
Machine Learning in Colorectal Cancer Risk Prediction from Routinely Collected Data: A Review

 , ,
, ,
Abstract
:1. Introduction
- Lack of external validation
- Differences in how factors are measured, e.g., blood pressure
- Management of missing data related to these factors
- Lack of calibration curves
2. Materials and Methods
2.1. Eligibility Criteria
2.2. Inclusion Criteria for Publications
- used one or more machine-learning methods, including comparison with logistic regression
- used at least two risk factors
- used an experimental or observational study design
2.3. Exclusion Criteria for Publications
- used images or image parameters as risk factors
- included genetic information
- included molecular markers
- utilised questionnaire-derived data, e.g., nutrition questionnaires
- were designed to test performance of a risk factor for colorectal cancer
- were review articles
- were conference abstracts
2.4. Information Sources
2.5. Search Strategy for PubMed (L3 Heading)
2.6. Data Charting
3. Results
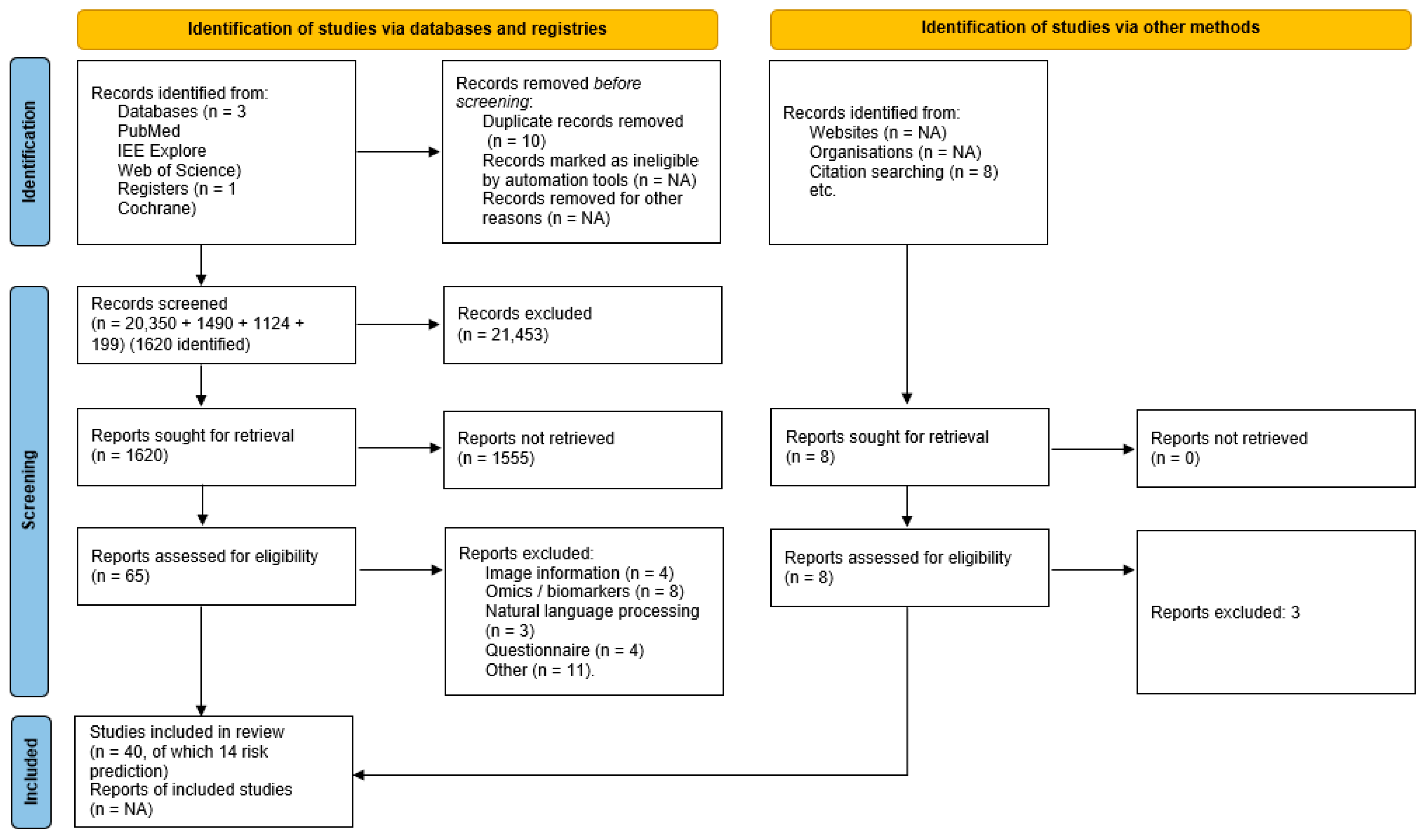
3.1. Article Selection
3.2. Model Descriptions
3.3. Model Purpose and Population Description
3.4. Model Performance
3.5. Model Comparison and Benchmarking with CHARM Criteria
4. Discussion
4.1. Models of Note
4.2. Main Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- International Association of Cancer Registries. Global Initiative for Cancer Registry Development Cancer Today. Available online: http://gco.iarc.fr/today/home (accessed on 10 August 2021).
- Cancer Research UK. Bowel Cancer Survival Statistics. Available online: https://www.cancerresearchuk.org/health-professional/cancer-statistics/statistics-by-cancer-type/bowel-cancer/survival (accessed on 10 August 2021).
- Smittenaar, C.R.; Petersen, K.A.; Stewart, K.; Moitt, N. Cancer incidence and mortality projections in the UK until 2035. Br. J. Cancer 2016, 115, 1147–1155. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Cheng, Z.; Ma, Y.; He, C.; Lu, Y.; Zhao, Y.; Chang, X.; Zhang, Y.; Bai, Y.; Cheng, N. Effectiveness of Screening Modalities in Colorectal Cancer: A Network Meta-Analysis. Clin. Color. Cancer 2017, 16, 252–263. [Google Scholar] [CrossRef]
- NHS Digital Bowel Cancer Screening. Available online: https://digital.nhs.uk/services/screening-services/bowel-cancer-screening-services (accessed on 27 January 2020).
- Cairns, S.R.; Scholefield, J.H.; Steele, R.J.; Dunlop, M.G.; Thomas, H.J.W.; Evans, G.D.; Eaden, J.A.; Rutter, M.D.; Atkin, W.P.; Saunders, B.P.; et al. Guidelines for colorectal cancer screening and surveillance in moderate and high risk groups (update from 2002). Gut 2010, 59, 666–689. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lew, J.-B.; John, D.J.B.S.; Xu, X.-M.; Greuter, M.J.E.; Caruana, M.; Cenin, D.R.; He, E.; Saville, M.; Grogan, P.; Coupé, V.M.H.; et al. Long-term evaluation of benefits, harms, and cost-effectiveness of the National Bowel Cancer Screening Program in Australia: A modelling study. Lancet Public Health 2017, 2, e331–e340. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Naber, S.K.; Kundu, S.; Kuntz, K.M.; Dotson, W.D.; Williams, M.S.; Zauber, A.G.; Calonge, N.; Zallen, D.T.; Ganiats, T.G.; Webber, E.M.; et al. Cost-Effectiveness of Risk-Stratified Colorectal Cancer Screening Based on Polygenic Risk: Current Status and Future Potential. JNCI Cancer Spectr. 2020, 4, pkz086. [Google Scholar] [CrossRef] [PubMed]
- Young, G.P.; Rabeneck, L.; Winawer, S.J. The Global Paradigm Shift in Screening for Colorectal Cancer. Gastroenterology 2019, 156, 843–851.e2. [Google Scholar] [CrossRef] [Green Version]
- Health Matters: Improving the Prevention and Diagnosis of Bowel Cancer. Available online: https://www.gov.uk/government/publications/health-matters-preventing-bowel-cancer/health-matters-improving-the-prevention-and-detection-of-bowel-cancer (accessed on 10 August 2021).
- Cancer Research UK. We are Macmillan, NHS England, ACE Colorectal Cancer Pathway Cluster. In Colorectal Pathways: Interim Report; NHS England: London, UK, 2016; p. 17. [Google Scholar]
- Hull, M.A.; Rees, C.J.; Sharp, L.; Koo, S. A risk-stratified approach to colorectal cancer prevention and diagnosis. Nat. Rev. Gastroenterol. Hepatol. 2020, 17, 773–780. [Google Scholar] [CrossRef]
- Hippisley-Cox, J.; Coupland, C. Development and validation of risk prediction equations to estimate survival in patients with colorectal cancer: Cohort study. BMJ 2017, 357, j2497. [Google Scholar] [CrossRef] [Green Version]
- Hippisley-Cox, J.; Coupland, C. Development and validation of risk prediction algorithms to estimate future risk of common cancers in men and women: Prospective cohort study. BMJ Open 2015, 5, e007825. [Google Scholar] [CrossRef]
- Price, S.; Spencer, A.; Medina-Lara, A.; Hamilton, W. Availability and use of cancer decision-support tools: A cross-sectional survey of UK primary care. Br. J. Gen. Pract. 2019, 69, e437–e443. [Google Scholar] [CrossRef] [PubMed]
- Hamilton, W.; Green, T.; Martins, T.; Elliott, K.; Rubin, G.; Macleod, U. Evaluation of risk assessment tools for suspected cancer in general practice: A cohort study. Br. J. Gen. Pract. 2013, 63, e30–e36. [Google Scholar] [CrossRef]
- Freedman, A.N.; Slattery, M.L.; Ballard-Barbash, R.; Willis, G.; Cann, B.J.; Pee, D.; Gail, M.H.; Pfeiffer, R.M. Colorectal Cancer Risk Prediction Tool for White Men and Women Without Known Susceptibility. J. Clin. Oncol. 2008, 27, 686–693. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Park, Y.; Freedman, A.N.; Gail, M.H.; Pee, D.; Hollenbeck, A.; Schatzkin, A.; Pfeiffer, R.M. Validation of a Colorectal Cancer Risk Prediction Model Among White Patients Age 50 Years and Older. J. Clin. Oncol. 2008, 27, 694–698. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Glasziou, P.; Chalmers, I. Research waste is still a scandal—An essay by Paul Glasziou and Iain Chalmers. BMJ 2018, 363, k4645. [Google Scholar] [CrossRef]
- McGeoch, L.; Saunders, C.L.; Griffin, S.J.; Emery, J.D.; Walter, F.M.; Thompson, D.J.; Antoniou, A.C.; Usher-Smith, J.A. Risk Prediction Models for Colorectal Cancer Incorporating Common Genetic Variants: A Systematic Review. Cancer Epidemiol. Biomark. Prev. 2019, 28, 1580–1593. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Y.; Hua, X.; Win, A.K.; MacInnis, R.J.; Gallinger, S.; Marchand, L.L.; Lindor, N.M.; Baron, J.A.; Hopper, J.L.; Dowty, J.G.; et al. A new comprehensive colorectal cancer risk prediction model incorporating family history, personal characteristics, and environmental factors. Cancer Epidemiol. Prev. Biomark. 2020, 29, 549–557. [Google Scholar] [CrossRef]
- Jeon, J.; Du, M.; Schoen, R.E.; Hoffmeister, M.; Newcomb, P.A.; Berndt, S.I.; Caan, B.; Campbell, P.T.; Chan, A.T.; Chang-Claude, J.; et al. Determining Risk of Colorectal Cancer and Starting Age of Screening Based on Lifestyle, Environmental, and Genetic Factors. Gastroenterology 2018, 154, 2152–2164.e19. [Google Scholar] [CrossRef]
- Riley, R.D.; Moons, K.G.; Debray, T.P.; Snell, K.I.; Steyerberg, E.W.; Altman, D.G.; Collins, G.S. Prognostic model research. In Prognosis Research in Healthcare; van der Windt, D.A., Hemingway, H., Croft, P., Eds.; Oxford University Press: Oxford, UK, 2019; pp. 139–187. ISBN 978-0-19-879661-9. [Google Scholar]
- Sidey-Gibbons, J.A.M.; Sidey-Gibbons, C.J. Machine learning in medicine: A practical introduction. BMC Med. Res. Methodol. 2019, 19, 18. [Google Scholar] [CrossRef] [Green Version]
- Usher-Smith, J.A.; Walter, F.M.; Emery, J.D.; Win, A.K.; Griffin, S.J. Risk Prediction Models for Colorectal Cancer: A Systematic Review. Cancer Prev. Res. 2016, 9, 13–26. [Google Scholar] [CrossRef] [Green Version]
- Peng, L.; Weigl, K.; Boakye, D.; Brenner, H. Risk Scores for Predicting Advanced Colorectal Neoplasia in the Average-risk Population: A Systematic Review and Meta-analysis. Am. J. Gastroenterol. 2018, 113, 1788–1800. [Google Scholar] [CrossRef]
- Smith, T.; Muller, D.C.; Moons, K.G.M.; Cross, A.J.; Johansson, M.; Ferrari, P.; Fagherazzi, G.; Peeters, P.H.M.; Severi, G.; Hüsing, A.; et al. Comparison of prognostic models to predict the occurrence of colorectal cancer in asymptomatic individuals: A systematic literature review and external validation in the EPIC and UK Biobank prospective cohort studies. Gut 2019, 68, 672–683. [Google Scholar] [CrossRef] [PubMed]
- Grigore, B.; Lewis, R.; Peters, J.; Robinson, S.; Hyde, C.J. Development, validation and effectiveness of diagnostic prediction tools for colorectal cancer in primary care: A systematic review. BMC Cancer 2020, 20, 1084. [Google Scholar] [CrossRef]
- Kourou, K.; Exarchos, T.P.; Exarchos, K.P.; Karamouzis, M.V.; Fotiadis, D.I. Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. J. 2015, 13, 8–17. [Google Scholar] [CrossRef] [Green Version]
- Cruz, J.A.; Wishart, D.S. Applications of Machine Learning in Cancer Prediction and Prognosis. Cancer Inform. 2006, 2, 117693510600200. [Google Scholar] [CrossRef]
- Richter, A.N.; Khoshgoftaar, T.M. A review of statistical and machine learning methods for modeling cancer risk using structured clinical data. Artif. Intell. Med. 2018, 90, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Bowman, S. Impact of Electronic Health Record Systems on Information Integrity: Quality and Safety Implications. Perspect. Health Inf. Manag. 2013, 10, 1–19. [Google Scholar]
- Lin, F.P.; Groza, T.; Kocbek, S.; Antezana, E.; Epstein, R.J. Cancer Care Treatment Outcome Ontology: A Novel Computable Ontology for Profiling Treatment Outcomes in Patients With Solid Tumors. JCO Clin. Cancer Inform. 2018, 2, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Carroll, R.J.; Hinz, E.R.M.; Shah, A.; Eyler, A.E.; Denny, J.C.; Xu, H. Applying active learning to high-throughput phenotyping algorithms for electronic health records data. J. Am. Med. Inform. Assoc. 2013, 20, e253–e259. [Google Scholar] [CrossRef] [Green Version]
- Christodoulou, E.; Ma, J.; Collins, G.S.; Steyerberg, E.W.; Verbakel, J.Y.; Van Calster, B. A systematic review shows no performance benefit of machine learning over logistic regression for clinical prediction models. J. Clin. Epidemiol. 2019, 110, 12–22. [Google Scholar] [CrossRef] [PubMed]
- Munn, Z.; Peters, M.D.J.; Stern, C.; Tufanaru, C.; McArthur, A.; Aromataris, E. Systematic review or scoping review? Guidance for authors when choosing between a systematic or scoping review approach. BMC Med. Res. Methodol. 2018, 18, 143. [Google Scholar] [CrossRef]
- Moons, K.G.M.; de Groot, J.A.H.; Bouwmeester, W.; Vergouwe, Y.; Mallett, S.; Altman, D.G.; Reitsma, J.B.; Collins, G.S. Critical Appraisal and Data Extraction for Systematic Reviews of Prediction Modelling Studies: The CHARMS Checklist. PLoS Med. 2014, 11, e1001744. [Google Scholar] [CrossRef] [PubMed]
- Wolff, R.F.; Moons, K.G.M.; Riley, R.D.; Whiting, P.F.; Westwood, M.; Collins, G.S.; Reitsma, J.B.; Kleijnen, J.; Mallett, S.; for the PROBAST Group†. PROBAST: A Tool to Assess the Risk of Bias and Applicability of Prediction Model Studies. Ann. Intern. Med. 2019, 170, 51. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moons, K.G.M.; Wolff, R.F.; Riley, R.D.; Whiting, P.F.; Westwood, M.; Collins, G.S.; Reitsma, J.B.; Kleijnen, J.; Mallett, S. PROBAST: A Tool to Assess Risk of Bias and Applicability of Prediction Model Studies: Explanation and Elaboration. Ann. Intern. Med. 2019, 170, W1. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wan, J.-J.; Chen, B.-L.; Kong, Y.-X.; Ma, X.-G.; Yu, Y.-T. An Early Intestinal Cancer Prediction Algorithm Based on Deep Belief Network. Sci. Rep. 2019, 9, 1–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, H.-C.; Chang, C.-J.; Lin, C.-C.; Tsai, M.-C.; Chang, C.-C.; Tseng, M.-H. Developing Screening Services for Colorectal Cancer on Android Smartphones. Telemed. E-Health 2014, 20, 687–695. [Google Scholar] [CrossRef] [Green Version]
- Kinar, Y.; Kalkstein, N.; Akiva, P.; Levin, B.; Half, E.E.; Goldshtein, I.; Chodick, G.; Shalev, V. Development and validation of a predictive model for detection of colorectal cancer in primary care by analysis of complete blood counts: A binational retrospective study. J. Am. Med. Inform. Assoc. 2016, 23, 879–890. [Google Scholar] [CrossRef] [Green Version]
- Hsieh, M.-H.; Sun, L.-M.; Lin, C.-L.; Hsieh, M.-J.; Sun, K.; Hsu, C.-Y.; Chou, A.-K.; Kao, C.-H. Development of a Prediction Model for Colorectal Cancer among Patients with Type 2 Diabetes Mellitus Using a Deep Neural Network. J. Clin. Med. 2018, 7, 277. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.-H.; Nguyen, P.-A.; Islam Md, M.; Li, Y.-C.; Yang, H.-C. Development of Deep Learning Algorithm for Detection of Colorectal Cancer in EHR Data. In Proceedings of the MEDINFO 2019: Health and Wellbeing e-Networks for All, Lyon, France, 25–30 August 2019; IOS Press: Amsterdam, The Netherlands, 2019; Volume 264, pp. 438–441. [Google Scholar]
- Hornbrook, M.C.; Goshen, R.; Choman, E.; O’Keeffe-Rosetti, M.; Kinar, Y.; Liles, E.G.; Rust, K.C. Early Colorectal Cancer Detected by Machine Learning Model Using Gender, Age, and Complete Blood Count Data. Dig. Dis. Sci. 2017, 62, 2719–2727. [Google Scholar] [CrossRef] [Green Version]
- Birks, J.; Bankhead, C.; Holt, T.A.; Fuller, A.; Patnick, J. Evaluation of a prediction model for colorectal cancer: Retrospective analysis of 2.5 million patient records. Cancer Med. 2017, 6, 2453–2460. [Google Scholar] [CrossRef]
- Kinar, Y.; Akiva, P.; Choman, E.; Kariv, R.; Shalev, V.; Levin, B.; Narod, S.A.; Goshen, R. Performance analysis of a machine learning flagging system used to identify a group of individuals at a high risk for colorectal cancer. PLoS ONE 2017, 12, e0171759. [Google Scholar] [CrossRef]
- Goshen, R.; Mizrahi, B.; Akiva, P.; Kinar, Y.; Choman, E.; Shalev, V.; Sopik, V.; Kariv, R.; Narod, S.A. Predicting the presence of colon cancer in members of a health maintenance organisation by evaluating analytes from standard laboratory records. Br. J. Cancer 2017, 116, 944–950. [Google Scholar] [CrossRef]
- Hilsden, R.J.; Heitman, S.J.; Mizrahi, B.; Narod, S.A.; Goshen, R. Prediction of findings at screening colonoscopy using a machine learning algorithm based on complete blood counts (ColonFlag). PLoS ONE 2018, 13, e0207848. [Google Scholar] [CrossRef] [PubMed]
- Kop, R.; Hoogendoorn, M.; ten Teije, A.; Büchner, F.L.; Slottje, P.; Moons, L.M.G.; Numans, M.E. Predictive modeling of colorectal cancer using a dedicated pre-processing pipeline on routine electronic medical records. Comput. Biol. Med. 2016, 76, 30–38. [Google Scholar] [CrossRef]
- Cooper, J.A.; Parsons, N.; Stinton, C.; Mathews, C.; Smith, S.; Halloran, S.P.; Moss, S.; Taylor-Phillips, S. Risk-adjusted colorectal cancer screening using the FIT and routine screening data: Development of a risk prediction model. Br. J. Cancer 2018, 118, 285–293. [Google Scholar] [CrossRef] [Green Version]
- Nartowt, B.J.; Hart, G.R.; Roffman, D.A.; Llor, X.; Ali, I.; Muhammad, W.; Liang, Y.; Deng, J. Scoring colorectal cancer risk with an artificial neural network based on self-reportable personal health data. PLoS ONE 2019, 14, e0221421. [Google Scholar] [CrossRef] [Green Version]
- Shi, Q.; Gao, Z.; Wu, P.; Heng, F.; Lei, F.; Wang, Y.; Gao, Q.; Zeng, Q.; Niu, P.; Li, C.; et al. An enrichment model using regular health examination data for early detection of colorectal cancer. Chin. J. Cancer Res. 2019, 31, 686–698. [Google Scholar] [CrossRef] [PubMed]
- Nartowt, B.; Hart, G.R.; Muhammad, W.; Liang, Y.; Deng, J. A Model of Risk of Colorectal Cancer Tested between Studies: Building Robust Machine Learning Models for Colorectal Cancer Risk Prediction. Int. J. Radiat. Oncol. Biol. Phys. 2019, 105, E132. [Google Scholar] [CrossRef] [Green Version]
- Vergouwe, Y.; Steyerberg, E.W.; Eijkemans, M.J.C.; Habbema, J.D.F. Substantial effective sample sizes were required for external validation studies of predictive logistic regression models. J. Clin. Epidemiol. 2005, 58, 475–483. [Google Scholar] [CrossRef]
- Bouwmeester, W.; Zuithoff, N.P.A.; Mallett, S.; Geerlings, M.I.; Vergouwe, Y.; Steyerberg, E.W.; Altman, D.G.; Moons, K.G.M. Reporting and Methods in Clinical Prediction Research: A Systematic Review. PLoS Med. 2012, 9, e1001221. [Google Scholar] [CrossRef] [Green Version]
- Hoogendoorn, M.; Moons, L.M.G.; Numans, M.E.; Sips, R.-J. Utilizing Data Mining for Predictive Modeling of Colorectal Cancer Using Electronic Medical Records. In Proceedings of the Brain Informatics and Health, Warsaw, Poland, 11–14 August 2014; Ślȩzak, D., Tan, A.-H., Peters, J.F., Schwabe, L., Eds.; Springer International Publishing: Cham, Germany, 2014; pp. 132–141. [Google Scholar]
- Centers for Disease Control and Prevention NHIS—National Health Interview Survey Homepage. Available online: https://www.cdc.gov/nchs/nhis/index.htm (accessed on 24 February 2020).
- Choi, Y.; Sateia, H.F.; Peairs, K.S.; Stewart, R.W. Screening for colorectal cancer. Semin. Oncol. 2017, 44, 34–44. [Google Scholar] [CrossRef]
- Semmler, G.; Wernly, S.; Wernly, B.; Mamandipoor, B.; Bachmayer, S.; Semmler, L.; Aigner, E.; Datz, C.; Osmani, V. Machine Learning Models Cannot Replace Screening Colonoscopy for the Prediction of Advanced Colorectal Adenoma. J. Pers. Med. 2021, 11, 981. [Google Scholar] [CrossRef] [PubMed]
- NHS England; NHS Improvement. NHS Diagnostic Waiting Times and Activity Data; NHS England: London, UK, 2020; p. 19. [Google Scholar]
- SAIL Databank. SAIL Databank—The Secure Anonymised Information Linkage Databank. Available online: https://saildatabank.com/about-us/ (accessed on 17 November 2020).
- Stirland, L.E.; González-Saavedra, L.; Mullin, D.S.; Ritchie, C.W.; Muniz-Terrera, G.; Russ, T.C. Measuring multimorbidity beyond counting diseases: Systematic review of community and population studies and guide to index choice. BMJ 2020, 368, m160. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sharabiani, M.T.A.; Aylin, P.; Bottle, A. Systematic Review of Comorbidity Indices for Administrative Data. Med. Care 2012, 50, 1109–1118. [Google Scholar] [CrossRef] [PubMed]
- Yurkovich, M.; Avina-Zubieta, J.A.; Thomas, J.; Gorenchtein, M.; Lacaille, D. A systematic review identifies valid comorbidity indices derived from administrative health data. J. Clin. Epidemiol. 2015, 68, 3–14. [Google Scholar] [CrossRef]
- Brusselaers, N.; Lagergren, J. The Charlson Comorbidity Index in Registry-based Research. Methods Inf. Med. 2017, 56, 401–406. [Google Scholar] [CrossRef] [PubMed]
- Wei, M.Y.; Kawachi, I.; Okereke, O.I.; Mukamal, K.J. Diverse Cumulative Impact of Chronic Diseases on Physical Health–Related Quality of Life: Implications for a Measure of Multimorbidity. Am. J. Epidemiol. 2016, 184, 357–365. [Google Scholar] [CrossRef] [Green Version]
- Boakye, D.; Jansen, L.; Schneider, M.; Chang-Claude, J.; Hoffmeister, M.; Brenner, H. Personalizing the Prediction of Colorectal Cancer Prognosis by Incorporating Comorbidities and Functional Status into Prognostic Nomograms. Cancers 2019, 11, 1435. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Renzi, C.; Lyratzopoulos, G.; Hamilton, W.; Maringe, C.; Rachet, B. Contrasting effects of comorbidities on emergency colon cancer diagnosis: A longitudinal data-linkage study in England. BMC Health Serv. Res. 2019, 19, 311. [Google Scholar] [CrossRef] [Green Version]
- Milton, S.; Emery, J.D.; Rinaldi, J.; Kinder, J.; Bickerstaffe, A.; Saya, S.; Jenkins, M.A.; McIntosh, J. Exploring a novel method for optimising the implementation of a colorectal cancer risk prediction tool into primary care: A qualitative study. Implement. Sci. 2022, 17, 31. [Google Scholar] [CrossRef]
- Demb, J.; Gupta, S. Realizing the Promise of Personalized Colorectal Cancer Screening in Practice. JNCI J. Natl. Cancer Inst. 2021, 113, 1120–1122. [Google Scholar] [CrossRef]
- Wang, P.; Liu, X.; Berzin, T.M.; Brown, J.R.G.; Liu, P.; Zhou, C.; Lei, L.; Li, L.; Guo, Z.; Lei, S.; et al. Effect of a deep-learning computer-aided detection system on adenoma detection during colonoscopy (CADe-DB trial): A double-blind randomised study. Lancet Gastroenterol. Hepatol. 2020, 5, 343–351. [Google Scholar] [CrossRef]
- Skyrud, K.D.; Myklebust, T.Å.; Bray, F.; Eriksen, M.T.; de Lange, T.; Larsen, I.K.; Møller, B. How Many Deaths from Colorectal Cancer Can Be Prevented by 2030? A Scenario-Based Quantification of Risk Factor Modification, Screening, and Treatment in Norway. Cancer Epidemiol. Biomark. Prev. 2017, 26, 1420–1426. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Downing, A.; Hall, P.; Birch, R.; Lemmon, E.; Affleck, P.; Rossington, H.; Boldison, E.; Ewart, P.; Morris, E.J.A. Data Resource Profile: The COloRECTal cancer data repository (CORECT-R). Int. J. Epidemiol. 2021, 50, 1418–1418k. [Google Scholar] [CrossRef] [PubMed]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: New York, NY, USA, 2013; Volume 26, ISBN 978-1-4614-6848-6. [Google Scholar]
- Navarro, C.L.A.; Damen, J.A.A.G.; Takada, T.; Nijman, S.W.J.; Dhiman, P.; Ma, J.; Collins, G.S.; Bajpai, R.; Riley, R.D.; Moons, K.G.; et al. Protocol for a systematic review on the methodological and reporting quality of prediction model studies using machine learning techniques. BMJ Open 2020, 10, e038832. [Google Scholar] [CrossRef]
- Collins, G.S.; Dhiman, P.; Navarro, C.L.A.; Ma, J.; Hooft, L.; Reitsma, J.B.; Logullo, P.; Beam, A.L.; Peng, L.; Calster, B.V.; et al. Protocol for development of a reporting guideline (TRIPOD-AI) and risk of bias tool (PROBAST-AI) for diagnostic and prognostic prediction model studies based on artificial intelligence. BMJ Open 2021, 11, e048008. [Google Scholar] [CrossRef] [PubMed]
- Collins, G.S.; Reitsma, J.B.; Altman, D.G.; Moons, K.G.M. Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD): The TRIPOD Statement. Ann. Intern. Med. 2015, 162, 55. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
| Lead Author | Machine-Learning Technique | Variables Assessed | Development (with Internal Validation)/Development with External Validation/Validation Only | Outcome | Case Definition |
|---|---|---|---|---|---|
| Wan, J.-J. 2019 [40] | Multiple 1 | 50 features assessed from endoscopic report, patient history and blood sample, age, gender, smoking history, and drinking history, endoscopic features (e.g., lesion location, polyp size, and no leaf) and blood attributes (e.g., white blood cells and haemoglobin) | Development No external validation | Prediction in 2 years (unclear) | Colonoscopy report confirmed neoplasia |
| Wu, H.-C. 2014 [41] | DT | 20 parameters; demographic data (age, sex, body height, body weight, and body mass index), reasons for colonoscopy (bloody stool, abdominal pain, constipation, bowel habit change, anemia, tenesmus, positive faecal occult blood test (FOBT), colon polyp history, family history of CRC, or elevation in carcinoembryonic antigen level, and patient’s habits (smoking, drinking, betel nut chewing, or tea or coffee consumption) | Development No external validation | Adenoma presence Screening app 2 | Colonoscopy pathology, adenomatous neoplasm |
| Kinar, Y. 2016 [42] | DT/RF | Sex, birth year and blood counts (20 parameters) | Development and validation | Prediction up to 2 years prior to diagnosis | CRC diagnosis in Israeli Cancer Registry/The Health Improvement Network (THIN) general practice database |
| Hsieh, M.-H. 2018 [43] | DNN | Demographic data, comorbidity and medication use; age, mean (SD) year, gender, urbanisation level, occupation, hypertension, hyperlipidemia, stroke, congestive heart failure, colorectal polyps, obesity, chronic obstructive pulmonary disease, coronary artery disease, asthma, smoking, inflammatory bowel disease, irritable bowel syndrome, alcohol-related illness, chronic kidney disease, diabetes complication (aDCIs component), retinopathy, nephropathy, neuropathy, cerebrovascular, cardiovascular, peripheral vascular disease, metabolic, mean aDCIs score onset, end of follow-up, statins, insulin, sulfonylureas, metformin, thiazolinedione, other antidiabetic drugs and mean follow-up for endpoint. Selection of input features ND, the abstract states “All the available possible risk factors for CRC were also included in the analyses” | Development No external validation | Prediction, timeframe unclear | CRC diagnosis recorded in National Health Insurance Research Database (NHIRD) |
| Wang, Y.-H. 2019 [44] | CNN | Comorbidity and medication use with age and sex | Development No external validation | Prediction within 3 years | CRC diagnosis recorded in Registry for Catastrophic Illness Patient |
| Hornbrook, M.C. 2017 [45] | DT/RF | Gender, age, and blood count (number of parameters—at least one) | Validation of Kinar 2016 | Prediction within 6 months to 1 year | CRC diagnosis in Kaiser Permanente Tumor Registry |
| Birks, J. 2017 [46] | DT/RF | Gender, age, and blood count (20 parameters) | Validation of Kinar 2016 | Prediction in 18–24 months | CRC diagnosis recorded in Clinical Practice Research Datalink (CPRD) |
| Kinar, Y. 2017 [47] | DT/RF | Gender, age, and blood count (20 parameters) at 2 timepoints | Evaluation of Kinar 2016 | Prediction within 6 months | CRC diagnosis in Israeli Cancer Registry |
| Goshen, R. 2017 [48] | Linear Regression | Gender, age, blood count, liver function, metabolic blood tests, and iron, folic acid, and vitamin B12 levels. | Development, extension of Kinar 2016 | Prediction within 6 months | CC diagnosis in Israeli Cancer Registry |
| Hilsden, R.J. 2018 [49] | DT/RF | Gender, age, and blood count; one or more from haemoglobin, haematocrit, mean corpuscular volume, mean corpuscular haemoglobin, mean corpuscular haemoglobin concentration, red blood cell count, red blood cell distribution width, white blood cell count, platelets, % neutrophils, lymphocytes, monocytes, eosinophils, and basophils—up to 15 variables. | Validation of Kinar 2016 | Prediction within 12 months | Colonoscopy result of CRC or high-risk polyp. |
| Kop, R. 2016 [50] | RF/CART | Age and gender with medical-record-based data for consultations, medication, referral, diagnoses and lab. test results; drugs for constipation; iron deficiency anaemia; lipid modifying agents (s); drugs for constipation; age; drugs for acid-related disorders (s); drugs for constipation; diabetes non-insulin-dependent; abdominal pain/cramps general; diabetes non-insulin-dependent (s); diabetes non-insulin-dependent; beta-blocking agents (s) ; drugs for constipation; hypertension uncomplicated (s) ; hypertension uncomplicated; agents acting on the renin–angiotensin system (s); drugs for constipation; diuretics; flu vaccination (a); agents acting on the renin–angiotensin system (s); Antithrombotic agents; abdominal pain localized other; general consult (s); agents acting on the renin–angiotensin system (s) ; drugs for acid-related disorders; agents acting on the renin–angiotensin system | Development No external validation | ND | CRC diagnosis in general practice dataset |
| Cooper, J.A. 2018 [51] | ANN | Age, sex, deprivation index, screening history, FIT test result | Development No external validation | Predict CRC/high risk adenoma versus none following FIT | Bowel cancer screening database record of CRC or advanced adenoma |
| Nartowt, B.J. 2019 [52] | ANN | Health questionnaire responses; current or cancer age, hypertension, number of first-degree relatives with CRC (NHIS years 2000, 2005, 2010, and 2015 only), coronary heart disease, pooled heart conditions, myocardial infarction, diabetes (non-gestational), heart condition/disease, vigorous exercise frequency, angina pectoris, ulcer (stomach, duodenal, peptic), Hispanic ethnicity, stroke, emphysema, American Indian, African American, other, or multiple race, sex (male), body-mass index, smoking frequency | Development No external validation | Risk score generation | Confirmed colorectal cancer (any) in NHIS dataset |
| Shi, Q. 2019 [53] | CART | Rate of albumin to globulin, albumin, alanine transaminase, aspartate transaminase, percent basophils, calcium, creatinine, percent eosinophils, glucose, hematocrit, high-density lipoprotein-cholesterol, haemoglobin, potassium, low-density lipoprotein-cholesterol, percent lymphocytes, mean corpuscular haemoglobin, mean corpuscular haemoglobin concentration, mean corpuscular volume, percent monocytes, mean platelet volume, percent neutrophils, phosphorus, platelet large cell ratio, plateletcrit, platelet distribution width, platelet, red blood count, variable coefficient of red blood cell distribution width, standard deviation of red blood cell distribution width, total bilirubin, total cholesterol, triglyceride, total protein, uric acid, white blood count Final model used: age, albumin, haematocrit, % lymphocytes | Development, internal validation. | Risk score generation | Confirmed colorectal cancer |
| Lead Author | Age Range (Years) | Sample Size | Data Source |
|---|---|---|---|
| Wan, J.-J. 2019 [40] | ND | ND | China, Jiangsu Provincial Hospital of Traditional Chinese Medicine |
| Wu, H.-C. 2014 [41] | Cases 21–80 Controls 34–80 | 225 (97 cases) | Taiwan, single centre, unnamed |
| Kinar, Y. 2016 [42] | Cases > 40 Controls 50–75 | Complex (*) | UK, The Health Improvement Network (THIN) database/Israel, Maccabi Health Services |
| Hsieh, M.-H. 2018 [43] | >20 | 1,315,899 train 337,410 test (14,867 cases) | Taiwan, subset of National Health Insurance Research Database (NHIRD) and Longitudinal Cohort of Diabetes Patients (LHDP) |
| Wang, Y.-H. 2019 [44] | >20 | 47,967 controls, 10,185 cases | Taiwan, National Health Insurance Research Database (NHIRD) |
| Hornbrook, M.C. 2017 [45] | 40–89 | 10,008 (900 cases) | USA, Single Institution Registry, Kaiser Permanente Northwest Region |
| Birks, J. 2017 [46] | >40 | 2,220,108 (25,430 cases) | UK, Clinical Practice Research Datalink (CPRD) |
| Kinar, Y. 2017 [47] | 50–75 | 112,584 (133 cases) | Israel, Maccabi Health Services and Israeli Cancer Registry |
| Goshen, R. 2017 [48] | 40–75 | 105,067 (2294 cases) 1755 cases and 54,730 matched controls in study | Israel, Maccabi Health Services and Israeli Cancer Registry |
| Hilsden, R.J. 2018 [49] | 50–75 | 17,676 (60 CRC, 1104 high risk polyps—cases) (screened) | Canada, Alberta Health Services Forzani and MacPhail Colon Cancer Screening Centre in Calgary, AB, Canada by linking the Centre’s electronic medical records with provincial laboratory data. |
| Kop, R. 2016 [50] | ≥30 | 263,879 (1292 cases) | Netherlands, Julius General Practitioners’ Network, Utrecht; Academic Network of General Practice, VU University Medical Center Amsterdam (ANH VUmc); Leiden General Practitioner Registration Network RNUH-LEO, LUMC, Leiden. |
| Cooper, J.A. 2018 [51] | 60–74 | 1810 (548 cases—cancer, high or intermediate risk polyps) (screened patients only) | UK, two regional cancer screening hubs (NHS Bowel Screening) |
| Nartowt, B.J. 2019 [52] | 18–85 (18–49, 50–75) | 525,394 train (1269 cases) 58,376 test (140 cases) | USA (National Health Interview Survey) (**) |
| Shi, Q. 2019 [53] | ND | PUCH 81,310 (4211 cases 70:30 train:test PUSH 57,235 (436 cases) 80:20 train:test Validated on PUCH test set | China: Peking University Cancer Hospital (PUCH) and Peking University Shougang Hospital (PUSH) |
| Reference | Model Type | Model Performance Measure | Misc | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AUROC | Sensitivity | Specificity | PPV | NPV | FPR | FNR | Accuracy | Precision | F1 Score | OR | |||
| Wan, J.-J. 2019 [40] | Neural network (ECP) | 0.6 | 0.7321 | 0.8148 | 0.8571 | 0.7059 | |||||||
| Wu, H.-C. 2014 [41] | Decision tree | 0.937 | 0.825 | 0.922 | 0.078 | 0.175 | 26 (+/− 5) | ||||||
| Kinar, Y. 2016 [42] | Combined | 0.82 (+/− 0.01) | 0.88 (+/− 0.02) | 0.005 | 40 (+/− 6) | FPR and OR at 50% case detection | |||||||
| 0.81 | 0.94 (+/− 0.01) | ||||||||||||
| Hsieh, M.-H. 2018 [43] | Neural Network | 0.7 (0.674–0.727) | 0.886 | 0.98 | 0.929 | Test set values | |||||||
| Wang, Y.-H. 2019 [44] | Neural network | 0.922 (SD 0.0004) | 0.837 | 0.867 | 0.532 | ||||||||
| * Hornbrook, M.C. 2017 [45] | Combined | 0.8 (0.79–0.82) | 34.7 (28.9–40.4) | OR at 99% specificity | |||||||||
| * Birks, J. 2017 [46] | Combined | 0.776 (0.771–0.781) | 3.91 (3.4–4.48) | 82.73 (82.68–82.78) | 0.088 | 0.996 | |||||||
| * Kinar, Y. 2017 [47] | Combined | 0.173 | 21.8 (13.8–34.2) | At 1% percentile of scores, yield 2.1% | |||||||||
| ** Goshen, R. 2017 [48] | Logistic regression | 0.31 | 0.95 | 0.073 | males | ||||||||
| 0.24 | 0.95 | 0.042 | females | ||||||||||
| * Hilsden, R.J. 2018 [49] | Combined | 0.081 (0.064–0.098) | 5.1 (2.3–8.9) | At 95% specificity, OR versus no findings | |||||||||
| Kop, R. 2016 [50] | Logistic regression | 0.891 | 0.642 | 0.03 | 0.058 | ||||||||
| Cooper, J.A. 2018 [51] | ANN | 0.686 (0.659–0.712) | 0.3515 | 0.8557 | 0.5147 | 0.7519 | 10.66% CRC detection rate | ||||||
| Nartowt, B.J. 2019 [52] | Neural net | 0.80 (+/− 0.05) | 0.57 (+/− 0.03) | 0.89 (+/− 0.02) | NPV and PPV in abstract | ||||||||
| Shi, Q. 2019 [53] | CART | 0.88 (0.87–0.90) | 0.622 (0.581–0.662) | Sensitivity at 99% specificity | |||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Burnett, B.; Zhou, S.-M.; Brophy, S.; Davies, P.; Ellis, P.; Kennedy, J.; Bandyopadhyay, A.; Parker, M.; Lyons, R.A. Machine Learning in Colorectal Cancer Risk Prediction from Routinely Collected Data: A Review. Diagnostics 2023, 13, 301. https://doi.org/10.3390/diagnostics13020301
Burnett B, Zhou S-M, Brophy S, Davies P, Ellis P, Kennedy J, Bandyopadhyay A, Parker M, Lyons RA. Machine Learning in Colorectal Cancer Risk Prediction from Routinely Collected Data: A Review. Diagnostics. 2023; 13(2):301. https://doi.org/10.3390/diagnostics13020301
Chicago/Turabian StyleBurnett, Bruce, Shang-Ming Zhou, Sinead Brophy, Phil Davies, Paul Ellis, Jonathan Kennedy, Amrita Bandyopadhyay, Michael Parker, and Ronan A. Lyons. 2023. "Machine Learning in Colorectal Cancer Risk Prediction from Routinely Collected Data: A Review" Diagnostics 13, no. 2: 301. https://doi.org/10.3390/diagnostics13020301