

Impact of Cross-Validation on Machine Learning Models for Early Detection of Intrauterine Fetal Demise
 , and
, and
Abstract
:1. Introduction
2. Related Works
Motivation and Contribution
- Investigating different cross-validation techniques applied.
- Performing Exploratory Data Analysis for inferences of data.
- Selecting the ideal model and using Blackbox evaluation to assess that model’s performance.
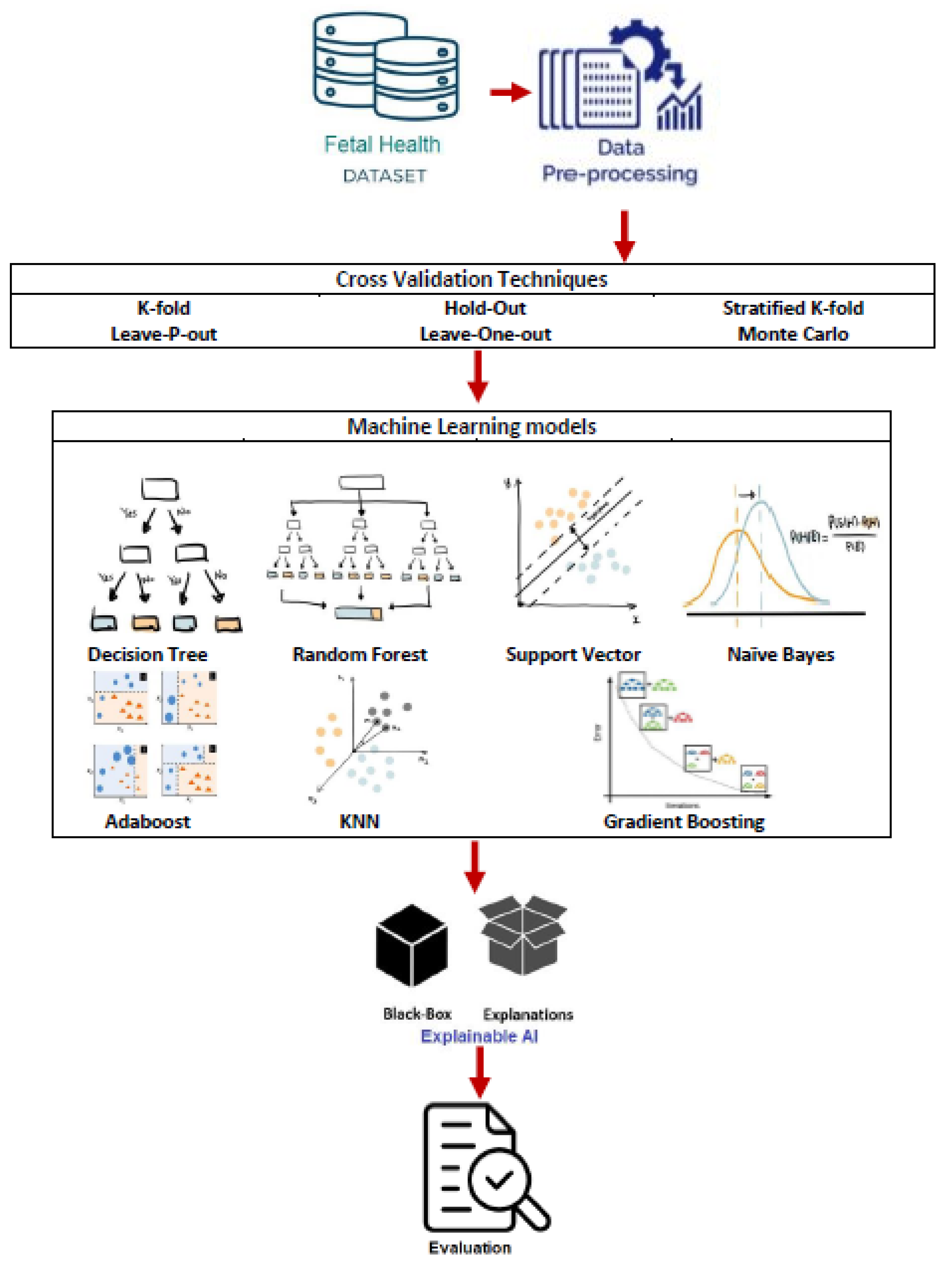
3. Materials and Methods
3.1. Data Description
- Baseline Value—This feature describes the baseline fetal heart rate.
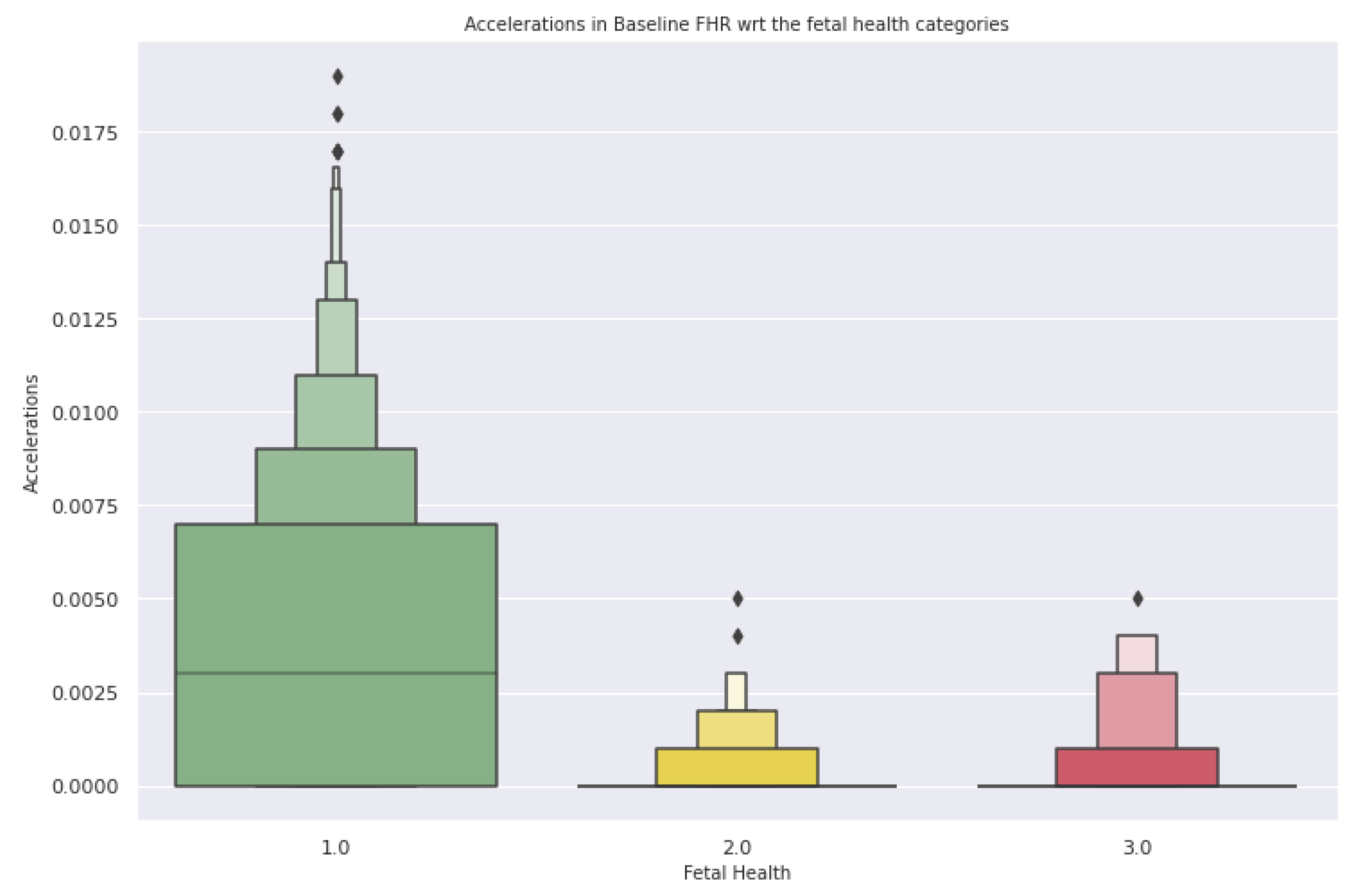
- Acceleration—This feature indicates the number of accelerations per second.
- Fetal Movement—This feature indicates the number of fetal movements per second.
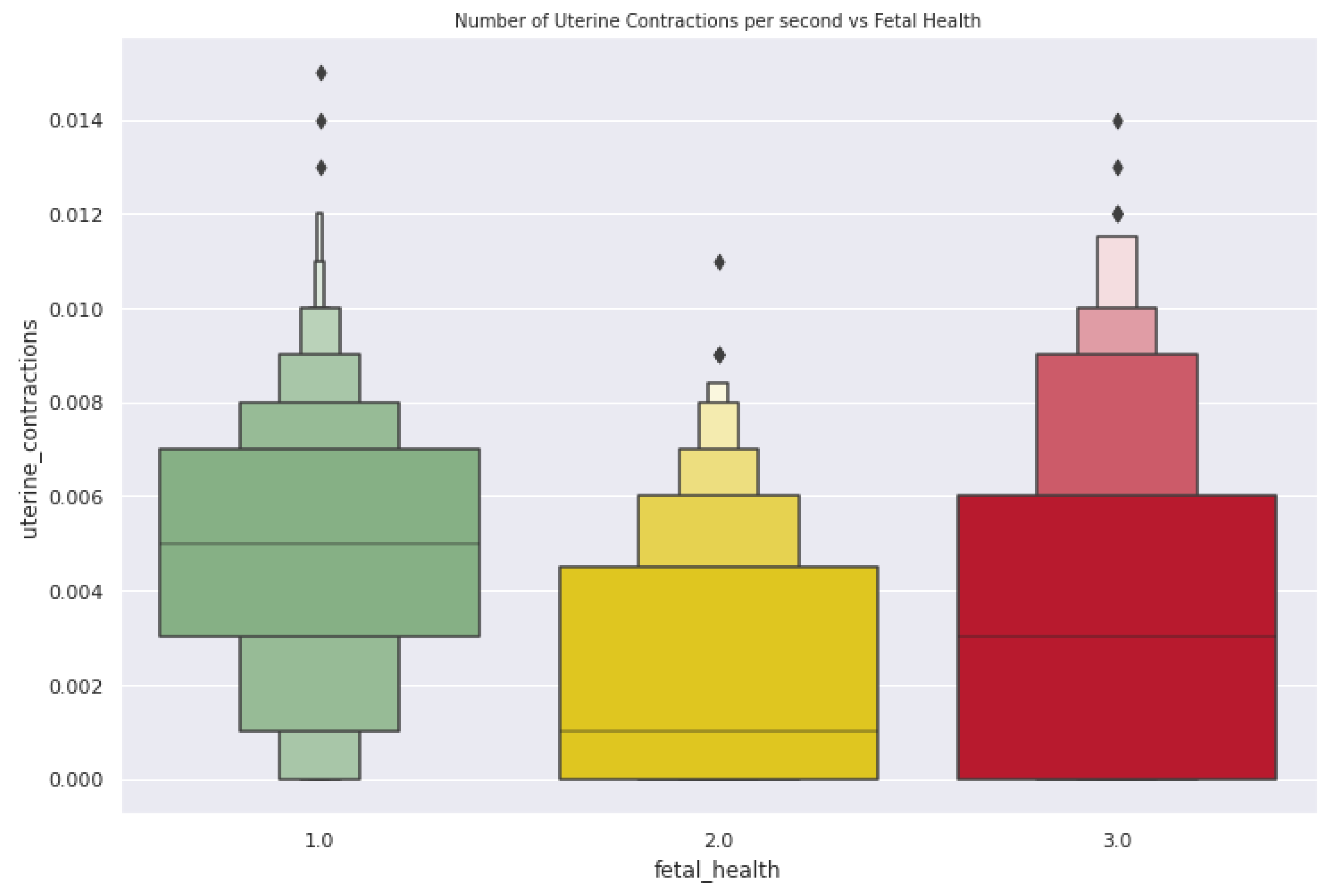
- Uterine Contraction—This feature indicates the number of uterine contractions per second.
- Abnormal short-term variability—This feature provides the percentage of time with abnormal short-term variability.
- Severe Deceleration—This feature presents the number of SDs per second.
- Light Deceleration—This feature presents the number of LDs per second.
- Prolonged Deceleration—This feature presents the number of PDs per second.
3.2. Preprocessing
3.3. Stages of Work Performed
- Exploratory Data Analysis
- 2.
- Classification
- 3.
- Blackbox Evaluation
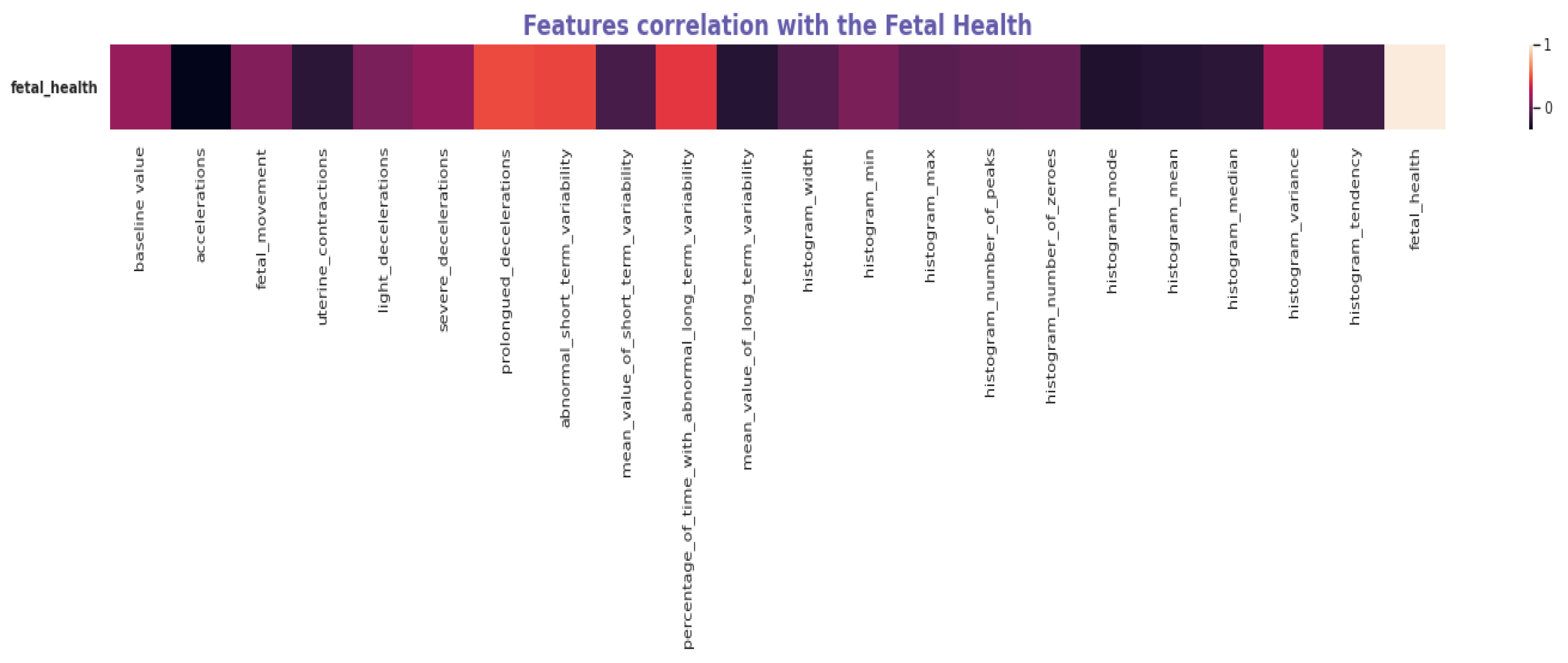
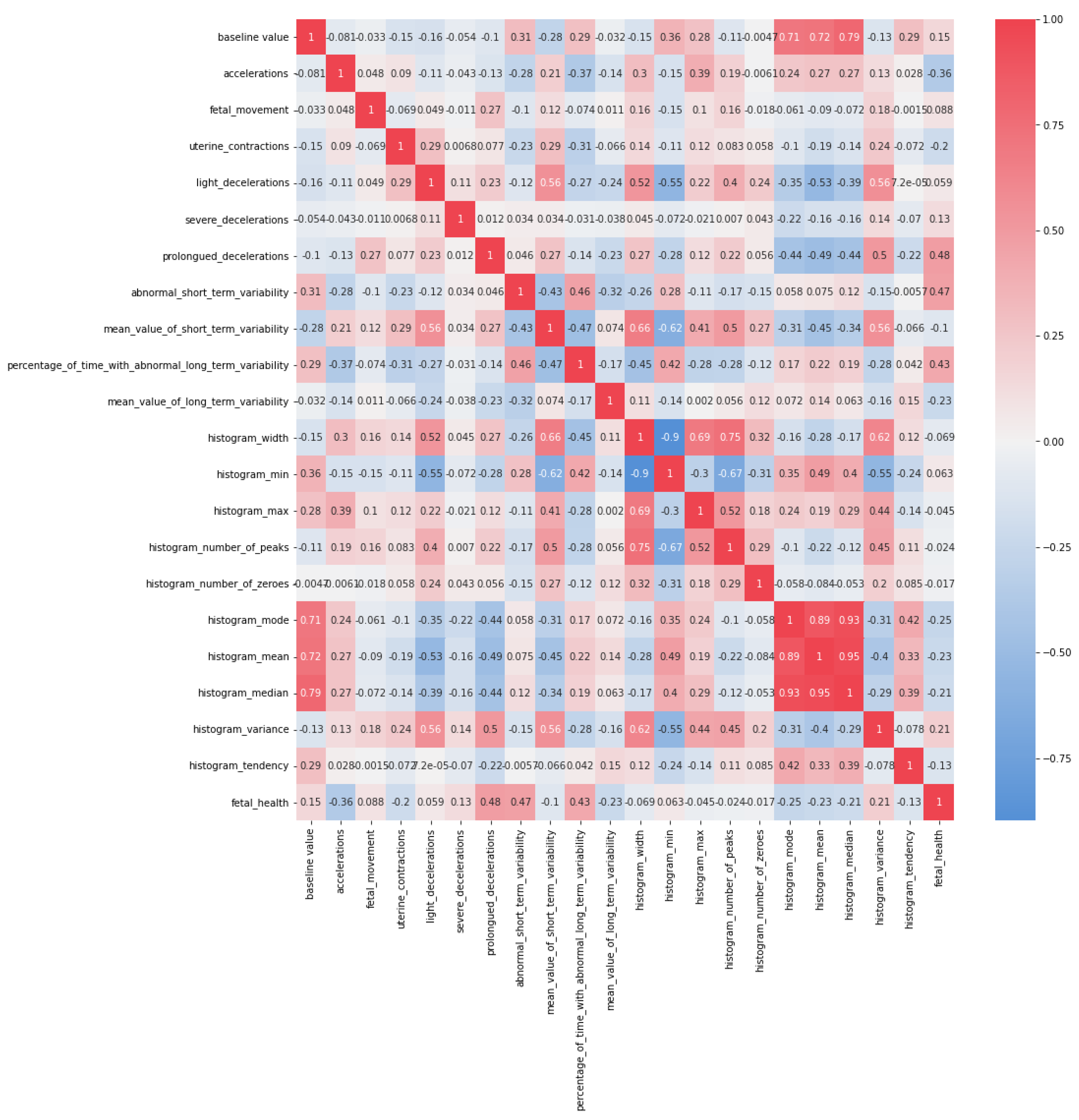
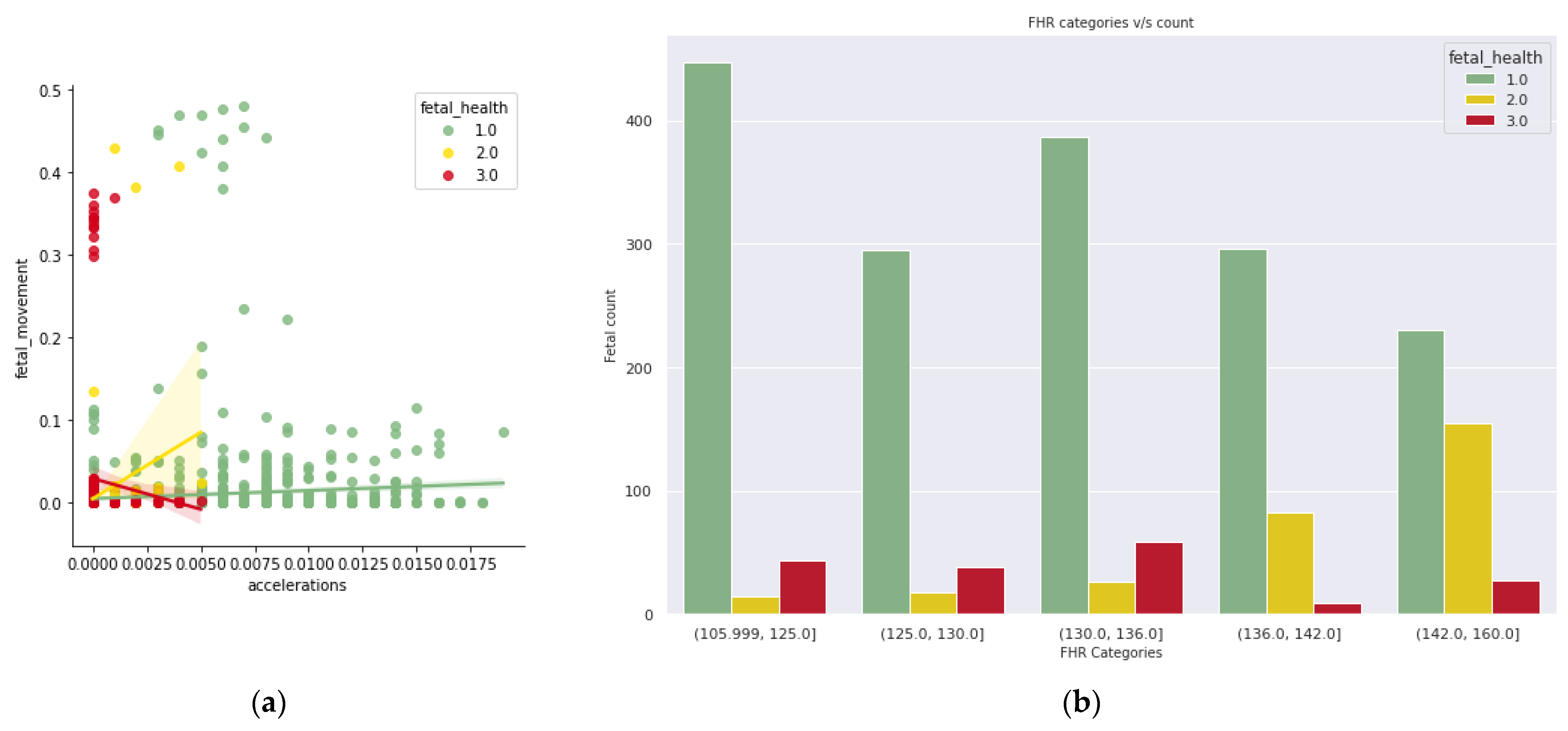
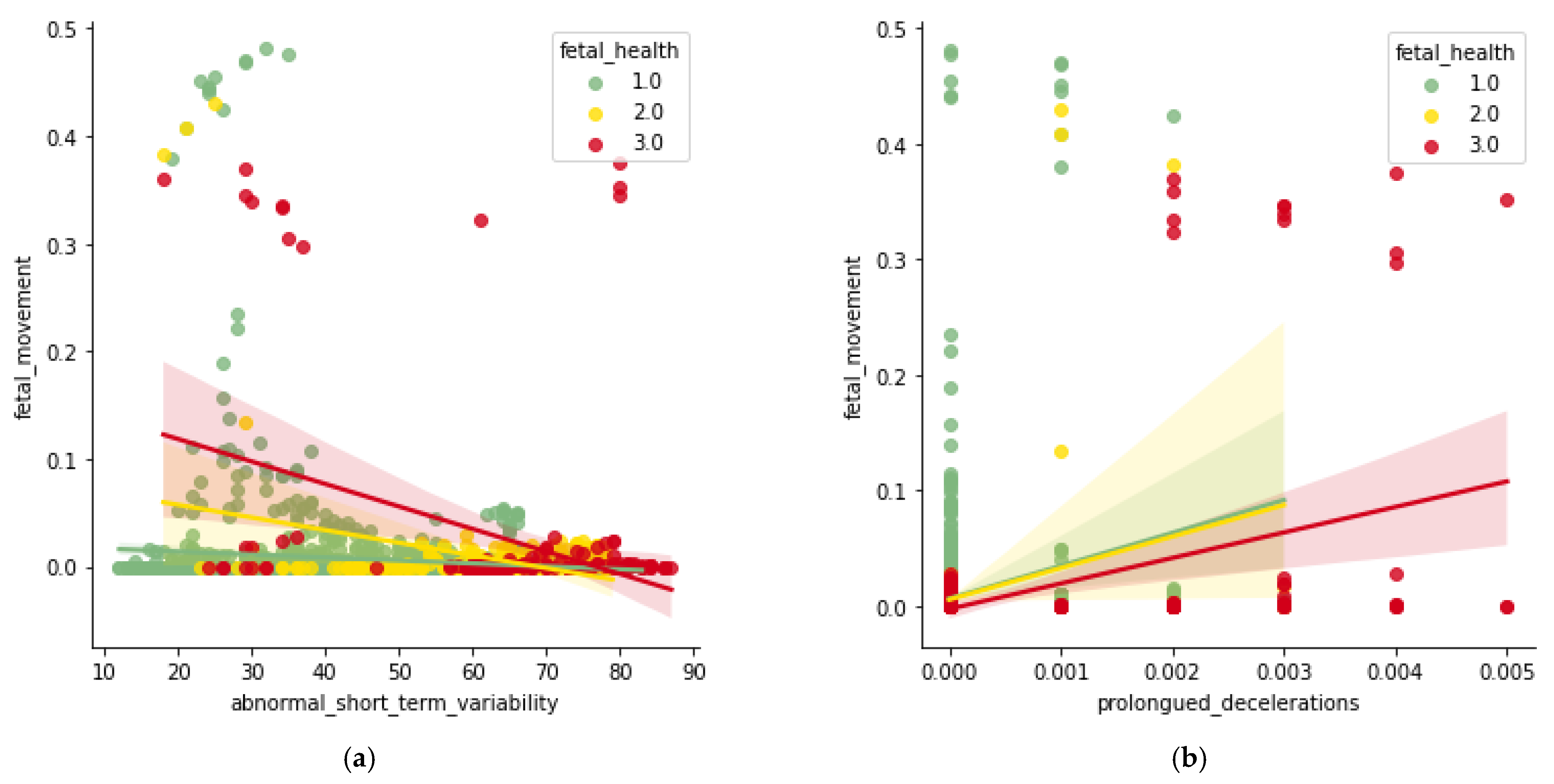
3.3.1. Exploratory Data Analysis
3.3.2. Classification
- Decision Tree Classifier
- 2.
- Random Forest Classifier
- 3.
- KNN Classifier
- 4.
- Gaussian Naïve Bayes
- 5.
- Adaboost Classifier
- 6.
- Gradient Boosting
- 7.
- Support Vector Classifier
- 8.
- Voting Classifier
- 9.
- Feed Forward Network
3.3.3. Cross-Validation Techniques
- K-fold Cross-Validation
- 2.
- Hold-Out Cross-Validation
- 3.
- Stratified K-fold Cross-Validation
- 4.
- Leave-P-Out Cross-Validation
- 5.
- Leave-One-Out Cross-Validation
- 6.
- Monte Carlo
- 7.
- Repeated K-folds
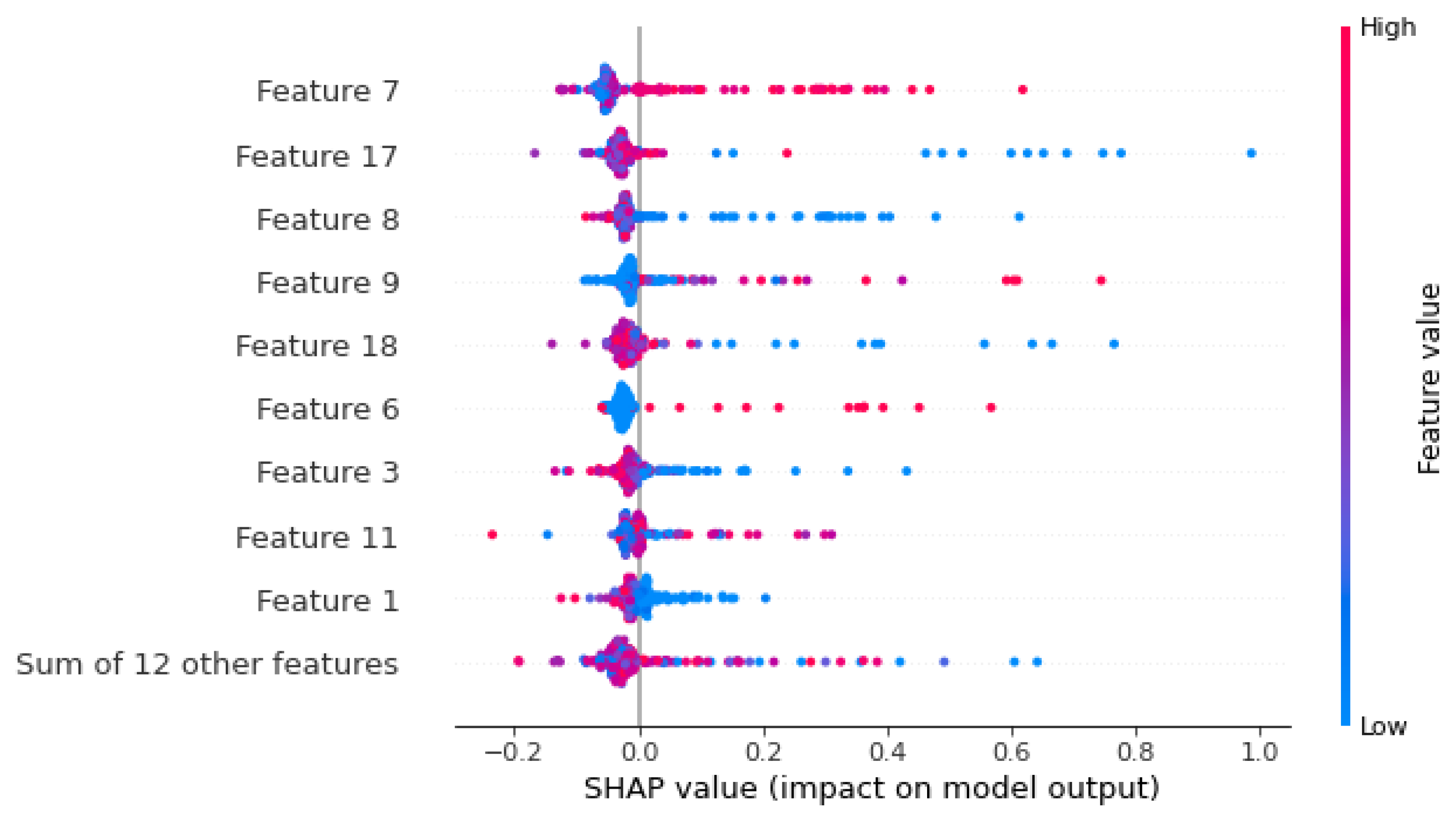
3.3.4. Black-Box Evaluation
4. Results
| Algorithm 1 Proposed Methodology |
|
- True positive (TP)—Correct positive prediction
- False positive (FP)—Incorrect positive prediction
- True negative (TN)—Correct negative prediction
- False negative (FN)—Incorrect negative prediction
- Accuracy
- 2.
- Precision
- 3.
- Recall
- 4.
- F1-Score
- 5.
- Kappa
- 6.
- Matthews Correlation Coefficient (MCC)
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mehbodniya, A.; Lazar, A.J.P.; Webber, J.; Sharma, D.K.; Jayagopalan, S.; Singh, P.; Rajan, R.; Pandya, S.; Sengan, S. Fetal health classification from cardiotocographic data using machine learning. Expert Syst. 2022, 39, e12899. [Google Scholar] [CrossRef]
- Rahmayanti, N.; Pradani, H.; Pahlawan, M.; Vinarti, R. Comparison of machine learning algorithms to classify fetal health using cardiotocogram data. Procedia Comput. Sci. 2022, 197, 162–171. [Google Scholar] [CrossRef]
- Sharma, S.; Sidhu, H.; Kaur, S. Analytical study of intrauterine fetal death cases and associated maternal conditions. Analytical study of intrauterine fetal death cases and associated maternal conditions. Int. J. Appl. Basic Med. Res. 2016, 6, 11–13. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Liu, X. Fetal health classification based on machine learning. In Proceedings of the 2021 IEEE 2nd International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Nanchang, China, 26–28 March 2021; pp. 899–902. [Google Scholar] [CrossRef]
- Tougui, I.; Jilbab, A.; El Mhamdi, J. Impact of the choice of cross-validation techniques on the results of machine learning-based diagnostic applications. Healthc. Inform. Res. 2021, 27, 189–199. [Google Scholar] [CrossRef] [PubMed]
- Piri; Jayashree; Mohapatra, P. Exploring fetal health status using an association based classification approach. In Proceedings of the 2019 International Conference on Information Technology (ICIT), Bhubaneswar, India, 19–21 December 2019; pp. 166–171. [Google Scholar] [CrossRef]
- Tran, D.; Cooke, S.; Illingworth, P.J.; Gardner, D.K. Deep learning as a predictive tool for fetal heart pregnancy following time-lapse incubation and blastocyst transfer. Hum. Reprod. 2019, 34, 1011–1018. [Google Scholar] [CrossRef]
- Sontakke, S.A.; Lohokare, J.; Dani, R.; Shivagaje, P. Classification of cardiotocography signals using machine learning. In Intelligent Systems and Applications, Proceedings of the 2018 Intelligent Systems Conference (IntelliSys), London, UK, 6–7 September 2018; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; Volume 2, pp. 439–450. [Google Scholar] [CrossRef]
- Ventura Dadario, A.M.; Espinoza, C.; Araújo Nogueira, W. Classification of Fetal State through the application of Machine Learning techniques on Cardiotocography records: Towards Real World Application. medRxiv 2021. [Google Scholar] [CrossRef]
- Rayhana, T.; Arefina, A.S.; Chowdhury, S.A. Automatic detection of fetal health status from cardiotocography data using machine learning algorithms. J. Bangladesh Acad. Sci. 2021, 45, 155–167. [Google Scholar] [CrossRef]
- Malacova, E.; Tippaya, S.; Bailey, H.D.; Chai, K.; Farrant, B.M.; Gebremedhin, A.T.; Leonard, H.; Marinovich, M.L.; Nassar, N.; Phatak, A.; et al. Stillbirth risk prediction using machine learning for a large cohort of births from Western Australia, 1980–2015. Sci. Rep. 2020, 10, 5354. [Google Scholar] [CrossRef]
- Navuluri, N.R. Fetal Health Prediction using Classification Techniques. Int. J. Eng. Res. Technol. 2021, 10, 383–386. [Google Scholar]
- Moreira, M.W.L.; Rodrigues, J.J.; Oliveira, A.M.; Saleem, K.; Neto, A.J.V. Predicting hypertensive disorders in high-risk pregnancy using the random forest approach. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–5. [Google Scholar]
- Abry, P.; Spilka, J.; Leonarduzzi, R.; Chudáček, V.; Pustelnik, N.; Doret, M. Sparse learning for Intrapartum fetal heart rate analysis. Biomed. Phys. Eng. Express 2018, 4, 034002. [Google Scholar] [CrossRef]
- Piri, J.; Mohapatra, P.; Dey, R. Fetal health status classification using moga-cd based feature selection approach. In Proceedings of the 2020 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 2–4 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Dwivedi, P.; Khan, A.A.; Mugde, S.; Sharma, G. Diagnosing the major contributing factors in the classification of the fetal health status using cardiotocography measurements: An automl and xai approach. In Proceedings of the 2021 13th International Conference on Electronics, Computers and Artificial Intelligence (ECAI), Pitesti, Romania, 1–3 July 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Agrawal, K.; Mohan, H. Cardiotocography analysis for fetal state classification using machine learning algorithms. In Proceedings of the 2019 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 23–25 January 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Li, J.; Chen, Z.-Z.; Huang, L.; Fang, M.; Li, B.; Fu, X.; Wang, H.; Zhao, Q. Automatic classification of fetal heart rate based on convolutional neural network. IEEE Internet Things J. 2018, 6, 1394–1401. [Google Scholar] [CrossRef]
- KUZU, A.; SANTUR, Y. Fetal Health Pattern Classification Using Ensemble Learning. In Proceedings of the 3rd International Conference on Applied Engineering and Natural Sciences, Konya, Turkey, 10–13 November 2022. [Google Scholar]
- Cardiotocography Data Set. Available online: https://archive.ics.uci.edu/ml/datasets/cardiotocography (accessed on 10 February 2023).
- Arif, Z.; Ahmed, R.; Sadia, U.H.; Tultul, M.S.I.; Chakma, R. Decision tree method using for fetal state classification from cardiotography data. J. Adv. Eng. Comput. 2020, 4, 64–73. [Google Scholar] [CrossRef]
- Noor, N.F.M.; Ahmad, N.; Noor, N.M. Fetal Health Classification Using Supervised Learning Approach. In Proceedings of the 2021 IEEE National Biomedical Engineering Conference (NBEC), Kuala Lumpur, Malaysia, 9–10 November 2021; IEEE: Piscataway, NJ, USA; pp. 36–41. [Google Scholar] [CrossRef]
- Alam, T.; Khan, A.I.; Dola, N.N.; Tazin, T.; Khan, M.M.; Albraikan, A.A.; Almalki, F.A. Comparative Analysis of Different Efficient Machine Learning Methods for Fetal Health Classification. Appl. Bionics Biomech. 2022, 2022, 6321884. [Google Scholar] [CrossRef]
- Jebadurai, I.J.; Paulraj, G.J.L.; Jebadurai, J.; Silas, S. Experimental analysis of filtering-based feature selection techniques for fetal health classification. Serb. J. Electr. Eng. 2022, 19, 207–224. [Google Scholar] [CrossRef]
- Aslam, N.; Khan, I.U.; Aljishi, R.F.; Alnamer, Z.M.; Alzawad, Z.M.; Almomen, F.A.; Alramadan, F.A. Explainable Computational Intelligence Model for Antepartum Fetal Monitoring to Predict the Risk of IUGR. Electronics 2022, 11, 593. [Google Scholar] [CrossRef]
- Baldi, P.; Vershynin, R. The capacity of feedforward neural networks. Neural Netw. 2019, 116, 288–311. [Google Scholar] [CrossRef]
- Haque, E.; Gupta, T.; Singh, V.; Nene, K.; Masurkar, A. Detection and Classification of Fetal Heart Rate (FHR). In International Conference on Artificial Intelligence and Sustainable Engineering: Select Proceedings of AISE 2020; Springer Nature: Singapore, 2022; Volume 1, pp. 437–447. [Google Scholar] [CrossRef]
- Pahar, M.; Klopper, M.; Warren, R.; Niesler, T. COVID-19 cough classification using machine learning and global smartphone recordings. Comput. Biol. Med. 2021, 135, 104572. [Google Scholar] [CrossRef]
- Magnusson, M.; Vehtari, A.; Jonasson, J.; Andersen, M. Leave-one-out cross-validation for Bayesian model comparison in large data. In Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics (AISTATS) 2020, Palermo, Italy, 26–28 August 2020; pp. 341–351. [Google Scholar]
- Rafało, M. Cross validation methods: Analysis based on diagnostics of thyroid cancer metastasis. ICT Express 2022, 8, 183–188. [Google Scholar] [CrossRef]
- Gabbay, F.; Bar-Lev, S.; Montano, O.; Hadad, N. A lime-based explainable machine learning model for predicting the severity level of COVID-19 diagnosed patients. Appl. Sci. 2021, 11, 10417. [Google Scholar] [CrossRef]
- Knapič, S.; Malhi, A.; Saluja, R.; Främling, K. Explainable artificial intelligence for human decision support system in the medical domain. Mach. Learn. Knowl. Extr. 2021, 3, 740–770. [Google Scholar] [CrossRef]
- Joshi, V.R.; Srinivasan, K.; Vincent, P.M.D.R.; Rajinikanth, V.; Chang, C.-Y. A Multistage Heterogeneous Stacking Ensemble Model for Augmented Infant Cry Classification. Front. Public Health 2022, 10, 819865. [Google Scholar] [CrossRef] [PubMed]
- Ashwini, K.; Vincent, P.M.D.R.; Srinivasan, K.; Chang, C.-Y. Deep learning assisted neonatal cry classification via support vector machine models. Front. Public Health 2021, 9, 670352. [Google Scholar] [CrossRef]
- Ashwini, K.; Vincent, P.D.R.; Srinivasan, K.; Chang, C.-Y. Deep convolutional neural network based feature extraction with optimized machine learning classifier in infant cry classification. In Proceedings of the 2020 International Conference on Decision Aid Sciences and Application (DASA), Sakheer, Bahrain, 8–9 November 2020; pp. 27–32. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accelerations | Prolonged Decelerations | Abnormal Short-Term Variability | Percentage of Time with Abnormal Long-Term Variability | Mean Value of Long-Term Variability | Fetal Health | |
|---|---|---|---|---|---|---|
| Accelerations | 1 | −0.127748624 | −0.27957 | −0.37394 | −0.14236 | −0.36407 |
| Prolonged Decelerations | −0.12775 | 1 | 0.04622 | −0.13733 | −0.22651 | 0.484859 |
| Abnormal Short-term Variability | −0.27958 | 0.04622 | 1 | 0.459413 | −0.31510 | 0.471191 |
| Percentage of Time with Abnormal Long-term Variability | −0.37394 | −0.13733 | 0.45941 | 1 | −0.17111 | 0.426146 |
| Mean Value of long-term Variability | −0.14236 | −0.22651 | −0.31510 | −0.17111 | 1 | −0.22679 |
| Fetal Health | −0.36407 | 0.48485 | 0.47119 | 0.42614 | −0.2268 | 1 |
| Model | Feature | Percentage of Importance |
|---|---|---|
| Decision Tree Classifier | Prolonged Deceleration | 0.25 |
| Histogram Mean | 0.21 | |
| Histogram Minimum | 0.18 | |
| Acceleration | 0.14 | |
| Random Forest Classifier | Prolonged Deceleration | 0.13 |
| Histogram Mean | 0.10 | |
| Acceleration | 0.05 | |
| Histogram Median | 0.05 | |
| KNN Classifier | Histogram Minimum | 0.05 |
| Abnormal Short-term Variability | 0.05 | |
| Histogram Mode | 0.03 | |
| Histogram Median | 0.02 | |
| Gaussian Naïve Bayes | Histogram Variance | 0.27 |
| Acceleration | 0.24 | |
| Histogram Mean | 0.12 | |
| Histogram Mode | 0.10 | |
| Adaboost Classifier | Prolonged Deceleration | 0.41 |
| Acceleration | 0.14 | |
| Histogram Mode | 0.08 | |
| Gradient Boosting | Histogram Mean | 0.37 |
| Prolonged Deceleration | 0.19 | |
| Acceleration | 0.15 | |
| Histogram Mode | 0.07 | |
| Support Vector Classifier | Histogram Variance | 0.24 |
| Histogram Median | 0.11 | |
| Histogram Mode | 0.09 | |
| Histogram Mean | 0.07 | |
| Feed Forward Network | Abnormal Short-term Variability | 0.34 |
| Acceleration | 0.22 | |
| Histogram Minimum | 0.12 | |
| Histogram Mean | 0.02 | |
| Voting Classifier | Abnormal Short-term Variability | 0.04 |
| Acceleration | 0.02 | |
| Histogram Minimum | 0.02 | |
| Histogram Mean | 0.02 |
| Class Label | Count |
|---|---|
| Normal Condition | 1655 |
| Suspect Condition | 295 |
| Pathological Condition | 176 |
| Model | Accuracy | Precision | Recall | F1 Score | Kappa | MCC |
|---|---|---|---|---|---|---|
| Decision Tree Classifier | 0.92 | 0.896 | 0.85 | 0.8733 | 0.79 | 0.79 |
| Random Forest Classifier | 0.95 | 0.886 | 0.9233 | 0.9 | 0.84 | 0.84 |
| KNN classifier | 0.91 | 0.78 | 0.88 | 0.8233 | 0.72 | 0.73 |
| Gaussian Naïve Bayes | 0.71 | 0.72 | 0.62 | 0.6166 | 0.43 | 0.50 |
| Adaboost Classifier | 0.92 | 0.8933 | 0.8566 | 0.8733 | 0.77 | 0.77 |
| Gradient Boosting | 0.96 | 0.9266 | 0.9366 | 0.93 | 0.89 | 0.89 |
| SVC | 0.89 | 0.7533 | 0.83 | 0.78 | 0.65 | 0.66 |
| Voting Classifier | 0.93 | 0.81 | 0.91 | 0.85 | 0.78 | 0.78 |
| Feed Forward Network | 0.79 | 0.62 | 0.79 | 0.70 | 0.65 | 0.67 |
| Model | CV Technique | Accuracy | Precision | Recall | F1-Score | Kappa | MCC |
|---|---|---|---|---|---|---|---|
| Decision Tree Classifier | K-fold | 0.96 | 0.90 | 0.90 | 0.90 | 0.86 | 0.86 |
| Stratified K-fold | 0.95 | 0.91 | 0.92 | 0.92 | 0.86 | 0.86 | |
| Hold-Out | 0.93 | 0.92 | 0.87 | 0.90 | 0.82 | 0.82 | |
| Leave-P-Out | 0.72 | 0.47 | 0.73 | 0.50 | 0.30 | 0.33 | |
| Leave-One-Out | 0.99 | 0.98 | 0.98 | 0.98 | 0.99 | 0.99 | |
| Repeated K-fold | 0.93 | 0.89 | 0.88 | 0.88 | 0.80 | 0.80 | |
| Monte Carlo | 0.95 | 0.90 | 0.92 | 0.91 | 0.84 | 0.84 | |
| Random Forest Classifier | K-fold | 0.96 | 0.90 | 0.95 | 0.92 | 0.88 | 0.89 |
| Stratified K-fold | 0.95 | 0.88 | 0.94 | 0.91 | 0.85 | 0.86 | |
| Hold-Out | 0.94 | 0.89 | 0.91 | 0.90 | 0.82 | 0.83 | |
| Leave-P-Out | 0.75 | 0.48 | 0.77 | 0.49 | 0.30 | 0.38 | |
| Leave-One-Out | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | |
| Repeated K-fold | 0.94 | 0.86 | 0.91 | 0.88 | 0.82 | 0.82 | |
| Monte Carlo | 0.94 | 0.86 | 0.90 | 0.88 | 0.83 | 0.83 | |
| KNN Classifier | K-fold | 0.92 | 0.81 | 0.87 | 0.83 | 0.76 | 0.77 |
| Stratified K-fold | 0.92 | 0.81 | 0.90 | 0.85 | 0.75 | 0.76 | |
| Hold-Out | 0.91 | 0.78 | 0.88 | 0.83 | 0.71 | 0.73 | |
| Leave-P-Out | 0.71 | 0.43 | 0.73 | 0.44 | 0.21 | 0.26 | |
| Leave-One-Out | 0.99 | 0.99 | 0.99 | 0.99 | 0.80 | 0.80 | |
| Repeated K-fold | 0.90 | 0.78 | 0.85 | 0.81 | 0.71 | 0.71 | |
| Monte Carlo | 0.91 | 0.78 | 0.88 | 0.82 | 0.73 | 0.74 | |
| Gaussian Naïve Bayes | K-fold | 0.81 | 0.77 | 0.72 | 0.72 | 0.63 | 0.61 |
| Stratified K-fold | 0.86 | 0.79 | 0.78 | 0.76 | 0.65 | 0.67 | |
| Hold-Out | 0.85 | 0.77 | 0.72 | 0.73 | 0.64 | 0.66 | |
| Leave-P-Out | 0.78 | 0.89 | 0.61 | 0.65 | 0.40 | 0.42 | |
| Leave one out | 0.73 | 0.76 | 0.66 | 0.65 | 0.47 | 0.53 | |
| Repeated K-fold | 0.84 | 0.75 | 0.75 | 0.72 | 0.62 | 0.64 | |
| Monte Carlo | 0.74 | 0.78 | 0.69 | 0.67 | 0.49 | 0.55 | |
| Adaboost Classifier | K-fold | 0.93 | 0.88 | 0.90 | 0.89 | 0.81 | 0.81 |
| Stratified K-fold | 0.91 | 0.85 | 0.88 | 0.86 | 0.75 | 0.75 | |
| Hold-Out | 0.91 | 0.78 | 0.89 | 0.82 | 0.61 | 0.74 | |
| Leave-P-Out | 0.86 | 0.79 | 0.87 | 0.82 | 0.72 | 0.72 | |
| Leave-One-Out | 0.90 | 0.83 | 0.85 | 0.84 | 0.66 | 0.66 | |
| Repeated K-fold | 0.91 | 0.83 | 0.85 | 0.84 | 0.68 | 0.69 | |
| Monte Carlo | 0.92 | 0.85 | 0.88 | 0.86 | 0.67 | 0.68 | |
| Gradient Boosting | K-fold | 0.99 | 0.96 | 0.99 | 0.98 | 0.96 | 0.96 |
| Stratified K-fold | 0.99 | 0.98 | 0.98 | 0.98 | 0.96 | 0.96 | |
| Hold-Out | 0.96 | 0.93 | 0.92 | 0.93 | 0.83 | 0.88 | |
| Leave-P-Out | 0.99 | 0.98 | 0.98 | 0.98 | 0.95 | 0.95 | |
| Leave-One-Out | 0.99 | 0.98 | 0.98 | 0.98 | 0.94 | 0.94 | |
| Repeated K-fold | 0.99 | 0.99 | 0.98 | 0.99 | 0.93 | 0.93 | |
| Monte Carlo | 0.99 | 0.98 | 0.98 | 0.98 | 0.96 | 0.96 | |
| SVC | K-fold | 0.94 | 0.79 | 0.91 | 0.83 | 0.78 | 0.79 |
| Stratified K-fold | 0.92 | 0.81 | 0.92 | 0.86 | 0.78 | 0.78 | |
| Hold-Out | 0.89 | 0.75 | 0.83 | 0.78 | 0.84 | 0.66 | |
| Leave-P-Out | 0.88 | 0.76 | 0.88 | 0.81 | 0.72 | 0.72 | |
| Leave-One-Out | 0.92 | 0.80 | 0.89 | 0.84 | 0.75 | 0.76 | |
| Repeated K-fold | 0.93 | 0.80 | 0.90 | 0.84 | 0.77 | 0.77 | |
| Monte Carlo | 0.94 | 0.83 | 0.94 | 0.87 | 0.81 | 0.82 | |
| Voting Classifier | K-fold | 0.98 | 0.96 | 0.98 | 0.97 | 0.95 | 0.95 |
| Stratified K-fold | 0.98 | 0.95 | 0.98 | 0.97 | 0.94 | 0.94 | |
| Hold-Out | 0.93 | 0.81 | 0.91 | 0.85 | 0.78 | 0.78 | |
| Leave-P-Out | 0.97 | 0.95 | 0.98 | 0.97 | 0.94 | 0.94 | |
| Leave-One-Out | 0.98 | 0.96 | 0.98 | 0.97 | 0.96 | 0.96 | |
| Repeated K-fold | 0.99 | 0.97 | 0.99 | 0.98 | 0.96 | 0.96 | |
| Monte Carlo | 0.99 | 0.96 | 0.99 | 0.97 | 0.96 | 0.96 | |
| Feed Forward Network | K-fold | 0.81 | 0.90 | 0.81 | 0.89 | 0.87 | 0.85 |
| Stratified K-fold | 0.78 | 0.90 | 0.78 | 0.88 | 0.87 | 0.86 | |
| Hold-Out | 0.79 | 0.89 | 0.79 | 0.88 | 0.85 | 0.86 | |
| Leave-P-Out | 0.70 | 0.90 | 0.67 | 0.80 | 0.82 | 0.80 | |
| Leave-One-Out | 0.90 | 0.85 | 0.89 | 0.87 | 0.86 | 0.87 | |
| Repeated K-fold | 0.79 | 0.88 | 0.79 | 0.88 | 0.86 | 0.87 | |
| Monte Carlo | 0.80 | 0.90 | 0.80 | 0.89 | 0.85 | 0.83 |
| Models | Description | Accuracy (%) |
|---|---|---|
| Random Forest Classifier [1] | The paper implemented Z-Normal to standardize the data and applied only 10-fold Cross-Validation. | 94.5 |
| XG Boost [2] | Parameter optimization is conducted using Grid search CV, studied the minimum child weight and subsample ratio. | 98 |
| Blender Model [3] | Combined Gradient Boosting Classifier, CatBoost Classifier, Extreme Gradient Boosting with soft voting parameter, and Light Gradient Boosting Machine. | 95.9 |
| Random Forest Classifier with Leave one out CV [4] | RF pipeline applied hyperparameter Elasticnet, which is used for penalising the weights of the model. | 81.3 |
| XG Boost Classifier [5] | The researchers applied Classification based on the association (CBA)-M1/M2 algorithm. | 93 |
| IVY [6] | IVY is a feed-forward model which inputs time-lapsed video and outputs a confidence score. | 93 |
| Random forest Classifier [7] | The model applies nested Cross-Validation. | 93 |
| Light GBM [8] | The researchers use the LightGBM with Bayesian Optimisation and Gaussian process regression and apply K-fold Cross-Validation ensembling. | 95.82 |
| XG Boost Classifier [9] | The model applied Multiclass log loss for the early stopping method. | 96.75 |
| XG Boost Classifier [10] | The model applied Stratified K-fold CV. | 84.2 |
| Sparse Support Vector Machine [13] | The model penalizes the weight by imposing l1 norm. | 75 |
| XG Boost Classifier [14] | For the feature selection process, the researchers applied MOGA-CD, which follows the Genetic algorithm. | 94 |
| CNN [16] | The proposed CNN model consists of three convolutional layers with ReLU as the activation function and Fully connected layer. | 94.3 |
| Proposed Model | Monte Carlo, one of the CV techniques which applies shuffle splitting of the data, enhances Gradient Boosting and Voting Classifier. | 99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kaliappan, J.; Bagepalli, A.R.; Almal, S.; Mishra, R.; Hu, Y.-C.; Srinivasan, K. Impact of Cross-Validation on Machine Learning Models for Early Detection of Intrauterine Fetal Demise. Diagnostics 2023, 13, 1692. https://doi.org/10.3390/diagnostics13101692
Kaliappan J, Bagepalli AR, Almal S, Mishra R, Hu Y-C, Srinivasan K. Impact of Cross-Validation on Machine Learning Models for Early Detection of Intrauterine Fetal Demise. Diagnostics. 2023; 13(10):1692. https://doi.org/10.3390/diagnostics13101692
Chicago/Turabian StyleKaliappan, Jayakumar, Apoorva Reddy Bagepalli, Shubh Almal, Rishabh Mishra, Yuh-Chung Hu, and Kathiravan Srinivasan. 2023. "Impact of Cross-Validation on Machine Learning Models for Early Detection of Intrauterine Fetal Demise" Diagnostics 13, no. 10: 1692. https://doi.org/10.3390/diagnostics13101692