

BRMI-Net: Deep Learning Features and Flower Pollination-Controlled Regula Falsi-Based Feature Selection Framework for Breast Cancer Recognition in Mammography Images
 , , ,
, , ,  and
and
Abstract
:1. Introduction
1.1. Major Challenges
1.2. Major Contributions
- A fusion-based contrast enhancement technique was proposed for lesion contrast enhancement of the original images.
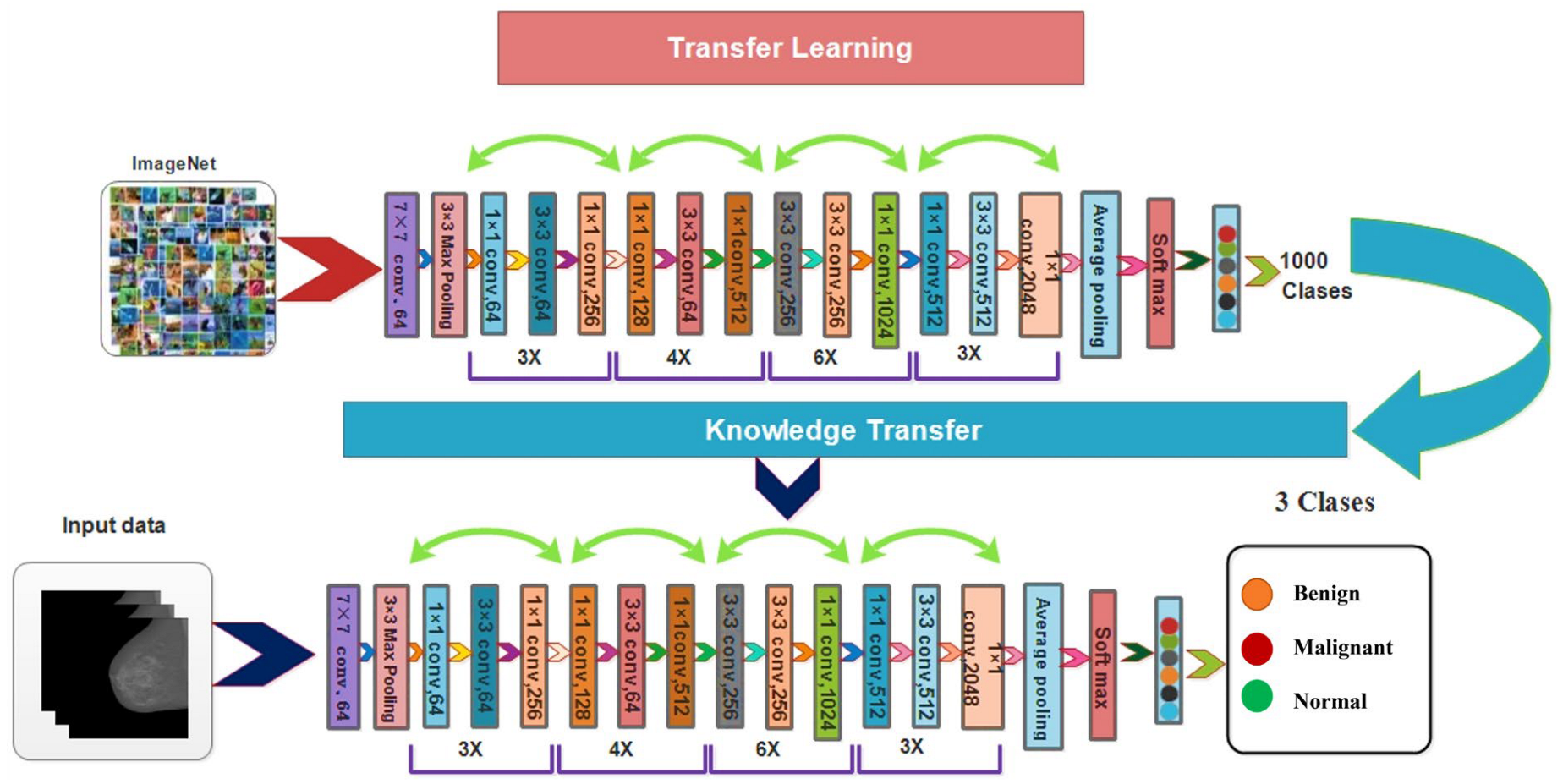
- We used a deep learning model called ResNet50 that had already been trained to perform the fine-tuning. After that, deep transfer learning with set hyper-parameters was used to train both the original and enhanced images.
- After that, a fusing method known as serial mid-value feature fusion was proposed.
- Flower pollination was proposed, using a controlled regula falsi-based best features selection method before using machine learning classifiers to classify the results.
2. Materials and Methods
2.1. Dataset Collection
2.2. Dataset Augmentation

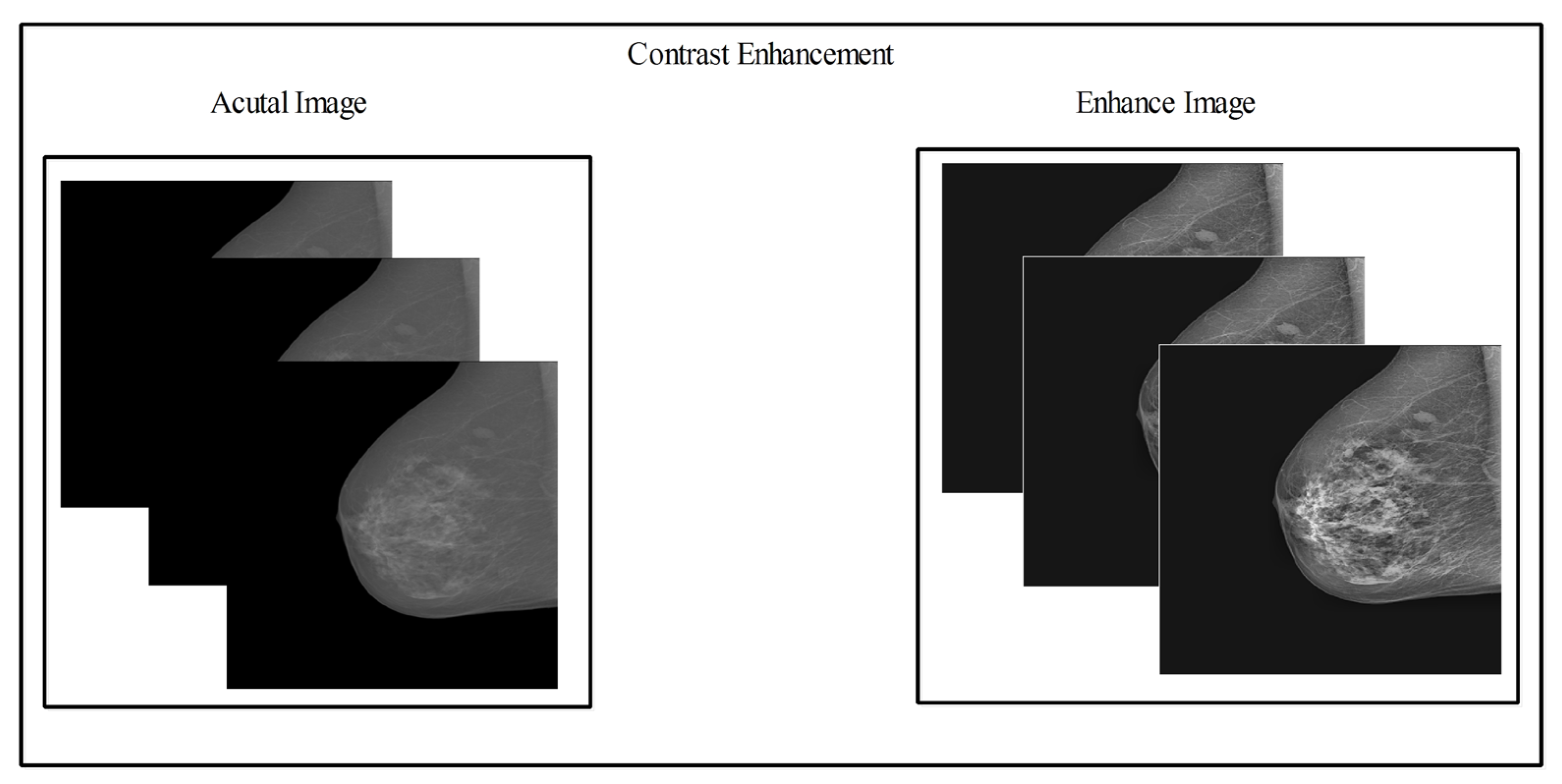
2.3. Contrast Enhancement
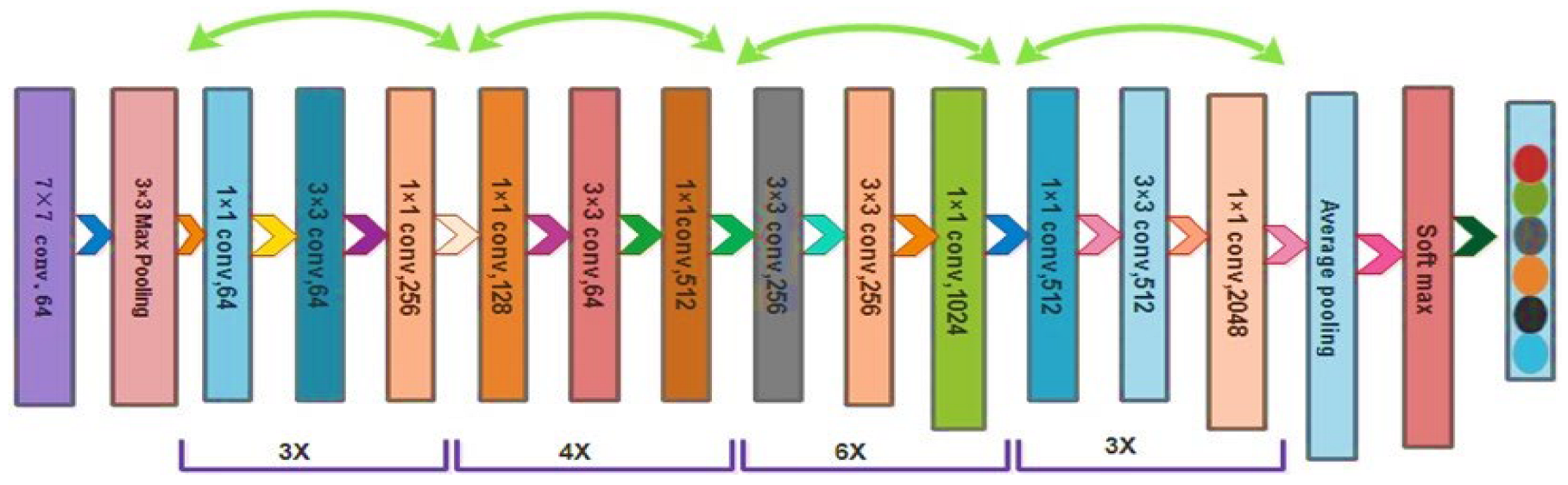
2.4. ResNet50 Deep Learning Features
2.5. Novelty 2: Serial Based Mid Value Fusion
2.6. Feature Optimization
| Algorithm 1 Proposed Breast Cancer Classification Algorithm |
| Input: Original Image Step 1: Dataset Augmentation Step 2: Contrast Enhanced using Equations (1)–(9) - The resultant Image is denoted by Step 3: Trained Deep Learning Model Step 4: Deep Features Extraction from Original and Enhanced Datasets Step 5: Features Fusion using Equations (10)–(13) - Step 6: Best Feature Selection - Objective function: minimum and maximum |
| - Initialization: A population of flower with a random solution |
| - Find the best solution: initial population |
| - Probability: |
| While for i = 1: n |
| if rand , |
| Draw step levy distribution is given as |
| Global pollination via |
| Else |
| Draw Q from a uniform distribution |
| Local pollination via L , end if Evaluate new solution end for best solution Find best root using Equations (17)–(18) Final Best Solution end while |
3. Experimental Results and Discussion
3.1. Datasets and Experiments
3.2. Experimental Setup
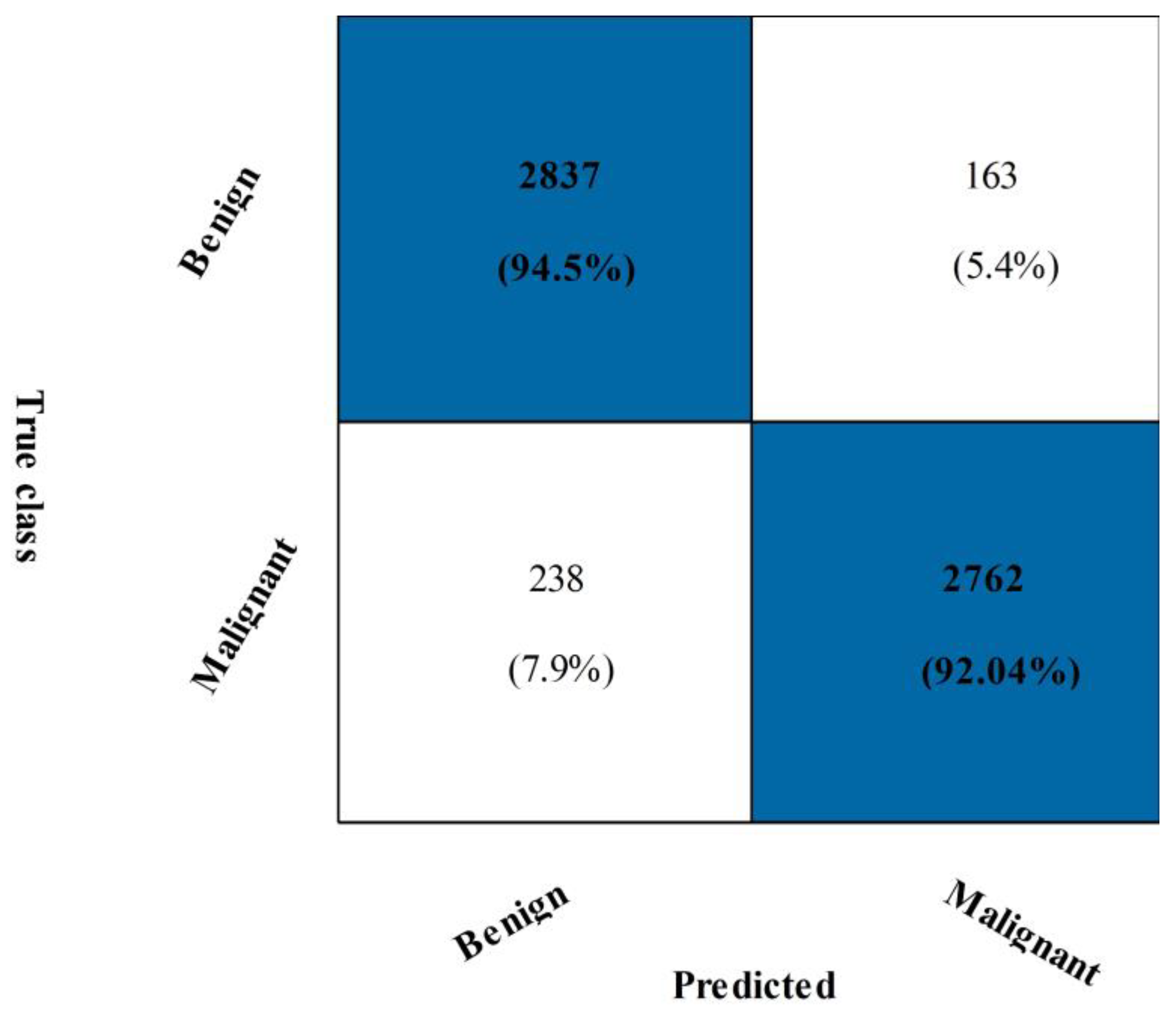
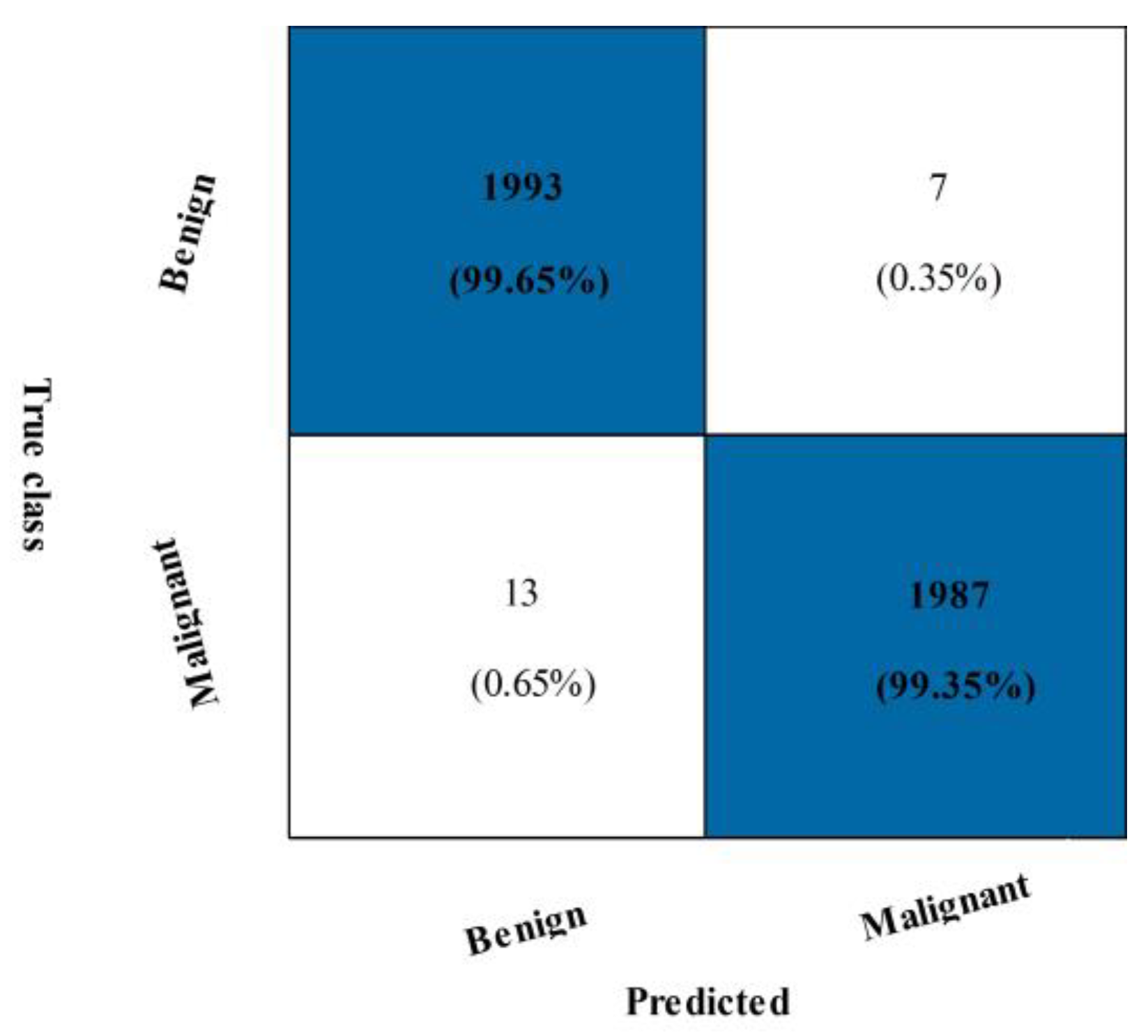
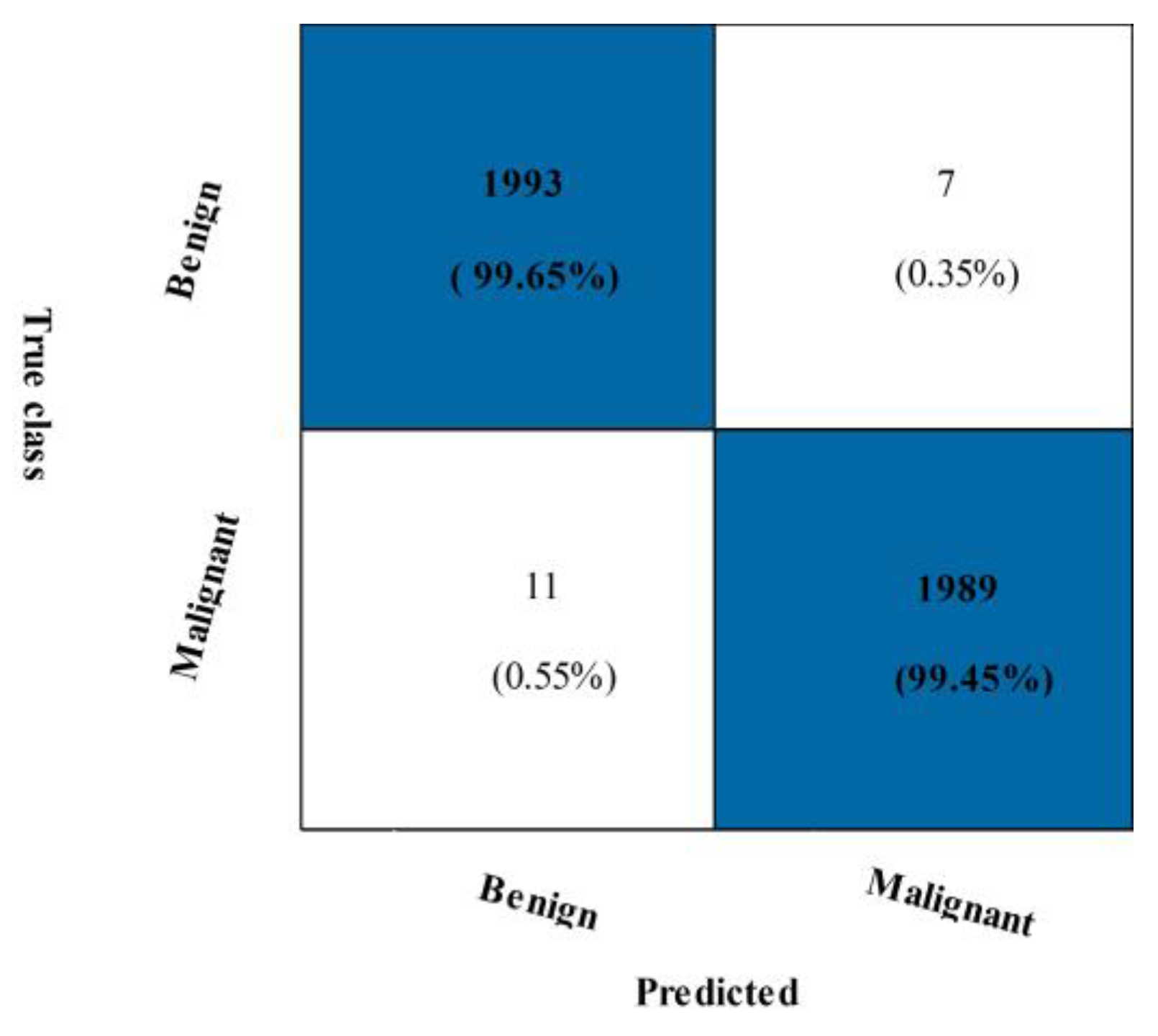
3.3. CBIS-DDSM Breast Cancer Dataset Results
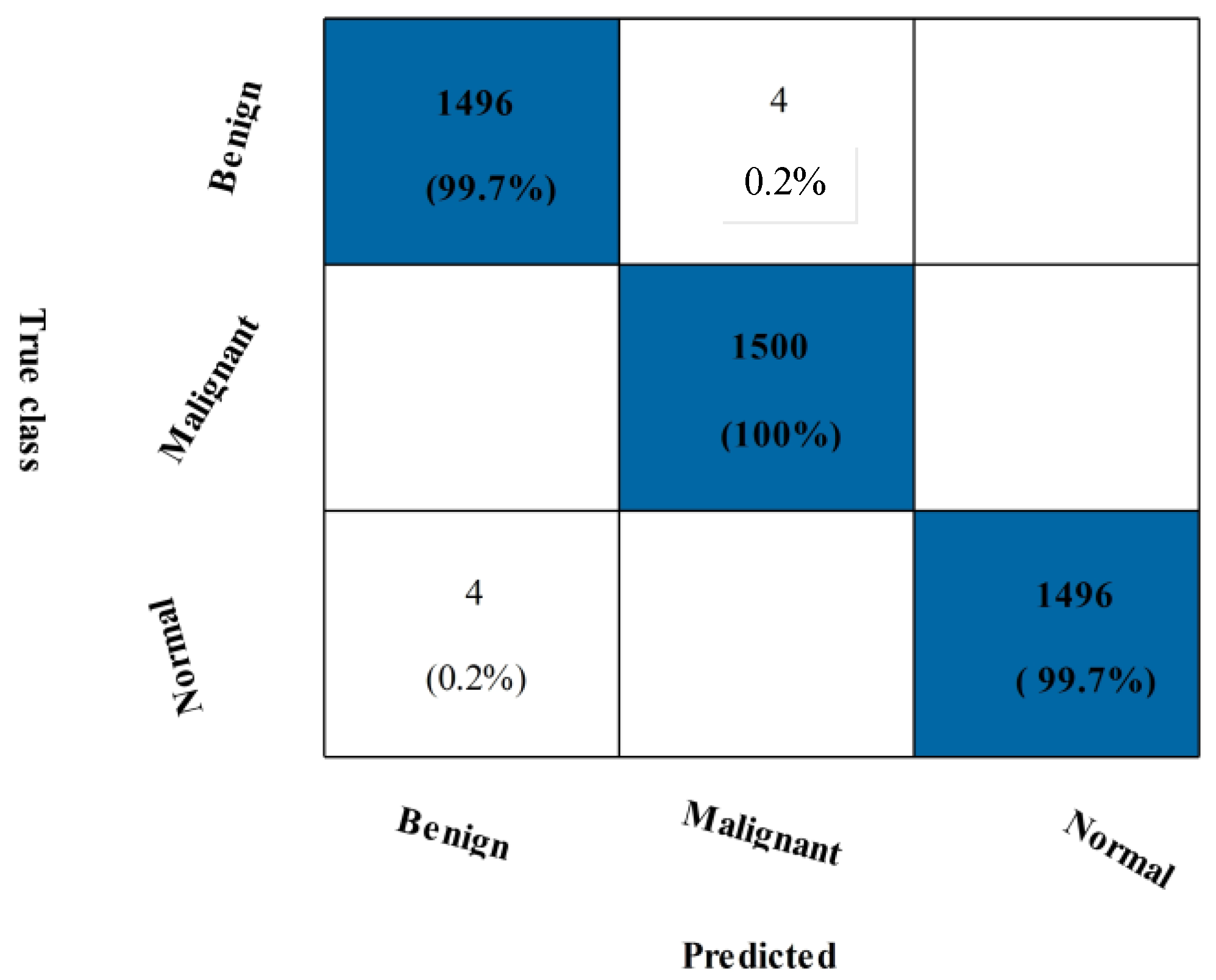
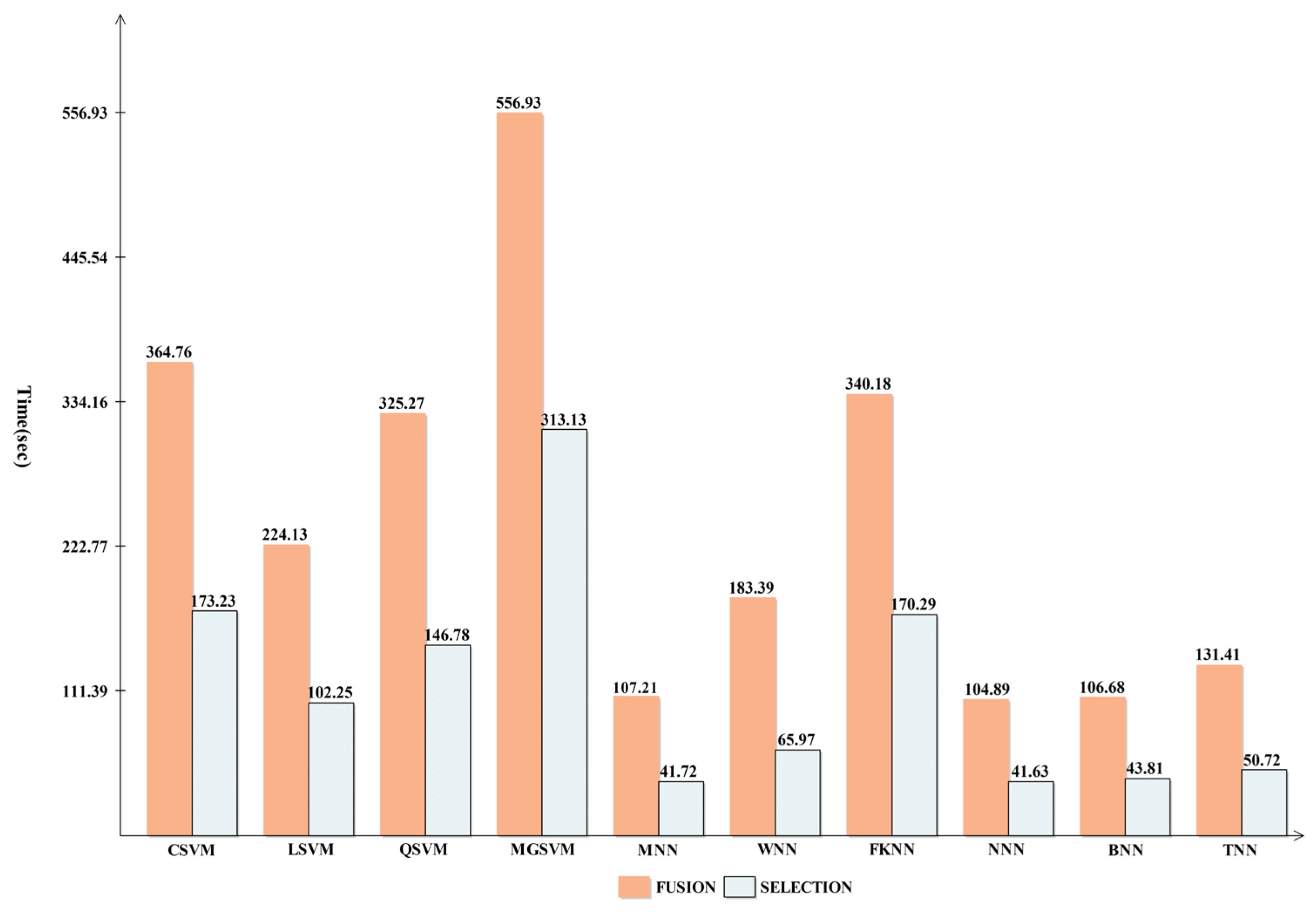
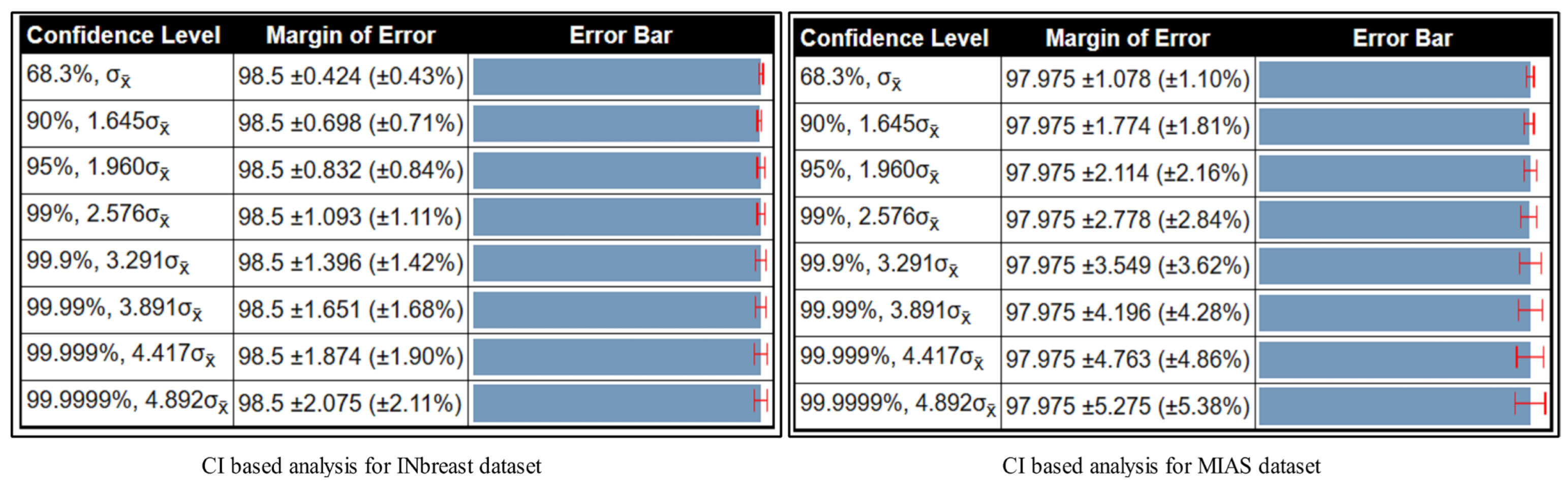
3.4. INbreast Breast Cancer Dataset Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | Precision | Sensitivity | F1-Score | FPR | Kappa | MCC | Accuracy | Time (s) |
|---|---|---|---|---|---|---|---|---|
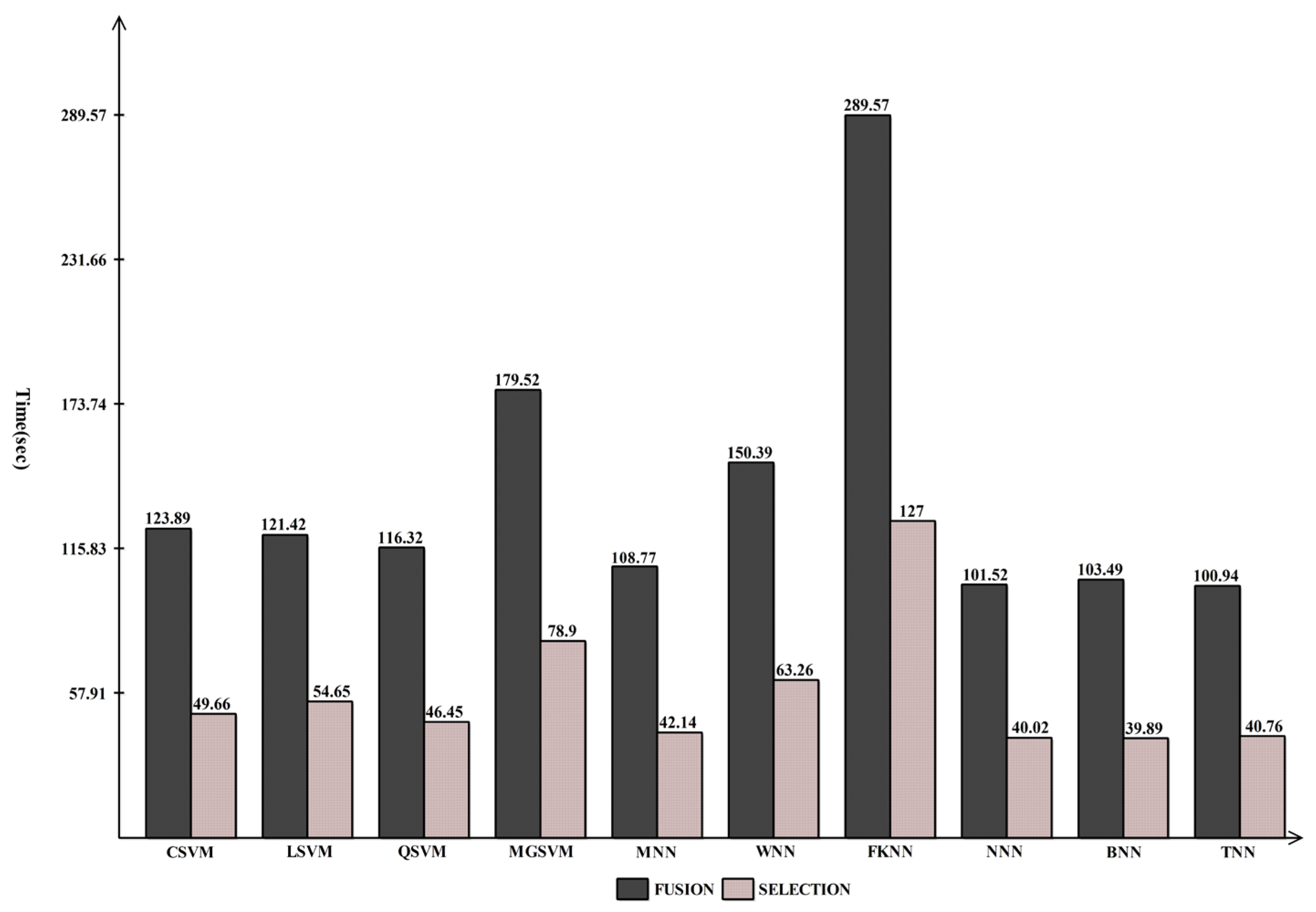
| CSVM | 99.15 | 99.70 | 99.43 | 0.08 | 98.85 | 98.85 | 99.4 | 123.89 |
| LSVM | 98.37 | 99.60 | 98.98 | 0.01 | 97.95 | 97.96 | 99.0 | 121.42 |
| QSVM | 99.20 | 99.55 | 99.38 | 0.08 | 98.75 | 98.75 | 99.4 | 116.32 |
| MGSVM | 98.71 | 99.45 | 99.08 | 0.01 | 98.15 | 98.15 | 99.1 | 179.52 |
| MNN | 99.25 | 99.70 | 99.48 | 0.07 | 98.95 | 98.95 | 99.5 | 108.77 |
| WNN | 99.25 | 99.60 | 99.43 | 0.07 | 98.85 | 98.85 | 99.4 | 150.39 |
| FKNN | 98.70 | 99.00 | 98.85 | 0.01 | 97.70 | 97.70 | 98.9 | 289.57 |
| NNN | 99.35 | 99.65 | 99.50 | 0.06 | 99.00 | 99.00 | 99.5 | 101.52 |
| BNN | 98.45 | 99.40 | 99.42 | 0.05 | 98.85 | 98.85 | 99.4 | 103.49 |
| TNN | 99.35 | 99.40 | 99.38 | 0.06 | 98.75 | 98.75 | 99.4 | 100.94 |
| Classifier | Precision | Sensitivity | F1-Score | FPR | Kappa | MCC | Accuracy | Time (s) |
|---|---|---|---|---|---|---|---|---|
| CSVM | 99.35 | 99.65 | 99.50 | 0.06 | 99.0 | 99.0 | 99.5 | 49.65 |
| LSVM | 98.32 | 99.60 | 98.96 | 0.01 | 97.90 | 97.91 | 99.0 | 54.65 |
| QSVM | 99.30 | 99.65 | 99.48 | 0.07 | 98.95 | 98.95 | 99.5 | 46.45 |
| MGSVM | 98.66 | 99.55 | 99.10 | 0.01 | 98.20 | 98.20 | 99.1 | 78.90 |
| MNN | 99.25 | 99.50 | 99.38 | 0.07 | 98.75 | 98.75 | 99.4 | 42.14 |
| WNN | 99.35 | 99.45 | 99.40 | 0.06 | 98.80 | 98.80 | 99.4 | 63.26 |
| FKNN | 98.90 | 99.20 | 99.05 | 0.01 | 98.10 | 98.10 | 99.1 | 127.00 |
| NNN | 99.55 | 99.50 | 99.52 | 0.04 | 99.05 | 99.05 | 99.5 | 40.01 |
| BNN | 99.45 | 99.65 | 99.55 | 0.05 | 99.10 | 99.10 | 99.6 | 39.88 |
| TNN | 99.35 | 99.45 | 99.40 | 0.06 | 98.80 | 98.80 | 99.4 | 40.75 |



3.5. Mias Dataset Results
3.6. Comparison with Other State-of-the-Art Techniques
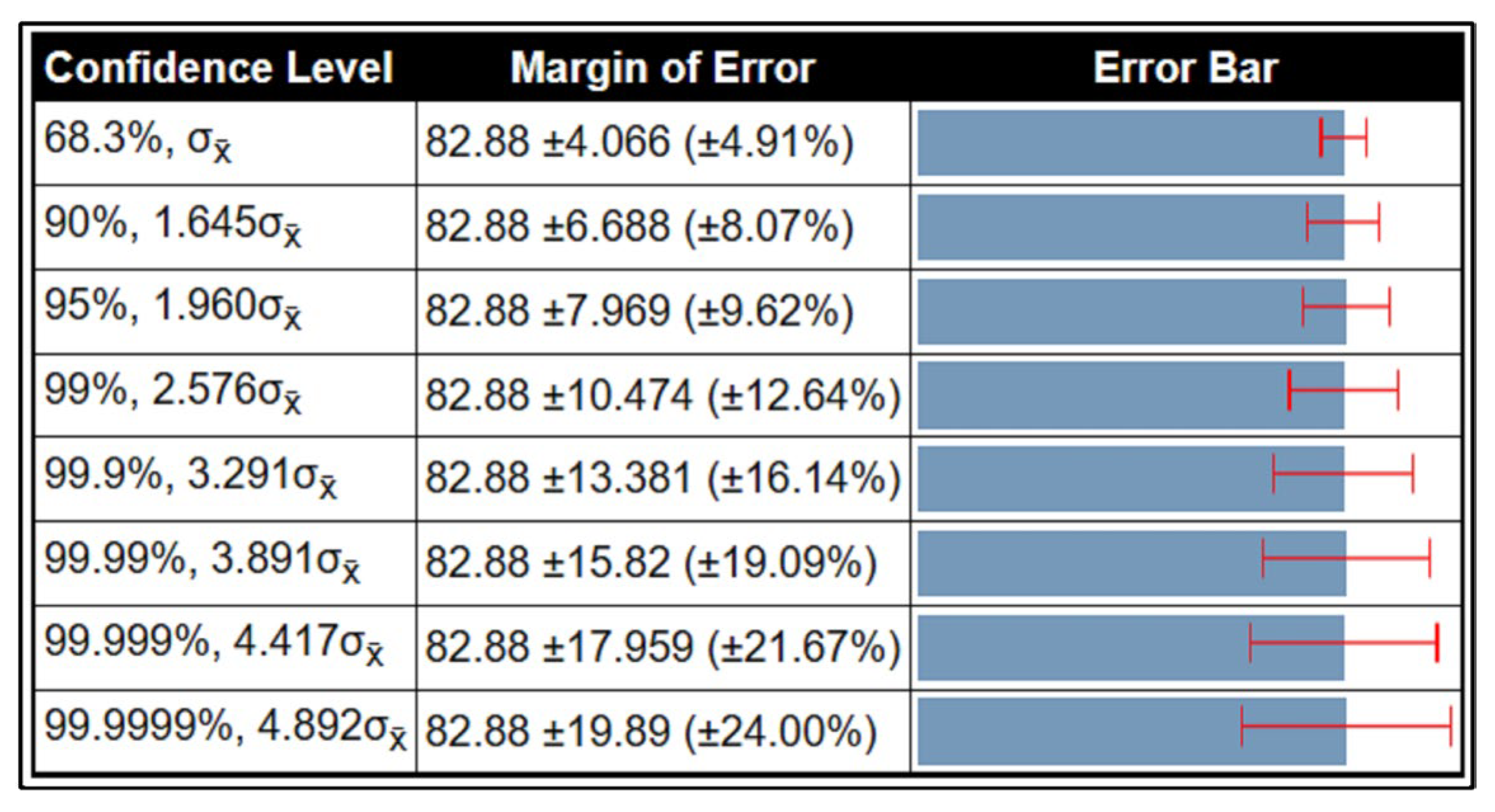
3.7. Confidence Interval-Based Analysis
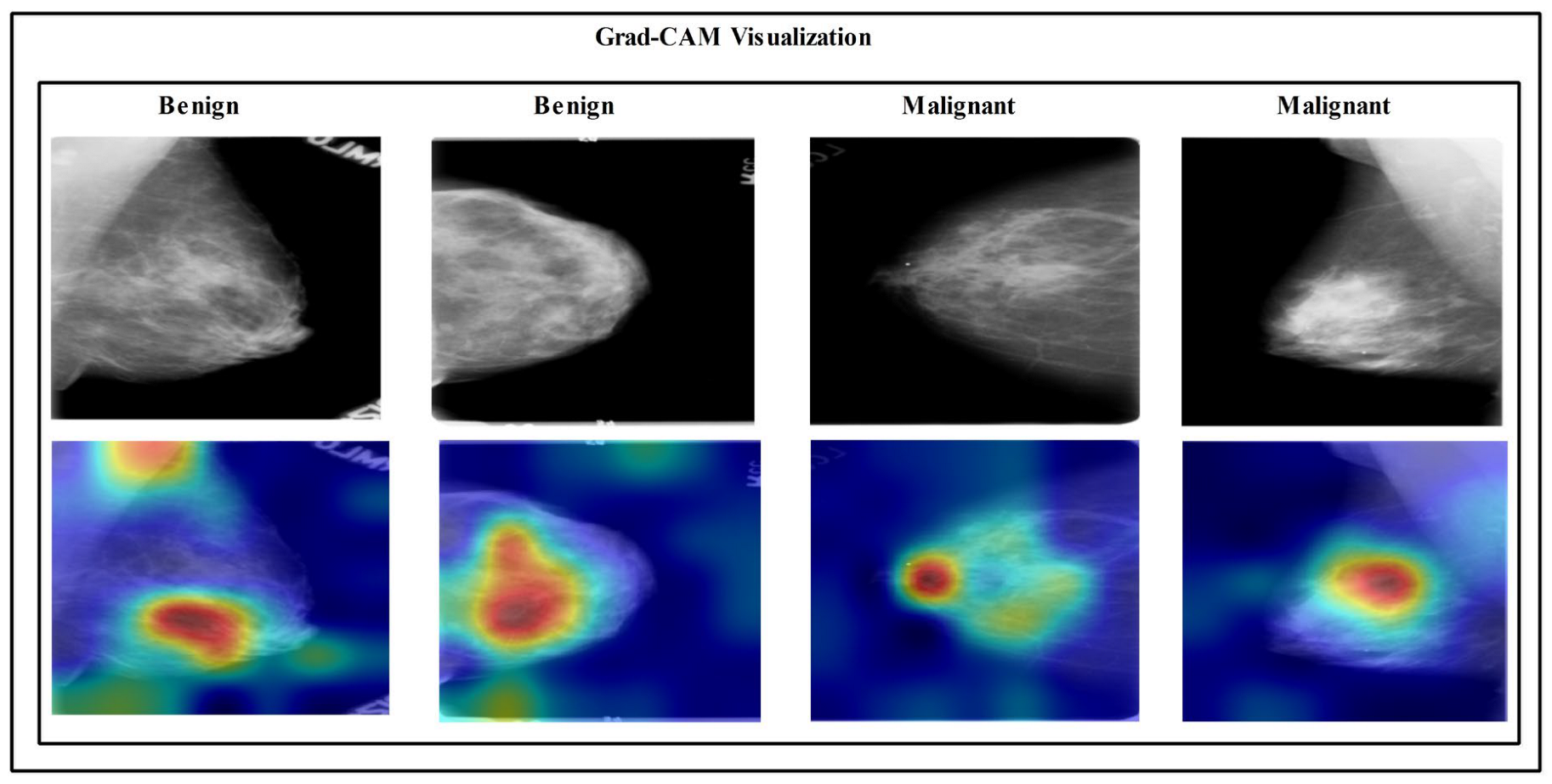
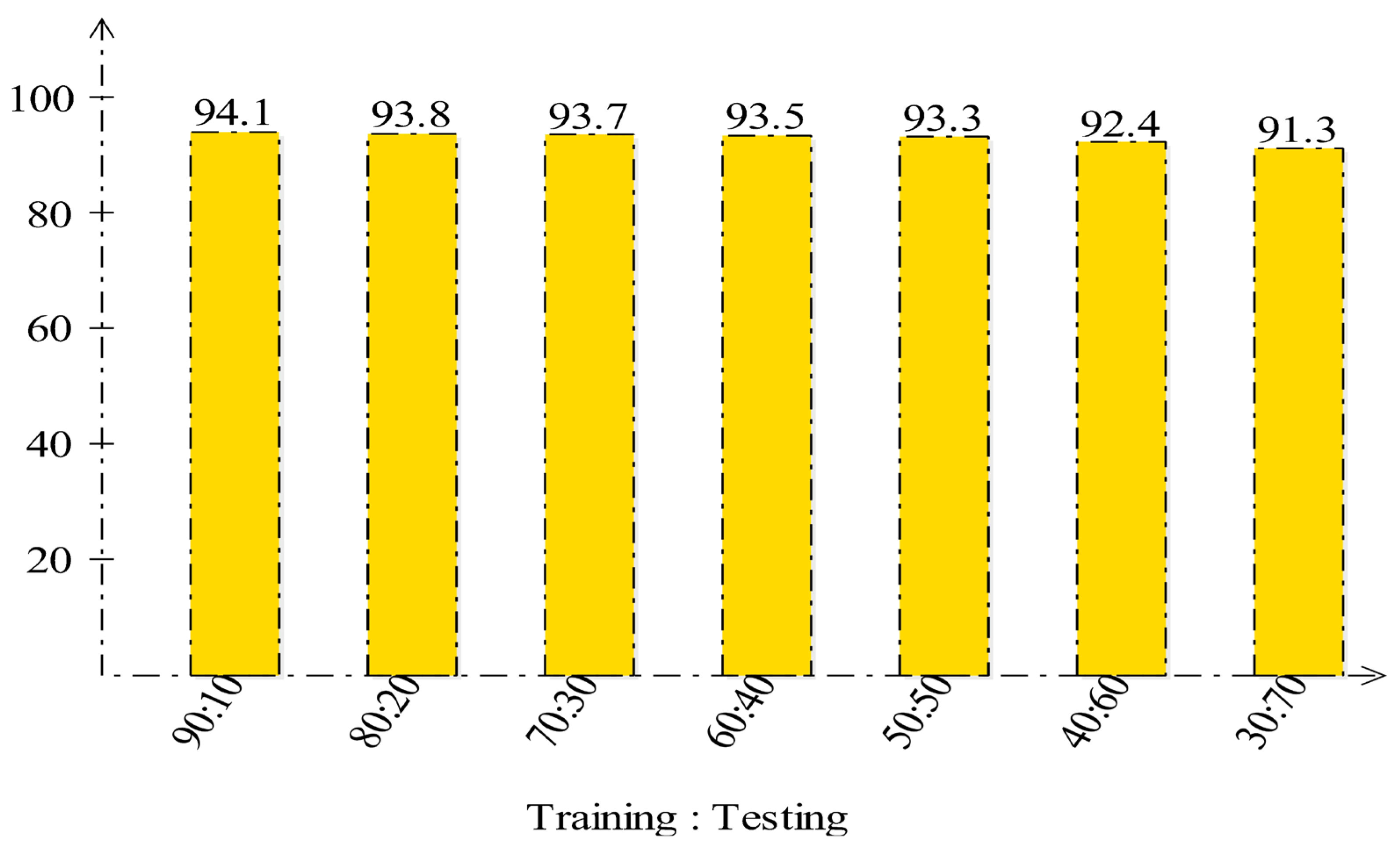
3.8. Visual Facts
4. Conclusions
Future Scope
- Propose a new method for improving the contrast of the infected region pixels, which will improve the visibility of the lesion region and help with the correct segmentation.
- Propose a segmentation technique using deep learning and a saliency map for tumor detection. The residual block will be added in the deep learning model, which can aid in better learning for the detection process.
- Develop a fusion-based deep learning architecture with Bayesian optimization-based hyperparameters initialization.
- Propose a new feature selection technique that will stop the iteration in a maximum of two constant cost values.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jabeen, K.; Khan, M.A.; Alhaisoni, M.; Tariq, U.; Zhang, Y.-D.; Hamza, A.; Mickus, A.; Damaševičius, R. Breast Cancer Classification from Ultrasound Images Using Probability-Based Optimal Deep Learning Feature Fusion. Sensors 2022, 22, 807. [Google Scholar] [CrossRef] [PubMed]
- Naseem, U.; Rashid, J.; Ali, L.; Kim, J.; Haq, Q.E.U.; Awan, M.J.; Imran, M. An Automatic Detection of Breast Cancer Diagnosis and Prognosis Based on Machine Learning Using Ensemble of Classifiers. IEEE Access 2022, 10, 78242–78252. [Google Scholar] [CrossRef]
- Arooj, S.; Rahman, A.U.; Zubair, M.; Khan, M.F.; Alissa, K.; Mosavi, A. Breast Cancer Detection and Classification Empowered With Transfer Learning. Front. Public Health 2022, 10, 924432. [Google Scholar] [CrossRef] [PubMed]
- Aljuaid, H.; Alturki, N.; Alsubaie, N.; Cavallaro, L.; Liotta, A. Computer-aided diagnosis for breast cancer classification using deep neural networks and transfer learning. Comput. Methods Programs Biomed. 2022, 223, 106951. [Google Scholar] [CrossRef]
- Rashid, A.; Farhad, S.S.B.; Bhuyian, A.; Yeasmin, N.; Azim, M.A.; Alom, Z. A Comparative Analysis of Machine Learning techniques on Breast Cancer diagnosis using WEKA. In Proceedings of the 2022 25th International Conference on Computer and Information Technology (ICCIT), Cox's Bazar, Bangladesh, 17–19 December 2022; pp. 663–668. [Google Scholar] [CrossRef]
- Ye, G.; He, S.; Pan, R.; Zhu, L.; Zhou, D.; Lu, R. Research on DCE-MRI Images Based on Deep Transfer Learning in Breast Cancer Adjuvant Curative Effect Prediction. J. Health Eng. 2022, 2022, 4477099. [Google Scholar] [CrossRef]
- Sultana, Z.; Khan, A.R.; Jahan, N. Early Breast Cancer Detection Utilizing Artificial Neural Network. WSEAS Trans. Biol. Biomed. 2021, 18, 32–42. [Google Scholar] [CrossRef]
- Ganesan, K.; Acharya, U.R.; Chua, C.K.; Min, L.C.; Abraham, K.T.; Ng, K.-H. Computer-Aided Breast Cancer Detection Using Mammograms: A Review. IEEE Rev. Biomed. Eng. 2012, 6, 77–98. [Google Scholar] [CrossRef]
- Bhidé, A.; Datar, S.; Stebbins, K. Mammography: Case histories of significant medical advances. Harv. Bus. Sch. Account. Manag. Unit Work. Pap. 2021, 20-002. [Google Scholar] [CrossRef]
- Hooley, R.J.; Andrejeva, L.; Scoutt, L.M. Breast Cancer Screening and Problem Solving Using Mammography, Ultrasound, and Magnetic Resonance Imaging. Ultrasound Q. 2011, 27, 23–47. [Google Scholar] [CrossRef]
- Kelly, K.M.; Dean, J.; Lee, S.-J.; Comulada, W.S. Breast cancer detection: Radiologists’ performance using mammography with and without automated whole-breast ultrasound. Eur. Radiol. 2010, 20, 2557–2564. [Google Scholar] [CrossRef]
- Rehman, K.U.; Li, J.; Pei, Y.; Yasin, A.; Ali, S.; Mahmood, T. Computer Vision-Based Microcalcification Detection in Digital Mammograms Using Fully Connected Depthwise Separable Convolutional Neural Network. Sensors 2021, 21, 4854. [Google Scholar] [CrossRef]
- Ramani, R.; Vanitha, N.; Valarmathy, S. The Pre-Processing Techniques for Breast Cancer Detection in Mammography Images. Int. J. Image, Graph. Signal Process. 2013, 5, 47. [Google Scholar] [CrossRef]
- Tripathy, S.; Swarnkar, T. Unified Preprocessing and Enhancement Technique for Mammogram Images. Procedia Comput. Sci. 2020, 167, 285–292. [Google Scholar] [CrossRef]
- Zahoor, S.; Lali, I.U.; Khan, M.A.; Javed, K.; Mehmood, W. Breast Cancer Detection and Classification using Traditional Computer Vision Techniques: A Comprehensive Review. Curr. Med. Imaging 2020, 16, 1187–1200. [Google Scholar] [CrossRef]
- Mousa, R.; Munib, Q.; Moussa, A. Breast cancer diagnosis system based on wavelet analysis and fuzzy-neural. Expert Syst. Appl. 2005, 28, 713–723. [Google Scholar] [CrossRef]
- Udayakumar, E.; Santhi, S.; Vetrivelan, P. An investigation of Bayes algorithm and neural networks for identifying the breast cancer. Indian J. Med. Paediatr. Oncol. 2017, 38, 340–344. [Google Scholar] [CrossRef]
- Luo, S.-T.; Cheng, B.-W. Diagnosing Breast Masses in Digital Mammography Using Feature Selection and Ensemble Methods. J. Med. Syst. 2012, 36, 569–577. [Google Scholar] [CrossRef]
- Aalaei, S.; Shahraki, H.; Rowhanimanesh, A.; Eslami, S. Feature selection using genetic algorithm for breast cancer diagnosis: Experiment on three different datasets. Iranian J. Basic Med. Sci. 2016, 19, 476–482. [Google Scholar] [CrossRef]
- Abreu, P.H.; Santos, M.S.; Abreu, M.H.; Andrade, B.; Silva, D.C. Predicting breast cancer recurrence using machine learning techniques: A systematic review. ACM Comput. Surv. (CSUR) 2016, 49, 1–40. [Google Scholar] [CrossRef]
- Sharma, N.; Sharma, K.P.; Mangla, M.; Rani, R. Breast cancer classification using snapshot ensemble deep learning model and t-distributed stochastic neighbor embedding. Multimedia Tools Appl. 2023, 82, 4011–4029. [Google Scholar] [CrossRef]
- Houssein, E.H.; Emam, M.M.; Ali, A.A.; Suganthan, P.N. Deep and machine learning techniques for medical imaging-based breast cancer: A comprehensive review. Expert Syst. Appl. 2021, 167, 114161. [Google Scholar] [CrossRef]
- Ali, W.; Saeed, F. Hybrid Filter and Genetic Algorithm-Based Feature Selection for Improving Cancer Classification in High-Dimensional Microarray Data. Processes 2023, 11, 562. [Google Scholar] [CrossRef]
- Nadira, T.; Rustam, Z. Classification of cancer data using support vector machines with features selection method based on global artificial bee colony. In AIP Conference Proceedings; AIP Publishing LLC: New York, NY, USA, 2018; p. 020205. [Google Scholar] [CrossRef]
- Jiménez-Sánchez, A.; Tardy, M.; Ballester, M.A.G.; Mateus, D.; Piella, G. Memory-aware curriculum federated learning for breast cancer classification. Comput. Methods Programs Biomed. 2023, 229, 107318. [Google Scholar] [CrossRef] [PubMed]
- Khashei, M.; Bakhtiarvand, N. A novel discrete learning-based intelligent methodology for breast cancer classification purposes. Artif. Intell. Med. 2023, 7, 102492. [Google Scholar] [CrossRef] [PubMed]
- Loizidou, K.; Elia, R.; Pitris, C. Computer-aided breast cancer detection and classification in mammography: A comprehensive review. Comput. Biol. Med. 2023, 153, 106554. [Google Scholar] [CrossRef]
- Zebari, D.A.; Ibrahim, D.A.; Zeebaree, D.Q.; Mohammed, M.A.; Haron, H.; Zebari, N.A.; Damaševičius, R.; Maskeliūnas, R. Breast cancer detection using mammogram images with improved multi-fractal dimension approach and feature fusion. Appl. Sci. 2021, 11, 12122. [Google Scholar] [CrossRef]
- Siddiqui, S.Y.; Haider, A.; Ghazal, T.M.; Khan, M.A.; Naseer, I.; Abbas, S.; Rahman, M.; Khan, J.A.; Ahmad, M.; Hasan, M.K.; et al. IoMT Cloud-Based Intelligent Prediction of Breast Cancer Stages Empowered With Deep Learning. IEEE Access 2021, 9, 146478–146491. [Google Scholar] [CrossRef]
- Huynh, B.; Drukker, K.; Giger, M. MO-DE-207B-06: Computer-Aided Diagnosis of Breast Ultrasound Images Using Transfer Learning From Deep Convolutional Neural Networks. Med. Phys. 2016, 43, 3705. [Google Scholar] [CrossRef]
- Hamed, G.; Marey, M.A.E.-R.; Amin, S.E.-S.; Tolba, M.F. Deep learning in breast cancer detection and classification. In Proceedings of the International Conference on Artificial Intelligence and Computer Vision (AICV2020), Proceedings of the Artificial Intelligence and Computer Vision (AICV 2020), Cairo, Egypt, 8–10 April 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 322–333. [Google Scholar]
- Zheng, J.; Lin, D.; Gao, Z.; Wang, S.; He, M.; Fan, J. Deep Learning Assisted Efficient AdaBoost Algorithm for Breast Cancer Detection and Early Diagnosis. IEEE Access 2020, 8, 96946–96954. [Google Scholar] [CrossRef]
- Bayramoglu, N.; Kannala, J.; Heikkilä, J. Deep learning in magnification independent breast cancer histopathology image classification. In Proceedings of the 2016 23rd International conference on pattern recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2440–2445. [Google Scholar]
- Khuriwal, N.; Mishra, N. Breast cancer diagnosis using deep learning algorithm. In Proceedings of the 2018 International Conference on Advances in Computing, Communication Control and Networking (ICACCCN), Greater Noida, India, 12–13 October 2018; pp. 98–103. [Google Scholar] [CrossRef]
- Mambou, S.J.; Maresova, P.; Krejcar, O.; Selamat, A.; Kuca, K. Breast Cancer Detection Using Infrared Thermal Imaging and a Deep Learning Model. Sensors 2018, 18, 2799. [Google Scholar] [CrossRef]
- Ahmed, L.; Iqbal, M.M.; Aldabbas, H.; Khalid, S.; Saleem, Y.; Saeed, S. Images data practices for Semantic Segmentation of Breast Cancer using Deep Neural Network. J. Ambient. Intell. Humaniz. Comput. 2020, 1–17. [Google Scholar] [CrossRef]
- Aruna, S.; Rajagopalan, S.; Nandakishore, L. Knowledge based analysis of various statistical tools in detecting breast cancer. Comput. Sci. Inf. Technol. 2011, 2, 37–45. [Google Scholar]
- Kumar, K.; Rao, A.C.S. Breast cancer classification of image using convolutional neural network. In Proceedings of the 2018 4th International Conference on Recent Advances in Information Technology (RAIT), Dhanbad, India, 15–17 March 2018; pp. 1–6. [Google Scholar]
- Khalid, A.; Noureldien, N.A. Determining the efficient structure of feed-forward neural network to classify breast cancer dataset. Int. J. Adv. Comput. Sci. Appl. 2014, 5. [Google Scholar] [CrossRef]
- Albalawi, U.; Manimurugan, S.; Varatharajan, R. Classification of breast cancer mammogram images using convolution neural network. Concurr. Comput. Pract. Exp. 2022, 34, e5803. [Google Scholar] [CrossRef]
- Ganesh, N.; Shankar, R.; Čep, R.; Chakraborty, S.; Kalita, K. Efficient Feature Selection Using Weighted Superposition Attraction Optimization Algorithm. Appl. Sci. 2023, 13, 3223. [Google Scholar] [CrossRef]
- Kurman, S.; Kisan, S. An in-depth and contrasting survey of meta-heuristic approaches with classical feature selection techniques specific to cervical cancer. Knowl. Inf. Syst. 2023, 65, 1881–1934. [Google Scholar] [CrossRef]
- Falconi, L.G.; Perez, M.; Aguila, W.G.; Conci, A. Transfer Learning and Fine Tuning in Breast Mammogram Abnormalities Classification on CBIS-DDSM Database. Adv. Sci. Technol. Eng. Syst. J. 2020, 5, 154–165. [Google Scholar] [CrossRef]
- Huang, M.-L.; Lin, T.-Y. Dataset of breast mammography images with masses. Data Brief 2020, 31, 105928. [Google Scholar] [CrossRef]
- Charan, S.; Khan, M.J.; Khurshid, K. Breast Cancer Detection in Mammograms Using Convolutional Neural Network. In Proceedings of the 2018 International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Wuhan, China, 7–8 February 2018; pp. 1–5. [Google Scholar]
- Fatima, N.; Liu, L.; Hong, S.; Ahmed, H. Prediction of Breast Cancer, Comparative Review of Machine Learning Techniques, and Their Analysis. IEEE Access 2020, 8, 150360–150376. [Google Scholar] [CrossRef]
- Munien, C.; Viriri, S. Classification of Hematoxylin and Eosin-Stained Breast Cancer Histology Microscopy Images Using Transfer Learning with EfficientNets. Comput. Intell. Neurosci. 2021, 2021, 5580914. [Google Scholar] [CrossRef]
- Lobbes, M.; Smidt, M.; Houwers, J.; Tjan-Heijnen, V.; Wildberger, J. Contrast enhanced mammography: Techniques, current results, and potential indications. Clin. Radiol. 2013, 68, 935–944. [Google Scholar] [CrossRef] [PubMed]
- Behar, N.; Shrivastava, M. ResNet50-Based Effective Model for Breast Cancer Classification Using Histopathology Images. Comput. Model. Eng. Sci. 2022, 130, 823–839. [Google Scholar] [CrossRef]
- Ashtaiwi, A. Optimal Histopathological Magnification Factors for Deep Learning-Based Breast Cancer Prediction. Appl. Syst. Innov. 2022, 5, 87. [Google Scholar] [CrossRef]
- Ayana, G.; Park, J.; Jeong, J.-W.; Choe, S.-W. A Novel Multistage Transfer Learning for Ultrasound Breast Cancer Image Classification. Diagnostics 2022, 12, 135. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Chen, J.-H.; Lin, Y.; Chan, S.; Zhou, J.; Chow, D.; Chang, P.; Kwong, T.; Yeh, D.-C.; Wang, X.; et al. Prediction of breast cancer molecular subtypes on DCE-MRI using convolutional neural network with transfer learning between two centers. Eur. Radiol. 2021, 31, 2559–2567. [Google Scholar] [CrossRef]
- Rezaeijo, S.M.; Ghorvei, M.; Mofid, B. Predicting breast cancer response to neoadjuvant chemotherapy using ensemble deep transfer learning based on CT images. J. X-ray Sci. Technol. 2021, 29, 835–850. [Google Scholar] [CrossRef]
- Yang, X.-S.; Karamanoglu, M.; He, X. Flower pollination algorithm: A novel approach for multiobjective optimization. Eng. Optim. 2014, 46, 1222–1237. [Google Scholar] [CrossRef]
- Kavitha, T.; Mathai, P.P.; Karthikeyan, C.; Ashok, M.; Kohar, R.; Avanija, J.; Neelakandan, S. Deep Learning Based Capsule Neural Network Model for Breast Cancer Diagnosis Using Mammogram Images. Interdiscip. Sci. Comput. Life Sci. 2021, 123–129. [Google Scholar] [CrossRef]
- Shen, L. End-to-end training for whole image breast cancer diagnosis using an all convolutional design. arXiv 2017, arXiv:1711.05775. [Google Scholar]
- Mobark, N.; Hamad, S.; Rida, S.Z. CoroNet: Deep Neural Network-Based End-to-End Training for Breast Cancer Diagnosis. Appl. Sci. 2022, 12, 7080. [Google Scholar] [CrossRef]
















| Dataset Name | Classes | Images | Augmented | Training/Testing |
|---|---|---|---|---|
| CBIS-DDSM | Benign | 557 | 6000 | 3000/3000 |
| Malignant | 637 | 6000 | 3000/3000 | |
| INbreast | Benign | 76 | 4000 | 2000/2000 |
| Malignant | 70 | 4000 | 2000/2000 | |
| MIAS | Benign | 52 | 4000 | 2000/2000 |
| Malignant | 39 | 4000 | 2000/2000 | |
| Normal | 209 | 4000 | 2000/2000 |
| Classifier | Precision | Sensitivity | F1-Score | FPR | Kappa | MCC | Accuracy | Time (s) |
|---|---|---|---|---|---|---|---|---|
| CSVM | 93.09 | 94.70 | 93.89 | 0.07 | 87.67 | 87.68 | 93.8 | 743.76 |
| LSVM | 89.83 | 90.67 | 90.25 | 0.10 | 80.40 | 80.40 | 90.2 | 598.94 |
| QSVM | 92.03 | 93.20 | 92.61 | 0.08 | 85.13 | 85.14 | 92.6 | 598.17 |
| MGSVM | 91.55 | 92.47 | 92.01 | 0.08 | 83.93 | 83.94 | 92.0 | 824.48 |
| MNN | 90.79 | 92.03 | 91.41 | 0.09 | 82.70 | 82.71 | 91.3 | 249.39 |
| WNN | 91.45 | 92.00 | 91.72 | 0.08 | 83.40 | 83.40 | 91.7 | 255.09 |
| FKNN | 91.96 | 93.73 | 92.84 | 0.08 | 85.53 | 85.55 | 92.8 | 531.48 |
| NNN | 90.03 | 90.57 | 90.30 | 0.10 | 80.53 | 80.53 | 90.3 | 344.00 |
| BNN | 89.37 | 89.63 | 89.50 | 0.01 | 78.97 | 78.97 | 89.5 | 419.86 |
| TNN | 88.86 | 89.90 | 89.38 | 0.11 | 78.63 | 78.64 | 89.3 | 764.00 |
| Classifier | Precision | Sensitivity | F1-Score | FPR | Kappa | MCC | Accuracy | Time (s) |
|---|---|---|---|---|---|---|---|---|
| CSVM | 92.26 | 94.57 | 93.40 | 0.07 | 86.63 | 86.66 | 93.3 | 330.67 |
| LSVM | 89.04 | 89.87 | 89.45 | 0.11 | 78.80 | 78.80 | 89.4 | 295.41 |
| QSVM | 90.95 | 92.77 | 91.85 | 0.09 | 85.53 | 83.55 | 91.8 | 287.11 |
| MGSVM | 91.03 | 92.30 | 91.66 | 0.091 | 83.20 | 83.21 | 91.6 | 411.00 |
| MNN | 89.99 | 90.50 | 90.24 | 0.10 | 80.43 | 80.43 | 90.2 | 82.53 |
| WNN | 90.47 | 90.80 | 90.63 | 0.09 | 81.23 | 81.23 | 90.6 | 128.72 |
| FKNN | 92.06 | 93.50 | 92.77 | 0.08 | 85.43 | 85.44 | 92.7 | 264.14 |
| NNN | 88.48 | 89.37 | 88.92 | 0.11 | 77.73 | 77.74 | 88.9 | 171.24 |
| BNN | 88.81 | 89.40 | 89.10 | 0.11 | 78.13 | 78.14 | 89.1 | 400.99 |
| TNN | 87.91 | 89.43 | 88.66 | 0.12 | 77.13 | 77.14 | 88.6 | 503.23 |
| Classifier | Precision | Sensitivity | F1-Score | FPR | Kappa | MCC | Accuracy | Time (s) |
|---|---|---|---|---|---|---|---|---|
| CSVM | 99.82 | 99.82 | 99.82 | 0.08 | 99.60 | 99.73 | 99.8 | 364.76 |
| LSVM | 99.49 | 99.49 | 99.49 | 0.02 | 98.85 | 99.23 | 99.5 | 224.13 |
| QSVM | 99.76 | 99.76 | 99.76 | 0.01 | 99.45 | 99.63 | 99.8 | 325.27 |
| MGSVM | 99.82 | 99.82 | 99.82 | 0.08 | 99.60 | 99.73 | 99.8 | 556.93 |
| MNN | 99.56 | 99.56 | 99.56 | 0.02 | 99.00 | 99.33 | 99.6 | 107.21 |
| WNN | 99.67 | 99.67 | 99.9 | 0.01 | 99.25 | 99.50 | 99.7 | 183.39 |
| FKNN | 98.50 | 98.47 | 98.46 | 0.07 | 96.55 | 97.72 | 98.5 | 340.18 |
| NNN | 99.51 | 99.51 | 99.51 | 0.02 | 98.90 | 99.27 | 99.5 | 104.89 |
| BNN | 99.47 | 99.47 | 99.47 | 0.02 | 98.80 | 99.20 | 99.5 | 106.68 |
| TNN | 98.98 | 98.98 | 99.98 | 0.05 | 97.70 | 98.47 | 99.0 | 131.41 |
| Classifier | Precision | Sensitivity | F1-Score | FPR | Kappa | MCC | Accuracy | Time (s) |
|---|---|---|---|---|---|---|---|---|
| CSVM | 99.78 | 99.78 | 99.78 | 0.01 | 99.50 | 99.67 | 99.8 | 173.23 |
| LSVM | 99.34 | 99.33 | 99.33 | 0.03 | 98.50 | 99.00 | 99.3 | 102.25 |
| QSVM | 99.69 | 99.69 | 99.69 | 0.01 | 99.30 | 99.53 | 99.7 | 146.78 |
| MGSVM | 99.82 | 99.82 | 99.82 | 0.08 | 99.60 | 99.73 | 99.8 | 313.13 |
| MNN | 99.45 | 99.44 | 99.44 | 0.02 | 98.75 | 99.17 | 99.4 | 41.72 |
| WNN | 99.51 | 99.51 | 99.51 | 0.02 | 98.90 | 99.27 | 99.5 | 65.96 |
| FKNN | 98.47 | 98.42 | 98.42 | 0.07 | 96.45 | 97.65 | 98.3 | 170.29 |
| NNN | 99.36 | 99.36 | 99.36 | 0.03 | 98.55 | 99.04 | 99.4 | 41.62 |
| BNN | 98.96 | 98.96 | 98.96 | 0.05 | 97.65 | 98.44 | 99.0 | 43.81 |
| TNN | 98.69 | 98.69 | 99.69 | 0.06 | 97.05 | 98.04 | 98.7 | 50.72 |
| Model | Year | Method | F1-Score | Accuracy |
|---|---|---|---|---|
| [55] | 2022 | Capsule Neural Network Model | CBIS-DDSM/ INbreast/MIAS | 98.4 |
| [56] | 2017 | All Convolutional Design | CBIS-DDSM/ INbreast/MIAS | 96 |
| [57] | 2022 | CoroNet | CBIS-DDSM/ INbreast/MIAS | 99.7 |
| Proposed Method | - | Fine-Tuned ResNet50 Model, Fusion & Flower Pollination Optimization Algorithm | CBIS-DDSM/ INbreast/MIAS | 93.3% 99.5% 99.8% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rehman, S.u.; Khan, M.A.; Masood, A.; Almujally, N.A.; Baili, J.; Alhaisoni, M.; Tariq, U.; Zhang, Y.-D. BRMI-Net: Deep Learning Features and Flower Pollination-Controlled Regula Falsi-Based Feature Selection Framework for Breast Cancer Recognition in Mammography Images. Diagnostics 2023, 13, 1618. https://doi.org/10.3390/diagnostics13091618
Rehman Su, Khan MA, Masood A, Almujally NA, Baili J, Alhaisoni M, Tariq U, Zhang Y-D. BRMI-Net: Deep Learning Features and Flower Pollination-Controlled Regula Falsi-Based Feature Selection Framework for Breast Cancer Recognition in Mammography Images. Diagnostics. 2023; 13(9):1618. https://doi.org/10.3390/diagnostics13091618
Chicago/Turabian StyleRehman, Shams ur, Muhamamd Attique Khan, Anum Masood, Nouf Abdullah Almujally, Jamel Baili, Majed Alhaisoni, Usman Tariq, and Yu-Dong Zhang. 2023. "BRMI-Net: Deep Learning Features and Flower Pollination-Controlled Regula Falsi-Based Feature Selection Framework for Breast Cancer Recognition in Mammography Images" Diagnostics 13, no. 9: 1618. https://doi.org/10.3390/diagnostics13091618