
COVID-19 Prediction Using Black-Box Based Pearson Correlation Approach
 , , and
, , and
Abstract
:1. Introduction
2. Material and Methods
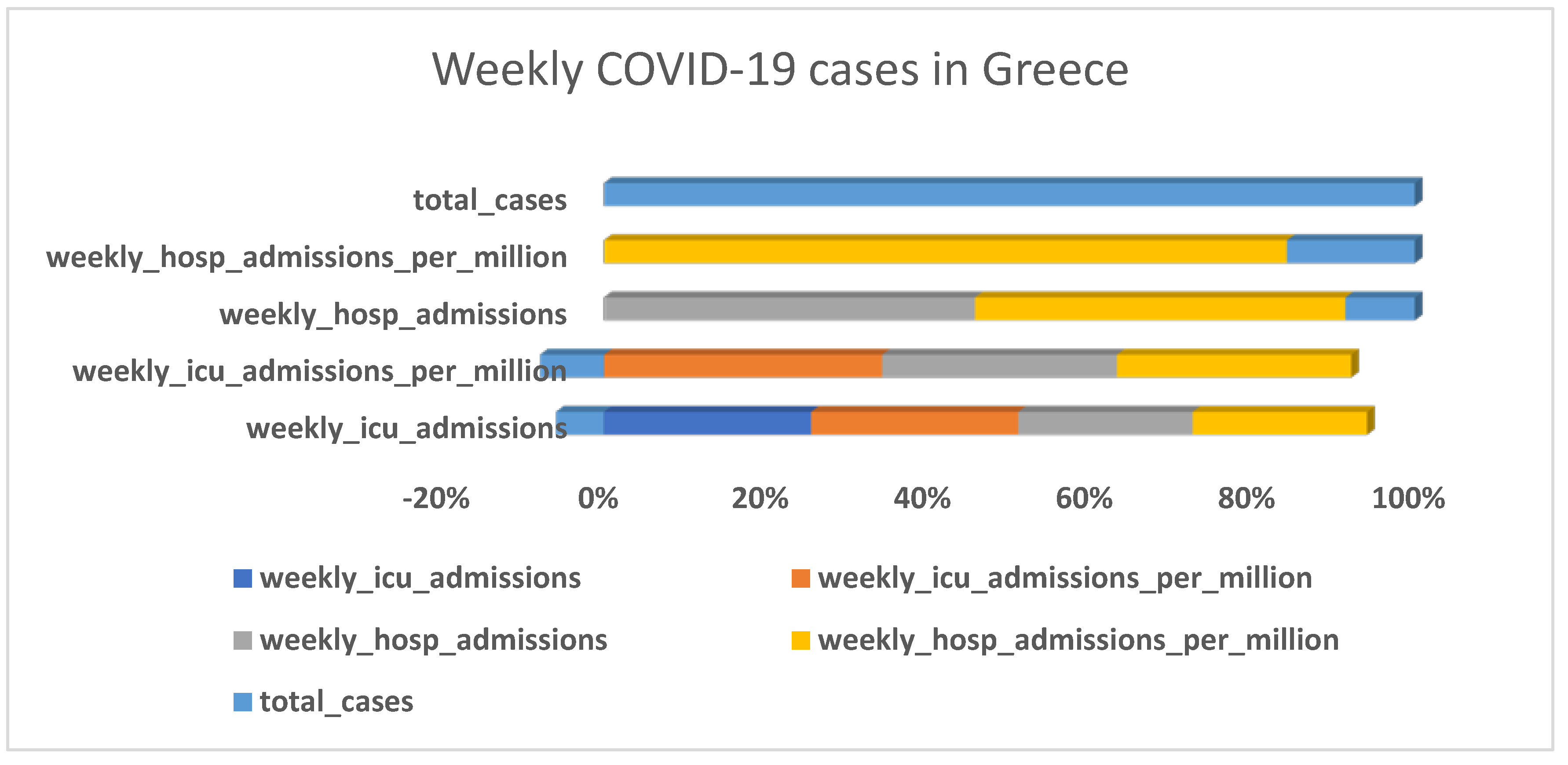
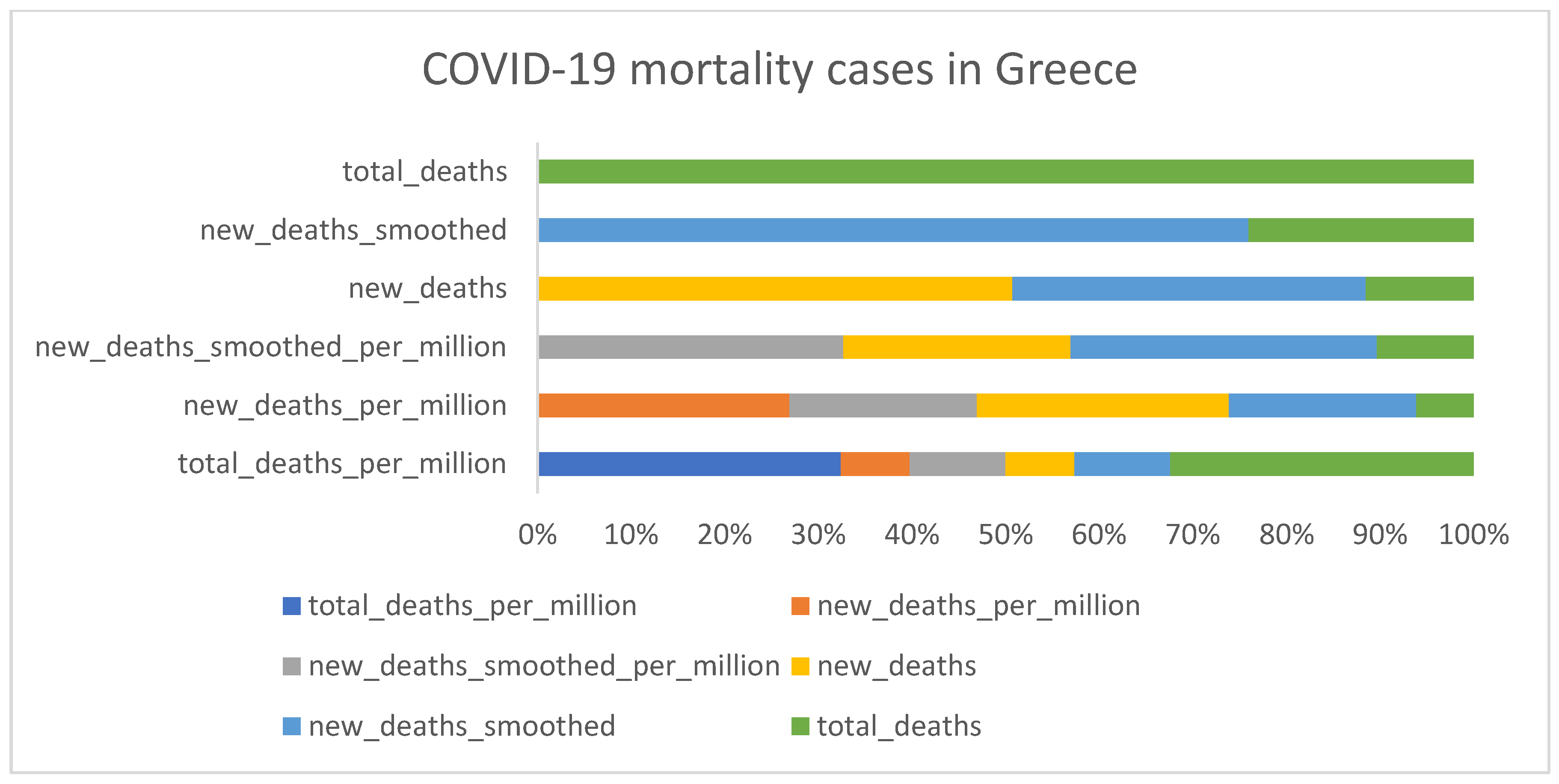
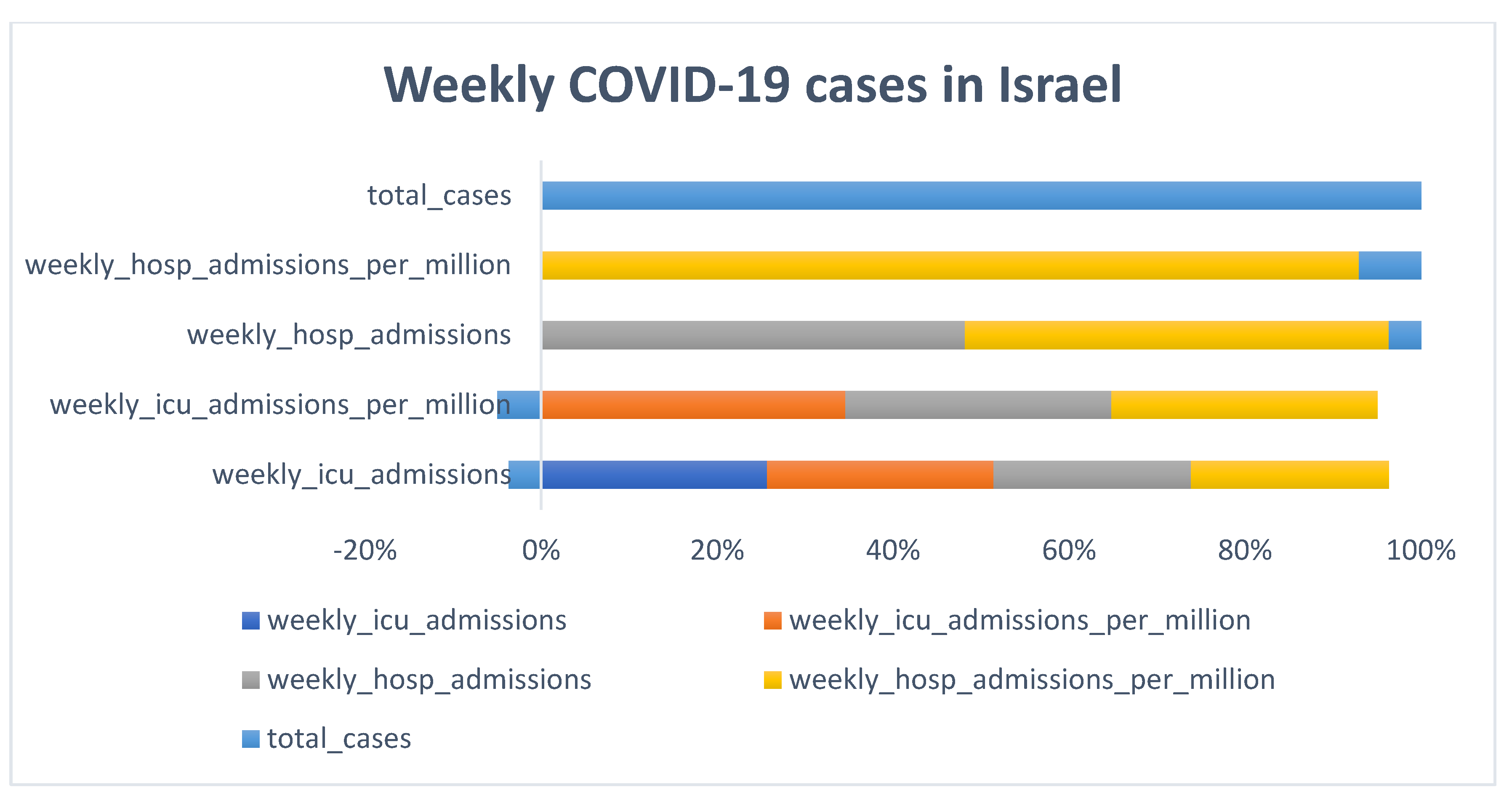
2.1. Data Collection
2.2. Filtering and Pre-Processing the Data
- Data from two countries (Greece and Israel) were collected from the overall dataset to enable us to carry out the evaluation.
- Columns and rows containing no valid data were deleted.
- For our prediction, only datasets from Israel were used to train the model.
2.3. Prediction Models
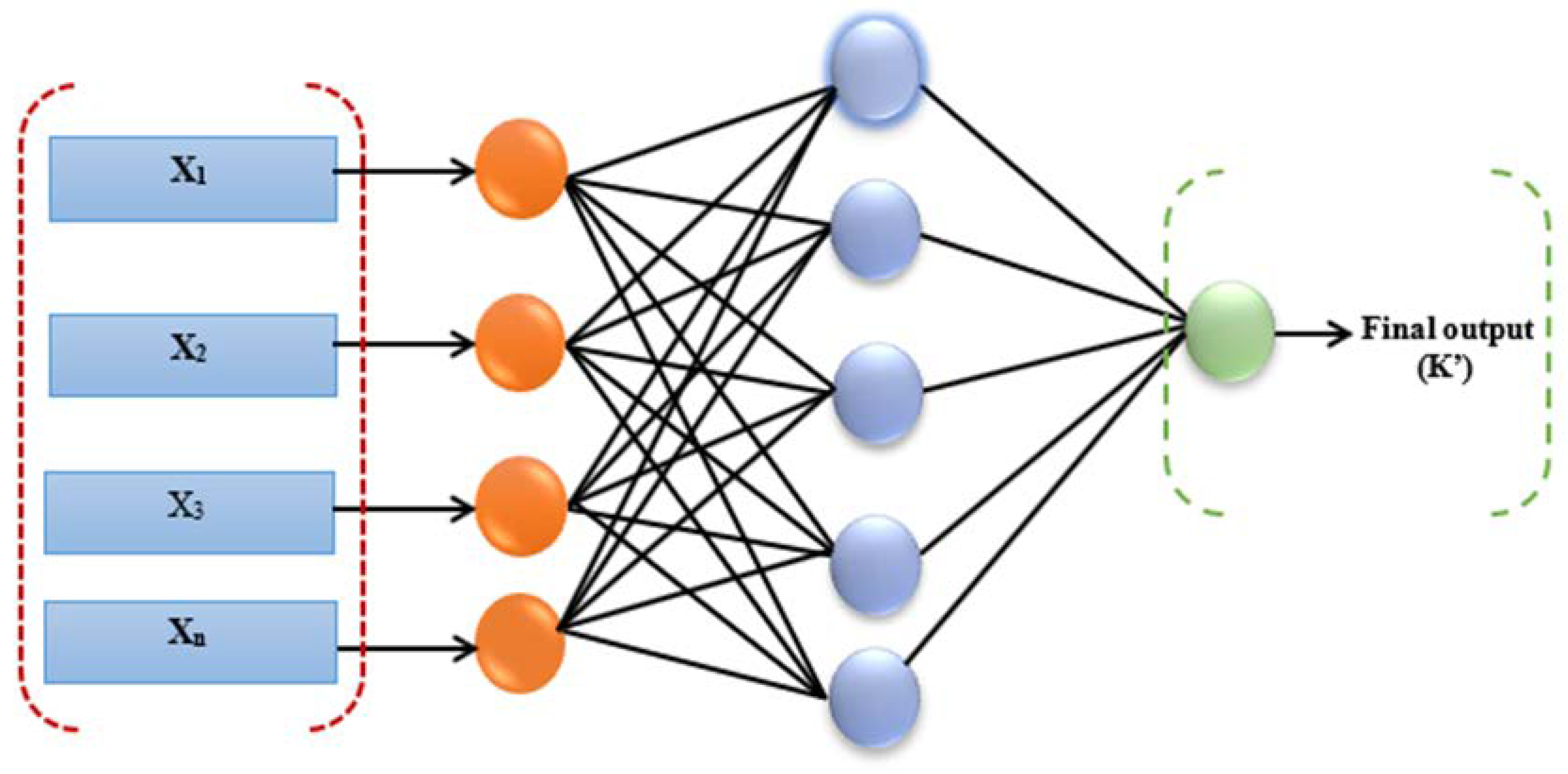
2.3.1. Artificial Neural Network (ANN)
2.3.2. Multiple Linear Regression (MLR)
2.4. Model Validation
2.5. Model Performance Criteria
3. Application of Results and Discussion
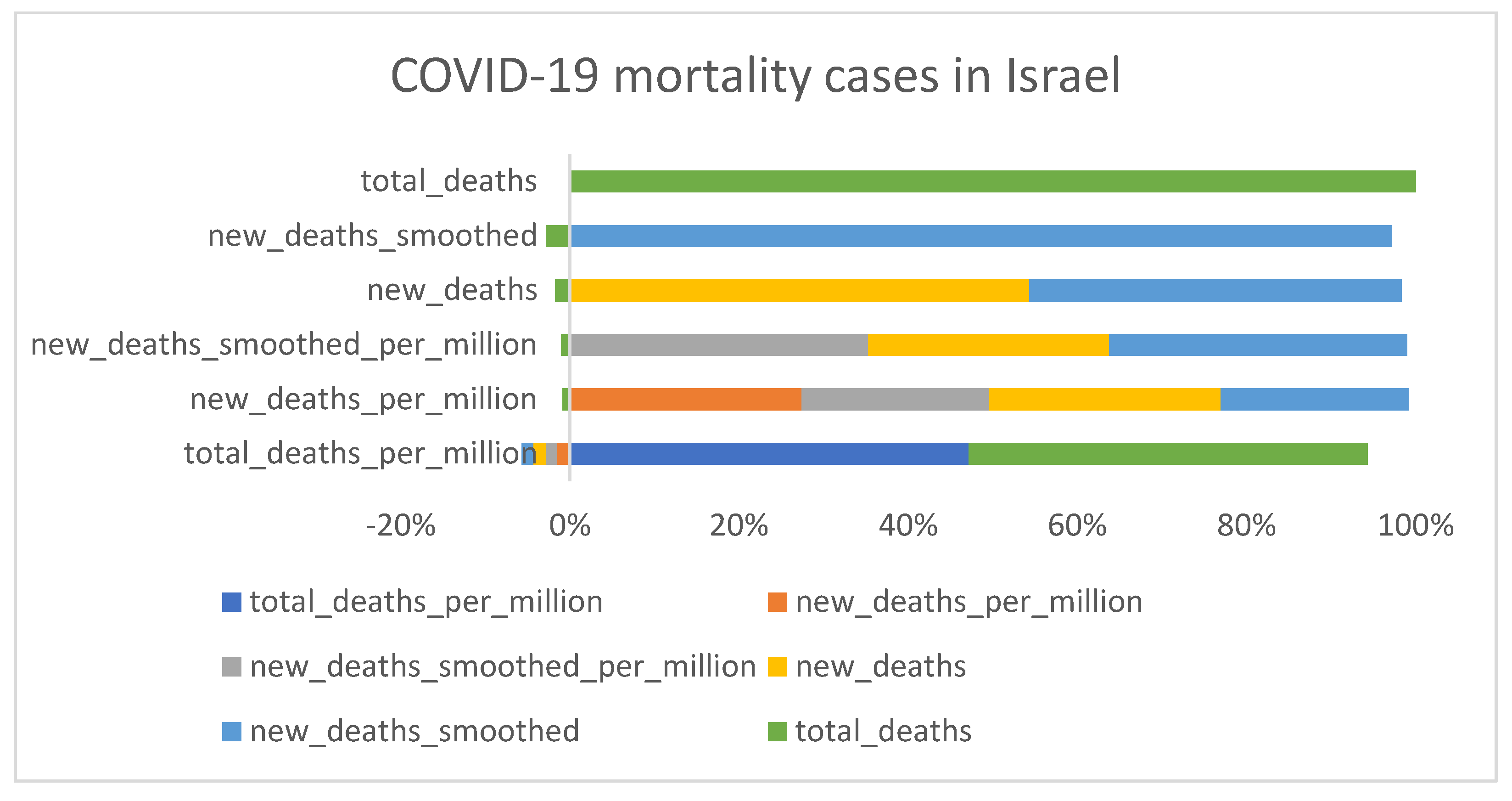
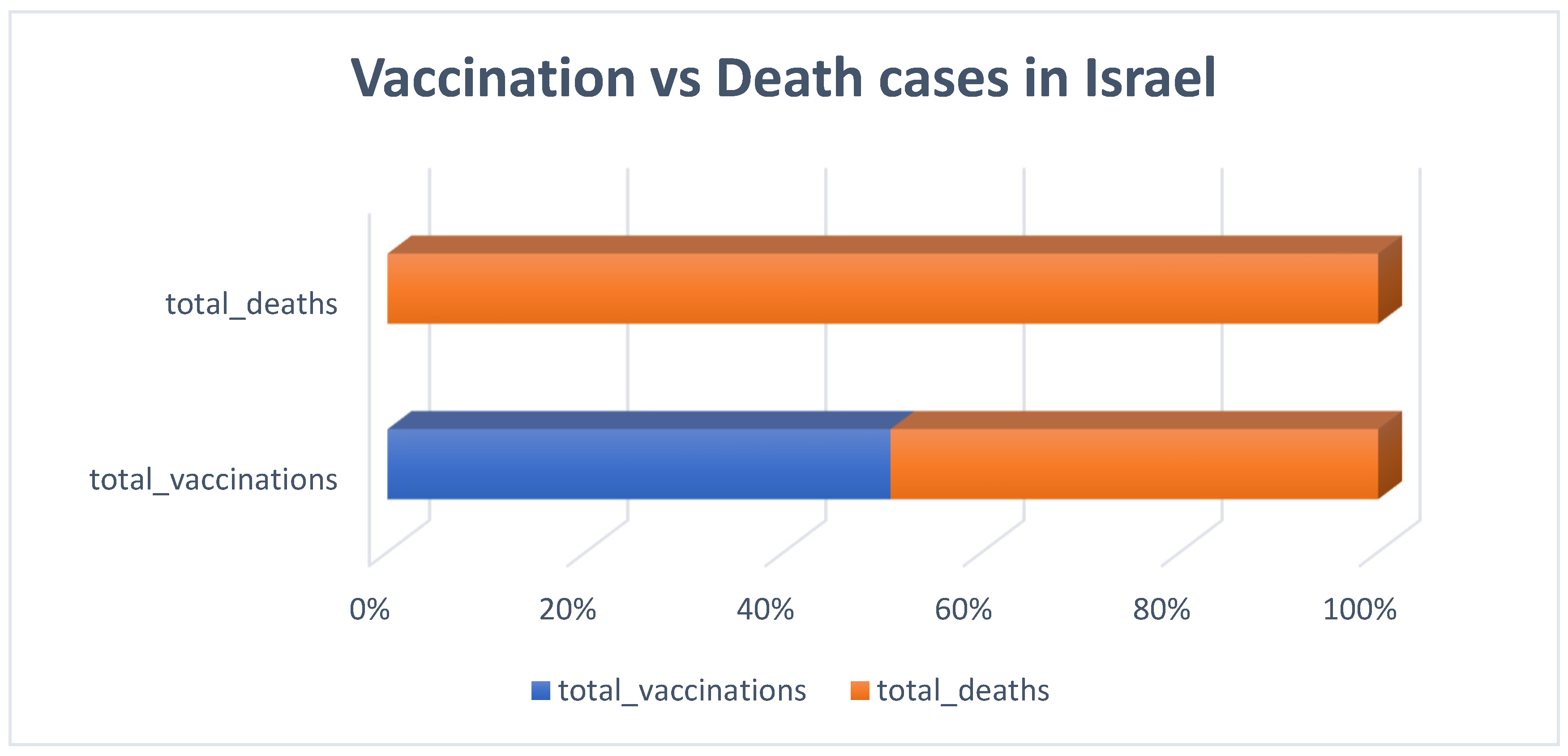
3.1. Descriptive Analysis
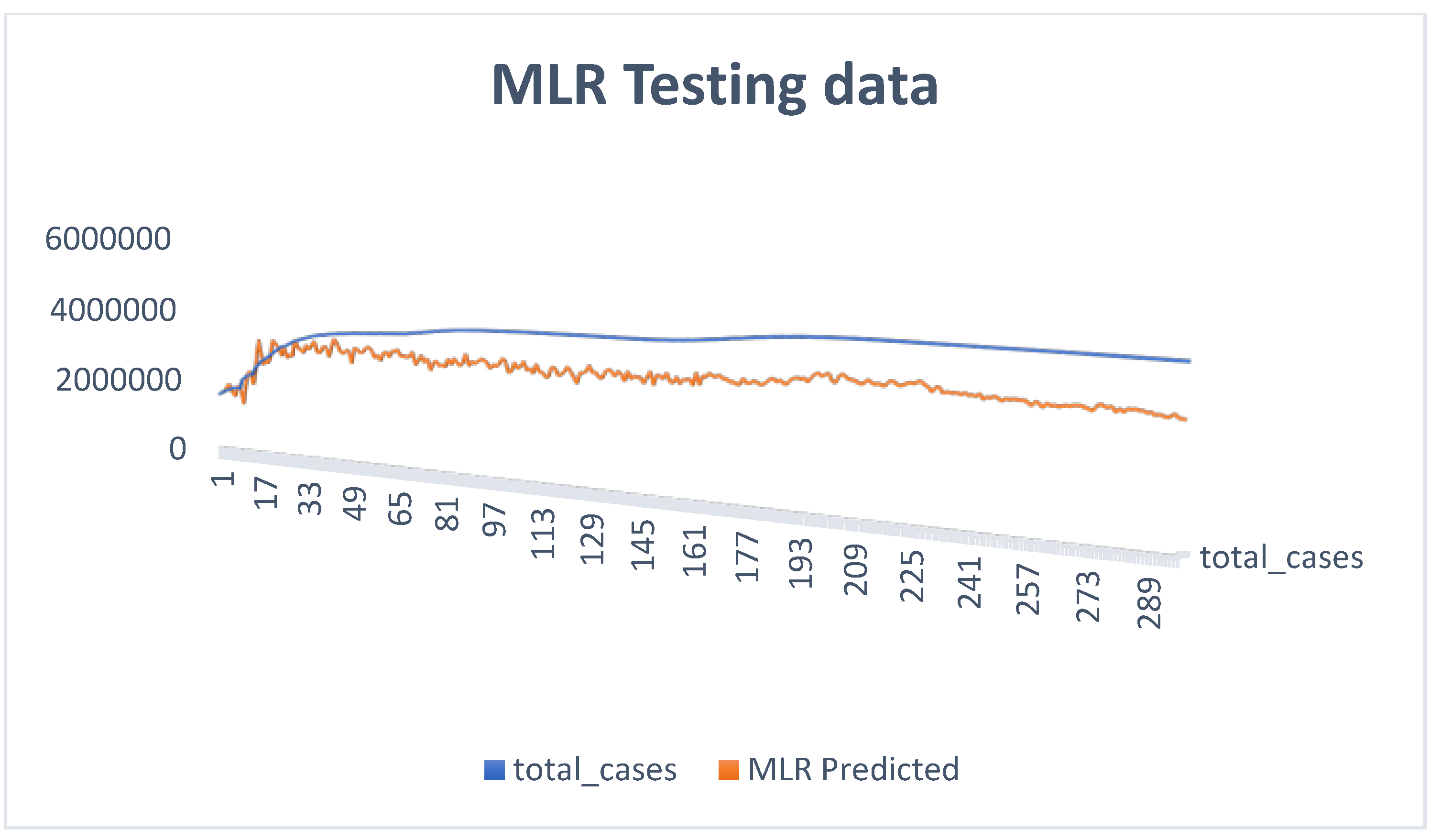
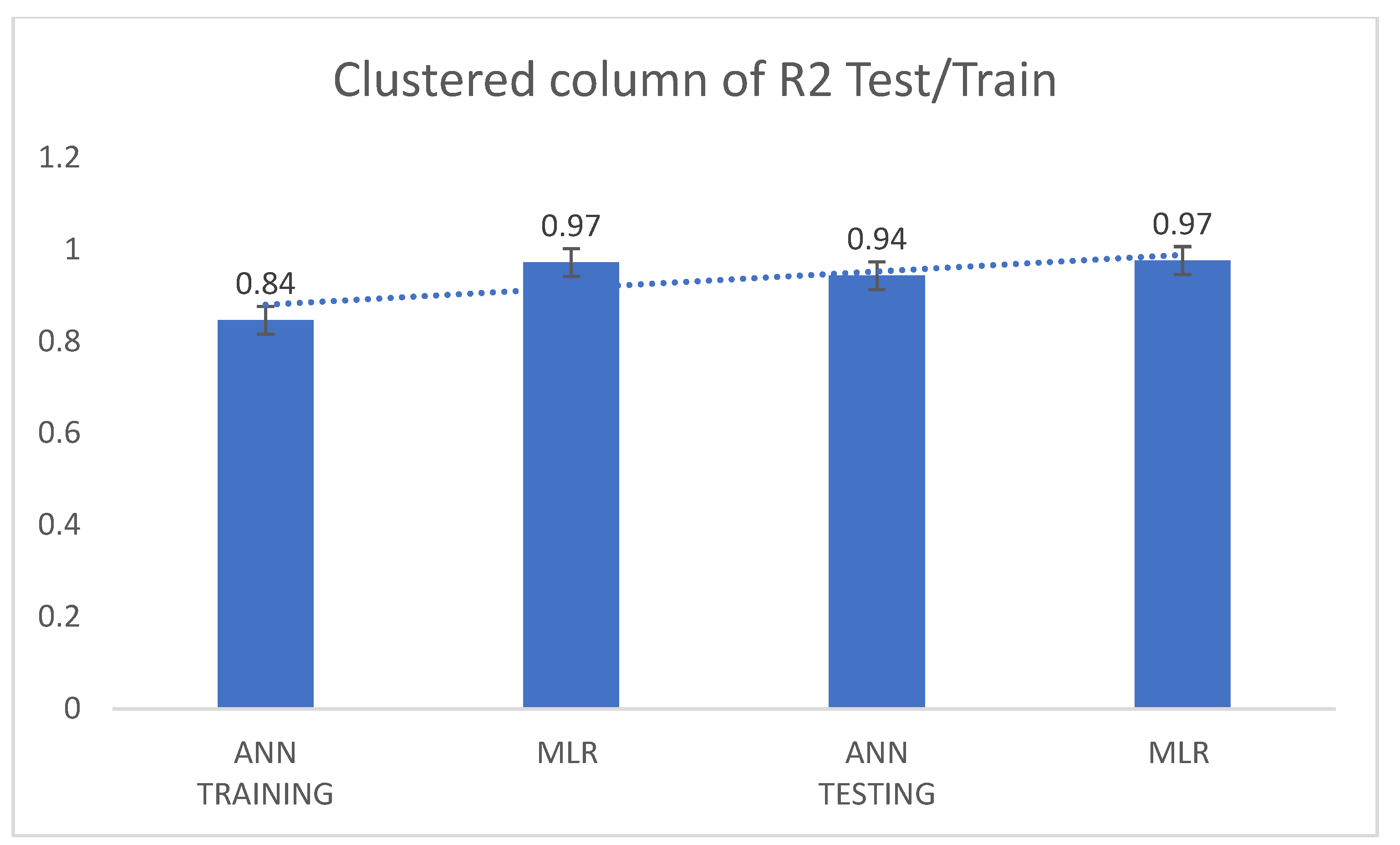
3.2. Results of the Models
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ozsahin, I.; Sekeroglu, B.; Musa, M.S.; Mustapha, M.T.; Ozsahin, D.U. Review on Diagnosis of COVID-19 from Chest CT Images Using Artificial Intelligence. Comput. Math. Methods Med. 2020, 2020, 9756518. [Google Scholar] [CrossRef] [PubMed]
- Ozsahin, D.U.; Gelisen, M.I.; Taiwo, M.; Agachan, Y.; Rahi, D.; Uzun, U. Decision Analysis of the COVID-19 Vaccines. EuroBiotech J. 2021, 5, 20–25. [Google Scholar] [CrossRef]
- Chen, J. Novel statistics predict the COVID-19 pandemic could terminate in 2022. J. Med. Virol. 2022, 94, 2845–2848. [Google Scholar] [CrossRef]
- Wu, Z.; McGoogan, J.M. Characteristics of and Important Lessons From the Coronavirus Disease 2019 (COVID-19) Outbreak in China: Summary of a Report of 72 314 Cases From the Chinese Center for Disease Control and Prevention. JAMA J. Am. Med. Assoc. 2020, 323, 1239–1242. [Google Scholar] [CrossRef] [PubMed]
- Malki, Z.; Atlam, E.-S.; Ewis, A.; Dagnew, G.; Ghoneim, O.A.; Mohamed, A.A.; Abdel-Daim, M.M.; Gad, I. The COVID-19 pandemic: Prediction study based on machine learning models. Environ. Sci. Pollut. Res. 2021, 28, 40496–40506. [Google Scholar] [CrossRef]
- Asgharnezhad, H.; Shamsi, A.; Alizadehsani, R.; Khosravi, A.; Nahavandi, S.; Sani, Z.A.; Srinivasan, D.; Islam, S.M.S. Objective evaluation of deep uncertainty predictions for COVID-19 detection. Sci. Rep. 2022, 12, 815. [Google Scholar] [CrossRef]
- Cabello-Torres, R.J.; Estela, M.A.P.; Sánchez-Ccoyllo, O.; Romero-Cabello, E.A.; Ávila, F.F.G.; Castañeda-Olivera, C.A.; Valdiviezo-Gonzales, L.; Eulogio, C.E.Q.; De La Cruz, A.R.H.; López-Gonzales, J.L. Statistical modeling approach for PM10 prediction before and during confinement by COVID-19 in South Lima, Perú. Sci. Rep. Inst. 2022, 12, 16737. [Google Scholar] [CrossRef]
- Rath, S.; Tripathy, A.; Tripathy, A.R. Prediction of new active cases of coronavirus disease (COVID-19) pandemic using multiple linear regression model. Diabetes Metab. Syndr. Clin. Res. Rev. 2020, 14, 1467–1474. [Google Scholar] [CrossRef]
- Yadav, M.; Perumal, M.; Srinivas, M. Analysis on novel coronavirus (COVID-19) using machine learning methods. Chaos Solitons Fractals 2020, 139, 110050. [Google Scholar] [CrossRef]
- Li, M.; Zhang, Z.; Cao, W.; Liu, Y.; Du, B.; Chen, C.; Liu, Q.; Uddin, N.; Jiang, S.; Chen, C.; et al. Identifying novel factors associated with COVID-19 transmission and fatality using the machine learning approach. Sci. Total. Environ. 2020, 764, 142810. [Google Scholar] [CrossRef]
- Singh, S.; Parmar, K.S.; Makkhan, S.J.S.; Kaur, J.; Peshoria, S.; Kumar, J. Study of ARIMA and least square support vector machine (LS-SVM) models for the prediction of SARS-CoV-2 confirmed cases in the most affected countries. Chaos Solitons Fractals 2020, 139, 110086. [Google Scholar] [CrossRef]
- Das, B. An implementation of a hybrid method based on machine learning to identify biomarkers in the Covid-19 diagnosis using DNA sequences. Chemom. Intell. Lab. Syst. 2022, 230, 104680. [Google Scholar] [CrossRef]
- Ribeiro, M.H.D.M.; da Silva, R.G.; Mariani, V.C.; Coelho, L.D.S. Short-term forecasting COVID-19 cumulative confirmed cases: Perspectives for Brazil. Chaos Solitons Fractals 2020, 135, 109853. [Google Scholar] [CrossRef]
- Comito, C.; Pizzuti, C. Artificial intelligence for forecasting and diagnosing COVID-19 pandemic: A focused review. Artif. Intell. Med. 2022, 128, 102286. [Google Scholar] [CrossRef]
- Barstugan, M.; Ozkaya, U.; Ozturk, S. Coronavirus (Covid-19) classification using CT images by machine learning methods. CEUR Workshop Proc. 2021, 2872, 29–35. [Google Scholar]
- Gozes, O.; Frid-Adar, M.; Greenspan, H.; Browning, P.D.; Zhang, H.; Ji, W.; Bernheim, A.; Siegel, E. Rapid AI Development Cycle for the Coronavirus (COVID-19) Pandemic: Initial Results for Automated Detection & Patient Monitoring using Deep Learning CT Image Analysis. arXiv 2020, arXiv:2003.05037. [Google Scholar]
- Wathore, R.; Rawlekar, S.; Anjum, S.; Gupta, A.; Bherwani, H.; Labhasetwar, N.; Kumar, R. Improving performance of deep learning predictive models for COVID-19 by incorporating environmental parameters. Gondwana Res. 2023, 114, 69–77. [Google Scholar] [CrossRef]
- Du, H.; Dong, E.; Badr, H.S.; Petrone, M.E.; Grubaugh, N.D.; Gardner, L.M. Incorporating variant frequencies data into short-term forecasting for COVID-19 cases and deaths in the USA: A deep learning approach. Ebiomedicine 2023, 89, 104482. [Google Scholar] [CrossRef]
- Ayyoubzadeh, S.M.; Zahedi, H.; Ahmadi, M.; Kalhori, S.R.N. Predicting COVID-19 Incidence Through Analysis of Google Trends Data in Iran: Data Mining and Deep Learning Pilot Study. JMIR Public Health Surveill. 2020, 6, e18828. [Google Scholar] [CrossRef]
- Mustapha, M.T.; Ozsahin, D.U.; Ozsahin, I.; Uzun, B. Breast Cancer Screening Based on Supervised Learning and Multi-Criteria Decision-Making. Diagnostics 2022, 12, 1326. [Google Scholar] [CrossRef] [PubMed]
- Ozsahin, D.U.; Mustapha, M.T.; Mubarak, A.S.; Ameen, Z.S.; Uzun, B. Impact of Outliers and Dimensionality Reduction on the Performance of Predictive Models for Medical Disease Diagnosis. In Proceedings of the 2022 International Conference on Artificial Intelligence in Everything, Lefkosa, Cyprus, 2–4 August 2022; pp. 79–86. [Google Scholar] [CrossRef]
- Cagatan, A.S.; Mustapha, M.T.; Bagkur, C.; Sanlidag, T.; Ozsahin, D.U. An Alternative Diagnostic Method for C. neoformans: Preliminary Results of Deep-Learning Based Detection Model. Diagnostics 2022, 13, 81. [Google Scholar] [CrossRef] [PubMed]
- Shad, M.; Sharma, Y.D.; Singh, A. Forecasting of monthly relative humidity in Delhi, India, using SARIMA and ANN models. Model Earth Syst. Environ. 2022, 8, 4843–4851. [Google Scholar] [CrossRef] [PubMed]
- Bakhtiarvand, N.; Khashei, M.; Mahnam, M.; Hajiahmadi, S. A novel reliability-based regression model to analyze and forecast the severity of COVID-19 patients. BMC Med. Inform. Decis. Mak. 2022, 22, 123. [Google Scholar] [CrossRef] [PubMed]
- Metekia, W.A.; Usman, A.G.; Ulusoy, B.H.; Abba, S.I.; Bali, K.C. Artificial intelligence-based approaches for modeling the effects of spirulina growth mediums on total phenolic compounds. Saudi J. Biol. Sci. 2022, 29, 1111–1117. [Google Scholar] [CrossRef] [PubMed]
- Abba, S.; Hadi, S.J.; Abdullahi, J. River water modelling prediction using multi-linear regression, artificial neural network, and adaptive neuro-fuzzy inference system techniques. Procedia Comput. Sci. 2017, 120, 75–82. [Google Scholar] [CrossRef]
- Abba, S.I.; Abdulkadir, R.A.; Sammen, S.S.; Usman, A.G.; Meshram, S.G.; Malik, A.; Shahid, S. Comparative implementation between neuro-emotional genetic algorithm and novel ensemble computing techniques for modelling dissolved oxygen concentration. Hydrol. Sci. J. 2021, 66, 1584–1596. [Google Scholar] [CrossRef]
- Usman, A.G.; Ghali, U.M.; Degm, M.A.A.; Muhammad, S.M.; Hincal, E.; Kurya, A.U.; Işik, S.; Hoti, Q.; Abba, S.I. Simulation of liver function enzymes as determinants of thyroidism: A novel ensemble machine learning approach. Bull. Natl. Res. Cent. 2022, 46, 73. [Google Scholar] [CrossRef]
- Abba, S.; Benaafi, M.; Usman, A.; Ozsahin, D.U.; Tawabini, B.; Aljundi, I.H. Mapping of groundwater salinization and modelling using meta-heuristic algorithms for the coastal aquifer of eastern Saudi Arabia. Sci. Total. Environ. 2023, 858, 159697. [Google Scholar] [CrossRef]
- Ghali, U.M.; Usman, A.; Alsharksi, A.N.; Degm, M.A.A.; Naibi, A.M.; Abba, S.I. Applications of Artificial Intelligence-Based Models and Multi-Linear Regression for the Prediction of Thyroid Stimulating Hormone Level in the Human Body. Int. J. Adv. Sci. Technol. 2020, 29, 3690–3699. [Google Scholar]
- Ozsahin, D.U.; Mustapha, M.T.; Duwa, B.B.; Ozsahin, I. Evaluating the Performance of Deep Learning Frameworks for Malaria Parasite Detection Using Microscopic Images of Peripheral Blood Smears. Diagnostics 2022, 12, 2702. [Google Scholar] [CrossRef]
- Usman, A.G.; Işik, S.; Abba, S.I. Qualitative prediction of Thymoquinone in the high-performance liquid chromatography optimization method development using artificial intelligence models coupled with ensemble machine learning. Sep. Sci. PLUS 2022, 5, 579–587. [Google Scholar] [CrossRef]
- Etemadi, S.; Khashei, M. Etemadi multiple linear regression. Measurement 2021, 186, 110080. [Google Scholar] [CrossRef]
- Yi, Q.-X.; Huang, J.-F.; Wang, F.-M.; Wang, X.-Z.; Liu, Z.-Y. Monitoring Rice Nitrogen Status Using Hyperspectral Reflectance and Artificial Neural Network. Environ. Sci. Technol. 2007, 41, 6770–6775. [Google Scholar] [CrossRef]
- Ghanim, M.S.; Muley, D.; Kharbeche, M. ANN-Based traffic volume prediction models in response to COVID-19 imposed measures. Sustain. Cities Soc. 2022, 81, 103830. [Google Scholar] [CrossRef]
- Kuvvetli, Y.; Deveci, M.; Paksoy, T.; Garg, H. A predictive analytics model for COVID-19 pandemic using artificial neural networks. Decis. Anal. J. 2021, 1, 100007. [Google Scholar] [CrossRef]
- Ibrahim, Z.; Tulay, P.; Abdullahi, J. Multi-region machine learning-based novel ensemble approaches for predicting COVID-19 pandemic in Africa. Environ. Sci. Pollut. Res. 2022, 30, 3621–3643. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | ||||
|---|---|---|---|---|
| Models | R2 | R | RMSE | MSE |
| ANN | 0.846 | 0.919 | 0.035 | 0.001 |
| MLR | 0.971 | 0.985 | 0.037 | 0.001 |
| Testing | ||||
| ANN | 0.943 | 0.971 | 0.056 | 0.003 |
| MLR | 0.976 | 0.988 | 0.057 | 0.004 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Uzun Ozsahin, D.; Precious Onakpojeruo, E.; Bartholomew Duwa, B.; Usman, A.G.; Isah Abba, S.; Uzun, B. COVID-19 Prediction Using Black-Box Based Pearson Correlation Approach. Diagnostics 2023, 13, 1264. https://doi.org/10.3390/diagnostics13071264
Uzun Ozsahin D, Precious Onakpojeruo E, Bartholomew Duwa B, Usman AG, Isah Abba S, Uzun B. COVID-19 Prediction Using Black-Box Based Pearson Correlation Approach. Diagnostics. 2023; 13(7):1264. https://doi.org/10.3390/diagnostics13071264
Chicago/Turabian StyleUzun Ozsahin, Dilber, Efe Precious Onakpojeruo, Basil Bartholomew Duwa, Abdullahi Garba Usman, Sani Isah Abba, and Berna Uzun. 2023. "COVID-19 Prediction Using Black-Box Based Pearson Correlation Approach" Diagnostics 13, no. 7: 1264. https://doi.org/10.3390/diagnostics13071264