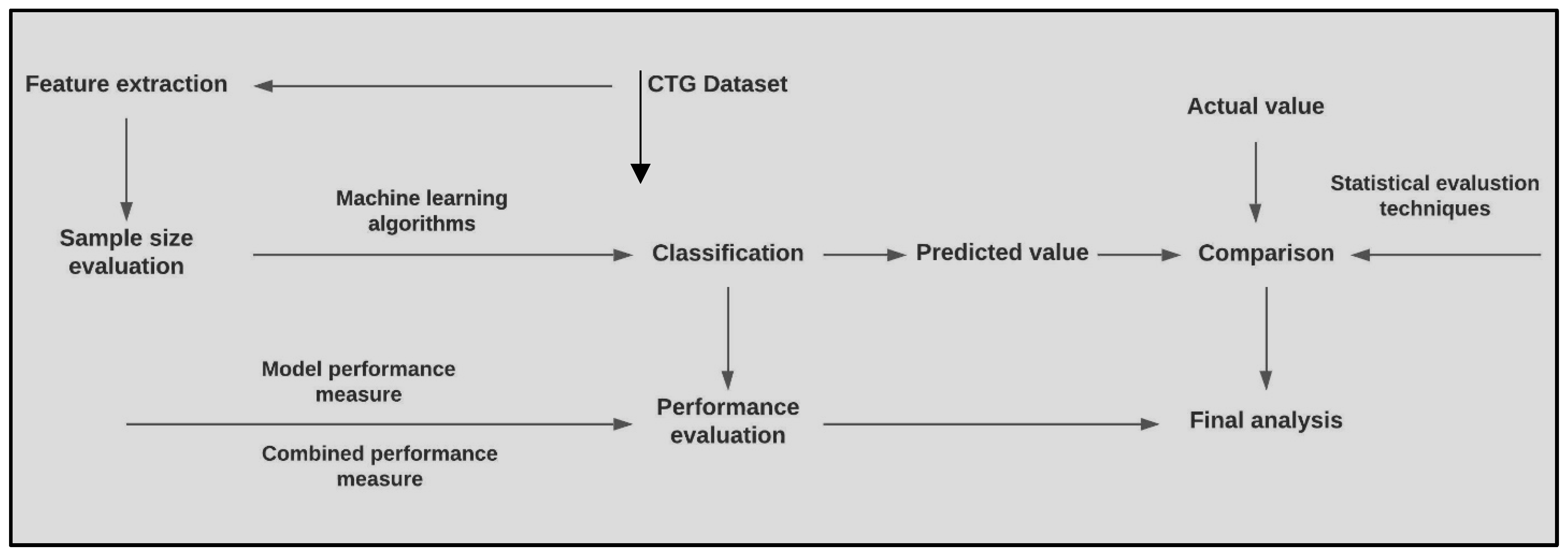
Figure 1.
Overview of the proposed methodology.
Figure 1.
Overview of the proposed methodology.
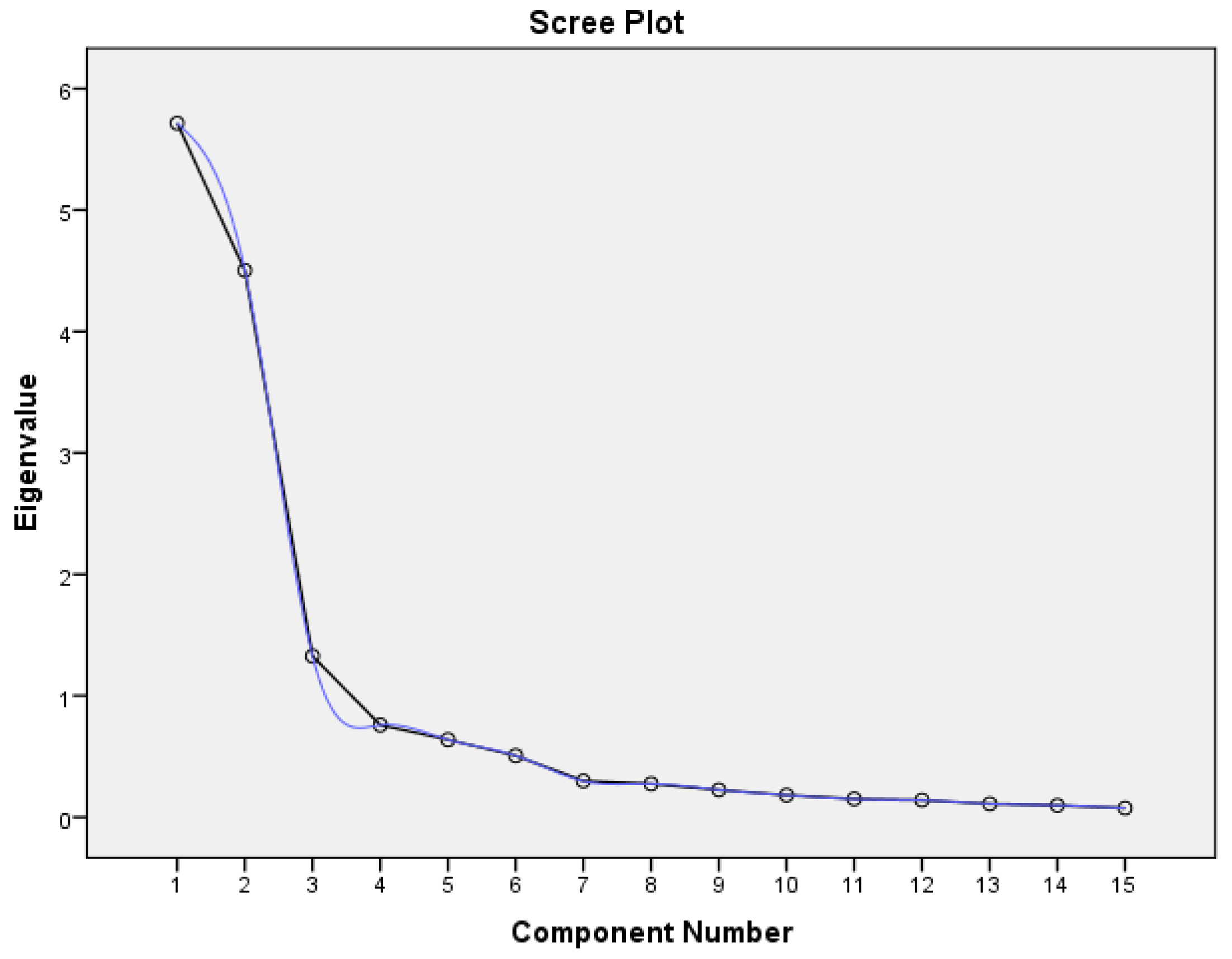
Figure 2.
The scree plot begins to flatten from the 9th feature.
Figure 2.
The scree plot begins to flatten from the 9th feature.
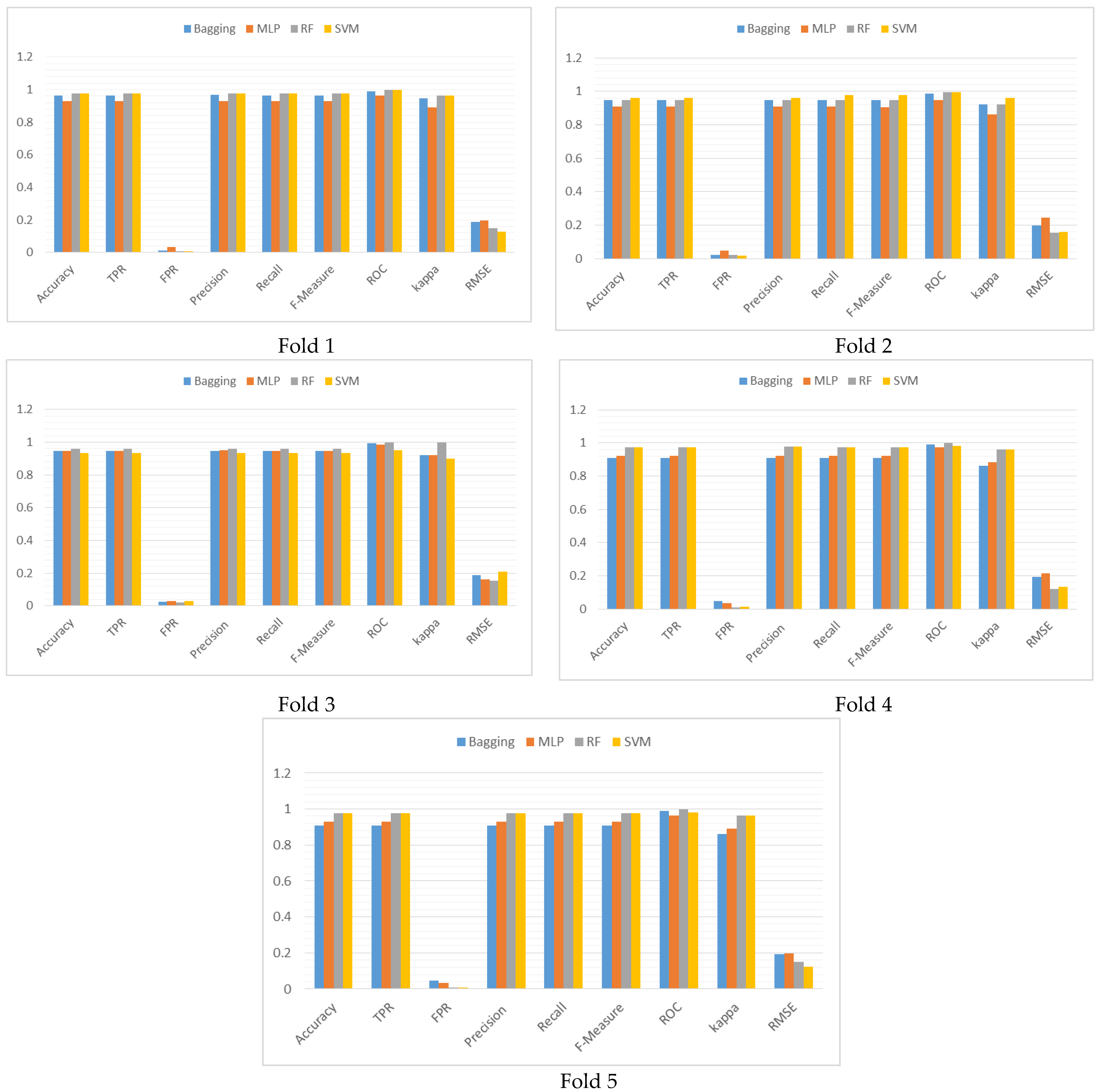
Figure 3.
Graphical representation of the performance comparison of the classifiers for each fold of the 5-fold cross validation in terms of the performance metrics.
Figure 3.
Graphical representation of the performance comparison of the classifiers for each fold of the 5-fold cross validation in terms of the performance metrics.
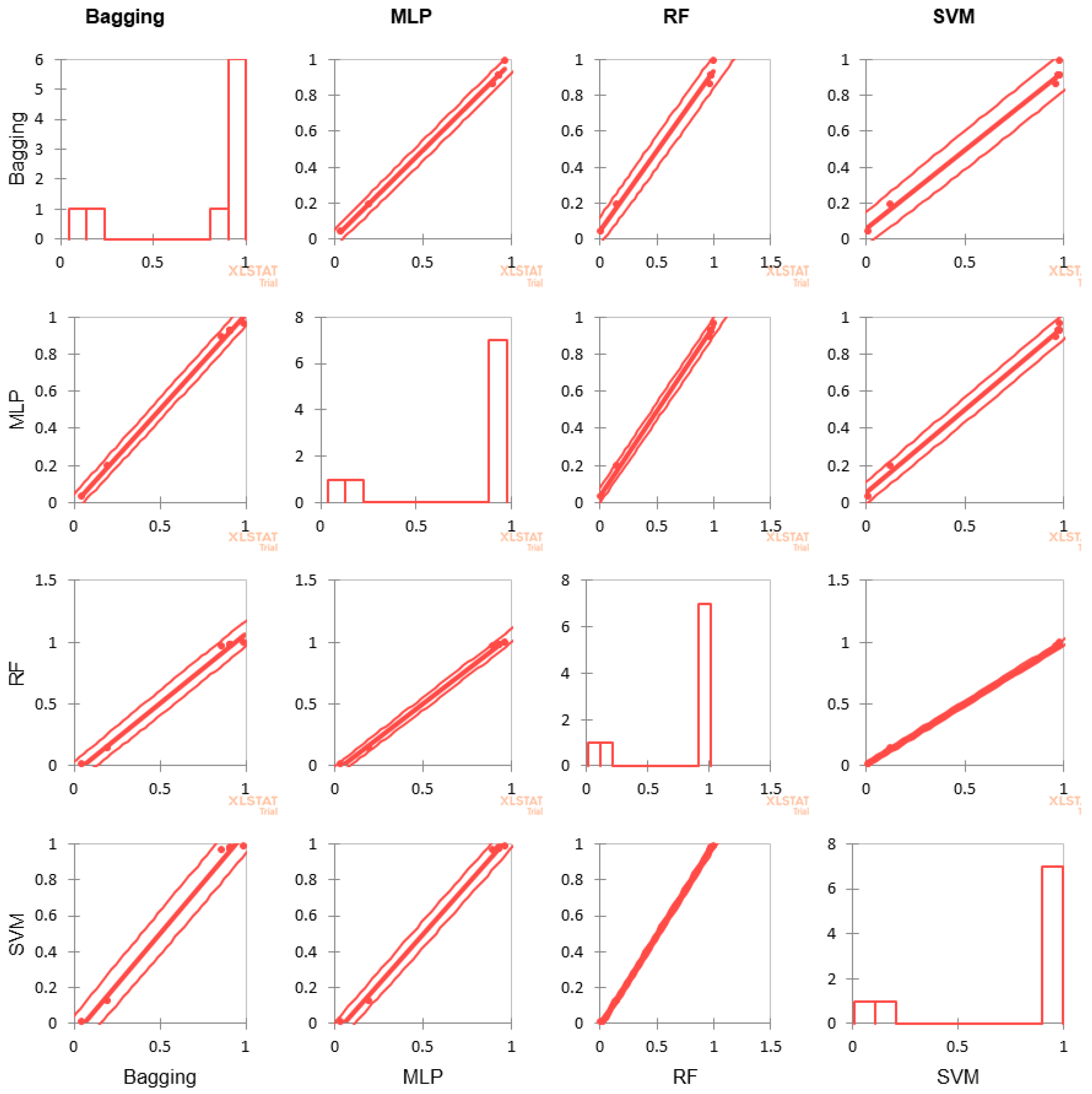
Figure 4.
Scatter plot of the correlation analysis for the four classifiersestablishes how well the chosen value of k matches across the different algorithms.
Figure 4.
Scatter plot of the correlation analysis for the four classifiersestablishes how well the chosen value of k matches across the different algorithms.
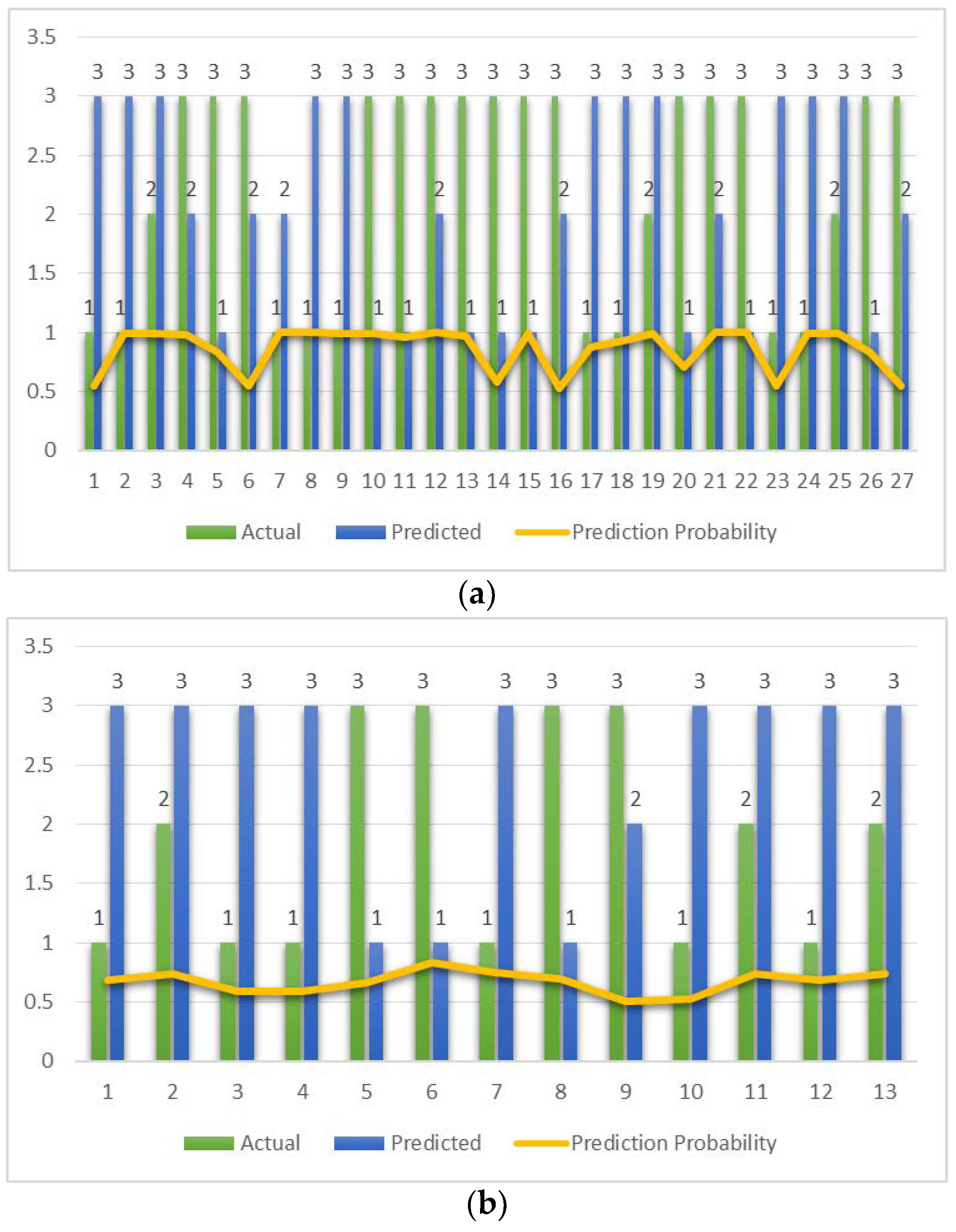
Figure 5.
Data points where actual and predicted classifications differ for each of the classifiers. The prediction probability is shown as a yellow line. (a) MLP. (b) RF. (c) SVM. (d) Bagging.
Figure 5.
Data points where actual and predicted classifications differ for each of the classifiers. The prediction probability is shown as a yellow line. (a) MLP. (b) RF. (c) SVM. (d) Bagging.
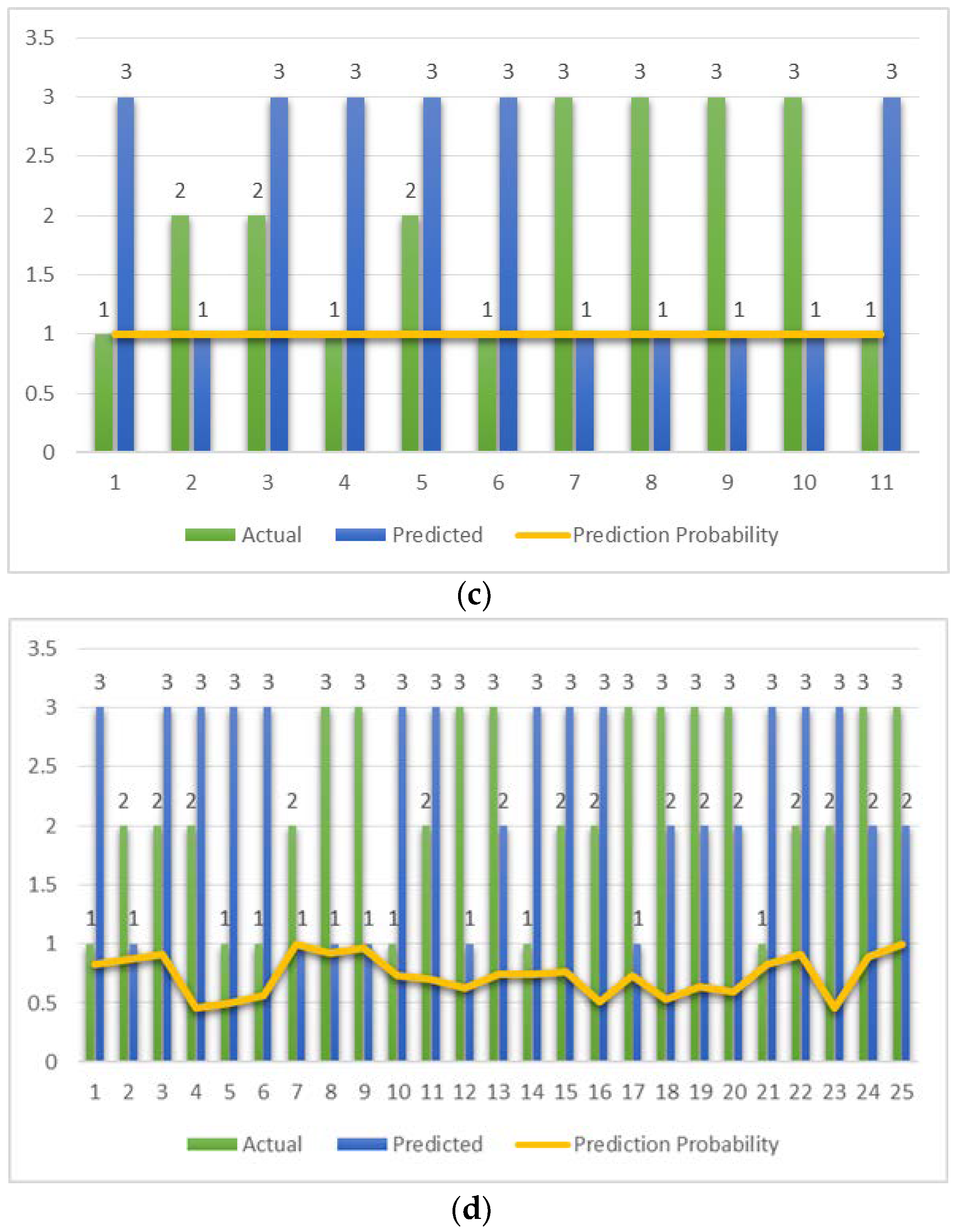
Figure 6.
ROC curve for the four classifiers. Predicted has at least one tie between the positive actual state group and the negative actual state group. (a) MLP, AUC-ROC: 0.966. (b) RF, AUC-ROC: 0.997. (c) SVM, AUC-ROC: 0.966. (d) Bagging, AUC-ROC: 0.989.
Figure 6.
ROC curve for the four classifiers. Predicted has at least one tie between the positive actual state group and the negative actual state group. (a) MLP, AUC-ROC: 0.966. (b) RF, AUC-ROC: 0.997. (c) SVM, AUC-ROC: 0.966. (d) Bagging, AUC-ROC: 0.989.
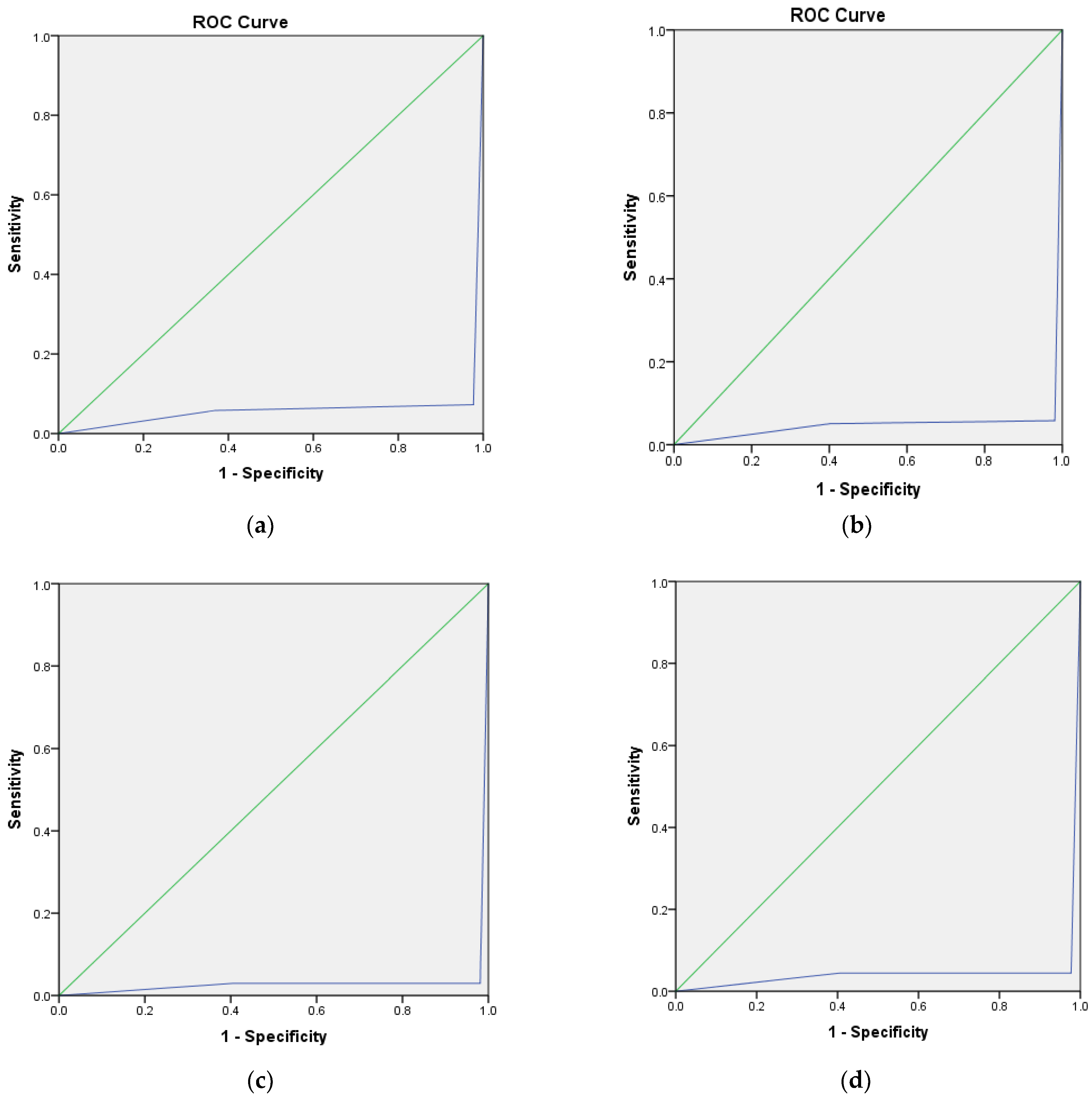
Figure 7.
Scatter plots show the difference between the actual and predicted classifications. The bar charts show the number of instances in each class and the scatter plots show the number of outliers in each class for all four classifiers. (a) MLP. (b) RF. (c) SVM. (d) Bagging.
Figure 7.
Scatter plots show the difference between the actual and predicted classifications. The bar charts show the number of instances in each class and the scatter plots show the number of outliers in each class for all four classifiers. (a) MLP. (b) RF. (c) SVM. (d) Bagging.
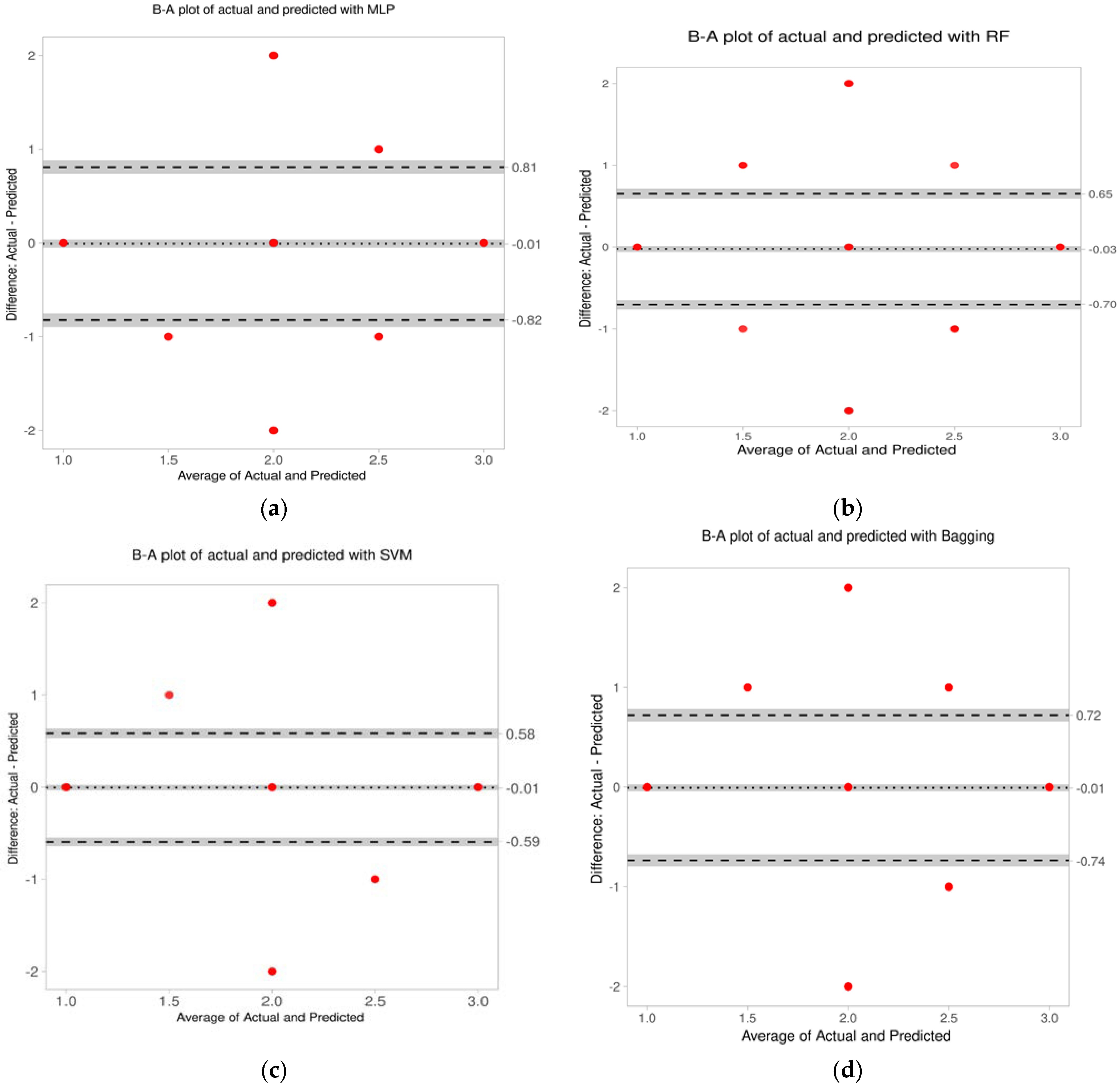
Figure 8.
Bland–Altman plot of the actual and predicted classifications for all the classifiers. (a) For MLP, the average difference is −0.01 and the limits of agreement: −0.82 and 0.81. (b) For RF the average difference is −0.03 and the limits of agreement: −0.7 and 0.65. (c) For SVM, the average difference is −0.01 and the limits of agreement: −0.59 and 0.58. (d) For bagging the average difference is −0.01 and the limits of agreement: −0.74 and 0.72.
Figure 8.
Bland–Altman plot of the actual and predicted classifications for all the classifiers. (a) For MLP, the average difference is −0.01 and the limits of agreement: −0.82 and 0.81. (b) For RF the average difference is −0.03 and the limits of agreement: −0.7 and 0.65. (c) For SVM, the average difference is −0.01 and the limits of agreement: −0.59 and 0.58. (d) For bagging the average difference is −0.01 and the limits of agreement: −0.74 and 0.72.
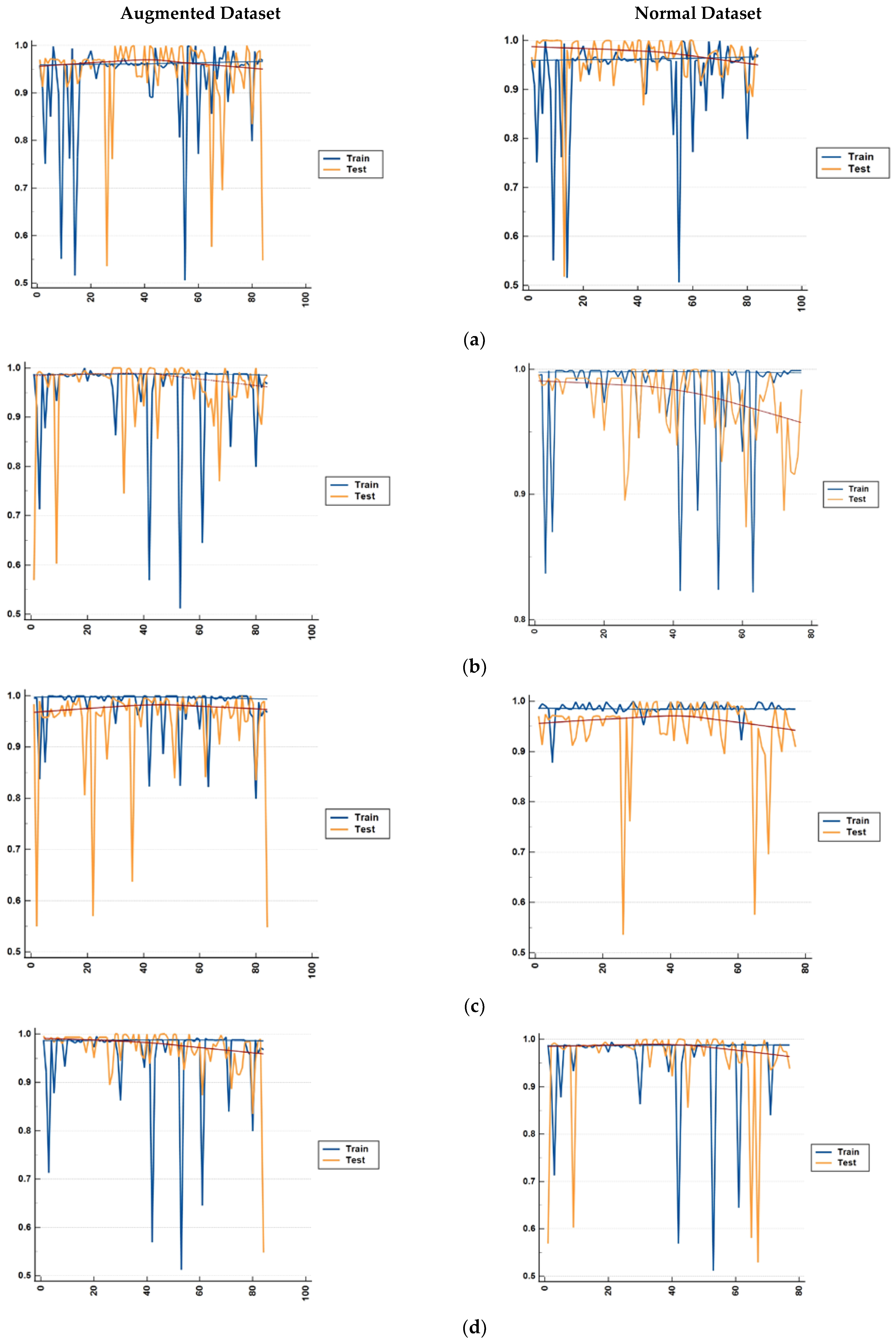
Figure 9.
Comparison of the differences in accuracy for both the augmented and normal datasets for both the training data and test data. The result is shown for each fold of the 5-fold cross validation for (a) bagging, (b) random forest, (c) MLP, and (d) SVM.
Figure 9.
Comparison of the differences in accuracy for both the augmented and normal datasets for both the training data and test data. The result is shown for each fold of the 5-fold cross validation for (a) bagging, (b) random forest, (c) MLP, and (d) SVM.
Table 1.
Description of the feature set for the classification of CTG.
Table 1.
Description of the feature set for the classification of CTG.
| Feature Number | Feature Set | Description |
|---|
| 1 | Baseline (BL) | Baseline of the FHR |
| 2 | Baseline type (B_type) | Classification of BL as Normal, Bradycardia, or Tachycardia |
| 3 | Variability (V) | Variability of FHR baseline |
| 4 | Variability type (V_type) | Classification variability as Absent, Minimal, Moderate, or Marked |
| 5 | Acceleration (Ac) | Acceleration of FHR |
| 6 | Number of accelerations | Total number of accelerations present in a CTG trace. |
| 7 | Number of Early decelerations | Number of Early decelerations present in a CTG trace |
| 8 | Number of Late decelerations | Number of Late decelerations present in a CTG trace |
| 9 | Number of Variable decelerations | Number of Variable decelerations present in a CTG trace |
| 10 | Sinusoidal heart rate (SHR) | Sinusoidal heart rate pattern present or not. SHR in a CTG trace is denoted as Present, Absent, or Undetermined. |
| 11 | Stage of labor | Stage of labor can be normal, stage 1, or stage 2. |
Table 2.
KMO and Bartlett’s test. A KMO value greater than 0.8 indicates the presence of a strong partial correlation among the features and the number for the significance of Bartlett’s test is less than 0.05.
Table 2.
KMO and Bartlett’s test. A KMO value greater than 0.8 indicates the presence of a strong partial correlation among the features and the number for the significance of Bartlett’s test is less than 0.05.
| KMO and Bartlett’s Test |
|---|
| Kaiser-Meyer-Olkin Measure of Sampling Adequacy. | 0.867 |
| Bartlett’s Test of Sphericity | Approx. Chi-Square | 5612.158 |
| df | 105 |
| Sig. | 0.000 |
Table 3.
Correlation matrix of the classifiers depicting the degree of correlation in terms of .
Table 3.
Correlation matrix of the classifiers depicting the degree of correlation in terms of .
| Fold 1 |
| Variables | Bagging | MLP | RF | SVM |
| Bagging | 1 | 0.888 | 0.953 | 0.953 |
| MLP | 0.888 | 1 | 0.931 | 0.931 |
| RF | 0.953 | 0.931 | 1 | 1.000 |
| SVM | 0.953 | 0.931 | 1.000 | 1 |
| Fold 2 |
| Bagging | 1 | 0.888 | 1.000 | 0.832 |
| MLP | 0.888 | 1 | 0.888 | 0.615 |
| RF | 1.000 | 0.888 | 1 | 0.832 |
| SVM | 0.832 | 0.615 | 0.832 | 1 |
| Fold 3 |
| Bagging | 1 | 0.888 | 0.538 | 1.000 |
| MLP | 0.888 | 1 | 0.478 | 0.888 |
| RF | 0.538 | 0.478 | 1 | 0.538 |
| SVM | 1.000 | 0.888 | 0.538 | 1 |
| Fold 4 |
| Bagging | 1 | 0.901 | 0.742 | 0.742 |
| MLP | 0.901 | 1 | 0.931 | 0.931 |
| RF | 0.742 | 0.931 | 1 | 1.000 |
| SVM | 0.742 | 0.931 | 1.000 | 1 |
| Fold 5 |
| Bagging | 1 | 0.901 | 0.742 | 0.742 |
| MLP | 0.901 | 1 | 0.931 | 0.931 |
| RF | 0.742 | 0.931 | 1 | 1.000 |
| SVM | 0.742 | 0.931 | 1.000 | 1 |
Table 4.
Metric values of the model performance measure.
Table 4.
Metric values of the model performance measure.
| Classifier | Accuracy | Sensitivity | Specificity | Precision |
|---|
| MLP | 0.927 | 0.927 | 0.962 | 0.928 |
| RF | 0.967 | 0.964 | 0.984 | 0.968 |
| SVM | 0.964 | 0.964 | 0.983 | 0.966 |
| Bagging | 0.936 | 0.936 | 0.968 | 0.936 |
Table 5.
Metrics values of the combined performance measure.
Table 5.
Metrics values of the combined performance measure.
| Classifier | G-Mean | Discriminant Power (DP) | Balanced Accuracy | Matthew’s Correlation Coefficient (MCC) | Cohen’s Kappa | Youden’s Index |
|---|
| MLP | 0.944 | 1.382 | 0.446 | 0.784 | 0.889 | 0.889 |
| RF | 0.974 | 1.774 | 0.474 | 0.696 | 0.950 | 0.948 |
| SVM | 0.973 | 1.774 | 0.474 | 0.970 | 0.946 | 0.947 |
| Bagging | 0.952 | 1.459 | 0.453 | 0.904 | 0.902 | 0.904 |
Table 6.
Correlation between the actual and the predicted values for the classifiers.
Table 6.
Correlation between the actual and the predicted values for the classifiers.
| Classifier | Variable | Mean | Std. Deviation |
|---|
| MLP | Actual | 1.927 | 0.781 |
| Predicted | 1.912 | 0.770 |
| RF | Actual | 1.927 | 0.781 |
| Predicted | 1.947 | 0.786 |
| SVM | Actual | 1.927 | 0.778 |
| Predicted | 1.932 | 0.785 |
| Bagging | Actual | 1.937 | 0.782 |
| Predicted | 1.945 | 0.787 |
Table 7.
Observed frequencies for actual and predicted classification of CTG.
Table 7.
Observed frequencies for actual and predicted classification of CTG.
| Classifier | Actual/Predicted | 1 | 2 | 3 |
|---|
| MLP | 1 | 128 | 1 | 8 |
| 2 | 0 | 151 | 3 |
| 3 | 9 | 8 | 91 |
| RF | 1 | 131 | 0 | 6 |
| 2 | 0 | 151 | 3 |
| 3 | 3 | 1 | 104 |
| SVM | 1 | 132 | 0 | 4 |
| 2 | 1 | 152 | 3 |
| 3 | 4 | 0 | 103 |
| Bagging | 1 | 129 | 0 | 6 |
| 2 | 2 | 145 | 7 |
| 3 | 4 | 6 | 100 |
Table 8.
Contingency table showing the chi-squared values and the p-value for each classifier.
Table 8.
Contingency table showing the chi-squared values and the p-value for each classifier.
| Classifier | Chi-Squared (Observed Value) | Chi-Squared (Critical Value) | p-Value |
|---|
| MLP | 624.194 | 9.488 | <0.0001 |
| RF | 717.664 | 9.488 | <0.0001 |
| SVM | 723.633 | 9.488 | <0.0001 |
| Bagging | 650.510 | 9.488 | <0.0001 |
Table 9.
Parameters of the Bland–Altman analysis.
Table 9.
Parameters of the Bland–Altman analysis.
| MLP |
| Parameter | Value | 95%CI lower limit | 95%CI upper limit |
| Difference | 0.02 | −0.03 | 0.06 |
| Upper Limit of Agreement | 0.89 | 0.82 | 0.97 |
| Lower Limit of Agreement | −0.86 | −0.94 | −0.79 |
| Intercept | −0.02 | −0.14 | 0.11 |
| Slope | 0.02 | −0.04 | 0.08 |
| RF |
| Parameter | Value | 95%CI lower limit | 95%CI upper limit |
| Difference | −0.02 | −0.05 | 0.01 |
| Upper Limit of Agreement | 0.60 | 0.55 | 0.65 |
| Lower Limit of Agreement | −0.64 | −0.69 | −0.59 |
| Intercept | −0.01 | −0.09 | 0.08 |
| Slope | −0.01 | −0.05 | 0.03 |
| SVM |
| Parameter | Value | 95%CI lower limit | 95%CI upper limit |
| Difference | −0.01 | −0.03 | 0.02 |
| Upper Limit of Agreement | 0.58 | 0.53 | 0.64 |
| Lower Limit of Agreement | −0.59 | −0.65 | −0.54 |
| Intercept | 0.01 | −0.07 | 0.09 |
| Slope | −0.01 | −0.05 | 0.03 |
| Bagging |
| Parameter | Value | 95%CI lower limit | 95%CI upper limit |
| Difference | −0.01 | −0.04 | 0.03 |
| Upper Limit of Agreement | 0.72 | 0.66 | 0.78 |
| Lower Limit of Agreement | −0.74 | −0.80 | −0.67 |
| Intercept | 0.01 | −0.09 | 0.11 |
| Slope | −0.01 | −0.06 | 0.04 |
Table 10.
Accuracies for each class for each of the four classifiers.
Table 10.
Accuracies for each class for each of the four classifiers.
| Classifier | Stage of Labor |
|---|
| Stage 1 | Stage 2 |
|---|
| Normal | Suspicious | Pathological | Normal | Suspicious | Pathological |
|---|
| MLP | 93.4% | 98% | 84.3% | 89.3% | 88.7% | 79.2% |
| RF | 95.6% | 98% | 96.3% | 92.8% | 89.3% | 92.3% |
| SVM | 97% | 97.4% | 96.3% | 91.2% | 90.6% | 92.7% |
| Bagging | 95.6% | 94.2% | 90.9% | 89.8% | 86.5% | 86.7% |
Table 11.
A comparison with some of the recent works for the classification of CTG.
Table 11.
A comparison with some of the recent works for the classification of CTG.
| Author | Dataset | Number of Samples | Annotations | Method Used | Outcome |
|---|
| Comert et al. (2017) [12] | UCI Machine Learning Repository | 2126 with 21 features and 3 classifications. | 3 obstetricians | ANN with 21 inputs, 10 hidden layer, 3 output nodes.
Tan sigmoid and softmax functions were used in the hidden layer. | Sensitivity = 97.9%
Specificity = 99.7% |
| Signorini et al. (2019) [32] | Ob-Gyn Clinics at the Azienda Ospedaliera Universitaria Federico II, Napoli, Italy | 60 normal and 60 IUGR samples | Normal and IUGR | Linear Logistic Regression, SVM, Naïve Bayes, Random Forest, RIDGE Regression | Sensitivity = 83.8–86.7%
Specificity = 76.7–87.1% |
| Rahmayanti et al.(2021) [24] | UCI Machine Learning Repository | 2126 with 21 features and 3 classifications | 3 obstetricians | ANN and LSTM with ReLU activation and Adam optimizer. | Accuracy = 9–37% |
| Ogasawara et al (2021). [23] ) | CTG data from Keio University hospital | 380 with 2 classifications—normal and abnormal | Umbilical artery pH value and apgar score | Deep Neural Network (DNN) with 3 convolution layers. Normal and abnormal are 2 outputs. | AUC-ROC = 0.73 ± 0.04 |
| Petroziello et al (2019) [22]. | Oxford archive | 35,429 CTG data | Umbilical artery pH value and apgar score | Multimodal-CNN | Only 1% improvement in FPR and 19% improvement in TPR compared to normal clinical practice. |
| Zhao et al. (2019) [33] | CTU-UHB dataset for CTG | 552 CTG data | 9 obstetricians | Deep CNN with 8 layers | Sensitivity = 93.45%, Specificity = 91.22% |
| Current Work | CTU-UHB dataset for CTG | 399 data with three classifications | 6 obstetricians | Best result with Random Forest | Sensitivity = 96.4%
Specificity = 98.4% |
Table 12.
Performance measure of the classifiers in terms of various statistical evaluation metrics and classification performance in comparison with the clinicians’ interpretations.
Table 12.
Performance measure of the classifiers in terms of various statistical evaluation metrics and classification performance in comparison with the clinicians’ interpretations.
| | Evaluation Metrics | MLP | SVM | RF | Bagging |
|---|
| Performance Measure of the Classifiers | Combined Performance Measure | × | √ | √ | × |
| Model Performance Measure | × | √ | √ | × |
| AUC-ROC | √ | √ | √ | √ |
| Sensitivity and Specificity | × | √ | √ | × |
| Accuracy of Detecting Suspect Class | √ | √ | √ | × |
| Performance Comparison with Clinicians’ Annotation | Covariance Correlation | √ | √ | √ | × |
| Limits of Agreement of B-A Plot | × | √ | √ | × |














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}