

A Proposed Framework for Early Prediction of Schistosomiasis

 , ,
, ,  , ,
, ,
Abstract
:1. Introduction
- A latest and imbalanced dataset related to Schistosomiasis has been employed for this research.
- Preprocessing like missing values imputation, data transformation, feature selection techniques correlation. Information gain, gain ratio, ReliefF, and OneR minimise the features for prediction and resampling techniques, Random undersampling and oversampling, Cluster Centroid, Near miss, and SMOTE have been employed to carter the problems in the dataset.
- Advanced machine learning techniques have been employed, which outperformed state-of-the-art methods.
- Our proposed framework can aid medical and healthcare practitioners in the early identification and improved treatment of Schistosomiasis.
2. Literature Survey
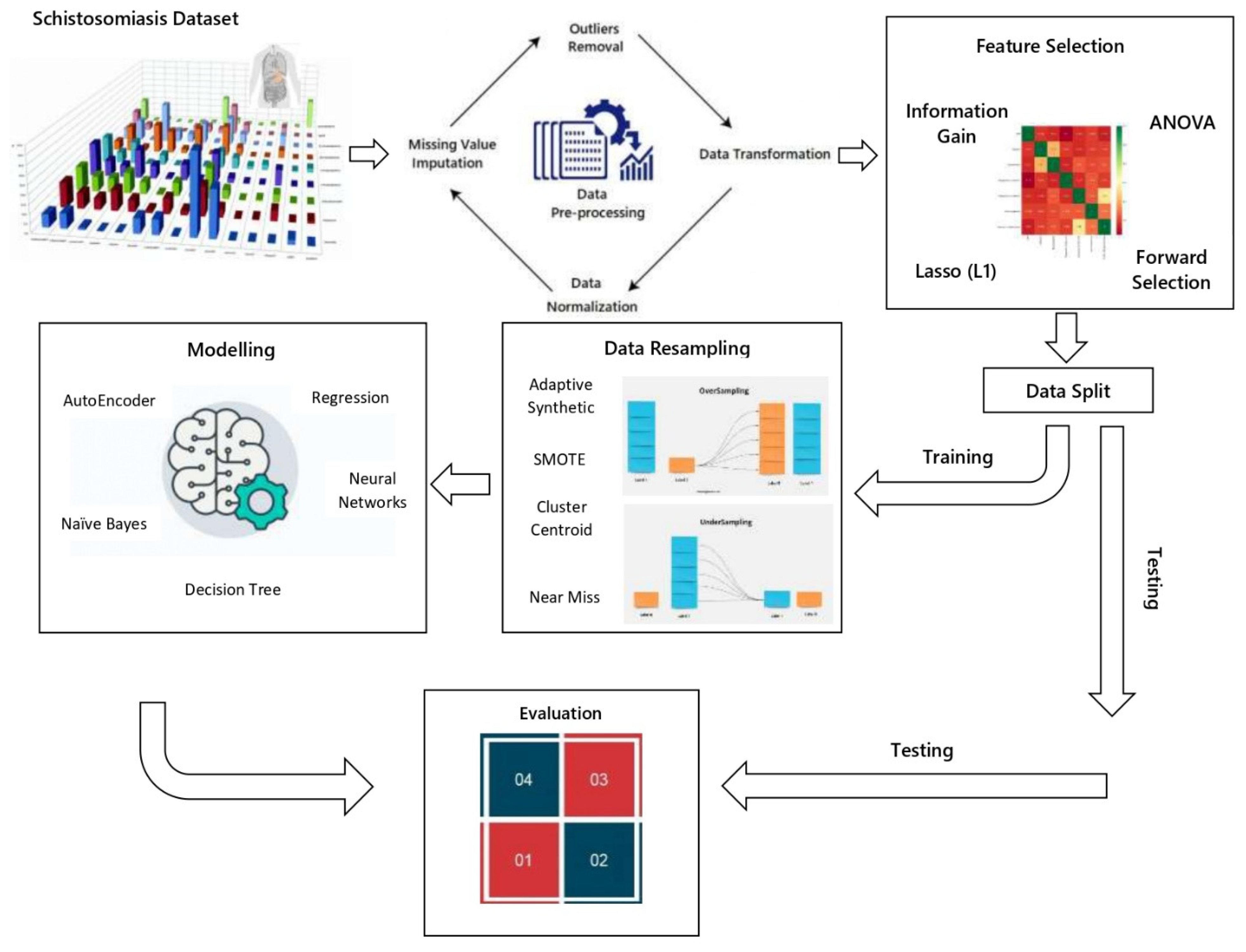
3. Methodology
3.1. Dataset
3.2. Missing Data Imputation
3.3. Data Normalization
3.4. Data Transformation
3.5. Feature Selection
3.5.1. Information Gain
3.5.2. Correlation-Based Feature Selection (CFS)
3.5.3. ReliefF
3.6. Data Resampling
3.6.1. Random Undersampling
3.6.2. Near Miss
3.6.3. Cluster Centroid
3.6.4. Synthetic Minority Oversampling Technique
- For each sample in the minority class . Get the collection of k-nearest neighbours, .
- Determine the number of nearest neighbours who are members of the majority class for each Select observations such that in Equation (26):
- After that, the observations are run through the standard SMOTE method to generate synthetic points that solely include the minority and majority classes.
- Euclidean distance was calculated for selected clusters (s), ignoring the majority class. The mean distance of each cluster is obtained by adding all non-diagonal entries of the distance matrix and dividing them with non-diagonal elements.
- Divide the number of minority instances in each cluster by the average minority distance raised to the power of the number of features n to get density, i.e., .
- To acquire a measure of sparsity, invert the density measure: .
- We can calculate the cluster’s sampling weight by dividing the cluster’s sparsity factor by the sum of all cluster’s sparsity factors.
3.7. Gradient Boosting
| Algorithms 1 Gradient Boosting |
|
CatBoost
4. Results
- True Positive (TP): It identifies how much the data instances are identified as recovery cases.
- True Negative (TN): It identifies how many data instances are categorised as death cases.
- False Positive (FP): It identifies how much the data instances are incorrectly categorised as recovery cases.
- False Negative (FN): It Identifies how many data instances are incorrectly categorised as death cases;
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, G.; Zhou, X.; Liu, J.; Chen, Y.; Zhang, H.; Chen, Y.; Liu, J.; Jiang, H.; Yang, J.; Nie, S. Comparison of three data mining models for prediction of advanced schistosomiasis prognosis in the Hubei province. PLoS Negl. Trop. Dis. 2018, 12, e0006262. [Google Scholar] [CrossRef] [PubMed]
- Fusco, T.; Bi, Y.; Wang, H.; Browne, F. Data mining and machine learning approaches for prediction modelling of schistosomiasis disease vectors: Epidemic disease prediction modelling. Int. J. Mach. Learn. Cybern. 2020, 11, 1159–1178. [Google Scholar] [CrossRef] [PubMed]
- Olveda, D.U.; Olveda, R.M.; Jan Montes, C.; Chy, D.; Modesto Abellera III, J.B.; Cuajunco, D.; Lam, A.K.; McManus, D.P.; Li, Y.; Ross, A.G.; et al. Clinical management of advanced Schistosomiasis: A case of portal vein thrombosis-induced splenomegaly requiring surgery. Case Rep. 2014, 2014, bcr2014203897. [Google Scholar] [CrossRef] [PubMed]
- Huang, L.H.; Qiu, Y.W.; Hua, H.Y.; Niu, X.H.; Wu, P.F.; Wu, H.Y.; Zhu, H.Y.; Yang, X.J.; Yao, S.Z.; Li, Y.G. The efficacy and safety of entecavir in patients with advanced Schistosomiasis co-infected with hepatitis B virus. Int. J. Infect. Dis. 2013, 17, e606–e609. [Google Scholar] [CrossRef]
- Schistosomiasis (Bilharzia). Available online: https://www.who.int/health-topics/schistosomiasis#tab=tab_1 (accessed on 1 March 2022).
- Zhang, L.J.; Xu, Z.M.; Dang, H.; Li, Y.L.; Lü, S.; Xu, J.; Li, S.Z.; Zhou, X.N. Endemic status of schistosomiasis in People’s Republic of China in 2019. Zhongguo Xue Xi Chong Bing Fang Zhi Za Zhi 2020, 32, 551–558. [Google Scholar] [CrossRef]
- Alam, T.M.; Milhan, M.; Khan, A.; Iqbal, M.A.; Wahab, A.; Mushtaq, M. Cervical Cancer Prediction through Different Screening Methods Using Data Mining. IJACSA Int. J. Adv. Comput. Sci. Appl. 2019, 10. Available online: https://www.ijacsa.thesai.org (accessed on 1 March 2022). [CrossRef]
- Osakunor, D.N.M.; Woolhouse, M.E.J.; Mutapi, F. Paediatric schistosomiasis: What we know and what we need to know. PLoS Negl. Trop. Dis. 2018, 12, e0006144. [Google Scholar] [CrossRef]
- Ashour, A.S.; Hawas, A.R.; Guo, Y. Comparative study of multiclass classification methods on light microscopic images for hepatic schistosomiasis fibrosis diagnosis. Health Inf. Sci. Syst. 2018, 6, 7. [Google Scholar] [CrossRef]
- Zhao, M.; Zhang, Z.; Chow, T.W.S. Trace ratio criterion based generalised discriminative learning for semi-supervised dimensionality reduction. Pattern Recognit. 2012, 45, 1482–1499. [Google Scholar] [CrossRef]
- Baig, T.I.; Khan, Y.D.; Alam, T.M.; Biswal, B.; Aljuaid, H.; Gillani, D.Q. ILipo-PseAAC: Identification of lipoylation sites using statistical moments and general PseAAC. Comput. Mater. Contin. 2022, 71, 215–230. [Google Scholar]
- Tariq, A.; Awan, M.J.; Alshudukhi, J.; Alam, T.M.; Alhamazani, K.T.; Meraf, Z. Software Measurement by Using Artificial Intelligence. J. Nanomater. 2022, 2022, 7283171. [Google Scholar] [CrossRef]
- Alam, T.K.; Shaukat, M.; Mushtaq, M.; Ali, Y.; Khushi, M. Corporate Bankruptcy Prediction: An Approach Towards Better Corporate World. Available online: https://academic.oup.com/comjnl/article-abstract/64/11/1731/5856206 (accessed on 14 April 2022).
- Alam, T.K.; Shaukat, I.; Hameed, S.; Li, J.; Khushi, M. An Investigation of Credit Card Default Prediction in the Imbalanced Datasets. Available online: https://ieeexplore.ieee.org/abstract/document/9239944/ (accessed on 14 April 2022).
- Baig, T.I.; Alam, T.M.; Anjum, T.; Naseer, S.; Wahab, A.; Imtiaz, M.; Raza, M.M. Classification of Human Face: Asian and Non-Asian People. In Proceedings of the 2019 International Conference on Innovative Computing (ICIC), Lahore, Pakistan, 1–2 November 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Ghani, M.U.; Alam, T.M.; Jaskani, F.H. Comparison of Classification Models for Early Prediction of Breast Cancer. In Proceedings of the 2019 International Conference on Innovative Computing (ICIC), Lahore, Pakistan, 1–2 November 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Jiang, H.; Deng, W.; Zhou, J.; Ren, G.; Cai, X.; Li, S.; Hu, B.; Li, C.; Shi, Y.; Zhang, N.; et al. Machine learning algorithms to predict the 1 year unfavourable prognosis for advanced Schistosomiasis. Int. J. Parasitol. 2021, 51, 959–965. [Google Scholar] [CrossRef]
- Olanloye, O.D.; Olasunkanmi, O.; Oduntan, O.E. Comparison of Support Vector Machine Models in the Classification of Susceptibility to Schistosomiasis. Balk. J. Electr. Comput. Eng. 2020, 8, 266–271. [Google Scholar] [CrossRef]
- Asarnow, D.; Singh, R. Determining Dose-Response Characteristics of Molecular Perturbations in Whole-Organism Assays Using Biological Imaging and Machine Learning. In Proceedings of the 2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Madrid, Spain, 3–6 December 2018; pp. 283–290. [Google Scholar] [CrossRef]
- Kasse, B.; Gueye, B.; Diallo, M.; Santatra, F.; Elbiaze, H. IoT based Schistosomiasis Monitoring for More Efficient Disease Prediction and Control Model. In Proceedings of the 2019 IEEE Sensors Applications Symposium (SAS), Sophia Antipolis, France, 11–13 March 2019. [Google Scholar] [CrossRef]
- Chicco, D.; Rovelli, C. Computational prediction of diagnosis and feature selection on mesothelioma patient health records. PLoS ONE 2019, 14, e0208737. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Mazurowski, M.A.; Habas, P.A.; Zurada, J.M.; Lo, J.Y.; Baker, J.A.; Tourassi, G.D. Training neural network classifiers for medical decision making: The effects of imbalanced datasets on classification performance. Neural. Netw. 2008, 21, 427–436. [Google Scholar] [CrossRef] [PubMed]
- García-Pedrajas, N.; Ortiz-Boyer, D.; García-Pedrajas, M.D.; Fyfe, C. Class imbalance methods for translation initiation site recognition. In Proceedings of the International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, Cordoba, Spain, 1–4 June 2010; pp. 327–336. [Google Scholar] [CrossRef]
- Blagus, R.; Lusa, L. Class prediction for high-dimensional class-imbalanced data. BMC Bioinform. 2010, 11, 523. [Google Scholar] [CrossRef]
- Xia, S.; Xue, J.B.; Zhang, X.; Hu, H.H.; Abe, E.M.; Rollinson, D.; Bergquist, R.; Zhou, Y.; Li, S.Z.; Zhou, X.N. Pattern analysis of schistosomiasis prevalence by exploring predictive modeling in Jiangling County, Hubei Province, China. Infect. Dis. Poverty 2017, 6, 91. [Google Scholar] [CrossRef]
- Ali, Y.; Farooq, A.; Alam, T.M.; Farooq, M.S.; Awan, M.J.; Baig, T.I. Detection of Schistosomiasis Factors Using Association Rule Mining. IEEE Access 2019, 7, 186108–186114. [Google Scholar] [CrossRef]
- Wrable, M.; Kulinkina, A.V.; Liss, A.; Koch, M.; Cruz, M.S.; Biritwum, N.-K.; Ofosu, A.; Gute, D.M.; Kosinski, K.C.; Naumova, E.N. The use of remotely sensed environmental parameters for spatial and temporal schistosomiasis prediction across climate zones in Ghana. Environ. Monit. Assess. 2019, 191, 301. [Google Scholar] [CrossRef] [PubMed]
- Gong, Y.-F.; Zhu, L.-Q.; Li, Y.-L.; Zhang, L.-J.; Xue, J.-B.; Xia, S.; Lv, S.; Xu, J.; Li, S.-Z. Identification of the high-risk area for schistosomiasis transmission in China based on information value and machine learning: A newly data-driven modeling attempt. Infect. Dis. Poverty 2021, 10, 88. [Google Scholar] [CrossRef] [PubMed]
- Van Buuren, S. Flexible Imputation of Missing. 2018. Available online: https://scholar.google.com/scholar?hl=en&as_sdt=0%2C5&q=Van+Buuren%2C+S.+%282018%29+Flexible+Imputation+of+Missing+Data.+Chapman+and+Hall%2FCRC&btnG= (accessed on 11 April 2022).
- Patro, S.G.K.; Sahu, K.K. Normalisation: A preprocessing stage. arXiv 2015, arXiv:1503.06462. [Google Scholar]
- Fan, Q.; Zhu, C.J.; Xiao, J.Y.; Wang, B.H.; Yin, L.; Xu, X.L.; Rong, F. An application of apriori algorithm in SEER breast cancer data. In Proceedings of the 2010 International Conference on Artificial Intelligence and Computational Intelligence, Sanya, China, 23–24 October 2010. [Google Scholar]
- Shaukat, K.; Luo, S.; Abbas, N.; Mahboob Alam, T.; Ehtesham Tahir, M.; Hameed, I.A. An analysis of blessed Friday sale at a retail store using classification models. In Proceedings of the 4th International Conference on Software Engineering and Information Management (ICSIM 2021), Yokohama, Japan, 16–18 January 2021. [Google Scholar]
- Joseph, J.; Badrinath, P.; Basran, G.S.; Sahn, S.A. Is albumin gradient or fluid to serum albumin ratio better than the pleural fluid lactate dehydroginase in the diagnostic of separation of pleural effusion? BMC Pulm. Med. 2002, 2, 1. [Google Scholar] [CrossRef] [PubMed]
- Alam, T.M.; Mushtaq, M.; Shaukat, K.; Hameed, I.A.; Sarwar, M.U.; Luo, S. A Novel Method for Performance Measurement of Public Educational Institutions Using Machine Learning Models. Appl. Sci. 2021, 11, 9296. [Google Scholar] [CrossRef]
- Azhagusundari, B.; Thanamani, A.S. Feature selection based on information gain. Int. J. Innov. Technol. Explor. Eng. 2013, 2, 18–21. [Google Scholar]
- Hall, M. Correlation-Based Feature Selection for Machine Learning. Doctoral Dissertation, The University of Waikato, Hamilton, New Zealand, 1999. [Google Scholar]
- Wang, Y.; Makedon, F. Application of Relief-F feature filtering algorithm to selecting informative genes for cancer classification using microarray data. In Proceedings of the 2004 IEEE Computational Systems Bioinformatics Conference, 2004. CSB 2004, Stanford, CA, USA, 19 August 2004. [Google Scholar]
- Mejía-Lavalle, M.; Sucar, E.; Arroyo, G. Feature selection with a perceptron neural net. In Proceedings of the International Workshop on Feature Selection for Data Mining, Hyderabad, India, 21 June 2010. [Google Scholar]
- Wu, X.; Kumar, V.; Quinlan, J.R.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef]
- Praveena, H.D.; Subhas, C.; Naidu, K.R. Automatic epileptic seizure recognition using reliefF feature selection and long short term memory classifier. J. Ambient Intell. Humaniz. Comput. 2021, 12, 6151–6167. [Google Scholar] [CrossRef]
- Fernández, A.; Garcia, S.; Herrera, F.; Chawla, N.V. SMOTE for learning from imbalanced data: Progress and challenges, marking the 15-year anniversary. J. Artif. Intell. Res. 2018, 61, 863–905. [Google Scholar] [CrossRef]
- Mani, I.; Zhang, I. kNN approach to unbalanced data distributions: A case study involving information extraction. In Proceedings of the Workshop on Learning from Imbalanced Datasets, Mclean, VA, USA, 21 August 2003. [Google Scholar]
- Yen, S.J.; Lee, Y.S. Cluster-based under-sampling approaches for imbalanced data distributions. Expert Syst. Appl. 2009, 36, 5718–5727. [Google Scholar] [CrossRef]
- Nasir, A.; Shaukat, K.; Iqbal Khan, K.; A. Hameed, I.; Alam, T.M.; Luo, S. Trends and Directions of Financial Technology (Fintech) in Society and Environment: A Bibliometric Study. Appl. Sci. 2021, 11, 10353. [Google Scholar] [CrossRef]
- Khushi, M.; Shaukat, K.; Alam, T.M.; Hameed, I.A.; Uddin, S.; Luo, S.; Yang, X.; Reyes, M.C. A Comparative Performance Analysis of Data Resampling Methods on Imbalance Medical Data. IEEE Access 2021, 9, 109960–109975. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In Proceedings of the International Conference on Intelligent Computing, Hefei, China, 23–26 August 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887. [Google Scholar]
- Last, F.; Douzas, G.; Bacao, F. Oversampling for Imbalanced Learning Based on K-Means and SMOTE. Inf. Sci. 2017, 465, 1–20. [Google Scholar] [CrossRef]
- Douzas, G.; Bacao, F.; Sciences, F.L.-I. Improving imbalanced learning through a heuristic oversampling method based on k-means and SMOTE. Inf. Sci. 2018, 465, 1–20. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3147–3155. [Google Scholar]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient boosting with categorical features support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Shaukat, K.; Luo, S.; Varadharajan, V.; Hameed, I.A.; Xu, M. A Survey on Machine Learning Techniques for Cyber Security in the Last Decade. IEEE Access 2020, 8, 222310–222354. [Google Scholar] [CrossRef]
- Shaukat, K.; Luo, S.; Varadharajan, V.; Hameed, I.A.; Chen, S.; Liu, D.; Li, J. Performance Comparison and Current Challenges of Using Machine Learning Techniques in Cybersecurity. Energies 2020, 13, 2509. [Google Scholar] [CrossRef]
- Shaukat, K.; Luo, S.; Varadharajan, V. A novel method for improving the robustness of deep learning-based malware detectors against adversarial attacks. Eng. Appl. Artif. Intell. 2022, 116, 105461. [Google Scholar] [CrossRef]
- Nasir, A.; Shaukat, K.; Khan, K.I.; Hameed, I.A.; Alam, T.M.; Luo, S. What is core and what future holds for blockchain technologies and cryptocurrencies: A bibliometric analysis. IEEE Access 2020, 9, 989–1004. [Google Scholar] [CrossRef]
- Ibrar, M.; Muhammad, A.H.; Kamran, S.; Talha, M.A.; Khaldoon, S.K.; Ibrahim, A.H.; Hanan, A.; Suhuai, L. A Machine Learning-Based Model for Stability Prediction of Decentralized Power Grid Linked with Renewable Energy Resources. Wirel. Commun. Mobile Comput. 2022, 2022, 2697303. [Google Scholar] [CrossRef]
- Batool, D.; Shahbaz, M.; Shahzad Asif, H.; Shaukat, K.; Alam, T.M.; Hameed, I.A.; Ramzan, Z.; Waheed, A.; Aljuaid, H.; Luo, S. A Hybrid Approach to Tea Crop Yield Prediction Using Simulation Models and Machine Learning. Plants 2022, 11, 1925. [Google Scholar] [CrossRef] [PubMed]
- Alam, T.M.; Shaukat, K.; Hameed, I.A.; Khan, W.A.; Sarwar, M.U.; Iqbal, F.; Luo, S. A novel framework for prognostic factors identification of malignant mesothelioma through association rule mining. Biomed. Signal Process. Control. 2021, 68, 102726. [Google Scholar] [CrossRef]
- Shaukat, K.; Luo, S.; Chen, S.; Liu, D. Cyber threat detection using machine learning techniques: A performance evaluation perspective. In Proceedings of the 2020 International Conference on Cyber Warfare and Security (ICCWS), Norfolk, VI, USA, 20–21 October 2020; pp. 1–6. [Google Scholar]
- Shaukat, K.; Masood, N.; Khushi, M. A Novel Approach to Data Extraction on Hyperlinked Webpages. Appl. Sci. 2019, 9, 5102. [Google Scholar] [CrossRef]
- Kumar, M.R.; Vekkot, S.; Lalitha, S.; Gupta, D.; Govindraj, V.J.; Shaukat, K.; Alotaibi, Y.A.; Zakariah, M. Dementia Detection from Speech Using Machine Learning and Deep Learning Architectures. Sensors 2022, 22, 9311. [Google Scholar] [CrossRef]
- Alam, T.M.; Shaukat, K.; Khelifi, A.; Khan, W.A.; Raza, H.M.E.; Idrees, M.; Luo, S.; Hameed, I.A. Disease Diagnosis System Using IoT Empowered with Fuzzy Inference System. Comput. Mater. Contin. 2022, 70, 5305–5319. [Google Scholar] [CrossRef]
- Alam, T.M.; Shaukat, K.; Mahboob, H.; Sarwar, M.U.; Iqbal, F.; Nasir, A.; Hameed, I.A.; Luo, S. A Machine Learning Approach for Identification of Malignant Mesothelioma Etiological Factors in an Imbalanced Dataset. Comput. J. 2021, 65, 1740–1751. [Google Scholar] [CrossRef]
- Shaukat, K.; Rubab, A.; Shehzadi, I.; Iqbal, R. A socio-technological analysis of cyber crime and cyber security in Pakistan. Transylv. Rev. 2017, 1, 84. [Google Scholar]
- Shabbir, S.; Asif, M.S.; Alam, T.M.; Ramzan, Z. Early Prediction of Malignant Mesothelioma: An Approach Towards Non-invasive Method. Curr. Bioinform. 2021, 16, 1257–1277. [Google Scholar] [CrossRef]
- Latif, M.Z.; Shaukat, K.; Luo, S.; Hameed, I.A.; Iqbal, F.; Alam, T.M. Risk Factors Identification of Malignant Mesothelioma: A Data Mining Based Approach. In Proceedings of the 2020 International Conference on Electrical, Communication, and Computer Engineering (ICECCE), Istanbul, Turkey, 12–13 June 2020; pp. 1–6. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Description | Range | ||
|---|---|---|---|---|
| Occupation |
| Categorical | ||
| Annual Income |
| Boolean | ||
| Height Weight | BMI | >18.5—Underweight | 0 | Categorical |
| 18.5–24.5 Normal | 1 | |||
| 25.0–29.5 overweight | 2 | |||
| ≤30.0 Obese | 3 | |||
| Viability/Development (disease) |
| Categorical | ||
| Nourishment (nutrient level inside the body) |
| Categorical | ||
| Diagnostic Evidence 1 |
| Categorical | ||
| Diagnostic Evidence 2 |
| Categorical | ||
| Prior Treatment |
| Boolean | ||
| History of Splenectomy |
| Boolean | ||
| History of ascites |
| Boolean | ||
| Other Disease |
| Categorical | ||
| Extent of Ascites |
| Boolean | ||
| Clinical Classification |
| Categorical | ||
| Type of treatment the patient |
| Categorical | ||
| Means of Treatment |
| Categorical | ||
| Cost of Treatment |
| Categorical | ||
| OneR | Information Gain | ReliefF | Gain Ratio | Correlation |
|---|---|---|---|---|
| Viability | Cost of treatment | Diagnostic Evidence 1 | The extent of ascites | Cost of treatment |
| Means of treatment | Annual Income | BMI | Viability | Annual Income |
| The extent of ascites | Clinical classification | Clinical classification | Clinical classification | Clinical classification |
| BMI | History of splenectomy | Type of treating patients | Means of treatment | History of splenectomy |
| Diagnostic Evidence 2 | Viability | History of ascites | Cost of treatment | Viability |
| Diagnostic Evidence 1 | The extent of ascites | Diagnostic Evidence 2 | Annual Income | Means of treatment |
| Nourishment | Means of treatment | Cost of treatment | History of splenectomy | The extent of ascites |
| Annual Income | Diagnostic Evidence 1 | History of splenectomy | Occupation | Diagnostic Evidence 2 |
| Features | Score |
|---|---|
| Cost of treatment | 0.07295 |
| Annual Income | 0.04749 |
| Clinical classification | 0.00604 |
| History of splenectomy | −0.05814 |
| Viability | −0.05815 |
| Means of treatment | −0.06133 |
| The extent of ascites | −0.07251 |
| Diagnostic Evidence 2 | −0.07253 |
| Diagnostic Evidence 1 | −0.07254 |
| Type of treating patients | −0.07434 |
| Occupation | −0.11227 |
| BMI | −0.11531 |
| Nourishment | −0.16426 |
| History of ascites | −0.17023 |
| Prior treatment | −0.20311 |
| Other diseases | −0.27979 |
| Total Instances | Status | Imbalanced Dataset Instance | After Undersampling | After Oversampling |
|---|---|---|---|---|
| 4136 | Recovery | 1232 | 1232 | 2904 |
| Death | 2904 | 1232 | 2904 |
| Performance | Classifier | Correlation | Info Gain | ReliefF | OneR | Gain Ratio |
|---|---|---|---|---|---|---|
| Accuracy (%) | GB | 82.2 | 82.7 | 68.1 | 68.6 | 82.2 |
| LGBoost | 82.2 | 82.2 | 67.4 | 64.8 | 81.8 | |
| XGBoost | 82.8 | 82.8 | 67 | 66.4 | 82.4 | |
| CatBoost | 82.7 | 82.7 | 67.7 | 66.4 | 82.8 | |
| Precision (%) | GB | 82.5 | 82.5 | 67.7 | 68.6 | 82.1 |
| LGBoost | 82.1 | 82.1 | 67.1 | 66.3 | 81.1 | |
| XGBoost | 82.6 | 82.6 | 66.6 | 67.4 | 82.2 | |
| CatBoost | 82.5 | 82.5 | 67.4 | 67.1 | 82.6 | |
| Recall (%) | GB | 82.5 | 82.5 | 67.4 | 68.8 | 82.1 |
| LGBoost | 82.1 | 82.1 | 66.6 | 65.9 | 81.8 | |
| XGBoost | 82.6 | 82.6 | 66.3 | 67.2 | 82.3 | |
| CatBoost | 82.5 | 82.5 | 66.7 | 67.1 | 82.7 | |
| F1-Score (%) | GB | 82.5 | 82.5 | 67.5 | 68.5 | 82.1 |
| LGBoost | 82.1 | 82.1 | 66.8 | 64.7 | 81.7 | |
| XGBoost | 82.6 | 82.6 | 66.4 | 66.4 | 82.2 | |
| CatBoost | 82.5 | 82.4 | 66.8 | 66.4 | 82.6 |
| Performance | Classifier | Correlation | Info gain | ReliefF | OneR | Gain Ratio |
|---|---|---|---|---|---|---|
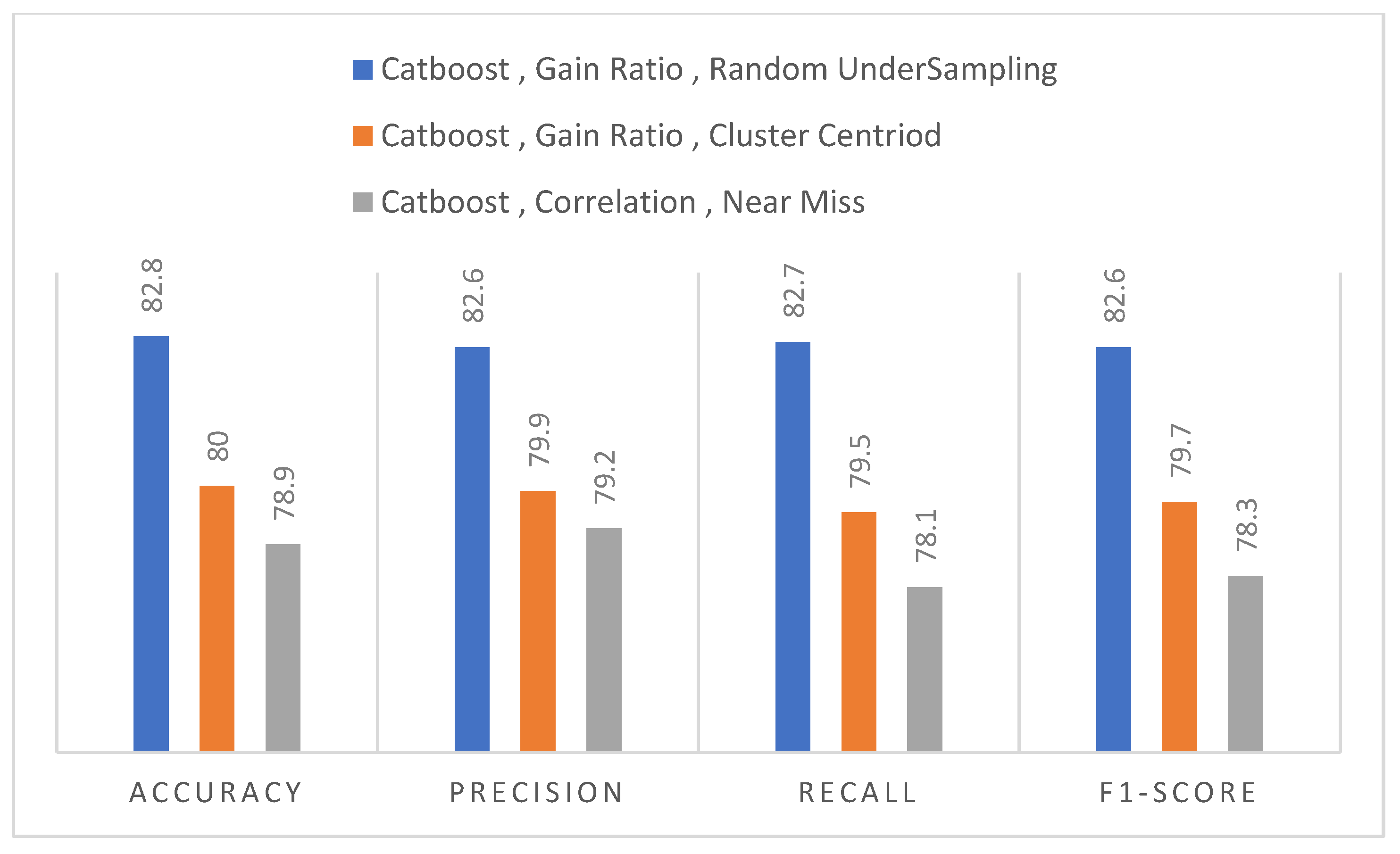
| Accuracy (%) | GB | 76.4 | 74.8 | 68.5 | 64.1 | 78.9 |
| LGBoost | 78.1 | 77.9 | 68.7 | 63.6 | 78.6 | |
| XGBoost | 78.5 | 77.9 | 67.9 | 63.9 | 79.4 | |
| CatBoost | 78.7 | 78.1 | 69 | 64.7 | 80 | |
| Precision (%) | GB | 76.3 | 74.6 | 68.2 | 63.7 | 78.7 |
| LGBoost | 77.9 | 77.7 | 68.5 | 63.9 | 78.4 | |
| XGBoost | 78.4 | 77.7 | 67.6 | 64.2 | 79.3 | |
| CatBoost | 78.7 | 77.9 | 68.7 | 65 | 79.9 | |
| Recall (%) | GB | 76.4 | 74.4 | 68.3 | 63.4 | 78.4 |
| LGBoost | 77.7 | 77.9 | 68.6 | 64 | 78.3 | |
| XGBoost | 78 | 77.9 | 67.6 | 64.3 | 79.1 | |
| CatBoost | 78.3 | 78 | 68.8 | 65.1 | 79.5 | |
| F1-Score (%) | GB | 76.3 | 74.5 | 68.3 | 63.4 | 78.7 |
| LGBoost | 77.8 | 77.8 | 68.5 | 63.6 | 78.4 | |
| XGBoost | 78.1 | 77.8 | 67.7 | 63.9 | 79.1 | |
| CatBoost | 78.4 | 77.9. | 68.8 | 64.7 | 79.7 |
| Performance | Classifier | Correlation | Info Gain | ReliefF | OneR | Gain Ratio |
|---|---|---|---|---|---|---|
| Accuracy (%) | GB | 78.6 | 78.6 | 64.5 | 71.8 | 78.6 |
| LGBoost | 78.1 | 78.1 | 68.3 | 72.1 | 77.5 | |
| XGBoost | 78.7 | 78.7 | 68.2 | 72.4 | 78.1 | |
| CatBoost | 78.9 | 78.9 | 68.6 | 71.8 | 78.1 | |
| Precision (%) | GB | 78.9 | 78.9 | 66.7 | 71.7 | 78.9 |
| LGBoost | 78.1 | 78.1 | 68.3 | 72.1 | 77.7 | |
| XGBoost | 79.1 | 79.1 | 68.1 | 72.4 | 78.3 | |
| CatBoost | 79.2 | 79.2 | 68.5 | 71.7 | 78.3 | |
| Recall (%) | GB | 77.8 | 77.8 | 65.9 | 71.9 | 77.8 |
| LGBoost | 77.4 | 77.4 | 68.4 | 72.4 | 76.8 | |
| XGBoost | 77.8 | 77.9 | 68.3 | 72.6 | 77.3 | |
| CatBoost | 78.1 | 78.1 | 68.7 | 71.9 | 77.3 | |
| F1-Score (%) | GB | 78.1 | 78.1 | 64.4 | 71.7 | 78.1 |
| LGBoost | 77.6 | 77.6 | 68.2 | 72.1 | 77 | |
| XGBoost | 78.2 | 78.2 | 68.1 | 72.3 | 77.5 | |
| CatBoost | 78.3 | 78.3 | 68.5 | 71.7 | 77.5 |
| Performance | Classifier | Correlation | Info Gain | ReliefF | OneR | Gain Ratio |
|---|---|---|---|---|---|---|
| Accuracy (%) | GB | 82.6 | 82.6 | 71.6 | 68 | 82 |
| LGBoost | 83.4 | 83.4 | 73.3 | 67.6 | 82.9 | |
| XGBoost | 83.4 | 83.4 | 73 | 68.3 | 82.9 | |
| CatBoost | 83.7 | 83.7 | 72.9 | 67.8 | 82.9 | |
| Precision (%) | GB | 82.6 | 82.6 | 72.1 | 68 | 82 |
| LGBoost | 83.4 | 83.4 | 74.1 | 67.9 | 82.9 | |
| XGBoost | 83.5 | 83.5 | 73.6 | 68.4 | 82.9 | |
| CatBoost | 83.7 | 83.7 | 73.1 | 67.9 | 82.9 | |
| Recall (%) | GB | 82.6 | 82.6 | 71.5 | 68 | 82 |
| LGBoost | 83.4 | 83.4 | 73.2 | 67.7 | 82.9 | |
| XGBoost | 83.4 | 83.4 | 73 | 68.3 | 82.8 | |
| CatBoost | 83.7 | 83.7 | 72.9 | 67.8 | 82.9 | |
| F1-Score (%) | GB | 82.6 | 82.6 | 71.4 | 68 | 82 |
| LGBoost | 83.4 | 83.4 | 73 | 67.5 | 82.9 | |
| XGBoost | 83.4 | 83.4 | 72.8 | 68.2 | 82.8 | |
| CatBoost | 83.6 | 83.6 | 72.8 | 67.8 | 82.9 |
| Performance | Classifier | Correlation | Info Gain | ReliefF | OneR | Gain Ratio |
|---|---|---|---|---|---|---|
| Accuracy (%) | GB | 82.4 | 82.4 | 74.8 | 69.7 | 82.2 |
| LGBoost | 83.1 | 83.1 | 76.1 | 70.9 | 82..9 | |
| XGBoost | 83.3 | 83.3 | 75.8 | 70.7 | 82.8 | |
| CatBoost | 82.9 | 82.9 | 75.9 | 71.0 | 82.7 | |
| Precision (%) | GB | 82.4 | 82.4 | 75.0 | 69.7 | 82.2 |
| LGBoost | 83.2 | 83.2 | 76.4 | 71.5 | 82.9 | |
| XGBoost | 83.3 | 83.3 | 76.1 | 71.3 | 82.4 | |
| CatBoost | 82.9 | 82.9 | 76.2 | 71.8 | 82.7 | |
| Recall (%) | GB | 82.4 | 82.4 | 74.7 | 69.7 | 82.2 |
| LGBoost | 83.1 | 83.1 | 76.1 | 70.9 | 82.9 | |
| XGBoost | 83.3 | 83.3 | 75.8 | 70.8 | 82.8 | |
| CatBoost | 82.9 | 82.9 | 75.8 | 71.1 | 82.7 | |
| F1-Score (%) | GB | 82.4 | 82.4 | 74.7 | 69.7 | 82.2 |
| LGBoost | 83.1 | 83.1 | 76.0 | 70.7 | 82.9 | |
| XGBoost | 83.3 | 83.3 | 75.7 | 70.6 | 82.8 | |
| CatBoost | 82.9 | 82.9 | 75.8 | 70.8 | 82.7 |
| Performance | Classifier | Correlation | Info Gain | ReliefF | OneR | Gain Ratio |
|---|---|---|---|---|---|---|
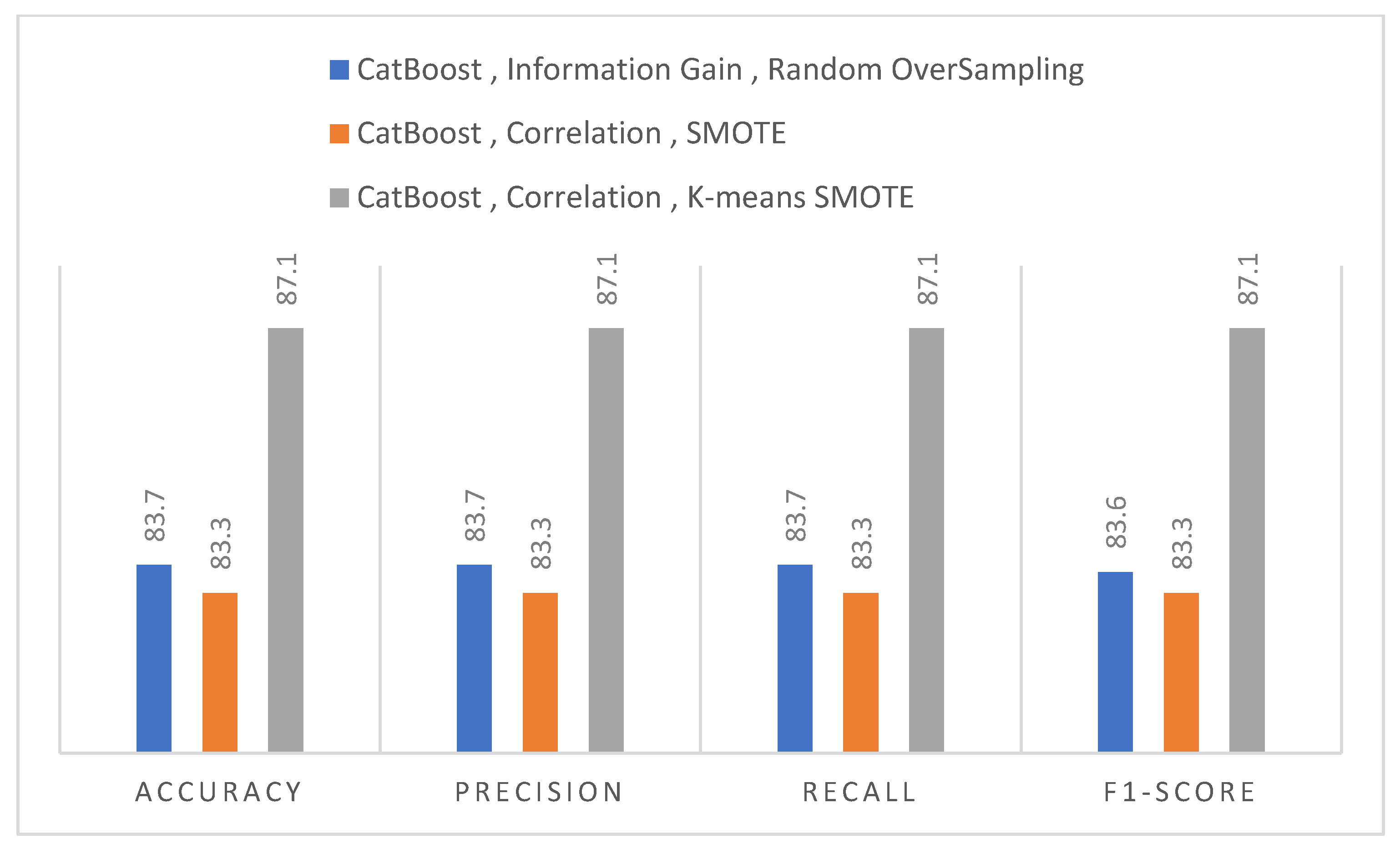
| Accuracy (%) | GB | 86.0 | 76.9 | 74.8 | 77.6 | 86.2 |
| LGBoost | 86.7 | 79.2 | 76.1 | 77.9 | 86.4 | |
| XGBoost | 86.9 | 79.1 | 76.0 | 78.0 | 86.6 | |
| CatBoost | 87.1 | 79.1 | 77.0 | 78.4 | 86.8 | |
| Precision (%) | GB | 86.0 | 77.0 | 74.8 | 78.0 | 86.4 |
| LGBoost | 87.0 | 79.3 | 76.8 | 77.9 | 86.6 | |
| XGBoost | 87.2 | 79.1 | 76.6 | 78.0 | 86.9 | |
| CatBoost | 87.1 | 79.3 | 77.7 | 78.4 | 87.0 | |
| Recall (%) | GB | 85.9 | 77.0 | 74.8 | 77.6 | 86.2 |
| LGBoost | 86.7 | 79.2 | 76.1 | 77.9 | 86.3 | |
| XGBoost | 86.9 | 79.1 | 76.0 | 78.0 | 86.6 | |
| CatBoost | 87.1 | 79.1 | 77.0 | 78.4 | 86.7 | |
| F1-Score (%) | GB | 85.9 | 76.9 | 74.8 | 77.5 | 86.2 |
| LGBoost | 86.7 | 79.2 | 75.9 | 77.9 | 86.3 | |
| XGBoost | 86.9 | 79.1 | 75.9 | 78.0 | 86.6 | |
| CatBoost | 87.1 | 79.1 | 76.8 | 78.4 | 86.7 |
| Reference | Year | Objective | Approach | Undersampling Technique | Oversampling Technique | Outcome |
|---|---|---|---|---|---|---|
| [27] | 2017 | To check the pattern analysis of Schistosomiasisdisease | K-mean algorithm, clustering | ✗ | ✗ | N.A |
| [1] | 2018 | To detect advanced Schistosomiasis in the people of Hubei province | ANN, DT, LR | ✗ | ✗ | 80% |
| [21] | 2019 | To detect and predict the diagnosis of disease on an imbalanced dataset | PNN, RF, one rule, and DT | ✗ | ✗ | 82% |
| [28] | 2019 | Detection of disease factor | Association Rule Mining | ✗ | ✗ | N.A |
| [29] | 2019 | Relationship between climate change and disease factor | K- means clustering | ✗ | ✗ | N.A |
| [18] | 2020 | Comparison to check the level of susceptibility of Schistosomiasis | SVM, Gaussian Methods | ✗ | ✗ | 76.6–94% |
| [17] | 2021 | 1 year prognosis for advanced Schistosomiasis | LR, RF, DT, ANN, XGBoost | ✗ | ✗ | 79% |
| [30] | 2021 | Identify the high-risk areas of Schistosomiasis | LR, RF, GB | ✗ | ✗ | 73–87% |
| Our study | 2022 | Early prediction of Schistosomiasis | GB, LGBoost, XGBoost, CatBoost | ✓ | ✓ | 87.1% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, Z.; Hayat, M.F.; Shaukat, K.; Alam, T.M.; Hameed, I.A.; Luo, S.; Basheer, S.; Ayadi, M.; Ksibi, A. A Proposed Framework for Early Prediction of Schistosomiasis. Diagnostics 2022, 12, 3138. https://doi.org/10.3390/diagnostics12123138
Ali Z, Hayat MF, Shaukat K, Alam TM, Hameed IA, Luo S, Basheer S, Ayadi M, Ksibi A. A Proposed Framework for Early Prediction of Schistosomiasis. Diagnostics. 2022; 12(12):3138. https://doi.org/10.3390/diagnostics12123138
Chicago/Turabian StyleAli, Zain, Muhammad Faisal Hayat, Kamran Shaukat, Talha Mahboob Alam, Ibrahim A. Hameed, Suhuai Luo, Shakila Basheer, Manel Ayadi, and Amel Ksibi. 2022. "A Proposed Framework for Early Prediction of Schistosomiasis" Diagnostics 12, no. 12: 3138. https://doi.org/10.3390/diagnostics12123138