
Automatic Classification of Histopathology Images across Multiple Cancers Based on Heterogeneous Transfer Learning
Abstract
:1. Introduction
- (1)
- We demonstrate that features extracted from CRC can aid in the learning of lymph node metastasis and breast cancer, potentially reducing the amount of data needed for these cancer types;
- (2)
- The presented HTL method demonstrates generalizability across different types of cancers and has the potential to accelerate the development of HAI.
2. Methods
2.1. Datasets
2.2. Data Preprocess Pipeline
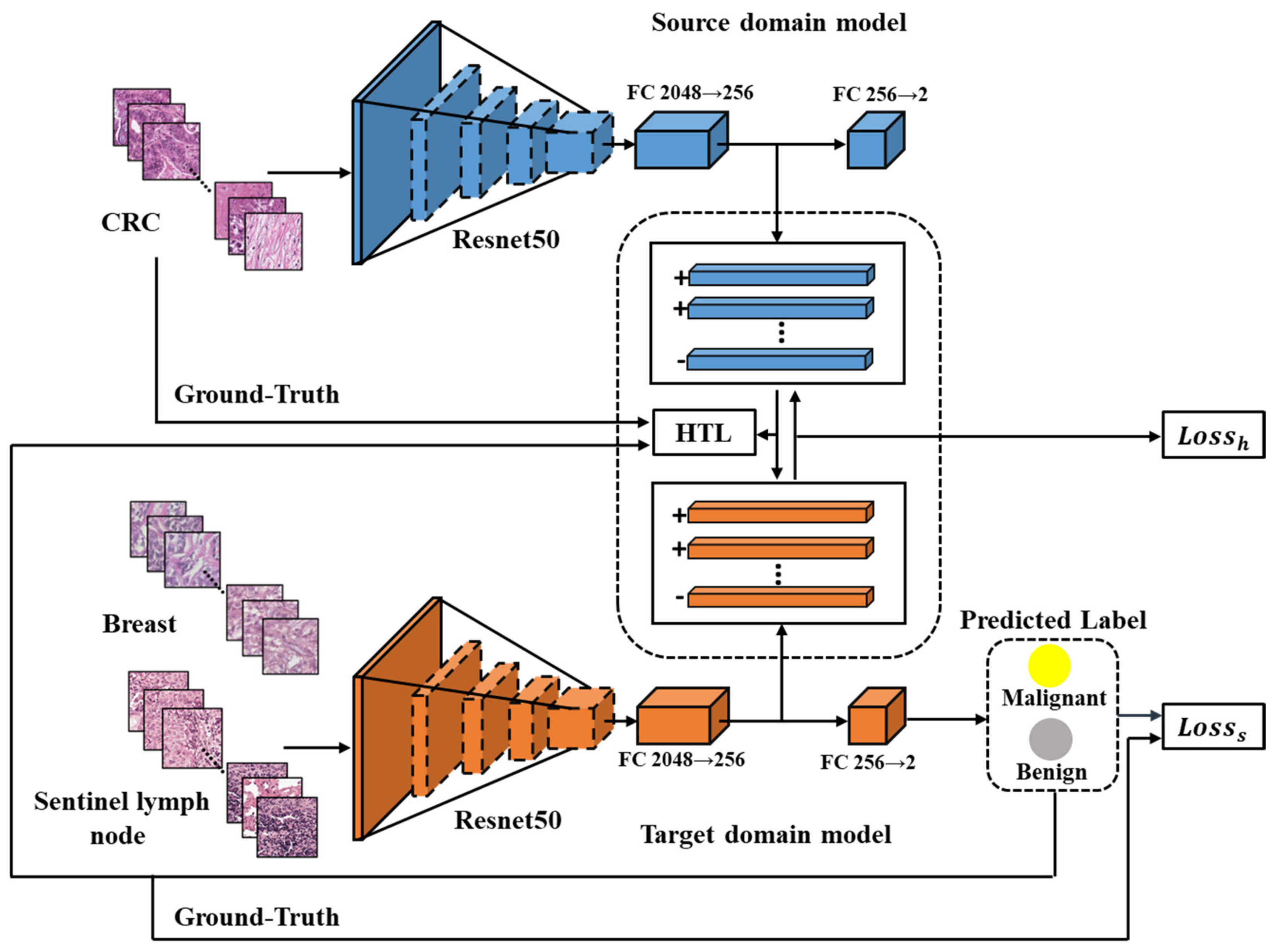
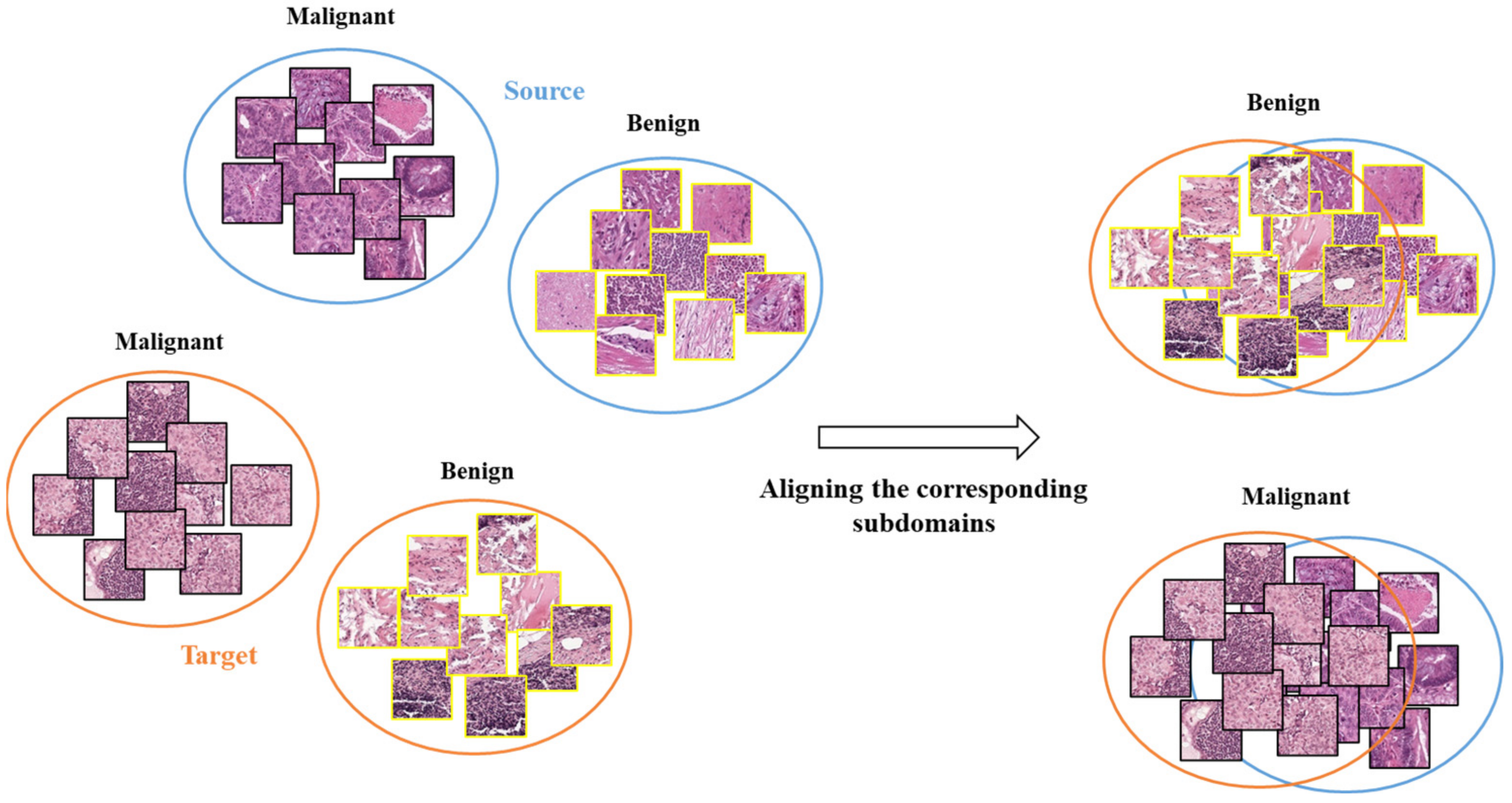
2.3. HTL Framework
Cross-Cancer Domain Adaptation Using HTL Operation
2.4. Experiment Setting
2.4.1. Sentinel Lymph Node Metastasis Models
2.4.2. Breast Cancer Models
3. Results
3.1. Classification of CRC, Breast and Sentinel Lymph Node Metastasis by Source Domain Model
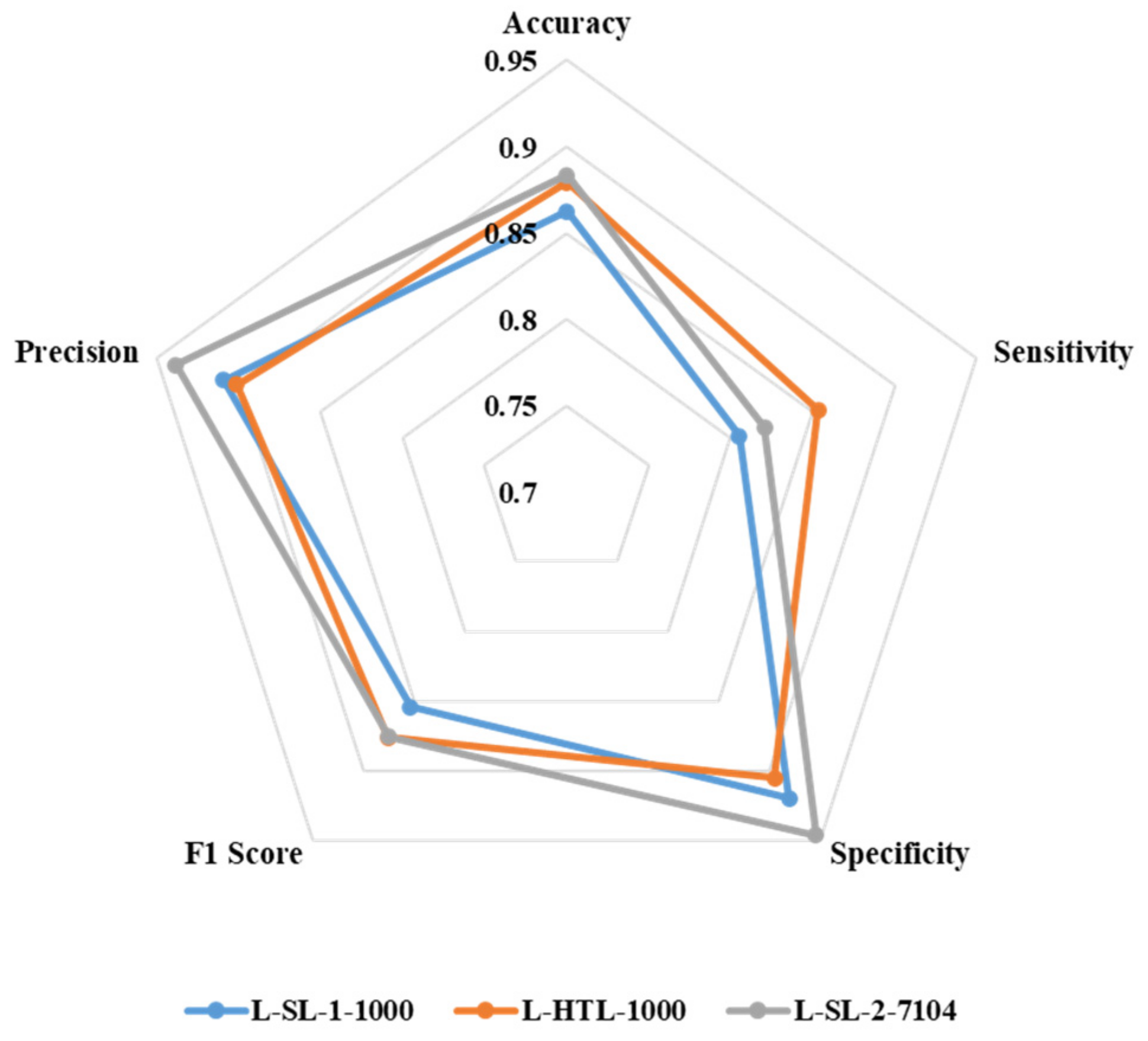
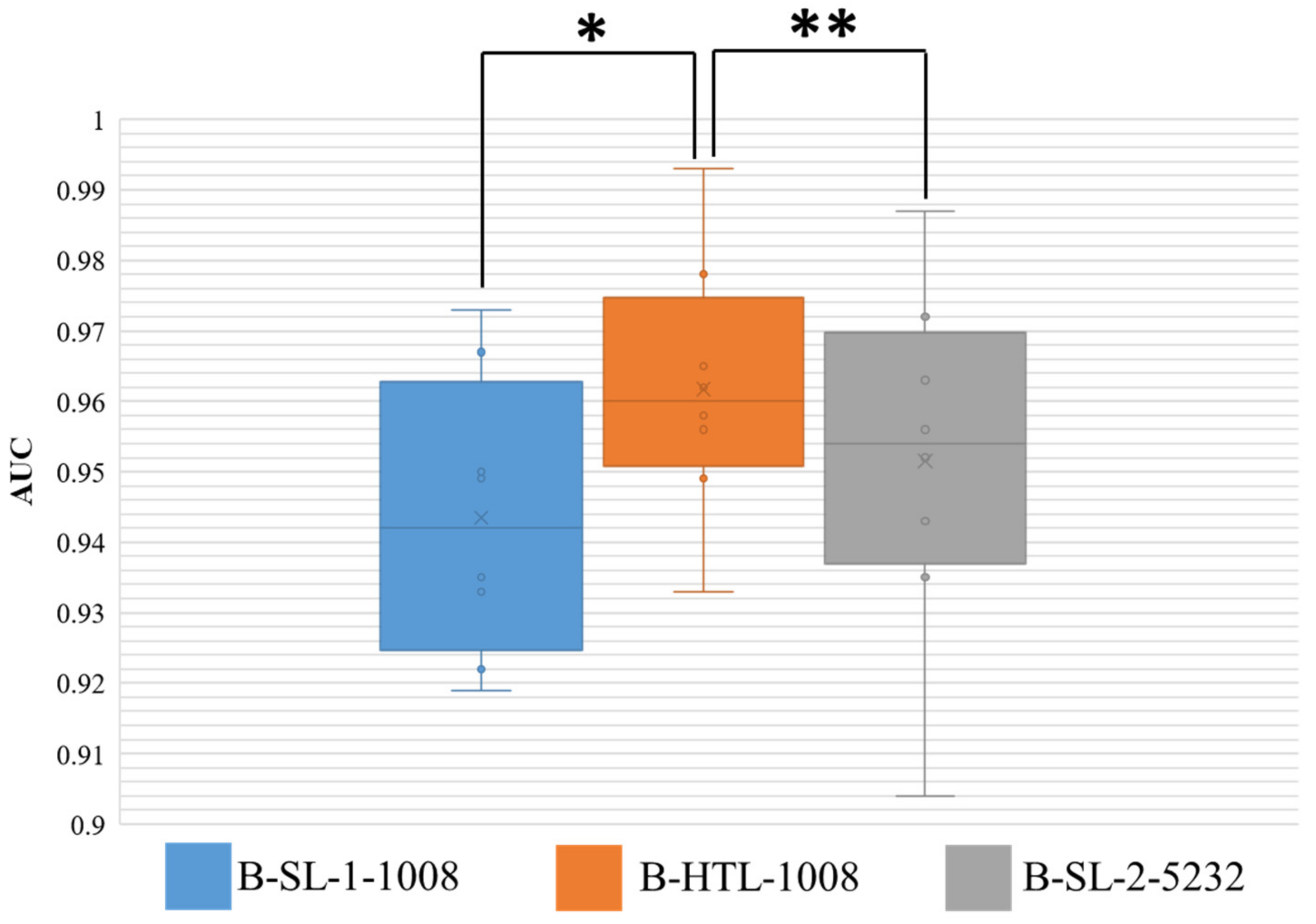
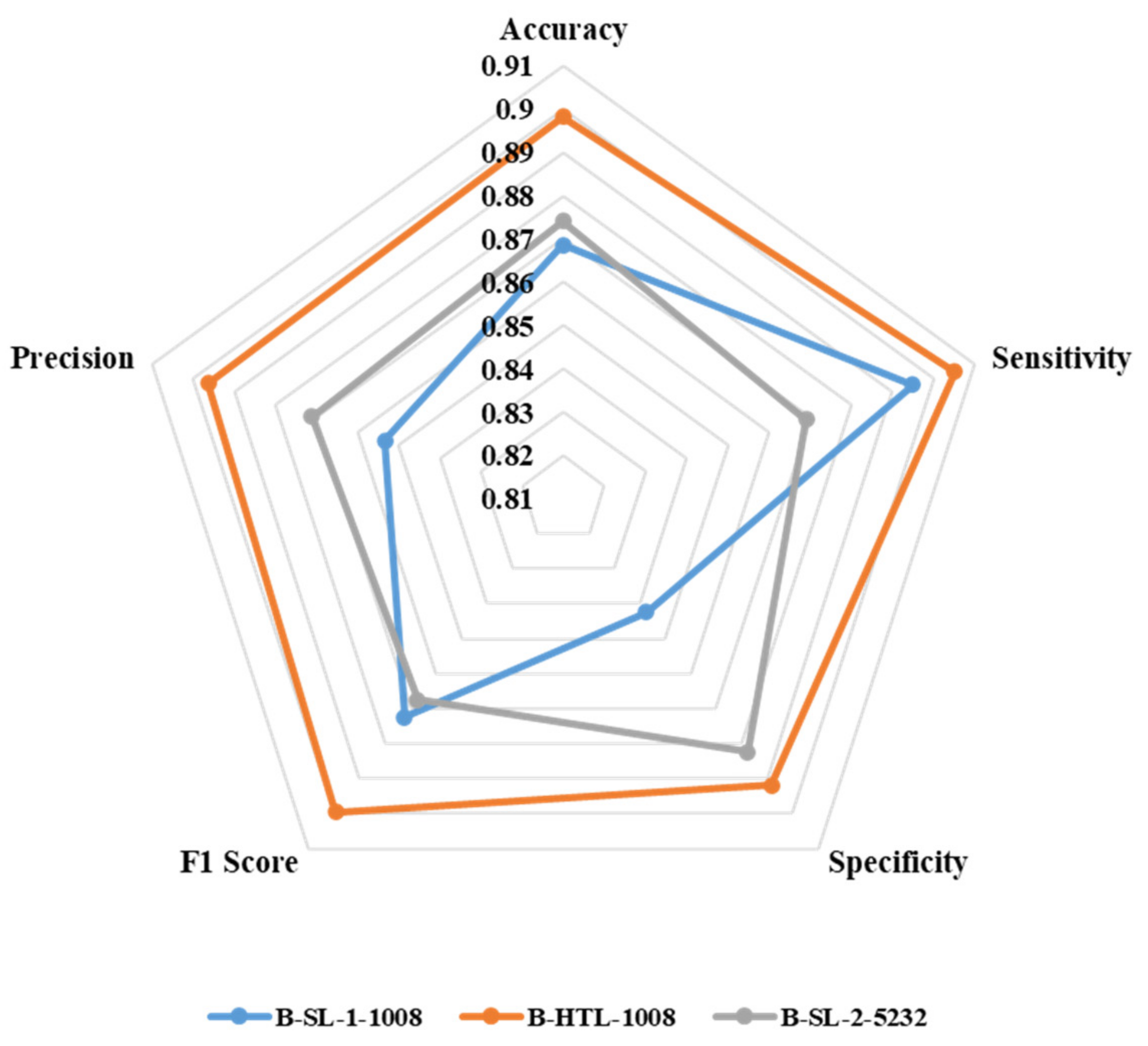
3.2. Classification of Sentinel Lymph Node Metastasis
3.3. Classification of Breast Cancer
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xia, C.; Dong, X.; Li, H.; Cao, M.; Sun, D.; He, S.; Yang, F.; Yan, X.; Zhang, S.; Li, N.; et al. Cancer statistics in China and United States, 2022: Profiles, trends, and determinants. Chin. Med. J. 2022, 135, 584–590. [Google Scholar] [CrossRef]
- Mobadersany, P.; Yousefi, S.; Amgad, M.; Gutman, D.A.; Barnholtz-Sloan, J.S.; Vega, J.E.V.; Brat, D.J.; Cooper, L.A.D. Predicting cancer outcomes from histology and genomics using convolutional networks. Proc. Natl. Acad. Sci. USA 2018, 115, E2970–E2979. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Metter, D.M.; Colgan, T.J.; Leung, S.T.; Timmons, C.F.; Park, J.Y. Trends in the US and Canadian Pathologist Workforces From 2007 to 2017. JAMA Netw. Open 2019, 2, e194337. [Google Scholar] [CrossRef] [Green Version]
- Sayed, S.; Lukande, R.; Fleming, K.A. Providing Pathology Support in Low-Income Countries. J. Glob. Oncol. 2015, 1, 3–6. [Google Scholar] [CrossRef] [PubMed]
- Niazi, M.K.K.; Parwani, A.V.; Gurcan, M.N. Digital pathology and artificial intelligence. Lancet Oncol. 2019, 20, e253–e261. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.S.; Yu, G.; Xu, C.; Meng, X.H.; Zhou, J.; Zheng, C.; Deng, Z.; Shang, L.; Liu, R.; Su, S.; et al. Accurate diagnosis of colorectal cancer based on histopathology images using artificial intelligence. BMC Med. 2021, 19, 76. [Google Scholar] [CrossRef]
- Kanavati, F.; Toyokawa, G.; Momosaki, S.; Rambeau, M.; Kozuma, Y.; Shoji, F.; Yamazaki, K.; Takeo, S.; Iizuka, O.; Tsuneki, M. Weakly-supervised learning for lung carcinoma classification using deep learning. Sci. Rep. 2020, 10, 9297. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Wang, X.; Zhang, K.; Fung, K.-M.; Thai, T.C.; Moore, K.; Mannel, R.S.; Liu, H.; Zheng, B.; Qiu, Y. Recent advances and clinical applications of deep learning in medical image analysis. Med. Image Anal. 2022, 79, 102444. [Google Scholar] [CrossRef] [PubMed]
- van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef] [Green Version]
- Peikari, M.; Salama, S.; Nofech-Mozes, S.; Martel, A.L. A Cluster-then-label Semi-supervised Learning Approach for Pathology Image Classification. Sci. Rep. 2018, 8, 7193. [Google Scholar] [CrossRef] [Green Version]
- Yu, G.; Sun, K.; Xu, C.; Shi, X.-H.; Wu, C.; Xie, T.; Meng, R.-Q.; Meng, X.-H.; Wang, K.-S.; Xiao, H.-M.; et al. Accurate recognition of colorectal cancer with semi-supervised deep learning on pathological images. Nat. Commun. 2021, 12, 6311. [Google Scholar] [CrossRef] [PubMed]
- Solorio-Fernández, S.; Carrasco-Ochoa, J.A.; Martínez-Trinidad, J.F. A review of unsupervised feature selection methods. Artif. Intell. Rev. 2020, 53, 907–948. [Google Scholar] [CrossRef]
- Sari, C.T.; Gunduz-Demir, C. Unsupervised Feature Extraction via Deep Learning for Histopathological Classification of Colon Tissue Images. IEEE Trans. Med. Imaging 2018, 38, 1139–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, J.; Liu, J.; Yue, H.; Cheng, J.; Kuang, H.; Bai, H.; Wang, Y.; Wang, J. DARC: Deep adaptive regularized clustering for histopathological image classification. Med. Image Anal. 2022, 80, 102521. [Google Scholar] [CrossRef]
- Qi, G.-J.; Luo, J. Small Data Challenges in Big Data Era: A Survey of Recent Progress on Unsupervised and Semi-Supervised Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 2168–2187. [Google Scholar] [CrossRef]
- Frid-Adar, M.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. Synthetic data augmentation using GAN for improved liver lesion classification. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 289–293. [Google Scholar] [CrossRef] [Green Version]
- Quiros, A.C.; Murray-Smith, R.; Ke, Y. Learning a low dimensional manifold of real cancer tissue with pathology GAN. arXiv 2020, arXiv:2004.06517. [Google Scholar]
- Gupta, L.; Klinkhammer, B.M.; Boor, P.; Merhof, D.; Gadermayr, M. GAN-Based Image Enrichment in Digital Pathology Boosts Segmentation Accuracy. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2019; Springer: Cham, Switzerland, 2019; pp. 631–639. [Google Scholar] [CrossRef]
- Kazeminia, S.; Baur, C.; Kuijper, A.; van Ginneken, B.; Navab, N.; Albarqouni, S.; Mukhopadhyay, A. GANs for medical image analysis. Artif. Intell. Med. 2020, 109, 101938. [Google Scholar] [CrossRef]
- Wetstein, S.C.; de Jong, V.M.T.; Stathonikos, N.; Opdam, M.; Dackus, G.M.H.E.; Pluim, J.P.W.; van Diest, P.J.; Veta, M. Deep learning-based breast cancer grading and survival analysis on whole-slide histopathology images. Sci. Rep. 2022, 12, 15102. [Google Scholar] [CrossRef]
- Rubin, R.; Strayer, D. Rubin’s Pathology: Clinicopathologic Foundations of Medicine; Lippincott Williams & Wilkins: Philadelphia, PA, USA, 2008. [Google Scholar]
- Zhu, Y.; Zhuang, F.; Wang, J.; Ke, G.; Chen, J.; Bian, J.; Xiong, H.; He, Q. Deep Subdomain Adaptation Network for Image Classification. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 1713–1722. [Google Scholar] [CrossRef]
- Xu, G.X.; Liu, C.; Liu, J.; Ding, Z.; Shi, F.; Guo, M.; Zhao, W.; Li, X.; Wei, Y.; Gao, Y.; et al. Cross-Site Severity Assessment of COVID-19 From CT Images via Domain Adaptation. IEEE Trans. Med. Imaging 2022, 41, 88–102. [Google Scholar] [CrossRef]
- Li, W.; Zhao, Y.; Chen, X.; Xiao, Y.; Qin, Y. Detecting Alzheimer’s Disease on Small Dataset: A Knowledge Transfer Perspective. IEEE J. Biomed. Health Inform. 2018, 23, 1234–1242. [Google Scholar] [CrossRef] [PubMed]
- Kather, J.N.; Krisam, J.; Charoentong, P.; Luedde, T.; Herpel, E.; Weis, C.-A.; Gaiser, T.; Marx, A.; Valous, N.A.; Ferber, D.; et al. Predicting survival from colorectal cancer histology slides using deep learning: A retrospective multicenter study. PLoS Med. 2019, 16, e1002730. [Google Scholar] [CrossRef] [PubMed]
- Ehteshami Bejnordi, B.; Veta, M.; Johannes van Diest, P.; van Ginneken, B.; Karssemeijer, N.; Litjens, G.; van der Laak, J.A.W.M.; the CAMELYON16 Consortium. Diagnostic Assessment of Deep Learning Algorithms for Detection of Lymph Node Metastases in Women with Breast Cancer. JAMA 2017, 318, 2199–2210. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Spanhol, F.A.; Oliveira, L.S.; Petitjean, C.; Heutte, L. A Dataset for Breast Cancer Histopathological Image Classification. IEEE Trans. Biomed. Eng. 2015, 63, 1455–1462. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning transferable features with deep adaptation networks. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 97–105. [Google Scholar]
- Gretton, A.; Borgwardt, K.M.; Rasch, M.J.; Schölkopf, B.; Smola, A. A kernel two-sample test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Fluss, R.; Faraggi, D.; Reiser, B. Estimation of the Youden Index and its associated cutoff point. Biom. J. J. Math. Methods Biosci. 2005, 47, 458–472. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Slides/Patients | Images/Patches | |||||
|---|---|---|---|---|---|---|---|
| Malignant | Benign | Total | Malignant | Benign | Total | ||
| NCT-CRC-HE-100K | NA | NA | 86 | 14,317 | 85,683 | 100,000 | |
| Camelyon16 | Training set | 110 | 160 | 270 | NA | NA | NA |
| Test set | 49 | 80 | 129 | ||||
| BreaKHis | 58 | 24 | 82 | 1390 | 623 | 2013 | |
| Domain | Dataset Name | Dataset Usage | Type | Slides/Patients | Patches |
|---|---|---|---|---|---|
| Source domain | Dataset-CRC | Training set | Malignant | NA | 14,317 |
| Benign | NA | 14,317 | |||
| Total | 86 | 28,634 | |||
| Target domain | Dataset-SLN | Training set | Malignant | 88 | 3520 * |
| Benign | 128 | 3584 * | |||
| Total | 216 | 7104 | |||
| Validation set | Malignant | 22 | 880 * | ||
| Benign | 32 | 896 * | |||
| Total | 54 | 1776 | |||
| Test set | Malignant | 49 | 54,105 | ||
| Benign | 80 | 54,014 | |||
| Total | 129 | 108,119 | |||
| Dataset-BRE | Training set | Malignant | 42 | 2616 | |
| Benign | 18 | 2616 | |||
| Total | 60 | 5232 | |||
| Validation set | Malignant | 5 | 374 | ||
| Benign | 2 | 374 | |||
| Total | 7 | 748 | |||
| Test set | Malignant | 11 | 748 | ||
| Benign | 4 | 748 | |||
| Total | 15 | 1496 |
| Datasets | HTL | SL-1 | SL-2 | ||
|---|---|---|---|---|---|
| Dataset-SLN | Training | Malignant | 500 | 500 | 3520 |
| Benign | 500 | 500 | 3584 | ||
| Total | 1000 | 1000 | 7104 | ||
| Validation | Malignant | 100 | 100 | 880 | |
| Benign | 100 | 100 | 896 | ||
| Total | 200 | 200 | 1776 | ||
| Test | Malignant | 54,105 | 54,105 | 54,105 | |
| Benign | 54,014 | 54,014 | 54,014 | ||
| Total | 108,119 | 108,119 | 108,119 | ||
| Dataset-BRE | Training | Malignant | 504 | 504 | 2616 |
| Benign | 504 | 504 | 2616 | ||
| Total | 1008 | 1008 | 5232 | ||
| Validation | Malignant | 57 | 57 | 374 | |
| Benign | 57 | 57 | 374 | ||
| Total | 114 | 114 | 748 | ||
| Test | Malignant | 748 | 748 | 748 | |
| Benign | 748 | 748 | 748 | ||
| Total | 1496 | 1496 | 1496 | ||
| Hyperparameters | Value |
|---|---|
| Optimizer | SGD |
| Epochs | 200 |
| Momentum | 0.9 |
| L2 weight decay | 0.0005 |
| Learning rate | 0.01 |
| Batch size | 32 |
| Dataset | AUC | Accuracy | Sensitivity | Specificity |
|---|---|---|---|---|
| CRC-VAL-HE-7K | 0.986 | 0.948 | 0.951 | 0.944 |
| Dataset-SLN (Test set) | 0.692 | 0.540 | 0.009 | 0.986 |
| Dataset-BRE (Test set) | 0.307 | 0.304 | 0.004 | 0.991 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, K.; Chen, Y.; Bai, B.; Gao, Y.; Xiao, J.; Yu, G. Automatic Classification of Histopathology Images across Multiple Cancers Based on Heterogeneous Transfer Learning. Diagnostics 2023, 13, 1277. https://doi.org/10.3390/diagnostics13071277
Sun K, Chen Y, Bai B, Gao Y, Xiao J, Yu G. Automatic Classification of Histopathology Images across Multiple Cancers Based on Heterogeneous Transfer Learning. Diagnostics. 2023; 13(7):1277. https://doi.org/10.3390/diagnostics13071277
Chicago/Turabian StyleSun, Kai, Yushi Chen, Bingqian Bai, Yanhua Gao, Jiaying Xiao, and Gang Yu. 2023. "Automatic Classification of Histopathology Images across Multiple Cancers Based on Heterogeneous Transfer Learning" Diagnostics 13, no. 7: 1277. https://doi.org/10.3390/diagnostics13071277