1. Introduction
In recent years, extensive research has focused on the motion control of mobile robots [
1,
2,
3,
4]. As a typical omnidirectional mobile robot, the mecanum-wheeled mobile robot (MWMR) has been widely used in family service and industrial production fields because of its flexibility in confined spaces and capability of moving to any direction without a turning radius [
5]. Four specially made mecanum wheels are symmetrically mounted around the mobile robot, while each mecanum wheel is separately driven by a motor. Some rollers are angled at 45° to the hub circumference of a mecanum wheel [
6], which enables the MWMR to move in sideways.
Mobile robot formation aims to control multiple mobile robots to synchronously move in a certain formation pattern, which is one of the hotspot problems in the study of robotics [
7,
8]. There are some typical techniques for solving the formation control problem, for example, the leader–follower method, virtual structure method, and behavior-based methods [
9,
10,
11,
12,
13]. Formation control of multiple MWMRs has also attracted extensive attention from researchers. Aditya et al. [
14] established the collaborative kinematics of the MWMR’s system to realize the cooperative transformation of large-scale goods in formation. Mehrez et al. [
15] established a formation set-point stabilization of MWMRs using the model predictive control (MPC) method without terminal constraints. However, the MWMR actually is a complex mechanic system with kinematics, dynamics, and input saturation constraints. Treating it as a mass point or only considering the kinematics will reduce the control accuracy.
The MWMR has the complexity of nonlinearity, uncertainty, and external disturbances in its dynamics. Additionally, the input saturation constraints can also bring great challenge to the precise control of MWMRs [
16,
17]. Alakshendra et al. [
18] derived a generalized dynamic equation of a MWMR using Newton–Euler method. Sun et al. [
19] presented the integrated kinematic–dynamic model of MWMRs, and the formation control of MWMRs under changing topologies was considered [
20,
21]. However, uncertainties and unmodeled disturbances can usually bring up the instability in the control system [
22,
23]. Thus, it is highly necessary to handle the uncertainties and disturbances in the MWMRs’ formation control problem. Lu et al. [
22] employed the artificial neural network to estimate various uncertain disturbances and proposed a novel adaptive sliding mode control (SMC) method to design the trajectory tracking controller of MWMR. Zhao et al. [
23] employed a fuzzy approximator to approximate unknown dynamics and applied the fixed-time extended state observer (FTESO) to estimate external disturbances for improving the tracking accuracy of MWMR. Wang et al. [
24] proposed a robust control strategy combing the adaptive SMC method and extended state observer (ESO) to compensate for total disturbances during the formation control process of MWMRs. However, the observer-based method can only estimate the constant and slowly varying parameters. In real contexts, uncertainties and disturbances are usually time-varying parameters, which are more suitable for feedback compensation strategies. Moreover, the collision of MWMRs with obstacles and other MWMRs should be avoided to ensure the safety of the MWMRs’ formation [
25]. Potential field-based methods are often used to handle the collision avoidance [
26,
27], but these methods have the drawback of trapping in the local extremum. Barrier function-based finite-time SMC is also an effective control method for mobile robots under uncertainties and input saturations [
28,
29]. Mostafa et al. [
28] proposed an optimal adaptive barrier function-based super-twisting SMC scheme for the trajectory tracking control of parallel robots with highly complex dynamics in the presence of uncertainties and external disturbances, where the global property of the controller eliminates the reaching phase, thereby guaranteeing system stability, and the barrier function-based adaptation law removes the requirement to know the upper bounds of the external disturbances. Khalid et al. [
29] proposed an adaptive barrier function-based non-singular terminal SMC approach for the trajectory tracking of a quadrotor drone, where the non-singular terminal sliding surface was employed to ensure the finite time convergence of the linear sliding surfaces and tracking errors.
Distributed model predictive control (DMPC) is an effective method to handle the distributed cooperative control problem with dynamic uncertainties and disturbances [
30,
31], and can be applied to formation control of mobile robots [
32,
33,
34,
35]. Using the distributed framework, robots can share information with neighbors and solve their own local optimal control commands based on the prediction model. Zhao et al. [
32] proposed a DMPC framework for autonomous underwater vehicles (AUV) through combining the alternating direction multiplier (ADMM) solver with feedforward compensation to deal with certain disturbances. Mario et al. [
33] proposed a DMPC law for differentially driven robots and ensured system asymptotic stability. Qin et al. [
34] proposed a Nash-based DMPC strategy for the formation control of multiple mobile robots, and the optimal control input is solved by a primal–dual neural network. However, there are few studies on MWMR formation control using the DMPC method. Wang et al. [
24] applied linear MPC in the outer loop kinematic controller of MWMRs, but dynamics were not considered. Xiao et al. [
35] proposed the self-triggered organized formation (STOF) system by combing the DMPC framework and the consensus protocol to achieve the smoother control performance for the MWMR’s formation, but the collision avoidance and obstacle avoidance were not considered.
The particle swarm optimization (PSO) algorithm is a typical swarm intelligence optimization algorithm with the advantages of being a concise concept, having convenient implementation, high precision, and fast convergence. Benefitting from a fast convergence speed and global search capability, the PSO optimizer is more efficient and stable than traditional optimization solvers. Today, there are still many recent studies applying the PSO optimizer in solving MPC problems, achieving good results [
36,
37,
38,
39,
40,
41].
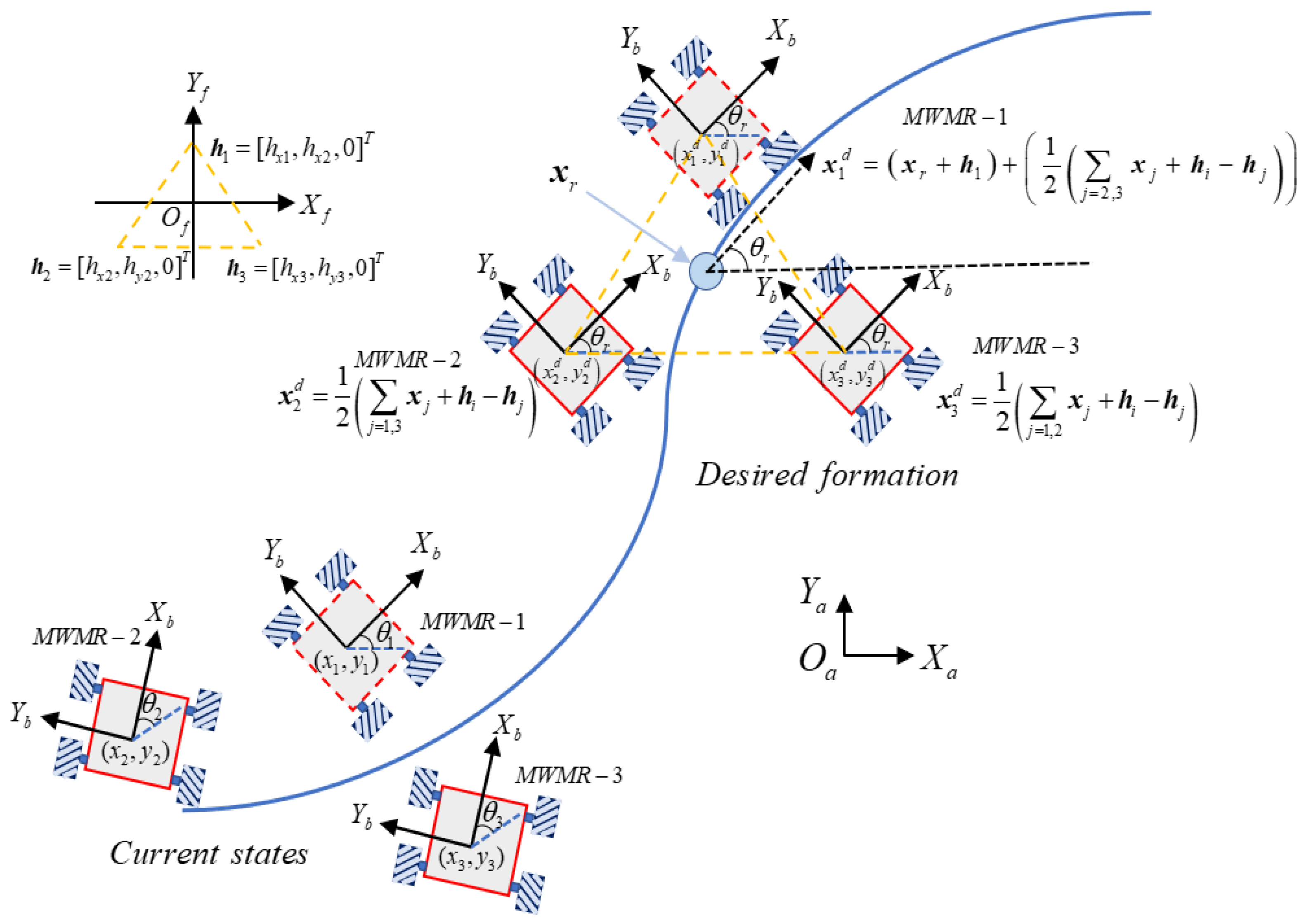
Although lots of existing works have been available, the issue of formation control of MWMRs has not been well addressed yet when simultaneously considering various physical constraints, including kinematics/dynamics constraints, uncertainties, and disturbances, as well as collision and obstacle avoidance. In this paper, taking into account the model physical constraints and uncertainties, the collision-free trajectory tracking control of the MWMR’s formation is solved using a closed-loop DMPC strategy. Based on the leader-follower framework, the formation predictive model, which describes both the kinematics and dynamics of MWMRs with the uncertainties and external disturbances, is established. Under the distributed protocol, the MWMR can share the information among itself and its neighbors. A finite-horizon optimal control problem is assigned to each MWMR to minimize the objective/cost function consisting of formation maintenance, trajectory tracking, and collision avoidance terms. The PSO algorithm is introduced to find feasible optimal control solutions for each MWMR. Then, a novel double closed-loop disturbance feedback controller is proposed to compensate for model uncertainties and external disturbances. Theoretical analysis assures the stability of the proposed distributed formation control approach. The main contribution of the paper is described in the following part:
- (1)
The leader–follower predictive model of MWMR formation, considering the kinematics and dynamics with the uncertainties and external disturbances, is established.
- (2)
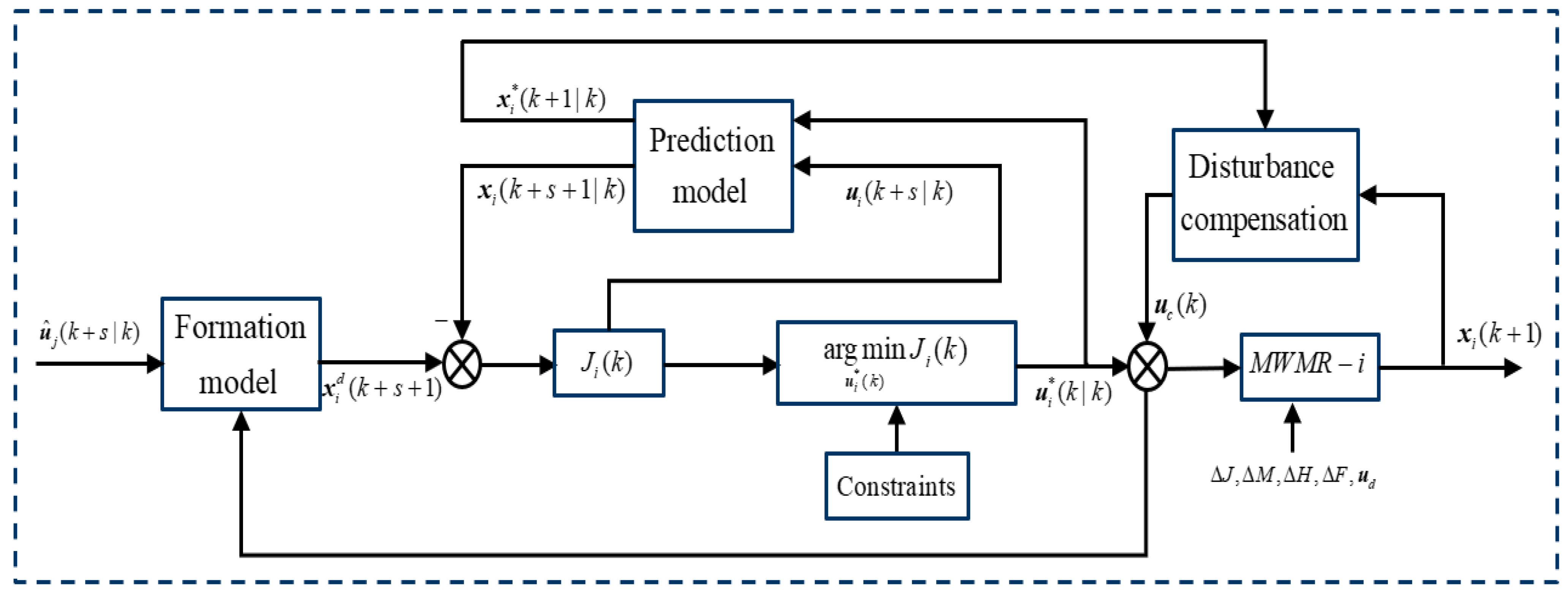
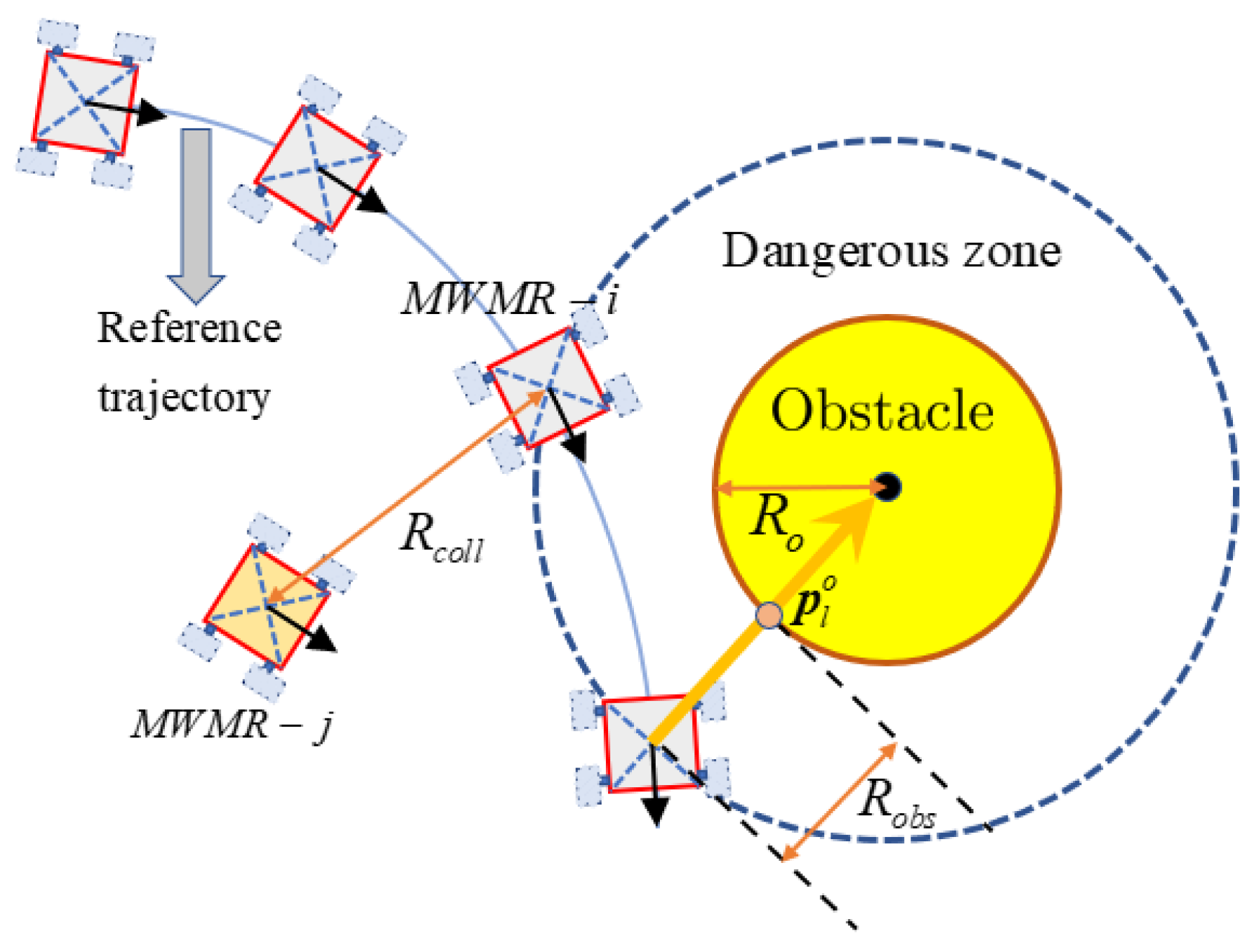
By combining information from itself and its neighbors, each MWMR is given its own finite-horizon optimal control problem within the proposed framework of DMPC, whose objective/cost function compromises of formation maintenance, trajectory tracking, and collision avoidance terms simultaneously, is established.
- (3)
A PSO-based control solver is used to find the feasible solutions to these finite-horizon optimal control problems, which shows better performance than traditional solvers.
- (4)
A novel double closed-loop feedback compensation controller is developed to compensate for model uncertainties and external disturbances in real-time.
The rest of this paper is constructed as follows.
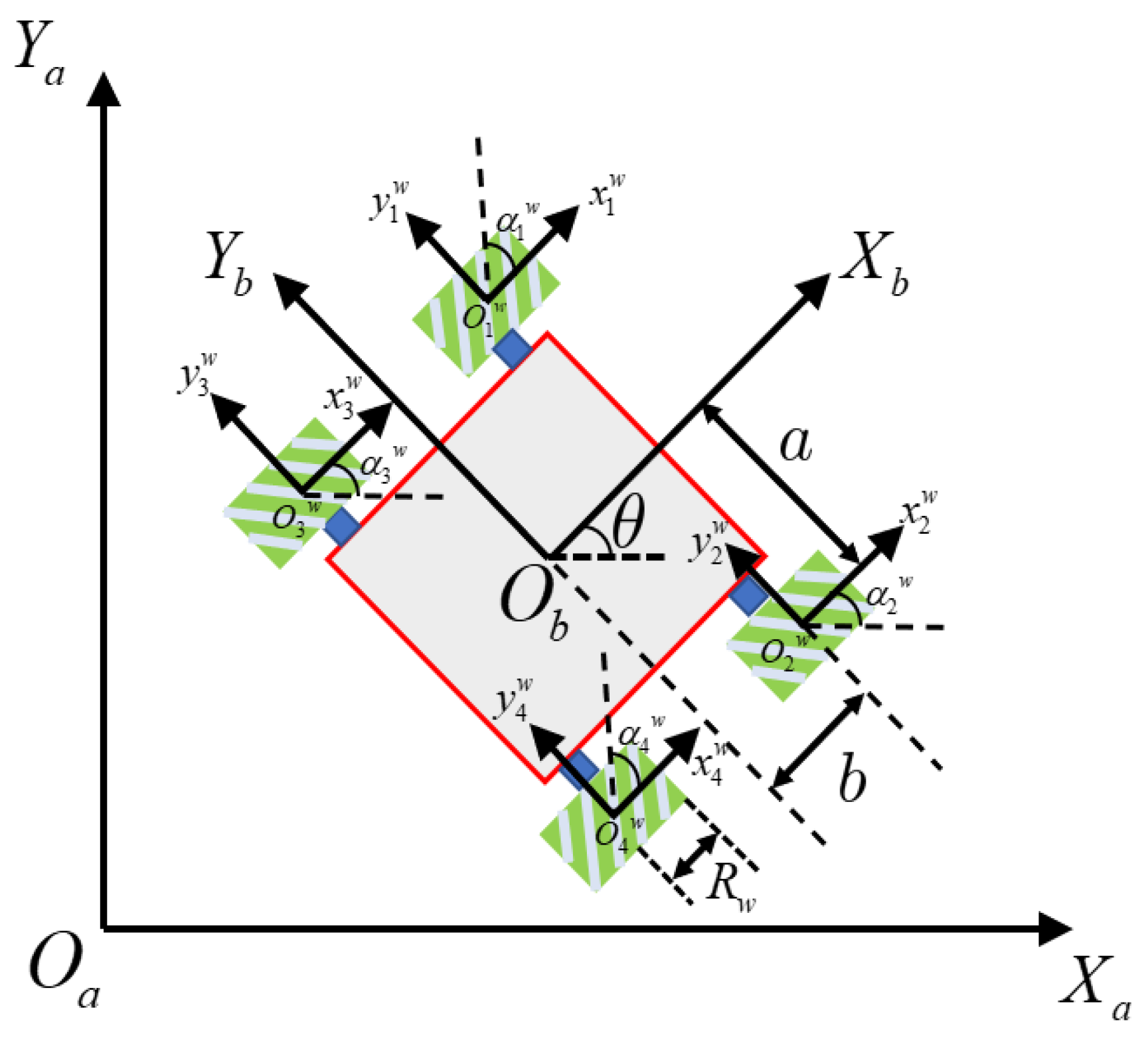
Section 2 describes the problem description and definition of the MWMR’s formation.
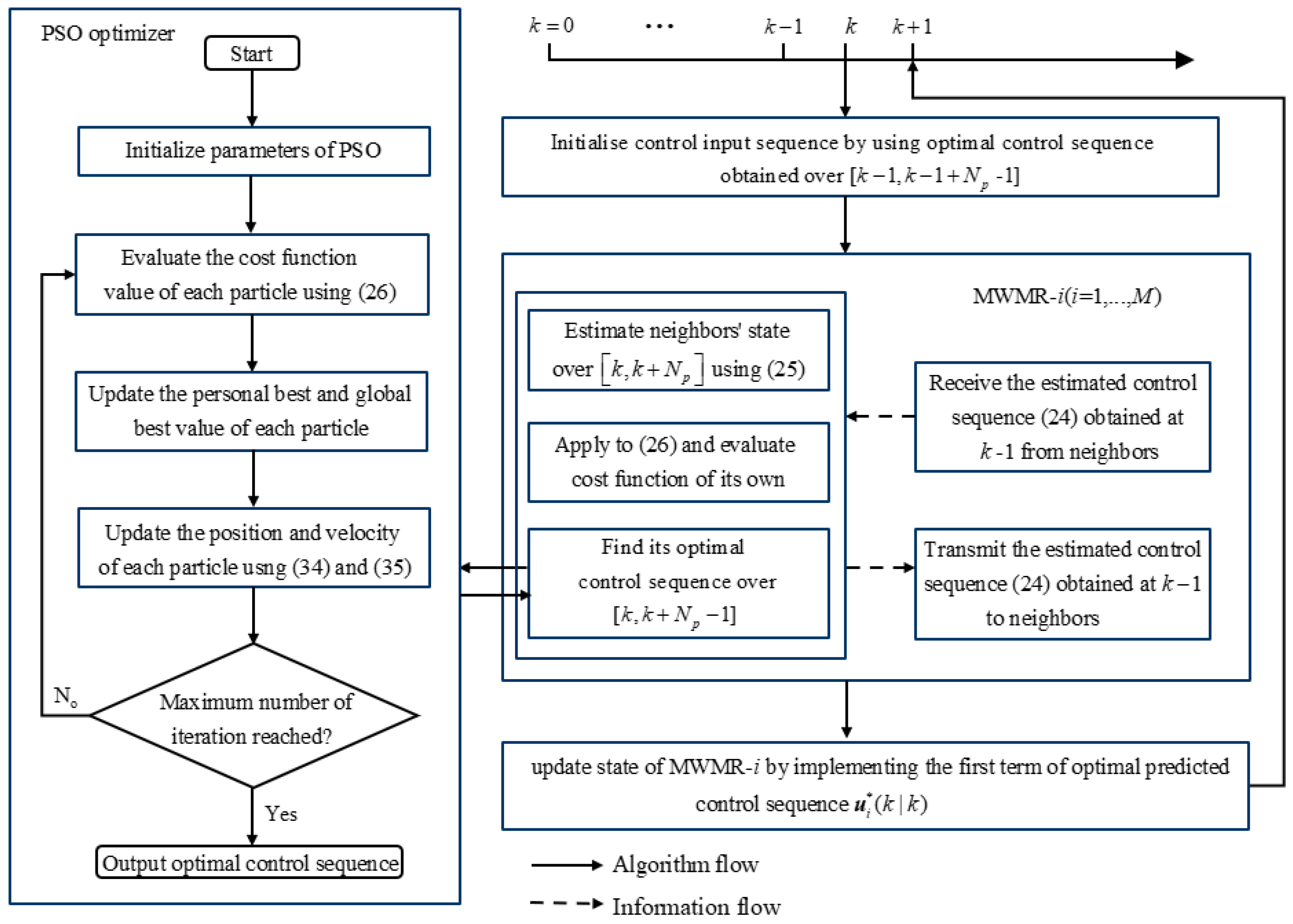
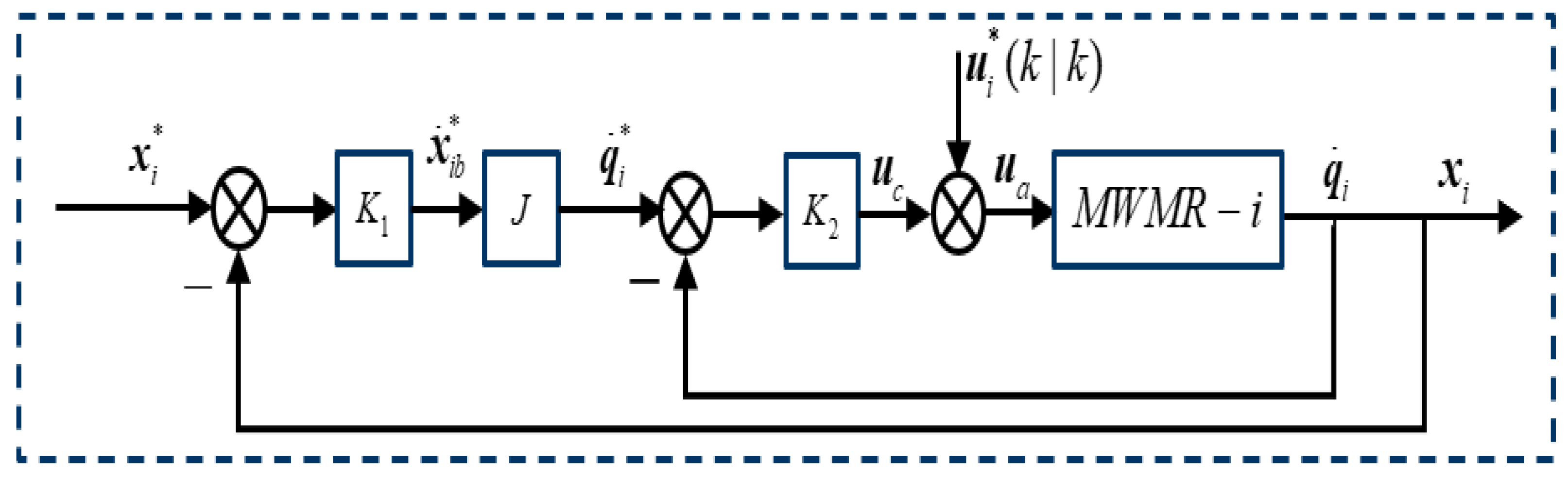
Section 3 presents the proposed PSO-based DMPC controller for the MWMR’s formation in detail, including the DMPC framework, PSO optimizer, double closed-loop feedback compensator, as well as the stability analysis. In
Section 4, numerical results demonstrate the superiority and effectiveness of our proposed strategy.
Section 5 gives the concluding remarks finally.
4. Experimental Results
In order to evaluate the effectiveness of our proposed PSO-DMPC-based control method, three simulation scenes for formation trajectory-tracking of the MWMRs considering the various physical constraints are performed in the MATLAB environment. The control effect of PSO-DMPC is compared with the SQP-DMPC and traditional PID controllers. SQP is a typical optimizer that is often used to solve MPC problems in recent research [
42,
43,
44,
45], while PID is the typical and widely-used control method [
46,
47,
48]. Each MWMR uses the DC brushless gear motor to drive the four mecanum wheels. The definition and values of the main parameters of the MWMR are shown in
Table 1.
The parameters in the uncertain terms ΔM, ΔJ, and ΔH are given as [aij]3×4, [bij]3×4, [cij]3×4, |aij| < 0.1, |bij| < 0.1, |cij| < 0.1; the uncertain terms of static friction ΔF are given as [dij]4×1, |dij| < 0.1, and the unknown time-varying input disturbances are given as . The detection range of each robot is given as Rdet = 5 m. Parameters of the DMPC are set as , , and . The feedback compensation gain matrixes are chosen as , , where , , , and are identity matrices of appropriate dimensions. The penalty gains of collision avoidance and obstacle avoidance are chosen as . The maximum and minimum output torque of the motor are set as umax = 5 N∙m and umin = 5 N∙m. The parameters in the PSO optimizer are set as Mpop = 50, Ncmax = 5, wmax = 0.9, wmin = 0.4, c1 = 2, and c2 = 2. The parameters of the SQP optimizer are set as the initial guess of (k): [uij]28×1, |uij| < umax; the maximum number of iterations Imax = 30; and termination error ϵ = 10−20. The parameters of the PID controller are set as: Kp = 15, Ki = 0.1, and Kd = 0.3.
To quantitatively illustrate the average tracking errors of the MWMRs’ formation, the following indices are introduced to evaluate the formation average tracking performance:
where
Nt is the total number of sampling steps.
,
, and
are average tracking performance along the
x and
y directions, as well as the heading angle, respectively.
Further, to illustrate the formation performance based on the relative position of MWMRs, the position consensus error is defined as follows:
4.1. Example 1 (Straight Line Formation Tracking)
In the first numerical simulation an example is used to test its ability to generate and maintain the desired formation without a change of reference direction using the proposed PSO-DMPC method. The target shape of the formation is designed as a square with a side length of 1 m.
Table 2 shows the initial states of four MWMRs.
Table 3 shows the parameter settings of the obstacles. The reference trajectory
xr is assumed to be available only to MWMR-1, and the desired line trajectory is given as:
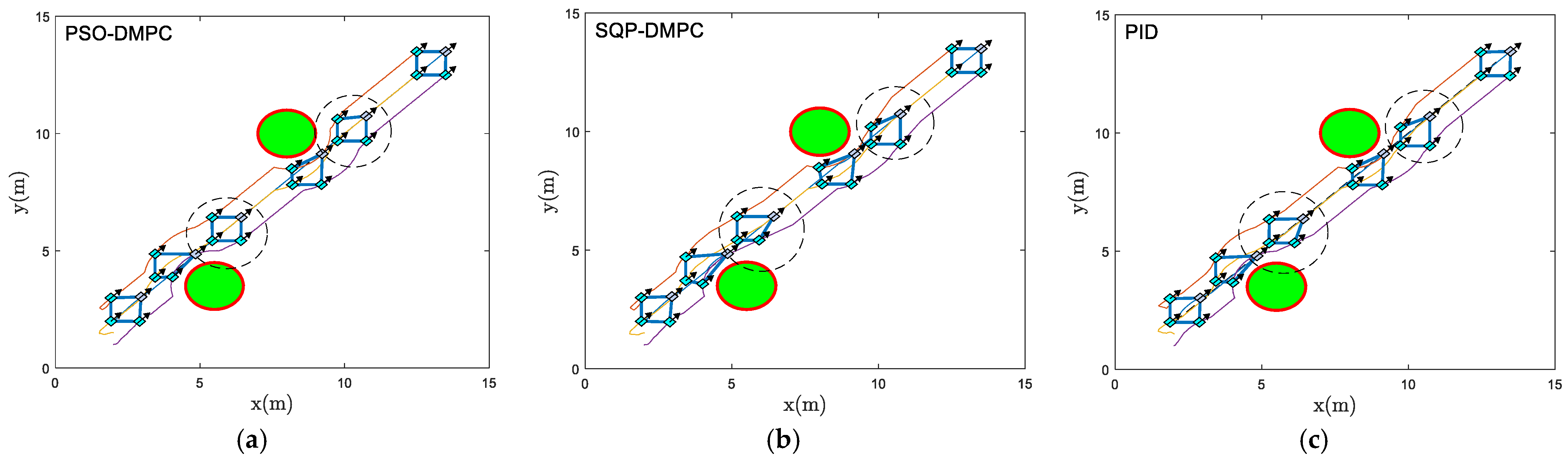
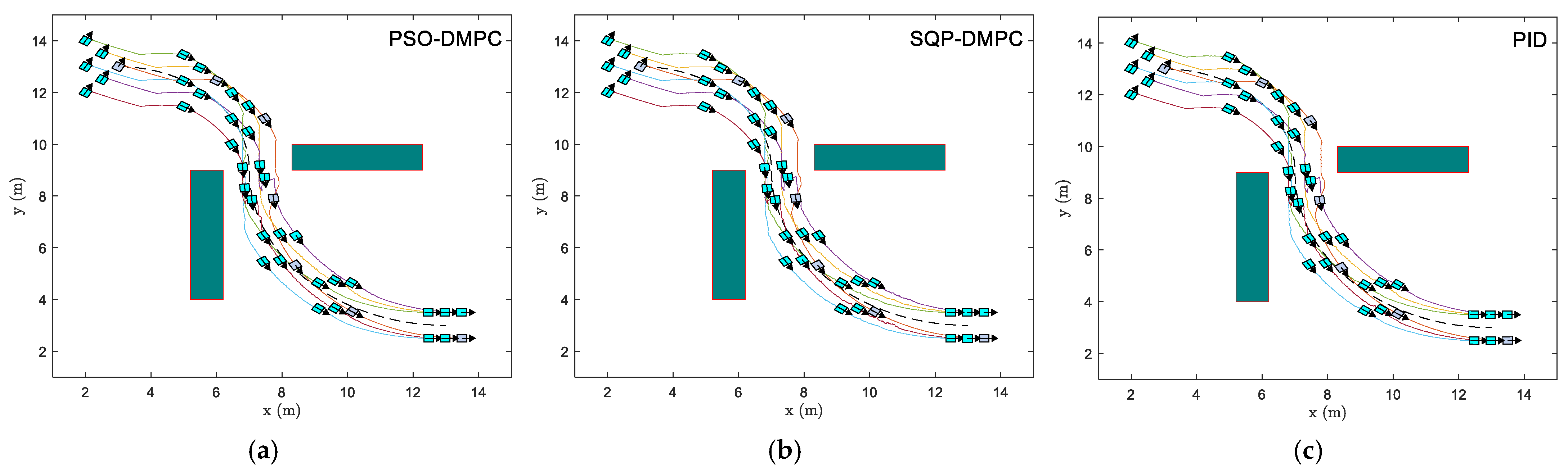
The formation trajectory-tracking results of example 1 using the traditional PID controller, the SQP-DMPC controller and PSO-DMPC controller in the x–y plane are presented in
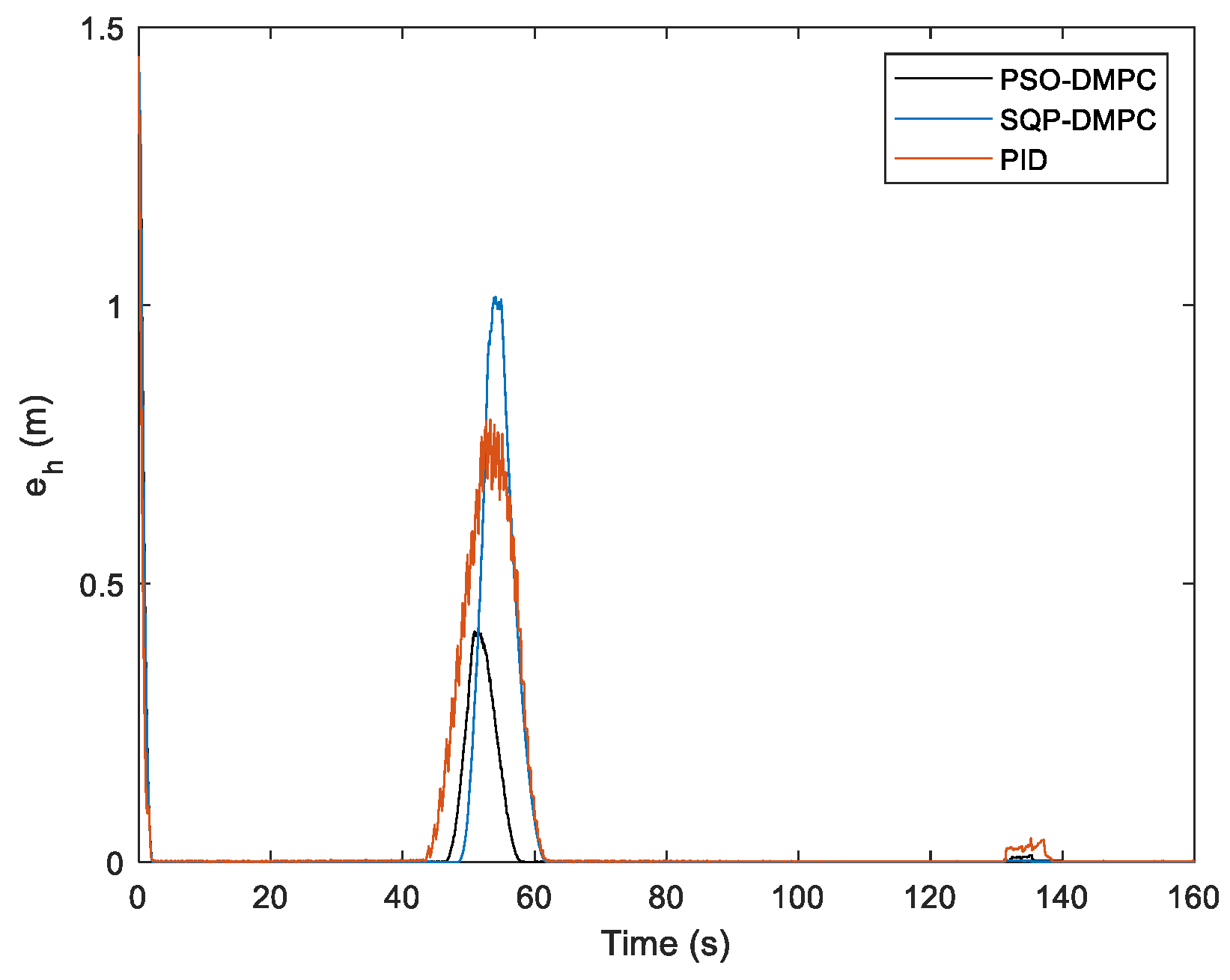
Figure 7. It can be seen that by implementing the PSO-DMPC, the formation is restored immediately after the obstacle avoidance is completed, while the SQP-DMPC and PID controllers have a transition process before restoring the initial formation. This is because PSO has a better processing ability for nonlinear obstacle avoidance and collision avoidance constraints with input limitation and has a stronger ability to find the global optimal solution. The relative distances of the three methods are presented in
Figure 8. It can be seen from
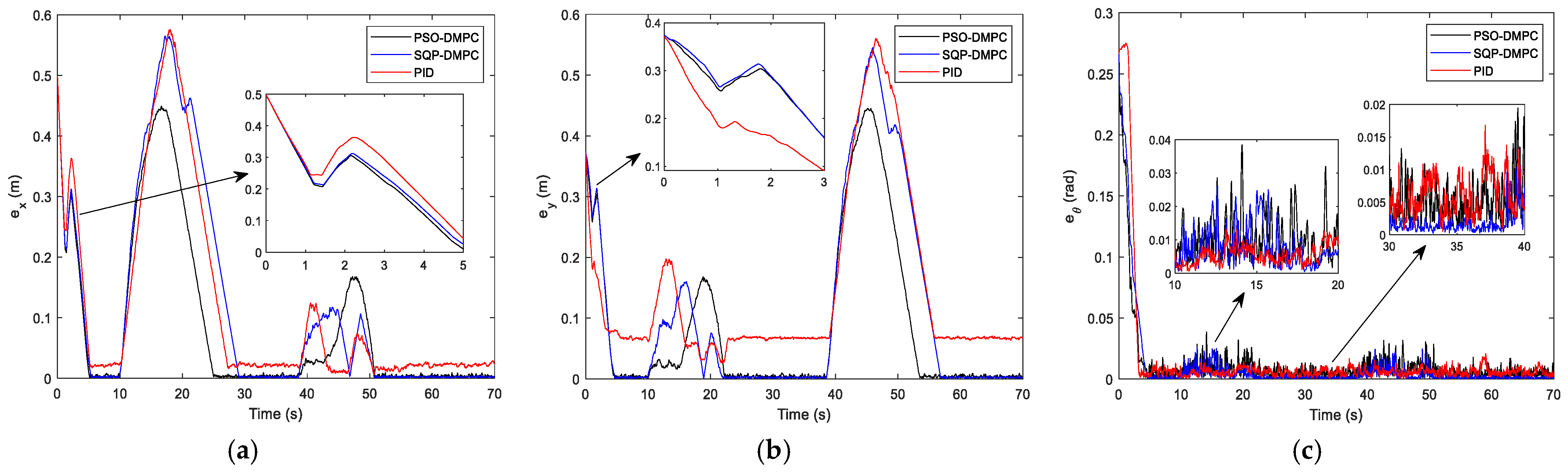
Figure 8 that the PSO-DMPC has the smallest mutual distance fluctuations when avoiding obstacles, which further shows that the quality of the optimal solution obtained via PSO is the best, and the deformation of the formation can be effectively reduced. The tracking performance along the x and y directions are shown in
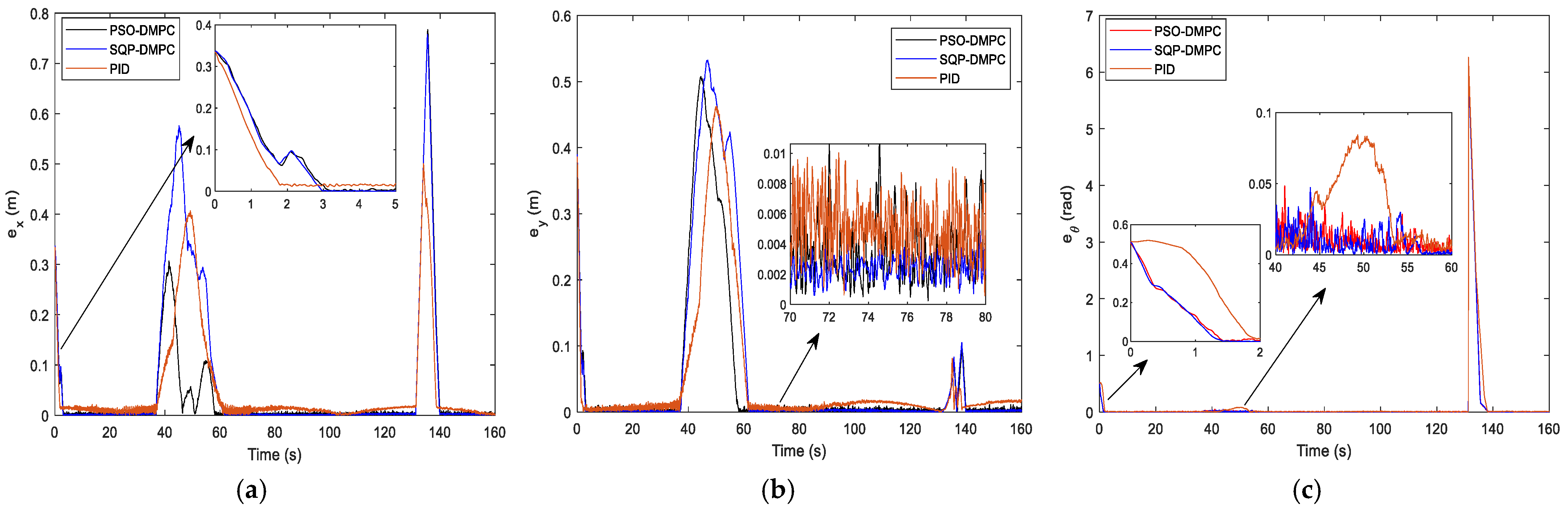
Figure 9a,b, respectively, and
Figure 9c presents the heading angle tracking results of the MWMRs. It can be seen that the DMPC method has good tracking performance but that the PID controller has large steady-state tracking errors in the x and y coordinates. This is because the recede horizon optimization of the DMPC has a stronger ability to predict and correct nonlinear systems than the PID controller. The PSO-DMPC has a faster convergence rate than the SQP-DMPC and PID controllers. The RMS errors are show in
Table 4. It can be observed that both the tracking error of the position and heading angle of the PSO-DMPC have the highest precision. The comparison of position consensus errors is presented in
Figure 10. It can be observed that position consensus errors of the three methods converge to zero after about 2.5 s, and when avoiding obstacles, the PSO-DMPC have smaller consensus errors and faster formation convergence rates than the SQP-DMPC and PID controllers. The speeds of the MWMRs are shown in
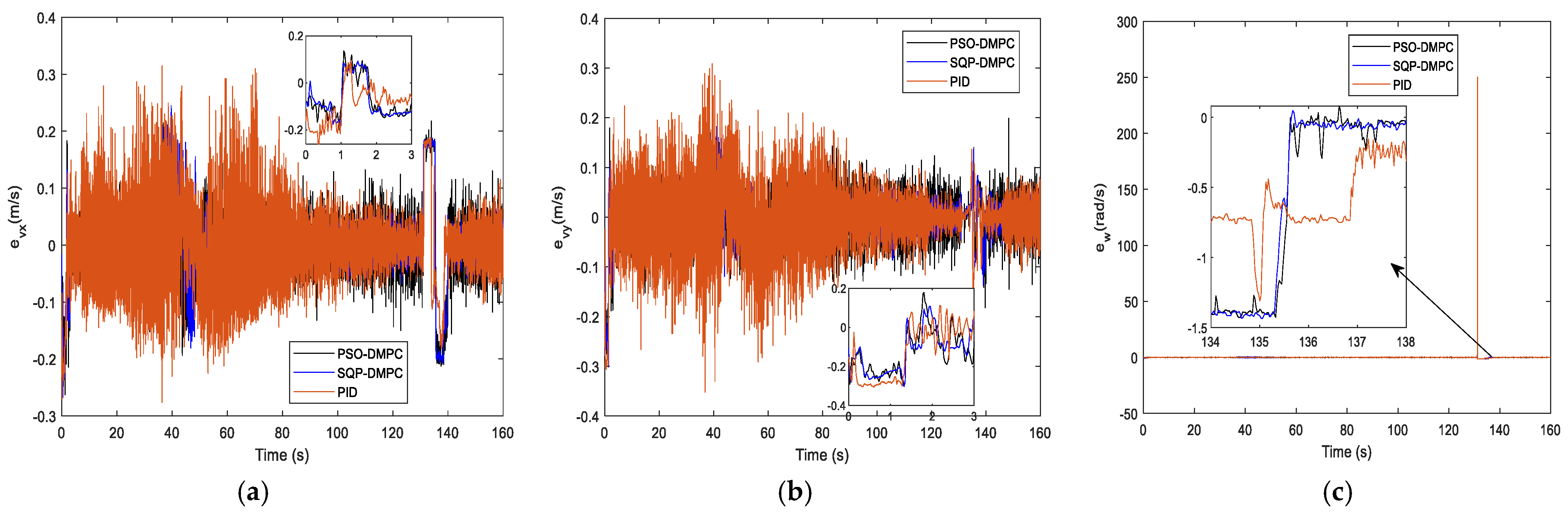
Figure 11.
4.2. Example 2 (Circle Line Formation Tracking)
In this example, a numerical simulation is performed further to test the ability to generate and maintain the desired formation with the time-varying heading angle using the proposed PSO-DMPC method. The desired formation shape is designed as an equilateral triangle with a side length of 1 m.
Table 5 shows the initial states of three MWMRs.
Table 6 shows the obstacle settings. The equation of the desired circle trajectory is given as:
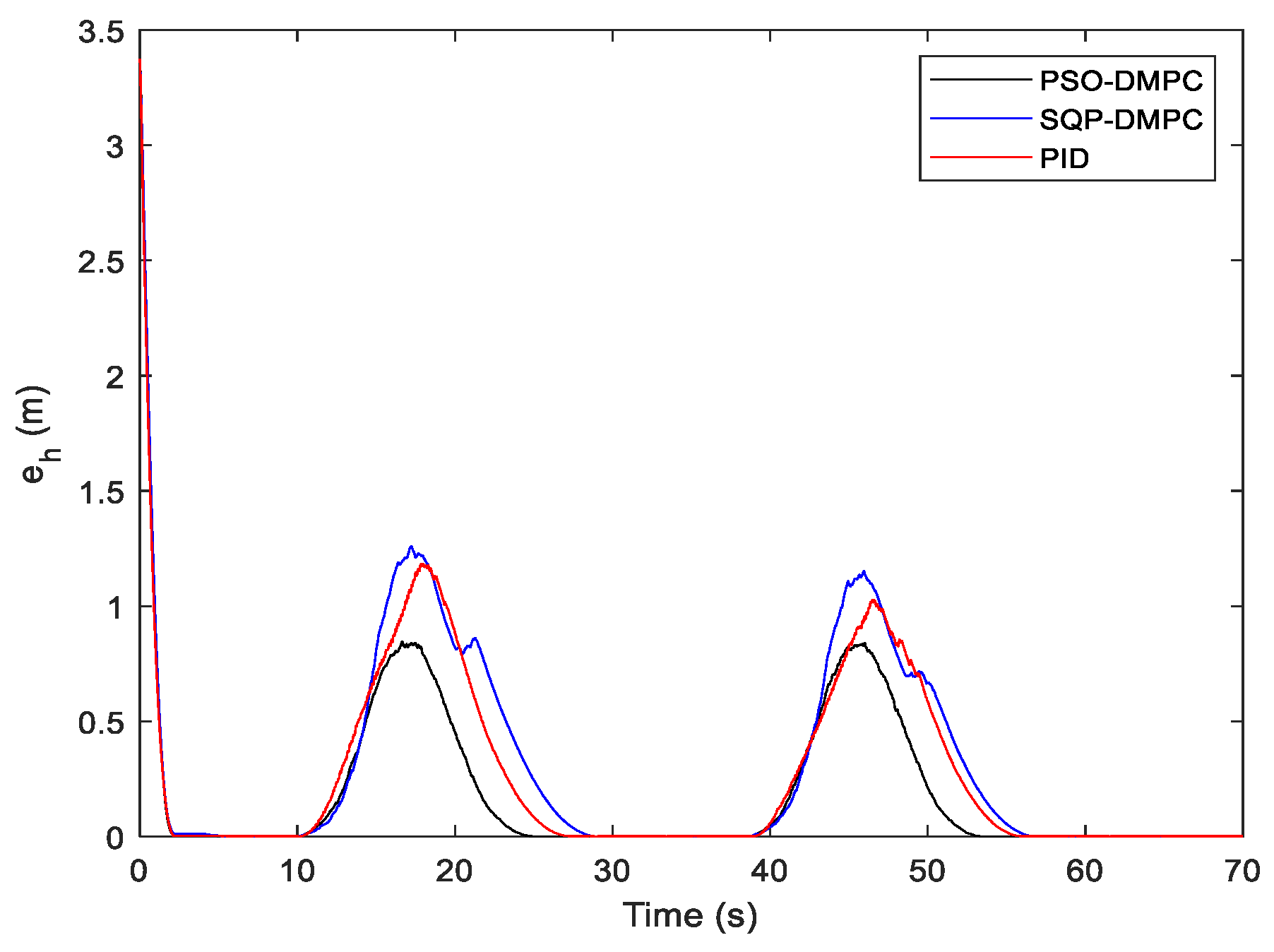
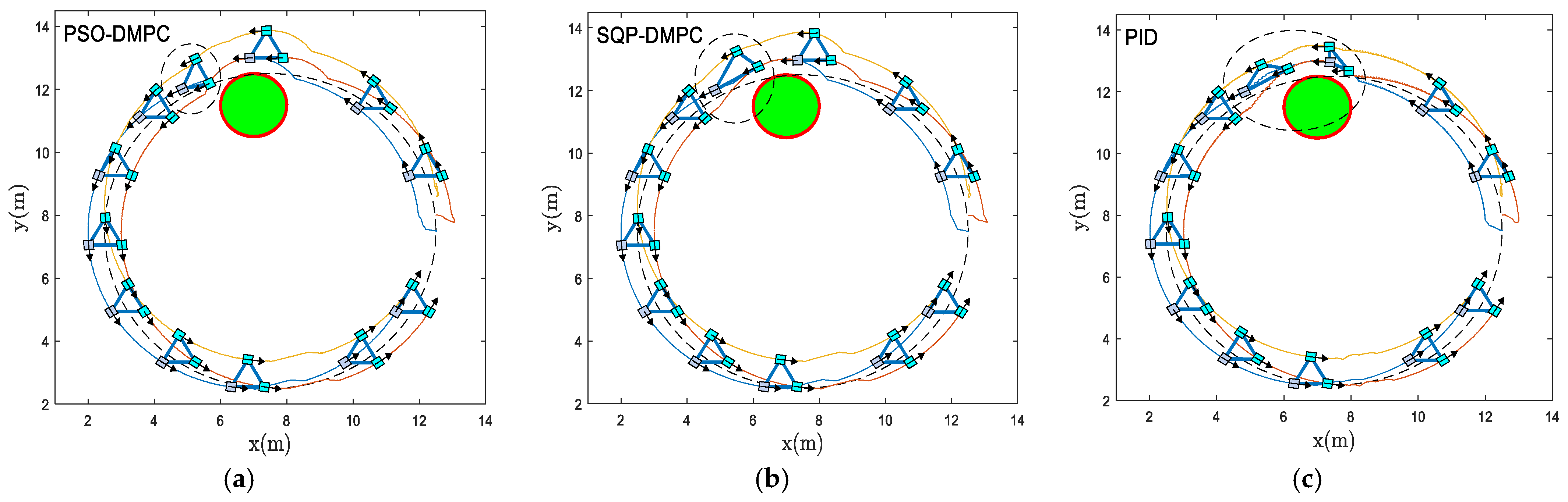
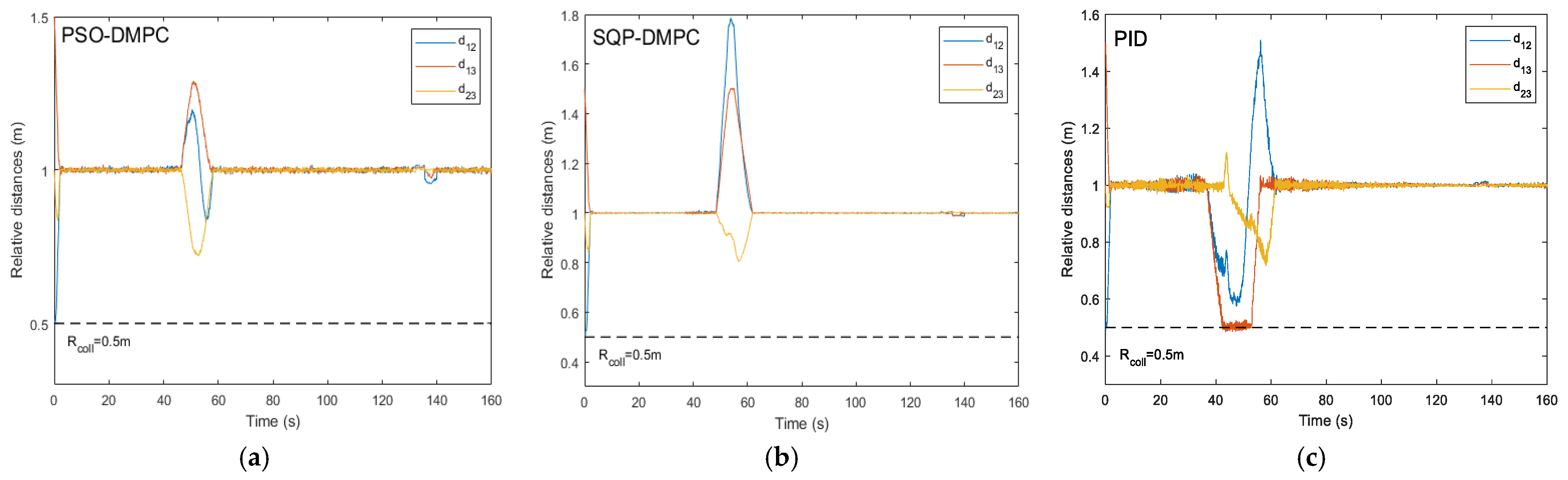
Figure 12 shows the formation trajectory-tracking results of the PSO-DMPC, SQP-DMPC, and traditional PID controller of example 2, and the relative distances of the MWMRs are shown in
Figure 13. From
Figure 12 and
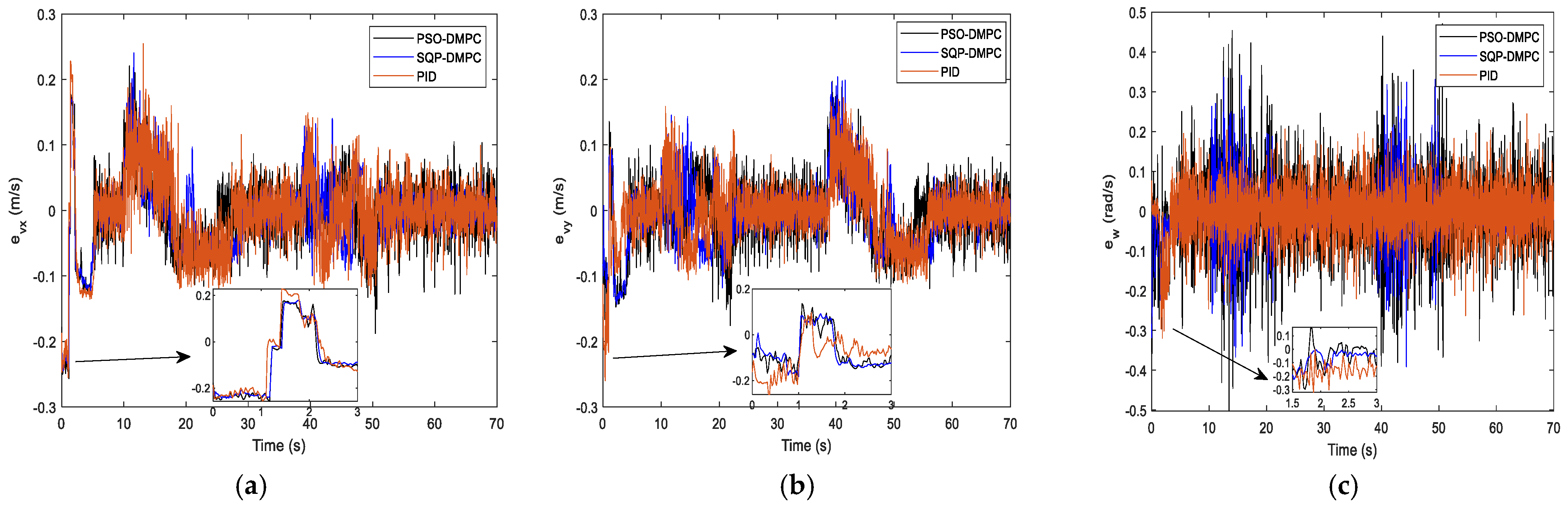
Figure 13, it can be seen that when the critical distance to the obstacle is reached, the formation deformations of the two DMPC methods are quite small, while the PID controller has a large formation deformation due to the insufficient ability to deal with constraints and disturbances. When PSO-DMPC ends the obstacle avoidance process, the SQP-DMPC and PID controllers still have larger formation deformation due to the insufficient ability to find global optimal solutions. The tracking performance along the x and y direction and the heading angle are shown in
Figure 14a–c, respectively. It can be seen that the DMPC–based controller has a bigger tracking error when avoiding obstacles than the PID controllers but has a smaller tracking error during the formation maintaining process. To further illustrate the tracking performance, the RMS errors are show in
Table 7. It can be observed that both the tracking error of the position and heading angle of the PSO-DMPC have the highest precision. The comparison of the position consensus errors is presented in
Figure 15. It can be observed that all three methods have the capability of generating and maintaining the desired formation swiftly, and when avoiding obstacles, the PSO-DMPC has a smaller position consensus error and faster formation convergence rate than the SQP-DMPC and PID controllers. In
Figure 16, the speeds of the MWMRs are shown.
4.3. Example 3 (Curve Formation Tracking with Formation Reconstruction)
Example 3 is performed to test the formation maintenance and reconstruction ability of our proposed PSO-DMPC method. The desired trajectory is an irregular segmented trajectory containing two semicircles. The desired formation shape to be maintained is designed as an isosceles triangle with a bottom length of 2 m and a height length of 1 m. The desired formation shape to be reconstructed is designed as a rectangle with both the length and width as 1 m.
Table 8 shows the initial states of six MWMRs.
Table 9 shows the parameter settings of the obstacles.
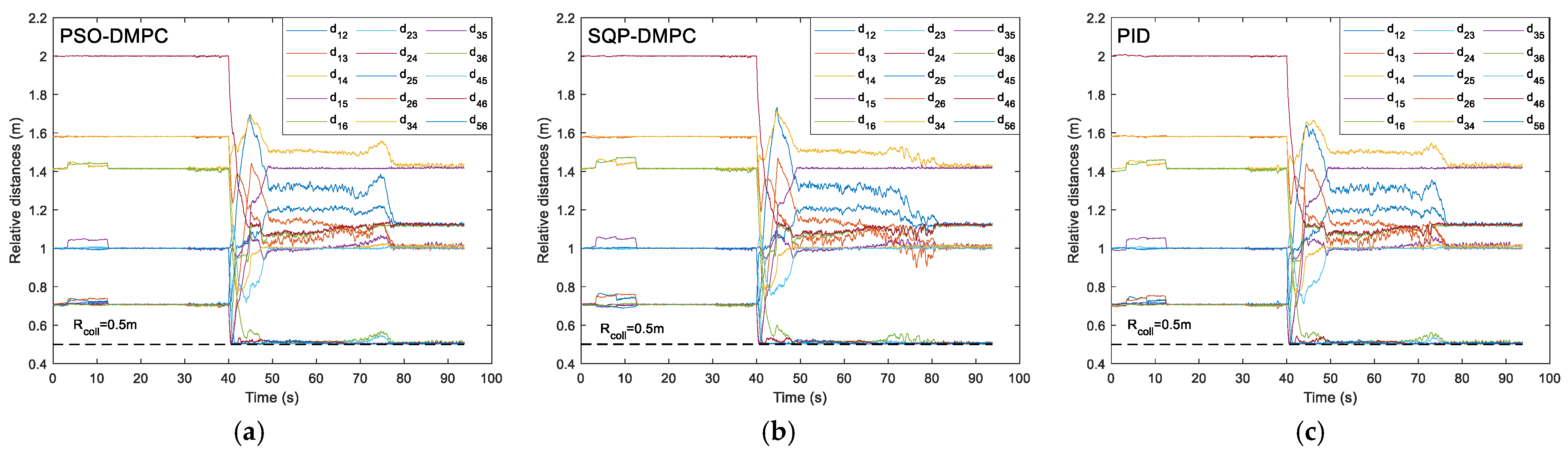
Figure 17 shows the formation trajectory-tracking results of the PSO-DMPC, SQP-DMPC, and traditional PID controller of example 3; we can see that the six MWMRs have good performance in generating, maintaining the desired formation, and tracking the desired trajectory.
Figure 18 shows the relative distances between each of the two MWMRs in the formation. It can be found that the distances can maintain the desired initial values, and no collision between MWMRs occurs.
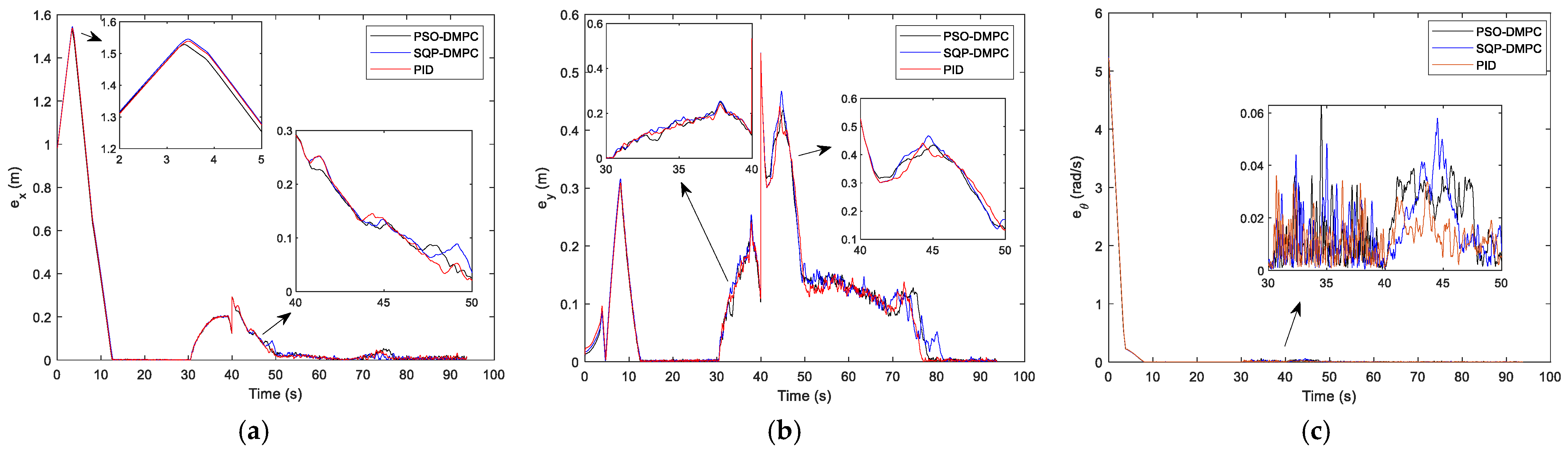
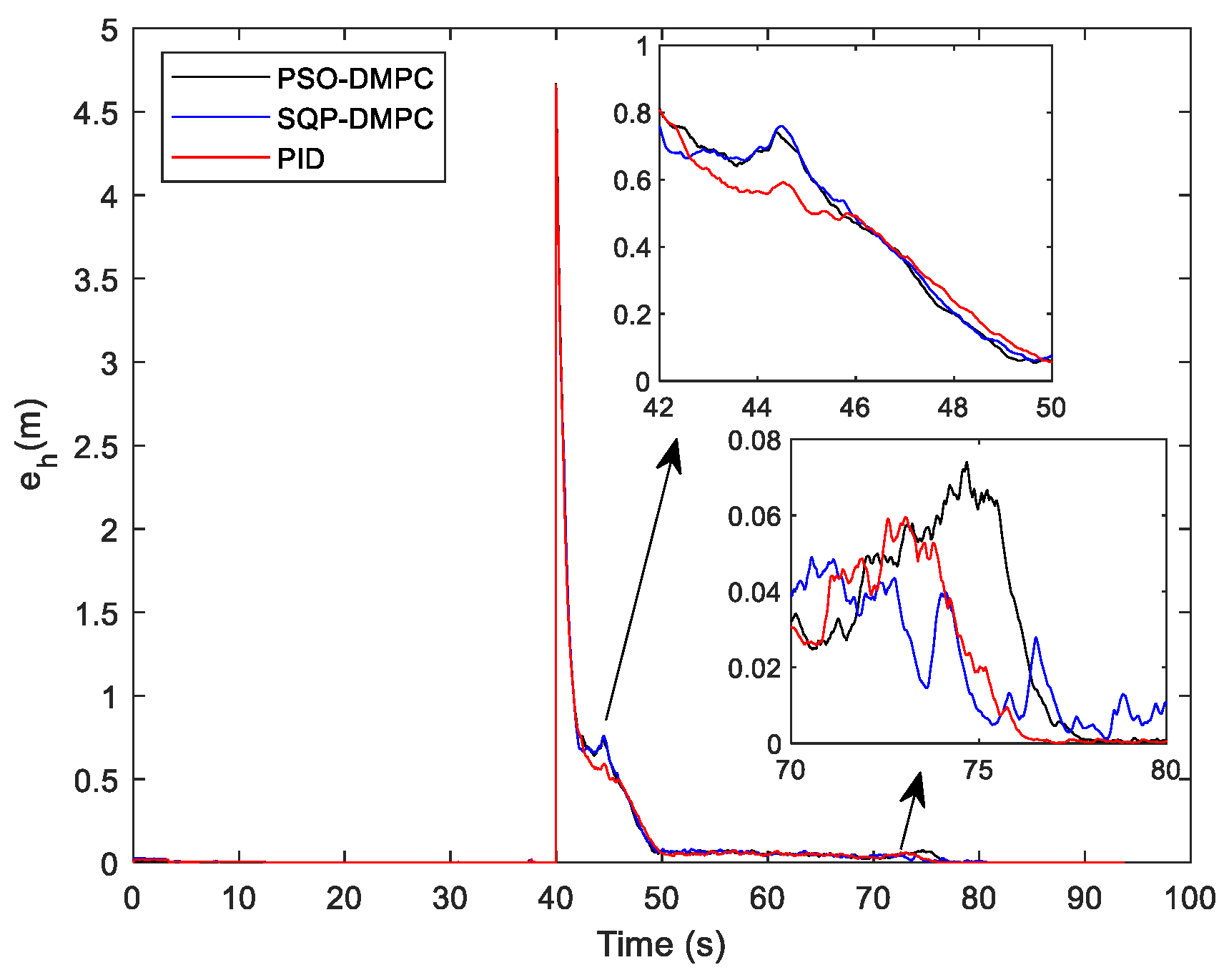
Figure 19a–c shows the tracking performance along the x and y direction and the heading angle, respectively. The comparison of the position consensus errors is presented in
Figure 20. From
Figure 19 and
Figure 20, it can be seen that the three methods perform equally well. Therefore, to further illustrate the tracking performance, the RMS errors are show in
Table 10. It can be observed that although the tracking error in the y direction of the PSO-DMPC controller is slightly less than that of the PID controller, both the tracking error of the x direction and heading angle of the PSO-DMPC have the highest precision. In
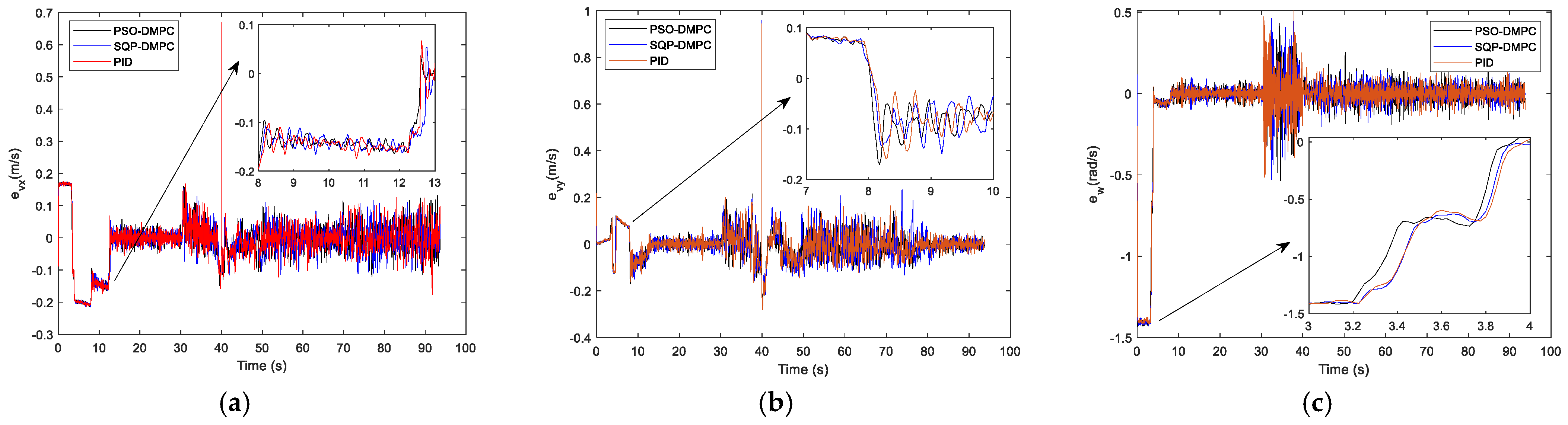
Figure 21 the speeds of the MWMRs are shown.
From the above simulation results, it can be concluded that the proposed PSO-DMPC controller has the better and more robust capability in terms of convergence time, tracking error, and consensus error than both the SQP-DMPC and PID controllers. Moreover, the simulation results also reflect the adaptability of the PSO-DMPC, which makes the designed closed-loop compensator have much better adaptive ability for the MWMRs in the presence of uncertainties and external disturbances. Therefore, the PSO-DMPC control method is effective and feasible for formation trajectory-tracking control of MWMRs with physical constraints and collision/obstacle avoidance simultaneously.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}