1412.6115. [Google Scholar] [CrossRef]
- Dettmers, T. 8-bit approximations for parallelism in deep learning. arXiv 2015, arXiv:1511.04561. [Google Scholar] [CrossRef]
- Lebedev, V.; Ganin, Y.; Rakhuba, M.; Oseledets, I.; Lempitsky, V. Speeding-up convolutional neural networks using fine-tuned cp-decomposition. arXiv 2014, arXiv:1412.6553. [Google Scholar] [CrossRef]
- Oseledets, I.V. Tensor-train decomposition. Siam J. Sci. Comput. 2011, 33, 2295–2317. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv 2016, arXiv:1612.03928. [Google Scholar] [CrossRef]
- Fan, S.; Liang, X.; Huang, W.; Zhang, V.J.; Pang, Q.; He, X.; Li, L.; Zhang, C. Real-time defects detection for apple sorting using NIR cameras with pruning-based YOLOV4 network. Comput. Electron. Agric. 2022, 193, 106715. [Google Scholar] [CrossRef]
- Lv, X.; Hu, Y. Compression of YOLOv3-spp Model Based on Channel and Layer Pruning. In Intelligent Equipment, Robots, and Vehicles; Springer: Singapore, 2021; pp. 164–173. [Google Scholar]
- Shao, Y.; Zhang, X.; Chu, H.; Zhang, X.; Zhang, D.; Rao, Y. AIR-YOLOv3: Aerial Infrared Pedestrian Detection via an Improved YOLOv3 with Network Pruning. Appl. Sci. 2022, 12, 3627. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | mAP | Precision | Recall | F1-Score | Parameters |
|---|---|---|---|---|---|
| Faster R-CNN | 90.20% | 80.63% | 90% | 84.00% | 108 MB |
| SSD | 98.73% | 96.85% | 96.25% | 96.35% | 100 MB |
| YOLOv3 | 95.30% | 82.90% | 95.70% | 88.70% | 235 MB |
| YOLOv4 | 91.15% | 88.70% | 88.00% | 87.50% | 244 MB |
| Model | mAP | Precision | Recall | F1-Score | Parameters | Speed |
|---|---|---|---|---|---|---|
| Prune_channel | 96.80% | 89.50% | 97.00% | 92.80% | 69.9 MB | 8.9 ms |
| Prune_layer | 95.70% | 89.50% | 95.70% | 91.90% | 132 MB | 9.2 ms |
| Prune_channel_layer | 97.20% | 89.90% | 97.50% | 93.30% | 61.5 MB | 8.7 ms |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, S.; Liu, T.; Wang, H.; Hasi, B.; Yuan, C.; Gao, F.; Shi, H. Using Pruning-Based YOLOv3 Deep Learning Algorithm for Accurate Detection of Sheep Face. Animals 2022, 12, 1465. https://doi.org/10.3390/ani12111465
Song S, Liu T, Wang H, Hasi B, Yuan C, Gao F, Shi H. Using Pruning-Based YOLOv3 Deep Learning Algorithm for Accurate Detection of Sheep Face. Animals. 2022; 12(11):1465. https://doi.org/10.3390/ani12111465
Chicago/Turabian StyleSong, Shuang, Tonghai Liu, Hai Wang, Bagen Hasi, Chuangchuang Yuan, Fangyu Gao, and Hongxiao Shi. 2022. "Using Pruning-Based YOLOv3 Deep Learning Algorithm for Accurate Detection of Sheep Face" Animals 12, no. 11: 1465. https://doi.org/10.3390/ani12111465