

Feature Transformation for Efficient Blood Glucose Prediction in Type 1 Diabetes Mellitus Patients


Abstract
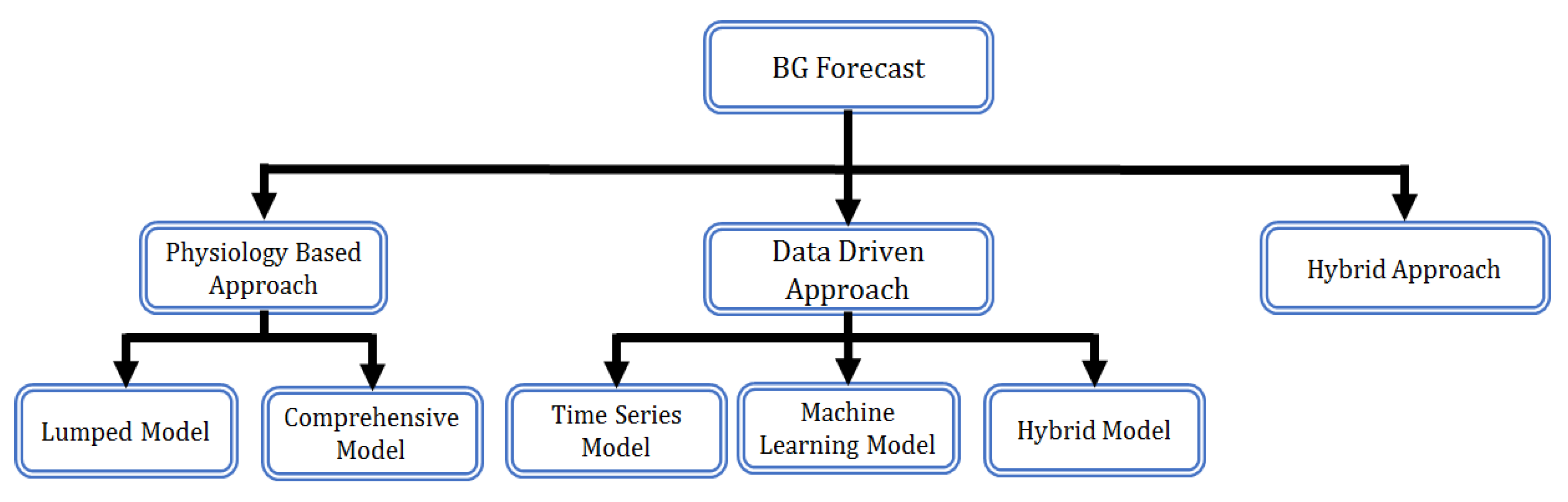
:1. Introduction
- Pre-processing of the T1DM dataset is performed including the incorporation of time-consistency in features as per the target values, interpolation for missing values, and filtering to achieve smoothing.
- Based on the relation with blood glucose levels, two event-based features, namely, meal and insulin, are transformed into continuous features, which led to improved accuracy.
- The LSTM and Bi-LSTM-based RNN models are developed and optimized to achieve minimum prediction error for blood glucose levels.
- The proposed models outperformed the state-of-the-art methods for the prediction horizons of 30 and 60 min.
2. Dataset and Pre-Processing
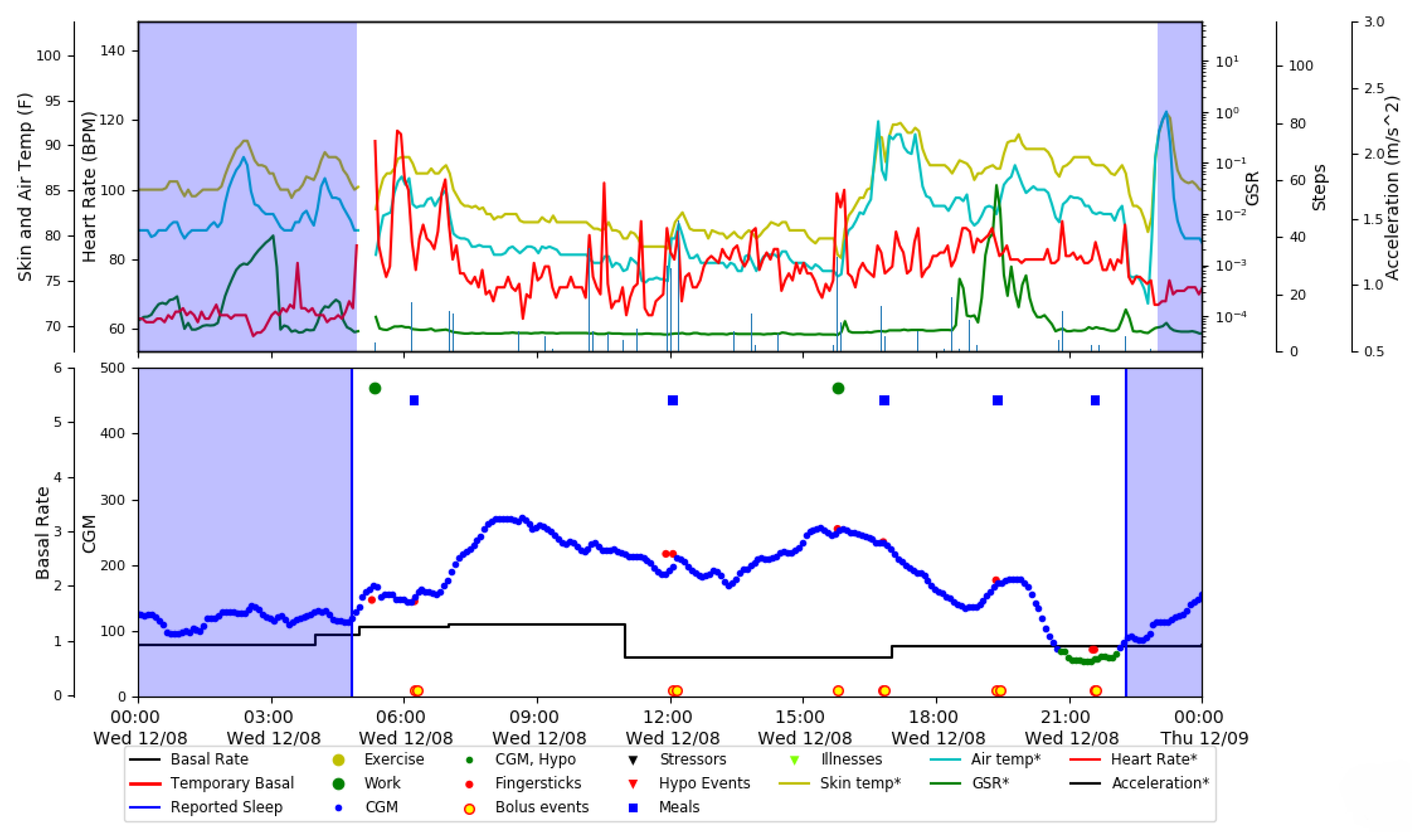
2.1. Dataset
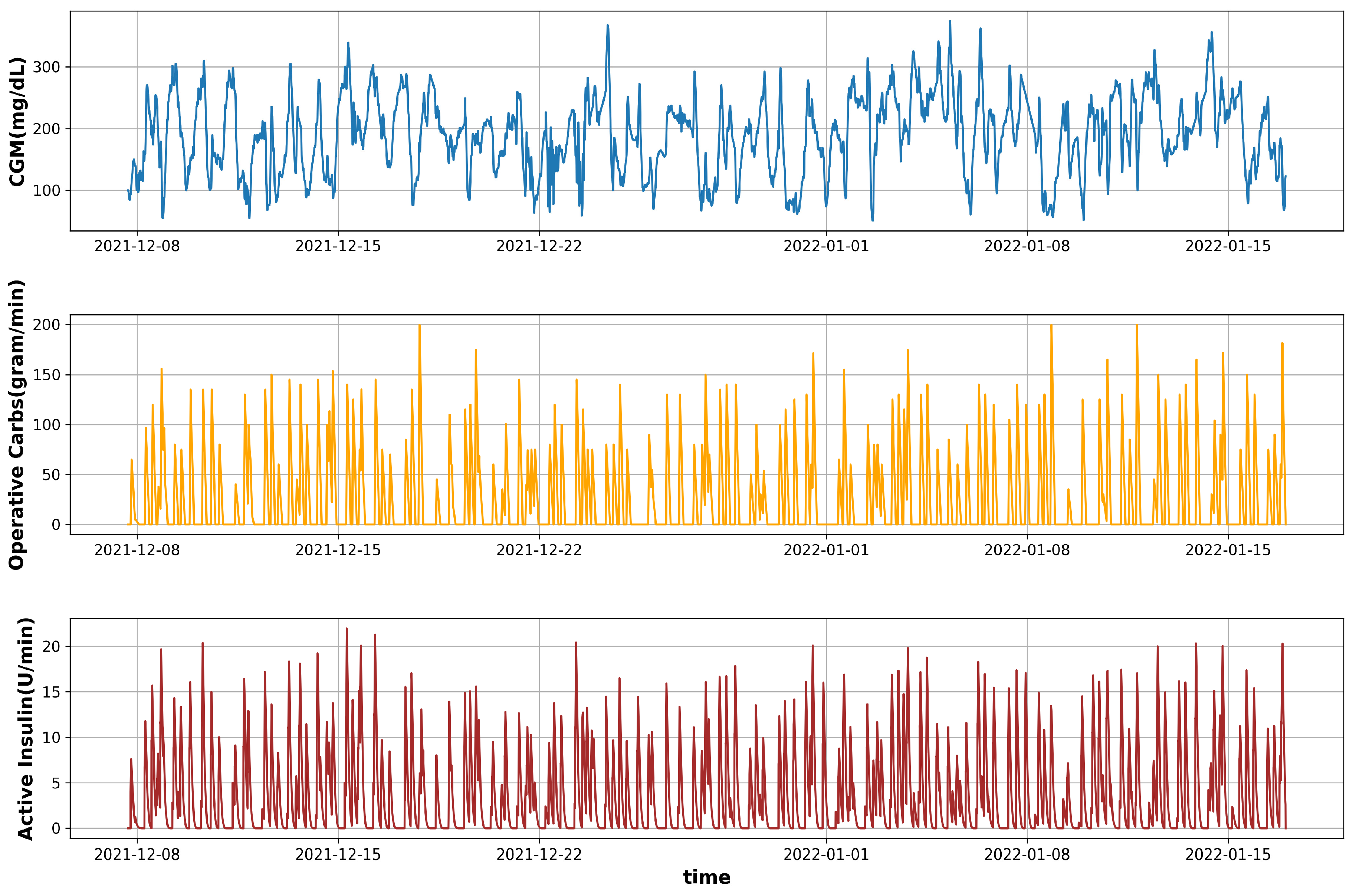
2.2. Feature Vector
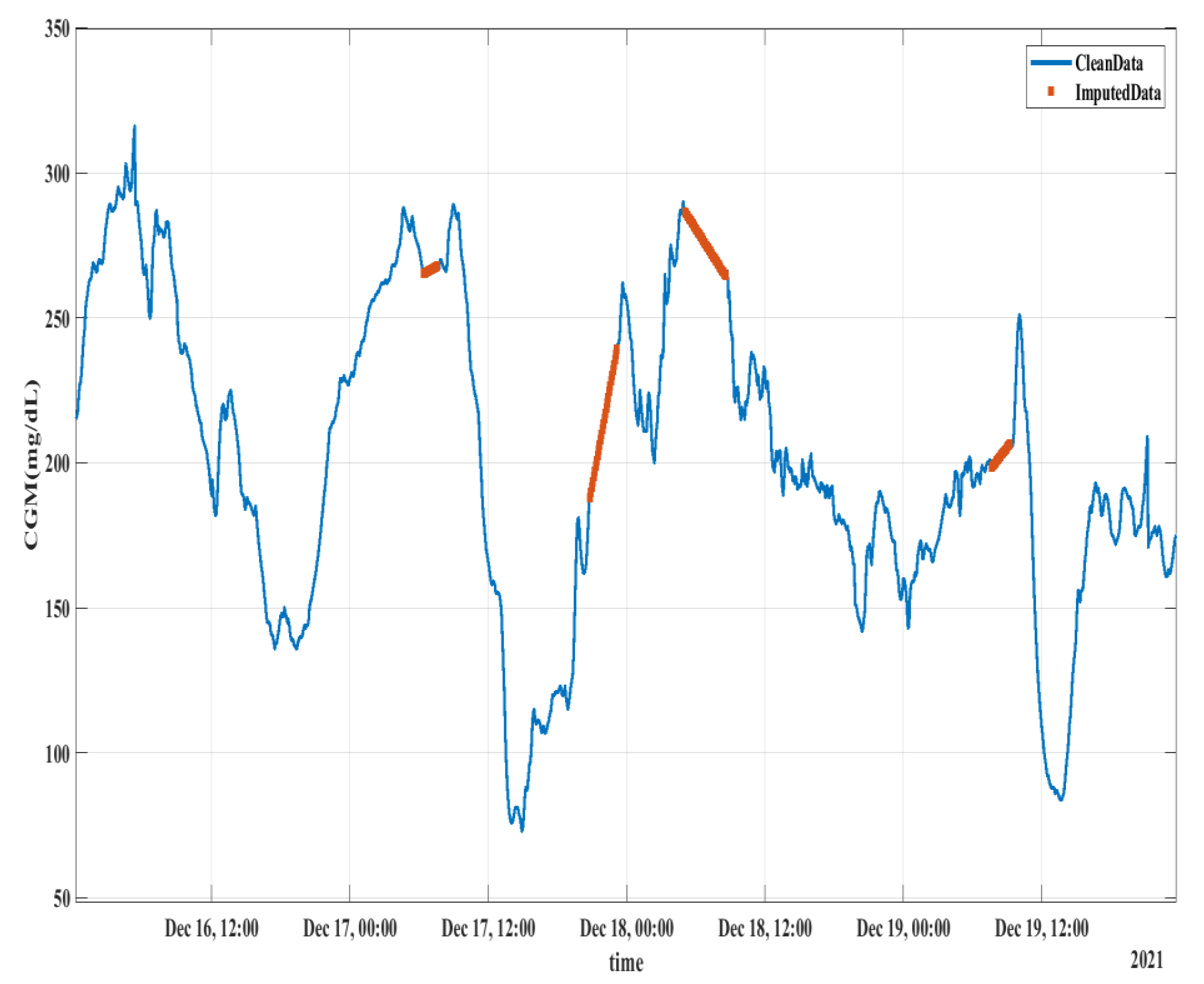
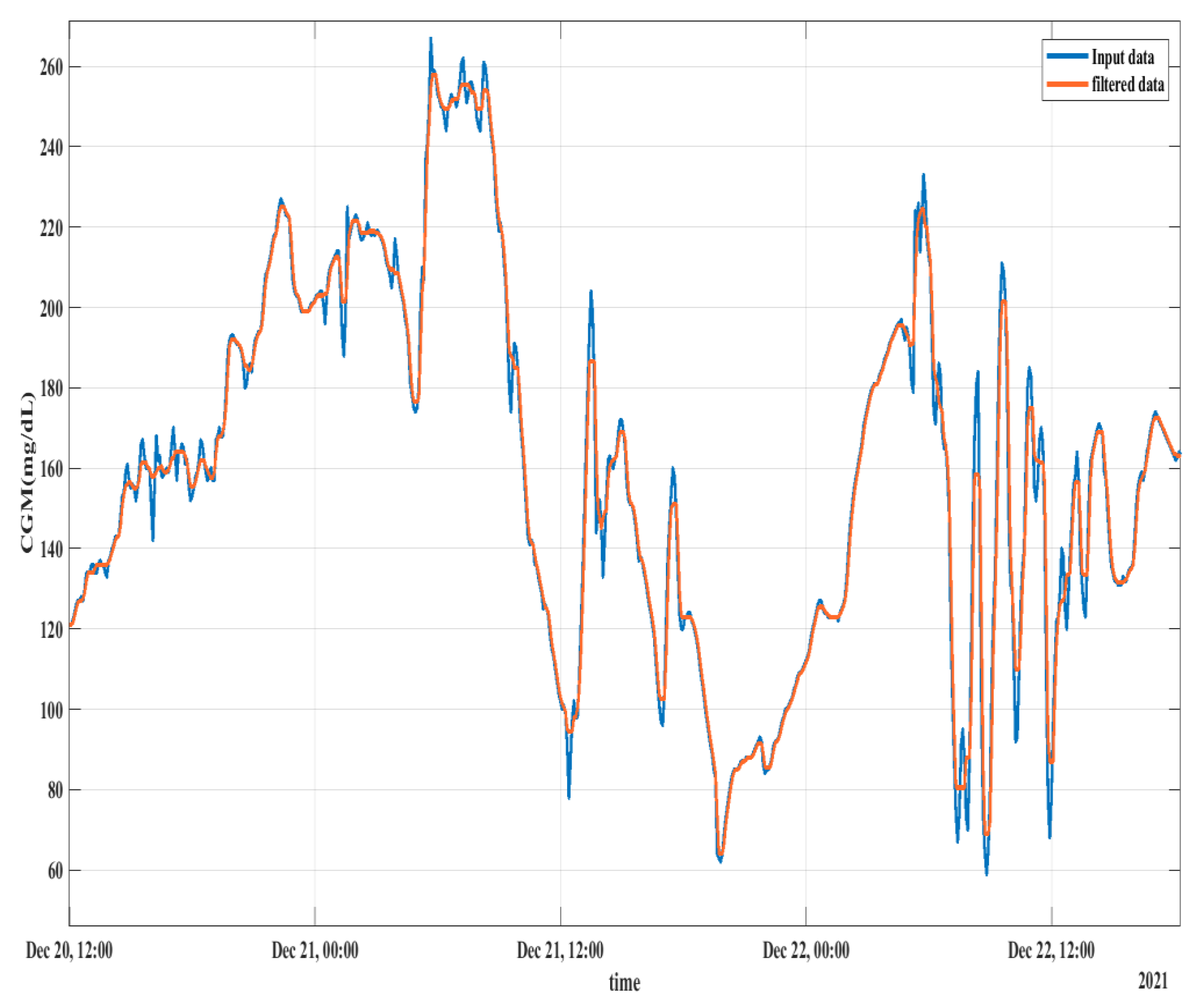
2.3. Pre-Processing
2.3.1. Time Coherence
2.3.2. Interpolation
2.3.3. Median Filtering
3. Feature Transformation
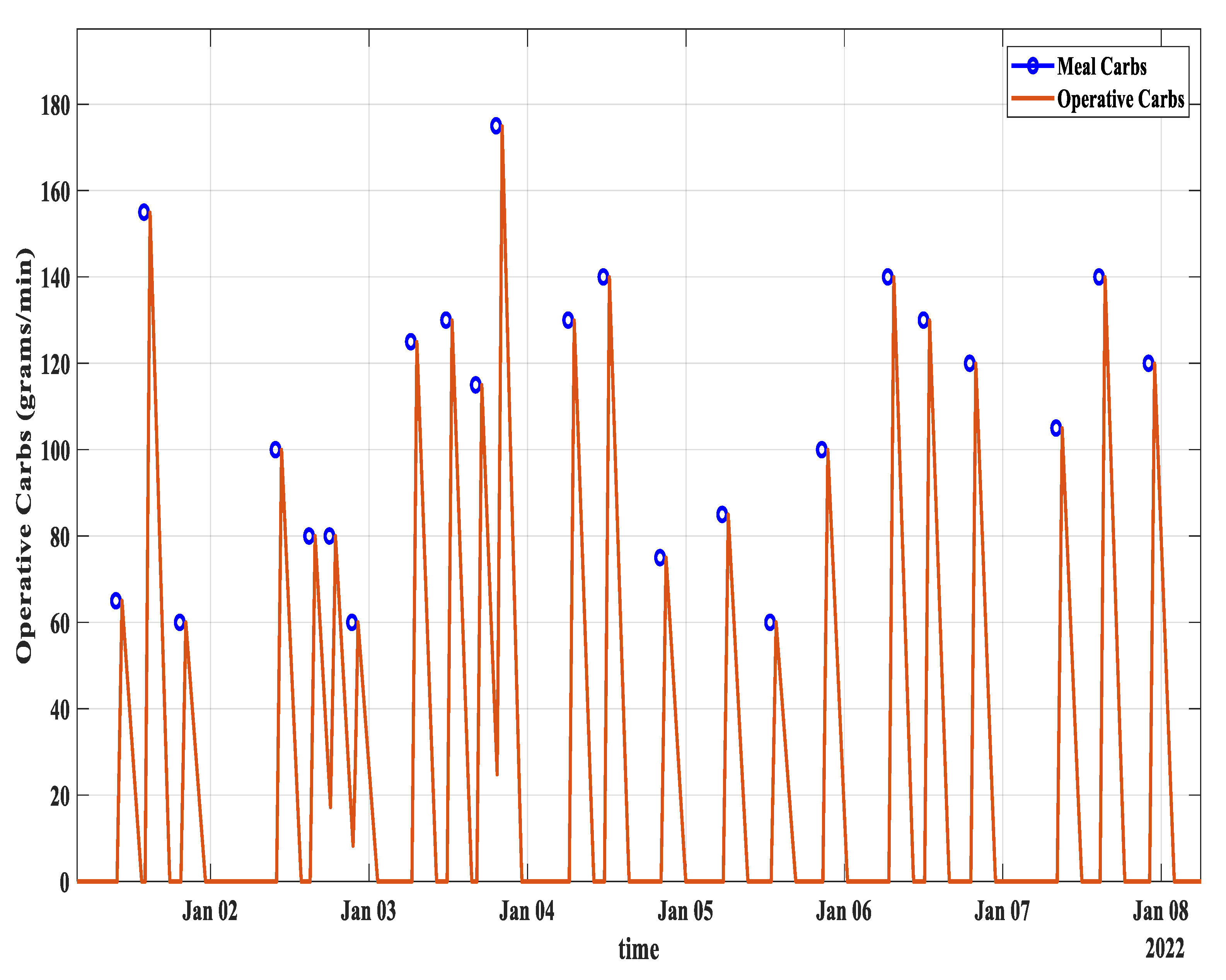
3.1. Carbs from Meal to Operative Carbs Transformation
- i
- Based on the assumption of working at a 5 min reference time scale, the first three samples after taking the meal have zero operative carbs.
- ii
- The operative carbs start rising at a rate of 0.11 (11.1%).
- iii
- At the 12th sample or the 60th minute after having the meal, the value of operative carbs attains its maximum value, which is almost equal to the total amount of carbs.
- iv
- After that, the operative carbs start decreasing at a rate of 0.028 (2.8%). It reaches zero after 3 h.
- is the sampling time.
- is the time when the meal is encountered.
- is the effective carbohydrates at any given time.
- is the total amount of carbohydrates taken in a meal.
- is the time when reaches its maximum value .
- is the increasing rate of the curve.
- is the decreasing rate of the curve.
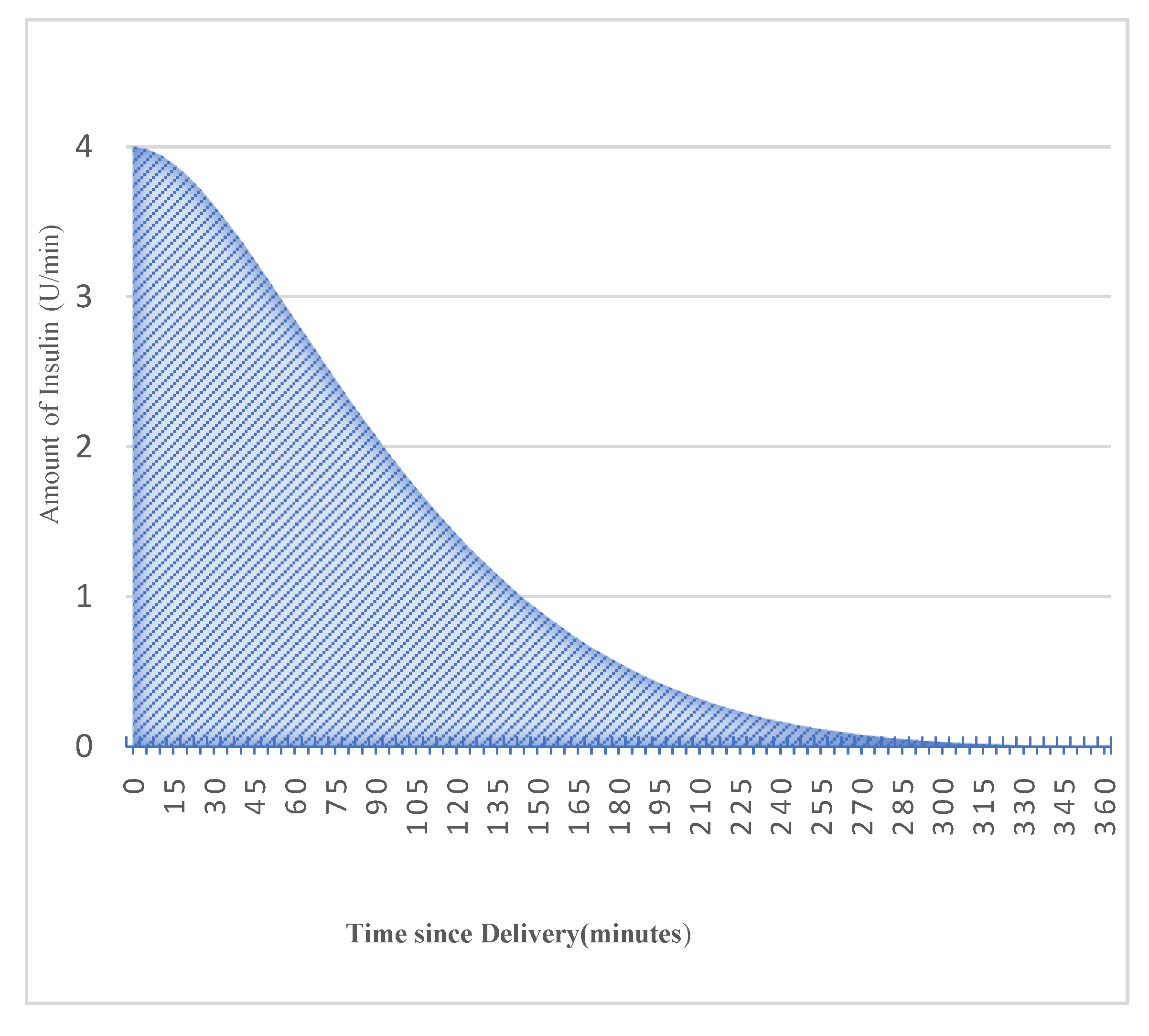
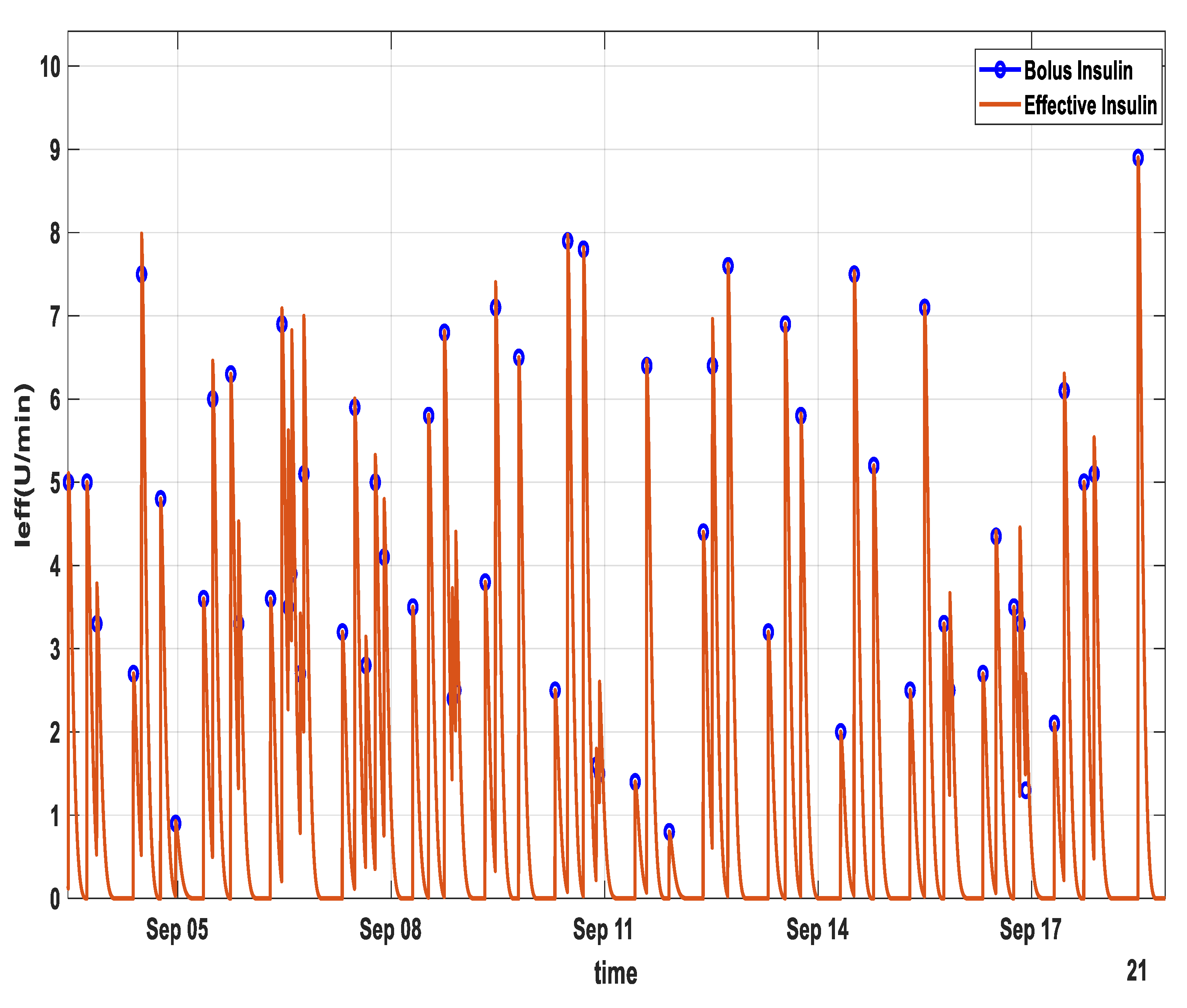
3.2. Bolus Insulin to Active Insulin Transformation
- is the sampling time.
- is the total duration of insulin activity.
- is the time constant of exponential decay.
- is the Rise time factor.
- is the Auxiliary Scale factor.
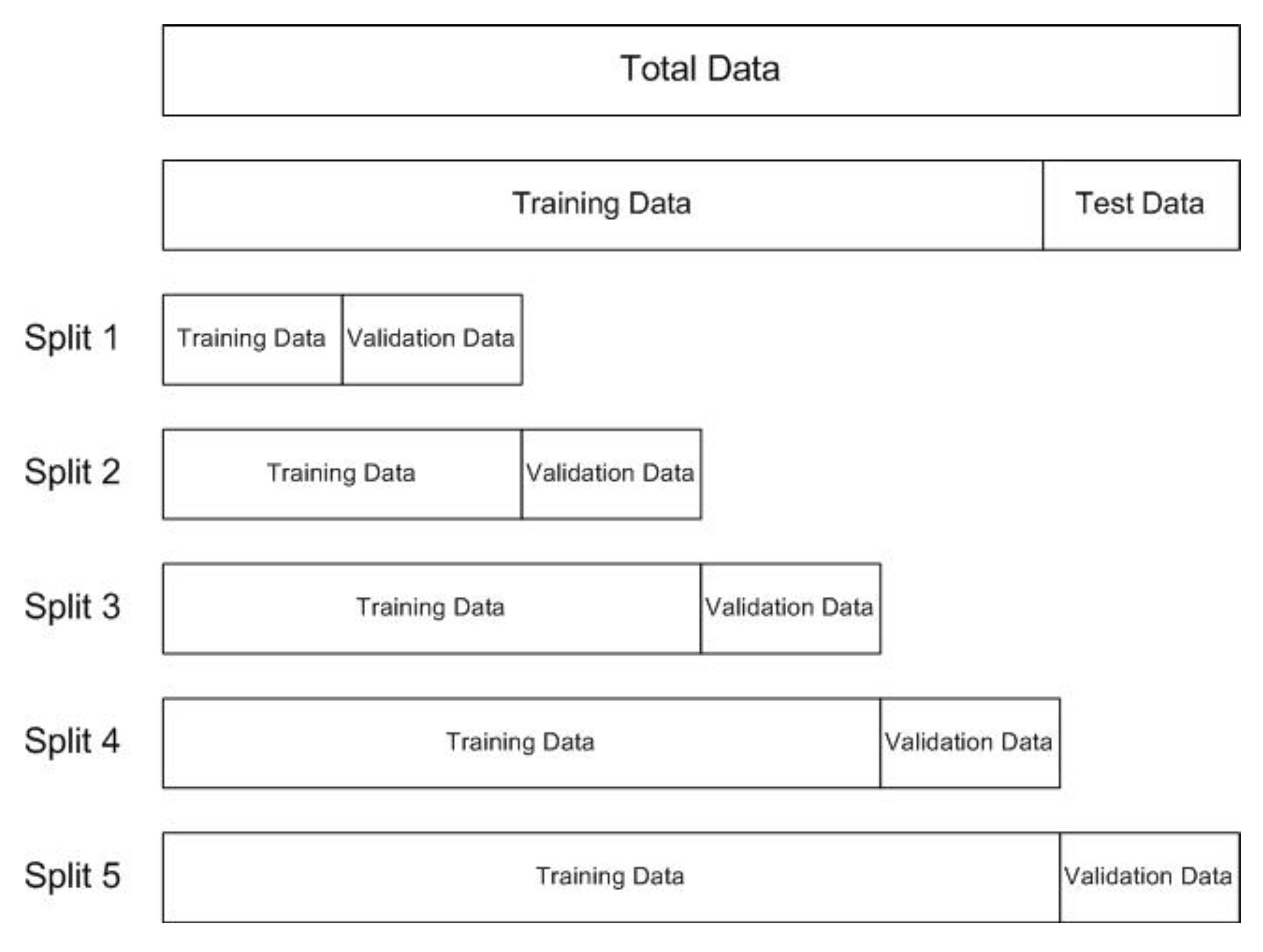
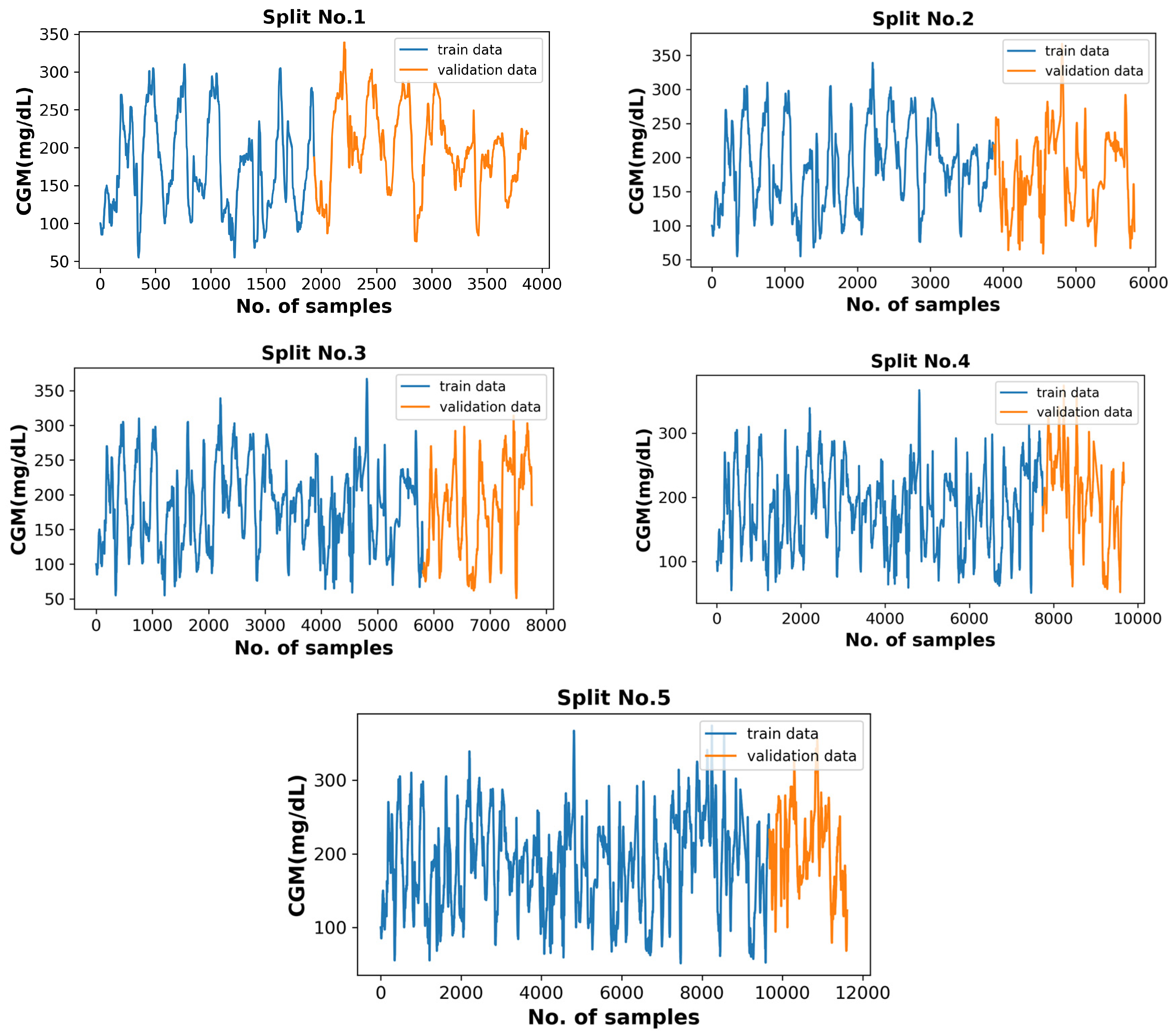
4. Evaluation Strategy
4.1. Evaluation Metric
4.2. Feature Configurations
- Configuration 1 (C-01): In this scheme, a univariate model is developed using CGM data only.
- Configuration 2 (C-02): For this scheme, a combination of CGM and operative carbs is used as a feature set.
- Configuration 3 (C-03): This is the combination of three features: CGM, operative carbs, and active insulin.
5. Learning Model
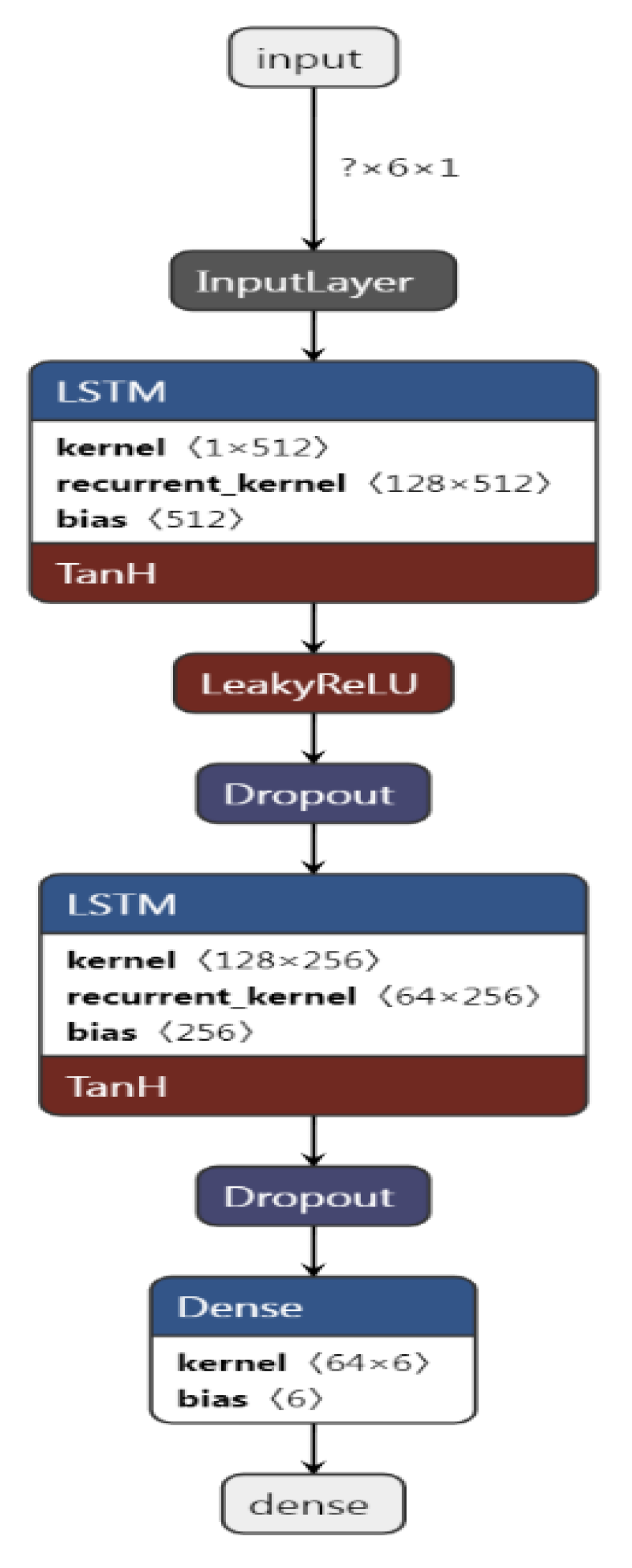
5.1. Model Arhitecture
- Total Number of training samples = 10,982.
- Total Number of training samples after resampling and interpolation = 11,611.
- Number of training samples (80%) = 9288 [1548, 6, 1].
- Number of training examples = 1548 (9288/6).
- Number of test samples (20%): 2322 [387, 6, 1].
- Number of test examples 387 (2322/6).
5.2. Model Training and Optimization
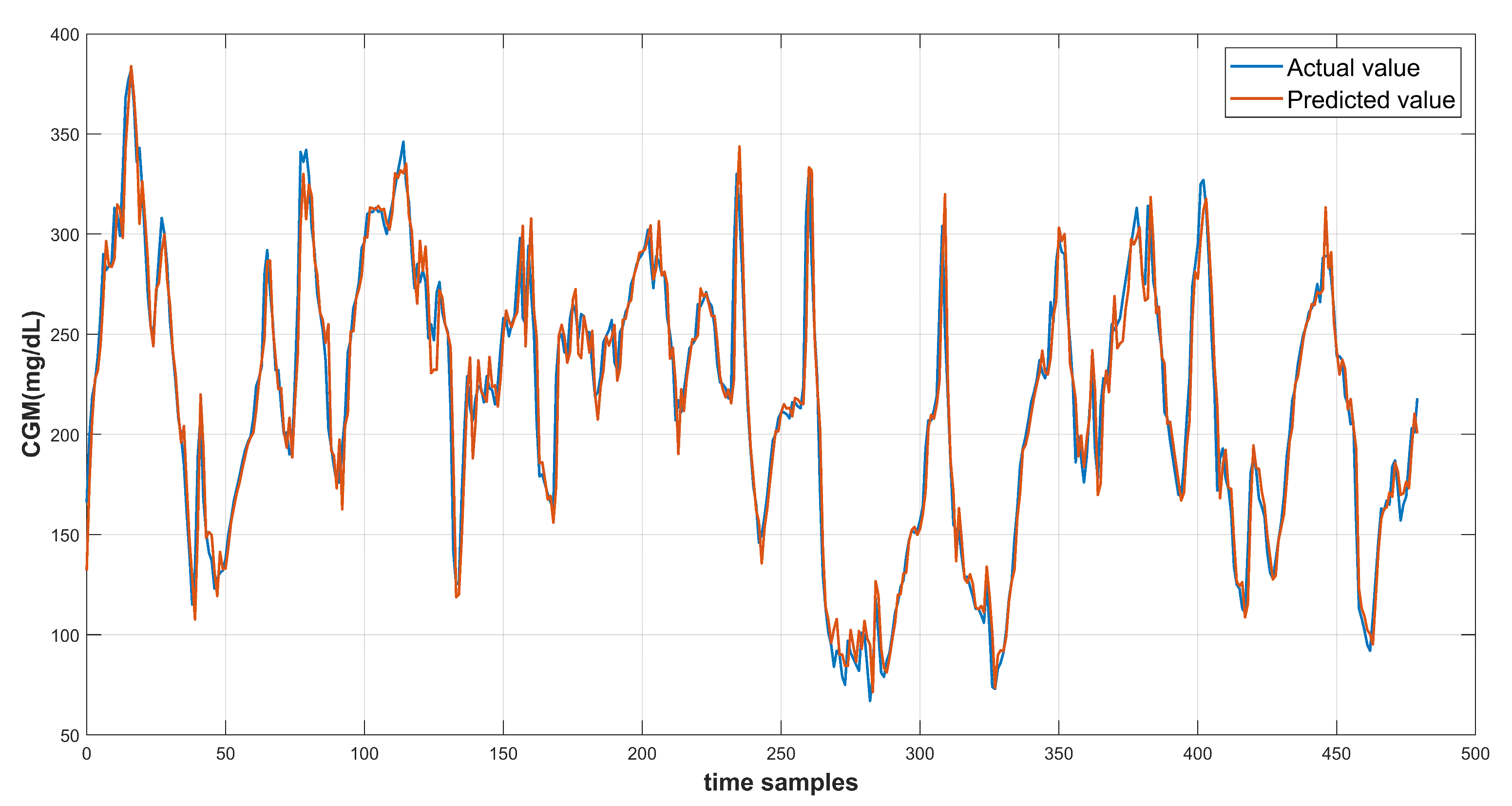
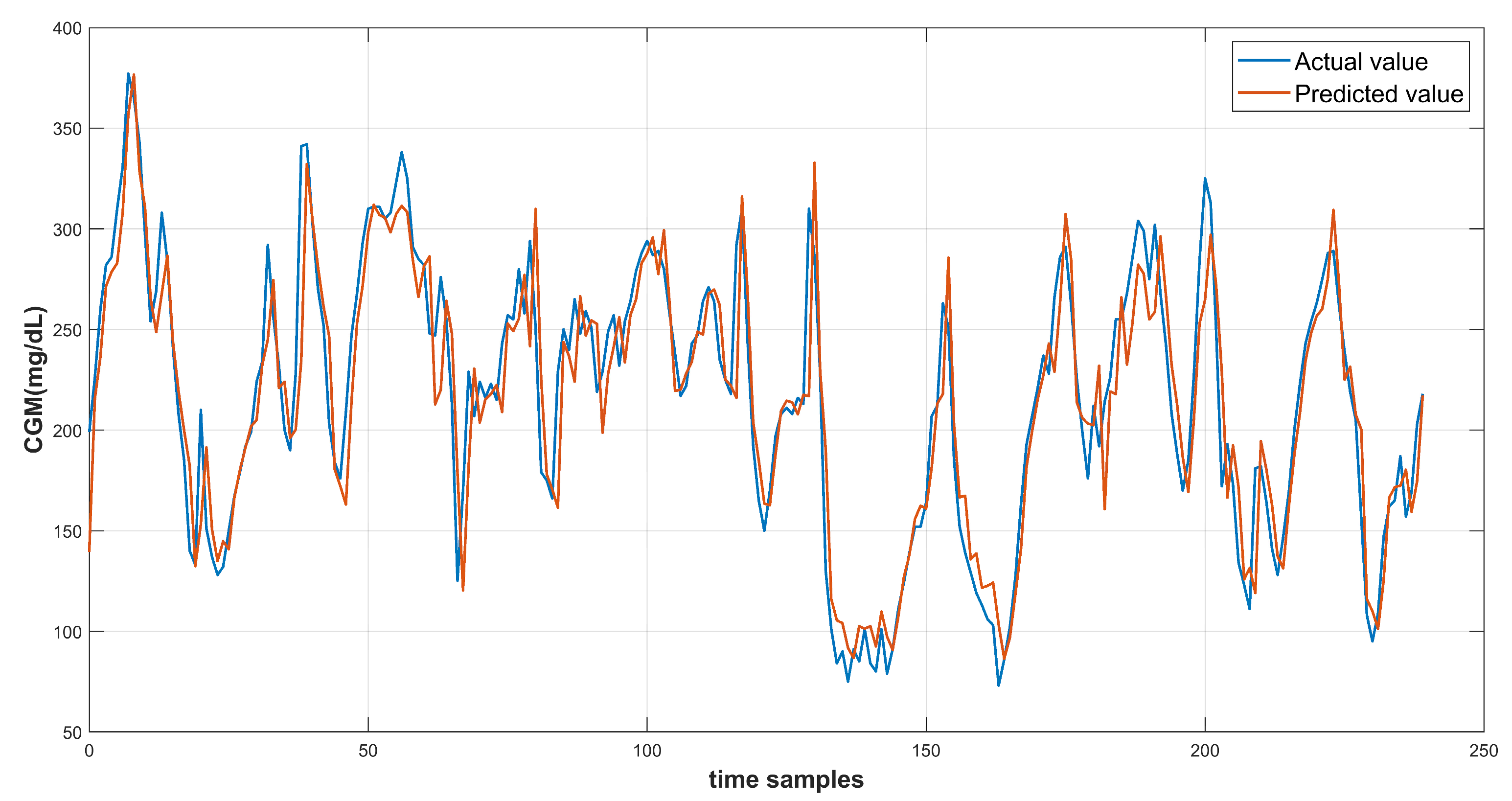
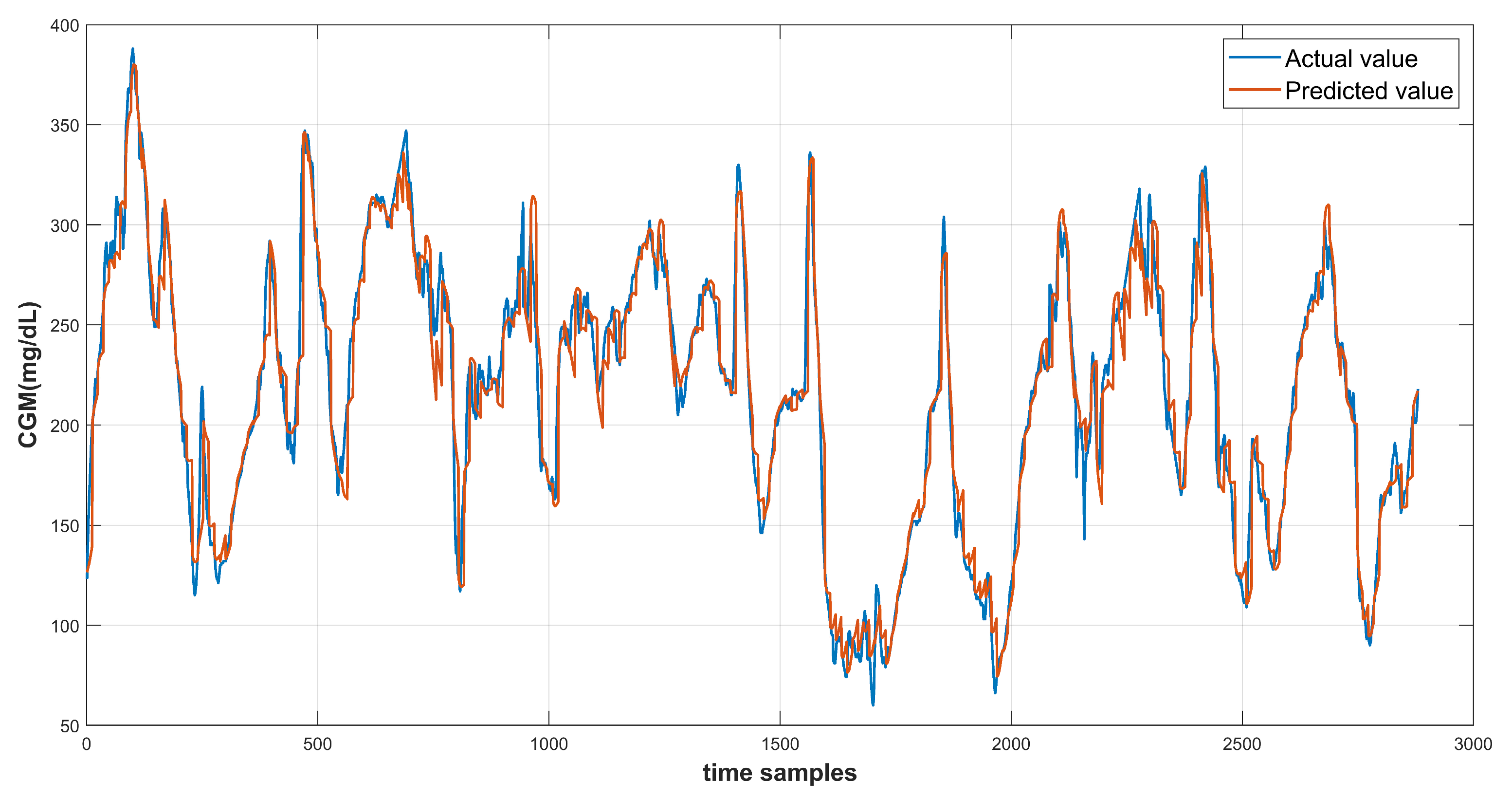
6. Results and Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Atlas, I.D. Global Estimates for the Prevalence of Diabetes for 2015 and 2040. Diabetes Res. Clin. Pract. 2017, 128, 40–50. [Google Scholar]
- Elflein, J. Number of Adults with Diabetes in the U.S. as of 2019 (in Millions); Statista: Hamburg, Germany, 2022. [Google Scholar]
- Woldaregay, A.Z.; Årsand, E.; Walderhaug, S.; Albers, D.; Mamykina, L.; Botsis, T.; Hartvigsen, G. Data-Driven Modeling and Prediction of Blood Glucose Dynamics: Machine Learning Applications in Type 1 Diabetes. Artif. Intell. Med. 2019, 98, 109–134. [Google Scholar] [CrossRef] [PubMed]
- Oviedo, S.; Vehí, J.; Calm, R.; Armengol, J. A Review of Personalized Blood Glucose Prediction Strategies for T1DM Patients. Int. J. Numer. Methods Biomed. Eng. 2017, 33, e2833. [Google Scholar] [CrossRef] [PubMed]
- Sun, X.; Rashid, M.; Sevil, M.; Hobbs, N.; Brandt, R.; Askari, M.R.; Shahidehpour, A.; Cinar, A. Prediction of Blood Glucose Levels for People with Type 1 Diabetes Using Latent-Variable-Based Model. CEUR Workshop Proc. 2020, 2675, 115–119. [Google Scholar]
- Xie, J.; Wang, Q. Benchmark Machine Learning Approaches with Classical Time Series Approaches on the Blood Glucose Level Prediction Challenge. CEUR Workshop Proc. 2018, 2148, 97–102. [Google Scholar]
- Zecchin, C.; Facchinetti, A.; Sparacino, G.; Cobelli, C. Jump Neural Network for Online Short-Time Prediction of Blood Glucose from Continuous Monitoring Sensors and Meal Information. Comput. Methods Programs Biomed. 2014, 113, 144–152. [Google Scholar] [CrossRef]
- McShinsky, R.; Marshall, B. Comparison of Forecasting Algorithms for Type 1 Diabetic Glucose Prediction on 30 and 60-Minute Prediction Horizons. CEUR Workshop Proc. 2020, 2675, 12–18. [Google Scholar]
- Midroni, C.; Leimbigler, P.J.; Baruah, G.; Kolla, M.; Whitehead, A.J.; Fossat, Y. Predicting Glycemia in Type 1 Diabetes Patients: Experiments with XGBoost. CEUR Workshop Proc. 2018, 2148, 79–84. [Google Scholar]
- Dave, D.; Erraguntla, M.; Lawley, M.; DeSalvo, D.; Haridas, B.; McKay, S.; Koh, C. Improved Low-Glucose Predictive Alerts Based on Sustained Hypoglycemia: Model Development and Validation Study. JMIR Diabetes 2021, 6, e26909. [Google Scholar] [CrossRef]
- Martinsson, J.; Schliep, A.; Eliasson, B.; Meijner, C.; Persson, S.; Mogren, O. Automatic Blood Glucose Prediction with Confidence Using Recurrent Neural Networks. CEUR Workshop Proc. 2018, 2148, 64–68. [Google Scholar]
- Zhu, T.; Li, K.; Herrero, P.; Chen, J.; Georgiou, P. A Deep Learning Algorithm for Personalized Blood Glucose Prediction. CEUR Workshop Proc. 2018, 2148, 64–78. [Google Scholar]
- Li, K.; Liu, C.; Zhu, T.; Herrero, P.; Georgiou, P. GluNet: A Deep Learning Framework for Accurate Glucose Forecasting. IEEE J. Biomed. Health Inform. 2020, 24, 414–423. [Google Scholar] [CrossRef]
- Daniels, J.; Herrero, P.; Georgiou, P. Personalised Glucose Prediction via Deep Multitask Networks. CEUR Workshop Proc. 2020, 2675, 110–114. [Google Scholar]
- Caruana, R. Multitask Learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Rabby, M.F.; Tu, Y.; Hossen, M.I.; Lee, I.; Maida, A.S.; Hei, X. Stacked LSTM Based Deep Recurrent Neural Network with Kalman Smoothing for Blood Glucose Prediction. BMC Med. Inform. Decis. Mak. 2021, 21, 101. [Google Scholar] [CrossRef]
- Staal, O.M.; Salid, S.; Fougner, A.; Stavdahl, O. Kalman Smoothing for Objective and Automatic Preprocessing of Glucose Data. IEEE J. Biomed. Health Inform. 2019, 23, 218–226. [Google Scholar] [CrossRef]
- Marling, C.; Bunescu, R. The OhioT1DM Dataset for Blood Glucose Level Prediction: Update 2020. CEUR Workshop Proc. 2020, 2675, 71. [Google Scholar]
- Chen, J.; Li, K.; Herrero, P.; Zhu, T.; Georgiou, P. Dilated Recurrent Neural Network for Short-Time Prediction of Glucose Concentration. CEUR Workshop Proc. 2018, 2148, 69–73. [Google Scholar]
- Kraegen, E.W.; Chisholm, D.J.; McNamara, M.E. Timing of Insulin Delivery with Meals. Horm. Metab. Res. 1981, 13, 365–367. [Google Scholar] [CrossRef]
- Boiroux, D.; Finan, D.A.; Jørgensen, J.B.; Poulsen, N.K.; Madsen, H. Optimal Insulin Administration for People with Type 1 Diabetes. IFAC Proc. Vol. 2010, 43, 248–253. [Google Scholar] [CrossRef] [Green Version]
- LoopDoc. Glucose Prediction. Available online: https://loopkit.github.io/loopdocs/operation/algorithm/prediction/ (accessed on 3 February 2022).
- Manaswi, N.K. RNN and LSTM. In Deep Learning with Applications Using Python; Apress: Berkeley, CA, USA, 2018. [Google Scholar] [CrossRef]
- Hochreiter, S. Recurrent Neural Net Learning and Vanishing Gradient. Int. J. Uncertainity Fuzziness Knowl. Based Syst. 1998, 6, 8. [Google Scholar]
- TimeSeriesSplit. Sklearn.Model_selection.TimeSeriesSplit—Scikit-Learn 1.2.0 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection (accessed on 19 December 2022).
- Brownlee, J. Introduction to Time Series Forecasting with Python: How to Prepare Data and Develop Models to Predict the Future; Machine Learning Mastery: Vermont, Australia, 2017; Available online: https://books.google.com.pk/books/about/Introduction_to_Time_Series_Forecasting.html?id=-AiqDwAAQBAJ&redir_esc=y (accessed on 19 December 2022).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Gender | Pump Model | Sensor Band | Train Samples | Test Samples |
|---|---|---|---|---|---|
| 559 | female | 530 G | Basis | 10,796 | 2514 |
| 563 | male | 530 G | Basis | 12,124 | 2570 |
| 570 | male | 530 G | Basis | 10,982 | 2745 |
| 575 | female | 530 G | Basis | 11,866 | 2590 |
| 588 | female | 530 G | Basis | 12,640 | 2791 |
| 591 | female | 530 G | Basis | 10,847 | 2760 |
| Ser # | Feature Name | Type | Source |
|---|---|---|---|
| 1 | glucose level | periodic | medtronic Sensor |
| 2 | basal insulin | event | self-Reported |
| 3 | bolus insulin | event | self-Reported |
| 4 | finger stick | event | self-Reported |
| 5 | meal | event | self-Reported |
| 6 | exercise | event | self-Reported |
| 7 | sleep | event | self-Reported |
| 8 | work | event | self-Reported |
| 9 | hypo Events | event | self-Reported |
| 10 | air temperature | periodic | basis Sensor |
| 11 | GSR | periodic | basis Sensor |
| 12 | heart Rate | periodic | basis Sensor |
| 13 | skin temperature | periodic | basis Sensor |
| 14 | sleep | periodic | basis Sensor |
| 15 | steps | periodic | basis Sensor |
| Configuration | RMSE @ PH = 30 min | RMSE @ PH = 60 min | ||
|---|---|---|---|---|
| Vanilla-LSTM | Bi-LSTM | Vanilla-LSTM | Bi-LSTM | |
| C-01 | 15.43 | 15.22 | 26.41 | 26.10 |
| C-02 | 15.67 | 15.12 | 26.12 | 25.48 |
| C-03 | 15.48 | 14.76 | 26.18 | 25.65 |
| Patient ID | Configuration | RMSE @ PH = 30 min | RMSE @ PH = 60 min | ||
|---|---|---|---|---|---|
| Vanilla-LSTM | Bi-LSTM | Vanilla-LSTM | Bi-LSTM | ||
| 588 | C-02 | × | × | 30.44 | 30.17 |
| C-03 | 18.29 | 17.55 | × | × | |
| 563 | C-02 | × | × | 29.98 | 29.11 |
| C-03 | 18.58 | 18.14 | × | × | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Butt, H.; Khosa, I.; Iftikhar, M.A. Feature Transformation for Efficient Blood Glucose Prediction in Type 1 Diabetes Mellitus Patients. Diagnostics 2023, 13, 340. https://doi.org/10.3390/diagnostics13030340
Butt H, Khosa I, Iftikhar MA. Feature Transformation for Efficient Blood Glucose Prediction in Type 1 Diabetes Mellitus Patients. Diagnostics. 2023; 13(3):340. https://doi.org/10.3390/diagnostics13030340
Chicago/Turabian StyleButt, Hatim, Ikramullah Khosa, and Muhammad Aksam Iftikhar. 2023. "Feature Transformation for Efficient Blood Glucose Prediction in Type 1 Diabetes Mellitus Patients" Diagnostics 13, no. 3: 340. https://doi.org/10.3390/diagnostics13030340