
An Explainable Machine Learning Pipeline for Stroke Prediction on Imbalanced Data

 ,
,  , , ,
, , ,
Abstract
:1. Introduction
2. Materials and Methods
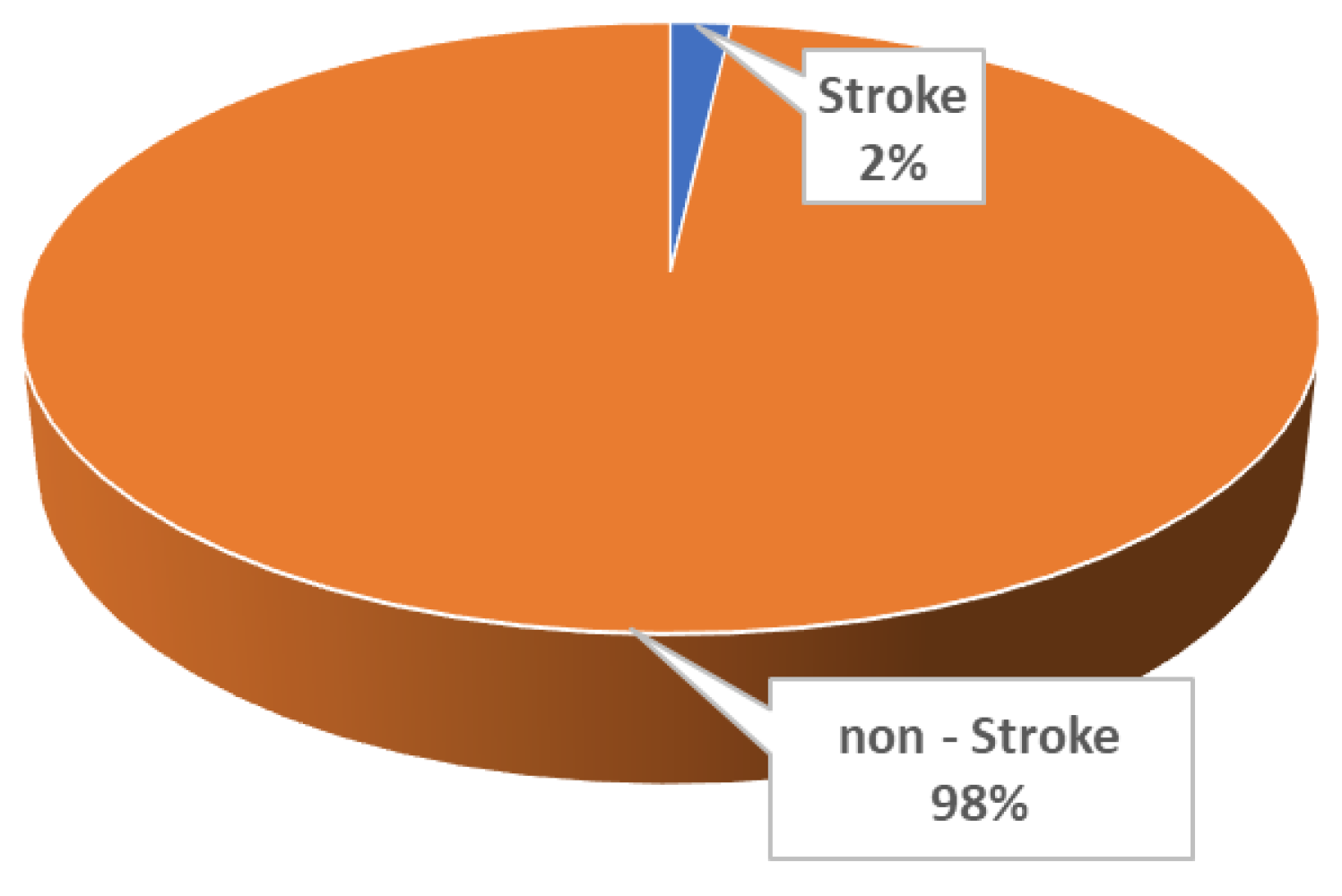
2.1. Data Description
2.2. Problem Definition
2.3. Proposed Methodology
2.4. Feature Engineering
2.5. Learning
2.6. Validation and Evaluation Metrics
2.7. Explainability
3. Results
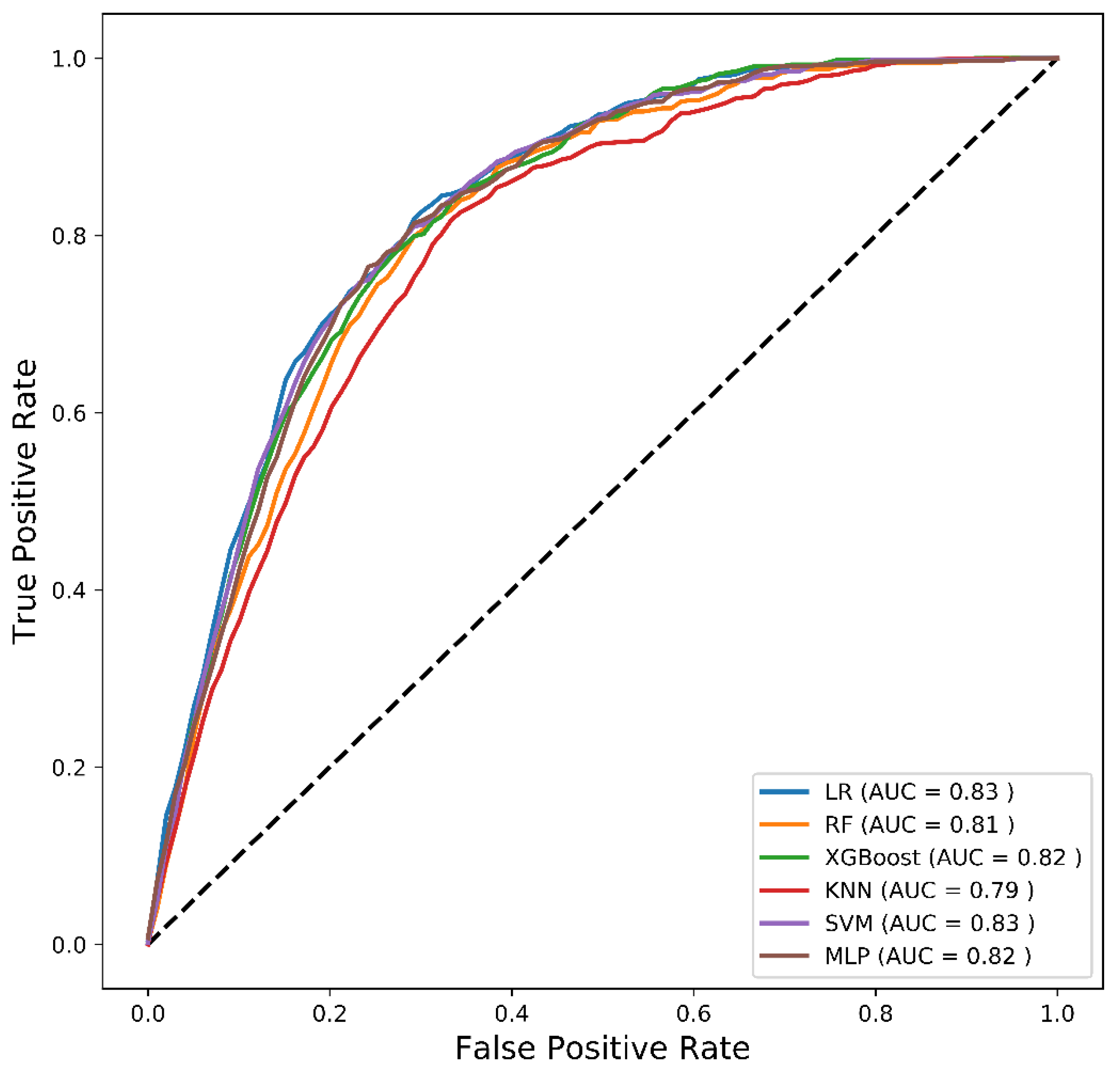
3.1. Comparative Analysis
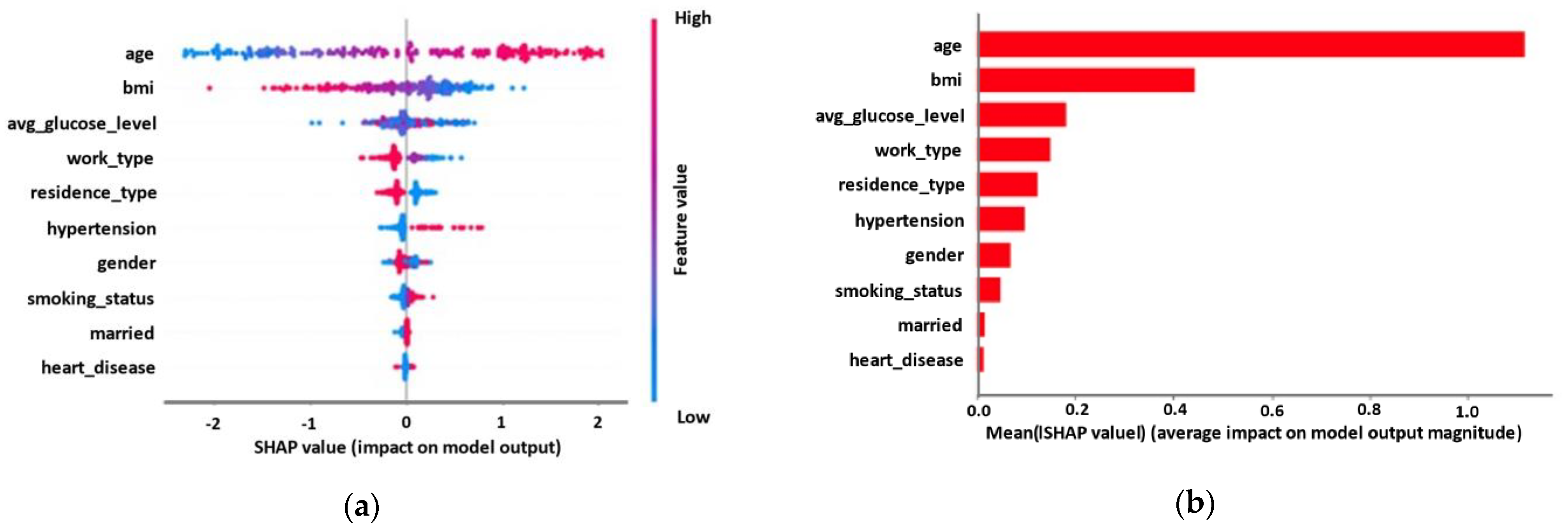
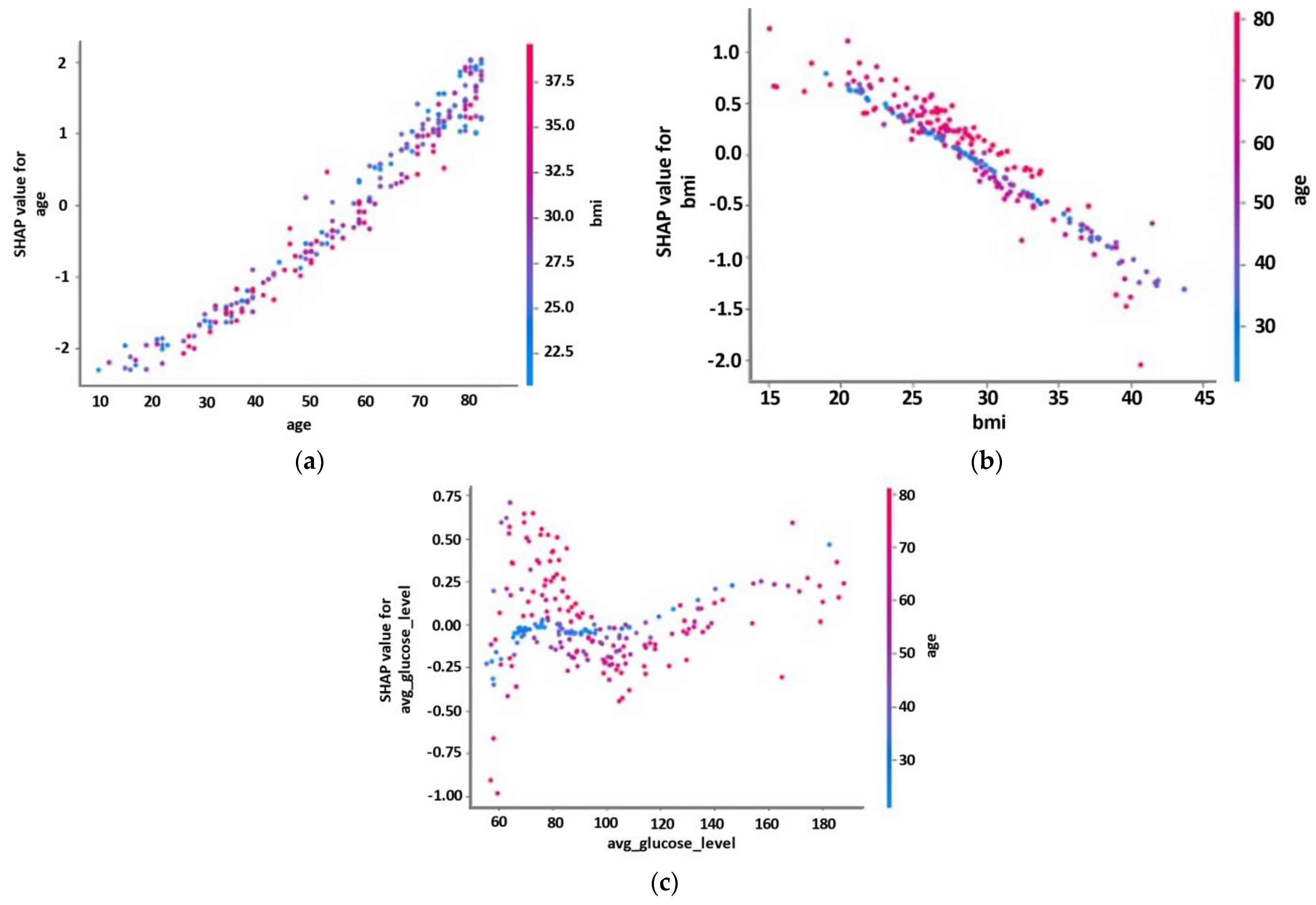
3.2. Explainability Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Feigin, V.L.; Krishnamurthi, R.V.; Parmar, P.; Norrving, B.; Mensah, G.A.; Bennett, D.A.; Barker-Collo, S.; Moran, A.E.; Sacco, R.L.; Truelsen, T.; et al. Update on the global burden of ischemic and hemorrhagic stroke in 1990–2013: The GBD 2013 study. Neuroepidemiology 2015, 45, 161–176. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Feigin, V.L.; Lawes, C.M.; A Bennett, D.; Anderson, C.S. Stroke epidemiology: A review of population-based studies of incidence, prevalence, and case-fatality in the late 20th century. Lancet Neurol. 2003, 2, 43–53. [Google Scholar] [CrossRef]
- Reeves, M.J.; Bushnell, C.D.; Howard, G.; Gargano, J.W.; Duncan, P.W.; Lynch, G.; Khatiwoda, A.; Lisabeth, L. Sex differences in stroke: Epidemiology, clinical presentation, medical care, and outcomes. Lancet Neurol. 2008, 7, 915–926. [Google Scholar] [CrossRef] [Green Version]
- Khan, S.; Siddique, R.; Hao, X.; Lin, Y.; Liu, Y.; Wang, X.; Hua, L.; Nabi, G. The COVID-19 infection in children and its association with the immune system, prenatal stress, and neurological complications. Int. J. Biol. Sci. 2022, 18, 707–716. [Google Scholar] [CrossRef] [PubMed]
- Defebvre, L.; Krystkowiak, P. Movement disorders and stroke. Rev. Neurol. 2016, 172, 483–487. [Google Scholar] [CrossRef] [PubMed]
- Jaafar, N.; Daud, A.Z.C.; Roslan, N.F.A.; Mansor, W. Mirror Therapy Rehabilitation in Stroke: A Scoping Review of Upper Limb Recovery and Brain Activities. Rehabil. Res. Pract. 2021, 2021, 9487319. [Google Scholar] [CrossRef] [PubMed]
- Strilciuc, S.; Grad, D.A.; Radu, C.; Chira, D.; Stan, A.; Ungureanu, M.; Gheorghe, A.; Muresanu, F.-D. The economic burden of stroke: A systematic review of cost of illness studies. J. Med. Life 2021, 14, 606–619. [Google Scholar] [CrossRef]
- Kokkotis, C.; Moustakidis, S.; Papageorgiou, E.; Giakas, G.; Tsaopoulos, D. Machine learning in knee osteoarthritis: A review. Osteoarthr. Cartil. Open 2020, 2, 100069. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Chen, E.; Banerjee, O.; Topol, E.J. AI in health and medicine. Nat. Med. 2022, 28, 31–38. [Google Scholar] [CrossRef]
- Hügle, M.; Omoumi, P.; Van Laar, J.M.; Boedecker, J.; Hügle, T. Applied machine learning and artificial intelligence in rheumatology. Rheumatol. Adv. Pract. 2020, 4, rkaa005. [Google Scholar] [CrossRef]
- Murray, N.M.; Unberath, M.; Hager, G.D.; Hui, F.K. Artificial intelligence to diagnose ischemic stroke and identify large vessel occlusions: A systematic review. J. NeuroInterv. Surg. 2020, 12, 156–164. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Fu, S.; Bielinski, S.J.; A Decker, P.; Chamberlain, A.M.; Roger, V.L.; Liu, H.; Larson, N.B. Natural Language Processing and Machine Learning for Identifying Incident Stroke from Electronic Health Records: Algorithm Development and Validation. J. Med. Internet Res. 2021, 23, e22951. [Google Scholar] [CrossRef] [PubMed]
- McDermott, B.J.; Elahi, A.; Santorelli, A.; O’Halloran, M.; Avery, J.; Porter, E. Multi-frequency symmetry difference electrical impedance tomography with machine learning for human stroke diagnosis. Physiol. Meas. 2020, 41, 075010. [Google Scholar] [CrossRef]
- Bivard, A.; Churilov, L.; Parsons, M. Artificial intelligence for decision support in acute stroke—Current roles and potential. Nat. Rev. Neurol. 2020, 16, 575–585. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Kiik, M.; Peek, N.; Curcin, V.; Marshall, I.J.; Rudd, A.G.; Wang, Y.; Douiri, A.; Wolfe, C.D.; Bray, B. A systematic review of machine learning models for predicting outcomes of stroke with structured data. PLoS ONE 2020, 15, e0234722. [Google Scholar]
- Sirsat, M.S.; Fermé, E.; Câmara, J. Machine learning for brain stroke: A review. J. Stroke Cerebrovasc. Dis. 2020, 29, 105162. [Google Scholar] [CrossRef] [PubMed]
- Arslan, A.K.; Colak, C.; Sarihan, M.E. Different medical data mining approaches based prediction of ischemic stroke. Comput. Methods Programs Biomed. 2016, 130, 87–92. [Google Scholar] [CrossRef] [PubMed]
- Liu, T.; Fan, W.; Wu, C. A hybrid machine learning approach to cerebral stroke prediction based on imbalanced medical dataset. Artif. Intell. Med. 2019, 101, 101723. [Google Scholar] [CrossRef]
- Zhao, H.; Xu, Z.; Zhu, Y.; Xue, R.; Wang, J.; Ren, J.; Wang, W.; Duan, W.; Zheng, M. The Construction of a Risk Prediction Model Based on Neural Network for Pre-operative Acute Ischemic Stroke in Acute Type a Aortic Dissection Patients. Front. Neurol. 2021, 12, 792678. [Google Scholar] [CrossRef]
- Alanazi, E.M.; Abdou, A.; Luo, J. Predicting Risk of Stroke from Lab Tests Using Machine Learning Algorithms: Development and Evaluation of Prediction Models. JMIR Form. Res. 2021, 5, e23440. [Google Scholar] [CrossRef]
- Cui, J.; Yang, J.; Zhang, K.; Xu, G.; Zhao, R.; Li, X.; Liu, L.; Zhu, Y.; Zhou, L.; Yu, P.; et al. Machine Learning-Based Model for Predicting Incidence and Severity of Acute Ischemic Stroke in Anterior Circulation Large Vessel Occlusion. Front. Neurol. 2021, 12, 749599. [Google Scholar] [CrossRef]
- Dickinson, Q.; Meyer, J.G. Positional SHAP (PoSHAP) for Interpretation of machine learning models trained from biological sequences. PLoS Comput. Biol. 2022, 18, e1009736. [Google Scholar] [CrossRef]
- Angelini, F.; Widera, P.; Mobasheri, A.; Blair, J.; Struglics, A.; Uebelhoer, M.; Henrotin, Y.; Marijnissen, A.C.; Kloppenburg, M.; Blanco, F.J.; et al. Osteoarthritis endotype discovery via clustering of biochemical marker data. Ann. Rheum. Dis. 2022, 81, 666–675. [Google Scholar] [CrossRef]
- Utkin, L.V.; Meldo, A.A.; Kovalev, M.S.; Kasimov, E.M. A Review of Methods for Explaining and Interpreting Decisions of Intelligent Cancer Diagnosis Systems. Sci. Tech. Inf. Process. 2021, 48, 398–405. [Google Scholar] [CrossRef]
- Kim, S.-H.; Jeon, E.-T.; Yu, S.; Oh, K.; Kim, C.K.; Song, T.-J.; Kim, Y.-J.; Heo, S.H.; Park, K.-Y.; Kim, J.-M.; et al. Interpretable machine learning for early neurological deterioration prediction in atrial fibrillation-related stroke. Sci. Rep. 2021, 11, 20610. [Google Scholar] [CrossRef]
- Kokkotis, C.; Moustakidis, S.; Giakas, G.; Tsaopoulos, D. Identification of Risk Factors and Machine Learning-Based Prediction Models for Knee Osteoarthritis Patients. Appl. Sci. 2020, 10, 6797. [Google Scholar] [CrossRef]
- Shanker, M.; Hu, M.; Hung, M. Effect of data standardization on neural network training. Omega 1996, 24, 385–397. [Google Scholar] [CrossRef]
- Ali, A.A. Stroke Prediction using Distributed Machine Learning Based on Apache Spark. Stroke 2019, 28, 89–97. [Google Scholar]
- Fernandez-Lozano, C.; Hervella, P.; Mato-Abad, V.; Rodríguez-Yáñez, M.; Suárez-Garaboa, S.; López-Dequidt, I.; Estany-Gestal, A.; Sobrino, T.; Campos, F.; Castillo, J.; et al. Random forest-based prediction of stroke outcome. Sci. Rep. 2021, 11, 10071. [Google Scholar] [CrossRef] [PubMed]
- Yu, D.; Liu, Z.; Su, C.; Han, Y.; Duan, X.; Zhang, R.; Liu, X.; Yang, Y.; Xu, S. Copy number variation in plasma as a tool for lung cancer prediction using Extreme Gradient Boosting (XGBoost) classifier. Thorac. Cancer 2020, 11, 95–102. [Google Scholar] [CrossRef] [PubMed]
- Okun, O.; Priisalu, H. Dataset complexity in gene expression based cancer classification using ensembles of k-nearest neighbors. Artif. Intell. Med. 2009, 45, 151–162. [Google Scholar] [CrossRef] [PubMed]
- Mohr, M.; von Tscharner, V.; Emery, C.A.; Nigg, B.M. Classification of gait muscle activation patterns according to knee injury history using a support vector machine ap-proach. Hum. Mov. Sci. 2019, 66, 335–346. [Google Scholar] [CrossRef] [PubMed]
- Chan, L.; Li, H.; Chan, P.; Wen, C. A machine learning-based approach to decipher multi-etiology of knee osteoarthritis onset and deterioration. Osteoarthr. Cartil. Open 2021, 3, 100135. [Google Scholar] [CrossRef]
- Park, D.; Jeong, E.; Kim, H.; Pyun, H.W.; Kim, H.; Choi, Y.-J.; Kim, Y.; Jin, S.; Hong, D.; Lee, D.W.; et al. Machine Learning-Based Three-Month Outcome Prediction in Acute Ischemic Stroke: A Single Cerebrovascular-Specialty Hospital Study in South Korea. Diagnostics 2021, 11, 1909. [Google Scholar] [CrossRef]
- Hicks, S.A.; Strümke, I.; Thambawita, V.; Hammou, M.; Riegler, M.A.; Halvorsen, P.; Parasa, S. On evaluation metrics for medical applications of artificial intelligence. Sci. Rep. 2022, 12, 5979. [Google Scholar] [CrossRef]
- Branco, P.; Torgo, L.; Ribeiro, R.P. A Survey of Predictive Modeling on Imbalanced Domains. ACM Comput. Surv. 2016, 49, 1–50. [Google Scholar] [CrossRef] [Green Version]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems 30, Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017. [Google Scholar]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.-I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef]
- Janzing, D.; Minorics, L.; Blöbaum, P. Feature relevance quantification in explainable AI: A causal problem. In Proceedings of the 23th International Conference on Artificial Intelligence and Statistics, PMLR means Proceedings of Machine Learning Research, Online, 26–28 August 2020. [Google Scholar]
- Yousufuddin, M.; Young, N. Aging and ischemic stroke. Aging 2019, 11, 2542–2544. [Google Scholar] [CrossRef]
- Elagizi, A.; Kachur, S.; Lavie, C.J.; Carbone, S.; Pandey, A.; Ortega, F.B.; Milani, R.V. An Overview and Update on Obesity and the Obesity Paradox in Cardiovascular Diseases. Prog. Cardiovasc. Dis. 2018, 61, 142–150. [Google Scholar] [CrossRef] [Green Version]
- Park, H.; Lee, H.W.; Yoo, J.; Lee, H.S.; Nam, H.S.; Kim, Y.D.; Heo, J.H. Body Mass Index and Prognosis in Ischemic Stroke Patients with Type 2 Diabetes Mellitus. Front. Neurol. 2019, 10, 563. [Google Scholar] [CrossRef]
- Zheng, L.; Wen, L.; Lei, W.; Ning, Z. Added value of systemic inflammation markers in predicting pulmonary infection in stroke patients: A retrospective study by machine learning analysis. Medicine 2021, 100, e28439. [Google Scholar] [CrossRef]
- Wajngarten, M.; Silva, G.S. Hypertension and Stroke: Update on Treatment. Eur. Cardiol. Rev. 2019, 14, 111–115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, Y.; Xu, S.; Hua, J.; Zhu, D.; Liu, C.; Hu, Y.; Liu, T.; Xu, D. Association between job strain and risk of incident stroke: A meta-analysis. Neurology 2015, 85, 1648–1654. [Google Scholar] [CrossRef] [PubMed]
- Sealy-Jefferson, S.; Roseland, M.; Cote, M.L.; Lehman, A.; Whitsel, E.A.; Booza, J.; Simon, M.S. Rural–Urban Residence and Stroke Risk and Severity in Postmenopausal Women: The Women’s Health Initiative. Womens Health Rep. 2020, 1, 326–333. [Google Scholar] [CrossRef] [PubMed]
- Peters, S.A.; Carcel, C.; Millett, E.R.; Woodward, M. Sex differences in the association between major risk factors and the risk of stroke in the UK Biobank cohort study. Neurology 2020, 95, e2715–e2726. [Google Scholar] [CrossRef] [PubMed]
- Shah, R.S.; Cole, J.W. Smoking and stroke: The more you smoke the more you stroke. Expert Rev. Cardiovasc. Ther. 2010, 8, 917–932. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Risk Factors | Description | Type of Variable |
|---|---|---|
| Age | Current age | Continuous |
| BMI | Body mass index (BMI) is a measure of body fat | Continuous |
| Gender | Female/Male | Categorical |
| Average glucose | Average glucose is an estimated average of blood sugar | Continuous |
| Work type | Never worked/Children/Government job/Self-Employed/Private | Categorical |
| Residence type | Rural/Urban | Categorical |
| Smoking status | Never/Formerly/Smoker | Categorical |
| Heart disease | No/Yes | Categorical |
| Married | No/Yes | Categorical |
| Hypertension | No/Yes | Categorical |
| ML Model | Description |
|---|---|
| LR | C: [0.01, 0.1, 1, 10, 100], penalty: [‘l1’, ‘l2’] |
| RF | criterion: [‘gini’, ‘entropy’], min_samples_leaf: [1, 2, 3, 4, 5], min_samples_split: [2, 3, 4, 5, 6, 7], n_estimators: [10, 15, 20, 25, 27, 30] |
| XGBoost | max_depth: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], min_child_weight: [1, 2, 3, 4, 5, 6, 8, 10], gamma: [0, 0.4, 0.5, 0.6,0.7,0.8,0.9,1] |
| KNN | algorithm: [‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’], leaf_size: [1, 2, 3, 5], n_neighbors: [3, 4, 5, 7, 9, 12, 14, 15, 16, 17], weights: [‘uniform’, ‘distance’] |
| SVM | kernel: [‘rbf’, ‘linear’, ‘sigmoid’], C: [0.001, 0.1, 0.1, 10, 25, 50, 100, 1000], gamma: [0.01, 0.001, 0.0001, 1 × 10−5] |
| MLP | activation: [‘tanh’, ‘relu’], alpha: [0.0001, 0.05], hidden_layer_sizes: [(2, 5, 10), (5, 10, 20), (10, 20, 50)], learning_rate: [‘constant’, ‘adaptive’], solver: [‘sgd’, ‘adam’] |
| ML Models | Accuracy | Sensitivity | Specificity | G-Mean | AUC | FPrate | FNrate |
|---|---|---|---|---|---|---|---|
| LR | 73.52 | 78.12 | 73.43 | 75.73 | 83.30 | 26.57 | 21.89 |
| RF | 71.19 | 79.22 | 71.04 | 75.02 | 81.24 | 28.96 | 20.79 |
| XGBoost | 72.58 | 78.30 | 72.47 | 75.33 | 82.50 | 27.53 | 21.70 |
| KNN | 69.16 | 78.84 | 68.98 | 73.70 | 79.35 | 31.02 | 21.17 |
| SVM | 71.28 | 80.48 | 71.10 | 75.65 | 82.85 | 28.90 | 19.52 |
| MLP | 70.85 | 81.40 | 70.65 | 75.83 | 82.14 | 29.35 | 18.60 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kokkotis, C.; Giarmatzis, G.; Giannakou, E.; Moustakidis, S.; Tsatalas, T.; Tsiptsios, D.; Vadikolias, K.; Aggelousis, N. An Explainable Machine Learning Pipeline for Stroke Prediction on Imbalanced Data. Diagnostics 2022, 12, 2392. https://doi.org/10.3390/diagnostics12102392
Kokkotis C, Giarmatzis G, Giannakou E, Moustakidis S, Tsatalas T, Tsiptsios D, Vadikolias K, Aggelousis N. An Explainable Machine Learning Pipeline for Stroke Prediction on Imbalanced Data. Diagnostics. 2022; 12(10):2392. https://doi.org/10.3390/diagnostics12102392
Chicago/Turabian StyleKokkotis, Christos, Georgios Giarmatzis, Erasmia Giannakou, Serafeim Moustakidis, Themistoklis Tsatalas, Dimitrios Tsiptsios, Konstantinos Vadikolias, and Nikolaos Aggelousis. 2022. "An Explainable Machine Learning Pipeline for Stroke Prediction on Imbalanced Data" Diagnostics 12, no. 10: 2392. https://doi.org/10.3390/diagnostics12102392